
Abstract
This study presents a systematic framework that optimizes text-to-image generation prompts through Large Language Model (LLM) personas in fashion design applications. While generative models like Stable Diffusion show significant creative potential, prompt engineering remains challenging for domain experts lacking technical expertise. We developed a systematic five-stage methodology to optimize text-to-image prompts. First, we generate prompts using different AI personas with varying expertise. Then we create images, evaluate their quality, identify weaknesses, and optimize the prompts accordingly. Our optimized prompts demonstrated significant improvements over persona-based approaches across multiple evaluation dimensions. The Multi-expert persona achieved the highest baseline performance (9.11/11 points), which our optimization process enhanced to 10.05 points—a statistically significant 10.3% improvement (p<0.01). Optimized prompts significantly outperformed all persona approaches in requirement implementation and showed superior performance in human preference assessments. The optimized prompts achieved maximum CLIP scores of 0.9043 and ImageReward scores of 1.7452, demonstrating peak performance advantages across all metrics. In head-to-head comparisons, optimized prompts secured first-place rankings in 50% of human preference evaluations, significantly exceeding the 20% random expectation. This framework bridges the gap between language models and image generation systems, enabling fashion professionals to achieve consistent, high-quality AI-generated designs without prompt engineering expertise, thereby accelerating creative workflows and reducing design iteration time.
Keywords
1. Introduction
Text-to-image generative models like Stable Diffusion, DALL-E, and Midjourney represent significant advances in artificial intelligence.1,2 These systems transform natural language descriptions into corresponding visual outputs, revolutionizing creative workflows across visually-oriented industries.3–5 Fashion design, product development, and interior design increasingly adopt open-source models due to their accessibility and creative potential.6,7 Architecture exemplifies successful implementation, where generative AI enables innovative facade design through effective human-AI collaboration, advancing both conceptual development and visualization practices.8,9
A critical gap separates these models’ technical capabilities from practical use by domain experts who lack prompting experience. Prompts—the text instructions given to AI systems—fundamentally determine output quality and whether the results meet specific requirements.10,11 Effective prompt construction demands technical expertise in structure, terminology, and weight application—knowledge that extends beyond simple descriptive writing.12,13 This expertise barrier significantly limits adoption among domain professionals, despite the technology’s transformative potential.14,15
This expertise gap creates opportunities for bridging technical and domain expertise through Large Language Models (LLMs). Systems like GPT-4 and Claude demonstrate sophisticated text generation capabilities and can adopt specialized personas for domain-specific content creation.16–19 By leveraging these persona-based approaches, we can bridge prompt engineering expertise gaps and enhance human-AI collaboration in design workflows.
We propose a systematic framework that couples LLMs with text-to-image models to achieve high-quality visual generation. Our data-driven methodology establishes iterative feedback loops connecting persona-based prompt generation, systematic evaluation, and optimization processes. This approach addresses critical accessibility needs in creative domains, particularly fashion design, where visual complexity demands both technical and domain expertise.
This study pursues four objectives. First, we establish distinct LLM personas and analyze their prompt generation patterns. Second, we evaluate prompt effectiveness through systematic image generation and assessment protocols. Third, we develop data-driven optimization methods that integrate persona strengths while addressing weaknesses. Fourth, we validate framework performance using objective checklists, semantic alignment measures, and human preference metrics.
2. Related works
2.1. Text-to-image generation technologies
Text-to-image generation has progressed from early GAN-based systems to sophisticated diffusion models. Generative Adversarial Networks (GANs) pioneered competitive learning between generator and discriminator networks, establishing foundational principles for the field. 20 GAN-CLS achieved the first successful text-conditioned image generation, 21 while StackGAN introduced two-stage high-resolution generation 22 and AttnGAN incorporated attention mechanisms for fine-grained text-image alignment. 23 The Contrastive Language-Image Pre-training (CLIP) model marked a paradigm shift, learning semantic associations between text and images from massive datasets. 24 CLIP’s foundation enabled DALL-E’s autoregressive approach1 and GLIDE’s diffusion-based text conditioning. 25
Diffusion models emerged as a new paradigm, generating high-quality images through iterative noise addition and removal processes. Google’s Imagen demonstrated exceptional realism using powerful language models for text encoding. 26 Stable Diffusion achieved computational efficiency through latent diffusion architectures. 2 The system employs CLIP text encoders to transform prompts into embeddings, conditioning the latent space denoising process for high-quality generation. Recent advances include DALL-E 3 and Stable Diffusion XL, further pushing generation capabilities. This evolution highlights prompt engineering’s growing importance—our study’s focus. However, systematic optimization methodologies remain underdeveloped, particularly for specialized domains like fashion design.
2.2. Prompt engineering methodologies
Prompt engineering research predominantly employs empirical approaches, lacking systematic methodologies for optimization.13,14 Current practices depend on trial-and-error experimentation and community-derived guidelines instead of data-driven frameworks.11,12 This methodological gap creates substantial barriers for non-expert adoption.
Recent systematic optimization efforts incorporate Kansei engineering and knowledge graphs for UI generation, achieving measurable designer-model alignment improvements. 27 Automated systems like BeautifulPrompt transform simple descriptions into sophisticated prompts, 28 while PRISM enables black-box prompt identification. 29 Yet these approaches struggle with semantic consistency and cross-model transferability.
LLM integration for prompt generation offers promising solutions. Research confirms that LLM personas effectively simulate domain expertise30,31 and reliably reproduce expert characteristics under controlled configurations. 32 Nevertheless, consistency and authenticity limitations persist,33,34 emphasizing the need for systematic evaluation and optimization frameworks.
2.3. AI applications in fashion design
Fashion design actively integrates AI across applications spanning trend prediction to generative design. Text-to-image generation emerges as particularly valuable, allowing designers to create visual outputs from textual descriptions of their design ideas. 35 Early fashion-specific approaches emphasized pose-preserving garment generation 36 and natural language-to-visual feature mapping. 37 Advanced systems now achieve end-to-end fashion image retrieval and generation. 38
Diffusion models dramatically enhance fashion image generation quality. Recent research integrates fashion domain knowledge with Stable Diffusion, achieving superior attribute preservation in generated designs. 39 Yet semantic gaps persist between textual descriptions and fashion visuals, especially for nuanced elements like texture, drape, and styling details.
Fashion AI generation faces key challenges: accurately representing detailed design elements, producing consistent outputs when using the same design specifications, and effectively communicating design requirements through prompts. Despite demonstrated technical capabilities, fashion professionals struggle with adoption due to prompt engineering complexity. This usability gap drives our systematic framework development, bridging domain expertise with technical requirements.
3. Material and methods
We used a comparative approach to test our AI image generation framework, systematically evaluating LLM personas’ impact on prompt quality and image generation outcomes. Fashion design provides ideal experimental context, demanding both creative expression and technical precision—requirements that comprehensively test framework capabilities.
3.1. Framework overview
Our framework employs five sequential stages that optimize text-to-image generation through systematic persona-based prompt engineering (Figure 1). Each stage contributes to a data-driven feedback loop connecting initial prompt generation with optimized output derivation: 1. 2. 3. 4. 5. LLM persona-based optimization framework for AI image generation.
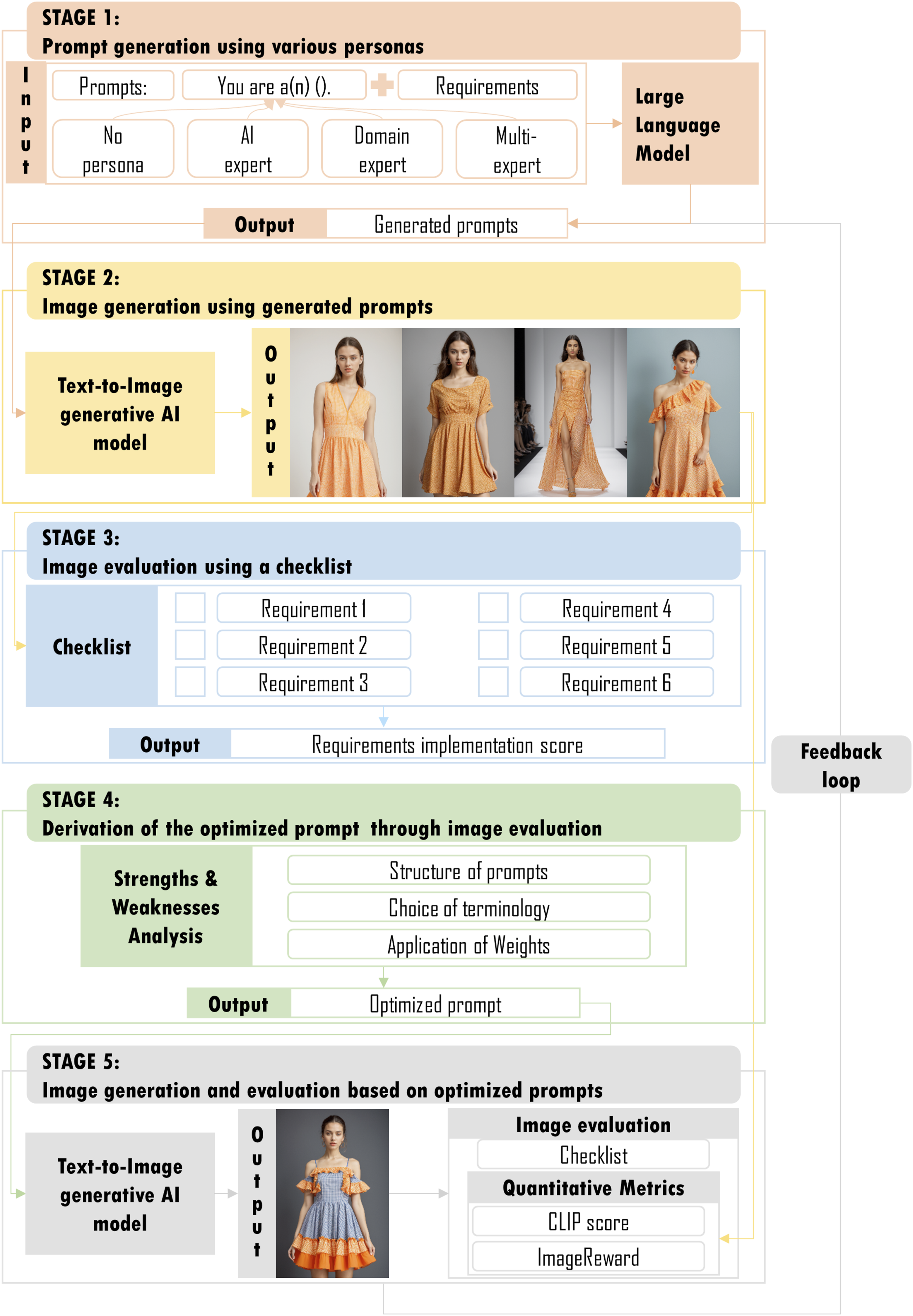
This iterative approach systematically integrates diverse expertise while maintaining objective evaluation standards, establishing data-driven feedback mechanisms that generate improved prompts from evaluation results. The framework leverages multiple persona strengths while compensating for individual limitations.
3.2. Persona configuration and prompt generation
We designed four persona types to systematically examine how different types of expertise affect prompt generation quality. Each persona represents a distinct knowledge domain: No-persona (baseline with no specialized role), AI Expert (technical prompt engineering expertise), Fashion Designer (domain-specific fashion knowledge), and Multi-expert (combined technical and fashion expertise). This experimental design enables controlled testing of whether domain knowledge, technical knowledge, or their combination produces superior prompting performance.
To create each persona, we began conversations with Claude 3.5 Sonnet by providing specific role assignments. No-persona received standard instructions without any specialized role. AI Expert was assigned “You are an expert in AI image generation,” focusing on technical optimization without fashion knowledge. Fashion Designer received “You are a world-renowned fashion designer,” emphasizing garment expertise without technical prompting skills. Multi-expert used a two-step approach: first generating fashion descriptions as a designer, then converting these into technical prompts as an AI expert.
Fashion design requirements for persona-based prompt generation experiment.

3.3. Image generation protocol
We generated images using Stable Diffusion under controlled parameters, standardizing generation parameters to focus on prompt-specific effects. Our experimental setup included AMD Ryzen 7 CPU, NVIDIA GeForce RTX 4060 GPU (8GB VRAM), 32GB RAM, and AUTOMATIC1111’s Stable Diffusion WebUI (v1.6.0). Realistic Vision v5.1, a fine-tuned checkpoint based on Stable Diffusion v1.5 and optimized for realistic image generation, served as the base model throughout all experiments.
We standardized generation parameters across conditions: CFG scale 5, 20 sampling steps, DPM++ SDE Karras sampler, 512×768 initial resolution with 1.5× upscaling via 4×-UltraSharp (denoising strength 0.45). Adetailer enhanced anatomical accuracy using face_yolo8n and hand_yolo8n models for faces and hands respectively.
Each persona generated 40 images using consecutive seeds (1-40), ensuring reproducibility and adequate statistical power. Persona-specific prompts occupied the positive prompt field, while all conditions used Realistic Vision v5.1’s recommended negative prompt template to prevent anatomical deformities, unrealistic rendering styles, and technical artifacts. We systematically organized generated images by persona and seed number, creating a comprehensive dataset for evaluation and analysis.
3.4. Evaluation methodology
We developed a systematic checklist that converts subjective design requirements into measurable criteria, focusing exclusively on objectively observable elements in generated images. The checklist deliberately excluded highly subjective aspects like “funky style” assessment due to difficulties in establishing reliable inter-rater agreement for such aesthetic judgments.
Objective evaluation checklist for fashion design requirement implementation.

Binary scoring (1: present/clear, 0: absent/unclear) maximized objectivity and minimized subjective interpretation, avoiding Likert scale biases. Two independent researchers experienced in fashion design and AI evaluation assessed images blindly, without persona attribution knowledge.
3.5. Prompt optimization algorithm
We established a data-driven optimization procedure analyzing checklist results across personas. The procedure prioritizes weakness identification and strength balancing, systematically integrating optimal elements from each persona approach (Algorithm 1).

The process begins by selecting the highest-scoring persona prompt as base structure, establishing a performance-proven foundation. Systematic weakness analysis follows, identifying and prioritizing lowest-scoring checklist items to focus optimization on critical improvement areas.
Cross-persona analysis is conducted for each weakness. When other personas score higher on specific items, we examine their expressions, structure, and positioning to identify effectiveness factors. For universally low-scoring items, we identify common challenges and develop novel solutions while considering how improving one checklist item might affect others.
Strength balancing parallels weakness analysis, examining exceptionally high-scoring items. We consider weight reductions for perfectly implemented elements, adjust over-emphasized expressions hindering other items, and simplify redundancies. This reallocates attention from over-performing to under-performing areas.
This analysis yields specific improvement strategies: borrowing effective expressions from superior personas, replacing ambiguous terms with specific alternatives, repositioning important elements, modifying weights for balanced attention, and grouping related elements strategically.
Final integration sequentially applies improvements while maintaining prompt coherence. This process balances length against complexity, evaluates inter-item impacts, preserves base prompt strengths, and ensures natural consistency. Final review confirms comprehensive requirement coverage with all improvements implemented.
3.6. Multi-metric validation
We validated optimized prompts using multiple metrics to assess different dimensions of improvement. Checklist assessment provided objective evaluation of requirement implementation through systematic analysis of 40 new images generated with optimized prompts under identical parameters, enabling direct quantitative comparison.
CLIP scores assessed prompt-image semantic alignment. Using ViT-B/32 architecture, we calculated weighted cosine similarity:
ImageReward evaluation measured human preference alignment through a model trained on expert rankings. Trained on 137,000 expert comparisons, ImageReward captures visual quality and appeal beyond text-image alignment, outperforming BLIP, CLIP, and Aesthetic methods. 41 The same reference prompts used for CLIP evaluation enabled direct comparison between semantic alignment and human preference metrics.
This multi-faceted validation approach allows comprehensive assessment of optimization effectiveness across technical accuracy, semantic alignment, and human preference dimensions, providing robust evaluation beyond single-metric limitations.
4. Results
4.1. Persona-based prompt generation analysis
Prompts generated by each LLM persona for fashion design requirements.

Component analysis revealed distinct persona patterns. No-persona balanced 19 components across quality enhancement, garment specification, and photographic composition, strategically weighting orange as primary and light blue as accent. AI Expert’s 24-component prompt emphasized technical excellence through “editorial photography,” “professional lighting setup,” and “sharp focus” terminology. Fashion Designer’s 18 components concentrated on garment terminology and haute couture references, uniquely avoiding all technical weights. Multi-expert efficiently integrated domain and technical knowledge in 16 components, combining professional construction terminology with strategic weight application.
4.2. Image generation results
Persona-specific prompts yielded 160 images exhibiting distinct visual characteristics. Representative samples reveal systematic variations in style, composition, and design elements across personas (Figure 2). Systematic visual differences emerged across personas. No-persona and AI Expert produced clean backgrounds with straightforward garment presentation. Fashion Designer unexpectedly generated runway contexts without explicit prompt instructions. Multi-expert achieved rich clothing details and superior asymmetrical design implementation. Representative fashion design images generated by each LLM persona (selected seed numbers: 8, 18, 28, 38).
4.3. Checklist evaluation results
Checklist evaluation results by LLM persona and optimized prompt.
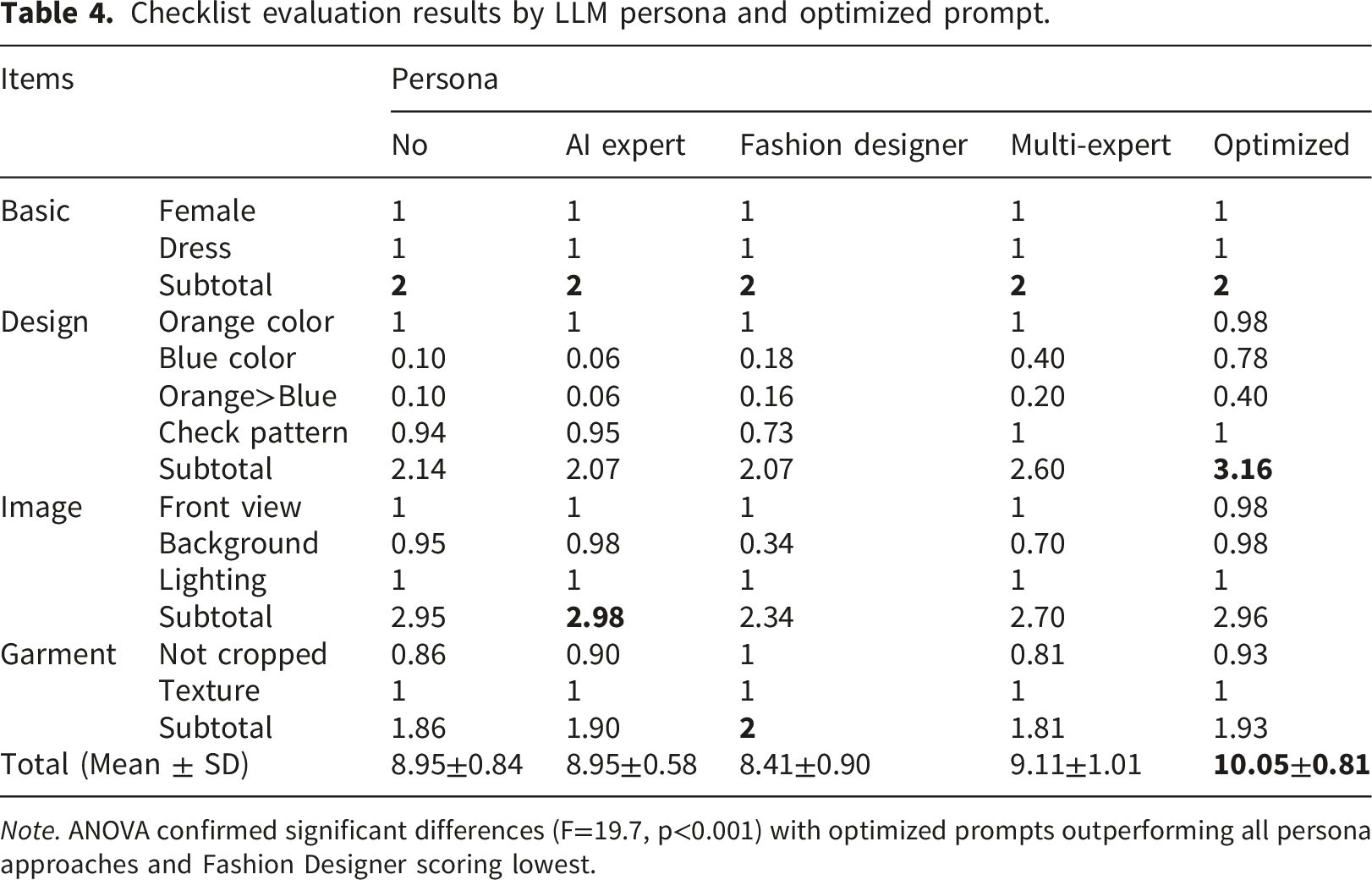
Note. ANOVA confirmed significant differences (F=19.7, p<0.001) with optimized prompts outperforming all persona approaches and Fashion Designer scoring lowest.
All personas perfectly executed Basic Requirements, generating female dress-wearing models without explicit gender prompts. Design Elements revealed maximum variation—Multi-expert excelled in blue color and check pattern implementation. Image Composition exposed background control differences: AI Expert and No-persona succeeded while Fashion Designer failed due to runway generation. Paradoxically, Fashion Designer achieved perfect Garment Presentation scores because runway contexts naturally feature full-body model presentations, preventing any garment cropping despite failing background requirements.
4.4. Prompt optimization process
Based on checklist evaluation analysis, the Multi-expert prompt served as the optimization base structure due to its highest total performance. Systematic weakness analysis identified color-related items as primary optimization targets: “orange covers larger area than blue” and “blue color presence” showed the lowest implementation scores, followed by “background” and “not cropped” items that demonstrated room for improvement.
Strategic modifications addressed each weakness through cross-persona analysis. Blue color implementation proved universally challenging—most images showed minimal blue despite explicit requirements. We increased summer blue weight from 1.2 to 1.3 while reducing orange from 1.3 to 1.1, rebalancing color dominance to enhance blue expression.
Structural optimization resolved background issues by repositioning “front view, plain background, dramatic lighting” early in the prompt and specifying “dramatic studio lighting” based on No-persona and AI Expert’s successful background implementation strategies. For garment visibility, we adopted “fashion model pose, full body shot” from high-performing personas, avoiding Fashion Designer’s runway context triggers. Style refinements transformed “one-shoulder A-line dress” to “A-line funky dress,” better capturing original requirements while adjusting structural weights for balanced attention distribution.
The systematic integration of all improvements resulted in the final optimized prompt that maintained overall coherence while addressing identified weaknesses:
“masterpiece, professional fashion photography, front view, plain background, dramatic studio lighting, (A-line funky dress:1.1), (irregular check pattern:1.1) in (vibrant orange:1.1) and (summer blue:1.3), asymmetrical ruffle detail, bias-cut layers, contemporary design, highly detailed, 8k uhd, sharp focus, full body shot, fashion model pose, fashion editorial style”
4.5. Optimized prompt performance validation
4.5.1. Checklist evaluation
We generated 40 new images using the optimized prompt under identical parameters, with representative samples in Figure 3. Checklist evaluation demonstrated statistically significant improvement over all persona-based approaches, achieving the highest total score (10.05±0.81) compared to the best baseline performance of Multi-expert (9.11±1.01) (Table 4). One-way ANOVA confirmed significant differences between approaches (F=19.7, p<0.001), with post-hoc Tukey HSD tests showing optimized prompts significantly outperformed all individual persona approaches (p<0.01 for all comparisons), representing a substantial 10.3% improvement over the Multi-expert baseline. Representative fashion design images generated by the optimized prompt (selected seed numbers: 8, 18, 28, 38).
Design Elements achieved maximum improvement, especially blue color presence and proportions. Increasing summer blue weight to 1.3 enhanced visibility but caused overcorrection in some images where blue dominated orange, contradicting the ‘orange primary color’ requirement—revealing inherent limitations in weight-based color control. Image Composition scores improved through strategic repositioning and specification refinements. Early placement of “front view, plain background, dramatic studio lighting” with enhanced specificity resolved Multi-expert’s background implementation challenges. Garment Presentation advanced through strategic full-body expression additions. Incorporating “fashion model pose, full body shot” improved garment completeness while avoiding Fashion Designer’s problematic runway context generation.
4.5.2. CLIP score evaluation
CLIP score evaluation results for persona-based and optimized prompts.
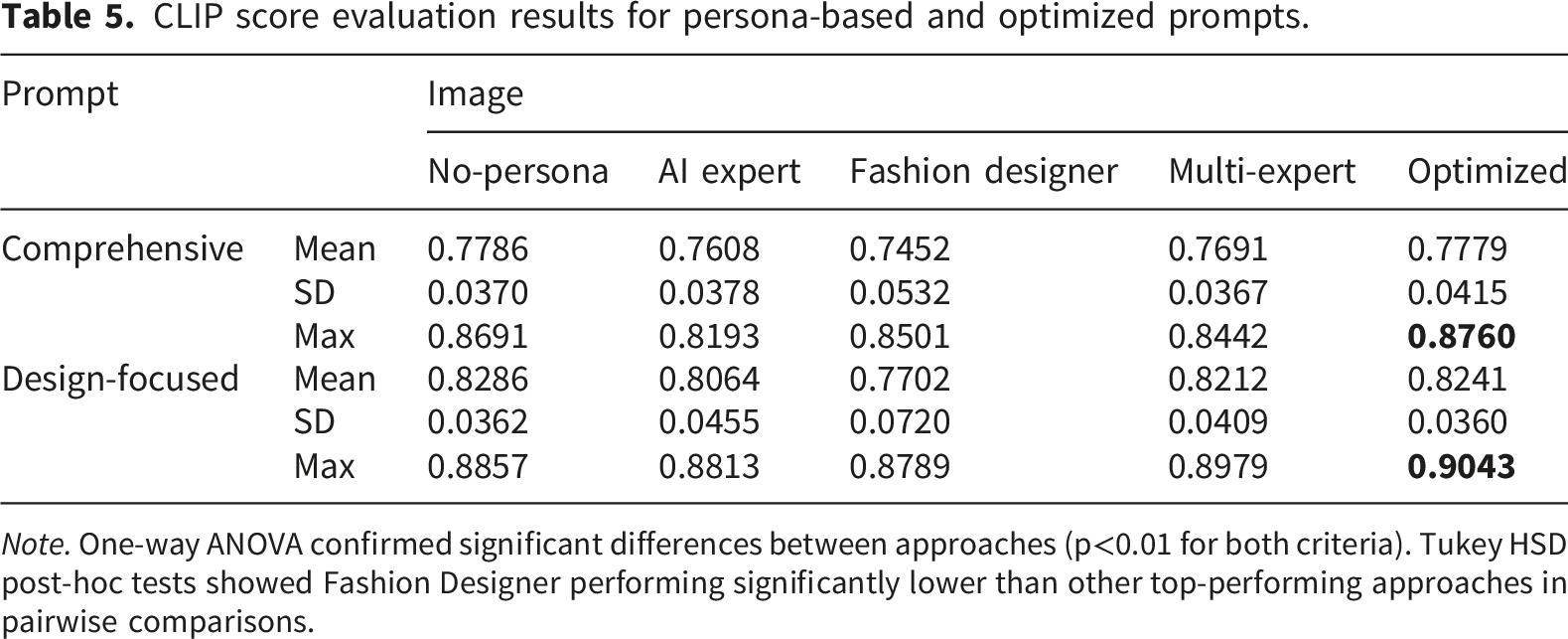
Note. One-way ANOVA confirmed significant differences between approaches (p<0.01 for both criteria). Tukey HSD post-hoc tests showed Fashion Designer performing significantly lower than other top-performing approaches in pairwise comparisons.
Despite similar average performance among top approaches, optimized prompts achieved the highest maximum scores in both criteria (0.8760 comprehensive, 0.9043 design-focused) versus No-persona (0.8691, 0.8857). This distinction proves critical for practical applications, as fashion practitioners select the best outputs from multiple generations rather than using average results, making peak quality more relevant than average consistency.
Top-performing image analysis (n=200) revealed evaluation criteria impacts (Figure 4). Comprehensive evaluation selected two Optimized and three No-persona images, while design-focused evaluation chose one each from Optimized and No-persona plus three Multi-expert images. Among the top-5 images, only the first-ranked image was selected by both evaluation criteria, with the remaining four positions showing completely different images—highlighting how reference prompts significantly affect CLIP’s image ranking. Top 5 highest-scoring images in CLIP score evaluation across all personas. (a) Comprehensive; (b) Design-focused.
Figure 4(a) favored simple backgrounds and prominent shadows, aligning with “plain background” and “dramatic lighting” requirements. However, these images featured simpler garments—only two included frills or lace—suggesting “plain” inadvertently simplified garment design. Conversely, Figure 4(b) prioritized garment complexity with four of five images featuring decorative elements, reflecting “funky” style interpretation while tolerating non-plain backgrounds. Color assessment limitations emerged across criteria. Figure 4(a) selected three images entirely lacking blue, while Figure 4(b) better captured requirements with three images displaying blue check patterns. These findings reveal CLIP’s limitations in evaluating fashion design requirements. Despite high semantic alignment scores, top-ranked images often failed to implement critical design elements, questioning CLIP’s suitability for complex creative evaluation where multiple requirements must be simultaneously satisfied.
4.5.3. ImageReward evaluation
ImageReward evaluation results for persona-based and optimized prompts.
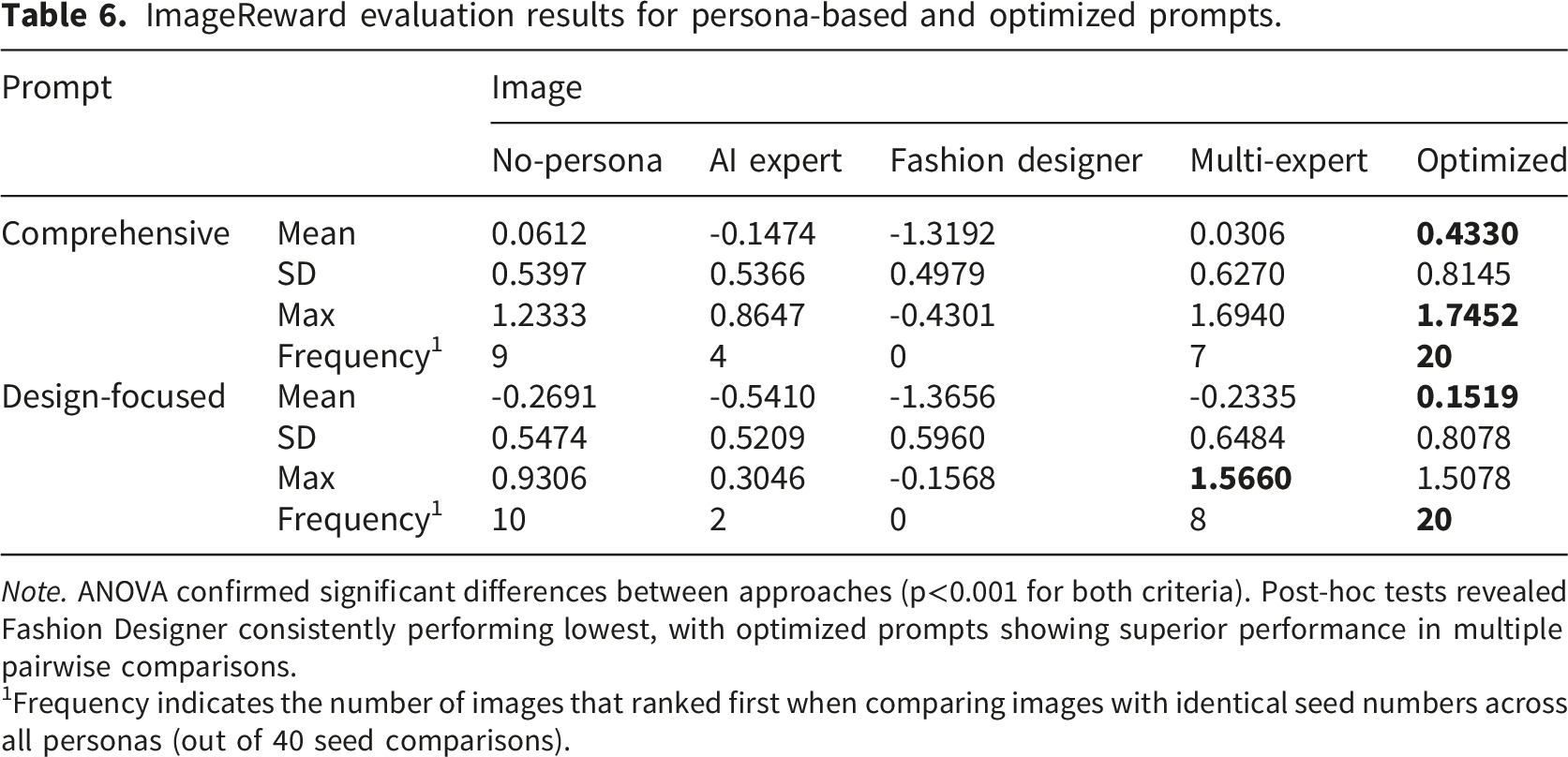
Note. ANOVA confirmed significant differences between approaches (p<0.001 for both criteria). Post-hoc tests revealed Fashion Designer consistently performing lowest, with optimized prompts showing superior performance in multiple pairwise comparisons.
1Frequency indicates the number of images that ranked first when comparing images with identical seed numbers across all personas (out of 40 seed comparisons).
Tukey HSD post-hoc tests showed optimized prompts outperformed AI Expert and Multi-expert in comprehensive evaluation, and exceeded No-persona and AI Expert in design-focused evaluation (p<0.01-0.05). Fashion Designer scored lower than all other approaches across both criteria (p<0.01), confirming poor human preference alignment despite domain expertise. These statistical findings align with frequency analysis results where optimized prompts achieved first place in 50% of head-to-head competitions (20/40 cases)—substantially exceeding random expectation (20%). Maximum scores and ranking frequency confirmed optimized prompt superiority across all ImageReward measures, indicating human preferences capture quality dimensions beyond semantic alignment that CLIP evaluation missed.
ImageReward’s top-performing images (n=200) showed remarkable consistency between criteria (Figure 5). Both comprehensive (Figure 5(a)) and design-focused (Figure 5(b)) evaluations selected four Optimized and one Multi-expert image. Four identical images appeared in both Figure 5(a) and (b) but with different ranking positions; only fifth place differed completely. Top 5 highest-scoring images in ImageReward evaluation across all personas. (a) Comprehensive; (b) Design-focused.
All selected images incorporated essential requirements: orange/blue check patterns, plain backgrounds, and funky styling with frills or lace. This comprehensive implementation contrasts CLIP’s tolerance for missing elements. Evaluation consistency despite different prompt specifications proves particularly noteworthy. Design-focused evaluation favored plain backgrounds despite lacking explicit background specifications, suggesting ImageReward implicitly enforces fashion photography standards. The model prioritizes professional presentation even when prompts specify only garment design, reflecting training bias toward clean, uncluttered fashion imagery.
5. Discussion
5.1. Prompt-image generation dynamics and implicit biases
Our framework reveals systematic biases in AI-generated imagery. All 160 images featured female models despite no gender specification—only “funky-style dress” appeared in prompts. This consistent bias reflects Stable Diffusion’s training data associations, raising concerns about gender representation in AI-assisted fashion design. Such implicit assumptions could limit creative diversity in applications requiring gender-neutral or inclusive representations.
Fashion Designer’s results exposed how domain language activates unintended model behaviors. Professional terminology like “haute couture design” and “elegant draping” triggered runway contexts in 65% of outputs without explicit mentions. While this enhanced garment visibility scores, it violated background requirements—demonstrating the double-edged nature of domain expertise. This phenomenon reveals how specialized vocabulary can activate latent biases in diffusion models, producing technically superior but contextually inappropriate results.
Performance gaps between personas challenge assumptions about expertise value in AI systems. Multi-expert’s superiority (9.11/11) over Fashion Designer (8.41/11) suggests effective AI collaboration requires understanding system interpretation patterns, not just domain knowledge. The hybrid approach balanced technical precision with fashion understanding, while pure domain expertise activated unwanted behaviors. These emergent dynamics, invisible in traditional prompt engineering, emphasize systematic evaluation’s necessity for developing predictable AI design tools.
5.2. Multi-metric evaluation challenges
Multi-metric evaluation revealed distinct patterns across assessment approaches, highlighting fundamental differences in how AI-generated creative content should be evaluated. Statistical analysis confirmed significant performance differences across all three metrics, but with varying patterns that illuminate the complexity of creative AI assessment.
Checklist and ImageReward evaluations demonstrated clear optimization advantages, with optimized prompts significantly outperforming persona approaches in objective requirement implementation (p<0.01) and human preference alignment. These metrics’ sensitivity to systematic improvement reflects their focus on measurable design specifications and perceptual quality. However, CLIP evaluation revealed more modest mean differences, with statistical significance emerging primarily from Fashion Designer’s consistently lower performance rather than clear optimization advantages among top-performing approaches.
These divergent results indicate that different metrics capture distinct quality dimensions—checklist measures objective requirement implementation, ImageReward approximates human aesthetic preferences, while CLIP focuses on semantic text-image alignment. For practical creative applications, evaluation method selection significantly influences perceived optimization effectiveness, with checklist and human preference metrics providing the most relevant assessment for design workflows where practitioners prioritize requirement satisfaction and aesthetic appeal.
5.3. Model limitations and technical constraints
Our framework analysis reveals both the interpretability advantages of systematic approaches and fundamental limitations in current text-to-image architectures. Unlike black-box optimization systems, our methodology enables tracing how linguistic patterns influence generation outcomes. This transparency proved essential for understanding how specialized vocabulary activates unexpected model behaviors, producing contextually inappropriate results that compromise design requirements.
However, optimization effectiveness encounters architectural constraints that transcend prompt engineering solutions. Color control challenges exemplify these limitations—despite systematic weight adjustments increasing blue emphasis to 1.3 while reducing orange to 1.1, precise color balance remained elusive. Some images showed overcorrection with blue dominating orange, revealing how diffusion models process color semantically rather than through direct RGB control.
These constraints emphasize that while prompt optimization achieves significant improvements in requirement implementation and human preference alignment, fundamental model limitations necessitate hybrid approaches. Effective creative AI systems require combining systematic prompt optimization with complementary techniques to address architectural constraints, suggesting directions for future research in controllable generation methods.
5.4. Implications for creative AI systems
Our findings redefine expertise requirements for AI-assisted creative work. While systematic optimization demonstrated clear advantages in objective requirement implementation and human preference metrics, effectiveness varies across different assessment approaches. Fashion professionals must develop “AI translation” skills alongside traditional expertise, learning how their specialized language triggers specific model behaviors. This paradigm shift transforms professional development needs, as success depends on bridging human creative intent with machine understanding.
Human-in-the-loop optimization preserves creative agency while leveraging AI capabilities. Unlike automated systems risking output homogenization, our method maintains designer control through transparent modification steps. Each adjustment—from weight modifications to terminology changes—remains interpretable and reversible, crucial for subjective qualities where human judgment guides optimization beyond metrics. This transparency empowers designers to develop intuition about AI behavior, gradually building prompt engineering expertise through understanding rather than memorization.
The framework enables organizational transformation of AI capabilities. Optimized prompts become reusable templates, converting individual prompt engineering skills into institutional knowledge. Organizations can develop style-specific prompt libraries aligned with brand aesthetics or seasonal themes. Different evaluation approaches serve distinct creative purposes—practical applications benefit from checklist and human preference optimization for requirement satisfaction and market appeal, while semantic alignment assessment provides insights for experimental design contexts. This flexibility allows the same framework to serve varied purposes from mainstream fashion to haute couture experimentation.
5.5. Limitations and future research directions
Several limitations emerge despite significant contributions. Color balance challenges reveal architectural constraints transcending prompt engineering solutions, necessitating hybrid approaches combining optimization with complementary techniques. Subjective aesthetic assessment limitations mirror broader computational creativity challenges. Systematic creative quality evaluation remains contentious in AI-generated content research.
The four-persona selection, while systematically designed, introduces potential biases. The personas represent Western-centric perspectives of expertise—AI Expert reflects Silicon Valley technical culture, while Fashion Designer embodies haute couture traditions. Alternative persona configurations incorporating diverse cultural perspectives, emerging design philosophies, or interdisciplinary expertise might yield different optimization patterns. Additionally, the binary distinction between technical and domain expertise oversimplifies real-world knowledge integration, where practitioners often possess hybrid competencies.
Fashion-specific validation limits generalizability claims. Creative domains possess unique vocabularies and aesthetic criteria affecting framework transferability. Future work must test cross-domain applicability and explore coupling diverse multimodal AI systems beyond LLM-image generation pairs. Workflow integration through user experience studies constitutes the critical implementation step. Real-world adoption requires understanding how designers adapt creative processes to systematic AI collaboration.
6. Conclusions
We developed and validated a systematic framework optimizing text-to-image generation through LLM personas, bridging critical gaps in AI-assisted creative workflows. Our five-stage methodology demonstrates that data-driven expertise integration achieves measurable improvements over individual approaches across multiple assessment dimensions. Optimized prompts significantly enhanced objective requirement implementation and human preference alignment while achieving superior peak performance across all evaluation criteria, though effectiveness patterns varied depending on the specific assessment approach employed.
Three key contributions emerge: First, systematic prompt optimization through weakness prioritization and strength balancing transcends trial-and-error methods. Second, empirical evidence confirms synergistic effects when combining domain and technical expertise via LLM personas. Third, comprehensive evaluation integrating objective requirements with human preferences enables robust creative content validation.
Practically, our framework democratizes high-quality AI image generation by removing expertise barriers and enabling consistent creative outputs. Fashion professionals gain systematic AI integration approaches that enhance design workflow efficiency while maintaining quality standards. The methodology enables organizations to transform individual prompt engineering insights into institutional knowledge, supporting scalable creative production across diverse application contexts.
Future research must extend cross-domain applicability, develop systematic aesthetic evaluation methods, and integrate real-world design workflows. This foundation for systematic human-AI collaboration demonstrates how effective LLM-image model coupling enhances creative capabilities while preserving human agency and professional expertise.
Footnotes
Author note
Author contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Korea Institute of Industrial Technology (SE240044) and the Technology development Program (RS-2022-00141433) funded by the Ministry of SMEs and Startups (MSS, Korea).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during the current study are available from the corresponding author upon request.