
Abstract
Background/aims:
Regulatory approval of a drug or device involves an assessment of not only the benefits but also the risks of adverse events associated with the therapeutic agent. Although randomized controlled trials (RCTs) are the gold standard for evaluating effectiveness, the number of treated patients in a single RCT may not be enough to detect a rare but serious side effect of the treatment. Meta-analysis plays an important role in the evaluation of the safety of medical products and has advantage over analyzing a single RCT when estimating the rate of adverse events.
Methods:
In this article, we compare 15 widely used meta-analysis models under both Bayesian and frequentist frameworks when outcomes are extremely infrequent or rare. We present extensive simulation study results and then apply these methods to a real meta-analysis that considers RCTs investigating the effect of rosiglitazone on the risks of myocardial infarction and of death from cardiovascular causes.
Results:
Our simulation studies suggest that the beta hyperprior method modeling treatment group-specific parameters and accounting for heterogeneity performs the best. Most models ignoring between-study heterogeneity give poor coverage probability when such heterogeneity exists. In the data analysis, different methods provide a wide range of log odds ratio estimates between rosiglitazone and control treatments with a mixed conclusion on their statistical significance based on 95% confidence (or credible) intervals.
Conclusion:
In the rare event setting, treatment effect estimates obtained from traditional meta-analytic methods may be biased and provide poor coverage probability. This trend worsens when the data have large between-study heterogeneity. In general, we recommend methods that first estimate the summaries of treatment-specific risks across studies and then relative treatment effects based on the summaries when appropriate. Furthermore, we recommend fitting various methods, comparing the results and model performance, and investigating any significant discrepancies among them.
Keywords
Introduction
Regulatory approval of a drug or device involves an assessment of not only the benefits but also the risks of adverse events associated with the therapeutic agent. Although we design randomized controlled trials (RCTs), the gold standard for evaluating effectiveness, to be large enough to detect a benefit of clinical importance, the number of treated patients may not be enough to detect infrequent adverse events. The rarer the adverse event, the less likely one or even two randomized clinical trials will provide enough of a signal, which could be problematic if a side effect of a treatment is rare but serious. The Council for International Organizations of Medical Sciences defined adverse drug reactions to be uncommon (or infrequent) with a frequency from 0.1% to 1%, rare with a frequency from 0.01% to 0.1%, and very rare with a frequency smaller than 0.01%. 1
Meta-analysis plays a role in the evaluation of the safety of medical products, whether drugs or medical devices. A single clinical trial may individually not provide sufficient information to make statements on the differential rate of occurrence of adverse events. Meta-analysis pools information on events over trials conducted prior to regulatory approval or surveillance studies after the marketing of a product to increase the number of treated patients and thereby increases the chance of seeing rare and unintended effects of the treatment. 2
Although meta-analysis has advantages over analyzing a single clinical trial when estimating the rate of adverse events, there are some discussions that traditional meta-analysis methods may be ill-defined or have poor performance properties with rare events.3–9 The main issues include (1) sparsity of data with many trials having no events (so-called zero-event trials), (2) insufficient statistical power to infer the effect heterogeneity across studies, and (3) the impact of trials with large sample sizes relative to smaller ones.
It is not hard to find published investigations of the performance of many different meta-analysis methods through extensive simulation studies under the rare event settings.6,9–11 One common limitation of most simulation studies is that the simulated datasets were generated assuming no heterogeneity in treatment effects across trials. Most studies listed above focused mainly on traditional frequentist meta-analytic methods (such as Peto, Mantel–Haenszel, and inverse variance estimators). Bayesian models for meta-analysis are gaining popularity12,13 and they are suitable to deal with rare events because they can handle trials with zero events more naturally than frequentist methods. In addition, Bayesian methods provide model flexibility and many choices of prior specifications based on different model assumptions. 14 There are, however, few publications investigating the performance of different Bayesian meta-analytic methods in the setting of rare events. Alternative meta-analysis methods for rare events have been proposed: likelihood-based Poisson random effects models, 15 combining confidence intervals, 16 and using an arcsine difference. 17
The objective of this article is to provide a comprehensive comparison of widely used meta-analysis methods under both frequentist and Bayesian frameworks and then to understand the current state of meta-analytic methods for rare events. The remainder of this article is structured as follows. The “Methods” section provides details of different meta-analysis methods. The “Simulation study” section reports the settings and results of our extensive simulations studies. Then we apply all these methods to a real data example, and the “Rosiglitazone data analysis” section presents the results. Finally, the “Discussion” section discusses our work and unmet methodological challenges.
Methods
In this section, we present models estimating the log odds ratio (LOR). Relative risk and risk difference scales could be used for rare events, 6 and the related models and results are presented in Supplementary Material. We summarize the results in the “Discussion” section.
Models may assume treatment effects to be either constant across studies or heterogeneous; we denote the former assumption as “common treatment effect (CTE)” and the latter as “heterogeneous treatment effect (HTE).” We include moment-based estimators for frequentist meta-analysis methods and likelihood-based approaches for Bayesian meta-analysis methods under both CTE and HTE assumptions. Table 1 summarizes all models we consider.
Model specifications.
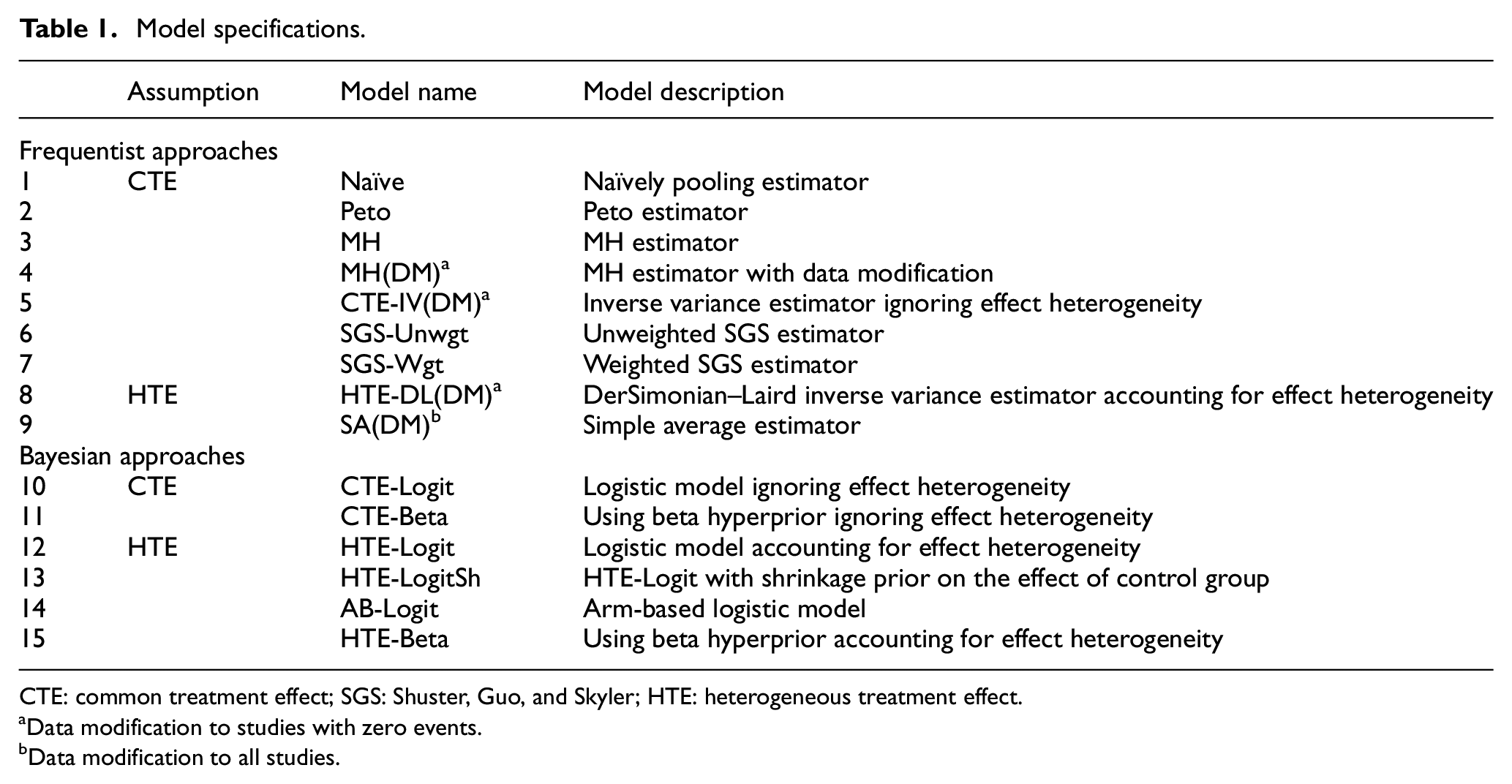
CTE: common treatment effect; SGS: Shuster, Guo, and Skyler; HTE: heterogeneous treatment effect.
Data modification to studies with zero events.
Data modification to all studies.
With binary data, each study in a meta-analysis forms a 2 × 2 table as in Table 2. Here, i indexes study (

Data structure for study i.

where for the kth treatment in the ith study,
Frequentist meta-analysis models
Naïve estimator
We first consider an estimator that naïvely pools multiple contingency tables, without accounting for effect heterogeneity across studies (denoted by “Naïve”). The naïve LOR estimator is written as

where
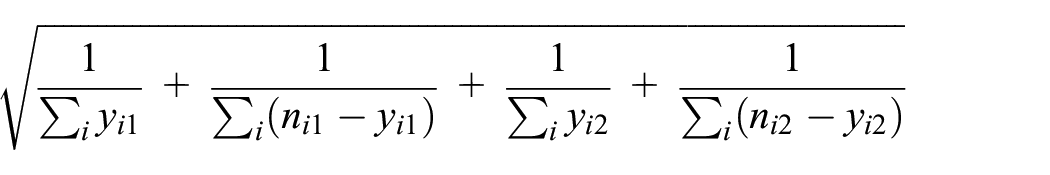
Peto and Mantel-Haenszel estimators
Peto 18 and Mantel-Haenszel 19 estimators assume CTE across studies (denoted by “Peto” and “MH” respectively). The Peto estimator and its variance are
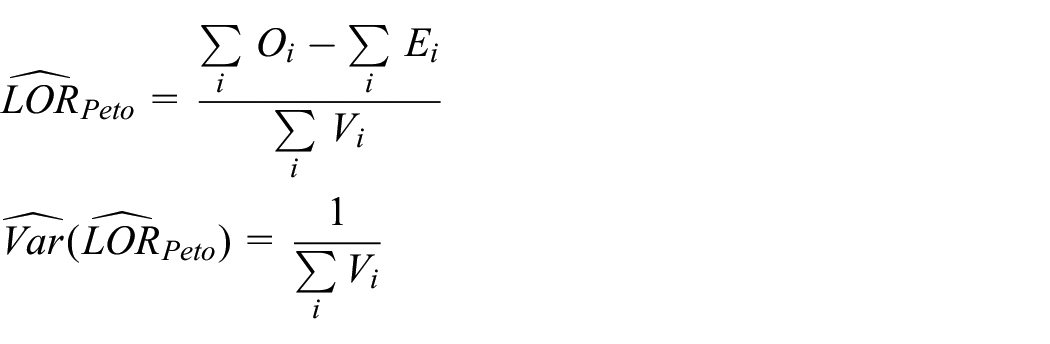
where
The Mantel-Haenszel estimator and its approximate variance proposed by Robins et al. 20 can be written as
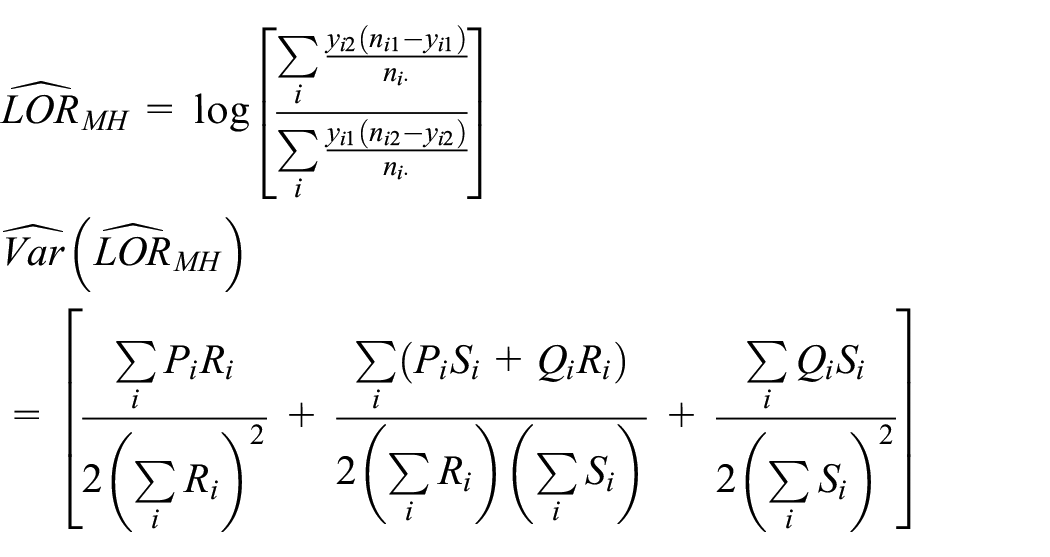
where
Studies with zero cells are not a problem for the Peto and Mantel-Haenszel estimators because they do not calculate the observed LORs of the individual studies. Nevertheless, a data modification that adds a constant 0.5 to all cells of the 2 × 2 table for a trial with zero events in either group as in Table 3 is often considered with the Mantel-Haenszel estimator. We denote the Mantel-Haenszel estimator with data modification by “MH(DM).” A few alternative data modification approaches have been proposed by Sweeting et al. 9
Data modification for study i with zero events (i.e. either

Inverse variance estimators
The inverse variance method
21
is commonly used in meta-analysis. This method can assume either CTE or HTE. When HTE is assumed, we follow DerSimonian and Laird (DL)
21
to estimate effect heterogeneity,

where
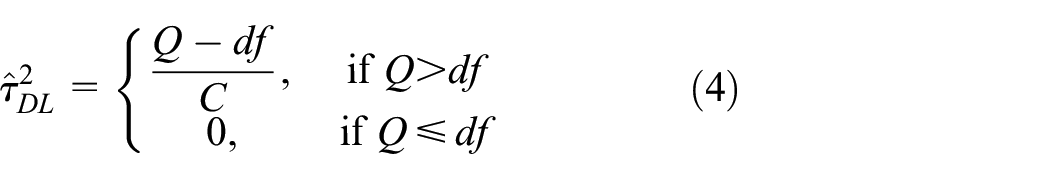
where df is the number of studies minus 1,
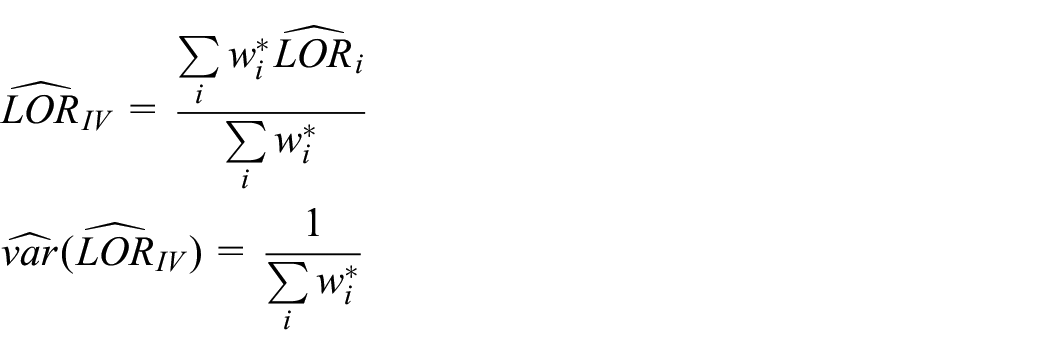
We apply the data modification approach introduced in the previous section to the inverse variance method to handle zero events. Under the CTE assumption, we force
Other estimators
Shuster, Guo, and Skyler (SGS) 11 proposed estimators that are the functions of risk estimates in each group. These estimators are non-parametric and assume independence between studies, an assumption called studies at random. They proposed unweighted and weighted estimators, denoted by “SGS-Unwgt” and “SGS-Wgt,” respectively, for odds ratio (OR), risk ratio, and risk difference scales.
For these estimators, one first estimates study-specific risks as
Bhaumik et al. 10 proposed a simple average estimator. It is calculated as an average of study-specific LORs after adding 0.5 to all cells in Table 2 for all trials. That is, the study-specific log odds ratio is
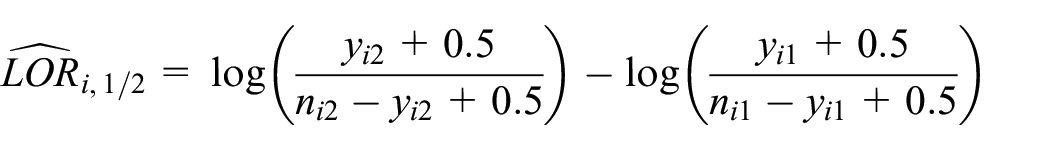
Then, the simple average estimator and its variance are defined as
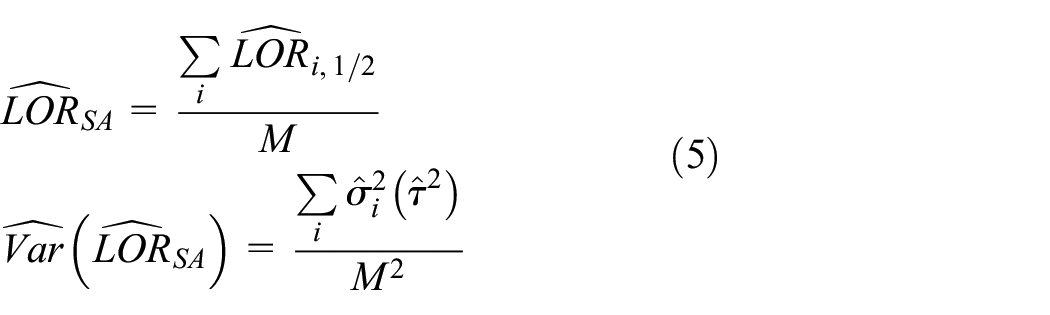
where M is the number of studies,
Bayesian meta-analysis models
Logistic regression
Using the likelihood (1), we model the unknown parameter
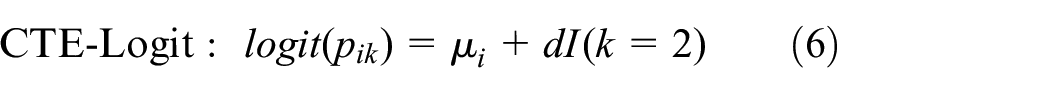
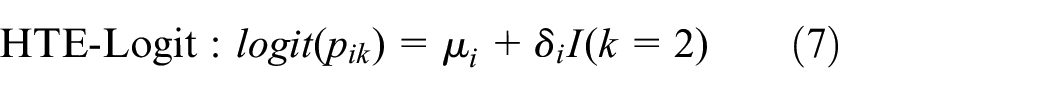
where
Under the heterogeneous treatment effect assumption in equation (7),
Arm-based model
Recently, Hong et al. 22 proposed an arm-based parameterization in network meta-analysis, an extension of meta-analysis to compare more than two treatments simultaneously. We simplify this model to fit an arm-based meta-analysis. This model estimates the treatment-specific risks and allows heterogeneity across studies. The model can be written as

where
Beta hyperprior distribution
We also consider pooling studies’ arm-specific risks using beta hyperprior distributions. First, we assume that the probability of having an event with treatment k is constant across studies. For the likelihood, we replace

Then, we assign prior distributions
We also assume heterogeneity across studies, that is, the
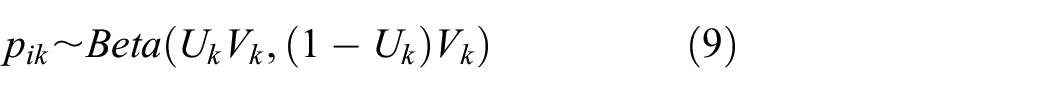
With this notation,
Bayesian model comparison
We compare the performance of fitted Bayesian models in our data example using the Watanabe–Akaike or widely applicable information criterion. 23 This criterion evaluates predictive accuracy for a fitted model and then adjusts for overfitting based on the effective number of parameters. In addition, it provides more stable estimates than the deviance information criterion. One prefers models that have smaller values of Watanabe–Akaike information criterion. 24
Computation
Simulation studies and data analyses were conducted in R. 25 We fit the Peto, Mantel-Haenszel, and inverse variance estimators using the R package metafor; 26 we used user-written functions to compute the remaining frequentist estimators. Bayesian models were fitted using the R package R2jags 27 for simulations and Rstan 28 for the data analysis, as Rstan provided reliable Watanabe–Akaike information criterion values. For Bayesian models, a total of 10,000 posterior samples were used after a 10,000 burn-in from a single Markov chain for our simulation studies, while our data analyses used two Markov chains, with each chain having a total of 30,000 posterior samples after a 20,000 burn-in. We checked trace plots and scatter plots of pairs of parameters to ensure convergence; they converged well. The R code and the associated Bayesian model files are available at https://github.com/HwanheeHong/MetaAnalysis_RareEvents.
Simulation study
Settings
In this simulation study, we compare the performance of 15 meta-analysis methods (9 frequentist and 6 Bayesian), summarized in Table 1. The results compare bias, mean squared error, and coverage probability of 95% intervals for each method’s LOR estimate. The simulation settings and results with relative risk and risk difference scales are presented in Supplementary Material.
Our simulation setup is built upon that used in Shuster et al.
11
We generated 10,000 simulated meta-analysis datasets, each consisting of 30 studies comparing a treatment of interest to a control. The control group’s sample size in study i,
True risk parameters,
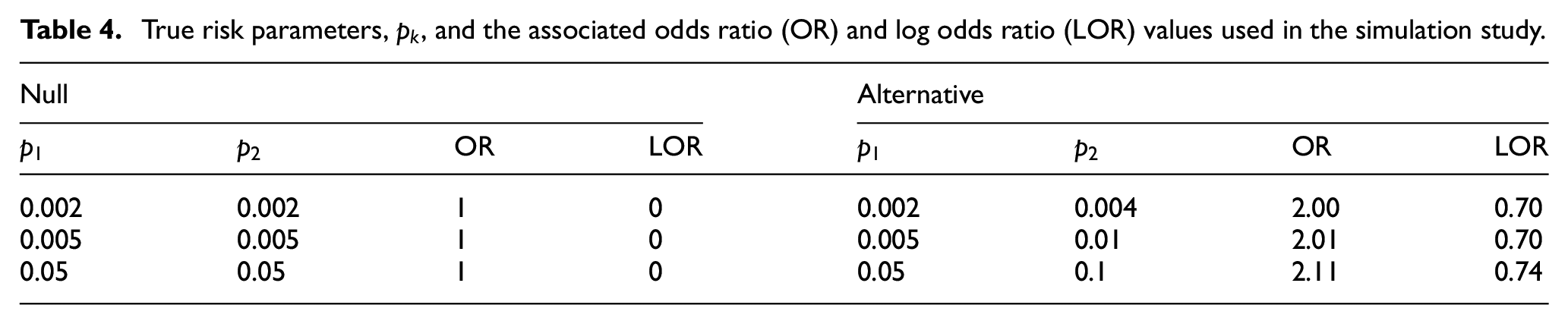
Results
Figures 1 and 2 exhibit bias, mean squared error, and coverage probability of log odds ratio estimates for three null and three alternative cases, respectively. Frequentist and Bayesian models are plotted in red and blue, and common and heterogeneous treatment effect models are plotted using circle and triangle characters, respectively. We present results under
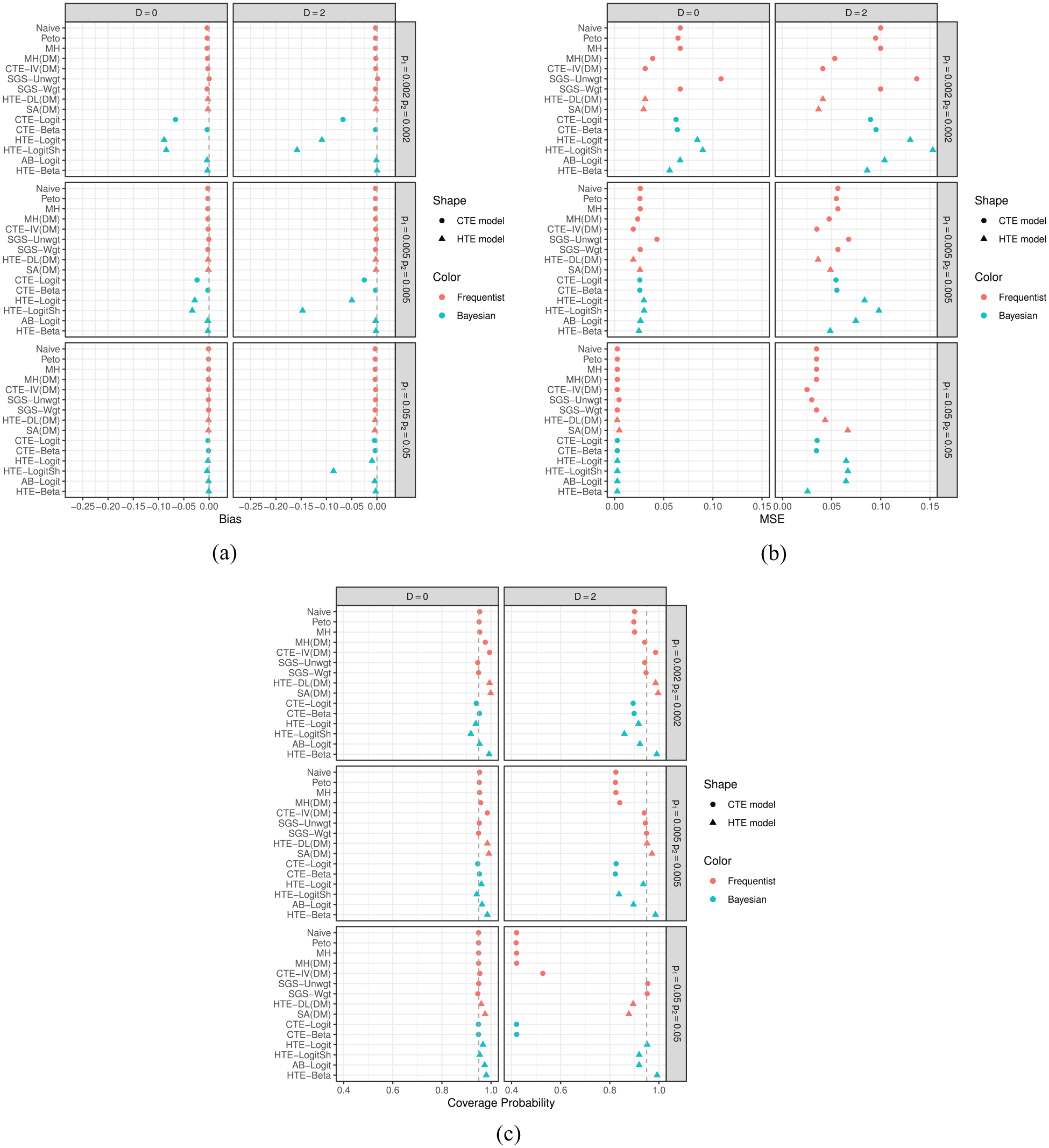
Simulation results in the null case: (a) bias, (b) mean squared error, and (c) coverage probability. Frequentist and Bayesian models are plotted in red and blue, respectively; common and heterogeneous treatment effect models are plotted using circles and triangles, respectively.
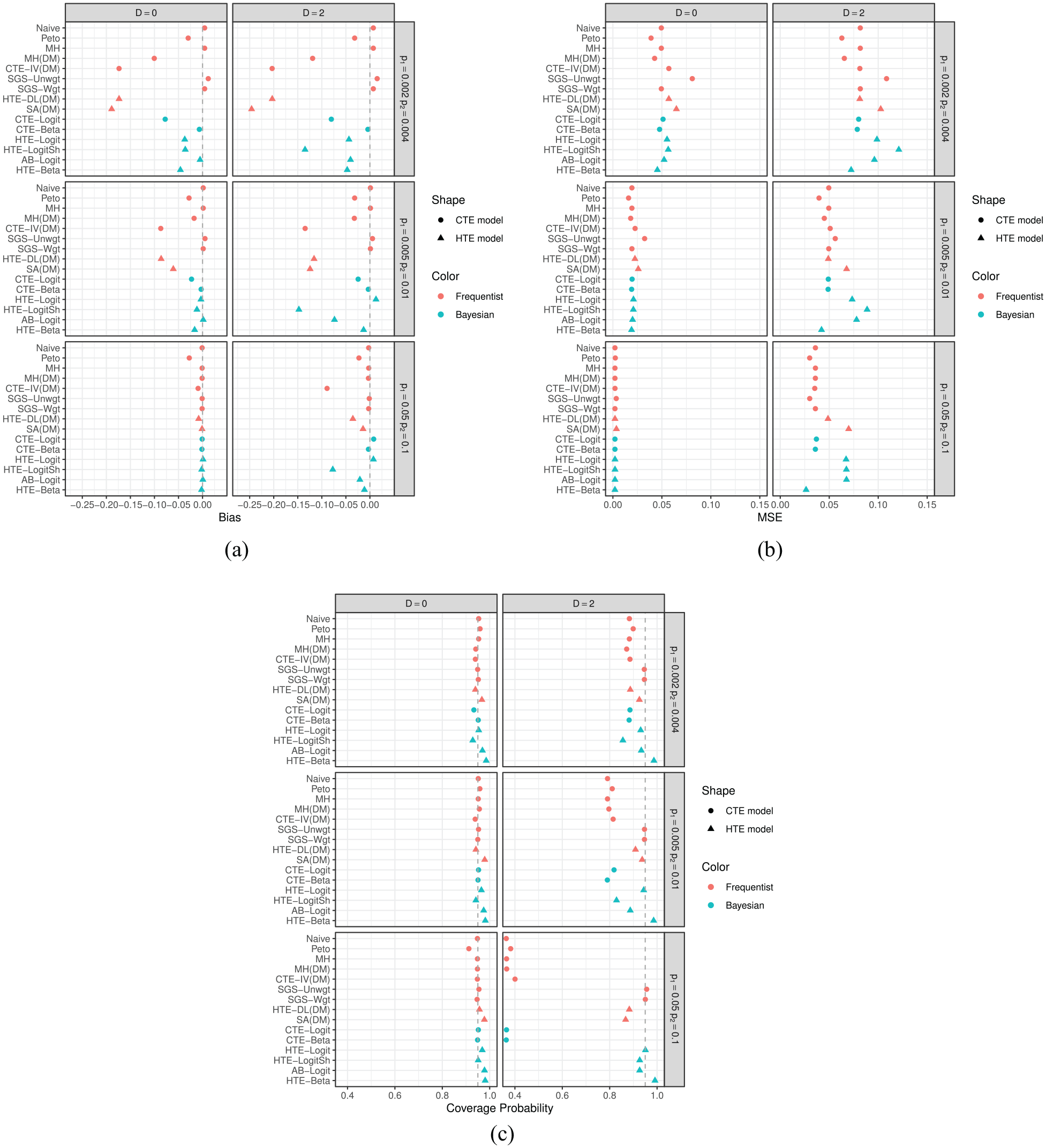
Simulation results in the presence of a treatment effect (i.e. the alternative case): (a) bias, (b) mean squared error, and (c) coverage probability. Frequentist and Bayesian models are plotted in red and blue, respectively; common and heterogeneous treatment effect models are plotted using circles and triangles, respectively.
Under the null cases in Figure 1, all frequentist estimators, which are moment-based estimators, showed little or no bias, as did the three Bayesian methods that model treatment-specific risks, namely CTE-Beta, AB-Logit, and HTE-Beta. CTE-Logit, HTE-Logit, and HTE-LogitSh, however, showed relatively large biases, and the true risks were small. The bias may arise because these three methods rely on a logistic regression model. We generated each meta-analysis dataset from a binomial distribution after we sampled treatment-specific risks,
Mean squared error decreased as true risks increased (i.e. fewer rare events). When
Figure 2 shows the results for the three alternative cases. The Naïve, Mantel-Haenszel, SGS-Unwgt, SGS-Wgt, CTE-Beta, AB-Logit, and HTE-Beta methods had smaller biases when
In the alternative cases, we note two interesting findings that were not observed under the null cases. First, applying the data modification to Mantel-Haenszel resulted in large bias when the true risks were small. That is, adding 0.5 to the contingency table of studies with zero events may bias estimation, especially when a large number of studies report zero events and there is a treatment effect. Second, SGS-Unwgt, SGS-Wgt, and SA(DM) provided very different point estimates, with SA(DM) exhibiting large biases. This discrepancy between the methods may relate to the simulated data generating mechanism being aligned with the SGS-Unwgt and SGS-Wgt estimators’ structure but not that of SA(DM). The target of the SGS-Unwgt and SGS-Wgt estimators is the estimation of treatment-specific risks. These estimators calculate log odds ratio or other treatment effects based on estimates (weighted or unweighted) of treatment-specific risks,
Rosiglitazone data analysis
The rosiglitazone dataset 29 is a popular example with which to study different meta-analysis models with rare events. Many researchers have re-analyzed these data using various methods.8,30–32 The authors have updated the data by adding a few more relevant trials, 33 and we use these updated data as our real data example. They collected and analyzed these data to investigate the effect of rosiglitazone on the risks of myocardial infarction and of death from cardiovascular causes. There are 56 trials, of which 15 did not report any myocardial infarction, and 29 trials did not report any cardiovascular death in either group.
We apply all models in Table 1 to the rosiglitazone data. For the Bayesian methods, we calculate the Watanabe–Akaike information criterion to compare fitted models. We conducted meta-analyses under four different data settings: (1) include all 56 studies; (2) exclude the RECORD trial, considered as large following Nissen and Wolski 33 (55 studies included); (3) select studies comparing rosiglitazone+X to X alone, where X can be either placebo or an active treatment (42 studies included); and (4) select studies strictly comparing rosiglitazone to placebo (13 studies included). In the 56 studies, the total number of subjects in the rosiglitazone group is 19,509 with 159 (pooled risk = 0.00815) and 105 (0.00538) myocardial infarction and cardiovascular death events, respectively; the total number of subjects in the control group is 16,022, with 136 (0.00848) and 100 (0.00624) myocardial infarction and cardiovascular death events, respectively. We note that the correlation between sample size and observed log odds ratio in each data setting varies from −0.32 to 0.37.
Figure 3 shows the estimated log odds ratios for the four different data settings. log odds ratios less than zero favor rosiglitazone, that is, lower odds of having a myocardial infarction or cardiovascular death event than the control group. For the myocardial infarction outcome, the Peto, Mantel-Haenszel, and SGS-Wgt methods yielded 95% confidence intervals that excluded 0 when all studies were included. The estimated between-study variability in log odds ratio estimates,
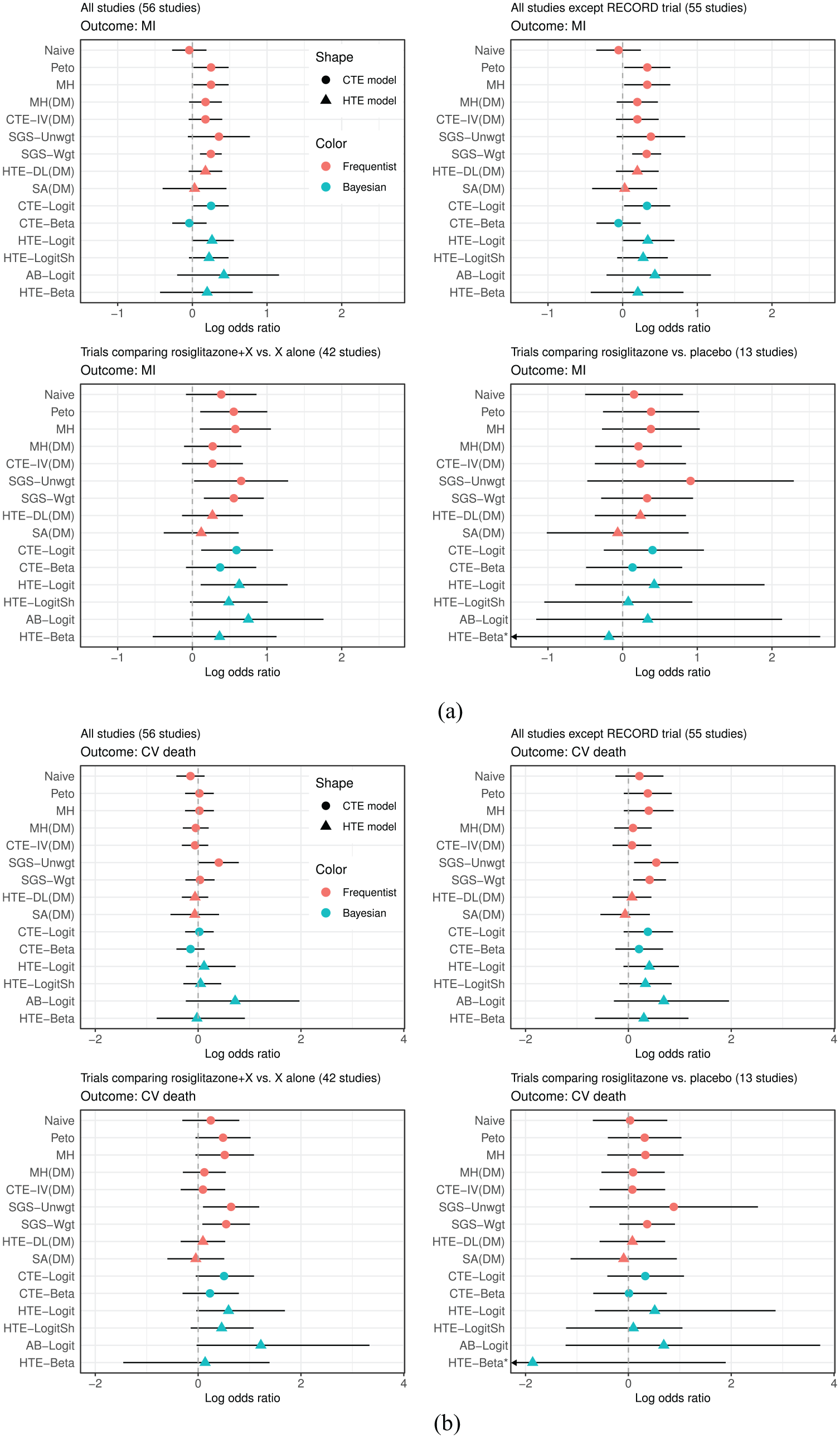
Results of the rosiglitazone data analyses: (a) myocardial infarction and (b) death from cardiovascular causes (CV death). LORs less than zero favor rosiglitazone with lower odds of having an event than control.
When we considered the trials comparing rosiglitazone+X to treatment X alone, the estimated log odds ratios became larger (i.e. stronger effect of rosiglitazone on the odds of having an myocardial infarction event) than those from the other data settings. The Peto, Mantel-Haenszel, SGS-Unwgt, SGS-Wgt, and CTE-Logit methods’ 95% intervals excluded zero. When we included only the 13 studies that compared rosiglitazone to placebo, the associated 95% intervals were wide because of the small number of events: 25 and 14 events out of 7449 and 4860 subjects in the rosiglitazone and placebo groups, respectively. As a result, the HTE-Beta model did not converge and a more informative prior of
For cardiovascular death, all methods except SGS-Unwgt provided point estimates close to zero and 95% intervals that included zero in the 56-study dataset. The
Table 5 displays Watanabe–Akaike information criterion values obtained from the six fitted Bayesian models for all outcomes and data settings. For the myocardial infarction outcome, HTE-LogitSh was the best model by the Watanabe–Akaike information criterion for the first three data settings. Although HTE-Beta provided the smallest Watanabe–Akaike information criterion in the fourth setting, when single-agent placebo was the control, the model did not converge. AB-Logit was second place in terms of the Watanabe–Akaike information criterion in each of the data settings. For the cardiovascular death outcome, HTE-Logit (under the first two data settings), HTE-LogitSh (third data setting), and HTE-Beta (fourth data setting) provided the smallest Watanabe–Akaike information criterion values. Again, note that HTE-Beta did not converge in the fourth data setting and AB-Logit provided the second smallest Watanabe–Akaike information criterion value. Across all outcomes and data settings, CTE-Beta provided the largest or second largest Watanabe–Akaike information criterion values, indicating a poor fit to the rosiglitazone data.
WAIC values for six Bayesian models fit to the rosiglitazone data.
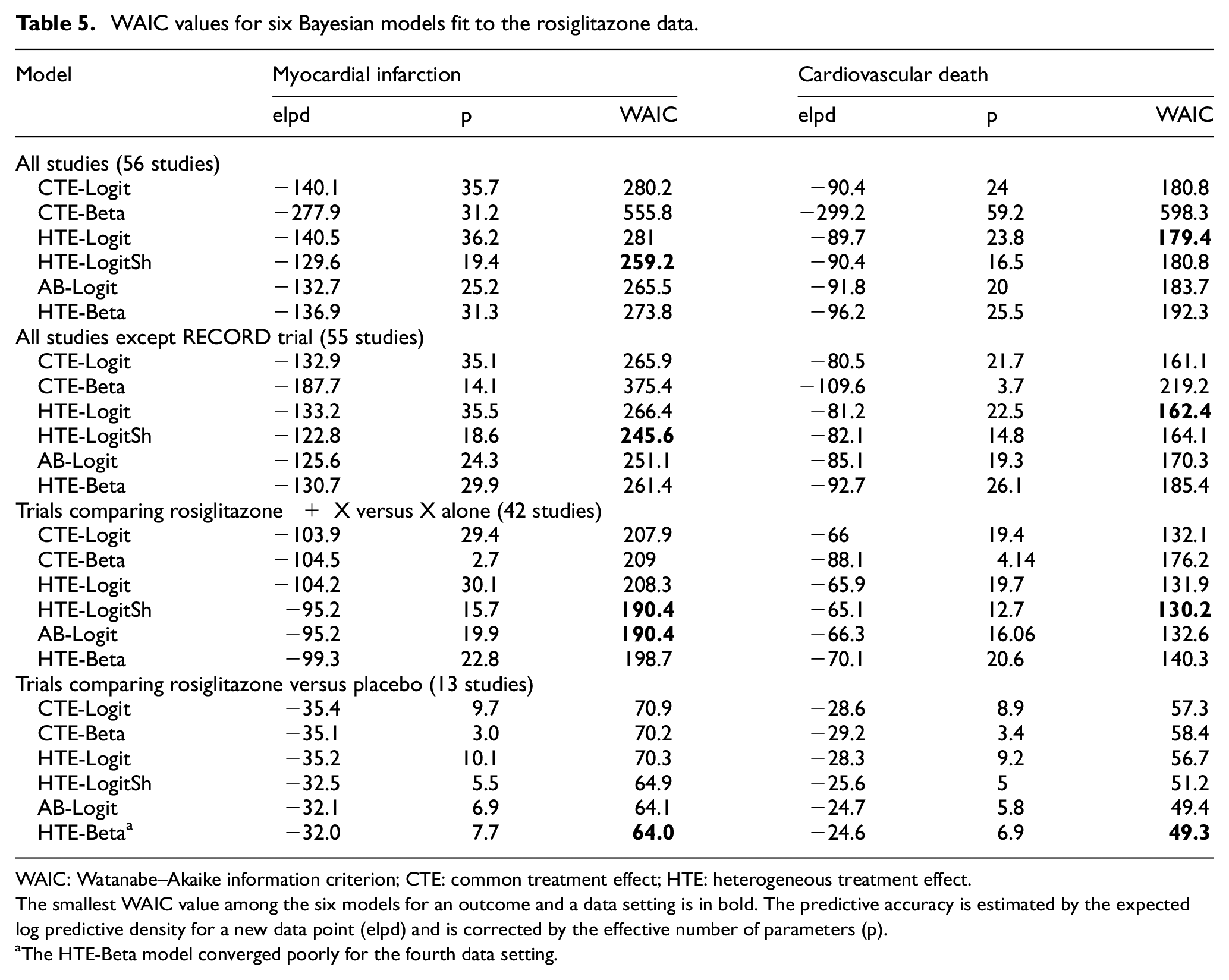
WAIC: Watanabe–Akaike information criterion; CTE: common treatment effect; HTE: heterogeneous treatment effect.
The smallest WAIC value among the six models for an outcome and a data setting is in bold. The predictive accuracy is estimated by the expected log predictive density for a new data point (elpd) and is corrected by the effective number of parameters (p).
The HTE-Beta model converged poorly for the fourth data setting.
Discussion
We considered many different meta-analytic models when the outcome event is rare. We assessed and compared the performance of frequentist and Bayesian approaches through an extensive simulation study under various data generating settings. The simulations considered really low frequency to somewhat rare event risks and examined no between-study heterogeneity to large heterogeneity. We also fitted all models to the rosiglitazone data and compared the Bayesian models using the Watanabe–Akaike information criterion.
Our simulation results suggest that we should interpret results of meta-analyses carefully in very low-frequency settings. Overall, HTE-Beta seemed to perform among the best. AB-Logit also performed consistently well across all settings, except for mean squared error when between-study heterogeneity in risks existed. Among moment-based frequentist estimators, the SGS-Unwgt and SGS-Wgt estimators performed well, although the SGS-Unwgt estimator gave relatively large mean squared error under the low-risk settings. The Mantel-Haenszel estimator without a data modification provided no or little bias but had somewhat large mean squared error and under-coverage. Peto performed similarly to Mantel-Haenszel but was slightly more biased than Mantel-Haenszel in the alternative case. All frequentist and Bayesian common treatment effect models, except the SGS-Unwgt and SGS-Wgt estimators, tended to provide poor coverage probabilities when between-study heterogeneity existed.
In our data analyses, log odds ratio estimates and their 95% intervals differed by method. We would not expect all of the methods to be quantitatively the same, but most should be qualitatively similar. If there is great discrepancy across methods, then it may be because of a high degree of study-to-study heterogeneity or correlation between-study design and risks.5,11 One should investigate the source of such discrepancies, particularly in terms of model goodness of fit. Any method that assumes a common effect across studies may be wrong if there is evidence of a large degree of heterogeneity across studies as, for example, if the studies incorporate different controls.
We noticed a few interesting results in the rosiglitazone data analysis. First, the Naïve and CTE-Beta methods provided similar results because the closed form of the posterior mean of risks for the CTE-Beta model is equivalent to the Naïve pooled risks. Second, CTE-IV(DM) and HTE-DL(DM) provided exactly the same results because the estimated between-study heterogeneity
Furthermore, the rosiglitazone data analysis showed some findings that differed from what we observed in the simulation study. Simulation study results are valid and applicable to a real data analysis only when the simulation data generating mechanism agrees with the true data generating mechanism of the real data. It is untestable, however, whether the rosiglitazone data follow the same data generating mechanism that we used in our simulation study. Instead, we investigated key empirical features (such as correlation between sample size and risks) in the rosiglitazone data and assessed difference between simulated and real data. First, although our simulation studies suggested that HTE-Beta, AB-Logit, and SGS-Wgt are the generally favored models and HTE-LogitSh may be one of the least favorite models, the Bayesian model comparison using the Watanabe–Akaike information criterion in our rosiglitazone data analysis suggested that HTE-LogitSh was the best fitting model. Second, SGS-Wgt always provided much narrower 95% confidence intervals than SGS-Unwgt. This trend was not observed in our simulations, though. The difference may be because of a non-zero correlation between-study design and observed log odds ratio in the rosiglitazone data, whereas the simulations did not include such correlation. Shuster et al. 11 pointed out that SGS-Wgt could be more influenced by large trials than SGS-Unwgt. One advantage of SGS-Wgt, however, is that it tends to have narrower confidence limits as the number of studies increases.
Shuster and Walker 5 stated two points that need to be considered in meta-analysis methods. One may need to properly handle an interaction between sample size and treatment effect with meta-analysis methods that use weights based on sample sizes, and one may also need to consider the weights as random variables. They argued that most widely used meta-analysis methods with binary outcomes do not consider these two issues. Instead, these methods assume independence of within-study effects and design, called effects at random, and could provide biased estimates. Our simulation study did not address these issues specifically, and further studies are needed.
The rosiglitazone data have flaws that limit the ability to assess if rosiglitazone increases the risks of myocardial infarction and cardiovascular death. A major concern is that it is unclear what the control group is. The dataset includes some studies with active treatments as the control groups and some with placebo controls. Some trials compared rosiglitazone to placebo while a few trials compared rosiglitazone to glyburide. It is questionable whether we can consider placebo and glyburide as comparable control groups. Similarly, it is questionable whether the log odds ratio of rosiglitazone compared to placebo can be combined with log odds ratio of rosiglitazone + X compared to X alone. Nissen and Wolski 33 tackled this issue by providing results from several meta-analyses that included studies having the same comparator (insulin, metformin, sulfonylurea, or placebo). For these specific data, a network meta-analysis may be a more reasonable approach because the data have non-comparable treated and control groups across the trials. 22
Although our findings and discussion were mainly based on the log odds ratio scale, it is important to consider other scales, such as the log relative risk and risk difference, and check the consistency of findings. 35 Our simulation and data analysis results with the log relative risk scale were very similar to those for the log odds ratio scale. This is expected as the odds ratio and relative risk are similar numerically for rare events. In our simulations with the risk difference scale, all methods provided very small biases and mean squared errors, but some methods showed poor coverage when outcomes were frequent and heterogeneity was large (see section 2 in Supplementary Material). In the data analysis, the conclusions about treatment effect with risk difference and log odds ratio estimates were the same as those with log odds ratio. Note that reporting both absolute measures (e.g. risk difference) and relative measures (e.g. log odds ratio and log relative risk) might be useful in a meta-analysis that concerns rare events. Absolute measures usually provide a more clinically straightforward interpretation than relative measures, while relative measures tend to have less statistical heterogeneity than absolute measures. 35 However, Efthimiou 36 warns against use of risk differences when faced with rare events. Bayesian methods are advantageous and flexible when estimating different effect scales and interpreting them based on posterior probabilities.
In summary, when a rare binary event is the outcome of interest, treatment effect estimates obtained from traditional meta-analytic methods may be biased and provide poor coverage probability. This trend worsens when there is large between-study heterogeneity. Effect estimates vary when applying different models and are likely to depend on the characteristics of the data (e.g. level of between-study heterogeneity, rarity of outcomes, correlation between sample size and effect size, and so on). As such, inferences should be drawn cautiously. In general, we recommend methods that focus on first estimating treatment-specific risks and then estimating treatment differences based on summaries of the risks across the studies. Of course, this approach makes most sense when the studies in the meta-analysis share the same treatment and control arms. To avoid making a wrong decision, we recommend fitting various methods, comparing the results and model fit (for Bayesian approaches) and investigating any significant discrepancies across them.
Supplemental Material
sj-pdf-1-ctj-10.1177_1740774520969136 – Supplemental material for Meta-analysis of rare adverse events in randomized clinical trials: Bayesian and frequentist methods
Supplemental material, sj-pdf-1-ctj-10.1177_1740774520969136 for Meta-analysis of rare adverse events in randomized clinical trials: Bayesian and frequentist methods by Hwanhee Hong, Chenguang Wang and Gary L Rosner in Clinical Trials
Footnotes
Acknowledgements
The authors thank for the helpful comments from the Associate Editor and two anonymous reviewers. They also thank Drs Estelle Russek-Cohen and Mark Levenson from the US Food and Drug Administration (FDA) for valuable comments which improved this manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was made possible by U01 FD004977-01 from FDA, which supports the Johns Hopkins Center of Excellence in Regulatory Science and Innovation. Its contents are solely the responsibility of the authors and do not necessarily represent the official views of the Department of Health and human services or FDA. Hwanhee Hong was supported by R00MH111807 from the National Institute of Mental Health, and Chenguang Wang and Gary L. Rosner were supported by P30CA006973 from the National Cancer Institute.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.