
Abstract
Trial designs using cluster-level randomization are necessary when interventions have intended effects that cannot be measured with individual randomization. When an intervention is intrinsically only able to be delivered to a cluster or when implementation of an individual level intervention is only feasibly implemented at a cluster level, cluster-level randomization is required. In designing the strategy for evaluation of the primary outcome of a cluster randomized trial, there are a multitude of important decisions to consider. While these decisions are guided primarily by the intervention—who benefits, what is the intended effect and when will it be achieved—there are important detailed choices that affect potential bias and statistical power, and implementation considerations that require compromise for considerations of feasibility and practicality. Through the lens of three large completed cluster randomized trials in HIV prevention, we present specific choices made for the overall evaluation plan, together with some of the detailed considerations, compromises and modifications that occurred during trial implementation.
Background
Trial designs using cluster-level randomization are necessary when interventions have intended impact that cannot be measured with individual randomization. When an intervention is intrinsically only able to be delivered to a cluster (e.g. HIV testing using mobile vans within a community), or when implementation of an individual level intervention is only feasibly implemented at a cluster level (e.g. implementation of financial incentives in a medical facility), cluster-level randomization is a requirement of the design. Cluster randomized trials (CRTs) have a plethora of important operational, logistical and measurement details to be decided in the design and implementation of the evaluation strategy. Both practical and statistical considerations must be weighed in these decisions.
Cluster randomized designs require evaluation of intervention impact for the cluster, but the strategy for that evaluation has myriad possibilities depending on whether the intended intervention impact is in the same or a different population from the intervention delivery population. Sometimes the intervention has intended direct impact on the delivery population; sometimes indirect impact on a population different from the delivery population; commonly in CRTs, intended impact is both direct and indirect. Identifying the group targeted by the intervention will guide the strategy for outcome evaluation and have important implications for the cost and resources needed. Often, practical and budget considerations require compromises in the evaluation strategy; early deliberations by the study team are important in assessing the risks and limitations of these choices, and discussion of potential mitigation strategies. Unwelcome surprises are almost a certainty as implementation proceeds, even with the best laid plans; ongoing review of any adaptations needs the same attention to risks and limitations for the evaluation.
This manuscript describes some of the practical considerations in the design and implementation of the evaluation of outcomes in a CRT, through illustration with three diverse case studies of CRTs in HIV prevention. Our goal is to assist those contemplating the logistics of future CRTs to design and implement evaluation strategies that will increase the chance of successful execution of a high-quality evaluation for these large, expensive and important studies.
Methods
The following three case studies are used to illustrate five key implementation decision areas required in implementing and designing CRT evaluations.
Three case studies
NIMH Project ACCEPT (HPTN 043):1,2 Project ACCEPT sought to evaluate whether increased access to HIV testing and post-test support could decrease HIV incidence in a community. Increased testing access was implemented through HIV testing in mobile vans deployed throughout the community; peer-based support groups addressed stigma and disclosure to modify norms for HIV testing. The trial was conceived, designed and conducted before 2009, in an era with no proven effective biomedical prevention (ClinicalTrials.gov number NCT00203749).
Financial Incentives for viral suppression (HPTN 065):3,4 HPTN 065 was a trial with five components: for the case study we use the component that was a CRT of financial incentives in health clinics in Washington, DC and the Bronx, NY (HPTN 065-FI). The trial evaluated whether clinics implementing a quarterly financial incentive given to persons living with HIV on antiretroviral therapy who maintained viral suppression would increase adherence to antiretroviral therapy and lead to higher rates of viral suppression (Clinicaltrials.gov number NCT01152918).
HPTN 071 (PopART):5,6 The study of the PopART intervention evaluated whether universal HIV testing and treatment throughout a community would decrease the rate of new infections in the community. Treatment as prevention has been shown to be 95% effective in preventing HIV transmission; this CRT was designed to measure the impact of community-level implementation of household-based HIV testing and referral to treatment on reducing risk of HIV infection throughout the community. (ClinicalTrials.gov number, NCT01900977).
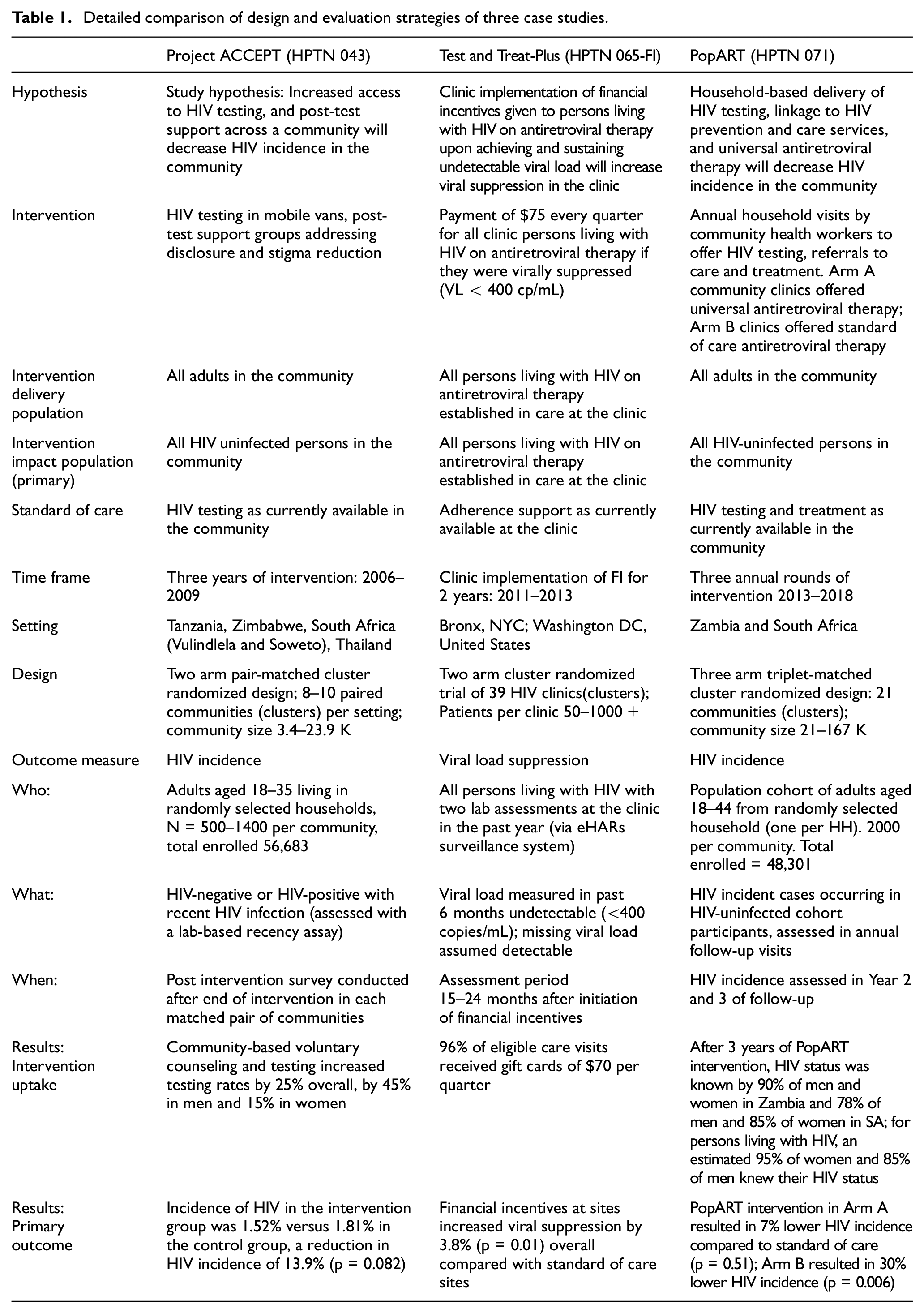
The detail of design and outcome evaluation strategies for these three CRTs in HIV prevention is detailed in Table 1.
Detailed comparison of design and evaluation strategies of three case studies.
Results
Five operational areas of the CRT evaluation are considered: randomization, design of the outcome evaluation, risk of Hawthorne effect, representativeness, size and weighting of the evaluation clusters.
Randomization
The goal of randomization is to reduce risk of confounding by achieving balance in measured and unmeasured variables associated with the outcome. However, CRTs can have a relatively small number of randomization units, increasing the risk of chance imbalance. Operationally, most CRTs mitigate this risk by ensuring good balance through restrictions on the randomization, specifically to ensure balance on community characteristics known to be related to the (1) uptake of the intervention and (2) outcome, pre-intervention. Commonly CRTs use some combination of stratification, matching, restricted randomization and statistical adjustment. Matching and restricted randomization clearly require community-level information prior to randomization; planning to obtain this information is an important effort in the implementation timeline, since randomization typically needs to occur early (6–12 months prior to intervention start), for planning intervention implementation.
In both Project ACCEPT and PopART, stratified, matched designs were selected. Matching of communities, stratified by country, were decided on the basis of geographic, sociodemographic, cultural and infrastructure characteristics established by formative 7 or prior 8 research. A well-known bias-variance trade-off of a matched design is the reduction in the number of independent assessments of intervention effect: for example, matched pairs in Project ACCEPT reduced the assessments from the 34 communities to 17, in PopART, from 21 to 7.
Restricted randomization selects from all possible randomized allocations a restricted subset with an acceptable level of balance in baseline (pre-existing) data. 9 Restricted randomization is intuitive and simple, since with a small number of clusters complete enumeration (and ordering) of randomizations is feasible. Restricted randomization provides a natural permutation test framework, allowing for a non-parametric assessment of the statistical significance of the trial result. Note that the size of the restricted pool of randomizations determines the number of realizations in the permutation testing, hence pools of at least 5000 are recommended. However, there are risks. Restricted randomization may rely on pre-existing data (not collected by the study) that is old and/or not purpose built. Efforts made to select a balanced randomization may come to naught if the data used for the randomization are inaccurate.
Both HPTN 065-FI and PopART used stratified, restricted randomization to ensure balance in specific factors. In HPTN 065-FI, critical factors to balance between arms within each city were distribution of clinic sizes and baseline viral suppression. Using baseline data from eHARS 10 (the US National HIV Surveillance System that was used to assess outcome), we found the 10,000 randomizations with the smallest sum of squared t-statistics comparing between arms, and selected one at random for each city. PopART (in addition to matching) used restricted randomization to achieve baseline balance in community size (intervention coverage), HIV prevalence (correlate of incidence) and uptake of antiretroviral therapy (intervention uptake). Data for some communities were available from a prior trial; 8 extension to new communities was imputed based on available data in that health district. Operationally, randomization choice was restricted to the 5000 randomizations where (1) average HIV prevalence was within 2%, (2) average antiretroviral therapy uptake among HIV-positive individuals was within 4% and (3) average community population size was within 5000, for all trial arm comparisons. Randomization occurred in a public ceremony where communities (1) selected from the restricted randomizations by generating a random number between 0 and 4999 and (2) assigned arm to the three symbols in the selected randomization. In both PopART and HPTN 065-FI, pre-existing data were used: for PopART, baseline balance on restricted factors was ultimately good; for HPTN 065-FI, baseline balance of the restricted factors was outside the specified limits, as a result of (later discovered) quality issues in the data.
Baseline imbalance can be mitigated by statistical methods in the primary analysis, typically by pre-specified primary outcome models that adjust for baseline measures known to be predictors of outcome. This necessitates collection of baseline data across all communities and can represent a substantial additional cost and/or delay. All three trials had baseline assessments: Project ACCEPT completed a baseline survey prior to randomization, with randomization occurring 1 year later, and intervention starts 6 months after that.
Both PopART and HPTN 065-FI included adjustment for baseline community measures predictive of the primary outcome; this was an important adjustment for HPTN 065-FI, given a baseline imbalance in viral suppression. This approach was not available for the primary outcome in Project ACCEPT, because the intervention (uptake of HIV testing) meant the team could not measure HIV at baseline or during the intervention without interfering with the study intervention. Therefore, no adjustment for baseline HIV prevalence was used.
Measuring the outcome in each cluster
There are three key considerations in designing the outcome evaluation strategy. These essentially amount to understanding the principles that guide the choice of who to measure, what to measure and when to measure. The decision of who to measure derives from the intended impact population of the intervention delivery, that is, who it is intended to benefit (see Figure 1 for the case studies). The first task is to design a sampling strategy for this ideal outcome (impact) population. In the simplest case, the impact and delivery populations are the same. The outcome evaluation could then occur as part of the intervention delivery (in the intervention communities), unless (as is often the case) coverage of the intervention is an integral part of the investigation. In that case, evaluation strategies that define a group representative of the entire population, irrespective of receipt of the intervention, are necessary. Outcome measurements must be implemented in the non-intervention communities, with minimal disturbance to the outcome. It is common for cluster randomized designs to have both direct and indirect mechanisms of action (i.e. benefits accrue not only to those receiving the intervention, but also to partners/children/neighbors), in which case the best practice for outcome assessment includes representation from these other groups. It is also possible that an intervention impact is wholly indirect—for example, in HPTN 071, increased antiretroviral therapy for persons living with HIV had an intended prevention effect for HIV-uninfected.
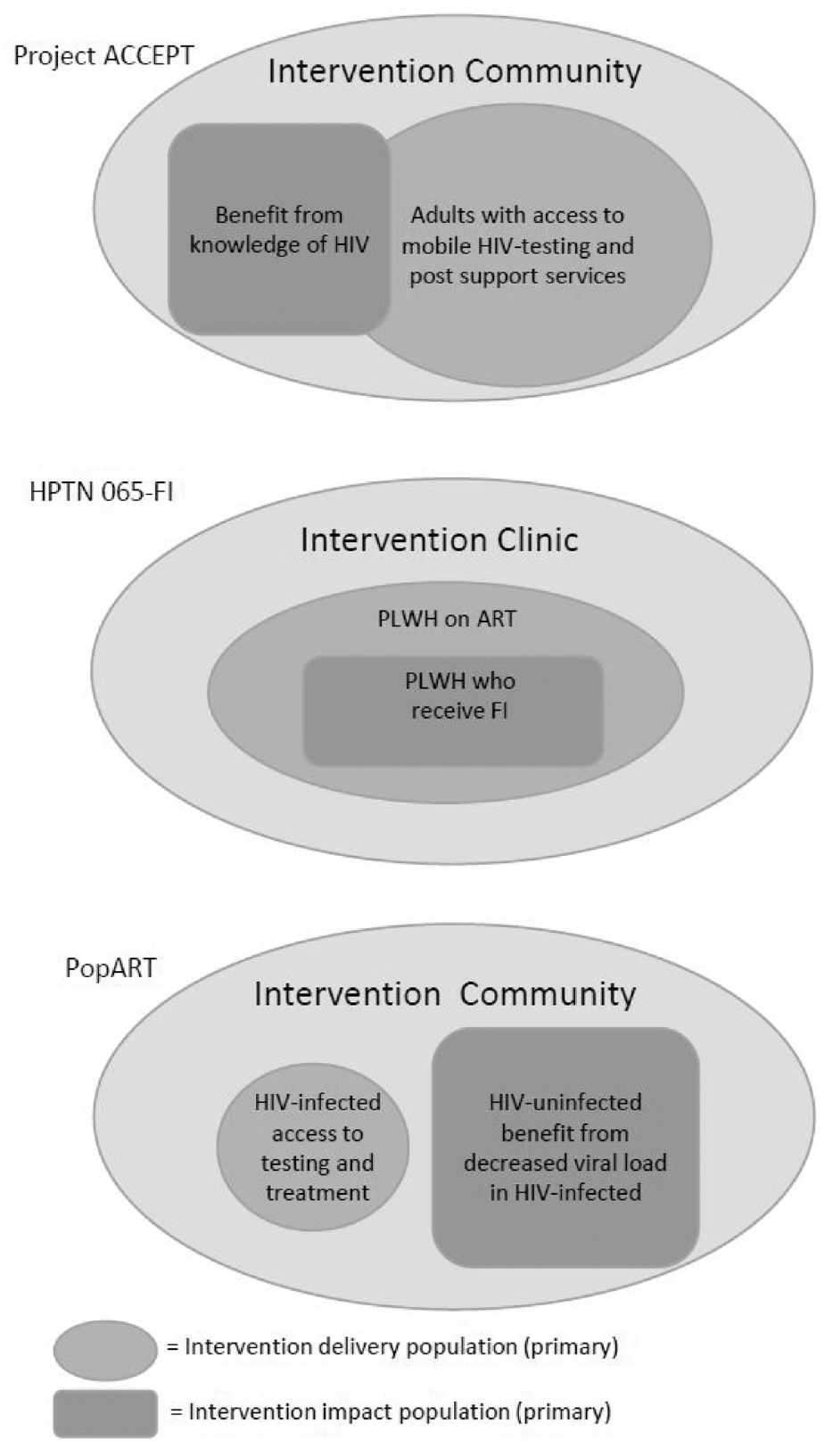
Design of the evaluation strategy determines who benefits (intervention impact population) from the delivery of the intervention (intervention delivery population). In Project ACCEPT, any member of the community could benefit from those who accepted HIV testing. In HPTN 065, only those who received the financial incentive could benefit from the intervention. For the primary endpoint of HIV infections in HPTN 071, the primary intervention mechanism for impact in HIV-uninfected persons was viral suppression resulting from delivery of the test and treat intervention to HIV-infected persons.
In a study with indirect effects, the outcome assessment usually requires a dedicated research activity, for example, recruiting and following an evaluation cohort, entirely separate from the intervention work. An evaluation cohort often uses a sampling design to recruit a representative group from each cluster. Unbiased estimates will require definition and elucidation of the sampling frame and a well-defined approach to random sampling within each cluster. Alternatively, pre-existing surveillance data systems may allow comprehensive evaluation of the outcome in the community, potentially reducing the cost of the trial, but at the risk of repurposing data systems designed for other use.
In individual randomized trials, a common design choice is to assess the outcome in a subset of the community at higher risk of disease, for example, where HIV infection risk is higher in younger ages, HIV prevention trials typically restrict enrollment by age. Similar strategies can be applied to recruitment of the evaluation cohort, that is, evaluating the impact in a subgroup of the community with higher risk of disease. The trade-off between generalizability 11 (effects assessed in the subgroup may not generalize to the entire target population) and efficiency (higher disease rates typically result in more precision in estimated effect) is an important consideration in this choice. Transportability of results to other settings may also be challenging if the targeted subgroup is setting-specific or narrowly defined.12,13 While generalizability and transportability are not primary drivers of the design decisions, the underlying importance of these epidemiologic principles often do influence the outcome definition.
Project ACCEPT and PopART interventions both had intended indirect impacts, and both implemented an evaluation cohort independent of the intervention. Project ACCEPT and PopART sampled households at random from a sampling frame of all households elucidated in the community to recruit a target number of individuals; Project ACCEPT recruited all eligible members of the household, PopART only a single member (see section on Hawthorne effect). Both PopART (recruited ages 18–45) and Project ACCEPT (recruited ages 18–35) placed an age restriction on the evaluation cohort.
Financial incentives in HPTN 065-FI invoked only direct effects: only those receiving the intervention could benefit. Yet because financial incentives were implemented as a clinic-wide program, rather than implementing individual data collection, HPTN 065-FI used eHARS Surveillance data which collated viral load data from all persons with confirmed diagnosis of HIV. Working with the Centers for Disease Control and Prevention and local departments of health, the study funded the development of clinic-specific evaluations of aggregate viral suppression for persons living with HIV at a clinic. A significant compromise in using eHARS was not being able to restrict the evaluation to persons living with HIV who were on antiretroviral agents (an item not collected in surveillance); the outcome assessed viral load in all persons living with HIV at a clinic, which would have included some not on antiretroviral agents and not eligible to receive the intervention.
The second decision is what outcome to measure. Considerations of power, effect size and interpretability are critical. As with any trial, there is a gradation of quality of evidence, with objective evidence of clinical outcomes being more impactful than self-reported measures or measurements of service uptake. The strength of prior evidence of efficacy, the components of the intervention and the complexity of implementation all play a part in determining the appropriate outcome. Fundamentally, the outcome should reflect as closely as possible the intended effect of the intervention, where that effect has clear clinical or public health benefit. However, even then, it can be difficult to determine the best outcome measure to select. For example, achieving viral suppression in HIV-infected persons is strongly predictive of reduced risk of HIV infection; however, the pathway to viral suppression includes (1) knowledge of HIV infection, (2) initiation of antiretroviral therapy and (3) sustained viral suppression. Is it sufficient to measure uptake of HIV testing to show benefit? Or sufficient to show increase in sustained viral suppression over the entire population? Or is it necessary to directly measure reduction in new HIV infections? An outcome defined for the whole evaluation cohort, rather than only a subset, typically has more reliable power and interpretability. For example, rather than using detectable viral load as an outcome restricted to the HIV-infected population (measuring transmission risk from a subset of the community), an outcome of detectable viral load in HIV infected as an outcome restricted (measuring transmission risk from a subset of the community), a more directly interpretable measure of transmission risk is detectable viral load in the entire population (HIV-uninfected persons assigned undetectable viral load).
In all three of the case studies, the outcome selected was a biologic outcome of known public health significance: HIV incidence and viral suppression. A consequence of this rigorous assessment was large assessment cohorts—HIV incidence outcomes required cohorts of ∼50,000.
The third decision is when to measure and depends on the expected time to achieve benefit: is it immediate or delayed impact, or are benefits not expected until sufficient uptake has occurred? In the case where benefits are theorized to increase over time, the trial will need to balance evaluation time frames with intervention activities: it will be rare that study logistics permit for study-measured outcomes to be assessed much after the intervention is complete. A common solution is to time the assessment toward the end or immediately after conclusion of the intervention. An advantage of external (non-study) evaluation is the ability to continue to assess outcomes after the intervention has completed.
Project ACCEPT evaluated HIV incidence after the completion of 3 years of intervention, using a cross-sectional incidence assessment. In parallel with the 3 years of intervention delivery, PopART followed a cohort with annual visits for 3 years, using longitudinal assessment of incident HIV infection. The initial plan included all 3 years in the outcome assessment; however, based on the pace of intervention rollout, this was changed to HIV incidence in the second and third year, anticipating that impact in the first year was minimal. A delay was built in for HPTN 065-FI—financial incentives could only have an impact after all patients qualified, thus the outcome assessment occurred in months 15–24 of the 2-year program. HPTN 065-FI also completed a long-term assessment of durability of impact. 14
The risk of Hawthorne effect in outcome evaluation
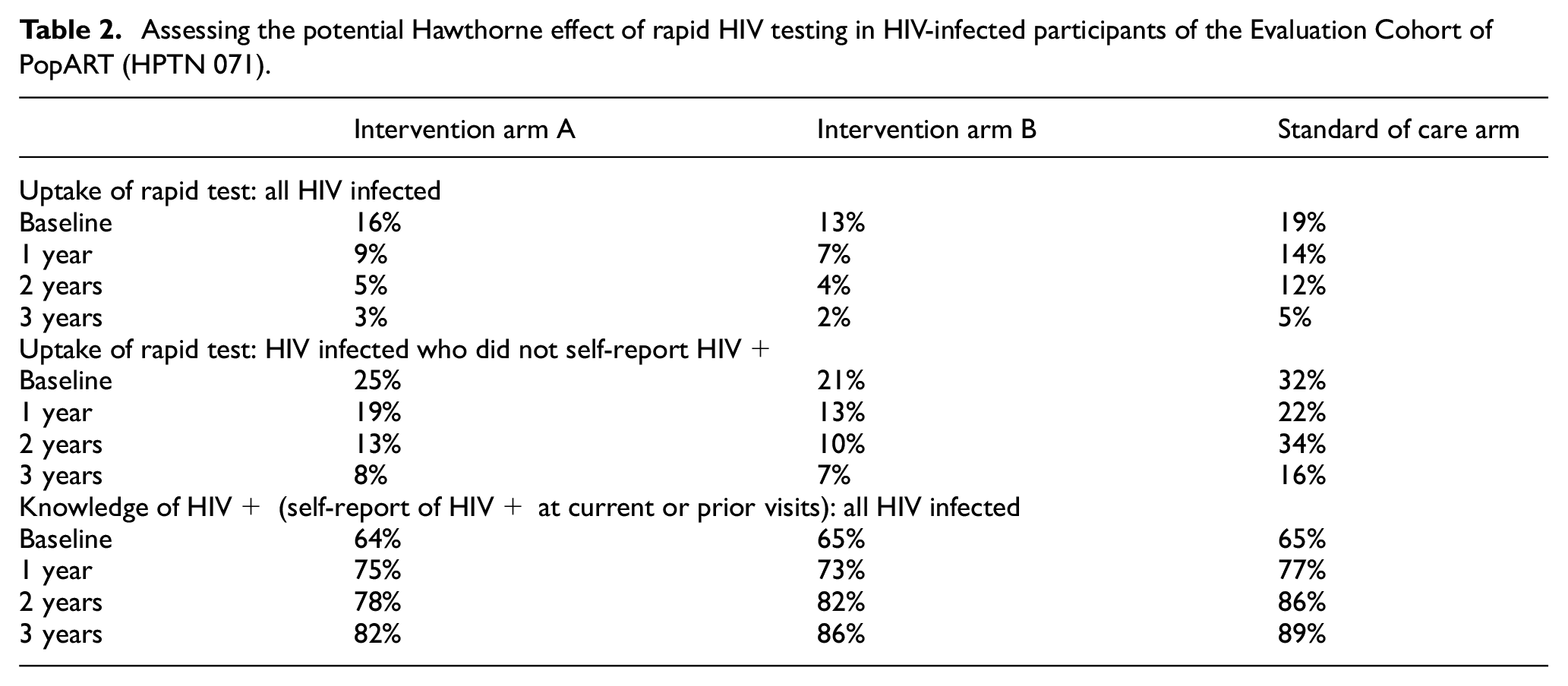
Hawthorne effect in the context of a CRT refers to the risk of changing the estimate of intervention effect through the outcome measurement process. This is a common issue when the communities in the standard of care condition have no intervention component, and the research evaluation is the only study activity in the standard of care communities. This potential is clearly illustrated in Project ACCEPT, where the crux of the proposed intervention pathway was people learning their HIV status through increased ease of HIV testing. If the study measured HIV at baseline, or repeated HIV testing to assess HIV incidence, all persons in the outcome cohort would have received the intervention through measuring the outcome, invalidating measurement of intervention effect. This realization led to the decision to use a cross-sectional incidence assessment as the primary outcome, an assessment occurring only after the completion of intervention delivery. A similar issue existed for PopART, where the backbone of the intervention was household-based HIV testing. Participants in the outcome cohort were offered a rapid HIV test in the household (similar to intervention), raising the risk of a Hawthorne effect, as those in the outcome cohort had more ready access to an HIV test. The mitigations implemented in the outcome evaluation were (1) only one adult enrolled per household—to limit potential effect of research participation in the household; (2) rapid HIV tests were offered but not required; the research evaluation used blood collected from all participants. Considering the HIV status of the person enrolled, however, reveals more subtle consideration of Hawthorne effect in PopART. The hypothesized primary mechanism for decreased incidence was increased antiretroviral therapy uptake in HIV-infected persons. For an HIV-infected participant, testing itself was unlikely to affect the risk of HIV infection in another household’s cohort participant, so the risk of Hawthorne effect on HIV incidence was likely to be minimal. However, a Hawthorne effect on the secondary outcome of viral suppression in HIV-infected participants was quite likely: research participation could increase knowledge of HIV infection and increase viral suppression, compared to those not in the outcome cohort. Table 2 compares the uptake of rapid testing and knowledge of HIV status in intervention versus standard of care arms. Higher uptake in the standard of care arm suggests that participation in the evaluation in standard of care communities resulted in a similar knowledge of HIV infection in all arms of the evaluation cohort over the course of the study, potentially decreasing the observed intervention effect on viral suppression in the evaluation cohort, that is, not accurately reflecting differences in viral suppression between intervention and standard of care arms.
Assessing the potential Hawthorne effect of rapid HIV testing in HIV-infected participants of the Evaluation Cohort of PopART (HPTN 071).
The assessment approach in HPTN 065-FI completely avoids the risk of Hawthorne effect, using an existing data surveillance system, rather than implementing a research evaluation. The advantages of existing data systems include (1) ability to evaluate pre-intervention measures to balance randomization and facilitate statistical adjustment, (2) no risk of Hawthorne effect, (3) consistent data across all clusters and (4) potential for post-intervention evaluation. Typical challenges encountered are compromises in the data available, lack of control of the quality, completeness and timing of access to data. Collaboration with surveillance personnel is essential, as additional quality control will need to be implemented to ensure accuracy of fields critical to the study (i.e. cluster identification).
Challenges with representativeness: recruitment and retention
Unbiased evaluation of cluster outcomes commonly requires representative sampling from persons in the cluster, meaning the study team is tasked with recruiting randomly selected persons, leading to trial participation that is more passive. Unlike a cohort recruited and consented in a clinic, household-based or community recruitment of participants do not experience high participation or retention rates. Almost inevitably, this leads to difficulty in attaining the ideal of a representative sample. The resulting potential for bias is difficult to remediate. This is a difficulty well known in survey sampling, and the same weighting methods used to correct for selection probability and non-response can be incorporated in the statistical analysis of a CRT, albeit with a cost to statistical efficiency. Ongoing monitoring of field work is important for detecting and correcting trends in quality and representation of the assessment cohort. For example, adjusting hours of operation in PopART resulted in increased participation in the evaluation cohort from working age members of the community. One approach is to plan and conduct sensitivity analyses to assess the potential impact any bias in evaluation might have on the assessment of effect: these might include evaluation of representation (e.g. age, gender) between arms, and assessment of potential effect moderators (e.g. different effects in men and women). Most CRTs acknowledge as a limitation the evaluation of effect in a cohort imperfectly representative of the communities.
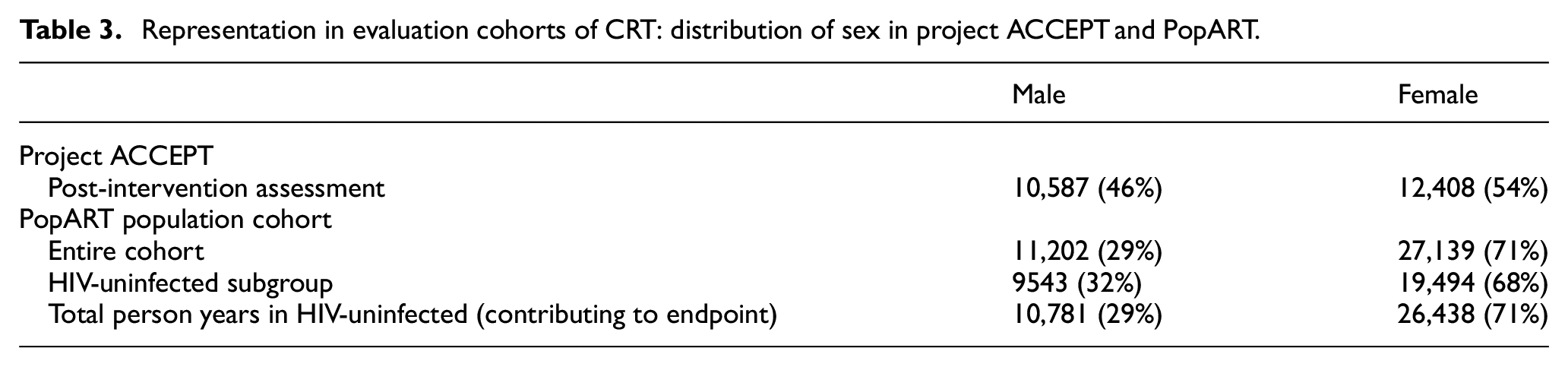
Both Project ACCEPT and PopART experienced higher participation by females than males in the evaluation cohort (Table 3), likely a consequence of household-based recruitment. The cross-sectional sample of Project ACCEPT achieved more balanced representation; in PopART both enrollment and retention were higher in females, resulting in an effect evaluation with majority contribution by females (71% female, 29% male).
Representation in evaluation cohorts of CRT: distribution of sex in project ACCEPT and PopART.
Cohort size and weighting in evaluation
The size of the intervention clusters in a CRT is typically not fully controlled by design, and it is not uncommon for intervention clusters to be very different in size. Provided cluster size itself is not informative about intervention impact, size of the cohort for each cluster is a design choice in the research evaluation strategy. For a community intervention using a separate research evaluation, there are two common choices. The simplest is to choose the same evaluation cohort size for all communities. This is relatively robust statistically and operationally and is a safe choice when outcome effect across clusters is expected to be similar. The second choice is to select evaluation cohort size to have similar outcome precision in each (pair of) clusters. This typically results in greater efficiency and power for the evaluation when knowledge about outcome precision was accurate.
Equal size was the strategy used in PopART: while the size of the 21 communities ranged from 21,000 to 167,000, the evaluation strategy was to enroll 2000 in each community. In the primary analysis, each community was given equal weight in the two-way analysis of variance (ANOVA) used for this three-arm trial, resulting in a simple interpretation of the average intervention effect across the seven triplets. Project ACCEPT based the recruitment strategy on expected incidence: communities expected to have lower HIV incidence had higher planned recruitment. In addition, the analysis weighted pairs of clusters based on outcome variance: a weighted paired t-test was used, where community pairs were assigned weights based on the harmonic mean of the number of events contributed in that pair. The weighted analysis means that communities with greater number of infection (more “information”) had a greater contribution in the estimate of intervention effect. The intervention effect was a weighted mean of the (log) relative risk of intervention versus standard of care pairs. In HPTN 065-FI, cluster size corresponded to the number of HIV-infected patients in a clinic (varying from 50 to 2000). The clinic-implemented individual level intervention was assessed using an aggregate clinic outcome of proportion of clinic patients virally suppressed. In analysis, clusters were weighted by size to reflect the desired estimand of change in viral suppression for an individual attending a clinic with or without financial incentives.
Conclusion
In designing the strategy for evaluation of the primary outcome of the CRT, there are a multitude of important decisions to consider. While these decisions are guided primarily by the intervention—who benefits, what is the intended effect and when will it be achieved—there are important detailed choices that affect potential bias and statistical power, and implementation considerations that require compromise, for considerations of feasibility and practicality. Through the lens of three large completed CRTs in HIV prevention, we present specific choices made for the overall evaluation plan, together with some of the detailed considerations, compromises and modifications that occurred during trial implementation.
Commonalities in the outcome evaluations of these three exemplary CRT include (1) careful attention to ensuring balance between arms in the evaluation cohort through the use of matched clusters and/or restricted randomization; (2) evaluation in a broadly representative, most affected cohort—not linked to receiving the intervention; and (3) objective endpoints of clear public health importance.
Differences in intervention mechanisms, target effects and choice of data source for research evaluation led to different decisions for defining the cohort for research evaluation, the size of the evaluation cohort and the primary analysis approach, particularly with respect to weighting in the analysis.
In the implementation of each of these CRTs, the overall strategy of the evaluation was decided during the design phase. However, in all cases, unanticipated challenges in implementation, as the intervention and evaluation unfolded over the years of the trial, led to modifications and refinements that were necessary to achieve a high-quality evaluation.
Any CRTs is an ambitious, high resource, intensive effort involving a large group with different research expertise. The outcome evaluation strategy is clearly a critical component of the CRT, and careful attention to the multiple decisions, both big and small, is necessary to ensure a high-quality trial.
Footnotes
Author’s note
Clinicaltrials.gov numbers: NCT01152918, NCT01152918, NCT01900977.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: Research is supported by NIH grant UM1A1068617.