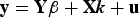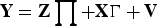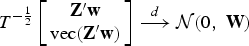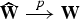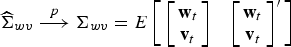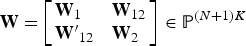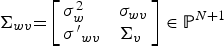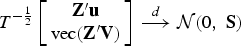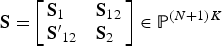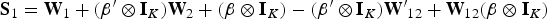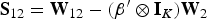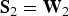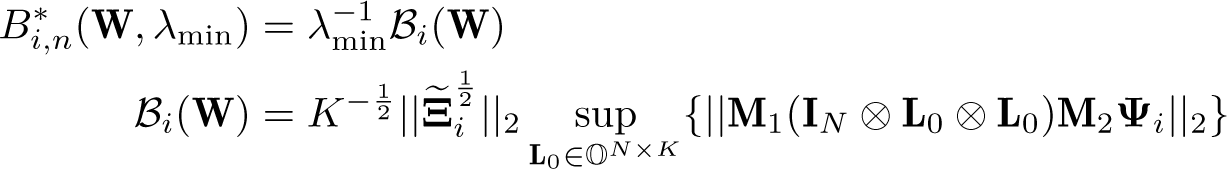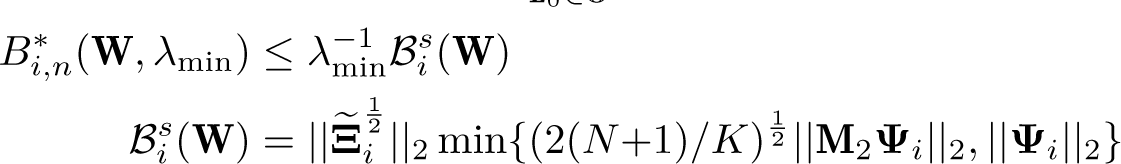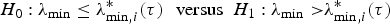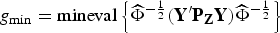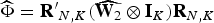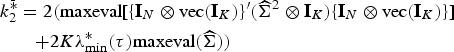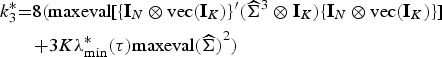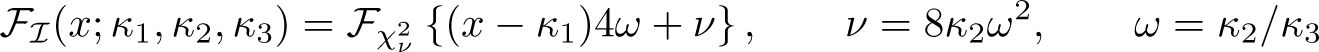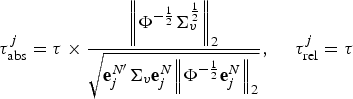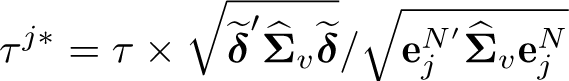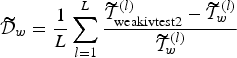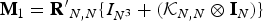In this article, I introduce a novel command, weakivtest2, that implements the robust bias-based test for weak instruments for two-stage least squares with multiple endogenous regressors proposed by Lewis and Mertens (Forthcoming, Review of Economic Studies, https://doi.org/10.1093/restud/rdaf103). The weakivtest2 command allows for absolute and relative bias criteria, local-to-zero and local-to-rank-reduction-of-one asymptotics, and testing for either the full vector or the individual elements of the two-stage least-squares estimator. weakivtest2 is a postestimation command for ivreg2, xtivreg2, and ivreghdfe.
Instrumental-variables (IV) regressions are widespread in empirical research. However, weak instruments can bias the IV estimates and cause size distortions in related tests; see Andrews, Stock, and Sun (2019) for a detailed summary of weak-instrument problems. These problems call for IV pretests to assess the instrument strength. Stock and Yogo (2005) propose a widely adopted weak-instrument test under the assumption of conditionally homoskedastic and serially uncorrelated model errors. Montiel Olea and Pflueger (2013) extend the test to more general assumptions on model errors, albeit limited to models with a single endogenous regressor. However, multiple endogenous regressors are commonplace in empirical applications, such as forward-looking macroeconomic models (Mavroeidis, Plagborg-Møller, and Stock 2014; Inoue, Rossi, and Wang 2024) and state-dependent models (Ramey and Zubairy 2018). Andrews, Stock, and Sun (2019) point to the lack of more general weak-instrument tests as an important remaining gap in the IV pretesting literature. Fortunately, Lewis and Mertens (Forth-coming, LM) fill this gap by deriving the test procedure for weak instruments with both multiple endogenous regressors and errors that are conditionally heteroskedastic and serially correlated.
Some community-contributed commands have been developed to test for weak instruments. For instance, commands ivreg2 (Baum, Schaffer, and Stillman 2007, 2002), xtivreg2 (Schaffer 2005), and ivreghdfe (Correia 2018) provide Cragg and Donald’s (1993) Wald F statistic and Kleibergen and Paap’s (2006) rk-Wald F statistic, together with Stock and Yogo’s (2005) critical values. Pflueger and Wang’s (2015) postestimation command weakivtest implements the robust weak-instrument test for a single endogenous regressor by calculating Montiel Olea and Pflueger’s (2013) effective F statistic. This article develops the robust weak-instrument test routine in Stata to models with multiple endogenous regressors using the method developed by LM. The method is implemented in MATLAB by LM.
In this article, I introduce a novel command, weakivtest2, to implement LM’s robust weak-instrument test for two-stage least squares (2SLS) estimation as a postestimation command for the ivreg2, xtivreg2, and ivreghdfe commands. Specifically, my weakivtest2 command tests the null hypothesis that the approximate asymptotic bias (also known as Nagar [1959] bias) of the 2SLS estimator exceeds some tolerance level under the local-to-zero assumption. Both the absolute and the relative bias criteria, relative to a “worst-case” benchmark, can be evaluated using the command. The null hypothesis is rejected when the test statistic exceeds the critical value. The critical value depends on the bias criterion, the desired bias tolerance level τ, and the significance level α. The weakivtest2 command can also conduct other hypothesis tests, including tests for individual elements of the 2SLS estimator and tests under local-to-rank-reduction-of-one asymptotics. The command requires the avar package developed by Baum and Schaffer (2013).
I conduct Monte Carlo simulations and an empirical application using the command weakivtest2. The simulation results verify that weakivtest2 produces results that are numerically consistent with the MATLAB implementation across all supported cases. The results also illustrate the relationship between weakivtest2 and existing Stata commands such as ivreg2 and weakivtest. Moreover, the computation time is moderate for typical model sizes and can be substantially reduced by using more conservative critical values. An empirical example, motivated by Ramey and Zubairy (2018) and LM, illustrates the implementation of the weakivtest2 command.
The remainder of this article is organized as follows. Section 2 lays out the econometric framework. Section 3 presents details of the weakivtest2 command. Section 4 reports Monte Carlo simulation results. Section 5 provides an implementation example. Section 6 concludes.
Econometric framework
In this section, we lay out the econometric framework of LM’s weak-instrument test. Before doing so, we introduce the notation: Ip denotes the (p × p) identity matrix. 1p and 0p denote the (p × 1) vectors with elements 1 and 0. Let be a matrix. denotes the spectral norm of A. A′ denotes the transpose of A. and denote the projection and annihilator matrix of A. tr(A) denotes the trace of A. vec(A) vertically stacks columns of A. denotes the (p × q) commutation matrix such that . Let . and −denote convergence in probability and distribution. and denote the sets of (p × 1) real vectors and (p × q) real matrices. denotes the set of positive-definite (q × q) matrices. denotes the set of (p × q) orthogonal real matrices A such that .
Model setup
Linear IV models
Let us consider a linear IV model with N endogenous regressors, K ≥ N excluded instruments, L included instruments, and T observations as follows:
Equation (1) denotes the structural-form relationship between the dependent variable and endogenous regressors, and (2) denotes the first-stage relationship between the endogenous regressors and the instruments. , , , and denote, respectively, the matrix of dependent variables, endogenous regressors, excluded instruments, and included instruments. The parameter of interest is . contains the first-stage parameters; and contain coefficients of the included instruments. The intercept term and fixed effects are included in X for notational simplicity.
Substituting Y into the structural form, we have the reduced-form relationship , where and .
Without loss of generality, let us project out the included instruments X. For simplicity, we still use y, Y, Z, u, and V to denote their projection errors onto X. For instance, we replace the endogenous regressors Y by MXY. We further normalize the instruments such that Z′Z/T = IK . The above normalization leaves the 2SLS estimator unchanged. The 2SLS estimator of β is .
Model assumptions
LM makes the following two assumptions to derive the robust weak-instrument test. First, LM models the weak instruments by assuming that the first-stage relationship is local-to-zero. Second, LM characterizes the asymptotic distributions of reduced-form and first-stage residuals interacted with excluded instruments. The asymptotic covariance W can be any positive definite matrix. Thus, this model allows for arbitrary distributional assumptions on the model errors.
Assumption 1., where is a fixed full-rank matrix.
Assumption 2. The following limits hold as T → ∞:
where
Recalling that w = Vβ+u, let us further define the asymptotic variance of structural-form and first-stage residuals interacted with excluded instruments as S:
where
Under assumptions 1 and 2, LM shows that the bias of the 2SLS estimator, , converges in distribution to a limit, denoted by . Intuitively, the goal of the weak-instrument test is to test whether is significantly different from zero.
Definition of the weak-instrument set
The following definitions formally introduce the weak-instrument set.Definition 1. The concentration matrix is , where . Let λmin = mineval(Λ) be the minimum eigenvalue of Λ.
Definition 1 gives the concentration matrix for a general asymptotic variance matrix W and N ≥ 1. The minimum eigenvalue of this matrix will be used to derive a tractable boundary of the weak-instrument set.
Definition 2. The bias criterion for i ∈ {abs, rel} is , where , ; , .
LM considers instruments weak when a weighted quadratic loss function of the asymptotic bias is large in either an absolute or a relative sense. Definition 2 gives the absolute and the relative bias criteria. The choice of weighting matrix and scaling factor bi determines whether the bias criterion is expressed in absolute or relative terms. In particular, the absolute bias criterion, Babs, uses the same weighting and scaling as Stock and Yogo (2005)’s absolute bias criterion. The relative bias criterion, Brel, is extended from Montiel Olea and Pflueger (2013) and can be interpreted as the asymptotic bias relative to a worst-case benchmark.
LM applies the standard Nagar (1959) methodology to obtain a tractable proxy for the bias criterion Bi for i ∈ {abs, rel}. They define the Nagar bias as Bi,n and derive the upper bounds on Bi,n for a given λmin, showing that , where
where , , , , and .
forms a sharp upper bound for the Nagar bias Bi,n, which can be obtained through a numerical optimization algorithm by Wen and Yin (2013). forms another nonsharp upper bound that requires no numerical optimization. Section 4.3 discusses the computational burden.
Definition 3. The weak-instrument set for i ∈ {abs, rel} is .
Definition 3 describes the weak-instrument set. It depends on the asymptotic variance W, which can be consistently estimated. Because C and β cannot be estimated consistently, the null hypothesis will be tested based on the upper bound of Bi,n.
Robust weak-instrument test
Null and alternative hypotheses
Given a bias tolerance level τ, LM’s weak-instrument test evaluates whether the minimum eigenvalue of Λ is less than or equal to a threshold value . Formally, the null and alternative hypotheses are
Where can take the form of either . The null hypothesis implies that the Nagar bias is less than or equal to the bias tolerance level τ, that is, .
Test statistic
The test statistic is the sample realization of λmin, denoted by gmin.
where
LM shows that under assumptions 1 and 2, the test statistic gmin converges in distribution to mineval . The random matrix ζ follows a noncentral Wishart distribution with degrees of freedom d = 1, scale matrix , and noncentrality matrix , where .
Critical value
Because of the complexity of the limiting distribution of gmin, it is difficult to derive analytical critical values for the test. LM considers a class of approximating distributions, proposed by Imhof (1961), that match the first three cumulants of the target distribution of gmin. LM shows that the first cumulant of gmin is and the upper bounds of the second and third cumulants are
where denotes the matrix obtained by replacing W with in . Moreover, the Imhof (1961) distribution is defined as
where is the cumulative distribution function of a central distribution with ν degrees of freedom. The critical value for the robust weak-instrument test at significance level α is the (1 − α) × 100% percentile of the Imhof (1961) distribution with the upper bounds of the cumulants . LM proves that these critical values are conservative relative to the unknown critical values from the true distribution of gmin.
Following LM, the weakivtest2 command always verifies that the Kuhn–Tucker conditions of the associated maximization problem are satisfied at the upper bound. If this is not the case, the code numerically solves for the most conservative critical value respecting the bounds. This involves an optimization problem with a nonlinear objective function and linear inequality constraints, which cannot be solved by the built-in Stata optimizer. Therefore, we transform the constrained optimization problem into an unconstrained one using a penalty method (Nocedal and Wright 2006). Section 4.1 shows that the transformation will not alter the optimization result compared with an existing MATLAB package.
Modifications for models with K ≤ N + 1
Because plausible instruments are often scarce, models with only N or N + 1 instruments are of particular practical relevance. However, the bias criterion, Bi, does not exist when K = N. Depending on the assumptions, the bias may not exist when K = N + 1, or it may be difficult to approximate accurately using the Nagar bias, Bi,n. LM provides the following solutions.
For models with K = N + 1, LM recommends using the more conservative bound .
For models with K = N, LM recommends testing for the median bias rather than the mean bias. When K = N = 1, LM formally shows that a test based on the median bias of 2SLS can be implemented with the same testing procedure simply by rescaling the tolerance, τmed = τ /0.455. However, when K = N> 1, a tractable Nagar approximation of median bias cannot be obtained. In this case, LM turns to the more conservative bound.
Extension to other hypothesis tests
Test for individual elements of
The test using the bias criterion for the full vector can be modified to test the bias of a single element of . Denote as the N × 1 vector with the jth element equal to 1 and 0s otherwise. LM defines the bias criterion and weak-instrument set for the jth element in .
Definition 2-j. The bias criterion for i ∈ {abs, rel} and the jth element in is .
Definition 3-j. The weak-instrument set for i ∈ {abs, rel} and the jth element in is .
LM shows that under assumptions 1 and 2, the weak instruments test for an individual coefficient can be conducted exactly as the testing procedure in section 2.2, with a simple adjustment to τ,
Tests under local to rank reduction of one
In addition to testing the weak instruments under the local-to-zero assumption, where all instruments are uniformly weak, Sanderson and Windmeijer (2016) consider a local-to-rank-reduction-of-one (LRR1) asymptotic embedding and show that an F statistic proposed by Stock and Yogo (2005) can be used to conduct a bias-based test for models with homoskedastic and serial uncorrelated errors. LM extends the test to allow for heteroskedasticity and autocorrelation. In particular, the LRR1 embedding is formulated as follows.
Assumption 3. The jth column of Π is , where , , and the matrix containing the remaining N − 1 columns of Π is of full column rank.
Assumption 3 indicates that Πj is asymptotically collinear with the remaining columns . We emphasize that the results introduced below are valid only under the specific assumed asymptotic embedding given the choice of Πj instead of being uniformly valid under arbitrary rank reductions.
LMs show that under assumptions 2 and 3, the test statistic and critical values for absolute bias of the 2SLS estimator can be constructed using the testing procedure in section 2.2, with the transformed outcome variable , endogenous regressor and instruments where Yj denotes the jth regressor and Y−j the remaining regressors in Y, , and contains any K − N + 1 columns of Z. Note that the test based on the relative bias criterion under LRR1 asymptotics is not provided.
Given the choice of Πj, the test can be further extended to evaluate the absolute bias of the jth element of the 2SLS estimator by adjusting the tolerance level
where is such that and .
The weakivtest2 command
The command weakivtest2 implements the robust weak-instrument test with multiple endogenous regressors for 2SLS, as developed by LM. It serves as a postestimation command for ivreg2, xtivreg2 (fixed effects only), and ivreghdfe.
weakivtest2 estimates the variance–covariance matrix of errors as specified in the preceding ivreg2, xtivreg2, or ivreghdfe estimation. The following options are supported: 1) robust, which estimates an Eicker–Huber–White heteroskedasticity-robust variance–covariance matrix; 2) robust bw(#), which estimates a heteroskedasticity and autocorrelation consistent (HAC) variance–covariance matrix computed with a Bartlett (Newey–West) kernel; and 3) cluster(varlist), which estimates a variance–covariance matrix clustered on the specified variable.
The weakivtest2 command stores and displays LM’s test statistic and critical values in the Stata Results window. For reference, weakivtest2 stores the test statistic of either Stock and Yogo (2005) or Sanderson and Windmeijer (2016), depending on whether local-to-zero or LRR1 asymptotics are assumed, as well as the critical values based on Nagar approximations when K>N + 1.
Syntax
The syntax of the weakivtest2 command is as follows:
weakivtest2 I, level(numlist) tau(numlist) asymptotics(string)
criterion(string) index(#)target(#) points(#) fast record ]
Options
level(numlist) specifies one or more confidence levels 100(1 − α) for the critical values. The default is level(95 90).
tau(numlist) specifies one or more bias tolerance levels τ for the critical values. The default is tau(0.05 0.1 0.2 0.3).
asymptotics(string) chooses the asymptotic embedding used in the test. The option asymptotics(“l0”) corresponds to the L0 embedding, in which all first-stage coefficients are local to zero. The option asymptotics(”lrr1”) corresponds to the LRR1 embedding, in which the first-stage coefficient matrix is local to rank deficiency. The default is asymptotics(“l0”).
criterion(string) selects the bias criterion used to evaluate the Nagar bias. The option criterion(”absolute”) evaluates the bias relative to the maximum ordinary least-squares bias. The option criterion(”relative”) evaluates the bias relative to its worst-case benchmark. The default is criterion(”absolute”). When asymptotics(“lrr1”) is specified, criterion(“absolute”) must be used.
index(#) specifies an integer j (1 ≤ j ≤ N) corresponding to the location of the retained regressor in the vector of endogenous regressors (or Πj in assumption 3), where N is the number of endogenous regressors. This option is required only when asymptotics(“lrr1”) is specified.
target(#) specifies the target of 2SLS coefficients: either 0 for the entire vector or an integer j (1 ≤ j ≤ N) corresponding to the location of the individual coefficient in , where N is the number of endogenous regressors. This option must be 0 or the number specified in index() when asymptotics(“lrr1”) is specified. The default is target(0).
points(#) sets the number of random starting points used in the optimization routine to obtain . The default is points(1000).
fast requests that only simplified conservative critical values are computed. This option is useful when you want a quick diagnostic; the resulting critical values are guaranteed to be conservative but may be less sharp than the full set of critical values.
record reports the progress of the numerical optimization used to compute the critical values. This option is intended mainly for diagnostic or debugging purposes.
Stored results
The weakivtest2 command stores the following results in r():
Relationship with existing commands
The weakivtest2 command is closely related to existing weak-instrument tests for 2SLS in Stata. Section 4.2 investigates the relationship numerically.
Commands ivreg2 (Baum, Schaffer, and Stillman 2007, 2002), xtivreg2 (Schaffer 2005), and ivreghdfe (Correia 2018) report Cragg and Donald’s (1993) Wald F statistic and critical values in Stock and Yogo’s (2005) tables for both bias-and size-based tests, where the critical value for the bias-based test is available only when K>N + 1. weakivtest2 provides the same bias-based test statistic under both relative and absolute bias criteria for models with conditionally homoskedastic and serially uncorrelated errors when K>N + 1. The critical value exhibits some numerical differences because weakivtest2 uses Nagar approximation instead of Monte Carlo integration to evaluate the bias. In addition, weakivtest2 covers models with K ≤ N + 1 by considering median bias for K = N and adopting a conservative bound for K = N + 1. weakivtest2 also reports robust test statistic and critical values for models with general dependence structures in error terms, while those reported by ivreg2, xtivreg2, or ivreghdfe are invalid for these models. Nevertheless, weakivtest2 does not report critical values for the size-based test.
The community-contributed command weakivtest (Pflueger and Wang 2015) reports Montiel Olea and Pflueger’s (2013) effective F statistic and critical values for both 2SLS and limited-information maximum-likelihood estimators when there is a single endogenous regressor. weakivtest2 provides the same test statistic as weakivtest for the 2SLS estimator when N = 1. For models with K> 2 and N = 1, weakivtest2 provides the analytically identical critical value as weakivtest under the relative bias criterion. For models with K = 2 and N = 1, LM recommends using a more conservative bound , while Montiel Olea and Pflueger (2013) stick with the sharp upper bound . Therefore, weakivtest2 generally provides larger critical values than weakivtest. For models with K = N = 1, the mean bias of 2SLS does not exist. LM considers median bias of the 2SLS estimator, while weakivtest does not make the modification. Therefore, weakivtest2 provides smaller critical values than weakivtest. In addition, weakivtest2 covers models with multiple endogenous regressors N> 1, in which case weakivtest returns an error message. weakivtest2 also allows for the absolute bias criterion instead of the relative bias criterion. Nevertheless, weakivtest2 does not report test results for limited-information maximum-likelihood estimators.
Monte Carlo simulations
In this section, we conduct Monte Carlo simulations to investigate the numerical properties of weakivtest2, including its numerical consistency with the MATLAB package, its relationship with other tests in Stata, and its computational burden. We note that the purpose here is not to validate LM’s test. For a comprehensive examination of the size and power of the test, as well as performance comparisons with other tests such as Stock and Yogo (2005) and Montiel Olea and Pflueger (2013), we refer the reader to LM. All simulation results are based on L = 100 replications.
Consistency with the MATLAB package
In this subsection, we assess the numerical consistency between weakivtest2 and LM’s accompanying MATLAB package, available at gweakivtest.zip (version dated 2025-07-02).
This comparative study considers scenarios that reflect all algorithmic components implemented in weakivtest2. We consider all three types of hypothesis tests: 1) the test for absolute bias under local-to-zero embedding; 2) the test for relative bias under local-to-zero embedding; and 3) the test under LRR1 embedding, retaining the first endogenous regressor. We consider tests for both the full estimator and the first component of . We cover four different model sizes: 1) K = 4, N = 2, where the standard algorithm is applied; 2) K = 3, N = 2, where the conservative critical value is calculated; 3) K = N = 2, where the test for median bias is applied with a conservative critical value; and 4) K = N = 1, where the test for median bias is applied with an adjusted tolerance level.
We follow the data generation process (DGP) in gweakivtest_Example.m from the MATLAB package. In particular, we set ,, , , ,, , and , as specified in (1)–(2). We set T = 200 and L = 3 and define as an m × n matrix with each element independently drawn from the standard normal distribution. is defined as the first N rows of the K × K orthogonal matrix generated from the QR decomposition of a random matrix .
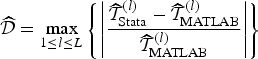
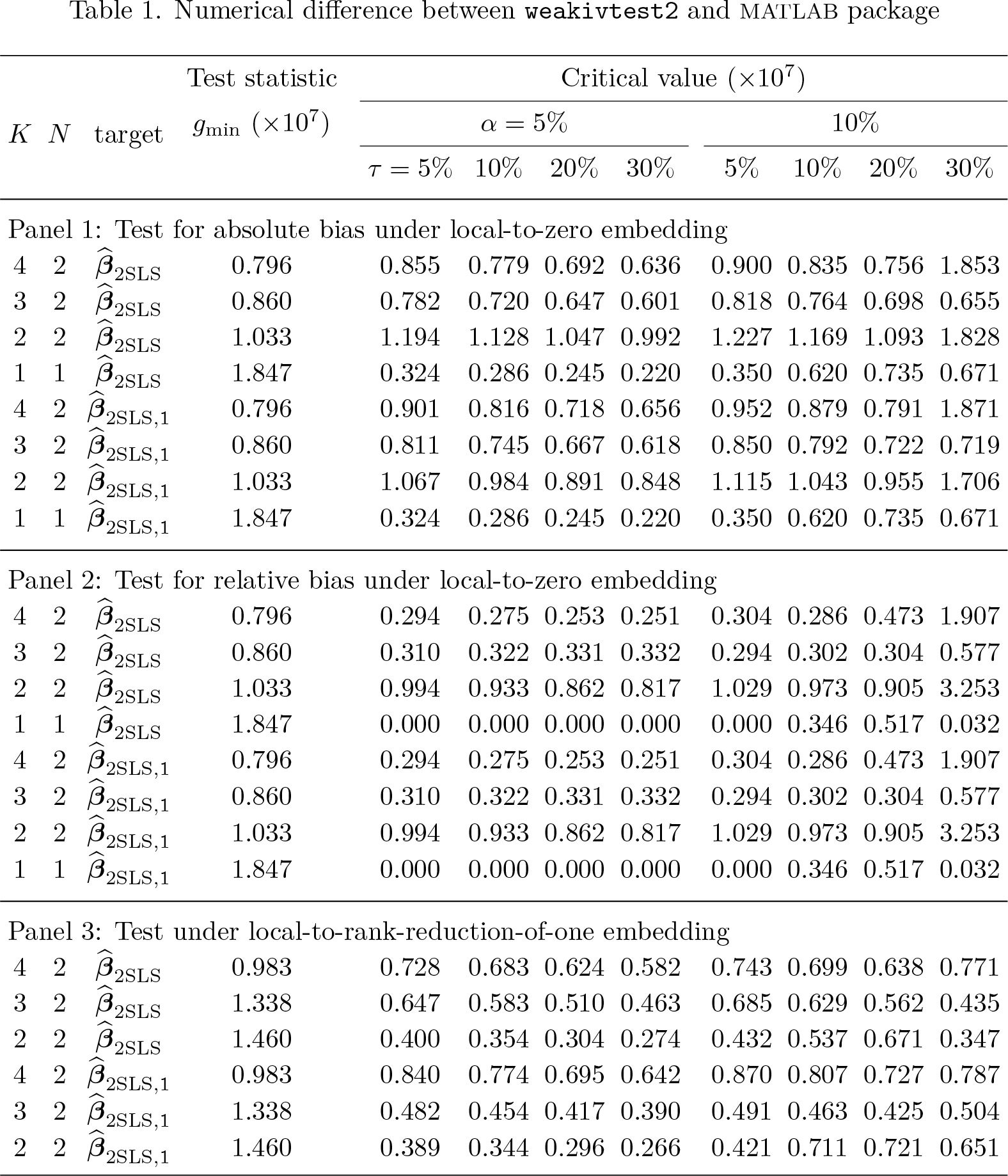
Table 1 reports the scaled numerical difference between weakivtest2 and the MATLAB package, using Stata/MP 17 and MATLAB R2023a, respectively. The maximal relative numerical difference is defined as
where denotes a generic statistic (gmin or critical value) for w ∈ {Stata, MATLAB} in the lth replication. Within each scenario, we report the numerical difference for the test statistic gmin and critical values for α ∈ {0.05, 0.1} and τ ∈ {0.05, 0.1, 0.2, 0.3}. The maximal difference across all scenarios is on the order of 10−7 or lower, indicating a high degree of numerical equivalence between the Stata and MATLAB implementations.
Numerical difference between weakivtest2 and matlab package
K
N
target
Test statistic
Critical value (×107)
α = 5%
10%
τ = 5%
10%
20%
30%
5%
10%
20%
30%
Panel 1: Test for absolute bias under local-to-zero embedding
4
2
0.796
0.855
0.779
0.692
0.636
0.900
0.835
0.756
1.853
3
2
0.860
0.782
0.720
0.647
0.601
0.818
0.764
0.698
0.655
2
2
1.033
1.194
1.128
1.047
0.992
1.227
1.169
1.093
1.828
1
1
1.847
0.324
0.286
0.245
0.220
0.350
0.620
0.735
0.671
4
2
0.796
0.901
0.816
0.718
0.656
0.952
0.879
0.791
1.871
3
2
0.860
0.811
0.745
0.667
0.618
0.850
0.792
0.722
0.719
2
2
1.033
1.067
0.984
0.891
0.848
1.115
1.043
0.955
1.706
1
1
1.847
0.324
0.286
0.245
0.220
0.350
0.620
0.735
0.671
Panel 2: Test for relative bias under local-to-zero embedding
4
2
0.796
0.294
0.275
0.253
0.251
0.304
0.286
0.473
1.907
3
2
0.860
0.310
0.322
0.331
0.332
0.294
0.302
0.304
0.577
2
2
1.033
0.994
0.933
0.862
0.817
1.029
0.973
0.905
3.253
1
1
1.847
0.000
0.000
0.000
0.000
0.000
0.346
0.517
0.032
4
2
0.796
0.294
0.275
0.253
0.251
0.304
0.286
0.473
1.907
3
2
0.860
0.310
0.322
0.331
0.332
0.294
0.302
0.304
0.577
2
2
1.033
0.994
0.933
0.862
0.817
1.029
0.973
0.905
3.253
1
1
1.847
0.000
0.000
0.000
0.000
0.000
0.346
0.517
0.032
Panel 3: Test under local-to-rank-reduction-of-one embedding
4
2
0.983
0.728
0.683
0.624
0.582
0.743
0.699
0.638
0.771
3
2
1.338
0.647
0.583
0.510
0.463
0.685
0.629
0.562
0.435
2
2
1.460
0.400
0.354
0.304
0.274
0.432
0.537
0.671
0.347
4
2
0.983
0.840
0.774
0.695
0.642
0.870
0.807
0.727
0.787
3
2
1.338
0.482
0.454
0.417
0.390
0.491
0.463
0.425
0.504
2
2
1.460
0.389
0.344
0.296
0.266
0.421
0.711
0.721
0.651
Comparison with other tests for weak instruments in Stata
In this subsection, we show the relationship between weakivtest2 and other commands designed for testing instrument strength in Stata, following the discussion in section 3.4.
We use the same DGPs as in section 4.1. In addition to the independent and identically distributed (i.i.d.) design, we model serial correlation by drawing u, V, X, and Z from first-order autoregressive processes with mean 0 and variance 1. We fit models with serially correlated errors using the HAC variance–covariance matrix. We consider both absolute and relative bias-based tests, using a significance level of α = 5% and a bias tolerance level of τ = 10%.
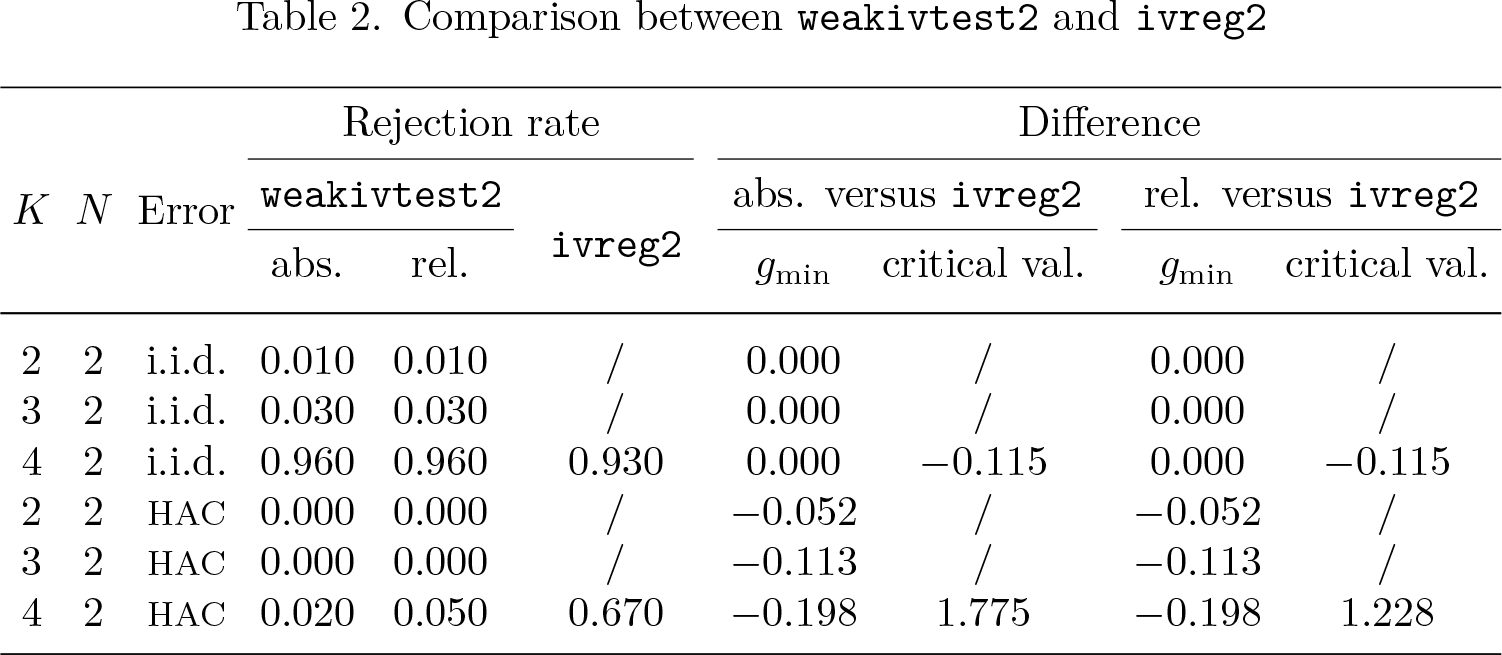
Table 2 compares weakivtest2 with ivreg2, which reports the results of Stock and Yogo’s (2005) test. The first three columns report the average rejection rate, and the remaining four columns report the differences . The numerical difference is defined as
where denotes a generic statistic for each w ∈ {ivreg2,weakivtest,weakivtest2} in the lth replication. The results convey the following. First, for models with K ≤ N + 1, ivreg2 does not provide bias-based critical values, while weakivtest2 fills this gap. Second, for models with K>N + 1 and i.i.d. errors, the two commands generate similar test results with a slight difference, due to different methodologies used to compute the critical values. Finally, for models with K>N + 1 and non-i.i.d. errors, the two commands draw opposite conclusions on the instrument strength. In such a case, we note that LM’s test is theoretically justified, whereas Stock and Yogo’s (2005) test lacks theoretical support.
Comparison between weakivtest2 and ivreg2
K
N
Error
Rejection rate
Difference
weakivtest2
ivreg2
abs.
versus ivreg2
rel.
versus ivreg2
abs.
rel.
gmin
critical val.
gmin
critical val.
2
2
i.i.d.
0.010
0.010
/
0.000
/
0.000
/
3
2
i.i.d.
0.030
0.030
/
0.000
/
0.000
/
4
2
i.i.d.
0.960
0.960
0.930
0.000
−0.115
0.000
−0.115
2
2
HAC
0.000
0.000
/
−0.052
/
−0.052
/
3
2
HAC
0.000
0.000
/
−0.113
/
−0.113
/
4
2
HAC
0.020
0.050
0.670
−0.198
1.775
−0.198
1.228
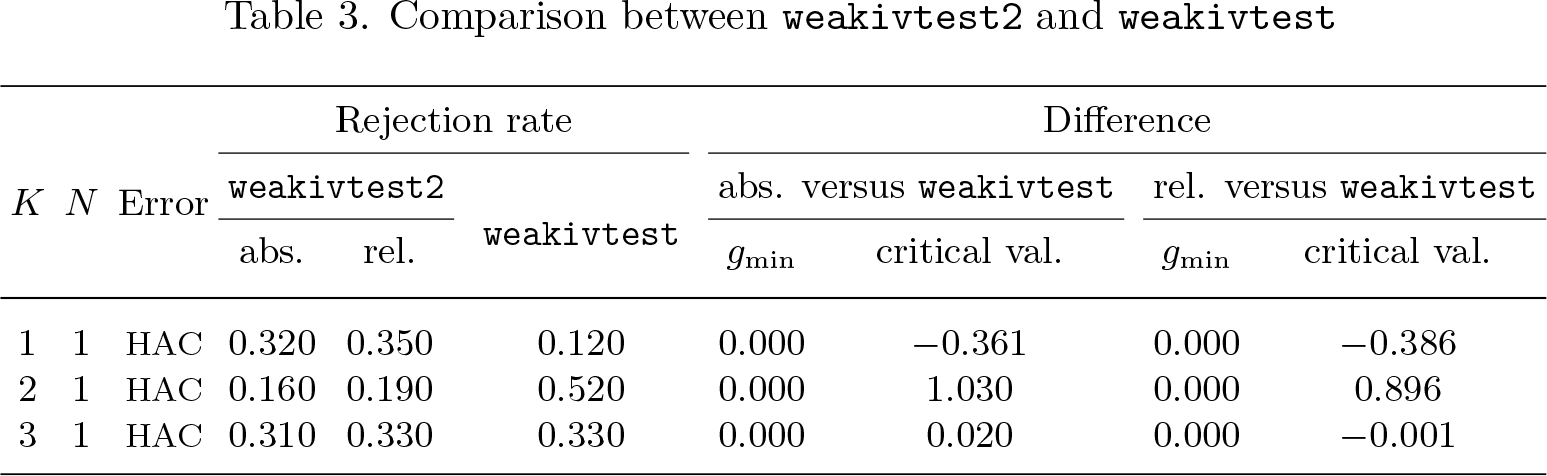
Table 3 compares weakivtest2 with weakivtest, which reports results of Montiel Olea and Pflueger’s (2013) test. The first three columns report the average rejection rate, and the remaining four columns report the differences . The results convey the following. First, the test statistics reported by weakivtest2 and weakivtest are identical when N = 1. Second, for models with K = N = 1, weakivtest2 focuses on median bias, resulting in smaller critical values and a higher rejection rate. Third, for models with K = 2 and N = 1, weakivtest2 relies on a more conservative and therefore larger set of critical values, resulting in a lower rejection rate. Fourth, for models with K>N + 1 and N = 1, weakivtest2 generates essentially the same critical value as weakivtest with negligible numerical difference due to different approximation techniques. Montiel Olea and Pflueger (2013) use the Patnaik (1949) approximation to match the first two cumulants. Finally, weakivtest does not provide results when N> 1.
Comparison between weakivtest2 and weakivtest
K
N
Error
Rejection rate
Difference
weakivtest2
weakivtest
abs.
versus weakivtest
rel.
versus weakivtest
abs.
rel.
gmin
critical val.
gmin
critical val.
1
1
HAC
0.320
0.350
0.120
0.000
−0.361
0.000
−0.386
2
1
HAC
0.160
0.190
0.520
0.000
1.030
0.000
0.896
3
1
HAC
0.310
0.330
0.330
0.000
0.020
0.000
−0.001
Computation time
In this subsection, we investigate the computation time of weakivtest2. The main computational burden arises from simulating the sharp upper bound via numerical optimization.
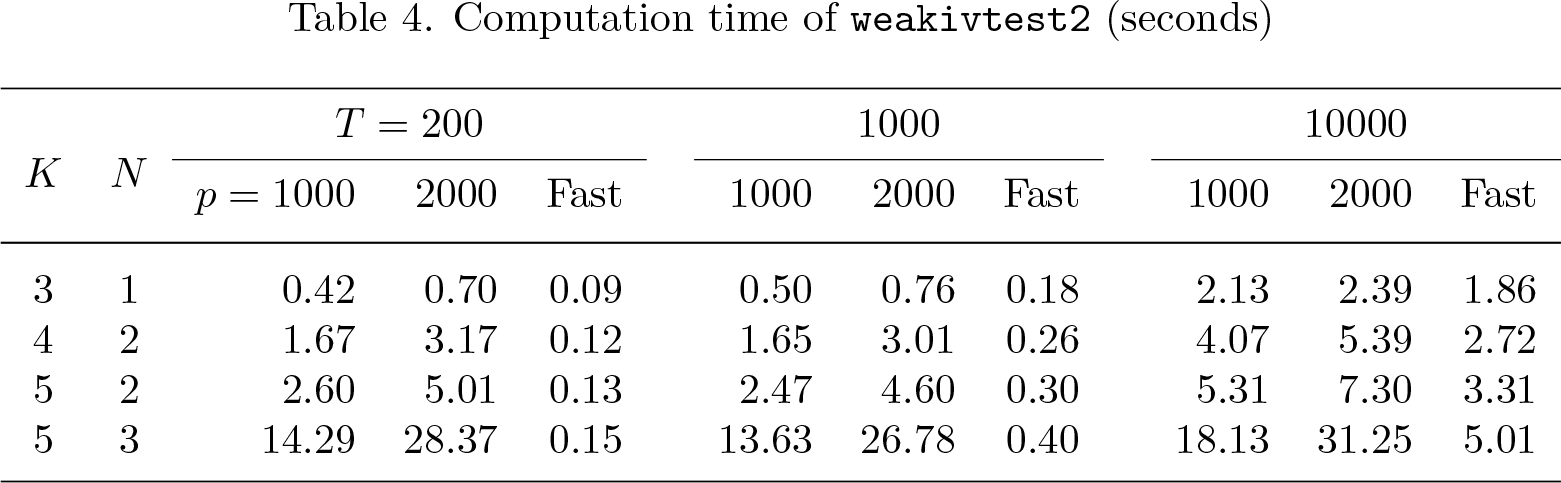
Table 4 reports the computation time of weakivtest2 (without parallel computing) on a MacBook M1 Pro (3.20 GHz and 8-core CPU). The DGPs follow the design described in section 4.1. In general, both the computational power of the machine and the characteristics of the dataset affect the computation time. The number of random draws in obtaining (specified by points()),p, linearly increases the computation time, while the sample size T has a smaller effect. In addition, the computation time is negligible when N and K are moderate but increases significantly with model size. If we were to increase the model size—say, to N = 4 and K = 8—the computation time would become prohibitively long. In such cases, the fast option effectively reduces the computation time (at the cost of a more conservative critical value).
Computation time of weakivtest2 (seconds)
K
N
T = 200
1000
10000s
p = 1000
2000
Fast
1000
2000
Fast
1000
2000
Fast
3
1
0.42
0.70
0.09
0.50
0.76
0.18
2.13
2.39
1.86
4
2
1.67
3.17
0.12
1.65
3.01
0.26
4.07
5.39
2.72
5
2
2.60
5.01
0.13
2.47
4.60
0.30
5.31
7.30
3.31
5
3
14.29
28.37
0.15
13.63
26.78
0.40
18.13
31.25
5.01
Implementation example
In this section, we follow the empirical application of Ramey and Zubairy (2018) used by LM to illustrate the robust weak-instrument test. Ramey and Zubairy (2018) estimate the state-dependent cumulative government spending multipliers using military news shocks and recursive government spending shocks as instruments. The specification is
where h = 0, 1,… is the number of horizons, I is the dummy variable that indicates the state of economy, g is the government spending divided by gross domestic product, y is the detrended gross domestic product, and z is the vector of control variables. The endogenous regressors and are instrumented by It−1 × nt, It−1 × gt, (1 − It−1) × nt, and (1 − It−1) × gt, where n is the military news shock. Therefore, K = 4 and N = 2. Following Ramey and Zubairy (2018), we set h = 12, L = 4, and zt = (yt, gt, nt). The number of lags in Newey and West’s (1987) HAC model is chosen by Newey and West’s (1994) automatic procedure. We are interested in whether the interest rate is at or near the zero lower bound (ZLB).
The following script implements LM’s weak-instrument test for (3). Because of space limitations, we omit the code used to generate the variables. The local macros endog, inexog, and exexog respectively store the lists of endogenous regressors, included instruments, and excluded instruments.
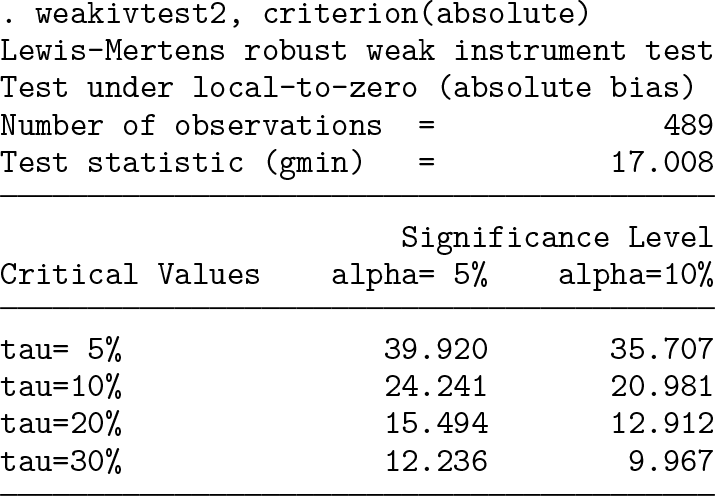
The results indicate that LM’s test statistic is gmin = 17.008, which is smaller than the robust critical value of 23.632 (24.241) under a relative (absolute) bias tolerance level of τ = 10% and a significance level of α = 5%. Therefore, the null hypothesis of weak instruments cannot be rejected.
The result of weakivtest2 can be compared with the results of its related commands, including ivreg2 and weakivtest. On one hand, the ivreg2 command reports a Cragg and Donald’s (1993) Wald F statistic of 28.385, with Stock and Yogo’s (2005) critical values of 7.56 for τ = 10% at a significance level of 5%, indicating that Stock and Yogo’s (2005) test rejects the null hypothesis of weak instruments under an even stricter tolerance level τ . The discrepancy comes from the size distortion of Stock and Yogo’s (2005) test when the model errors are conditionally heteroskedastic and serially correlated, which causes the test to overreject the null hypothesis. The weakivtest2 command gives a more reliable test result when the distributional assumptions on model errors are relaxed.
On the other hand, Pflueger and Wang’s (2015)weakivtest command is inapplicable in this example because of the existence of multiple endogenous regressors. To test instrument strength, Ramey and Zubairy (2018) apply Montiel Olea and Pflueger’s (2013) test to individual subsamples identified by the regime indicators. The regime-specific tests lead to contradictory conclusions. Montiel Olea and Pflueger’s (2013) effective F statistic for the non-ZLB periods is 15.211, with a critical value of 18.311 for τ = 10% at a significance level of 5%, indicating that the instruments are weak. However, the effective F statistic for the ZLB periods is 15.198, with a critical value of 12.698, and thus the null hypothesis of weak instruments is rejected. These conflicting results may cause confusion among practitioners about whether to use weak-instrument robust inference techniques in the subsequent analysis. The weakivtest2 command avoids this dilemma and provides a unified test result on the instrument strength.
Conclusions
In this article, I introduced the weakivtest2 command that implements LM’s (Forth-coming) robust test for weak instruments with multiple endogenous regressors in Stata. Given the popularity of IV models, weakivtest2 can be applied to various fields and help the practitioners better evaluate the instrument strength.
The weakivtest2 command is flexible with respect to both the number of endoge-nous regressors and the assumptions on model errors, but it applies only to 2SLS at this stage because of a lack of further theoretical justification. It would be interesting to see the future development of weak-instrument tests for limited-information maximum likelihood and generalized method of moments estimation, along with corresponding statistical software in Stata.
Supplemental Material
sj-txt-2-stj-10.1177_1536867X261425792 - Supplemental material for A robust test for weak instruments with
multiple endogenous regressors in Stata
Supplemental material, sj-txt-2-stj-10.1177_1536867X261425792 for A robust test for weak instruments with
multiple endogenous regressors in Stata by Lingyun Zhou
Supplemental Material
sj-dta-1-stj-10.1177_1536867X261425792 - Supplemental material for A robust test for weak instruments with
multiple endogenous regressors in Stata
Supplemental material, sj-dta-1-stj-10.1177_1536867X261425792 for A robust test for weak instruments with
multiple endogenous regressors in Stata by Lingyun Zhou
Footnotes
Acknowledgments
I am grateful to Wenxin Huang and Yiru Wang for their guidance and support. I appreciate the valuable feedback from Daniel Lewis and Luca Sala. I thank the coeditor and the anonymous referee for many constructive comments on the previous version of the article and the command.
7
To install the software files as they existed at the time of publication of this article, type
About the author
Lingyun Zhou is a PhD student in the PBC School of Finance at Tsinghua University.
References
1.
AndrewsI.StockJ. H.SunL.. 2019. Weak instruments in instrumental variables regression: Theory and practice. Annual Review of Economics11: 727–753. 10.1146/annurev-economics-080218-025643.
2.
BaumC. F.SchafferM. E.. 2013. avar: Stata module to perform asymptotic covariance estimation for iid and non-iid data robust to heteroskedasticity, autocorrelation, 1- and 2-way clustering, and common cross-panel autocorrelated disturbances. Statistical Software Components S457689, Department of Economics, Boston College. https://ideas.repec.org/c/boc/bocode/s457689.html.
3.
BaumC. F.SchafferM. E.StillmanS.. 2002. ivreg2: Stata module for extended instrumental variables/2SLS and GMM estimation. Statistical Software Components S425401, Department of Economics, Boston College. https://ideas.repec.org/c/boc/bocode/s425401.html.
4.
BaumC. F.SchafferM. E.StillmanS.. 2007. Enhanced routines for instrumental variables/generalized method of moments estimation and testing. Stata Journal7: 465–506. 10.1177/1536867X0800700402.
5.
CorreiaS.2018. ivreghdfe: Stata module for extended instrumental variable regressions with multiple levels of fixed effects. Statistical Software Components S458530, Department of Economics, Boston College. https://ideas.repec.org/c/boc/bocode/s458530.html.
6.
CraggJ. G.DonaldS. G.. 1993. Testing identifiability and specification in instrumental variables models. Econometric Theory9: 222–240. 10.1017/S0266466600007519.
7.
ImhofJ. P. 1961. Computing the distribution of quadratic forms in normal variables. Biometrika48: 419–426. 10.2307/2332763.
8.
InoueA.RossiB.WangY.. 2024. Has the Phillips curve flattened? CEPR Discussion Paper 18846, Centre for Economic Policy Research. https://cepr.org/publications/dp18846.
9.
KleibergenF.PaapR.. 2006. Generalized reduced rank tests using the singular value decomposition. Journal of Econometrics133: 97–126. 10.1016/j.jeconom.2005.02.011.
10.
LewisD. J.MertensK.. Forthcoming. A robust test for weak instruments for 2SLS with multiple endogenous regressors. Review of Economic Studies.10.1093/restud/rdaf103.
11.
MavroeidisS.Plagborg-MøllerM.StockJ. H.. 2014. Empirical evidence on inflation expectations in the New Keynesian Phillips curve. Journal of Economic Literature52: 124–188. 10.1257/jel.52.1.124.
12.
Montiel OleaJ. L.PfluegerC. E.. 2013. A robust test for weak instruments. Journal of Business and Economic Statistics31: 358–369. 10.1080/00401706.2013.806694.
13.
NagarA. L. 1959. The bias and moment matrix of the general k-class estimators of the parameters in simultaneous equations. Econometrica27: 575–595. 10.2307/1909352.
14.
NeweyW. K.WestK. D.. 1987. A simple, positive semi-definite, heteroskedasticity and autocorrelation consistent covariance matrix. Econometrica55: 703–708. 10.2307/1913610.
15.
NeweyW. K.WestK. D.. 1994. Automatic lag selection in covariance matrix estimation. Review of Economic Studies61: 631–653. 10.2307/2297912.
PatnaikP. B. 1949. The non-central χ2- and F -distributions and their applications. Biometrika36: 202–232. 10.1093/biomet/36.1-2.202.
18.
PfluegerC. E.WangS.. 2015. A robust test for weak instruments in Stata. Stata Journal15: 216–225. 10.1177/1536867X1501500113.
19.
RameyV. A.ZubairyS.. 2018. Government spending multipliers in good times and in bad: Evidence from US historical data. Journal of Political Economy126: 850–901. 10.1086/696277.
20.
SandersonE.WindmeijerF.. 2016. A weak instrument F -test in linear IV models with multiple endogenous variables. Journal of Econometrics190: 212–221. 10.1016/j.jeconom.2015.06.004.
21.
SchafferM. E.2005. xtivreg2: Stata module to perform extended IV/2SLS, GMM and AC/HAC, LIML, and k-class regression for panel-data models. Statistical Software Components S456501, Department of Economics, Boston College. https://ideas.repec.org/c/boc/bocode/s456501.html.
22.
StockJ. H.YogoM.. 2005. “Testing for weak instruments in linear IV regression”. In Identification and Inference for Econometric Models: Essays in Honor of Thomas Rothenberg, edited by AndrewsD. W. K.StockJ. H., 80–108. New York: Cambridge University Press. 10.1017/CBO9780511614491.006.
23.
WenZ.YinW.. 2013. A feasible method for optimization with orthogonality constraints. Mathematical Programming142: 397–434. 10.1007/s10107-012-0584-1.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.