
Abstract
The Asbestos Ontology is a domain application ontology designed for use in an ontology-based approach that estimates the probability of the existence of asbestos products in a building. However, new issues in the building domain, such as predicting the presence of lead in buildings, renovating asbestos floors, or the reuse and recycling of components or parts of buildings as part of the circular economy, require a generalization of this ontology to a building ontology. The lack of relevant data tends to make decision-making difficult. The purpose of our approach is to show how instance-level knowledge graphs can be populated without having to manually create hundreds of instances using large language models (LLMs) and prompt engineering. This paper introduces a novel method for populating ontologies using the latest generative LLMs, such as GPT-3.5. Our method is characterized by an innovative recursive zero-shot prompting technique. The key contributions of this study are: (i) a new strategy for recursively prompting LLMs to elicit pertinent knowledge from the asbestos application domain; (ii) ontology population informed by the ontology metamodel; and (iii) formalization of the results into OWL axioms for the automatic integration of new instances. To evaluate the efficacy of our approach, we employed two main methodologies: (1) querying for instances linked to each entity; and (2) recursively querying for instances to leverage our recursive prompting strategy. Our initial strategy focused on evaluating the effectiveness of zero-shot prompting in retrieving relevant values for entities and data properties. This was facilitated through the development of the PromptGeneration function, which adjusted the input
Introduction
Asbestos has long been recognized for its harmful effects, but its dangers were explicitly identified early in the 20th century. Addressing this, Asbestos Ontology has been developed as a domain application ontology specifically tailored for use in ontology-based systems that estimate the likelihood of asbestos presence in buildings. This specialized ontology enhances the precision of identifying asbestos-containing materials, which is crucial for operational planning in asbestos monitoring programs. For instance, it plays a significant role in supporting initiatives such as the French national project Origami (Systems, 2023).
An application domain ontology, such as the Asbestos Ontology, is designed to organize domain-specific knowledge through a structured framework that defines key concepts and their interrelationships. Application domain knowledge refers to the specialized information, expertise, and understanding that pertains to a particular domain or field of application, encompassing both theoretical principles and practical insights specific to that context. By formalizing this knowledge into an ontology, application domain ontologies enable standardized representation, integration, and retrieval of domain information (El-Diraby, 2013; Jiang & Tan, 2010; Sattar et al., 2020). This, in turn, facilitates data integration and semantic search by establishing a unified vocabulary that enhances the consistency, sharing, and reuse of knowledge across different systems and stakeholders. Moreover, domain application ontologies are essential tools for capturing both shared and specialized knowledge, allowing for the development of targeted, context-sensitive solutions that address specific needs within an industry. Consequently, their use contributes to enhanced efficiency and effectiveness in the implementation of domain-specific applications.
While the Asbestos Ontology improves the estimation of asbestos presence, this approach cannot substitute the formal process of professional identification and laboratory analysis of asbestos-containing materials. Professional identification involves collecting samples during building inspections, which must be conducted according to the French NF X 46-100 standard (AFNOR, 2019). These inspections, carried out by trained professionals, are vital to confirm the actual presence of asbestos in building components. Beyond the identification of asbestos, a major challenge in the building industry lies in detecting materials containing asbestos, especially due to the severe health hazards associated with its exposure and the prevalence of such materials in buildings such as hospitals. This, alongside the detection of other hazardous materials such as lead and innovations in asbestos floor renovation using specific techniques, represents a significant ongoing concern for the industry.
Additionally, the move toward a circular economy calls for the reuse and recycling of building components. These developments necessitate the expansion of an asbestos-specific ontology into a broader building ontology that captures general building information. A major obstacle in this expansion is the limited availability of detailed building descriptions that accurately reflect the diversity of real estate properties. This lack of rich, detailed descriptions hinders the effective generalization of the building ontology, thus complicating decision-making in addressing these new challenges.
Ontology population is a critical process in the development and enhancement of ontologies. It involves enriching an existing ontological framework by systematically adding a substantial base of actual knowledge or instances. The automatic population of an ontology represents a significant challenge in the field of semantic web technologies and artificial intelligence. This challenge primarily arises from the need to insert concrete data or instances into an established conceptual framework without compromising the integrity and semantic consistency of the ontology.
This paper introduces a groundbreaking approach for automatically populating ontologies, leveraging the latest advancements in generative large language models (LLMs), notably GPT-3.5. We have developed a novel method of recursive zero-shot prompting that significantly enhances the efficiency and effectiveness of the ontology population. This technique is designed to intricately align with the specific needs of domain applications, particularly within the context of asbestos-related data.
The main contributions of this study are threefold: Firstly, we have devised an innovative strategy that utilizes recursive prompting to extract domain-specific knowledge effectively. Secondly, this strategy strengthens our approach to populating ontologies directly from the extracted information. Thirdly, we structure the outcomes into OWL axioms, facilitating the seamless integration of new instances into the ontology framework. To evaluate the robustness and practicality of our approach, we implemented two distinct methodologies. The first involves querying for instances associated with each entity within the ontology, and the second, more complex strategy, employs recursive querying for data properties. This recursive nature allows us to utilize our zero-shot prompting technique to its fullest potential, ensuring a comprehensive assessment of our method’s performance.
The initial stages of our research focused on assessing the potential of zero-shot prompting to gather relevant entity and data property values. We achieved this through the development of the PromptGeneration function, which dynamically adjusts inputs across various contexts to maximize the relevance and accuracy of the information retrieved. This paper seeks to provide a detailed exploration of these methodologies and discuss the implications of our findings for the field of ontology population and semantic web technologies.
Our paper is structured as follows: Section 2 presents related work, summarizing recent research on the application of LLM in the semantic web domain and identifying gaps in the current research landscape. Section 3 provides a brief overview of the Asbestos Ontology. In Section 4, we delve into the detailed methodology applied to the ontology population. Section 5 discusses the schema representation and the steps taken for its refinement. Section 6 describes the recursive zero-shot LLM prompting modules and functions. Finally, Section 7 is dedicated to validating our methodology through practical implementation and assessment.
Related Work
An ontology is made up of two main parts: the TBox and the ABox. The TBox outlines the structure of the ontology by defining concepts and relationships between them. On the other hand, the ABox contains specific examples or instances that fit into the structure defined by the TBox (Ren et al., 2019). Enriching the ontology’s ABox with a substantial base of factual knowledge or instances is known as ontology population. This process aims to add a lot of real-world facts or instances to the ontology. By doing this, we insert real data into the framework set by the TBox. Making this process automatic is especially important because it helps us quickly use logical reasoning on different kinds of databases (Ghidalia et al., 2024).
We categorize ontology population approaches into two distinct types. The first approach involves populating ontologies from textual sources. The second approach utilizes LLMs to generate new instances.
Ontology population from texts is a widely studied field. Lubani et al. (2019) examine various methods of data extraction and integration for populating ontologies. Trajanoska et al. (2023) evaluated the performance of ChatGPT in extracting knowledge graphs from texts. Kordjamshidi and Moens (2015) utilize vector machines within the framework of ontology population, particularly for spatial information extraction from natural language texts. They employ structured support vector machines along with structured and averaged perceptrons for processing the linguistic features derived from texts. Moreover, Ayadi et al. (2019) present an ontology population approach utilizing deep learning and natural language processing (NLP) for the biomolecular network ontology (BNO). Their methodology, distinct for integrating deep learning with traditional NLP, aims to automate the extraction and classification of new instances from biological texts. Their methodology involves three steps: first, gathering relevant biological texts to form a knowledge base; second, preprocessing these texts for deep learning, utilizing the Word2vec algorithm for semantic analysis; and third, validating and incorporating the extracted information into the BNO by a domain expert.
Regarding the second approach, the emergence of LLMs offers new opportunities for creating semantic representations or generating triples in resource description framework format and presents fresh opportunities for generating application domain knowledge. These models operate based on queries, or what are commonly referred to as prompts. The engineering of these prompts involves the design of specialized instructions to guide LLMs in generating outputs according to the specified requirements. In general, LLMs have the potential to contribute to the semantic web by filling the application domain knowledge gap, thereby enhancing the efficiency and accuracy of data representation. Several studies have explored the ability of LLMs to generate a populated ontology. Trajanoska et al. (2023) assessed the effectiveness of ChatGPT in extracting knowledge graphs from text, highlighting the potential applications of LLMs in this area. Several LLMs have been introduced: OpenAI’s GPT (Kalyan, 2023), Anthropic’s Claude (Ali et al., 2023; Ren et al., 2023), Google’s Bard (Rahaman et al., 2023; Siad, 2023), and Facebook’s Llama (Macko et al., 2015). They are used in various applications and have demonstrated that, in the context of named entity recognition and language understanding, the models have almost the same effectiveness. Borji and Mohammadian (2023) investigated the capabilities of these LLMs across several applications, and explained that in the context of named entity recognition and language understanding, the models have almost the same effectiveness.
The process of ontology population, particularly using LLMs, has not been extensively explored, revealing a significant gap in the current research landscape. The potential of LLMs, such as GPT-3.5, extends beyond traditional machine learning approaches, offering innovative methods for the ontology population. Recent research has explored the utility of LLMs for open-domain question answering and the extraction of knowledge in the form of “subject–relation–object” triples, often using cloze statements (Funk et al., 2023). While these efforts demonstrate the capabilities of LLMs in generating structured knowledge, few have directed their focus toward integrating these capabilities into ontology population and refinement, particularly in building detailed concept hierarchies. Notably, some studies have begun using fine-tuned bidirectional encoder representations and transfomers models for tasks such as subsumption prediction to aid in completing ontologies (Chen et al., 2023), similar to our approach of inserting newly discovered concepts into ontological hierarchies. However, these studies typically lack a comprehensive strategy for concept discovery and hierarchy construction, which are crucial for the dynamic expansion and updating of ontologies. Our research aims to bridge these gaps by leveraging the sophisticated text generation capabilities of ChatGPT-3.5 to automate and refine the process of ontology population. This approach is particularly applied in the context of the Asbestos Ontology, where we seek to populate and expand the ontology with new instances and concepts efficiently.
Motivation
Ontology population is motivated by the need to maintain and update structured knowledge bases with new facts and instances extracted from various knowledge sources.
Recent research points out that the motivation behind ontology population is multifaceted and includes the following key points:
Enhancing knowledge reuse and sharing: Ontologies are essential for formalizing and sharing knowledge across different systems and domains. They provide a structured representation that facilitates data interoperability, integration, and reuse. By populating ontologies, we ensure that the latest and most relevant information is available in a structured format that can be easily accessed and utilized by various applications and users (Clarkson et al., 2018). Dealing with dynamic and heterogeneous data: The dynamic nature of many domains, such as the biomedical field, necessitates continuous updates to the ontology to reflect the latest findings and knowledge. Ontology population allows for the integration of new data from diverse and heterogeneous sources, ensuring that the knowledge base remains current and comprehensive (Khadir et al., 2021). Supporting advanced data analysis and decision-making: Structured knowledge in the form of populated ontologies can significantly enhance data analysis, decision support, and other advanced computational tasks. For instance, in the healthcare domain, accurately populated ontologies can improve the precision of decision support systems, leading to better patient outcomes (Clarkson et al., 2018). Overcoming manual knowledge acquisition limitations: Manual ontology population is labor-intensive, time-consuming, and prone to errors. Automated and semi-automated ontology population approaches leverage techniques such as information extraction, machine learning, and natural language processing to streamline the process. This reduces the reliance on human experts and accelerates the knowledge acquisition process (Lubani et al., 2019). Addressing specific domain challenges: Different domains have unique challenges that necessitate specialized ontology population approaches. For example, the medical domain requires near-perfect accuracy due to the critical nature of the data. User-centric ontology population methodologies, which involve human experts in the loop, help address these challenges by ensuring high-quality and relevant ontology updates (Clarkson et al., 2018). Ensuring consistency and redundancy management: Ensuring consistency and eliminating redundancy in the ontology are crucial for maintaining its usability and integrity. Automated consistency and redundancy checks during the ontology population process help maintain a coherent and reliable knowledge base, which is essential for practical applications (Lubani et al., 2019).
Our motivation is mainly overcoming manual knowledge acquisition limitations. In fact, building the Asbestos Ontology was motivated by the French national project Origami, which aims to help asbestos experts. Beyond asbestos, emerging challenges in the building industry include predicting the presence of lead—also harmful, and innovating in asbestos floor renovation using specific techniques. Additionally, the move toward a circular economy calls for the reuse and recycling of building components. These developments necessitate the expansion of an asbestos-specific ontology into a broader building ontology that captures general building information. We are facing a lack of data to describe buildings and the components and products that compose these buildings.
Asbestos 1 has been known to be harmful for quite a long time, nevertheless, the dangers associated with it have only been identified since the beginning of the 20thcentury. Breathing the air that contains asbestos fibers can lead to asbestos-related diseases, such as lung cancer and chest lining. However, for its fireproof qualities, many countries have extensively used asbestos in buildings, especially from 1950 to 1970. To help and guide an operator in the preparation of its tracking program (called the Origami Project), professionals regularly inspect buildings and collect samples to detect the presence of asbestos in building components. For this purpose, Asbestos Ontology was built to describe a building with its different components and materials to be used in an ontology-based approach that estimates the probability of the existence of asbestos products in a building (Mecharnia et al., 2019, 2021).
An excerpt of the Asbestos Ontology, shown in Figures 1 and 2, presents the main concepts as follows:
an optional code (e.g. a CSTB internal code corresponding to a specific type of building such as a school or housing), indicating that it is used for internal classification within certain organizations; a type; the construction year; an address; and its geographic area. its name; provider name; and asbestos type.
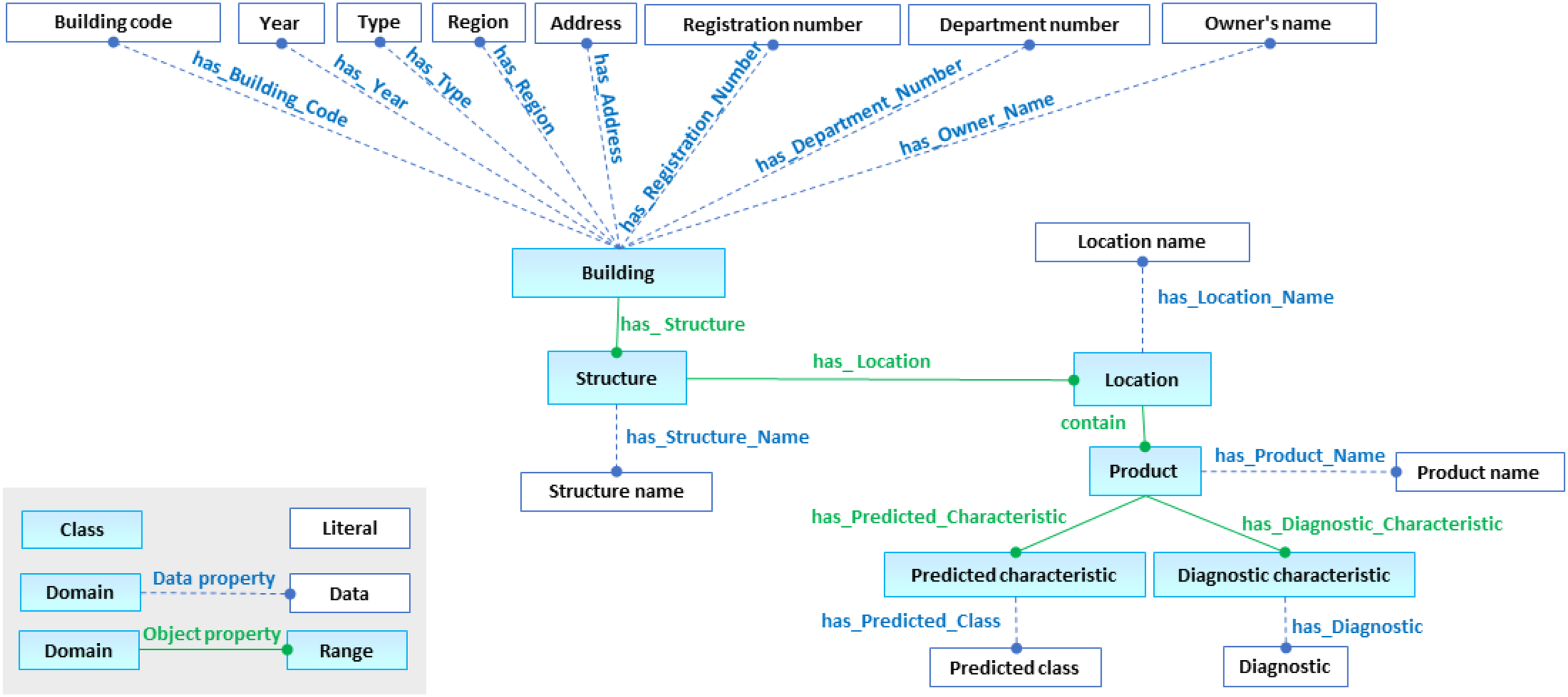
Asbestos Ontology Extract.
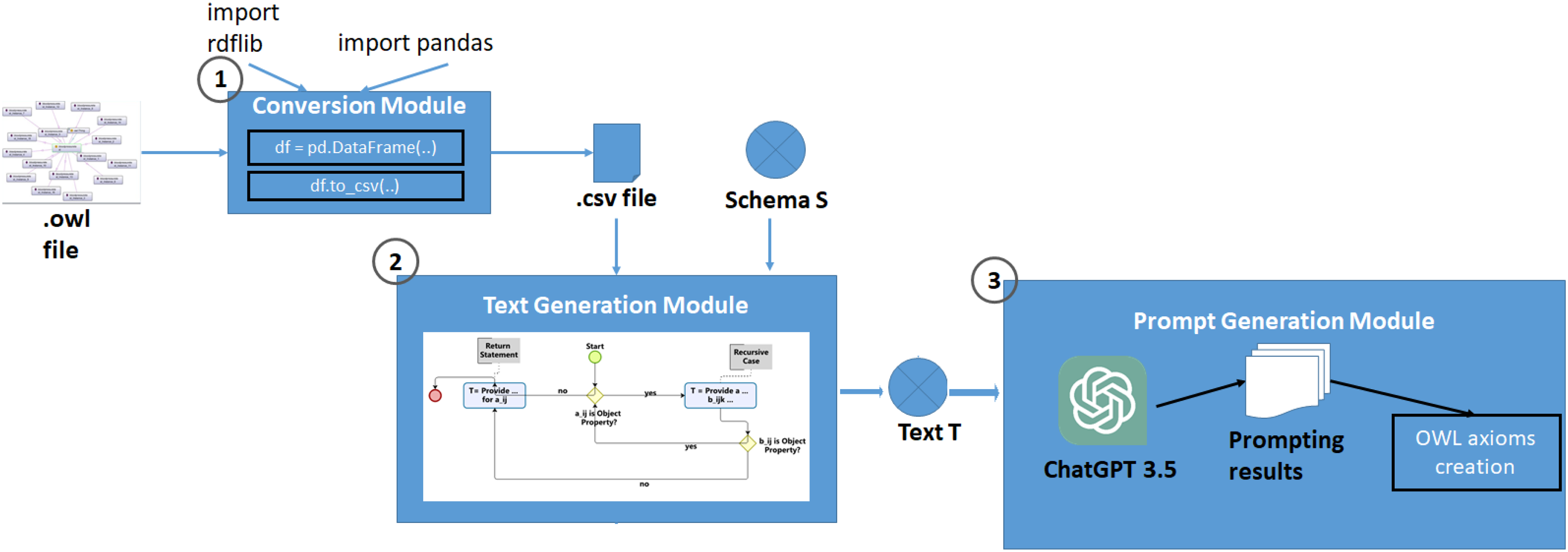
Our Methodology.
In the aim to generalize the use of this ontology to other use cases such as predicting the presence of lead which is as harmful as asbestos in buildings, we need to enrich this ontology with new instances. We have designed a structured approach aimed at enriching an existing ontology with new instances derived from the knowledge provided by ChatGPT 3.5. This process is broken down into three primary modules, each serving a distinct purpose in the ontology population approach.
Conversion Module
The initial step involves the transformation of our ontology, stored in an OWL format, into a more manipulable CSV format. For this task, we utilize two Python libraries: “rdflib” and “pandas.” “rdflib” is employed to parse the OWL file, extracting its constituent elements, while “pandas” is used to format this data into a CSV file. This .csv file then serves as the input for the next module of our process.
Text Generation Module
Upon the conversion of the ontology to a CSV format, we progress to the text generation module. This module accepts a CSV file and the Ontology Schema S as inputs. Based on these inputs, it generates a prompting text. This module is centered around a recursive function designed for zero-shot prompting, aimed at generating textual prompting for both object properties and data properties within our ontology. This function operates under various input scenarios to ensure accuracy and precision of the resulted knowledge which subsequently becomes the input for the third module details in Section 7.
Prompt Generation Module
In the prompt generation module, where the domain application knowledge provided by ChatGPT3.5 is transformed into OWL axioms. This step is critical as it formalizes the unstructured text into formal logic that can be directly incorporated back into the ontology. The innovation here lies in the automation of axiom generation, which significantly reduces the need for manual intervention and human interpretation, thereby streamlining the process of ontology enrichment.
Our methodology is designed to use the expansive knowledge base of ChatGPT 3.5 for the purpose of ontology population, ensuring that the enhanced ontology is both enriched and aligned with current knowledge domains. Our approach is designed to be application domain-independent.
Schema Representation
By definition, an ontology is a specification of a representational vocabulary for a shared domain, and it is developed to support the sharing and interpretation of formally represented knowledge in artificial intelligence systems (Gruber, 1993). In the process of translating an ontology into a CSV format, significant semantic details are inevitably lost. Initially, it is crucial to recognize that an ontology inherently represents a structured hierarchy. The conversion into a CSV format, which is inherently flat and linear, results in the loss of the distinctions and interrelations between object properties and data properties which are not preserved in the CSV environment. In such a format, entities, object properties, and data properties are uniformly treated as mere variables or features. Furthermore, the complex interrelationships that define the connectivity between instances within the ontology are significantly compromised. Within the confines of a CSV file, these relationships are flattened, leading to a homogenization where diverse relational links are merely placed side by side within the same row, effectively stripping away the depth and context provided by the ontology’s original structure. To preserve the inherent semantics of the ontology, we have developed a mathematical schema.
While OWL’s inverse properties offer a degree of bi-directionality, they are primarily intended for logical inference rather than facilitating recursive prompting with LLMs. Relying solely on OWL and inverse properties does not adequately meet the specific needs of our methodology for several reasons. Firstly, OWL’s inverse properties are not inherently suitable for generating the detailed and context-rich prompts required by our recursive zero-shot prompting technique. Our prompt generation module demands a representation that allows for more flexible and navigable structures, which OWL’s standard framework does not readily provide. Secondly, converting the OWL ontology directly into a CSV format using libraries such as RDFLib and pandas results in significant semantic loss. The flat structure of CSV cannot adequately capture the complex interrelations between object properties and data properties inherent in the ontology. By redefining the ontology’s structure using the ontology definition metamodel (ODM) before conversion, we preserve these relationships and maintain the semantic richness necessary for our approach. Finally, our recursive prompting algorithm is specifically tailored to work with the mathematical schema derived from the ODM. This schema enables us to handle recursive relationships and nested attributes effectively, capabilities that would be challenging with a direct OWL-to-CSV conversion. Therefore, incorporating the ODM into our methodology is essential for meeting the specific requirements of our recursive prompting technique and ensuring the integrity of the ontology’s semantic structure throughout the process.
To construct our schema, we exploit the foundational structure provided by the ontology metamodel. 2 A domain ontology encapsulates a comprehensive representation of a domain through entities (classes), along with their relationships and characteristics (Gašević et al., 2006). These are manifested as object properties, data properties, and individuals (instances), which collectively form the bedrock of our schema definition (Gašević et al., 2006).
Our schema, based on the structure provided by the ontology metamodel (Group, Year), defines a mathematical foundation for detailed prompting.
Classes
Our schema
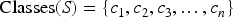
Attributes within a class have a specified range, which is categorically divided into three types: (1) primitive types, such as string or num, indicative of basic data properties; (2) other classes, signifying object properties that establish relationships between classes; and (3) enumerations of possible value tokens, which also pertain to data properties.
Attribute Properties
Each attribute
Data Properties
Data properties are defined as attributes whose range is limited to primitive types or enumerations of possible value tokens, enabling the representation of intrinsic properties of a class. Formally, the data properties
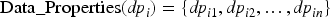
In instances where an attribute is identified as a data property, a structured prompt engineering is initiated to propose values for the data properties of the class.
Object Properties
Conversely, object properties are attributes with a range of classes, thereby facilitating the interconnection amongst classes within the schema. The object properties
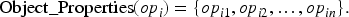
In instances where an attribute is identified as an object property, a dedicated process is initiated to elucidate the attributes of the class denoted by its range.
Schema Refinement
To summarize the schema: let
Thus, the value of
In summary, the schema’s recursive nature allows for the representation of complex hierarchical structures where attributes can themselves be classes, leading to a flexible and scalable data model.
To illustrate, consider a scenario where:
Let The attributes Specifically, the attribute The subattribute Among these, The deeper level of attributes In this hierarchy, Finally,
In traditional ontologies, object properties have defined domains and ranges, and are inherently unidirectional. This structural attribute dictates that when creating instances, specific object and data properties can be associated with each instance type, where the instance itself serves as the domain. However, our research methodology demands a bidirectional traversal capability to effectively deploy our prompting approach.
Our row-based csv format is not just a simple structural alteration but a fundamental redefinition of data interactions within our model. By reformatting the mathematical representation of the ontology into this row-based structure, we facilitate free navigation between entities in either direction. This flexibility inherent in our specific CSV formatting allows our algorithm to process any given data, ensuring that all other rows are appropriately populated regardless of the original domain and range constraints of the associated data properties.
Further enhancing our model, we created a specific mathematical approach tailored to our recursive prompting algorithm. This model is particularly well-suited and specialized for our approach, integrating seamlessly with the enhanced data interaction capabilities of our transformed ontology representation. This integration is vital for leveraging the full potential of our prompting approach, allowing for sophisticated data manipulation and improved algorithmic performance.
Recursive Zero-Shot LLM Prompting
Considering the challenges in the research area of ontology enrichment, this study introduces a methodology aimed at addressing numerous problems associated with ontology population. Specifically, our objective is to utilize pertinent application domain knowledge from the LLM, ChatGPT 3.5, and systematically structure the outcomes utilizing OWL axioms.
Given the context and the nature of our request, it would be classified as zero-shot prompting because we are asking for information without providing explicit examples for the model to follow. In zero-shot prompting, the model generates a response based on its pre-existing knowledge and the instructions given in the prompt, without any prior examples to guide the response specific to the task at hand. Although no explicit examples were provided in the prompt, the request for a detailed scenario with specified attributes (Schema S) implicitly relies on the model’s ability to generate information based on understanding and integrating several concepts.
We have developed an approach that integrates three key elements to generate structured prompting texts.
Schema: The foundational structure that outlines the framework within which our data is organized is described in Section 6. Context value ( OWL template: A template based on OWL standards, which is used to systematically format the responses generated by our algorithm.
In the research, we developed a Python-based method to systematically extract and organize data from OWL ontologies using the RDFLib library, focusing on the semantic relationships and attributes of ontology instances.
The initial step involves using the rdflib library to decode the OWL file. This step is crucial as it involves parsing the structured format of the OWL document to extract entities, including classes, properties, and instances. Upon loading the OWL document into our Python environment with rdflib, we proceed to methodically extract essential elements such as the names of entities, their respective instances, and the data and object properties associated with them. The extracted data is then structured into a DataFrame using the pandas library. This involves organizing the data into a tabular format. The final step is the exportation of the DataFrame into a CSV file.
For further clarity, initially, a SPARQL query is executed to retrieve all distinct ontology classes defined as “owl:Class” and not represented by blank nodes. For each identified class, another SPARQL query enumerates all instances (“rdf:type”). Subsequently, for every instance, a function called “fetch_properties” is invoked, which retrieves all associated properties except the “rdf:type” to avoid redundancy. This function leverages a SPARQL query to select both the property and its value for the given instance. Each property–value pair extracted is then processed based on its RDF type—URI references are simplified to their local names, whereas literals are directly converted to strings. These pairs are stored in a dictionary, tagged with their corresponding entity and instance labels. The aggregation of these dictionaries across all instances forms a comprehensive dataset that represents the structural and semantic composition of the ontology in detail. This dataset is then transformed into a pandas DataFrame for efficient data manipulation. To align the data for analytical purposes, we employ a pivot table operation, indexing by entity and instance identifiers, and aggregating property values. This structured data is finally outputted to a CSV file, providing a clear and actionable format suitable for further analysis or integration into data-driven applications. One significant challenge encountered in our research was the proper formatting of the CSV file derived from ontology data. The structure of the CSV, especially the column naming and the population of instances into rows, required meticulous attention to detail. For our prompt engineering tasks, it was crucial that the CSV file conformed to a precise format. Given the variability in instances, where each could possess a unique set of properties, the number and names of columns in the CSV file were subject to dynamic changes. Consequently, to maintain consistency across the dataset, fields corresponding to non-existent properties were populated with “na” (Figure 3).
Conversion Module.
The transformation of an OWL document into a CSV format utilizing Python encompasses a sequence of steps.
In the conversion of complex ontologies into a CSV format, one of the principal challenges we encountered was maintaining the integrity of hierarchical relationships and property constraints within the inherently flat structure of CSV files. To tackle this, we extracted core components such as entity names, and their associated object and data properties, and represented them as columns in the CSV. However, the relational dynamics among these elements are not naturally preserved in this format. To address this limitation, we applied our mathematical representation of the ontology that explicitly maps these relationships, coupled with the application of a recursive function. Each row in the CSV is carefully constructed to represent an instance with its corresponding properties. Validating this approach involved rigorous testing against the original OWL content.
In the created CSV file, columns correspond to variables and contain the names of entities or the names of data properties (Figure 4).
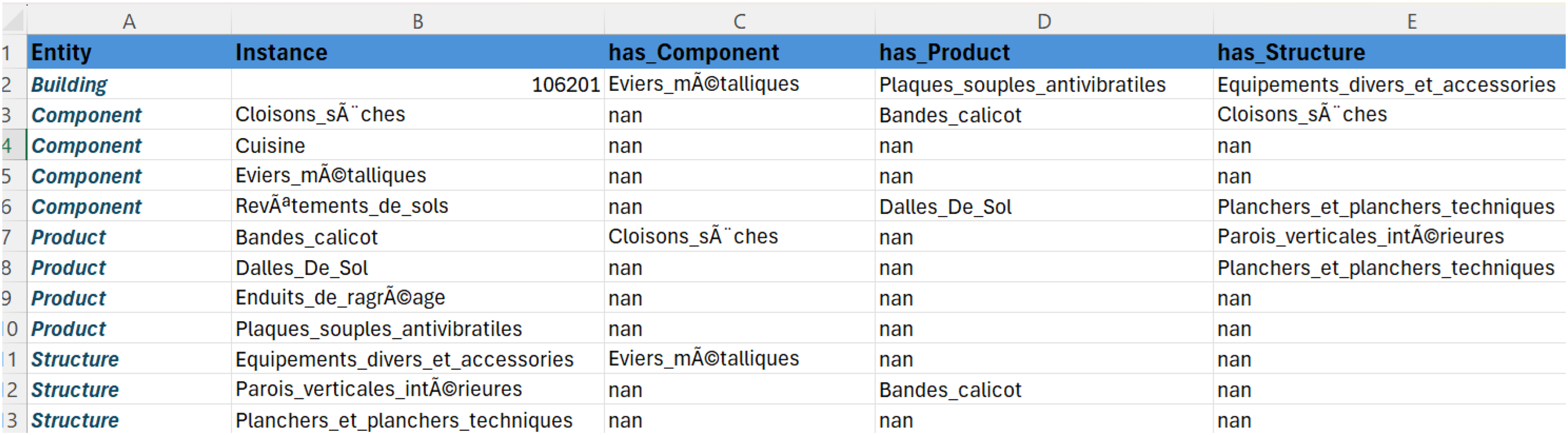
Extract of the .CSV File.
To generate the prompt text, we need the schema as an input. We follow the following recursive algorithm (Figure 5).
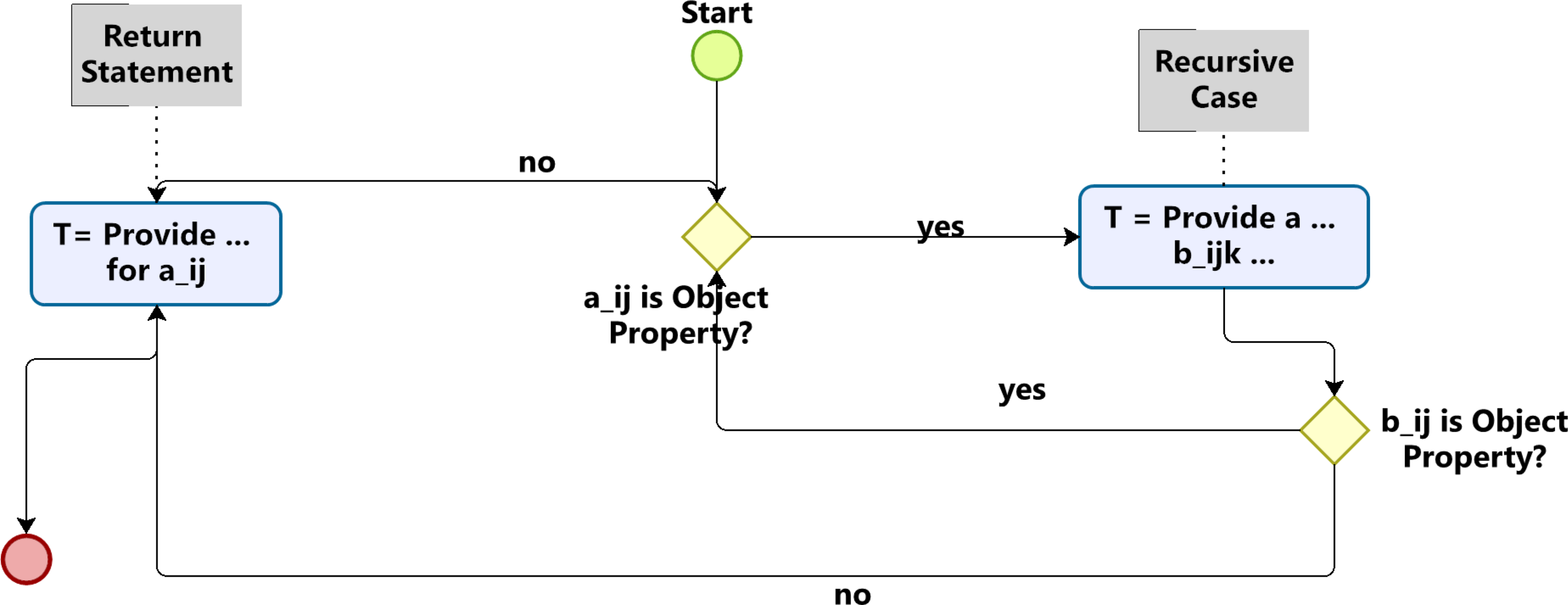
Text Generation Module.

In our approach, we explored the capabilities of knowledge extraction by guiding ChatGPT through a series of diverse input conditions. These conditions included scenarios with no input, as well as singular inputs such as the name of a structure, a product, or a component. Additionally, to enhance the precision of our results, we experimented with dual-input scenarios, combining (“Structure,” “Component”)and (“Product” and “Component”) as the inputs. The input data is extracted using a specific extraction module using Python code that you can find in the following link: (https://github.com/SarahayadAOU/OntologyPopulation). The extracted information will be stored in an array list that will serve as input into our recursive function thus it will be the input to our zero-shot prompting.
In our methodology, as mentioned previously, the prompt generation module’s functionality is predicated upon both the underlying schema and the provided input. Our objective is to produce outputs conforming to OWL functional syntax, whereby the outputs are structured as axioms.
The process results in the formulation of OWL axioms, articulated as follows:
Use the ClassAssertion axiom to specify that an individual is an instance of a certain class (entity).
ClassAssertion(:Entity :Individual) For each entity identified in the prompting results that will be associated with data properties, declare it using the Declaration axiom if it has not been previously declared.
Declaration(NamedIndividual(:value)) Utilize the DataPropertyAssertion axiom to assign each value to the respective individual’s data property.
DataPropertyAssertion(:DataProperty :Individual “Value”) For each individual identified through the prompting results that will participate in an object property relationship, ensure they are declared using the Declaration axiom, if not already present.
Declaration(NamedIndividual(:IndividualA))Declaration(NamedIndividual(:IndividualB)) Use the ObjectPropertyAssertion axiom to assert the relationship between each pair of individuals through the identified object property.
ObjectPropertyAssertion(:ObjectProperty :IndividualA :IndividualB)
In this section, we present the validation of our methodology, employing two widely recognized approaches in the evaluation of LLM outputs: (1) comparison with ground truth data, and (2) human evaluation.
Comparison With Ground Truth Data
Our first evaluation approach involves comparing the outputs generated by the LLM with the ground truth dataset to assess correctness and completeness. This method is commonly used in recent studies (Jiang et al., 2020; Petroni et al., 2019; Roberts et al., 2020; Zhong et al., 2021), where researchers evaluate the factual knowledge and recall capabilities of language models by comparing generated outputs against established datasets.
In our case, we utilized the Origami dataset as the ground truth. The Origami project is a French national initiative that provides real data collected from laboratory analyses related to asbestos presence in buildings.
To validate the instances generated by our model, we conducted a comparative analysis between the outputs of ChatGPT-3.5 and the actual values within the Origami dataset. Specifically, we:
We then calculated the 


This quantitative evaluation allowed us to measure the exactness and completeness of our model in identifying valid instances.
The second evaluation approach involves involving domain experts to manually assess the quality of the outputs based on predefined criteria. This method is recognized in recent studies (Ammanabrolu et al., 2020; Chen et al., 2021; Dale, 2020; Gehrmann, 2019; Hashimoto et al., 2019) as an effective way to capture qualitative aspects of the generated content.
We engaged two domain experts with extensive experience in asbestos management and building inspections to evaluate the ontology instances generated by our model. The evaluation process was as follows:
The domain experts’ assessments provided valuable insights:
As previously mentioned, the result given by our approach depends heavily on the input prompt provided. In this section, we detail the prompt engineering used. Several studies have discussed the impact of prompt engineering on the performance of the LLM and the variance in responses generated for the same task using different prompts. Gao (2023) and Arawjo et al. (2023) have shown that the response of the LLM has a strong correlation with the input prompt provided. On the other hand, White et al. (2023) proposed a catalog of prompt engineering techniques, presented in the form of patterns, which have been applied to solve common problems during interactions with ChatGPT.
We applied two distinct methodologies: (1) Querying for instances associated with each entity and (2) querying for data properties recursively to employ our recursive prompting technique. Our preliminary approach was centered around assessing the effectiveness of zero-shot prompting in acquiring values pertinent to entities and data properties. This involved the implementation of the
As observed in Tables 1 to 4, the absence of inputs results in both low precision (P) and low recall (R), which is understandable given that ChatGPT lacks contextual information and possesses only variable names. Consequently, it generates generic variable values that do not always make sense.
Prompting Results for the Following Text: “Provide Other Values for Product_name Related to the Product Glue.”
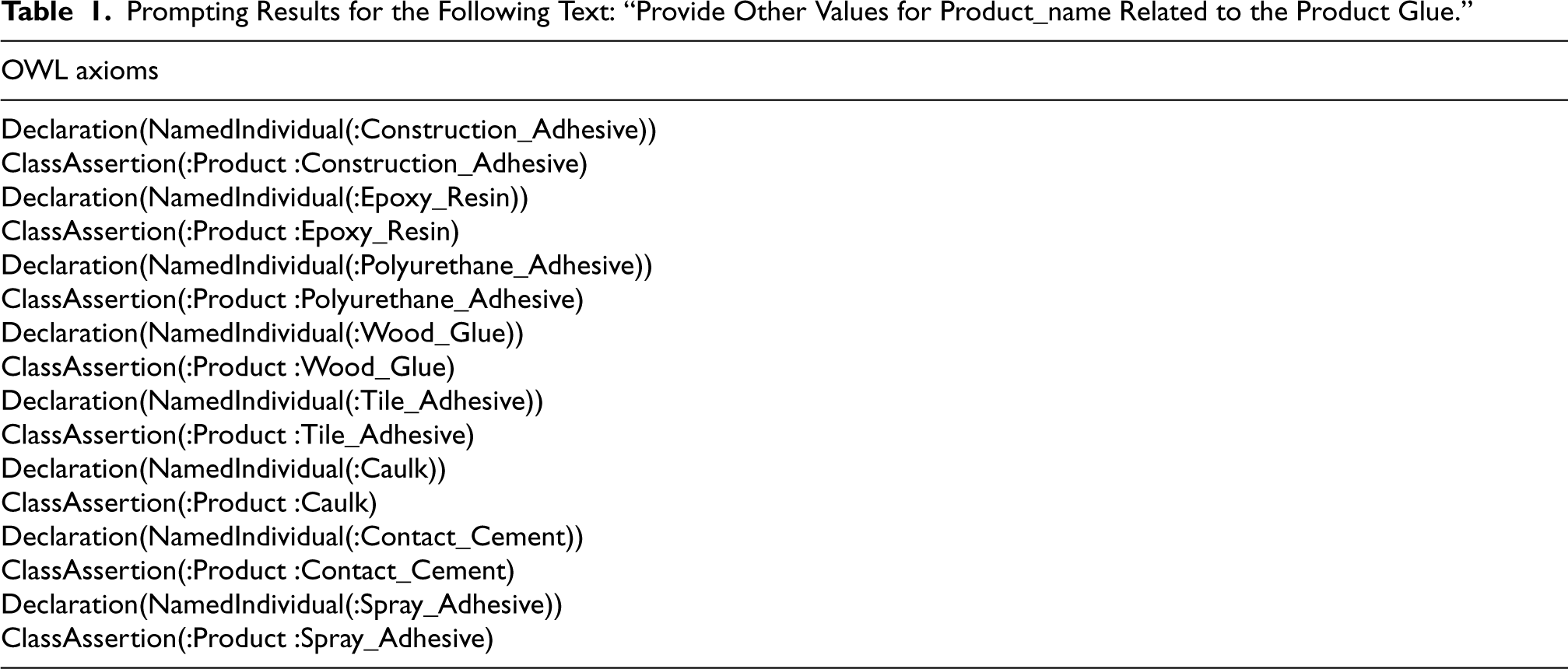
Prompting Results for the Following Text: “Provide Other Values for Product_name Related to the Product Glue.”
Prompting Results for the Following Prompt: T = “Provide a Detailed Instance of Component that Includes all Component_Name and has_Structure Within it, Specially in a Context Related to Glue. Provide Detailed Instance of Structure That Includes all Structure_Name Within it, Specially in a Context Related to Glue.”

Precision and Recall: Both are notably low ( F1 Score: Consequently, the F1 score is also low (F1 = 0.091), reflecting the inadequacy of generic prompts in producing valuable ontology instances.
Building_id and Simple Inputs
When the input is something general, not context related, or more less valuable, such as a building ID, precision and recall values remain s low.
Precision and Recall: Slightly improved from no input but still low ( F1 Score: Marginal improvements seen (F1 = 0.106 for Building_id), but still far from optimal.
Descriptive Inputs (Building_type, Structure_name)
Conversely, when more descriptive inputs, such as building type or structure name, are supplied, there is an improvement in precision and a remarkable increase in the recall value. This enhancement can be attributed to the additional contextual clues that allow the model to generate more relevant and precise responses. The more we detailed the description of the building, the better the results.
Precision and Recall: Significantly better results with more descriptive inputs such as Building_type ( F1 Score: Correspondingly higher (F1 = 0.383 for Building_type and F1 = 0.555 for Structure_name), highlighting the benefit of detailed descriptive inputs in enhancing model performance.
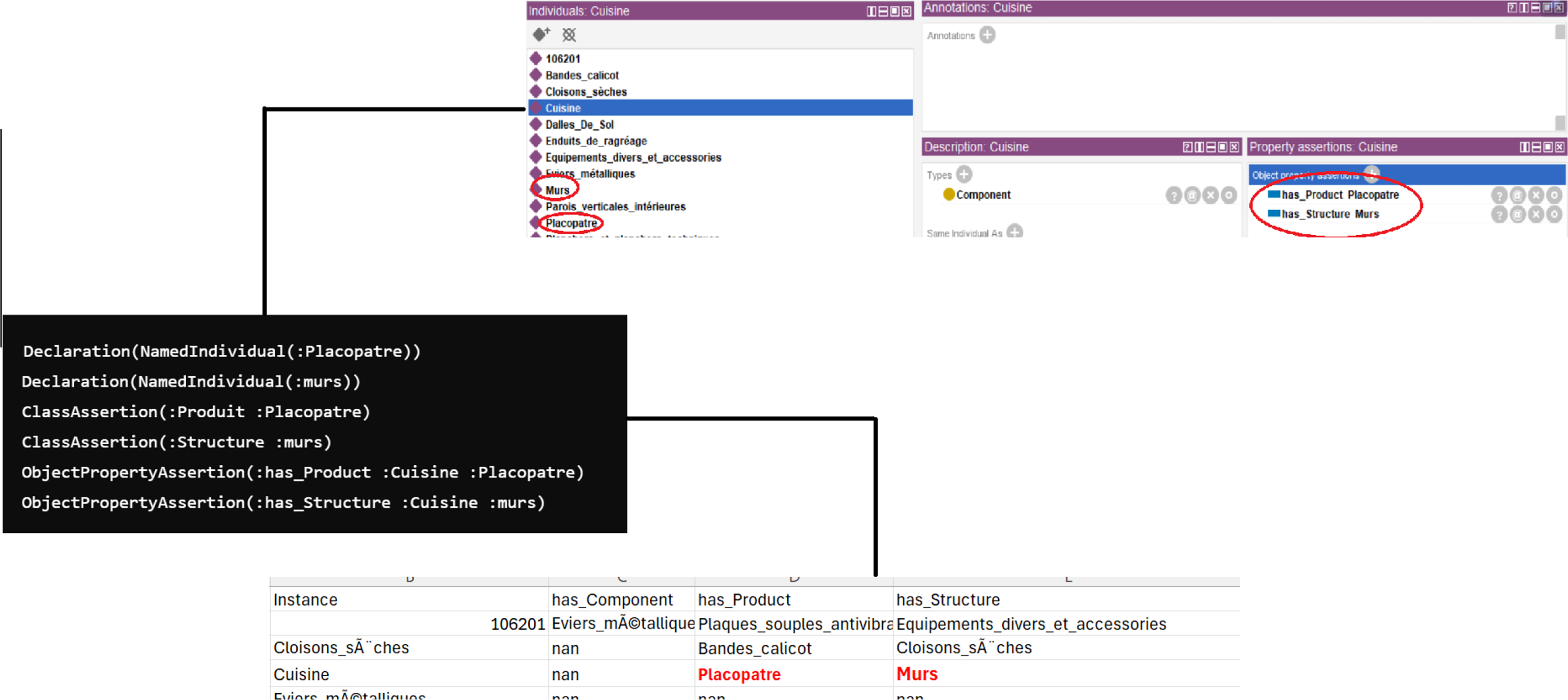
OWL Axioms Creation Module.
OWL Axioms for Prompting Results With Input: Building_type = “Maison Individuelle.”

Comparison of Prompting Results With Multiple Inputs.
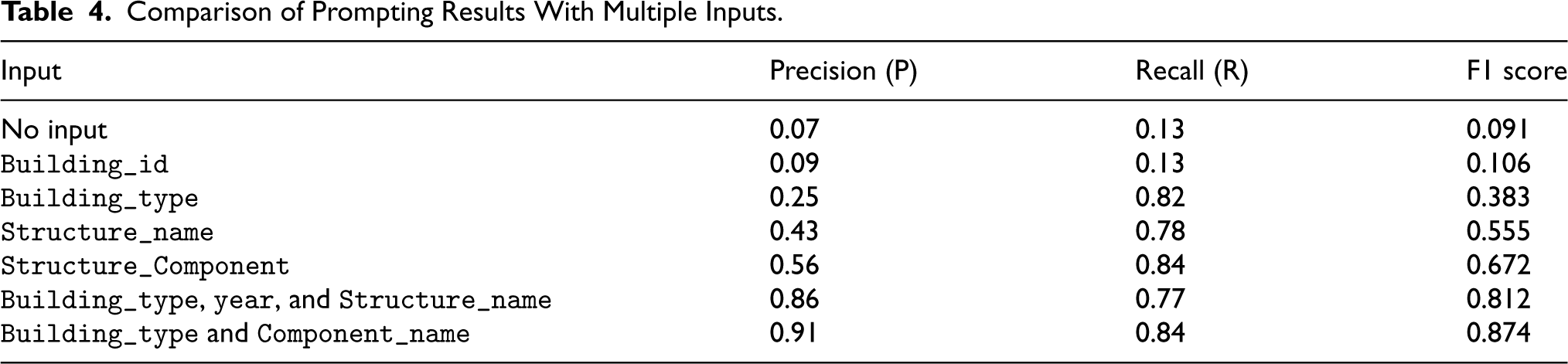
Finally, when multiple inputs are provided, such as a combination of building type, year, structure name, or building type with component name, the F1 score sees a significant boost. This is because the several inputs give ChatGPT a richer context, enabling it to make more informed and accurate predictions, effectively balancing precision and recall to achieve a higher F1 score.
Precision and Recall: Highest scores are observed when multiple contextual inputs are combined, such as Building_type and Component_name ( F1 Score: Reflects a strong balance between precision and recall, achieving the highest scores (F1 = 0.874 for Building_type and Component_name), which indicates an optimal performance in ontology population tasks.
In Table 2, we applied the input combination, querying for values associated with the component, including both data and object properties pertinent to each component instance. For each input, identified by Product_Name, we extracted values for the data property Component_Name, utilizing a similar prompting text approach as in our initial methodology.
However, for the object property has_Structure, which is integral to the component, our methodology adapted to include additional recursive prompting. This recursive element enabled the extraction of both data and object properties related to the structure, such as Structure_Name. The recursive prompting facilitated a deeper exploration of the ontology, allowing for a comprehensive representation of relationships and attributes within the OWL framework.
The suggestions by ChatGPT are formatted in OWL axioms. Our objective is to produce outputs conforming to OWL functional syntax, whereby the outputs are structured as axioms. Figure 6 provides a detailed example. The suggested values are highlighted in red, showing how they are written in OWL axioms and inserted into our ontology. Specifically, the instances “Placopatre” and “murs” are declared and associated with the “Component” instance “Cuisine” through the object properties “has_Product” and “has_Structure.” The figure demonstrates these associations visually within the ontology editor, highlighting how the axioms are applied to establish the relationships.
Similarly, as presented in Table 3, we employed ChatGPT to derive values for structure, component, and product by providing it with specific details of a building, specifically building b1, identified by “Building_id = 101604” and “Building_type = Maison individuelle.” Utilizing our recursive prompting function, we generated the subsequent prompting texts. This method enabled a targeted extraction of relevant information across multiple hierarchical levels within the ontology, effectively mapping the interconnected properties and entities associated with the specified building.
Provide a detailed instance of structure that includes all Structure_name, components within it, especially in a context related to building 101604 Building_type = “Maison individuelle.” Provide a detailed instance of the component that includes all Component_name, product within it, especially in a context related to building 101604 Building_type = “Maison individuelle.” Provide a detailed instance of a product that includes all Product_name, provider within it, especially in a context related to building 101604 Building_type = “Maison individuelle.”
Using the Origami dataset as ground truth, we calculated the precision, recall, and F1 score of the instances generated by our model under various input scenarios. The results are summarized in Table 4.
Conclusion
Ontology population involves automatically identifying, extracting, and integrating information from various sources to instantiate the classes and properties of an ontology, thus creating a knowledge graph for a specific domain. In this paper, we demonstrate the significant potential of the zero-shot prompt engineering technique in enriching domain ontologies when integrated with LLMs such as ChatGPT. Our analysis of the application domain knowledge provided by ChatGPT reveals that carefully tailored prompts can lead to an accurate ontology population.
The primary goal of our approach is to overcome the challenges associated with ontology population by showing how instance-level knowledge graphs can be populated without the need to manually create hundreds of instances. Our method leverages the capabilities of LLMs and prompts engineering to automate this process efficiently.
Certainly, the granularity of input values is directly proportional to precision. Specific details such as the type of building, the name of the structure, or the component name lead to higher precision than numerical identifiers such as a building ID or building code, or broader inputs such as an address, which lack specificity regarding products. Additionally, it has been observed that an increase in input quantity tends to raise the F1 score. This is because with a single input, while precision may be high, recall is often low. However, when dual or triple inputs are provided, the balance between precision and recall is improved, thereby enhancing the F1 score.
Beyond ontology population, our findings also highlight a promising research direction for LLM-assisted ontology alignment. While our focus in this study was not on refining the Asbestos Ontology itself, we acknowledge the importance of integrating upper ontologies such as DOLCE to improve semantic consistency. Rather than manually aligning the ontology, we propose a novel approach combining LLMs with graph traversal techniques such as Depth-First Search (DFS) and Breadth-First Search (BFS) to semi-automate the ontology mapping process.
Our envisioned methodology for DOLCE integration involves:
Extracting ontology hierarchies using OWL and representing them as directed graphs. Using LLMs to generate initial concept mappings by categorizing domain-specific entities into DOLCE’s foundational categories (e.g., Endurant, Perdurant, and Quality). Refining mappings with DFS for deep hierarchy exploration and BFS for broad conceptual alignment. Generating OWL axioms automatically, validated using ontology reasoners such as HermiT or Pellet.
This approach paves the way for a future research project that will explore how LLMs can be leveraged not only for ontology population but also for ontology alignment and completion. The ability of LLMs to generate semantic mappings, infer missing links, and align domain ontologies with foundational frameworks represents a significant advancement in ontology engineering and the semantic web community.
Thus, while this study demonstrates the efficacy of LLMs in ontology population, it also opens new avenues for enhancing ontology interoperability through artificial intelligence-driven semantic reasoning and alignment strategies. In future work, we will investigate the integration of ontology embeddings, reinforcement learning techniques, and domain expert validation to further refine the accuracy of LLM-driven ontology mapping.
Footnotes
Acknowledgements
The authors extend their appreciation to the Arab Open University for funding this work.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors extend their appreciation to the Arab Open University for funding this work.
Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.