
Abstract
For many years, research on attention has been dominated by theories based on the assumption that attention is limited in capacity. These include the limited-capacity-channel theories of Welford and Broadbent and capacity or resource theories by Moray, Posner, and Kahneman. This article challenges these theories and their many descendants by asking why capacity is limited and what role capacity plays in the computations required to perform attention tasks. There are few satisfactory answers in limited-capacity and resource theories of attention. I show that the effects of load on performance, which are commonly interpreted as evidence for limited capacity, can be produced by models that assume unlimited, limited, and fixed capacity. I argue that attention is better construed as a selection of information that we need to achieve our goals. Following current research on computational models of attention in associative learning, categorization, perceptual learning, cognitive development, neuroscience, and artificial intelligence, I propose that attention is a process of choice in which selection is implemented as multiplicative gain control and processing is constrained by normalization. This perspective focuses on interactions between representations and decision processes applied to them, explaining many attentional phenomena without assuming attention is a limited resource.
To paraphrase G. A. Miller (1956), I have been persecuted by a concept. For 50 years this concept has followed me around, has intruded in my most private data, and has assaulted me from the pages of our most public journals. This concept assumes a variety of disguises but never changes so much as to be unrecognizable. For me, the concept is limited-capacity attention. It arose in the 1950s with seminal articles by Welford (1952) and Broadbent (1957), who explained attention as a limited-capacity channel that can do only one thing at a time. The idea expanded in the 1960s and 1970s with seminal articles by Moray (1967) and Posner and Boies (1971) and an outstanding book by Kahneman (1973) that covered all known phenomena of attention. These works explained attention as a pool of capacity or resources that could be allocated selectively to activate processes but was limited so only a few things—usually one thing—could be done at a time.
The concept of limited-capacity attention dominates research on attention and performance in cognitive psychology. The basic paradigms in this line of research are illustrated in Figure 1. The concept appears in every textbook and in nearly every article that uses these paradigms. To paraphrase James (1890), “everyone knows” that attentional capacity is limited, that capacity limits explain dual-task and divided-attention deficits, that capacity limits explain the costs and benefits of selective attention, that selective attention is necessary because capacity is limited, and that selective attention protects the limited-capacity channel from overload. These ideas are appealing because they explain a lot of behavior in situations that require focusing and dividing attention or performing two tasks at once. Performance is worse when attention is divided or shared between tasks because the limited-capacity channel can process only one thing at a time or because the increased demand for capacity exceeds the limited supply.
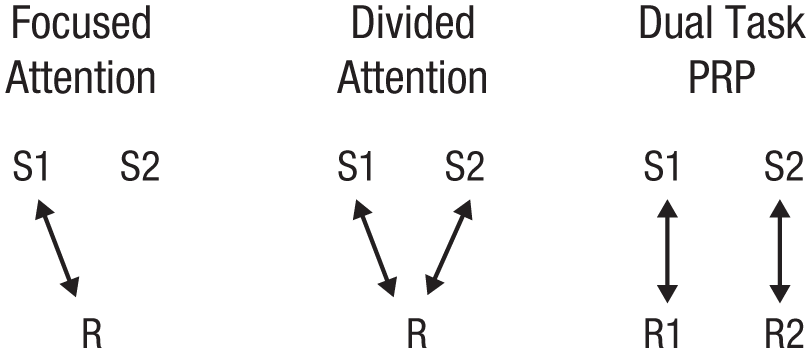
Three basic attention paradigms involve presenting at least two stimuli. The stimuli presented, S1 and S2, can be different stimuli or different dimensions of the same stimulus. Selective-attention tasks require a response (R) to one of the stimuli (S1). Divided-attention and visual-search tasks require a response (R) based on the two or more stimuli, one of which may be a target. Dual-task procedures require a separate response to each of the stimuli (R1 to S1, R2 to S2). The psychological refractory period procedure manipulates the delay between S1 and S2 to vary the amount of temporal overlap between the processes generating R1 and R2.
There are problems with the concept of limited-capacity attention (Allport, 1987, 1993; Logan, 1997; Navon, 1984; Neumann, 1987). For 50 years, there has been no explanation of why capacity is limited. There has been no explanation of the role capacity plays in the actual computations people engage while performing tasks. This was sensible in the early days before computational modeling of those processes became commonplace, but it is no longer acceptable. There are issues of mimicry. Divided-attention and dual-task deficits can be explained by models that assume unlimited capacity. Most importantly, the concept of limited-capacity attention is limited in scope in explaining focused- and divided-attention and dual-task studies in the cognitive psychology of attention and performance. Its explanation of selective attention is rudimentary: Filters can be set to regulate the input to the limited-capacity channel, or capacity can be allocated to desired activities. It does not explain the many selective-attention phenomena in other literatures, including associative learning in animals and humans, categorization, development of attention, perceptual learning, neuroscience, and artificial intelligence (AI). There are prominent theories of attention in each of those domains that explain selection without assuming a limited-capacity channel or limited resources. I show that they can be extended to account for dual-task and divided-attention deficits attributed to limited-capacity attention.
My purpose in this article is to describe these problems and offer solutions. Ultimately, I argue that the purpose of attention is to select the information we need to achieve our goals. Limitations on performance derive from the nature of choice and the nature of selection. Attention can be explained as selection and normalization without assuming a limited-capacity channel or limited resources. I do not challenge the empirical results. Dual-task and divided-attention deficits are robust and reliable. So are the benefits and costs of selective attention. I agree that those are the things that attention researchers must explain. I do not challenge the idea that these deficits can be described as limitations on capacity, if capacity is defined as a measure instead of a theory. I do challenge the explanations that limited-capacity attention theories provide.
My challenge can be expressed succinctly as a distinction between capacity and a resource. Capacity is a measure, expressed as a rate or an amount. A resource is a theoretical entity. It is a capacity that is limited or fixed, can be allocated voluntarily, and is necessary to enable processes that deal with stimuli and produce responses. I challenge the interpretation of capacity as a resource and the extra assumptions that interpretation requires, beyond the assumption of limited capacity. One can measure capacity while imagining no resources.
Capacity Theories
Welford (1952) and Broadbent (1957) introduced the idea of limited-capacity attention to the field. Inspired by Shannon (1948), they applied information theory to problems of attention to simultaneous and temporally overlapping stimuli (Fig. 2, left). They viewed the human “operator” as a communication channel, which, by Shannon’s theorem, must have limited capacity. Whereas Shannon viewed capacity as a measure of the performance of a communication channel, Welford and Broadbent thought of limited capacity as more than a measure. It was an explanatory construct in a theory of attention that accounted for a lot of data in a broad range of tasks (Broadbent, 1958; Welford, 1968).
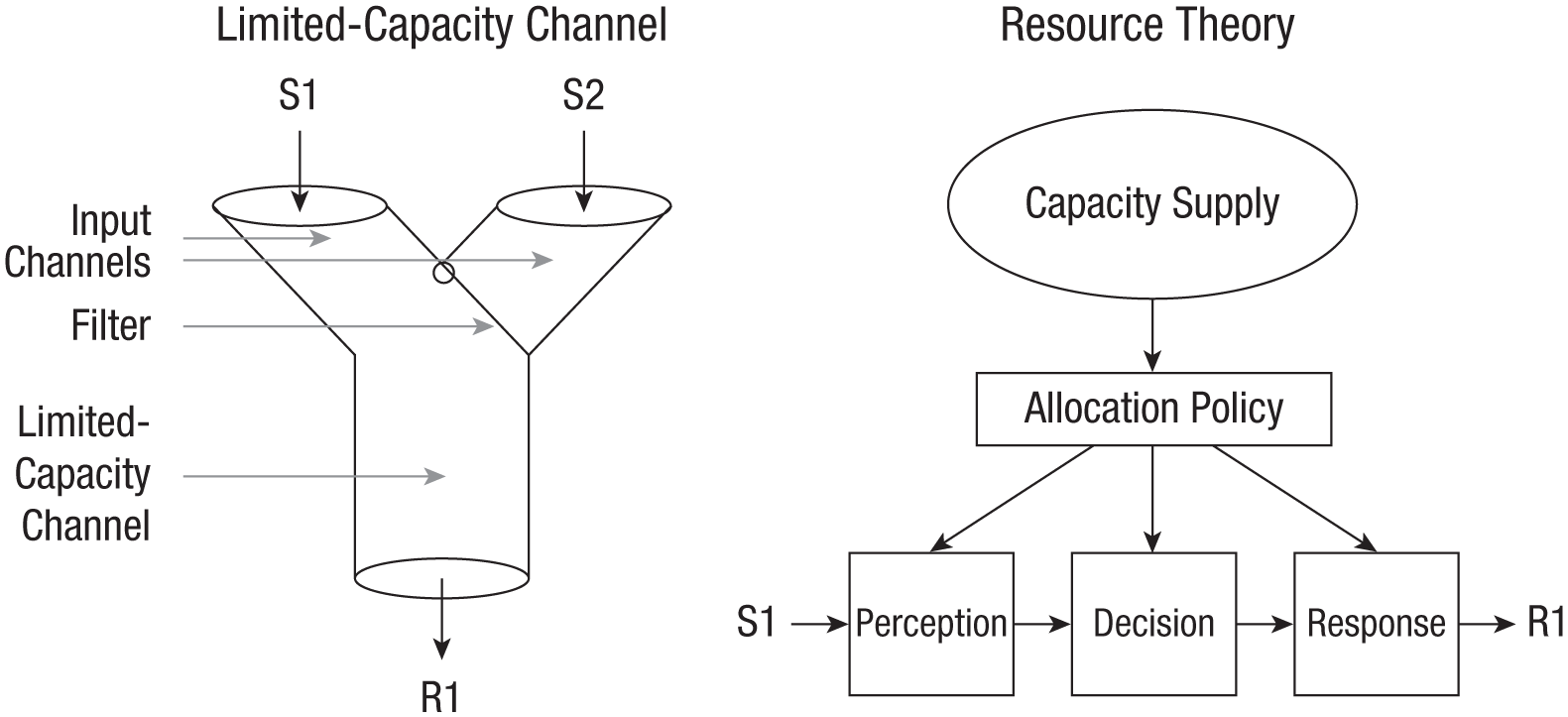
Broadbent’s (1957) limited-capacity-channel theory of attention and Kahneman’s (1973) capacity theory of attention. Broadbent’s limited-capacity-channel theory of attention (left) posits that stimuli enter separate input channels. The filter determines which input channel has access to the limited-capacity channel, which can process only one stimulus at a time. Kahneman’s capacity theory of attention (right) posits that stimuli are processed in stages (perception, decision, and response). The activation of each stage depends on input from the stimulus or prior stages and input of capacity. A limited-capacity supply is allocated selectively to stages required for task performance.
Later, Moray (1967), Posner and Boies (1971), and Kahneman (1973) challenged the assumption that the limited-capacity channel could do only one thing at a time. Instead, they suggested that the capacity in the channel could be divided between inputs and tasks so they were processed in parallel at rates proportional to the amount of capacity allocated to them (Fig. 2, right). This idea also accounted for a lot of data in a broad range of tasks (see, e.g., Kahneman, 1973). The debate over the assumption still continues (Navon & Miller, 2002; Tombu & Jolicoeur, 2003). As in other domains, parallel (limited pool of capacity) and serial (limited-capacity channel) models mimic many of each other’s predictions and are hard to distinguish (Townsend, 1971, 1990).
To account for behavior, capacity theories must make additional assumptions beyond the fundamental idea that capacity is limited (Navon & Gopher, 1979). They assume that performance is sensitive to the amount of capacity allocated, improving as more capacity is allocated; that the allocation of capacity is controlled voluntarily by an explicit policy; and that capacity is fixed or slightly elastic (see Fig. 2). They also assume additivity of demands such that if Task 1 demands X amount and Task 2 demands Y amount, the total demand is X + Y. If the demand exceeds the supply, performance suffers. And they assume complementarity of supplies such that all of the capacity taken away from one task can be used for another task with no loss. The quantitative implications of these assumptions are rarely tested (for important exceptions, see Bays, 2014; Sewell et al., 2014; Shaw, 1978; Shaw & Shaw, 1977; P. L. Smith et al., 2016).
Serial theories must assume some kind of selection mechanism that governs access to the limited-capacity channel and distinguish between information that can be processed without the limited-capacity channel (preattentively) and information that requires it. These assumptions were tested in an enduring debate about the locus of selection (Kahneman & Treisman, 1984) and a mostly settled debate about the locus of the limited-capacity channel in the chain of processes extending from stimulus to response (Pashler & Johnston, 1989). Parallel theories must assume a mechanism that allocates capacity selectively and specify how performance depends on the amount of capacity allocated (Navon & Gopher, 1979). These assumptions inspired many experiments on trade-offs between tasks and trade-offs in divided and focused attention that continue today. In my view, much of the explanatory power of capacity theories lies in these additional assumptions. The assumption of limited capacity justifies the proposed mechanisms and explains why they are necessary, but other assumptions can explain the trade-offs without invoking limited capacity.
Multiple Resources
Theories such as Kahneman’s (1973) and Posner and Boies’ (1971) assume there is one pool of central processing capacity that is required for every task. Experiments in the 1970s challenged this assumption, showing that tasks with different input and output modalities and different central processes did not trade off with each other. The resources required for performance were not additive or complementary (Brooks, 1968; Treisman & Davies, 1973; Wickens, 1976). These results suggested that more than one capacity limited performance. Seminal articles by Navon and Gopher (1979) and Wickens (1980) proposed multiple-resource theories as alternatives to single-capacity theories.
Multiple-resource theories assume that performance is limited by several resources, each of which meets the assumptions of single-capacity theory (sensitivity to demands, fixed supply, additivity of specific resources, complementarity of specific resources). Unlike single-capacity theories, they assume there is no single central resource that all tasks share. Instead, they assume that different tasks may require different combinations of resources, so some pairs of tasks will interfere with each other but other pairs will not. Different resources are not additive or complementary, and overall capacity is not fixed. It can be larger or smaller depending on the number and amount of resources allocated. These assumptions and the diversity of dual-task effects they account for are a serious challenge to single-resource theories, falsifying their core assumptions. To my knowledge, single-resource theories have never addressed these challenges.
Multiple-resource theory was criticized on several grounds (Navon, 1984). It is too flexible. It provides post hoc accounts of dual-task effects but does not make clear a priori predictions. It says there is more than one resource but not how many there are or what they are. Wickens (1980) suggested a taxonomy based on input modalities, codes, processing stages, and response modalities that serves as a useful heuristic but is not complete as a computational theory. Research on dual-task performance shifted to the psychological refractory period (PRP) procedure (Fig. 1), which is simpler and more constrained (there are only two stimuli, each requires a response, and the interval between them is brief). The main questions shifted to the locus and the nature of the bottleneck (Meyer & Kieras, 1997; Navon & Miller, 2002; Pashler & Johnston, 1989; Tombu & Jolicoeur, 2003). Researchers still think in terms of single-capacity theory, but they have not resolved the fundamental challenge that multiple-resource theory presents.
Like capacity theory and single-channel theory, multiple-resource theory does not explain why the capacity of any resource is limited, and it does not specify the role the resources play in the computations that produce behavior. Wickens’s (1980) taxonomy proposed different resources for inputs, codes, stages, and responses that may require different computations, but he defined these concepts operationally in terms of the experimental manipulations that affect them rather than explicit computations on representations.
Shannon’s Capacity Limit
In 1948, Claude Shannon published two articles describing his theory of communication that changed the world for everyone. He formalized the concepts of information and uncertainty and defined communication as the reduction of uncertainty. These ideas had a huge impact on psychology, forming the basis of the cognitive revolution. Mental states, eschewed by the behaviorists, could be described mathematically in Shannon’s terms, and cognition could be described mathematically as processing information. Shannon’s ideas inspired an explosion of research applying concepts of information and channel capacity to studies of reaction time (RT; Hick, 1952; Hyman, 1953), motor control (Fitts, 1954), absolute judgment (Garner, 1953; Pollack, 1952), and memory (G. A. Miller, 1956), among others.
Shannon defined communication as the transmission of a message from a sender to a receiver and defined a communication system as consisting of an information source that generates a message, a transmitter that translates the message into a code that is appropriate for transmission, and a channel that conveys the information from the transmitter to a receiver that accepts the code and translates it into a format compatible with the destination of the message—the person or device that receives the message. The channel could be corrupted by noise, which distorts the message and reduces the amount of information transmitted.
Shannon’s theory inspired psychologists to think of cognition differently, to think of humans as communication systems processing information. The information source could be the external environment; the transmitter could be the perceptual system; the receiver could be the motor system, which generates a response; and the destination could be the external world, which changes when the response is made. The information source could be one person speaking, and the destination could be the person’s conversational partner. Many of the foundational articles and books in the cognitive revolution addressed Shannon’s theory (Attneave, 1959; Garner, 1962; G. A. Miller, 1956).
Shannon (1948) defined capacity as the rate of transmission of information and proved it is limited. This idea inspired attention researchers. If humans were communication systems, there must be a limit on their capacity to transmit information. Their communication channel would be a bottleneck that would limit their ability to process information. Welford (1952, 1968), Broadbent (1957, 1958), and others saw the limited-capacity channel as an explanation of dual-task limitations and the costs of dividing attention: When demand for the channel exceeded its capacity, less information would be transmitted and performance would suffer. This idea remains the core assumption of modern theories of dual-task performance, in which the limited-capacity channel is associated with response selection (Pashler & Johnston, 1989).
Shannon’s (1948) concept of the channel was different: “The channel,” he stated, “is merely the medium used to transmit the signal from transmitter to receiver. It may be a pair of wires, a coaxial cable, a band of radio frequencies, a beam of light, etc.” (p. 7). The channel carried signals but did no computation on them (Fig. 3). The computation was done in generating the message and translating it into a code to be sent through the channel and then in receiving the message and decoding it for the destination. The capacity limit of a communication system that produces symbols at a fixed rate, like a telegrapher sending Morse code or a typist sending text through a teletype, was defined as the maximum amount of information that could be transmitted at that rate. Different codes are based on different numbers of symbols that may take different amounts of time to transmit (dot, dash, and space in Morse code; 26 letters in English text), so the rate of information transmission through the same channel depends on the code. The rate at which symbols are produced depends on the properties of the message generator and the translation process. The rate at which symbols are received and understood depends on properties of the receiver and the destination. These processes are outside the channel in Shannon’s theory. They appear to be inside the channel in limited-capacity theories of attention, contrary to Shannon’s conception.
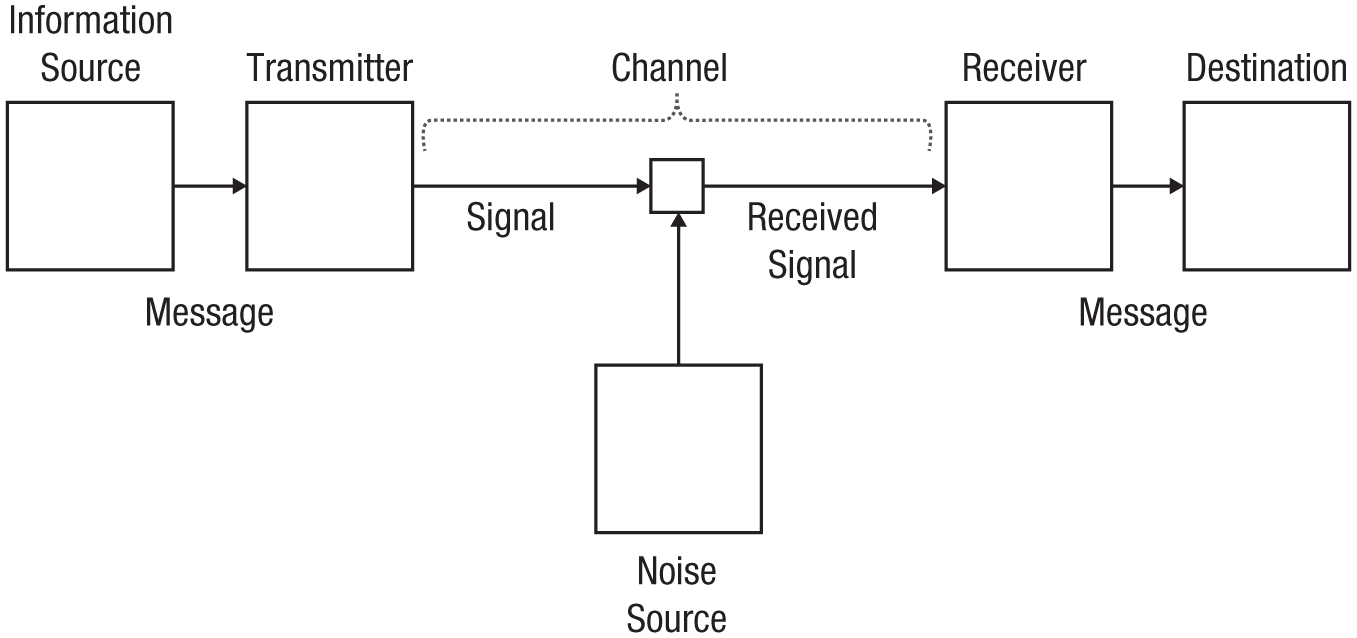
Shannon’s communication system. Shannon defined a communication system as consisting of an information source that generates a message; a transmitter that translates the message into the code to be transmitted through a channel that conveys the message, possibly corrupted by noise; and a receiver that translates the message in the channel into a format comprehensible to the destination.
Shannon defined information in terms of choice. The sender chooses one message from a set of possible messages and transmits it, and the recipient must choose which message was sent from another set of possible messages (hopefully the same). The information in a given message is proportional to the size of the set (N) and the probabilities (pi) of the different messages. Shannon proved that information (H) could be described by
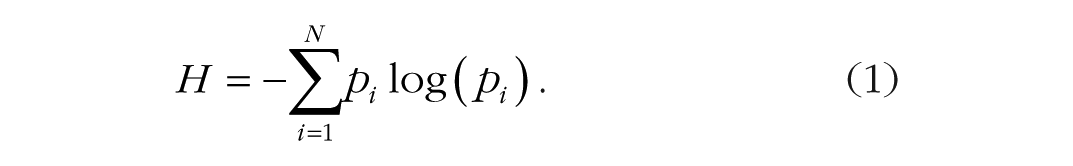
Shannon proved that H was largest when the alternatives were equally likely (pi = 1/N), in which case H = log(N). He identified the equal-likelihood case to be the limit on the amount of information that could be passed through a discrete, noiseless communication channel. Capacity is limited because the amount of information transmitted cannot exceed log(N). Departures from equally likely alternatives reduce the amount of information transmitted, so redundant messages (like those expressing language) carry less information. Noise in the channel reduces the amount of information transmitted by corrupting valid signals or by adding irrelevant symbols (smartphones, crowded restaurants). The communication system may transmit symbols at the same rate, but they contain less information.
Shannon defined the capacity of a discrete, noiseless channel, C, as the maximum rate at which it can transmit information, expressed as bits per second. He showed that the limit on the rate is equal to the logarithm of the number of allowed messages, N(T), of duration T divided by T when T is sufficiently long:
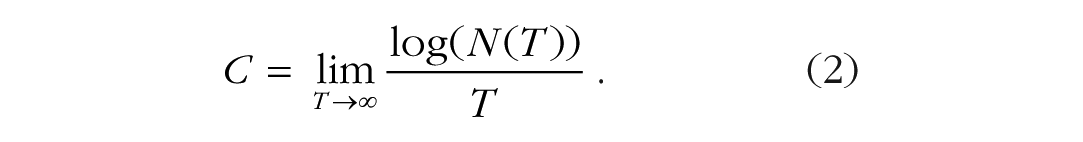
The actual rate of transmission can approach C only if the alternative messages are equally noise-free. Departures from equal likelihood reduce the amount of information to a value less than log(N), so the rate of transmission is less than the maximum. If the channel is noisy, capacity is reduced in proportion to the noise:
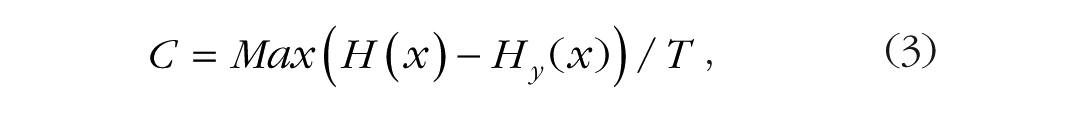
where H(x) is the uncertainty of the message and Hy(x) is the remaining (conditional) uncertainty of the message after it has been received (y refers to the received message), which represents the noise. If the channel is noiseless, Hy(x) is zero and capacity equals Max(H(x)). Most of the applications to psychology used the discrete, noiseless case (Garner, 1953; Hick, 1952; Hyman, 1953; Pollack, 1952; but see Fitts, 1954).
Shannon’s limit is about the efficiency of coding and error correction. He attributed the efficiency of coding to the information source and the transmitter and to the receiver and the destination rather than the channel (Fig. 3). Noise could occur at all stages, including the channel. His research motivated research on efficient coding and data compression to remove redundancy (we can thank Shannon for zip files and MP3s) and research on noise reduction and error correction to reduce errors, which was intended to increase the actual rate of transmission to approach the limit.
Attention researchers interpreted Shannon’s capacity limit differently. They agreed there was a limit to the amount that could be processed but did not define the amount in terms of Shannon’s information measure. Limited-capacity-channel theories assumed only one “thing” could pass through the channel at a time but were vague about the nature of the thing that was passed (Broadbent, 1957; Pashler & Johnston, 1989; Welford, 1952). Parallel theories assumed a limited amount of capacity could be divided among inputs and tasks but did not specify the units of capacity or say how many inputs or tasks could be processed (Kahneman, 1973; Moray, 1967; Posner & Boies, 1971). These ideas have inspired decades of important research, but in abandoning Shannon’s information metric, they are no longer supported by his mathematical proofs and arguments. Capacity need not be limited.
Capacity Measures
Attention researchers often measure capacity limitations by manipulating the number of elements to be processed, such as the number of objects in a visual-search task or the number of items on a memory list, to vary the load on attention. Performance generally gets worse as load increases, and this is often interpreted as evidence of capacity limitations. Formal analyses of the concept of capacity suggest that interpretation may not always be warranted (Duncan, 1980; Townsend & Altieri, 2012; Townsend & Wenger, 2004). These analyses focus on capacity as a measure rather than an explanatory theory. They are compatible with interpretations of capacity as a resource that can be allocated voluntarily, and so on, but they neither make nor require the assumptions of resource theory.
Townsend and Ashby (1983) presented measures of capacity that distinguish between unlimited, limited, and fixed capacity instead of assuming limited capacity a priori. They defined capacity in terms of the effects of load on the rate of processing of a single element, defined as vN, where v is the rate and N is the number of elements being processed in the task. They proposed that changes in the rate when another element is added to the task distinguish unlimited, limited, and fixed capacity. If capacity is unlimited, the rate of processing does not change:

The total capacity, defined as the sum of the processing rates over the N elements, increases with N without limit:

If capacity is limited, the rate of processing decreases as elements are added to the task:
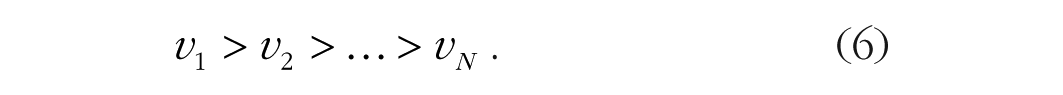
The total capacity is less than the total capacity if capacity is unlimited:

If capacity is fixed, as capacity theories of attention assume, the rate of processing decreases as elements are added to the task such that the sum of the rates remains constant. If the total capacity C is divided equally among the elements, then
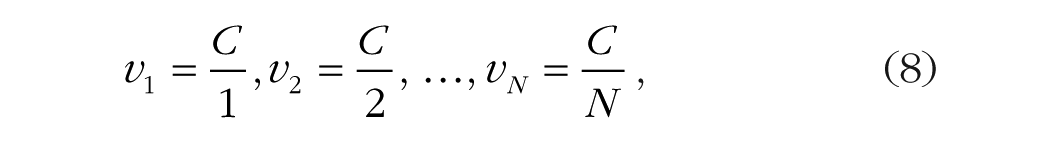
and

and the sum of the capacity is fixed at C:

How processes defined this way play out in behavior depends on several factors, including the architecture (parallel, serial, coactive), the dependence among the elements (dependent, independent), and the stopping rule for the decision process (stop when the first [race] or last [exhaustive] element finishes; Townsend & Ashby, 1983). Intuition might suggest that unlimited-capacity systems will show no load effects, limited-capacity systems will show some load effects, and fixed-capacity systems will show the classic load effects that are taken as evidence for capacity theories of attention. That intuition is misleading (see also Duncan, 1980).
Consider a parallel processing system in which N elements compete for selection. If we assume the rates represent the strength of competition in a Luce choice model (Luce, 1959, 1977) or the rates of processing in a race between the elements with exponentially distributed finishing times (Bundesen, 1990, 1993; Marley & Colonius, 1992), the probability that element i is chosen is the rate of processing element i divided by the sum of the rates of processing for all of N elements in the set:
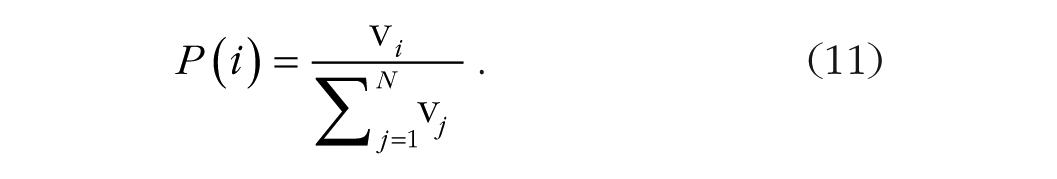
Consider the effect of adding one element to the competition. If capacity is fixed, P(i) will decrease because the numerator decreases (Eq. 8). If capacity is limited, P(i) will decrease because the numerator decreases and the denominator increases. If capacity is unlimited, P(i) will decrease because the denominator increases. Thus, fixed, limited, and unlimited capacity all predict load effects. This is important. It means that the observation of a load effect does not justify the assumption of fixed or limited capacity (Duncan, 1980). Load effects are a consequence of competition whether or not capacity is limited. Further analysis and other manipulations are necessary to decide the issue of capacity (see Townsend, 1971, 1990; Townsend & Altieri, 2012; Townsend & Wenger, 2004).
This analysis of capacity does not say why capacity is limited or how capacity determines the rate of processing. It does not say what computations the elements perform or the role that capacity plays in them. This is an advantage because it allows questions about capacity to be asked very generally, independent of the details of the task. It is a disadvantage for the same reason: It does not provide much insight into the role of attention in the computations the task requires. It does provide powerful tools to gain such insight.
Townsend and Ashby’s (1983) analysis does not assume that capacity is a resource. It does not make the additional assumptions required by resource theory (e.g., voluntary allocation, additivity of demands, complementarity of supplies). Using these methods to determine that capacity is limited in some task may allow us to conclude that some internal process is limited in capacity, but it does not allow us to conclude that the capacity is a resource. That conclusion requires further tests of the additional assumptions of resource theory. Finding load effects and evidence of limited capacity is not sufficient.
Interim Summary
Limited-capacity and resource theories of attention are useful metaphors that have inspired a lot of research, but there are serious problems that suggest the theories need to be substantially revised or replaced. Resource theories make strong assumptions that are rarely tested (fixed capacity, voluntary allocation, additivity of demands, complementarity of supplies). Multiple-resource theory challenges all of these assumptions except voluntary allocation, and resource theorists have not yet addressed these challenges. Resource theories were inspired by Shannon’s (1948) capacity limit but abandoned his mathematical justification for it. The common use of load effects to diagnose limited capacity is plagued by mimicry and demands more sophisticated analyses to distinguish between fixed, limited, and unlimited capacity. Resource theories have not kept up with the increasing mathematical and computational sophistication in other theories of attention addressed to other phenomena.
Given these problems, one can revise and extend resource theory or consider alternative approaches. There is value in both. I prefer an alternative approach.
Attention Is Selection Plus Normalization
Imagine no resources. What is the essence of attention if not limited capacity? An alternative view is that attention is a process of choice. Driven by goals, it chooses inputs, analyses, outputs, and responses to achieve them (Allport, 1987; Logan, 2002; Neumann, 1987; Treisman, 1969; Wu, 2011, 2024). Selection is its essence. It ensures that the choice is based on the most relevant information. Selection is necessary because the world is full of irrelevant information. The choice process is constrained by the nature of the task at hand, and its implementation in the brain is constrained by the need to balance excitation and inhibition. These constraints, known as “normalization,” produce trade-offs in divided-attention and dual-task situations and explain the costs and benefits of selective attention without assuming limited resources and the theory that goes with them. Of course, capacity can be measured in these models, but it is no longer an explanatory construct.
Normalization
Normalization in choice
Normalization is ubiquitous in statistics, computer science, psychology, and neuroscience, in which it is a transformation of a score or a signal to a scale defined relative to other scores or signals, often to restrict its range. In cognitive psychology, normalization is ubiquitous in formal models of choice, in which it describes the competition between choice alternatives and transforms their strengths into RTs and response probabilities. Many models use the Luce choice ratio (Eq. 11; Luce, 1959) to predict choice probabilities (e.g., accuracy). Luce derived the choice ratio from the choice axiom, which posits that the ordering of preferences among items in the choice set remains invariant after additions to or deletions from the set. He showed that if the choice axiom holds, the choice probabilities must follow the choice ratio. The probability, P(A, B), of choosing A over B is independent of the other alternatives in the choice set (Arrow, 1951). The absolute probabilities depend on the choice set (vA/(vA + vB) > vA/(vA + vB + vC), but the ratio of P(A) to P(B), which expresses the preference, does not:
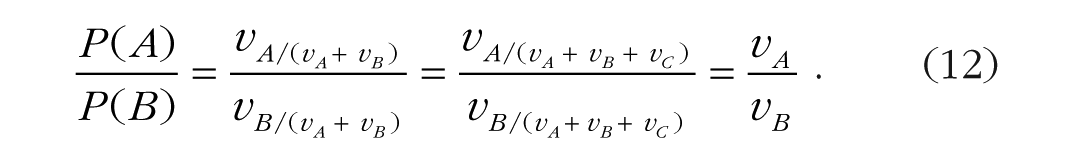
Luce derived the v scale from the choice axiom to describe the “strengths” of the alternatives on a ratio scale, and he derived Equation 11 to relate ratios of v values to choice probabilities.
Luce (1963) applied choice theory to detection and recognition tasks in psychophysics, which required him to distinguish between stimulus strength and response bias. Following Shepard (1957), he defined the strength, v(x, i), of choice alternative x as the product of its similarity to the desired object i, η(x, i), and the value or bias, β i , for object i
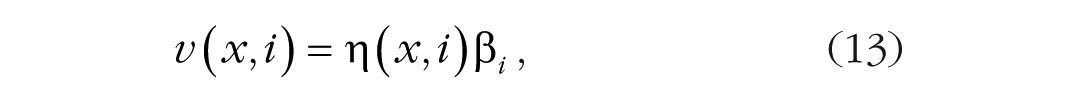
and the choice ratio as
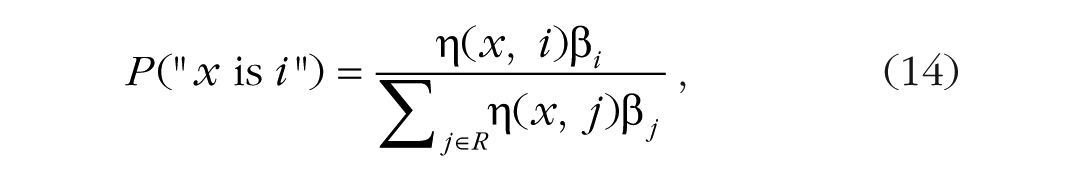
where R is the set of relevant objects.
The choice ratio forms the core of Bundesen’s (1990) theory of visual attention, Nosofsky’s (1986) generalized context model of categorization, and many theories that followed them (Logan, 2002, 2004). It is used frequently in computational models of memory and cognition. Under certain conditions, the choice ratio produces the same choice probabilities as race models of RT, in which the competition is expressed in time and the first alternative to finish is chosen (Bundesen, 1993; Marley & Colonius, 1992). More generally, the choice ratio is an example of the softmax function (Bridle, 1990), which is used in a broad range of sciences from statistical mechanics to AI.
Luce’s framing of the choice problem is based on the idea of trade-offs between competing alternatives. Increasing the strength of one option inevitably reduces the choice probabilities for the other options, but the trade-off does not depend on capacity limitations or resources. Strength can be modulated from the bottom up by manipulating the stimulus properties of an alternative x to increase or decrease its similarity to i. It can be modulated from the top down by manipulating β i to increase the likelihood of selecting desired choices and reduce the likelihood of selecting undesired choices. Both modulations produce trade-offs among choice alternatives, such as those capacity theorists attribute to resource limitations, without assuming resources. Similarity is a relation between stimuli or between stimuli and memory representations. Bias is a value placed on a result. The trade-offs follow from the nature of choice and the constraints imposed by the choice set without the need to invoke resources.
Luce’s perspective suggests that normalization is inherent in the choice problem. It is an inevitable consequence of choice regardless of who chooses or how they choose. Choice requires selecting one element from a set of mutually exclusive alternatives. We can go up the hill to eat berries or down to the stream for a drink. Choice is normalized by the choice set. The probability of choosing an element will depend on the number of alternatives in the set and the properties of the alternatives. Adding another choice alternative with strength greater than zero will necessarily affect the probabilities of the other choices, reducing the probability of at least one of them. Noticing a tree with ripe apples right behind us would change our probability of going up the hill to the berries. As shown in the analysis of Equation 11, changing the choice set changes response probabilities whether capacity is unlimited, limited, or fixed. The properties of the environment do not depend on the capacity of the person living in it.
Herrnstein’s (1961, 1970) matching law for concurrent reinforcement schedules illustrates this trade-off clearly. If given a choice between two keys to peck for reinforcement, pigeons distribute their responses in proportion to the rates at which the keys produce reinforcement:
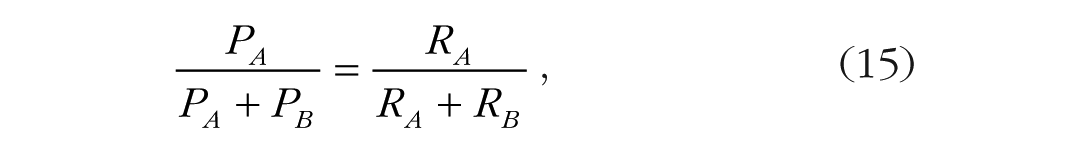
where PA and PB are the rates of responding with keys A and B and RA and RB are the rates of reinforcement for keys A and B. The trade-off is necessary because the choices are mutually exclusive: The keys are separated so the pigeon can peck only one at a time, whether or not its attentional capacity is limited. The berries and the stream are in different places and going to one implies not going to the other.
It may be tempting to interpret normalization in choice in terms of resource theory. The denominator of the choice ratio (Eqs. 11 and 14) could represent the total amount of capacity, and the ratio could represent the proportion of capacity allocated to each choice option (cf. Eqs. 5, 7, and 10). This temptation should be resisted. The denominator expands and contracts as alternatives are added and taken away, so the “capacity” need not be fixed. More fundamentally, the components of the choice ratio are products of two factors: similarity and bias. Similarity depends on content. It depends on the stimulus and its match to memory representations. It is not like a limited resource that is independent of content and can be divided and allocated at will. Bias also depends on content. It expresses the content of the chooser’s goal. It can be “allocated” voluntarily, but there are no constraints on its capacity. Together, similarity and bias are sufficient to explain choice probability, as demonstrated in the many applications of the Luce choice rule. Describing the choice process in terms of capacity and resource allocation adds no explanatory value.
Of course, capacity can be measured in Luce choice models using the Townsend and Ashby (1983) analyses described above (Eqs. 4, 6, and 8; see also Townsend & Altieri, 2012; Townsend & Wenger, 2004). From this perspective, Luce choice normalization is unlimited in capacity because the strengths of the alternatives do not change when the choice ratio is computed. The output of the decision process is normalized (choice probabilities must sum to 1.0), but the strengths themselves are unchanged. The strengths may be normalized by other parts of a theory, but they are not normalized in the Luce decision process.
Normalization in brains
Normalization is a pervasive concept in neuroscience. Divisive normalization has been proposed as a canonical neural circuit throughout the brain (Carandini & Heeger, 2012; Grossberg, 1973; Kouh & Poggio, 2008). Neurons are excited by their input and inhibited by the global activity of neurons in the surrounding population. Normalization achieves a balance between excitation and inhibition that allows neurons to be maximally sensitive to input and supports winner-take-all computation.
Formally, the firing rate of neuron i, Ri, depends on the input drive, Dj, to that neuron divided by the suppressive drive, which is a constant σ plus the sum of the drives, Dj, from all the neurons in the pool
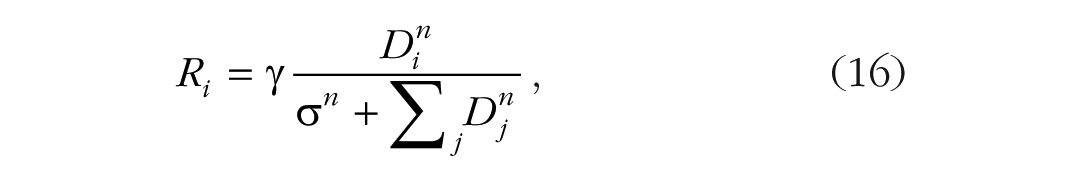
where γ is a constant that determines overall responsiveness, σ is a constant that prevents division by 0 and determines how responses saturate, and n is a constant that amplifies individual signals. The drive for neuron i is a weighted sum of inputs Ik from “earlier” neurons:

The relation to the Luce choice ratio is clear: If γ and n are set to 1 and σ is set to 0, Equation 16 becomes Equation 11. Equation 17 weighs the evidence provided by the inputs in a way that is analogous to Equation 13.
In neuroscience, divisive normalization has become the core of normalization theories of attention (Reynolds & Heeger, 2009; Schmitz & Duncan, 2018), in which it explains the effects of load and attention on the activity of single neurons in monkeys in V1 and V4, among other areas. Increasing load by presenting a second stimulus in the receptive field of a neuron reduces its response to its preferred stimulus because of normalization. The second stimulus adds to the suppressive drive in the denominator of Equation 16, reducing the firing rate of the first stimulus. Directing attention to one of the two stimuli increases its stimulus drive, which increases the suppressive drive and reduces the response to the other stimulus.
It is tempting here as well to think of the activity of a population of neurons as a resource that can be divided and allocated voluntarily to different activities (Bays, 2014; Bundesen et al., 2005). But again, that temptation should be avoided. The activation of neurons depends on content. It depends on the match (similarity) between their preferences (tuning curves) and the input and on the attention weight applied to the content, which depends on the monkey’s goal. Normalization may be better understood in terms of representations and processes than in terms of putative resources that energize them.
Neural normalization is not voluntary. It is a consequence of the circuitry. Increasing the activation of one neuron increases the suppressive drive obligatorily, like putting one’s hand in a bucket of water automatically increases the water level in the bucket. It is unlike resource allocation, which is assumed to be voluntary (Kahneman, 1973; Moray, 1967; Posner & Boies, 1971).
Townsend and Ashby’s (1983) analysis of capacity can also be applied to normalization in neurons and in models of the circuitry that implements normalization. In neurons and circuitry, normalization has limited capacity because it reduces the activation of each neuron or element by an amount proportional to the number of active neurons or elements (Eq. 16).
Normalization in choice versus brains
Normalization in choice and brains results from competition between alternatives. Normalization in choice is the consequence of an intention to choose. The purpose of the choice—the goal—and the possibilities in the environment determine the choice set, which determines the competition. The choice is normalized with respect to the choice set in that only one alternative will be chosen (Luce, 1959; McFadden, 1976). Normalization in brains is the consequence of the circuitry. Normalization occurs throughout the brain, from sensory reception to the tuning of movements (Carandini & Heeger, 2012). It is determined by competition between stimuli that fall within the suppressive field and the neural circuitry that represents them. The normalization in the choice process may be implemented as a neural circuit (e.g., Gold & Shadlen, 2007; Purcell et al., 2012; Ratcliff et al., 2016), but processing before and after the choice is also normalized by neural circuits. Thus, evidence of neural normalization is not evidence of attention without further analysis of its role in choice. If normalization indicates capacity limitation, then processes other than attention are limited in capacity.
Normalization in choice and brains are described at different levels of Marr’s (1982) analysis. Normalization in choice is described at the computational level and the algorithmic level. The computational goal is to choose the one alternative out of many that best satisfies a goal. The algorithm is described in the Luce choice ratio and other mathematical theories of choice (P. L. Smith & Ratcliff, 2025). Normalization in brains is described at all three levels. The computational goal is to keep the system in a state of maximum sensitivity, the algorithm is described in the theory of the normalization circuit, and the implementation is evaluated in actual neurons. The computational goals are different but compatible. It should be possible to have a neural theory of choice (Gold & Shadlen, 2007; Purcell et al., 2012; Ratcliff et al., 2016).
There are voluntary and obligatory components in both kinds of normalization. Normalization in choice depends not only on the goals we adopt voluntarily but also obligatorily on the possibilities available in the environment. We can choose only what the current environment affords. Normalization in brains depends obligatorily on the input, but the input depends on the organism’s goals and its orientation to aspects of the environment. Our brains receive different inputs when we choose to pick berries instead of drinking from the stream.
Normalization in choice is more specific than normalization in brains. It addresses a single cognitive process, whereas normalization in brains addresses circuits everywhere. Choice is unlikely to be the only cognitive process that is subject to normalization, but in my view, it is the one that most clearly expresses the normalization that is inherent in attention.
Normalization and resources
Normalization is a core concept in resource theories of attention. There is only so much capacity to be allocated, and performance must suffer if demands exceed the supply. Resource theories describe normalization at Marr’s (1982) computational level but not generally at the algorithmic or implementational level. Resource theories are rarely expressed as computational or mathematical models (but see Bays, 2014; Sewell et al., 2014; Smith et al., 2016; Shaw, 1978; Shaw & Shaw, 1977). Such models are necessary to connect resource theory with the computational and mathematical models of normalization in choice and in neural circuits. Without this formal connection, neither neural evidence nor behavioral evidence of normalization can be interpreted as evidence for the normalization of resources. The onus is on resource theorists to show that the additional assumptions of resource theory are necessary to explain attentional phenomena. The arguments above and the examples below suggest that many phenomena can be explained very well with computational theories of choice and normalization that do not assume resource limitations.
Selection
As Titchener (1908) said, “attention is the nerve of the whole psychological system” (p. 173). It is involved in every deliberate choice and act, so it is important in every area of psychology beyond immediate research on attention and performance. In those areas, selection is paramount. Selective attention is a critical factor in theories of associative learning in animals (Mackintosh, 1975) and humans (Kruschke, 2001), in theories of categorization (Nosofsky, 1986), in theories of perceptual learning (E. J. Gibson, 1963; Dosher & Lu, 2017), and in theories of cognitive development (L. B. Smith, 1989). Selective attention has become very important in AI, in which it simplifies the computation and produces vast improvements in performance (de Santana Correia & Colombini, 2022; Vaswani et al., 2017).
In each domain, selective attention is implemented with the same computation: multiplicative gain control. The bottom-up signal produced by the input is multiplied by a top-down signal representing the current goal, like similarity and bias multiply in the Luce choice ratio. The products are higher for inputs that match goals, which makes them more likely to be selected.
A salient difference between these theories of selective attention and limited-capacity resource theories is that the former address the content that must be processed to perform the task whereas the latter do not. Multiplicative gain control enhances some content at the expense of other content. Limited-capacity and resource theories are cast more generally, independent of content. Resources are described as central processing capacity (Posner & Boies, 1971), a source of mental energy (Kahneman, 1973), or a mental workspace (Moray, 1967) that can be shared by all central processes and all kinds of content. The theories of selective attention described below address how content is selected. I believe this is an important step forward. The rest of cognitive science and much of cognitive neuroscience are concerned with content. Theories of attention that address content can inform that broader literature.
The remainder of this section provides equations that describe multiplicative gain control in each of the domains. My purpose is to show that it is incorporated in the core assumptions of the computational and mathematical theories in each domain. Readers interested in more complete specifications of the theories and their applications to empirical phenomena may consult the references provided.
Behavior theory
The first mathematical model to incorporate selection by multiplicative gain control was Hull’s (1943) behavior theory, published before the cognitive revolution. It assumed that the potential to give a habitual response to a stimulus, SER, is the product of habit strength, SHR, and the current motivational state, expressed as drive, D:

If habit strength for going up the hill to the berries is equal to the habit strength for going down to the stream, we would go up the hill when we are hungry (Dhunger > Dthirst) and down to the stream when we are thirsty (Dthirst > Dhunger). In Hull’s theory, drive is determined by bodily needs and states of deprivation. It is not under voluntary control as it is with selective attention.
Associative learning
Selective attention plays an important role in more recent theories of associative learning in animals, which follow Hull’s tradition. Mackintosh (1975) proposed that attention modulates the learning of responses to cues that produce reinforcement. The increment in strength of response A, ΔVA, is the product of the remaining strength to be gained (λ − VA) and a learning rate, θ, that is common to all associations, multiplied by an attention weight, α A , given to response A:
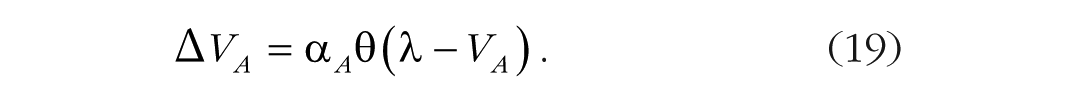
The attention weight increases with reinforcement, so the animal learns to attend to cues that produce reinforcement. Mackintosh explicitly eschewed explanations in terms of capacity limitations, saying “subjects control their own exposure to the discriminative stimuli; they are under no constraints to respond rapidly, and there is little reason to suppose, therefore, that they are processing information at rates close to the limits of their capacity” (p. 281).
Kruschke (2001) proposed an attentional theory of associative learning in humans that retained the core assumptions of Mackintosh’s (1975) theory about the role of attention in gating input cues and added assumptions about the role of attention in selecting outputs (responses) along with richer assumptions about the (categorical) representations of the stimuli and tasks. His model is a neural network defined by a set of nodes that represent features and categories and a set of connections between them. In his model, the activation of output node k,
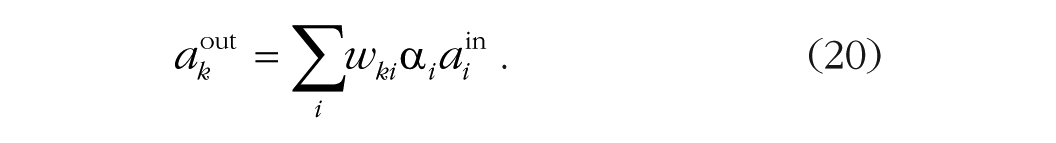
Output strength increases with the strength of the inputs and the attention paid to them. Increasing the attention weight on a cue increases its influence on learning and behavior.
Kruschke (2001) represented the attention weights as a vector of values constrained to have length P, which he interpreted as a capacity limitation on the weights. The connection to limited capacity is not necessary. Kruschke did not use any of the ideas in capacity or resource theories of attention beyond the assumption that capacity is limited. The constraint on the length of the vector may be better construed as normalization.
Categorization
Selective attention plays a central role in research on categorization, which examines how people learn to attend to features that distinguish categories. Nosofsky’s generalized context model of categorization incorporates multiplicative gain control in the selection of categories and the selection of features (Nosofsky, 1986, 1988; Nosofsky & Palmeri, 1997). Like Luce, Nosofsky modeled response choice as a ratio of products of similarities, η(x, i), between objects, x, and categories, i, and attentional biases for categories, β i . Subjects categorize a test probe i as a member of category X or Y by comparing its similarity to all the memorized instances of category X with its similarity to all the memorized instances of category Y using the Luce choice ratio:
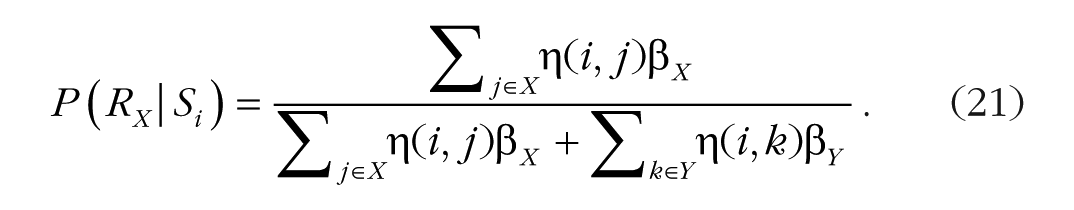
The βs act as multiplicative gain controls on the similarities, elevating evidence for desired categorizations to ensure they are selected. Subjects will have many instances of many categories in their memories; β X and β Y select the ones relevant to the current task.
Nosofsky assumed that the similarities are exponential functions of the distance between the object and the category representation in multidimensional space (Shepard, 1957, 1987):
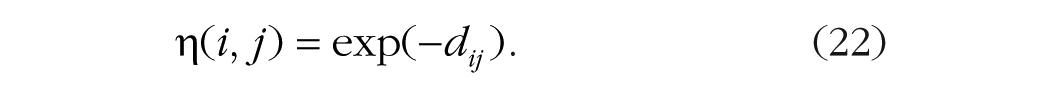
More similar objects are closer to each other than less similar objects. He defined distance in terms of the matches of the features of the representations weighted multiplicatively by attention
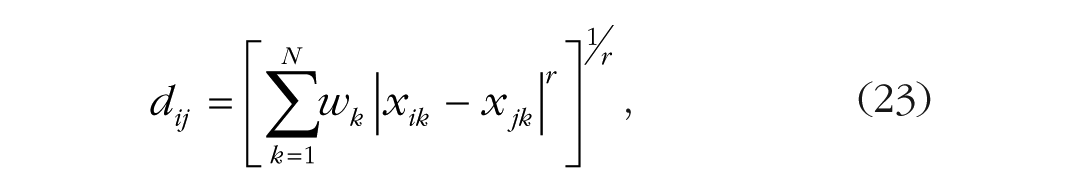
where |xik − xjk| is the absolute difference between objects i and j on feature k, wk is the attentional weight on feature dimension k, N is the number of features, and r determines whether the distance metric is city block (1) or Euclidean (2). The attention weights allow the model to focus on different features for different categories, increasing the gain on the ones relevant to the current task. Nosofsky’s approach to attention has been very productive. It explains many phenomena in the categorization literature in terms of multiplicative biases for categories and multiplicative weights on dimensions (e.g., Nosofsky, 1988; Nosofsky & Palmeri, 1997) and has inspired other models (e.g., Kruschke, 2001; Logan, 2002; L. B. Smith, 1989).
Perceptual learning
E. J. Gibson (1963) described perceptual learning as the education of attention, in which people learn to perceive the aspects of their environment that are most relevant to their goals. She defined attention as perception with respect to a goal and explicitly eschewed limited-capacity and resource theories of attention (E. J. Gibson & Rader, 1979, pp. 5–7). Perceptual learning allowed people to differentiate objects in increasingly intricate ways, focusing more sharply on the most relevant percepts (J. J. Gibson & Gibson, 1955).
Formal models describe perceptual learning as the (multiplicative) weighting and reweighting of cues from the environment to support optimal decisions, progressively giving more weight to the more valid cues and less weight to the less valid ones (e.g., Petrov et al., 2005). Dosher and Lu (2017) claimed that “all current computational models of perceptual learning are [dimension] reweighting models” (p. 349), enhancing selection by multiplicative gain control.
Cognitive development
The development of selective attention is a central theme in studies of cognitive development. Young children show a transition from attending to objects holistically to selectively attending to specific dimensions (Inhelder & Piaget, 1964). Linda Smith and colleagues (Hanania & Smith, 2010; L. B. Smith, 1989) explained the change in terms of the attention weights in Nosofsky’s (1986) generalized context model (Eq. 23). They modeled holistic processing of objects with equal weights on all dimensions and selective attention to dimensions with stronger weights on desired dimensions. They modeled rule-based processing as focused attention on a single dimension, assigning a weight near 1.0 to the relevant dimension and weights near 0 to the other dimensions. Selective attention also occurs through multiplicative gain control in this domain.
Neuroscience
The idea that selective attention is implemented as multiplicative gain control is common in neuroscience (Desimone & Duncan, 1995; Schmitz & Duncan, 2018). Reynolds and Heeger (2009) proposed a normalization model of attention, in which selection is implemented as a multiplicative increase in the stimulus drive (Eq. 16) for preferred locations or stimulus properties. In their notation, the response rate, R(x, θ), for a neuron responding to a grating with orientation θ at location x is a function of the stimulus drive, E(x, θ), from the input and the suppressive drive, S(x, θ), from itself and the other neurons in the population (see Eq. 16) plus a constant, σ, that determines contrast gain:
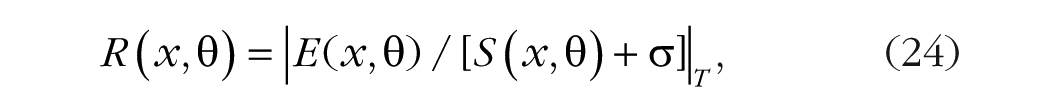
where | . | T denotes rectification with respect to a threshold T. Selective attention is modeled as a set of weights called the “attentional field,” A(x, θ), that multiplies selected values of the task-relevant features, which increases their activation in the stimulus drive and the suppressive drive, while normalization decreases the activation of task-irrelevant features:
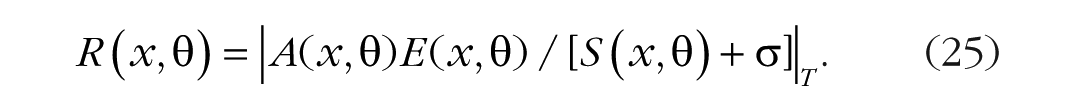
The suppression of the unattended stimulus is an obligatory consequence of normalization. The attention field enhances the activation of task-relevant features, which increases the suppressive drive for all features, reducing their activation. The normalization process applies to every stimulus in the receptive field. Attention takes advantage of normalization. It uses multiplicative gain control to bias the competition, increasing the activation of the stimuli it wants, which automatically suppresses the stimuli it does not want. The bias driving the activation may be voluntary. The subsequent suppression is not. It is an obligatory consequence of the circuitry.
Artificial intelligence
In the last 10 years, AI has been transformed by the advent and proliferation of deep learning (LeCun et al., 2015), which underlies the miracles we see in AI applications every day. Researchers discovered that selective attention was essential in these developments. It improved the performance of AI systems dramatically. In their seminal article “Attention Is All You Need,” Vaswani et al. (2017) showed that transformer models based on selective attention could achieve many of the miracles of AI without convolution or recurrence. This reduced training time and the number of required computations significantly and revolutionized the field. Currently, selective attention is used almost universally in AI (De Santana Correia & Colombini, 2022).
The attention model from Vaswani et al. (2017) assumes a matrix K of keys that represents the model’s knowledge, a matrix Q of queries that represents the features relevant to the goal, and a matrix V that represents the values of the keys. Selective attention is implemented as “scaled dot-product attention,” which is a form of multiplicative gain control. It is computed as the dot product (similarity) of the queries and keys divided by the square root of the number of dimensions. The dot products are normalized with softmax to range between 0 and 1 and are multiplied by the values (biases) to produce output. Formally,
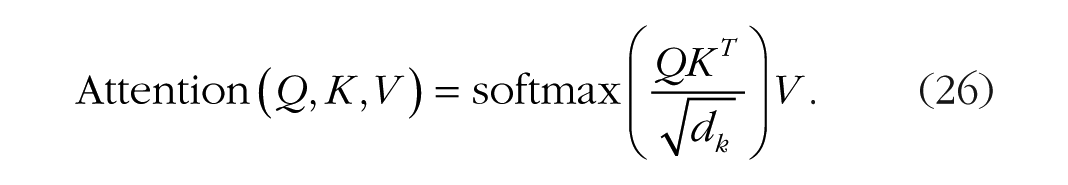
Vaswani et al.’s model assumes multiple attention “heads” can be applied to different aspects of the input at the same time. Their implementation of the model assumed eight different attention heads processing in parallel. In principle, there is no limit on the number of simultaneous attention heads, in contrast with limited-capacity and resource theories of human attention. Attention is useful even if capacity is unlimited.
Attention, multiplicative gain control, and normalization
These examples show how selective attention can be accomplished by multiplicative gain control. It produces the trade-offs characteristic of selective attention: Goal-relevant objects, dimensions, and categories can be selected by increasing their weight in the decision process, which increases the likelihood they will determine performance. Irrelevant objects, dimensions, and categories can be ignored by giving them no weight or suppressed by giving them lower weight. In either case, they will have less impact on the decision process and a lower likelihood of determining performance.
It is tempting to think of the attentional weights in terms of capacity theories, as a mental resource that can be allocated to the input. In many theories, attention weights are normalized to sum to a constant, like a resource. Nosofsky (1986) and Kruschke (2001) made the connection explicitly, interpreting the constant as a capacity limit on attention, although they did not use the concept or the ideas associated with capacity or resource theory in their accounts of categorization and associative learning phenomena. Again, I think it is best to resist the temptation. Normalization can be useful for other reasons, and there may be no escaping it in the choice process.
Normalizing attention weights is useful computationally because it reduces the number of parameters to be estimated (Nosofsky, 1986) and constrains the range of parameter values (e.g., to probabilities; Vaswani et al., 2017). The top panel of Figure 4 represents the effect of attention weights on two dimensions normalized so that the weight is w for Dimension 1 and 1 − w for Dimension 2, as in Nosofsky’s model. Increasing w increases the distance between the objects on Dimension 1, which increases discriminability, and shrinks the distance between objects on Dimension 2, which decreases discriminability. This ensures that decisions will be based on relevant information. However, the same result can be obtained by increasing only the weight on the relevant dimension. The bottom panel of Figure 4 shows that changing the weight only on the relevant dimension increases its distance without reducing the distance on the other dimension. The dimension with the higher weight is enhanced relative to the dimension with the lower weight whether or not the weights are constrained to sum to a constant. The assumption of limited capacity is not necessary to account for performance. The weights themselves are sufficient.
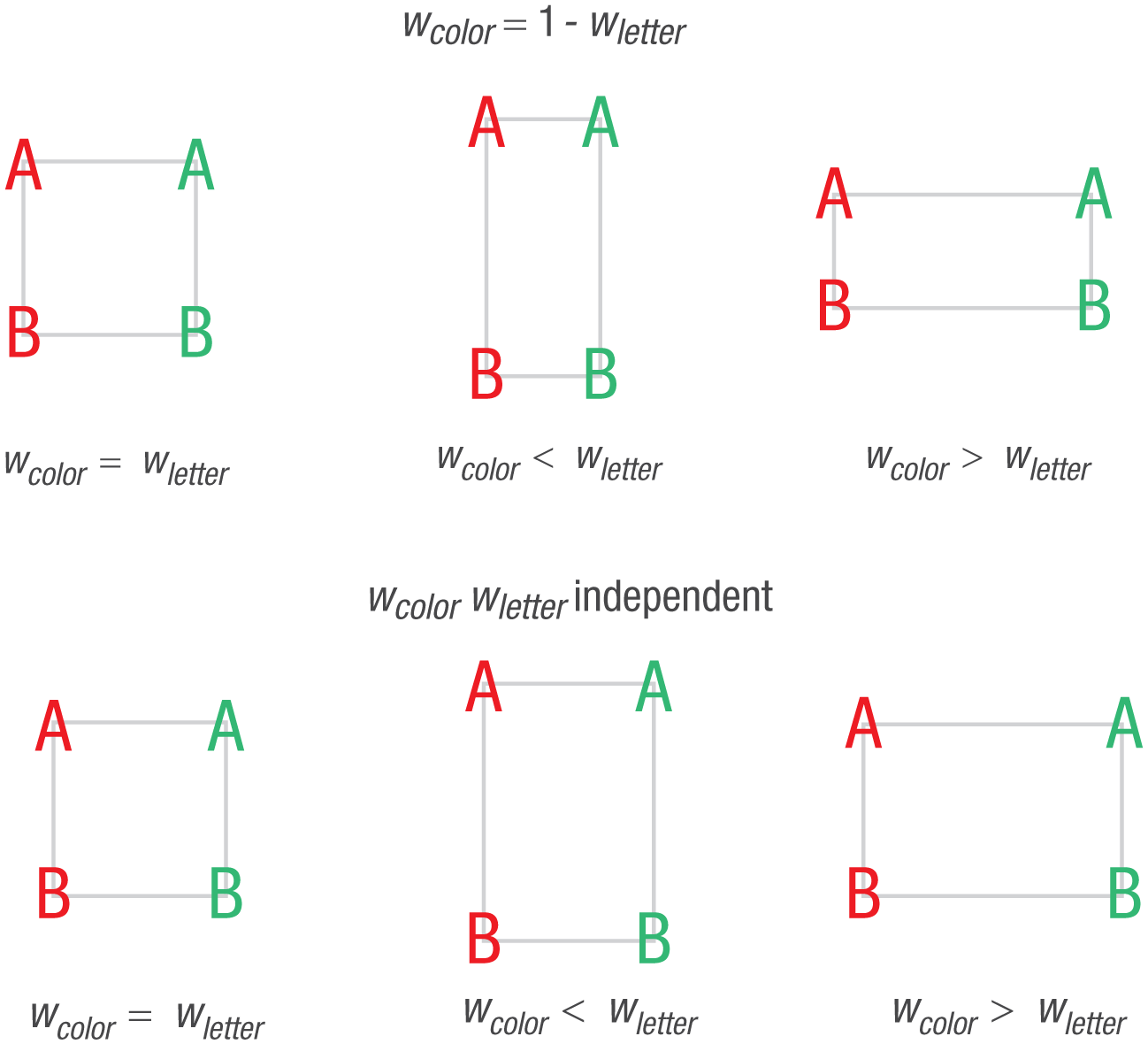
Effects of attentional weights on discrimination. Equal weights on the color and letter dimensions are shown in the left panels, a higher weight on the letter dimension than on the color dimension is shown in the middle panels, and a higher weight on the color dimension than on the letter dimension is shown in the right panel. Weights in the top panel are constrained to sum to a constant (1.0). Unconstrained weights are shown in the bottom panel. Both constrained and unconstrained weights favor the dimension with the higher weight.
Weights are often normalized in the decision process. The weights multiply the input values given by the stimulus, and the products are evaluated by a process similar to the Luce choice ratio or softmax that normalizes the products. Normalizing the products normalizes the effect of the weights, allowing larger products that represent relevant information to dominate smaller products that represent less relevant or irrelevant information. Higher weights will dominate the choice process whether or not the weights are normalized. If the normalization of weights is necessary for interpreting weights as a resource, the possibility of nonnormalized weights breaks the analogy. Selection by multiplicative gain control gives us ways to imagine attention with no resources.
Why we do only one thing at a time
Limited-capacity-channel and resource theories do not provide satisfactory answers to the question of why we do only one thing at a time. Limited-capacity-channel theories assume it axiomatically (Broadbent, 1957; Pashler & Johnston, 1989; Welford, 1952, 1959), and resource theories assume it happens because tasks demand more capacity than the system can provide (Kahneman, 1973; Moray, 1967; Posner & Boies, 1971). These assumptions internalize the observation that people generally do one thing at a time and claim that there is part of the mind (part of the brain) that can do only one thing at a time. Internalizing the observation does not explain the observation. Other principles are required.
Choosing one thing at a time
I propose that choosing is one thing that we do only one at a time (Logan, 2002; Logan et al., 2023). There may be other things we do one at a time and some things we do more than one at a time, but we choose one thing at a time. It is required by the nature of choice and the constraints on our choices. In cognitive psychology (Luce, 1959; Tversky, 1972), judgment and decision-making (Johnson & Busemeyer, 2016; Tversky & Kahneman, 1992), and economics (McFadden, 1976; von Neumann & Morgenstern, 1944), choice is defined as selecting one alternative from a set of mutually exclusive possibilities. The formal theories in these literatures and formal models of choice, including signal-detection theory and stochastic accumulator models of RT, are designed to do just that. They all select one thing at a time. These theories and models are among the best and most sophisticated in cognitive science, covering a broad range of phenomena. Each of the selective-attention models described above includes a decision model that chooses a response to the selected information. Applied to dual tasks, the decision models predict a bottleneck whenever choice is required, and they provide computational explanations of why it happens. The PRP task, which demonstrates the bottleneck most clearly, involves two choices—one for each stimulus. Stochastic accumulator models account for those choices and predict a bottleneck because they make only one choice at a time (see, e.g., Koob et al., 2023; Logan & Gordon, 2001).
Figure 5 illustrates the bottleneck in a diffusion decision model (P. L. Smith & Ratcliff, 2025). The current state of evidence begins at z and drifts toward one alternative (A) or the other (B). The choice is decided when the current state of evidence reaches a boundary. It is clear from Figure 5 that the diffusion process can reach only one boundary at a time. In this two-alternative formulation of the model, evidence for one alternative is evidence against the other, so movement toward one boundary is movement away from the other. Choices among more alternatives are usually modeled as a race between stochastic accumulators (Tillman et al., 2020; Usher & McClelland, 2001). Those models treat decision time as a real number, so the probability of an exact tie is very close to zero. Only one runner can win. The growth of evidence with time is more than theoretical. Stochastic accumulator models describe the growth of activation in movement- and decision-related neurons to a threshold, suggesting that the brain makes one choice at a time (Cox et al., 2022; Gold & Shadlen, 2007; Purcell et al., 2012).
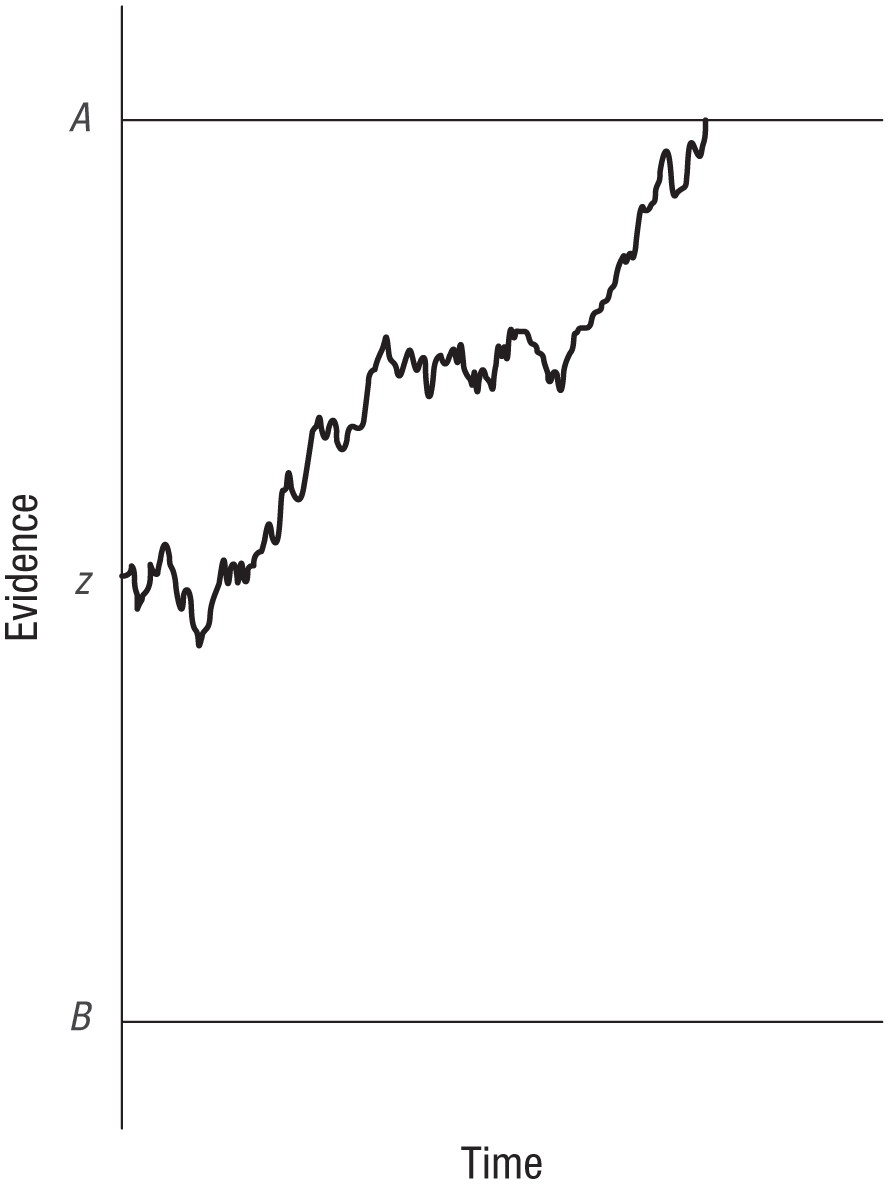
The trajectory of a diffusion decision process making a choice on a single trial. Evidence accumulates over time with drift rate d. Accumulation begins at the starting point, z, and proceeds until the accumulated evidence reaches one of the two boundaries, A or B. The decision ends when the evidence reaches a boundary and the response associated with the boundary is executed. The decision-time component of the reaction time is the interval from the onset of the diffusion process to the point at which the diffusion reaches a boundary.
This point about models of choice is important. It makes the claim that choice is a bottleneck more than a metaphor. The models make the process of choosing explicit computationally and mathematically. Their computational goal of choosing one alternative out of many explains why only one choice is made at a time. Their algorithms implement constraints that achieve that goal. The mechanics of random walk (Nosofsky & Palmeri, 1997), diffusion (Ratcliff, 1978), race (Tillman et al., 2020), and Luce choice models (Luce, 1959) are designed to choose one thing at a time. We can simulate them and see how they do it (Fig. 5). The broad application of choice models in many domains suggests that bottlenecks are ubiquitous. They will occur in any situation in which behavior can be described by a choice model. This claim is as broad in scope as the original limited-capacity-channel models of Welford (1952) and Broadbent (1957), suggesting a general model of attention, but the choice models provide mechanisms that explain why only one thing can be done at a time instead of assuming it axiomatically.
The idea that we are constrained to choose one thing at a time is consistent with research on the PRP effect, which has converged on the conclusion that the bottleneck computation that requires serial processing is response selection (Navon & Miller, 2002; Pashler & Johnston, 1989; Tombu & Jolicoeur, 2003; Welford, 1959). Response selection is defined as the process of choosing which response to make given the evidence from the stimulus (choosing one out of many), and researchers generally assume that only one choice can be made at a time (but see Meyer & Kieras, 1997).
The necessity of choosing one thing at a time follows from the nature of choice and the geographic, bodily, life, and economic constraints imposed on it. We choose because the world demands it. We live in extended environments and must choose where to be and where to go. The berries are up the hill; the stream is down the hill. We choose one school, one job, and one partner. We buy one car, one house, and one guitar (at a time; McFadden, 1976). Our choices are constrained by the nature of our bodies (Allport, 1987; E. J. Gibson & Rader, 1979; Neumann, 1987; Wu, 2011). We have one mouth, one voice, one set of hands, one set of legs, and two eyes that are constrained to focus on the same object. Our success as individuals and as a species depends on the effectiveness of our choices in fulfilling our goals and needs. These constraints impose pressures on our behavior that drive evolution, development, and learning to find solutions that optimize our choices. We live in a world full of irrelevant information. Selective attention is a response to those pressures that ensures our choices are based on the most relevant information. Serial attention is imposed on us by the requirement to choose just one alternative.
Constraints on selection may provide further encouragement to attend serially. The information sampled from perception or memory is gated multiplicatively by attention weights, and the weights for different goals may be incompatible. Gates that are open to one source of information may be closed to another. The weight on a feature may be low for Task A and high for Task B. Attention to Task A would block information about that feature from the decision process, which would postpone any decision about that feature in Task B. These constraints may not force serial attention to one thing at a time. The weights may sample information from several sources simultaneously, as in parallel visual search, or they may be combined conjunctively to focus specifically on one object, as in attentional cuing.
There are computational advantages of choosing one alternative at a time that have been documented in dual-task studies. Choosing serially instead of in parallel reduces the cross talk and interference between the processes required for each choice (Navon & Miller, 1987). Choosing serially solves the “dual-task binding problem” of associating decision outcomes with the stimuli that drove them (Logan & Gordon, 2001). And it minimizes total completion time for the two tasks (J. Miller et al., 2009). At larger timescales, doing one task at a time is often more efficient than multitasking. People get things done by finishing one task before starting another.
Complications
Stimulus-driven attention
It is well established that salient stimuli disrupt performance when they are irrelevant to the current task, as if they capture attention (Egeth & Yantis, 1997; Theeuwes, 2024). In these tasks, the target is often a salient singleton (e.g., a square in a display of circle distractors), and the salient distractor is also a singleton (e.g., a triangle in a display of circle distractors). Subjects may use salience as a cue for the target, increasing
The broader problem of how we are sensitive to stimuli and events outside our current focus of attention is an important challenge to attention-as-choice theory and to all other theories of attention. How does something outside the choice set alter the choice? Moray’s (1959) famous demonstration that people recognize their own names on the unattended channel demonstrates the phenomenon clearly. The subject’s name was accompanied by an instruction to stop shadowing (“John Smith, you may stop now”). Following such instructions was not part of the task set for shadowing, which required repeating all the words, but subjects were sensitive to the meaning and stopped anyway. Theories usually focus on performance of instructed tasks (single or dual), and experiments try to remove extraneous sources of information that might distract attention, as if the current task is all there is. My proposal that attention is choice makes the same implicit assumption.
Automaticity
Automaticity is a challenge for attention theories if it is defined as processing without attention. However, abundant evidence shows that the acquisition and expression of automaticity depends on attention (Kahneman & Treisman, 1984; Logan, 1990; Logan & Etherton, 1994). In Stroop and flanker tasks, automaticity is expressed as interference from irrelevant stimulus dimensions or stimuli (Eriksen & Eriksen, 1974; Stroop, 1935). The interference is typically explained as obligatory sampling of irrelevant information that adds to (or subtracts from) the evidence on which decisions are based. The correct response is selected by giving more (multiplicative) weight to the relevant information (Cohen et al., 1990; Logan, 1980).
In skilled performance, automaticity is expressed as faster, more fluent performance after practice. I believe it is best explained as basing choices on memory retrieval: Automatization reflects a transition from performance based on a general algorithm for solving problems in a domain to performance based on retrieving past solutions from memory (Logan, 1988, 1990). Automatic and “controlled” performance both require sampling (to determine what is retrieved and to determine the arguments for the computation, respectively), and both require deciding (to choose one alternative out of many), so both fit the definition of attention as choice.
Practice effects in the PRP task are consistent with the hypothesis that automatized tasks still require a decision process. The PRP effect is commonly interpreted as evidence that only one thing can be done at a time. It decreases with practice but is very hard to eliminate (Hazeltine et al., 2002; Ruthruff et al., 2001; Van Selst et al., 1999). The decrease is interpreted as a reduction in the time required for the central bottleneck (decision process) with practice. There have been no computational models of these effects, but the empirical demonstrations that the choice process remains after extensive practice are important.
Hierarchical control
Hierarchical control is an important phenomenon of automaticity and skill (Logan & Crump, 2011; Vallacher & Wegner, 1987). It allows us to think at a higher level and let the lower levels take care of the details: As I write this manuscript, I am composing sentences and choosing words at the same time as I am choosing which keys to press and which fingers to use. These simultaneous choices, apparent in many hierarchically controlled skills, appear to contradict the claim that we make only one choice at a time. It is possible that we accomplish such skills by rapidly switching between levels (choosing a word and then choosing the letters to type), but intuition and the speed of skilled performance suggest the choices are simultaneous.
Logan (2018) proposed a model of hierarchical control of skilled typing in which a higher level goal to type a word recruits lower level goals to type letters. Decisions about which letter to type are made at the lower level, driven only by the word to be typed and the letters typed so far (e.g., if your goal is to type “dog” and you’ve typed “d,” then type “o”). The lower level begins when it receives a word to type from the higher level and ends by sending a “done” signal to the higher level after the last keystroke. This hierarchical structure allows the lower level processes to function as a separate module (Fodor, 1983), dependent on higher level processing only for its input. The higher level can be thinking (deciding) about the next word while the lower level types the current one. The model accounts for many typing phenomena but is mute on the question of whether higher level and lower level decisions are concurrent. The decision about the word to type is made before the goal of typing it is sent to the lower level processes. It is possible that the next higher level decision has to wait until the lower level decisions have all been made. Whether or not that is the case is an empirical question.
Conclusions and Implications
I have asked you to imagine no resources when you think about attention. Imagine choice, selection, and normalization instead. They account for the phenomena of attention in many different disciplines, including associative learning, categorization, cognitive development, neuroscience, and AI, without assuming capacity limitations. Selective attention is the result of multiplicative gain control, intended to focus on aspects of the world that are most relevant to our goals. Measured capacity limitations are the result of competition and normalization.
I have argued that the concepts of limited-capacity, limited-resource, and single-channel attention do not explain their key assumption (why capacity is limited) or the roles that capacity, resources, and the single channel play in the computations that implement attention (what capacity does). I have shown that load effects—the hallmark of capacity limitations—result from normalization whether capacity is fixed, limited, or unlimited. I have not challenged capacity measures, which can be useful and informative without the extra trappings of resource theories. I have argued for a computational perspective in which attention is explained in terms of representations and the processes applied to them. This perspective dominates theoretical work in cognition and cognitive neuroscience. So should it dominate theories of attention.
What about my persecution? I am sure that the concept of limited-capacity attention will persist in the literature and lecture halls for years to come. I hope it will be overcome by the concept of attention as choice based on selection and normalization, but there is an intuitive appeal to the limited-capacity concept that will not be overcome easily. It provides apt metaphors that describe limitations on attention: The limited-capacity channel forces us to do one thing at a time, and limited resources given to one task reduce the resources available for others. My thesis here is that the metaphors do not work very well as computational theories of attention because they do not explain why capacity is limited, why the limited-capacity channel can do only one thing at a time, or how content is processed.
To reduce my persecution, I ask you to be careful in your use of the concept of limited-capacity attention. It is not absolutely necessary to explain dual-task and divided-attention deficits or the costs and benefits of selective attention. Selective attention is necessary because it provides information relevant to choice, not because capacity is limited. Its function is to guide choice, not to protect the limited-capacity channel from overload. If you invoke the resource concept, you must be prepared to explain why capacity is limited, defend the ancillary assumptions I described earlier, and address the challenge of multiple resources. Sometimes authors invoke the concept of limited-capacity attention in research on other topics to explain apparent limitations or to do necessary computational work whose nature is not explained. I would encourage those authors—and everyone else—to imagine selection and normalization for choice instead. It’s easy if you try.
Footnotes
Acknowledgements
I am grateful to Philip Smith for insightful comments on the manuscript, Jim Townsend for perspicuous thoughts about Shannon’s limit, and Jeremy Wolfe and two anonymous reviewers for very helpful reviews.
Transparency
Action Editor: Zhicheng Lin
Editor: Arturo E. Hernandez