
Abstract
A core task in computational genomics is transforming input sequences into their constituent k-mers. Efficiently storing these k-mer collections is crucial for scaling bioinformatics workflows. A common strategy involves representing the k-mers as a de Bruijn graph (dBG) and deriving a compact plain text form through a minimum path cover. In this article, we introduce USTAR-CR (Unitig STitch Advanced constRuction with Colors Reordering), a fast and space-efficient algorithm for compressing multiple k-mer sets. USTAR-CR exploits the structural properties of colored dBGs to construct a succinct plain text representation while also incorporating an effective scheme for encoding k-mer color information. We evaluate USTAR-CR on real sequencing datasets and benchmark it against the state-of-the-art tool GGCAT. USTAR-CR achieves superior compression ratios, significantly reduces memory usage, and offers substantial speed improvements—up to 64× faster—highlighting its effectiveness for large-scale genomic data processing.
INTRODUCTION
k-mer-based algorithms have become central tools in bioinformatics, offering scalable and efficient alternatives to traditional sequence alignment approaches. By operating directly on sets of k-mer substrings, these methods bypass the need for full read alignment and enable fast, memory-efficient analysis pipelines. Over the past decade, they have seen widespread adoption due to their conceptual simplicity and ability to handle large-scale data. These approaches have demonstrated exceptional performance across a range of applications. In genome assembly, tools such as SPAdes (Bankevich et al., 2012) leverage k-mer-based strategies to reconstruct complete genomes with high accuracy. In metagenomics, a variety of tools (Wood and Salzberg, 2014; Andreace et al., 2021; Qian and Comin, 2019; Cavattoni and Comin, 2023; Storato and Comin, 2022) employ k-mers to classify microbial content in complex samples, achieving speedups of up to 900× compared to traditional methods like MegaBLAST. Similarly, in genotyping, k-mer-centric tools (Denti et al., 2019; Sun and Medvedev, 2019; Marcolin et al., 2022; Monsu and Comin, 2021) identify genetic variants across individuals and populations without reliance on full-sequence alignment. In phylogenomics, Mash (Ondov et al., 2016) uses k-mers to estimate genomic distances, facilitating fast evolutionary analysis. Numerous other tools (Harris and Medvedev, 2020; Marchet et al., 2020) also apply k-mer techniques to enable rapid sequence search over large genomic databases.
The scalability of k-mer methods lies in their ability to handle datasets containing billions of k-mers. A key factor in their performance is how these sets are represented. Depending on the application, this choice balances between time-efficient representations with good cache locality and compressed formats that reduce memory footprint. As sequencing data grows, minimizing the space required to store and query k-mer sets has become an active area of research. Conway and Bromage (2011) showed that storing n k-mers requires at least
A widely adopted method to reduce redundancy is to organize the k-mer set K into maximal unitigs, derived from the de Bruijn graph (dBG). In this graph, nodes represent k-mers and edges indicate
An important extension of the dBG is the colored dBG, which allows for the representation of multiple datasets simultaneously. It was proposed for applications like de novo assembly and genotyping (Iqbal et al., 2012; Andreace et al., 2023), this structure annotates each k-mer with the dataset identifiers (colors) in which it appears. Colored dBGs enable compact joint representations while retaining dataset-specific provenance. This model is widely used in pangenomics (Zekic et al., 2018), RNA sequencing quantification (Bray et al., 2016), microbial classification (Luhmann et al., 2021), and related domains.
The current state-of-the-art for colored k-mer compression is GGCAT (Cracco and Tomescu, 2023), which builds compacted colored dBGs by combining k-mer counting and unitig generation with efficient color encoding. GGCAT outperforms earlier tools like Cuttlefish (Khan and Patro, 2021) and BiFrost (Luhmann et al., 2021), offering significant improvements in both compression and query speed. GGCAT uses external memory, like Cuttlefish, while BiFrost does not. However, for large datasets, GGCAT still requires several hours of computation and a large amount of memory.
In this work, we introduce USTAR-CR 1 (Unitig STitch Advanced constRuction with Colors Reordering), a fast and memory-efficient algorithm for compressing multiple k-mer sets using a plain text representation of colored dBGs. USTAR-CR generates a compact spectrum-preserving string set (SPSS) while supporting efficient color storage, enabling scalable compression of large genomic datasets with minimal computational overhead.
Related works
Plain text representations of k-mer sets have become a widely used strategy for practical and efficient data compression. Formally, such representations are defined as SPSSs—collections of strings that include all k-mers from the input data (including reverse complements), while excluding extraneous k-mers. This concept ensures that the original k-mer spectrum is preserved without redundancy.
Initially, Rahman and Medvedev (2020) and Břinda et al. (2021) independently proposed methods for constructing such representations without repeated k-mers. Rahman and Medvedev introduced the SPSS framework, while Břinda et al. coined the term simplitigs. To avoid ambiguity with the later, broader definition of SPSS (which allows repeated k-mers), we adopt simplitigs to specifically refer to representations where each k-mer appears only once.
Both UST (from Rahman and Medvedev) and ProphAsm (from Břinda et al.) apply greedy heuristics to merge k-mers into longer strings. UST builds a node-centric dBG to extend unitigs, whereas ProphAsm uses a hash-based extension strategy without explicit graph construction. These techniques aim to reduce two key metrics: the cumulative length (CL)—the total number of characters in the representation—and the string count (SC)—the number of separate strings. Lowering CL decreases the memory needed to store the strings, while reducing SC simplifies indexing, leading to overall storage savings.
Building on these ideas, the USTAR heuristic (Rossignolo and Comin, 2023, 2024a) was recently introduced. USTAR improves the traversal of dBGs by leveraging graph connectivity and local density to guide the construction of longer and fewer paths. This connectivity-aware strategy often leads to better compression than earlier greedy approaches, particularly on dense graphs.
An important breakthrough came with matchtigs (Schmidt et al., 2023), which introduced the first algorithm to compute an SPSS of minimum CL, while allowing repeated k-mers. Matchtigs formulates the problem as a min-cost path cover with a many-to-many path matching strategy, solvable in polynomial time. However, its high computational complexity—
While these methods focus on compressing single k-mer sets, GGCAT remains the leading tool for handling multiple datasets through compacted colored dBGs. GGCAT integrates k-mer counting and unitig construction, using contextual information to construct globally valid unitigs across datasets. It also improves color encoding by mapping color sets to compact indices, storing differences between consecutive color sets via run-length encoding (RLE), both at the individual k-mer level and across unitigs. GGCAT can also incorporate greedy matchtigs to further compress unitigs before final storage.
In the following sections, we introduce USTAR-C (Unitig STitch Advanced constRuction with Colors) and USTAR-CR (Unitig STitch Advanced constRuction with Colors Reordering), two new greedy heuristics built upon the USTAR2 paradigm, designed specifically for compressing multiple k-mer sets. USTAR-C and USTAR-CR extend these principles to colored dBGs, enabling fast and memory-efficient construction of compact SPSS representations while also efficiently encoding color information.
METHOD
Preliminaries
We consider strings composed of characters from the DNA alphabet
To compress a set of k-mers K, we aim to represent it using a set of longer strings S such that the complete collection of k-mers (and their reverse complements) contained in S exactly recovers K. The spectrum of a string set S, denoted
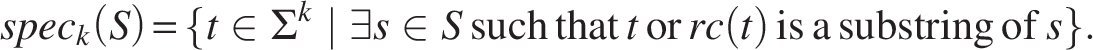
The goal is to find a minimal set of strings S such that its spectrum exactly matches that of the original k-mer set K. We formalize this as follows:
A central property of an SPSS is that it compactly encodes the same set of k-mers as the original input while allowing for flexible string lengths. To assess the efficiency of such a representation, we consider the CL:
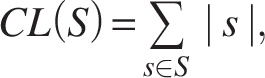
This problem can be addressed using graph-based techniques. A k-mer set can be represented as a dBG, where nodes represent k-mers and edges connect overlapping k-mers. It was shown in Schmidt et al. (2023) that this minimization problem can be solved exactly in polynomial time using an algorithm based on many-to-many minimum-cost path queries combined with minimum-cost perfect matching. The resulting algorithm, matchtigs, guarantees optimal solutions but has a time complexity of
To overcome these limitations, USTAR2 (Rossignolo and Comin, 2024b) was introduced as a fast and memory-efficient heuristic. USTAR2 approximates a minimal SPSS by leveraging the connectivity structure of the compacted dBG produced by BCALM2 (Chikhi et al., 2016) and runs in linear time with respect to the number of nodes/unitigs.
The algorithm proceeds by iteratively selecting seed nodes and extending them into paths as far as possible through unvisited neighboring nodes. This path extension continues until all nodes are included in some path. USTAR2’s key innovation lies in its seed and extension heuristics: it selects seed nodes with the highest imbalance (difference between in-degree and out-degree) and prioritizes extending into nodes with fewer connections. This strategy preserves highly connected nodes for future paths, reducing fragmentation and promoting longer paths.
By doing so, USTAR2 significantly reduces CL by producing fewer, longer strings, thus improving both compression efficiency and downstream query performance. Overall, USTAR2 achieves better compression than UST and delivers performance comparable to that of greedy matchtigs (Rossignolo and Comin, 2025a).
USTAR-CR: SPSS with colors reordering
USTAR2 compresses individual k-mer sets by generating a plain text representation of the dBG. In this article, we present USTAR-C that extends the method to handle multiple k-mer sets, each linked to a distinct color. In order to detect the k-mers colors, we use GCCAT as preprocessing. USTAR2 begins by constructing the dBG for a single k-mer set and compresses the sequences by finding a path cover on the graph. To manage multiple k-mer sets, USTAR-C simply adds a color set to each node in the graph, which tracks the colors of all k-mers represented by that node. The compression process in USTAR-C follows the same path cover approach as USTAR2, with the added step of merging these color sets to maintain color information across different sets. An example of the resulting sequences and their color sets is provided in Table 1.
Example Spectrum-Preserving String Set with Color Set Indices for

Example Spectrum-Preserving String Set with Color Set Indices for
Each sequence is associated with a series of color set indices, which can be compacted using RLE.
RLE, run-length encoding.
Encoding colors for each k-mer in a dBG presents two main challenges: (1) efficiently recording all colors associated with each k-mer and (2) storing this information in a way that minimizes space usage and speeds up processing. To address this, for colored dBGs, we use GGCAT as preprocessing in order to detect and manage the color. Instead of storing a separate compressed color bitmap for every k-mer, GGCAT groups colors into color set indices, following a method similar to (Almodaresi et al., 2017). Moreover, each color set is encoded by capturing the differences between consecutive colors and applying RLE. When writing to disk, the color set indices of consecutive k-mers within each unitig are also run-length encoded. This is highly effective because unitigs tend to be “variation-free,” meaning they usually contain only a few distinct color set indices associated with their k-mers.
Consider that USTAR-C has produced a representation of a set of colored k-mers with
Example of Color Table, a Lookup Table for Color Set Indices

GGCAT, USTAR-C, and USTAR-CR associate each k-mer to a color set index to save space.
USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.
The k-mers in the previous example cannot be further compressed at the sequence level, as the resulting sequences do not overlap and thus cannot be concatenated. However, some sequences do share the same color patterns, which presents an opportunity to further compress the color information through improved RLE.
Specifically, if two adjacent sequences in the output share the same color at their junction—that is, the last color of one matches the first color of the next—we can merge their color sets into a single run, enhancing RLE efficiency. For instance, in Table 1, the sequences CTTGAA and AATAGA have color sets
To exploit this compression opportunity, we can reorder the sequences to maximize consecutive matching color sets. This idea was already introduced in Pibiri (2023) for k-mers counts. Building on this idea, we introduce USTAR-CR, an extension of USTAR-C that incorporates an optimized sequence and colors reordering.
This enhancement introduces the construction of an end-point weight graph (ewG) as part of the compression pipeline. Following the formalism introduced in Pibiri (2023), in the ewG, each sequence is represented as a node with two labeled sides—its first and last color sets. Edges are drawn between node sides that share the same color set, allowing merged color runs for any connected path. This structure enables USTAR-CR to systematically reorder sequences to minimize the number of runs in the final color encoding.
This configuration enables the traversal of paths in the ewG to reorder sequences and their corresponding color sets, thereby allowing adjacent runs to be merged. To maximize such merging while ensuring that each sequence is included exactly once, the goal is to construct long, vertex-disjoint paths. As a result, minimizing the number of color runs translates to solving the problem of finding a minimum vertex-disjoint path cover.
It is worth recalling that computing a minimum-cardinality path cover in a directed graph is, in general, an NP-hard problem. However, in the specific context of k-mers with associated counts, it has been demonstrated that the problem can be solved optimally in polynomial time (Pibiri, 2023). Although an exact polynomial solution is described in Pibiri (2023), it requires additional preprocessing steps that may slow down the compression pipeline. To avoid this, we adopt an efficient greedy approximation strategy, inspired by USTAR (Rossignolo and Comin, 2024a). This method builds a path cover by always selecting the least connected node as the next extension point.

The pseudo code for USTAR-CR is shown in Algorithm 1. The process starts by sorting nodes in increasing order based on their degree, thereby giving priority to nodes with a smaller degree. A non-visited node is then selected as a seed to begin path construction. The path is grown in both directions from this seed by iteratively choosing the least connected, non-visited neighbor as the next node in the path. This approach helps preserve the more connected nodes for later use, reducing the chance of leaving isolated nodes. As nodes are added to the path, they are marked as visited to prevent reuse. Additionally, the orientation (forward or reverse) of each node relative to the path is tracked during construction.
Figure 1 illustrates an example of an ewG built from the sequences in Table 1. The red-highlighted path cover represents an arbitrary solution consisting of two paths, resulting in a total of 7 runs. In contrast, USTAR-CR constructs a more efficient path cover (shown in green) by repeatedly extending paths through nodes with the lowest degree. This approach yields a single path that visits all nodes, reducing the total number of runs to 6.
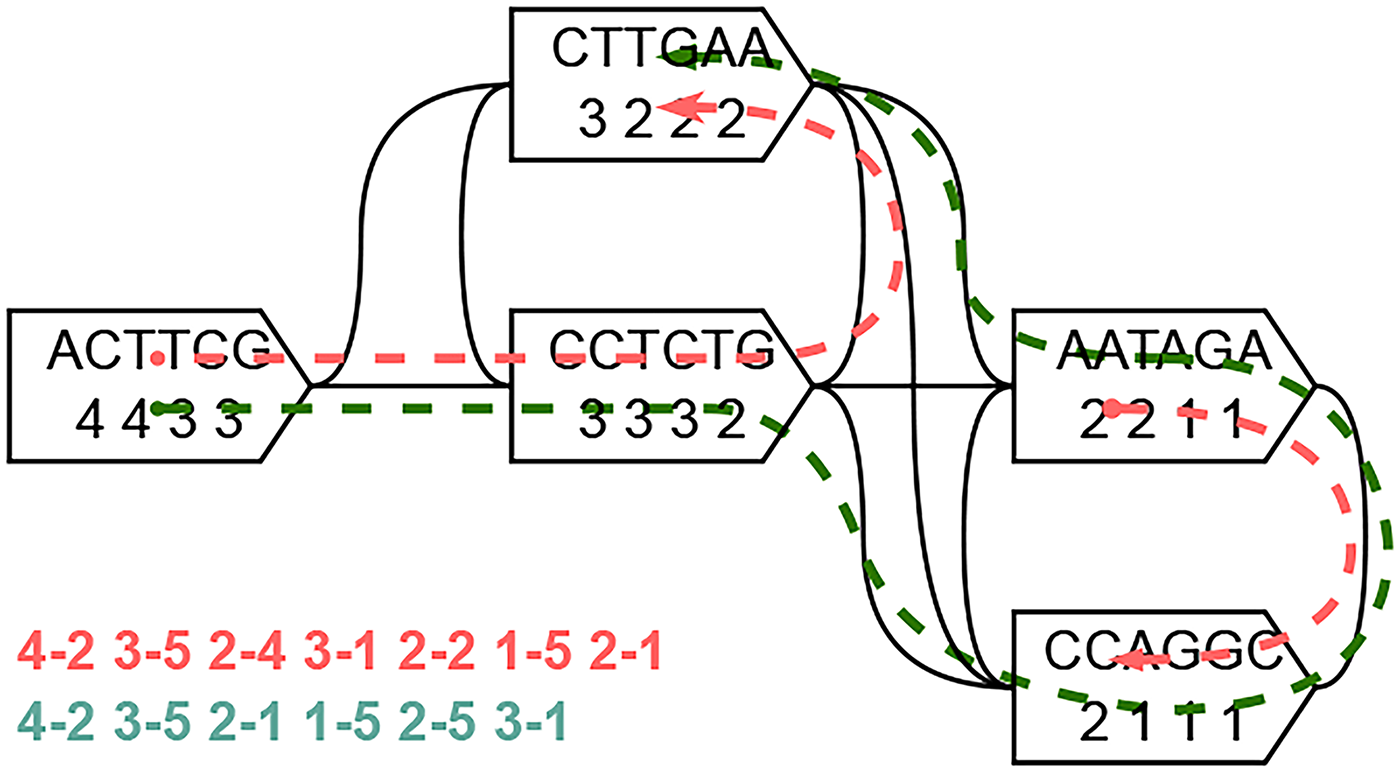
End-point weight graph from sequences in Table 1. Red: Arbitrary path cover (seven runs). Green: Optimized path cover by USTAR-CR (six runs). USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.
This example demonstrates how leveraging the ewG can significantly enhance color compression. Starting from 10 individual runs (as shown in Table 1), the application of an arbitrary path cover reduces this number to 7, while the optimized path cover produced by USTAR-CR brings it further down to 6. The final output, presented in Table 3, reflects this reordering. Because a single path covers all nodes, all color sets can be concatenated and encoded as one unified run-length-encoded vector, achieving the minimal number of runs.
Output of USTAR-CR After Sequence Reordering

Color sets are merged, and RLE is compressed.
RLE, run-length encoding; USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.
In the next section, we evaluate USTAR-C and USTAR-CR on real sequencing datasets, benchmarking its compression efficiency and runtime performance against state-of-the-art tools.
In this section, we compare our proposed methods with the state-of-the-art colored k-mer compression tool, GGCAT. Specifically, we evaluate both GGCAT configured for maximal unitigs and its variant GGCAT GM (which uses greedy matchtigs), alongside our approaches: USTAR-C, which applies plain RLE to color sets, and USTAR-CR, which further improves compression through optimized reordering of color runs.
The benchmarking was performed on a collection of 20 sequencing datasets (detailed in Table A1), previously used in related studies (Pandey et al., 2018; Rizk et al., 2013; Kokot et al., 2017; Chikhi et al., 2016; Břinda et al., 2021). These datasets span a range of sequencing properties—including paired-end and single-end reads, varying read lengths, and different coverage levels—offering a diverse and representative testing ground for evaluating compression performance under real-world conditions.
To simulate a colored k-mer setting, we merged all datasets and assigned colors to each k-mer based on the input files in which it appears. Table A2 reports the number of distinct k-mers considered in the evaluation, ranging from 400 million to over 2 billion, depending on the selected k-mer length.
To assess the performance of the evaluated tools, we focused on three primary metrics: CL, SC, and the number of runs.
CL: The total length of all compressed k-mer sequences across the datasets, reflecting the effectiveness of sequence-level compression. SC: The number of separate sequences in the output, which serves as an indicator of fragmentation in the compressed representation. Number of color runs (
Together, these metrics provide a detailed evaluation of how compact and well-structured the k-mer representations are after compression.
To further compare overall compression performance, we measured the total compressed size, which includes the sequence file compressed using MFCompress (Pinho and Pratas, 2014), the encoded color table, and—for USTAR-C and USTAR-CR—the color sets compressed with bzip3. Note that for GGCAT, the most effective compression is obtained when the sequences and their colors are compressed together in a single file, which corresponds to the tool’s default output format (see Table A3).
In the following analysis, we present a detailed comparison of all tools based on compression ratio, runtime, and memory consumption.
Compression of k-mer sets
In our first experiment, we used the commonly adopted k-mer length of
Comparison of Tools Before Compression Using Cumulative Length, Sequence Count, and Number of Runs
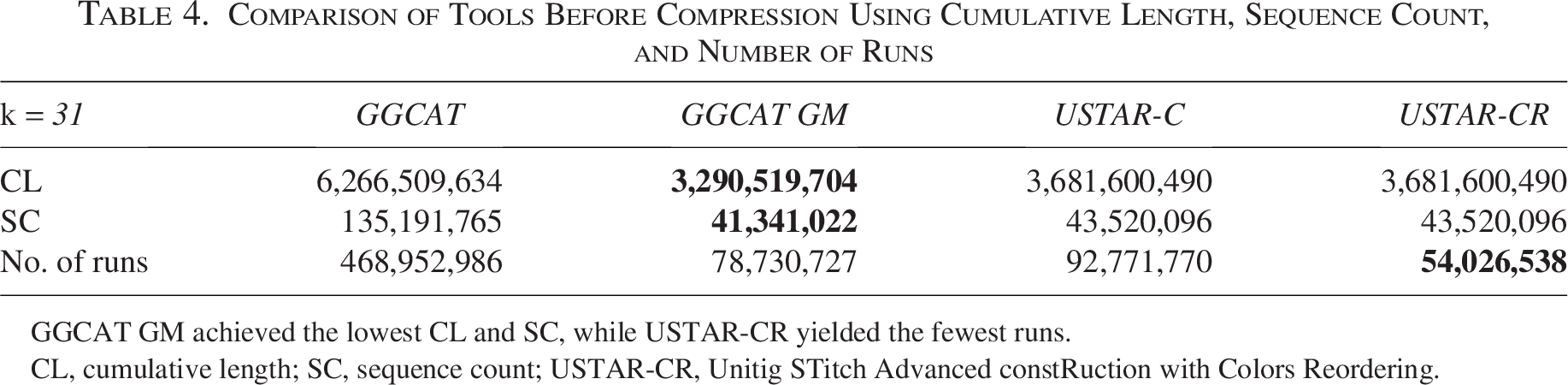
Comparison of Tools Before Compression Using Cumulative Length, Sequence Count, and Number of Runs
GGCAT GM achieved the lowest CL and SC, while USTAR-CR yielded the fewest runs.
CL, cumulative length; SC, sequence count; USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.
As expected, GGCAT (which generates maximal unitigs) performed the worst across all metrics, yielding the highest CL, SC, and number of runs—indicating significant redundancy in both sequences and associated color sets.
GGCAT GM, which applies a greedy matchtig strategy, significantly improved compression performance—reducing CL by 47%, SC by 69%, and the number of runs by 83%, with respect to GGCAT. USTAR-C also delivered substantial improvements, with reductions of 41%, 67%, and 80% in CL, SC, and the number of runs, respectively.
While USTAR-C and USTAR-CR produced identical results for CL and SC, USTAR-CR dramatically reduced the number of runs by 88% with respect to GGCAT and by 31% with respect to GGCAT GM, demonstrating the benefit of sequence reordering in compressing color runs.
In summary, GGCAT GM achieved the smallest CL and SC, indicating strong sequence compression, whereas USTAR-CR attained the lowest number of runs, showcasing the effectiveness of RLE-based color compression through path-based reordering.
The compression results for each method are presented in Table 5. As anticipated, GGCAT generated the largest FASTA file. GGCAT GM reduced the sequence file size by approximately one-third. In contrast, USTAR-C and USTAR-CR achieved further reductions by off-loading color information to a separate file and compressing it independently from the sequences. Thanks to its lower number of runs, USTAR-CR yielded a significantly smaller color file, resulting in the most efficient overall compression.
Tools Comparison: Considering the Sequences File Compressed with MFCompress (Sequences), the Colors File Compressed with bzip3 (Colors), the Colors Table, and the Total Compression Size
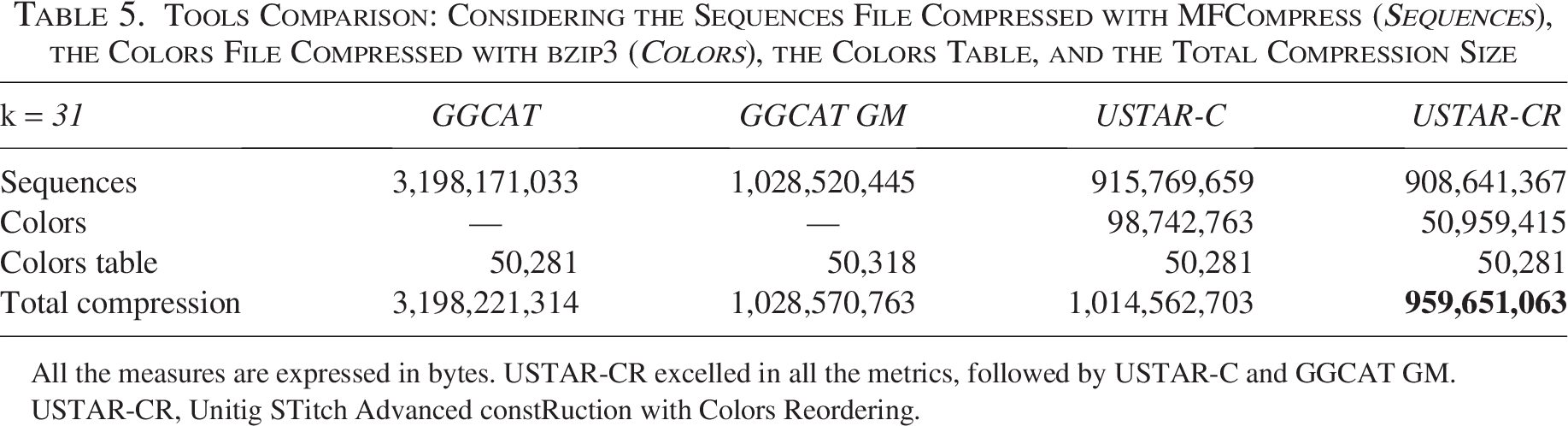
All the measures are expressed in bytes. USTAR-CR excelled in all the metrics, followed by USTAR-C and GGCAT GM.
USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.
In total, USTAR-CR reduced the final file size by 70% compared to GGCAT and by 6.7% compared to GGCAT GM, demonstrating the effectiveness of colors reordering and RLE in optimizing compression.
In the next section, we examine how varying the k-mer length influences the compression of colored k-mers. Changing the value of k affects both the total number of k-mers and the connectivity between them. In general, smaller k values lead to a denser graph structure due to an increased number of overlaps (refer to Table A2).
Since GGCAT produces only unitigs, its compression performance is relatively limited, as shown in the previous section. In this experiment, we instead evaluate GGCAT using its simplitigs option, which employs the greedy simplitig construction method proposed by Břinda et al. (2021) to achieve improved compression. The tools were tested using
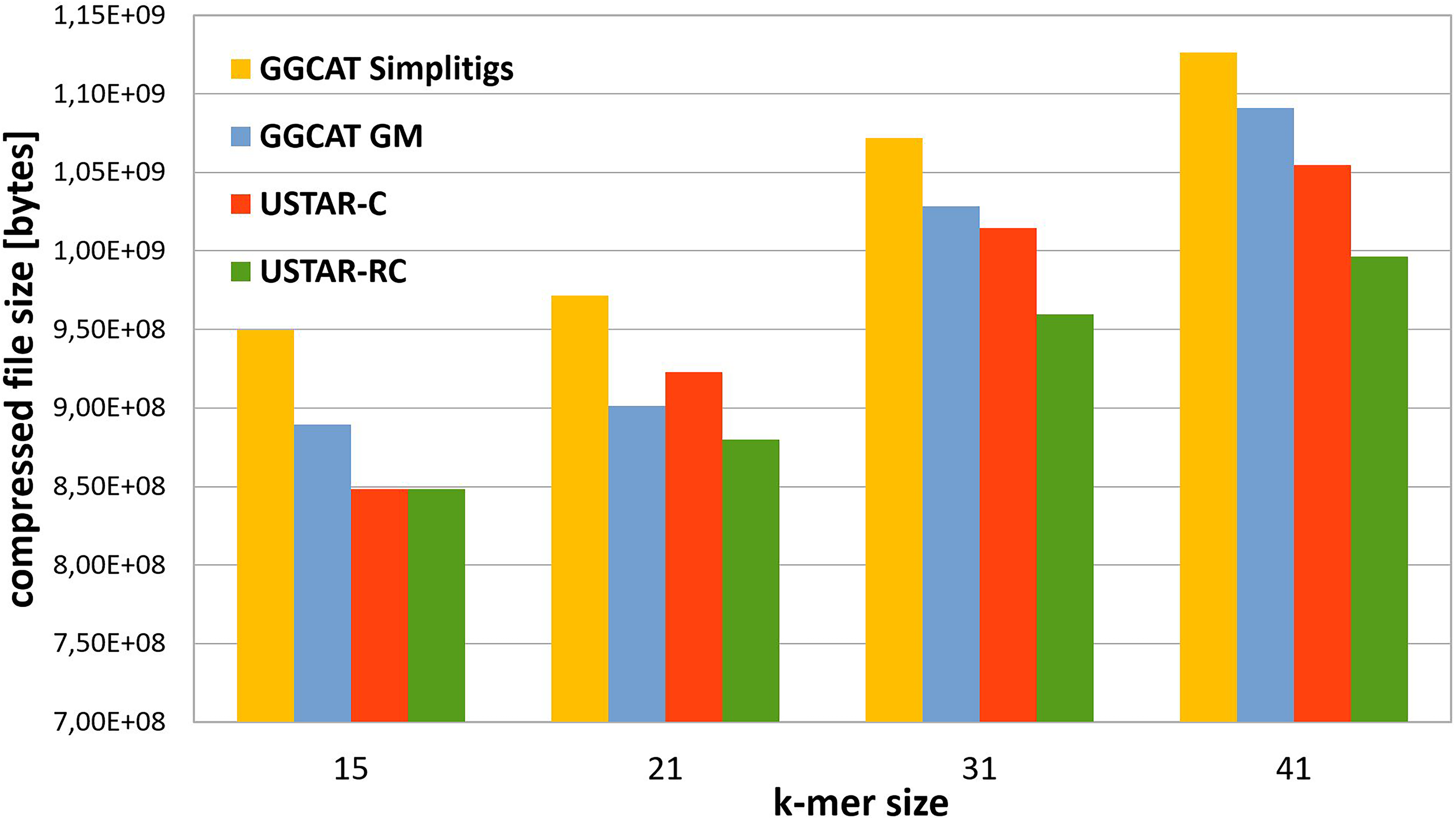
Comparison of the total compressed file size (in bytes) obtained using the tools GGCAT simplitigs, GGCAT GM, USTAR-C, and USTAR-CR. The figure illustrates how the total compressed size varies for different k-mer lengths. USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.
In the previous section, we identified GGCAT GM as the primary competitor to USTAR-CR. We now evaluate how both tools perform as the number of colors—that is, the number of input files—increases. To do this, we subsampled the dataset with color counts
Number of Runs and Total Compression Size Varying the Number of Colors
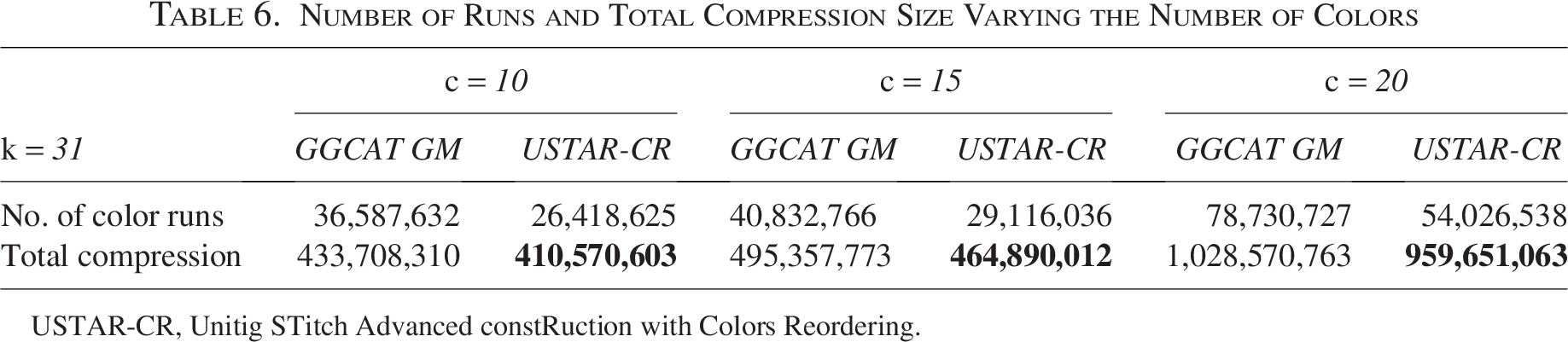
Number of Runs and Total Compression Size Varying the Number of Colors
USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.
USTAR-CR consistently achieved the lowest number of runs, resulting in the best overall compression across all tested numbers of colors. A complete comparison with USTAR-C can also be found in Table A5. The greatest difference between GGCAT GM and USTAR-CR occurred at
In this section, we evaluate and compare the execution time and memory consumption of the compression tools. Since USTAR-CR relies on GGCAT for preprocessing, we include both the preprocessing time (CPU time) and memory consumption as part of the overall USTAR-CR pipeline evaluation.
In Figure 3a and b, we examine execution performance across different k-mer lengths used for compression.
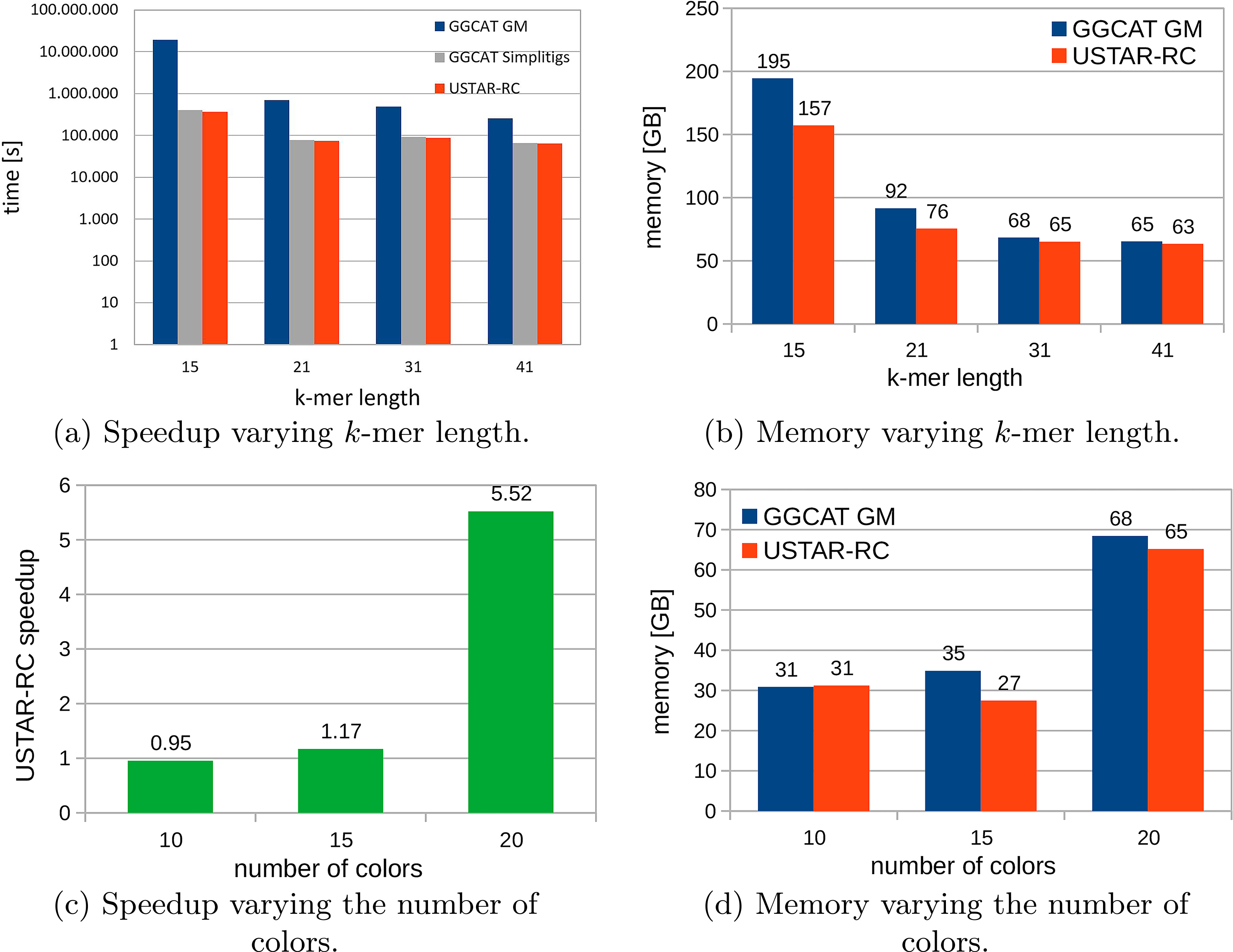
CPU time (seconds), speedup, and memory requirement of USTAR-CR with respect to GGCAT GM. USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.
Overall, USTAR-CR consistently achieves the fastest execution times, followed closely by GGCAT simplitigs, while GGCAT GM is the slowest. In terms of memory usage, GGCAT GM requires the most RAM, whereas USTAR-CR and GGCAT simplitigs (not shown) use the same amounts, that is, the memory needed for the GGCAT preprocessing step. In summary, GGCAT simplitigs does not offer any clear advantage over USTAR-CR, either in compression efficiency or computational resources. Therefore, in the following comparisons, we focus on the two best-performing compression methods: GGCAT GM and USTAR-CR.
The speedup of USTAR-CR compared to GGCAT GM ranges from
Overall, despite relying on GGCAT for preprocessing, USTAR-CR consistently achieves faster execution times and lower resource consumption compared to GGCAT GM. Notably, USTAR-CR is currently single-threaded, whereas GGCAT GM employs multithreading, indicating potential for further reductions in the actual running time of our tool.
In this section, we evaluate the compression quality and performance of GGCAT GM and USTAR-CR on large-scale datasets. For this purpose, we selected the human read dataset from the Genome in a Bottle Consortium (HG004_NA24143_mother), 2 which includes 35 files/colors and contains over 7.2 billion 31-mers.
Following the approach in Section 3.1.2, we fixed
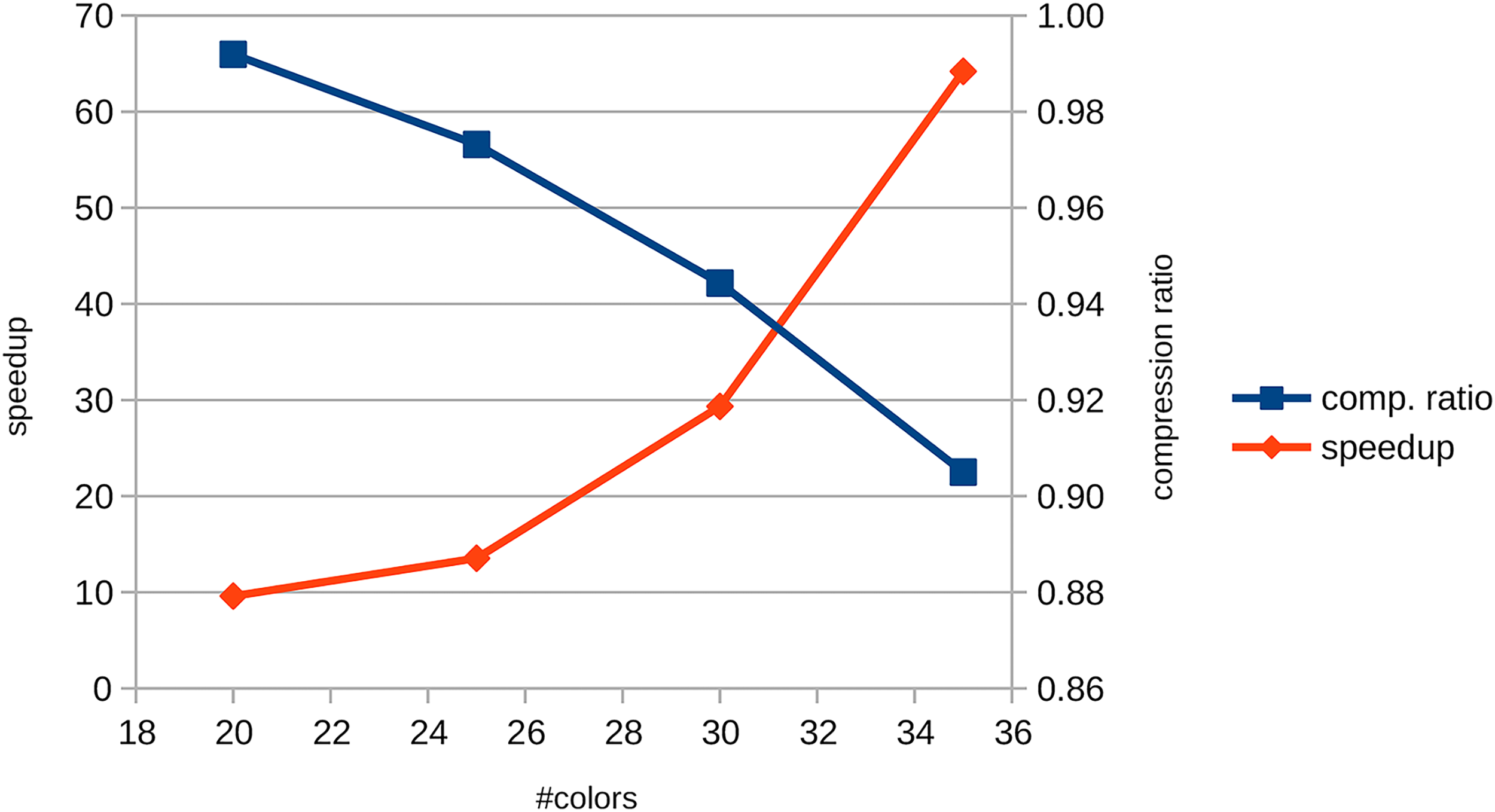
Results related to the human reads dataset. In the figure, the speedup and the compression ratio change with the number of colors while
Finally, we evaluated the tools using complete genomes. Unlike the read sequences analyzed in the previous sections—short fragments with high coverage—genomes consist of long, contiguous sequences. For this experiment, we used a dataset of 10,000 Salmonella genomes, previously employed in GGCAT (Cracco and Tomescu, 2023). This dataset comprises approximately 168 million k-mers, which is significantly smaller than the 7.2 billion k-mers contained in the human read dataset.
Table 7 summarizes the results obtained when varying the number of genomes (colors). For 100 genomes, USTAR-CR achieves better overall compression than GGCAT GM. However, as the number of genomes increases, this advantage gradually diminishes, and for larger datasets, the compression performance becomes comparable. For both tools, on these large datasets, the total compression size is largely influenced by the efficiency of the color encoding.
Tools Comparison Varying the Number of Colors: Considering the Sequences File Compressed with MFCompress (Sequences), the Colors File Compressed with bzip3 (Colors), the Colors Table, and the Total Compression Size
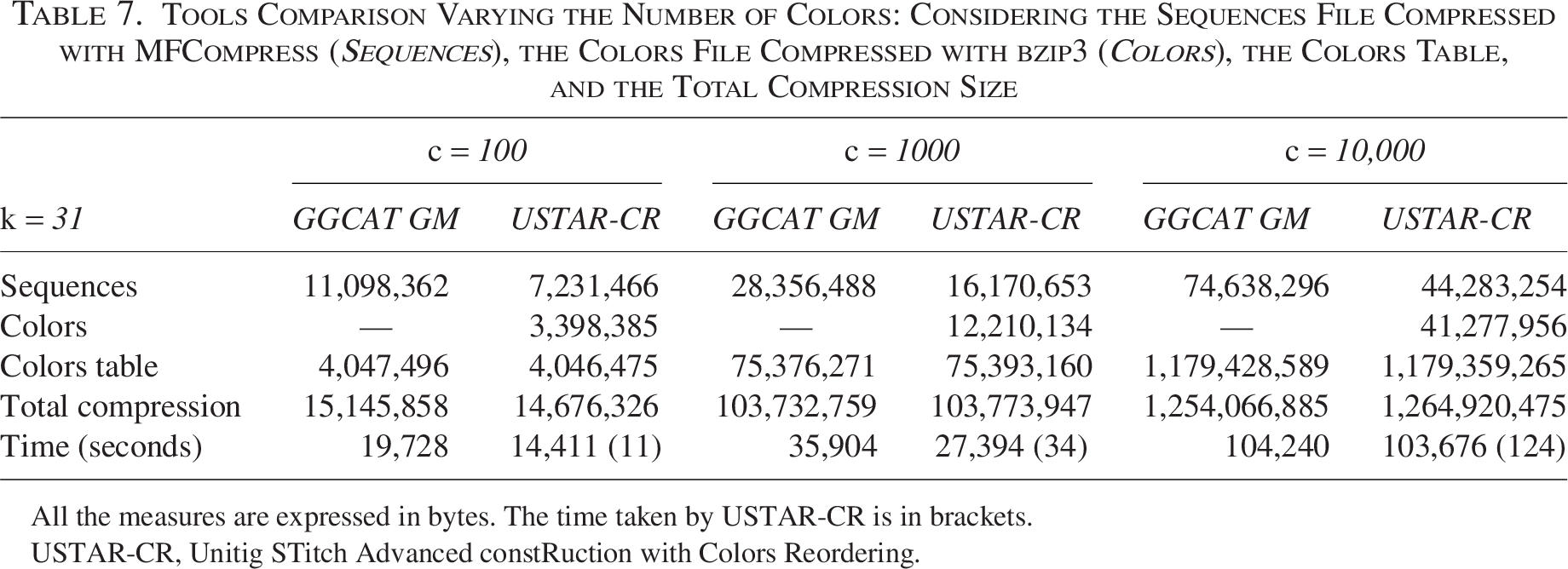
Tools Comparison Varying the Number of Colors: Considering the Sequences File Compressed with MFCompress (Sequences), the Colors File Compressed with bzip3 (Colors), the Colors Table, and the Total Compression Size
All the measures are expressed in bytes. The time taken by USTAR-CR is in brackets.
USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.
It is worth noting that both USTAR-CR and GGCAT GM rely on the same GGCAT preprocessing phase, which constructs the unitigs and the compression table. In these experiments, it becomes evident that, for large datasets, the color table dominates the total storage cost, and this inefficiency is inherited by both tools. Recent studies have proposed improved color encoding schemes (Campanelli et al., 2024), which could potentially enhance USTAR-CR’s performance as well.
Regarding execution time, USTAR-CR is substantially faster than GGCAT GM for datasets with 100 genomes, though the performance gap narrows as the dataset size grows. Interestingly, for the largest dataset, the time spent on GGCAT’s preprocessing far exceeds that of USTAR-CR (shown in parentheses), which typically completes within seconds.
Overall, when working with large datasets, the main bottleneck remains the construction of the colored dBG. Although color encoding can become challenging as the number of colors increases, USTAR-CR can take advantage of recent advances in this area (Campanelli et al., 2024).
In this article, we present USTAR-CR, a novel algorithm designed for efficient compression of multiple k-mer sets. USTAR-CR leverages node connectivity in the colored dBG to produce a more compact plain text representation and employs an optimized encoding scheme for k-mer colors.
Our comparative analysis against GGCAT and GGCAT GM demonstrates that USTAR-CR outperforms these tools in both compression effectiveness and resource usage. For the widely used k-mer length of 31, USTAR-CR achieved the lowest number of runs (
Regarding speed and memory consumption, USTAR-CR proved to be highly efficient, achieving up to a
AUTHORS’ CONTRIBUTIONS
All authors conceived the study and drafted the article. E.R. implemented the software and performed the experiments. All authors have read and approved the article for publication.
Footnotes
ACKNOWLEDGMENTS
The authors would like to thank the reviewers for their constructive comments.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
Authors are supported by the Project funded under the National Recovery and Resilience Plan (NRRP), Mission 4 Component 2 Investment 1.4—Call for tender No. 3138 of December 16, 2021, rectified by Decree No. 3175 of December 18, 2021, of Italian Ministry of University and Research funded by the European Union—NextGenerationEU, and by the EUAqua Project funded by the European Union under Grant Agreement 101181589.
Appendix
Human Reads Dataset CPU Time (Seconds) and Speedup of USTAR-CR with Respect to GGCAT GM
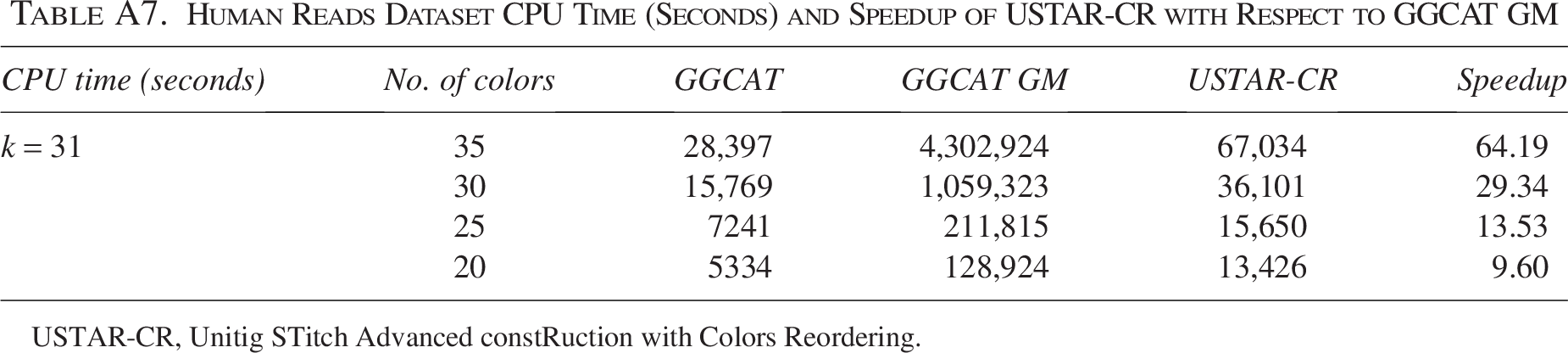
| CPU time (seconds) | No. of colors | GGCAT | GGCAT GM | USTAR-CR | Speedup |
|---|---|---|---|---|---|
| k = 31 | 35 | 28,397 | 4,302,924 | 67,034 | 64.19 |
| 30 | 15,769 | 1,059,323 | 36,101 | 29.34 | |
| 25 | 7241 | 211,815 | 15,650 | 13.53 | |
| 20 | 5334 | 128,924 | 13,426 | 9.60 |
USTAR-CR, Unitig STitch Advanced constRuction with Colors Reordering.