
Abstract
Over the past two decades, research about the role of oxytocin (OT) in human behavior has grown exponentially. However, a unified theory of OT effects has yet to be developed. Relatedly, growing concerns about the robustness of conclusions drawn in the field have been raised. The current article contributes to this debate by reporting on and discussing key conclusions from a systematic review of published studies addressing the interactive effects of intranasal OT (IN-OT) administration on psychosocial outcomes in a healthy population. The review indicates that (a) tested interactive IN-OT effects were highly heterogeneous; (b) for most published interactions, no replication was attempted; (c) when attempted, replications were largely unsuccessful; (d) significance was unrelated to sample size; (e) statistical power was critically low and unrelated to the rate of significant results; and (f) research practices were characteristic of an exploratory approach. This concerning state of affairs makes it virtually impossible to tease apart true from false interactive IN-OT effects. We provide constructive directions on the basis of this observation and positive predictive value simulations for future research that should help extract true effects from noise and move the IN-OT field forward.
Over the past two decades or so, a growing number of researchers have adopted a mechanistic perspective on human behavior and looked at the endocrinological roots of social behavior in humans. Prominent in this research stream is evidence that has accumulated suggesting that oxytocin (OT) may play a critical role in humans’ emotional and social lives. However, both the reliability of intranasal OT (IN-OT) effects on psychological outcomes (Walum, Waldman, & Young, 2016) and the very physiological plausibility of such effects (Leng & Ludwig, 2016) have been questioned. The aim of the current article is to foster advances in OT research by reporting on and discussing key conclusions of a systematic review of published IN-OT studies on psychosocial outcomes. To introduce the research questions examined in this article and their relevance for the field, we first provide the reader with a brief state of the art. We then report on and discuss the main outcomes of the review, essentially focused on interactive effects of IN-OT. Finally, we suggest constructive avenues for strengthening the reliability of research published in the field.
OT as a Social Hormone
A large number of empirical studies have suggested that IN-OT administration promotes a wide range of prosocial behavioral tendencies, such as trusting strangers (Kosfeld, Heinrichs, Zak, Fischbacher, & Fehr, 2005), boosting perceived trustworthiness and attractiveness (Theodoridou, Rowe, Penton-Voak, & Rogers, 2009), and promoting self-confidence (Cardoso, Ellenbogen, & Linnen, 2012). IN-OT is also hypothesized to foster relationship maintenance and relational efficiency by improving emotion recognition (Domes, Heinrichs, Michel, Berger, & Herpertz, 2007), enhancing the recognition of familiar faces (Rimmele, Hediger, Heinrichs, & Klaver, 2009), improving constructive communication in couples (Ditzen et al., 2009), and facilitating parent–infant attachment (Naber, van IJzendoorn, Deschamps, van Engeland, & Bakermans-Kranenburg, 2010). These findings helped build OT’s reputation as the “prosocial hormone.” Several meta-analyses have examined the aggregated effects of OT on emotion recognition (Leppanen et al., 2017; Shahrestani et al., 2013) and threat processing (Leppanen et al., 2018) in healthy subjects, as well as social cognition in patients suffering from neurodevelopmental disorders (Keech, Crowe, & Hocking, 2018) and schizophrenia (Bürkner, Williams, Simmons, & Woolley, 2017). These meta-analyses have reported small-to-medium effect sizes.
However, several findings have tempered this positive view of IN-OT by suggesting that OT may also facilitate antisocial behaviors, such as defensive aggression (De Dreu et al., 2010), ethnocentrism (De Dreu, Greer, Van Kleef, Shalvi, & Handgraaf, 2011), and gloating (Shamay-Tsoory et al., 2009). This apparent contradiction was accommodated by new theories about the role of OT stating that, rather than promoting affiliation or prosociality per se, as originally postulated (Insel, 1992), OT may either enhance the salience of social stimuli (Shamay-Tsoory & Abu-Akel, 2016) or facilitate social approach and inhibit social withdrawal (Kemp & Guastella, 2011). As the field grew, a number of findings that could not be accommodated by existing theories emerged (see, e.g., Lane et al., 2015).
Growing Concerns in IN-OT Research
Although research about the role of OT in human behavior has grown exponentially over the past two decades, a unified theory of IN-OT effects has yet to be developed (Bartz, Zaki, Bolger, & Ochsner, 2011). Relatedly, a set of troublesome findings has elicited growing concerns about the robustness of conclusions drawn in the field.
A first set of concerns has to do with the pharmacodynamics of OT. OT research has relied on the pharmacokinetic properties of arginine vasopressin (AVP) administration (Born et al., 2002). The structure of this peptide hormone is structurally similar yet not identical to OT (Meyer-Lindenberg, Domes, Kirsch, & Heinrichs, 2011). Small molecular differences, however, may imply large functional differences. For instance, whereas OT is typically related to prosocial behavior, AVP has primarily been related to social behaviors that are stereotypically related to masculinity (see Heinrichs, von Dawans, & Domes, 2009). Moreover, the efficiency of IN administration on the elevation of OT levels in the cerebrospinal fluid (CSF) has been questioned (Lee et al., 2018). IN administration is typically tested by measuring OT levels on peripheral samples (e.g., blood, urine, saliva) because they are far easier to obtain than more invasive CSF samples. Some researchers have argued, however, that peripheral levels of OT do not necessarily reflect cerebral levels (Amico, Challinor, & Cameron, 1990; Kagerbauer et al., 2013), and some have argued that OT might not even cross the blood-brain barrier to a substantial degree (Landgraf & Neumann, 2004). As a result, IN-OT studies might lack a signal-to-noise ratio sufficient to observe reliable effects.
Carson and colleagues (2015) observed that blood and CSF levels of OT are positively related. However, Leng and Ludwig (2016) estimated that 0.005% of the IN-OT solution, at most, makes its way to the CSF. Huge amounts of IN-OT may therefore be required to induce detectable behavioral effects (see, e.g., Kirkpatrick, Francis, Lee, De Wit, & Jacob, 2014). Of further concern is that Born et al. (2002) showed that it takes not less than 60 min for 40 IU of AVP to reach significant concentrations in the CSF. The median time window between IN-OT administration and the first task is 45 min in the studies that are included in this review. It is therefore unclear whether time windows generally used in IN-OT research are adequate, especially because one study (Striepens et al., 2013) showed that IN-OT yields elevated CSF OT levels 75 min (not 45 min) after administration. Recent research suggests that IN-OT effects are most effective from 45 to 70 min after the administration of 24 IUs (Spengler et al., 2017). More research that advances our understanding of the pharmacokinetics of OT is definitely needed.
A second major concern relates to the statistical power of OT studies. Walum et al. (2016) estimated that the average statistical power of human IN-OT studies is only 16% and concluded on the basis of this finding that many published IN-OT effects might actually reflect Type I errors. Low power may have also hindered the detection of true effects and, in some instances, contributed to replication failures. Several attempts to replicate seminal results of the IN-OT literature (e.g., Domes et al., 2007; Kosfeld et al., 2005) have failed, suggesting that the effects may not be as robust as one might have thought (Lane et al., 2015; Nave, Camerer, & McCullough, 2015; Radke & de Bruijn, 2012; Tabak et al., 2019). Furthermore, when underpowered studies detect true effects, effect sizes are typically overestimated. As a result, aggregated (small-to-medium) effect sizes that are reported in meta-analyses are likely to be overestimated as well (Pereira & Ioannidis, 2011).
The abovementioned issues may account for inconsistencies in IN-OT research. Another way to account for them is to consider that the effects of OT may be constrained by features of situations and/or individuals (Bartz et al., 2011). This interactionist approach may explain why IN-OT main effects are not systematically observed (see, e.g., in emotion-recognition studies: Bartz et al., 2010; Domes et al., 2007; Guastella et al., 2010; Hurlemann et al., 2010). Bartz et al. (2011) noted that a majority of IN-OT studies reported significant moderations of IN-OT effects, consistent with this idea. Accordingly, they recommended a shift from asking “Does OT improve social cognition?” to asking “Under what circumstances does OT improve social cognition?” This approach suggests that interactive rather than main effects of IN-OT administration are the effects of interest for behavioral researchers.
The Current Review
We examined interactive effects of IN-OT on psychosocial outcomes according to recommendations from Bartz et al. (2011). Our objectives were to (a) gather knowledge about the diversity of tested moderations, (b) provide information on the general pattern of reported results and interpret them in light of different theoretical scenarios, and (c) examine current research practices in the field. Our overarching goal for this analysis is to provide constructive recommendations for moving research on IN-OT forward.
Method
Literature search
The current review was conducted according to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines (Moher, 2009). Studies were sourced from PsychInfo 1 and PubMed. 2 We collected articles in May 2018, and our database includes studies published between January 2003 and April 2018.
Inclusion criteria
In this review, we focus on the effect of IN administration of OT on psychosocial outcomes measured on healthy adults, which represents the most frequently addressed circumstance (see Tabak et al., 2019). Findings and conclusions should therefore not be overgeneralized to other categories of outcomes or to outcomes observed on clinical populations (a point we return to later).
We included studies that met all of the following criteria (see Fig. 1):
The study consisted of an experimental investiga-tion.
The study involved a placebo-controlled IN-OT administration.
The study was conducted on healthy volun-teers.
The study focused on psychosocial (affective, behavioral, or cognitive) variables measured externally (i.e., not via functional MRI, electroencephalography, electromyography, or electro-cardiography).
The study was written in English

Flowchart illustrating the literature search process in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines.
We excluded studies on the basis of the following criteria:
The study was a theoretical contribution (e.g., reviews), meta-analysis, case study, qualitative study, or animal study.
The study involved intravenous administration of OT or peripheral (plasmatic/salivary) OT assessments.
The study was conducted on a clinical sample (e.g., individuals with schizophrenia).
The study focused on parturition/breastfeeding (for a review, see Wei et al., 2009), physical (e.g., pain), or neuro/physiological variables.
The study was published before 2003
Coding protocol
For each article, we coded the following types of information: (a) study identifiers (authors, year of publication, journal, keywords); (b) study characteristics (quantity of the OT dose in international units, OT solution brand, time interval between OT administration and data collection, total sample size, gender breakdown of the sample); and (c) transparent research practices (a priori power analysis, preregistration, disclosure of full report, open data). Research practices were probed by searching for relevant words (e.g., “preregistration”) in the search function of the PDF reader application. In addition, a visual-inspection search was realized on the abstract, supplemental materials, and methods.
We coded all reported interactions that included the IN-OT factor. More specifically, for each interaction, we coded the dependent variable assessed, the interaction including the IN-OT administration and moderator(s), the interaction type (the number of factors present in the interaction, the quantity of within-subjects factors present in the interaction), and the significance of the interaction.
Reliability check
To assess coding reliability, a randomly selected subset of 20% of the studies was coded by. This allows sufficient precision to estimate a Cohen’s κ coefficient as small as .67 at the effect level (Gwet, 2014). Selected articles were identified by the author names and publication year. The coding reliability was estimated according to the percentage of agreement between coders and Cohen’s κ coefficient, which are well suited to assess the accuracy of categorical coding while controlling for chance agreement.
Study-level variables
First, we assessed the coding reliability of the study-level variables (i.e., journal, keywords, OT dose, OT manufacturer, interval, sample size, gender, presence of power analysis, preregistration, disclosure, and data availability). There were 24 matching cases for which study-level agreement was computed. Interrater agreement was good overall (i.e., the median value of Cohen’s κ was 1). The largest number of disagreements (four cases; 83% agreement) was found for sample size; the disagreement reflected the coding of a full sample versus a retained sample (after exclusions). The coding protocol was clarified, and the retained sample size was coded for all studies. Agreement was perfect for six of 11 variables; a maximum of one or two disagreements were found for the remaining four variables (agreement between 90% and 96%). Cases of disagreement were resolved by discussion.
Effect-level variables
The effect sizes were aligned via an identifier variable that was jointly assigned by both coders. Agreement was very good overall (98%–99%; median κ = .95) except that (a) the number of within-persons factors had a substantial proportion of disagreements and (b) there was a substantial proportion of cases in which a given interaction was included by the second coder but not the first (main) coder. These exceptions were due to systematic differences in the strategies used to identify statistical tests of interactions (i.e., one coder used a more conservative approach and coded an interaction only when a test statistic was reported; the other coder inferred that an interaction was tested when results were reported in the text). The main coding relied on the more conservative approach, integrating only the reported test statistics. Therefore, our results represent a lower-bound estimate of the number of statistical tests that were conducted by researchers.
Analyses and Results
In the following sections, we estimate and report (a) the heterogeneity of the tested interactive effects, (b) the replication attempts and successes, (c) the relation between the sample size and the rate of significant findings, (d) the statistical power, and (e) the adherence to open-science practices. We then discuss three extreme scenarios of how the observed results pattern affected the statistical power, the proportion of true effects, and the proportion of false positives as an interpretative background, and we turn to simulations to provide more nuanced interpretations as well as informed recommendations.
A large number of interactive IN-OT effects have been tested
A first analysis reports the number and rate of significant interactions for IN-OT interactions whose statistical outcomes were reported in the reviewed studies. The 117 published articles included in the current review reported 127 studies that tested a total of 829 interactive IN-OT effects (e.g., IN-OT × Gender). This list of interactive IN-OT effects does not contain interactions between IN-OT and time (i.e., before vs. after IN-OT administration). These interactions conceptually reflect main IN-OT effects controlled for baseline and will be addressed separately. Hence, on average, an IN-OT study reported 6.5 interactive effects involving IN-OT. An average of 26% of the interactive effects were reported as significant, and 91% of the studies reported at least one significant interactive effect involving IN-OT. These proportions are difficult to interpret in and by themselves or to relate to other domains of research. We discuss extreme and more nuanced interpretative scenarios later.
Tested interactions are highly heterogeneous, and most interactions have been tested only once
A second analysis examined the heterogeneity and rate of conceptual replication for the tested interactive effects of IN-OT. More specifically, we were interested in the diversity of outcomes studied (i.e., the dependent variable coded at a conceptual level), as well as the combination of variables included in a given interaction effect (i.e., IN-OT × Gender, IN-OT × Gender × Age). Of the 127 studies addressed in this review, we identified a large heterogeneity of interactive effects involving the IN-OT factor and a given conceptual dependent variable. 3 A total of 350 different interactions were identified (e.g., IN-OT × Gender), and 95 distinct conceptual variables were identified (e.g., altruism, lie detection, empathy, threat perception, emotion recognition). The most frequent categories of response involved were subjective ratings and accuracy scores as well as response times collected in speeded tasks. A total of 467 combinations was tested in the published literature, less than half of which (n = 210) were conceptually tested one or more times. Most interactions were tested only once (i.e., no replication attempts; n = 257) or twice (n = 151); only 59 cases (13%) were tested more than twice (i.e., two or more replications). The tested IN-OT interactions are therefore characterized by a very large heterogeneity and a modest rate of replication attempts (see Fig. 2a).
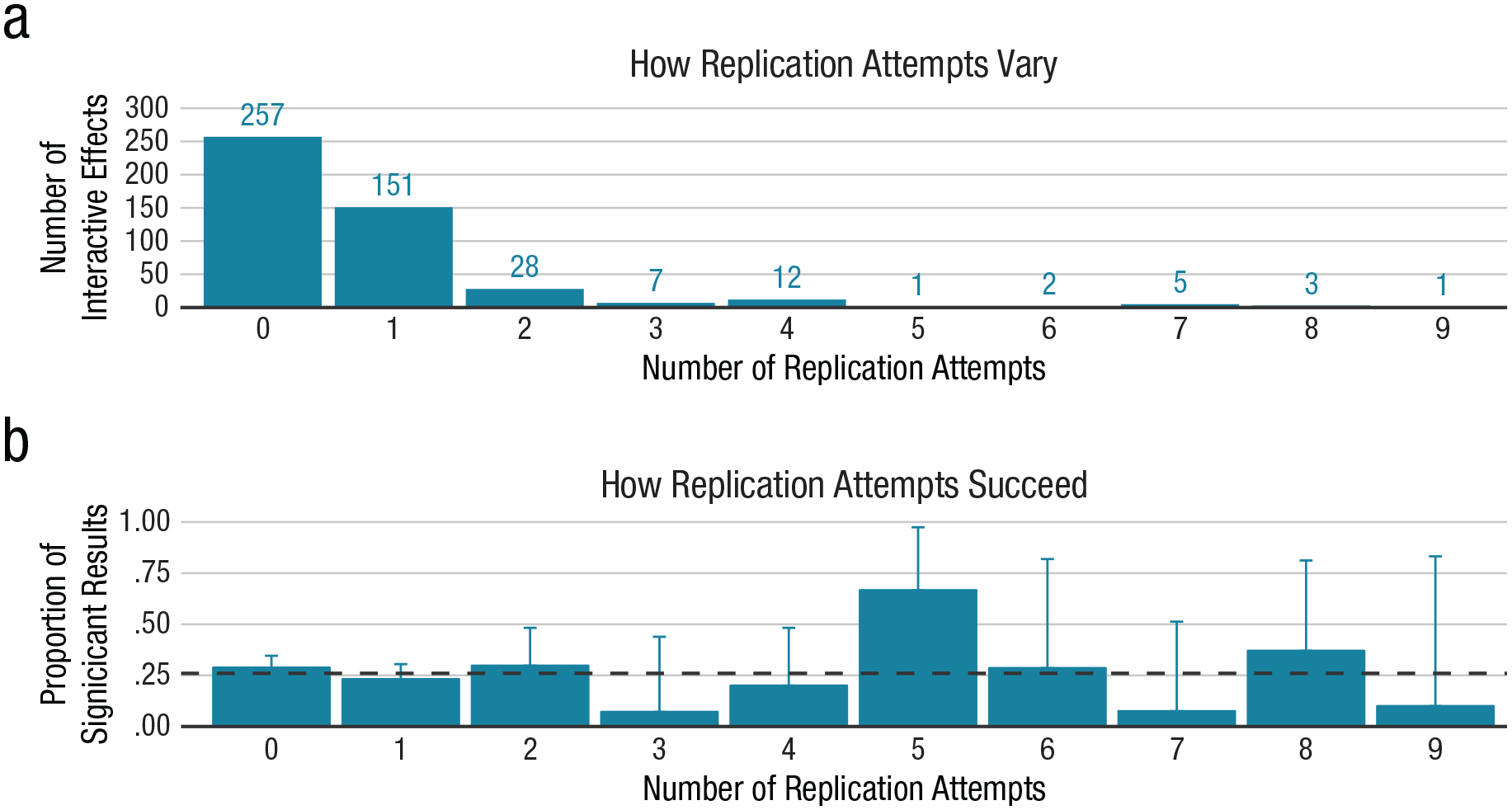
Analyses of replication attempts: (a) frequency of replication attempts in the sample of 467 tests of interactions of intranasal oxytocin with potential moderators and (b) proportion of the tests with significant results as a function of number of replication attempts. The error bars in (b) represent the upper bound of the 95% confidence interval for the binomial proportion. The dashed line in (b) represents the average proportion of significant results.
For repeatedly tested interactions, replication attempts are largely unsuccessful
Next, we examined the success of conceptual replications in interactive IN-OT effects. As can be seen in Figure 2b, IN-OT research is characterized by a low rate of successful conceptual replications. It should be noted that Figure 2b represents an optimistic estimate of successful replication because (a) significant effects are reported here independent of their direction (i.e., two significant effects may reflect effects of opposite direction) and (b) the largest value concerns data coming from a single study that replicated the same interaction six times across six conceptually related dependent variables.
The rate of significant results does not increase with the sample size
As a further test of the overall reliability of published IN-OT interactive effects, we examined the relation between sample sizes and the proportion of significant results. It is possible that IN-OT effects are true but remain undetected (false negatives) because of a lack of statistical power. If this is the case, studies with larger samples should be associated with a more frequent detection of true effects. That is, because larger sample sizes are associated with enhanced statistical power, the sample size and rate of significant results should be positively associated if most nonsignificant effects are false negatives rather than true negatives.
As can be seen in Figure 3, the relation between sample-size deciles and the proportion of significant results is flat. The fact that, on average, significant effects are not more frequently observed with larger sample sizes could mean that (a) weaker effects were examined in studies with larger sample sizes (which seems unlikely considering the general lack of power analyses; see below), (b) reported interactive effects generally do not reflect true effects, or (c) the statistical power of IN-OT studies should be considerably larger than it currently is to reliably detect true interactive effects.
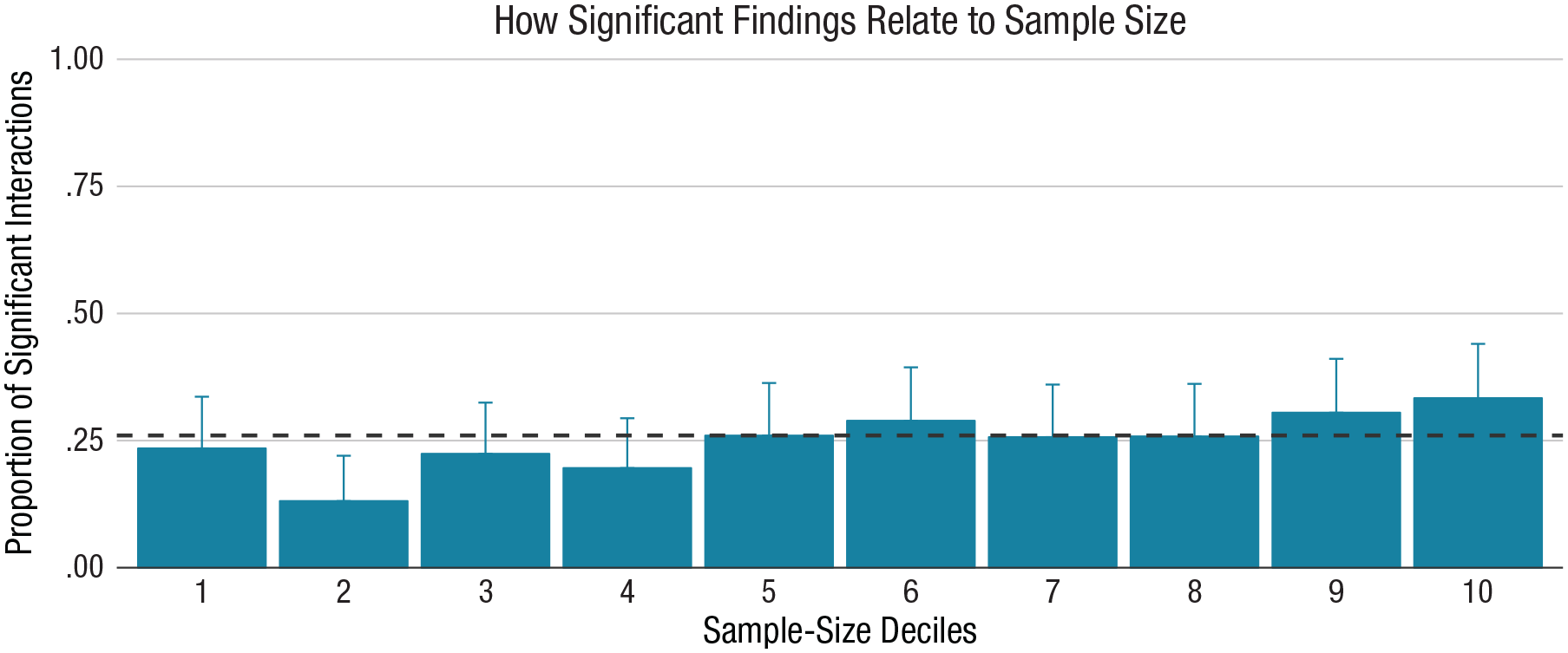
Proportion of significant interactions as a function of deciles of sample size. Approximately 83 interactive effects are given, separately by decile. The error bars represent the 95% confidence interval for the binomial proportion. The dashed line represents the average proportion of significant results.
Statistical power is low
Although the current review is concerned primarily with interactive IN-OT effects, we based our considerations about statistical power on the assumption that the study goal was to investigate main effects to obtain an estimate of statistical power (albeit perhaps an optimistic one). The median sample size was 57 participants, a relatively small sample size that corroborates the concerns raised by Walum et al. (2016) regarding the low statistical power for detecting main IN-OT effects. As displayed in Figure 4b, the sample sizes are generally too small to enable reliable detection of the main IN-OT effect size—estimated by Walum et al. (2016) to be d = 0.28. And this is true both when considering the IN-OT main effect in between-subjects and within-subjects designs. To detect an effect size (d) of 0.28 in a between-subjects design with a statistical power of .8 and a two-tailed Type I error of .05, the minimal sample size needed is 404. Figure 4c (blue bars) illustrates the statistical power for detecting an effect of 0.28 with α = .05 and the distribution of sample sizes, assuming a between-subjects design. As can be seen, none of the studies analyzed in the current review reached sufficient statistical power. Assuming a within-subjects design, one would require 103 pairs of observations to achieve such statistical power (assuming d = dz = 0.28; i.e., a between-measures correlation of r = .5). Even if the current studies had all used within-subjects designs with the given sample sizes, only 12% of the studies would be sufficiently powered to detect an effect of 0.28. In line with previous findings, the power to detect an effect of 0.28 with the observed median N of 57 was approximately .18 (between-subjects) or .55 (within-subjects).

Histograms of the frequency of sample sizes, minimum detectable effect sizes, and statistical power of the studies. The green vertical line in (b) indicates the effect size estimated by Walum, Waldman, and Young (2016; i.e., Cohen’s d = 0.28), and the black vertical dashed lines indicate the thresholds of small (left line), medium (middle line), and high (right line) effect sizes. The green vertical line in (c) indicates the threshold of satisfactory statistical power of 80%.
The reported IN-OT studies were not sensitive enough to investigate main or interactive IN-OT effects of small or medium size. On average, they were capable of detecting only medium-to-large effects. For within-subjects studies, the median sample size yields sufficient power (.8; α = .05) to detect an effect size of dz = .38; for a between-subjects study, the power is sufficient for detecting only large effects (d = 0.76).
Main IN-OT effects probed by an IN-OT × Time interaction
IN-OT × Time interactions can be seen as main IN-OT effects controlled for baseline measures. Hence, this interaction test provides a more controlled estimate of main IN-OT effects. We repeated the analyses reported above for the interactive IN-OT effects with this special interactive case. There were 72 IN-OT × Time interactions on 14 different conceptual dependent variables. Only 8% of these interactions were reported as significant. The median sample size was N = 40, meaning that the statistical power to detect a main IN-OT effect of 0.28 was only (1 – β) = .41 assuming a within-subjects design and (1 – β) = .24 assuming a between-subjects design.
Adherence to transparent research practices is uncommon
Finally, we analyzed the reported use of transparent research practices. Our search returned three articles reporting a preregistration of the experimental design and hypotheses (one article reported a registration on the EU Clinical Trial Registry, and two articles reported a registration on clinicaltrials.gov), and no articles contained a disclosure of full reporting. Only 1% of the studies provided public access to the data. Only 10% of the studies reported power analyses. These numbers, possibly underestimating the true state of affairs because of a few identification misses, are consistent with the notion that IN-OT research at this point is largely exploratory, as also suggested by the large set of possible combinations of moderators and conceptual dependent variables and low rate of replication attempts. Finally, only 4% of the articles reported more than one study using IN-OT administration. Hence, single-article replications of one’s own findings are extremely uncommon in IN-OT research (compared with the more common practice of reporting multiple replications in a single article as observed in other fields of research).
How should we interpret these findings?
In sum, we found that (a) effects tested were highly heterogeneous; (b) for a majority of published interactions, no replication was attempted; (c) when attempted, replications were largely unsuccessful; (d) significance was unrelated to sample size; (e) statistical power was critically low (and unrelated to the rate of significant results); and (f) research practices were characteristic of an exploratory approach.
In this section, we first discuss three extreme scenarios for interpreting the key outcomes of this review. As a consequence, none of these scenarios is likely to perfectly depict the current state of affairs. Instead, they offer useful conceptual backgrounds against which interactive IN-OT effects reported in the published literature can be interpreted. We then turn to positive predictive value (PPV) simulations allowing for more nuanced interpretations of the current state of affairs as well as guidance for moving IN-OT research forward. This approach presents the combined benefits of being able to (a) approximate how much we can trust research on interactive effects of OT by quantifying the proportion of significant results that reflect true effects, (b) highlight whether a bias is necessary to reach the pattern of results observed, and (c) quantify the benefits of adhering to open and cumulative research practices.
Three extreme scenarios as an interpretative background
The first scenario specifies that 100% of the tested hypotheses were true and that the average statistical power of the studies was 26% (which reflects the rate of significant results in the current data). According to this first scenario, the average effect size should therefore be 0.35 (with a between-subjects design), which corresponds to a small-to-medium effect size according to Cohen’s (1988) norms. This first extreme stands in contrast to estimates that only 10% of the tested hypotheses in experimental psychology are likely to be true, especially in exploratory studies (Pashler & Harris, 2012). Furthermore, it is inconsistent with the fact that the sample size was not related or was only weakly related to the proportion of significant moderations. As discussed above, one should expect more significant effects with larger sample sizes.
The second scenario specifies that 26% of the tested hypotheses were true and that published studies that tested them were maximally (i.e., 100%) powered for detecting a true effect. According to this second scenario, the average effect size should be 1.15 (using 99.9% power for computation and a between-subjects design), which is considerably larger than Cohen’s large effect norm (d = 0.8). This implausible scenario stands in contrast to the very low proportion of significant results among the relatively few studies that were conceptually replicated.
If we take the observations at face value and ignore possible biases, then IN-OT effect sizes must be either very small (first scenario, assuming low power) or very large (second scenario, assuming low a priori probability). Considering the possibility of publication bias, it is more likely that true effects are small and that mean effect-size estimates as well as the rate of significant findings in the literature were overestimated. In this vein, a third extreme scenario attributes the findings entirely to publication bias and specifies that the 26% significant interactions are false positives. This third scenario is consistent with the fact that almost every article reports at least one significant interaction but that those are rarely replicated when a replication attempt is made (see Franco, Malhotra, & Simonovits, 2014; Simmons, Nelson, & Simonsohn, 2011).
Simulations for more nuanced interpretations and ways forward
In an attempt to outline more realistic scenarios, we calculated the PPV according to the approach used by Ioannidis (2005). The PPV, which is the proportion of significant findings that actually reflect true effects, depends on the α and β levels as well as the rate of true relationships in a field (R) and a bias parameter (u) that subsumes all other influences leading to the publication of a significant finding (e.g., flexibility in data collection, analysis, and reporting). These influences may stem, for instance, from an unbalanced assignment of participants across conditions in between-subjects designs (i.e., unsuccessful randomization, likely to apply to low sample sizes), lack of double blindness, coding errors, and, more generally, all influences that may contribute to increasing the rate of false positives.
Within this approach, the three extreme scenarios we have just discussed can be conceptualized as follows. In the first scenario, it was assumed that statistical power = .26, R = 1, and u = 0 (these assumptions would yield a perfect PPV value of 1 given that there are no false hypotheses). In the second scenario, it was assumed that statistical power (i.e., 1 – β) = 1, R = .26, and u = 0 (this scenario would yield a PPV of 88%, and approximately 30% of results would be statistically significant). Both would suggest high rates of successful replication (inconsistent with observations). More consistent with the observed low rates of replication success, the third scenario of 26% false positives in the absence of true effects (R = 0) can be accommodated in this approach either via α-level inflation (i.e., α = .26 and u = 0) or via the bias parameter (i.e., α = .05 and u = .22); given that there are no true hypotheses, the PPV of the third scenario would be 0 (regardless of statistical power).
Turning to more realistic scenarios, we simulated the PPV for a two-sided independent-samples t test. As a starting point, we relied on the observation that the median sample size was 57, and we set the α level to .05. On the basis of the median sample size, we considered very small, medium, and very large effect sizes (i.e., d = 0.1, 0.5, and 0.9) for computing statistical power (i.e., 1 – β; the resulting power values were .07. .46, and .92). For the probability of true hypotheses, we considered the values 1 in 100 (.01), 1 in 10 (.1), or 1 in 3 (.33). Regarding bias, we considered values between .2 and .8 (see Ioannidis, 2005) as well as a zero-bias baseline.
We also considered the rate of significant results 4 : First, we found that 26% of all reported results were significant. On the other hand, 91% of all articles reported at least one significant result. If we assume that all reported results are equally theoretically relevant, we should consider scenarios more relevant that yield approximately 26% of significant findings. If, on the other hand, one of the reported results is of theoretical interest and the other results are reported for completeness, then we should mainly consider scenarios with 91% of significant results. We will compute both variants, but because typically a single psychological hypothesis is the focus of an investigation, we will focus our discussion on the latter scenario.
In an initial step, we narrowed down the possible scenarios by identifying those scenarios that are consistent with either the 26%-significant-results mark or the 91%-significant-results mark. It turned out that low values of bias (≤ .2) were necessary to approximate the 26% observation, whereas high rates of bias (≥ .8) were required to approximate the 91% observation. Therefore, we discuss these two cases separately, assuming bias levels of .2 and .8, respectively.
Under the above set of assumptions, a high rate of significant results (≥ .8) comes about only with large values of bias (i.e., u = .8). Within these cases, the PPV (i.e., the proportion of significant findings that represent a true effect) ranges from 1% to 55%, depending largely on the a priori proportion of true effects (and to a lesser degree on statistical power):
If 1 in 100 tested hypotheses are true, then approximately 1 in 100 significant findings (1%–1.2%) represents a true effect, regardless of power.
If 1 in 10 tested hypotheses are true, we end up with 10% to 12% of true findings among the significant results (again, power has little effect).
If 1 in 2 tested hypotheses are true, the scenario yields between 50% and 55% of true findings among significant results.
Assuming an a priori proportion of true hypotheses considered typical for psychology (i.e., .1; see Pashler & Harris, 2012), this implies that only approximately 829 (total number of interactive effects) × .26 (overall proportion of significant results) × .12 (most likely PPV) = 26 of the reported significant findings in the IN-OT literature (i.e., only 3% of the tested interactive IN-OT effects) represent true effects. This unsatisfactory state of affairs can and should be improved in future IN-OT research. We now discuss how.
Simulations for concrete guidance
To provide more concrete guidance for increasing the reliability of IN-OT research, we simulated the effects on PPV of increasing power, reducing bias, and conducting replications. These are familiar recommendations (see, e.g., Walum et al., 2016). We quantify here how adherence to these recommendations may increase the reliability of IN-OT research.
The first and most straightforward way to improve the PPV is to reduce bias. This can be achieved, for instance, by shifting to a confirmatory approach and using a registered-report article format, in which a journal reviews and accepts a study before data collection and commits to publishing the results. Another way to reduce bias is by systematically implementing double blindness. In the absence of bias, the PPV increases from 10% to 12% (depending on power) to 13% (for low power), 50% (for medium power), or 67% (for high power). In other words, although eliminating bias does not help much given low power, if a study reaches at least medium levels of power (here 1 − β ≥ .46), reducing bias yields a massive increase in PPV.
Second, from this it immediately follows that increasing power can increase the PPV, but this increase depends on the level of bias: With high levels of bias, an increase in power (from low to medium or from medium to high) increases the PPV by only 1%. Without bias, in contrast, increasing power from low to medium improves PPV by 37%, whereas an increase from medium to high yields an additional improvement of 17%.
The third way to improve the PPV is by conducting (unbiased) replications of the significant results. Successful replication improves the PPV of a set of findings, but the magnitude of the benefit again depends on power (of both the initial and replication study): Compared with a PPV of 10% to 12% among initial findings, with low power, the rate of true findings among the significant replications is only slightly increased to 13%. With medium power, already more than half of significant replications (53%) represent true findings. With high power, 71% of successful replications represent true findings.
Take-home messages from simulations
If the goal is to increase the PPV, it is helpful to combine at least two recommendations: Reducing bias yields little improvement in the PPV unless statistical power is medium or high. Conversely, increasing power is of little effect unless bias is reduced. When the three are combined (i.e., low-bias, high-powered replications), a PPV of 97% can be achieved. Note, however, that reducing bias alone would have important benefits by substantially lowering the rate of significant findings and therefore helping to focus researchers’ resources on a smaller set of potential true effects.
Increasing power typically implies using larger samples: The present simulation is based on a median sample size of 57, which yields high power only for unusually large effects (d = 0.9). To achieve acceptable power (1 − β = .8) for medium effects (d = 0.5), a sample size of at least 128 is required; medium-to-small effects (d = 0.28) require a sample size of 404; for (very) small effects (d = 0.14), the required sample size increases to 1,604. Such sample sizes appear difficult to achieve for a typical researcher alone. Please note that we set effect sizes rather than estimating them. Estimating the effect size would be highly questionable in the current context. This is because of the very high heterogeneity of effects tested along with the suspected presence of a large number of false positives. This issue precisely motivated our current approach (compared with, e.g., a meta-analytic one). Therefore, it appears necessary to pool resources across labs and coordinate efforts. It should be kept in mind, however, that increased power can also be achieved, for instance, by (a) switching to within-subjects designs, (b) maximizing the effect of IN-OT administration (e.g., by using to-be-determined optimal dosage and optimal time elapsed after administration), and (c) improving the reliability of dependent measures.
General Discussion
Over the past decade, IN-OT has built a reputation as the social hormone in the literature. Press coverage polarized this view by referring to OT as a “love hormone” (e.g., Pappas, 2015), a “trust potion” (e.g., Carey, 2005), or a “social glue” (e.g., Penenberg, 2010). This prompted companies to sell OT sprays for improving social competences, connectedness, and emotional well-being (e.g., https://www.verolabs.com). This simplistic view was rightly questioned on both empirical and theoretical grounds: IN-OT effects should be addressed in interaction with contextual and interindividual factors (Bartz et al., 2011). In this review, we examined published studies reporting interactive effects of IN-OT on psychosocial outcomes. This review informs us that an impressively large diversity of conceptual moderations was tested but that the moderations were rarely tested more than once or twice and, when they were, were rarely replicated successfully.
We discussed three extreme scenarios in which the 26% of significant moderations are accounted by low statistical power, a low rate of a priori correct hypotheses, or Type I errors. The first scenario relies on the very implausible assumption that 100% of the tested interactions were true, and it is inconsistent with the fact that the sample size is unrelated to the proportion of significant moderations. The second scenario relies on the implausible assumption that all studies that detected a true effect were maximally powered and is inconsistent with the observation of a low conceptual replication rate. The third scenario is consistent with the finding that 91% of the published articles contained at least one significant moderation and the low conceptual replication rate. We additionally relied on simulations for allowing a more nuanced interpretation of the current state of research and for methodological guidance.
In all likelihood, the number of true interactive IN-OT effects is largely overstated. We estimated that about 90% of the reported significant findings on the interactive IN-OT effects on human social behaviors are likely to be false positives. PVV simulations clearly point to the combined need for larger samples sizes, independent replications, and better attempts at controlling biases.
It should be stressed that some of the interactions reported in the IN-OT literature may correspond to true effects. Other true effects may also have gone undetected because of a lack of power or because replicative attempts were most of the time conceptual rather than direct or simply because dosage or elapsed time were not optimal. It is most unfortunate, however, that the very large heterogeneity of published moderations, combined with the low replication rate and the low reliance on open-research practices, makes it virtually impossible to discover the theoretically relevant signal (i.e., true effects) in the empirical noise (i.e., Type I errors). As a result of this disappointing state of affairs, the development of strong theories is hardly possible, and IN-OT seems therapeutically unexploitable at present.
In one of the most influential IN-OT articles, Bartz and colleagues (2011) strongly recommended switching from a main to an interactive view of IN-OT effects, stressing the role of contextual and individual variables. Bartz et al. argued that adopting this interactionist approach is a way to overcome disappointing limitations associated with research probing main IN-OT effects. They highlighted that “inconsistencies across studies should not be seen as ‘noise,’ but rather as clues to the context- and person-dependent nature of the effects of oxytocin” (Bartz et al., 2011, p. 301) and stressed that “characterizing this context- and person-dependency could enable more refined theorizing on the social effects of oxytocin in humans” (p. 301).
The results from the current systematic review and simulations suggest that, quite disappointingly, the thesis laid out by Bartz et al. (2011)—although conceptually relevant—is actualized in a broad heterogeneity of largely underpowered and inconsistent tests of interactive IN-OT effects. Although the argument Bartz et al. (2011) make is well grounded theoretically, a more reliable and coordinated implementation is needed. We now discuss general recommendations to increase the trustworthiness of IN-OT research.
General recommendations for future research
There is a positive side to the large number and diversity of studies conducted on IN-OT. Undoubtedly, OT research attracts multidisciplinary interest and addresses theoretically and practically important questions. Growing concerns regarding the reliability of IN-OT research, however, mitigate the interpretation of the effects reported and prevent meaningful advances in the field. The current review points to two necessary changes for promoting robust advances in the field (see below). These recommendations should be familiar to the informed reader. In the past decade, the replicability of research findings in psychology has been increasingly questioned (Ioannidis, 2005; Lehrer, 2010; Yong, 2012). This “credibility revolution” (Vazire, 2018) stimulated the adherence to open-science practices, which are now gaining momentum (Nosek & Lindsay, 2018).
First, the lack of coordinated efforts in identifying and testing interactive IN-OT effects is detrimental to both theoretical and practical advances. Although researchers should be left free to address the specific question they are interested in, the accumulation of hundreds of (arguably largely underpowered) studies that addressed different combinations between moderators and dependent variables ultimately prevents the establishment of robust knowledge and strong theories in this field. We strongly encourage researchers to report multiple experiments on a given research project. Within the 117 published articles that were identified here, only five presented more than one experiment. And, among those five, four presented only two experiments, and one presented a set of eight “file-drawer” studies. As we discussed earlier, a greater attention to statistical power is also highly recommended, and this likely involves multicentric research efforts.
Second, there should be much greater transparency in research practices, which is a precondition for collaboration and coordinated research efforts. In particular, the preregistration of studies stating relevant theories, hypotheses, measures, analyses, and power estimations would greatly help limit the risk of false positives (Nosek et al., 2019). All moderators that are measured and tested should be reported as well as their effect (whether significant or not). Reviewers and editors should encourage such efforts and facilitate the publication of well-conducted studies regardless of the results. One way to achieve this goal is to institutionalize such changes: As suggested by Leng and Ludwig (2016), journals may explicitly encourage researchers to preregister trials, to declare hypotheses and outcomes in advance, to specify statistical methods to be applied, and to fully disclose materials, measures, and data, including assessed moderators that did not influence the results. Although effortful at first, this increased transparency of research practices seems necessary if we want to build a solid empirical basis for elaborating strong theories on the psychosocial effects of IN-OT.
These recommendations were framed in this review in terms of increasing “significant” findings that reflect true effects. Null-hypothesis significance testing (or NHST) is the most common approach in this domain of research. The recommendations we suggest are not relevant only for the traditional NHST approach, however. One could argue that correcting α levels or turning to Bayesian statistics would be sufficient for improving the reliability of published results. Simmons and colleagues (2011), however, argued that such recommendations are clearly insufficient and could even make the problem worse by introducing more ambiguity and researcher degrees of freedom. These authors argued that flexibility in data collection, analysis, and reporting are the main drivers of low-reliability research. Constraining or at least disclosing this flexibility requires adopting transparent research practices.
Limitations
In examining conceptual moderations, we made sure not to impose our own categorization strategy in establishing the conceptual dependent variables by relying on keywords selected by the authors themselves. It is possible and even likely that other categorization decisions would have brought a different picture. Because the current contribution is meant to advance IN-OT research, we share our data publicly and encourage the IN-OT research community to come up with their own theory-driven categorization of these dependent variables. We would like to insist, however, that this categorization should be theory-driven (i.e., the risk of falsely “discovering” an informative categorization increases with the number of attempts). Note that we also coded for additional factors (e.g., gender, dosage, elapsed time) that may also be helpful for complementary analyses (with a similar note of caution).
The current review highlights that the interactive effects of IN-OT on psychosocial outcomes in a healthy population are highly heterogeneous. The broad focus of the review implies that a large number of conceptual dependent variables were entered in the analyses. Admittedly, it cannot reasonably be assumed that OT has the same interaction effects on conceptual dependent variables as diverse as emotion recognition, aggression, memory, and mood, as these might involve distinct physiological networks. By allowing public access to the data covered in this review, we encourage the test of more specific hypotheses. Again, however, we would like to stress points of caution. It is possible that confounding variables or further moderators should be taken into account. As an illustration, interactions between IN-OT and gender could be qualified by additional moderators (e.g., menstrual-cycle phase, hormonal contraception, age) that were not considered in this article. In particular, recent meta-analytic evidence suggests that endogenous OT levels may fluctuate during the menstrual cycle (Engel et al., 2019). So, for instance, the IN-OT × Gender interactions might very well depend on the menstrual-cycle phase. However, the inclusion of covariates and higher-order moderators should be theoretically motivated and preregistered, consistent with the conclusions reached in this review. Otherwise, their consideration has the potential to make things even worse, as they would add researcher degrees of freedom that could in turn further increase the rate of false positives. Second, some variables are unlikely to yield informative results (e.g., because of a lack of variability). For instance, if one is interested in the effect of IN-OT dosage, one should accommodate the fact that a very large majority of studies used only a 24-IU administration.
In the quantitative analyses that we conducted, we were mainly interested in the rate of significant findings compared with other estimates such as effect sizes. In estimating the rate of significant findings, we essentially aimed to answer how much we can trust the IN-OT research. In contrast, estimating effect sizes would have addressed how much IN-OT affects social behavior. Estimating effect sizes is typically done in meta-analyses. As explained earlier, previous meta-analyses have pointed to small-to-medium effect sizes of main IN-OT effects. However, these meta-analyses only focused on main IN-OT effects, which are now thought to have little theoretical relevance compared with interactive ones (Bartz et al., 2011). These meta-analyses also concluded that effects existed that could not be replicated in later studies (Tabak et al., 2019). In the current review, we also reported a very low rate of significant IN-OT effects in studies relying on a pre–post design, that is, in studies that included a baseline control. In addition, as we discussed, if effect sizes estimated in previous meta-analyses reflected true effect sizes, these effect sizes are likely to be inflated because of various sources of bias and their reliance on underpowered studies (Pereira & Ioannidis, 2011; Walum et al., 2016). More generally, by focusing on the rate of significant findings, we could provide estimations of the quantity of bias as well as the proportion of false positives reported. We also covered a much broader range of dependent variables than what could be achieved in typical meta-analyses.
The current analysis focuses on interactive IN-OT effects on nonclinical samples. One could argue that interactive effects are more reliable and stronger in studies that examined clinical samples. Several studies examining the effects of IN-OT on socioemotional variables have found different effects in clinical compared with healthy samples. For instance, in a recent meta-analysis, Bürkner et al. (2017) observed that IN-OT improves high-level social cognition in participants diagnosed with schizophrenia but not in healthy controls. Another meta-analysis reported a stronger sensitivity to IN-OT in healthy controls than clinical samples on emotional intelligence (Leppanen et al., 2017). Finally, another meta-analysis (Keech et al., 2018) did not observe an effect of IN-OT on emotion recognition and empathy but found a small effect on theory of mind.
A final limitation of the current work is inherent to the broad perspective in which it was conducted (i.e., a mechanistic perspective aiming to track down the biological foundations of human behavior). Although it is certainly stimulating and important to understand how biology shapes social behaviors, mechanistic research bears the risk of oversimplifying the understanding of human functioning, especially if we overlook complex interactions between hormones and between different body systems more broadly, all of which are in constant interaction with dynamic environments.
Conclusion
This systematic review points to important concerns about the current state of IN-OT research. However, it also points to clear and helpful recommendations. After a decade of what may be fairly considered an exploratory phase of research, time has now come to establish a more empirically sound and theoretically grounded research on IN-OT in humans. First and foremost, this requires a better understanding of the pharmacokinetics of IN-OT in humans to guarantee the use of biologically sensible doses and administration-to-effects time windows. Second, this requires engaging in collective, multicentric research efforts that allow for the necessary coordination to systematically conquer the conceptual space. Finally, research practices should conform to contemporary research transparency criteria. Although we realize that these recommendations may be demanding, it is mandatory to meet them better if we want to move beyond the current stimulating but empirically and theoretically problematic exploratory stage of research.