
Abstract
To address the challenges of balancing detection accuracy and computational efficiency in silk fabric defect detection, this paper proposes a lightweight model GSS-YOLOv8, designed to reduce parameter complexity while enabling real-time detection capabilities. A three-stage optimization strategy is adopted to target key bottlenecks. Firstly, in the backbone network, GhostHGNetV2 replaces the original feature extractor to enhance the feature representation of multiscale fabric defects while reducing the number of parameters. Secondly, a Slim-Neck structure is introduced, where the C2f module is replaced with VoVGSCSP and standard convolutions are substituted with GSConv, effectively reducing computational costs without sacrificing accuracy. Finally, a Shared Detail-Enhanced Head (SDEH) is designed. By sharing the parameters of two detail-enhanced convolutions, this module enhances the ability to capture fine-grained defect features and reduces parameter redundancy. The ablation experiments further evaluate the individual contributions of the GhostHGNetV2 backbone, the Slim-Neck paradigm design, and the proposed SDEH module, verifying the effectiveness of each improvement component. Additionally, experiments conducted on both the self-built silk fabric dataset and the Tianchi Fabric Defect Dataset confirm the feasibility and strong generalization capability of the proposed GSS-YOLOv8 model. The experimental results illustrate that compared with YOLOv8n, the GSS-YOLOv8 improves precision by 5.1 percentage points to 85.9% and mean average precision (mAP@0.5) by 2.1 percentage points to 86.5% with 80.0% recall, while reducing parameters by 51.3% to 1.46M, GFLOPs by 45.7% to 4.4G, and model size to only 3.7 MB, which fully meets the real-time detection requirements for silk fabric defects in industrial settings.
Keywords
1. Introduction
Fabric defects refer to flaws or imperfections during the production process, which may affect the performance or compromise the visual quality of the textile products. These defects typically manifest as color inconsistencies, surface damage, irregular shapes, or texture variations, appearing along or perpendicular to the direction of fabric movement. With advancements in spinning technology and the increasing variety and complexity of fabric types and patterns, the range of defect types has grown significantly, including issues such as holes, yarn breakage, and pattern misalignment. 1 These defects not only degrade the quality and appearance of fabrics but also lead to substantial resource waste, increased production costs, reduced market competitiveness, and significant economic losses. At present, many factories still rely on manual inspection, which is time-consuming, labor-intensive, and limited in accuracy only 60–75%, while small defects are easily overlooked. Furthermore, prolonged inspection can cause visual fatigue and negatively impact workers’ health. 2 Therefore, replacing manual inspection with computer vision–based fabric defect detection technologies is of great practical and economic significance. Such approaches can achieve high-speed, high-efficiency, and high-precision defect identification, and accelerating the intelligent transformation of the textile industry. 3
Although traditional large-scale models offer high detection accuracy, they are often computationally intensive and resource-demanding, making them unsuitable for real-time defect detection in resource-constrained environments such as edge devices or on-site factory settings. Moreover, fabric defect detection models are typically deployed on embedded systems and edge computing platforms, where computing power and memory resources are limited. As a result, developing lightweight and easily deployable defect detection models has become a prominent research focus.
More and more deep learning-based methods are applied to inspect fabric defects. These methods are mainly categorized into two types: single-stage regression-based algorithms and two-stage algorithms that involve candidate region generation and classification. Currently, Faster R-CNN, 4 Feature Pyramid Network (FPN), 5 and Cascade R-CNN 6 are considered the most effective and widely used two-stage detection algorithms in fabric defect detection. These methods typically generate a large number of region proposals using traditional image processing techniques or convolutional neural networks (CNNs), followed by classification and bounding box refinement.
However, the need to process numerous candidate regions results in high computational complexity and slow detection speed for two-stage algorithms. In contrast, single-stage algorithms perform classification and regression simultaneously using a single CNN, eliminating the proposal generation stage. Representative approaches include the Single Shot MultiBox Detector (SSD) 7 and the You Only Look Once (YOLO) series. 8 Compared with two-stage methods, single-stage detectors simplify the detection pipeline and achieve a better balance between speed and accuracy. Their advantages in fast inference, lightweight architecture, and deployment efficiency, particularly well-suited for real-time, high-throughput inspection scenarios on fabric production lines.
Among various object detection algorithms, YOLO stands out as a representative single-stage architecture with significant advantages in lightweight deployment. Compared with two-stage detectors, YOLO integrates feature extraction, region proposal generation, and classification/regression into a unified end-to-end network, greatly simplifying the detection pipeline and reducing model complexity. In particular, YOLOv8 further incorporates anchor-free structures, C2f modules, and lightweight feature fusion mechanisms, achieving a favorable trade-off between accuracy and speed. Despite these architectural advances, YOLOv8 still introduces relatively complex feature extraction and fusion modules, resulting in increased network depth, large parameter sizes, high computational complexity, and substantial memory usage. These factors pose challenges for practical deployment in industrial scenarios, especially in resource-constrained environments. Therefore, the real-time deployment performance of YOLOv8 remains limited in such settings and requires further optimization.
Based on the above observations, this paper proposes a GSS-YOLOv8 fabric defect detection algorithm designed to achieve fast and accurate real-time detection. The main contributions of this work are summarized as follows. 1. Replacing the original YOLOv8 backbone with GhostHGNetV2 significantly reduces the number of model parameters while maintaining strong feature extraction performance. 2. The Slim-Neck paradigm design is introduced into the neck network, where the VoVGSCSP module and GSConv are used to replace the C2f and standard convolution layers, respectively. This approach reduces the number of model parameters and computational complexity while maintaining model accuracy. 3. A shared detail-enhanced detection head is designed, which shares parameters between two detail-enhanced convolutions to enhance the ability to capture defect details while reducing the number of detection head parameters and further simplifying the network.
2. Related works
This section briefly reviews related studies on fabric defect detection and lightweight model design.
2.1. Traditional detection methods
Since the 1980s, fabric defect detection has progressed from traditional image processing techniques to advanced deep learning-based approaches. Early methods are generally classified into four categories: model-based, spectral analysis-based, statistical, and structural approaches.9,10 Model-based methods treat fabric textures as stochastic processes and detect defects by evaluating deviations from a learned texture model, 11 such as autoregressive models 12 or Markov random field models. 13 Spectral methods—such as Fourier, 14 wavelet, 15 and Gabor transforms 16 —leverage the periodic nature of fabric patterns by analyzing frequency-domain features. Statistical methods compare feature distributions between normal and defective regions, using tools like histograms, gray-level co-occurrence matrices, and morphological operations. 17 Structural methods extract handcrafted features based on the repetitive primitives within fabric textures. 18
Deep learning models, particularly convolutional neural networks (CNNs), have demonstrated superior performance in fabric defect detection by leveraging end-to-end training and robust feature extraction. These approaches are mainly divided into two categories: two-stage algorithms and single-stage algorithms. Chen et al. 19 embedded Gabor kernels into the Faster R-CNN framework to perform frequency-domain analysis and proposed a two-stage training strategy combining a genetic algorithm with backpropagation to optimize the model. Liu et al. 20 were the first to apply the SSD model to fabric defect detection and improved its performance for small defect identification by adding a third feature layer, making the enhanced SSD more suitable for this task. Su et al. 21 incorporated squeeze-and-excitation (SE) modules into the FPN structure of the YOLOX network, achieving a 2.7% improvement in detection accuracy across eight fabric defect datasets while maintaining real-time performance. Si et al. 22 developed a YOLOv8-based model by integrating the RepGhost module and introducing a novel information redistribution mechanism. They further employed Wasserstein distance loss to optimize localization of small objects, resulting in an 18.9% accuracy improvement on the AITEX dataset, albeit at the cost of increased model complexity.
2.2. Works on lightweight
Although the aforementioned methods have achieved significant progress in improving detection accuracy, they still face considerable challenges in lightweight deployment. Existing models generally pursue higher precision by introducing deeper and more complex network architectures, which inevitably leads to an excessive number of parameters and high computational overhead, thereby restricting their applicability to real-time scenarios on embedded or edge industrial devices. Current research on lightweight optimization has mainly focused on three mainstream detection frameworks, namely YOLO, SSD, and Faster R-CNN, while this paper concentrates on the YOLO framework to conduct lightweight exploration.
Some researchers have concentrated on improving the backbone network of YOLOv8 to achieve lightweight design and reduce computational complexity while maintaining robust feature extraction capabilities. Tie 23 reconstructs the YOLOv8n main core network, using low computing KWConv to reconstruct the network’s Bottleneck, C2f, and use BiFPN character integration method to enhance the context information on the model, effectively reducing the number of model parameters and computing requirements. Ma et al. 24 introduced GhostNet to replace the YOLOv8 backbone network, substituting the original Conv layers with GhostConv and the original C2f layers with C3Ghost, thereby reducing computation and inference time while maintaining the accuracy and integrity of feature representation. Liu et al. 25 adopted the MobileNetv3 model to replace the C3 modules and convolutional modules in the YOLOv8 backbone, enabling the model to achieve a lightweight design while maintaining high detection accuracy.
Other works have focused on optimizing the neck structure to enhance multi-scale feature fusion efficiency and improve the detection performance for small targets. Xu et al. 26 integrated a lightweight adaptive downsampling (ADOWN) convolution module to reduce dimensionality and achieve high processing efficiency. Ma et al. 27 adopted a feature fusion network structure that combines a small-target detection head with a bidirectional feature pyramid network (SBiFPN) to capture the multi-scale information of defects, enhance the model’s feature fusion capability. In addition, some studies have aimed at refining the detection head of YOLOv8 by simplifying its structure, reducing computational overhead, and further improving detection accuracy. An et al. 28 replaced the original Decoupled Head with a Shared Lightweight Convolutional Detection (SLCD) Head, reducing the model’s computational complexity while increasing detection accuracy. Wang et al. 29 replaced the original detection head with a more efficient LADH detection head and removed the head processing 32×32 feature maps, effectively reducing the model complexity and significantly improving detection accuracy.
Although existing lightweight fabric defect detection methods have made notable progress in reducing model complexity and improving detection accuracy, most have optimized only a single module, and still suffer from large parameter sizes, high computational complexity, and considerable memory consumption, which limit their application in real industrial environments. To overcome these shortcomings, this paper proposes a systematic lightweight optimization strategy applied to the backbone, neck, and detection head, aiming to reduce computational complexity and memory usage while maintaining real-time detection performance, thereby improving adaptability to various production conditions.
3. Methods
This section presents the overall architecture of the proposed fabric defect detection model, GSS-YOLOv8. Then, it provides a detailed description of the GhostHGNetV2 feature extraction backbone, the Slim-Neck feature fusion network, and the shared detail-enhanced detection head.
The YOLO series algorithms are typical representatives of single-stage approaches in the field of object detection. YOLOv8 mainly consists of four components: the input module, backbone network, neck network, and detection head. The backbone is composed of convolutional layers, C2f modules, and the SPPF module. The C2f module is an optimized version of the C3 structure in YOLOv5, featuring double convolution and multi-branch connections to enhance gradient flow. Inspired by the ELAN module in YOLOv7, parallel branches are introduced to improve feature representation capability. The SPPF module expands the receptive field through multi-scale pooling. The neck adopts a PAN-FPN structure to achieve multi-scale feature fusion. The head employs a decoupled structure with an anchor-free mechanism and incorporates Distribution Focal Loss and Task Aligned Assigner to optimize training and improve detection performance. However, YOLOv8 introduces a complex feature extraction and fusion structure, leading to increased network depth, a large number of parameters, high computational complexity, and significant memory consumption, which impose certain limitations in practical industrial applications.
Therefore, this paper proposes the GSS-YOLOv8 model to achieve lightweight detection of fabric defects. Ghost convolution is introduced to optimize the HGBlock, resulting in the creation of Ghost_HGBlock. GhostHGNetV2 replaces the original backbone network and serves as the model’s feature extraction network. This enhances the model’s ability to independently learn cross-channel features and further capture local features of defect images, thereby improving its representation capability for fabric defect characteristics while effectively reducing the number of parameters in the backbone. Secondly, in the feature fusion stage, lightweight GSConv is employed to replace the original convolutional kernels, and the Slim-Neck feature fusion network is introduced. This enables each feature layer to simultaneously consider the semantic information of deep features and the fine-grained details of shallow features. The model is thus simplified and computational complexity reduced, while maintaining detection accuracy. Finally, a shared detail-enhanced detection head (SDEH) is designed. By sharing convolutional parameters, the convolutional computation of multi-scale feature maps during detection is reduced, which decreases the number of parameters in the detection head and further simplifies the overall network, making it more suitable for deployment. The architecture of the improved GSS-YOLOv8 model is shown in Figure 1. The structure diagram of the GSS-YOLOv8 algorithm.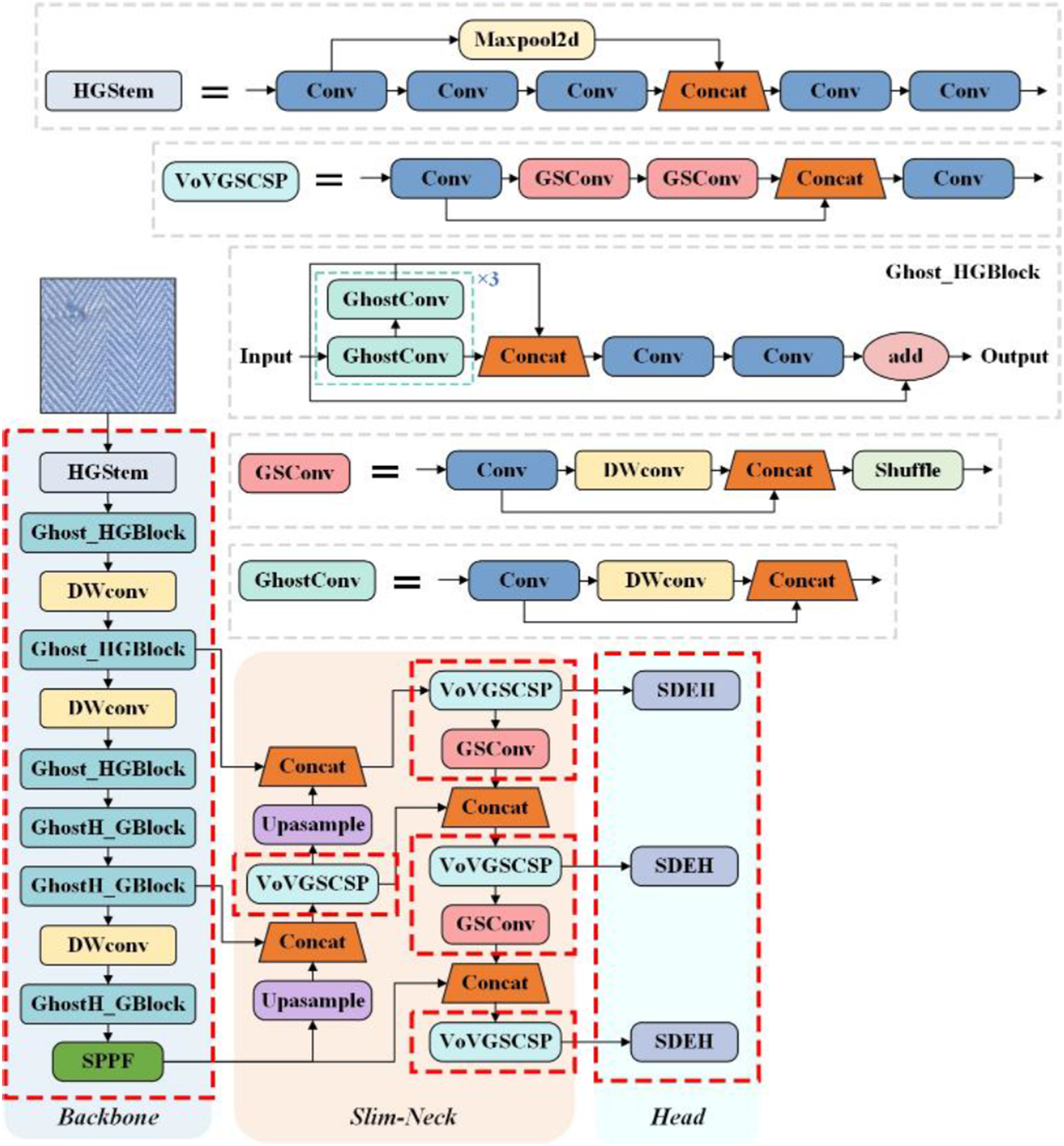
3.1. GhostHGNetV2 feature extraction network
The original YOLOv8 backbone adopts a deep convolutional structure with many standard convolutions and C2f modules, resulting in relatively high computational cost and parameter redundancy. As the network depth increases, the computational burden becomes heavier, which limits its suitability for real-time inference and edge deployment. To address this issue, GhostHGNetV2 is introduced as the backbone of the proposed model. Based on the HGNet architecture in RT-DETR, 30 GhostHGNetV2 employs Ghost convolution 31 to optimize the convolutional layers in HGBlock and constructs the proposed Ghost_HGBlock. In addition, standard convolutions and C2f modules in the original YOLOv8 backbone are replaced with Ghost_HGBlock and depthwise separable convolution, thereby reducing model complexity while preserving effective feature extraction capability. As shown in Figure 1, GhostHGNetV2 mainly consists of HGStem, Ghost_HGBlock, depthwise separable convolutions, and the SPPF module.
HGStem serves as the initial preprocessing layer of the network, performing preliminary feature extraction from the input image using convolution operations. It applies max pooling to downsample and reduce dimensionality, enabling the capture of multi-scale features. The workflow of the HGStem module is shown in Figure 2(a). Flow diagram of HGStem and HGBlock.
The specific process is expressed by the following equation:



HGBlock is used for feature extraction, as shown in Figure 2(b). It employs convolutional layers of different sizes to capture multi-scale features, followed by channel compression and feature reweighting. Through this process, the module enhances important features and improves the representation of hierarchical and contextual information.
Ghost convolution uses inexpensive linear transformations to generate additional “Ghost” feature maps from intrinsic features, thereby enriching feature representation at low cost, as shown in Figure 3. Specifically, a standard 1×1 convolution is first applied to compress the channels and produce the intrinsic feature maps. Then, a series of simple linear operations Cn, implemented by depthwise separable convolutions, are used to generate additional Ghost feature maps. Finally, the intrinsic and Ghost feature maps are concatenated to form the output feature maps. In this way, Ghost convolution effectively reduces the computational cost of conventional convolution while accelerating model inference. The structure diagram of Ghost convolution.
The process framework of Ghost_HGBlock is shown in Figure 4. The input features are fused using multiple Ghost convolutions followed by a Concat operation. Then, two standard 1×1 convolutions are applied to adjust the size of the output feature maps, extract local information, and improve the detection accuracy for tiny and sparse fabric defects. The specific implementation is described by the following formula: The structure diagram of Ghost_HGBlock.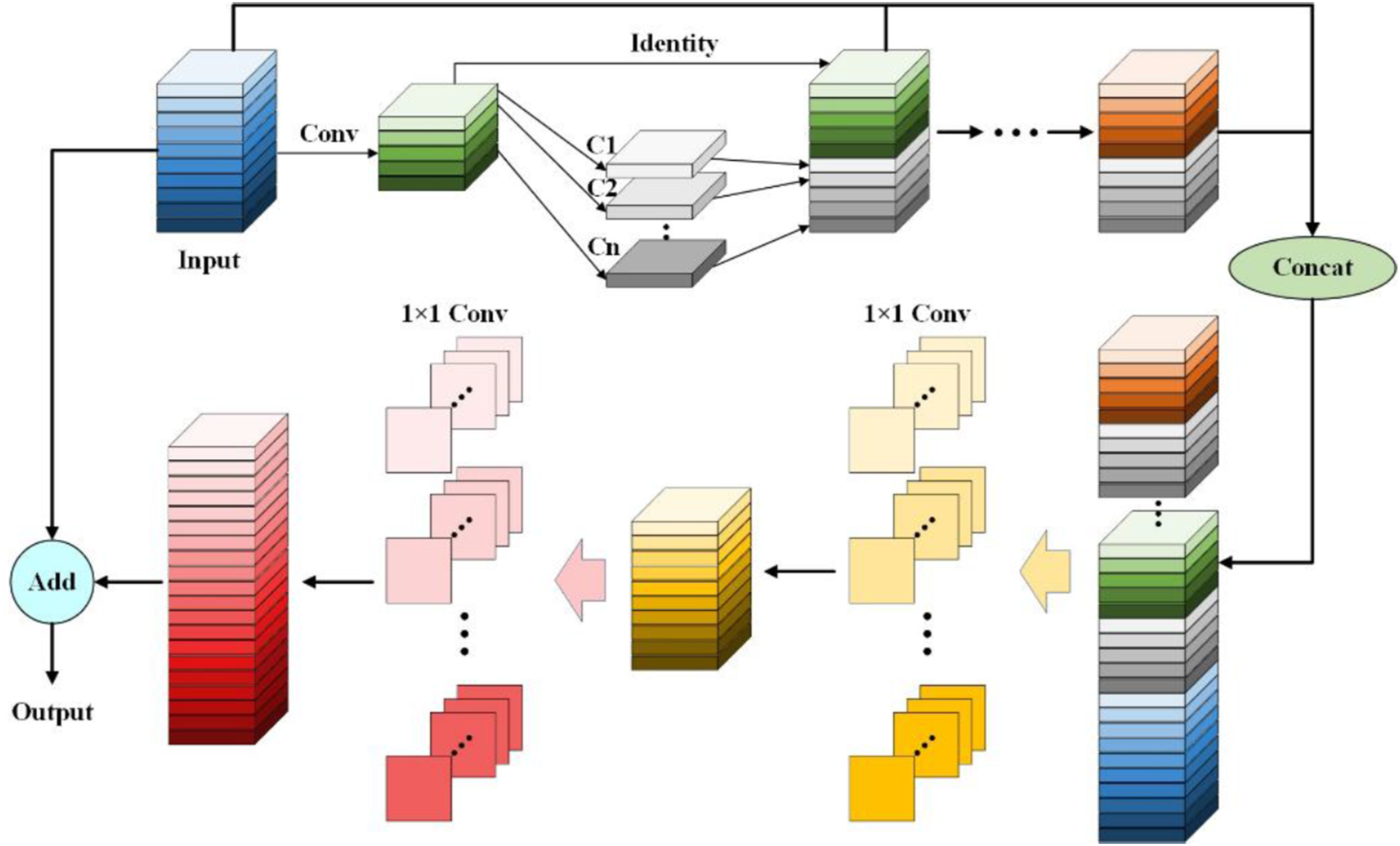

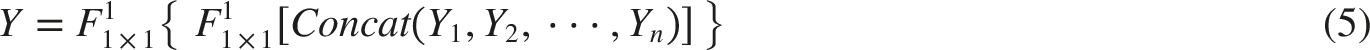
Depthwise separable convolution is a combination of depthwise convolution and pointwise convolution, as illustrated in Figure 5. In pointwise convolution, each kernel performs a weighted combination of the feature maps produced by the depthwise convolution along the channel dimension, generating new feature maps. Each kernel corresponds to one output channel, enabling both cross-channel feature fusion and adjustment of the number of output channels. The structure diagram of the depth-separable convolution.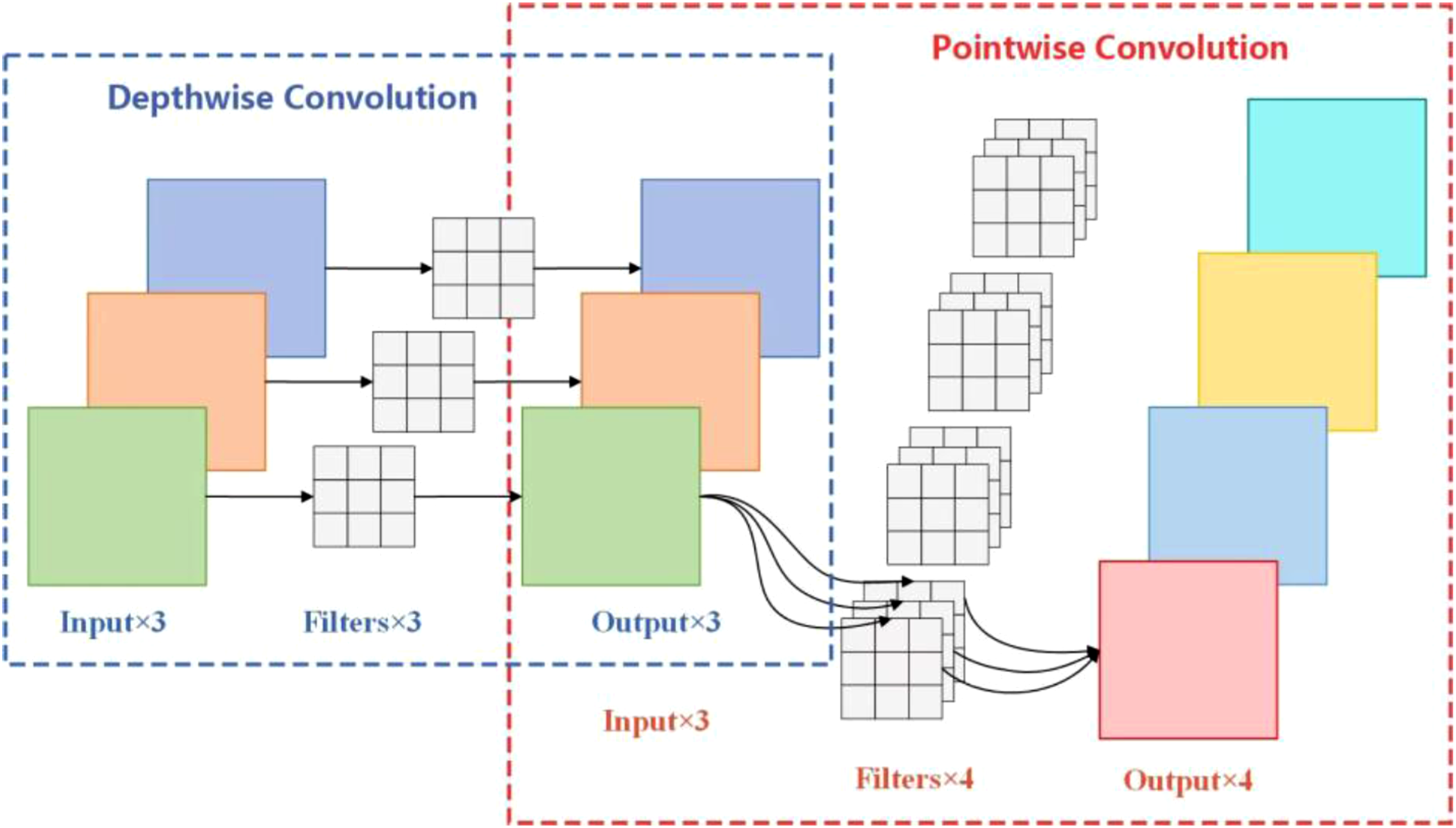
The parametric quantities of the standard convolution and the depth-separable convolution are calculated separately by the following equations:



3.2 Slim-Neck feature fusion network
YOLOv8 uses many standard convolutions in its neck network for feature fusion, which increases inference time and computational cost. To address this issue, the Slim-Neck design is introduced into the neck of YOLOv8. Slim-Neck is a lightweight feature fusion network mainly composed of GSConv, GS Bottleneck, and VoVGSCSP, which can be flexibly combined to construct an efficient neck architecture. In this design, GSConv is used to replace standard convolutions. As shown in Figure 6, GSConv combines standard convolution, depthwise separable convolution, and channel shuffle operations. It concatenates features generated by standard and depthwise separable convolutions, and then uses channel shuffle to enhance cross-channel information interaction, enabling the output of depthwise separable convolution to better approximate that of standard convolution. The computational cost of GSConv is about 50% of that of standard convolution, while maintaining comparable feature learning ability. The structure diagram of GSConv:The blue labeled “Conv” denotes standard convolution; the pink labeled “DWConv” denotes depth separable convolution.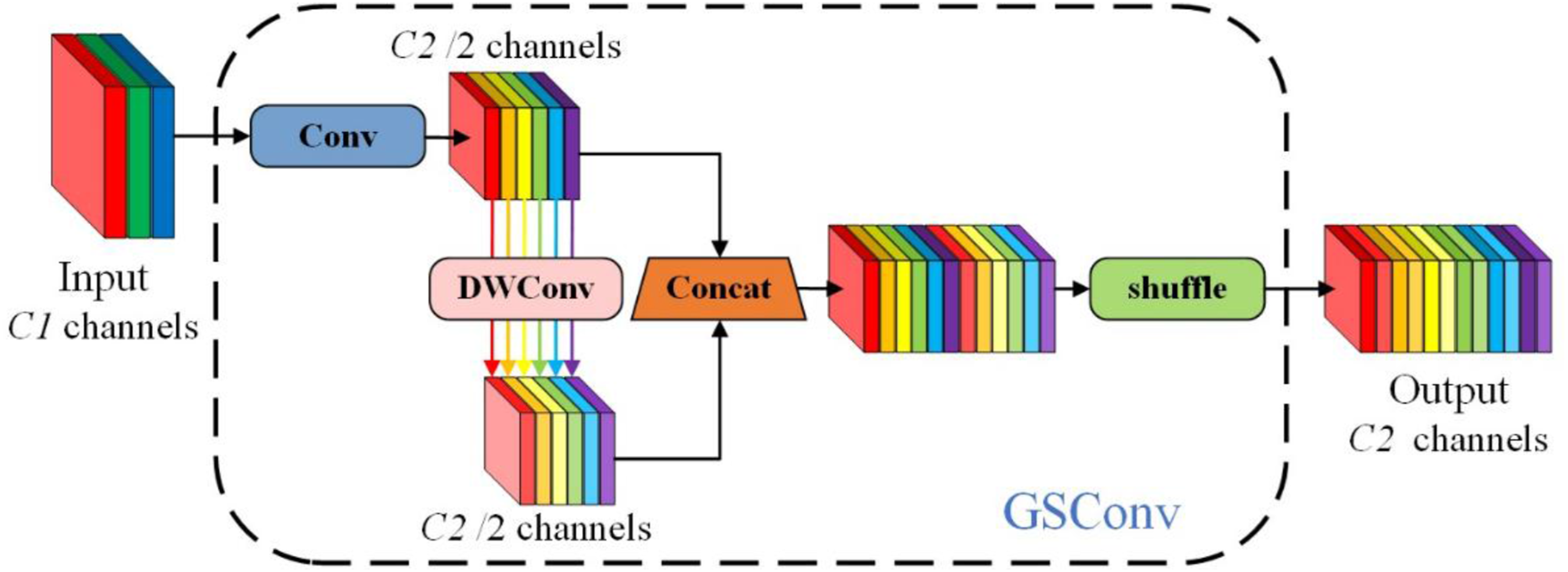
Secondly, based on GSConv, Slim-Neck further incorporates the GS Bottleneck module to further reduce the model’s computational load, as illustrated in Figure 7(a). In addition, a one-time aggregation strategy is adopted to design an efficient cross-stage partial (CSP) module, VoVGSCSP, which aims to reduce computational complexity and inference time while maintaining accuracy. The structure of VoVGSCSP is shown in Figure 7(b). The structure diagram of GS bottleneck and VoVGSCSP.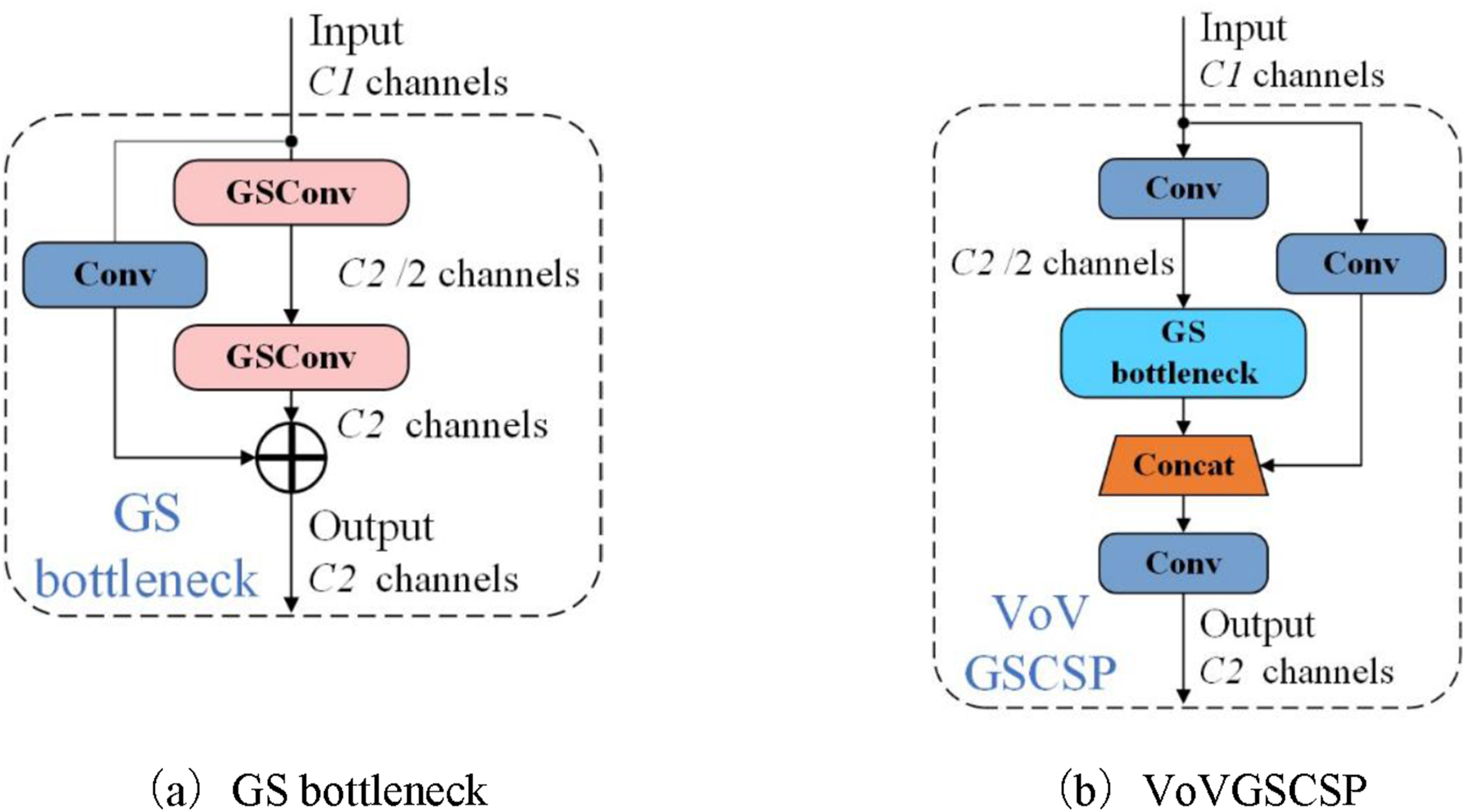
The architecture of the complete Slim-Neck feature fusion network is shown in Figure 8. In this structure, the VoVGSCSP module and GSConv module replace the C2f and standard convolution in the original YOLOv8 neck, respectively, while retaining the original FPN-PAN architecture unchanged. Comparison of original YOLOv8 neck structure and Slim-Neck structure.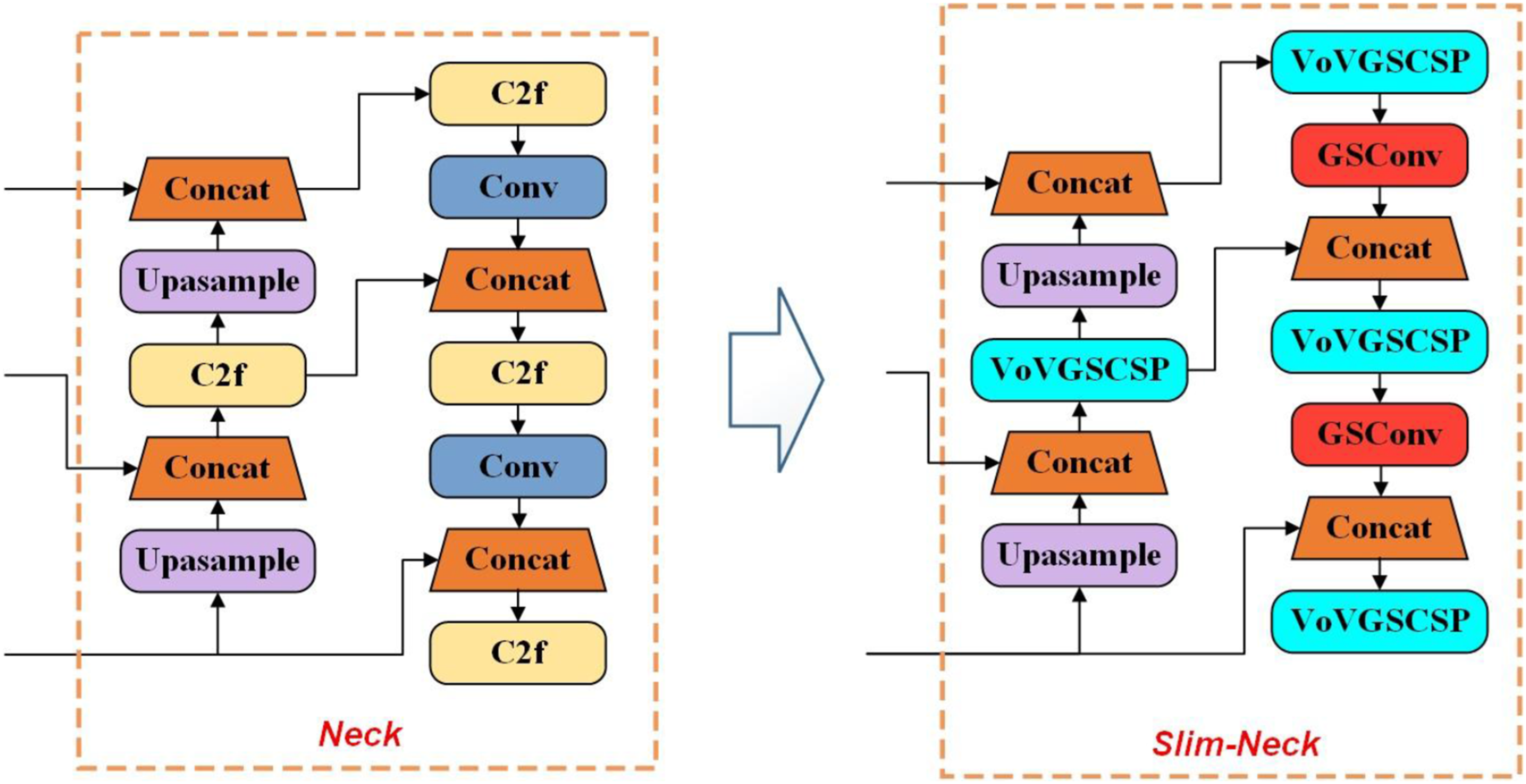
3.3 SDEH
The original detection head of YOLOv8 performs detection on feature maps of three different scales (P3, P4, and P5), each of which requires an independent detection head that performs separate convolutional computations to adjust channels and extract features. As a result, the detection head includes multiple standard convolutional layers, leading to an increase in the number of model parameters and high computational overhead. To address these issues, this paper proposes a shared detail-enhanced detection head (SDEH), which aims to reduce the amount of convolutional computation across different-scale feature maps during detection by sharing convolutional parameters. The SDEH consists of the following three main strategies.
The Batch Normalization (BN) method in convolution is replaced by Group Normalization (GN)
32
to solve the problem of BN increasing the explicit memory due to storing the mean and variance.The batch size of BN affects the model error, which is limited by memory consumption, and GN does not need to store additional parameters, which can be used to inference in small batches of data to maintain stable performance and reduce computational overhead, which is more suitable for deployment on lightweight devices. In addition, due to the characteristics of fabric defects with tiny and high similarity to the background, silk fabric images tend to have high resolution, while GN avoids the feature distortion problem of BN normalization at high resolution, is more robust to high resolution detection, and enhances the model’s adaptability to multi-scale features. A comparison of the BN and GN normalization methods is shown in Figure 9. Normalization methods for BN and GN.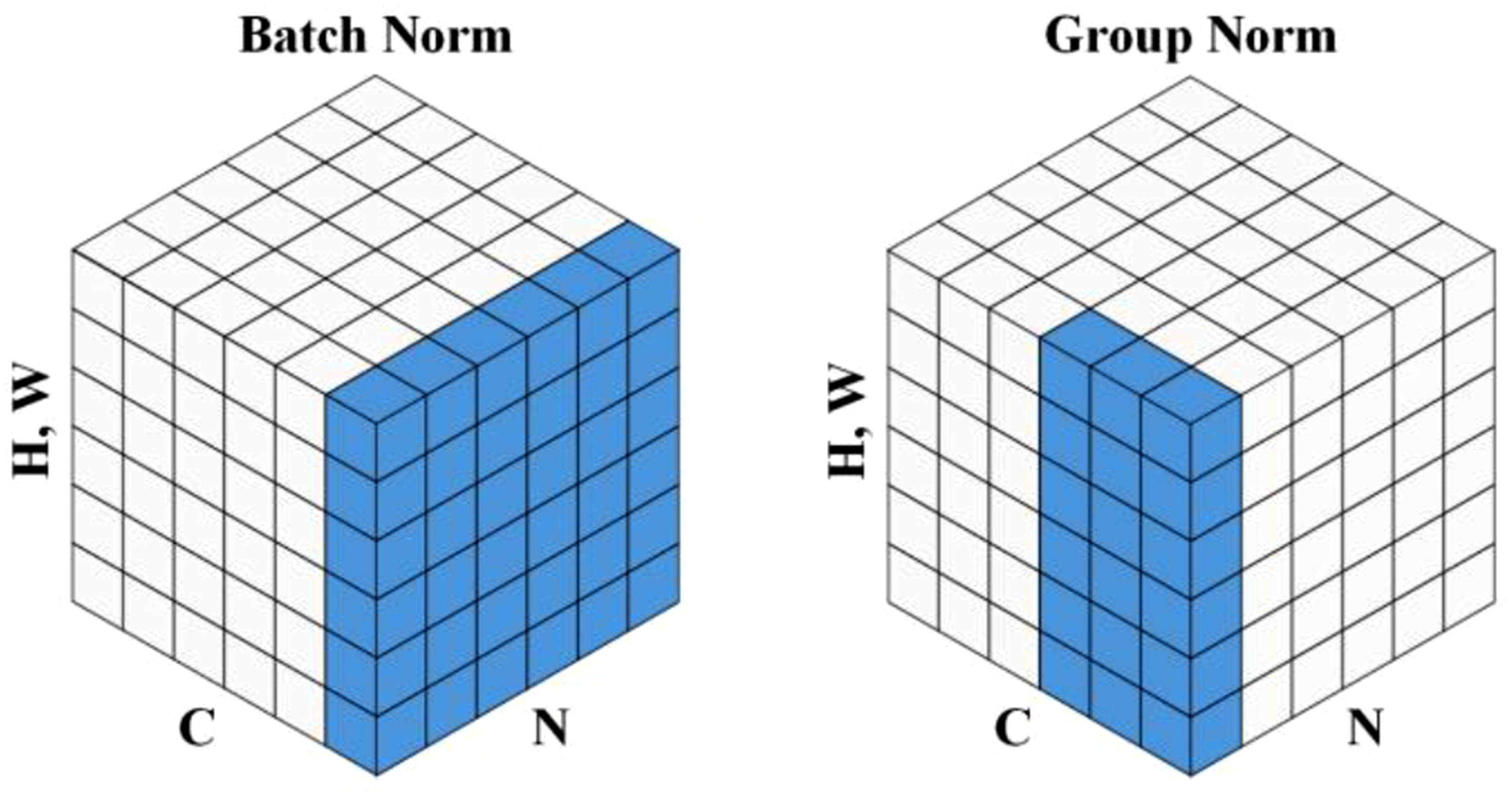
GN groups the channel directions and then normalization is done within each group.The GN feature normalization method performs the following calculations:




Detail-Enhanced Convolution (DEConv)
33
is introduced to construct a shared convolutional layer, which integrates the semantic and contextual information contained in the feature maps captured by the three detection heads at different scales, thereby generating prediction boxes and classification targets. By sharing the weight parameters of the convolutional layers, the model’s efficiency and accuracy are improved, while memory consumption and redundant computational overhead are reduced. Detail-Enhanced Convolution (DEConv) integrates prior information into standard convolutional layers. It combines the learned features from five parallel convolutional branches to generate the final output, thereby enhancing the model’s representational and generalization capabilities. Its structural diagram is shown in Figure 10. By leveraging re-parameterization techniques, DEConv is able to extract richer features without increasing the number of parameters, and without adding additional computational or memory burden during the inference stage. The specific formula for the re-parameterized reconstruction of the layer is as follows: The structure diagram of the enhanced detail convolution:VC, CDC, ADC, VDC, and HDC are the five parallel convolutional layers in the enhanced detail convolution.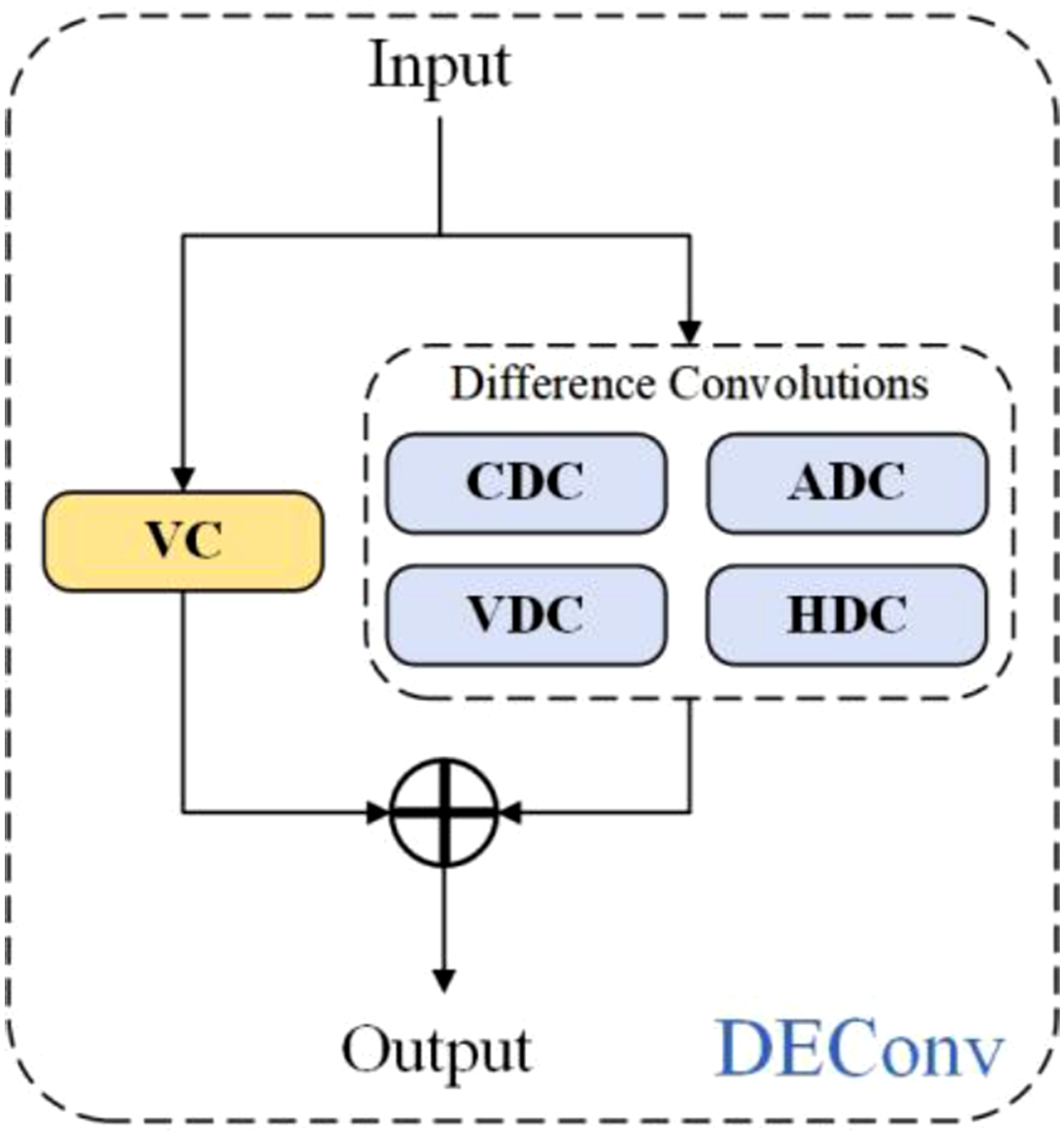

When using a shared convolutional layer, the target scales detected by each detection head may be inconsistent. To address this issue, a Scale layer is introduced to rescale the features. By adjusting the scale of the features, it helps improve the stability of model training. The structure of the shared detail-enhanced detection head (SDEH) is illustrated in Figure 11. The structure diagram of the SDEH.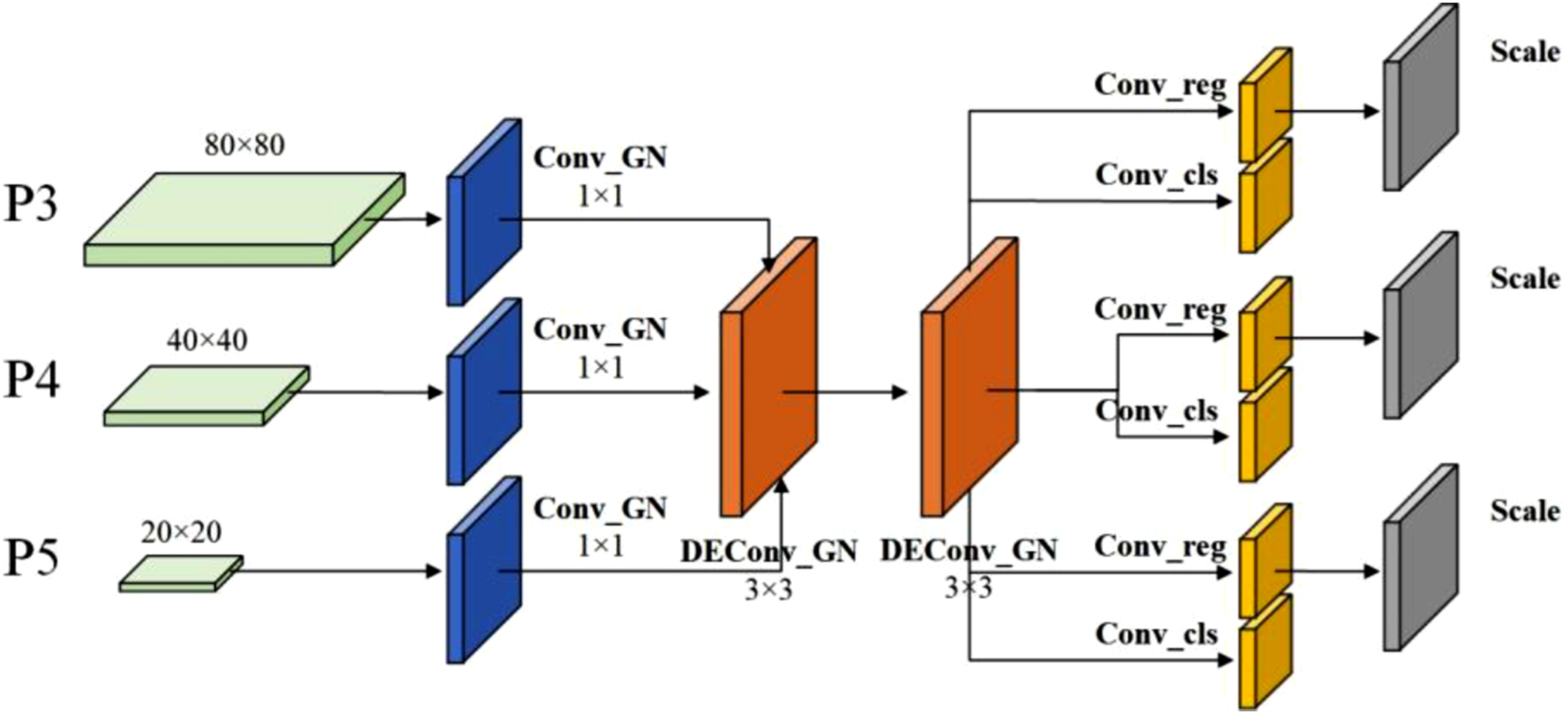
The SDEH module receives three feature maps of different scales (P3, P4, and P5) from the neck network. To integrate the feature information effectively, three 1×1 convolutional layers with Group Normalization are applied respectively to adjust the number of channels for each feature map. Then, two weight-shared 3×3 Detail-Enhanced Convolutions are used to enhance the model’s representational capacity, aggregating rich contextual and multi-scale information while reducing the overall number of parameters. Finally, a 1×1 standard convolution is employed to decouple the computation of classification and regression losses. In addition, a Scale layer is added after each regression branch to dynamically adjust the target scale, thereby addressing the discrepancies in target sizes handled by different detection heads.
4 Experimental results and analysis
4.1 Dataset
The experimental images for this dataset were collected from Guangde Xinfeng Silk Co. Ltd. and the Shengzhou Innovation Research Institute of Zhejiang Sci-Tech University, with defect images captured using high-resolution mobile devices. The silk fabrics primarily consist of Songjin, a brocade-like fabric made with pure mulberry silk or mulberry silk warp. The dataset contains nine types of silk fabric defects: Broken thread, Grease stain, Cracked tangle, Tight warp, Bar, Thick streak, Filament turndown, Sloughed-off weft and Missing end, comprising 677 high-resolution images (3000×3000 pixels), as shown in Figure 12. Image of defects in silk fabric.
Class distribution of the self-built silk fabric defect dataset.

4.2. Experimental details
Experimental parameters.

4.3. Evaluation indicators
In this paper, the evaluation metrics for model performance are precision (P), recall (R), mean Average Precision at IoU threshold 0.5 (mAP@0.5), floating-point operations (GFLOPs), FPS, and the formulas for precision and recall are as follows:




The calculation formula for FPS is as follows:
4.4. Ablation experiment
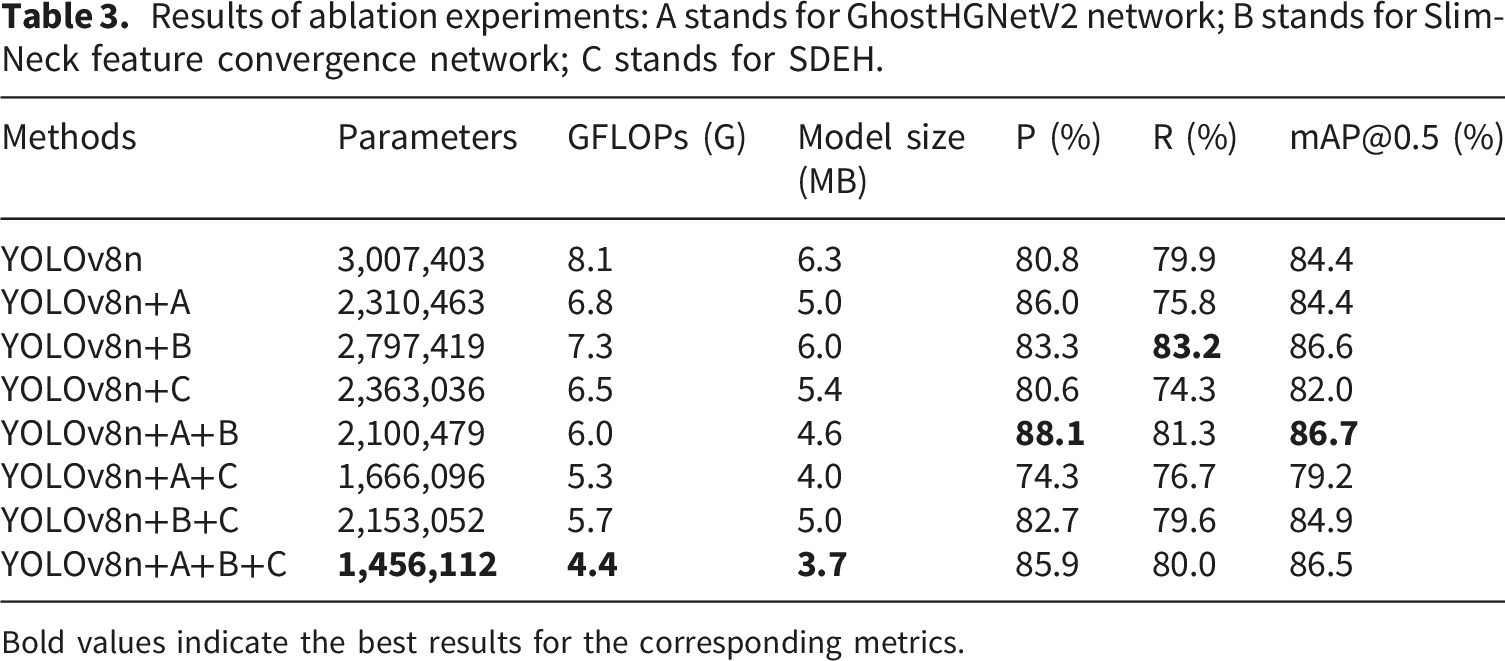
Results of ablation experiments: A stands for GhostHGNetV2 network; B stands for Slim-Neck feature convergence network; C stands for SDEH.
Bold values indicate the best results for the corresponding metrics.
As shown in the ablation results in Table 3 and the dual Y-axis bar-line chart of parameter count and GFLOPs in Figure 13, replacing the original YOLOv8n backbone with the A (GhostHGNetV2) structure resulted in a 23% reduction in the number of parameters and a 16% decrease in computational cost. This improvement is attributed to the design of GhostHGNetV2, which integrates Ghost convolution with the lightweight HGNet architecture. Specifically, the use of depthwise separable convolutions avoids cross-channel computations, while the Ghost_HGBlock module reduces the number of channels, enabling feature extraction with fewer parameters and effectively minimizing computational redundancy. In addition, GhostHGNetV2 leverages the linear operations of the Ghost module to capture richer feature representations. Despite the reduction in model complexity, the improved network maintains an mAP@0.5 of 84.4%, with a 5.2% increase in precision, indicating that GhostHGNetV2 achieves strong detection performance while significantly improving computational efficiency. However, since the optimization primarily targets the backbone, the model exhibits limitations in identifying certain complex and subtle silk fabric defects, resulting in a 4.1% drop in recall. Different number of modular parameters and GFLOPs.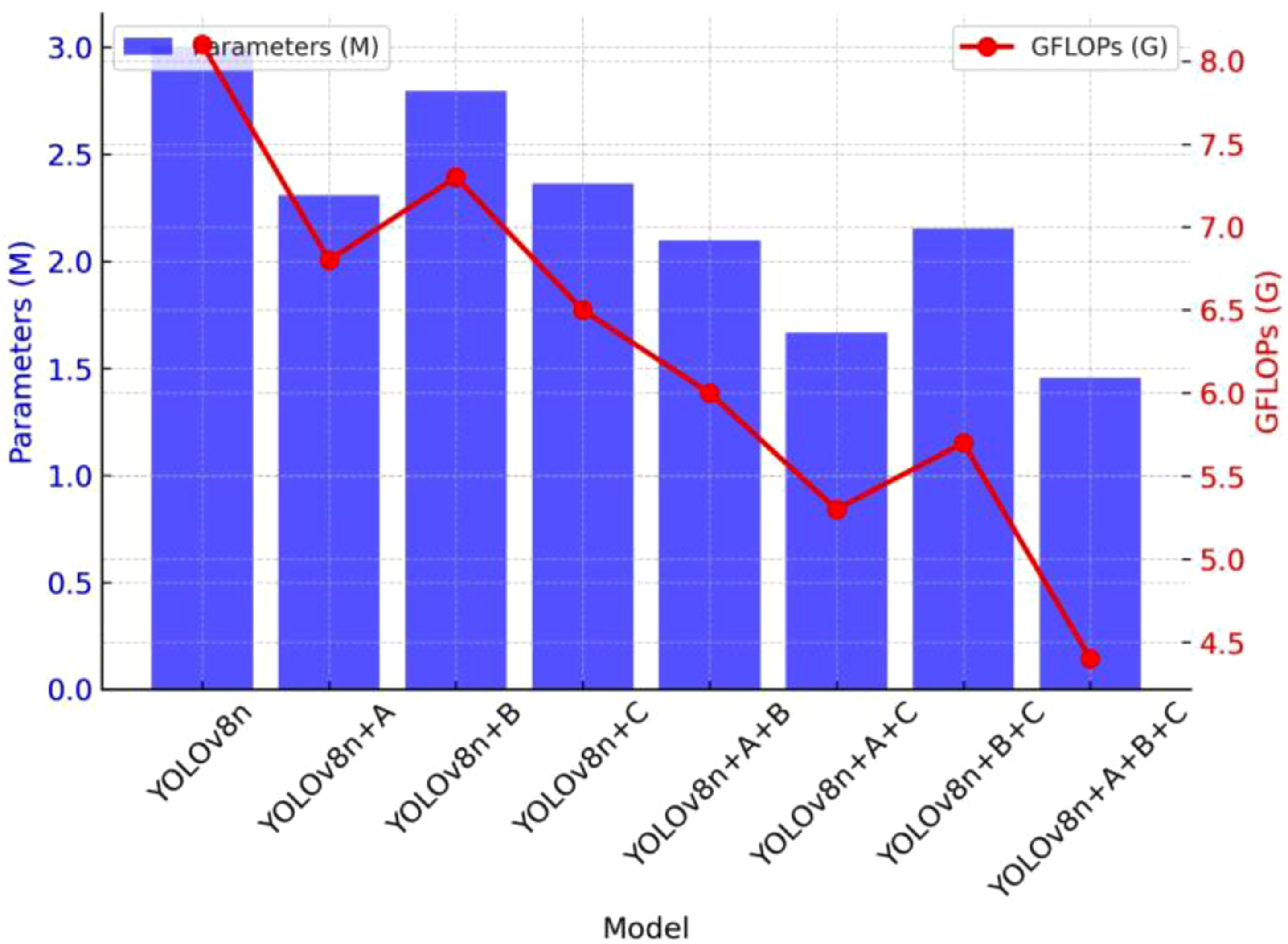
By introducing the B (Slim-Neck paradigm) design after the backbone network, feature fusion is optimized, enabling high-level features to be transmitted more effectively to the detection head while simultaneously reducing computational complexity. Compared with the baseline model, this improvement leads to a 2.2% increase in mAP@0.5 and a 3.3% increase in recall, significantly enhancing the model’s ability to detect silk fabric defects.
The proposed C (SDEH) is applied to optimize the detection head, reducing the number of parameters by 21.3% through parameter sharing in convolutional layers, and decreasing the computational cost by 19.8%. Meanwhile, the use of DEconv in the detection head enhances the model’s ability to capture fine-grained defect details. However, a slight decline in detection accuracy is observed, which may be attributed to the limited adaptability of the detection head to defects with relatively large annotation regions, such as Grease stain and Cracked tangle, that are present in the silk fabric dataset.
The A+B combination achieves better overall detection performance, indicating a strong complementarity between the two modules. Module A mainly operates at the backbone feature extraction stage, improving cross-channel feature modeling efficiency and local defect representation capability. However, its lightweight compression may also weaken part of the fine-grained information, thereby reducing the model’s feature representation capability and leading to a decrease in recall. Module B mainly operates at the neck feature fusion stage and can more effectively fuse shallow texture details with deep semantic information, thus compensating for the detail loss caused by feature compression in A. For silk fabric defects, which are typically small in scale, weak in texture, and highly similar to the background, module A provides more efficient feature extraction, while module B enhances cross-level feature transmission and fusion. Therefore, the combination of the two achieves better overall detection performance while maintaining lightweight characteristics, demonstrating a strong synergistic effect.
The A+C combination leads to a decline in detection performance, suggesting that these two modules do not form effective synergy under the current task setting. Module A mainly operates at the backbone feature extraction stage. Although it improves feature extraction efficiency and reduces model complexity, its lightweight compression may also weaken part of the fine-grained information. Module C mainly operates at the detection head stage. By sharing convolutional parameters, it reduces redundant computation, but at the same time it may limit the independent adaptability of different-scale detection branches to some extent. For silk fabric defects, which are typically small in scale, weak in texture, and highly similar to the background, the combination of A and C is more likely to cause insufficient detail representation and inadequate scale adaptation when no feature-fusion compensation from module B is provided. As a result, precision, recall, and mAP@0.5 all decrease.
The detection performance of the B+C combination is generally comparable to that of the baseline. This is because module B improves feature representation by enhancing the fusion of shallow details and deep semantic information, while module C, although reducing redundant computation in the detection head, also imposes some constraints on the independent adaptability of different-scale detection branches. As a result, the performance gain brought by B partially compensates for the limitation introduced by C, allowing this combination to maintain detection performance close to the baseline while remaining lightweight.
Experimental results show that the GSS-YOLOv8 model with the A+B+C configuration achieves strong overall performance while reducing computational complexity, parameter count, and model size. Compared with the baseline YOLOv8n, GSS-YOLOv8 improves precision by 5.1% to 85.9%, while maintaining a recall of 80.0%. mAP@0.5 increases from 84.4% to 86.5%, corresponding to a gain of 2.1%. In addition, the number of parameters is reduced by 51.3% to 1,456,112, the computational cost decreases by 45.7% to 4.4 GFLOPs, and the model size is further reduced to 3.7 MB. Although the A+B combination achieves better detection performance, the A+B+C configuration further reduces parameter count, GFLOPs, and model size while maintaining competitive accuracy. Therefore, from an overall perspective, GSS-YOLOv8 achieves a better balance between detection performance and lightweight deployment requirements, making it suitable for industrial silk fabric defect detection applications.
4.5. Comparison with YOLOv8 performance
To evaluate the effectiveness of the lightweighting strategy adopted in GSS-YOLOv8, we conduct a visual comparison of the number of parameters and computational cost between each module of GSS-YOLOv8 and the original YOLOv8 model. As shown in Figure 14, the comparison covers the backbone, neck, detection head, and the overall network architecture, clearly illustrating the reduction in both parameter count and computational complexity achieved by the proposed lightweight design. Comparison of parameter counts and GFLOPs of each model component.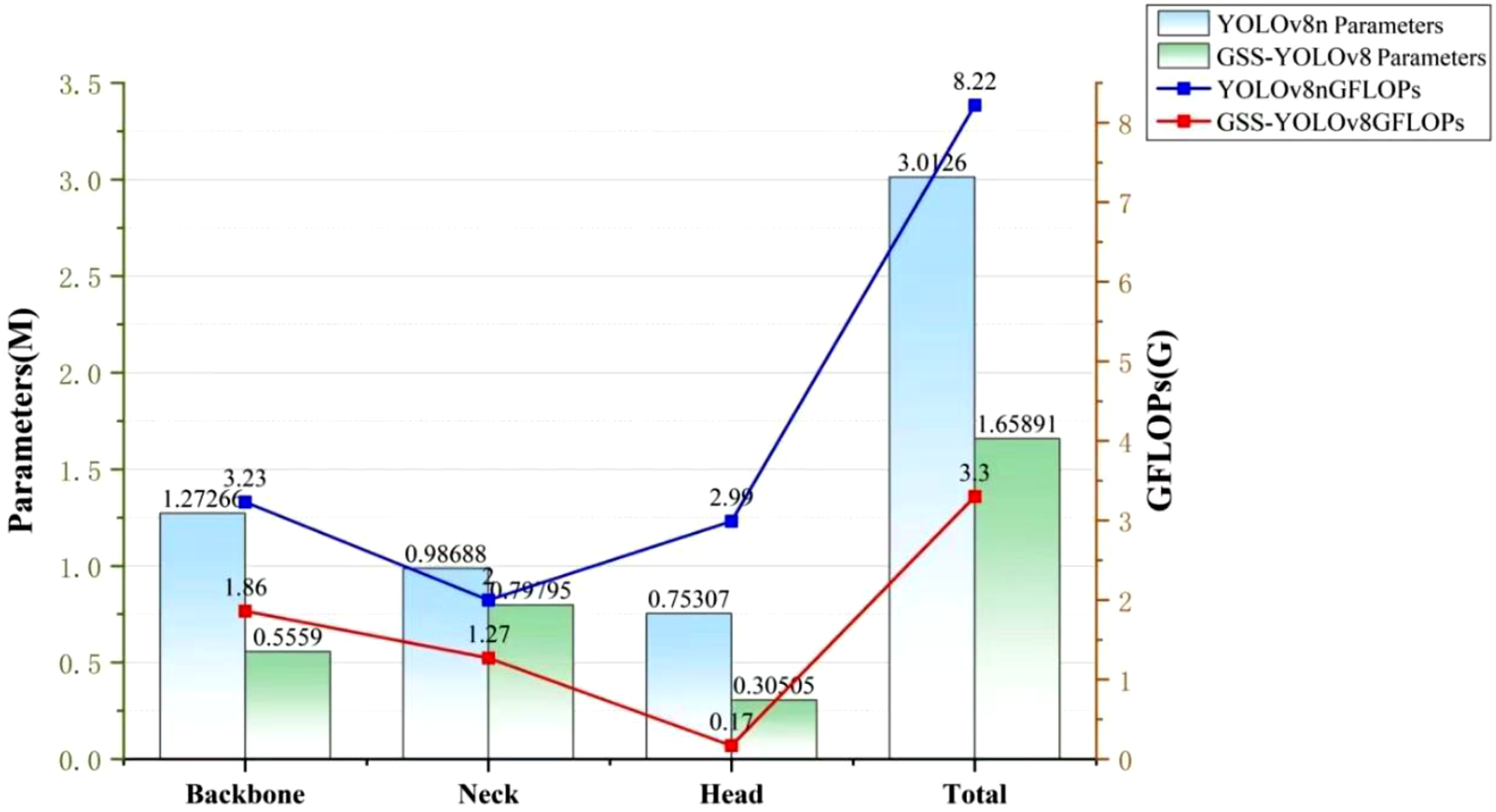
From the perspective of parameter quantity, GSS-YOLOv8 exhibits significantly fewer parameters across all parts of the network compared to YOLOv8n, indicating the high effectiveness of the proposed lightweighting strategy in reducing model complexity. Specifically, replacing the original backbone with GhostHGNetV2 for feature extraction reduces the parameter count in this component by approximately 56%. In the neck structure, substituting the original C2f and standard convolution with the VoVGSCSP and GSConv modules further reduces parameters by about 42%. Additionally, the proposed shared detail-enhanced detection head (SDEH) reduces the parameter count at the detection head by approximately 59%. Overall, the total number of parameters in GSS-YOLOv8 is reduced from 3.26 million in YOLOv8n to 1.66 million, achieving a reduction of roughly 51%. This substantial decrease in parameter count effectively lowers the model’s storage requirements, contributing to a more lightweight architecture.
From the perspective of computational cost, GSS-YOLOv8 exhibits lower complexity across all modules compared to YOLOv8n, further validating the effectiveness of the proposed lightweighting strategy. Specifically, the computational cost of the backbone and neck modules is reduced by approximately 42% and 36.5%, respectively, significantly decreasing overall resource consumption. Notably, the SDEH reduces the computation of the detection head by 90%, with GFLOPs dropping from 2.99 to 0.17, thereby greatly improving inference efficiency. Overall, the total computational cost of GSS-YOLOv8 is reduced by around 60% compared to YOLOv8n, significantly optimizing computational complexity and making the model more suitable for low-power devices, edge computing, and embedded applications.
In summary, GSS-YOLOv8 achieves dual compression of parameters and computational cost by optimizing the backbone, neck, and detection head. Compared to YOLOv8n, it reduces the number of parameters by 50% and the computational cost by 60%, significantly enhancing the model’s lightweight characteristics and improving its applicability in resource-constrained environments.
Figure 15 presents a comparison of the defect detection visualization results between the improved algorithm and the original YOLOv8 on the silk testing dataset. It presents eight groups of images (a–h), covering the detection results for all nine types of silk fabric defects. Each image contains one or more defect types. As illustrated, the improved algorithm demonstrates superior detection accuracy compared to the original YOLOv8. For certain defects with extreme aspect ratios, which are often characterized by loose structures or a high degree of similarity to the background, the prediction boxes generated by YOLOv8 fail to accurately enclose the target regions. In contrast, the proposed GSS-YOLOv8 model generates prediction boxes that more closely align with the ground truth annotations. For instance, in group (a), the “Duan Si” defect is more completely covered by the prediction box of GSS-YOLOv8, indicating that the proposed enhancements improve the model’s localization capability and recall. Furthermore, the original YOLOv8 exhibits a higher tendency for false positives when detecting small-target defects. In group (e), for example, fabric textures are erroneously detected as “You Wu” defects. These false detections are significantly reduced in the results generated by GSS-YOLOv8, demonstrating its stronger discriminative ability in distinguishing true defects from normal textures.In addition, the confidence scores predicted by GSS-YOLOv8 are generally higher and more stable. For example, in group (g), the confidence score for the “Que Jing” defect increases from 0.7 (YOLOv8) to 0.9 (GSS-YOLOv8), indicating more reliable defect classification and stronger robustness in category recognition. Comparison image of defect detection results.
4.6 Comparison experiment
Comparative experimental results.

Bold values indicate the best results for the corresponding metrics.
Although YOLOv8n demonstrates strong detection performance among mainstream lightweight models, its parameter count and computational complexity remain relatively high. YOLOv11n, the latest algorithm proposed by the authors of YOLOv8, reduces the number of parameters and computational cost by 14.1% and 22.2%, respectively, compared to YOLOv8n, achieving a balanced between lightweight design and detection accuracy. However, in terms of overall performance, GSS-YOLOv8 outperforms both by adopting a more efficient lightweight architecture. It significantly reduces model parameters and computational complexity while maintaining high detection accuracy, thereby achieving superior inference efficiency.
YOLOv3-tiny achieves the highest inference speed with 632.1 FPS. However, its accuracy in silk fabric defect detection is relatively poor. YOLOv8n demonstrates excellent detection speed while maintaining higher detection accuracy. The proposed GSS-YOLOv8 model reaches 236.2 FPS on the silk fabric dataset. Although GSS-YOLOv8 achieves clear reductions in parameter count and GFLOPs, its inference speed is lower than that of the original YOLOv8n. This indicates that reductions in theoretical model complexity do not necessarily translate into higher practical inference speed. A possible reason is that the proposed network introduces several lightweight but less hardware-friendly operations, including Ghost-based feature generation, channel shuffle, multi-branch feature processing, and frequent feature concatenation. While these operations are effective in reducing parameters and arithmetic cost, they may also increase memory access, tensor rearrangement, and runtime scheduling overhead on the GPU. As a result, part of the theoretical computational advantage may be offset during actual execution, leading to a lower FPS. Therefore, the lightweight advantage of GSS-YOLOv8 is mainly reflected in parameter count, GFLOPs, and model size, whereas its inference speed still leaves room for further improvement.
Figure 16 presents a comparison of the mAP@0.5 values during the training process of the proposed algorithm and several baseline models on the silk fabric dataset. With the number of epochs set to 500, most models converge and stabilize as training progresses. The YOLOv3-tiny model, in particular, employs early stopping at epoch 270. Among the models, YOLOv8n (purple curve), YOLOv7-tiny (red curve), and GSS-YOLOv8 (yellow curve) achieve the highest mAP@0.5 scores on silk fabric defect images, making them suitable for target detection tasks with high precision requirements. Notably, the GSS-YOLOv8 model demonstrates the best overall performance, indicating that the proposed algorithm achieves superior detection accuracy and robustness in fabric defect detection tasks. mAP@0.5 Variation curves of different algorithms.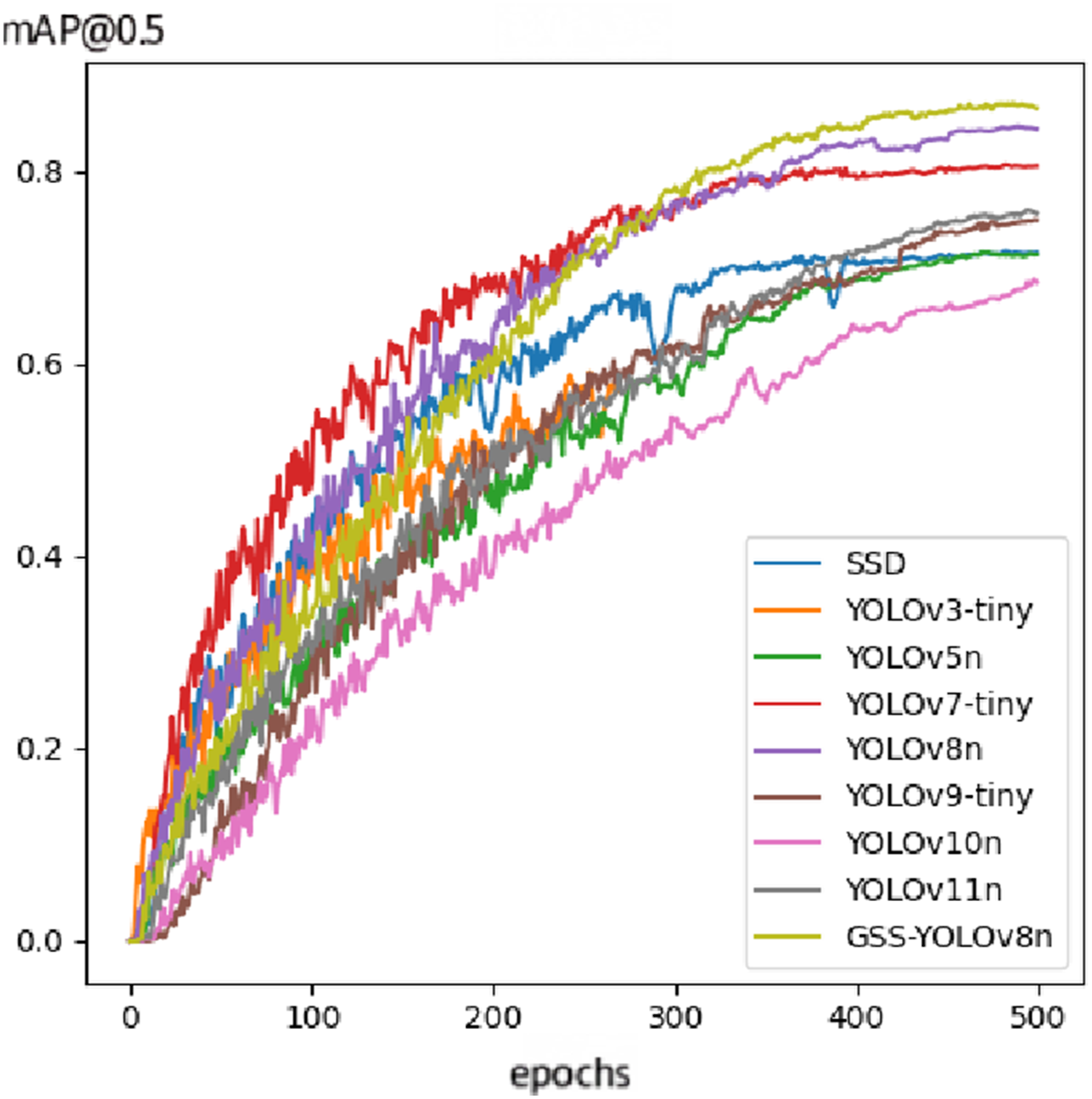
4.7. Validation on a public dataset
To further evaluate the feasibility and generalization capability of GSS-YOLOv8, validation experiments were conducted on the publicly available Tianchi fabric defect dataset. Figure 17 presents the qualitative detection results on weft shrinkage and warp breakage defects. It can be observed that YOLOv8n, YOLOv10n, and GSS-YOLOv8 all generate prediction boxes with relatively accurate localization and shape alignment, while GSS-YOLOv8 shows higher-confidence predictions and no missed detections in the selected samples. These qualitative results indicate that GSS-YOLOv8 can maintain stable and effective detection performance under complex defect scenarios. Detection results of different algorithms on the Tianchi fabric images:(a) original image; (b) SSD; (c) YOLOv3-tiny; (d) YOLOv5n; (e) YOLOv7-tiny; (f) YOLOv8n; (g) YOLOv9-tiny; (h) YOLOv10n; (i) YOLOv11n; (j) GSS-YOLOv8.
Comparison of detection results of different algorithms on the Tianchi fabric dataset.

5. Conclusion
Aiming at the problems of limited storage resources, and limited application scenarios in fabric industrial inspection, this paper proposes a novel model named GSS-YOLOv8. The proposed model achieves a superior balance between detection accuracy and computational cost. Specifically, the GhostHGNetV2 feature extraction network and the Slim-Neck feature fusion network are employed to replace the original backbone and neck structures of YOLOv8n, respectively. These two modules effectively reduce the number of model parameters without compromising detection performance. Furthermore, a SDEH is designed to further optimize the model architecture and improve inference efficiency.
The experimental results show that the number of parameters and the computational amount of GSS-YOLOv8 are substantially reduced by 51.3% and 45.7%, respectively, compared with the original YOLOv8n model, while the detection accuracy is better, with the accuracy, recall, and mAP@0.5 values of 85.9%, 80.0%, and 86.5%, respectively. This shows that GSS-YOLOv8 optimizes the complexity of the model while maintaining the detection accuracy. In addition, the feasibility of the model on the public dataset of Tianchi Fabric is verified, and the detection mAP@0.5 value reaches 75.7%, which is better than other lightweighting algorithms.
Despite the promising results, this study still has some limitations. Although GSS-YOLOv8 achieves clear reductions in parameter count, GFLOPs, and model size, its practical inference speed is still lower than that of the original YOLOv8n, indicating that reductions in theoretical model complexity do not necessarily translate into higher runtime efficiency. In addition, the actual runtime memory consumption and deployment performance of the proposed model on specific edge devices have not yet been systematically evaluated. Furthermore, the synergy and constraint mechanisms among the lightweight modules are mainly discussed from a qualitative perspective in the current work. In future research, we will further investigate hardware-friendly lightweight optimization, conduct deployment experiments on edge platforms, and perform more detailed profiling and analysis of runtime efficiency, memory usage, and module interaction mechanisms.
Footnotes
Consent to participate
Informed consent was obtained from all individual participants included in the study. Participants signed informed consent regarding publishing their data.
Author contributions
Jianye Wang conceived the study, performed the majority of the experiments, and drafted the manuscript. Peiyao Guo contributed substantially to data analysis, model development, and manuscript revision. Yanping Liu assisted with experimental validation, while Panpan Zhao supported data collection and figure preparation. Ying Wu provided overall supervision, guided the research design, and served as the corresponding author.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Zhejiang Provincial Philosophy and Social Sciences Planning Project (Grant No. 26NDJC035YBMS), the Fundamental Research Funds of Zhejiang Sci-Tech University (Grant No. 26076076-Y), and the Scientific Research Fund of Zhejiang Provincial Education Department (Grant No. Y202558694).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.