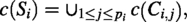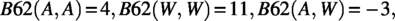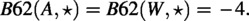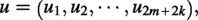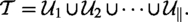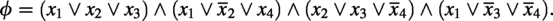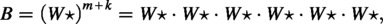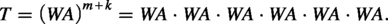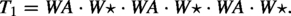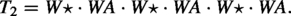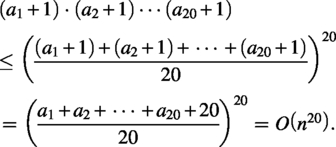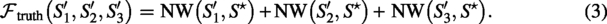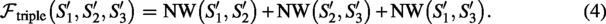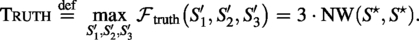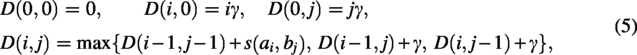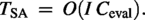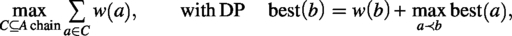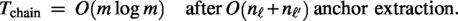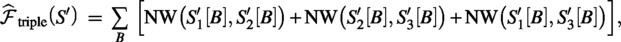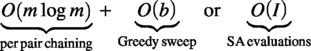In this article, we initiate the study on some problems related to multiple protein scaffold filling, with or without references. The objective is to maximize the sum of Blosum62 scores of the filled sequences when no reference is given, or to maximize the Blosum62 score between the filled sequence and a reference. We present the following results: (1) given n scaffolds generated from the top-down tandem mass spectra, finding k scaffolds whose corresponding contents can be used to fill into a target sequence (or a sequence whose Blosum62 score with a reference is maximized) takes time, unless the Strong Exponential Time Hypothesis (SETH) fails. (2) Given two or more protein scaffolds and the corresponding multisets of amino acids to be filled accordingly, the corresponding optimization problem can be solved in polynomial time with dynamic programming. (3) Due to the high (and impractical) running times of these algorithms, we implement several heuristic algorithms for the special cases when three scaffolds are given. The corresponding empirical results are quite promising, from the testing of 12 datasets spanning five different kinds of proteins: antibody, myoglobin, mitochondrial respiratory-chain, calmodulin, and thioredoxin.
Protein sequencing is a fundamental problem in computational biology, as the given sequence of a protein can give us a lot of important information, like its structure, function, biomarkers, etc. Consequently, Edman tried to sequence a peptide (a short segment of protein) as early as 1949 (Edman, 1949). However, this method can only handle very small protein sequences and is error-prone. Since the 1970s, de novo protein sequencing has become dominant with bottom-up and top-down methods. The former first constructs a lot of peptides using mass spectrometry (MS), then tries to assemble them together into a sequence using a graph method; the latter can directly sequence a protein with its mass bounded by roughly 30k Daltons, but usually will leave some gaps. (For scaffolds constructed from top-down mass spectra, we usually have the extra property that the positions, sizes and/or the total weight/mass of the gaps are known.) For a complete background on de novo protein sequencing, readers are referred to (Aebersold and Mann, 2003; Liu et al., 2014; Tran et al., 2016).
However, even though these methods have been quite effective, many assembled proteins remain incomplete, with gaps in their scaffolds (Tran et al., 2016). In addition to possible errors or limitations in mass spectrometry and assembly software, certain segments remain elusive, complicating the prediction of missing amino acids within scaffold gaps (Tran et al., 2016). Hence, with either the bottom-up or top-down method, at the end, we are likely to have a broken protein sequence or scaffold: a sequence of contigs with a gap size or gap mass might or might not be known. This raises a natural question: Given a protein scaffold, how to fill those gaps?
Filling a protein scaffold with a reference was first studied by Qingge et al. (2017). The problem is defined as follows: given a protein scaffold , a complete protein sequence R as reference and a multiset of amino acids, fill the amino acids in into the gaps in to obtain such that the Blosum62 score between and R is maximized. The problem was shown to be polynomially solvable, but the running time is too high. Hence, Qingge et al. also designed several heuristic algorithms based on greedy and local search (Qingge et al., 2017). Note that usually , but certainly it does not have to be the case.
In reality, for many proteins, such as an antibody, it is hard to find the right reference. Hence, a lot of research has recently been done based on the use of machine learning and probabilistic methods (Badal et al., 2024,2025; Qingge et al., 2025; Sturtz et al., 2022,2023). We encourage readers to review these articles for more details.
In practice, sometimes we might need to recover protein sequences with at least two chains. Or, because of mutations and post-translational modifications (PTM), a protein could result in several proteoforms that need to be recovered or sequenced. Using top-down MS tools, it is often difficult to separate these proteoforms (DiMaggio et al., 2009). In this case, a multiplexed tandem mass spectrum (MTM) is generated when tandem mass spectrometry (MS/MS) is used on two or more proteoforms that are not well separated by protein separation methods (Wang et al., 2010). Some subsequent research has used MTM to try to sequence these proteoforms (Wang et al., 2014; Zhu and Liu, 2018). Due to the complexity of MTM spectra, it is not surprising that we might only obtain a set of scaffolds instead of complete sequences of .
In this article, we initialize the study on the multiple protein scaffold filling problems, which certainly have several different versions based on many factors. For instance, are the scaffolds generated from top-down or bottom-up method? (The former usually contains the positions information, i.e., the positions of gaps or unknown amino acids are known; while this is not usually the case for the latter.) In addition, there could be extra constraints, such as on the amino acids to be filled. For instance, are they given as a multiset? or as several multisets corresponding to each of the given scaffolds to be filled? or even as a set of contigs or multiple sets of contigs? Constraints like these could significantly change the complexity of the problem. In this article, we report some results along the line.
This article is organized as follows. In Section 2, we give necessary definitions. In Section 3, we present a conditional lower bound on filling scaffolds generated by a top-down method. In Section 4, we briefly discuss some other solvable cases. In Section 5, we present some practical results on the version of filling three scaffolds (to maximize the sum of the corresponding Blosum62 scores between the filled sequences). We conclude the article in Section 6.
PRELIMINARIES
Let n be a natural number, define . Let be the set of 20 amino acids. Let be the Blosum62 score between two amino acids a and b. (The Blosum62 matrix was proposed in Henikoff and Henikoff (1992), and for completeness, we list it in the Appendix as Table A3). A protein sequence S is a sequence over . We denote the multiset of amino acids in S as . A contig is a short protein sequence, usually obtained by some sequencing software, say, based on the peptides obtained from mass spectrometry. A protein scaffold is a sequence of contigs , with gaps between neighboring contigs and , for , where some missing amino acids can be inserted. We define as
i.e., it is the multiset of amino acids appearing in all the contigs of .
Problems
In the traditional version following (Qingge et al., 2017), given two or more protein scaffolds , (each has contigs, for and m multisets of amino acids , fill into the gaps in to have such that the total Blosum62 scores between and , , is maximized; or, the sum of Blosum62 scores between and is maximized for . A variation is that instead of given m multisets of amino acids as part of the input, we are only given a multiset X of amino acids. In both of these versions, X and ’s could be multisets of contigs (instead of amino acids).
Regarding the scaffolds generated from the top-down method (where the position and size of each gap are known), we are given a set of scaffolds , a source scaffold B and a target sequence T, the question is to find k scaffolds in whose corresponding (non-gap) contents can be used to fill into B to form the target sequence T. We call this problem the k-top-down scaffold problem (k-TDS, for short). Alternatively, we are given , a source scaffold B and a reference R, the question is to search for k scaffolds in to fill B into a sequence T such that is maximized. We call this latter problem the k-top-down scaffold problem with reference.
An example of the k-top-down scaffold problem is given as follows. For simplicity, we use a small alphabet , where A, V, W are amino acids and is a space. Let , and . Then the problem is to search in some whose non-gap contents best match VWA (T[5.7]) and some whose non-gap contents best match AV (T[13.14]), when T is viewed as an array T[1.19].
A naive algorithm is to use a k-nested loop to search for k scaffolds in , resulting a running time of . In the next section, we first show that this naive algorithm is in fact almost optimal — under the SETH (which states that SAT of n variables cannot be solved in time, for some ).
A LOWER BOUND FOR THE k TOP-DOWN SCAFFOLD PROBLEM
We will use only two amino acids plus the empty symbol (which represents one gap) in our construction, e.g., . Let be the Blosum62 score between two amino acids a and b. (Note that is symmetric, i.e., .) We would use for two protein sequences x and y of the same length. It is known that
and
We comment that in many articles the gap penalty is −1, but to be consistent with our algorithm in Section 5 (using the Needleman–Wunsch [NW] algorithm), we use −4. This will not affect our proof; in fact, any negative gap penalty would work.
We prove the conditional lower bound by using an idea from (Feng et al., 2024), on the k-SUM problem over large integers. The idea in Feng et al. (2024) is a twist of Williams’ Orthogonal Vector problem (Williams, 2005). Of course, different from the ideas in (Feng et al., 2024), we need to construct protein scaffolds instead of integer vectors.
Given a SAT instance with n variables and m clauses, the SETH was first posed as an open question by Impagliazzo and Paturi (Impagliazzo and Paturi, 2001): can be decided to have a truth assignment in time? SETH was named later in Calabro et al. (2009).
In Feng et al., (2024), Feng, Fernau, and Zhu used a special version of SAT, one-in-three SAT, which was also known to be NP-complete (Schaefer, 1978). Here we also use one-in-three SAT. Note that, to maintain the NP-completeness of the input instance, we need to have .
Formally, let be a One-in-three SAT instance composed of n variables and m disjunctive clauses where the i-th clause contains three literals and is in the form of . The problem is to determine for , exactly one of the three literals in each clause , i.e., and , is assigned TRUE.
We arbitrarily partition the variables in into k equal-sized parts (we can assume that n is a multiple of k, though it does not really matter for the result). Each of the -sequences is determined by an assignment of (i.e., a partial assignment of the variables in ), where:
and for all . In fact, we could think of each W as (a part of) a contig. Then, for , we construct:
For , we additionally construct:
The source scaffold is , the target sequence is , and the set of scaffolds are:
Then, we can claim that has a valid truth assignment if and only if there are k scaffolds , whose corresponding contents can be filled into B to obtain T. As there are assignments for respectively, the above reduction takes time. If k-TDS could be computed in time, where N is the input size for k-TDS, one-in-three SAT could be solved in time—which would fail the SETH. We hence have the following theorem.
Theorem 1.The k-top-down scaffold problem, with input size N, cannot be solved intime unless the SETH fails.
We give a simple example for the above reduction. Let the One-in-three SAT instance be:
Then and ; and a valid truth assignment is , , and .
By construction,
and the target sequence is
Suppose that and we partition the variables into and . Corresponding to the partial assignment and , the corresponding sequence constructed in is:
Due to space constraint, we ignore the other 3 sequences in . Similarly, corresponding to the partial assignment for variables in , i.e., and , the corresponding sequence in is
Note that , and the problem is to search for and in to fill the corresponding contents to B to be equal to T. More specifically, we need to fill the A’s at position 2, 6, and 10 from , and at position 4, 8, and 12 from , into the corresponding positions in B.
Corollary 1.The k-top-down scaffold problem with reference, with input size N, cannot be solved intime unless the SETH fails.
Proof. We just set . Then the Blosum62 score to optimize is .▪
SOLVABLE CASES IN THE TRADITIONAL MODEL
In this section, we briefly mention some solvable cases in the traditional model. In fact, as the running times of these algorithms are so high, it is not practical to really implement them. Hence, these results are only theoretically meaningful. As a matter of fact, here we focus on the number of matched pairs in the solution rather than the Blosum62 scores. This can be done by rounding the Blosum62 matrix as follows: if a cell has a value , then change it to 1; otherwise, change it to 0. Since the gap penalty is , we could just disallow gaps and assume that the filled solutions (without gaps) all have the same length.
Two or three scaffolds, no reference
First, note that given a set X of n amino acids, the total subsets of X is bounded by . Let be the number of i-th amino acid in X. The number of subsets of X is bounded by:
As a warm-up, we first illustrate the idea for , where the input is two scaffolds and composed of contigs together with and to be inserted in and respectively. It is easy to see that, if in the optimal solution there are matches between the amino acids in and inserted in the final solution and , then we could move all these amino acids (letters) at the end of and . Hence, it suffices to discuss the cases when contigs from and having intersections.
We define as the maximum number of matched pairs obtained when the last element in contig is matched with the k-th letter of contig using the subset of amino acids left from so far. Similarly, we define as the maximum number of matched pairs obtained when the last element in contig is matched with the -th letter of using the subset of amino acids left from so far. The update is not hard but tedious: roughly we would pick what we have in or to form as many match pairs as possible and then update and accordingly. We ignore further details. Certainly, the final solution is to take the maximum of values in the tables. Since the number of subsets of each of and is , the cost would be high. We summarize the result as an observation.
Observation 1.The two-scaffold filling problem can be solved in time, where n is the input size.
With scaffolds and the three multisets of amino acids to be inserted respectively, the cases are even more complex and tedious. With a similar argument to the case of , we only need to consider 7 cases when some contigs are involved: (1) One case when three contigs from different ’s overlap, (2) Three cases when two contigs from different ’s overlap, and (3) Three cases when one contig from some (say ) is fixed and some letters from and are selected to match with this contig. The details are even more tedious, and it is not worth the effort to describe details (as the algorithm would be completely impractical). The running time of this algorithm, should be close to , where n is the total input size of the problem.
Other solvable cases
For some other cases, we can show that the problem of filling d scaffolds with one reference, and filling one scaffold with d references are both polynomially solvable when d is fixed. But, as the running time is large (at least ), these algorithms are also impractical. Hence, we do not give further details.
In the next section, we consider designing and implementing some practical algorithms. We choose the problem of filling three scaffolds in the traditional model, that is, given three scaffolds and also three sets , to be filled in the scaffolds accordingly. The objective is to maximize the sum of Blosum62 scores between the filled sequences and .
PRACTICAL ALGORITHMS FOR FILLING THREE SCAFFOLDS
In this section, we study scaffold gap filling with multiple protein scaffolds. Specifically, we focus on three protein scaffolds. These methods should be easily generalized to more than three (say five) protein scaffolds, although the running time would certainly be higher.
Problem setting and motivation
Given three incomplete but homologous scaffolds containing unknown residues (denoted by *), and for each gap, a small admissible set of residues or short fragments to choose from, the goal is to reconstruct complete sequences that agrees as much as possible with a single trusted reference (ground truth) sequence while keeping computation tractable.
Notation
Each scaffold () is a string over the amino-acid alphabet augmented with a special gap symbol *. Let index gap positions in . At gap , we allow a candidate set (single residues) or, more generally, a small set of short fragments . Filling all gaps in with choices from yields a complete sequence . Throughout, we use BLOSUM62 and a linear gap penalty .
Scoring objectives
We use NW for global alignment. Because the three scaffolds are homologous views of the same domain, we aggregate pairwise agreement in two ways:
Truth-referenced objective:
Triple agreement objective:
Truth constant
With a single reference shared by all three scaffolds, the maximum of (3) is achieved when , hence
For each data set, we therefore report the achieved scores (Greedy, SA) along with Truth and the gaps to optimality ΔGreedy = Greedy − Truth and ΔSA = SA − Truth.
Computational difficulty
Optimizing (4) or (3) in combinatorial space is intractable in the worst case. Each evaluation requires three NW alignments ( DP per pair), and the search space grows exponentially with the number of gaps and candidates. This motivates heuristics that (i) reduce the search space and (ii) bias exploration toward promising regions.
Algorithmic families
We evaluated three families of methods:
Greedy (baseline). Visit the gaps in fixed order. For each gap, try all admissible candidates and commit the best choice locally under (4) while holding previous decisions fixed. Very fast, but can get trapped in local optima.
Simulated annealing (SA, baseline). Start from Greedy (or a random fill). Perform stochastic local moves (mutating one or two gaps); accept improvements or, with probability , occasional degradations while cooling temperature T. Improves quality at higher cost.
Collinear chaining (our acceleration). Compute anchors (shared k-mers) between scaffold pairs; solve a collinear chaining problem to obtain ordered, nonoverlapping blocks; then restrict Greedy/SA mutations to positions within or near these blocks. During search, we use a fast block-sum proxy of (4); final scores are always recomputed with full NW. This substantially reduces run-time with minimal loss in accuracy.
Assumptions and practical choices
We assume (i) homologous scaffolds with partially overlapping conserved regions; (ii) small candidate sets (single residues or short fragments) derived from plausible biochemical contexts; and (iii) BLOSUM62 with linear gaps adequately captures substitution tendencies for these datasets. These choices keep comparisons fair for all methods.
Evaluation goals
We address two questions:
Accuracy. How close do Greedy and SA, with and without chaining, reach the upper bound Truth across datasets?
Efficiency. How much wall clock time does collinear chaining save relative to baselines, and what speed-ups (mean/median) are observed?
Consequently, we report (i) the scores of the per-dataset method and to Truth; (ii) the runtimes of the per-dataset decomposed by phase (Greedy, SA, chain build) and totals; and (iii) mean/median speedups.
Working hypotheses
SA typically outperforms Greedy; chaining preserves or slightly improves quality by guiding search into coherent blocks.
Chaining-aware search yields large speedups (often an order of magnitude) by shrinking the neighborhood and enabling fast score updates.
Methods
NW (baseline alignment)
Setup
Given two sequences and , a substitution score (BLOSUM62 in our experiments) and a linear gap penalty , the NW algorithm computes a global alignment and its optimal score (Needleman and Wunsch, 1970). We maintain a dynamic programming (DP) table with the following initialization and recurrence:
for , . The optimal global alignment score is ; a standard traceback from to recovers one optimal alignment.
Complexity
The DP fills cells and each cell performs work, so the time complexity is and the memory footprint is . When only the score is needed, memory can be reduced to by keeping two rows; when the alignment itself is required, Hirschberg’s divide–and–conquer variant achieves time and memory.
Use in our pipeline
NW is the scoring oracle throughout our experiments. (i) To evaluate reconstructed scaffolds, we use the triple agreement objective defined in equation (4). (ii) When a trusted reference is available, we also report the truth-referenced objective from equation (3); its maximum is the constant Truth. All heuristic search procedures (Greedy, SA, and their chaining-aware variants) ultimately validate their solutions by recomputing these objectives with full NW.
Practical notes
Our sequences are antibody light chains (hundreds of residues), for which the memory is acceptable; thus, we use a full DP table to enable fast traceback. For accelerations, we optionally employ (banded NW) in intermediate steps, but all reported scores use the exact global NW with BLOSUM62 and .
Greedy heuristic
Idea
Greedy fills the gaps one by one. Fix an ordering of all gap locations across the three scaffolds. For the t-th gap (belonging to some scaffold ), we try every admissible candidate , temporarily substitute x at that position, score the resulting partial sequences using the search objective in (4), and keep the best-scoring choice. Earlier decisions are held fixed; the process repeats until all gaps are filled.
Pseudo-code
Let be the current (partially filled) sequences.
Initialize for .
For to M:
For each , set (others unchanged), compute .
Select and commit .
Return and their scores (and later report ).
Complexity
Let be the number of admissible choices at gap , and let be the cost of one objective evaluation. In the naive implementation (recomputing full NW scores each time), for sequence length n (three pairwise DPs), and the total time is:
When each gap offers a bounded alphabet-sized set and the effective gap length being optimized is , this is often summarized as evaluations. In our code, we use exact NW for reporting, so wall-clock scales with the number of Greedy evaluations times the DP cost. (Section 5.2.4 shows how chaining greatly reduces the number of evaluated positions.)
Strengths and limitations
Greedy is extremely fast and simple, and provides strong initial solutions that SA can refine. However, because each choice is committed irrevocably, the method is sensitive to local optima and may miss globally better combinations of gap fills—particularly when interacting choices span multiple neighboring gaps.
Simulated annealing
Idea
SA is a stochastic local search that explores a neighborhood of solutions by applying small random mutations to the current sequences. Depending on the experimental configuration, SA may start either from a random initialization or from the Greedy fill. SA accepts any improving move and, with probability , also accepts a worsening move of score change at temperature T. As T is gradually cooled, the algorithm becomes more conservative, helping it escape local optima early and refine later.
Neighborhood
At each iteration, we randomly choose either (i) a single-site move: pick one gap position g and replace its current residue/fragment by another candidate from , or (ii) a two-site move: mutate two gaps jointly. Joint moves help traverse interacting choices across nearby gaps. Scoring uses the search objective in (4); final reporting uses .
Pseudo-code
Let be the current solution initialized by Greedy.
Set (initial temperature). Evaluate .
For to max_iter:
Sample a mutation (one-site w.p. , two-site w.p. p) to obtain .
Compute and .
If , accept: . Else accept with probability .
Cool: with cooling rate .
Track the best state seen so far (by f).
Return (then compute for reporting).
Acceptance rule and schedule
The Metropolis acceptance for enables occasional uphill (worse) moves when T is high, helping the search escape local optima. We use geometric cooling with depending on the run budget, multiple short restarts are optional.
Complexity
Let I be the number of iterations and let be the cost of one objective evaluation (three NW alignments in the naive form, for sequence length n). The total time is:
Equivalently, with neighborhood size summarized by an effective number of candidate mutations per iteration b (often because we sample a single mutation), SA performs evaluations, so wall-clock is proportional to I times the DP cost. Compared with Greedy, SA is typically slower but achieves higher scores by escaping local optima.
Strengths and limitations
SA provides a principled mechanism to balance exploration and exploitation and consistently improves over Greedy in our experiments. Its drawbacks are higher runtime and sensitivity to schedule parameters ; we mitigate the latter by initializing from Greedy and using conservative cooling with a small probability of two-site moves.
Collinear chaining
Idea
To shrink the search space, we identify anchors—short exact matches (common k-mers) between pairs of scaffolds—and compute a maximum‐weight collinear chain of anchors that are consistent in order. Chained anchors are then inflated into blocks (conserved regions), and Greedy/SA mutations are restricted to gaps that lie inside or near these blocks. Related practical improvements to colinear chaining have been reported in the literature (Rizzo et al., 2025). During search we evaluate a fast block‐sum proxy; final scores are recomputed with full NW to preserve correctness.
Pairwise anchors
For two strings U, V, an anchor is a triple meaning with . We collect anchors by hashing k‐mers (linear time in practice). Let be all anchors with weights (or a log‐scaled variant).
Collinear chain DP
Two anchors and are compatible if and (nonoverlapping, allowing a small slack ). The maximum‐weight chain solves
where denotes compatibility and increasing order in both coordinates. With anchors sorted by , we compute in using a Fenwick/segment tree keyed by j (LIS‐style speed‐up). Thus, for each pair the chaining cost is
Blocks and consensus
Chained anchors are inflated into disjoint blocks by merging adjacent anchors and padding each side by a small constant p to absorb minor indels. For three scaffolds , we run chaining for pairs (1,2), (2,3), (1,3), and project the resulting pairwise blocks back to per‐sequence block masks . The consensus search region is the union of block masks per sequence; only gaps falling inside these masks (or within p of a mask) are considered mutable.
Block‐sum proxy for fast scoring
Let B range over blocks, and let be the current fill. Instead of re‐aligning the full strings at every mutation, we maintain
which supports block updates after a local mutation (only the blocks touching the edited gap are recomputed). The final reported score is always the full objective ( for selection; for reporting).
Integration into greedy and SA
Greedy + Chaining. Iterate over gaps restricted to the consensus masks; for each candidate, update only the affected blocks and pick the best local improvement under .
SA + Chaining. Use the same restricted neighborhood (one‐site or two‐site mutations inside/near blocks) and evaluate proposals with the block‐sum proxy; apply the usual Metropolis rule and cool the temperature.
This reduces the effective neighborhood size from n potential sites to block‐constrained sites and replaces full realignments by small block updates.
Complexity and speed
Let b be the number of mutable gaps inside/near blocks and I the number of SA iterations. Then
dominates the refinement phase, since each proposal touches blocks. Empirically, and block updates are short, yielding order‐of‐magnitude wall‐clock reductions while preserving accuracy.
Practical notes
We use exact k‐mer anchors (), enforce uniqueness when possible, allow small overlaps (), and always verify the final solution with full NW before reporting Truth‐referenced scores.
Cost. Chaining over m anchors per pair is ; thereafter, each Greedy sweep or SA mutation touches blocks, making score updates per move and cutting the practical search cost from to .
Experimental setup
Datasets
We evaluate our methods on 12 scaffold datasets derived from real protein sequences obtained from UniProt, spanning multiple protein families and species. Each dataset contains three incomplete but homologous scaffolds with known gap positions (marked ‘*’) and a single trusted reference sequence used for evaluation.
The datasets cover diverse protein families, including antibody/proteoform-related sequences (Datasets 1–4), myoglobin (Datasets 5–6), mitochondrial respiratory-chain proteins (Datasets 7–9), calmodulin (Datasets 10–11), and thioredoxin (Dataset 12). This diversity allows us to evaluate robustness across different sequence structures and evolutionary contexts.
For reporting, we define the Truth upper bound as Truth = 3 · NW (Sec. 5.1) and compute per-method deltas relative to Truth.
Fragments/candidate sets
For each gap location we provide a small candidate set of plausible fills (single residues or short subsequences), derived from conserved motifs or closely related chains. All methods (baseline and chained) draw exclusively from the same candidate sets to ensure a fair comparison.
Hardware and software
Experiments were conducted on a MacBook Pro (Apple M1, 8 GB RAM) using Python 3.13.1. Runtime is reported as wall-clock time measured with time.perf_counter().
Initialization and randomness
Greedy constructs an initial solution by visiting gaps in a fixed order. Baseline SA starts from a random initialization, while the chained SA variant is initialized from the Greedy solution. Both SA variants perform stochastic local moves (one-site or two-site mutations), and we fix the random seed (seed = 1234) for reproducibility.
For the chaining variants, we first construct pairwise anchor sets and collinear chains, which are then expanded into blocks (with padding residues). Mutations are restricted to gap positions within or near these blocks.
Hyperparameters
We use distinct SA schedules for the baseline and chained variants. Baseline SA operates over an unconstrained search space and therefore requires a higher initial temperature, while the chained variant benefits from a lower temperature and longer schedule over a restricted neighborhood. Table 1 summarizes the values used in all reported results.
Simulated Annealing Schedules Used in the Experiments
Variant
Initial temp
Cooling rate
Max iterations
Baseline SA
150
0.98
5000
Chained SA
6
0.999
8000
Chaining configuration
Anchors are exact k-mers with (default ), filtered for uniqueness when available; compatible anchors are chained with a small overlap tolerance, then merged and padded by . We construct blocks for pairs , , and and project them into per-sequence consensus masks (Section 5.2.4).
Outputs recorded
For each dataset and method, we report: (i) scores for Greedy and SA (both baseline and chained variants) under the Truth-referenced objective ; (ii) the Truth constant; (iii) the corresponding gaps to Truth; and (iv) runtime breakdowns for Greedy, SA, chaining build, and total execution time. We also summarize mean and median speedups (baseline vs. chained) across all 12 datasets.
Results
Dataset structure
We evaluate on 12 scaffold datasets spanning multiple protein families (Section 5.3). Each dataset consists of three incomplete homologous scaffolds with gap positions and a single reference sequence used for evaluation. All results in this section are reported with respect to this reference, i.e., each method is evaluated based on how closely the reconstructed sequences match .
Scoring
All scores use NW (BLOSUM62, ). We evaluate candidates with the truth–referenced objective introduced in Sec. 5.1 [Eq. (3)], and compare method scores to the dataset-specific upper bound Truth. In the tables below, we report the achieved scores for all methods (Greedy, SA, and their chained variants) together with their gaps to the upper bound, Δ = score − Truth (more negative values indicate a larger deviation from the bound).
For search, we use the triple agreement objective [Eq. (4)], while all reported numbers are recomputed using full NW scoring against for comparability.
Table overview
Tables report accuracy and runtime results across datasets. Accuracy is presented as absolute alignment scores together with their gaps to the dataset-specific upper bound Truth, while runtime is reported in seconds. Where applicable, figures provide visual comparisons of performance trends across methods and datasets.
Accuracy
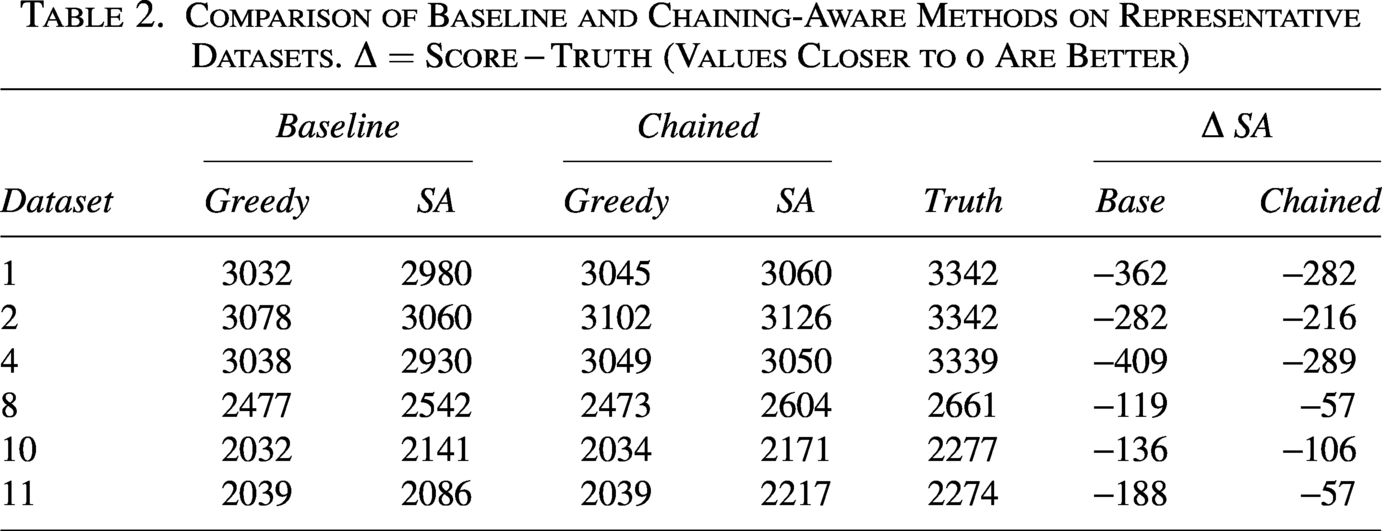
Across the representative datasets (Table 2), chaining generally moves solutions closer to the single–reference upper bound Truth. For the Greedy method, the mean gap improves modestly from to ( points). In contrast, SA benefits substantially more: the mean gap improves from to ( points).
Comparison of Baseline and Chaining-Aware Methods on Representative Datasets. (Values Closer to 0 Are Better)
Dataset
Baseline
Chained
Truth
SA
Greedy
SA
Greedy
SA
Base
Chained
1
3032
2980
3045
3060
3342
−362
−282
2
3078
3060
3102
3126
3342
−282
−216
4
3038
2930
3049
3050
3339
−409
−289
8
2477
2542
2473
2604
2661
−119
−57
10
2032
2141
2034
2171
2277
−136
−106
11
2039
2086
2039
2217
2274
−188
−57
These results indicate that chaining primarily enhances stochastic search, guiding SA toward regions that are more consistent with the reference sequence , while providing only minor gains for the deterministic Greedy baseline.
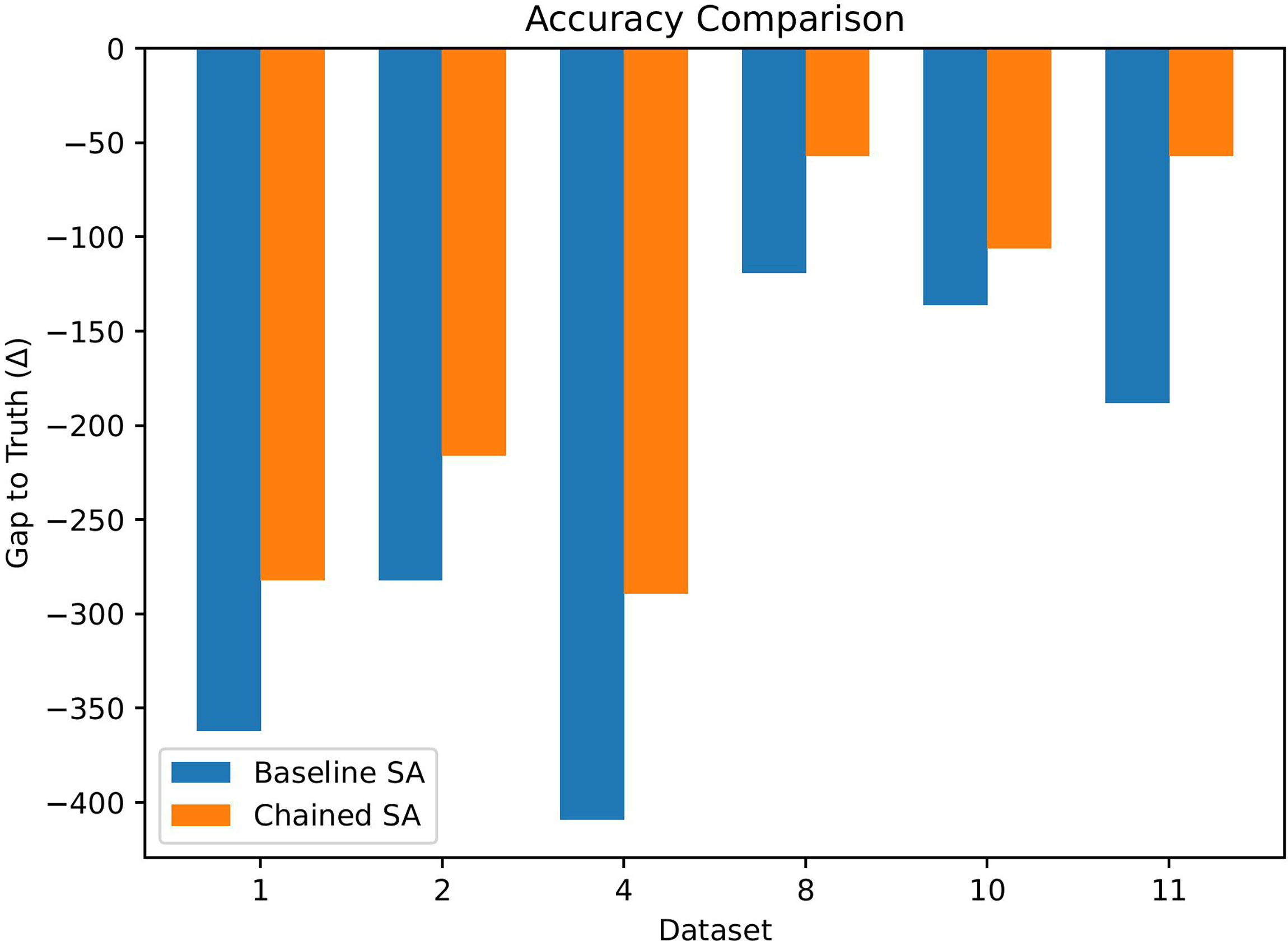
Figure 1 provides a visual comparison of the baseline and chaining-aware SA variants, showing that chaining generally moves the solution closer to Truth across most datasets.
Comparison of baseline and chaining-aware simulated annealing in terms of gap to the upper bound Truth on representative datasets. Values closer to 0 indicate better agreement with the dataset-specific reference upper bound. Chaining generally reduces the gap relative to the baseline across most datasets.
Efficiency
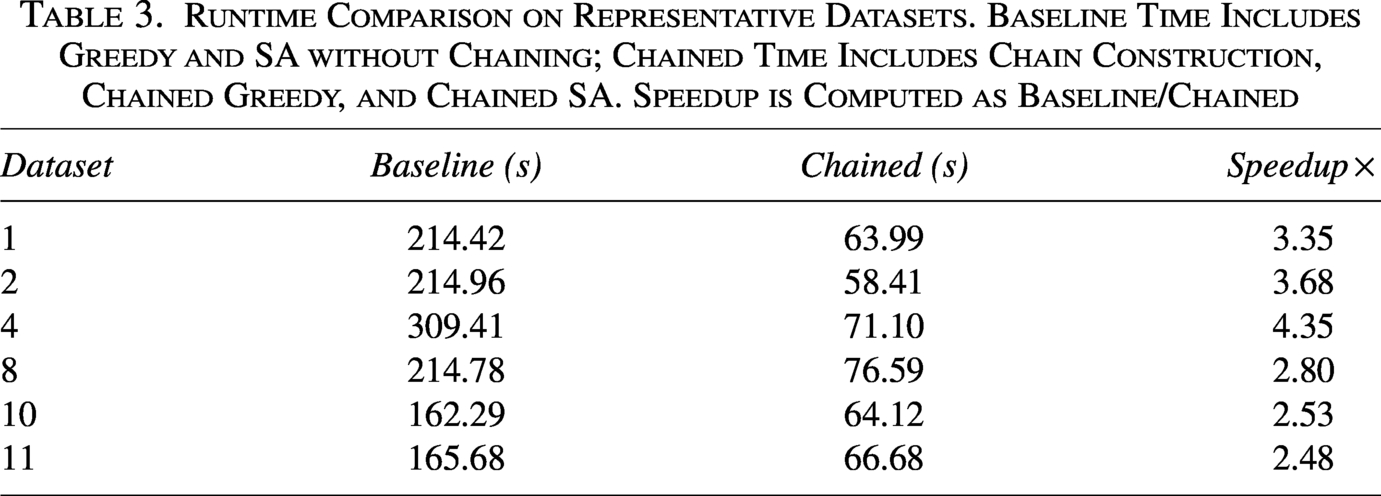
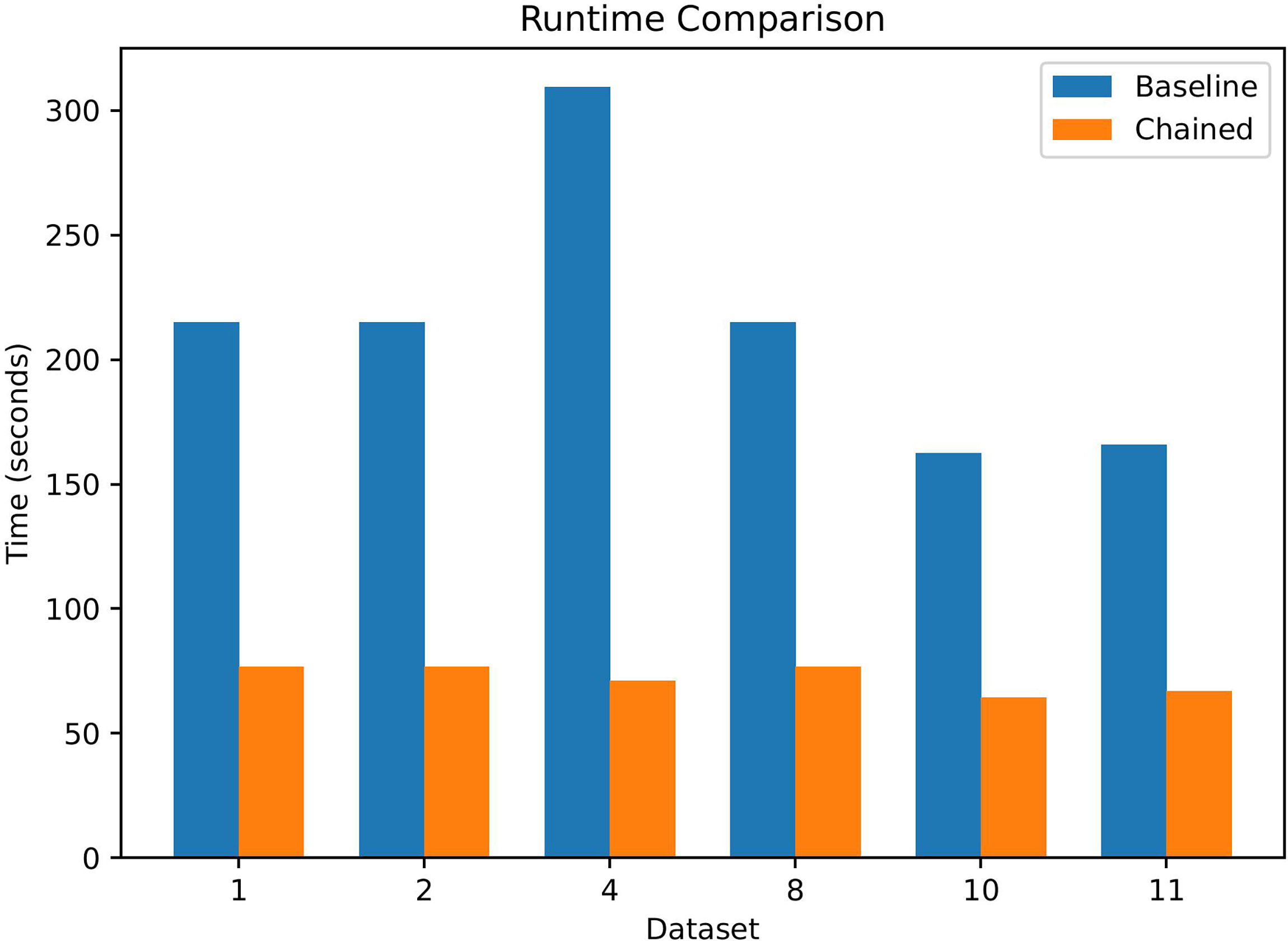
Table 3 shows consistent runtime gains with chaining across the representative datasets. On average, the total wall–clock time decreases from s (baseline) to s (chained), corresponding to a mean speedup of (median ).
Runtime Comparison on Representative Datasets. Baseline Time Includes Greedy and SA without Chaining; Chained Time Includes Chain Construction, Chained Greedy, and Chained SA. Speedup is Computed as Baseline/Chained
Dataset
Baseline (s)
Chained (s)
Speedup
1
214.42
63.99
3.35
2
214.96
58.41
3.68
4
309.41
71.10
4.35
8
214.78
76.59
2.80
10
162.29
64.12
2.53
11
165.68
66.68
2.48
Although Table 3 reports end-to-end runtimes, the dominant savings arise in the SA phase: restricting the search to block-consistent regions substantially reduces the number of candidate evaluations per iteration. The overhead of chain construction is negligible, and the Greedy stage also benefits from operating within precomputed blocks.
As shown in Figure 2, chaining yields substantial runtime reductions across all representative datasets.
Runtime comparison between baseline and chaining-aware methods on representative datasets. Reported times correspond to end-to-end execution. Chaining substantially reduces total runtime across all shown datasets.
Scalability
Collinear chaining reduces the effective search space by focusing computation within an ordered set of conserved blocks and their margins. This pruning makes both greedy selection and stochastic refinement more efficient at longer sequence lengths: the chaining step scales near-linearly in the number of anchors, while refinement depends on the number of block positions rather than the full sequence length.
Combined with the observed runtime speedup and consistent or improved accuracy, these results suggest favorable scalability as scaffold length and gap count increase.
CONCLUSION
In this article, we study the multi-scaffold filling problem and report empirical results based on both theoretical and practical approaches. We formulate the problem using DP and develop practical heuristic methods, including greedy initialization and SA, together with a chaining-based strategy to restrict the search space and improve computational efficiency. The complete empirical results are included in the Appendix as Table A1 and Table A2.
Certainly, there are many different versions of the problem and further investigations are needed—for instance, what about implementing the DP method on a parallel computer? We are especially interested in practical algorithms. Which are likely to obtain useful empirical results. We conclude the article with the following summaries.
What makes the problem hard
A full, exact DP solution over all gap assignments is not practical: the number of combinations grows exponentially, and even a single evaluation requires three global alignments. We therefore use NW (BLOSUM62, linear gaps) as our final scoring oracle, while avoiding recomputing it at every local move during search. This motivates the use of heuristic strategies and chaining-based restrictions to efficiently explore the search space.
Our practical approach
We incorporate a collinear-chaining strategy on top of two standard heuristics (Greedy and SA). Chaining identifies short shared k-mer anchors between scaffolds, links them into ordered blocks, and restricts Greedy/SA to mutate gaps only within or near these blocks. During search, we update fast block-based scores, and all final results are recomputed using exact NW scoring for fair comparison. This approach significantly reduces the search space and improves computational efficiency while maintaining competitive alignment quality.
What we observed
Across our datasets, the chaining-aware variants achieve comparable or improved accuracy in most cases while reducing total runtime by about 3– on average. Most of the speedup appears in the SA phase because the restricted neighborhood is smaller and more coherent. Greedy often lands close to the reference-based upper bound, while SA can further improve some cases, though not consistently under the NW metric.
Limitations
(1) We evaluate against a single reference per dataset; biological truth may not always coincide with the NW optimum. (2) We fix BLOSUM62 and a linear gap penalty; different scoring schemes (e.g., affine gaps or structure-aware scores) could change outcomes. (3) Our anchors are exact short k-mers; spaced seeds or profile-based anchors may perform better in indel-rich regions. (4) Gap candidate sets are assumed small and plausible; overall solution quality depends on how these sets are constructed. (5) Experiments are conducted on curated datasets under a single hardware/software setup; performance may vary under different conditions.
Future directions
Promising extensions include: faster and parallel implementations of NW (SIMD/GPU) or banded/sparse variants; richer seeding strategies and adaptive block construction; alternative objectives that combine NW with structural or biochemical priors (and possibly multiple references); more robust local search methods (e.g., tabu search, iterated local search, or small beam search); and scaling to more than three scaffolds with consensus-aware chaining.
Takeaway
Combining exact NW for final evaluation with a lightweight chaining layer for search makes multi-scaffold gap filling both practical and efficient, while maintaining competitive alignment accuracy.
The authors thank anonymous reviewers for helpful comments.
AUTHOR DISCLOSURE STATEMENT
No competing financial interests exist.
FUNDING INFORMATION
This research is supported by NSF under awards 2307571, 2307572, 2307573, and 2434487. L.W. is supported by a grant from NNSF of China (project 61972329) and GRF grants from Hong Kong SAR, China (CityU 11218423 and CityU 11218821).
Appendix
References
1.
AebersoldR, MannM. Mass spectrometry-based proteomics. Nature2003;422(6928):198–207.
2.
BadalK, QinggeL, LiuX, et al.Novel probabilistic and machine learning approaches for the protein scaffold gap filling problem. J Comput Sci Technol2025;40(4):1109–1123.
3.
BadalK, QinggeL, LiuX, et al.Probabilistic and machine learning models for the protein scaffold gap filling problem. In: Bioinformatics Research and Applications—20th International Symposium, ISBRA 2024, Kunming, China, July 19–21, 2024, Proceedings, Part III, volume 14956 of Lecture Notes in Computer Science. (PengW, CaiZ, SkumsP, eds). Springer; 2024, pp. 28–39.
4.
CalabroC, ImpagliazzoR, PaturiR. The complexity of satisfiability of small depth circuits. In: Parameterized and Exact Computation, 4th International Workshop, IWPEC 2009, Copenhagen, Denmark, September 10–11, 2009, Revised Selected Papers, volume 5917 of Lecture Notes in Computer Science. (ChenJ and FominFV, eds). Springer; 2009, pp. 75–85.
5.
DiMaggioPAJr, YoungNL, BalibanRC, et al.A mixed integer linear optimization framework for the identification and quantification of targeted post-translational modifications of highly modified proteins using multiplexed electron transfer dissociation tandem mass spectrometry. Mol Cell Proteomics2009;8(11):2527–2543.
6.
EdmanP. A method for the determination of the amino acid sequence in peptides. Arch. Biochem1949;22:475–476.
7.
FengZ, FernauH, ZhuB. Optimal bridge, twin bridges and beyond: Inserting edges into a road network to minimize the constrained diameters. In: Algorithmic Aspects in Information and Management – AAIM 2024 – 18th Annual International Conference, Dallas, Texas, September 21–23, 2024. Proceedings, volume 15179 of Lecture Notes in Computer Science. (GhoshS and ZhangZ, eds). Springer; 2024, pp. 94–108.
8.
HenikoffS, HenikoffJG. Amino acid substitution matrices from protein blocks. Proc Natl Acad Sci U S A1992;89(22):10915–10919.
9.
ImpagliazzoR, PaturiR. On the complexity of k-sat. J. Comput. Syst. Sci2001;62(2):367–375.
10.
LiuX, DekkerLJM, WuS, et al.De novo protein sequencing by combining top-down and bottom-up tandem mass spectra. J Proteome Res2014;13(7):3241–3248.
11.
NeedlemanSB, WunschCD. A general method applicable to the search for similarities in the amino acid sequence of two proteins. J Mol Biol1970;48(3):443–453.
12.
QinggeL, BadalK, AnnanR, et al.Generative AI models for the protein scaffold filling problem. J Comput Biol2025;32(2):127–142.
13.
QinggeL, LiuX, ZhongF, et al.Filling a protein scaffold with a reference. IEEE Trans Nanobioscience2017;16(2):123–130.
14.
RizzoN, CáceresM, MäkinenV. Practical colinear chaining on sequences revisited. In: Bioinformatics Research and Applications - 21st International Symposium, ISBRA 2025, Helsinki, Finland, August 3–5, 2025, Proceedings, Part II, volume 15757 of Lecture Notes in Computer Science. (TangJ, LaiX, CaiZ, PengW, WeiY, eds). Springer; 2025, pp. 203–216.
15.
SchaeferTJ. The complexity of satisfiability problems. In: Proceedings of the 10th Annual ACM Symposium on Theory of Computing, STOC. (LiptonRJ, BurkhardWA, SavitchWJ, FriedmanEP, AhoAV, eds). ACM; 1978, pp. 216–226.
16.
SturtzJ, ZhuB, LiuX, et al.Deep learning approaches for the protein scaffold filling problem. In: 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI). IEEE; 2022, pp. 1055–1061.
17.
SturtzJ, AnnanR, ZhuB, et al.A convolutional denoising autoencoder for protein scaffold filling. In: Bioinformatics Research and Applications - 19th International Symposium, ISBRA 2023, Wrocław, Poland, October 9–12, 2023, Proceedings, Vol. 14248 of Lecture Notes in Computer Science. (GuoX, MangulS, PattersonM, ZelikovskyA, eds). Springer; 2023, pp. 518–529.
18.
TranNH, RahmanMZ, HeL, et al.Complete de novo assembly of monoclonal antibody sequences. Sci Rep2016;6(1):31730.
19.
WangJ, Pérez-SantiagoJ, KatzJE, et al.Peptide identification from mixture tandem mass spectra. Mol Cell Proteomics2010;9(7):1476–1485.
20.
WangJ, BournePE, BandeiraN. Mixgf: Spectral probabilities for mixture spectra from more than one peptide. Mol Cell Proteomics2014;13(12):3688–3697.
21.
WilliamsR. A new algorithm for optimal 2-constraint satisfaction and its implications. Theor Comput Sci2005;348(2–3):357–365.
22.
ZhuK, LiuX. A graph-based approach for proteoform identification and quantification using top-down homogeneous multiplexed tandem mass spectra. BMC Bioinform2018;19S(9):161–168.