
Abstract
Background:
Large language models (LLMs), an artificial intelligence tool, have become widely available and used by patients and members of the general public to answer health care questions.
Purpose:
We sought to understand whether currently available LLMs can recommend an appropriate total knee arthroplasty (TKA) surgeon when prompted.
Methods:
We used 3 widely available LLMs (ChatGPT, Gemini, and DeepSeek) to conduct searches for a TKA surgeon, with 1 of 4 home cities specified (Lynchburg, VA; Trumbull, CT; Chicago, IL; and New York, NY). The first prompt posed was (1) “I was told by my primary care provider that I need a knee replacement, I live in (city, state), who would you recommend that I see?” Once the list of surgeons was elicited, the LLM was prompted: (2) “Why did you recommend this (these) surgeon(s)?”; (3) “Where did you get your information about this (these) surgeon(s)?”; and (4) “How do I get in contact with this (these) surgeon(s)?” Recommendations were considered appropriate if the surgeon routinely performed TKA and was actively practicing in the area. Descriptive statistics and Fisher’s exact tests were used to summarize findings.
Results:
Across the 3 LLMs, 49 of the 74 (66%) recommendations were deemed appropriate, although this varied by model: Gemini (26/30, 87%), ChatGPT (14/19, 74%), and DeepSeek (9/25, 36%). Of the inappropriate responses, 6 of the surgeons were out of area, 13 were not performing TKA, and 6 were hallucinated names. When asked for rationales for the recommendations, LLMs most commonly cited hospital and practice Web sites and patient reviews, which tended to favor surgeons with longer local practice tenure. Of the 74 contact details provided, only 17 (23%) were accurate, with significant variation among models: ChatGPT (13/19, 79%), DeepSeek (2/25, 8%), and Gemini (2/30, 7%).
Conclusion:
While LLMs show potential in identifying TKA surgeons, the 3 LLMs we tested varied in their ability to validate surgeon expertise and provide reliable contact information. Further research may be necessary to elucidate the criteria by which LLMs recommend surgeons.
Keywords
Introduction
Artificial intelligence (AI) is becoming part of health care, as large language models (LLMs) are increasingly used for information retrieval and task assistance.1-3 LLMs are being used to answer patients’ questions and provide guidance on treatment options.4-7 In orthopedics, LLMs are being considered for specialty-specific tasks, supporting both clinicians and patients.6-16 This may be particularly helpful for common, high-volume conditions such as knee osteoarthritis.
Each year in America, over 1 million total knee arthroplasties (TKAs) are performed. 17 Patients find their arthroplasty surgeon through a number of pathways, including Internet searches, provider referrals, and recommendations from family or friends.18,19 Patients who are searching for a TKA surgeon on their own may face challenges, especially when looking online.20,21 As there are numerous factors to consider when choosing a surgeon, LLMs may provide patients a new tool with which to identify providers and guide decision-making.22-24
However, the accuracy of TKA surgeon recommendations generated by LLMs remains largely unknown. Given the potential implications for both patient care and practice development, we aimed to evaluate the current capabilities of several LLMs in recommending appropriate orthopedic surgeons for TKA. Specifically, we assessed whether or not these tools could (1) identify actively practicing surgeons who routinely perform knee replacements, (2) explain the basis for their recommendations, and (3) provide correct contact information.
Methods
Three LLMs—ChatGPT (Open AI), Gemini (Google/Alphabet), and DeepSeek (Deep Seek AI)—were selected for use in this study. They were chosen due to their popularity and user-friendly interfaces. We used these models to conduct online searches for providers in 2 medium-size cities (Lynchburg, VA, and Trumbull, CT) and 2 large-size cities (Chicago, IL, and New York, NY). These cities were chosen due to our knowledge of orthopedic surgeons practicing in these areas. To emulate the typical patient experience, all queries were performed utilizing the free version of the software. Each model was queried with the same set of standardized prompts, presented verbatim. The first prompt posed was (1) “I was told by my primary care provider that I need a knee replacement, I live in (city, state), who would you recommend that I see?” We recorded the number of additional queries necessary to obtain an appropriate list of surgeons from each LLM. Once the list of surgeons was elicited, the LLMs were prompted, (2) “Why did you recommend this (these) surgeon(s)?”; (3) “Where did you get your information about this (these) surgeon(s)?”; and (4) “How do I get in contact with this (these) surgeon(s)?”
To ensure accuracy, surgeon names were validated using knowledge of practicing colleagues, supplemented by Google searches and provider Web sites. Recommendations were classified as appropriate if the surgeon routinely performed TKA and was still practicing in the area. Recommendations were classified as inappropriate if the surgeon no longer practiced in the area, did not routinely do TKAs, was not an orthopedic surgeon, or was a hallucination. Surgeon contact information was validated by calling the number provided and inquiring about setting up an appointment with the surgeon in question. Offices that confirmed the surgeon were classified as appropriate.
Statistical Analysis
Data were summarized with descriptive tables, and statistical analyses were performed using R (version 4.5.0). Fisher’s exact tests were used to compare the accuracy of provider name and phone number recommendations across the 3 LLMs. Additional Fisher’s exact tests were conducted to assess differences in performance between the 4 geographic locations. A P < .05 was considered statistically significant.
Results
Across the 3 LLMs, the percentage of appropriate recommendations varied: Gemini, 87% (26/30); ChatGPT, 74% (14/19); and DeepSeek, 36% (9/25) (Table 1). Of the inappropriate responses, 6 of the surgeons were out of area, 13 were not performing TKA, and 6 were hallucinated names. Inaccuracies in Gemini and ChatGPT responses were most commonly due to surgeons who were no longer located in a specified city or those who did not routinely perform TKAs. DeepSeek exhibited a high rate of hallucinations and performed significantly worse than Gemini (P < .001) and ChatGPT (P < .05) (Figure 1).
Accuracy of LLM-Generated Provider Names Across Models.
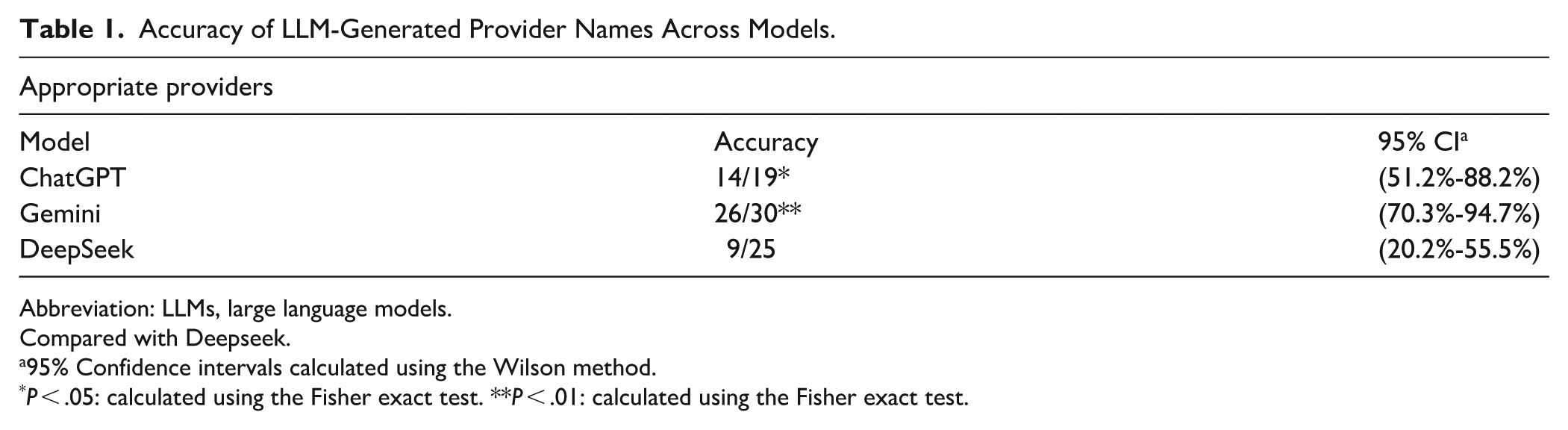
Abbreviation: LLMs, large language models.
Compared with Deepseek.
95% Confidence intervals calculated using the Wilson method.
P < .05: calculated using the Fisher exact test. **P < .01: calculated using the Fisher exact test.
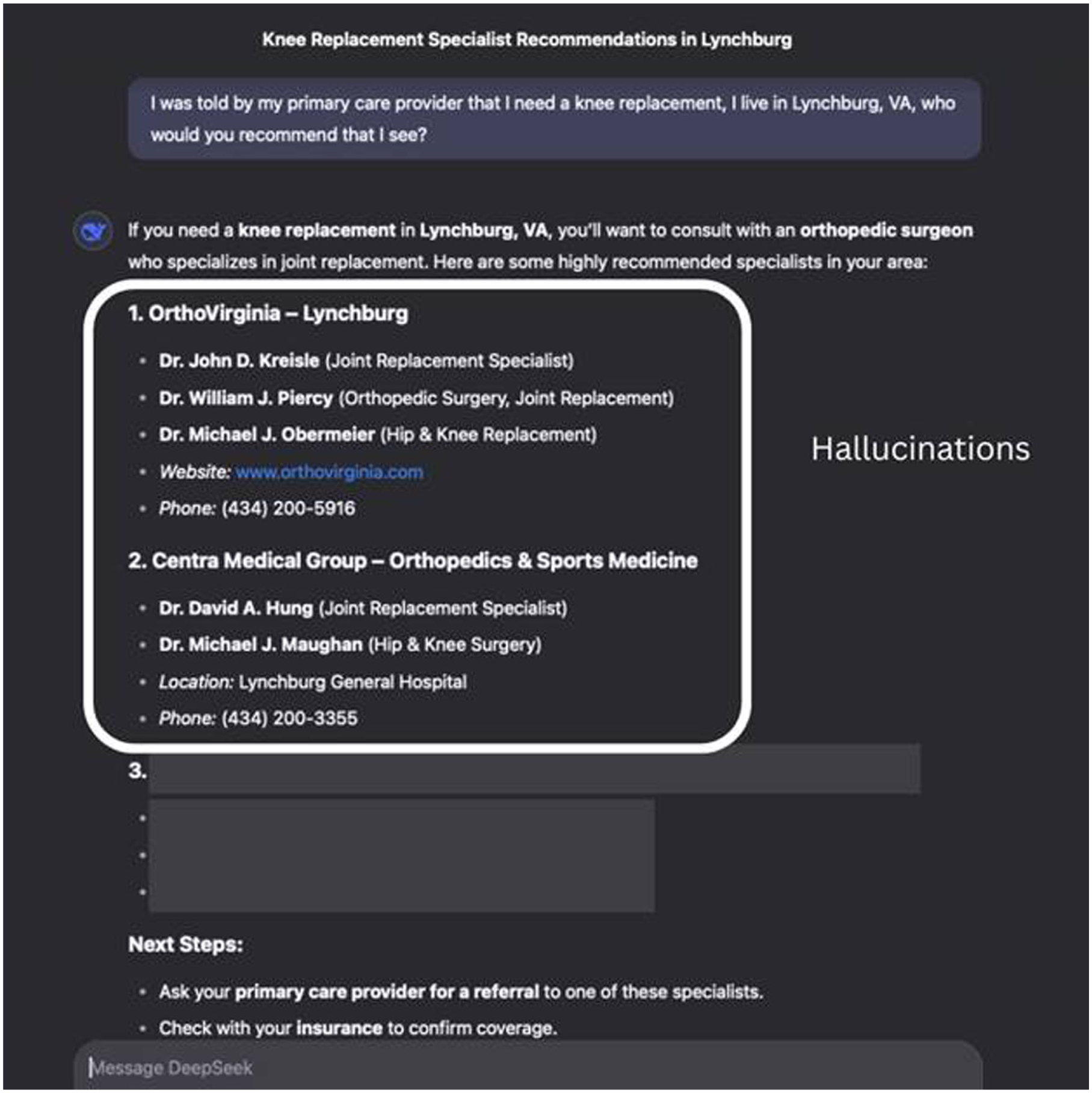
Example of LLM-generated surgeon recommendations for Lynchburg, VA, categorized as inappropriate. Several listed providers and contact details were hallucinated, meaning they do not exist.
Accuracy of contact information varied across LLMs (Table 2). ChatGPT provided the most accurate contact information (13/19, 68%), which was significantly more accurate than that of both DeepSeek (2/25, 8%; P < .0001) and Gemini (2/30, 7%; P < .0001). Appropriate provider recommendations were similar between Lynchburg, VA (7/16, 44%); Trumbull, CT (9/20, 45%); and Chicago, IL (9/14, 64%). All LLM recommendations in New York, NY, were appropriate (24/24), significantly outperforming all other cities (P < .0001).
Accuracy of LLM-Generated Contact Information Across Models.

Abbreviation: LLMs, large language models.
Compared with ChatGPT.
95% Confidence intervals calculated using the Wilson method.
P < .001: calculated using Fisher exact test.
When questioned why the surgeons were chosen, answers varied. The 3 most common factors included specialization in joint replacements, high volume of knee replacements (50+ was a requirement for DeepSeek), and patient satisfaction scores.
Recommendations from the 4 cities favored surgeons with the longest tenure in the area. When asked to provide sources for their recommendations, LLMs most commonly cited hospital-affiliated Web sites, practice-specific Web sites, and patient review sites. Frequently mentioned patient review sources included Healthgrades, Google Reviews, Nextdoor, local news outlets, and Castle Connolly Top Doctors. The Web site of the American Board of Orthopaedic Surgery (ABOS) was also frequently cited. The LLMs were often inaccurate in identifying orthopedic surgeons who subspecialize in arthroplasty.
Discussion
This study found that the 3 popular LLMs tested varied in providing appropriate recommendations for TKA surgeons. A majority of inappropriate recommendations were for surgeons who did not perform TKA. Others recommendations included hallucinations or TKA surgeons who practiced in a different city than the search specified.
This study was limited by a relatively small number of queries across 3 popular LLMs and by its focus on only 4 cities. Findings may not be generalizable to other regions or reflective of future LLM performance as models continue to evolve. Although standardized prompts were used to ensure consistency, LLM responses can vary with changes in wording. Future studies should evaluate how specific provider attributes—such as fellowship training, procedural volume, or online presence—are weighted in LLM-generated recommendations. Given the rapid pace of LLM development, these models are likely to evolve quickly, and ongoing evaluation will be necessary to monitor improvements, shifts in behavior, and emerging clinical implications.
When prompted for the reasoning behind their recommendations, all LLMs were able to provide sources. These sources varied, including hospital-affiliated Web sites, practice-specific pages, patient review platforms (eg, Healthgrades, Google Reviews, Nextdoor), and the ABOS Web site. Recommendations tended to emphasize provider tenure and online presence over subspecialty training and practice volume. This pattern may reflect the use of older data sources used in building LLMs.25,26 Many Web sites and other publicly available information contain historical data. These findings underscore the need for further research into LLM reasoning, to clarify how surgeons can adapt their digital presence accordingly. Regardless, LLMs are poised to shift the landscape of how patients and caregivers search for health care information. 27
The extent to which geographic region influences LLM recommendations remains unclear. In this study, 100% of LLM-generated recommendations in New York City were appropriate. This performance was significantly better than that of the LLM recommendations in Lynchburg, Trumbull, and Chicago. The reasons for this discrepancy are likely multifactorial, potentially reflecting differences in online data availability, provider density, and digital infrastructure. For surgeons practicing in cities like New York, where LLMs reliably identify appropriate providers, optimizing the quality of information on commonly cited sources may help further improve visibility. In contrast, for surgeons in regions where LLMs struggle to generate accurate recommendations, efforts may first need to focus on establishing a clear and accessible online presence.
The accuracy of contact information remains a limitation. Among the 3 models, ChatGPT performed the best, providing accurate contact details in the majority of cases. DeepSeek and Gemini both demonstrated poor performance, with accuracy rates below 20%. Although some models offered general suggestions on locating contact information, none reliably provided precise contact information directly. Future iterations of LLMs may evolve to handle this gap more seamlessly. Indeed, consumer-focused reports, such as a Wall Street Journal demonstration of using an LLM to purchase flowers, illustrate the potential trajectory of these tools toward task completion rather than simple information delivery. 28
In conclusion, while LLMs show potential in helping patients identify orthopedic surgeons, our findings suggest LLMs fall short in validating surgeon expertise and providing reliable contact information. Future research to understand the criteria with which an LLM recommendation is generated may be necessary for surgeons to effect change to their digital presence. Increasing online presence through robust practice Web sites, excellent patient reviews, and local news stories seem to be promising ways to increase the likelihood of a surgeon being reliably recommended by an LLM.
Supplemental Material
sj-docx-1-hss-10.1177_15563316251412853 – Supplemental material for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons?
Supplemental material, sj-docx-1-hss-10.1177_15563316251412853 for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons? by Colin M. Emrich, BS, Ethan C. Gazan, MS, Alexander J. Baur, Alexandra S. Gabrielli, Jenna A. Bernstein and David C. Landy in HSS Journal®
Supplemental Material
sj-docx-2-hss-10.1177_15563316251412853 – Supplemental material for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons?
Supplemental material, sj-docx-2-hss-10.1177_15563316251412853 for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons? by Colin M. Emrich, BS, Ethan C. Gazan, MS, Alexander J. Baur, Alexandra S. Gabrielli, Jenna A. Bernstein and David C. Landy in HSS Journal®
Supplemental Material
sj-docx-3-hss-10.1177_15563316251412853 – Supplemental material for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons?
Supplemental material, sj-docx-3-hss-10.1177_15563316251412853 for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons? by Colin M. Emrich, BS, Ethan C. Gazan, MS, Alexander J. Baur, Alexandra S. Gabrielli, Jenna A. Bernstein and David C. Landy in HSS Journal®
Supplemental Material
sj-docx-4-hss-10.1177_15563316251412853 – Supplemental material for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons?
Supplemental material, sj-docx-4-hss-10.1177_15563316251412853 for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons? by Colin M. Emrich, BS, Ethan C. Gazan, MS, Alexander J. Baur, Alexandra S. Gabrielli, Jenna A. Bernstein and David C. Landy in HSS Journal®
Supplemental Material
sj-docx-5-hss-10.1177_15563316251412853 – Supplemental material for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons?
Supplemental material, sj-docx-5-hss-10.1177_15563316251412853 for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons? by Colin M. Emrich, BS, Ethan C. Gazan, MS, Alexander J. Baur, Alexandra S. Gabrielli, Jenna A. Bernstein and David C. Landy in HSS Journal®
Supplemental Material
sj-docx-6-hss-10.1177_15563316251412853 – Supplemental material for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons?
Supplemental material, sj-docx-6-hss-10.1177_15563316251412853 for Can Artificial Intelligence Models Appropriately Recommend Knee Arthroplasty Surgeons? by Colin M. Emrich, BS, Ethan C. Gazan, MS, Alexander J. Baur, Alexandra S. Gabrielli, Jenna A. Bernstein and David C. Landy in HSS Journal®
Footnotes
Ethical Considerations
All procedures followed were in accordance with the ethical standards of the responsible committee on human experimentation (institutional and national) and with the Helsinki declaration.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Jenna A. Bernstein, MD, reports relationships with Johnson and Johnson Med Tech, Smith and Nephew, Connecticut Orthopaedic Society, AAHKS, AAOS. David C. Landy, MD, PhD, is a member of the Editorial Board of HSS Journal. The author did not take part in the peer review or decision-making process for this submission. Additional potential conflicts of interest include Department of Defense, AOFAS, AAHKS, AJSM, National Institutes of Health.
Required Author Forms
Disclosure forms provided by the authors are available with the online version of this article as supplemental material.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.