
Abstract
Objective
This study aims to investigate how authors attribute causality in case reports and case series describing ischaemic stroke following cervical manual therapy.
Methods
This qualitative, document-based study is nested within a larger epidemiological investigation evaluating the association between cervical manual therapy and ischaemic stroke (PROSPERO ID: CRD42024602659). Eligible case reports and case series will be identified through a systematic review of biomedical databases. A software-assisted qualitative content analysis will be undertaken in MAXQDA, combining deductive coding, guided by counterfactual theory and the concept of hypothesis generation, with inductive coding to capture linguistic patterns.
Conclusion
This research protocol presents a novel approach to examining how causality is attributed in case reports and case series, addressing the relationship between ischemic stroke following cervical manual therapy for headaches or neck pain. The anticipated findings have implications for improving the clarity and responsibility of scientific communication and informing the interpretive boundaries and appropriate use of descriptive research designs in clinical and policy contexts.
Background
Neck pain and headaches are among the most common contributors of pain and disability globally and rank among the top reasons why individuals seek care from physicians, chiropractors, and other primary healthcare providers (Côté et al., 2022; Jenkins et al., 2023; Shin et al., 2022). A common approach to managing these conditions involves cervical manual therapy (e.g., spinal manipulation or mobilization), typically administered by chiropractors, physiotherapists, osteopaths, or naprapaths (Côté et al., 2022; Fernandez et al., 2020; Kjaer et al., 2017). However, the safety of cervical manual therapy, in relation to the benefits, continues to be a widely debated and controversial topic (Albuquerque et al., 2011; Carlesso et al., 2010; Cassidy et al., 2012; Erhardt et al., 2015; Funabashi & Carlesso, 2021; Kranenburg et al., 2019; Moser et al., 2019; Norris et al., 2000). Central to this debate is concern regarding the potential risk of cervical artery dissection and ischemic stroke following cervical manipulative therapy (Albuquerque et al., 2011; Carlesso et al., 2010; Cassidy et al., 2012; Erhardt et al., 2015; Funabashi & Carlesso, 2021; Kranenburg et al., 2019; Moser et al., 2019; Norris et al., 2000).
Evaluating the risk of ischemic stroke following cervical manual therapy poses significant methodological challenges and must rely on well-designed case-control (Cassidy et al., 2009; Wynd et al., 2013), case-crossover and cohort studies (Cassidy et al., 2009, Cassidy et al., 2017). Nevertheless, case reports and case series (Wynd et al., 2013) have been used to comment on the risk of ischemic stroke. While case reports and case series lack control groups, and, therefore, cannot inform causality, limiting the use of counterfactual theory (i.e. we cannot determine whether an ischemic stroke would have occurred if spinal manipulation had not occurred) (Gerstenberg, 2022; Höfler, 2005), they nonetheless play a role in initiating causal reasoning. Specifically, case reports and case series can be used to generate hypotheses and construct plausible clinical narratives that inform future analytic research.
Despite these recognized contributions to the scientific literature, authors of case reports and case series sometimes use interpretive language that implies a degree of causal certainty that extends beyond what these designs can support (Carey & Boden, 2003). Whether intentional or inadvertent, such language may contribute to inaccuracies regarding the strength and nature of the evidence (Al-Azdee et al., 2018; Alvarez-Vargas et al., 2023; Haber et al., 2022; Laeeque & Boon, 2004; Swire-Thompson & Lazer, 2022). This may reflect, in part, a lack of training in quantitative scientific methods and epidemiology, a poor understanding of causal inference, or a misunderstanding about the appropriate role of case reports and case series in the hierarchy of biomedical evidence (Al-Azdee et al., 2018; Alvarez-Vargas et al., 2023; Haber et al., 2022; Laeeque & Boon, 2004; Swire-Thompson & Lazer, 2022). Careful attention to how language is used to attribute causality is essential to avoid misinterpretation of evidence.
Language is central to how scientific knowledge is constructed, interpreted, and applied (Duranti, 2011). The words chosen by authors describe observations but also shape how research findings are interpreted and used (Haraway, 2013). Subtle shifts in phrasing can alter the perceived strength of evidence (Lakoff & Johnson, 2008; Latour et al., 2013). In fields where evidence relies heavily on descriptive reports, such as the literature on cervical manual therapy and stroke, the precision of language becomes especially important. Imprecise phrasing shapes how evidence is interpreted and applied, limiting how risk is understood in clinical, legal and policy contexts (Latour et al., 2013). Examining the language used in case reports and case series, therefore, provides critical insight into how evidence is framed and how scientific claims about causality are communicated.
Scientific approaches to assessing causality have shifted from the emphasis on observation and inductive reasoning (e.g., drawing general claims from repeated descriptions of events) towards deductive reasoning and falsification (Mitra, 2020; Popper, 1963). Inductive reasoning, while useful for generating hypotheses, cannot establish causality. In order to understand causality, scientific claims must be testable and potentially disproven (Mitra, 2020; Popper, 1963). As such, case reports and case series reside within inductive logic and are best used for hypothesis generation. Drawing on the concept of hypothesis generation (Albrecht et al., 2005; Vandenbroucke, 2001), the principle of falsifiability (Mitra, 2020; Popper, 1963), and counterfactual theory (Höfler, 2005), our study examines how language is used to articulate evidentiary claims in case reports and case series. To this end, we ask:
In case reports and case series, how do authors attribute the relationship between cervical manual therapy and ischemic stroke within a causality framework?
Research Methods and Theoretical Framework
Our qualitative study is situated within an epidemiological investigation evaluating the association between cervical manual therapy and ischemic stroke in individuals seeking care from manual therapy providers (e.g., chiropractors, physiotherapists, etc.) (PROSPERO ID: #CRD42024602659). Our proposed study complements this work by exploring how authors of case reports and case series use language to attribute causality, specifically how clinical reports shape causal discourses in health care. The communication of causality in case reports and case series is shaped by authors’ understanding of evidence, narrative choices, and interpretive language. Our use of qualitative content analysis is well-suited to examine the explicit (e.g., direct phrasing) and implicit (e.g., suggestive phrasing) attributions of causality in these written reports. We will collect data using a systematic review undertaken as part of our broader research assessing the association between cervical manual therapy and ischemic stroke. This review will identify clinical case reports and case series describing ischemic stroke following cervical manual therapy.
We will conduct a document-based qualitative content analysis informed by both theory and data. Our study will combine both deductive (theory-driven, top-down) and inductive (data-driven, bottom-up) approaches. The deductive component will be informed by counterfactual theory and the concept of hypothesis generation, while the inductive component enables identification of novel language patterns or causal phrases not predefined by theory (Azungah, 2018; Neuendorf, 2017; Vaismoradi et al., 2013). Our analysis will also be guided by established methodological frameworks developed by Kaefer et al. (2015) and Deng et al. (2019), which enable semi-automated, reproducible coding of large volumes of text. To ensure transparency in how we design, analyze, and report this study, we will follow the Standards for Reporting Qualitative Research (SRQR) (O’Brien et al., 2014), which have been adapted for document-based qualitative content analysis, and the PRISMA 2020 guidelines (Page et al., 2021) for the systematic review component of the study.
Methods
Study Design
Our qualitative content analysis methodology incorporates quantifying the frequency of specific words or phrases (manifest content analysis) and exploring the underlying meanings and contextual use of language (latent content analysis) (Hsieh & Shannon, 2005; Kaefer et al., 2015). To support rigour and reproducibility, we have adapted the software-assisted qualitative content analysis methodologies developed by Kaefer et al. (2015) and Deng et al. (2019). This approach allows for consistent and efficient analysis of large volumes of text while enabling systematic identification of patterns and relationships within the data.
Data Collection
The case reports and case series used in our qualitative content analysis will be identified in a systematic review of the literature that will be conducted for the larger body of research assessing the association between cervical manual therapy and ischemic stroke (PROSPERO ID: #CRD42024602659). Our content analysis represents one part of this larger body of work. We will search MEDLINE, Embase, CINAHL, PsycINFO, and Index to Chiropractic Literature from inception to present. The search strategy will be developed in collaboration with an experienced health sciences librarian and will combine subject headings (e.g., MeSH terms in MEDLINE) with free-text keywords targeting key concepts such as ischemic stroke, cervical spine, spinal manipulation or mobilization, manual therapy, and relevant healthcare providers (e.g., chiropractors, physiotherapists, osteopaths, physicians, naprapaths).
Eligibility Criteria
We will include studies that involve individuals who are seeking care for neck pain or headache. Eligible exposures are cervical manipulation or mobilization involving manual movement of the cervical spine, as well as visits to providers who commonly deliver these interventions (e.g., chiropractors, physiotherapists, osteopaths, naprapaths, or physicians). The primary outcome of interest is cervical artery dissection with or without ischemic stroke. We will include case reports and case series, while excluding observational studies (e.g., cohort, case-control, analytic cross-sectional, case-crossover), randomized controlled trials, qualitative studies, pilot or feasibility studies, systematic reviews, non-peer-reviewed research, such as protocols, trial registrations, commentaries, editorials, conference abstracts or proceedings, thesis dissertations, government reports, and books.
Study Selection
Studies will be selected in two sequential stages by pairs of independent reviewers in the larger systematic review. In the first stage, titles and abstracts will be screened for relevance. In the second stage, full-text articles of potentially eligible studies will be reviewed to determine inclusion. Reviewers fluent in the original language will assess non-English reports. Before screening begins, all reviewers will complete a training session using a random sample of 100 citations for each phase, with a target inter-rater agreement of at least 80%. Disagreements at either stage will be resolved through discussion or, if needed, consultation with a third reviewer. In cases where disagreements remain, even after a third reviewer, a consultation with a senior team member and/or a detailed review of the study’s selection criteria will be conducted to reach a resolution.
Qualitative Content Analysis Procedures
We will follow a five-step process of software-assisted qualitative content analysis methodology: 1) Software selection and familiarity; 2) Building the dictionary; 3) Importing and analyzing the data; 4) Coding procedure; and 5) Visualizing the data and presenting findings (Figure 1) (Deng et al., 2019; Kaefer et al., 2015). The five-step process of the software-assisted qualitative content analysis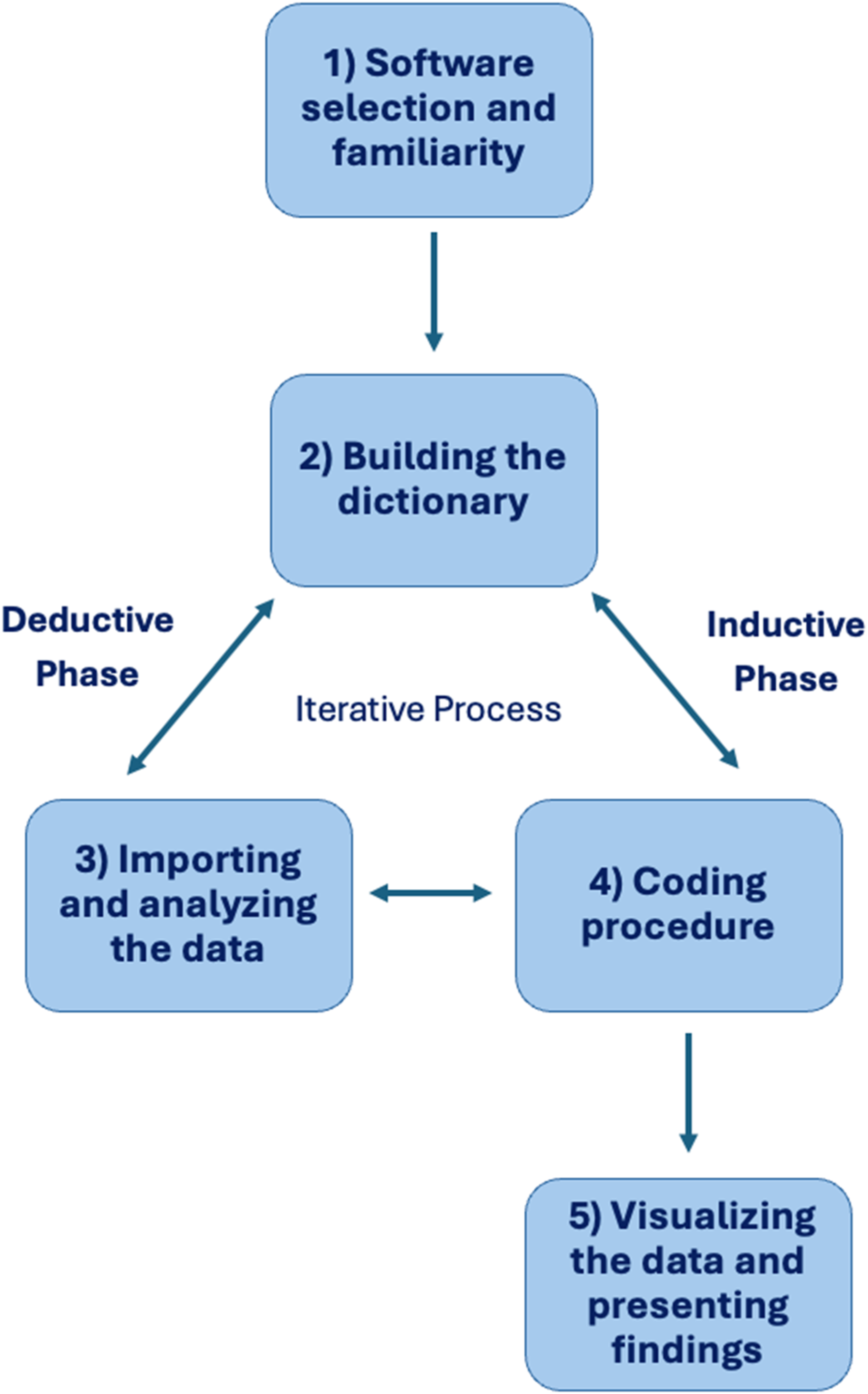
Step 1: Software Selection and Familiarity
We reviewed qualitative analysis tools, including NVivo, Dedoose and MaxQDA, and selected MaxQDA based on its compatibility, functionality, and accessibility. MaxQDA is a text mining tool that enables the identification, coding, and extraction of words and phrases (Software, 1989-2024). Preliminary testing will be conducted on a conveniently selected corpus (sample of published case reports and case series identified from our systematic literature search) to evaluate the software’s importability and usability.
Step 2: Building the Data Dictionary
In qualitative content analysis, a dictionary refers to a predefined set of terms (i.e.,words, word stems, or phrases) organized into conceptually meaningful categories (Deng et al., 2019). In our study, the dictionary serves as the foundation for systematically identifying how causal language is used to attribute the exposure (e.g., cervical spinal manipulation) to the outcome (e.g., ischemic stroke) in clinical case literature. Given the novelty of our research topic, we developed a semi-automatic, iterative approach to dictionary building, adapted from Deng et al. (2019). This method involves deductive category construction, theory-informed empirical refinement using text mining, and expert panel review. A dictionary for qualitative content analysis usually comprises three components: entries, categories, and associations (Deng et al., 2019).
Definition of Coding Categories
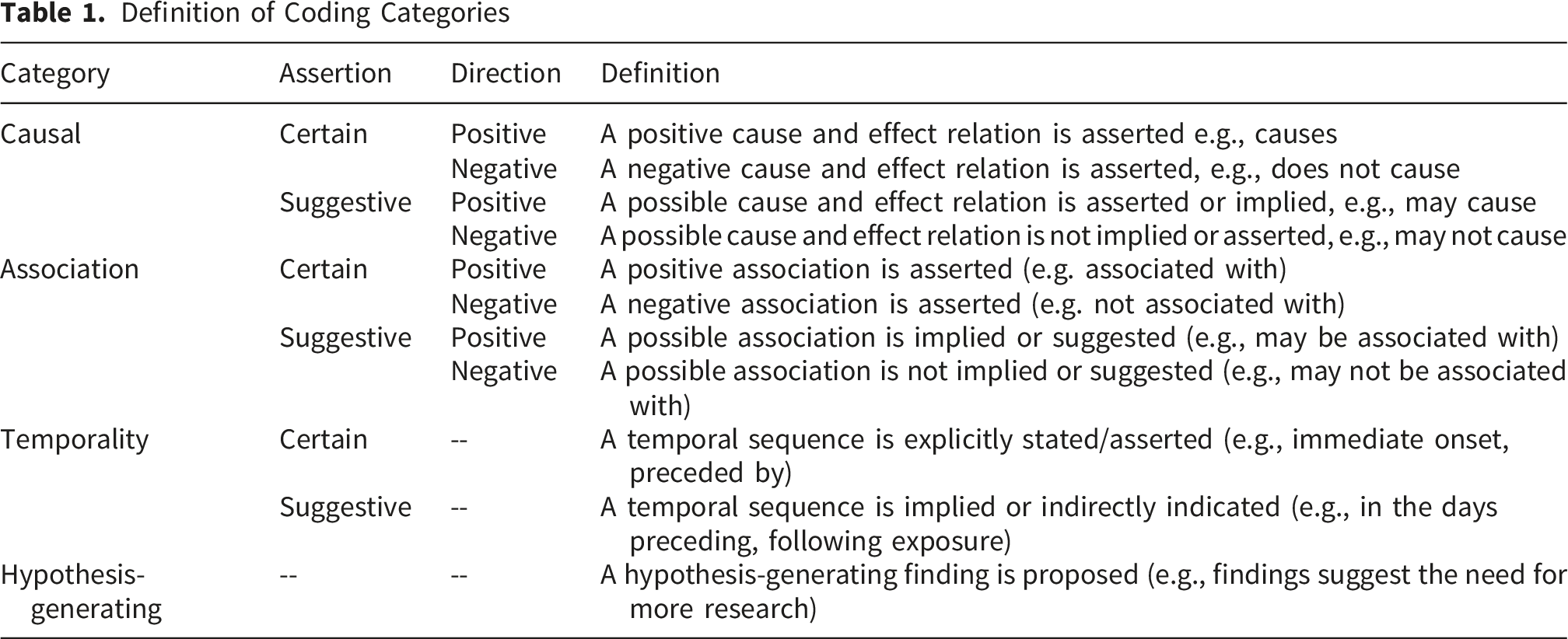
Entries will be assigned to one of these categories based on contextual interpretation, forming associations that connect specific language to broader theoretical constructs. For example, “lead to” would be mapped to causation, while “related to” would be mapped to association. This dictionary will be iteratively refined through text mining and expert input to ensure alignment with principles of causal inference and scientific reasoning.
To populate these categories, we will select a sample corpus comprising 5% of the included studies. The sample will be chosen to ensure diversity in publication year, journal, language, and geographic setting(s). A working group will review this sample corpus to identify preliminary entries (words, word stems and phrases) for each category. These entries will then be tested in MaxQDA using Boolean search strategies (e.g., “manipulation AND cause AND stroke”) to determine whether they consistently extract relevant text segments. This sample corpus will serve as a reference point for identifying commonly used entries based on the literature review and theoretical framework.
MaxQDA’s lemmatization function retains word morphology (e.g., capturing “cause” and “caused”), improving precision compared to stemming (i.e.,a technique that reduces words to the base form by removing suffixes). The software also identifies segments containing each code and provides information on both code frequency (how often a term appears in a document) and occurrence (where it appears in each document). To refine the identification of relevant segments, we will use Boolean operators (e.g., “AND,” “OR”) to detect co-occurrences of predefined term combinations. These combinations will include one
The expert working group will validate the data dictionary to ensure comprehensive and meaningful coverage of relevant language patterns aligned with our conceptual framework and analytic goals. The initial data dictionary will be refined iteratively throughout the review of studies. As those conducting the analysis engage with the literature, new terms that warrant inclusion may be identified. These will be discussed with the analytic team, and upon consensus, added to the dictionary and applied across all studies within the software to ensure consistent coding across the full corpus.
Step 3: Importing and Analyzing the Data
This step involves selecting, importing and preparing the corpus for analysis. Data will be analyzed from the entire text (e.g., abstract, introduction, methods, results, discussion and conclusion, except for the study references). The corpus comprises case reports and case series identified through comprehensive database searches. Full-text PDFs identified by our systematic review will be uploaded to MaxQDA using its “Import” function. Non-editable PDFs (e.g., scanned pages) will be converted to an editable format using Foxit PDF Editor Pro. (Inc, 2004-2024). Articles published in languages other than English will be translated into English using professional translation services or verified automated tools (e.g., ChatGPT 4.0) and reviewed by a team member fluent in the source language. If we are unable to review non-English studies for accuracy, these studies will be excluded from the analysis.
Each document will be tagged with metadata to facilitate advanced search and analysis (Kaefer et al., 2015). Metadata variables will include language, report type (case report or case series), article title, location of text within the article (e.g., introduction, methods, results, etc.) author(s), journal, year of publication, geographic setting(s) of the report or series, and profession(s) represented by the corresponding author. These tags will enable structured queries and facilitate comparisons across study characteristics. Mapping studies in this way will also allow us to explore trends in reporting, for instance, examining how causal relationships are presented within each study, how patterns vary by report type or year of publication, and which professions and journals are shaping the discourse.
Step 4: Coding Procedure
This study will employ semi-automated deductive coding followed by inductive coding, guided by the approach described by Kaefer et al. (Kaefer et al., 2015). Deductive coding will be conducted in MaxQDA using the Extended Text Search function to extract entries (i.e.,words and phrases) from the predefined dictionary. Compound queries will combine exposure and descriptor terms (e.g., “causation” AND “manipulation,” or “causation” AND “dissection”) using Boolean operators such as “AND” and “OR”. Search parameters will be configured to recognize complete words and all lemmatized forms (e.g., “cause,” “caused”) to ensure comprehensive data capture. Extracted segments, defined as the minimum textual unit needed to interpret the meaning of an entry, may consist of a sentence, paragraph, or a prespecified number of words surrounding the entries.
To validate the auto-coding process, the same sample corpus used in dictionary development will be independently coded inductively by two investigators. This step will evaluate whether MaxQDA is applying codes accurately and consistently. Reviewers will examine how entries are interpreted in context, refine category definitions, and ensure shared understanding. Discrepancies in interpretation will be resolved through discussion, and the coding framework will be iteratively refined based on consensus. At this stage, we will also determine the optimal segment length for analysis (e.g., one or two sentences, one paragraph, or a set number of words).
Once validated, the full corpus will be auto-coded using MaxQDA, applying the finalized dictionary. A random sample of 10% of the auto-coded corpus will be independently reviewed by two reviewers, who will apply inductive coding to these segments. The reviewers will meet to discuss their analysis, resolve discrepancies, reach consensus and update the data dictionary. Subsequently, one reviewer will verify all extracted segments to assess reliability, eliminate duplication, and ensure consistent interpretation aligned with the study’s theoretical framework. During this phase, segments will also be tagged based on their location within each manuscript (e.g., introduction, case description, results). A second-level compound query will then be conducted within the coded dataset to refine the results, following the sequential search strategy outlined by Kaefer et al. (2015). These refined segments will form the primary dataset for subsequent qualitative analysis.
The inductive phase will involve a line-by-line review of the extracted segments to examine how language is used to attribute causality between the exposure and outcome. This process will identify specific words, qualifiers, and contradictory or uncertain language. The reviewer will manually apply codes to capture both manifest content (explicit statements) and latent content (implied meaning). An audit trail will be maintained to document coding decisions and promote transparency.
As this is an iterative process, any new entries identified during inductive coding will be added to the dictionary and reapplied across the dataset through automated recoding in MaxQDA. The research team will review the final set of codes and categories to ensure consistency and alignment with the study’s theoretical and methodological framework.
Step 5: Visualizing the Data and Presenting Findings
We will begin the analysis by descriptively summarizing all identified codes, including their frequencies and occurrences across the included studies. This summary will provide an overview of commonly used terms related to exposure, outcome, and causality attribution. Frequencies refer to how often each code appears, while occurrences indicate where the codes are applied within individual documents.
Next, these coded segments will be mapped onto the structured categories within our conceptual framework—causation, association, temporality, and hypothesis generation—to evaluate how language used in case reports and case series aligns with core constructs of causal inference. This mapping will support the assessment of conceptual saturation and inform the interpretation of the findings within our theoretical lens. We will then use visual tools (e.g., frequency charts, distribution graphs) to illustrate patterns of code use across the dataset. These visualizations will help identify trends in language use and facilitate comparisons across study characteristics. Finally, we will analyze code frequencies and occurrences stratified by predefined variables language, report type (case report or case series), article title, location of text within the article (e.g., introduction, methods, results, etc.) author(s), journal, year of publication, geographic setting(s) of the report or series, and profession(s) represented by the corresponding author. This comparative analysis will allow us to explore whether and how causal language differs by study characteristics.
Positionality and Reflexivity
Our research team brings together a range of disciplinary and professional perspectives, including expertise in qualitative and quantitative research methods, epidemiology, statistics, rehabilitation sciences, manual therapy, and neurology. We recognize that our backgrounds shape the questions we ask, the frameworks we apply, and the way we interpret clinical evidence. By drawing on this diversity of experience, we aim to provide a balanced analysis that acknowledges both the methodological complexities of descriptive research and the clinical realities of patient care. Reflexivity is actively embedded in our analytic practice. The primary analysts will maintain a reflexive journal throughout the study to document emerging interpretive assumptions and decisions. The research team will hold regular debriefs to surface and discuss potential sources of interpretive bias, particularly those arising from members’ clinical or disciplinary backgrounds. All coding decisions, including resolutions of ambiguous or contested segments, will be documented in an audit trail.
Discussion
Our study outlines a novel approach to examining how causality is attributed in case reports and case series that describe the relationship between ischemic stroke and cervical manual therapy for headaches or neck pain. While case reports and case series are at the lower end of evidence hierarchies (level 4), they are often erroneously used to support causal claims (Carey & Boden, 2003; Dekkers et al., 2012; Hoppe et al., 2009). While our broader epidemiological investigation will assess the strength and validity of empirical associations, this study offers a complementary perspective on how causality is framed in descriptive evidence. To our knowledge, our study will be the first to critically examine how authors use language to attribute causality in case reports and case series, and how these linguistic attributions align with current understanding of these methodologies within the existing structures of biomedical evidence synthesis.
The findings of this study are expected to have several implications. The first is to provide empirical evidence on how authors use language to attribute causal relationships, which can inform best practices for responsible scientific communication. Second, this study will contribute to broader conversations on the interpretive boundaries of case-based evidence, particularly its role in causal reasoning. We anticipate that this work will lay the foundation for future investigations into how language is used in clinical reporting and how it influences research translation, clinical practice, and public understanding of complex and often controversial clinical issues.
Strengths and Limitations
We acknowledge limitations in this study protocol. First, although we will include studies published in non-English languages, challenges related to translation and cultural differences in language use may affect the accuracy of our linguistic analysis. To address this, translations will be reviewed by an epidemiologist or clinical researcher fluent in the original language to ensure accuracy and proper coding. We will also stratify our results by language to examine potential differences in causal language across various linguistic contexts. Second, while we are using a dictionary-based approach, even with iterative refinement, we may not capture all constructs; however, we will mitigate this by manually reviewing the software’s auto-coded segments.
This study has several strengths. First, our systematic review methods ensured a comprehensive and rigorous identification of relevant literature. We searched multiple databases from inception using a librarian-developed, peer-reviewed strategy, applied no language or geographic restrictions, and screened the references of included studies to capture additional eligible reports. This approach enhances the completeness, reproducibility, and credibility of our corpus. Second, we developed a robust, flexible analytical approach by combining both deductive, theory-informed content analysis and inductive exploration. The integration of MaxQDA improves transparency, replicability, and scalability, enabling systematic analysis across a large volume of literature.
Conclusion
This research protocol presents a novel approach examining how causality is attributed in case reports and case series, addressing the relationship between ischemic stroke following cervical manual therapy for headaches or neck pain. The anticipated findings have implications for improving the clarity and responsibility of scientific communication while informing the interpretive boundaries and appropriate use of descriptive research designs in clinical and policy contexts.
Supplemental Material
Supplemental Material - The Use of Causal Language in Case Reports and Case Series Reporting Ischemic Stroke Following Cervical Manual Therapy: A Qualitative Study Protocol
Supplemental Material for The Use of Causal Language in Case Reports and Case Series Reporting Ischemic Stroke Following Cervical Manual Therapy: A Qualitative Study Protocol by Nora Bakaa, Melissa Atkinson-Graham, Joshua Plener, Pierre Côté, Carol Cancelliere, L. Rachid Salmi, Jan Hartvigsen, J. David Cassidy, Chiara Arienti, Marco Campello, Sheilah Hogg-Johnson, Fred Johansson, Heather Shearer, Eva Skillgate, Jessica J. Wong , Cecilie K. Øverås, ben Axén, Manav V. Vyas, Cesar A Hincapié, Silvano Mior in International Journal of Qualitative Methods.
Footnotes
ORCID iDs
Author Contributions
NB was responsible for writing the original manuscript. NB, MAG, and SM were responsible for developing the methodology. SM provided supervision. All authors contributed to conceptualization, reviewed the manuscript critically for important intellectual content, and approved the final version for submission.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Canadian Chiropractic Research Foundation.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.