
Abstract
The hierarchical approximate optimal coordinated control of modular robot manipulators (MRMs) modeled by joint torque feedback is developed via adaptive dynamic programming (ADP). Taking advantage of the Nash-Stackelberg differential game framework, the coordinated control issue is transformed into Stackelberg differential game between MRM as leader formulated as Nash differential game and coordinate operate objective as follower. The critic neural network (NN) is built to deal with the nonlinear cost function and then derived for obtaining the approximate optimal control strategy. Theoretical analysis and experimental verification have respectively proved the effectiveness of the proposed control algorithm.
Keywords
Introduction
Modular robot manipulator (MRM)1,2 refers to a category of robots equipped with standard modules and interfaces, enabling them to recombine and reconfigure their own configurations in accordance with diverse task requirements. Guided by the design concepts of modularity and reconfigurability, each joint module of MRM integrates units for communication, sensing, actuation, and control. Through the reconfiguration of these modules, the robot can adopt multiple assembly configurations to accomplish various work tasks, thereby demonstrating advantages that traditional robots do not possess. Furthermore, robot coordinated operation embodies synergy between the precision and efficiency of robotic system as well as the flexibility and intelligence inherent to human operator.3,4 Consequently, the collaborative task execution between humans and MRMs with operation object has been continuously advancing and widely applied in various daily application fields such as medical care, industry, and elderly care.
During robot coordinated operation task, both humans and robots make corresponding decisions according to every other’s strategies. Therefore, game theory has employed in recent years to describe the coordinated operation process and quantify interaction behavior that are otherwise difficult to characterize. 5 The well-known Nash equilibrium for zero-sum6,7/non-zero-sum8,9 games and Pareto equilibrium for cooperative games10,11 are both achieved through the adoption of differences in the strategic behavior exhibited by participants. A pivotal aspect of the Nash/Pareto equilibrium framework is that, each participant can obtain information fairly within the dynamic system. However, in robot coordinated operation task, humans and robots cannot possess absolutely equal dominant relationship, nor can they perceive all information about each other. 12 Instead, the follower can only respond to the leader’s actions. Consequently, the aforementioned game approaches, which assume equal roles among participants, are not applicable in this context.
The theoretical framework of the Stackelberg game originates from the 1934 work of German economist Stackelberg and has been applied to address a wide range of economic issues.13–15 Subsequently, it has also found beyond its core applications to fields like nonlinear process, 16 biology, 17 and decision-making issue. 18 Stackelberg game comprises two distinct types of agents: leaders and followers. Its core characteristic lies in addressing sequential decision-making processes, where the leader formulates and implements its strategy prior to the follower. Following this, the follower attempts to make an optimized response according to leader’s strategy. Simultaneously, the leader adjusts its strategy to generate the optimal response based on follower’s potential actions, according to the perceived information of the follower’s strategy. When humans and MRMs perform coordinated operation tasks, humans can assist robots in operations, thus, humans/coordinate operate objectives are regarded as followers while robots act as leaders. Addressing the problem of finding the optimal control strategies for the coordinated operation system, a crucial step in the analysis involves finding the Stackelberg equilibrium solution within the dynamic system. However, for complex problems such as coordinated operation, the occurrence of the curse of dimensionality means that deriving the optimal solution through analytical equations is not always feasible.19,20 Therefore, researchers have adopted learning methods based on adaptive dynamic programming (ADP)21–23 to ensure the system’s convergence to an approximate equilibrium state.
Building upon this foundation, a hierarchical approximate optimal coordinated control strategy is proposed for MRMs modeled with joint torque feedback, according to ADP. Leveraging the Nash-Stackelberg differential game framework, the coordinated control problem is converted into a Stackelberg differential game, where the MRM formulated as Nash differential game acts as the leader and the coordinated operation objective serves as the follower. To handle the nonlinear cost function, a critic NN is constructed; subsequently, the approximate optimal control strategy is obtained with the aid of this critic NN. The performance of the proposed control algorithm is rigorously assessed through theoretical analysis and experimental verification.
The highlights of this article are reflected in following:
The creative Nash-Stackelberg differential game framework is developed for the coordinated operation task, that is with Stackelberg game between MRM acted as Nash game deemed as leader and operation objective as follower.
The developed method with Stackelberg differential game highlights the sequential decision-making process. Besides, the proposed methods have been respectively confirmed by theory and experiments, unlike only in simulation.24,25
MRM’s dynamic model analysis
Formulation of the MRM dynamics
Following the framework in Ref.,
26
we employ the joint torque feedback technique to describe the
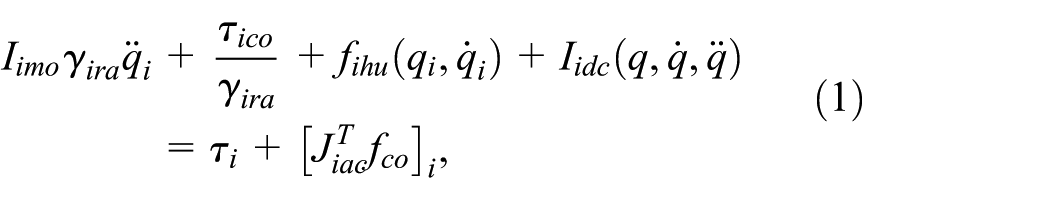
with the subscript
1) Joint friction
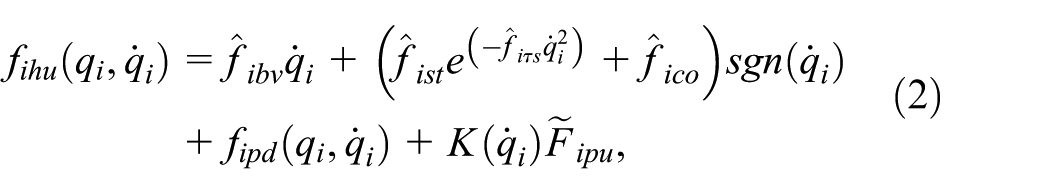
in which

where
2) IDC effect
The IDC coupling among joint modules is mathematically characterized by:

in which
Define state vector

where
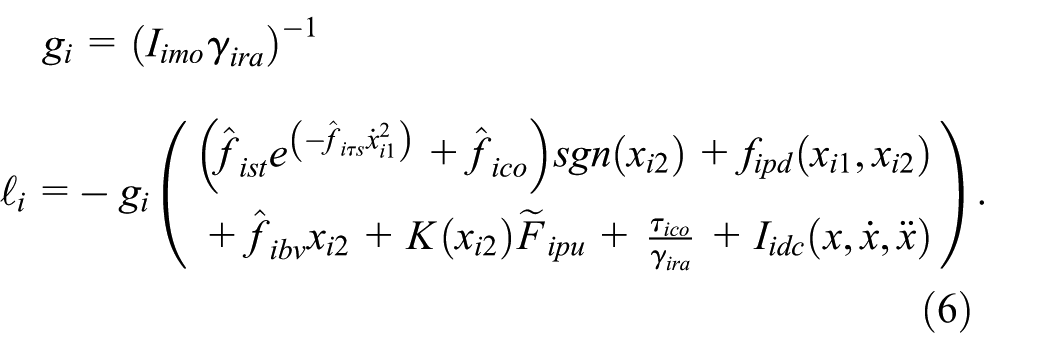
In this paper, the primary control objective of this work is to optimally guarantee that the tracking error of MRM system in coordinated operation task is UUB. To address this challenge, the next section proposes a hierarchical approximate optimal coordinated control approach based on Nash-Stackelberg differential game.
Nash-Stackelberg differential game-based hierarchical approximate optimal coordinated control approach of MRM system
Derivation of Nash-Stackelberg differential game
This investigation focuses on leveraging Nash-Stackelberg differential game for approximating optimal coordinated control that MRM can optimally ensure systems’ tracking error UUB. Furthermore, Nash-Stackelberg differential game features a leader-follower hierarchy. The leader prioritizes strategy selection. The follower subsequently determines its optimal strategy in reaction to the leader’s decision. The leader, in turn, formulates its best response by anticipating the follower’s strategic behavior. In the MRM’s coordinated operation task, MRM is deemed as the leader, and the coordinated operation object is regarded as the follower. Besides, MRM system is composed of
The diagram of the Nash-Stackelberg differential game-based hierarchical approximate optimal coordinated control is illustrated in Figure 1. Each joint of the MRM system (the leader) is regarded as a player in Nash differential game, while forming Stackelberg game with the object being manipulated (the follower). Consider a scenario where a robot and a human are required to transport a large object that neither could handle independently. In this setup, a desired trajectory is prescribed for the robot, and the manipulated object is designed to follow the robot’s position, thereby establishing hierarchical control framework (Stackelberg game). By employing ADP algorithm, critic neural networks are utilized to approximate the Hamiltonian functions of both the leader and the follower. The resulting residuals are then used to adjust the update laws of the critic networks, ultimately yielding approximate optimal control laws for both the leader and the follower.

The diagram of the Nash-Stackelberg differential game-based hierarchical approximate optimal coordinated control.
According to (5), one expresses the overall state space equation is as follow:

where
Define the cost function of coordinated operation object and MRM system as:
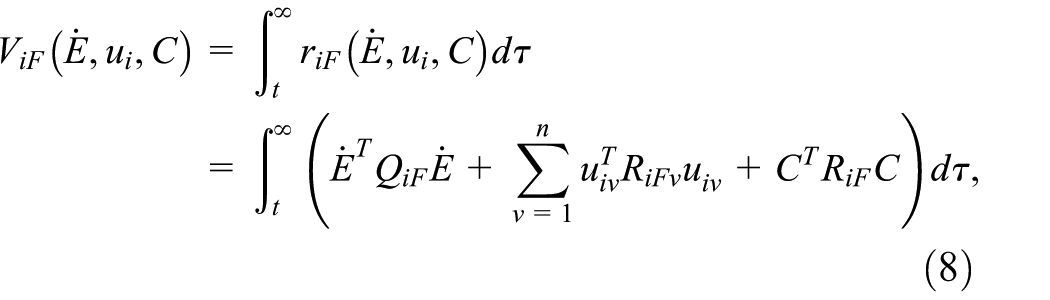
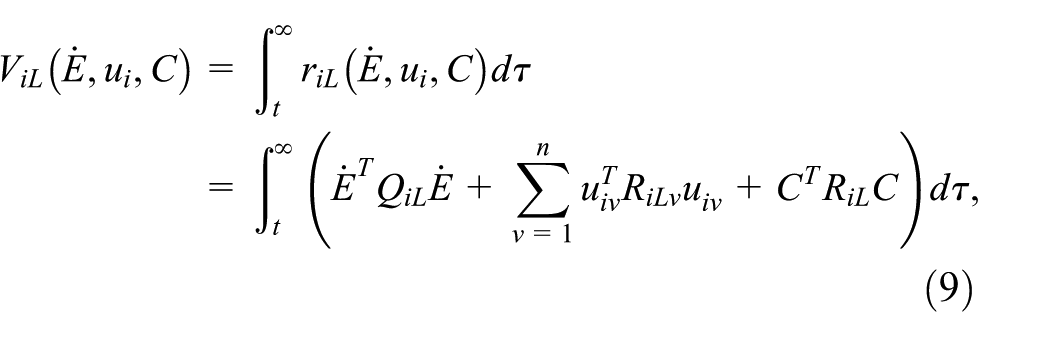
where
The coordinated operation object is seeking an optimal control policy for the MRM in response to the current system state, formulated as the problem of minimizing a cost function defined by:
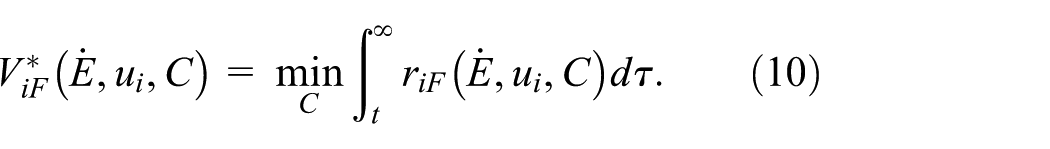
The follower’s Hamiltonian function is constructed by combining the infinitesimal version of (10) with equations (1) and (5):
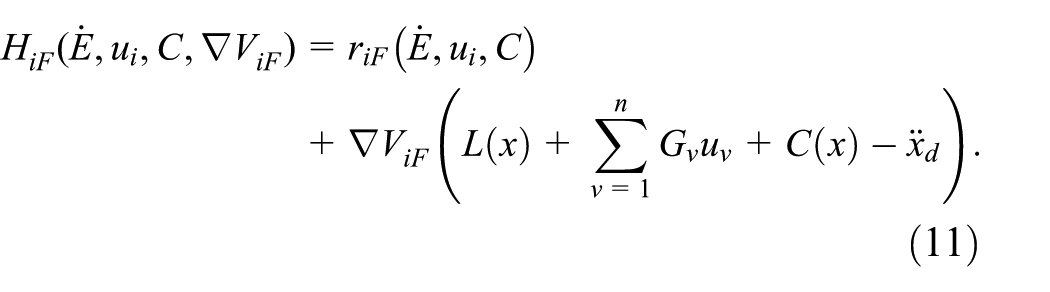
According to the stationary condition
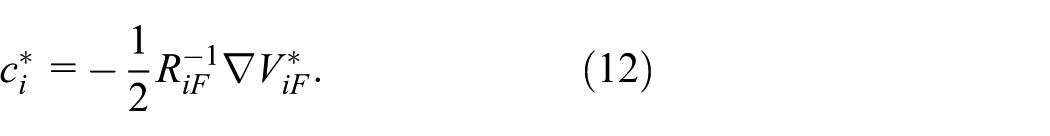
Subsequently, a costate
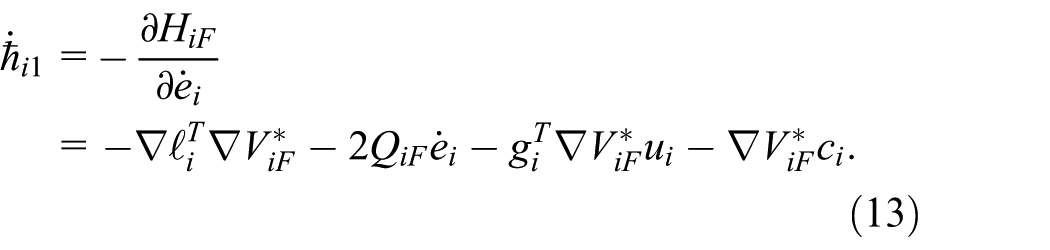
Based on costate (13) and
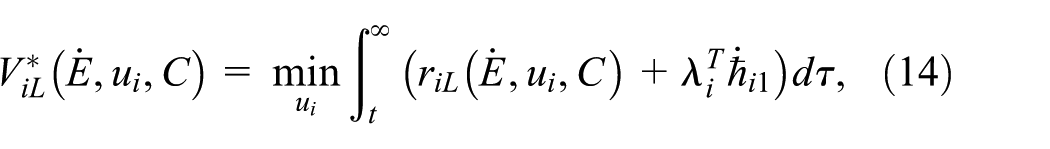
where
By an analogous procedure, the leader’s Hamiltonian function and optimal control policy can be formulated:

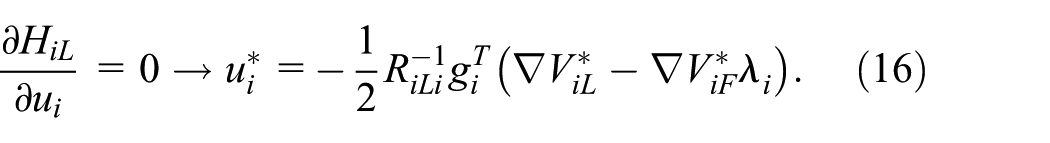
The behavior of the costate is characterized by:
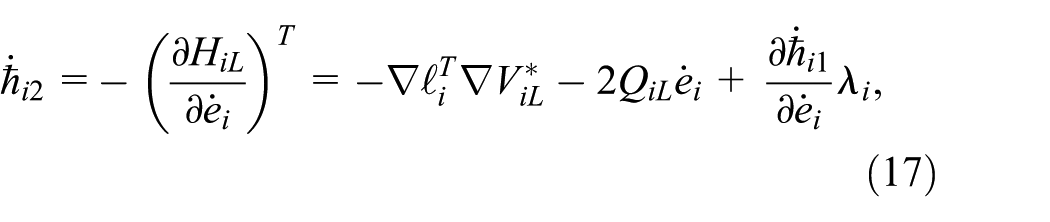
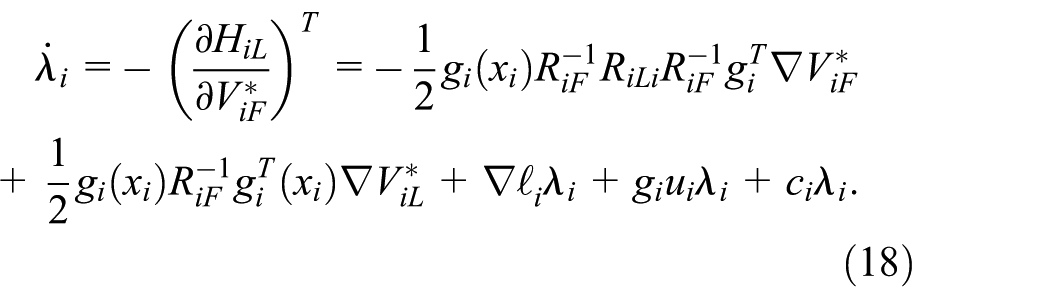
The coupled Hamilton-Jacobi equations are obtained by substituting policies (12) and (16) into their respective Hamiltonian functions (11) and (15), leading to:
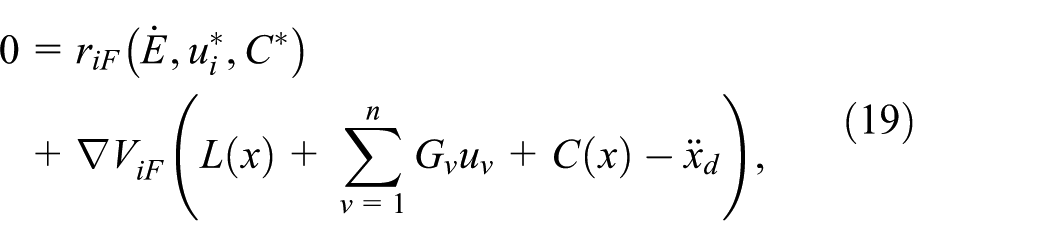
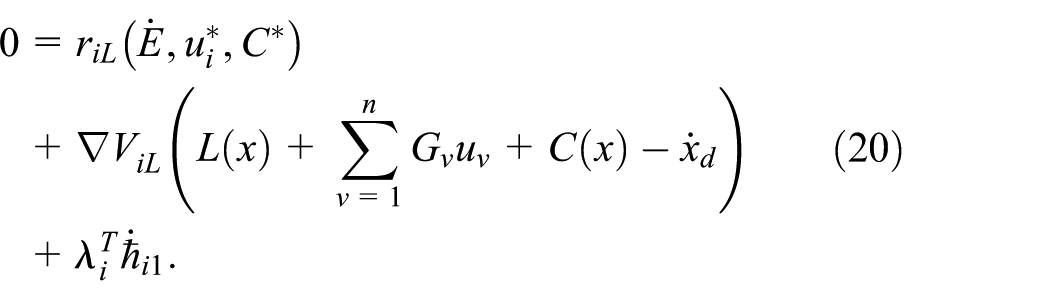
The solution to the coupled Hamilton-Jacobi equations (19) and (20) for
Approximate solution of the Nash-Stackelberg differential game-based hierarchical approximate optimal coordinated control via the implementation of critic NN
From decomposition (16), one obtains the representation:
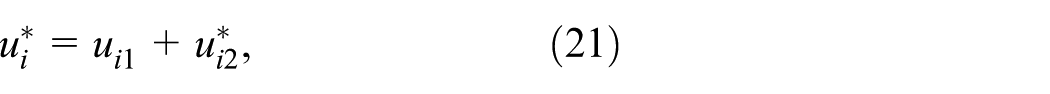
where
According to (6),
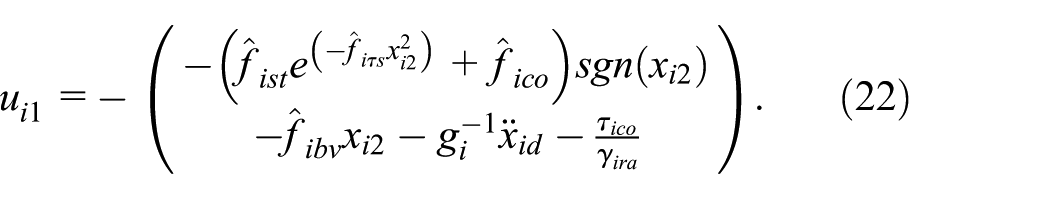
The optimal compensation control issue is thereby recasted as a hierarchical approximate optimal control problem based on Nash-Stackelberg differential game. To address this, critic neural network is employed to approximate the corresponding cost functions (10) and (14):
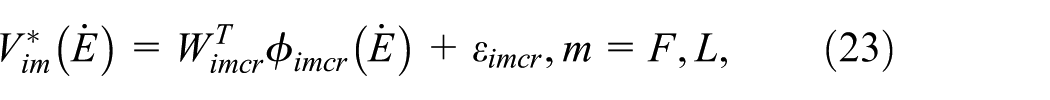
where
The gradient of the expression in (23) is obtained as follows:
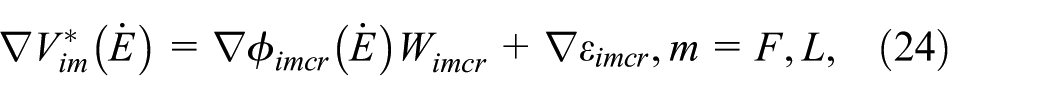
where
By substituting (24) into (12) and (16), the optimal control torques are given by:
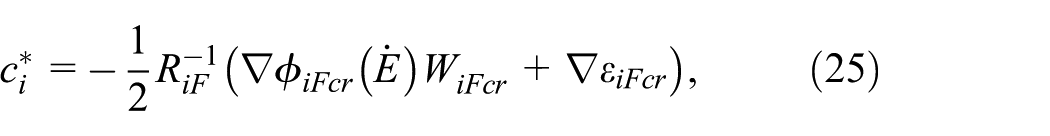
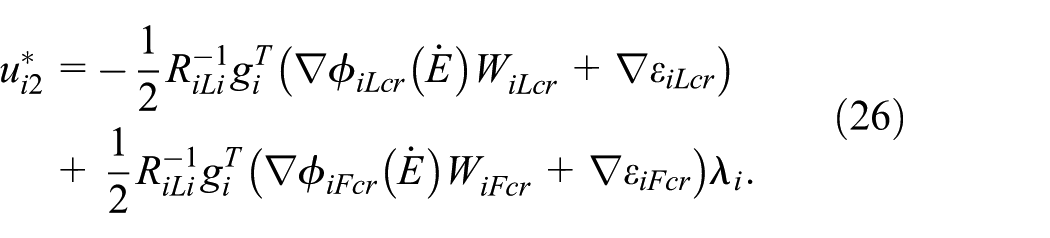
Substituting (25), (26) into (11) and (15), one yields:
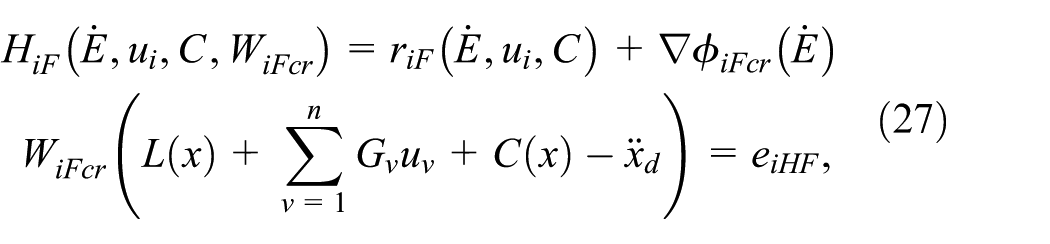
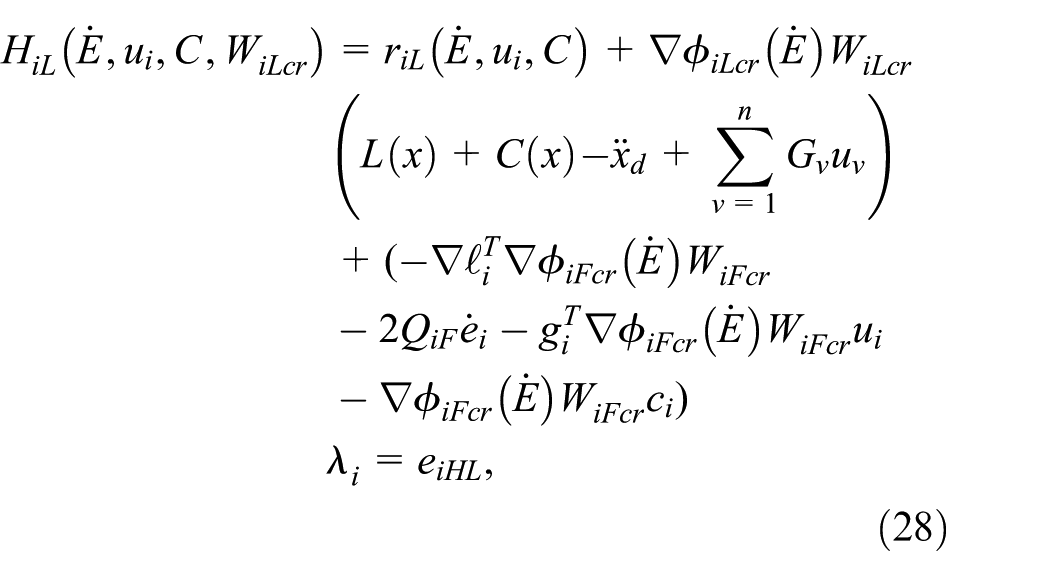
where
The estimated optimal cost function is:
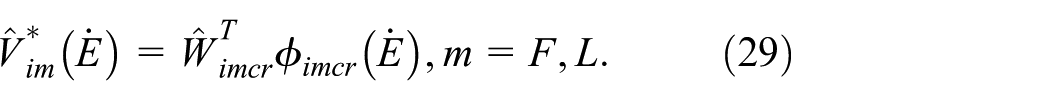
According to (25), (26) as well as (29), approximate optimal control policies are:
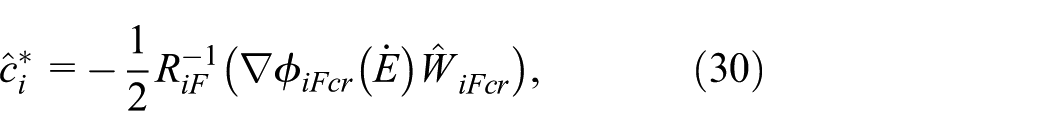
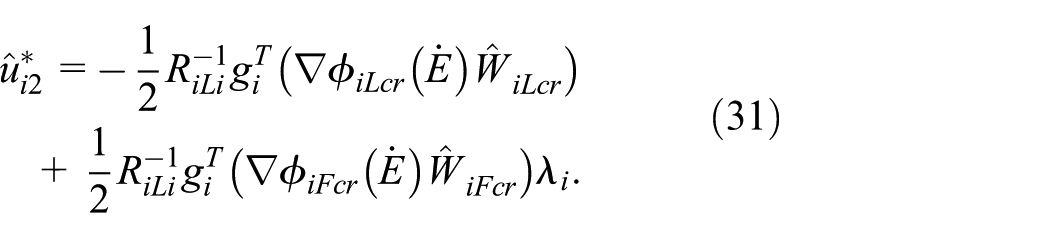
Applying (30) and (31) into (27) and (28), the approximated Hamiltonian functions are given by:
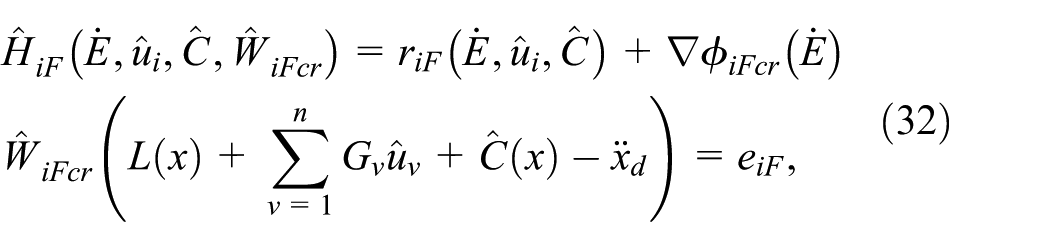
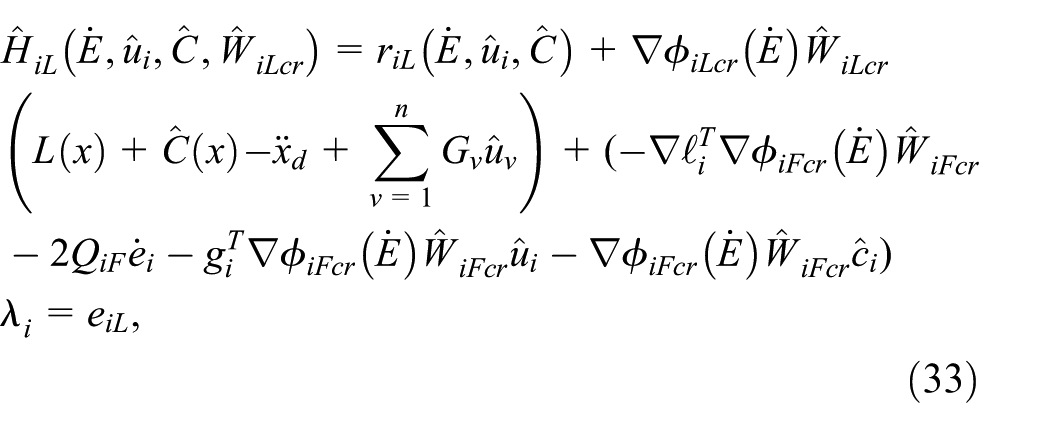
The approximated Hamiltonian error functions

where
When defining
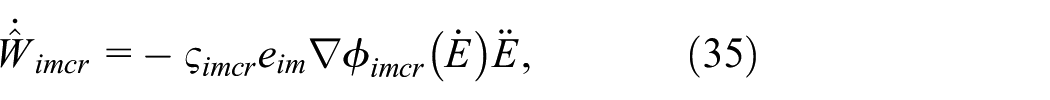
where
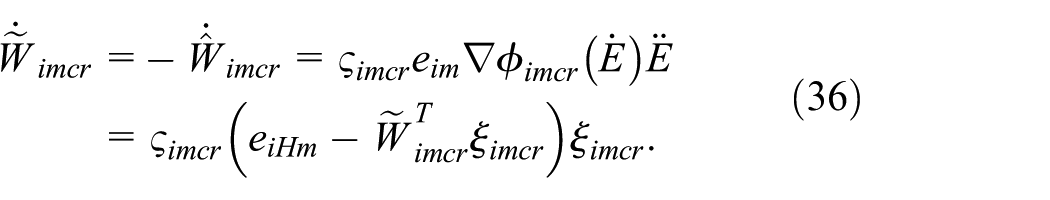
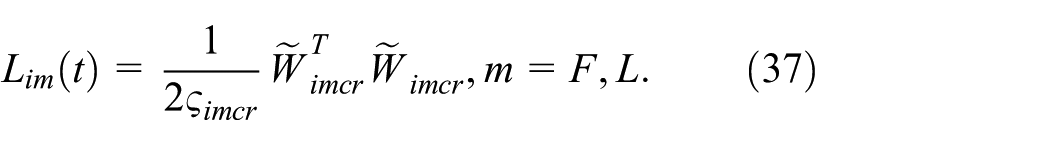
Time derivative of
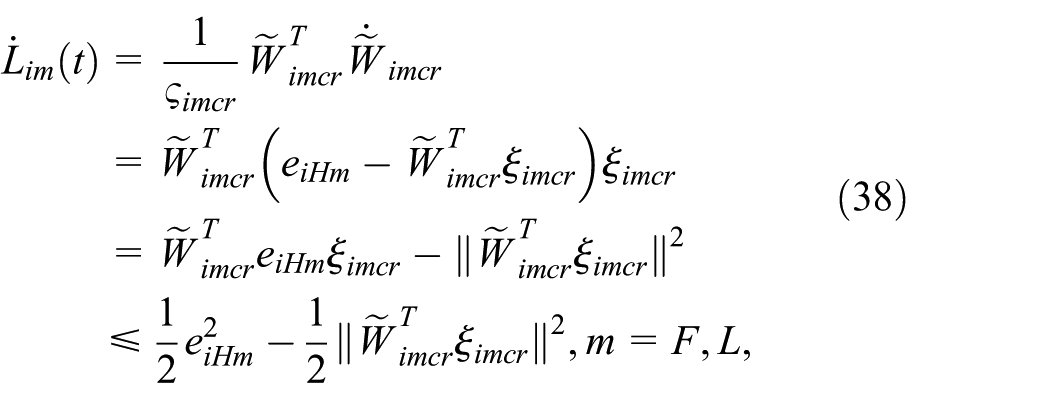
where
According to (22) and the hierarchical optimal coordinated control (31),
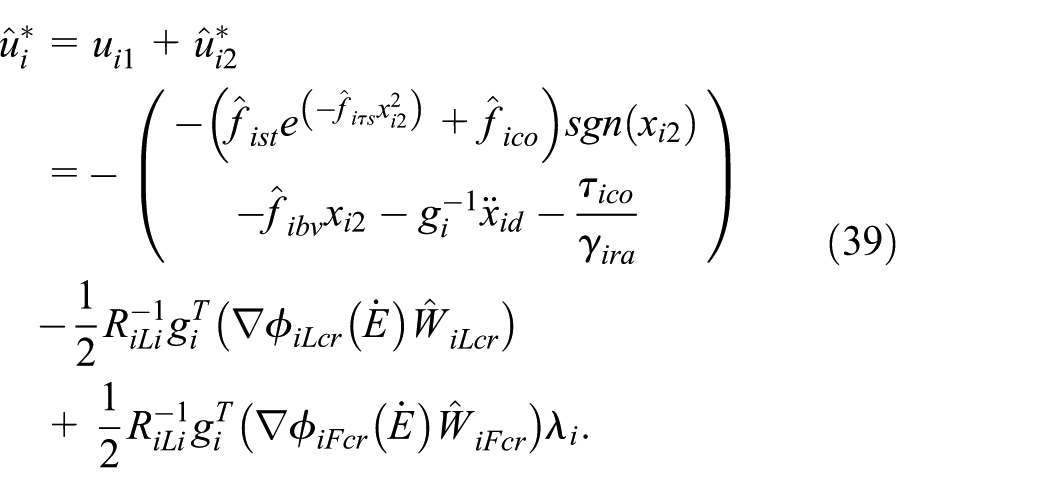

Derivative (40) as follow equation:
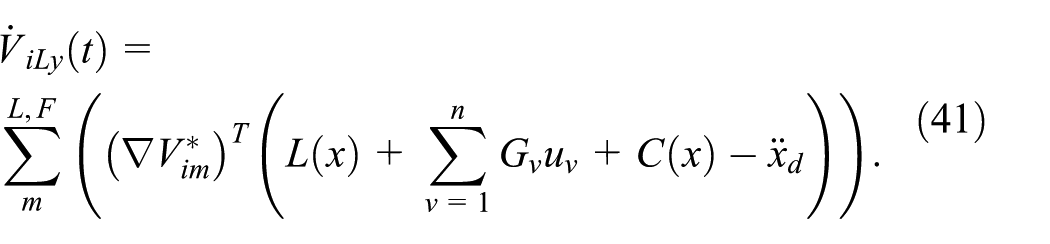
Base on HJ equations in (19) as well as (20), one has:
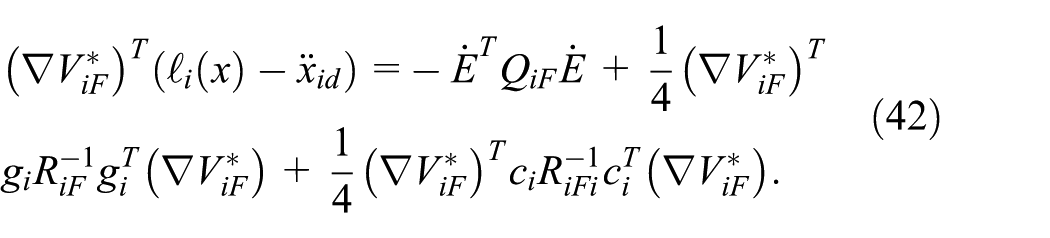

Combining (42), (43) into (41), we obtain:
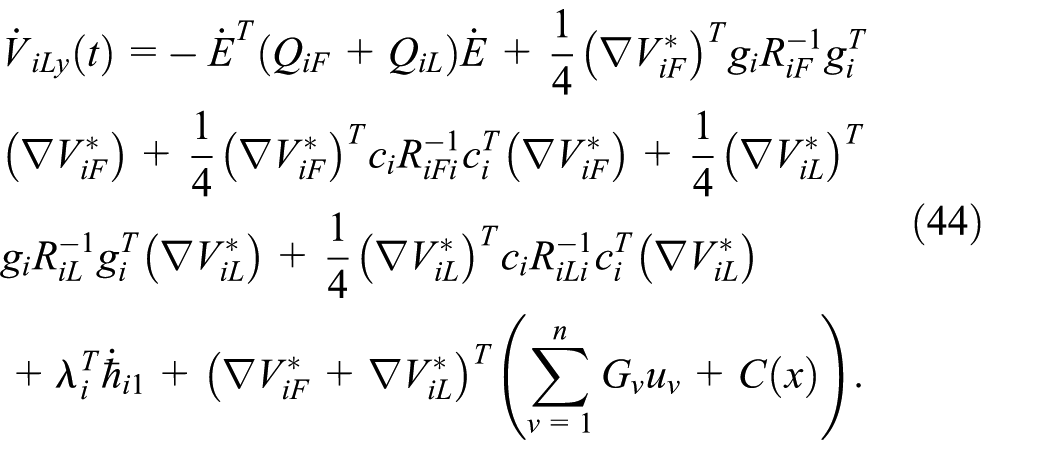
Considering (44), one obtains:
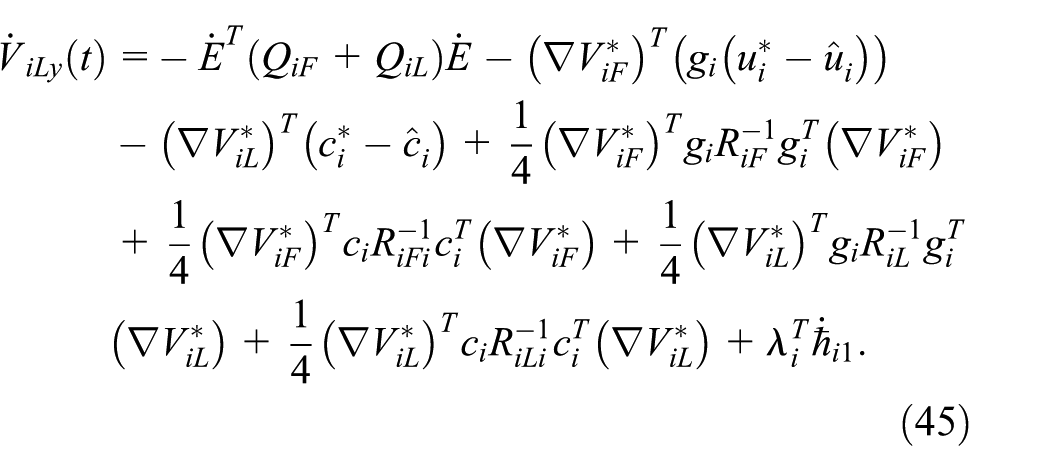
Then, substituting (41) into (45), we have:
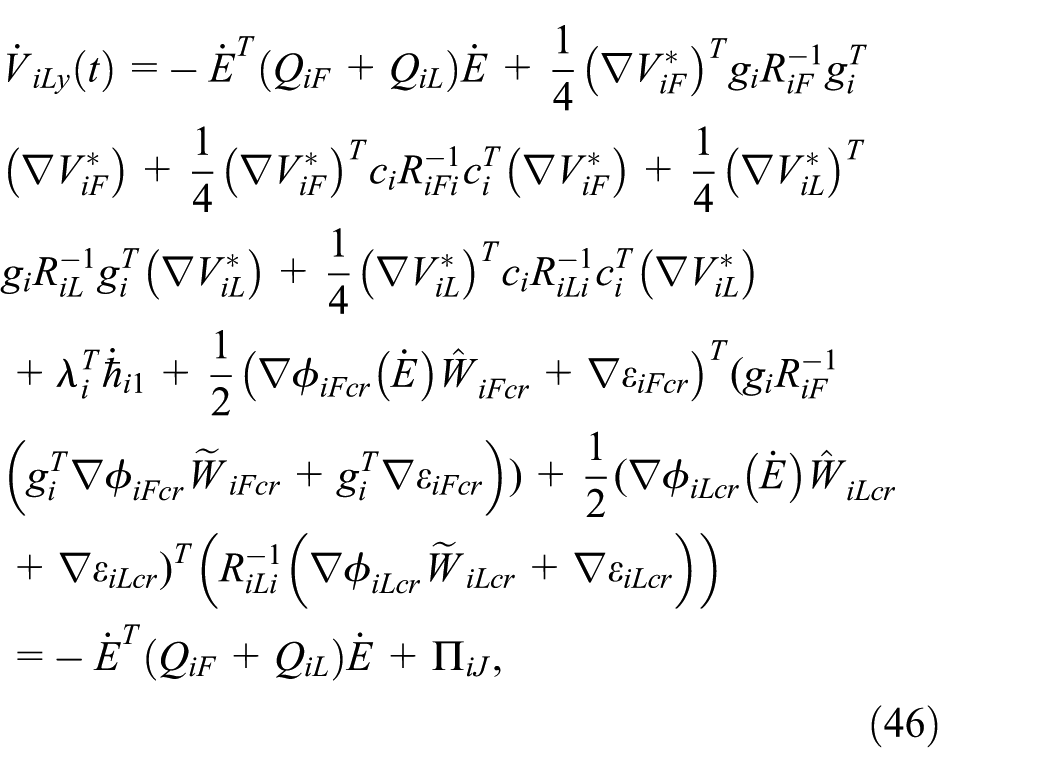
in which

where
Combining (46),
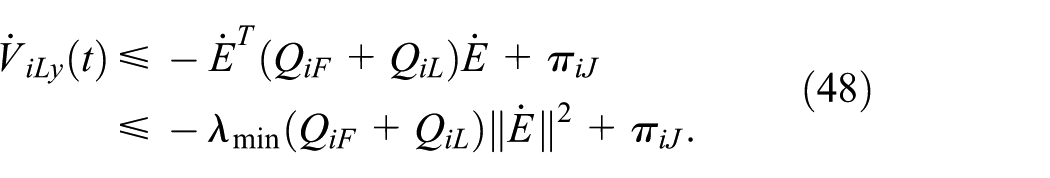
If
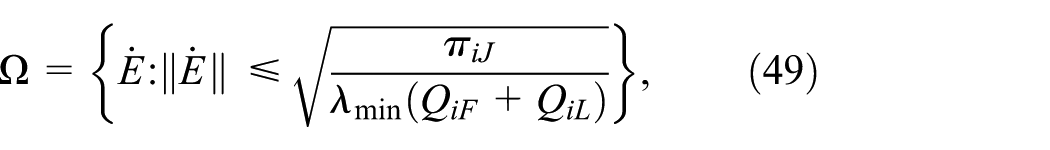
(41) is negative. Therefore,
UUB means regardless of the complexity of the environment, and even in the presence of unavoidable disturbance and modeling error, the robot’s tracking error will not spiral out of control. It will ultimately be confined within a predetermined, acceptable range.
Experiments
Experiment 1 setup
This study evaluates the proposed hierarchical approximate optimal control strategy, grounded in the Nash-Stackelberg differential game, against a coordinated operation vertical moving task (Figure 2) on a 7-DOF MRM platform (Figure 3). The experiment is designed to fulfill dual control objectives: ensuring high-fidelity position tracking and minimizing control effort during coordinated manipulation. The proposed control algorithm, though initially developed in continuous time, necessitates discrete implementation during experimental procedures to enable real-time control. Specifically, the robotic control system is integrated within the Robot Operating System (ROS) framework on a host computer, which interfaces with the Sawyer controller to handle experimental data processing. This parameter sampling configuration substantially improves the online processing efficiency of the robotic system while conforming to real-time coding standards. In this experiment, the sampling frequency is set as 1000 Hz, that means controller processing 1000 sampling data every second.

Experimental with coordinated operation task.

Experimental platform setup.
Relevant system dynamics and controller configurations are provided in Table 1. The modular robot manipulator exhibits seven degree-of-freedom. Leveraging the forward computation characteristic of ADP, the curse of dimensionality is effectively circumvented. Each neural network, which comprises a single hidden layer with five neurons, entails a computational cost quantified by the number of operations performed per inference
Parameter definition.

Experiment 1 results
A comparative evaluation is conducted to validate the proposed method, encompassing an existing learning-based optimal control approach without Nash-Stackelberg differential game (e.g. distributed optimal control via ADP27,28) and the novel Nash-Stackelberg differential game-based hierarchical approximate optimal coordinated control framework introduced herein.
(1) Position tracking
The experimental results, as presented in Figures 4 through 6, demonstrate a significant improvement in tracking accuracy within both Cartesian and joint spaces when utilizing the proposed Nash-Stackelberg game-theoretic coordinated control framework. Compared to conventional control method, the error magnitudes achieved under this approach are markedly lower. Importantly, although trajectory errors tend to increase when navigating sharp corners, the proposed strategy effectively constrains these deviations within a narrow margin during steady state operation. This robust performance is largely attributed to the effective compensation provided by the Stackelberg game.
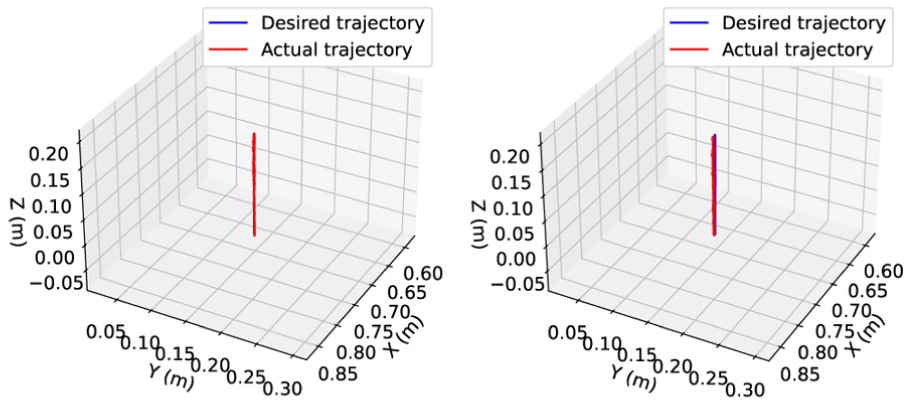
Position tracking in Cartesian space via existed optimal control (right) and developed control approach (left).
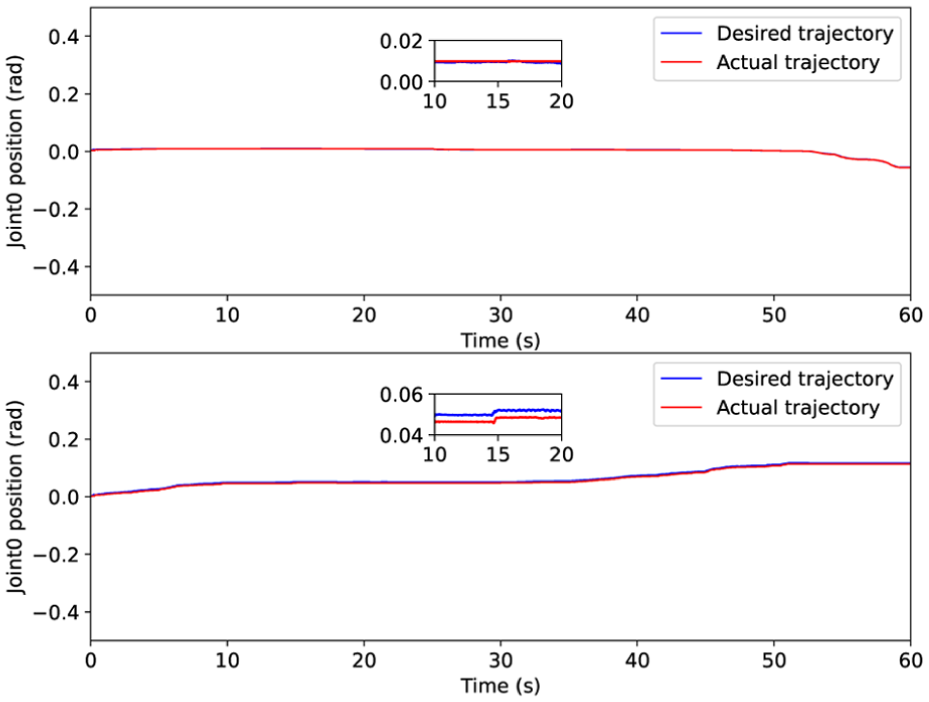
First joint of position tracking via existed optimal control (lower) and developed control approach (upper).
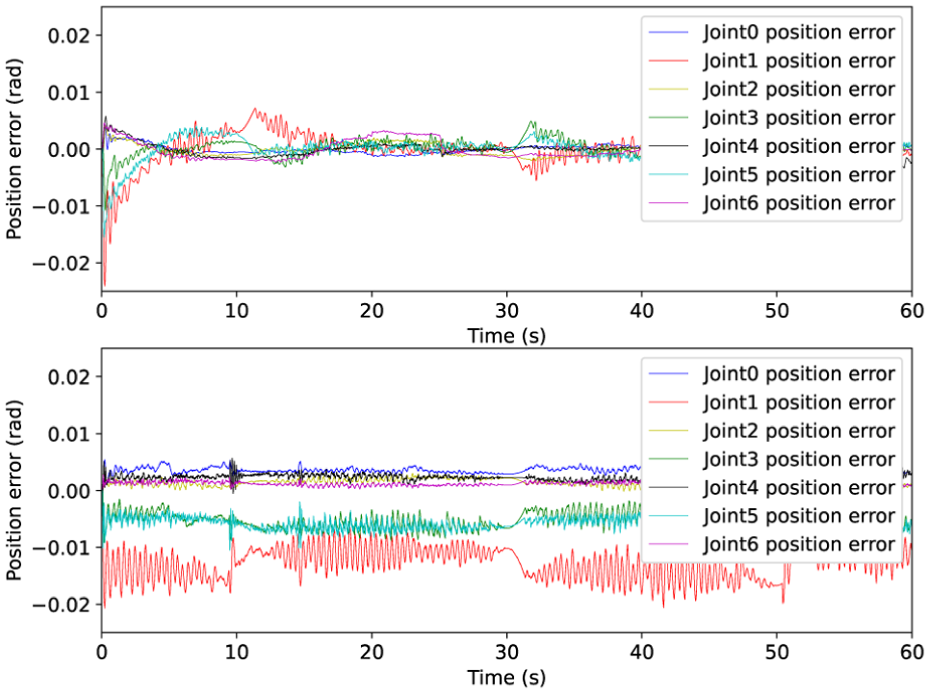
Joint position tracking error via existed optimal control (lower) and developed control approach (upper).
(2) Control torque
Figure 7 illustrates the control torque responses observed during the coordinated operation task, employing both the existing and proposed Nash-Stackelberg differential game-based hierarchical approximate optimal coordinated control strategies. The proposed hierarchical control framework, rooted in the Nash-Stackelberg differential game, effectively maintains control torque transients within predefined safe operational limits. This capability stems from its inherent approximate optimal control mechanism, which is specifically designed to optimize output torques, thereby ensuring both stability and efficiency during task execution.
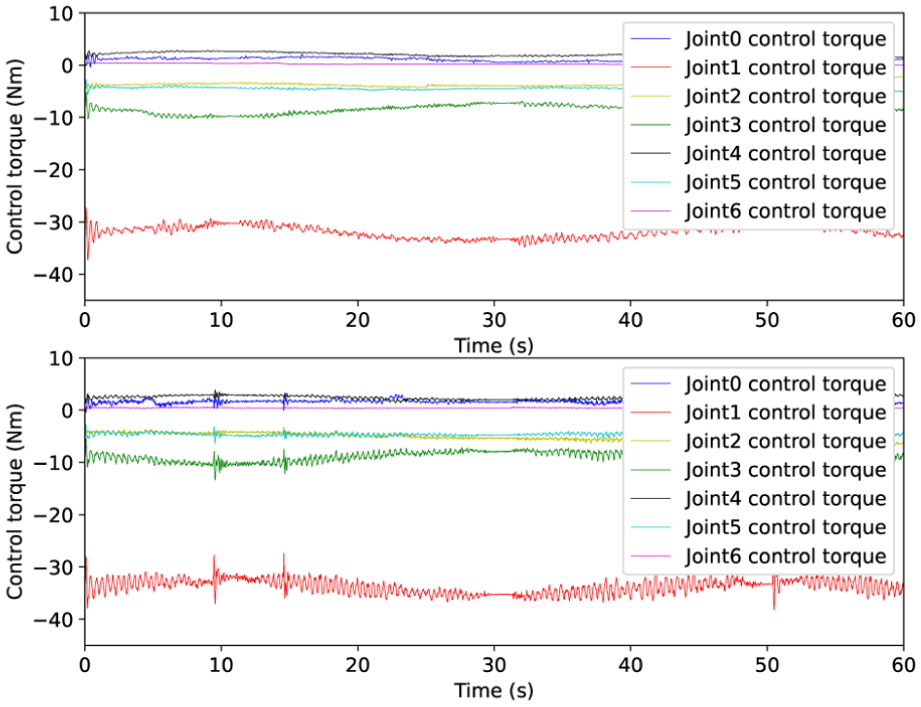
Control torque via existed optimal control (lower) and developed control approach (upper).
(3) Interaction torque
An analysis of interaction torque is presented in Figure 8. The proposed hierarchical control, leveraging the Nash-Stackelberg differential game, demonstrates superior torque regulation capability. It maintains interaction torque within a stable, reasonable bound and effectively attenuates chattering. This improvement stems from the game-theoretic mechanism’s ability to ensure operational security and seamlessly reconcile the dynamic coupling between the MRM and its task. Moreover, the integrated approximate optimal control further minimizes the torque magnitude, particularly during trajectory changing suddenly.
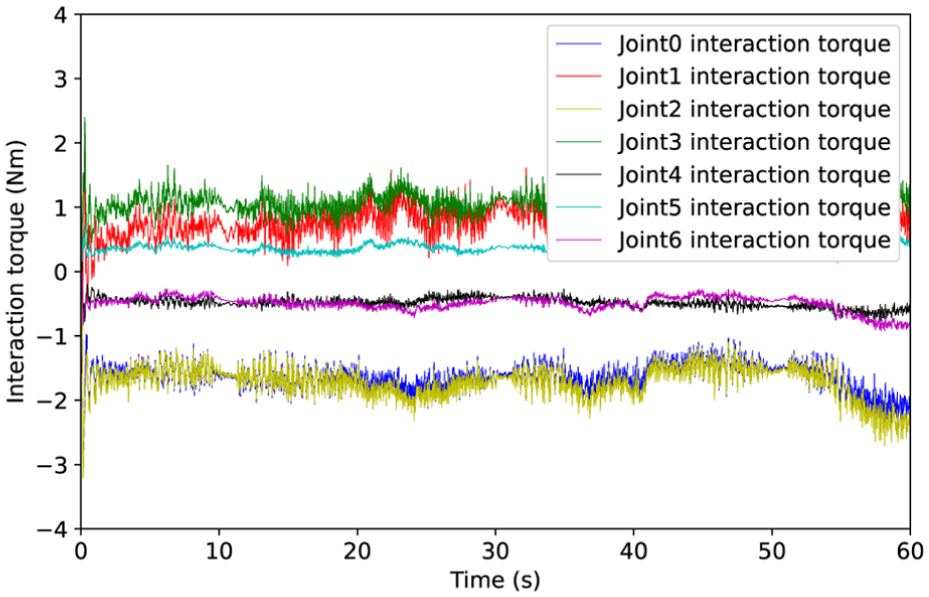
Interaction torque curves via proposed control approach.
(4) Critic NN weight
The evolution of the critic neural network weights, as depicted in Figure 9, reveals a direct correlation with the control torque. This observed dynamic correspondence confirms the NN’s capability to encode optimal control policies in real-time. The initial weights of critic NN are all 0 and learning rates are 0.99 and 0.96 for leader and followers.
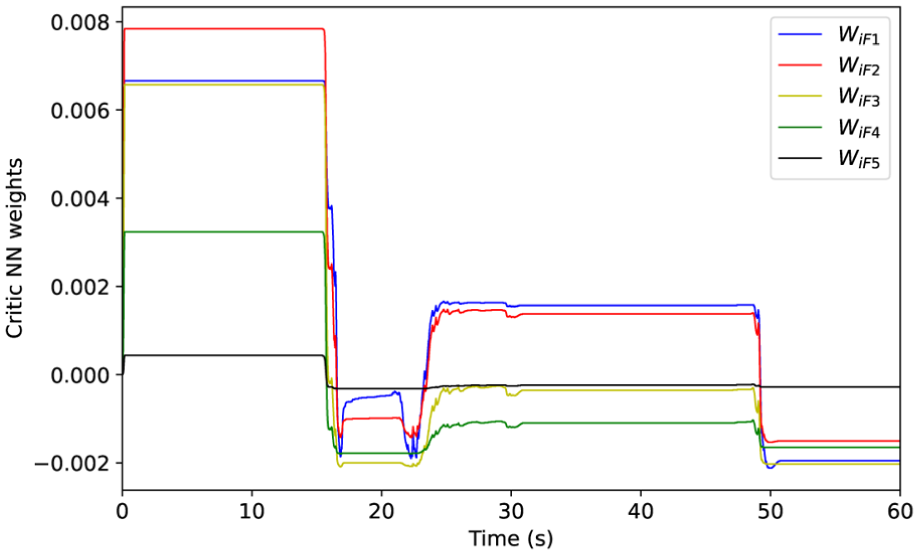
First joint of critic NN weight curves via proposed control approach.
Experiment 2
To further validate the Nash-Stackelberg differential game-based approach to approximate optimal coordinated control, a more demanding experiment involving a complex trajectory is conducted. To verify the robustness of the proposed algorithm, collision is applied on MRM for around 22 s.
(1) Position tracking
The experimental results in Figures 10 and 11 reveal a notable enhancement in tracking precision in Cartesian and joint space under the proposed Nash-Stackelberg game-theoretic coordinated control framework. Its error amplitude is substantially lower, while errors naturally increase at collision happened, the proposed scheme successfully confines them within a tight bound during steady-state phases, thanks to the robustness and effective compensation of the IDC dynamic.
(2) Control torque
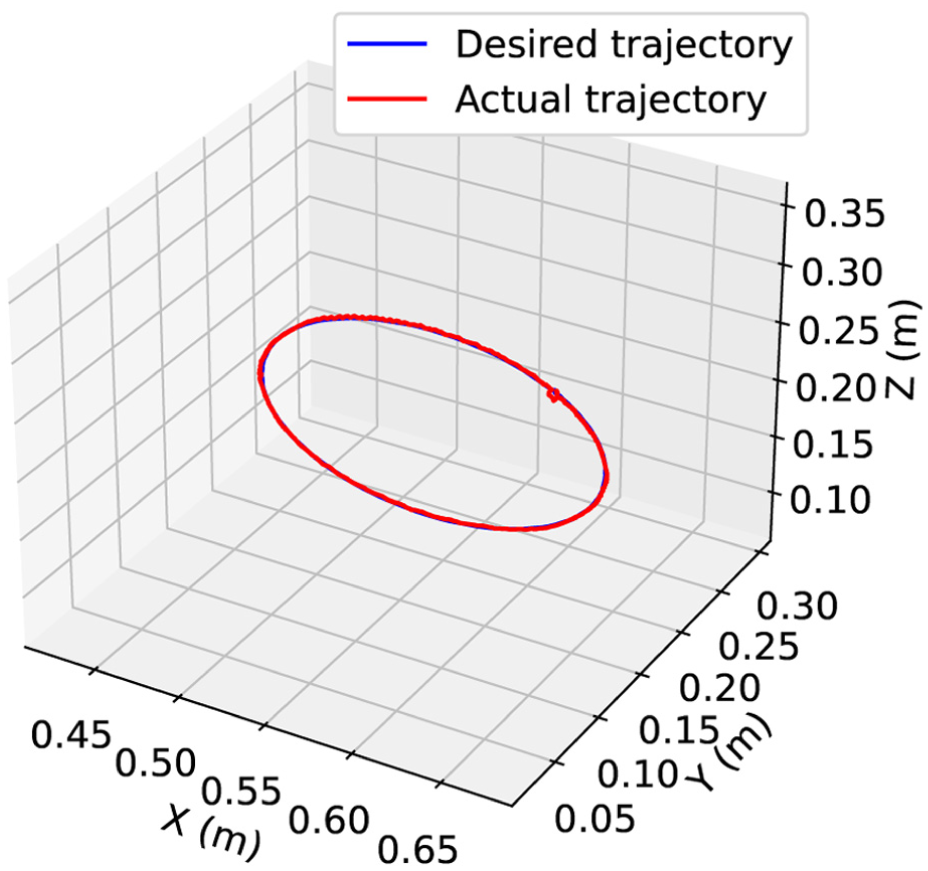
Position tracking in Cartesian space via developed control approach.
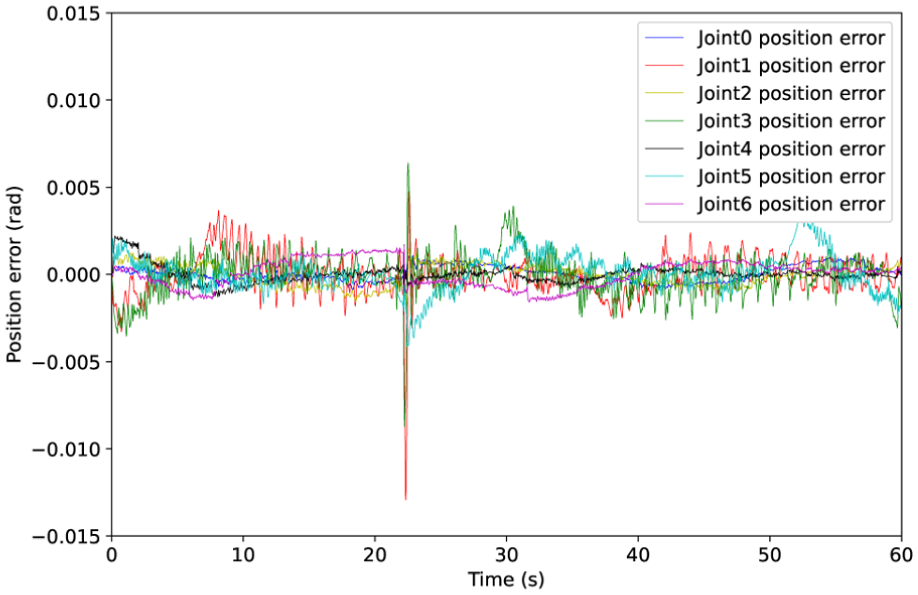
Joint position tracking error via developed control approach.
Figure 12 is control torque under coordinated operation task via proposed Nash-Stackelberg differential game-based hierarchical approximate optimal coordinated control. The proposed hierarchical control strategy, grounded in the Nash-Stackelberg differential game, ensures the restraint of control torque transients within safe operational bounds even collision happened. This performance is achieved through its inherent approximate optimal control mechanism, which explicitly addresses the optimization of output torques.
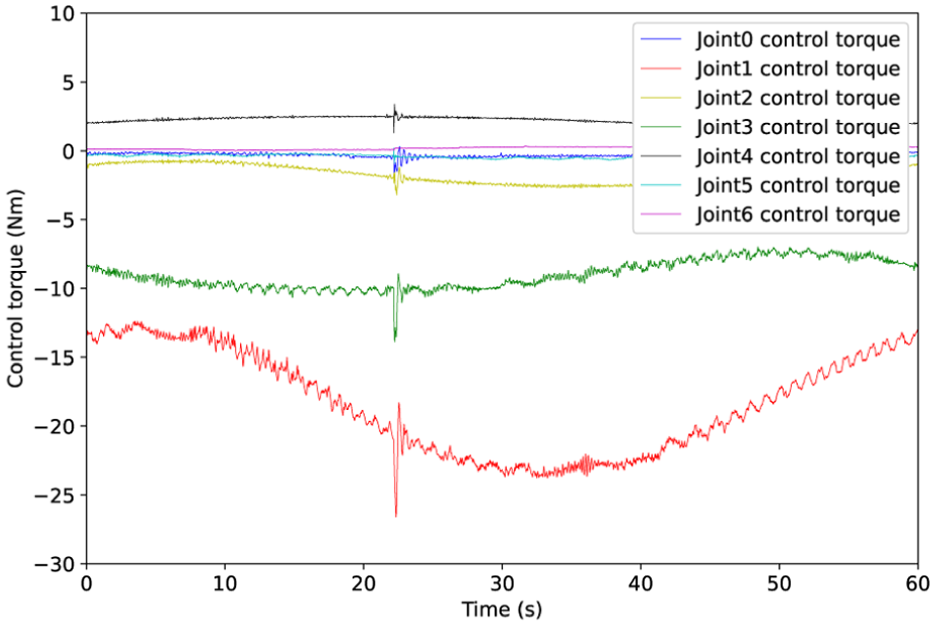
Control torque via developed control approach.
(3) Critic NN weight
Figure 13 presents the evolution of the critic neural network weights associated with joint 0. The weight parameters exhibit stable convergence within an acceptable range, thereby validating the feasibility of the proposed control approach.
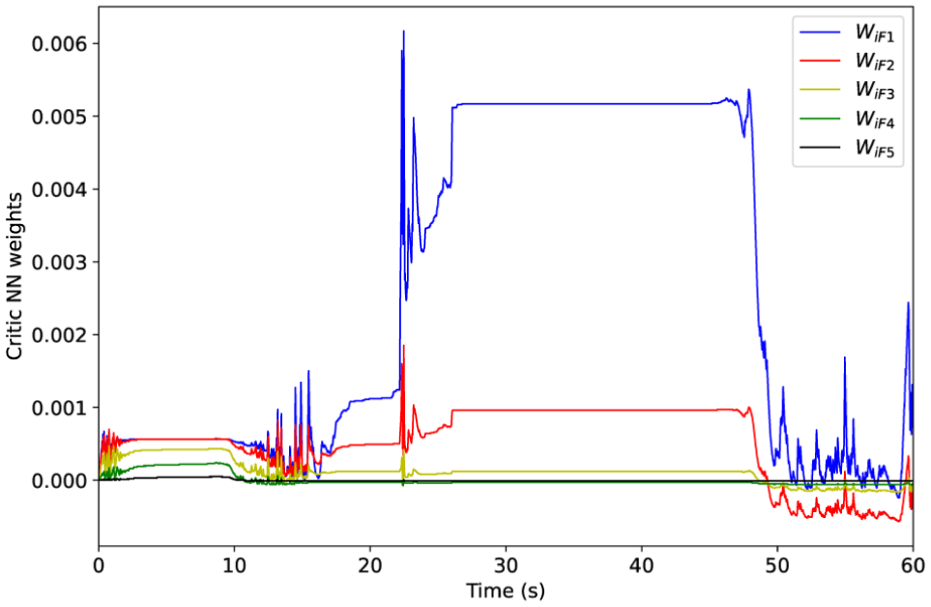
First joint of critic NN weight curves via proposed control approach.
Conclusion
This study develops a hierarchical approximate optimal coordinated control scheme for MRMs modeled via joint torque feedback, using ADP. Within the Nash-Stackelberg differential game framework, the coordinated control issue is reformulated as a Stackelberg differential game, where the MRM acts as the leader under a Nash differential game formulation and the coordination objective serves as the follower. The approximation of the nonlinear cost function is achieved via critic neural network, thereby deriving an optimal control strategy. Both rigorous theoretical analysis and comprehensive experimental results confirm the efficacy of the proposed control scheme. Computational complexity and scalability constraint continue to pose substantial obstacles to the practical deployment of adaptive dynamic programming and reinforcement learning methodologies in real-world application. This challenge is particularly pronounced in MRM systems engaged in coordinated manipulation tasks, where the demand for real-time computation intensifies. Achieving an optimal balance between high-precision task execution and computational efficiency in MRM system remains a critical challenge that requires immediate resolution.
Footnotes
Handling Editor: Aarthy Esakkiappan
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work is supported by the Scientific Technological Development Plan Project in Jilin Province of China (20260602029RC).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.