
Abstract
Background
Positron emission tomography (PET) is one of the most effective imaging methods for detecting lung cancer, and artificial intelligence-based approaches are increasingly being applied to PET-based lung cancer detection. However, this typically requires a large amount of labeled data for training, while obtaining sufficient labeled PET imaging data remains challenging.
Objective
To improve the accuracy of three-dimensional (3D) lung cancer detection in PET images and address the issue of scarce labeled data, this study aims to propose a novel self-supervised learning method based on the pseudo image generation.
Methods
This method first uses a spatial tumor simulator to generate 3D images resembling real lung cancer lesions, and randomly implants them into the lung regions of PET images to construct pseudo-lung-cancer PET images. Subsequently, a restoration task based on pseudo-cancer images and normal images is designed as a self-supervised pretraining objective, using the 55 training cases to generate paired original and pseudo-lesion PET images, which are used to pretrain a Dual-Attention Hybrid Unet (DH-Unet) encoder–decoder integrated with a self-attention mechanism. Finally, the model is fine-tuned using real labeled PET data from these same 55 cases, along with 10 additional test cases, all pathologically confirmed as lung cancer, to complete the 3D lung cancer detection task.
Results
Experimental results show that this method achieves significant performance in the lung cancer detection task, with an mAP@ 0.10 to 0.50 of 0.4616, which is 13.72% higher than that of the random initialization method and 11.1% higher than that of traditional self-supervised models.
Conclusion
The proposed self-supervised learning framework, which combines pseudo image generation and a self-attention-equipped DH-Unet, provides an effective approach for improving lung cancer detection in PET imaging, especially in scenarios with limited labeled data.
Keywords
Introduction
Positron emission tomography (PET) is a crucial three-dimensional (3D) imaging technique for diagnosing lung cancer. 1 Currently, with the widespread application of imaging scanning technology, the workload of radiologists continues to increase. Therefore, for radiologists, utilizing artificial intelligence technology to achieve computer-aided diagnosis can effectively alleviate their workload.
However, research on lung cancer detection based on PET images still faces several challenges. Firstly, there is a rapidly growing demand for labeled data. Yet, obtaining such labeled data, particularly for 3D lesion annotations, remains difficult. Since deep learning models trained on small datasets carry a high risk of over-fitting, the shortage of labeled image data has become a bottleneck in research experiments. Secondly, the accuracy requirements for 3D lung cancer detection based on PET imaging are also becoming increasingly demanding.
To address the above issues, this article proposes a novel self-supervised learning method based on 3D pseudo-lesion generation for 3D lung cancer detection using PET imaging. We first employ a spatial tumor simulator constructed based on Gaussian functions to generate 3D lesion patterns resembling lung cancer. These patterns are then embedded into the lung regions of PET images to create pseudo-lung-cancer PET images. Next, we improve the encoder-decoder architecture of Retina-UNet by incorporating a self-attention mechanism, resulting in a new network named Dual-Attention Hybrid Unet (DH-Unet) tailored for PET-based lung cancer detection. Subsequently, the DH-Unet is trained for image restoration using pairs of pseudo-cancer images and normal images, a process that requires no labeled data, enabling the model to learn lung-cancer-relevant representations from the pseudo 3D lung-cancer PET images. Finally, the pretrained encoder and decoder are fine-tuned with a limited set of labeled PET data to accomplish the task of 3D lung cancer detection.
Related Work
Characteristics of PET Imaging for Lung Cancer
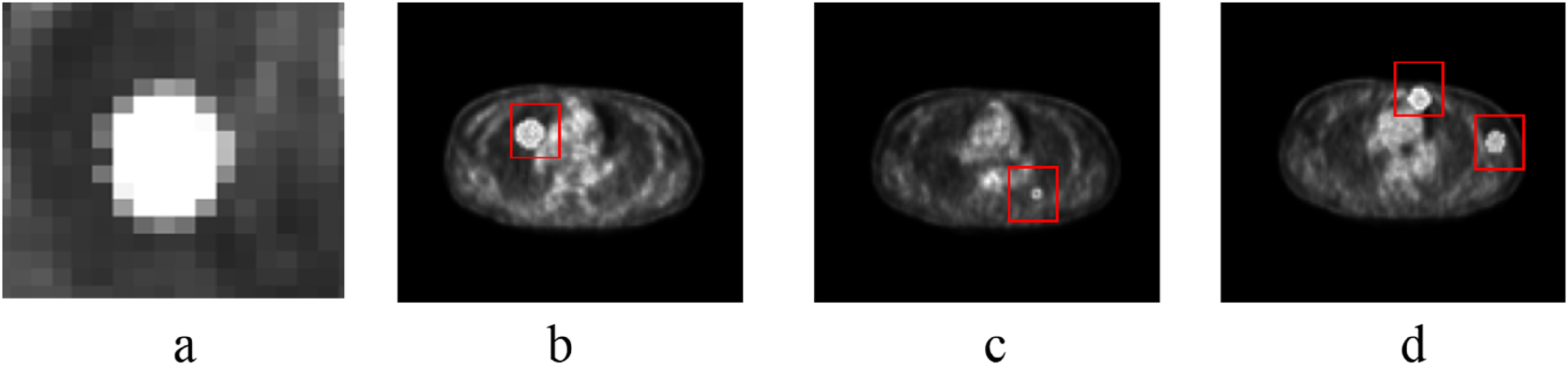
In PET imaging, lung cancer lesions exhibit relatively high SUVmax due to their increased glucose metabolism, presenting typical imaging features such as a round-like shape, central hyper-intensity, and a gradual attenuation of intensity toward the periphery. These imaging characteristics make it suitable to simulate similar lesion masses using Gaussian transformation, thereby generating pseudo-lesion images for self-supervised learning. Figure 1 illustrates the similarity between pseudo-tumor images generated by Gaussian function processing and actual PET lung cancer tumor imaging. Figure 1a and b shows a real lung cancer image and a zoomed-in view of the cancer, respectively; Figure 1c is a pseudo-lung cancer PET image, and Figure 1d is a zoomed-in view of the pseudo-cancer.

Real lung cancer images versus pseudo-cancer images; (a) is a real lung cancer image, (b) is a zoomed-in view of the cancer, (c) is a pseudo-lung cancer positron emission tomography (PET) image, and (d) is a zoomed-in view of the pseudo-cancer.
Deep Learning-Based 3D Lung Cancer Diagnosis With PET Imaging
In computer-aided diagnosis research, deep learning-based 3D tumor image analysis technology has demonstrated significant application value and superior performance. Zhou et al 2 proposed a lung tumor recognition model based on convolutional neural networks (CNNs) and attention mechanisms for detecting lung cancer. The model employs a three-branch network to learn lesion features from different modal images, enhances lesion information extraction within each modality, and utilizes two global attention mechanisms to cross-learn different features, achieving high accuracy in experiments. Dutande et al 3 introduced a multidimensional joint strategy for classifying and identifying 3D tumors. Due to the limited size of the dataset, a slice-aware network was proposed by Mei et al, 4 which can capture dependencies between arbitrary positions within slice groups and across channels, thereby effectively reducing false positives. Amyar et al 5 designed an encoder capable of simultaneously extracting features for multiple tasks, enabling the extraction of rich multiscale features from tumors. Wu et al 6 fused multiplanar features extracted by two-dimensional (2D) CNNs with 3D features obtained from 3D CNNs, achieving an accuracy of 90.08% on the LUNA16 dataset. Fu et al 7 first filtered out irrelevant slices and then incorporated a self-attention mechanism for learning, ultimately attaining high recognition accuracy. In contrast, Niu and Wang 8 transformed 3D images into vector features and adopted a transformer architecture, also achieving superior performance. Qiu et al 9 proposed a PET/CT tumor segmentation method based on an improved encoder–decoder structure. The encoder employs spatial-sequence layers to process features in spatial and sequential dimensions separately, while the decoder utilizes a dynamic scale attention module to handle skip connections, eliminating noise between soft tissues and enhancing the identification and segmentation of small tumors. This method achieved favorable segmentation results.
Self-Supervised Learning
Self-supervised learning is a representation learning paradigm whose core lies in designing specific pretext tasks that allow the model to generate supervisory signals from unlabeled data itself. By training on these self-constructed supervisory signals, the model learns transferable feature representations, thereby significantly enhancing performance in downstream tasks such as classification. 10 The value of self-supervised learning has been proven in the field of medical image analysis and is playing an increasingly critical role. 11 Specifically, Zhu et al 12 innovatively employed a diffusion model for representation learning and applied it to brain tumor image classification. This method effectively captures subtle features in the images, leading to a marked improvement in classification accuracy. The study by Wang et al 13 also confirmed the effectiveness of self-supervised methods, achieving excellent segmentation performance. Xie et al 14 developed a general self-supervised learning framework, which demonstrated outstanding performance across multiple medical image tasks, including segmentation and classification, showcasing its strong generalization capability. In the field of PET imaging, self-supervised learning has also shown promising potential. For instance, Yazdani et al 15 explored contrastive learning for tumor segmentation in PET/CT, improving segmentation performance under limited data conditions through carefully designed pretext tasks. Yazdani et al 16 proposed a mask-based reconstruction self-supervised pretraining method for lesion detection in PET images, effectively alleviating the issue of insufficient labeled data. These studies demonstrate the significant value of self-supervised learning in PET image analysis.
Method
Overview of the Method Framework
This article proposes a method for lung cancer detection that involves acquiring representations of lung cancer by restoring to pseudo-lung-cancer images, followed by fine-tuning with real images. The overall pipeline of the proposed method is illustrated in Figure 2. Firstly, pseudo-lung-cancer PET images generated by a Gaussian model are utilized. An image restoration pretext task is then designed to remove these pseudo-lung-cancer-like noises, thereby extracting the representations of the pseudo-lesions, as shown in Figure 2a. Subsequently, the pretrained network is fine-tuned using real PET lung cancer images to achieve lung cancer detection, as shown in Figure 2b.
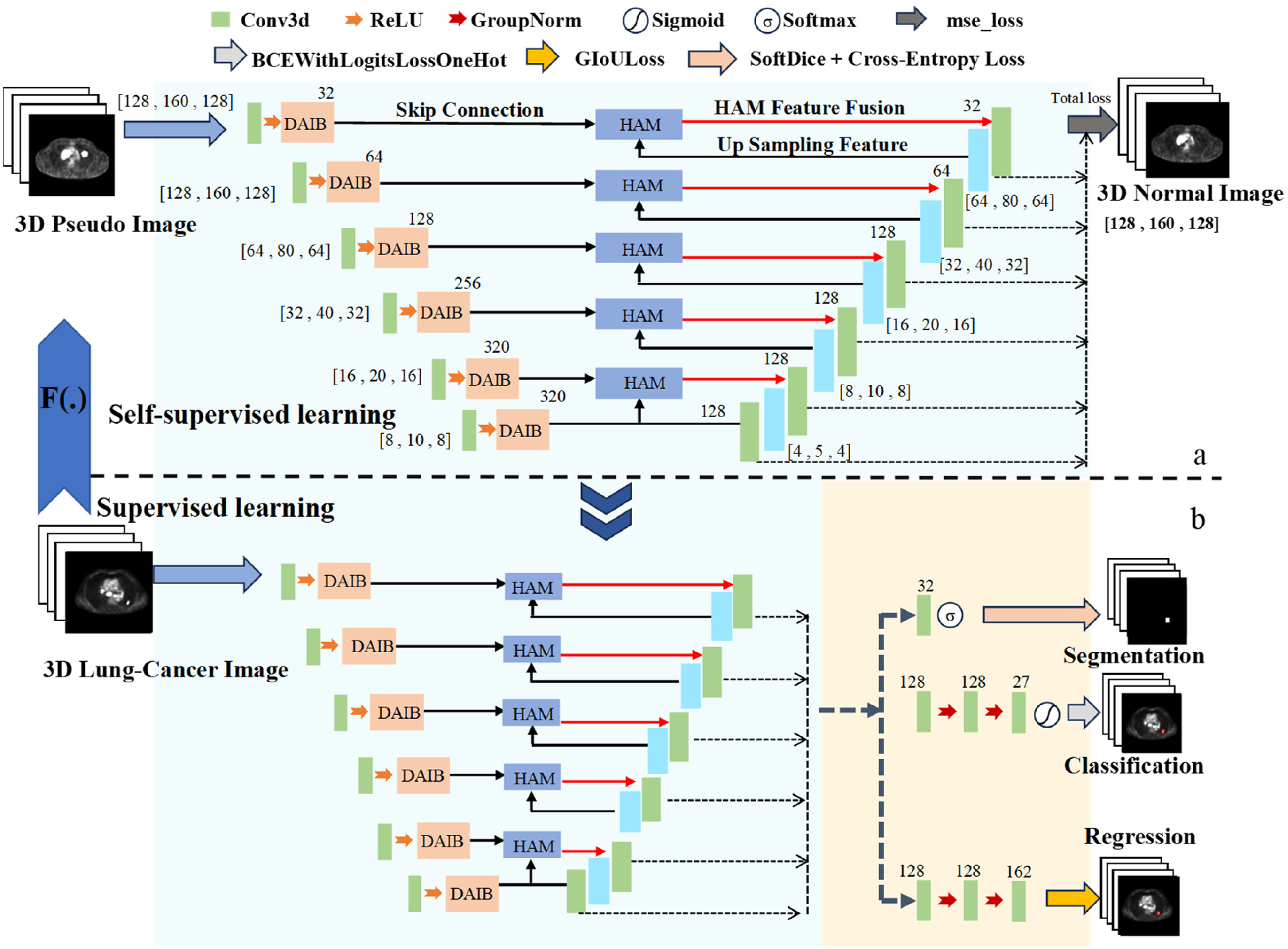
Self-supervised learning method for 3D lung cancer detection in PET images. (a) self-supervised pre-training based on DH-Unet and (b) fine-tuning of the self-supervised DH-Unet.
In terms of network architecture, this article proposes a novel network named DH-Unet, which integrates self-attention mechanisms. It is first employed for self-supervised pretraining, where the input and output images are the pseudo-lesion PET images and the original PET images without pseudo-lesions, respectively (Figure 2a). Following this, the encoder and decoder of DH-Unet are fine-tuned with labeled PET images for the target classification task (Figure 2b). To better suit the lung cancer detection task in this project, the encoder and decoder of DH-Unet are enhanced with a dual-attention integration block (DAIB) and a hybrid attention module (HAM), respectively.
Generation of Pseudo-Lung-Cancer and Pseudo-Cancer PET Images
This section proposes a method for generating pseudo-lung-cancer lesions in PET 3D images. Real lung cancer tumors in PET images typically appear as hypermetabolic hotspot regions with quasispherical or partially irregular shapes and heterogeneous intensity distributions. To simulate these characteristics, a pseudo-tumor generator based on 3D Gaussian distributions and irregular mask superposition was designed. This generator aims to create synthetic lesions with morphology and intensity approximating real tumors, for use in subsequent self-supervised restoration tasks.
Procedure for generating pseudo-lung cancer and pseudo-PET images:
Localization of pseudo-cancer: First, regions for pseudo-tumor placement are localized. This involves identifying the thoracic cavity position while avoiding normal tissue areas such as the heart. An initial segmentation of metabolically active body regions is performed using an intensity percentile-based thresholding method. This result is then further constrained by incorporating anatomical prior knowledge to obtain candidate regions suitable for generating pseudo-lung cancer. Initial generation of 3D pseudo-lung cancer:
① Generate an irregular mask on a 2D plane by applying random radial perturbation to a circular baseline, followed by interpolation, simulating the quasicircular and irregular contours of a cancer. ② Create a 2D Gaussian intensity map with the highest brightness at the center that gradually attenuates toward the periphery, mimicking the higher metabolic activity in the central region of a cancer and its transitional characteristics at the edges. ③ Multiply the quasicircular irregular mask with the Gaussian intensity map to obtain a 2D pseudo-cancer slice with irregular morphology and heterogeneous intensity. ④ Stack multiple 2D pseudo-tumor slices in 3D space, adjusting the size and intensity factor of each layer, to ultimately synthesize a pseudo cancer with 3D morphology. Refined generation of 3D pseudo-lung cancer and creation of pseudo-cancer PET images: To enhance the biological plausibility of the generated pseudo cancer in terms of intensity, a small set of PET images with real lesion annotations was first analyzed to extract statistical intensity features of real tumors. The maximum, minimum, median, 25th, and 75th percentile values of pixel intensities within real lung cancer tumors were calculated. When pasting a pseudo cancer onto a healthy PET image, its intensity values were adjusted according to these statistics. The baseline intensity of the pseudo cancer was set within the low-intensity range of real cancer, while its peak central brightness was randomly selected from the high-intensity range of real cancer. A distance-based intensity gradient and a small amount of random noise were also introduced to further improve realism.
Regarding the shape of pseudo cancer, 3D lung cancer lesions were modeled as quasispherical structures with a certain degree of deformation, having a longest radius of 2 ± 3 pixels. For each normal 3D PET image Xi, N pseudo cancers (N was ultimately set to 3 in this study) were randomly generated and sequentially pasted into the lung region. A minimum-distance constraint was applied to prevent excessive proximity or overlap between pseudo cancers. This process yielded a pseudo-cancer PET image Di. Each 3D pseudo cancer covered 3 to 7 consecutive PET slices, with a radius size of 4 to 10 pixels; each slice had dimensions of 168 × 168 pixels.
This procedure provides paired training data (Di and Xi) for the subsequent self-supervised learning task, where Di is the input (image with pseudo cancer) and the original PET image Xi is the restoration target (output image). Figure 3a shows examples of the generated pseudo cancers, while Figure 3b to d shows the pseudo-cancer PET images obtained after pasting the pseudo cancers onto PET images.
Pseudo cancers and the generated pseudo cancer images; (a) the generated pseudo cancers and (b) to (d) the pseudo cancer positron emission tomography (PET) images obtained after pasting the pseudo cancers onto PET images.
Additionally, box blur and local pixel rearrangement were employed to generate two other types of pseudo images for comparative experiments. Both box blur and local pixel rearrangement are common image processing methods used in pretext tasks for image restoration in self-supervised learning. For the box blur method, the average value of all pixels within a cubic region of kernel size 6 × 6 × 6 around each pixel was calculated and used to replace the original pixel value, thereby generating pretraining pseudo-images based on box blur. For the local pixel rearrangement method, Xi was divided into multiple blocks of size 6 × 6 × 6, and the pixels within each block were randomly shuffled to generate pretraining pseudo-images based on pixel rearrangement.
Using the proposed method, the box blur method, and the local pixel rearrangement method, three types of pseudo images were generated by processing the PET images Xi (where i = 1, 2, …, N), which were then used for model pretraining. Figure 4 illustrates examples of the different pseudo images: Figure 4a is the original image, Figure 4b is the pseudo image after pixel rearrangement, Figure 4c is the pseudo image after box blur processing, and Figure 4d is the pseudo-cancer image produced by the proposed method.

Examples of different pseudo-lesion images: (a) original image, (b) pseudo image after pixel rearrangement, (c) pseudo image after box blur processing, and (d) pseudo cancer image produced by the proposed method.
DH-Unet
DH-Unet is an encoder–decoder network architecture, with its detailed structure illustrated in Figure 2a and b. Building upon the backbone Retina-UNet from nnDetection, the encoder incorporates a DAIB to address core limitations such as insufficient CNN feature selectivity, lack of spatial sensitivity, and poor noise robustness during feature extraction in the encoder, thereby enhancing feature extraction performance. In the decoder, a HAM is designed to integrate low-level feature maps from skip connections, aiming to mitigate interference from thoracic boundary noise and reduce missed detection of small tumors.
DAIB: DAIB in the encoder: A DAIB is incorporated into the encoder, primarily aimed at addressing issues such as increased false positives caused by interferences like pulmonary inflammation and the high noise levels in PET images. This unit consists of a 3D convolutional layer, an instance normalization layer, and a convolutional block attention module (CBAM). Image features are first processed and transformed through the 3D convolutional and instance normalization layers before being fed into the CBAM. Within the CBAM, the channel attention module enhances sensitivity to high-uptake regions indicative of lung cancer while effectively suppressing irrelevant high-uptake features from sources such as inflammation, the heart, blood vessels, and noise. The spatial attention module focuses on the spatial locations of lung cancer within the PET images, highlighting subtle abnormal regions in the feature maps. The combined action of these dual attention mechanisms improves the detection sensitivity for lung cancer, particularly in scenarios with significant false positive interference or when small lung cancer tumors are present. As illustrated in Figure 5, C, D, H, and W denote the image dimensions as channels, depth, height, and width, respectively. HAM: HAM in the decoder: A HAM is designed in the decoder to address the issue that smaller lung cancer lesions are prone to complete target loss. First, an attention mechanism is employed to filter out irrelevant edges while preserving critical features. The decoder then constructs skip connections through multiple branch pathways to aggregate low-level details from the encoder with high-level semantic features generated during upsampling. Finally, comprehensive utilization of the encoder's input features is achieved by fusing these multiscale representations, as illustrated in Figure 6.

Dual attention integration block (DAIB).
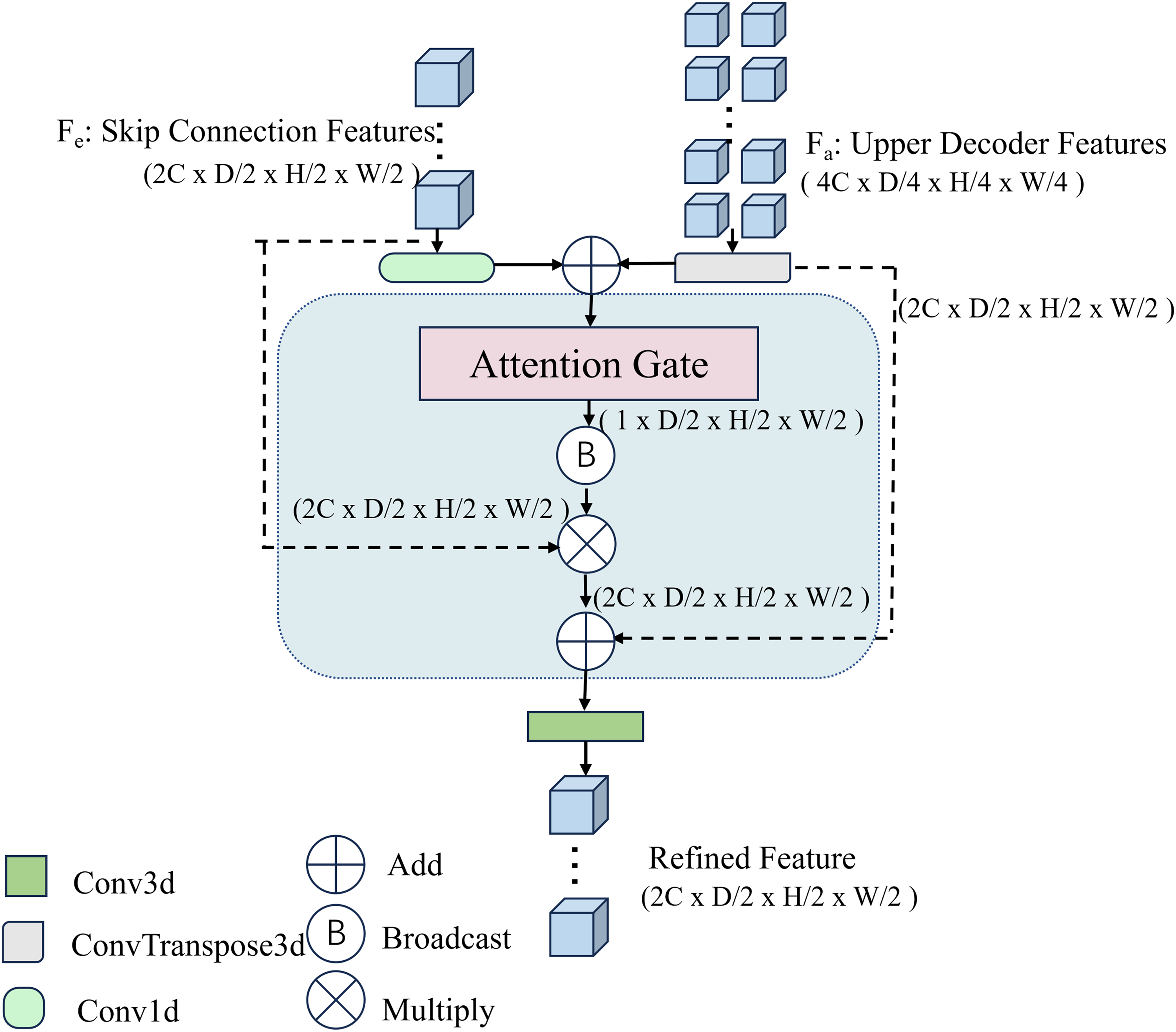
Hybrid attention module (HAM).
In this network, Fe and Fa represent the low-level features from the encoder containing the DAIB and the upsampled features from the previous layer of the decoder, respectively. The two main branches of the HAM operate along different dimensions:
The first branch initially processes Fe and Fa separately in their original input dimensions. Specifically, Fe undergoes a 1D convolution (conv1d) operation, while Fa is processed via a transposed convolution (ConvT) operation. After aligning their dimensions, the two feature sets are combined through element-wise addition. The resulting features are then refined through an attention gate mechanism, which selectively emphasizes locally extracted convolutional details and attention-weighted features. The computation is described by the following equation:

In Equation (1), Conv1d and ConvT denote the 1D-kernel 3D convolution and transposed convolution, respectively, and α represents the attention gate module.
The second part fuses the Fe and Fa features from the original input with the features from the first part through residual processing. This approach maintains the information integrity of the two original inputs while achieving fusion with the features from the first part.
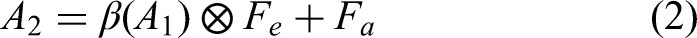
In Equation (2), β denotes the broadcasting operation, ⊗ represents the element-wise multiplication of feature maps, while + indicates the element-wise addition of feature maps. The combined expression after merging the two parts is as follows:

Self-Supervised Pseudo-Image Restoration
Given a set of N pseudo images Di (where i = 1,2, …, N) generated from PET images Xi, our pretext task is to restore Xi from Di. In this work, we employ DH-Unet as the encoder–decoder architecture for image restoration and later apply it to the PET-based lung cancer detection task. DH-Unet is composed of stacked 3D convolutional units, downsampling units, and DAIB blocks for feature extraction and reconstruction. The restoration part utilizes convolutional layers and upsampling layers to reconstruct the original PET image Xi, while skip connections incorporate the HAM to propagate multidimensional features across multiresolution levels. Through this process, the network learns deep features relevant to lung cancer in PET imaging, thereby facilitating the subsequent lung cancer detection task.
Fine-Tuning for the Downstream Lung Cancer Detection Task
After pretraining the DH-Unet on the pseudo-image regression task, the network learns representations of lesion patterns resembling 3D lung cancer tumors. These representations can be transferred to the lung cancer detection task. The detection network is formed by connecting the pretrained DH-Unet encoder and decoder with a detection head. A limited number of labeled PET images are then used to fine-tune this detection model.
Implementation
The proposed self-supervised pseudo-image restoration framework was implemented based on the PyTorch deep learning framework. All experiments were conducted on an Ubuntu 20.04.1 LTS system equipped with a single NVIDIA RTX A6000 48GB GPU.
For the image restoration task in the self-supervised pretraining stage, preprocessed full-size images were used. A custom data loader paired and fed pseudo images with their corresponding original images into the model. The model was trained using the SGD optimizer with an initial learning rate set to 1 × 10−3. A learning rate scheduling strategy combining linear warm-up and polynomial decay was employed, and the batch size was set to 4 due to GPU memory constraints.
In the downstream lung cancer detection fine-tuning stage, we loaded the weights of the pretrained encoder and then performed end-to-end training of the entire detection model using PET data with real labels. During fine-tuning, standard data augmentation strategies, including random scaling, rotation, and elastic deformation, were applied. A smaller initial learning rate of 1 × 10−4 was adopted to stabilize the training process, and ReduceLROnPlateau was used to adjust the learning rate. All model hyperparameters were selected and optimized based on performance on the validation set.
Experiments
Dataset Description
Detailed information regarding the training set and testing set of the dataset is summarized in Table 1. Sample images from the dataset are shown in Figure 7, with Figure 7a and c displays normal thoracic PET images and Figure 7b and d shows lung cancer PET images. The dataset used in this study was obtained from the Department of Nuclear Medicine, The First Affiliated Hospital of Naval Medical University (Shanghai Changhai Hospital). A total of 65 patients were included, with 55 cases in the training set, which were used for both pretraining and fine-tuning, and 10 cases in the test set. All lung cancer cases were pathologically confirmed as lung tumors.

Examples of images in the dataset: (a) and (c) normal thoracic positron emission tomography (PET) images, and (b) and (d) lung cancer PET images.
The Number of Training Data and Test Data.

Evaluation Metrics
This article adopts five widely used metrics in detection tasks: FROCIOU=0.1, FROCIOU=0.5, APIOU=0.1, APIOU=0.5, and mAP@ 0.10 to 0.50 to quantitatively evaluate the classification performance of different models. The formulas for these five metrics are given below:


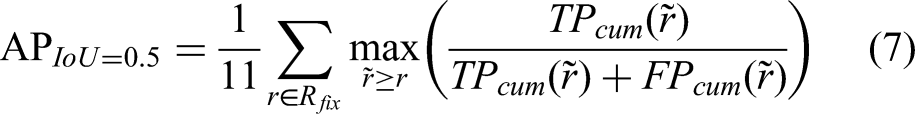

The matching condition for Equations (4) and (5) is that a predicted bounding box is considered a true positive if and only if its IoU ≥0.1 and ≥0.5, respectively. Here, the set T is defined as {1/8, 1/4, 1/2, 1, 2, 4, 8}. Sensitivity is calculated as TP/(TP + FN), where TP represents true positives, and FN represents false negatives. FPI denotes the average number of false positives per image.
The matching condition for Equations (6) and (7) is IoU ≥0.1 and IoU ≥0.5, respectively. Here, Rfix = {0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0}; TPcum(r) represents the cumulative number of true positives at recall rate r, and FPcum(r) represents the cumulative number of false positives at recall rate r.
Equation (8) is a core metric in the field of object detection for evaluating the overall performance of a model, where Tj ∈ {0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5}.
Experimental Settings
Implementation details: During the self-supervised pretraining stage, the DH-Unet model was trained for 60 epochs. The training, validation, and test sets were divided at the patient level. The training data were randomly split into training and validation sets at a ratio of 80:20 (ie, 80% for training and 20% for validation). To ensure the reproducibility of the experiments, a fixed random seed (12345) was used for data splitting and model training. In the downstream task fine-tuning stage, the model was also trained for 60 epochs, adopting the same validation set splitting strategy and random seed. The detection head employed a typical decoupled architecture, comprising independent classification and regression branches.
Due to the high computational cost of training 3D PET models, explicit cross-validation was not performed in this study, and each experimental configuration was run only once. Nevertheless, it is worth noting that stable performance improvements were observed across multiple experimental settings, including different proportions of labeled data (10%, 30%, 50%, and 100%) and different network architectures in the ablation study, which, to some extent, supports the reliability of the research findings.
Loss function: The calculation of the loss function in the fine-tuning stage is given by the equation below:
Ltotal denotes the weighted composite loss, and the value of α is set to 0.5.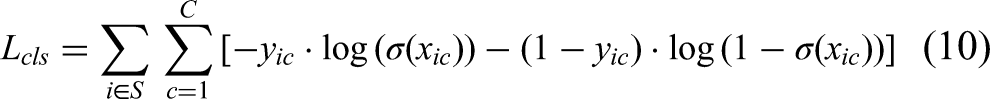
In Equation (10), S represents the total set of samples, C denotes the total number of classes, xic indicates the logit value of the ith anchor box predicted as class c, and yic is a binary indicator (Boolean value) specifying whether the ith anchor box belongs to class c.
In Equation (11), Spos denotes the set of positive anchor boxes, box_pred_i represents the predicted coordinates of the ith anchor box, and Box_gt_i indicates the ground truth coordinates of the ith anchor box. GIoU(A, B) refers to the generalized intersection over union between boxes A and B.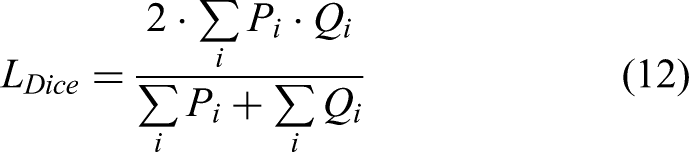
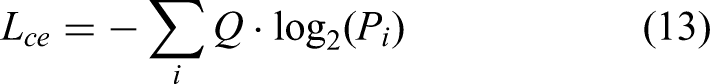
In Equations (12) and (13), 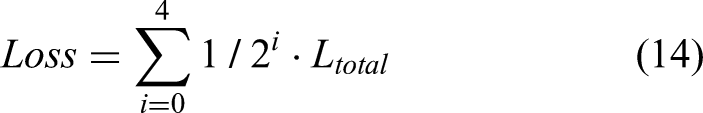
The total loss function consists of weighted losses from six hierarchical levels, as shown in Equation (14), where the parameter i is defined as the depth of the current layer within the network. The image restoration component employs the mse_loss function, and its overall loss is also composed of a weighted composite loss across the six network layers.
Baseline overview: To conduct a comprehensive comparison, we compare the proposed method against three network initialization and knowledge transfer approaches, as outlined in Table 2, including the following:
Random initialization. Local pixel randomization: restoring normal PET images from PET images with locally randomized pixels. Box blur: restoring PET images from box-blurred PET images.
Network Initialization Methods.

Training Details
To evaluate the training behavior of the model and verify that it does not overfit, we recorded the loss values and accuracy metrics on the training and validation sets during the fine-tuning stage as a function of training epochs, as shown in Figures 8 and 9.

Loss curves of the training and validation datasets over epochs with the proposed method.
Accuracy curves of the training and validation datasets over epochs with the proposed method.
Figure 8 presents the loss curves for the training and validation sets. It can be observed that as the number of training epochs increases, both the training loss and validation loss decrease rapidly and stabilize after approximately 30 epochs. The two curves remain close throughout the process, without exhibiting the typical overfitting pattern where the training loss continues to decrease while the validation loss increases. This indicates that the model has good generalization ability.
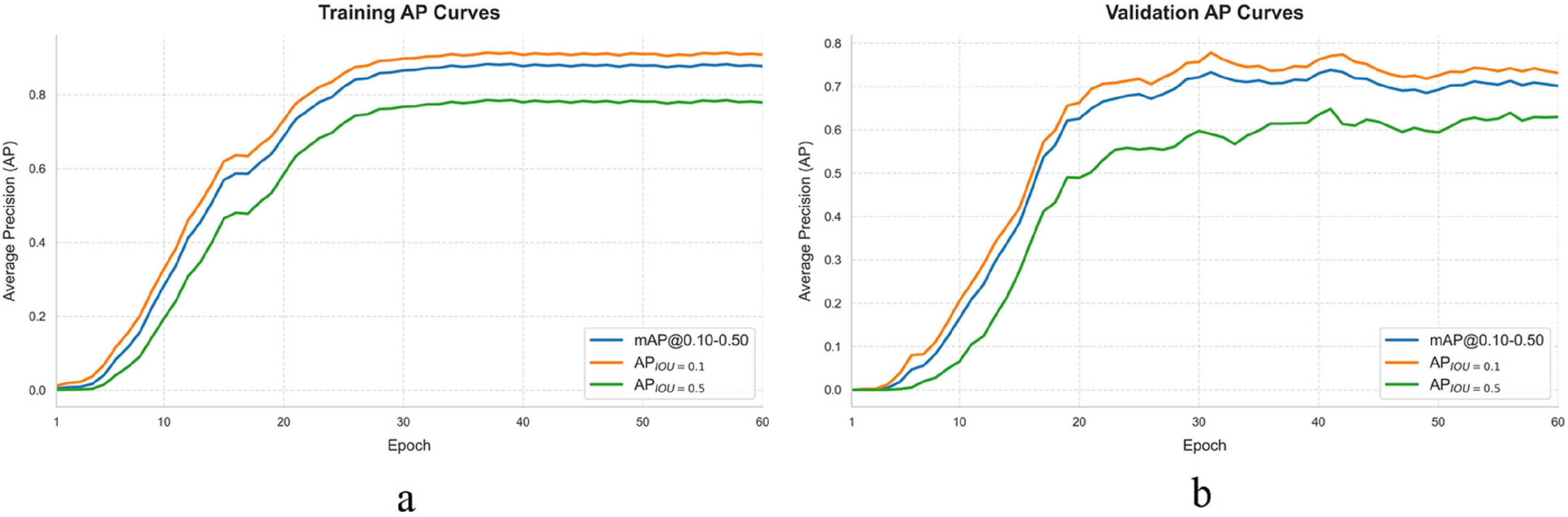
Figure 9 presents the accuracy curves for the training and validation sets, including three accuracy metrics: APIOU=0.1, APIOU=0.5, and mAP@ 0.10 to 0.50. Both the training accuracy and validation accuracy increase simultaneously, reaching a stable level after approximately 30 epochs and ultimately converging to relatively high values. The gap between the validation accuracy and training accuracy remains small, further confirming that the model does not overfit the training data.
In summary, the proposed method demonstrates favorable convergence characteristics and generalization ability during training. The improvement in detection performance is not due to memorization of the training data but rather reflects the model's ability to learn discriminative lesion features.
Selection of Hyperparameters
The number of pseudo-cancers pasted onto each PET image is an important hyperparameter. We denote this parameter as T. Figure 10 illustrates the change in classification performance as the number of pseudo-tumors per PET image varies. Our dataset consists of 55 cases, from which we generated 55 pairs of original PET images and pseudo-lung-cancer PET images to train the encoder, and used a validation set to evaluate its performance.

Classification performance with varying number of pseudo-tumors per case.
As shown in Figure 10, when T increases from 1 to 3, performance generally improves: although the values of FROCIOU = 0.5 slightly decrease, other metrics, especially the most comprehensive and representative metric, mAP@ 0.10 to 0.50, show a significant gain. When T increases further from 3 to 5, overall performance starts to decline, with a noticeable drop in mAP@ 0.10 to 0.50 in particular. Balancing efficiency and performance, we selected T = 3 for all subsequent experiments.
Selection of Self-Supervised Task
First, we visually compare the restoration quality of pseudo images generated by different methods. Figure 11 displays a normal example, pseudo images produced by three different pseudo-lesion generation methods, and the corresponding restored PET images. Figure 11a shows a normal PET image. Figure 11b shows a pseudo-PET image generated from Figure 11a using the proposed method. Figure 11c shows a pseudo-PET image generated from Figure 11a using the pixel shuffling method. Figure 11d shows a pseudo-PET image generated from Figure 11a using a box blur. Figure 11e shows the restored image of Figure 11b, Figure 11f shows the restored image of Figure 11c, and Figure 11g shows the restored image of Figure 11d. As can be seen from Figure 11c and f, although local random shuffling only restores the main outline of the lung, severe loss of textural information is observed. As shown in Figure 11d and g, box blur recovers the original PET image from the pseudo-lung-cancer image by enhancing details in the blurred image, but also sacrifices a portion of the textural information. We can observe from Figure 11b and e that the pseudo-lesion images generated based on the Gaussian transformation successfully fade the pseudo-lesions almost to the point of disappearance, while other textural information remains largely unaffected.
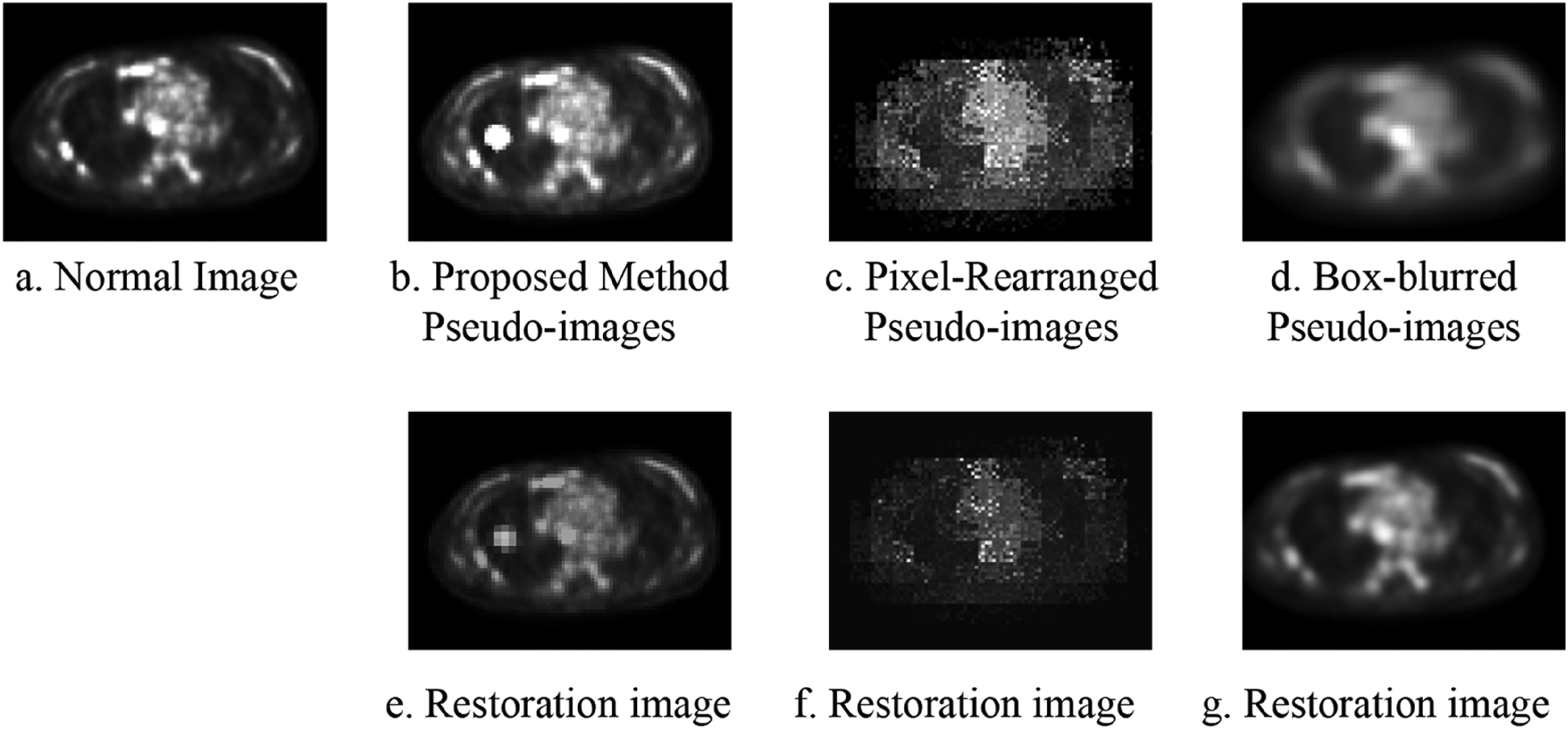
Recovery images of different pseudo-lesions: (a) a normal positron emission tomography (PET) image, (b) a pseudo-PET image generated from (a) using the proposed method, (c) a pseudo-PET image generated from (a) using the pixel shuffling method, (d) a pseudo-PET image generated from (a) using box blur, (e) the restored image of (b), (f) the restored image of (c), and (g) the restored image of (d).
Table 3 summarizes the results of different self-supervised tasks. As shown in Table 3, the proposed method consistently and significantly outperforms the other approaches across all evaluation metrics when fine-tuned with different proportions of the training set. Specifically, when fine-tuned on 100% of the training set, the most representative metric mAP@ 0.10 to 0.50 reaches 0.4616, which is 11.1% higher than the second-best self-supervised pretraining method. The FROCIOU=0.1, FROCIOU=0.5, APIOU=0.1, and APIOU=0.5 are also improved by 7.31%, 4.45%, 6.91%, and 1.98%, respectively.
Performance Comparison of Different Training Strategies on the Dataset.
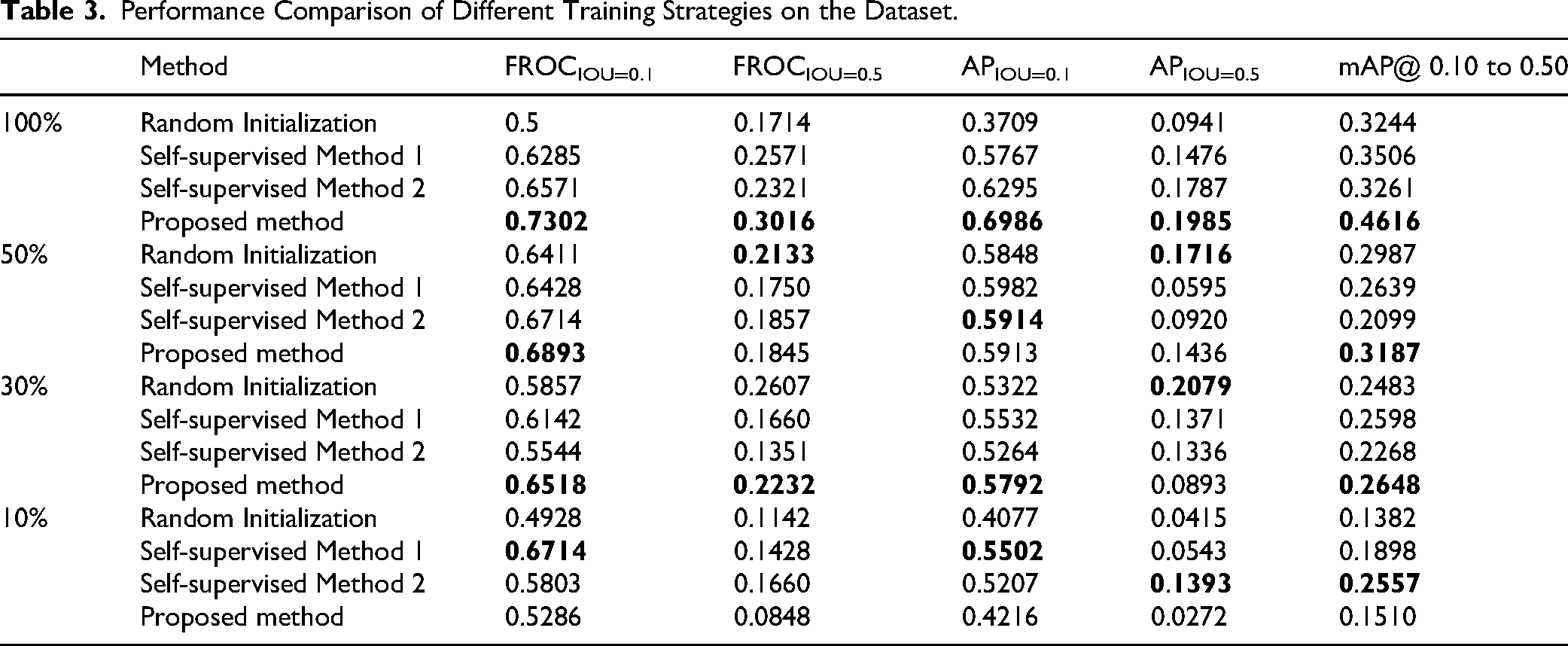
From Table 3, it can be observed that compared with random initialization, our method significantly enhances model performance. The mAP@ 0.10 to 0.50 of the pretrained network using our approach is 13.72% higher than that of the randomly initialized network. This demonstrates that the proposed method learns more effective features from lesion-like patterns for lung cancer detection.
To better illustrate the superiority of the proposed method under limited annotated data, a comparative experiment was conducted to evaluate its detection performance when fine-tuned with different amounts of labeled data. As shown in Table 3, our method remains effective even when fewer labeled training samples are available. When trained with 50% of the labeled data, the mAP@ 0.10 to 0.50 value is 0.3187, which is higher than those of other methods. When trained with only 30% of the labeled data, the mAP@ 0.10 to 0.50 value is 0.2648, still the highest among all methods and 0.5% above the second-best approach.
Figure 12 presents the experimental result visualization. Figure 12a shows the original images, Figure 12b displays the detection results, and Figure 12c provides the ground truth.

Detection results of the proposed method: (a) the original images, (b) the detection results, and (c) the ground truth annotations.
Ablation Study
We conducted an ablation study on the DH-Unet integrated with self-attention mechanisms, specifically by comparing the effects of the DAIB added to the encoder and the HAM incorporated into the skip connections. The experimental results indicate that both DAIB and HAM play a crucial role, as shown in Table 4. Compared to the network without these two structures, the performance improved significantly: FROCIOU=0.1, FROCIOU=0.5, APIOU=0.1, mAP@ 0.10 to 0.50 increased by 23.02%, 13.02%, 32.77%, and 14.05%, respectively. When only DAIB or HAM was included, the performance fell between that of the baseline Retina-UNet and the full DH-Unet, with the mAP@ 0.10 to 0.50 value lying in the intermediate range. This demonstrates the effectiveness of both DAIB and HAM, and the highest performance is achieved when they are used together.
Ablation Experiments.

Comparison with State-of-the-Art Methods
We compared the proposed method with state-of-the-art models, namely regRCNN 17 and SegFormer3D. 18 For SegFormer3D, we added a detection head to enable detection functionality. Details are shown in Table 5.
Comparison with State-of-the-Art Methods.

As can be seen from Table 5, regRCNN achieved values of only 0.4127, 0.2540, 0.2504, 0.1733, and 0.1887 on the five metrics, FROCIOU=0.1, FROCIOU=0.5, APIOU=0.1, APIOU=0.5, and mAP@ 0.10 to 0.50, respectively. The results obtained by SegFormer3D were slightly better than those of regRCNN, with improvements of 5.33%, 13.95%, and 6.79% over regRCNN in FROCIOU=0.1, APIOU=0.1, and mAP@ 0.10 to 0.50, respectively, but still fell short of the proposed method. The proposed method outperforms both of these methods across all five metrics. Specifically, it surpasses the best values from the other two methods by 26.42%, 4.76%, 30.87%, 2.52%, and 20.5% in FROCIOU=0.1, FROCIOU=0.5, APIOU=0.1, APIOU=0.5, and mAP@ 0.10 to 0.50, respectively.
Discussion
Main Findings and Result Analysis
This study proposes a self-supervised learning method based on pseudo-lesion generation for lung cancer detection in three-dimensional PET images. Experimental results demonstrate that the proposed method achieves significant performance on a PET dataset consisting of 65 patients. Specifically, when using 100% of the training data, the proposed method achieves an mAP@0.10 to 0.50 of 0.4616, which represents an improvement of 13.72% over the random initialization method, and improvements of 11.1% and 13.55%, respectively, over traditional self-supervised models based on pixel shuffling and box blur. These results validate the effectiveness of the pseudo-lesion generation strategy, indicating that by simulating the morphological and metabolic characteristics of real lung cancers, the model is able to learn more discriminative lesion representations.
Notably, the proposed method also exhibits good robustness when labeled data are limited. When using only 30% of the training data, the proposed method achieves an mAP@ 0.10 to 0.50 of 0.2648, which is still higher than that achieved by traditional self-supervised models using 50% of the data. This suggests that self-supervised pretraining based on pseudo-lesion generation can effectively alleviate the problem of insufficient labeled data, providing a feasible solution for clinical scenarios where obtaining annotated data is challenging.
The results of the ablation study further confirm the effectiveness of the two attention modules in DH-Unet. The DAIB and the HAM are optimized for encoder feature selection and decoder feature fusion, respectively. Their synergistic effect improves the mAP@ 0.10 to 0.50 from 0.3211 in the baseline model to 0.4616, representing a relative improvement of 14.05%. This fully demonstrates that, given the characteristics of high noise in PET images and substantial interference from lung boundaries, a specially designed attention mechanism can significantly enhance detection performance.
Comparison With Existing Methods
Compared with existing lung cancer detection methods, the proposed approach offers the following advantages:
First, in terms of detection performance, the proposed method achieves an mAP@ 0.10 to 0.50 of 0.4616, significantly outperforming regRCNN (0.1887) and SegFormer3D (0.2566). This advantage can be attributed to two innovations: (1) self-supervised pretraining based on pseudo-lesion generation enables the model to learn richer lesion features; and (2) the dual-attention mechanism in DH-Unet effectively addresses the issues of background noise and false-positive interference in PET images. Second, in terms of data efficiency, existing methods typically rely on large amounts of labeled data to achieve good performance. For instance, the cross-modal ConvFormer proposed by Zhou et al
2
was trained using hundreds of annotated cases. In contrast, by leveraging self-supervised pretraining, our method obtains competitive detection results using only 55 labeled cases. When the proportion of labeled data is reduced to 30%, the performance drop of our method is significantly smaller than that of the random initialization method, further demonstrating the value of self-supervised pretraining in data-scarce scenarios.
Furthermore, Ramien et al 17 and Perera et al 18 compared with self-supervised learning methods also applied to PET images, the uniqueness of our method lies in the dedicated pseudo-lesion generation strategy designed for the lung cancer detection task. Unlike generic contrastive learning or mask reconstruction approaches, the pseudo-lesions generated by our method more closely resemble real lung cancers in terms of morphology and metabolic distribution, thereby better aligning the pretraining task with the downstream detection task and achieving superior transfer performance.
Clinical Application Value
Aiding early detection and reducing false positives: In PET images, physiological uptake in the lungs and inflammatory lesions often appear as areas of high metabolism, which can easily lead to false-positive diagnoses. By enabling the model to learn the typical features of real lung cancers (eg, spherical shape, central high metabolism, and gradual attenuation toward the periphery) through self-supervised pre-training, our method can better distinguish malignant lesions from benign hypermetabolic foci. As shown in Table 3, the proposed method achieves an FROCIOU=0.5 of 0.3016, representing a 4.45% improvement over traditional self-supervised methods, indicating its ability to effectively reduce false-positive detection. In clinical practice, this characteristic can help reduce unnecessary biopsies and overdiagnosis, alleviating the physical and mental burden on patients.
Supporting personalized treatment planning: Accurate lung cancer detection is the foundation for developing individualized treatment plans. For early-stage lung cancer, precise localization facilitates the planning of stereotactic body radiotherapy or minimally invasive surgery; for advanced lung cancer, accurate lesion detection can be used to assess tumor burden and guide decisions regarding targeted therapy or immunotherapy. Our method achieves an mAP@ 0.10 to 0.50 of 0.3187 using only 50% of the training data, demonstrating that it can provide relatively reliable detection results even under data-limited conditions, which is of particular value for primary hospitals or rare cases.
Reducing the workload of radiologists: With the rapid increase in the number of PET-CT examinations, the reading burden on radiologists is growing. The automated detection method proposed in this study can serve as an auxiliary tool to help physicians quickly locate suspicious lesions and shorten reading time. Radiologists can then devote more energy to diagnosing complex cases and making treatment decisions, thereby improving overall clinical efficiency. It is important to emphasize that this method is intended to assist rather than replace physician decision making; the final diagnosis should still be made by professional physicians based on comprehensive clinical information.
Facilitating multicenter collaboration and standardization: The self-supervised learning strategy adopted in this method does not rely on large amounts of labeled data, lowering the threshold for data integration in multicenter studies. Although PET images from different hospitals and devices may exhibit variability, the self-supervised pre-training through pseudo-lesion generation enables the model to learn relatively generalizable lesion features, laying a foundation for future applications on multicenter data.
Conclusion
This paper presents a novel self-supervised learning method for 3D lung cancer diagnosis using PET imaging. The model is pretrained through a specially designed image restoration task to learn features relevant to lung cancer in PET images. Our approach has been evaluated by comparing it with various pretraining strategies. The experimental results demonstrate the superiority of the proposed self-supervised method, which achieves an improvement of 11.1% in the lung cancer detection accuracy (mAP@ 0.10 to 0.50) over conventional self-supervised models.
This study still has certain limitations. Although the imaging manifestations of lung cancer in datasets collected from different devices and hospitals may be similar, the current evaluation remains limited by the scale of the available dataset. It should be noted that, constrained by the computational cost of training 3D PET models, the main experiments in this study were conducted with only a single run, and standard deviations are not reported. Nevertheless, the consistent performance improvement trends observed across multiple experimental settings support the reliability of the results. Future studies are needed on large-scale multicenter datasets with an increased number of independent runs to provide statistical variability information and further validate the generalization ability and robustness of the proposed method.
In subsequent research, we will extend the current framework in several directions. First, we plan to extend the detection framework to a multitask learning model that simultaneously performs lesion detection, precise segmentation, and benign-malignant classification, thereby providing richer clinical information and exploring the potential for synergistic optimization among tasks. Second, we intend to incorporate CT or clinical text information to build a multimodal model, leveraging the anatomical priors provided by CT to further improve detection accuracy. Finally, we aim to conduct prospective studies in collaboration with clinical institutions, integrating the proposed method into real-world clinical workflows for evaluation, focusing on its practical benefits in terms of improving reading accuracy, reducing reading time, and lowering miss rates, as well as assessing radiologists’ acceptance and trust in automated detection tools through user satisfaction surveys.
Footnotes
Acknowledgments
The authors wish to thank Professor Changjing Zuo for his assistance in understanding and applying the PET-CT image.
Ethical Consideration
This study was approved by the Science and Technology Ethics Committee of Shenzhen Institute of Information Technology (Approval No. EC-[2026-011901]). The requirement for informed consent was waived by the committee due to the retrospective nature of the research and the use of fully anonymized data.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Natural Science Foundation of China International (Regional) Cooperation and Exchange Project (82261138629), Guangdong Basic and Applied Basic Research Foundation Enterprise Joint Fund (2023A1515220156), Shenzhen Science and Technology Innovation Commission Basic Research Project (JCYJ20220530155811025, 20231127152555002); Shenzhen Information Polytechnic University-Level Innovation Platform Project (PT2024E007).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.