
Abstract
Much of the recent masked nonword priming literature demonstrates no difference in priming between affixed and non-affixed nonword primes (e.g., maskity-MASK vs. maskond-MASK). A possible explanation for the absence of a difference is that studies have used affixed primes which were semantically uninterpretable. Therefore, this explanation indicates semantic interpretability plays a fundamental role in masked priming. To test this account, we conducted an experiment using the masked priming paradigm in the lexical decision task. We compared responses with targets which were preceded by one of four primes types: (1) interpretable affixed nonwords (e.g., maskless-MASK), (2) uninterpretable affixed nonwords (e.g., maskity-MASK), (3) non-affixed nonwords (e.g., maskond-MASK), and (4) unrelated words (e.g., tubeful-MASK). Our results follow the trend of finding no difference between affixed and non-affixed primes. Critically, however, we observed no difference in priming between uninterpretable and interpretable affixed primes. Thus, our results suggest that semantic interpretability does not influence masked priming.
Keywords
The role of morphological processing in the visual identification of complex words has been the subject of intensive study by psycholinguists. Morphemes are the building blocks of language, and the ability to recognise, analyse, and combine morphemes is critical for comprehension and production in skilled language use. For example, to understand a new word like unfriend we need to be able to identify its component morphemes. Evidence suggests that this process of decomposing a word into its morphemes continues to be important even after the word has become familiar in its whole word form (see Rastle & Davis, 2008, for a review). Thus, research over the last couple of decades has focussed on questions relating to how and when decomposition occurs. What information do readers make use of to decompose a complex word into its morphemic constituents, and does this occur before or after the lexical representation of the word is accessed?
Masked priming with word primes
A popular technique for investigating these issues is masked priming (e.g., Crepaldi et al., 2016; Forster et al., 1987; Frost et al., 1997; Grainger et al., 1991; Marslen-Wilson et al., 1994; Rastle et al., 2000). For example, participants can respond (e.g., by making a lexical decision) more rapidly to a target word like READ when it is preceded by a brief (~50 ms) presentation of a related morphologically complex word like reader than when it is preceded by a unrelated control word. Critically, this priming effect is greater than would be expected on the basis of semantic or orthographic information (e.g., Drews & Zwitserlood, 1995; Rastle et al., 2000). For example, Rastle et al. (2000) found that priming was greater for morphologically related prime–target pairs like vagueness-VAGUE than for prime–target pairs like electrode-ELECT, where there is equal orthographic overlap but no morphological relationship. Such priming effects have been interpreted as evidence of an early process that rapidly decomposes a prime into its morphemes, facilitating identification of the morpheme shared by prime and target.
Further evidence concerning the nature of this early decomposition process was provided by experiments reported by Longtin et al. (2003) and Rastle et al. (2004), who investigated the effect of pseudoaffixed word primes like corner, which have the orthographic appearance of affixed forms, but have no genuine morphological or semantic relationship to the target (i.e., a corner is not one who corns). These researchers found that masked priming effects for corner-CORN were just as great as for transparently related pairs like darkness-DARK, and significantly greater than for orthographic control primes like brothel-BROTH (where -el is not an English affix). Rastle and Davis (2008) concluded that this early decomposition process is based entirely on orthography and is blind to semantics. In addition to these initial investigations in French and English, similar results have been reported in Dutch (Diependaele et al., 2005), Hebrew (Frost et al., 1997), Spanish and Basque (Duñabeitia et al., 2007), and Russian (Heyer & Kornishova, 2018; Kazanina, 2011).
Although some studies have reported significantly greater priming for transparent than for opaque primes (e.g., Diependaele et al., 2005; Feldman et al., 2015), these empirical differences can probably be attributed to methodological differences (see M. H. Davis & Rastle, 2010). In particular, the difference between transparent and opaque primes is modulated by prime duration: When there is sufficient time for semantic processing to occur, priming is not observed for opaque forms. There is still some uncertainty concerning what constitutes sufficient time, but a reasonable estimate is 60 ms (in the masked priming paradigm, primes that are presented for longer than this duration are often consciously perceived, though of course this need not imply that conscious awareness is a critical factor). Indeed, Heyer and Kornishova (2018) investigated whether the difference in priming effect size between opaque and transparent primes would emerge regardless of prime duration. A significant difference between opaque and transparent primes appeared for trials involving a long prime duration (77 ms). However, this difference did not occur for trials involving a short prime duration (39 ms). Currently, the general consensus in the literature is that a difference between transparent and opaque primes is likely to be observed for primes that are presented for durations longer than 60 ms (e.g., Diependaele et al., 2005; Feldman et al., 2015; Rastle et al., 2000), whereas a difference is unlikely to reported for primes that are presented for durations less than 50 ms (see M. H. Davis & Rastle, 2010, for a meta-analysis).
There are a minority of studies which demonstrate semantic transparency effects with prime durations of 50 ms (e.g., Morris et al., 2007). However, this discrepancy in findings could again be attributed to methodological differences (M. H. Davis & Rastle, 2010). For example, while most studies which have reported no difference in priming between opaque and transparent primes used forward masking (e.g., Gold & Rastle, 2007; Kazanina et al., 2008), studies like Morris et al. (2007) used backward masking. In summary, a large body of evidence has been amassed to support the notion of an early morpho-orthographic decomposition process that is blind to semantics (and hence unaffected by semantic transparency). In summary, a large body of evidence has been amassed to support the notion of an early morpho-orthographic decomposition process that is blind to semantics (and hence unaffected by semantic transparency).
Masked priming with nonword primes
A common variation of the masked morphological priming paradigm uses nonwords as primes (e.g., Beyersmann et al., 2015, 2016; Heathcote et al., 2017; Longtin & Meunier, 2005; McCormick, Brysbaert, & Rastle, 2009; McCormick, Rastle, & Davis, 2009; Morris et al., 2011). From a methodological standpoint, the use of nonwords has some advantages. In particular, using nonwords as primes makes it much easier to compare different prime conditions with the same targets (morphological priming experiments with word primes usually require comparisons across different word targets). Furthermore, it is potentially advantageous to use primes that are not nonwords so as to minimise lexical influences (of words other than the target) on priming. It is well established that masked word form primes can give rise to inhibitory priming effects; for example, a prime-like rocket may result in slower lexical decision latencies to the target ROCK, relative to an unrelated word prime (e.g., C. J. Davis & Lupker, 2006; De Moor & Brysbaert, 2000; Segui & Grainger, 1990). This inhibitory priming effect may reflect competition between the lexical representations of the prime and the target. By contrast, inhibitory priming effects are not usually observed for nonword primes.
If letter strings containing (pseudo-)affixes automatically engage a morpho-orthographic decomposition mechanism, it is reasonable to expect that nonword primes formed by combining stems with affixes should give rise to similar priming effects as those observed with word primes (e.g., worder-WORD should give similar priming effects to corner-CORN or burner-BURN). Such results have indeed been observed. For example, McCormick, Brysbaert & Rastle, (2009) found that priming for nonword primes like alarmer-ALARM was statistically equivalent to that obtained for word primes like national-NATION and notional-NOTION (high and low frequency word primes, respectively). They interpreted this result as “lending strong support to the notion of a routine form of decomposition that is applied to all morphologically structured stimuli” (McCormick, Brysbaert & Rastle, 2009, p. 1706).
However, caution is required when interpreting priming effects obtained with morphologically complex nonword primes. A natural question to ask about such effects is whether they might more parsimoniously be interpreted as reflecting purely orthographic, as opposed to morpho-orthographic processing. After all, very similar priming effects are obtained in orthographic form priming experiments in which there is no reason to suppose morphological involvement. For example, Lupker et al. (2015) examined the effect of adding a consonant at the beginning or end of a word (e.g., zjudge-JUDGE or judgez-JUDGE) and observed priming effects of greater than 30 ms. Note that such form priming effects do not depend on preserving the contiguity of the target letters. For example, Grainger and colleagues (Van Assche & Grainger, 2006; Welvaert et al., 2008) have shown large priming effects for primes in which non-target letters are inserted within the word (e.g., musxtayrd-MUSTARD). The Form Priming Project (FPP; Adelman et al., 2014), a large-scale masked priming experiment in which over 1,000 participants were tested across 14 sites, found a 19 ms priming effect for primes formed by inserting two random (non-repeat) letters within the target word (e.g., desaxign-DESIGN). Related results on the perceptual similarity of orthographic neighbours formed by letter addition/deletion have been observed in unprimed lexical decision (C. J. Davis et al., 2009; C. J. Davis & Taft, 2005), eye-tracking (C. J. Davis et al., 2009), and semantic categorisation (Bowers et al., 2005). For example, Bowers et al. (2005) found that participants took longer (and were less accurate) to reject the word apex (which has the deletion neighbour ape) as a type of animal than to reject apex as a type of vehicle (and conversely scar took longer to reject as a type of vehicle than as a type of animal). The implication is that deletion neighbours are processed to the level of meaning, such that performance is impaired when these neighbours would require a different response than the word that was presented. It is important to emphasise that these empirical findings provided confirmations of the predictions made by a computational model of orthographic processing (C. J. Davis, 1999, 2010); the orthographic similarity of addition/deletion neighbours is also predicted by other models of orthographic processing (e.g., Adelman, 2011; Grainger et al., 2003; Norris et al., 2010; Whitney, 2001). In summary, finding that alarmer-ALARM results in priming relative to an unrelated prime cannot be interpreted as evidence for a morphological process, because such priming effects are predicted by models that include no morphological processing.
One approach to attempt to establish that priming effects with complex nonword primes do entail morphological processing would be to show that stronger priming is obtained for (pseudo-)affixed nonword primes like alarmer than for non-affixed nonword primes like alarmel, where form overlap is matched. Some experiments have reported such a difference (e.g., Longtin & Meunier, 2005; McCormick, Brysbaert & Rastle, 2009). However, in these experiments the relevant comparisons involved different targets and/or participants, which is not ideal. Furthermore, the priming effects for non-affixed nonword primes did not attain significance in these experiments, which is inconsistent with the usual pattern for orthographic form primes (e.g., Adelman et al., 2014). By contrast, more recent investigations using within-item designs have tended to find equivalent priming for non-interpretable affixed and non-affixed nonword primes (e.g., Beyersmann et al., 2015, 2016; Morris et al., 2011). Faced with these null effects, the most straightforward conclusion would appear to be that the priming effects obtained with morphologically complex nonword primes are driven entirely by form overlap, with no need to posit any role for morphological decomposition or other morphological processing.
Does semantic interpretability influence nonword priming?
However, an alternative interpretation of these data, recently suggested by Heathcote et al. (2017), is that the above-cited studies failed to find a difference in priming between affixed and non-affixed nonwords because the affixed nonwords were semantically noninterpretable. In support of this interpretation, Heathcote et al. (2017) reported a lexical decision experiment in which affixed nonword primes that had been rated as semantically plausible resulted in significantly greater priming than non-affixed control primes; for example, cheapize-CHEAP resulted in greater priming than cheapstry-CHEAP. As they note, “The obvious advantage of interpretable relative to non-interpretable complex novel words is that interpretable stem-affix combinations generate meaning, whereas non-interpretable stem-affix combinations do not.”
Evidently, readers are able to determine whether a novel affixed form is interpretable. Faced with a novel word like cheapize, skilled readers are able to determine a likely morphological structure and then use this to come up with a possible interpretation (e.g., “to make cheap”). In particular, Heathcote et al. (2017) appealed to the notion of a licencing mechanism governing the (re-)combination of stems and affixes (Schreuder & Baayen, 1995). This mechanism succeeds for interpretable primes like cheapize but is unsuccessful for uninterpretable and non-affixed primes, resulting in reduced priming effects. Potentially, then, the mixed empirical findings may reflect differences in the proportion of interpretable primes (or degree of prime interpretability) in different experiments.
As Heathcote et al. (2017) note, there are previous observations that provide support for the role of interpretability. Most relevantly, Meunier and Longtin (2007) found that morphologically complex pseudowords were effective primes of their stems in cross-modal priming, but only if the pseudoword was interpretable. That is, priming was found for rapidifier-RAPIDE (an English equivalent is quickify-QUICK), but not for sportation-SPORT. They concluded that “semantic interpretability plays a major role during pseudoword recognition” (p. 467). Other evidence for the role of interpretability (and support for a licencing mechanism) comes from studies that have found that interpretable morphologically complex nonwords take longer to reject in a lexical decision task than uninterpretable controls (Burani et al., 1999; Coolen et al., 1991; Wurm, 2000).
Nevertheless, the latter studies were not masked priming experiments, and do not challenge the claim that early processing involves a semantically blind orthographic parser. Indeed, as outlined earlier, masked priming experiments showing the absence of semantic transparency effects with word primes have led to an explanatory framework in which semantic processing does not begin until later (Heyer & Kornishova, 2018; Rastle & Davis, 2008). 1 This time course is consistent with semantic priming experiments: semantic/associative priming effects only start to become robust for primes that are presented for around 80 ms (for a meta-analysis, see Brysbaert et al., 2015). A relatively deep level of semantic processing is required to determine that cheapize is interpretable, perhaps more than one might expect could be afforded a masked prime. Thus, while interpretability is undoubtedly a factor that influences processing of nonwords, stronger evidence is required to support the claim that this factor exerts its influence sufficiently rapidly to provide an explanation of differences in masked form priming effects for different nonword primes.
Furthermore, the claim that interpretability influences priming effects for masked nonword primes is inconsistent with a previous examination of this issue. Longtin and Meunier (2005) found equivalent priming from interpretable (rapidifier-RAPIDE) and non-interpretable (sportation-SPORT) nonword primes. However, as noted earlier, these authors found no priming for nonword primes with non-affixed endings (rapiduit-RAPIDE). Evidently, the available literature provides a somewhat mixed picture. Longtin and Meunier’s (2005) result raises the possibility that the difference between interpretable and non-affixed primes observed by Heathcote et al. (2017) could reflect the presence of an affix, rather than the interpretability of the stem-affix combination. Indeed, Heathcote et al.’s (2017) experiment appears to be lacking the full set of conditions required to support any conclusion regarding prime interpretability.
In view of these considerations, a replication of Heathcote et al. (2017) was warranted. We took a few steps to achieve a higher level of power than their original experiment: (a) we greatly increased the size of the stimulus set, (b) we tested a relatively large number of participants, and (c) given that Heathcote et al. (2017) found that (numerically at least) the difference between the interpretable affixed and (non-interpretable) non-affixed conditions was greater for suffixes than for prefixes, we decided to focus our power by restricting our attention to suffixes. Critically, we added a new prime condition comprising uninterpretable affixed nonwords, that is, nonwords formed by stem-affix combinations that are not readily interpretable (e.g., maskity). If the difference reported by Heathcote et al. (2017) is a genuine interpretability effect, there should be greater priming for prime-target pairs like maskless-MASK than for pairs like maskity-MASK. If our findings do support Heathcote et al. (2017), then our study would be inconsistent with the trend in the literature reporting lack of semantic transparency effects during early processing.
Method
Participants
There were 122 participants in total. Of these, 73 participants were tested at the University of Bristol and 49 at the University of Hull. At both sites the participants were psychology undergraduates who participated in exchange for course credit; all had normal or corrected-to-normal vision. The study was approved by the University of Bristol Faculty of Science Research Ethics Committee and the University of Hull Faculty of Health Sciences Ethics Committee, and all participants provided their informed consent.
Stimuli and design
The experiment used a within-subjects design in which the independent variable was Prime Type and the dependent variables were reaction time and accuracy. The four prime types were (a) interpretable affixed nonwords, (b) uninterpretable affixed nonwords, (c) non-affixed nonwords, and (d) unrelated primes. A Latin square design was used to rotate the prime stimuli across targets, resulting in four counterbalanced lists. There were 208 target stimuli, half of which were real words. Three-eighths of the target stimuli were drawn from Heathcote et al.’s (2017) items, to which we added a further 130 stimuli. The target words were all monomorphemic, ranging in frequency from 0.6 to 510 per million (M = 87.7, SD = 112.4), and in length from 3 to 7 letters (M = 4.8, SD = 0.9). Each of the target words was a stem morpheme in at least one polymorphemic English word (e.g., round is the stem of the word roundness). Related primes were formed by adding an affix or a non-affix letter string to these stems. Following Heathcote et al. (2017), no orthographic alterations were made to stems when adding suffixes (e.g., final e was not dropped when adding an initial-vowel suffix).
Interpretable primes were created by combining each stem with a suffix to form a semantically plausible nonword (e.g., the suffix -less was added to the stem mask to generate the nonword maskless). In the case of target stimuli drawn from Heathcote et al. (2017), we used the same primes as in their experiment. For the new targets we obtained subjective evaluations of the plausibility of multiple candidate suffixed forms from a small group of native speakers (mostly undergraduates), who rated plausibility on a scale from 1 (not plausible) to 5 (very plausible). Interpretable affixed nonwords were judged as plausible (at least 3 out of 5) by at least half of the raters. Uninterpretable nonwords (e.g., maskity) were created in the same way as interpretable primes, except that the resulting affixed nonword was rated as implausible by at least half of the raters.
Non-affixed nonword primes were created by combining stems with a string of letters which were not suffixes (e.g., ort, lem). We attempted to minimise orthographic overlap between the stem and letter string endings, although some overlap could not be avoided. The unrelated prime condition comprised affixed words that shared no more than two letters with their corresponding targets (e.g., prideful-ACID). Stimulus characteristics for the primes paired with word targets are shown in Table 1.
Characteristics of prime stimuli.
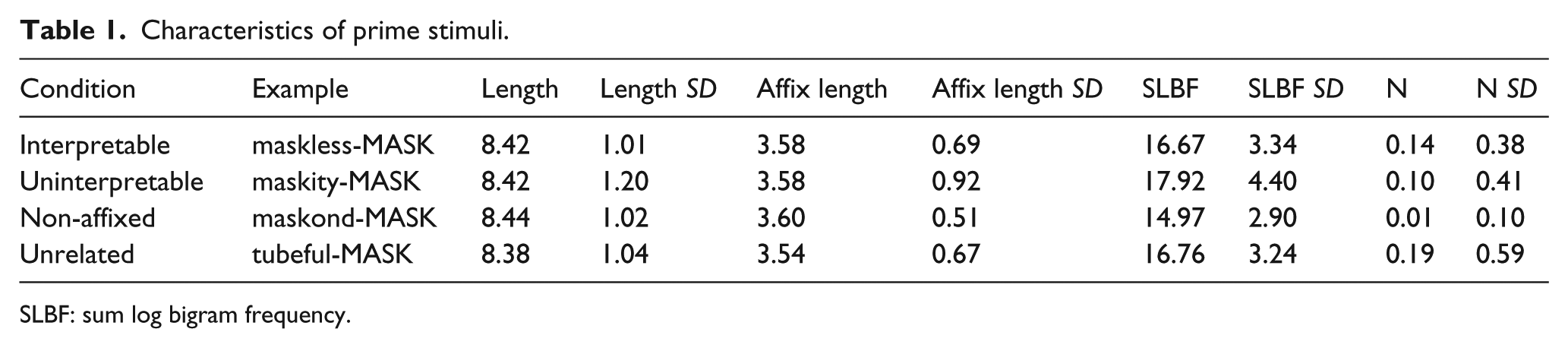
SLBF: sum log bigram frequency.
Pronounceable nonword stimuli were created by changing one or two letters of corresponding word targets. Primes were constructed by applying the same changes to the corresponding related primes. For example, the nonword target MISK was constructed by changing the a in MASK to an i, and the related primes then became miskless, miskity, and miskond. The same unrelated primes were used for the corresponding word targets (e.g., the word target MASK and the nonword target MISK were both preceded by the unrelated prime tubeful). Items were counterbalanced so that a participant would not see a word and a nonword target it was derived from (i.e., they wouldn’t see MASK and MISK). The full set of stimuli for this experiment, as well as the raw data, can be found at https://osf.io/7y2ve/.
Procedure
Participants were seated approximately 60 cm in front of a monitor attached to a PC running Microsoft Windows 7. DMDX software (Forster & Forster, 2003) was used to present the stimuli and record the reaction time and accuracy of responses. Each trial began with a forward mask (##########) that was displayed for 500 ms in the centre of the screen. The prime was then presented in lower case for approximately 50 ms, followed by the target which was presented in upper case until the participant responded (or until the trial timed out after 2 s). All stimuli were presented in white Courier New font on a black background. Primes were presented in 12 point font; the size of the target and mask stimuli was 50% greater (i.e., 18 point). Participants were instructed to decide whether each stimulus was a word or nonword as fast as possible without making too many errors. They used the left and right control keys to make nonword and word responses, respectively. Feedback (the word “Wrong”) was given on trials to which participants made incorrect responses or failed to respond within 2,500 ms. The experiment proper was preceded by eight practice trials. This part of the experiment took between 10 and 15 min.
Immediately following the lexical decision task, participants made ratings of the semantic plausibility of 52 nonwords, which were presented one at a time on the screen. These nonwords corresponded to the affixed primes that had been presented to that participant, preceding word targets, although there was no mention of any relationship between the two parts of the experiment. As in the pre-test, participants indicated the plausibility of each nonword on a scale of 1 to 5 (1 being not plausible and 5 being very plausible). This part of the experiment took around 5 min.
Data analysis
We used R (Version 3.5.1; R Core Team, 2018) and the R-packages BayesFactor (Version 0.9.12.4.2; Morey & Rouder, 2018), bindrcpp (Version 0.2.2; Müller, 2018), coda (Version 0.19.1; Plummer et al., 2006), dplyr (Version 0.7.6; Wickham et al., 2017), ez (Version 4.4.0; Lawrence, 2016), ggplot2 (Version 3.0.0; Wickham, 2009), Matrix (Version 1.2.14; Bates & Maechler, 2018), papaja (Version 0.1.0.9842; Aust & Barth, 2018), and rstudioapi (Version 0.7; Allaire et al., 2017) for our analyses.
Results
Interpretability ratings
Each of the affixed nonwords was rated by at least 30 participants. A response key other than digits 1 through 5 was recorded for 0.8% of the ratings, and these responses were discarded; for the remaining responses, the median rating was 3 and the modal rating was 1. The most interpretable nonword was “maskless” (given a rating of 5 by 83% of raters) and the least interpretable nonword was “happyation” (given a rating of 1 by 71% of raters, and a rating of 2 by a further 26%). An interpretability score was computed for each nonword based on its mean rating; these scores can be found at https://osf.io/7y2ve/.
In general, the preliminary assignment of nonwords to interpretability conditions was supported, such that the interpretable condition was associated with significantly higher scores than the uninterpretable condition, Welch’s
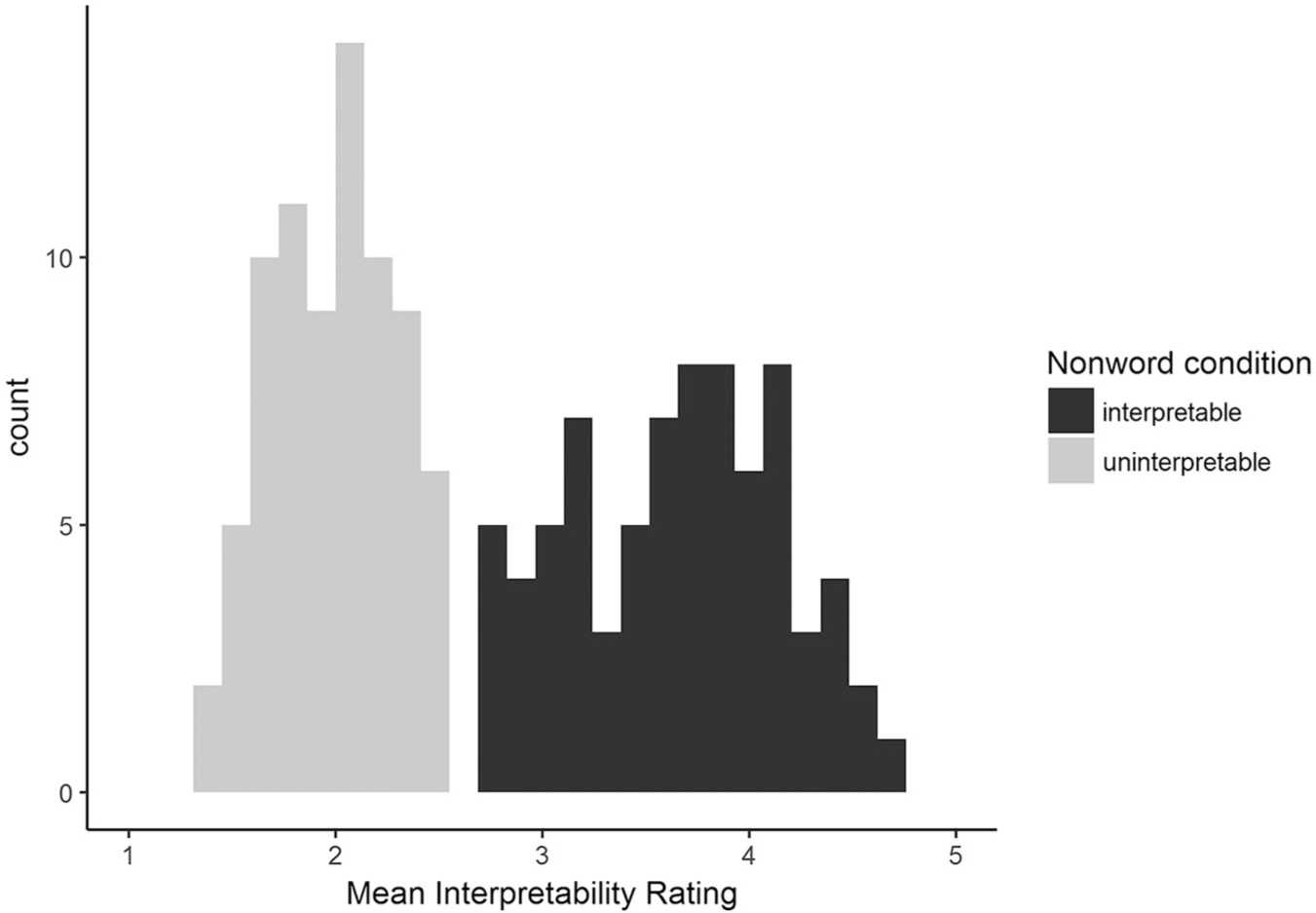
Distributions of mean interpretability ratings for items in the two affixed nonword conditions.
Lexical decision data
Data cleaning
Targets for which one or both nonword primes failed to satisfy the above rating criteria were treated as fillers, and were not included in the analysis of lexical decision data. Initial inspection of these data revealed one word target that was associated with a high error rate (greater than 2.5 SDs more than the mean). This target (FRILL) was excluded from further analysis. The same criterion led to the exclusion of four nonwords. The resulting set of target stimuli comprised 75 words and 98 nonwords.
Median accuracy across participants was 93.64%, and all but one participant had mean accuracies of greater than 75% correct; this error-prone participant was excluded from further analysis, as was one participant whose mean RT was more than 3 SDs slower than the mean. Following these exclusions, there were 30 participants for each of the four counterbalanced versions of the experiment.
Erroneous responses were excluded from the analysis of reaction times, as were responses faster than 150 ms or slower than 1,500 ms (1.18% of trials).
Words
Table 2 shows mean reaction time and error rates for each prime condition. Along with analysis using null hypothesis significance testing, we also provide Bayes factors (calculated using the BayesFactor R package; Rouder et al., 2009) for the three key comparisons of interest (the evidence of priming for the three prime types), which provides a quantitative measure of evidence for or against the null hypothesis. The main effect of prime condition on RT was statistically significant, F1(3, 357) = 5.09, p = .002; F2(3, 222) = 4.80, p = .003. Specifically, the three related conditions showed significant priming relative to the unrelated condition by subjects,
Mean correct reaction times (RT), standard deviations and standard errors and priming effects in ms, and error rates (ER) for target words in each prime condition.
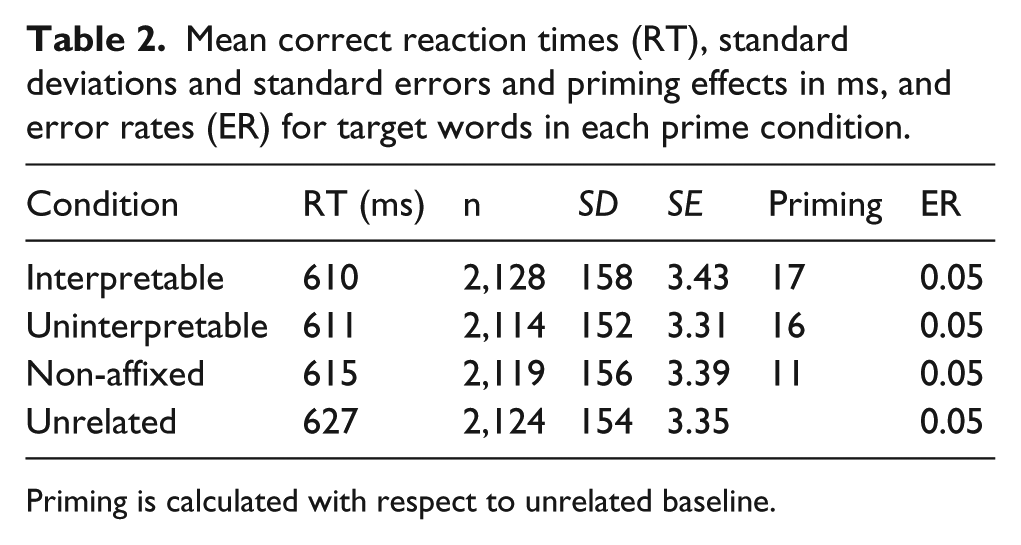
Priming is calculated with respect to unrelated baseline.
To check that a possible role of interpretability had not been masked by discretisation of this variable, we examined its continuous effect for the full set of 208 affixed nonword primes. Priming effects (relative to the unrelated condition) were computed for each of the affixed primes. As can be seen in Figure 2, the item-level data showed no indication of any positive relationship between nonword interpretability ratings and priming effects; there was a small, non-significant, negative correlation (r = −0.06, n = 208, p = .377).
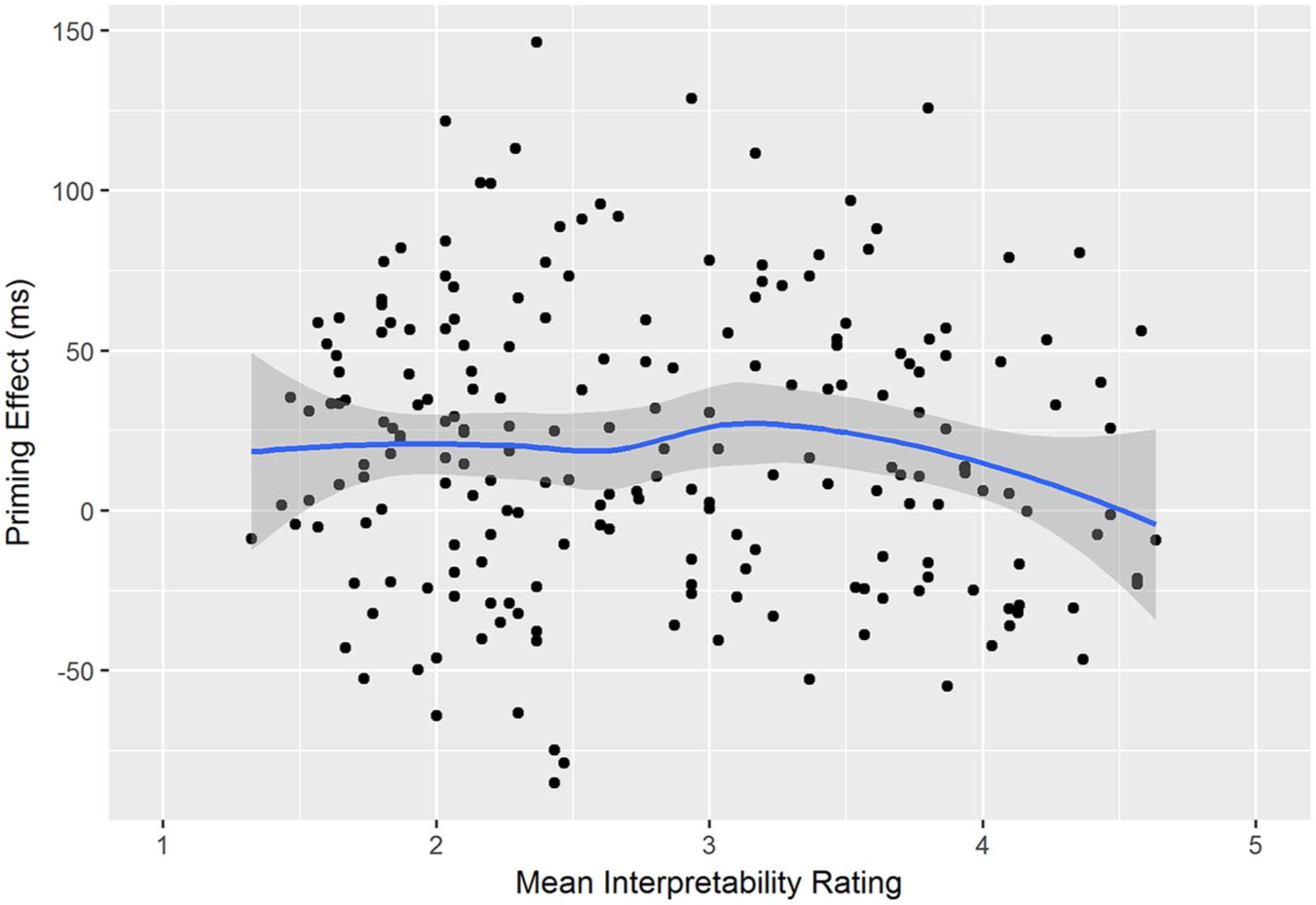
Item-level priming effects as a function of mean subjective interpretability for all affixed nonwords.
Nonwords
Table 3 shows mean reaction time and error rates for nonwords in each prime condition. As can be seen, each of the condition means was within 3 ms of the grand mean, that is, there was no difference in mean RT across conditions, F1(3, 357) = 0.44, p = .727; F2(3, 291) = 0.36, p = .779. Similarly, the analysis of accuracy data showed no effect of prime condition, F1(3, 357) = 0.25, p = .860; F2(3, 291) = 0.20, p = .897.
Mean correct reaction times (RT), standard deviations and standard errors and priming effects in ms, and error rates (ER) for target nonwords in each prime condition.
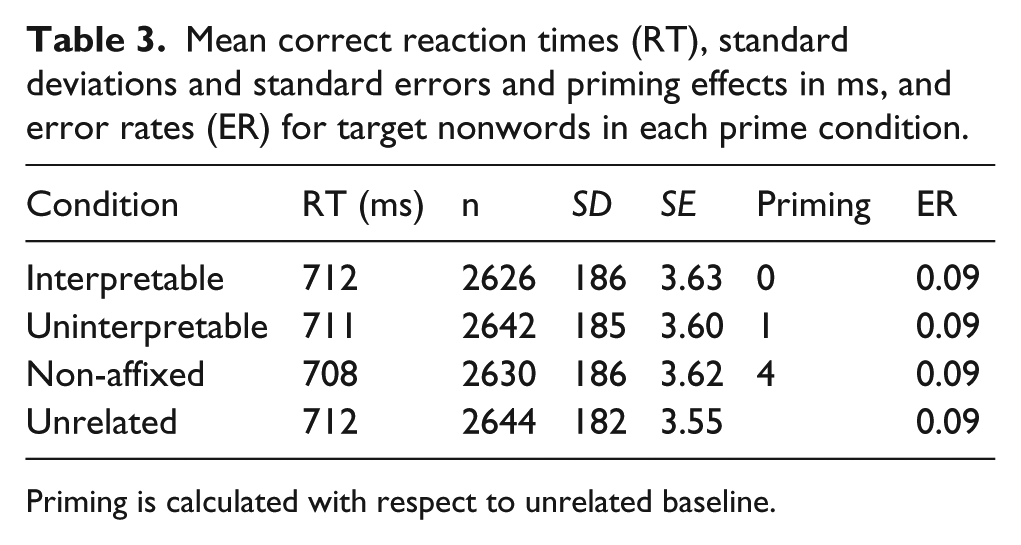
Priming is calculated with respect to unrelated baseline.
Discussion
The main goal of this experiment was to determine whether semantic interpretability influences masked priming for nonword primes, as suggested in a recent article by Heathcote et al. (2017). The results were unambiguous in showing that semantic interpretability had no influence on priming: equivalent priming was obtained for the interpretable and uninterpretable prime conditions.
The reader will note that we are in the (not uncommon) position of claiming a null effect of a variable for which an effect has previously claimed. We would address this concern in four ways. First, we believe that it is unlikely that our null effect reflects a lack of statistical power. Our analysis of reaction times for words includes over 2,100 observations per prime condition (by contrast, Heathcote et al.’s, 2017, experiment had 30 participants and 18 targets per prime condition, giving approximately 500 observations per condition). Second, the difference in mean RT between the interpretable and uninterpretable affixed prime conditions was 0.5 ms. Third, Bayes factors for the critical contrast (0.1 by-participants and 0.14 by-items) showed moderate to strong evidence in support of the null hypothesis, where less than 0.3 is considered moderate and less than 0.1 as strong evidence (Stefan et al., 2019). While this level of evidence might not be considered definitive, due to the slow rate of evidence accumulation for a true null as sample size increases (and particularly for default priors; Stefan et al., 2019) much larger sample sizes are necessary for stronger evidence (Brysbaert, 2019). This has led to <0.33 being suggested as a reasonable threshold to achieve to support the null hypothesis (Brysbaert, 2019). Finally, Figure 2 and the lack of significant correlation between interpretability and item-level priming suggest that the failure to find an effect of interpretability was not due to the dichotomisation of this variable in the analysis of variance.
However, perhaps the most important point to make in this respect is that our null effect does not represent a failure to replicate a significant effect, but rather the inclusion of a critical condition that was not present in Heathcote et al.’s (2017) experiment. The absence of an uninterpretable affixed nonword prime condition from their experiment means that the claim of an effect of interpretability rests on a comparison between interpretable affixed nonword primes and non-affixed nonword primes. The difficulty here is that such a comparison may reflect factors other than interpretability, most obviously the difference between affixes and non-affixes (though other uncontrolled factors may also be at work). To be fair to Heathcote et al. (2017), their conclusion was influenced by a body of prior empirical data that has presented a somewhat confusing picture as to whether there is a difference between affixed and non-affixed nonword primes, and the results of their experiment were presented as a possible reconciliation of this confusion.
It could be argued that our findings differ from Heathcote et al.’s (2017) because we only used suffixed primes. Previous studies have demonstrated differences between how prefixed and suffixed primes are processed (e.g., Beyersmann, Ziegler, & Grainger, 2015; Kim et al., 2015). Therefore, one may suggest that inclusion of prefixed primes would have increased our chances of reporting a semantic transparency effect. However, this still does not provide a sufficient reason of why our results are inconsistent with Heathcote et al. (2017) as they found no significant difference in priming between suffixed and prefixed primes.
Indeed, rather than being a failure to replicate, our results are consistent with those of Longtin and Meunier (2005), who found equivalent priming from interpretable (rapidifier-RAPIDE) and non-interpretable (sportation-SPORT) nonword primes. Furthermore, finding no effect of semantic interpretability for nonword primes aligns with the general finding of no semantic transparency effects for masked word primes (Rastle & Davis, 2008).
Another difference between our findings and those of Heathcote et al. (2017) is that we found no difference between affixed and non-affixed nonword primes. Given the equivalence of the interpretable and uninterpretable affixed conditions, we can eliminate the possible confound of interpretability (i.e., we found no difference between uninterpretable affixed pairs like maskity-MASK and uninterpretable non-affixed pairs like maskond-MASK). It is not clear why our result differs from Heathcote et al.’s (2017), but it is consistent with the findings reported in other recent experiments that found equivalent priming for affixed and non-affixed nonword primes (e.g., Beyersmann et al., 2015, 2016; Morris et al., 2011). Then again, as noted earlier, the initial investigations of this issue did find significant differences favouring affixed primes (Longtin & Meunier, 2005; McCormick, Brysbaert & Rastle, 2009), and we observed a numerical difference of 5 ms in this direction. The present data do not allow us to rule out the possibility that there is a small effect of nonword affixation to be found. Nevertheless, we would reiterate that our experiment was relatively high-powered by comparison with other experiments in this field, which mostly comprise experiments with fewer than 1,000 data points per condition, and often fewer than 500 (see M. H. Davis & Rastle, 2010, for relevant funnel plots for experiments with word primes). Brysbaert and Stevens (2018) recommend that at least 1,600 observations are required in repeated measures priming experiments that aim to detect effect sizes of around 15 ms. The danger associated with small sample sizes is not only that real effects may not be detected but also that the imprecision of measurement may lead to Type I errors, i.e., the “detection” of effects that are not really present (e.g., Button et al., 2013). A resolution of this empirical uncertainty is forthcoming, as the most recent form priming project (FPP2), which includes approximately 17,000 data points per condition, has compared pseudo-prefixed, pseudo-suffixed and orthographic control conditions. 2
We emphasise that our claim is not that semantic transparency is not an important factor, but rather that it does not emerge sufficiently rapidly to influence masked priming. This account agrees with the explanatory framework proposed by Rastle and colleagues based on experiments with word primes (Rastle & Davis, 2008; Rastle et al., 2000). As noted earlier, Heyer and Kornishova (2018) have recently presented converging evidence on this point, finding no evidence of semantic transparency when the prime duration was 33 ms or 39 ms, but a significant effect of transparency when the prime was presented for 67 ms or 77 ms; they also review the extant literature, and note that (with one exception, where methodological differences may have contributed) “significantly stronger priming for transparent in comparison to opaque items emerged only at SOAs of 50 ms or more” (p. 1121). That is, semantic transparency effects appear when the prime is presented for a duration sufficient to make conscious report possible. That is, semantic transparency effects appear to be restricted to situations in which the prime is presented so briefly that it is not unavailable for conscious report; when primes are perceptible, clear effects of transparency emerge. Whether or not conscious awareness of primes is critical is not clear. It may rather be that primes of 60 ms duration or more offer sufficient time for a deeper level of semantic processing, or enough time to allow a longer lasting record of the prime to be established, which can be processed semantically after the offset of the prime. It may take longer for semantic information to become available for novel (interpretable) pseudoword primes than for familiar word primes. Direct comparison of the time course of semantic transparency and semantic interpretability effects may be an interesting avenue for future experiments.
Ultimately, the question still remains on how corner facilitates (rather than inhibiting) the target CORN and also why recent masked nonword priming literature, including our study, report no difference in priming between affixed and non-affixed nonword primes. A recent proposal by Grainger and Beyersmann (2017) may potentially address both of these questions. They propose that morphological processing is triggered by stem activation. Stem activation is achieved by an edge-aligned stem activation mechanism which takes advantage of the fact stems are either part of the first or last letter of a morphologically complex word. Grainger and Beyersmann (2017) answers the question of why a pseudo-affixed prime such as corner facilitates the target CORN and yet a non-affixed prime like cashew inhibits the target CASH. They argue the prime cashew acts a lexical competitor against the target CASH and thus stem activation is inhibited. In contrast, the presence of the pseudo-affix in corner triggers morpho-orthographic decomposition and in turn, enables stem activation. The edge-aligned stem activation mechanism also addresses why nonword priming studies find no difference in priming between affixed and non-affixed primes. By definition, nonword primes are not contained in the lexicon. Therefore, stem activation is able to be activated regardless of whether the nonword primes are affixed or non-affixed. This is because neither types of nonwords acts as lexical competitors against the target.
Recent research appears to support the proposal of an edge-aligned stem activation mechanism. For example, Beyersmann and Grainger (2018) used the masked priming paradigm to investigate whether priming effects are modulated by morphological family size. Morphological family size is the number of different morphologically complex contexts in which a word can appear in. The results suggest morphological family size does indeed influence the size of priming effects where primes with a larger family size result in greater priming. This indicates lexical or supra-lexical representations are involved in activating words embedded in a morphologically complex word which is consistent with Grainger and Beyersmann’s (2017) proposal. Another study which supports Grainger and Beyersmann’s (2017) proposal is Beyersmann et al. (2018). They compared priming effects between stems which were either edge-embedded (e.g., pimebook-BOOK), mid-embedded (e.g., pibookme-BOOK), or outer-embedded (e.g., bopimeok-BOOK) in primes. Priming effects were only found for edge-aligned stems. This indicates activation of embedded words is influenced by edge-alignedness which, again, is in line with Grainger and Beyersmann’s (2017) proposal. Considering Beyersmann and Grainger’s (2018) and Beyersmann et al.’s (2018) results, the proposal for an edge-aligned stem activation mechanism, so far, appears to be promising in explaining how morphological processing is implemented.
Overall, the picture that emerges from our experiment with affixed nonword primes is consistent with the larger literature on orthographic form priming. Existing computational models of masked form priming are able to capture these results, despite including no morphological representations (e.g., Adelman, 2011; C. J. Davis, 2010, 2018). It may be that results that have been characterised as demonstrating morpho-orthographic decomposition are more parsimoniously characterised as further demonstrations of position-invariant orthographic input coding. This does not undermine the fact that there is something morphological to be explained—In particular, existing orthographic processing models do not explain the pattern observed with pseudo-derived word primes like corner. From the perspective of models such as the spatial coding model (C. J. Davis, 2010), the question to be answered is why corner facilitates (rather than inhibiting) the target CORN. Our results help to constrain the set of possible answers by arguing against the possibility that affixes are automatically and inevitably stripped from masked primes.
Footnotes
Authors’ note
Sine Bakumeni and Hannah Barnett assisted with data collection at the University of Hull.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.