
Abstract
Introduction
Adaptive platform trials (APTs), which are trials that compare multiple treatments under a single protocol, have become popular because their efficiency helps evaluate treatments faster.1,2 APTs gained popularity by rapidly testing numerous treatments during the COVID-19 pandemic, 3 with large APTs such as I-SPY2, 4 REMAP-CAP, 5 GBM AGILE, 6 and RECOVERY 7 recruiting thousands of patients. With this increased use, it is important to evaluate the statistical methods that drive APTs to ensure efficient study designs.
Efficient trials obtain conclusive results while minimizing resources, patients, and time. APTs improve efficiency by making decisions during the trial through interim analyses. Decision-making methods used at interim analyses are generally standard across APTs. Research on decision-making in frequentist trials8–10 and Bayesian enrichment trials 11 exists; however, minimal research has examined how these methods affect Bayesian APT performance. This article explores decision-making in Bayesian multi-arm multi-stage (MAMS) trials, which are a subset of APTs that do not add new treatments over time. 12 We evaluate MAMS trials to reduce computational complexity and focus on decision-making methodology.
In Bayesian MAMS trials, decisions about treatment efficacy are typically made by comparing posterior probabilities to prespecified decision thresholds. This determines whether the trial can be stopped for superiority or futility, allowing it to efficiently reach conclusions. 13 When multiple treatments are compared, efficacy is often evaluated by pairwise comparisons to a common control, 14 as in the PRINCIPLE trial and the HEALEY ALS platform trial.15,16 However, multiple treatments can also be compared by calculating the posterior probability that each treatment is best. This probability is then compared with decision thresholds to determine treatment superiority or futility.5,17
In the REMAP-CAP trial, 5 which uses the posterior probability that each treatment is best, the superiority threshold is 0.99 and the futility threshold is 0.01. This means that when the posterior probability that the treatment is best exceeds 0.99, the treatment is declared superior. Conversely, when this posterior probability falls below 0.01, the treatment is declared futile. These superiority and futility thresholds influence trial power and type I error. However, no research has focused on identifying optimal thresholds. In addition, while the posterior probability that each treatment is best is intuitive, 18 it has been criticized for ignoring available information about the treatment effect.19,20
This article focuses on two components of decision-making in Bayesian MAMS trials that directly compare multiple treatments: decision thresholds and treatment comparison methods. We first introduce an optimization approach using the Nelder–Mead algorithm to determine the decision thresholds that maximize the power of the trial while controlling family-wise type 1 error rate (FWER). We then identify three alternative treatment comparison methods, which are compared with the posterior probability that each treatment is best. Bayesian MAMS trials are simulated to evaluate the performance of each comparison method using FWER, power, and expected sample size per arm. Simulation scenarios vary by treatment effect size and number of arms. A key result is that the optimal decision thresholds differ from those currently used in Bayesian MAMS trials. We find that the thresholds used in practice are often overly conservative and could be adjusted to increase power while maintaining control of the FWER.
Decision-making is central to the structure and efficiency of Bayesian MAMS trials. Thus, understanding how these methods influence trial characteristics is essential. This study provides the first comprehensive look at how decision thresholds and treatment comparison methods can increase trial efficiency. An efficient trial will be cheaper with reduced patient recruitment, allowing researchers to allot more resources to new research questions.
Methods
A key advantage of APTs and MAMS trials is that they evaluate multiple treatments in a single trial.
21
Consider a MAMS trial evaluating
In the first approach, each treatment is compared with a control (or standard of care), with
The second approach to decision-making in Bayesian MAMS trials is to compute the posterior probability that a treatment is best (

where we define a higher summary measure to be better. This can be interpreted as the probability that, if all
Trial design
This MAMS design is clarified in Figure 1. Patients are randomized into one of
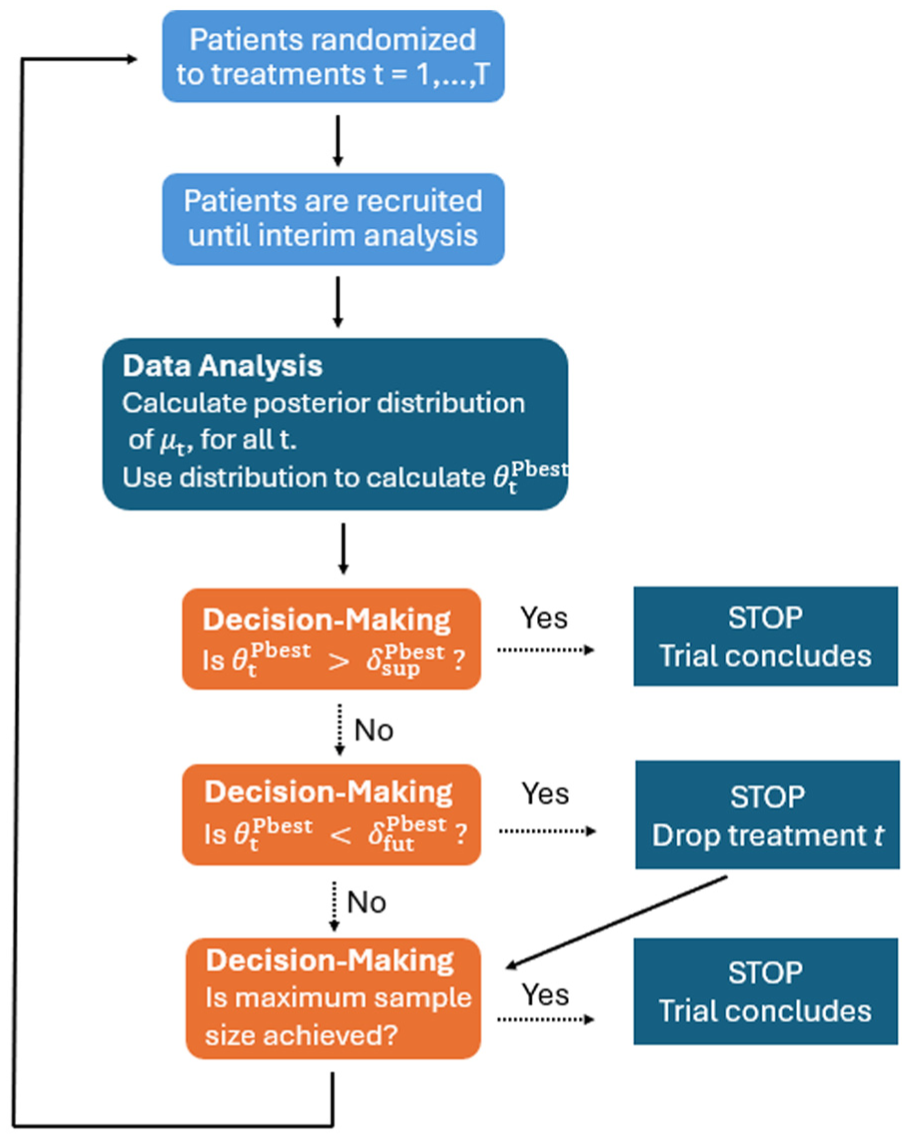
A flowchart of a multi-arm multi-stage trial that compares multiple treatments using decision thresholds and
Trial operating characteristics summarize the statistical properties of a trial design. In general, three operating characteristics are critical to MAMS trial efficiency: power, FWER, and expected sample size per arm. Power is the ability to detect that the optimal treatment is truly optimal at the end of the trial, which we aim to maximize to improve the detection of real effects. FWER is the probability of declaring any treatment superior when it is not. The expected sample size per arm is the average sample size in each treatment arm in a MAMS trial. The goal in trial design is to maximize power, minimize expected sample size per arm, and restrict FWER below a threshold, usually 5%.
Formally, this article uses FWER in the weak sense,
26
defined as the probability of detecting at least one superior treatment effect, given that the prior for

where
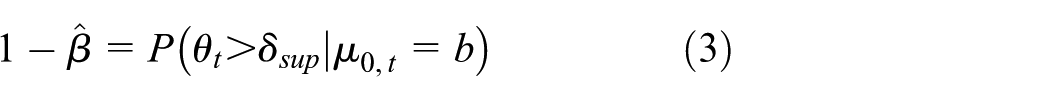
where
We also define the probability of correct dropping as the probability of correctly dropping the futile treatment, given that treatment is assigned a prior centred around a lower value
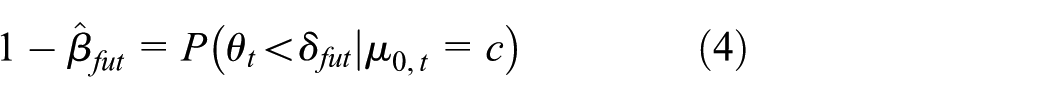
where
Finally, the expected sample size per arm is estimated as the average number of patients enrolled in the trial at the time the trial is stopped, divided by the initial number of treatment arms
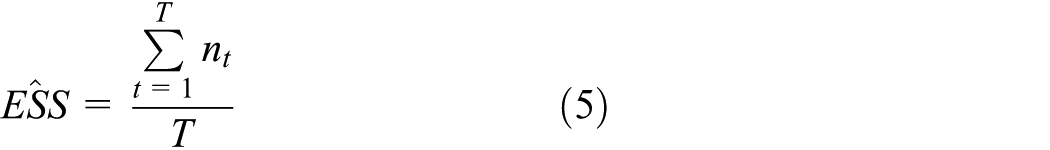
where
Decision thresholds
The first aspect of decision-making in Bayesian MAMS trials that we explore is decision thresholds for declaring superiority or futility, that is,
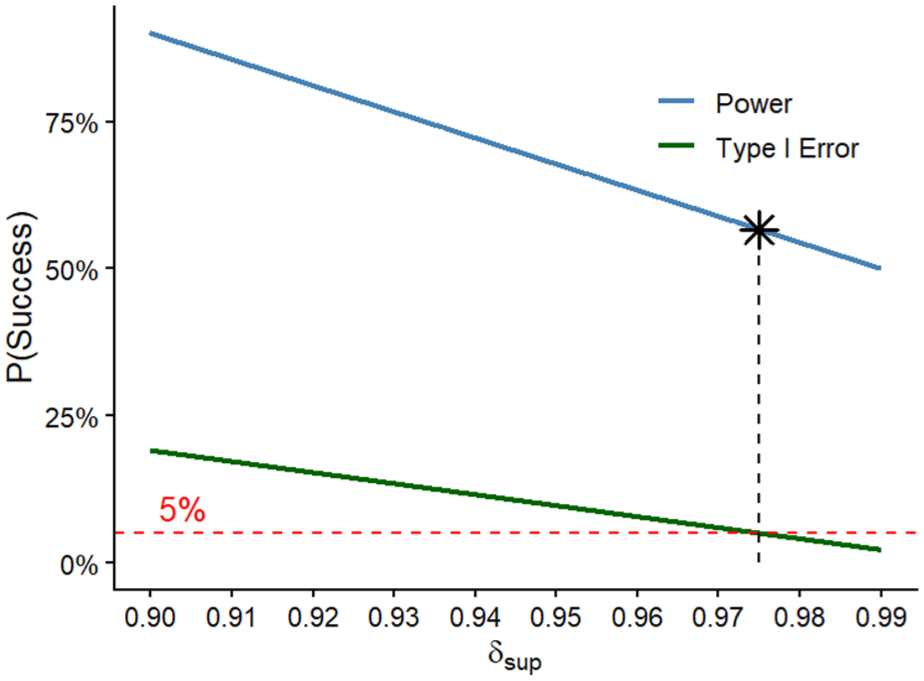
An illustration of our proposed optimization approach with one threshold. As the superiority threshold increases, the power of the trial and the family-wise error rate (FWER) decrease because it becomes more challenging to declare a successful treatment. The black star represents the superiority threshold that results in the highest possible power when the FWER reaches 5%. This is the superiority threshold found through optimization.
However, we aim to optimize two decision thresholds,
Treatment comparison approaches
The second aspect of decision-making in Bayesian MAMS trials that we explore is the treatment comparison approach. As stated above,
Surface Under the Cumulative Ranking Curve
The surface under the cumulative ranking curve (SUCRA) quantifies the average rank of
To calculate the SUCRA,
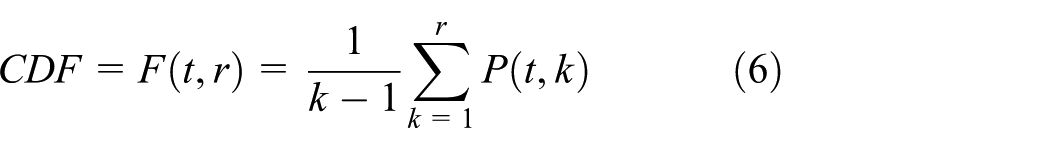
The CDF represents the probability that
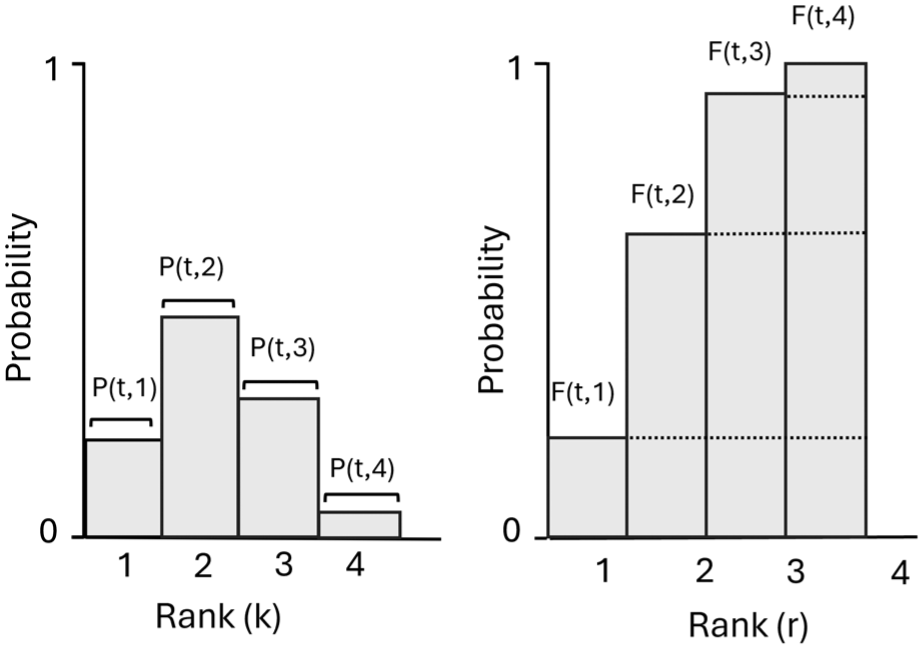
Illustration of ranking distributions used to compute the surface under the cumulative ranking curve. Left: probability ranking distribution for treatment
Once
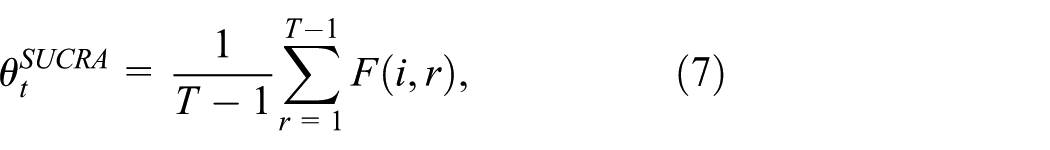
which is the mean of the cumulative ranking probabilities. When used in a MAMS trial for decision-making, we compare
Mean posterior rank
In network meta-analysis, the mean posterior rank is another summary of the ranking distribution that incorporates all possible ranks. The mean posterior rank simply averages the ranks for each treatment effect
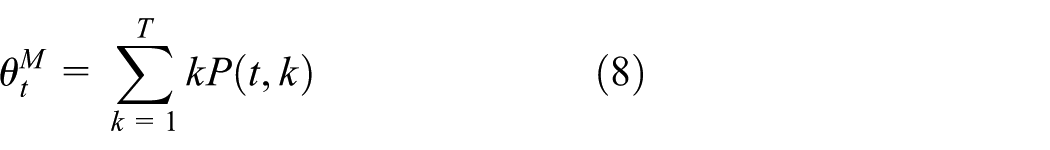
where
Pairwise comparison
Finally, clinical trials often compare treatments by assessing how much they improve outcomes, for example, by using the minimal clinically important difference.
31
Motivated by this, we developed a pairwise method that compares interventions using the magnitude of difference between treatment effects, a concept that the network meta-analysis ranking methods do not consider. This method begins by computing the posterior probability that treatment
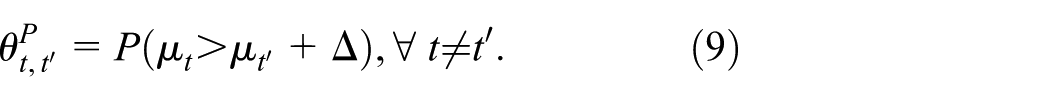
These probabilities can be organized in a

where the
For futility, each entry is compared with a futility threshold,
Simulation study
To investigate the combined impact of optimized decision thresholds and treatment comparison methods on the efficiency of Bayesian MAMS trials, we perform a simulation study. We simulate MAMS trials to compare the performance of
We use a conjugate normal distribution to simulate data from a potential MAMS trial.

where
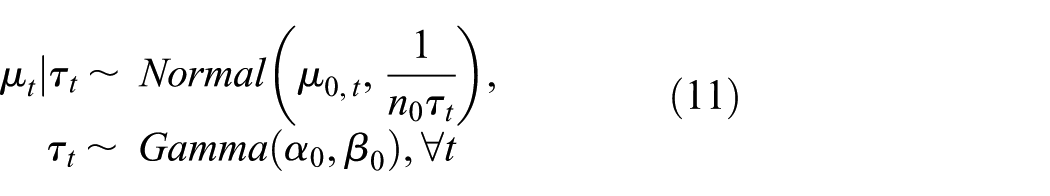
where
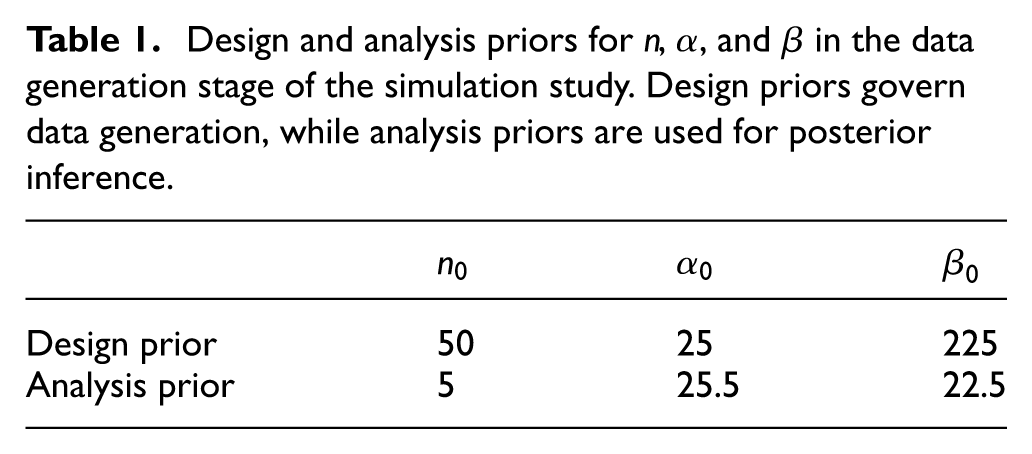
Table 1 shows the priors used in this simulation study, where
Design and analysis priors for
The simulation study consists of three scenarios:
1.
To estimate FWER, all treatments are assumed to have the same prior mean,
2.
To estimate power,
3.
To evaluate the probability of correct stopping,
Once patient data are generated, the posterior distributions for
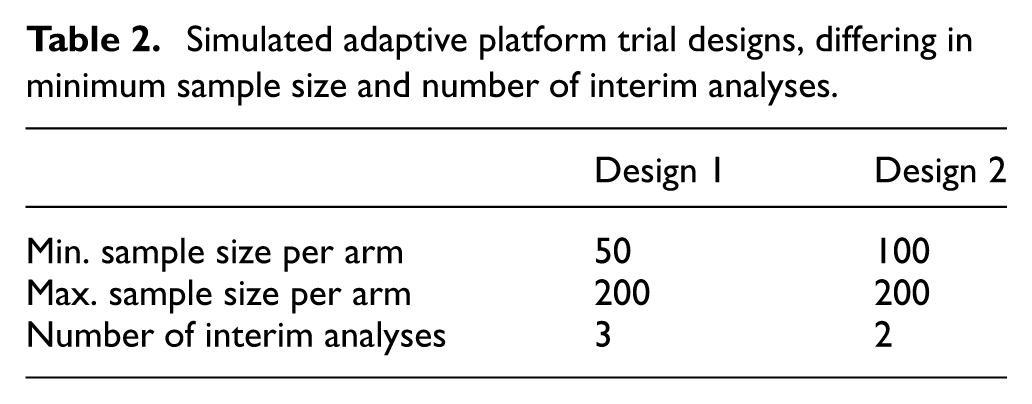
Two trial designs (Table 2) are simulated to test the impact of differing numbers of interim analyses. In Design 1, interim analyses occur at 50, 100, and 150 patients per arm. In Design 2, interim analyses occur at 100 and 150 patients per arm. Both designs have a maximum sample size of 200 patients per arm. At each interim analysis, superiority or futility is assessed. If no treatment is deemed superior, the trial continues to the next interim analysis. The trial concludes superiority if (1) a superior treatment is identified or (2) all but one treatment is declared futile. If the maximum sample size is reached, the trial is declared inconclusive. We run 10,000 Monte Carlo simulations per scenario, which limits simulation error to below 0.01.
Simulated adaptive platform trial designs, differing in minimum sample size and number of interim analyses.
Results
Decision thresholds
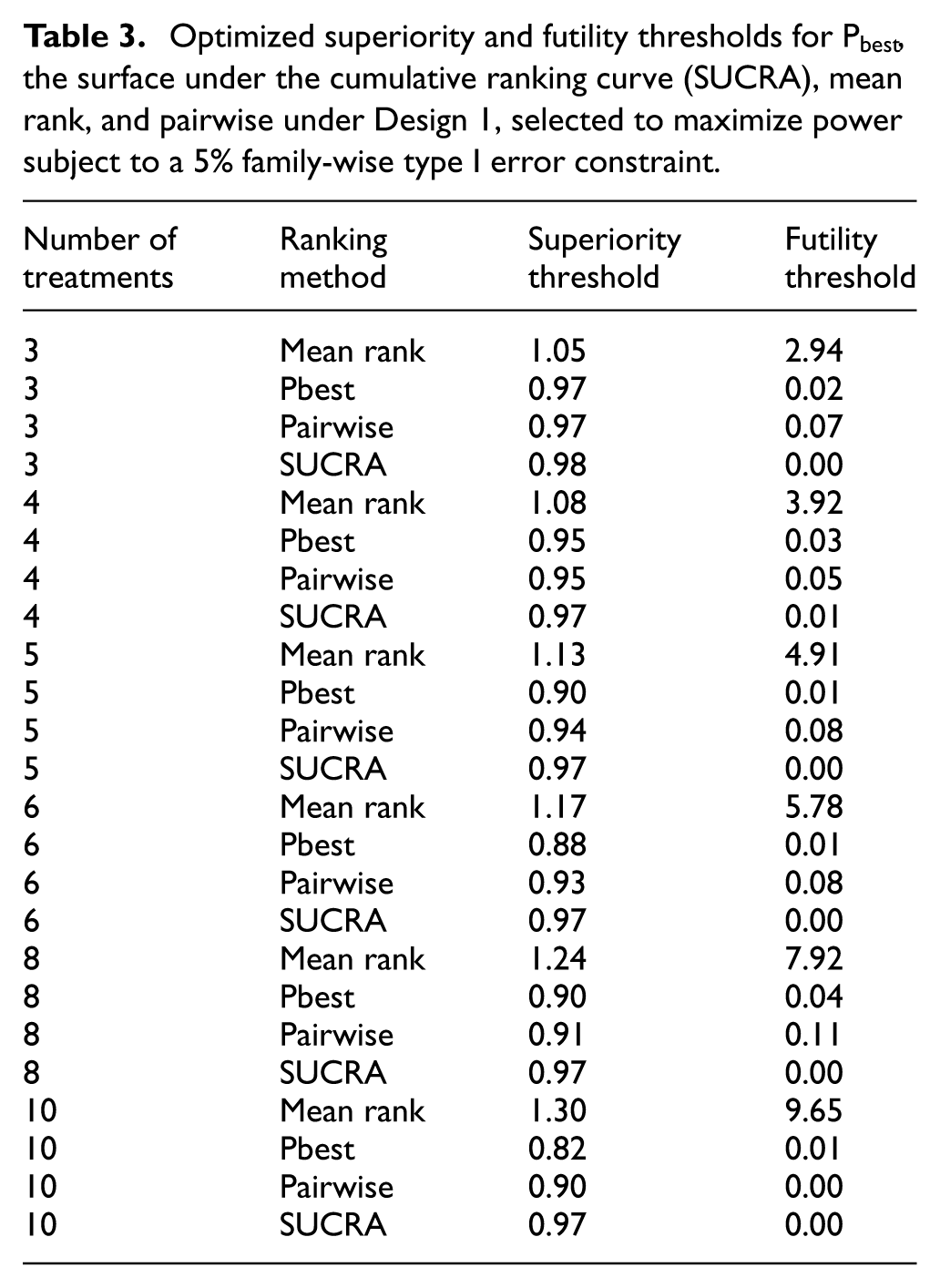
Table 3 lists the superiority and futility thresholds for each simulation scenario in Design 1. Thresholds in Design 1 are slightly higher than in Design 2, reflecting the need to control the FWER given the greater number of interim analyses. Design 2 results are in the Supplemental Material.
Optimized superiority and futility thresholds for
For
Treatment comparison methods
Figure 4 illustrates the power across superiority scenarios. All methods achieve roughly 71% power, which decreases as the number of treatments rise. Nonlinearities in the power reflect imprecision in the optimization for the decision thresholds rather than simulation error.
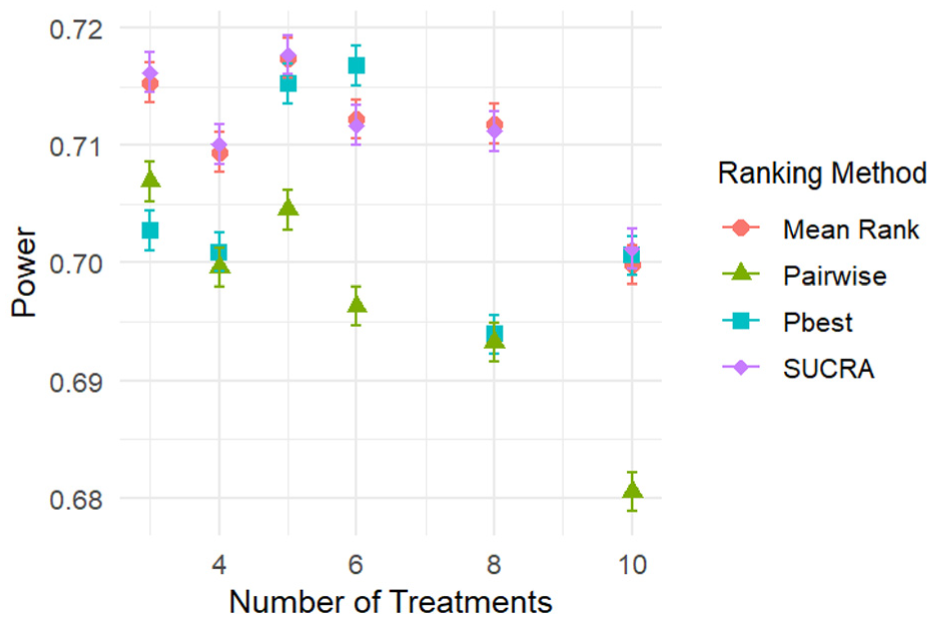
Power across superiority scenarios for Design 1 as a function of the number of treatments.
Figure 5 illustrates the expected sample size per arm in the superiority scenarios. As the number of treatments increases, the expected sample size per arm drops for
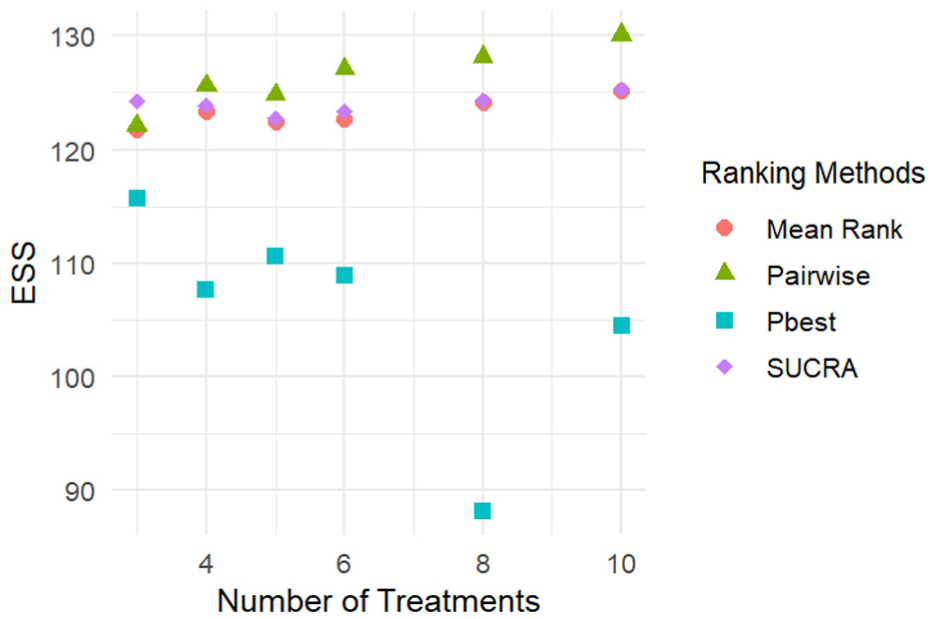
Expected sample size per arm under superiority scenarios for Design 1.
Figure 6 illustrates the probability of correct dropping in the futility scenarios. The error bars are not displayed due to the small error and the large y-axis range.
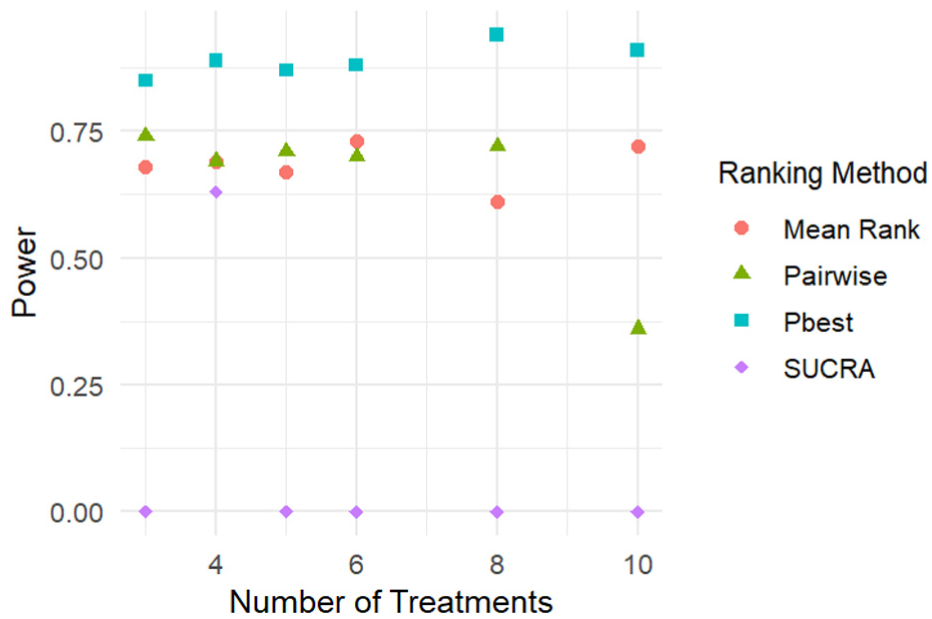
Power to correctly drop futile treatments under Design 1.
Figure 7 shows the expected sample size per arm in futility scenarios, mirroring trends found in the superiority scenario. Minimal differences between Designs 1 and 2 indicate that the number of interim analyses has little effect on the probability of correct dropping and expected sample size per arm, once thresholds have been optimized.
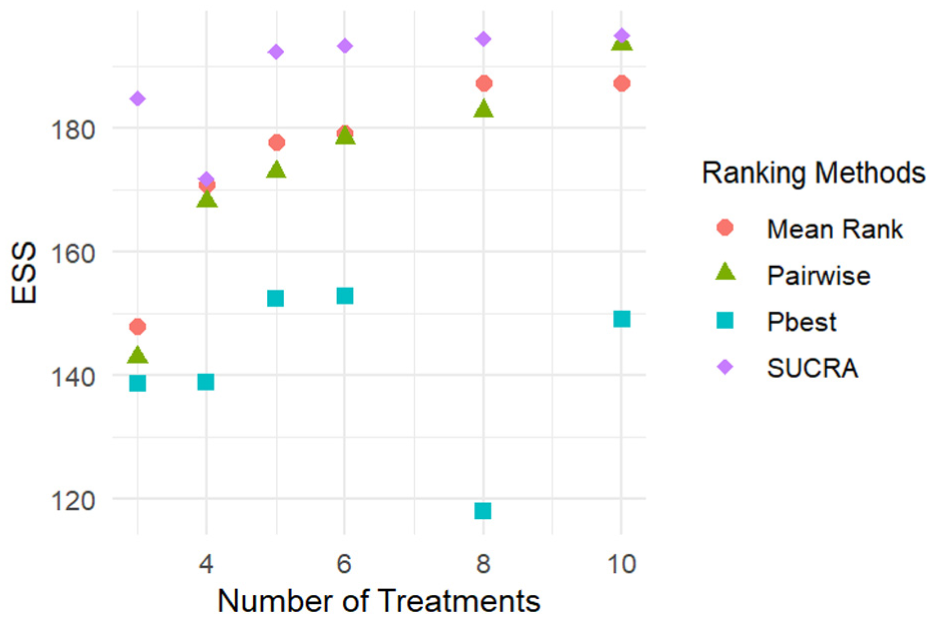
Expected sample size per arm under futility scenarios for Design 1.
Discussion
Bayesian MAMS trials offer flexible and efficient designs through efficient decision-making and comparing multiple treatments in a single trial. MAMS trials incorporate superiority and futility thresholds to guide early stopping, which are typically chosen to control FWER.
25
To our knowledge, no prior work has examined how decision thresholds should be determined, despite their central role in trial decision-making. In addition, the common method to compare multiple treatments in a Bayesian MAMS trial is
This study explores four treatment comparison methods using optimized decision thresholds.
In addition, we observe that the optimal superiority threshold for
In conclusion, we make the following recommendations:
Optimization should be used to determine decision thresholds. This is a simple and effective method to increase the power of the trial while controlling the FWER. We use the Nelder–Mead algorithm, which optimizes to a local maximum, meaning that we may not have obtained the global maximum every time. Future research should explore alternative optimization algorithms and objective functions, such as optimizing expected sample size per arm rather than power.
If decision thresholds are optimized, the SUCRA may provide a better alternative to
These recommendations may be specific to our simulation study. Thus, future research should extend this study to full APTs to improve the generalizability of the results. We also simulated the simplest setting where one treatment was effective. Future work could examine how decision-making methods capture disjunctive and conjunctive power,36,37 when multiple treatments are effective.
Supplemental Material
sj-pdf-1-ctj-10.1177_17407745261453566 – Supplemental material for A statistical evaluation of decision-making methods and the efficiency of Bayesian multi-arm multi-stage trials
Supplemental material, sj-pdf-1-ctj-10.1177_17407745261453566 for A statistical evaluation of decision-making methods and the efficiency of Bayesian multi-arm multi-stage trials by Abigail McGrory, Haolun Shi and Anna Heath in Clinical Trials
Supplemental Material
sj-png-2-ctj-10.1177_17407745261453566 – Supplemental material for A statistical evaluation of decision-making methods and the efficiency of Bayesian multi-arm multi-stage trials
Supplemental material, sj-png-2-ctj-10.1177_17407745261453566 for A statistical evaluation of decision-making methods and the efficiency of Bayesian multi-arm multi-stage trials by Abigail McGrory, Haolun Shi and Anna Heath in Clinical Trials
Supplemental Material
sj-png-3-ctj-10.1177_17407745261453566 – Supplemental material for A statistical evaluation of decision-making methods and the efficiency of Bayesian multi-arm multi-stage trials
Supplemental material, sj-png-3-ctj-10.1177_17407745261453566 for A statistical evaluation of decision-making methods and the efficiency of Bayesian multi-arm multi-stage trials by Abigail McGrory, Haolun Shi and Anna Heath in Clinical Trials
Footnotes
Acknowledgements
The authors would like to acknowledge Michael Escobar for his guidance and support throughout the development of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Anna Heath was funded by a Canada Research Chair in Statistical Trial Design and the Natural Sciences and Engineering Research Council of Canada (Award Number RGPIN-2021-03366). Abigail McGrory was funded by CAN-TAP-TALENT (CIHR Grant #184898).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.