
Abstract
Audit correspondence studies are field experiments that test for discriminatory behavior in active markets. Researchers measure discrimination by comparing how responsive individuals (“audited units”) are to correspondences from different types of people. This article elaborates on the tradeoffs researchers face between sending audited units only one correspondence and sending them multiple correspondences, especially when including less common identity signals in the correspondences. We argue that when researchers use audit correspondence studies to measure discrimination against individuals that infrequently interact with audited units, they raise the risk that these audited units become aware they are being studied or otherwise act differently. We also argue that sending multiple pieces of correspondence can increase detection risk. We present the result of an audit correspondence study that demonstrates how detection can occur for these reasons, leading to significantly attenuated (biased toward zero) estimates of discrimination.
Audit correspondence studies are a popular type of field experiment used to detect and measure discrimination (Bertrand and Duflow 2017). Audit studies are considered the gold standard for detecting discrimination, which otherwise may go undetected in more traditional methods, such as surveys or in-person interviews, because such behavior is often illegal or not revealed due to social desirability bias.
In audit correspondence studies, the researcher contacts individuals (e.g., politicians and landlords) or businesses, most frequently using email, to inquire about a service, seek employment, or ask a question. These individuals or businesses are the “audited unit.” In these correspondences, the researcher randomly assigns signals, such as names or other self-disclosed characteristics, that signal a specific identity (e.g., race, ethnicity, and gender) or attribute (e.g., education level and occupation) of the inquirer. Suppose the audited units respond less to a correspondence containing one type of signal (e.g., African American) compared to correspondences containing a different signal (e.g., White). In that case, this provides evidence that the audited units are discriminating against individuals possessing this signal. In a famous example, economists Bertrand and Mullainathan (2004) sent resumés containing stereotypical white names (e.g., Emily and Greg) and stereotypical black names (e.g., Lakisha and Jamal) to job openings. They found that resumés containing white names received 50% more callbacks for interviews.
In recent years, there has been a proliferation in the use of audit studies to study discrimination in new and emerging markets (e.g., the “sharing economy”), discrimination against smaller minority groups (Weichselbaumer 2015), and based on multiple treatments such as intersectional identities (e.g., Button et al. 2021; Edelman et al. 2017).
In these new contexts, the proper design of audit correspondence studies is even more critical. Sending correspondences that (1) signal that the inquirer belongs to a community that are infrequent customers, constituents, or clients of the audited unit (e.g., same-gender married couples) or (2) contain specific attributes that are unlikely to be disclosed (e.g., unsolicited information) increases the risk of detection by audited units. 1 Detection is also more likely to occur when researchers send multiple pieces of correspondence, audited units do not receive correspondence often, the correspondence pieces are similar to each other, or they are sent with little time delay between them. The increased risk of detection must be contrasted with the benefits of sending more pieces of correspondence (i.e., increased statistical power and/or contexts where data collection costs are high). However, it can be difficult for researchers to assess the extent of detection risk.
Regardless of its source or cause, detection leads to biased estimates of discrimination: Audited units may change their behavior if they think they are being monitored (i.e., an observer effect) or think the correspondence they get is unusual.
To show how exposing audited units to multiple infrequent identity signals and multiple correspondence pieces raises detection risk, we present the results of an email-based audit correspondence study of sexual orientation discrimination by mortgage loan originators (MLOs) in the United States. We find evidence that being exposed to more than one infrequent identity signal and multiple pieces of correspondence (three or more) significantly increase the likelihood of detection. This evidence stems from our discrimination estimates differing significantly between our “full sample,” where MLOs received four emails total in a month (two from same-gender couples), and “restricted samples,” where the MLOs were not exposed to multiple infrequent identities (i.e., they received an email from only one same-gender couple) or more than two pieces of correspondence.
While we do not know for certain the extent each MLO detected the experiment, the drastic changes in our discrimination estimates across samples with and without multiple exposures to infrequent identities strongly suggest that detection occurred. Our discrimination estimates in our restricted samples are two to three times greater relative to the full sample. Thus, the attenuation bias in our case study, likely due to detection, was severe.
Our finding that detection appears to have occurred and led to significant bias is critical for researchers to consider when designing correspondence studies. Deciding how many pieces of correspondence to send requires researchers to weigh the benefits of increased statistical power (and the ability to make within-unit comparisons) with increased detection risk (and thus bias). While detection risk is often unclear, we argue that when researchers send two or more pieces of correspondence from groups that audited units infrequently interact with or are otherwise atypical, they significantly increase the risk of detection and thus bias. We further posit that detection risk also exists when researchers send more than two pieces of correspondence, especially in a short period and when the correspondence is otherwise similar.
How Many Pieces of Correspondence Should Researchers Send?
Researchers face tradeoffs in how many pieces of correspondence they send to each audited unit. There are several benefits to sending more correspondences, including increased statistical power, reduced data collection costs, and the ability to make within-audited unit comparisons. However, sending more than one correspondence increases the risks of detection or spillovers, both of which could bias estimates of discrimination and invalidate the study. It also imposes additional time costs or other costs onto audited units. Below, we summarize these costs and benefits and existing research on them. 2 This article’s contribution is to illuminate the risks and costs of detection, a concern for which little is known.
Statistical Power
The primary benefit of sending more pieces of correspondence is that it can significantly increase statistical power. Sufficient statistical power is required to detect meaningful levels of discrimination. Sending, for example, two correspondences per audited unit rather than one will double the sample size (although not quite double power—see Lahey and Beasley 2018).
Including multiple correspondences per audited sample can be critical in certain study contexts where there is a finite sample of audited units (Vuolo et al. 2018) or experiments that include multiple groups or treatment arms. The benefits of sending additional pieces of correspondence are higher when correspondence to the same audited unit tend to be treated similarly (i.e., there is sufficient “concordance,” see Vuolo et al. 2018).
Reduced Data Collection Costs
Assuming a fixed cost of collecting information on each audited unit (e.g., finding an email), sending multiple pieces of correspondence to each audited unit often decreases data collection costs (i.e., cost per observation) by reducing the total number of audited units required in the study to measure a given level of discrimination.
Within-Audited Unit Comparisons
Sending multiple pieces of correspondence to each audited unit allows for within-audited unit comparisons. If audited units receive more than one correspondence, the researcher can include an audited unit fixed effect to control for important factors such as organizational culture, community demographics, local laws, and other audited unit characteristics. While most studies do not require the inclusion of these fixed effects since the correspondence sent to audited units is randomized, fixed effects do allow the researcher to control for fixed differences between audited units that may differ based on treatment status.
Spillovers Within an Audited Unit: Detection Risk and Induced Competition
Sending additional correspondence to each audited unit, however, can lead to spillovers, where pieces of correspondence within the same audited unit affect each other. Spillovers violate a required assumption for an experiment to have an unbiased estimated treatment effect: the stable unit treatment value assumption (SUTVA). Simply put, SUTVA means that each piece of correspondence is unaffected by other pieces of correspondence. Spillovers can occur for a few reasons, some of which are relevant in the context of this study (i.e., an audit of MLOs), while others are more relevant in other contexts (i.e., labor market audits).
Detection Risk
A common concern in audit studies is that the experiment is detected (audited units think something odd is happening, such as some enforcement action, a bot sending emails, etc.). Detection is a source of spillovers and can similarly bias discrimination estimates.
Detection risks are high if the correspondences are unusual, which is why researchers typically invest significant effort in making their correspondences appear typical. 3 However, even if the researcher sends normal-looking correspondence, it may be odd to receive multiple very similar correspondences (i.e., containing similar language) too close together or from members with whom the audited unit rarely interacts. Consider the audited unit in this study: MLOs, who help customers get mortgage loans. It may be relatively infrequent, but not unusual, for an MLO to interact with same-gender married couples. However, it may be improbable for an MLO to receive multiple emails in a short period from multiple same-gender couples, and it may be unusual to receive emails from frequent customers (e.g., different-gender couples) and infrequent customers (e.g., same-gender couples) that contain the same attributes. 4
The audited units could alter their behavior if they detect the experiment in some way. A priori, it is unclear how audited units would react if they knew the inquiries were fake, someone was monitoring their behavior, or they simply thought something was unusual. They could act in a way that they think is socially desirable, such as responding to all correspondences. Alternatively, they could instead see all pieces of correspondence as unusual and ignore them. Thus, changes in behavior can be thought of as statistical noise, which will attenuate estimates of discrimination (bias them toward zero). In a resume correspondence study of discrimination against lesbians, Weichselbaumer (2015) found that discrimination estimates were attenuated due to detection in a paired design (sending an application from both a lesbian and a straight woman) compared to when only one (randomized) job application was submitted.
Induced Competition
Spillovers can also occur when the pieces of correspondence compete, which Larsen (2020) referred to as “induced competition.” This could occur in audits of rental housing and, most notably, labor market audits. Phillips (2019) finds additional spillovers in many audit correspondence studies of hiring discrimination, but these types of spillovers are not relevant to our context of mortgage loan applications. 5 Larsen (2020) shows that spillovers are more common when the pool of other applications (or similar correspondence received) is smaller, which appears relevant to this study.
In the following sections, we detail an audit correspondence study that faced this detection issue. The detection issues were severe in this study—the estimated level of discrimination in the full sample is approximately 50% lower than in the samples less affected by detection. Our results demonstrate that detection issues can severely undermine the internal validity of a study. Thus, it may not be advisable to send too many pieces of correspondence as the costs outweigh the benefits.
Experimental Design
To test the likelihood of detection and spillover effects from sending multiple emails signaling infrequent identities, we used data from our audit correspondence study on sexual orientation discrimination in access to mortgage loans. Specifically, we conducted an email-correspondence study testing if MLOs discriminate against same-gender couples requesting assistance obtaining a mortgage loan. We initially designed our experiment as a pilot study. However, it serves the additional, unexpected purpose of being a case study in how the number and type of correspondences sent can cause detection and spillover issues.
We conducted our small-scale study with a convenience sample of 118 MLOs across all regions of the United States. To generate our sample, we collected publicly posted MLO email addresses through various websites (individual bank websites, Yellow Pages, Better Business Bureau, and LinkedIn).
In our experiment, each MLO received four emails, one week apart, in random order: one email from a same-gender male couple, one from a same-gender female couple, one from a different-gender couple with a male email sender, and one from a different-gender couple with a female email sender. We conducted our experiment between September and October 2018.
Our experiment’s general design follows similar email-correspondence studies (Ahmed and Hammarstedt 2009; Hanson et al. 2016; Schwegman 2019). In each email, following Ahmed and Hammarstedt (2009), we signaled sexual orientation by having each fictitious applicant introduce themselves as well as their wife or husband. Our Online Appendix A presents the templates for our emails and the email component and additional details about the experimental design.
Our primary measure of discrimination is whether the MLO responded to the original email. We considered a response to be one that appears to be written by a human. Thus, out-of-office or other automated responses were not counted as a response. We only consider responses sent within two weeks of the original inquiry email (following Hanson et al. 2016).
In this experiment, we consider same-gender customers to be infrequent customers. Since it is not unrealistic for an MLO to interact with a same-gender couple, a single inquiry from a same-gender couple is unlikely to raise concern. However, sending multiple somewhat similar correspondences and, most notably, multiple similar correspondences from same-gender couples, especially in a short period, could increase detection risks. Unless the MLO operates in specific urban markets with a large population of same-gender couples, it is unlikely that an MLO will receive an inquiry from multiple same-gender couples in the same month.
Statistical Estimation Methodology
Before we present how we determine how detection affects our estimates of discrimination, we first present how we estimate discrimination in our experiment. Our primary outcome is if there was a non-automated response to our inquiry. To quantify differences in response rates by couple type, we use a linear regression model of the form
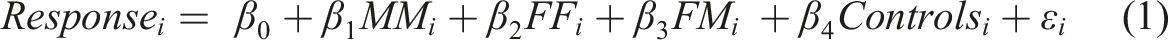
Comparison of Full and Restricted Samples.
Note: See the notes to Figure 1. Different/Diff. = different-gender couple; Same = same-gender couple; the sample size for the full sample is 469, 258 for restricted sample #1, 204 for restricted sample #2, and 118 for restricted sample #3.
To test if MLOs change their behavior when receiving (and after receiving) a second same-gender email, we compare the full sample (Panel A) to restricted sample #1 (Panel B). In restricted sample #1, we drop all second same-gender emails and any emails we sent after the second same-gender email (“DROPPED”). Comparing discrimination estimates between the full sample and restricted sample #1 allows us to test if discrimination estimates differ if the sample includes cases where the audited unit (MLO) received more than one piece of correspondence from an uncommon group, that is, same-gender married couples.
We also consider restricted sample #2, where we restrict the sample further by removing any round 3 emails not already excluded from restricted sample #1, and restricted sample #3, where we restrict to only the first-round emails. Comparing discrimination estimates among restricted samples #1, #2, and #3 allows us to determine if sending additional emails, conditional on only sending one email total from a same-gender married couple, causes any detection issues compared to just sending up to two emails. 6
Results
Before presenting our regression results for how discrimination estimates varied by our sample, we first present response rates by round. Figure 1 presents the response rate to emails from round 1 (the first email the MLO received) to round 4 (the fourth email the MLO received, four weeks later). Figure 1 shows that many MLOs changed their behavior between rounds and did so differently if the email was from a same-gender or different-gender couple. The MLOs’ response rate to different-gender couples was relatively constant in the first three rounds: 70.8%, 73.7%, and 72.1%. However, for same-gender couples, the response rate gradually increased from 42.9% to 50.8% to 60.4%. In round 4, response rates changed dramatically. The response rate for same-gender couples dropped to 42.9%. The response rate for different-gender couples dropped far below this, to 26.2%, the lowest response rate for either group for any round. Thus, discrimination appears to decrease rapidly by round, to the point that same-gender couples appear preferred in round 4. Response rates by email round and sexual orientation, full sample. Notes: Each round was about 1 week apart. Round 1 was at 1 p.m. CST on November 18, 2018; round 2 was at 2 p.m. CST on November 26, 2018; round 3 was at 11 a.m. CST on December 2, 2018; round 4 was at 9 a.m. CST on December 10, 2018. We present 95% confidence intervals for each mean response rate. Couple type within the same round is significantly different from each other at 1% level (***), 5% level (**), or 10% level (*), using a two-sided Fisher’s exact test.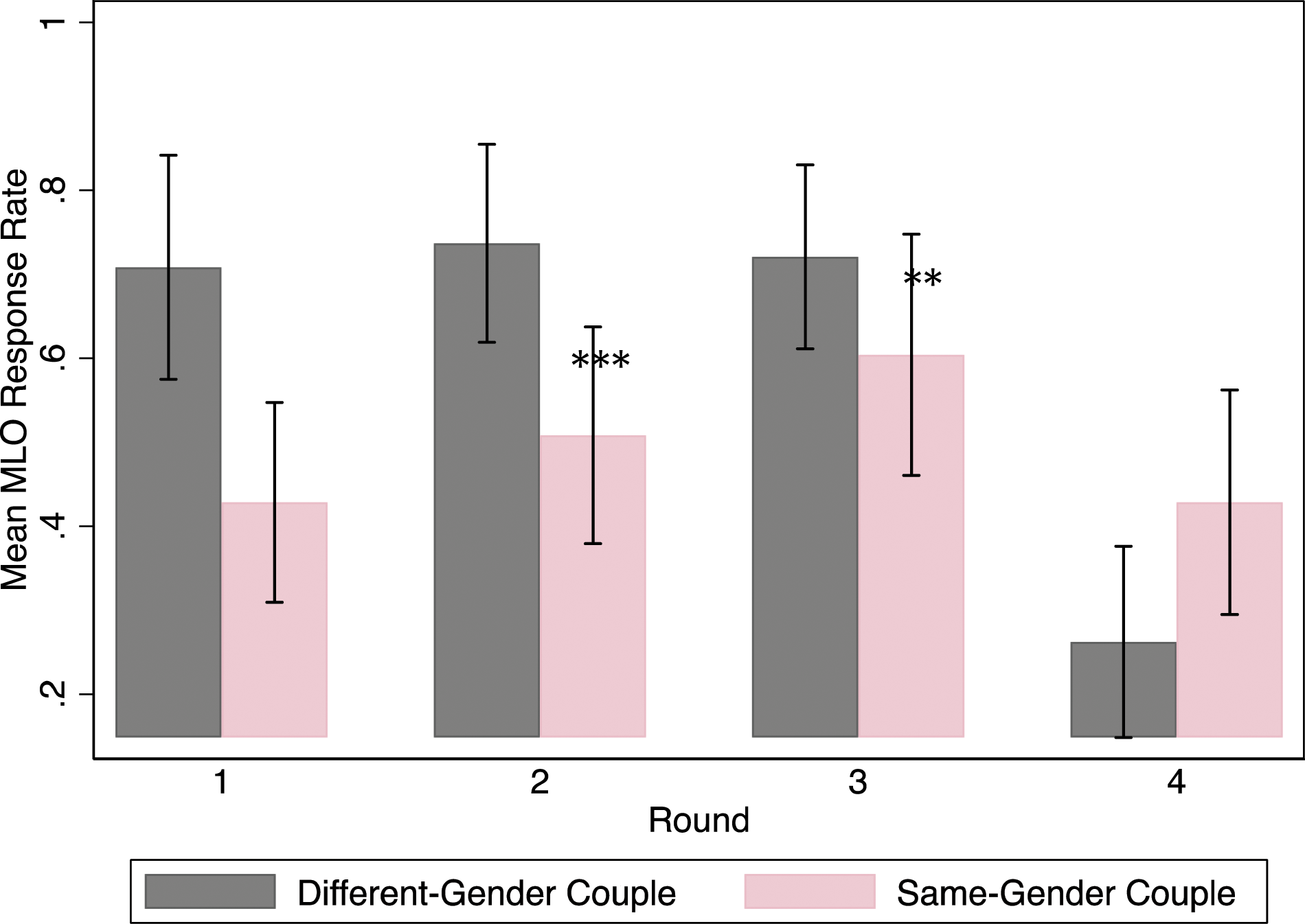
Regression Estimates for MLO Response, by Type of Married Couple.
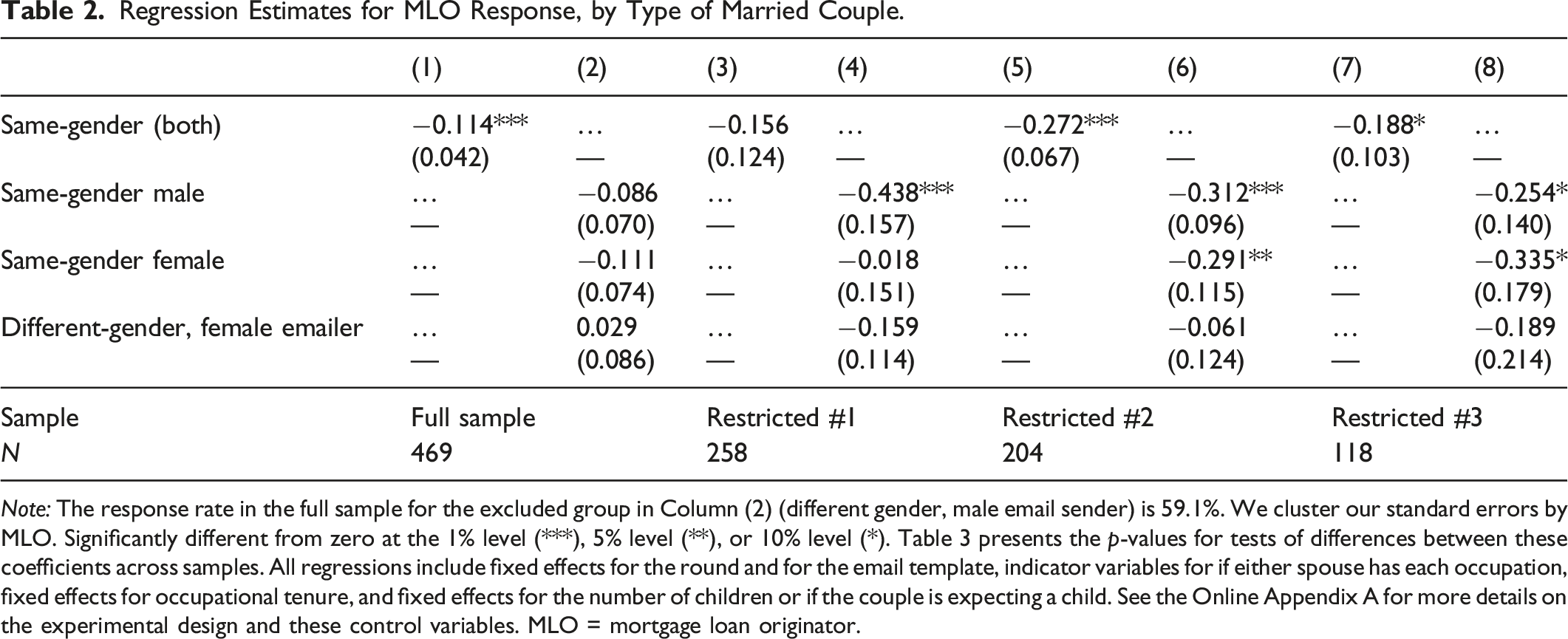
Note: The response rate in the full sample for the excluded group in Column (2) (different gender, male email sender) is 59.1%. We cluster our standard errors by MLO. Significantly different from zero at the 1% level (***), 5% level (**), or 10% level (*). Table 3 presents the p-values for tests of differences between these coefficients across samples. All regressions include fixed effects for the round and for the email template, indicator variables for if either spouse has each occupation, fixed effects for occupational tenure, and fixed effects for the number of children or if the couple is expecting a child. See the Online Appendix A for more details on the experimental design and these control variables. MLO = mortgage loan originator.
p-Values for Tests for Differences in Same-Gender Coefficients Across Samples.
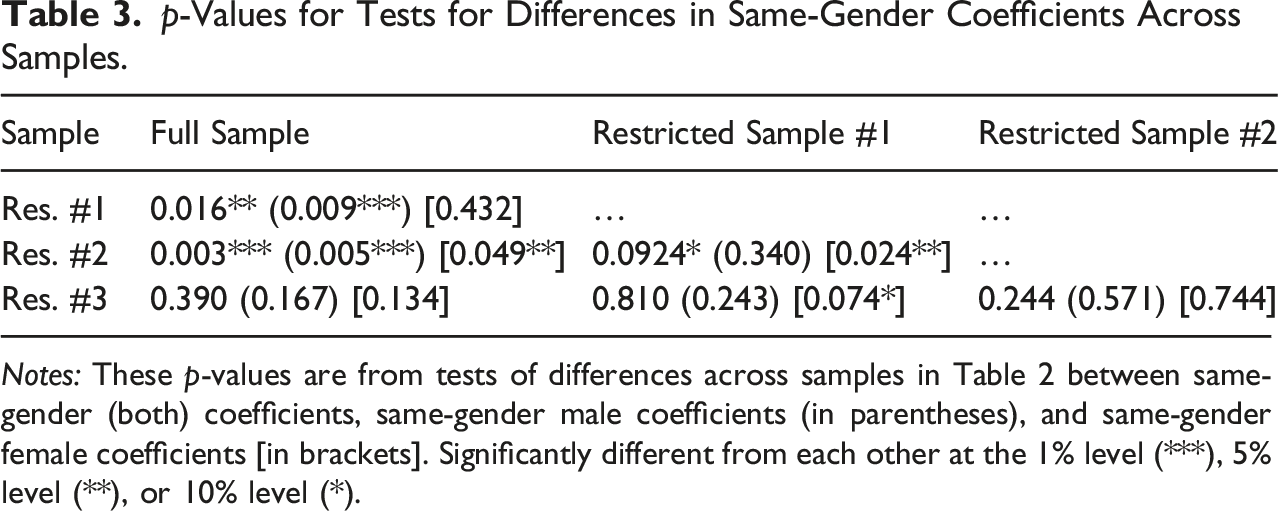
Notes: These p-values are from tests of differences across samples in Table 2 between same-gender (both) coefficients, same-gender male coefficients (in parentheses), and same-gender female coefficients [in brackets]. Significantly different from each other at the 1% level (***), 5% level (**), or 10% level (*).
Starting with the full sample and Table 2, Column 1, we find that same-gender couples were 11.4 percentage points less likely to receive a response compared to different-gender couples (significant at the 1% level). In Column 2, we separate the same-gender indicator into separate indicator variables for same-gender male couples and same-gender female couples. While we find large negative coefficients, these differences are not statistically significantly different from zero.
When we restrict the sample so that MLOs have only received one same-gender email (restricted sample #1, Columns 3 and 4), we generally find a larger estimate of discrimination, although the estimates are noisy. The estimated level of discrimination faced by same-gender couples (Column 3) slightly increased from 11.4 to 15.6 percentage points. However, this estimate has a large standard error, and it is therefore not statistically significant. We do, however, find that the difference between these two coefficients is statistically significant at the 5% level (Table 3, Panel A). Male same-gender couples are 43.8 percentage points (significantly at the 1% level) less likely to receive a response compared to different-gender couples with a male emailer. This change in coefficients is significant at the 1% level (Table 3, Panel B). For same-gender female couples, the response rate in restricted sample #1 is the same as for different-gender couples, and there is no difference in the coefficient compared to in the full sample.
We then further restrict our sample to restricted sample #2 (Columns 5 and 6), the results show even more discrimination against women and same-gender couples. Column 5 shows that the response rate was 27.2 percentage points lower for same-gender couples compared to different-gender couples (significant at the 1% level), with discrimination estimates being similar by gender (Column 6). As shown in Table 3, the restricted sample #2 coefficients are statistically significantly different from those in both restricted sample #1 and the full sample.
Finally, for restricted sample #3 (Columns 7 and 8), the estimates are much noisier due to the very small sample size. They are similar to the estimates using restricted sample #2. Table 3 shows that the coefficients from restricted sample #3 do not differ from restricted sample #2.
Discussion and Conclusion
The results from our audit correspondence study show that some MLOs may have become aware of our study and changed their behavior for two reasons. First, after receiving more than one email from infrequent customers (i.e., same-gender couples), we find that MLOs discriminate less. This can be seen when comparing discrimination estimates between the full sample and restricted sample #1, which only includes cases where the MLO was exposed to one same-gender email. We hypothesize that the decrease in measured discrimination between these two samples is from MLOs responding to same-gender couples more often (social desirability bias) and, by email round 4, responding less often to everyone (causing additional attenuation bias). Both lead us to underestimate discrimination.
Second, there is also evidence that receiving multiple similar correspondences in a short period of time, even if only one comes from an infrequent customer, also led to attenuation bias. This can be seen by comparing estimates between restricted samples #1 and #2, where #2 drops additional different-gender emails sent to the MLO. These discrimination estimates generally increase when restricting the sample further, suggesting that these additional emails cause detection (and thus attenuation bias). Overall, once we remove observations likely tainted by detection (we use restricted sample #2 or #3), our estimates of discrimination increase by around two to three times.
Our results suggest that researchers should reduce an audited unit’s exposure to multiple infrequent signals to minimize the detection risks and resulting spillovers and bias. We suggest sending either one piece of correspondence, randomized between treatment versus control, or sending one treatment and one control piece of correspondence.
Our results also suggest that researchers should be careful when sending multiple pieces of correspondence in general, particularly beyond two pieces. Detection risk could be high in situations such as ours, where audited units do not receive correspondence all that often, the correspondence is a bit too similar, and the correspondence is not sent with long enough of a time delay. While it may be tempting to send additional pieces of correspondence to each audited unit to increase the sample size and improve scarce statistical power, the risk of bias from detection or spillovers could be very high. Sending three or four correspondence pieces could perhaps avoid these high costs of detection or spillovers only if all the following apply: The audited units frequently get similar correspondence, the correspondence is distinct from each other, there are sufficient time delays between correspondence, and the spillover concerns detailed in Phillips (2019), where correspondence such as job applications that compete with each other, do not apply.
Supplemental Material
sj-pdf-1-fmx-10.1177_1525822X211057623 – Supplemental Material for Infrequent Identity Signals, Multiple Correspondence, and Detection Risks in Audit Correspondence Studies
Supplemental Material, sj-pdf-1-fmx-10.1177_1525822X211057623 for Infrequent Identity Signals, Multiple Correspondence, and Detection Risks in Audit Correspondence Studies by Catherine Balfe, Patrick Button, Mary Penn and David J. Schwegman in Field Methods
Footnotes
Acknowledgments
We thank seminar participants at Tulane University and the Association for Public Policy Analysis and Management (APPAM), American Economic Association (AEA), and American Real Estate and Urban Economics Association (AREUEA) conferences. We also thank Lei Gao, Andrew Hanson, Joanna Lahey, and Mike Martell for helpful comments, guidance, and discussions. We thank Eva Dils and Ilan Gressel for their excellent research assistance. This study was approved by Syracuse University’s IRB (#18-176).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We thank the National Institutes of Health for funding through a postdoctoral training grant for Patrick Button (5T32AG000244-23), which funded research on this project at the RAND Corporation.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.