
Abstract
Assessment of language skills for upper elementary and middle schoolers is important due to the strong link between language and reading comprehension. Yet, currently few practical, reliable, valid, and instructionally informative assessments of language exist. This study provides validation evidence for Monster, P.I., which is a gamified, standardized, computer-adaptive assessment (CAT) of language for fifth to eighth grade students. Creating Monster, P.I. involved an assessment of the dimensionality of morphology and vocabulary and an assessment of syntax. Results using multiple-group item response theory (IRT) with 3,214 fifth through eighth graders indicated morphology and vocabulary were best assessed via bifactor models and syntax unidimensionally. Therefore, Monster, P.I. provides scores on three component areas of language (multidimensional morphology and vocabulary and unidimensional syntax) with the goal of informing instruction. Validity results also suggest that Monster, P.I. scores show moderate correlations with each other and with standardized reading vocabulary and reading comprehension assessments. Furthermore, hierarchical regression results suggest an important link between Monster, P.I. and standardized reading comprehension, explaining between 56% and 75% of the variance. Such results indicate that Monster, P.I. can provide meaningful understandings of language performance which can guide instruction that can impact reading comprehension performance.
Keywords
Language knowledge has an intricate relationship with reading comprehension. Theories like the Simple View of Reading (Gough & Tumner, 1986) separate reading comprehension into decoding and linguistic comprehension. As students get older, the contribution of decoding decreases and the role of language increases (García & Cain, 2014). This stems from challenging language demands present in middle school academic texts. Simply put, it is easier to learn to sound out the 200,000 words in academic texts (Nagy & Anderson, 1984) than it is to learn their multiple, nuanced meanings and apply those meanings to parsing ideas conveyed via complex syntactical structures (Nagy & Townsend, 2012).
There are many ways to assess language, but few assessments are used at scale (Adlof & Hogan, 2019; Hart et al., 2015). 1 This is because “the presumed multidimensionality of language ability has practical import” (Language and Reading Research Consortium [LARRC], 2015, p. 1948) such that tests with multiple subtests in different language areas are used for the diagnosis of language disorders rather than to inform general instruction. As an alternative, we provide validation information for a language assessment that uses technology to tackle this complexity to provide scores that inform instruction for a broad swath of students. The assessment is more efficient as it is computer-adaptive (CAT), meaning that items are matched with the level of the learner being assessed, leading to fewer items being needed to determine a valid and reliable score. It also uses technology, meaning that it can be administered and scored at scale, and is delivered in an engaging way as a game. Studies such as Clark et al. (2016) and Mitchell and Savill-Smith (2004) suggest gamifying can increase motivation and self-esteem. Below, we explain our language model and the link between language and instruction.
Model of Language
Language has been conceptualized in many ways (see LARRC, 2015 for a discussion). Our language assessment, Monster, P.I., is grounded in theory and research on the relationship between language and reading comprehension. It focuses on three components of language that are particularly important for young adolescents 2 : morphology, vocabulary, and syntax (Foorman et al., 2015; Kieffer et al., 2016). Specifically, Perfetti and Stafura’s (2014) Reading Systems Framework argues that “word-to-text integration processes are central to comprehension” (p. 30) and involve updating “the situation model [in a way] that integrates a word with a text representation” (p. 29) across words, phrases, and sentences. For adolescents, most words are morphologically complex (Nagy & Anderson, 1984). Thus, in regard to integrating word knowledge, we first considered (a) knowledge of the units of meaning that make up words, like prefixes, suffixes, and root words, as well as how they are combined (i.e., morphology); (b) then broader lexical knowledge (vocabulary); and then (c) knowledge of how those words are put together to convey larger meaning (syntax), with syntax defined as knowledge of word order, grammatical rules, and connectives used to combine words to create meaning (Taylor et al., 2012). The emphasis on text links to the language of schooling, which is dense (i.e., embedded clauses, nominalizations) and uses challenging, morphologically complex words (Nagy & Townsend, 2012; Uccelli et al., 2015).
Multiple research studies provide evidence that language is made up of these three language areas. For example, Kieffer et al. (2016) showed for a Grades 3 to 5 sample and a Grade 6 sample that there is a general factor related to overall language skills and specific factors for morphology, vocabulary, and syntax. Similarly, Foorman et al. (2015) showed that the same model had the best fit for fourth to 10th graders. What this means is that performance on different components of language such as vocabulary, morphology, and syntax overlaps such that performance similarly reflects students’ language skills. But performance also is unique, reflecting distinct aspects of language that are likely differentially important to making meaning.
This idea of using modeling techniques to use the complexity of a construct like language to provide additional understandings and instructional guidelines is highlighted by Goodwin et al. (2018). Our language model considers construct-relevant versus construct-irrelevant variance when modeling. Related to language, examples of construct-relevant variance would be skills or areas of language that could be instructionally relevant like ability to identify units of meaning (morphology), access word knowledge (vocabulary), or determine the meaning of a combination of words (syntax). In contrast, construct-irrelevant variance would involve performance related to features of the task like the nature of a multiple-choice task. Here, even if such performance explained variance, educational research would not suggest teaching students how to complete multiple-choice items, but rather instructing the content that the multiple-choice item assesses. Another example might be word-specific versus word-general knowledge with the idea that looking across performance on a group of words is more informative to instruction than considering performance on a single word. We use these ideas to guide our theoretical model: the idea that modeling construct-relevant variance can build a nuanced understanding of the construct and provide instructionally relevant scores.
Our language model also builds on work suggesting some key aspects of language themselves are likely multidimensional (Cho & Goodwin, 2017; Goodwin & Cho, 2016; Goodwin et al., 2017, 2018; Kieffer & Lesaux, 2012). Vocabulary is multidimensional: Knowledge of one aspect relates to others such that a student who knows a word’s definition is more likely to be able to recognize synonyms or antonyms of the word, yet each assessment of word knowledge also provides unique information about a student’s lexicon. Goodwin and Cho (2016) and Kieffer and Lesaux (2012) confirm this: Goodwin and Cho showed performance on multiple-choice, self-report, and related-word production was related but also tapped different aspects of word knowledge, and Kieffer and Lesaux showed models of vocabulary consisted of “three highly related, but distinct dimensions—breadth, contextual sensitivity, and morphological awareness” (p. 347). Morphology is also likely multidimensional, with Goodwin et al. (2017) reporting best fit of a general factor for morphology (i.e., overlap of all morphological knowledge assessments) and seven specific factors representing the different morphological demands in tasks, many of which link to the different ways that morphemes convey information including semantic, syntactic, phonological, and orthographic information. Yet, no dimensionality studies indicate multidimensionality for syntax (Deacon & Kieffer, 2018). For both vocabulary and morphology, research (vocabulary: Pearson et al., 2007; morphology: Goodwin et al., 2017) and theory (Perfetti, 2007) suggest assessing in multidimensional ways can inform supports between the construct and reading comprehension, yet this is not the case with syntax where additional syntax measures do not explain significant additional variance in reading comprehension (Bowey & Patel, 1988; Cain, 2007). The exception is Brimo et al. (2017), but the syntax measure was a listening comprehension measure, drawing into question its relevance. Hence, we conceptualize vocabulary and morphology as multidimensional but, following the literature, theorize syntax as unidimensional.
Many of the complaints related to assessments of aspects of language such as current vocabulary, morphology, and syntax awareness assessments are that they fail to attend to the multidimensional nature of the constructs. For example, according to Pearson et al. (2007), few studies assess vocabulary in a valid manner, partly because current measures rarely consider multiple aspects of word knowledge within assessments. The same concerns are noted for morphology (Bowers et al., 2010; Nagy et al., 2014). Furthermore, assessments that consider the multidimensional nature of vocabulary (Hadley et al., 2019) tend to be individually administered, which is a challenge for classroom operationalization. We developed our work attending to these concerns as scores on different aspects of language likely have different instructional implications.
Written Orthography
In creating our assessment, we took a developmental view. With more formal literacy instruction, it is important to consider how the written orthography conveys meaning, moving beyond a purely oral view of language. For example, know and knowledge overlap in orthography but not in pronunciation, suggesting that written language conveys important clues to meaning that should be considered when assessing language knowledge for adolescents. In addition, written language tends to include words that are abstract, like analysis, which is difficult to assess with pictures. Therefore, our assessment takes into account developmentally the importance of assessing language within the written orthography.
Links to Instruction
The consideration of language as multidimensional is important for instruction because the areas of language and skills tend to be more malleable than general language within these areas. The recipe for instruction—how much vocabulary, morphology, and syntax instruction—is unknown. Research with preK-12 students emphasizes that vocabulary (Elleman et al., 2009; Wright & Cervetti, 2017), morphology (Bowers et al., 2010; Goodwin & Ahn, 2010, 2013), and syntax (Graesser et al., 2011) are teachable, with potential benefits to students with reading difficulties versus typical students (1.23 vs. 0.39 effect size; Elleman et al., 2009). Language data can inform such recipes of instruction.
Current Study
Our study explores the reliability and validity of Monster, P.I. First, we examine the dimensionality of vocabulary, morphology, and syntax with the goal of identifying construct-relevant variance related to teachable skills present in each language component. Second, we explore whether scores are reliable and valid. As part of this, we investigate links between Monster, P.I. and standardized reading vocabulary and reading comprehension.
Method
Participants
Across the 3 years of the study, we worked in an urban district in the Southeastern United States. For our first research question, we used our full sample of 3,214 fifth through eighth graders (n = 1,026 fifth graders, 742 sixth graders, 715 seventh graders, and 731 eighth graders) learning in the classrooms of 15, 38, and 37 teachers in Years 1, 2, and 3, respectively. 3 Demographic data from the district for 3,041 participants suggest the sample was 53.4% female and 33.3% Black, 40.4% White, 21.9% Latino, 4.3% Asian, and <1% American Indian. Fifty percent of students were classified as economically disadvantaged, and 8% were identified as English language learners (ELLs). For the second research question, we used a smaller sample that had taken the CAT version of Monster, P.I. during Year 3 along with the standardized measures. This sample included 1,002 students who were 53% female and were 42.8% White, 30.4% Black, 22.3% Latino, and 4.5% Asian. This sample had 30.6% students classified as economically disadvantaged, and 7.3% were identified as ELL.
Development
Year 1 development focused on exploring multidimensionality (i.e., of language and its components). We started with 10 morphological tasks, four vocabulary tasks, and one syntax task. 4 Tasks and items were either adapted from the literature or created by a panel of experts. Poorly performing tasks due to ceiling effects, poor discrimination, lack of range, and so on were discarded. Results indicated no effect of either reading items aloud (i.e., Cohen’s d = −0.23) or order effects (i.e., average Cohen’s d = −0.16; range d = −0.37 to 0.08). Year 2 included further piloting and operationalization via the assessment and confirmation of the dimensionality modeled in Year 1. Year 3 included delivery of the CAT, further item piloting, and exploration of links to standardized reading. Years 2 and 3 also included gamification efforts, with Year 2 developing the storyline and worlds and Year 3 including additional 30-s to 1-min games.
Ultimately, Monster, P.I. features a mischievous monster wreaking havoc on a city, including within a school, museum, library, sports arena, and amusement park. Students are assigned the role of detective and had to solve word puzzles (i.e., items from our assessment) to earn clues to identify and “catch the monster!” At the completion of each area (i.e., a few tasks), participants get a clue and play a 30- to 60-s mini game. The CAT (i.e., using a two-parameter logistic item response adaptive set of algorithms) takes between 20 and 40 min.
Measures
Measures are described below. All tasks were provided in print. Vocabulary and Syntax tasks were also read aloud (and could be repeated). Measures retained for the CAT are starred.
Morphology
Odd man out (OMO)*
This was adapted from Ku and Anderson (2003). Students identified two of the three words that shared morphemes by clicking on the word that did not fit in the set. Examples include corner, farmer, and swimmer (where the odd man out is corner) and season, seashore, and seaweed (answer: season). Items varied on whether words overlapped in suffixes, prefixes, or root words and whether relationships were transparent or opaque.
Meaning puzzles (MP)*
This was adapted from intervention work (Goodwin, 2016) and piloting (Pacheco & Goodwin, 2013). Students identified meaning overlap in morphologically complex words by choosing words that shared morphemes. They chose from four answer choices the word that shared a morpheme with the target word. Distractors had visual overlap, but only the correct answer had morphological overlap. Examples include astronomy, with choices of fast, strong, as, and astronaut, and divisibility, with choices of divide, visible, sibling, and ability.
Real world suffix (RWS)*
This was adapted from Tyler & Nagy (1989). Students identified the syntactically appropriate form of a root word from four choices to complete a sentence. An example was It was a ____________ occasion when Barack Obama was elected president. Students had to choose from choices of historic, historian, history, and historically.
Making it fit (MIF)*
This was adapted from Carlisle (1988). Students read a low-context sentence with a missing word and were given the base form of the missing word. They had to type the form of the word with that base that fit the sentence. For example, Some people argue that the ______ [sense] thing for Rosa Parks to do would have been to give up her seat, but instead, Ms. Parks stood up for what was right and started a movement (Correct: sensible).
Word detectives (WD)*
This was adapted from reading vocabulary tasks and Tyler and Nagy (1989). Students identified the meaning of the morphologically complex underlined target word given four choices. To increase motivation, the task was framed as a detective activity, with students encouraged to look for clues in the word and sentence to help figure out the word’s meaning. An example was There was
Sentence sense (SS)
Students were presented with a morphologically complex word in a sentence. Participants had to apply the meaning to choose the inference that best fit the situation. For example, participants read, After the hurricane, the city government set out to repair the streets only in
Morphological coherence (MC)
This was adapted from core academic skills (CALS-I; Uccelli et al., 2015). Participants read a three- to four-sentence passage in which the final sentence had an underlined morphologically complex word that students had to match with earlier text that refers to it. For example: Complex engineering problems are impossible to manage [correct] unless solved through teamwork. Construction workers and project managers have to work together. Often, projects that look
Morphological spelling (SP)*
Adapted from Carlisle (1988) to assess students’ ability to spell morphologically complex words. Students listened using headphones and were asked to spell the word heard using the iPad’s keyboard. Examples include selective and odorous. This task was presented orally and students could repeat the prompt.
Morphological word reading (WR)*
Students listened to three pronunciations of a morphologically complex word and chose the correct pronunciation. Distractors were mispronunciations most often used by middle schoolers based on pilot reading responses. An example is _________, (a) selective, (b) selecteyeve, and (c) seelecteyeve.
Word hunt (WH)
This was adapted from Goodwin (2016). Students identified 12 to 14 morphologically complex words from a larger line of words presented on a single line without any spaces between the words (i.e., camouflageobstaclediagramindigoshovel). Participants tapped where the word breaks should be.
Vocabulary
Definition (VOD)
Students identified the correct meaning of the word via a traditional multiple-choice task. An example is Which of the following is the correct meaning for the word “sweeping”? (a) Incomparable in beauty, (b) Having a wide scope or range, and (c) Making fresh.
Antonym/synonym (VOA)
Students identified words with the same (synonym) or opposite (antonym) meaning of a given word. An example is Which of the following is the opposite of the word famine? (a) Adequacy, (b) Success, and (c) Plenty. This task tends to be more difficult in item difficulty compared with word definitions (Spencer et al., 2015).
Word relations (VOR)
Students had to correctly discern the relationship between two word pairs, one of which contains the target vocabulary word. An example is Just is to unequal as smooth is to: (a) Rough, (b) Surface, and (c) Soft. This task follows Tzuriel and George’s (2009) work suggesting that verbal analogy is likely part of a vocabulary construct.
Polysemy (VOP)
Students identified multiple meanings of a given target word by answering five questions about each word with two to four meanings being accurate. For example, the target word charmed was tested by multiple items such as Does “charm” mean a piece of a bracelet? Does “charm” mean make mad? Does “charm” mean delight or please? Students responded yes or no to each question accordingly. This task attended to research suggesting knowing multiple meanings links to reading comprehension (Logan & Kieffer, 2017).
Syntax
Sentence correctives (SYN)
This was adapted from Foorman et al. (2017). Students were presented with two or three sentences. They determined the best answer that combined those sentences into one new sentence. Five types of connectives used were additive (i.e., and), causal (i.e., so), temporal (i.e., before), logical (i.e., similarly), and adversative (i.e., but). Distractors contained connectives that were incorrect, changing the overall meaning. An example is Gabby spent most of the summer at a camp. She liked it. She was eager to return home. Students had to choose the correct answer: After spending most of the summer at camp, Gabby was eager to return home, although she liked it.
Standardized measures
Reading Comprehension (Measures of Academic Progress [MAP]; Northwest Evaluation Association [NWEA], 2017) was assessed via the school district using the MAP, which is a multiple-choice CAT aligned to standards and nationally normed. It is designed to assess achievement and growth in reading as well as provide instructional information and link to high-stakes tests. Strong reliability has been shown (.90–.95), as well as concurrent validity. Overall reading scores derived from reading comprehension performance on literature and informational texts as well as performance on vocabulary items were used.
Vocabulary (Gates–MacGinitie Reading Vocabulary Assessment; MacGinitie et al., 2000) was assessed at the end of the first testing session using Form S of the Level 5 through 8 Gates–MacGinitie Standardized Reading Vocabulary Assessment. Students answered 45 multiple-choice items where they read an underlined word within a phrase and choose the word or phrase that conveyed a similar meaning. This task is used extensively in research with strong reliability and validity such that the Kuder-Richardson (K-R 20) reliability was .90–.92. Extended scale scores were used.
Procedures
Students took the assessment on iPads with headphones. Upon completion, students re-played some of the mini games and built their own monster. Two sessions were used to deliver the items (Years 1 and 2: two sessions of fixed items, Year 3: CAT version in Session 1 and additional fixed items in Session 2). A common-item, nonequivalent research design was used with planned missingness to maximize item deployment while minimizing testing time with individuals. Approximately 20% to 30% of items across samples were common items, whereas the rest were unique items tested. The common items served as anchor items for item-bank building.
Analysis Plan
Multiple-group item response modeling (MG-IRM)
To explore our first research question, a series of multiple-group unidimensional and multidimensional IRT models were fit to the item-level data within morphology, vocabulary, and syntax. This served to evaluate item properties (e.g., the item difficulty and discrimination) across a developmental scale of ability (i.e., vertical equating). MG-IRM allowed for simultaneous testing of the factor structure for the items, the vertical equating of item difficulty, and the vertical scaling of person ability. We began by testing whether the tasks were individually unidimensional and then explored skill-level models for morphology and trait-level models for morphology, vocabulary, and syntax. The supplemental online materials detail the skill and trait models for each task.
Reliability
For Research Question 2, the precision of resulting scores for the factors retaining construct-relevant variance was evaluated to understand broad-level reliability. IRT-based reliability differs from classical test theory as the former is reliant on individual-based estimates and the latter is based the assumption of equal reliability given the total test score. Marginal reliability (Sireci et al., 1991) using the factor scores (i.e., student ability scores) and standard errors from the MG-IRT was estimated with
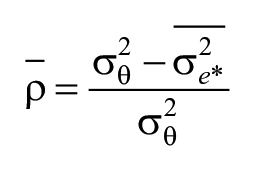
where
Concurrent, construct, and predictive validity
For Research Question 2, validity was explored via correlations and using hierarchical multiple regression modeling to explore links between performance on the Monster, P.I. assessment and standardized measures of reading achievement. The primary emphasis in Monster, P.I. is on morphology; hence, Step 1 included all morphology skills, Step 2 added vocabulary, and Step 3 added syntax. At each phase of modeling, R2 was taken so that the incremental value added for each predictor could be evaluated.
Results
Research Question 1: MG-IRM
Because data were collected over a 3-year period with a common-item, nonequivalent group design, data were specifically missing completely at random due to the planned missing data aspect of item deployment across samples. Table 1 includes descriptive statistics, with the number of items administered for each of morphology, vocabulary, and syntax by grade level, the mean percentage correct, and the standard deviation. What is noticeable about the pattern of responses is the developmental increases in the mean percentage grade by grade level for some tasks (OMO, MIF, RWS, MCO, SSE, WD, and Syntax) but not others (MPU, WH, SP, and WR tasks, along with all four vocabulary tasks). Such a phenomenon is expected prior to item culling and validation as creating stable linking items ensures a vertical scale.
Descriptive Statistics for Combined Data Over 3 Years.
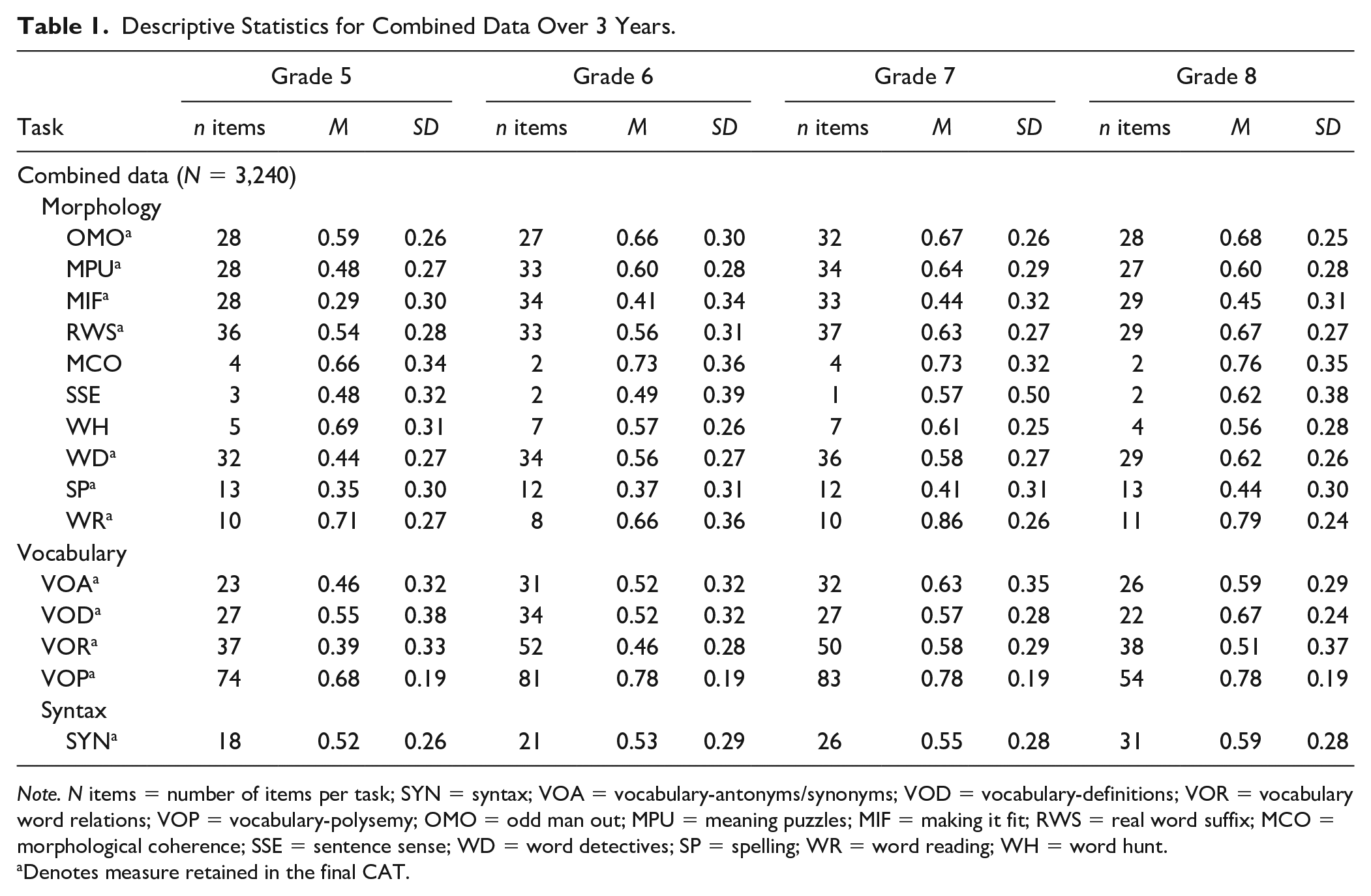
Note. N items = number of items per task; SYN = syntax; VOA = vocabulary-antonyms/synonyms; VOD = vocabulary-definitions; VOR = vocabulary word relations; VOP = vocabulary-polysemy; OMO = odd man out; MPU = meaning puzzles; MIF = making it fit; RWS = real word suffix; MCO = morphological coherence; SSE = sentence sense; WD = word detectives; SP = spelling; WR = word reading; WH = word hunt.
Denotes measure retained in the final CAT.
Summary of the task-level and skill-level MG-IRMs are reported in online supplemental Table S1 for morphology and Table S2 for vocabulary. Note that the four-factor correlated model of morphology did not converge with the inclusion of higher convergence criteria and increased iterations. Remaining models all demonstrated excellent fit: root mean square error of approximation (RMSEA) point estimates ranged from .000 to .048; the lowest comparative fir index (CFI) observed was .95; and the lowest Tucker–Lewis index (TLI) was .95. For skill-level morphology model results, the bifactor provided the best fit to the data for Skill 1, χ2(117) = 177.65, CFI = .95, TLI = .94, RMSEA = .031 (90% confidence interval [CI] = [.021, .039]), and Skill 2, χ2(75) = 73.75, CFI = 1.00, TLI = 1.00, RMSEA = .000 (90% CI = [.000, .023]). For both Skills 3 and 4, each of the unidimensional, correlated trait, and bifactor models yielded acceptable fit with CFI and TLI at or above ~.95 and RMSEA <.05.
Result for the trait-level models is provided in Table S1 (morphology) and Table S2 (vocabulary and syntax). For morphology, the bifactor model that included tasks as specific constructs and the four morphology skills as uncorrelated, global constructs fit the data well, χ2(13, 666) = 15,250, CFI = .97, TLI = .96, RMSEA = .015 (90% CI = [.012, .025]), as did a trifactor model that included task-level factors, skill-level factors, and a global construct of morphology, χ2(13, 524) = 14,445, CFI = .98 TLI = .98, RMSEA = .011 (90% CI = [.009, .017]). For vocabulary, the bifactor model that included specific factors for each task and a global factor fit the data acceptably, χ2(375) = 476.51, CFI = .93 TLI = .92, RMSEA = .024 (90% CI = [.017, .030]), yet the bifactor model that included word-level, specific factors and a global factor provided excellent fit to the data, χ2(228) = 214.39, CFI = 1.00, TLI = 1.00, RMSEA = .000 (90% CI = [.000, .015]). For syntax, the unidimensional, correlated trait, and bifactor models provided acceptable fit to the data; however, for parsimony purposes, the unidimensional model was selected, χ2(152) = 174.89, CFI = .97, TLI = .97, RMSEA = .017 (90% CI = [.000, .028]).
The viability of multiple trait-level models for morphology in the probit estimation (see Table S1 with TLI, CFI, and RMSEA values) led to an important consideration in the estimation of logit-based MG-IRM (see Table S3 for log likelihood, Akaike information criterion [AIC], and Bayesian information criterion [BIC] values)—specifically, the balancing of test information (i.e., reliability) gained by the model with malleability of the factor. In other words, we considered additional information about the operationalization of the model. For example, whereas a trifactor model for morphology would result in a global factor that would theoretically represent the most information about student performance, for the bifactor model, the skill-level constructs would represent the most reliable portion of the data and yield malleable factors that facilitate the provision of instructional recommendations for teachers. Details of the logit-based MG-IRMs from flexMIRT software are described in supplemental online materials as well as in Table S3 for morphology, vocabulary, and syntax. 5
A summary of trait-, skill-, and task-level marginal reliability and final item sets are reported in Table 2. Skill 1 represents Morphological Awareness, Skill 2 represents Morphological-Syntactic Knowledge, Skill 3 represents Morphological-Semantic Knowledge, and Skill 4 represents Morphological-Orthographic/Phonological Knowledge. Marginal reliability is presented for the subsample of 1,002 who took a CAT version of Monster, P.I. during Year 3 that included items from Years 1 and 2. Marginal reliability for Skill 1 was estimated at .90 compared with .93 for Skill 2, .70 for Skill 3, and .92 for Skill 4. Marginal reliability for vocabulary was estimated at .80 for the adaptive version of the assessment and .70 for syntax.
Trait-, Skill-, and Task-Level Reliability and Number of Items in CAT Item Bank.
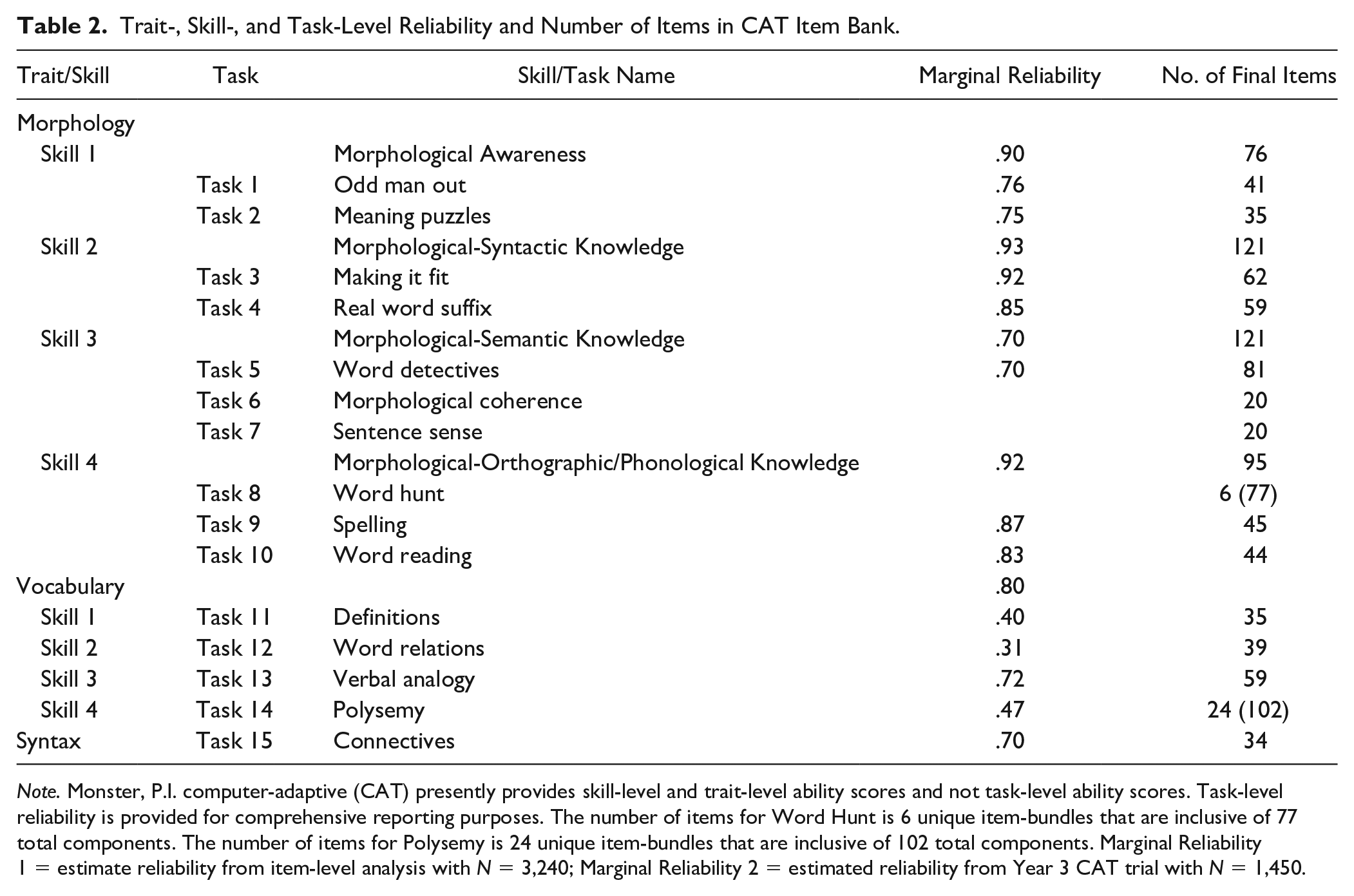
Note. Monster, P.I. computer-adaptive (CAT) presently provides skill-level and trait-level ability scores and not task-level ability scores. Task-level reliability is provided for comprehensive reporting purposes. The number of items for Word Hunt is 6 unique item-bundles that are inclusive of 77 total components. The number of items for Polysemy is 24 unique item-bundles that are inclusive of 102 total components. Marginal Reliability 1 = estimate reliability from item-level analysis with N = 3,240; Marginal Reliability 2 = estimated reliability from Year 3 CAT trial with N = 1,450.
Concurrent, Construct, and Predictive Validity
Table 3 reports correlations among the morphology, vocabulary, and syntax scores. Morphology skills were moderately correlated with each other across the grade levels with a lower bound of r = .47 between Skills 3 and 4 in Grades 5 and 6 to an upper bound of r = .69 between Skills 1 and 2 in Grade 8. Vocabulary was moderately correlated with all four morphology skills ranging from r = .40 between vocabulary and Skill 4 in Grade 6 to r = .61 between vocabulary and Skill 1 in Grade 7. Syntax was also moderately correlated with the morphology skill ranging from r = .37 with Skill 2 in Grade 7 to r = .54 with Skill 3 in Grade 8. Vocabulary and syntax correlated in a range from r = .40 to .48 across Grades 6 to 8.
Concurrent Correlations Among Monster, P.I. Ability Scores by Grade Level.
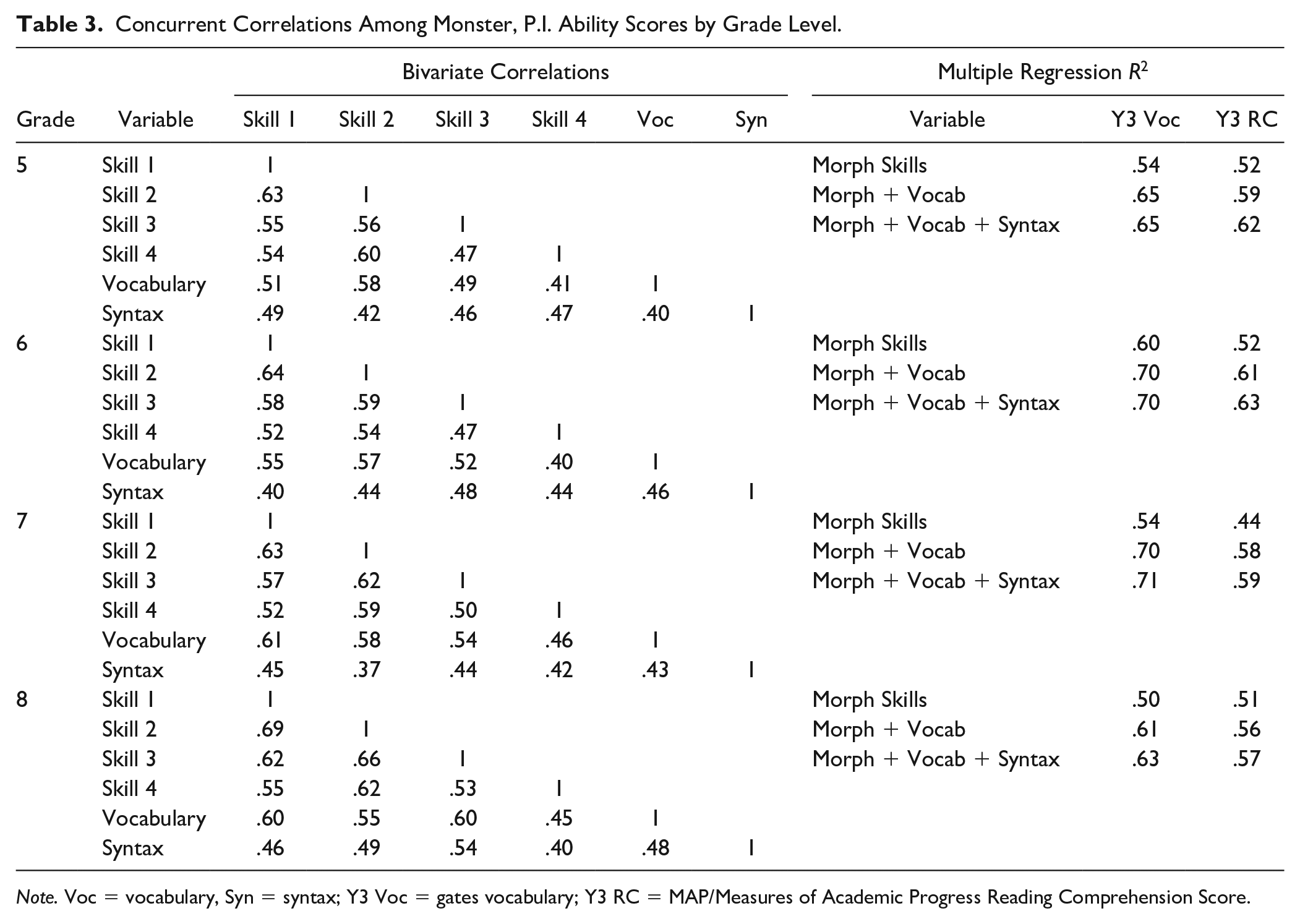
Note. Voc = vocabulary, Syn = syntax; Y3 Voc = gates vocabulary; Y3 RC = MAP/Measures of Academic Progress Reading Comprehension Score.
In terms of predictive validity, summary results for hierarchical regression inclusive of the three-stage model building (i.e., all morphology skills, followed by vocabulary and then by syntax) are presented in Table 3 via R2 for each model by outcome and grade level. Specific results for each model including the beta weights, standard errors, and p-values are present in the supplementary materials. Grade 5 results showed that the combination of morphology skill ability scores resulted in 52% to 54% of the variance explained in the selected outcomes compared with 52% to 60% in Grade 6, 44% to 54% in Grade 7, and 50% to 51% in Grade 8. Adding in both vocabulary and syntax indicated 62% to 65% of the variance in Grade 5 outcomes was explained as was 63% to 70% of the variance in Grade 6, 59% to 71% of the variance in Grade 7, and 57% to 63% of the variance in Grade 8.
Discussion
This study provides reliability and validity evidence for a CAT, gamified, standardized assessment of language for students from Grades 5 to 8. What is important about this assessment is that it provides scores at smaller levels (i.e., language areas and/or skills within language areas), which can inform instruction in ways that general language scores do not. It does this while engaging students in answering questions framed in a gaming environment. Our findings confirm and extend what is present in the literature, making clear advances in understanding how language can be assessed.
Assessment Advancements
Currently, language beyond vocabulary knowledge is rarely assessed in the standardized tests that schools and teachers use to guide their instruction (see Adlof & Hogan, 2019, for a discussion). That is largely due to the complicated nature of the language problem space and the challenges in assessing language as current assessments often take a long time, are individually administered, or do not assess the multidimensional nature of the areas of language that support reading comprehension. As such, teachers do not have language data to guide their instruction, and hence, fine-tuned language instruction in schools is rare.
Our findings indicate that Monster, P.I. can provide valid and reliable scores that can inform instruction—and the assessment capitalized on CAT and used a gamified format—indicating that teachers may be able to ascertain such scores in a more engaging context than traditional testing environments. The scores provided by Monster, P.I. can provide a detailed view of how the student is using their language skills to support reading comprehension, which can inform instruction that takes into account students’ strengths and weaknesses.
Building on LARRC’s (2015) call to assess “the extent to which the various theorized dimensions of language do indeed represent latent abilities at a given point in a child’s development” (p. 1948), our study confirms that for young adolescents, performance on morphological, vocabulary, and syntax together meaningfully represents a student’s general language knowledge. In addition, we extend this work to emphasize that morphology and vocabulary themselves are multidimensional such that they are made up of multiple skills or factors that represent construct-relevant variance that is practically meaningful to both researchers and practitioners. In contrast, no evidence for multidimensional syntax was found. This framework provides a foundation for assessments and confirms the importance of attending to multidimensionality in assessing language to inform instruction.
Our assessment also further unravels the complicated and thorough ways that language supports reading comprehension. Our analyses show each skill or component of language had a meaningful relationship to reading comprehension. With that said, considering multiple skills and areas of language highlighted the more extensive role of language in reading comprehension. Therefore, to understand how language is affecting reading comprehension, assessments must provide multidimensional information. From there, scores can drive research-based instruction in vocabulary (Elleman et al., 2009), morphology (Goodwin & Ahn, 2010, 2013), and syntax (Graesser et al., 2011).
The contribution of language can be highlighted by reflecting on an example. Say a middle schooler encounters Politicization of the indecisive nature of, in a text. Parsing this text requires morphology, vocabulary, and syntax knowledge to build meaning. For example, a middle school reader would consider the units of meaning within politicization and indecisive and connect to their larger morphological families such as political, politically, politicize and decide, decision, decisively, indecisively. The middle school students would also use the syntactic morphological information in the suffixes present in politicization, which convey noun meaning the process of becoming political, and in indecisive, which convey adjective describing. That student would also put the meanings of morphemes (i.e., use semantic morphological information) together to figure out these unfamiliar words and then use the phonological/orthographic morphological information to support their morphological word reading skills and building of orthographic representations via morphological spelling skills. An example is that indecisive is made up of the meanings and pronunciations and spellings of in (not) and decisive. At the same time, the reader would consider the definition of indecisive (lack of commitment to a decision) or link to synonyms like ambivalent or hesitant. Then he would put the word information together across the phrase, considering word order and structure of the phrase, linking it to two ideas that in less complex texts might have been presented in two sentences (i.e., syntax, Someone had an indecisive nature. Someone made used that nature in a political way). By providing scores related to each of these skills and language areas, researchers can better understand how language links to reading comprehension and practitioners can better design instruction to meet student’s needs. Monster, P.I. can provide teachers with scores that acknowledge the role of language in supporting reading comprehension as both broader and more specific than specified previously.
Limitations
While moving the field forward, there are certain limitations to take into consideration. As mentioned, this is just one conceptualization of language and theory, and research indicates many more areas of language that could be potentially supportive of reading comprehension and give a broader view of the role of language in reading comprehension. In fact, others have argued that considering just morphology, vocabulary, and syntax is too simplistic (Uccelli et al., 2015), but we felt these areas had the most grounding in theory and research. Another challenge relates to the number of items needed to assess these constructs. We built out the morphology section of the assessment, resulting in stable skill-level estimates, but for vocabulary, while a bifactor model fit best, we continued to use the general factor in our modeling due to a combination of less reliability in the word-level factors and the fact that we are keying into the part of the factor structure that is most instructionally relevant. In addition, following guidance from the literature (i.e., no dimensionality studies suggesting multidimensionality for syntax), we used a single syntax task, although considered potential multidimensionality within the task. This task included connectives (Crosson & Lesaux, 2013) as part of combining sentences, so future research should consider a broader range of syntax tasks to confirm dimensionality and future assessment tasks may need to be adjusted based on such findings. In addition, due to limits of testing time, we were unable to compare performance with standardized morphology and syntax measures. We hope future studies will continue to explore these questions. Another limitation involves our focus on students in general rather than individual differences. It is likely that our assessment may differ for groups of readers and we hope future work will unravel this.
Use in Classrooms
This study suggests Monster, P.I. can provide meaningful data for researchers and practitioners. Goodwin et al. (2019) include more information on how Monster, P.I. can inform instruction, but we close here with statements of three teachers from a pilot study who described how Monster, P.I. informed their instruction. Teachers reported that Monster, P.I. “confirmed the major problems that students have struggled with throughout the year”; “helped with intervention instruction to meet each student at their point of need”; and “included more specific information on vocabulary skills.” The teachers used this information “to create small group lessons, mini lessons, or flipped lessons for individuals”; “to add into center rotation or use as an intervention tool”; and to design “mini lessons that focus on the specific type of data that was collected.” Such data-informed instruction suggests Monster, P.I. can be a helpful assessment to drive instruction. Overall, this study involved an assessment of the dimensionality of morphology and vocabulary and an assessment of syntax resulting in Monster, P.I., a language assessment that provides scores on three component areas of language (multidimensional morphology and vocabulary and unidimensional syntax) with the goal of informing instruction.
Supplemental Material
Supplementary_Online_Materials_FINAL_updated_formating_TR_edit_FINAL_FINAL – Supplemental material for Monster, P.I.: Validation Evidence for an Assessment of Adolescent Language That Assesses Vocabulary Knowledge, Morphological Knowledge, and Syntactical Awareness
Supplemental material, Supplementary_Online_Materials_FINAL_updated_formating_TR_edit_FINAL_FINAL for Monster, P.I.: Validation Evidence for an Assessment of Adolescent Language That Assesses Vocabulary Knowledge, Morphological Knowledge, and Syntactical Awareness by Amanda P. Goodwin, Yaacov Petscher, Jamie Tock, Sara McFadden, Dan Reynolds, Tess Lantos and Sara Jones in Assessment for Effective Intervention
Footnotes
Acknowledgements
We thank the students, teachers, schools, and district that participated in this research. We also thank all research team members who worked on the project, staff Tonya Simmons who kept the project moving, and the Florida Center for Interactive Media team led by Cody Diefenthaler who put together the gaming environment for Monster, P.I.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The research reported here was supported by the Institute of Education Sciences, U.S. Department of Education, through Grant R305A150199 to Vanderbilt University. The opinions expressed are those of the authors and do not represent views of the Institute or the U.S. Department of Education.
Supplemental Material
Supplemental material for this article is available on the Assessment for Effective Intervention website with the online version of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.