
Abstract
Fine-grained data on religious communities are often considered sensitive in South Asia and consequently remain inaccessible. Yet without such data, statistical research on communal relations and group-based inequality remains superficial, hampering the development of appropriate policy measures to prevent further social exclusion on the basis of religion. The open-source algorithm introduced in this article provides a workaround by probabilistically exploiting the communal connotations of names; it transforms name lists—which are readily available—into a new source of demographic data. The algorithm proves highly accurate in identifying Muslim population shares in Uttar Pradesh, India’s most populous state, but could be employed more widely across South Asia. It potentially enables more detailed analyses in economics, development studies, and political science as well as better sampling procedures in sociology and anthropology. This article describes the algorithm, evaluates its accuracy, reflects on ethical implications, and introduces a sample data set; the software itself is available in an online supplement to this article.
Religion-based inequalities are of growing concern in several South Asian countries, particularly in India, where the Sachar Committee report recently revealed the extent of social exclusion suffered by the country’s Muslim minority (Sachar et al. 2006). To contextualize, qualify, and deepen the report’s findings, more fine-grained studies are urgently required, using both qualitative and quantitative methods (Basant and Shariff 2010:2; Gayer and Jaffrelot 2012:13). To better establish the material context of poverty, it would, for instance, be insightful to study landholding patterns among Muslims or the extent of their inclusion in welfare plans. Unfortunately, neither below the poverty line (BPL) lists nor land records contain religious categorizations. To see how electoral dynamics might increase and/or divert political pressure for change, it would be useful to know the religion composition of the electorate as well as the religious identity of elected representatives, yet such figures are unavailable. To understand how education could advance the socioeconomic condition of minorities, one would want to analyze admission pattern in schools and universities, but these are not tabulated by religion either; even basic literacy rates on aggregate district level have only been broken down by religion since the 2001 Census. Consequently, detailed studies of the dynamics of vertical inequality across various categories of horizontal diversity frequently get derailed by data scarcity, whether one wants to study them quantitatively or merely intends to identify promising field sites for qualitative research. Ultimately, the empirical basis on which policy decisions could be made thus remains fairly coarse, slowing attempts to make growth inclusive in South Asian societies.
In contrast, name lists are frequently available in higher resolution than other data; in India, for example, one can easily access electoral rolls on the election booth level, BPL lists on the block level, land records on the street level, university admission databases on the departmental level, and so on. Inspired by the observation that names around the world have social and religious connotations, this article introduces an open-source computer algorithm that attempts to infer population shares of minorities by probabilistically exploiting the religious connotations of names on such extensive lists while accounting for the empirically blurred nature of group boundaries. Although software lacks access to many additional clues on which people base their assessment of others (such as dress, language, spatial context, etc.), it does possess the advantage of scalability. Given sufficiently distinct name distributions, such software is capable of probabilistically minimizing errors across large data sets, resulting in reliable statistical inference. In the present context, this approach is the only feasible option to generate spatially and temporally fine-grained disaggregate statistics on religious demography across South Asia.
So, what’s in a name? After briefly reviewing earlier attempts to infer religious demography from name lists, this article describes the algorithm’s probabilistic logic and the name reference list used for classification, evaluates its accuracy against an independent gold standard, introduces a sample data set, and suggests further potential applications, while also reflecting on ethical limitations and pitfalls. On balance, I conclude that inferring religious community from South Asian names is a statistically and ethically viable second-best option for studies of religious demography as long as primary data remain inaccessible for political or practical reasons.
Existing Techniques
Research in the anthropology of kinship, demography, and public health has long established that “contemporary name frequency distributions retain distinct geographic, social and ethno-cultural patterning that can be exploited to understand population structure” (Mateos et al. 2011:2). In the South Asian context, too, names signify social structure in multiple ways: Surnames often bear regional, caste, or occupational connotations; given names can suggest religious community; and both frequently allow educated guesses about class. Although none of these significations are definite and all will vary with social and spatial context, most names are distinct enough for a reliable approximation of the religious composition of large name lists.
Some recent studies successfully used this coloring of names to enable more fine-grained analyses of social or political issues involving religion in South Asia, particularly in India. The Sachar Committee relied on name classification to identify Muslims on government payrolls and lists of beneficiaries in centrally sponsored development schemes (Sachar et al. 2006). Field et al. (2008) and Galonnier (2012) classified names on the electoral rolls of Ahmedabad and Aligarh to establish the extent of Muslims’ residential segregation. Jaffrelot and Kumar (2009) explored the religious and caste background of legislators, again partly relying on name matching. Likewise, Bhalotra et al. (n.d.) used name matching to analyze the role of legislators’ religious affiliation in communal violence. Most of these studies, however, matched names to religious community by hand, often relying on several local experts—a strategy not feasible for larger data sets.
In the wider field of computational linguistics, several research teams attempted to automate the matching process. Two software packages were designed specifically to classify South Asian names: Nam Pahchan (Macfarlane et al. 2007) and SANGRA (Nitsch et al. 2009). Both, however, concentrate on classifying ethnicity in an European context and output religion only as a by-product; moreover, neither algorithm’s source code is available in the public domain. South Asia is also covered by the OnoMAP project, which identified empirical name clusters rather than using predefined categories (Mateos et al. 2011), but OnoMAP, too, concentrates on ethnicity rather than religion, and the avoidance of predefined categories—theoretically convincing as it may be—limits comparisons and integration with existing data sources (particularly with government records).
A final shortcoming of all existing techniques, automated or not, is their focus on providing merely one “best bet” for a name bearer’s likely religion, without taking multiple possibilities or varying degrees of likelihood into account. In contrast, the algorithm introduced here approaches name matching as a probabilistic exercise throughout; it outputs not only the most plausible categorization but all potential alternatives as well as a certainty index that allows for flexible accuracy thresholds. This corresponds to the empirical messiness of name distributions and the fact that group boundaries are often blurred; the algorithm does not feign clarity if a name's connotations are inconclusive. The algorithm also specifically concentrates on religion, is capable of processing input in a range of Indian scripts as well as Latin transliteration, and integrates fuzzy soundex matching technology to alleviate the impact of spelling variants as well as, to an extent, misspellings. Finally, the algorithm and a sample data set (covering the religious demography of India’s largest state, Uttar Pradesh) are available under open licenses (Susewind 2013).
Reference List
The accuracy of name classification algorithms such as the one proposed here relies heavily on the quality of the reference list against which an individual’s name parts are matched. The reference list used here has been extracted from the website indiachildnames.com, a database that links roughly 23,000 given names to gender and the religious categories Hindu, Muslim, Sikh, Christian, Jain, Parsi, and Buddhist. It also lists 4,200 surnames, but apart from Christian and Muslim names, these are classified by regional origin rather than religion. Such regional names were fed into the matrimonial website vivaah.com; if the name was found in advertisements from a specific religious community at least twice as often as in those from the second-most-frequent community, it was categorized accordingly.
Importantly, the resulting reference list does not indicate the empirical frequency of names in different communities, merely whether they are thought to exist in a community at all. It is thus neither possible to estimate the convergence of the reference list with empirical name distributions nor does the probabilistic logic depend on this information. Moreover, 13% of all names were listed with more than one religious connotation, with Jain and Sikh names being particularly ambiguous: They overlap with Hindu names by 52% and 26%, respectively; the algorithm might thus be less successful in distinguishing between Hindu, Sikh, and Jain populations. Geographically, the reference list covers all of South Asia, even though the algorithm arguably works best in the North Indian, Pakistani, Nepali, or Bangladeshi context, where names tend to consist of a sequence of given names potentially prefixed by honorific titles and followed by family or caste names as well as designations of regional origin (Haroon 1984:23). South Indian and Sri Lankan conventions in contrast often prioritize village names, which are not specific to any religion and are also frequently abbreviated, as are (upper) caste names—a practice that significantly reduces the textual material available for classification and consequently reduces accuracy.
Finally, the reference list comes in Latin script, but was transliterated into a range of Indian scripts frequently used on public name lists using Google’s transliterate service. The algorithm can thus process input in Bengali, Gujarati, Hindi, Kannada, Malayalam, Oriya, Punjabi, Tamil, Telugu, as well as with limited functionality in Marathi, Nepali, Sanskrit, Sinhalese, and Urdu. Moreover, it incorporates the fuzzy IndicSoundex algorithm developed by Thottingal (2009), which matches names based on pronunciation rather than spelling and thus consolidates various spelling alternatives and ameliorates the impact of typographical mistakes (so, for instance, Chowdhury and Chaudry would be considered the same name). While both transliteration and fuzzy soundex matching introduce an unknown error margin, the evaluation below indicates that the same is outweighed by the positive effects of increased coverage.
Classification Algorithm
To achieve the actual classification, the algorithm first tries to distinguish surnames from (male or female) given names and subsequently counts how often each of those can be found in the respective subset of the reference list, noting the community suggested by each match. If no matches are found, these restrictions are incrementally lifted by looking for presumably male names among female ones or for given names among surnames as well. Since each match is conducted once according to spelling and once according to pronunciation, this first step results in a record similar to Table 1, which lists all matches for this article’s example, the fictional Mohammad Ram Lal Yadav, a person of unknown gender.
Number of Matches in the Reference List, Broken Down by Religious Connotation.

In a second step, a certainty index for each name part/community combine is calculated and further multiplied with the percentage of unambiguous names in the respective subsets of the reference list, assuming that increased overlap in a whole class of names or matching procedure renders this entire class or procedure less reliable. If, for instance, surnames matched by spelling tend to be less ambiguous than female given names matched by pronunciation, the “quality factor” applied to them would be higher too. The certainty index for the suggestion that name part X signifies community Y is calculated as follows. Let spelling (X) and pronunciation (X) be the frequency of this name part across all religious communities on the reference list, matched according to spelling and pronunciation, and let spelling (X, Y) and pronunciation (X, Y) be the frequency with which spelling or pronunciation matches indicated community Y: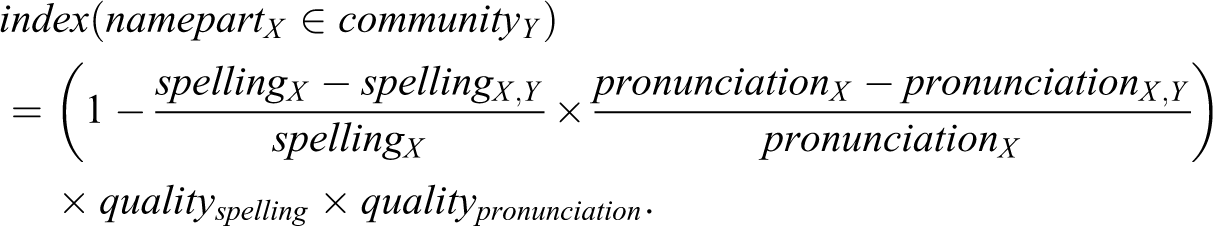
The outcome of this second step for Mohammad Ram Lal Yadav is listed in Table 2 (with all quality factors assumed to be 1 for the sake of simplicity). The certainty index is not a straightforward probability, nor does it necessarily reflect the likelihood of a given name part/community combine in empirical name distributions. The index does, however, vary between 0 and 1 for each name part/community combine, and rises if a classification seems more trustworthy (and, in this sense, likely).
Certainty Indices for Each Name Part/Community Combination.

In a final step, the certainty indices of individual name parts are further aggregated to arrive at an overall best bet and list of alternatives. This second step uses the following formula, with name parts reflecting the absolute count of name parts (in the example, this would be four) and entries reflecting the total number of matches in the reference list with either procedure (in the example, this would be 34):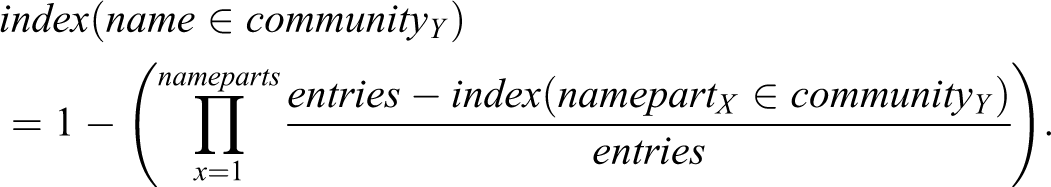
Based on this second aggregation, the algorithm guesses that Mohammad Ram Lal Yadav seems to be Hindu with a certainty index of .33, which is 16 index points more likely than him or her being Parsi, 19 index points more likely than him or her being Muslim, and 30 index points more likely than him or her being Christian. As mentioned before, these certainty indices are not to be confused with straightforward probabilities, but nonetheless indicate rank. How accurately this classification reflects the religious identity of Mohammad Ram Lal Yadav (i.e., the category legally assumed for matters of personal law or for purposes such as the decennial census) is evaluated in the next section.
Evaluation of Accuracy
Accuracy of name-matching algorithms can principally be assessed from two angles: with respect to the algorithm’s internal working—how often and how clearly does it succeed in providing a classification at all and does its probabilistic logic seem convincing?—and to an external gold standard—how well does this classification reflect the real world, especially the self-categorization of individuals involved? As to the first question, the breadth of the reference list and the relatively low ambiguity of its classifications ensure that the algorithm succeeds in classifying most names, albeit with varying certainty. Still, the extent of errors remains inestimable since the reference list does not reflect empirical name distributions. More important, therefore, is the evaluation against an external gold standard.
How well the algorithm reflects such a standard depends on both the specific list of names to be classified and on the religious categories of interest. The following remarks are limited to one exemplary context drawn from my own field of research; they only evaluate how well the algorithm categorizes Muslim versus non-Muslim names in Uttar Pradesh, India. This example seems appropriate for three reasons. First, Muslims are the state’s poorest religious minority, so understanding social exclusion better is arguably most urgent in their case (Sachar et al. 2006). Second, Muslim names in North India are also linguistically more distinct than those of other religious communities for historical reasons, making name matching a particularly promising technology (Christian names are similarly distinct, but frequently adopted as modern or Western names across the religious spectrum and thus no reliable indicator of religious demography). Finally, Muslims were chosen for the pragmatic reason that an independent test corpus of Muslim and non-Muslim names from Uttar Pradesh was readily available.
This test corpus consists of the names of 10,249 Hajj pilgrims from Uttar Pradesh in 2012, the names of 2,305 undergraduates admitted to Lucknow University through the scheduled caste (SC) quota in the same year, and the names of the 6,752 candidates who contested Uttar Pradesh’s state elections since independence. Since non-Muslims are legally barred from the Hajj and Muslims are legally barred from claiming SC benefits, the first two lists are mutually exclusive, while the third was manually categorized by Gilles Verniers (Jaffrelot and Verniers 2012). In addition to a Muslim/non-Muslim classification, the first two lists contain both a person’s own and his or her father’s (or male relative’s) names, while the third provides names and gender. Since the test corpus consists of roughly the same number of Muslim and non-Muslim names, the latter were randomly duplicated until the overall ratio reflected the religious demography of Uttar Pradesh; this does not affect sensitivity and specificity, but renders more meaningful positive and negative predictive values.
Accepting this test corpus as an external gold standard, the algorithm demonstrated a sensitivity (i.e., a rate of “true” Muslims classified correctly) of 96% and a specificity (i.e., a rate of true non-Muslims classified correctly) of 99%. The algorithm’s positive predictive value (i.e., the rate of true Muslims among all those identified as Muslims) stood at 95% and its negative predictive value (i.e., the rate of true non-Muslims among all those so identified) at 99%. Overall, 5% of names could not be classified and were discarded. Compared to other name matching technologies reviewed by Mateos (2007), the algorithm proved to be very capable of identifying Muslim population shares in this test corpus, which likely reflects both the distinctness of empirical name pattern among Muslims and non-Muslims in Uttar Pradesh and intrinsic advantages of the algorithm over earlier technologies, such as the fuzzy soundex logic.
One could potentially refine the outcome further by excluding unclear matches that either fall below an absolute threshold in the certainty index or whose certainty indices do not differ enough from the second most likely categorization. Such thresholds will always be a trade-off between coverage and accuracy; in this specific example, they did not markedly improve accuracy but significantly reduced coverage, so that even those classifications for which was the best bet seemed only marginally more likely than the second-best alternative were taken into account. In other contexts and/or to differentiate between other religious categories, flexible thresholds might be useful and might constitute a major advantage of this algorithm over earlier ones.
To reasonably assume a similarly high accuracy in categorizing a wider population, it is important to consider how the names in the test corpus might differ from those in this wider population. Those Muslims going on the Hajj, for instance, are arguably older, as are candidates in state elections—while university students are younger. Students admitted under the SC quota also tend to come from lower economic strata—a bias arguably offset by an elite bias in the list of candidates. Finally, the kind of names found in the test corpus might differ in clarity from the average Muslim and non-Muslim name. One could argue that those going on the Hajj tend to come from more pious backgrounds and might thus carry less ambiguous names; they might also hail from the richer sections of society, which, among north Indian Muslims, often means an Ashraf origin discernible in names drawn from Arabic or Persian heritage. With the SC admission lists, one could argue the opposite: Individuals on these lists tend to be poorer and less educated; thus, their names might on average be less Sanskrit, Arabic, or Persian in origin than that of an average non-Muslim. In the absence of empirical studies on naming practices in North India, it is hard to conclusively assess these potential distortions, but even with a generous margin of error, the algorithm’s accuracy would remain pretty high.
Ethical Implications
The mere fact that a new methodology is technically feasible does not mean that it is normatively unproblematic. This begins with the underlying notion of a stable communal identity and clear-cut group boundaries (Mateos 2011). Names are usually given by parents and need not reflect much more than that: The experience and (inter-)subjective meaning of “being Muslim” (or Hindu, Christian, Parsi, Sikh, Buddhist, or Jain) goes far beyond the respective legal category. This problem is not specific to the methodology suggested here, however, but is similarly problematic in the context of other data sets, such as the Indian Census. While it remains worth emphasizing that there can never exist a wholly accurate method of coding religion based on names because neither religious names nor religious categories exist as objective, bounded entities, religious categories do exist as statistical approximations. By explicitly taking a probabilistic stance, this algorithm tries to circumvent some of the ethical problems scholars have rightly identified in endeavors such as the ongoing Indian Caste Census. Often, the resulting data, simplified as their categories may be, should be better than the alternative: having no data at all or only insufficiently disaggregated sets.
More problematically, however, names have not only been used to discriminate (literally, distinguish) people but also to discriminate against them, for instance, on the housing market. More dramatically, rioters involved in major bouts of Hindu–Muslim violence are known to have used name lists to identify their targets. Unfortunately, the ethical implications of this and similar big data methodologies vis-à-vis such abuse are far from straightforward, and the process of formulating ethical guidelines is still very much in its infancy (Boyd and Crawford 2012:672). On the one hand, all name lists mentioned in the introduction—electoral rolls, admission lists, property records, or BPL lists—are in the public domain, as is knowledge about religious connotations of names. On the other hand, the algorithm makes these existing data and knowledge significantly more accessible by automating the matching process, effectively generating data otherwise considered too sensitive to be published, and doing so based on name lists not originally intended for this purpose. While accessibility is often valuable and desirable—not least to better understand religion-based discrimination and inequality—the new analytical possibilities this opens up have to be weighed against the risks that might go with them.
These risks differ with context and scale. In the Indian context, for instance, discrimination as well as violence against religious groups tends to be orchestrated on the local level; although parts of the state machinery have often been implicated for their slow and indecisive interventions, it is hard to see systematic, sustained, and large-scale state-led exclusion on the basis of religion. On the local level, however, the algorithm arguably makes the least difference: If rioters wish to identify members of a particular community in a few urban neighborhoods, they can easily match the electoral register by hand (and have done so in the past); likewise, if property owners wish to not rent to members of a particular community, they do not need a statistical tool to identify those community members. However, the algorithm plays out its computational strengths on larger scales of application, and it is on these scales that more fine-grained analyses of religion-based social exclusion might ultimately allow the state to better combat the same. Whether such political action will materialize is beyond the scope of this article, but without appropriate data, good policy design, implementation, and evaluation would certainly remain difficult.
Overall, the ethical benefits from employing name-matching technology thus arguably outweigh the risks in the South Asian context—even though a final ethical assessment will have to be made in the context of specific research applications.
Potential Applications and Sample Data Set
This article began by noting the scarcity of data on religious demography in South Asia, and in India in particular, and suggested exploiting the connotations of names as a probabilistic work-around. I presented a computer algorithm that automates this process and evaluated its accuracy with respect to one particularly relevant example: the identification of Muslim names in North India. The algorithm is not, however, limited to this task. In which development blocks of Pakistani Punjab are Sikhs underrepresented in the BPL lists? Why did Yadavs in Bihar not vote for the Samajwadi Party? How strong is religion-based residential segregation in rural versus urban areas of Bangladesh? These are just some of the questions that could potentially be explored with more fine-grained demographic data. The algorithm presented here allows us to generate such data.
To enable colleagues to experiment with this approach, I recently compiled a comprehensive data set on religion and politics in Uttar Pradesh (Susewind 2013). The data set combines election results, spatial data, and census records with an estimate of religious demography derived from the algorithm introduced in this article. The smallest unit of measurement is that of a polling booth, which serves roughly a 300-meter radius in urban areas or a small village in rural ones. Like the algorithm itself (which is available in an online supplement to this article), this data set is published under an open share-alike license and continuously updated. In Susewind and Dhattiwala (2014), we provide a first empirical application of this data, demonstrating that Muslims in Gujarat and Uttar Pradesh made much more localized electoral choices in the 2014 national elections than previously assumed and testing a variety of factors that might account for such spatial variation.
Conclusion
Names are important signifiers of social categorization, which, in turn, build the basis for many sociological studies. As long as official data on religion remain inaccessible for political or practical reasons in South Asia, inferring religious demography from the coloring of names might thus remain the only feasible way of making this basis more fine grained and reliable. This article has shown how such an approach can remain attentive to degrees of probability while nonetheless rendering fairly accurate approximations.
Footnotes
Acknowledgment
I thank Björn Alpermann, Kurt Salentin, Neelanchan Sircar, the editor of this journal, and three anonymous reviewers for their helpful suggestions; Gilles Verniers for his data set on Muslim legislators in Uttar Pradesh; and Santhosh Thottingal for the IndicSoundex technology. I would also like to acknowledge the use of the University of Oxford Advanced Research Computing (ARC) facility for helping me carry out this work.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.