
Abstract
This article offers a critical examination of contemporary graph databases, such as Google’s Knowledge Graph, from the perspective of media theory, philosophy of difference, and epistemology. It argues that the fundamental data structure of the “triple,” in essence a subject-predicate-object statement, constitutes a problem immanent to the database itself. The article begins with a brief meditation on numerical mediation before examining the emergence of the Knowledge Graph through Google’s research publications. It then moves on to demonstrate that a logic of representation underlies all graph databases, and that this logic of representation operates similarly to Aristotle’s theory of perception and categorization. Drawing on Gilles Deleuze’s criticism of Aristotle, this article argues that graph databases fall into similar traps of identity and representation and are unable to understand difference in itself. In closing, it offers an initial diagnosis of the limitations of graph databases, and more specifically how Google’s graph database’s inability to interrogate difference in itself leaves the Knowledge Graph unable to represent, let alone participate in, the discovery and invention of the new.
A Meditation on Number: Enumeration and Nomination
PROMETHEUS. [ . . . ] Number too, supreme among skills, I invented for them, and letters in combination, the record of all things, the mother and crafter of poetry. (Aeschylus, 2008, pp. 457-461, 113) [N]umeracy almost always, perhaps always, precedes literacy. (Hacking, 1982, p. 287)
The traditional story of Prometheus begins with the fault of Epimetheus, his brother Titan, who was charged with distributing attributes to animals at their origin. Lacking foresight, Epimetheus ran out of attributes at the last animal, the human. At this point, Prometheus moved to correct his brother’s error, stealing the arts of civilization and fire from Zeus and gifting them to humankind, a crime for which he was chained for all eternity to have his liver eaten from his body each day by an eagle. This story runs from Hesiod to Plato’s Protagoras, where it was embedded in the history of Western philosophy. From Plato to Jacques Derrida, one could argue that philosophy’s most frequent interpretations of the story are fundamentally rooted in the gift of logos, the word, language, reason, and its technical supplementation through prosthetic supports such as writing. As Aeschylus makes clear in Prometheus Bound, this is only half the story, for Prometheus gave humans number, which he considers “supreme among skills.” Perhaps, in hindsight, this story was so often overlooked because of a problematic translation of the Greek concept of number: arithmos.
As Martha Nussbaum (1979) has artfully demonstrated in her analysis of Philolaus’ response to Parmenides and his Eleatic Conventionalism, arithmos was intimately bound up with the capacity to apprehend, recognize, and even name an object. As Nussbaum notes, the translation of arithmos as “number” is problematic because a contemporary understanding of number implies abstraction, whereas for the ancient Greek, arithmos more often conveyed the sense of that which gets counted, in contrast to the mechanism by which we count (pp. 89-90). As Nussbaum writes,
The most general sense of arithmos in ordinary Greek of the fifth century would be that of an ordered plurality of its members, a countable system or its countable parts. The notion of arithmos is always very closely connected with the operation of counting. To be an arithmos, something must be such as to be counted—which usually means that it must either have discrete and ordered parts or be a discrete part of a larger whole. To give the arithmos of something in the world is to answer “how many” about it. (p. 90)
This notion of number is that which runs from Homer to Aristotle, and it is one in which the very act of perception is dependent upon the skill of number, the ability to bound or delimit a thing such that it can be recognized as a discrete object. We call this skill enumeration, and it is only atop this skill that humans are able to recognize ordered pluralities or subdivisions of objects. It is the bedrock of all counting, classifying, and measuring. Number is, thus, also the bedrock of apperception. To be perceived is to be enumerated.
The primary story of Prometheus’ gift describes only language, and is rooted in poetry and a metaphysics of presence, most clearly exemplified by the work of Martin Heidegger. One must look to Alain Badiou, a philosopher who privileges the mathematical, for the contrasting narrative. He writes, “The Greeks did not invent the poem. Rather, they interrupted the poem with the matheme” (Badiou, 2006, p. 126). In Badiou’s mathematical ontology, existence is tied to nomination. For something to be, it must have a (proper) name. And, for Badiou, all nomination requires enumeration, save one exception, nothing. Here, we can see the alternate history of Western thought, in which the very act of signification is afforded only by enumeration, by arithmos in the Greek sense of rendering something discretely, either as an organized plurality or a part of one. In a strong interpretation, being is literally preceded by the function of enumeration and nomination, but a lighter one might instead argue that ontology is epistemologically limited by this function.
What I mean to take from all of this is that number may be the first medium, if not in ontology, then certainly in epistemology. Language, be it written or spoken, is operative across time. It is mnemotechnical; it engages in processes of hypomnesis and anamnesis that require the presumption of at least two moments. Where language operates in the interstice between moments, number can operate at a single point. Number operates in the thickness of the present moment—in what Alfred North Whitehead would term “presentational immediacy,” or what William James would call “the specious present”—by rendering the discrete and affording the immediate perception of differentiated objects prior to their recognition and representation, their naming, classification, and categorization. In so doing, it is enumeration that affords nomination, and thus, it is number that is at the bedrock of our distinctions between what is in being and non-being, what exists and what does not. Number is the primary medium by which chaos communes with order. As Ian Hacking (1982) notes, “Enumeration demands kinds of things or people to count. Counting is hungry for categories” (p. 280).
This article aims to demonstrate the importance and purchase of this line of thinking by applying it to a specific case in computation. It is in the realm of computation that the function of enumeration and its political stakes in terms of determining what does and does not exist, and subsequently what can and cannot be perceived, is most readily apparent. This article examines the enumerative processes in Google’s Knowledge Graph, which represents in many ways their plans for the future of search, and thus, Internet navigation. It begins with an overview of the technologies that undergird Google’s Knowledge Graph system, outlining the processes by which objects and relations between them get enumerated and indexed into its database. The second section takes a theoretical detour through the tensions between Gilles Deleuze and Aristotle to highlight some important aspects of the stakes of the enumerative process behind Google’s system. The third section then applies this theoretical argument more concretely to Google’s Knowledge Graph and highlights some of the key problems with its enumerative processes.
Things, Not Strings
To exist is to be indexed by a search engine . . . (Introna & Nissenbaum, 2000, p. 171)
In 2012, Google made company-wide changes to reorient their focus from “search” to “knowledge,” all of which was based on the introduction of the Knowledge Graph, a graph database that had been in the works for years and, via an in-house implementation of a C++ application program interface (API), would now automatically populate content boxes with the most relevant information related to specific queries alongside standard search results (see Figure 1). Announcing its launch, Amit Singhal—Google’s senior vice president, software engineer, and head of its core ranking team—argued that the introduction of the Knowledge Graph signaled a critical first step toward a new generation of search capable of parsing semantics, of knowing exactly what you meant by your search terms. In the past, Google had been unable to do this. Singhal (2012) writes, “It’s why we’ve been working on an intelligent model—in geek-speak, a ‘graph’—that understands real-world entities and their relationships to one another: things, not strings.” No longer would Google be parsing arbitrary data values in table strings; instead, Google’s algorithms would now have the power to enumerate things: real-world people, places, and things.
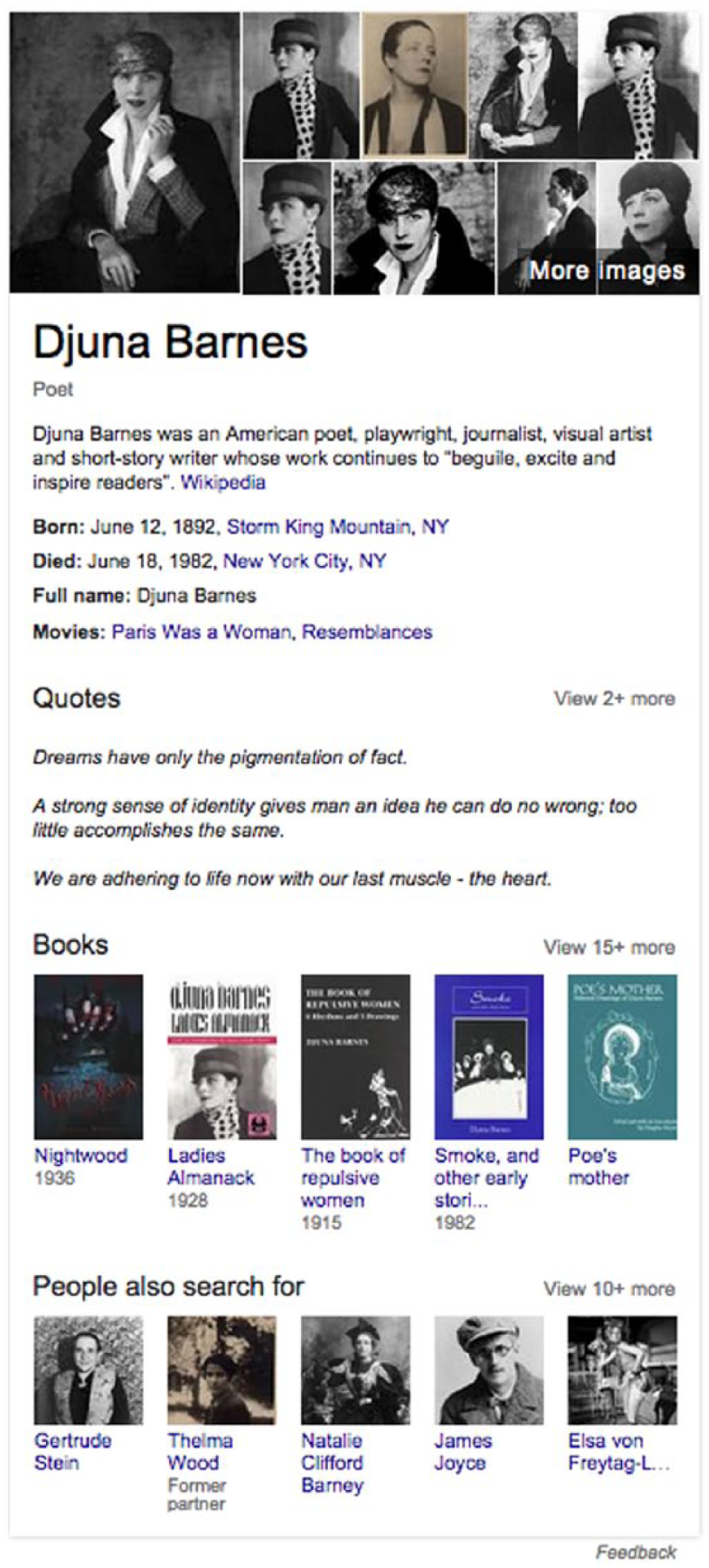
Knowledge Graph for Djuna Barnes.
By analyzing the content of the Internet at scale and monitoring our search practices, Google claimed it would be able to “[tap] into the collective intelligence of the web and [understand] the world a bit more like people do” (Singhal, 2012). Its hope was to enumerate semantic objects and relations between them so that it could transform unstructured web documents into the world’s largest repository of real-world “knowledge.” Google largely does this through the use of graph databases, which, as we’ll see, are graph structures that store relationships between entities in very large numbers. Graph databases only operate atop artificial intelligence and machine learning algorithms designed to extract (i.e., enumerate) machine-readable information from human semantics. These enumerations occur by quickly parsing web corpuses at the scale of billions of documents, and producing iterative ontologies and schemas that constantly adapt themselves to be able to classify and enumerate as much of the data they come across in those corpuses as possible. At its launch, Singhal noted that the Knowledge Graph had already enumerated more than 500 million objects and more than 3.5 billion facts about the relationships between them, largely based on its analysis of Freebase, Wikipedia, and the CIA World Factbook. The end result is a responsive database that knows which things your query actually corresponds to, that can summarize the most relevant information about them, and that can facilitate discovery and “sometimes help answer your next question before you’ve asked it” (Singhal, 2012). It is worth noting that in the same year, Google’s Search Quality Team was redubbed the Knowledge Team, which reflects their commitment to realizing this future expansion of search into the epistemic grounds of the real.
At the first World Wide Web Conference in 1994, Tim Berners-Lee (1994) called for the expansion of the Web to include machine-readable information and relationship values for links. For years, it was thought that this expansion would allow machines to comprehend (i.e., enumerate) semantic web corpuses (Berners-Lee, Hendler, & Lassila, 2001), and it is precisely this understanding of semantics as produced by metadata and typed links that is at the core of Google’s new knowledge infrastructure. At its simplest, the entire apparatus behind the Knowledge Graph can be boiled down to two interrelated processes: first, the automated enumeration of machine-readable information and metadata about the things on the Web and their interrelationships; and second, the learning and iterative production of an entire enumerative ontology and schema that describe what those things can be and/or how they can be related.
For years it has been Google’s position that the Web at large can be understood as a huge body of human knowledge in the form of (classes of and named) objects or entities, and facts constituted by their interconnecting relations (Paşca, 2007). These relations between entities are understood as “‘hidden’ arguments” about the world, and underlie implicit typologies of relations (p. 107). In essence, Google researchers look at the Web as a gigantic databank of expository statements about the world, and it is precisely as a collection of parsable expository statements that they understand knowledge. When enumerated in machine-readable form, these expository statements take the form of a “triple,” which essentially is the computer equivalent of a subject-predicate-object statement. 1 A graph database is a large aggregate of these triples, populated with enumerated “nodes” representing things or entities and enumerated “edges” representing relations (for a simple example, see Figure 2, and see Figure 3 for a more complex example; also see Sasaki, 2015). Any given thing or entity represented by a node in the graph can serve as either the subject or the object of any given triple, and which is determined by the direction of the edge. All edges are directional and enumerate subject/object relations by their directionality. Although this may seem complicated, it is rather simple to understand in application. It is rarely the case that the subject and object of any expository statement can be inverted without producing nonsense. For example, the fact that the subject [Djuna Barnes] has the relation [was born on] to the object [June 12, 1892] makes sense, but it is nonsensical to invert it and say that [June 12, 1892] [was born on] [Djuna Barnes].
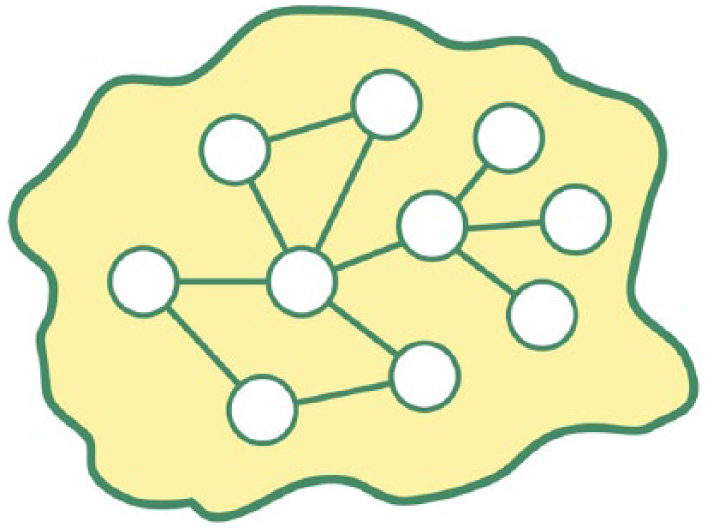
Simple Visualization of Graph Data.
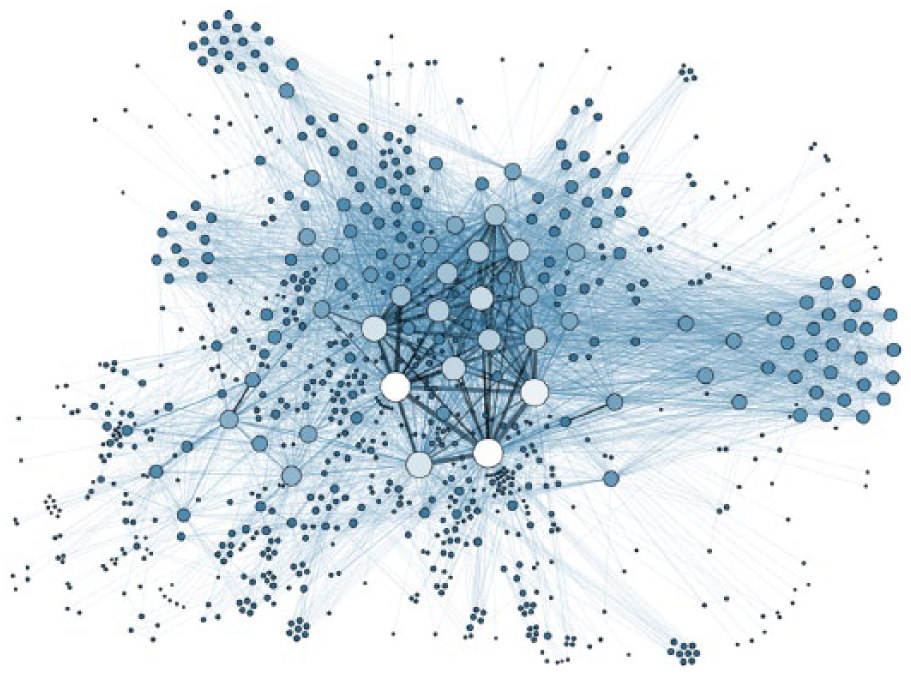
Complex Visualization of Graph Data.
From these large repositories of triples—constative claims or arguments enumerated in and reduced to the form of subject-predicate-object statements of “facts”—Google is able to learn and iteratively produce an entire enumerative ontology and schema for knowledge. 2 The enumerative schema it produces is a typology of relations or links, one of the key components Berners-Lee called for decades earlier. This schema ensures that across the graph, all represented relations are subsumable under a general typology, and that all relations of the same type are numerically equivalent (i.e., the same). The enumerative ontology it produces is a specification of what things or entities, and which relations, can exist; it is a pattern that determines what the graph database contains, what form search queries need to take for it to be parsed, and what the appropriate knowledge is in relation to any particular query. 3 And, here we come full circle to our opening meditation on number, where we can see that existence, at least in terms of epistemological, if not phenomenal, availability is literally determined by enumerability. What exists for Google is strictly that which can be statistically extracted through machine learning algorithms, and that which can be abstracted from its context into the numerical form of a triple. In a state of “information explosion” and constant dissemination of communications via digital media, what we are able to engage is strictly and necessarily limited to that which can be bounded and epistemologically differentiated, and it is precisely graph databases such as Google’s that are at the forefront of performing that labor for us. The sheer volume of web documents on the Internet fills its channel, like an old dual tone multi frequency (DTMF) telephone whose buttons are all pressed simultaneously, producing sheer noise. We rely on data indexes and parsing algorithms to enumerate those documents once again for us—an impractical task for humans because of its scale—and it is only after that having occurred that we can once again engage with them on the level of human language and nomination.
The problem with graph databases such as Google’s is not obvious, and were these databases not rapidly becoming the future of enumeration and identified with knowability per se, there would be little to no problems. Through what is called a “join function,” multiple nodes can be linked by their edges forming complex paths, even isolating clusters and regions that form sub- or regional graphs, and these operations allow for the performance of complex computations at an unimaginable speed 4 and the production of knowledge that was never before available—at least in this form—to humans. In these large-scale processes of enumeration, the human is afforded an expanded capacity of nomination, or, more simply, humans can know and perceive new things, relations, and aggregates of the two through machine enumeration. There are many problems with this whole system that seem to me, despite their utmost importance, to be outside the data structure itself, such as environmental damage caused by electricity consumption in server farms, unequal access to and blackboxing of the machines capable of performing these operations, and malicious use of the knowledge generated by these systems. 5 The problem that is instead immanent to the data structure itself is caused by the basic building block of the triple, which, despite some clever new maneuverings, still risks falling into the traps of representationalism that have plagued philosophical debates since Plato popularized them and Aristotle formalized them. As such, we will now turn to an examination of the relevant aspects of Aristotle, and look to Gilles Deleuze’s criticism of Aristotle to locate the source of the problem immanent to graph databases themselves.
Graph Probabilities and the Potentiality of Difference
In very general terms, we claim that there are two ways to appeal to “necessary destructions”: that of the poet, who speaks in the name of a creative power, capable of overturning orders and representations in order to affirm Difference in the state of permanent revolution which characterizes eternal return; and that of the politician, who is above all concerned to deny that which “differs,” so as to conserve or prolong an established historical order, or to establish a historical order which already calls forth in the world the forms of its representations. (Deleuze, 1990, p. 53)
Deleuze’s critique of Aristotle is largely grounded on the idea that Aristotle’s attempts to explain the genesis of the new all fail and that these failures have had catastrophic affects for the trajectory of thought ever since. Often these attempts are rooted in a need to explain aisthesis and the faculty for sense perception, and it is this explanation that necessitated Aristotle’s well-known theory of actuality (energeia) and potentiality (dynamis). We will first need to examine this latter theory before returning to its explanatory power in aisthesis and sense perception. 6
The theory of energeia/dynamis is largely the result of Aristotle’s efforts to explain becoming (genesis) in light of Eleatic Conventionalism—a school of thought initiated by Parmenides that essentially argued that nothing can come-into-being from non-being, and upon this assertion, erected a unified and undifferentiated universal One. Aristotle argued that Parmenides’ position had forced successive philosophers to reduce genesis to either qualitative change or the rearranging of basic elements, called the stoicheia (Physics I, 187a; De generatione et corruption I, 1-2). He instead argued that the basic elements (stoicheia) function as binary opposites (enantia), and each is always capable of changing into its opposite (De generatione et corruption II, 331a, 337a). He is able to explain genesis without need of non-being by positing three principles: an immanent form (eidos), elsewhere referred to as a species, an undefined substratum (hypokeimenon) to the world, which persists throughout change and houses the third principle, privation (steresis), which is the potential (dynamis) for any of the basic elements (stoicheia) to change into its opposite (enantion; Physics I, 190a-b). The substratum’s essence (ousia) is purely to serve as the ground for the genesis of other things (Metaphysics 1028b-1029a), though it has a material existence and, along with eidos, serves as a co-principle of being (on; Physics I, 190b). It is important to note that this substratum performs this function by serving as a reserve of potential (dynamis) for change, but this potential for change is limited to privation (steresis), which Aristotle defines as “the negation of something within a defined class” (Metaphysics 1011b). Here, this means that change is brought about by an actual (energeia) lack in each basic element (stoicheion) of its opposite (enantion), but a corollary potential (dynamis) for its passage into the opposite (enantion) that it lacks. The possibility of genesis is created by this substratum’s reserve of privation (steresis) as potential (dynamis) for the basic elements (stoicheia) to shift between their opposites (enantia; Physics I, 190a-192b; De generatione et corruption II, 324a, 328b-331a).
In De anima, Aristotle argues that perception requires two things: (a) that the perceiver has the capacity to perceive, regardless of whether he or she is actually perceiving anything, and (b) that he or she actually perceives something. The perceiving faculty of the soul must exist as a latent capacity or potential corollary to what the perceived thing is in actuality (II, 417a-418a). In terms of the soul, the perceptive faculty perceives an idea (eidos) without its materiality (see Peters, 1969). When described physically, the perceptive faculty is made possible by a balancing of opposite forces, 7 where they exist in the mean or in a proportional state in which the perceiver’s faculty exists as “actually neither, but potentially both” (De anima II, 423b-424a), and the actual perception comes about during their actualized adjustment to the perceived object. It is thus that “like can know unlike,” and the subject can (potentially) become like the object known to perceive it (De anima II, 417a-418a). Aristotle’s theory thus rests upon his concept of privation (steresis), wherein the faculty for sensation holds itself in reserve, always containing the potential to actually change into what it is not. Thus, at the level of actuality, things can be unlike one another, while they can maintain the potentiality of becoming alike through privation.
Although this may seem esoteric in terms of our topic, we can here see the source of the first firmly grounded representationalism in philosophy. The capacity for being represented is the necessary foundation for any perception or knowledge, and thus it precedes both aisthesis and noesis for Aristotle. In fact, anything that can be perceived or known is already present, but lying in potential, and is made actual by the senses and the mind becoming identical with that object’s sensible and intelligible form (De anima III, 429a, 431a-b). Here, the mode of representation determines what gets enumerated, and this comes to bear on the Knowledge Graph in the same sense that its basic form of the triple and its given ontology and schema precisely determine what is perceivable and knowable to—as well as enumerated within—the graph. Furthermore, this capacity to shift from potential to actual, for like to know unlike through its capacity to become the unlike, is grounded on the play of opposites in the basic elements.
Although Aristotle’s basic elements are no longer applicable, we can see the operation of similar elements in the Knowledge Graph. As I’ve shown, Google researchers understand knowledge as a large set of constative claims or “facts” that can all be formalized into subject-predicate-object statements, or aggregates thereof. Although the form of the triple is certainly more flexible than the original binary relations that Sergey Brin was analyzing back in 1998, it still boils down to basic elements that can be analyzed in terms of oppositions between subject and object, or node and edge. 8 What this means for us is that even those things that are not yet included in the Knowledge Graph can only ever be included through their entrance into this play of “basic elements” that constitute the graph’s capacity to know what it is “unlike.”
In his reading of Plato’s Sophist, Deleuze (1990) explains that the sophist leads Platonism into a confrontation with non-being where it’s “common sense” begins to fail, and yet, Platonism is unable to reduce that with which it is confronted to the negative, to non-being (p. 256). Deleuze (1994) instead argues that “non” in the expression “non-being” expresses “something other than the negative,” and it is this aporia that Deleuze will write as “(non)-being,” or better, “?-being” (pp. 63, 64). Deleuze repeatedly warns that representational philosophy, invested as such in identity, will always present one with the false dichotomy of either a fully determinate and positive being with no difference, or a being with differences produced by non-being, negation, and the negative (e.g., Deleuze, 1990, 1994). Instead, Deleuze looks for a purely positive and affirmative articulation of difference, and looks to ?-being for an opening. For Deleuze, ?-being is the source of affirmative differentiation, and thus is the first principle of all genesis. Negation is only the shadow of affirmative differentiation, and to confuse the two is always to allow the illusion of contradiction to slip into our understanding of genesis. There is always an affirmative differentiation behind the appearance of contradiction and the shadow of negation. Deleuze writes, “Beyond contradiction, difference—beyond non-being, (non)-being; beyond the negative, problems and questions” (p. 64). As we’ll see below, ?-being as the site of genesis via affirmative differentiation in a problematic field is precisely what perpetually eludes indexing because of its nonrepresentational nature.
Aristotle formalized and remained ensnared in this Platonic logic of negativity, as evidenced by his philosophy requiring the logic of representation and identity to function. For Aristotle, the essence of any thing is its position in an analytical taxonomy, its species and genus. 9 Thus, its essential difference is not its singular identity, but instead its membership in a species sharing a homogeneous differentiation. Individual members of the same species in their absolute specificity and singularity are only superficially different from one another. We can already see here that difference is being grounded and bracketed, only enumerated in the interstice between two genera or species. Deleuze argues that an ontology such as this only understands difference through the logic of representation. It makes difference reflective, mediated by the analogies and oppositions between conceptual identities and their predicates (Deleuze, 1994). Aristotle fully subsumes and brackets difference within the logic of (classificatory) identity, wherein it can only manifest itself as relations between conceptual groups of individuals. For Deleuze, this ontology has overlooked difference in itself, both at the level of species, within which individual members constitute an irreducible diversity of singular identities, and at the level of genus, where difference is already bracketed into particular conceptual differentiae by some overarching analogical generality. 10 We might push this further and note that for Aristotle, the categories that taxonomize differentiae and allow for the classification of species and genus predicate Oneness (Metaphysics 1003a-b, 1053b). 11 There is a particular enumerative operation that originates with categorization that affords individual differences, species, and genera their capacity to be recognized and represented in the world.
As I’ve already noted, this enumerative operation that is predicated by categorization is that of the triple, and it is only by the play of the “basic elements” of the triple—subject, predicate, and object, or nodes and edges—that the representations are made available for categorization. This Aristotelian impulse to examine only lesser and greater abstractions for taxonomical purposes is precisely that behind Google’s research. Google’s credo is that of simple models fueled by a lot of data, and this is because Google researchers understand anomalous events to be collectively frequent at large enough scales (Halevy, Norvig, & Pereira, 2009). Google’s taxonomy is more flexible because their simple models are meant to grow through iterative steps of machine learning, and thus the need for generative rules is alleviated. Yet, the modifications of schema and ontology across iterations are still limited by the “basic elements” that can be perceived and known. The data structure of the graph is, by necessity, encoded at the level of hardware, data serializations, assembly, and compiler code, and thus, its potential to become “unlike” is always bracketed to operations on triples. We can thus see that the Knowledge Graph functions through negation, as evidenced by its representational nature. This forecloses its ability to interrogate the problematic field upon which affirmative differentiations generate the new.
Drawing on Henri Bergson, Deleuze (1991) tells us that the form of difference composed by negative relations between identities at varying levels between genus and species is always abstracted from the real world, and is too broad and general to be of any real use. He writes, “The combination of opposites tells us nothing; it forms a net so slack that everything slips through” (p. 44-45). The differences between individuals of the same species, which Aristotle brackets because of its unsoundness for a philosophy of representation, are truly differences in kind, and thus elude an Aristotelian classificatory schema. This becomes most important in the distinction between “possibility” and “potentiality.” Deleuze argues that possibility has no reality before its exhaustion; it only exists in retrospect because it is only given to us ready-made, preformed, and pre-existent by its real(ized) form. Whereas one might assume that the real is some manifestation of a larger realm of possibilities, it is instead the case that that larger realm of possibilities is but a sterile duplicate abstracted a posteriori from the real. In this sense, the possible is always dependent on the real, exists secondarily, and is but a reflection of what already is or has been.
In contrast to this, Deleuze argues that a conception of potentiality is better understood by replacing the real/possible binary with that of the actual/virtual distinction. The virtual is always-already fully real, existing alongside and intertwined with the actual, and can be envisioned as a great plane populated with “nonnumerical multiplicities,” with singularities and forces intermingling with one another and allowing for an indefinite number of actualizations to arise (Deleuze, 1991, pp. 96-97). What is precisely the point here is that these nonnumerical multiplicities are not enumerable, they cannot be rendered into a stable identity, and despite the fact that multiple actualizations can arise from these same multiplicities, those actualizations are not numerically identical. Each actualization is different in kind, and provides an inflection of or perspective on the nonnumerical multiplicity from which it arose without being able to enumerate it. The nonnumerical multiplicity cannot be totalized for enumeration, does not even resemble its actualized counterpart, and thus cannot be represented. As such, the true commonality between different actual things is nonrepresentational in nature. They hang together only as affirmations of difference, as positive and creative lines of heterogenesis in an actual world of irreducible pluralism. For Deleuze, the virtual is difference in itself, and its actualization is the only productive understanding of differentiation.
Each actualized thing is the fruit of chance, a multiple phenomenon composed of “a plurality of irreducible forces” (Deleuze, 1983, pp. 39-40). Yet, in its actualization, any given thing is cut off from the virtual multiplicity from which it arose. Actualization is an arrest of difference, and thus classifications of species and genus based on already actualized differences is a diachronic, and somewhat arbitrary, endeavor that has little explanatory power for the actual rhythms of change in the world. To produce this taxonomy of differences, one must enumerate differentiations secondhand and abstractly, one must cut what is to be surveyed and classified off from difference in itself to enumerate stable and representable identities. The realm of possibilities that one produces as a reflection of the real things being surveyed then must constantly be refreshed, as the potentiality of the virtual continues to allow for the actualization of the impossible.
The Problem(s) With Graph Databases
You have the individuality of a day, a season, a year, a life (regardless of its duration)—a climate, a wind, a fog, a swarm, a pack (regardless of its regularity). Or at least you can have it, you can reach it. A cloud of locusts carried in by the wind at five in the evening; a vampire who goes out at night, a werewolf at the full moon. (Deleuze & Guattari, 1987, p. 262)
Although Deleuze’s rather dense and technical explications of difference in itself might seem far from the subject of graph databases and machine learning, they demonstrate a mode of thought capable of highlighting the future limitations of such endeavors. What escapes any graph database is difference in itself, the on-the-fly genesis of what, from a graphical perspective, we might describe as new entities, new relations between them, and new subgraphs, regions, or trends (which we might think of as milieus or contexts). The new is not enumerated. Perhaps most importantly, it is this genetic process that eventually crystallizes into the stable structures represented by the graph, but again, the genesis itself is not enumerated. It remains un-indexed, unknown, and imperceptible. It thus plays no role in the schema and ontology of the graph, and in its place we have the stale differentiations of a diachronic slice of actual things and entities. Although it certainly affords us some extremely useful insights into the possibility and probability of what already is, it has little capacity to engage with the truly new.
What Google understands any given entity to be is an abstracted set of relations, a participant in a certain isolatable graph region made up of subject-predicate-object triples, and this process of enumeration delimits the ontology, schema, and epistemology that are built atop it. There are certainly aspects of this problem that can be corrected for, and their manifestation is often comical, such as the inclusion of William Shakespeare and Diana, Princess of Wales, in the Knowledge Graph Carousel for “Famous Actors” (see Figure 4). It can also have some rather bizarre results, like including The Book of Repulsive Women and Other Poems among Djuna Barnes famous works, only to provide the following description of the text at the time of my writing: This updated guide covers everything readers need to know about electronic mail. New to this edition is: advice on choosing a service provider; an updated guide to service providers; more information on LAN-based email; and the latest developments on Windows 95.
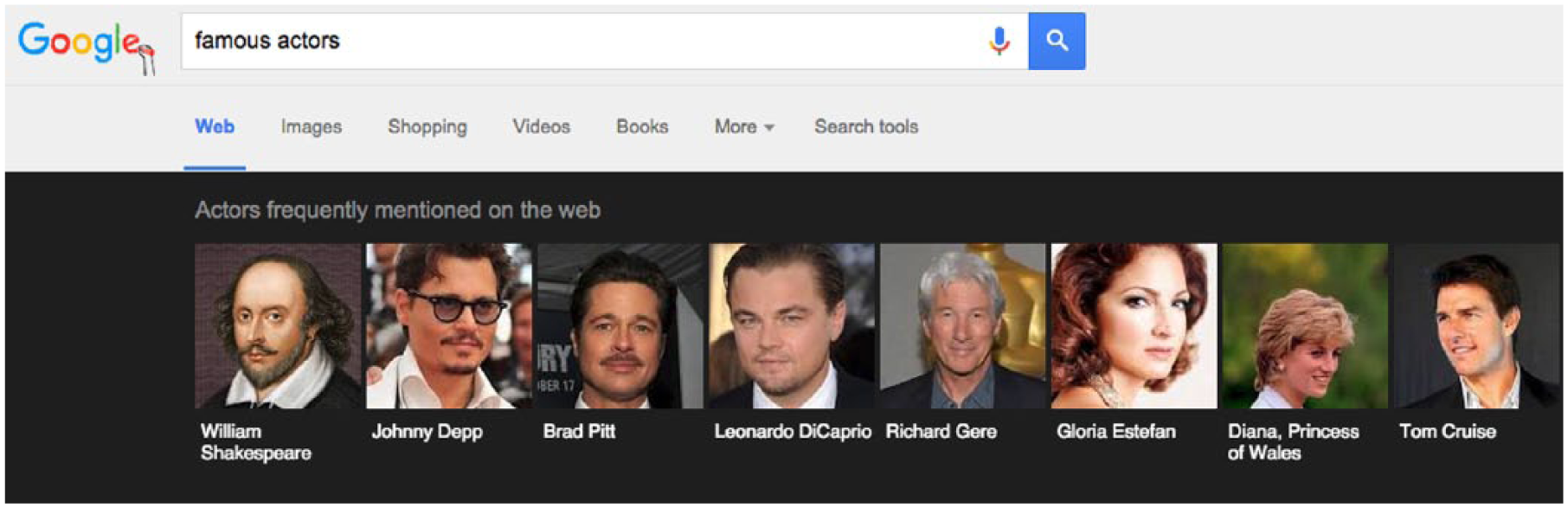
Knowledge Graph Carousel for ‘Famous Actors’ Query.
The problems that cannot be as easily corrected for are those that are engendered by the basic building blocks the system uses to enumerate its contents, the “basic elements” of the triple at the heart of the statistical abstraction of an entire schema and ontology. It is this numerical mediation that determines the pieces and form of information presented in the Knowledge Graph’s content box, which often include a selection of photos, a name, and profession, an opening line from Wikipedia, a date and place of birth and death, as well as notable works and related people (see Figure 1). These are the facts it can enumerate about a person, and it is upon these facts that they are presented, named, and made available for us to experience and know. And yet, the immediate question surfaces that, if this is knowledge, how incomplete is it? The logic of representation undergirding it produces an infinite series of questions about just how representative this information really is of a life lived. Is being born in the same place a homogeneous relation across people? Certainly not, as this abstraction loses the entire process by which a person individuates himself or herself from and comports himself or herself toward a place. Not only that, but are the most significant relations a person has to a place really those of birth and death? Where is the relation to Paris as a “moveable feast” that so marked a generation of American writers and expats such as Djuna Barnes?
In discarding the absolute specificity of the individual in favor of statistically enumerable genera, the Knowledge Graph is cut off from difference in itself, the play of the actual and the virtual. And, this is of great consequence for the future hopes of so many companies investing in graph database and parsing mechanisms, because although they can feign a certain capacity and flexibility unavailable in any previous Relational Database Management Systems (RDBMS), they still can’t quite grasp things such as style, comportment, individuation, and similar aspects of difference. And, this is precisely what they are angled to enumerate, as graph data are increasingly envisioned as the future of recommendation engines such as Netflix or Amazon’s, knowledge engines such as Google’s, and curatorial engines such as Pandora or Spotify’s. Graph databases are similarity engines, working on an established ground of possibility that is easily exhausted, despite all their efforts to simulate the serendipity of discovery, of offering you what you didn’t (yet) know that you wanted.
You cannot ask a graph database to present you with difference as a result of your query. You can simulate it by bracketing difference to particular subregions of the graph, to particular relations or entities, in which case you might get the different books Djuna Barnes wrote, or different horror movies that went straight to video. But graph data can’t seem to tell you who the next big undiscovered musical talent is, even though these are relations that they track. Graph data can’t tell you which actors were awkward or shy as children, which scientists write more clearly or speak more engagingly. Although these are processes that could conceivably be simulated one day, the issue with the simulation is that it operates only with problems/questions that already contain their own answers/solution because of the immanent structure of the system.
For Deleuze, there are questions, and beyond them problems, all populating a virtual problematic field that inflects potentialities as they are intensively actualized into concrete things and their interrelations. What the Knowledge Graph will never be able to do is make present this problematic field of nonrepresentational experiences and knowledge. The determination and differentiation of being, the problematic field of becoming, or what Deleuze calls ?-being is forever outside the purview of machinic overcoding and appropriation, instead leaving these machines to extract information outside of its event horizon about already actualized subjects and objects. Google cannot locate new problems or pose new questions, but instead indexes pre-existing pairs of problems/questions and answers/solutions at enormous scales. Its contribution is the capacity to extend pre-existing thought along further toward its teleological ends than any human mind could do alone. It can thus more perfectly simulate the present and extend that present into the future than anything we’ve seen before, but this implies a certain conservatism. Google’s Knowledge Graph cannot bring the future to the present by genesis of the new. If the Knowledge Graph does become the dominant mode of producing information out of the billions of documents on the Web, then these limitations take on serious political, epistemological, aesthetic, and ethical stakes. The nonrepresentational and affective milieus that so mark human worlds and ways of being in those worlds risk becoming increasingly imperceptible as they are overcoded by representational enumerative schemas and navigation practices.
These stakes include the impossibility of sub- and counter-cultures as they are overcoded by “mainstream” logic and lose their comportment as they are massively disseminated. That process is by no means new, but its automation may outpace the rate of genesis for new sub- and counter-cultures after the previous ones have been appropriated. We might also think of the future of real-world navigation practices and urban spaces as potential stakes, as the nonrepresentational components of urban space and navigation that scholars such as Nigel Thrift (2007) investigate become overcoded by their automated extraction and enumeration within a representational graph. By this, we might think of the difference of following flows of bodies, architecture, and design through city spaces—possibly in combination with human comportments, gestures, and facial expressions as they offer recommendations—toward a particular new restaurant to eat at, for instance. We might question the processes by which certain practices of web design and search engine optimization, in combination with information extraction performed on things such as the sentiment of written reviews, overcode food cultures, and distribute the perceptibility of eateries. It is important to note here that these underdeveloped examples warrant future research, and are but a few from a nearly limitless field of practical applications for a theory of numerical mediation qua enumeration. If nomination is indeed preceded by enumeration, then the very field of possible perceptions and knowledges is curtailed by the medium through which things and entities are enumerated. Existence will literally be found in the index of a graph database.
The struggle to find and/or maintain alternate routes to perception and knowledge is outside the purview of this article, as it is not a problem immanent to graph databases themselves. In terms of the internal limitations of graphs, at best, one can hope that the future holds graph databases and information extraction mechanisms that are open to the public, so that graphs might be made that could mutate themselves, that could create new and unexpected schemas and relations based on the introductions of new “basic elements” and combinations thereof. Rather than one graph, many graphs, a “proliferant continuance,” each engaging in the actualization of new forms of the virtual, and—like Cezanne and his apples—presenting new actualizations of a multiplicity rather than attempting to represent one in total. A new poetics that responds to the matheme, a poetics of data . . .
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
{kind=link}