
Abstract
On-device deployment often relies on lightweight models that require fine-tuning when deployment environments differ from development conditions or when model performance changes over time. Although recent LLM-enabled agents are capable of reasoning about system states and forming adaptive strategies, they often incur substantial computational and budgetary overhead, making them impractical for resource-constrained edge settings. This paper presents Budgeted Agentic AI for Adaptive Lightweight Model Fine-Tuning (BA2), a framework for budget-constrained lightweight model adaptation that combines bounded optimization steps with auxiliary evaluation, rollback, and compression actions. BA2 enables agents to dynamically adjust adaptation strategies according to real-time budget conditions while maximizing system performance. BA2 explicitly accounts for constrained resources, including limited fine-tuning steps, tool invocation quotas, and token consumption. An Engineer–Manager architecture is introduced, where an LLM-based Engineer generates parameterized candidate operations from system logs, and a lightweight contextual-bandit Manager selects actions conditioned on both environmental states and remaining budgets. Experimental results demonstrate that BA2 achieves superior cost-performance trade-offs compared with static heuristics and inference-time search agents under tight budget constraints, while remaining competitive with strong baselines in higher-budget regimes.
Introduction
On-device model deployment is typically constrained by limited edge-side resources and environmental heterogeneity. 1 First, these edge devices have limited compute, memory, and power budgets, so what can be deployed is usually a lightweight model that must meet requirements for low latency and energy consumption, but stable performance. 2 Second, sensor configurations, operating conditions, and data acquisition pipelines may vary substantially across environments, leading to non-negligible distribution shifts. As a result, lightweight models often require environment-specific fine-tuning and may need further adjustment as operating conditions evolve. Such fine-tuning typically proceeds under tight resource constraints and may involve bounded parameter updates together with auxiliary evaluation, rollback, and compression actions. Moreover, even after the initial rollout, edge-deployed models can suffer continuous performance degradation due to distribution drift, changes in sensor noise, and task switching, which in turn impacts the quality of online detection, prediction, or control. These realities make a fully automated, continuously maintainable adaptation mechanism a pressing necessity: the system should be able to respond to performance degradation under limited resources, execute budget-aware adaptation actions, and maintain performance more effectively under changing conditions. Therefore, enabling autonomous model adaptation has become a key challenge for scaling on-device intelligence to large-scale industrial deployment. 3
Large language models (LLMs) offer a new route to this problem. Compared with rule-based automation 4 or human-in-the-loop maintenance, 5 LLM-enabled agents provide stronger contextual understanding and reasoning: they can interpret training logs and diagnostic signals 6 (e.g., loss/accuracy trends, performance drops), produce causal explanations, 7 and propose appropriate optimization actions (e.g., hyperparameter tuning, checkpoint rollback, compression). This capability upgrades model maintenance from a static pipeline to context-aware closed-loop decision-making. In this way, on-device model adaptation can move beyond expert hand-tuning and extensive trial-and-error, toward an automated engineer maintenance process.
However, these advantages are subject to stringent constraints in real-world deployments. On-device systems must operate under multi-dimensional budgets, with adaptation steps limited by energy and time windows, online evaluation, compression, and recovery operations constrained by tool-call quotas, and LLM inference bounded by token cost and latency. Under such conditions, an agent cannot assume abundant resources or unrestricted usage, but must dynamically balance performance gains against computational and communication costs, including energy consumption, tool calls, and token usage, to identify the most cost-effective adaptation trajectory.
To solve this issue, we propose Budgeted Agentic AI for Adaptive Lightweight Model Fine-Tuning (BA2). We model the adaptation process as a budget-conditioned sequential decision problem. At each step, the agent selects an action according to the current model state, including loss and accuracy trends, together with the remaining budget vector, so as to maximize overall performance gains without exceeding resource limits. Concretely, when performance degrades, the agent will execute a bounded fine-tuning step followed by evaluation. When adaptation becomes unstable, it will roll back to a previous checkpoint. When resources become tight or deployment constraints must be satisfied, it will apply compression or terminate the episode. BA2 conditions the policy on the remaining adaptation-step budget, tool-call quota, and token budget, enabling the agent to learn the optimal benefit-cost trade-off under different budget regimes.
Building on this formulation, we introduce an Engineer–Manager framework to balance model performance and budget consumption. The Engineer is driven by an LLM: it reads training logs and generates a small set of feasible candidates with concrete parameters. The Manager is a lightweight contextual-bandit selector that chooses the next action from the candidate set by considering both the current state and remaining budgets. This selector can run with low overhead on the device under strict resource constraints. Through this process, the system can choose an effective action sequence from LLM-proposed candidates, and execute a cost-effective adaptation trajectory under multi-dimensional budget constraints.
Our contributions are summarized as follows: We formulate lightweight on-device deployment and adaptation as a budget-conditioned trajectory optimization problem, explicitly characterizing the trade-off between performance gains and resource consumption. We propose the Engineer–Manager framework, where an LLM performs low-frequency proposal generation and semantic diagnosis, and a lightweight contextual-bandit selector performs budget-conditioned selection, achieving dynamic strategies with low inference overhead. Experiments on a CIFAR-10
8
benchmark show that, under the same budget constraints, BA2 achieves a better cost-performance trade-off than static heuristics and search-based agents; in higher-budget regimes it remains competitive with search-based methods while offering stronger deployability and stability.
Literature review
Agentic artificial intelligence and budget-aware decision making
The transition from standard large language models to agentic artificial intelligence has enabled systems capable of autonomous planning, tool usage, and multi-step execution. 9 Early paradigms mainly emphasized open-ended reasoning and acting,10,11 while more recent systems such as SWE-agent, 12 Openhands, 13 and ChatDev 14 have demonstrated the potential of large-language-model-based agents in complex engineering workflows. However, these successes have largely been established in tasks with relatively clear execution feedback and without strict adaptation budgets. In budget-constrained model adaptation, by contrast, the system must operate under noisy optimization dynamics, delayed feedback, and hard resource constraints. 15 Existing approaches therefore remain limited in this setting. Planning-based methods such as Tree of Thoughts 16 and Look-Ahead Tree Search 17 improve long-horizon reasoning, but require repeated large language model queries and substantial planning overhead, which weakens scalability under tight budgets. Budget-aware tool-use systems, including ToolChain*, 18 EcoAssistant, 19 and budget-constrained tool learning with planning, 20 explicitly consider cost-aware tool use, yet still rely heavily on inference-time exploration or planning. Reinforcement learning offers another route to reducing online reasoning cost, 21 but end-to-end policy learning is often unstable when the action space is combinatorial and coupled with heterogeneous budgets.
Taken together, these studies provide strong semantic reasoning and tool-use capabilities, but still do not yield a framework that simultaneously preserves semantic flexibility, scales under hard budget constraints, and remains feasible for deployment. By contrast, the proposed framework bridges inference-time search and end-to-end policy learning by separating semantic proposal generation from lightweight online selection, thereby improving scalability and deployment feasibility while retaining adaptive decision-making capability.
Budget-constrained model adaptation and automated machine learning
Traditional approaches such as Bayesian optimization 22 and neural architecture search 23 are effective for global search over model or hyperparameter configurations. However, they are largely resource-oblivious with respect to the adaptation process itself and are mainly designed for offline optimization rather than sequential, deployment-time adaptation under evolving conditions. With the rise of foundation models, large-language-model-driven automated machine learning has introduced a more semantically informed paradigm. 24 Systems such as LLAMBO 25 use large language models to warm-start or score candidate configurations for Bayesian optimization, while EvoPrompt 26 employs large language models to iteratively propose optimization steps through evolutionary search.
These methods improve proposal quality and search efficiency, but still treat the large language model primarily as a predictor or scorer rather than as a mechanism for budget-aware sequential control. As a result, their support for scalable and feasible post-deployment adaptation under hard resource constraints remains limited. The proposed framework addresses this limitation by extending automated machine learning from static search and surrogate ranking to budget-aware sequential decision-making through semantic proposal generation and lightweight online selection.
Budgeted agentic framework for model adaptation
This section presents BA2 for adaptive lightweight model fine-tuning under deployment constraints. We first formalize the budget-conditioned adaptation problem and then introduce the Engineer–Manager architecture in Figure 1. Sections 3.3 and 3.4 describe the Engineer and the Manager, respectively, and Section 3.5 presents the executable tool interface and deployment protocol.
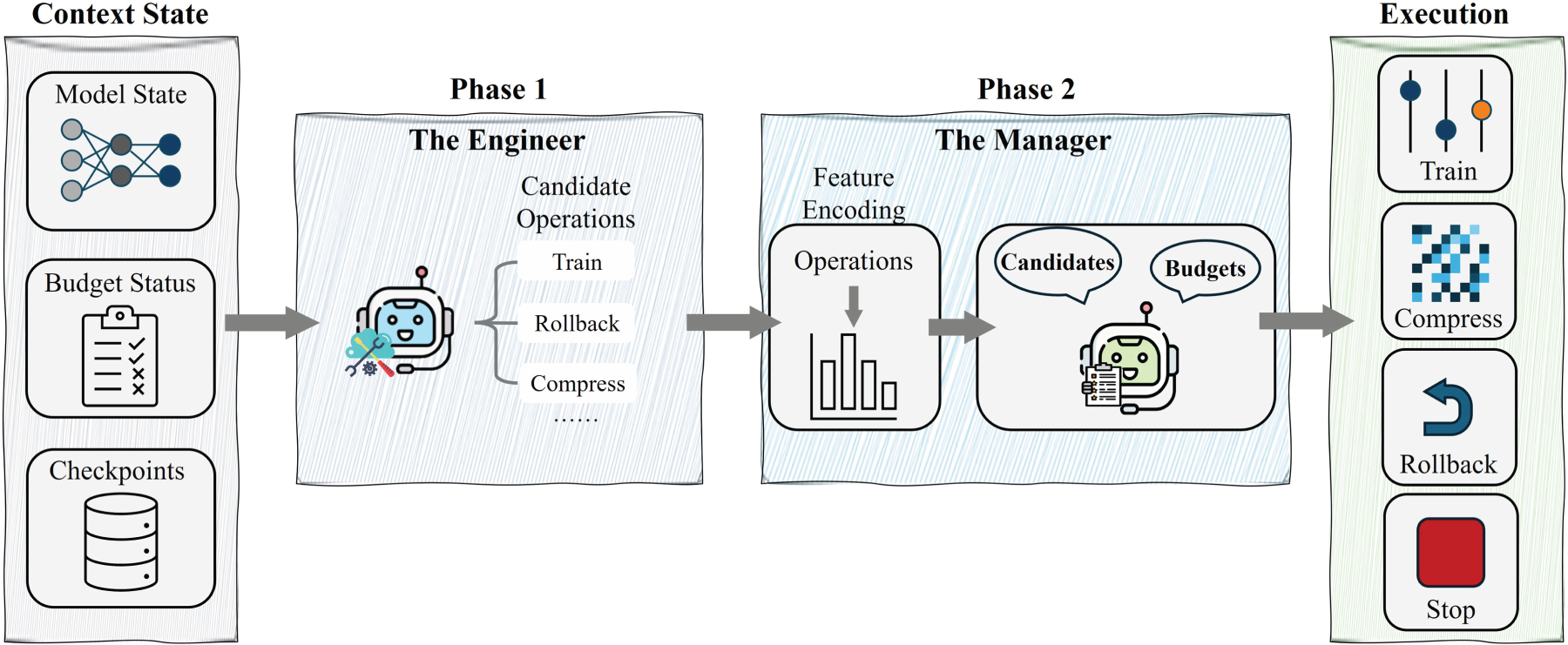
Overview of the proposed budgeted agentic framework for model adaptation.
We focus on the problem of autonomous model adaptation in resource-constrained environments, where an agent must strategically trade off performance gains against multi-dimensional budgets. To address this, we formulate the adaptation process as a finite-horizon Markov decision process,
27
explicitly conditioned on remaining resource budgets. Consider an agent tasked with optimizing a model
At each step, the agent selects an action
The agent operates under a multi-dimensional budget constraint vector:

The execution of action
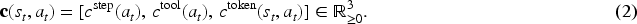

The objective is to learn a policy
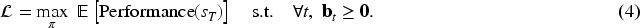
Although the overall adaptation process can be formulated as a finite-horizon Markov decision process, the sparse-refresh design of BA2 reduces the online decision problem to selecting among a small set of feasible, context-dependent candidates under the current summarized state and remaining budgets. This motivates our use of a lightweight contextual-bandit approximation for the Manager, which preserves budget-conditioned adaptivity while reducing online decision overhead.
To enable autonomous adaptation under strict on-device deployment constraints, BA2 decouples decision-making into two coordinated roles—the Engineer and the Manager. Concretely, the Engineer proposes feasible update candidates under the current budget, while the Manager allocates and enforces budgets and determines which candidate to deploy and when to deploy it.
A key design principle of BA2 is the temporal decoupling between semantic proposal generation and low-overhead action execution. Rather than invoking the LLM after every executed action, BA2 refreshes candidate proposals only at sparse candidate-refresh rounds. Between two successive refreshes, the Manager repeatedly selects executable actions from the currently active candidate pool. This design preserves the adaptive reasoning ability of the LLM while substantially reducing token consumption and LLM latency.
Figure 2 illustrates the propose-and-select workflow. At a refresh round, the Engineer first utilizes the summarized state
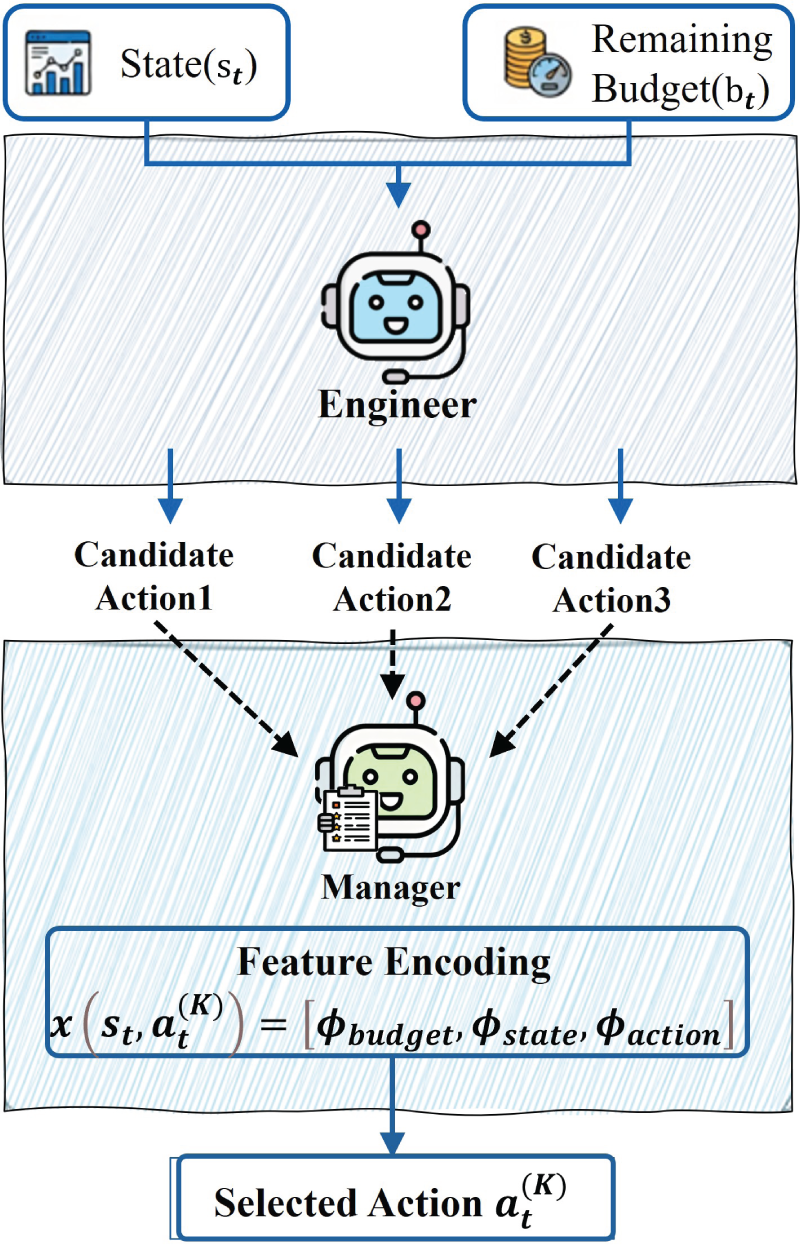
Illustration of the Engineer–Manager driven budget-aware action selection process.
Engineer: An LLM-based reasoning agent that analyzes the current summarized state and the recent trajectory, and then proposes a filtered subset of candidate operations for the Manager, thereby reducing the decision search space.
Manager: A lightweight contextual bandit policy based on the linear upper confidence bound method, 28 which enforces strict budget feasibility. It estimates the potential reward of each candidate under the remaining budget vector and selects the optimal action to maximize adaptation efficiency subject to constraints.
Let
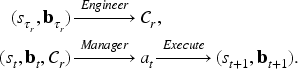
In our implementation, a refresh is triggered when one of the following conditions holds: (1) every
The Engineer is responsible for transforming the current summarized state and remaining budget into a small set of contextually plausible candidate operations for the Manager. This subsection describes the Engineer from four aspects: structured prompt construction, candidate generation, prompt-length management, and feasibility filtering.
At each candidate-refresh round
The LLM synthesizes this summarized context to generate a candidate pool
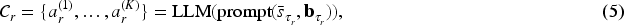
Below is an example of our structured prompt (abbreviated), which we provide to the LLM to generate
– Accuracy (last 3): 0.812
– Loss (last 3): 0.94
– Stability: unstable (loss increasing)
– Adaptation-step budget: 120 steps
– Tool-call quota: 6 calls
– Remaining token budget:
– Must output at most 3 candidates
– Each candidate must include: {tools, args, rationale}
– When training is unstable, prioritize stabilizing actions over aggressive actions.
Output schema
Each candidate includes 1) an operation type (e.g., continue adaptation with adjusted hyperparameters, revert to a previous checkpoint, apply compression, run evaluation, or terminate); 2) concrete parameters (e.g., step count, learning rate scale, compression target); and 3) an optional short rationale. The Engineer is allowed to return fewer than
Prompt-length management
To stabilize token usage, BA2 employs two complementary mechanisms. First, only recent metrics and compact trajectory statistics are retained in
Feasibility filtering
Before passing proposals to the Manager, BA2 estimates the execution cost of each candidate using deterministic metadata: training candidates expose their step counts and learning-rate settings; deployment candidates expose their associated local tool calls; and LLM token cost is accounted at refresh time rather than action-execution time. Formally, the feasible candidate set

The Manager must make fast decisions under tight budgets and intermittent connectivity. Given the sparse-refresh design above, the online decision problem at each step reduces to selecting one feasible candidate from a small context-dependent pool. We therefore instantiate the Manager as a lightweight contextual-bandit selector based on the linear upper confidence bound method, which provides strong sample efficiency, interpretable uncertainty estimates, and low online overhead. The Manager operates only on the feasible candidate set
Budget-aware feature representation
For each candidate
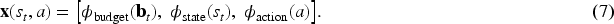
All feature components are hand-crafted and normalized to
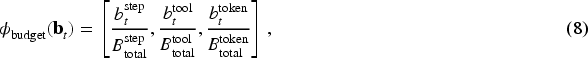
Accordingly, the feature representation is interpretable rather than learned end-to-end:
The Manager selects the action
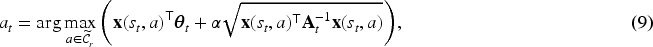
During training episodes, after executing
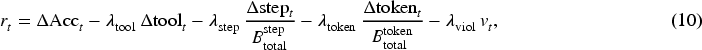
The Manager is trained offline on simulated adaptation episodes and then frozen during evaluation. Specifically, we train the linear upper confidence bound selector for
Tools
The framework executes the selected action
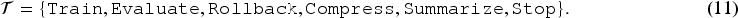
To avoid ambiguity, BA2 distinguishes between LLM invocation and local tool execution. Only Engineer refreshes consume the token budget
The framework includes six tools. The Train tool performs a bounded number of training steps under specified hyperparameters, such as step count and learning-rate scale, and returns updated metrics together with the consumed step budget. The Evaluate tool runs validation when explicitly selected by the system, consumes tool-call budget, and returns updated metrics used to refresh the state summary for subsequent decisions; it is not appended automatically to every model-modifying operation. The Rollback tool saves the current model state or restores a previous checkpoint to recover from degradation, thereby consuming tool-call budget. The Compress tool applies model compression, such as quantization, to satisfy deployment constraints, and returns updated size or latency indicators. The Summarize tool is a local log-compression routine that produces a compact summary of recent training signals to stabilize prompt length; it does not invoke the LLM and therefore consumes no token budget, although its lightweight local invocation is charged to the tool budget when explicitly triggered. Finally, the Stop tool terminates the episode when further adaptation is no longer cost-effective.
Safety and Deployment Guarantees
To ensure the production of valid, deployable models under strict constraints, the Manager enforces a three-tier safety protocol. First, feasibility masking removes, before selection, any candidate that would cause an immediate budget overrun. Second, the deployment guard prioritizes
Experiment
Experiment setup
Task: Autonomous model adaptation
We evaluate BA2 on a CIFAR-10 8 benchmark with a ResNet-18 backbone under explicit multi-budget constraints. This benchmark is designed to isolate the budget-conditioned decision mechanism in a reproducible setting, while broader heterogeneous industrial evaluations are left for future work.
Budget instantiation
Following the three-dimensional budget formulation in Section 3, we instantiate the step, tool, and token budgets in our experiments and treat all three components as hard constraints. An episode terminates immediately if any budget component is exhausted before reaching a deployable final state.
Behavioral regimes
To examine whether BA2 adapts its decision behavior under different resource levels, we evaluate it under two budget regimes that represent tighter and more relaxed budget conditions, respectively. In the Moderate regime, the budget setting is
For fair comparison, all compared agentic methods are evaluated under the same step, tool, and token budgets in each regime. In the Moderate regime, the maximum fine-tuning steps per training action are capped at
Implementation details
We instantiate the Engineer using
For the selector, we adopt a hybrid exploration strategy with confidence bound parameter
For each random seed, we train the Manager for 100 offline episodes and then evaluate the frozen policy on 20 test episodes. Here, the policy is frozen, meaning that the Manager parameters are no longer updated during evaluation. During evaluation, the model state is reset at the beginning of each test episode so that each episode is assessed under a fresh adaptation condition rather than continuing from the previous episode. The corresponding local data partition also varies across episodes in its class composition and sample allocation. Results are reported as mean values over 3 random seeds.
Baselines
Advanced agentic baselines
We compare BA2 with two advanced agentic baselines. The first is BTP, 20 which we adapt as a search-based planning baseline by implementing a depth-first search planner within the same BA2 action space and under the same step, tool, and token budgets. At each decision point, BTP simulates potential future trajectories from the candidate set to select the next action, and therefore represents a planning-based baseline with higher inference-time reasoning overhead. The second is LLAMBO, 25 adapted from its official implementation. We retain its core LLM surrogate scoring mechanism, under which the LLM zero-shot scores and ranks the candidate actions provided by the Engineer based on historical logs, rather than relying on a learned policy for action selection. LLAMBO is also evaluated under the same step, tool, and token budgets as BA2, and thus serves as a strong baseline for LLM-driven optimization without explicit budget-conditioned policy learning.
Standard heuristics
We also compare BA2 against four standard heuristic strategies. Fixed Schedule denotes a static automation rule with predefined training and deployment behavior. Greedy is a resource-oblivious strategy that maximizes immediate validation gain, for example by fine-tuning until the budget is exhausted. Random uniformly samples from valid adaptation actions. One-shot performs a single adaptation step and then deploys immediately.
In addition to validation performance, we record per-episode resource usage for all methods, including feasibility, LLM calls, token consumption, local tool calls, fine-tuning steps, and wall-clock runtime.
Evaluation metrics and reporting protocol
Metric definition
We report validation performance using episode-wise validation accuracy curves. Let
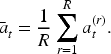
Feasibility
We additionally report the feasibility rate. Let
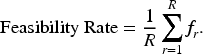
Cost metrics
To quantify resource overhead, we record the average number of LLM calls, total prompt and completion tokens, local tool calls, fine-tuning steps, and wall-clock runtime per episode.
Curve Reporting
For trajectory plots, each point denotes
Performance evaluation
Following the above protocol, we compare validation performance across methods and then report feasibility and resource usage under matched budgets. Tables 1 and 2 summarize the main accuracy results in the Moderate and High regimes. Figures 3 and 4 present the corresponding episode-wise validation trajectories.
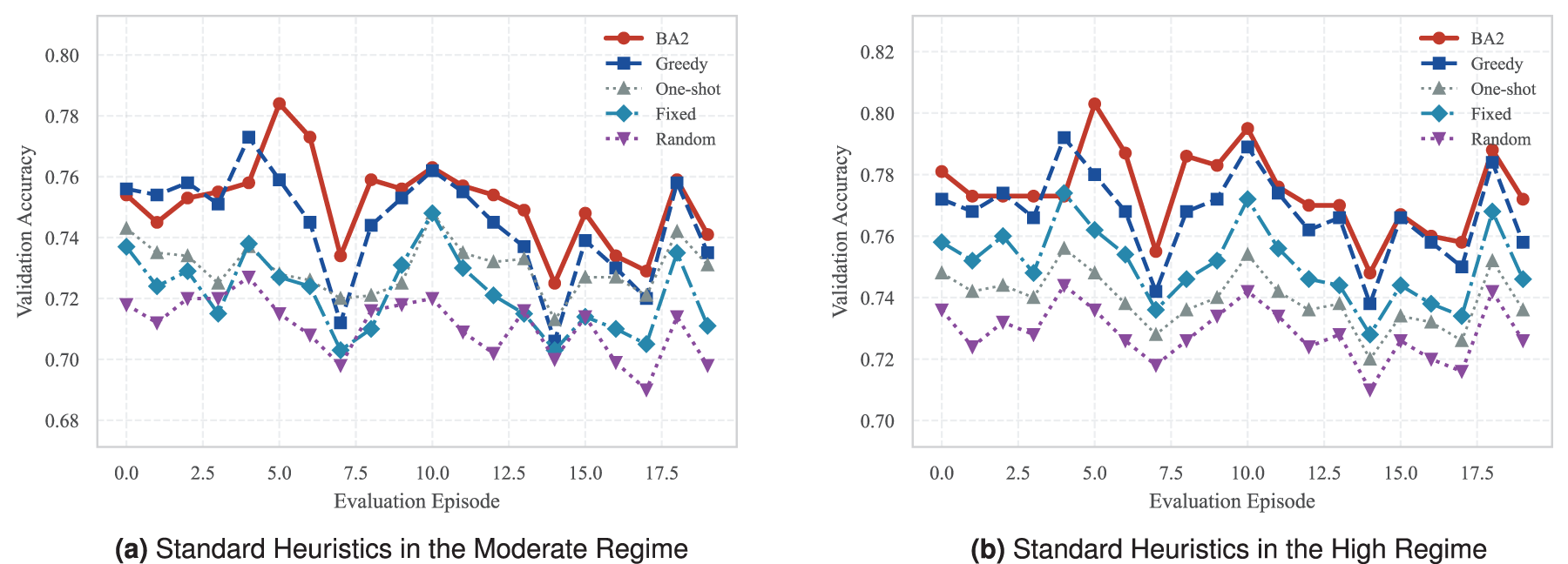
Mean episode-wise validation accuracy under matched budgets for the proposed framework and standard heuristics. Each point denotes the mean validation accuracy at the corresponding episode index across repeated evaluation runs. Variability is omitted for readability.
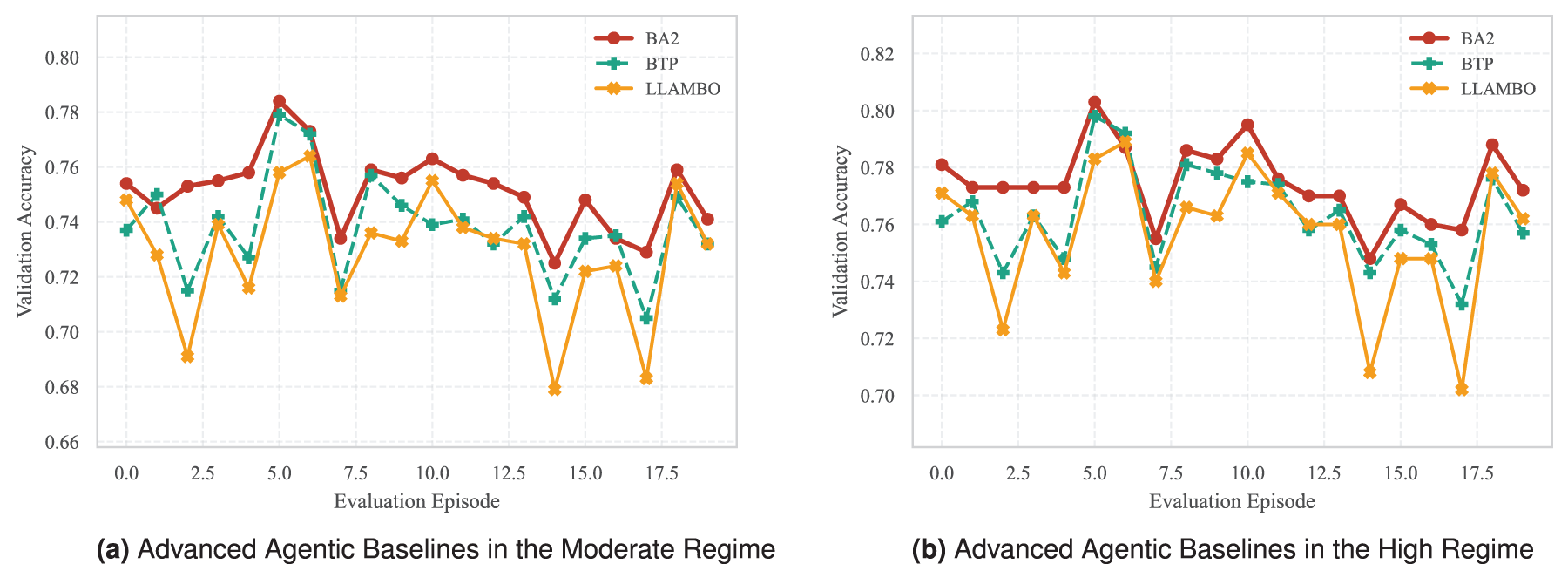
Mean episode-wise validation accuracy under matched budgets for the proposed framework and advanced agentic baselines. Each point denotes the mean validation accuracy at the corresponding episode index across repeated evaluation runs. Variability is omitted for readability.
Comparison with standard heuristics under moderate and high regimes.

.
Comparison with advanced agentic baselines under moderate and high regimes.

.
As shown in Table 1, BA2 achieves the highest validation performance among the compared heuristic baselines in both regimes. In the Moderate regime, BA2 reaches
Comparison with advanced agentic baselines
Table 2 shows that BA2 also achieves the highest validation performance among the advanced agentic baselines. In the Moderate regime, BA2 reaches
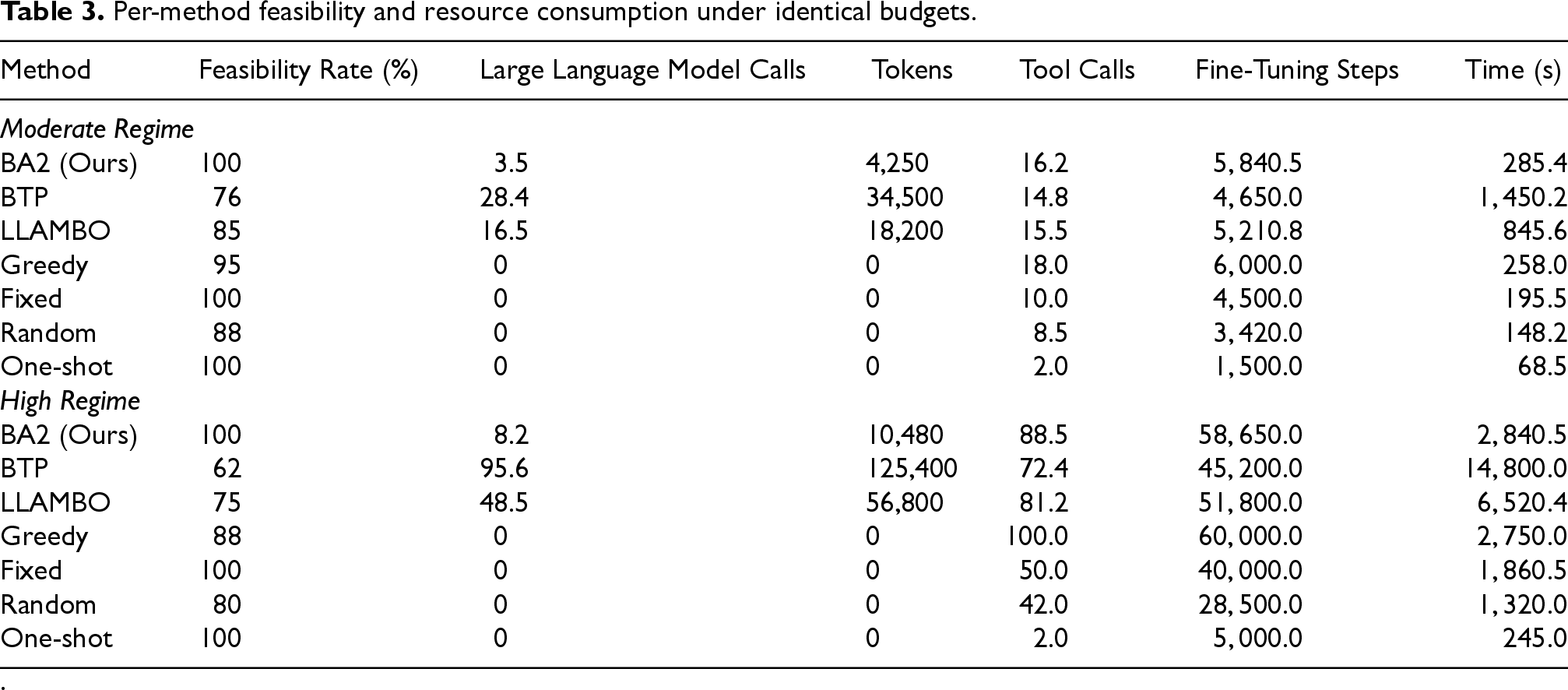
Cost and feasibility analysis
Table 3 reports feasibility and resource usage under identical budgets. BA2 attains the highest feasibility in both regimes and uses fewer LLM calls, fewer tokens, and lower runtime than BTP and LLAMBO. In the High regime, BA2 uses slightly more runtime than Greedy, but achieves higher validation performance and feasibility with fewer local tool calls and fewer fine-tuning steps. Figure 5 shows that BA2 occupies a favorable runtime–accuracy position under matched budgets.
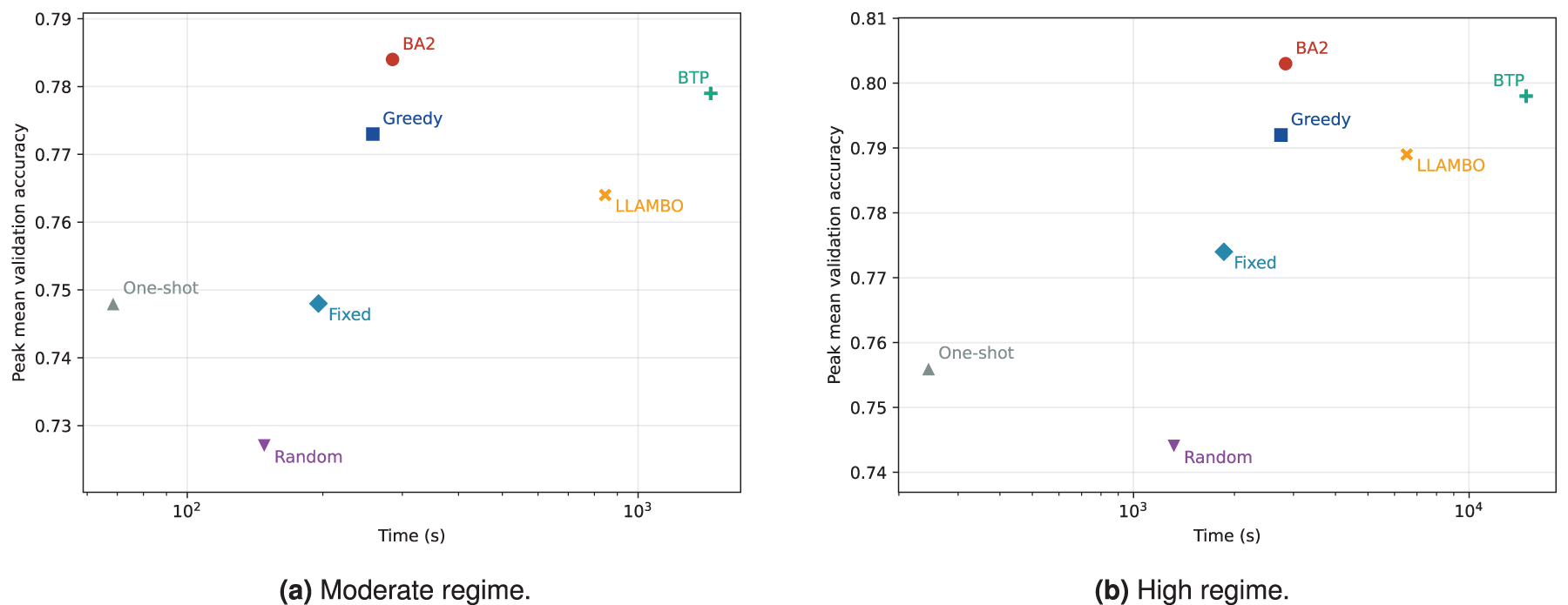
Runtime-based cost–performance frontier under matched budgets. The horizontal axis reports measured wall-clock runtime, and the vertical axis reports peak mean validation accuracy derived from the episode-wise curves. Methods closer to the upper-left region achieve stronger validation performance at lower runtime cost.
Per-method feasibility and resource consumption under identical budgets.
.
To validate the critical components of BA2, we conduct ablation studies focusing on the impact of the learned selector and explicit budget-conditioned state modeling.
Effectiveness of the Learned Selector
First, we analyze the optimization capability of the selector in the High regime. Table 4 shows that the learned selector achieves the highest validation performance among the compared selector variants in the High regime. BA2 reaches
Ablation on selector policy and budget conditioning (high regime).

Ablation on selector policy and budget conditioning (high regime).
.
Next, we investigate the role of explicit budget conditioning by ablating budget features from the state space. As shown in the bottom section of Table 4, removing budget information or replacing it with a constant prevents effective adaptation. Both variants remain at
Conclusion and discussion
In this paper, we presented BA2, a budget-aware framework for adaptive lightweight model fine-tuning under resource and deployment constraints. BA2 combines a frozen LLM-based Engineer for low-frequency candidate proposal with a lightweight contextual-bandit Manager for budget-aware action selection. In CIFAR-10 experiments under explicit step, tool, and token budgets, BA2 achieved a stronger cost–performance trade-off than static heuristics and inference-time search baselines, while maintaining lower reasoning overhead and high feasibility across different budget regimes. These results suggest that low-frequency semantic proposal generation together with lightweight downstream selection is an effective design for resource-constrained model adaptation, and that budget should be treated as an intrinsic state signal rather than merely an external stopping condition.
Future work will extend BA2 to broader deployment settings and stronger adaptation benchmarks, and further improve the Engineer–Manager interaction under richer budget constraints.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China under Grant Nos. 62503177 and 62573197; in part by the Shanghai Natural Science Foundation Project under Grant No. 24ZR1416400; in part by the Shanghai BaiyuLan Talent Program Pujiang Project under Grant No. 24PJD020; in part by the Postdoctoral Fellowship Program of CPSF under Grant Nos. GZB20250432, 2025T180476, and 2025M781639; in part by the Shanghai Science and Intelligence “Hundred Teams, Hundred Projects” Program under Grant No. RZ-RGZN-01-25-0951; and in part by the Industry-Academia-Research Collaboration Fund of the Eighth Academy of China Aerospace Science and Technology Corporation under Grant No. SAST2024-060.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.