
Abstract
Recently, a new crowd-sourced language metric has been introduced, entitled word prevalence, which estimates the proportion of the population that knows a given word. This measure has been shown to account for unique variance in large sets of lexical performance. This article aims to build on the work of Brysbaert et al. and Keuleers et al. by introducing new corpus-based metrics that estimate how likely a word is to be an active member of the natural language environment, and hence known by a larger subset of the general population. This metric is derived from an analysis of a newly collected corpus of over 25,000 fiction and non-fiction books and will be shown that it is capable of accounting for significantly more variance than past corpus-based measures.
In the study of lexical processing and retrieval, a host of explanatory variables have been proposed to account for human performance in tests of language processing. These variables include objective measures, based on environmental occurrence (such as frequency and contextual diversity [CD]) and surface characteristics (such as word length and orthographic neighbourhood density), as well as subjective measures, derived from human judgements (such as valence and concreteness; for a comprehensive review, see Baayen et al., 2016). In large-scale regression analyses incorporating these variables, word frequency (WF) has proved to be one of the most robust behavioural predictors across an array of tasks, including lexical decision and word naming (Adelman et al., 2014; Baayen et al., 2006; Balota et al., 2007; Brysbaert et al., 2019; Keuleers et al., 2012; Yap & Balota, 2009).
In the simplest case, a word’s normative frequency is a register of the number of separate occurrences of that word in a corpus—that is, a collection of text or speech comprising a large set of different documents. As an explanatory variable, WF acts as a kind of proxy for linguistic experience. A key simplifying assumption is that the corpus from which the counts are drawn is representative of the “average” speaker’s experience with the language. However, although this is almost certainly true for common words, which fall in the higher ranges of the frequency spectrum, it is far less likely to be true of lower frequency words, where individual exposure is highly variable, and not well-reflected by averages. Indeed, beyond grammar school, speakers sample language in increasingly directed and idiosyncratic ways (Gardner et al., 1987), making it impossible to reliably estimate the vocabulary size from small word samples (Ramscar et al., 2014). It has thus been argued that for certain psychometric tests, experiential familiarity ratings may prove a better measure than those that are corpus-based, particularly when sampling in the tail of the distribution (Allen & Garton, 1968; Gernsbacher, 1984).
In line with this, a novel measure has been proposed to help account for speaker variability at scale: word prevalence (WP; Brysbaert et al., 2016, 2019; Keuleers et al., 2015). WP is a measure of the proportion of the population that knows a given word, and relies on large samples of words and participants for its validity. To establish WP scores for Dutch, Keuleers et al. tested items from a 50,000+ word master list on over 275,000 native speakers from Belgium and the Netherlands. Subjects were presented with a sequence of words and non-words, and asked to identify which words were known to them, selecting from either “Yes, I know this word” or “No, I do not know this word.” One of the principal aims of the study was to establish whether WP would have explanatory value over and above corpus-based frequency measures. 1 On the face of it, WP 2 offers a complementary representation of the distribution of lexical experience: Words that are universally known, nevertheless, vary widely in their frequency of use, and words that are used rarely vary widely in their prevalence.
When WP was pitted against frequency in an analysis of visual lexical decision times (LDTs) in the Dutch Lexicon Project (DLP), it was found to explain similar amounts of unique variance, and to be the best overall predictor of response times (RTs; see also Brysbaert et al., 2016). A closer assessment of the contributions of each variable indicated that the better known a word was, the more its frequency mattered as a predictor; conversely, for rare words, in the lower half of the frequency spectrum, the effect size of frequency was minimal. Keuleers et al. concluded that prevalence provides the better estimate of rare words, and frequency of widely known words. More recently, Brysbaert et al. (2019) demonstrated that these findings also hold for data from the English lexicon project (ELP; Balota et al., 2007).
Although this finding is striking, the practice of using prevalence to predict lexical decision RTs should give room for pause. In a typical LDT, subjects are asked to determine whether an item is a real word in their language (rather than whether they know it), and are judged on both speed and accuracy (rather than accuracy alone). WP can thus be classified as a modified lexical decision task: The test design closely resembles that of a standard LDT, and the relevant variations—in the precise form of the question asked and in the variable(s) of interest—are minor.
This is where a potential issue arises. In lexical decision, RT and accuracy are tightly coupled, with a canonical trade-off between speed and accuracy. In a model of LDT response latencies, accuracy would thus invariably be a strong predictor. However, it is not common practice to predict RT from accuracy, because this has relatively little explanatory value. For the most part, cognitive modellers are less interested in characterising the relationship between behavioural outputs, and more in the environmental inputs that produce one or the other behaviour. 3 Yet using WP to explain lexical decision falls prey to precisely this criticism: One performance measure is being used to explain another.
In constructing a model of human behaviour, a cognitive modeller must specify both the representational input (the relevant environmental structure) and the cognitive process that operates over that input (Estes, 1975). For instance, in a highly simplified model of word recognition, each repetition of an item in experience serves to lower its resting state threshold; as a result, more frequently experienced items are processed more efficiently (Morton, 1969). In such a model, the relevant input for an item is its frequency, and the mechanism that produces behaviour is an internal counter that adjusts the item’s resting state. Clearly, representation and process are interdependent: The form and complexity of the assumed process is contingent on the choice of representation, and vice versa. The explanatory value of a model thus depends on the judicious choice of representation and process, and the validity of the assumptions underlying those choices (Johns et al., 2012, 2017; Johns & Jones, 2010).
Given this approach to modelling, a problem arises when representation and process are conflated, as occurs when one type of behaviour is used to predict a highly similar form of behaviour (for an extended critique, see Johns et al., in press; Jones et al., 2015). When WP is used as an independent variable it is subject to this critique: The vocabulary test devised by Brysbaert et al. (2019) and Keuleers et al. (2015) does not deliver a pure readout of the prior lexical experience of speakers; instead, what it delivers is an introspective human judgement (a behaviour) that reflects retrieval (process) from semantic memory (representation). 4 The process at work in lexical decision is thus already partially embedded in the WP measure. Jones et al. (2015) refer to this as a “Turk problem,” in reference to the famous 18th century chess-playing machine, which appeared to function as a self-operating automaton, but in fact, concealed a human chess master within. In cognitive modelling, a Turk problem arises when the representational input is derived directly from human behavioural data, hiding the requisite process complexity—the “man in the machine”—within the representation itself.
This is not to say that the data collected by Brysbaert et al. (2019) and Keuleers et al. (2015) are not valuable or important. Indeed, the data from these studies will likely play an important role in theory development in word processing for years to come. However, WP measures are still data, and data need to be understood with theory.
Corpus-based measures of prevalence
Psychologists studying lexical processing face a conundrum. Introspective measures of familiarity have revealed variability in lexical knowledge that is not well-captured by aggregate corpus-based measures, like frequency (Allen & Garton, 1968; Gernsbacher, 1984; Keuleers et al., 2015). However, objective, environmentally derived measures have the advantage of being interpretable, replicable, and more straightforwardly incorporated into computational models (McDonald & Shillcock, 2001). Deriving psycholinguistic measures from corpora offer a more objective measurement of the types of materials that one might have been exposed to, as they are not obtained through introspective judgements or other psycholinguistic tasks, but instead are measurements of a type of language that a wide variety of authors have used. An open question, then, is whether it might be possible to develop a prevalence measure that is estimated from the linguistic environment, rather than from introspective ratings.
In recent years, a number of corpus-based measures have been developed that improve on raw frequency counts. For instance, rather than computing a word’s overall occurrence rate, measures of CD return the number of separate documents a word occurs in (Adelman et al., 2006; McDonald and Shillcock, 2001). Like CD, measures of semantic diversity (SD) yield a weighted document count, with the weight determined by a similarity distance-metric between documents: The more similar the contexts in which a word occurs, the less each separate occurrence is weighted (see Hoffman et al., 2013; Hsiao & Nation, 2018; Johns et al., 2012, 2016a, 2016b; Jones et al., 2012). In terms of predictive power, context-based measures have been found to consistently outperform frequency (see Jones et al., 2017 for a review).
Here, we outline and contrast two different classes of environmental corpus-based variables: (1) occurrence-based variables and (2) prevalence-based variables. Occurrence-based variables include WF, CD, and SD models. The central principle of these variables is that the weight of a word is updated with each occurrence of a word (such as a WF count) or each occurrence within a limited size context (such as a paragraph or document in the case of the CD and SD variables).
The prevalence-based measures are adapted CD measures, taking place at much larger units of language. Specifically, prevalence will be measured at two levels: (1) book prevalence (BP) and (2) author prevalence (AP). BP measures the number of books that a word appears in, whereas AP measures the number of authors who used a word in their writings. We entitle these prevalence measures as they are simply measuring whether a word is used across large swathes of language. If all authors use a word, regardless of the frequency of that word, it is likely that a person would have experienced that word. However, if a word only occurs in certain writings (such as only in fantasy novels), then only a subset of the population may have encountered that word. Johns and Jamieson (2018) recently demonstrated that there is meaningful semantic variation at both the book and individual author level. In addition, more recent research has demonstrated that there are systematic differences in language usage based on the demographic characteristics of authors, such as gender (Johns & Dye, 2019) and time and place of birth (Johns & Jamieson, 2019). Thus, both measures will be modified with an SD transformation, using computational techniques adapted from the semantic distinctiveness model (SDM; Johns et al., 2012; Jones et al., 2012). This will yield two more measures: (1) semantic diversity-book prevalence (SD-BP) and (2) semantic diversity-author prevalence (SD-AP).
As stated, this study will contrast occurrence-based counting (counting at small units of context; the WF, CD, and vector-space SDM [vSDM] measures) and prevalence-based counting (counting at large units of measurements; the BP, AP, SD-BP, and SD-AP measures). However, there will also be a contrast of diversity measures—CD versus vSDM for the occurrence-based counts, and BP, AP versus SD-BP, SD-AP for the prevalence-based counts. The occurrence/prevalence comparisons will allow for a determination of the effect of measuring language at different levels, whereas the diversity measures will determine whether the SD transformations extend to new datasets, corpora, and levels of analysis, consistent with past results (Hoffman et al., 2013; Hsiao & Nation, 2018; Johns et al., 2012, 2016b; Jones et al., 2012).
The results of Brysbaert et al. (2016, 2019) and Keuleers et al. (2015) demonstrate that there is significant variability in terms of people knowing that a given word is a part of their language. The motivation for this work is determining whether better measures can be constructed to examine the reasons for this variability. Across the occurrence-based and prevalence-based variables there are a total of seven different variables. These variables will be contrasted on both lexical decision and naming data from lexicon projects (Balota et al., 2007; Keuleers et al., 2012) and the WP measures of Brysbaert et al. (2019). In addition, the language materials used to train the lexical variables are organised by the author’s country of birth and gender, enabling an analysis on the effects of differential linguistic experience on lexical behaviour, an important goal in the understanding on the interaction between experience and behaviour on language processing (see Johns et al., 2019; Johns & Jamieson, 2018; van Heuven et al., 2014).
Materials
The lexical materials assembled here consist of books organised by author and genre. To organise the book set, the dominant genre that an author wrote in was recorded using the most frequent tag on the book review websites GoodReads and online retailer Amazon. The books written by that author were then labelled as having being written in that genre. Although this is less precise than author studies examining the impact of genre on writing (see Johns & Jamieson, 2018), tagging each book by its genre was unfeasible for such a large collection.
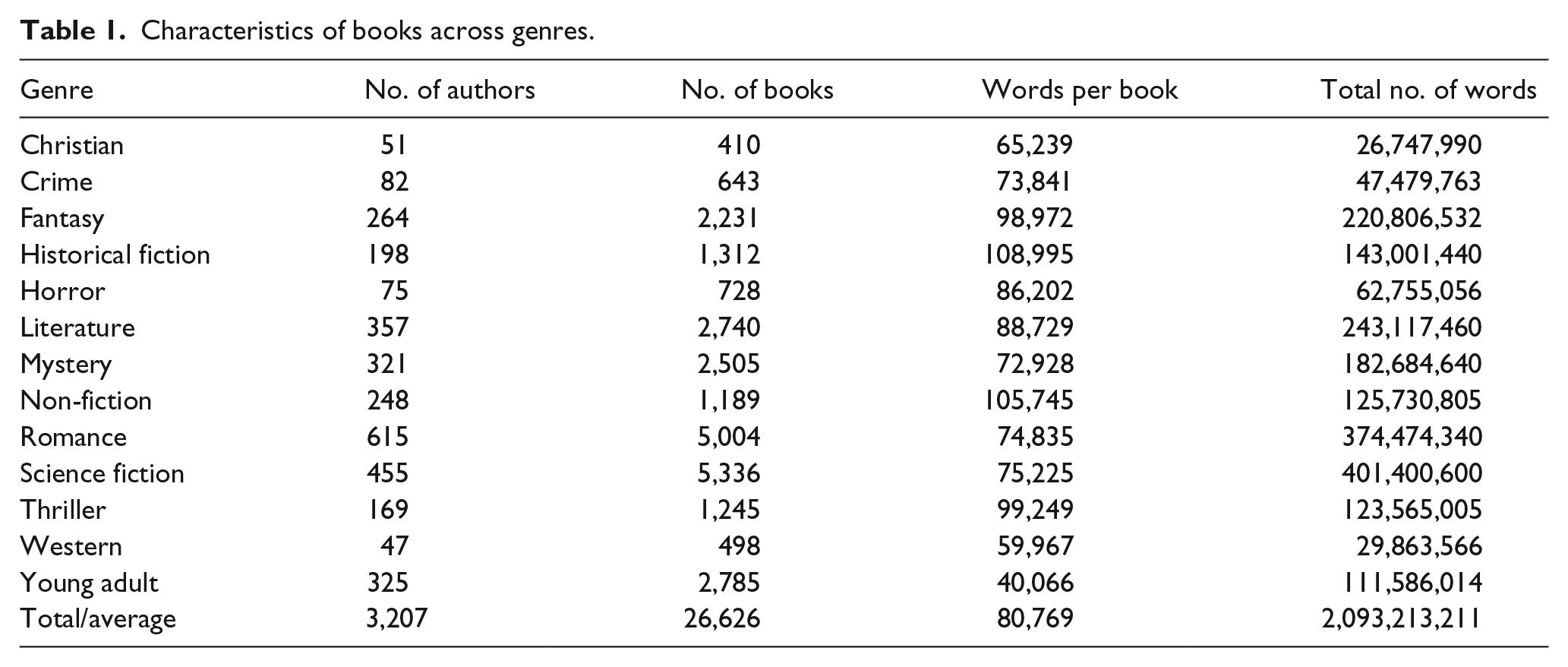
The characteristics of the book set, organised by genre, is contained in Table 1. Overall, there were 13 different genres of books, consisting of over 26,000 books written by 3,200 authors and containing approximately 2.1 billion words. There was some variability in terms of the number of words per book, with young adult novels having the lowest average number of words, and historical fiction books having the highest. However, all book types comprised large amounts of text, and should therefore offer a fair test of the different models of lexical organisation used here.
Characteristics of books across genres.
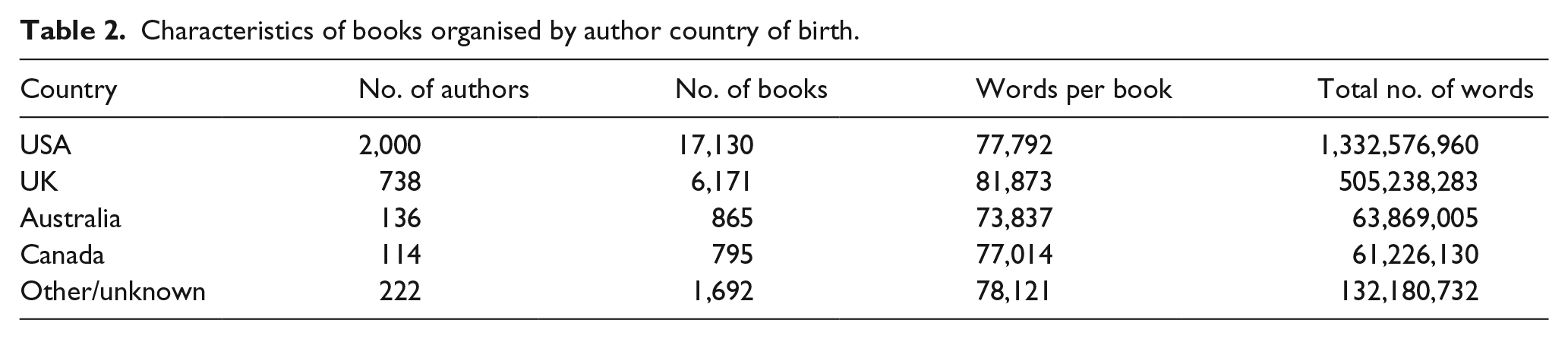
Given that the book set assembled here is organised by author, it was possible to organise the materials by the author characteristics. This is a benefit of using books as a lexical source, compared with subtitles or newspaper articles, as it is possible to isolate some personal characteristics of the person who produced the language source. Specifically, the country of birth and gender of each author was recorded, to determine how these factors influence a model’s fit to lexical behaviour. For country of birth, most authors came from the United States or the United Kingdom, with smaller collections from Canadian and Australian authors. The characteristics of the book set split by country of birth of the authors are contained in Table 2.
Characteristics of books organised by author country of birth.
Finally, Table 3 contains the characteristics of the book set, split by author gender. This table shows that there are slightly more female authors, but on average male authors produced more books that were slightly longer. This led to male authors producing about 130 million words more than female authors in this sample. The splits described in Tables 2 and 3 will be used to determine the effects of author demographics on fits to lexical behaviours.
Characteristics of books organised by author gender.

Models
As previously discussed, there will be both occurrence-based and prevalence-based variables used in this study. There are three occurrence-based models: WF, CD, and SDM. There are four prevalence-based models: BP, AP, SD-BP, and SD-AP. Each model will be described in turn.
WF and CD
As in previous studies (e.g., Johns et al., 2012; Jones et al., 2012), all models were compared against a WF and a CD; Adelman et al., 2006) baseline. A WF count computes the number of occurrences of a word across the entire corpus. A CD count computes the number of different contexts that a word occurs in. In a standard CD count, context is typically operationalised as a paragraph (Adelman et al., 2006; Jones et al., 2012) or a moving window (Johns et al., 2016b). Due to the difficulty of parsing paragraphs within electronic books, a moving window of 20 sentences is used here. Historically, operationalisations of context differ greatly across studies. For example, some studies have defined context as the list a word is contained in, to changes in time, or the room in which learning took place (Schmidt, 1991; Verkoeijen et al., 2004; Wickens, 1987). Thus, the definition of context is likely model-dependent (see Jones et al., 2017, for a review of context effects in language and memory).
SDM
A variation of the SDM (Jones et al., 2012) will be included in the analysis. The variation of the model is entitled the vSDM, first described by Johns et al. (2014), and empirically validated in Johns et al. (2016a). In the original SDM a given word’s strength in memory is represented in a Word x Document matrix, which can be trained over any large corpus of documents. For each new document that is encountered, a new column is added to the matrix. If a word occurred in that document, then it is assigned a semantic distinctiveness (SD) value in that column, which signals how redundant the new context is, compared with past experience (for details about how this is calculated, see Jones et al., 2012). A word’s strength in memory (corresponding to how easily a word is to retrieve from memory) is then just the summed semantic distinctiveness values across its row in the matrix.
Although this implementation of the model has proved successful, it is also difficult to scale due to the computational resources required for an ever-expanding matrix. A more tractable approach is to use a set vector size, similar to that employed in vector accumulation models, such as the BEAGLE model of semantics (Jones & Mewhort, 2007). The vSDM model uses this architecture, which is based on the same mechanisms as the original model, but is less computationally expensive. As the vSDM does not involve an increasing amount of computation due to more documents being processed, it can be run over much larger corpora, which is necessary given the amount of language materials contained in Table 1.
The fundamental operation of the SDM is that it utilises an expectancy-congruency mechanism to build a word’s semantic representation: The encoding strength for a word in a given context is relative to the information overlap between the context and the memorial representation of the word. This mechanism is very similar in principle to models that adjust attention across learning to dimensions that are more diagnostic. The vSDM will have underlying differences in terms of implementation, but this mechanism is the basic assumption about the importance of contextual variability.
In the vSDM, each word is represented by an initially empty distributed vector, representing the meaning of a word. When a word occurs in a context, that word’s vector is updated. How strongly that word is updated depends on the similarity between context and the word’s representation. To encode the representation of a context, the memory vectors of each word in the context are summed as
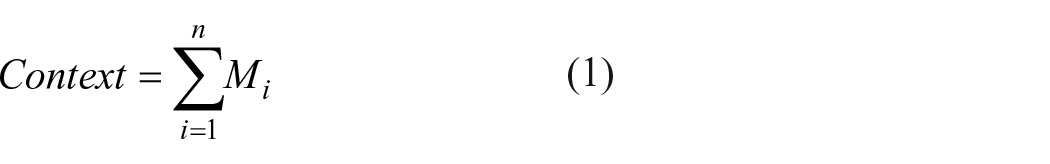
where Mi is the memory vector for word i and Context is the vector representing the meaning of the current context.
This context vector allows us to assess the similarity between the current document context and a word’s semantic representation. As in the original SDM model, we use the vector cosine (a normalised dot product) as our similarity metric, and subject it to an exponential transformation, so as to properly weight redundant contexts over distinctive ones. Semantic distinctiveness for a given word is thus computed as a function of

where λ is a free parameter that scales the differences between high and low similarity contexts. 5
In the original SDM, each new context is encoded as a new column in a Term x Document matrix. To replicate this process, in the vSDM a random Gaussian vector 6 is generated and added into each of the word’s memory vectors that occurred in the context. This is meant to be analogous to the original SDM model’s use of a new context being encoded as a new column. Only the words that occur in the context are updated with context vector. The strength with which the memory vector is updated is modulated by the SD value as

where RG is the randomly generated Gaussian vector and SDi is the SD value for word i in that context. Words that do not occur in the context are not updated.
In this version of the model, the strength of a word is an external counter that accumulates the SD values of a word across its occurrences. As with the WF and CD variables, the SD counts will be reduced with a natural logarithm.
BP and AP
The BP measure is similar to the CD measure, but defines context at the level of the book, rather than at the level of the paragraph (or paragraph-sized chunk). Specifically, BP computes the number of different books that a word occurs in. The words shine and plasma offer a simple demonstration of how the CD and BP measures diverge. Although both words occur in a similar number of paragraph contexts, shine occurs in nearly four times as many books as plasma. The two models thus make markedly different predictions of the lexical strength of these words, with CD yielding an even count, and BP yielding a notable asymmetry.
The AP measure builds upon the BP measure by counting only if a specified author used a word or not. The AP measure will provide a proxy of how widely used a certain word is across authors, and thus how likely it is to be an active member of the language environment, such that if a word is used by a wide variety of authors, it is likely that the general population would have experienced it. 7 In some ways, the AP measure could be conceptualised as being an account of an author’s productive vocabulary, as some authors have millions of tokens contained in their book collection.
To gain an understanding of the scale that the BP and AP model are operating at, Figure 1 contains a histogram of the number of unique words that each book and author use. Most books contain between 2,500 and 15,000 unique words, with an average of 5,986 unique words per book. Most authors use between 5,000 and 30,000 unique words across their writings, with an average of 14,213 unique words per author. In contrast to this, using a window of 20 sentences to calculate the CD and vSDM variables, there is an average of 136 unique words contained in each window. That is, the BP and AP measures are operating at a much greater unit of word occurrence than past measures.
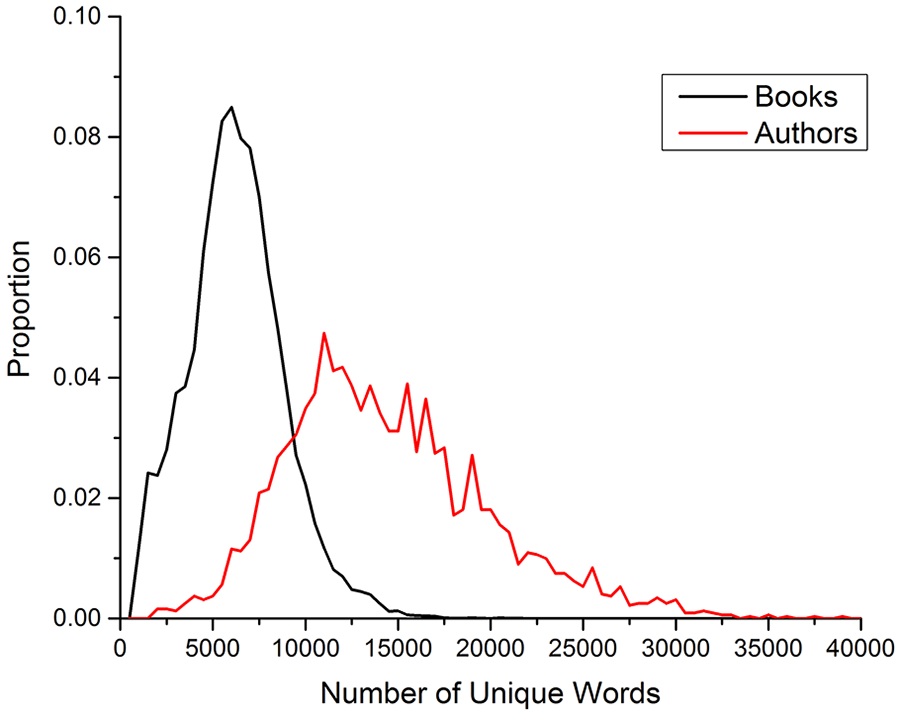
Histogram of the number of unique words that each book contains and each author uses.
SD-BP and SD-AP
To justify applying the semantic transformations described by the SDM to the BP and AP, it is worth considering the recent work in distributional semantics examining language at both the book and author levels. Specifically, in Johns and Jamieson (2018), a sample of fiction books was organised by author and genre. There was a small genre effect, where authors who wrote in the same genre had a small increase in the similarity of their writings when compared with authors who wrote in different genres. However, the biggest difference emerged at the individual-author level: each author had a unique signature of language usage.
However, Johns & Jamieson (2018) used a much smaller set of books than is used here (they used a collection of 1,850 books). To ensure that the genre- and author-signature effect are replicated with the larger set of books described in this article, the same methodology used to assess book similarity by Johns and Jamieson (2018) was used here. Specifically, to measure the similarity of the book set used here, we (1) identified the 100,000 highest frequency words across the corpus, (2) constructed a vector for each book which recorded the number of times that each of the 100,000 highest frequency words appeared in a book, (3) converted all word frequencies to their log equivalents, that is, n’ = ln(n + 1), where n is the count from the book, and (4) computed the cosine similarity of each author’s word vector to every other author’s word vector. All similarity values were then organised into one of three groups: (1) within author (i.e., similarity of books written by the same author), (2) within genre (i.e., similarity of books from the same genre), and (3) across genres (i.e., similarity of books from different genres). The within-author distribution was composed of over 280,000 comparisons, the within-genre distribution was composed of over 42 million comparisons, and the genre distribution was composed of over 312 million comparisons.
Figure 2 displays the results of this simulation, which shows that this book set shows an identical pattern to what was found by Johns and Jamieson (2018): there is a small positive shift in similarity for books written in the same genre (relative to books written in different genres), but there is a much larger positive shift for books written by the same author. Johns and Jamieson (2018, 2019) refer to this as the author signature effect. This finding demonstrates that there is semantic variance at both the book and author levels, which suggests that applying the SDM transformations to the BP and AP count will likely increase the performance of that count, similar to how the SDM improves upon a CD count.
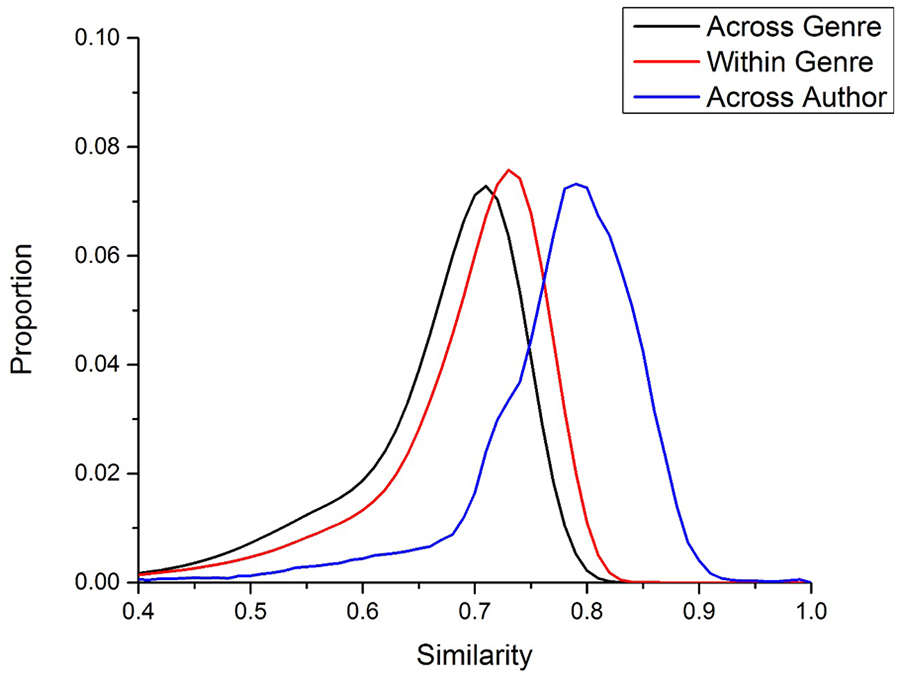
Similarity distributions across three levels: (1) books written by different authors across genres (black line), (2) books written by different authors within a genre (red line), and (3) books written by the same author (blue line). The similarity is the vector cosine between the frequency distribution of two books. This simulation replicates the findings of Johns and Jamieson (2018), with a much larger book set.
To accomplish this, a very similar model described in equations (1)–(3) will be used. However, instead of forming a context representation by summing Gaussian representations, the context representation will be the frequency distribution of a book (in the case of the SD-BP variable) or all of the books written by a single author (in the case of the SD-AP variable). A word’s representation will be incrementally constructed by summing the distribution of each book or author into a word’s memory representation, added in accordance with the strength of the SD signal. The SD value for a word is calculated by taking the cosine similarity between the context representation and the word’s representation. However, unlike the SDM and vSDM, it was found for both the SD-BP and SD-AP that a simple linear transformation performed best
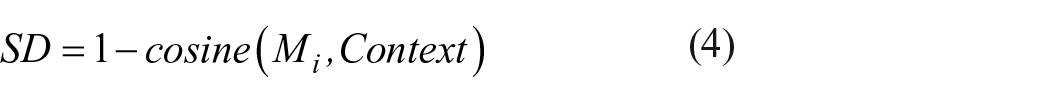
where Mi is the memory representation for word i.
To conceptualise the results of the SD transformations on the BP and AP variables, it is worth considering the nature of lexical experience and the content of books and the writings of different authors. As Figure 2 shows, the average book is quite similar to each other (i.e., the average cosine across books is above 0.7). This suggests that there is much semantic redundancy across books. By weighting each book (or each author’s writings) by how unique that writing is (compared with past experience), it allows for books with a large amount of overlap to be reduced in importance. Past research (e.g., Jones et al., 2012, 2017) has shown that this type of operation is important in lexical organisation when applied to smaller units. Here we will determine if the operations also work at large units of language.
Training methodology
The vSDM, SD-BP, and SD-AP models are sensitive to the word list used in training, as it impacts the context representation that is formed. The word list used to train these models are the 81,276 unique words contained in the prevalence norms of Brysbaert et al. (2019), the ELP (Balota et al., 2007), and the British lexicon project (BLP; Keuleers et al., 2012). Of those words, 78,033 occurred at least once in the corpus, demonstrating the diversity of the language that is contained in the book collection assembled here. The CD and vSDM variables will be derived from a moving window of 20 sentences across the entire corpus, similar to past research (e.g., Johns et al., 2016b).
Data
The two main data sources that will be used to assess the above described variables will be the recently released WP data of Brysbaert et al. (2019) and the LDT data from two lexicon projects—the ELP (Balota et al., 2007) and the BLP (Keuleers et al., 2012). In addition, naming time (NT) will be analysed from the ELP. For both ELP and BLP, the LDT that will be used is the z-transformed reaction times. Only words that had occurred one or more times in the corpus were included in the following analyses. We did not set an accuracy threshold as we are equally interested in explaining lexical decision and naming accuracy data as we are in explaining lexical decision and naming reaction time.
The advantages of using books to derive lexical statistics are that they contain a greater amount of low-frequency words compared with subtitles (Brysbaert & New, 2009) or social media (Herdağdelen & Marelli, 2017), enabling a more complete analysis of the data space. For example, the social media norms of Herdağdelen and Marelli (2017) contain roughly 24,883 of the 61,855 words from the Brysbaert et al. (2019) WP norms, whereas the book norms derived here contain 58,711 of the words from these norms. This also makes it difficult to compare the performance of the different frequency values.
Results
As a first pass at understanding the differences and similarities of the seven lexical variables, Table 4 contains the pairwise correlations of the variables. The first important aspect of this analysis is to notice that all variables are fairly redundant, similar to past work on contextual and SD (e.g., Adelman et al., 2006; Jones et al., 2012). Similar to these past studies, it will be necessary to use regression analyses to separate the unique contributions of these variables to the datasets analysed here. However, it is clear from these correlations that the occurrence-based variables cluster together, as do the prevalence-based variables. This suggests that these two classes are assessing relatively different types of lexical information.
Correlations between the lexical variables.
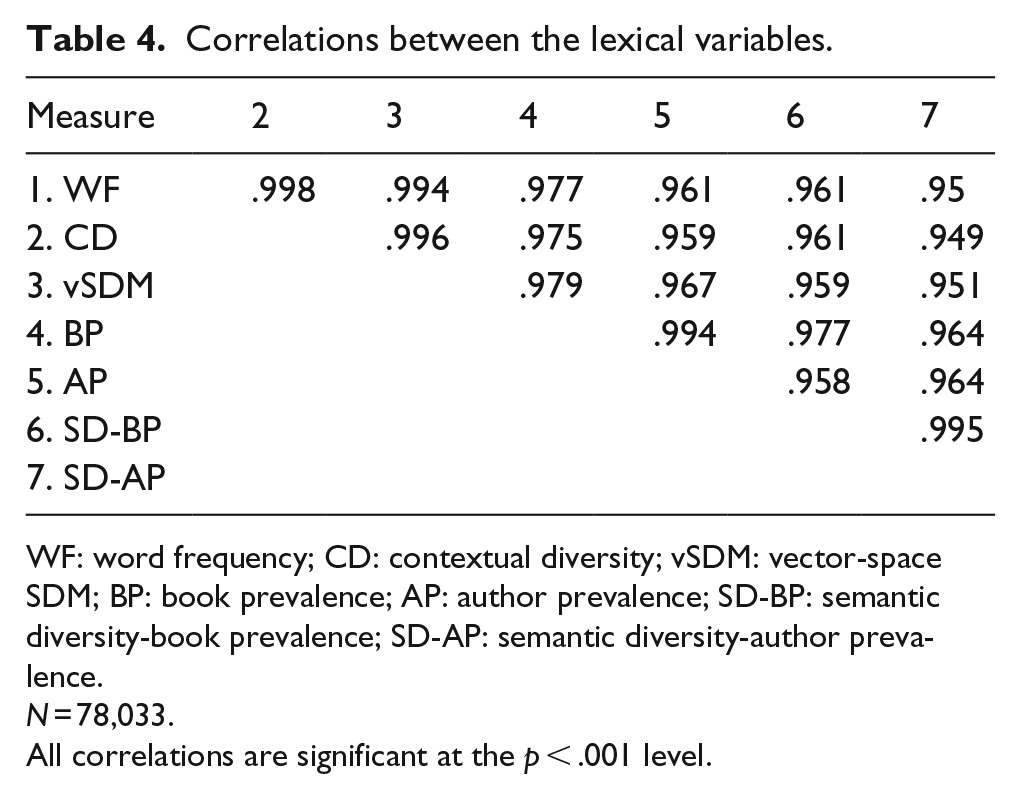
WF: word frequency; CD: contextual diversity; vSDM: vector-space SDM; BP: book prevalence; AP: author prevalence; SD-BP: semantic diversity-book prevalence; SD-AP: semantic diversity-author prevalence.
N = 78,033.
All correlations are significant at the p < .001 level.
To examine the fit of the different lexical variables to the different lexical databases, Table 5 contains the correlation between the seven lexical variables and the seven different lexical behaviours (WP, ELP LDT, ELP lexical decision accuracy, ELP NT, ELP naming accuracy, BLP LDT, and BLP lexical decision accuracy). For the occurrence-based variables, the results are consistent with past results (e.g., Jones et al., 2012) where the vSDM has a higher correlation to all datatypes, compared with the WF and CD variables. For the prevalence-based variables, this table shows that applying the SD transformations to the BP and AP count substantially increases the fit of these variables to all lexical behaviours.
Correlations between the lexical behaviours and lexical variables.
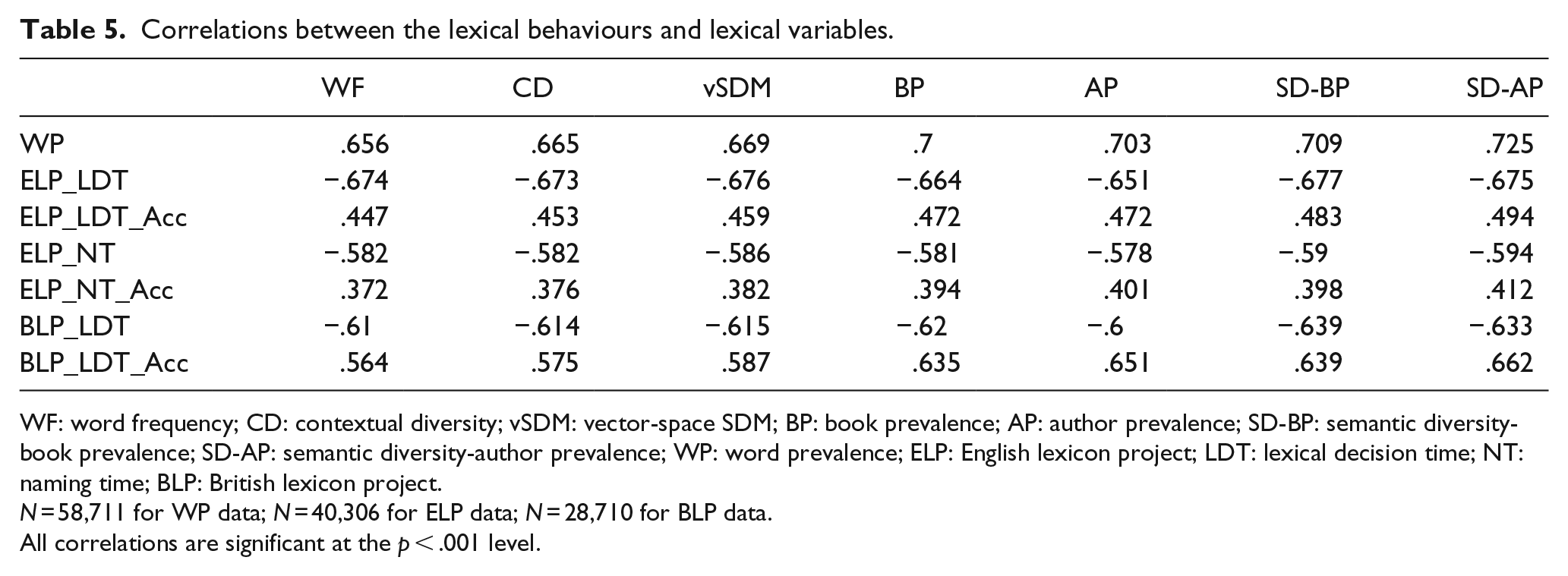
WF: word frequency; CD: contextual diversity; vSDM: vector-space SDM; BP: book prevalence; AP: author prevalence; SD-BP: semantic diversity-book prevalence; SD-AP: semantic diversity-author prevalence; WP: word prevalence; ELP: English lexicon project; LDT: lexical decision time; NT: naming time; BLP: British lexicon project.
N = 58,711 for WP data; N = 40,306 for ELP data; N = 28,710 for BLP data.
All correlations are significant at the p < .001 level.
Importantly, there are differences in the fits across WP, LDT, NT, and lexical decision accuracy. Specifically, the prevalence-based provide a very substantial increase in the fit to the WP data, compared with the occurrence-based variables. This is also the case for lexical decision and naming accuracy, where the prevalence-based variables substantially outperform the occurrence-based data. This is not the case for LDT, where the best performing occurrence-based variable (vSDM) is roughly the same as the best performing prevalence-based variable (SD-BP). For NT, the best overall predictor is the SD-AP variable.
In line with previous research (e.g., Adelman et al., 2006; Brysbaert & New, 2009; Jones et al., 2012), regression analyses were conducted to isolate the unique contribution of each variable to lexical processing. The analysis we conducted is standard and provides a measure of the predictive gain (i.e., measured as percent ΔR2 improvement) for one predictor over another competing predictor (see Adelman et al., 2006; Johns et al., 2016b). For the ELP and BLP, polynomial regression was used, such that each variable had two predictions: log(variable) + log2(variable). The inclusion of the square of the logarithm did not impact a variable’s fit to the WP data, and so was not included when analysing these data.
Given that there is likely little unique variance to explain across seven redundant lexical variables, the analysis was simplified by removing three variables: CD, BP, and AP. These were removed because the vSDM, SD-BP, and SD-AP are semantically weighted versions of these variables, respectively, and thus have overlapping theoretical conceptualisations. To justify the exclusion of these variables, a regression was done calculating the unique variance accounted for by the count variable (i.e., CD, BP, AP) over the SD-transformed variable (i.e., SD, SD-BP, SD-AP), and vice versa. Figure 3 contains the results of this analysis, and shows that the SD-transformed variables explain more variance than the count variable for each dataset.
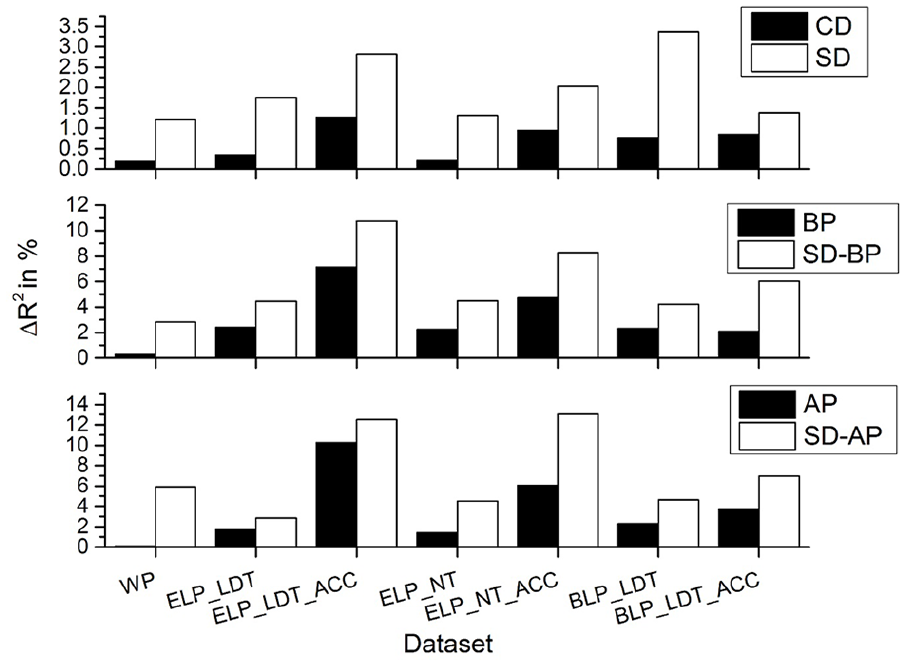
Results of a regression analysis demonstrating that the SD transformed variables accounts for more unique variance than the count variables for each set of data and across multiple levels, including counting in paragraphs (SD vs CD), books (BP vs SD-BP), and at the author level (AP vs SD-AP).
Table 6 contains the results of the regression analysis for the four variables (WF, SD, SD-BP, and SD-AP). This table shows that there is high agreement across all datatypes, where the SD-AP variable accounts for the most variance, the SD-BP variable accounts for some, whereas the WF and SD variable accounts for very little. This is especially true for the WP and lexical decision and naming accuracy, with smaller effects for the lexical decision and naming reaction time data. The finding that the SD-BP variable still accounts for large amounts of variance in some datasets suggests that there are differences in the semantic content of books versus the writings of an individual author.
Unique effects of WF, SD, SD-BP, and SD-AP in percentage change in ΔR2.
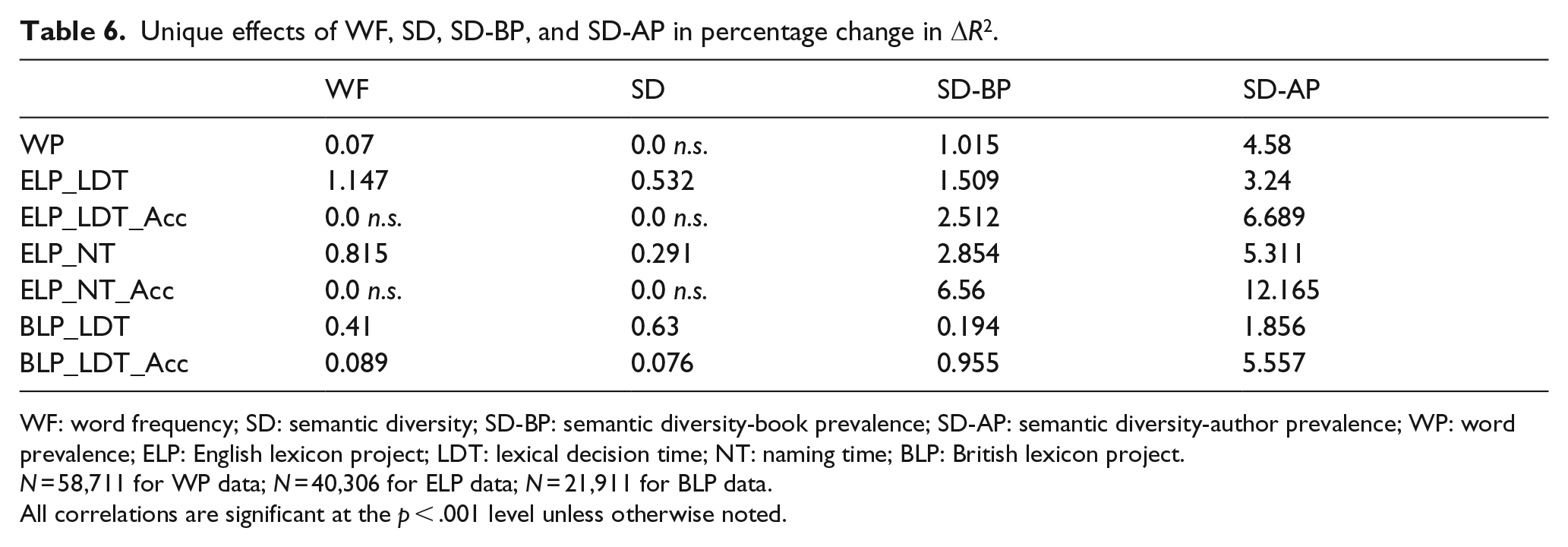
WF: word frequency; SD: semantic diversity; SD-BP: semantic diversity-book prevalence; SD-AP: semantic diversity-author prevalence; WP: word prevalence; ELP: English lexicon project; LDT: lexical decision time; NT: naming time; BLP: British lexicon project.
N = 58,711 for WP data; N = 40,306 for ELP data; N = 21,911 for BLP data.
All correlations are significant at the p < .001 level unless otherwise noted.
Split by country of birth
As Table 2 shows, the book collection used here has a large number of authors from both the United States and the United Kingdom. The WP data from Brysbaert et al. (2019) contains WP measures of subjects from the United States and the United Kingdom. In addition, the ELP was collected on subjects from the United States, whereas the BLP was collected from subjects in the United Kingdom. Thus, it is possible to determine whether the lexical statistics derived from the writings of an author born in the same country from where the data were collected provides a better accounting for that data. Recent research by Johns et al. (in press) suggests that lexical behaviour is strongly influenced by differential experience with language, thus splitting a corpus by place of birth offers another test of this hypothesis, and this hypothesis was validated by Johns and Jamieson (in press).
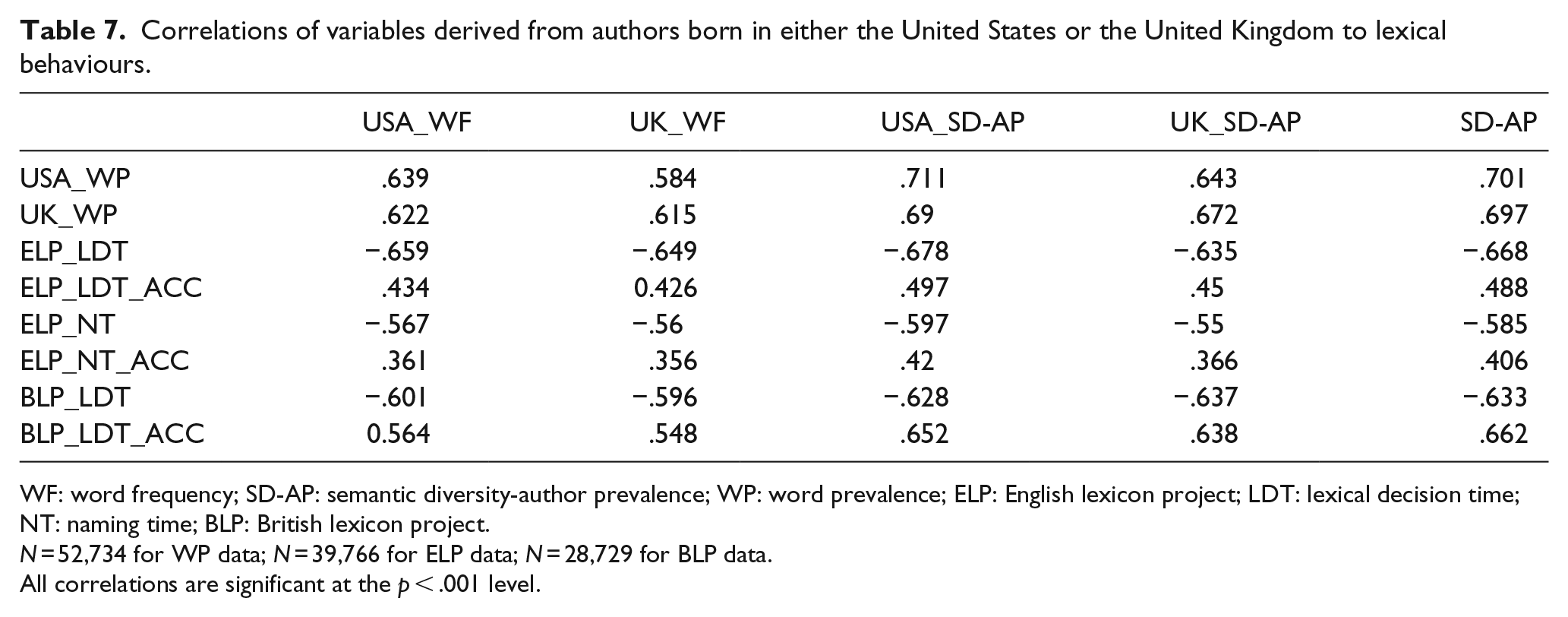
Table 7 contains the correlation between the WF and SD-AP variables, derived from a corpus of either US or UK authors, to the different datasets (the WP data was split into US or UK data). Although only the WF and SD-AP variables were included in this table, all variables showed very similar trends. As a comparison, the SD-AP variable trained on the entire corpus was included in this table. For the data collected in the United States (the USA_WP and ELP data), the SD-AP variable trained on the corpus of authors born in the United States (USA_SD-AP) offered the best fit across each datatype. In comparison, the variables derived from the authors born in the United Kingdom provide a poor accounting for the US data, suggesting that the lexical statistics of these writings do not map onto the lexical experience of American subjects. Indeed, the USA_SD-AP exceeds the correlation of the SD-AP variable, which was trained on a considerably larger amount of language.
Correlations of variables derived from authors born in either the United States or the United Kingdom to lexical behaviours.
WF: word frequency; SD-AP: semantic diversity-author prevalence; WP: word prevalence; ELP: English lexicon project; LDT: lexical decision time; NT: naming time; BLP: British lexicon project.
N = 52,734 for WP data; N = 39,766 for ELP data; N = 28,729 for BLP data.
All correlations are significant at the p < .001 level.
The UK_SD-AP provides a solid fit to the data collected in the United Kingdom (the UK_WP and BLP data). However, it does not provide as large an advantage as is seen in the US data for variables derived from the writings of Americans. Indeed, for the UK_WP and the BLP lexical decision accuracy data, the UK_SD-AP actually provides a worse fit than both the USA_SD-AP and the SD-AP.
Overall, the trends in the data contained in Table 7 suggest that subjects in the United States are relatively unfamiliar with the language used by British authors (in comparison to the lexical statistics derived from American authors), hence leading to a poor fit between the lexical statistics contained in the UK_WF and UK_SD-AP variables to the data collected in the United States. However, the UK subjects seem to have equal amounts of familiarity to both American and British authors, leading to neither corpus offering a large advantage. Similar results were found in Johns and Jamieson (in press) for word familiarity and category production data, suggesting a general trend. However, an alternative possibility for this trend is that there are other types of lexical experience that better account for the lexical experience of people from the United Kingdom, which do not seem to be captured with books, a question for future research.
To get a better understanding of the unique variance that each variable is accounting for, another regression analysis was conducted. The top panel in Figure 4 displays the amount of unique variance that the USA_SD-AP accounts for over the UK_SD-AP (and vice versa) across the eight data sources. This figure shows that the USA_SD-AP variable accounts for the most variance across seven of the eight datatypes, with the only exception being BLP lexical decision reaction times. The advantage for the USA_SD-AP is quite striking for the data collected in the United States, where it offers a considerable advantage over the UK_SD-AP variable. This advantage was smaller for the UK_WP and BLP lexical decision accuracy data.
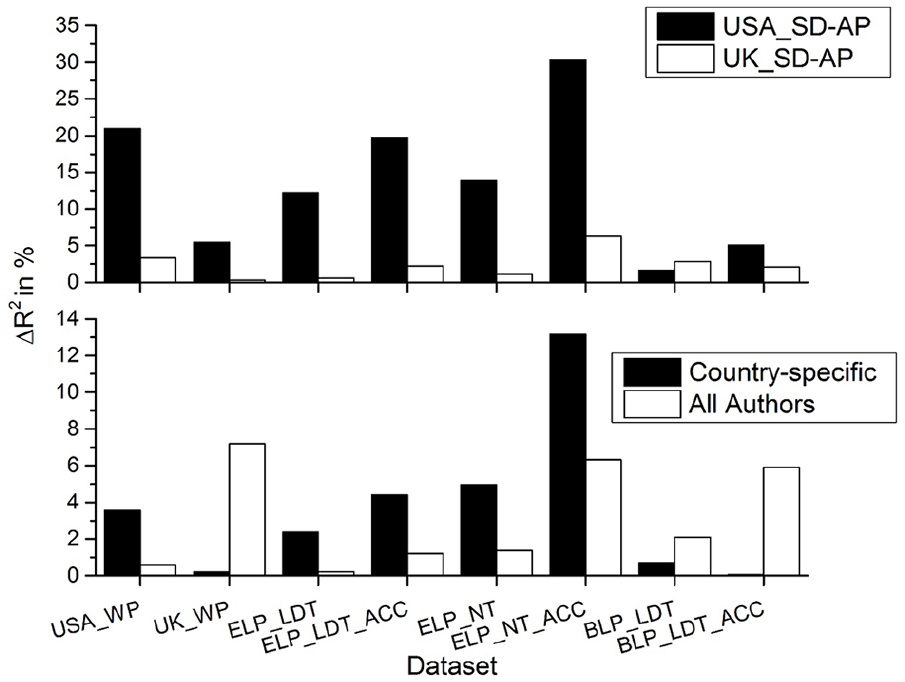
Results of regression analyses testing the amount of unique variance that the SD-AP accounts for when trained on authors from the United Kingdom versus authors from the United States (top panel), and when trained on a country-specific corpus versus all available authors (bottom panel).
To determine whether the variables derived from the country-specific corpus offers an advantage over the SD-AP variable that was trained across all of the writings contained in the book collection, an additional regression was done where the amount of unique variance that the SD-AP variable trained on a country-specific corpus (USA_SD-AP or UK_SD-AP) over the SD-AP variable trained on the entire book collection was calculated, and vice versa. The results of this analysis are contained in the bottom panel in Figure 4. For the UK data, the SD-AP variable offers the best fit to all datatypes. However, for the US data, the USA_SD-AP variable accounts for the most unique variance, suggesting that including authors from different countries actually harms the fit of lexical variables to the US data.
One possibility not yet discussed is that the differences in corpus size may be driving the differences seen in Table 7 and Figure 5. As can be seen in Table 2, the book collection contains almost three times more American authors than British authors. To test what effect this differential levels of information has on the fits to the WP data, a Monte Carlo simulation was done. In this simulation, 700 authors who were born in the United States and 700 authors born in the United Kingdom were randomly selected. UK_AP and USA_AP variables were then computed from these randomly selected authors. The AP measure was chosen because it is computationally inexpensive compared with the SD-AP measure, but still offers a good fit to these data. Given that there are only 738 authors from the United Kingdom, there is not likely to be much variance in the computed statistics for the UK_AP variable, but there should be for the authors from the USA_AP variable. Resampling was done 5,000 times and the average correlation to the USA_WP and UK_WP data was computed.
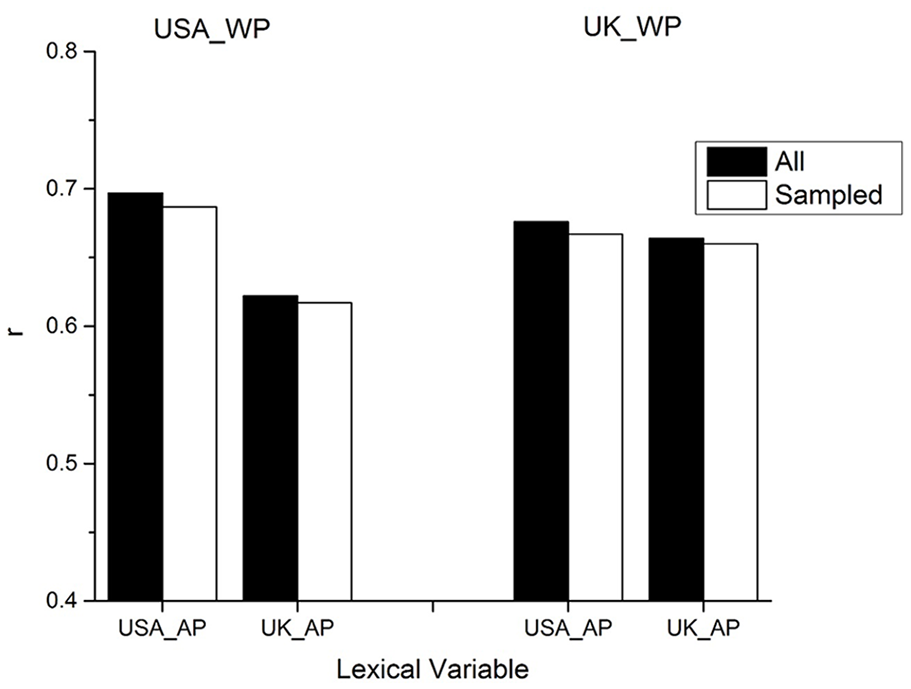
Results of a Monte Carlo analysis testing whether the superiority of the USA_AP variable results from the greater level of materials assembled from American authors.
The results of this simulation are contained in Figure 5, which displays the USA_AP and UK_AP fits to the USA_WP and UK_WP data when the measures are either sampled or computed from all of the authors from a certain country. This figure shows that there is a small drop in the correlation when only 700 authors are used, but there is not a change in trends. The US data is still well accounted for by the AP variable when trained on the US corpus, and still has a poor fit to the AP variable when it is trained on the UK corpus. The UK data are still well accounted for by either corpus. This simulation demonstrates that the different patterns in lexical statistics cause the discrepant fits to the lexical behaviour, and not the overall size of the different corpora.
Gender split
The WP data of Brysbaert et al. (2019) include data from both male and female subjects. Given that the book collection used here has also been categorised by male and female authors (see Table 3), the goal of the final analyses is to determine whether gender-specific corpora offer an advantage in accounting for lexical behaviour.
The correlations between the Female_WF, Female_SD-AP, Male_WF, and Male_SD-AP variables, to the Female_WP and Male_WP data are contained in Table 8. Again, the SD-AP variable trained on all materials was included in the table to serve as a comparison. Table 7 shows that, overall, the data collected from female subjects are better accounted for by the lexical variables. In addition, the female data are best accounted for by the lexical variables trained on the corpus of female authors, compared with the lexical variables trained on the corpus of male authors. For the data collected from male subjects, only the Male_SD-AP variable shows a slightly higher correlation to the Male_WP data, compared with the Female_SD-AP variable. However, the highest correlation to both the Female_WP and Male_WP data are from the SD-AP trained on all materials, suggesting that gender-specific corpora do not provide an overall advantage in accounting for gender-specific data.
Correlations of variables derived from male and female authors to male and female WP data.

WP: word prevalence; WF: word frequency; SD-AP: semantic diversity-author prevalence.
N = 53,247.
All correlations are significant at the p < .001 level.
To determine how much unique variance each variable accounts for, two more regression analyses were done. The top panel in Figure 6 displays the amount of unique variance the Female_SD-AP variable accounts for over the Male_SD-AP variable (and vice versa) for the Male_WP and Female_WP data. This figure shows that for the Female_WP data the Female_SD-AP accounts for the most variance, whereas the Male_SD-AP variable accounted for very little. The opposite was also true for the Male_WP, although the Female_SD-AP still accounted for some variance in this data. The bottom panel in Figure 6 contains the amount of unique variance that the gender-specific SD-AP variables account for over the SD-AP variable computed on the entire corpus. This figure shows that the SD-AP trained on all materials accounts for more variance in the data than the gender-specific corpus, demonstrating that there is no overall advantage to using gender-specific corpora.
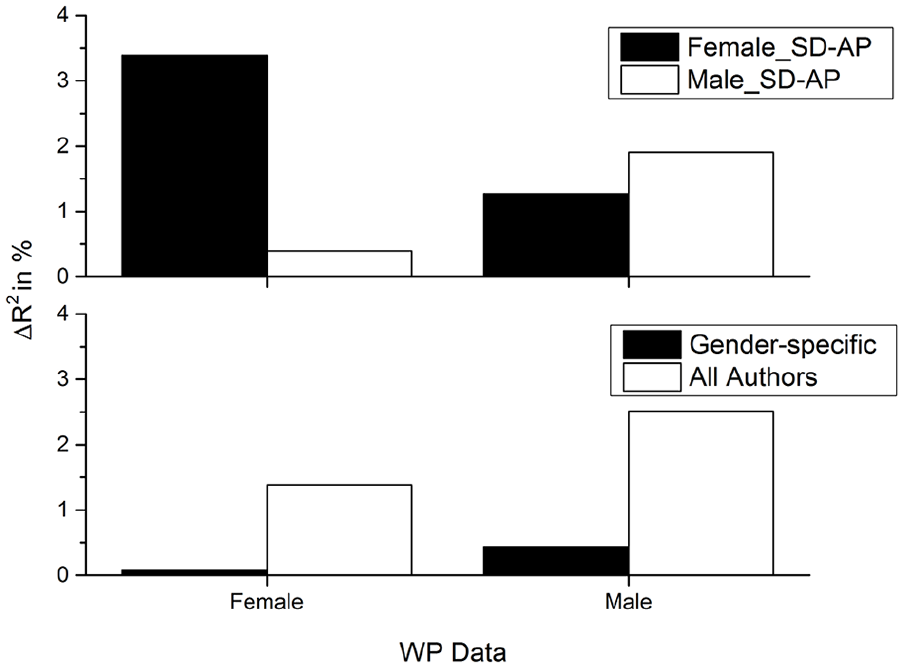
Results of regression analyses testing whether female or male WP data are better accounted for by the SD-AP variable when trained on male or female authors (top panel), and whether the gender-specific SD-AP variable accounts for more variance than the SD-AP variable trained on all authors (bottom panel).
The results of this analysis suggest that there are gender differences in the usage of language (at least on a very large scale; see Johns & Dye, 2019, for a more specific case of gender differences in language usage), and that there are some differences in lexical behaviour that are reflective of the gender discrepancy, such that a variable trained on a corpus of female authors outperforms a variable trained only on male authors, for female subjects. However, the best fitting model is still the one trained on all authors, suggesting that people have a mix of experience with the writings of both female and male authors.
Supplementary materials
The supplementary materials to this article contain the seven lexical variables (WF, CD, vSDM, BP, AP, SD-BP, and SD-AP) trained on both the complete book collection and also splits on place of birth (authors from the United States and the United Kingdom) and gender (male and female authors). It is our hope that these variables can be of use to other researchers examining lexical processing. The word list for the materials contains the lemmas from the Brysbaert et al. (2019) study, as well as inflected forms from the ELP (Balota et al., 2007) and the BLP (Keuleers et al., 2012).
General discussion
Subjective ratings (e.g., Age of Acquisition, familiarity, concreteness, meaningfulness) give excellent predictions of human behavioural data, and encourage the field to improve focus on valid psychological constructs. But in addition to being good predictors, they are ultimately dependent variables that need to be themselves explained, and provide a challenging target for mechanistic explanations of learning and processing (Baayen et al., 2016; Gernsbacher, 1984; Jones et al., 2015; Recchia & Jones, 2012; Westbury et al., 2013). A necessary intermediate step to explanation is the ability to link subjective ratings to objective environmental statistics.
This article introduced four novel measures of lexical strength, derived from much larger units of linguistic context than have previously been reported in the literature. Specifically, instead of relying on paragraph or document contexts (Adelman et al., 2006; Jones et al., 2012), whole books and the combined books of an individual author were used as the basic unit of measurement. When applied to various lexical behaviours, BP (a measure of the number of books a word occurred in) and (a measure of the number of authors that used a word) provided a better fit than occurrence-based variables (WF, CD, and SD). When the AP and BP measure was then combined with the machinery of the SDM (Johns et al., 2012, 2016a, 2016b; Jones et al., 2012, 2017), the resulting SD-BP and SD-AP variables were found to account for the most unique variance across multiple datasets, with the SD-AP being the overall best predictor.
The results reported here were inspired by the large-scale behavioural collection efforts of Keuleers et al. (2015) and Brysbaert et al. (2016, 2019), who used a crowd-sourcing methodology to estimate the proportion of the population that was familiar with a given word. The resulting “WP” measure explained significant unique variance in lexical decision performance, and revealed considerable variability in lexical knowledge across the population. We applaud their work as a huge step in the right direction; however, a potential limitation of that work is that it seeks to explain behaviour in terms of similar behavioural data, which raises a host of thorny theoretical issues (Jones et al., 2015). To address this problem, we sought to derive a similar measure directly from large-scale natural language materials, which lent the measure the added benefits of being objective and readily interpretable in a modelling context.
In most other respects, however, Keuleers et al.’s (2015) WP measure and our environmentally derived BP, AP, SD-BP, and SD-AP measures are complementary to one another. Measuring the probability that a word will occur in a particular book or be used by a particular author is not so different from measuring the probability that a word will be known to a particular speaker—words used across all discourse topics are more likely to be encountered, and thus more likely to be known by a larger proportion of speakers. Both measures allow for better estimation of how widely used a word is in the language, and the relationship between measures of prevalence and measures of frequency sets important constraints on theory construction, posing fresh challenges for language theorists.
The findings of this article suggest that by assessing the occurrence of words at quite high levels of measurement (e.g., whether it occurs in a book or whether an author used a word) provides important insight into how likely it is that a person had experienced that word before. This is borne out by the fact that the prevalence-based metrics offer a very significant improvement to lexical decision and naming accuracy data, and WP data. Likewise, occurrence-based metrics may over-inflate the likelihood of a person knowing that a word is a word, as a word may have a relatively high WF, but if that word is only used by a couple of authors, it is unlikely that many would have experienced that word before.
One advantage of using books as a source of lexical information is that it allows for control and understanding of the materials that are being used. In this article, we used author place of birth and gender to try to understand the influence of culture and gender on word processing. This follows previous work (e.g., Johns et al., 2019; Johns & Jamieson, 2019) in trying to understand the effects of differential experience on language processing. In this article, we found that using a country-specific corpus allows for a better accounting of behavioural data collected in the United States, such that a corpus derived from only American authors provided a better fit to this data than a corpus derived from the complete book set, similar to past work on the SUBTLEX corpus (van Heuven et al., 2014). Unique effects were also found for subjects from the United Kingdom, and also to male and female data. In addition, some effects of author gender were found, with a female author corpus providing a superior fit to WP data collected from female subjects, compared with a male author corpus. However, the overall corpus provided the best fit to the female subjects. These findings suggest that the fits of models are sensitive to the composition of the corpus that was used for training, and that by tailoring corpora to individual sets of data (depending on the subjects that were collected from), sometimes better and more insightful models can be developed.
However, even though books were the main unit of measurement used in this study, these norms can likely be modulated with other lexical information. The language contained in books likely differs significantly from other sources of language, such as subtitles, spoken language corpora, or social media posts. The issue becomes a question of scale of context—books provide a simple method of looking at word occurrence at quite large levels. Other sources are not so easily segmented, so determining the correct method of parsing other corpus types to estimate WP is a question for future research.
This work highlights the need for the continued evolution of corpus-driven analyses of lexical behaviour. Different collections of language contain different information, and have a different probability of being encountered by members of the language-speaking population. Determining the success of language materials in predicting performance, and establishing their connection to linguistic experience, will facilitate the development of better measures of verbal behaviour, and advance our understanding of lexical organisation in memory.
Supplemental Material
JDJ_Prev_supp – Supplemental material for Estimating the prevalence and diversity of words in written language
Supplemental material, JDJ_Prev_supp for Estimating the prevalence and diversity of words in written language by Brendan T Johns, Melody Dye and Michael N Jones in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.