
Abstract
The purpose of this study was to evaluate technical adequacy features of an online adaptation of vocabulary matching known as critical content monitoring. Validity and reliability studies were conducted with a sample of 106 students from one school in fifth-grade science content. Participants were administered 20 parallel forms of the general outcome measure over a 2-week period. Criterion-related validity correlations with a statewide accountability test ranged from .36 to .55 for the 20 parallel forms. A pooled estimate of a common correlation between the state test and the probes was found to be .45. While correlation differences were not found, statistically significant differences in probe mean scores were identified across the body of parallel forms. Student commentary regarding the online assessment process was largely positive. Alternate-form reliability correlations ranged from .21 to .73, with a median correlation of .56. Limitations and implications are addressed.
Academic language is the vocabulary of the content course. It relates to the words read and spoken in science and social studies classrooms that help us think and communicate about the subject matter (Nagy & Townsend, 2012). Academic language proficiency allows students to more completely access the meaning in academic text and discussion, act like scientists and historians, and better demonstrate achievement in school (Nagy & Townsend, 2012). However, the academic language of content courses presents a significant challenge for struggling learners and their teachers. Struggling learners know fewer words, process word meanings less completely, and learn fewer words across time than their regularly achieving peers (Baker, Kame’enui, Simmons, & Simonsen, 2007), negatively affecting achievement. This study begins with an examination of whether the technology-enhanced assessment of academic language can serve as a tool for improving teaching and learning in the content areas, as formative feedback to science and social studies teachers and their students. Specifically, the study addresses Stage 1 (Fuchs, 2004) research questions related to technical features of the static score for an online adaptation of a curriculum-based measure of content performance and progress known as vocabulary matching.
General Outcome Measurement and Vocabulary Matching
General outcome measurement, a technically adequate index of performance and progress, can be applied to the assessment of academic language. The focus of general outcome measurement is on an entire curriculum domain, such as science subject matter covered in 1 year, in contrast to the emphasis on single lessons or units in mastery measurement (Fuchs & Deno, 1991). In the present context, an entire body or domain of academic language is the target, with academic words assumed to be proxies for academic content learning. Sets of brief, timed, parallel tests (or probes) are developed that sample from the content domain and produce scores that are validated for their assessment purposes. In general outcome measurement, tests are developed by either identifying robust indicators of curricular proficiency (e.g., the read-aloud measure developed and validated as part of curriculum-based measurement [CBM]; Deno, Mirkin, & Chiang, 1982) or systematically sampling from the skills that comprise the annual curriculum (e.g., mathematics concepts and applications; Fuchs, Fuchs, & Zumeta, 2008) so that each test represents an equivalent snapshot of the grade-level curriculum (Fuchs, 2004). No matter the probe development approach, ongoing assessment using parallel forms of the curriculum domain is hypothesized to document student performance at a moment in time (performance) and/or growth over time (progress), offering data that are sensitive to instruction across time and, thus, formative in both design and practice. These data can serve as an efficient and effective indicator of performance or a vital sign (Deno, 1985) of academic health and a proxy for progress in a given subject area. Substantiating the soundness of progress measures involves three research stages (Fuchs, 2004), providing supporting evidence of the instrument’s static score, slope, and instructional utility, Stages 1, 2, and 3, respectively.
In the content areas, vocabulary matching (Espin, Busch, Shin, & Kruschwitz, 2001; Espin & Deno, 1993, 1994–1995; Espin & Foegen, 1996; Espin, Shin, & Busch, 2005) is a general outcome measure that has been designed to serve as a technique for teachers to use in monitoring the performance and progress of students engaged in content area learning. It is an example of an assessment of academic language. Early vocabulary matching probes have traditionally included randomly selected vocabulary terms and their accompanying definitions that were drawn from a classroom textbook and teacher notes and presentation materials (Espin et al., 2001). Paper–pencil versions of the probes have included vocabulary terms that were placed in alphabetical order on the left side of a page with the accompanying definitions organized in a random order on the right side. Students have been instructed to match the term with the appropriate definition and given 5 min to complete the task. Probes have been scored according to the number of correct matches in the time frame (Espin et al., 2001).
Research on vocabulary matching has addressed technical adequacy issues related to its static score and slope. A summary of Stages 1 and 2 statistical findings offers promise for the use of this tool for measuring academic learning. Researcher-developed vocabulary matching probes (a) had mean scores that were moderately correlated with multiple criterion measures including standardized subject matter and general knowledge and statewide accountability tests (Espin et al., 2001; Mooney, McCarter, Schraven, & Haydel, 2010); (b) had criterion-related correlations with a statewide accountability test that were significantly stronger than were linear relations between the criterion and general outcome measures of reading and writing (Mooney, McCarter, Schraven, & Callicoatte, in press); (c) shared the greatest proportion of variance with the statewide test score in predictive regression models, with unique variance attributed to it even when a standardized measure of general vocabulary was included in the model (Mooney et al., in press); (d) evidenced statistically significant growth patterns for weekly probe administrations for time periods ranging from 11 to 24 weeks (Borsuk, 2010; Espin et al., 2005; Mooney et al., in press); and (e) demonstrated strong interrater reliability correlations across studies (Borsuk, 2010; Espin et al., 2001; Mooney, McCarter, et al., 2010; Mooney, Schraven, & Cox, 2010).
However, there has been a dearth of research addressing the use of CBM vocabulary matching for instructional decision making. Positive Stage 3 research outcomes may push educational stakeholders to view general outcome methodologies as viable tools for impacting student achievement in content courses. Fuchs (2004) indicated that Stage 3 research focuses on teacher use of general outcome data in a formative sense to change teaching and improve student learning outcomes. A number of reasons may contribute to the relative scarcity of utility research. For general outcome measures as a whole, Fuchs posited that Stage 3 research is labor-intensive and less comfortable for researchers than more traditional psychometric inquiry. Specific to vocabulary matching, two other factors may also interfere with broader practical application. First, the technical adequacy studies to date have been initiated and conducted by researchers. That means that researchers have generally developed and administered the probes, and collected, organized, reported, and interpreted the data. Having researchers complete many of the procedures does not encourage practitioners to incorporate content-focused general outcome measures into their instructional practice (Mooney et al., in press). Prior research conducted in one form of general outcome measurement (i.e., CBM) indicated that teacher dissatisfaction with the time-consuming nature of the implementation process resulted in teachers not using the measurement system in spite of the fact that its use contributed to better student achievement outcomes (Fuchs & Fuchs, 2001; Wesson, King, & Deno, 1984).
Second, there may be some confusion related to the practical application of the existing vocabulary matching data. For example, the available mean weekly slopes may be difficult to interpret at the present time. Mean growth rates across three studies (Borsuk, 2010; Espin et al., 2005; Mooney et al., in press) have ranged from 0.02 to 0.65 words per week across various probe types and student populations. These data are difficult for the practitioner to translate into practical short- and long-term goals, particularly when it may take many weeks to evidence visible growth (e.g., an increase in scores from 6 to 7 correct matches at 0.02 words per week). Moreover, individual probe mean scores have generally been lower than might be expected for end-of-the-year administration. In theory, at any given point in time, a score serving as the proxy for learning in a subject area could represent that proportion of knowledge that has been taught in the academic year. Throughout the year, then, scores in this 20-question measure would move from 0 or a low number toward higher scores or all 20 correct once instruction is complete. Yet, mean scores reported in late-year vocabulary matching probes across studies have been variable and relatively low in some cases (e.g., mean scores of 6.7 out of 20 in Mooney, McCarter, et al., 2010, a range of 5.5–7.8 in Mooney et al., in press; a range of 9.7–10.9 in Espin et al., 2005). While it is true that these scores are mean scores that are moderately related to meaningful criteria, it is plausible that users of the scores may not understand them or see the relation between measurement of learning and the potential for positive impact on instruction and/or intervention because of their low values.
One mechanism used to make progress-monitoring practices more accessible to teachers is technology, specifically online progress-monitoring and/or instructional management systems. In the area of general outcome measurement, computer application has allowed for large-group administration of CBM instruments, automatic scoring of all probes administered, real-time reporting of scores on an individual and group basis, and even stakeholder feedback based on the gathered data related to end-of-year goals or mastery of grade-level academic skills (Fuchs & Fuchs, 2001; Stecker, Fuchs, & Fuchs, 2005). Technology-enhanced formative evaluation systems have been evaluated in less researched areas such as math and science. Research in math implementation has indicated that use of the systems as intended had positive effects on classroom grades and statewide accountability tests (Burns, Klingbeil, & Ysseldyke, 2010; Ysseldyke & Bolt, 2007). In science, attention has been directed at increasing engagement through use of classroom response systems or clickers (Beatty & Gerace, 2009) as well as assessment of critical academic language (Vannest, Parker, & Dyer, 2011). Vannest and colleagues (2011) reported findings from a 5- or 6-week implementation of a program that included computer generated, administered, and scored protocols based on important vocabulary. Probe content related to vocabulary definitions and use, with correlations with an assessment system developed to prepare students for the statewide accountability test ranging from .25 to .83 (median = .60) and evidence of variable growth rates for participants from pretest to posttest.
Critical Content Monitoring Description and Research Rationale and Questions
The promising initial technical adequacy findings for vocabulary matching and the possibilities of enhanced usefulness through the application of technology led to development of an online adaptation of vocabulary matching known as critical content monitoring. Designed as an online general outcome measure of course content, critical content monitoring retains some features of vocabulary matching, while adapting others. The content focuses on critical course vocabulary and accompanying definitions remain, with tests comprising terms that are sampled from the units listed in the complete curriculum domain. In the present study, the 5-min time frame, number of questions per probe, and scoring focus on the number of correct responses was also continued. Differences from vocabulary matching, in addition to use of the online format, included making the questions fit a multiple-choice format, having the probes automatically scored by the online system, and providing students and teachers with immediate access to the student’s probe score. The authors believed that the online format and use of multiple-choice questions would result in more questions being answered by students and higher scores being received.
The present research constitutes a necessary first step in the validation of the interpretation of scores derived from the online adaptation of vocabulary matching known as critical content monitoring. While validation across all three stages is imperative for widespread application of a technically sound progress-monitoring instrument, an essential starting point of programmatic research remains evaluation of the static score (Fuchs, 2004). Traditional Stage 1 research evaluates how well scores from a new instrument relate to scores from existing relevant assessments. In this case, questions relate to how scores from the online adaptation of vocabulary matching relate to an existing measure of content knowledge. This is an important consideration because if a test is going to be considered a tool or proxy for performance or progress, then its output needs to be strongly related to scores from measures that are already viewed or demonstrated to be indicators of learning and conceivably stronger than other existing predictor measures. Scores from a collection of parallel proxies of academic language were compared with scores from a statewide accountability test. The grade-level state science test was chosen because both scores were available and it is a meaningful measure of academic performance in the present academic context. That is, scores from statewide accountability tests have some measure of value to multiple educational stakeholders. Scores form the basis for perceptions related to student achievement. Test scores and their comparison to previous results also factor into teacher and school evaluation.
Second, researchers questioned the equivalence of the probes given recent findings indicating that seemingly parallel passages used as general outcome measures of reading “frequently show significant and substantial differences in terms of their difficulty levels” despite high reliability and validity correlations (Stoolmiller, Biancarosa, & Fien, 2013, p. 77). Developers of reading passages have historically relied on readability formulas in the development process. This practice is not applicable for tests such as those evaluated in this study because use of readability indices would likely result in inaccurate estimates of the grade level of the fifth-grade science academic language. Developers of content-focused general outcome measures have incorporated curriculum sampling (Fuchs, 2004; Fuchs et al., 2008) into the probe development process. That is, probes have been developed with content included from each of the units in a curriculum domain. In the present study, probes were weighted proportionally based on a formula that determined the percentage of time in the academic year that a pacing guide suggested be devoted to a given unit. Then, following the suggestion of Ardoin and colleagues (Ardoin, Suldo, Witt, Aldrich, & McDonald, 2005; Ardoin, Williams, Christ, Klubnik, & Wellborn, 2010), researchers field tested a set of parallel forms with students. Researchers hypothesized that the mean scores and correlations with a meaningful criterion would evidence statistical equivalence, thereby providing evidence for the validity of the development process. Third, researchers wondered how users of the system would evaluate its utility. Gathering data on the perceptions of student participants was another area where research had yet to be conducted in the content general outcome measurement literature. Finally, a series of alternate-form reliability correlations were conducted with researchers hypothesizing that the resulting linear relations probes would evidence similar magnitudes as those reported in the vocabulary matching literature. Results and discussion emanated from the following research questions:
Research Question 1: What was the strength of the linear relation between critical content monitoring probe scores and a statewide accountability content test score?
Research Question 2: Did the critical content monitoring probe development process produce a body of equivalent probes?
Research Question 3: What were participants’ perceptions of the online general outcome measurement process?
Research Question 4: What were the correlations between alternate forms of the general outcome measure?
Method
Participants and Setting
All fifth-grade students (N = 106) in a single public K-12 school in south Louisiana participated in the study, which was approved by a university Institutional Review Board. This convenience sample was chosen for two reasons. First, the teacher (and fourth author) was well versed in the general outcome measure, having overseen development of the entire body of grade-level subject terms and definitions. Second, the teacher volunteered her classroom and the students for which consent and assent were obtained. This was an important consideration because of the timing of the study and the time-intensive nature of the research design. Data collection took place in the 2 weeks prior to statewide accountability testing. Therefore, instructional time that otherwise might have been allocated for content teaching and statewide test preparation (10 to 15 min daily over 10 days) was devoted to completing the assessments and social validity survey.
As a group, participating students in this convenience sample were 58% female and 88% White. The ethnic breakdown included seven, two, and four students who were African American, Hispanic, and Asian Pacific Islander, respectively. Demographic and academic characteristics suggested a homogeneous group. That is, all participants paid full price for school lunches. No students were verified with exceptionalities. The median and most commonly reported quarter grade was in the A− range. No participating student received a failing quarterly grade in the school year in which the study took place. The average state accountability science test score was a 356.5 (SD = 32.1; range = 100–500). All but one of the participants scored at or above the basic level of proficiency—considered passing—on the science test, with 69% scoring at mastery (n = 48) or advanced (n = 25) levels. By contrast, 21% of students statewide met mastery or advanced levels and 62% passed.
All participants were taught by a single science teacher, who was in her 6th year at the school and her 21st year overall at the time of the study. The teacher was highly qualified to teach elementary science and had previously earned a master’s degree while teaching across the upper elementary and middle school grades. Fifth-grade science content and instruction was guided by the Louisiana Department of Education (LDE) Comprehensive Curriculum (2008), which was aligned with state content standards and grade-level expectations and organized into eight time-bound units. Materials were equally divided throughout the academic year across physical, life, and earth science and science as inquiry content. Participants were taught in a departmentalized setting and split into four sections that met daily for 60 min. Instruction generally included a combination of teacher lecture and student group and individual work.
Measures
The three measures were as follows: (a) 20 parallel forms of critical content monitoring in fifth-grade science, (b) the integrated Louisiana Educational Assessment Program (iLEAP; LDE, n.d.-a) criterion-referenced fifth-grade science test, and (c) a researcher-developed social validity instrument.
Critical content monitoring
Each of the 20 parallel forms included 20 multiple-choice questions targeting content vocabulary and their accompanying definitions. The question format had a definition included as the stem and the correct term and four distractors listed vertically below the stem. For example, the phrase, “to spin on an axis” comprised one stem, with the choices including the incorrect variable, energy transformation, microscope, and acceleration, and the correct revolve listed underneath. Another example had “the process of moving sediment by wind, moving water, or ice” as the stem and erosion, scientific method, decomposer, transpiration, and nitrogen cycle as choices. Students were expected to read the stem, place a mark beside the correct vocabulary choice, and scroll down to the next question. A timer on the screen counted down from 5 min and automatically stopped if the student used the full allotment of time. Students received their score in the form of a fraction (e.g., 6 out of 20). If a student had taken multiple probes, a line graph also was evident that provided the student with his or her scoring history. Probes were delivered through the Moodle learning management system. An open source software package, Moodle is described as a global development project designed to support a social constructionist framework of education (Moodle, n.d.). The Moodle system used in this project was managed at the university level and extensively customized to compare student performance in real time and show trends in student performance graphically.
A curriculum sampling approach (Fuchs, 2004; Fuchs et al., 2008) was used to create parallel forms. Terms in each probe were randomly selected from the full body of science terms by content unit. Each probe included terms selected from each of the eight fifth-grade units. The number of terms per unit was determined by calculating the proportion of the year’s curriculum that was devoted to each unit in the state pacing guide and then multiplying that proportion by 20, the number of questions in each probe. Adjustments were then made to the number of terms per unit if the total number of terms for all of the units did not add up to 20. For example, there were four terms chosen to be included in each probe from the ecosystems unit. The pacing guide suggested that ecosystems be taught for 6 of the 34.5 weeks of the academic calendar, which amounted to 17.4% of the calendar. That proportion multiplied by 20 questions resulted in the suggestion that 3.5 terms be included in each probe. Calculations across each of the 8 units did not result in a final sum of 20, so the decision was made to increase 3.5 terms to 4 terms in each probe because the ecosystems unit was one of the longer units in the pacing guide.
The probe development process evolved from procedures for vocabulary matching that were outlined in Espin et al. (2001) and Mooney, McCarter, et al. (2010; Mooney et al., in press). That is, an Excel file was created that included all glossary terms pulled from state-approved textbooks along with accompanying definitions. That file was reviewed by the fourth author, whose responsibility was to ensure that all terms were aligned with the state’s curriculum and assessment guides. The refined list was then distributed to that and other recommended fifth-grade-level science teachers, who were asked to identify all terms that each believed should be known by fifth-grade students at the end of the year. The final list comprised 107 terms that were identified by the majority of teachers as priority terms. Each term was also associated with one or more of the identified units in the grade-level curriculum (e.g., atomic number: Grade 5 Unit 2 Reactions).
iLEAP Grade 5 science criterion-referenced test
The iLEAP is Louisiana’s statewide assessment for students in Grades 3, 5, 6, 7, and 9. The fifth-grade iLEAP measures students’ proficiency in reaching Louisiana academic standards in English/language arts, math, science, and social studies. The fifth-grade science test consists of 46 multiple-choice questions and is an untimed test that is completed in 1 day. Fifth-grade science content strands (and the percentage of points associated with each) include science as inquiry (20%), physical science (22%), life science (22%), earth and space science (20%), and science and the environment (16%; LDE, n.d.-a). Students receive a score of 1 for a correct response and 0 for an incorrect response. Achievement levels and associated scaled scores were as follows: (a) unsatisfactory, 100–247; (b) approaching basic, 248–291; (c) basic, 292–340; (d) mastery, 341–377; and (e) advanced, 378–500 (LDE, n.d.-b). Students scoring at or above the basic level are considered to have passed the test. Technical adequacy data for the iLEAP fifth-grade social studies test were accessed from the LDE website. A Cronbach’s alpha of r = .85 was reported (LDE, n.d.-c) as evidence of the 2010 test’s internal consistency. Validity data were discussed in terms of a content validity process (LDE, n.d.-c). The technical summary included no criterion-related validity data.
Social validity
The researcher-developed and teacher-administered social validity scale included three testing process–related questions. The first two questions were Likert-type scale items related to the online testing system’s ease of use (i.e., very easy to very difficult) and likeability of the graphing functions (i.e., liked to did not like). Students rated each question on a 1 to 9 scale. The third question was open ended and asked students for one change that they would make “to make the online testing process better.”
Procedure
Critical content monitoring testing took place over 10 consecutive school days in late March/early April 2011, ahead of statewide accountability testing. The testing schedule for the 20 parallel forms was designed to account for potential order effects. Two probes were administered to each student daily. Probes were chosen randomly without replacement for each section until each of the 20 probes was included. For example, on the first day of testing, the first group of students was administered Probes 7 and 8, the second group, Probes 7 and 2, the third group, Probes 17 and 2, and the fourth group, Probes 9 and 8. Students logged in to the secure Moodle site using an individual log in ID and password. The teacher verbally guided students to the site first and then the actual probe. After receiving a standard instruction, students were expected to access the probe and answer the questions within the time limit. While the questions for each probe were the same, the order of questions was random for each student. Following the second day of testing, standard directions were no longer read by the teacher because the students were able to readily access the system when directed to do so. Once the last probe was administered, students were requested to complete the social validity scale.
Data Analysis Plan
Probe scores were accessed from the online site by the first author and exported in the form of individual Excel files once the testing process was complete. One Excel file included final scores for all participants and was used to complete criterion-related validity and alternate-form reliability analyses. The Excel file was then checked to determine whether there were any zero scores in the database. Previous pilot testing of the system indicated that a score of 0 may be related to technical issues with the system. Three 0 scores were detected and then manually regraded by the system administrator and third author, and were subsequently corrected in the database. No interscorer reliability checks were formally taken beyond a double checking of the entry of the questions into the online system to ensure that the right choice accompanied each stem. Demographic, statewide accountability test, and social validity data were provided to the first author by the fourth author. Data were entered and checked for accuracy prior to analysis.
Analysis addressed criterion-related validity, probe equivalence, social validity, and alternate-form reliability questions. Criterion-related validity for each of the 20 probes was assessed using the correlation between each probe and a relevant criterion measure. To facilitate analysis, point and 95% confidence interval (CI) estimates of the correlations between the iLEAP and each of the 20 critical content monitoring probes were obtained. Probe equivalence had several dimensions. The first involved equivalence in terms of the relation of the critical content monitoring probes with a criterion measure. An omnibus approach tested the equality of 190 criterion-predictor correlations at the same time. Full-information maximum likelihood was used to perform the analysis, allowing for inclusion of all of the available data even though there were missing data across probes. The second aspect of probe equivalence pertained to the critical content monitoring mean scores. ANOVA was used to compare the mean scores across the 20 probes. The design of the study allowed for determination of main effects but did not allow for determination of interaction effects. For the Likert-type scale social validity questions, descriptive statistics were computed. In addition, descriptive summaries of the responses to the open-ended question were reviewed and qualitatively summarized. The alternate-form reliability question involved quantifying the strengths of the linear relations between the various measures through correlation analysis. Two analyses were conducted, with the first comparison involving each probe mean score being correlated with each other and resulting in 190 associations. The second analysis took advantage of the research design, which had students in each of four sections taking 2 probes daily over 10 days. Forty comparisons were conducted.
Results
Test Descriptives
Table 1 provides sample means and standard deviations of the 20 critical content monitoring probes as well as 95% CI estimates of their true mean values. It also provides the number of available (i.e., nonmissing) scores per probe. Probe numbers in Table 1 (e.g., Probe 1, Probe 20) refer to the distinct test accessible in Moodle, and not to the order in which the probes were administered. Mean scores for the probes ranged from 17.0 to 18.2. Probe score standard deviations ranged between 1.6 and 2.6. Skewness and kurtosis statistics calculated for each of the 20 probes suggested that probe scores were not normally distributed, which was confirmed by formal normality tests. A formal normality test also indicated that the iLEAP variable was not normally distributed.
Critical Content Monitoring Means and Correlations With State Science Accountability Test in Fifth Grade.
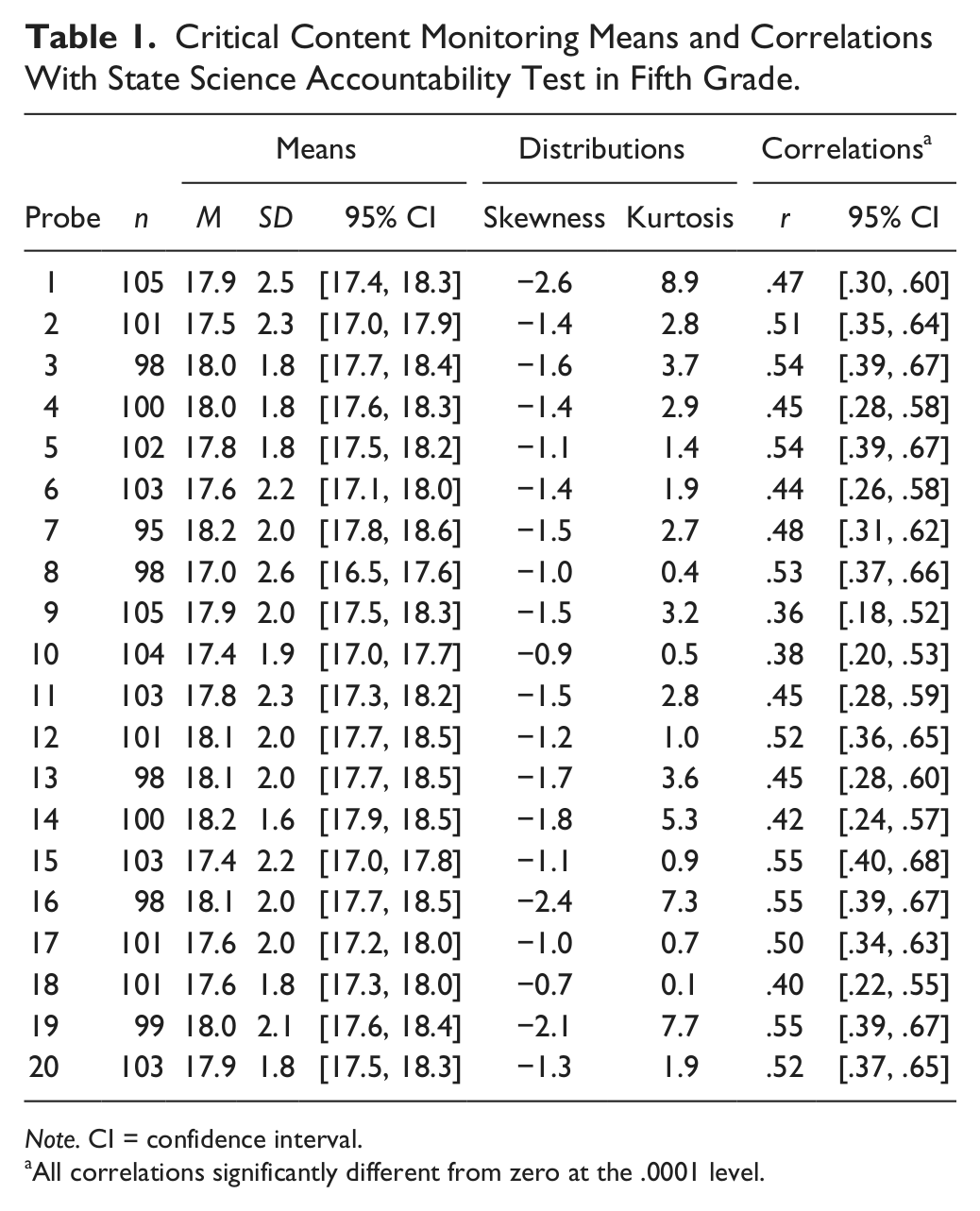
Note. CI = confidence interval.
All correlations significantly different from zero at the .0001 level.
Criterion-Related Validity
Correlations between each of the 20 critical content monitoring probes and the statewide accountability test in fifth-grade science are also reported in Table 1. Estimated correlations ranged from .36 to .55. A pooled estimate of the common correlation between the iLEAP and the probes was .45. Individual hypothesis tests showed that each of the correlations was significantly different from zero at the .0001 level of significance. Fifty percent of the correlations with iLEAP (n = 10) fell in the .50 to .59 decile. Table 1 also contains 95% CI estimates of the true correlations. Inspection of the intervals shows that there is a fair amount of overlap among the intervals, suggesting that the observed correlations may not be significantly different from one another.
Probe Equivalence
To assess the equivalence of the 20 probes with respect to their correlation with the iLEAP, a formal test of the equality of the correlations between the iLEAP and each of the 20 probes was performed. The alternative hypothesis was that at least two of these correlations differed. While point estimates of the 20 correlations ranged from .36 to .55 (see Table 1), these observed differences were not statistically significant (p = .13, df = 19). Hence, there was insufficient evidence to conclude that differences existed among the 20 correlations, and therefore insufficient evidence to conclude that the probes were not equivalent with respect to their correlation with iLEAP.
Mixed-model ANOVA was used to assess probe equivalence with respect to the critical content monitoring mean scores. The response variable for the model was the individual probe score. The model included class section (i.e., 1–4), day (i.e., 1–10), and probe number (i.e., 1–20) as fixed effects, and the individual student as a random effect to account for potential correlation of probe scores within a student. There was strong evidence of differences among population mean probes scores (p < .0001). Pairwise comparisons were performed to determine which probes differed in their mean scores. The Tukey–Kramer adjustment was used to maintain control on the Type I error rate. Based on these comparisons, five probes were identified as having different population mean scores than the rest, Probes 2, 7, 9, 15, and 18. Hence, the full complement of 20 probes failed to be equivalent with respect to probe score means. The section effect was not significant (p = .8306). The day effect was significant (p < .0001). Pairwise comparisons using the Tukey–Kramer adjustment were used to identify which days differed with respect to their mean probe scores. From these comparisons, it was determined that Day 1 had lower mean scores than Days 2 through 10. Day 2 had lower mean scores than Days 7 through 10. Days 4 and 5 had lower mean scores than Day 10. As in each case where differences between days existed the estimated mean scores were increasing over time, it appeared that learning was taking place, even over this relatively short time period.
Social Validity
Of the 106 participants, 103 completed survey questions related to the ease of use of the online system as well as the likeability of the online graphing function. Using a 1 (very easy) to 9 (very difficult) Likert-type scale, participants rated the system as easy to use, with an arithmetic mean score of 2.41 (SD = 1.46), median score of 2, and mode of 1. Nearly 81% of participants rated the ease of use between 1 and 3. Less than 2% of participants rated the system as difficult. For likeability of the visual graph, the mean, median, and mode scores were 2.99 (SD = 2.52), 2, and 1, respectively, for a 1 (liked) to 9 (did not like) scale. Nearly 69% of participants liked the graphing display, while nearly 10% did not. Participants were also asked what they would change to make the online testing process better. The most common response (n = 38) related to the desire for feedback on questions for which students did not obtain a correct response. Other relatively frequent suggestions related to changes in the time of the probes—both longer and shorter—and a greater variety of questions.
Alternate-Form Reliability
Table 2 provides 190 alternate-form reliability correlations between each of the 20 critical content monitoring probes. Pairwise comparison procedures were used, with the sample sizes across the 190 comparisons ranging from 87 to 105 (of the 106) participants. The average of all correlations calculated by probe was .55 (SD = .09), with the median correlation a .56. Correlations ranged from .21 to .73. More than one third of the correlations between probes (n = 82; 43%) were between .50 and .59. For the second analysis that used the design characteristics and was calculated by section, the mean and median scores across the 40 comparisons were .58 (SD = .08) and .57, respectively. More than half of the correlations between probes (n = 21; 53%) were between .50 and .59.
Alternate-Form Reliability Correlations for Critical Content Monitoring Probes in Fifth Grade Science.
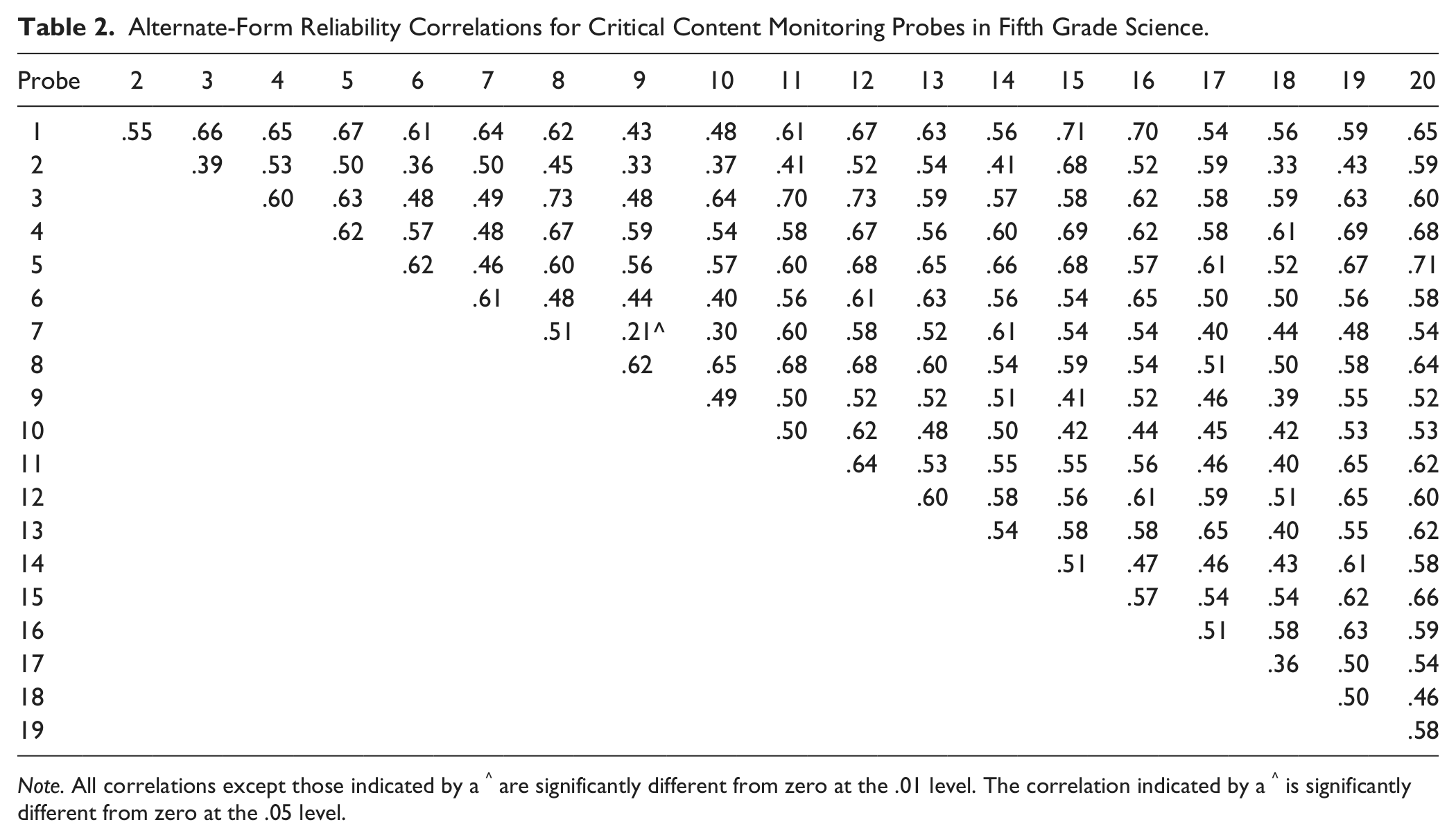
Note. All correlations except those indicated by a ^ are significantly different from zero at the .01 level. The correlation indicated by a ^ is significantly different from zero at the .05 level.
Discussion
The purpose of the present study was to evaluate an online adaptation of vocabulary matching known as critical content monitoring. Vocabulary matching is designed to serve as a measure of performance and progress in content courses and has a small body of research demonstrating the acceptability of its scores for those purposes across grade levels and subjects. However, concerns with the labor-intensiveness of implementation and potential confusion with existing data from an instructional utility perspective led to the proposed online application of the general outcome measure of academic language as a possible solution. The research questions were initial ones in a larger program of study and targeted Stage 1 tenability of the single probe static score collected online. Study findings are summarized prior to discussion of limitations and implications of critical content monitoring as a tool for improving teaching and learning in content courses.
Validity is a vital consideration in test development, defined as “the degree to which evidence and theory support the interpretations of test scores entailed by proposed uses of the test” (American Educational Research Association, American Psychological Association, & National Council on Measurement in Education, 1999, p. 9). Evidence supporting score interpretation includes that based on test content, relations to other variables, internal structure, response processes, and testing consequences. Validity findings in the present study addressed the measure’s scores in relation to a specific criterion and score equivalence.
At the instrument level, critical content monitoring scores were compared against scores from a statewide accountability for a homogeneous sample of fifth-grade students. Criterion-related correlations between the two instruments ranged from .36 to .55 with the Louisiana state science test, with a pooled correlation of .45 for all probes. Three fourth of the probe correlations with the state science test were in the moderate range (.3–.7; Reynolds, Livingston, & Wilson, 2009) in terms of magnitude, which is less than the moderate to strong range reported by different research teams (Espin et al., 2001; Mooney et al., in press) for social studies content in paper–pencil form. A number of factors may have impacted the lower magnitude linear associations. First, the sample used in the present study was more homogeneous than samples previously included in vocabulary matching research, impacting the dispersion of mean scores and reducing the correlation. This consideration is evident from a comparison of accountability test results which indicated that more than two thirds of the participants scored at an advanced level on the test. Second, the makeup of the quiz, which included 20 multiple-choice questions and a 5-min time frame, may have restricted the scores because a majority of the students had incidences where they correctly answered all of the 20 questions and in less time than was allotted for the test. These two factors resulted in variables that were not normally distributed and scatterplots that were not linear in form, possibly restricting the magnitude of the Pearson correlation. A third consideration relates to the domain itself. Correlations with criteria in the vocabulary matching literature have largely been determined in social studies content. With a tremendous number of names, places, and dates accounted for in the academic language of social studies, it may be that those domains lend themselves more easily to testing of the academic language. However, it should be noted that Vannest et al. (2011) did report some strong criterion-related correlations in their progress-monitoring study that targeted fifth-grade science content.
At the general outcome measurement level, validity issues relate to whether changes in scores over time can be attributed to learning as is assumed with the repeated administration of probes considered to be parallel measures of the domain of interest. Research examining probe development procedures for the read-aloud measure in CBM has demonstrated that not only do probe-specific (form) effects exist, but that from a progress-monitoring perspective these effects “can have a profound influence on the trajectory of monitored students” (Petscher, Cummings, Biancarosa, & Fien, 2013, p. 72). Strategies to deal with these effects include field testing probe sets with populations of students (Ardoin et al., 2010) as well as completing various equating procedures (Stoolmiller et al., 2013). Field testing of a set of 20 critical content monitoring probes demonstrated variable findings. When the correlations between each single probe and the statewide accountability test were directly compared, statistically equivalent results were evidenced. That is, there were no differences, for example, detected in the correlations with the iLEAP science test for Probes 1 and 17, meaning, in this sample, with the set of probes that were administered, form effects were not detected. However, a different result was obtained when the mean scores across the 20 probes were directly compared. Form effects were detected for this sample and probe set, with differences determined for 5 of the 20 mean scores. Overall findings suggest that empirical work to address impact of form effects on progress-monitoring practices has relevance in content subjects.
Interpretations of findings from the calculation of alternate-form reliability coefficients for the 20 critical monitoring probes do not appear to favor one side of any debate concerning the existence or nonexistence of form effects in critical content monitoring and their potential impact on measurement of performance and/or progress. The argument for form effects is bolstered by data demonstrating that the median of form comparisons was either .57 or .58 depending on the way the comparisons were conducted, which fails to meet the minimum reliability standard of .60 for low-stakes educational decision making (Salvia, Ysseldyke, & Bolt, 2007). Lower reliability coefficients would appear to indicate greater differences in form than would the higher correlations reported in the vocabulary matching literature (Espin et al., 2001; Mooney, Schraven, et al., 2010). However, the argument for equivalence in the present set of probes might be supported by factors including the homogeneity of the sample and a likely restriction in range brought about by the probe length. One other factor that may have alternate-forms reliability interpretation was the manner in which students took the probe. Because probes were administered in a group format, the questions and choices within questions appeared randomly. Because it was possible for a student to not complete all 20 questions within the time frame, that student, in essence, took a different probe than a student who did complete the probe. Possible effects of this occurrence were limited with this population because most participants finished before the time limit, but the possibility of the instrument not delivering parallel forms during implementation remains.
Social validity data generally indicated that students found the online system easy to use and informative. Students overwhelmingly rated the testing system as easy to use, which is important given the fact that upper elementary and middle school students seemingly have a greater ability to direct their own learning than do lower elementary school students. Students, then, were able to access the online system, initiate the completion of probes, access the numeric results of a single probe and visual display of their probe history, and exit the system. Moreover, mean scores from Days 1 through 10 showed an increasing trend, which might indicate that students improved their knowledge level and/or online test-taking skills over time in the few weeks before statewide accountability testing. Students were also able to demonstrate their interest in the system through their suggestions, including the most oft-provided request for feedback on those questions that were answered incorrectly.
Limitations
The implementation process issue that complicated the process of comparing alternate critical content monitoring forms was one limitation of the present study. Second, the characteristics of the present participant pool, which included all passing course grades and strong accountability test results and no students with verified disabilities and/or giftedness/talents, is likely not generalizable to the average public school student population. With the focus on a single grade and content level, commentary regarding generalizability to other grades and subjects is limited. In addition, this study’s comparisons between the online adaptation and the original vocabulary matching probes were indirect and complicated by the following considerations: (a) all previous published Stage-1 vocabulary matching research had been conducted in the area of social studies and with sixth- and seventh-grade students, whereas the present participants were fifth-grade students learning science content and (b) the online adaptation involved multiple-choice questions, whereas all previous research involved a matching format. Finally, analyses in the present study were limited by the research design not allowing for the testing of potential interactions between the fixed effects in the equivalence analysis related to probe mean scores.
Implications
With the present limitations and findings noted, it is evident that the research on online applications in the area of course content-related general outcome measurement is in its formative stages. It is still too early to ascertain whether critical content monitoring or other online general outcome measurement systems can serve as a tool for improving teaching and learning, as formative currency (Alexander, n.d.) to teachers and students. The present findings do, however, provide some practical implications as well as directions for future programmatic inquiry.
At a practical level, three positive considerations are noteworthy. First, large numbers of students were able to access and successfully navigate an assessment system that they were previously unfamiliar with in a relatively brief amount of time. Students were provided step-by-step explicit directions initially but quickly learned to access the system by themselves when prompted. By the nature of their responses to the open-ended social validity question, students also demonstrated an ability to evaluate potential strengths (e.g., immediate access to scores) and limitations (e.g., no immediate access to instructional feedback, similar question formats, and timed administrations) of online assessment systems. Having students able to access an assessment system independent of a specific teacher directive to take a quiz opens up the possibility of evaluating innovative uses of school time.
Second, data appeared logical, which may eventually contribute to more widespread use of the online system. That is, mean scores compiled near the end of the school year were higher were those reported from previous vocabulary matching research (e.g., Espin et al., 2001; Mooney, McCarter, et al., 2010). If scores are to be considered vital signs of academic language health, then they need to be interpreted as evidence of end-of-year performance when tested near the end of the year. Scores that are closer to 20 than 0 would be evidence of such a phenomenon in the present case, and that is what occurred, with mean scores averaging between 17.0 and 18.2 (out of 20). These scores, if proven technically adequate, may well be easier to interpret by practitioners. They may also lend themselves to more interpretable growth scores than those that have been reported in the vocabulary matching literature.
Third, in a short amount of time a tremendous amount of data was collected that could be used formatively by students and teachers, as Bloom (1969) noted, “to provide feedback and correctives . . . in the teaching-learning process” (p. 48). Ysseldyke and colleagues (e.g., Burns et al., 2010; Ysseldyke & Bolt, 2007) have reported on the capabilities of technology-enhanced formative evaluation systems. Germane to general outcome measurement, a body of literature in CBM (e.g., Fuchs & Fuchs, 1986; Stecker et al., 2005) demonstrates that the timely and effective use of data by teachers can improve student achievement. Consider that grade-level teachers in professional learning communities or teams of educators in prevention-oriented school level committees could gain access to these and other assessment materials on a regular basis to help determine whether learning is occurring at an expected rate or whether intervention programs are providing expected results. In addition, consider that body of test data collected did not have to be graded by teachers, recorded, and summarized. The data were instantly available to the teacher just as they were the student(s), along with summary statistics related to group means and individual item analysis for each of the parallel forms. The data-based decision-making opportunities that appear possible through the use of online application mechanisms would definitely be appropriate in upper elementary and middle school settings, where teachers have larger caseloads, struggling students are likely easier to identify, and a smaller but growing body of general outcome measurement literature exists to inform assessment and instructional practice.
In terms of research implications, focused efforts need to continue to refine the critical content monitoring process in ways that strengthen the technical adequacy of the probes across grade levels and subject areas for the purposes for which the instrument is aimed. First, regarding interpretation of evidence of test content, the existing probe development process should be compared with other methods for organizing content. Second, if critical content monitoring is to be used for progress-monitoring purposes, then expanding areas of inquiry related to the performance, progress, and instructional utility of the system (Fuchs, 2004) remains crucial. Stage 1 static score research can focus on altering the probe format to increase alternate-form reliability and produce parallel forms that are equivalent for the growth functions they are designed to serve. Alterations might involve the number of items, length of the probes, and content mix. Stage 1 validity research might focus on the seemingly growing number of criterion measures, particularly standardized measures of content along with assessments related to the pending content Common Core State Standards. Stage 1 inquiry might also evaluate critical content monitoring’s ability to evaluate the scores of students at various levels of achievement. Stage 2 growth research might provide findings comparable with those of Borsuk (2010), Espin et al. (2005), and Mooney et al. (in press) related to growth rates for various time frames (e.g., weekly, biweekly, monthly). Building on the work of Christ, Zopluoglu, Monaghen, and Van Norman (2013), attention must be paid to the validity, reliability, and precision of growth estimates for critical content monitoring. Stage 3 instructional utility inquiry might address the types of supports that are needed to help individual teachers, groups of teachers, and even students effectively and efficiently use data from online and other assessment sources to inform content area instruction (e.g., Stecker et al., 2005). Ardoin, Christ, Morena, Cormier, and Klingbeil (2013) indicate that there is considerable need for evidence that justifies recommendations for how to use general outcome data at the individual student level. Third, efforts might address the delivery process, evaluating different online formats at the system and individual feature level. Fourth, given the broad nature of and aims for science and social studies content learning, research might be directed at the exploration of what combination(s) of formal and informal, standardized and nonstandardized, general outcome and specific subskill mastery measurement, “big idea” and specific content assessments inform instruction in terms of features like effectiveness, efficiency, and/or meaningfulness. Finally, efforts to increase the heterogeneity and size of future samples will be a necessity. Together, answers to these practical and research questions may go a long way toward determining whether the assessment of academic language through general outcome measurement can serve as a useful tool for improving content teaching and learning.
Footnotes
Acknowledgements
Thanks to the editors and anonymous reviewers for their valuable comments regarding previous versions of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was supported by a grant from the Louisiana Board of Regents, Louisiana Systemic Initiatives Program.