
Abstract
Describing what one saw to another person is common in everyday experience, such as spatial navigation and crime investigations. Past studies have examined the effects of recounting on one’s own memory, neglecting an important function of memory recall in social communication. Here we report surprisingly low utility of one’s verbal descriptions for others, even when visual memory for the stimuli has high capacity. Participants described photographs of common objects they had seen to enable judges to identify the target object from a foil in the same basic-level category. When describing from perception, participants were able to provide useful descriptions, allowing judges to accurately identify the target objects 87% of the time. Judges’ accuracy decreased to just 57% when participants provided descriptions from memory acquired minutes ago, and to near chance (51.8%) when the verbal descriptions were based on memory acquired 24 hours ago. Comparison of participants’ own identification accuracy with judges’ accuracy suggests the presence of a common source of errors. This finding suggests that recall and recognition of visual objects share common memory sources. In addition, the low utility of one’s verbal descriptions constrains theories about the extension of one’s memory to the external world and has implications for eyewitness identification and laws governing it.
Introduction
Extensive research has shown that recounting one’s recent memory strengthens that memory and slows down forgetting. Known as the “testing effect,” this finding demonstrates the beneficial effect of memory retrieval for oneself (Roediger & Karpicke, 2006). Yet in many daily activities, people recount a memory not as a mnemonic device for themselves, but to provide information to others. Delivering a lecture, retelling a story, giving directions, and reporting a crime are such examples. The information provided in these recounts may guide the listener’s conceptual development, spatial navigation, and crime investigation. With easy access to smartphones and the internet, another person’s experience is just seconds away from being part of our own knowledge. The increasing reliance on others’ memories leads us to ask: how useful are one’s memory descriptions for someone else? This question has rarely been addressed; the vast literature on memory focuses instead on either the accuracy of one’s own memory or the accuracy of memory retrieved together with other people (Rajaram & Pereira-Pasarin, 2010). Few have examined how well one’s memory recall can be used by someone else. How well can somebody’s recounted memory enable others to recognise what was witnessed?
It would seem that the utility of one’s memory for other people can be derived without much experimentation. For it to be used by others, the memory needs to be highly accurate and easily verbalisable. It follows that an articulate person with an accurate, verbalisable memory should be able to provide valuable information to someone else. Such communicative acts are no doubt highly effective, attested by the accumulation of a vast amount of knowledge through civilisation and human history. Experimental research has therefore examined the type of memory that is less accurate or verbalisable. Concentrated around the 1980–1990s, this research examined the reliability of eyewitnesses’ descriptions of crimes. Though it does not directly reveal the usefulness of the witnesses’ descriptions for third-party usage, evidence suggests that the recounted information of one’s visual memory may be rather sparse.
van Koppen and Lochun (1997) examined archival data of police records from the Netherlands, containing eyewitness descriptions of robberies. The data showed that witnesses tend to provide general descriptions of the robbers such as their gender, race, and build. The witnesses gave little specific information about the robbers, such as their facial characteristics. When their descriptions were compared with the actual robbers’ characteristics, the little information that the witnesses did provide was generally accurate. This study suggests that witnesses retain some accurate memory about the crime, but their descriptions may be too sparse to be of significant value to others.
Several studies have examined the correspondence between a witness’ description of a perpetrator and the witness’ own accuracy in recognising the perpetrator from a lineup. This question was, in part, motivated by the US Supreme Court’s guidelines regarding the evaluation of identification evidence (Neil v. Biggers, 1972). One guideline includes the accuracy of the witness’ prior description of the perpetrator—more accurate prior description suggests that the subsequent identification through a lineup should also be more reliable.
Besides the practical significance, this question also has theoretical implications for understanding the relationship between recall and recognition. It is commonly accepted that both recall and recognition depend on declarative memory. In addition, non-declarative memory, such as priming, also contributes to recognition. Some studies have observed a dissociation between recognition and recall. Using line drawings of familiar objects and their names as stimuli, Tversky (1974) found no correlation between the recognition and recall performance of the same participants. In addition, amnesic patients showed impaired recall of objects but unimpaired forced-choice recognition (Holdstock et al., 2002). Other studies, however, have found strong correspondence between recall and recognition. Using word lists as stimuli, Haist et al. (1992) found that amnesic patients were impaired on both recall and recognition, providing no evidence of greater sparing of recognition than recall. These contradictory findings lead to competing hypotheses with regard to whether the same memory source underlies recall and recognition. As reviewed next, empirical evidence for a correspondence between a witness’ description and the witness’ own subsequent recognition accuracy has also been inconsistent.
To test whether description accuracy indeed corresponds to one’s own identification accuracy, Pigott and Brigham (1985) asked 120 college students to describe a person they saw for 15 s. The students were later asked to identify that person from a lineup. Pigott and Brigham coded each participant’s verbal description, and evaluated the correlation between the description accuracy and subsequent identification accuracy. No relationship was found—participants who provided a better description did not perform the lineup task better. The lack of correspondence is consistent with the idea that recall (e.g., the description task) and recognition (e.g., the lineup task) do not rely on the same memory source (Pozzulo et al., 2006; Tversky, 1974). It raises the possibility that a process beneficial to one’s own memory—recounting an experience—may not yield useful information for others.
Other studies have found some relationships between one’s own identification and verbal descriptions. Wells (1985) tested 176 participants using 21 faces. Each participant viewed one face and provided a description and an identification. Wells found a modest correspondence between the two measures (r = .27) and attributed the correlation to item differences—more distinctive faces yield better descriptions and better identification. Meissner (2002) showed that any inaccuracies generated during recall predicted participants’ identification accuracy later on. These findings suggest that there is likely some relationship between witness description and subsequent identification. In fact, a meta-analysis across 33 articles yielded a small but significant correlation, with an effect size r of .14 (Meissner et al., 2008).
Thus, previous studies on the correspondence between recall and recognition have found inconsistent results. The lack of a clear correspondence suggests that conclusions regarding the accuracy of one’s memory during identification need not generalise to the descriptions produced from memory, and hence the utility of that memory to others. Unfortunately, studies reviewed above did not specifically report how useful the participants’ verbal descriptions were. They either did not present data on the accuracy of verbal descriptions (Pigott & Brigham, 1985), or asked raters to classify the participants’ descriptions as “accurate,” “ambiguous,” or “inaccurate” (Wells, 1985). Although this rating indexes description accuracy, it is not a good measure of the utility of the descriptions. A description that is accurate but general does not allow others to identify what was described, and a description that is ambiguous may misguide others into choosing a foil that matches the inaccurate component of the description. A better index of the utility of a description is to examine how well other people can identify the perpetrator based on the description the witness provides.
Such an index has been used in several studies that examined different methods of description. Davies (1986) showed that judges could not reliably identify a composite face produced based on participants’ descriptions. However, when participants viewed a single face for 60 s and were prompted to describe key features immediately after, their descriptions were useful for judges (Christie & Ellis, 1981). More recently, Wilson et al. (2018) asked participants to read descriptions of faces written by a different group of people either immediately or 20 min after they had watched a video of a mock bank robbery. Using those descriptions, participants had to identify the target in an eight-person array. Participants who read the descriptions that were written immediately after encoding were better at identifying the target compared with those who read descriptions provided after the delay. More diagnostic-feature words were also included in the descriptions provided immediately after watching the video. These findings support the idea that recall immediately after prolonged viewing could lead to useful verbal descriptions being produced.
In summary, previous research has largely neglected the utility of one’s memory to third parties, particularly with regard to memory for objects. Though many studies on the testing effect ask people to describe their memory, the purpose of those studies is to identify effects of retrieval effort on one’s own memory (Roediger & Karpicke, 2006), rather than the usefulness of the descriptions to others. Studies from the 1980s examined description accuracy, yet the work focused almost exclusively on eyewitnesses’ descriptions of the perpetrator’s face and few studies probed the utility of those descriptions to others. Few studies tested memory of non-face stimuli, even though eyewitnesses often have to describe other crime details, such as what the person was wearing and which objects were present (Davies, 1986; Pozzulo et al., 2006).
Unlike face memory, memory for non-face objects has much higher capacity and is surprisingly detailed. In one study, participants encoded into memory thousands of photographs of categorically distinct objects, presented one at a time for 3 s each (Brady et al., 2008). In a recognition memory test immediately after encoding, participants were highly accurate (above 87%) at distinguishing old objects from new ones, even when the new objects were from the same basic-level category. Similar findings were observed for scene memory (Konkle et al., 2010). High-precision visual memory is not limited to objects to which people currently attend. Hollingworth et al. (2001) found that people continue to retain in memory previously attended objects, even after their eye gaze has moved away from those objects (Hollingworth & Henderson, 2002). Brady et al. (2008) estimated that people can hold 217.8 unique codes in visual long-term memory. The high capacity for objects makes it possible that unlike faces, verbal description of object memory may be highly useful for third parties.
The aim of the current study is to directly examine the usefulness of one’s memory descriptions to others. We also test whether participants’ recognition performance correlates with their recall, as reflected in the judges’ accuracy in identifying the target object based on participants’ descriptions. We extended previous work on faces to visual stimuli that are more memorable. To this end, we asked participants to describe photographs of common objects to enable someone else to identify the described objects. The descriptions were conducted under three conditions. In Experiment 1, participants described the photographs while viewing them, eliminating memory limitation as a source of inaccuracy. In Experiment 2, participants recounted memory of the photographs they saw minutes ago. In Experiment 3, recounting was done 24 hr after exposure to the photographs. In all cases, the participants’ descriptions were given to judges who had to choose the objects participants described in a two-alternative-forced-choice task (2AFC), including the described object (e.g., a tent) and a new exemplar from the same basic-level category as the target (i.e., a within-category foil) (e.g., a different tent). We examined the judges’ accuracy as an index of the utility of the participants’ verbal descriptions. Figure 1 illustrates the study procedure.
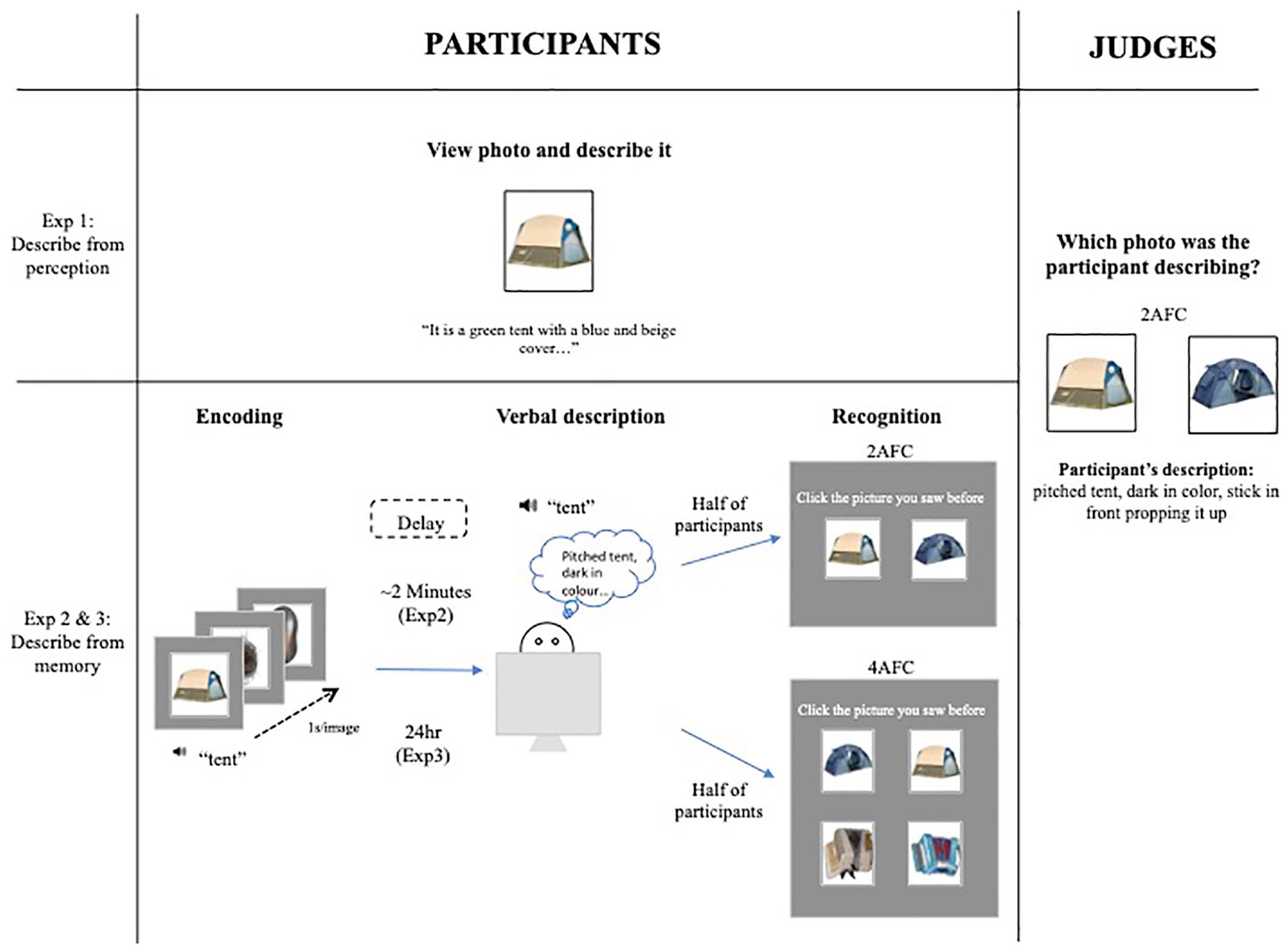
A schematic illustration of the participants’ task and the judges’ task. Participants’ task (left panels): In Experiment 1 (top left panel), participants were presented photographs of objects one at a time and asked to describe each object for someone else while the object remained on the screen. In Experiments 2 and 3 (bottom left panel), participants described the photographs from memory. During the encoding phase, each photograph was presented at a pace of 1s/image. There was then a delay (2 min in Experiment 2, 24 hr in Experiment 3). In the next verbal description phase, participants were asked to type out a description of the named object that they saw in the preceding phase from memory. In the third recognition phase, half of the participants in each experiment were given a 2AFC task and the other half a 4AFC task, and asked to select the photograph they had seen before. Judges’ task (right panel): A photograph of the described object and of a within-category foil were presented to judges. A participant’s verbal description of the photograph they had seen was also displayed. Judges were asked to decide which photograph the participant had described.
The study design addresses the following questions. First, to what degree do previous findings from witnesses’ descriptions of faces generalise to photographs of common objects? Although witnesses typically provide sparse descriptions of faces (van Koppen & Lochun, 1997), faces are a special category of visual stimuli (Yovel & Kanwisher, 2004). Unfamiliar faces, in particular, are especially difficult to remember (Bruce et al., 2001; Hancock et al., 2000). In addition, face recognition is holistic, relying on the configuration of the spatial relationship between various face parts (Young et al., 2013). Because configural information is difficult to verbalise, essential identification information of a face may not be describable. In fact, the conversion from visual to verbal codes of faces lowers the likelihood of one correctly identifying a target face later on, contributing to “verbal overshadowing” (Schooler & Engstler-Schooler, 1990). In contrast, non-face stimuli are typically recognised based on features, making it more likely that a verbal description is useful. These differences lead to the hypothesis that, unlike faces, photographs of common objects may yield highly useful, transmissible memory from a witness to another person.
Second, is there any correspondence between participants’ descriptions, as indexed by the judges’ accuracy in choosing what participants saw, and the participants’ own identification accuracy? This question has theoretical implications for understanding whether separate or common sources underlie recall and recognition performance. It also has practical importance, pertaining to the Supreme Court’s guideline on the evaluation of identification evidence (Neil v. Biggers, 1972), but this time on memory of objects instead of faces. By asking each participant to describe a large number of objects, we test the hypothesis that common sources may underlie recall and recognition of visual objects.
Experiment 1
We begin with an experiment asking participants to describe visual objects based on perception, with the objects in full view. This is a necessary first step to determine an approximate upper bound on the utility of verbal reports, when the descriptions are not limited by memory.
In Experiment 1, participants were shown a set of photographs of categorically-distinct objects, one at a time. They were asked to describe each object for someone else. Typically, in eyewitness situations and everyday experience, people do not know what the foils out in the world could be. For instance, if law enforcement is trying to locate a blue t-shirt with Mickey Mouse on it because it was last worn by a missing child, the witness who gave that description would not necessarily have known, for instance, that the shade of blue needed to be specified. Not knowing what the foils look like, thus, makes it difficult to tune encoding and verbal descriptions to the more diagnostic features of what was seen (diagnostic feature-detection hypothesis; Wilson et al., 2018). To mimic these real-world situations, we instructed participants to describe the objects with as much detail as possible, for the purpose of aiding someone else to identify the objects later on, without informing them of the nature of potential foils. The participants’ verbal descriptions were then provided to judges, who were presented with a photograph that the participants described and a foil object that belonged to the same basic-level category as the target object. For example, the judge may be presented with a tent that participants saw and a different tent that participants did not see. The judge’s task was to identify the target object based on the participant’s description. We examined the judge’s accuracy as an index of the utility of participants’ verbal descriptions.
Even though descriptions are based on perception, several factors can limit their utility. First, information may be lost when visual representations are converted into a verbal code (Schooler & Engstler-Schooler, 1990). Second, without knowing what the foils might be, participants may fail to include diagnostic information in their descriptions. Third, judges may introduce errors when interpreting participants’ verbal descriptions and identifying the objects. These factors jointly constrain the accuracy that judges can achieve, even when participants’ memories are not a limiting factor.
Method
Participants
Participants in all the experiments were students from the University of Minnesota between 18 and 35 years of age. They were native English speakers, naïve to the purpose of the study, had normal or corrected-to-normal visual acuity, and normal colour vision. Participants signed an informed consent and were compensated with extra course credit.
Twelve participants, eight females and four males (M = 22 years, SD = 5.8 years), provided verbal descriptions of objects in Experiment 1.
Materials
Participants were tested individually in a room with normal interior lighting. The programme was written in MATLAB (www.mathworks.com) and Psychtoolbox (Brainard, 1997; Pelli, 1997). Stimuli were displayed on a 19" CRT monitor (1024 × 768 pixels) subtending 24.6° × 24.6°.
Photographs of common objects were sampled from Brady and Oliva’s object database (http://cvcl.mit.edu/MM/stimuli.html). The image set contained 300 distinct basic-level categories, each with two exemplars. Each participant described 50 categorically distinct objects. The selection of the 50 categories and the specific exemplar shown to the participants were counterbalanced across participants.
Design and procedure
After informed consent, participants were led to a testing room and provided with the following instructions: Welcome to the study. You will be shown pictures. When the picture appears on the screen, you will also hear the name of the picture being said. Type out your description of the object. Once you are done, click “ok” . . . Try your best to describe how the object looks like. Take your time and provide a description that will allow someone else to identify the object you saw based on your description of it.
Participants were then shown 50 objects, one at a time, in the upper left corner of the computer monitor (image size: 14.7° × 14.7°). A voice naming the object accompanied the photograph. A text window opened to the right of the photograph for participants to type out a description. Participants had unlimited time to view and describe the objects. After they had finished typing, they clicked “OK” to proceed to the next trial.
Coding of the verbal descriptions
Four judges, including the first author and three research assistants, completed the coding phase independently. Each judge coded all 12 participants’ descriptions, one at a time. Because the photographs used as targets and foils were fully counterbalanced across participants, the judges had no information as to which photograph was more likely shown to a given participant. That is, the judges were blind to the correct answer and their coding depended entirely on the participants’ verbal descriptions.
Each judge went through 50 trials of each participant’s verbal descriptions. On each trial, the judge was presented with the target and a within-category foil. The two photographs were presented side-by-side, 15.7° to the left and right of fixation (each image subtended 14.7° × 14.7°). The left/right position was randomised. The verbal description the participant provided was presented below the photographs (see Figure 1). The judge clicked on the image that they thought the participant saw before proceeding to the next trial.
Results
The four judges produced highly similar levels of accuracy. Mean accuracy was as follows: Judge 1 87.5% (SE = 3.7%), Judge 2 87.8% (SE = 3.8%), Judge 3 87.2%, (SE = 4.4%), and Judge 4 87% (SE = 3.9%). The small standard error of each judge indicates that the variability in coding across the 12 participants was low. In addition, all judges produced mean accuracies within a narrow range. The mean across the four judges was 87.4% (SE = 0.18%). The low variability across judges suggests that their accuracy was determined mainly by the quality of the participants’ descriptions, rather than by noise introduced by the judges themselves. The high consistency across judges was also observed in subsequent experiments, justifying the pooling of data across judges in the data analysis.
Using the mean data across judges as the dependent measure (Figure 2), the judges’ accuracy of 87.4% was significantly above chance, t(11) = 9.57, p < .001, and significantly below perfect performance, t(11) = 3.23, p < .01.
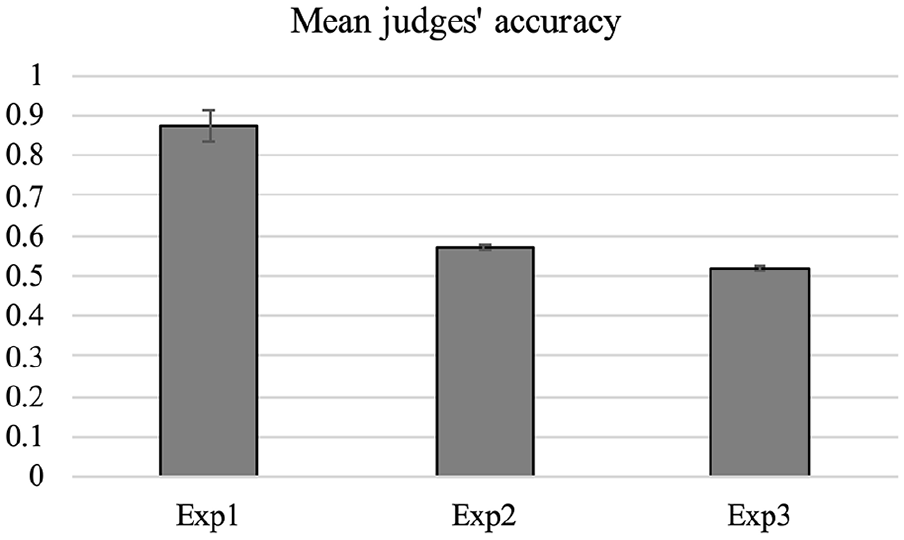
Mean judges’ accuracy from Experiments 1, 2, and 3. Chance is 0.5. Error bars show ±1 SE of the mean.
Discussion
Experiment 1 demonstrates that participants are able to provide useful verbal descriptions of visual objects, when the descriptions are given while the objects are in view. In the absence of a memory demand, participants’ verbal descriptions are useful, allowing judges to discriminate the object from a within-category foil. The accuracy of the judges—around 87%—is considerably higher than previous findings using faces (Christie & Ellis, 1981; Davies, 1986). These previous studies asked people to describe faces from memory. Hence, the discrepancy between our results and theirs could be explained by a difference between perception and memory (Pigott & Brigham, 1985), and by a difference between the type of stimuli described (objects vs. faces).
The judges’ accuracy is significantly below 100%, suggesting that visual information is lost when participants describe the objects. The loss of information can be attributed to two sources. First, it is not possible for participants to describe all the visual properties in words. Second, because participants did not know which features would be diagnostic in the judges’ task of identifying the target object, their verbal descriptions may not have included all the diagnostic information (Wilson et al., 2018). Both of these limitations are inherent in verbal description tasks. The 87% accuracy (rather than 100%) observed in Experiment 1 therefore serves as an approximate upper bound on what can be expected when participants describe visual objects based on memory. The next two experiments examine the degree of information loss when people describe their visual memory.
Experiment 2
Experiments 2 and 3 were part of a project investigating effects of intervening verbal recall on participants’ memory of visual stimuli (Tan & Jiang, 2019). In this previous study, we showed that describing visual memory could strengthen that memory, especially when testing was done after a 24-hr delay. As in other studies on the testing effect, Tan and Jiang (2019) focused on effects of verbal description on the participants’ own memory. The new focus of the current study is on the value of the verbal descriptions for third parties who did not witness the objects.
In Experiment 2, participants provided verbal descriptions from memory acquired minutes ago. Participants engaged in an initial memory encoding phase, during which they saw a sequence of photographs one at a time. Immediately after encoding, participants were cued with the name of the photograph and asked to write down as much as they could remember about the object. As in Experiment 1, participants were asked to describe the objects for someone else’s use. After the verbal description, participants’ own memory for the objects was assessed using either a 4AFC or a 2AFC task. The 4AFC task presented participants with the target object they encoded, a within-category foil, and two exemplars from a new basic-level category not encoded previously (i.e., between-category foils). The 2AFC task presented participants with the target and its within-category foil. As in Experiment 1, judges were provided with participants’ verbal descriptions and had to identify the object in a 2AFC task. This design allowed us to examine (a) the utility of participants’ verbal descriptions in enabling the judges to choose the target object, and (b) the correspondence between the participants’ own recognition accuracy and the judges’ accuracy.
Method
Data were collected as part of a project examining the testing effect on visual memory (Tan & Jiang, 2019). That study did not explore the utility of verbal descriptions for others. Here we present those data. Additional details on the testing effect can be found in Tan and Jiang (2019).
Participants
Forty-eight participants completed Experiment 2, which included three phases: (a) encoding, (b) verbal description, and (c) recognition. Half of the participants (18 females and 6 males, mean age = 19.5 years, SD = 1.6 years) were tested in a 4AFC recognition task in Phase 3, whereas the other half (13 females and 11 males, mean age = 19.8 years, SD = 1.7 years) were tested in a 2AFC recognition task.
Materials
Objects were drawn from the same object database as in Experiment 1, plus another 10 basic-level categories of objects that served as fillers in the encoding phase (see procedure below).
Phase 1: encoding
Participants first engaged in an encoding phase. During this phase, participants were presented with a sequence of visual objects at a pace of 1s/image. Each object was presented at the centre of the screen (24.6° × 24.6°). Participants were asked to remember the objects. To ensure task compliance, participants were asked to monitor occasional repetitions of objects. The encoding sequence had 150 objects that were presented once, and 10 filler objects that were presented twice at random intervals. The fillers were not included in subsequent phases. For 12 participants, the objects were presented on their own, and participants pressed the spacebar whenever they detected an object that appeared earlier in the sequence. For the other 36 participants, a voice naming the object was presented along with its visual presentation. The voice tied up the computer’s processor, preventing it from collecting button presses. These participants reported the number of repetitions they detected at the end of the encoding phase. Repetition detection accuracy was high (as reported in Tan & Jiang, 2019), suggesting that participants had complied with the task instruction. All the objects presented in the encoding phase were unique in terms of their basic-level categories. A random half of the 300 categories was assigned for encoding, while the other half was assigned as foils for the recognition phase (Phase 3). The assignment was reversed for half of the participants. Object categories and exemplars used for targets and foils were fully counterbalanced across participants.
Phase 2: verbal description
A random third of the encoded objects (N = 50) were used in this second phase. Assignment of stimuli for inclusion in Phase 2 was counterbalanced across participants. Participants were shown the written name of an object on the screen, and a voice announcing the object’s name was played. Participants were asked to type out a detailed description of the named object that they had seen in Phase 1 to enable someone else to identify the object based on their description. After they had finished typing, they clicked “OK” to proceed to the next trial. No feedback was given.
Phase 3: recognition memory test
The recognition memory test included 150 trials, including the 50 objects that participants were cued to recall in Phase 2 and the 100 objects not included in Phase 2. Our focus in this study is on participants’ recognition memory for the 50 objects they described in Phase 2. Memory for the other 100 objects was used to probe the testing effect, and data were reported previously (Tan & Jiang, 2019).
For a subset of the participants (N = 24), on each trial, four objects were presented in a 4AFC task, one in each quadrant (image size: 14.7° × 14.7°; the centre of each image was 11.7° from fixation, horizontally displaced by 7.9° and vertically displaced by 8.6° from fixation). One object was the target object, which participants had seen in Phase 1. Another was a within-category foil, and the other two were between-category foils. None of the foils were previously presented. The positions of the four objects were random. Participants were asked to click on the object they had seen before. A tone provided feedback. For the other subset of participants (N = 24), only two options (2AFC) were presented side by side on the horizontal meridian (the centre of each image was 7.9° away from fixation). One option was the target, while the other was the within-category foil. Participants were asked to click on the object they had seen before and a tone provided feedback.
Coding of the verbal descriptions
Three research assistants served as judges. As in Experiment 1, the judges were blind to the images that each participant saw. The coding procedure was the same as in Experiment 1. The judges were presented with each participant’s verbal description, along with the target object and a within-category foil. Judges had to identify the target object.
Results
Judges’ coding accuracy
Judges’ accuracy in identifying the target objects was surprisingly low (Figure 2). Mean accuracy was as follows: Judge 1 55.6% (SE = 1.4%), Judge 2 58.3% (SE = 1.03%), and Judge 3 57.4% (SE = 1.02%). As in Experiment 1, for each judge, accuracy across the 48 participants they coded fell within a narrow range. In addition, the three judges produced accuracies within 2.7% of each other. The mean for all judges was 57.1% (SE = 0.86%). The consistency across judges justified the pooling of data across all judges to provide an index of the utility of participants’ descriptions to others.
We compared the judges’ accuracy for the 12 participants in Experiment 1, with judges’ accuracy for the 48 participants in Experiment 2. This revealed a significant difference, t(58) = 11.8, p < .001, suggesting that the utility of verbal descriptions substantially declined when it was based on memory rather than perception. The judges’ accuracy in Experiment 2 was above chance (50%), t(47) = 8.27, p < .001, suggesting the presence of some, though limited, utility of one’s memory descriptions to third parties.
Difference between judges’ accuracy and participants’ own identification
Participants’ own identification exceeded the judges’ accuracy. Participants tested in the 2AFC recognition task essentially carried out the same task as the judges, except that their choice was based on their own memory rather than on the descriptions they provided. For the 50 objects they described, the 24 participants in the 2AFC recognition task had a mean accuracy of 67.7% (SE = 2.1%), significantly higher than the judges’ accuracy, 56.9% (SE = 1.3%), t(23) = 7.29, p < .001. Participants tested in the 4AFC task identified the correct category (either the target or the within-category foil) 88.1% (SE = 2.7%) of the time, suggesting good category memory. Among trials in which they identified the correct category, participants chose the target 70.4% (SE = 2.3%) of the time. This value was again significantly higher than the judges’ accuracy (M = 57.3%, SE = 1.2%), t(23) = 7.37, p < .001. The difference between participants’ own recognition accuracy and the judges’ identification accuracy indicates information loss when visual memory was transmitted to another person via verbal description. The loss could be due to a change in coding format (from visual to verbal) or to the failure of fully describing one’s visual memory.
Correspondence between judges’ accuracy and participants’ own identification
Although judges performed worse than the participants, the pattern of behaviour across images showed a clear correspondence between the two (Figure 3).
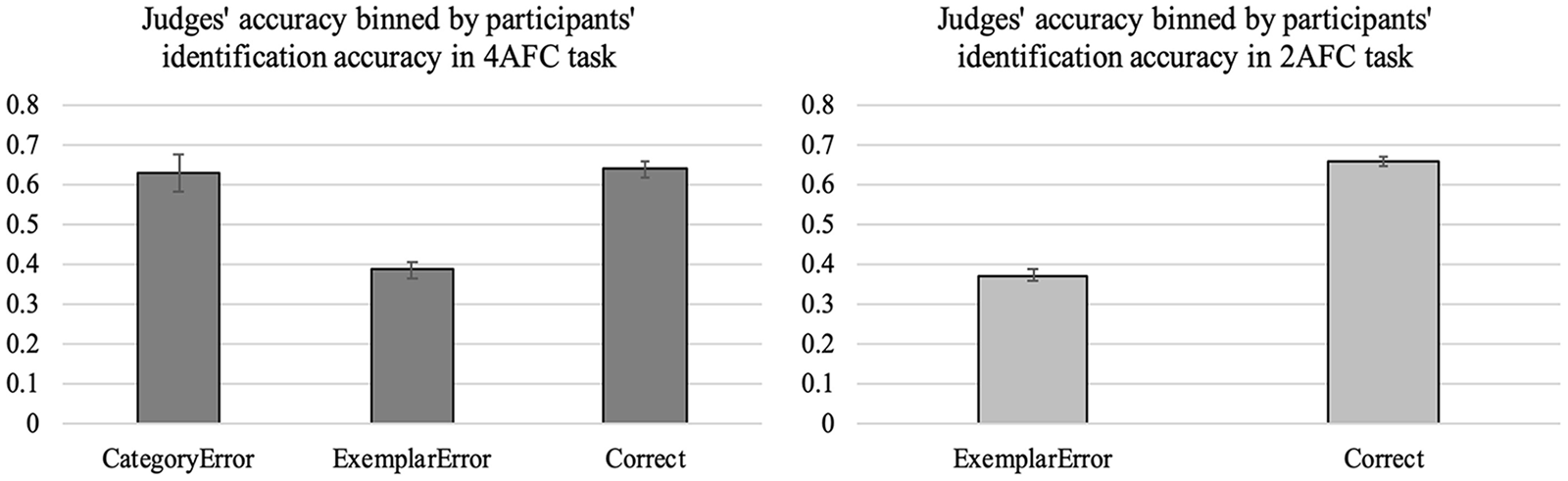
Judges’ mean accuracy binned by participants’ identification accuracy in Phase 3 (recognition memory test) in Experiment 2. Left: Results when participants were given the 4AFC task. Participants either committed a category error (i.e., choosing a between-category foil), an exemplar error (i.e., choosing a within-category foil), or chose the target and obtained a correct response. Right: Results when participants were given the 2AFC task. Error bars show ± 1 SE of the mean.
When participants were given the 4AFC task in Phase 3 (Figure 3, left), judges were significantly above chance (M = 63.9%, SE = 2.0%) for images that participants themselves successfully identified later on, t(23) = 6.99, p < .001. Judges’ accuracy declined to significantly below chance (M = 38.7%, SE = 2.1%) for images that participants later chose the within-category foil, t(23) = 5.46, p < .001. This suggests that when participants were mistaken with regard to which exemplar they had seen, their earlier verbal description was more consistent with the foil, misleading the judges towards choosing the foil more often than the target. Finally, for images that participants later chose a between-category foil, judges’ accuracy was above chance (M = 62.7%, SE = 4.7%), t(19) = 2.72, p = .013. 1
Correspondence between the participants’ own identification and the judges’ choices was also observed in participants who completed the 2AFC task in Phase 3 (Figure 3, right). Here, judges performed significantly above chance (M = 66%, SE = 1.3%) when participants later chose the target, t(23) = 11.78, p < .001, and performed significantly below chance (M = 37%, SE = 1.6%) when participants later chose the within-category foil, t(23) = 7.93, p < .001.
We also examined the relationship between the diagnosticity of the verbal descriptions and the participants’ recognition performance. We operationally defined diagnosticity based on judges’ accuracy. 2 If judges correctly chose the target based on a verbal description, that verbal description was diagnostic. Conversely, if judges chose the foil based on a verbal description, that description was not diagnostic or misleading. Did participants achieve higher recognition when they had earlier provided diagnostic rather than non-diagnostic/misleading descriptions? This was indeed the case. For objects that received a diagnostic description (i.e., when judges were correct), participants also had significantly higher recognition memory in the 4AFC recognition test (M = 70.3%, SE = 3.7%), compared with memory of objects that received a non-diagnostic description (i.e., when judges were incorrect) (M = 52.4%, SE = 3.3%), t(23) = 6.55, p < .001. 3 Likewise, in the 2AFC task, objects receiving a diagnostic description were better recognised (M = 78.1%, SE = 1.9%) than objects receiving a non-diagnostic description (M = 53.7%, SE = 2.3%), t(23) = 12.30, p < .001.
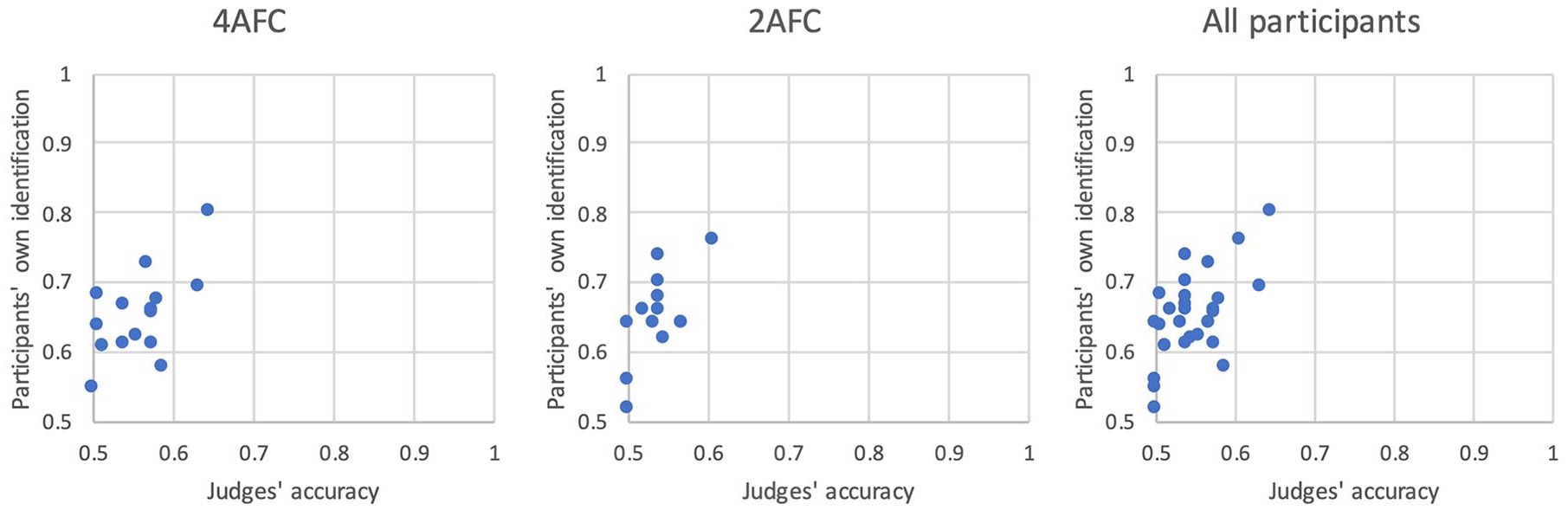
Good vs. bad descriptors, good vs. bad identifiers
The correspondence examined above was across stimuli—we found that objects that participants correctly identified were also more accurately described, compared with objects that participants misidentified. Here we investigated the between-participant variability in description and identification. Each participant yielded an identification score—percent of the time that they chose the target rather than the within-category foil. Each participant also yielded a description score—percent of the time that the judges chose the target based on their verbal descriptions. Figure 4 plots the correlation between the two measures, for participants in the 4AFC task (Figure 4, left), 2AFC task (Figure 4, middle), and for all participants (Figure 4, right). We found a significant correlation between the two measures, with Pearson’s correlation coefficient of .65 in the 4AFC task (p = .001), .70 in the 2AFC task (p < .001), and .67 when all participants were considered (p < .001). Consistent with the previous meta-analysis (Meissner et al., 2008), participants who provided better descriptions were also better identifiers themselves. Information loss is also apparent in Figure 4 (right), where the main diagonal shows equivalent performance between the judges and the participants. Nearly all participants’ data lie above the diagonal line, meaning that participants’ own identification accuracy exceeds the judges’ accuracy.
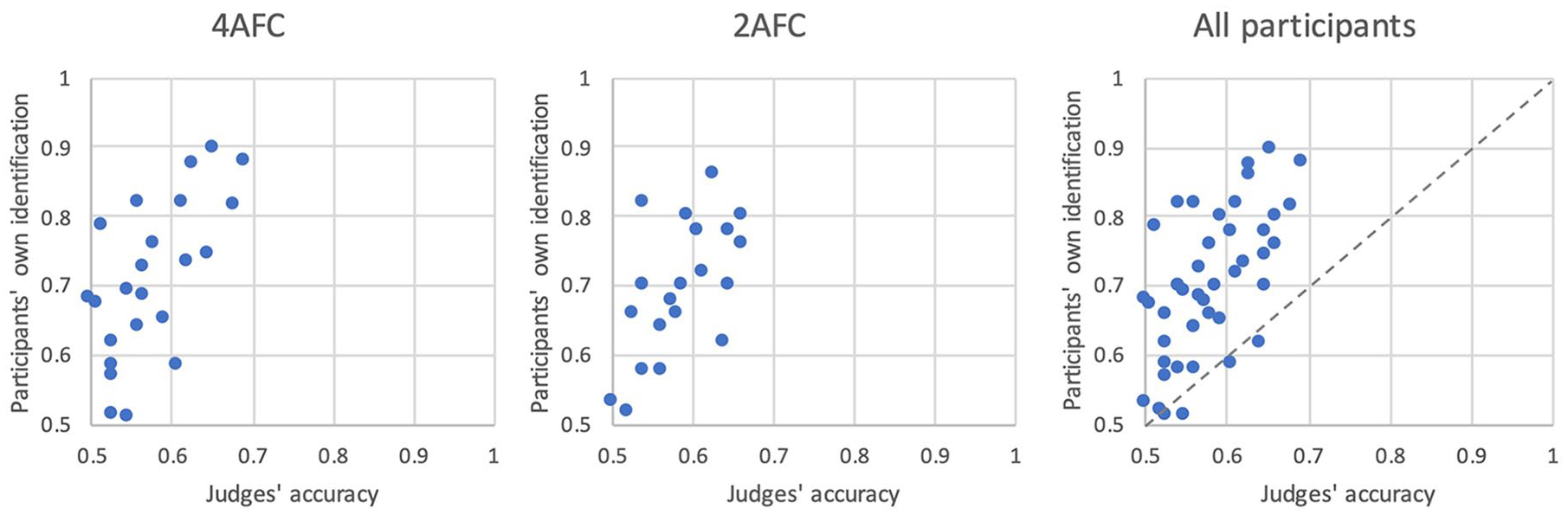
Scatterplots on the relationship between the judges’ accuracy and the participants’ own identification accuracy in Experiment 2. Each data point corresponds to a single participant.
Discussion
Experiment 2 shows that when describing objects from memory, participants provide some, though highly limited, information to others. Judges can only discriminate the target object participants saw from a within-category exemplar 57% of the time. This level is about 30% lower than that observed in Experiment 1 in which descriptions were based on perception rather than memory. Participants’ own identification accuracy exceeds the judges’, showing information loss when describing their visual memory. Thus, the judges’ poor identification accuracy can be attributed to participants’ memory inaccuracy, as well as to information loss when visual memory is transcribed into words.
This experiment also reveals strong correspondence between participants’ own identification accuracy and the diagnosticity of their descriptions. Participants who give better descriptions and therefore enable judges to reach higher accuracy, also themselves have higher identification accuracy. In addition, within a participant, objects receiving better, more diagnostic, descriptions are also ones that are more accurately identified by the participant. When participants choose the wrong exemplar, their earlier verbal description contains misinformation, resulting in judges’ tendency to choose the wrong exemplar more often than the target object. Likewise, when participants provide less diagnostic verbal descriptions for objects, they also tend to err during the final recognition test. These results align with Wilson et al. (2018), which found a relationship between how diagnostic a verbal description of a perpetrator was and the same person’s ability to discriminate the target from the foils during a recognition task later on. The less diagnostic the verbal description, the more impaired discriminability was later on. Our results, together with those in Wilson et al. (2018), suggest that participants, in addition to the judges, may rely on information in their own verbal descriptions during subsequent recognition tests. Furthermore, recall and recognition share common memory sources.
The correspondence between the participants’ description accuracy and their identification accuracy appears to be stronger in the current study than in previous studies (e.g., Pigott & Brigham, 1985). This may be due to stimulus differences: faces may be so difficult to describe such that what is described often has poor correspondence to the actual stimuli. Another difference is the way description accuracy is measured. Several previous studies measured description accuracy by rating the descriptions as “accurate,” “ambiguous,” or “inaccurate” (Wells, 1985). This classification may inflate the utility of the descriptions, given that an accurate but general description may not be useful, and a partly accurate description may be misleading. In addition, the ratings used in previous studies may lack reliability. In a pilot phase of our study, we asked raters to rate participants’ verbal descriptions by displaying the verbal descriptions along with the actual object they saw. We found that the raters lacked confidence in rating the descriptions—many statements contained both correct and misleading information and could not be easily classified as “partly accurate” or “inaccurate.” Instead of forcing the raters to make their best bet on the classification, the current study uses a method that is unambiguous—judges are asked to identify the target object based on the participants’ verbal descriptions. This way, everything in the verbal descriptions becomes relevant, and the judges’ task is essentially the same as the participants’ identification task (Phase 3). The low variability across judges indicates that this method is highly reliable. The strong correspondence between the participants’ identification accuracy and the utility of their descriptions provides support for one of the Supreme Court’s guidelines regarding the evaluation of identification evidence (Neil v. Biggers, 1972). Accurate earlier descriptions indeed have some correspondence to accurate subsequent identification, at least for visual memory of objects.
Experiment 3
Recounting one’s memory can be fairly immediate, as in Experiment 2. Often times, however, there is a delay before we can provide a verbal description of what we saw. How does the utility of verbal reports change with time? The retrieval effort account (Carpenter, 2009; Carpenter & Delosh, 2006) states that people remember what was encoded better if the time interval between the initial study and the first retrieval is longer. This suggests that delaying the first retrieval attempt makes the solution less accessible, necessitating an increase in retrieval effort on that attempt and enhancing one’s memory in subsequent tests. Along these lines, it is possible that a longer delay between encoding and the verbal recall in our study would lead to a more effortful retrieval during verbal recall, yielding a verbal description that has greater utility to third parties (e.g., perhaps only the more diagnostic information is retained in that description). On the other hand, memory decays during delays, and this may decrease the verbal description utility to others. As shown in Experiment 2, verbal descriptions from memory are much less useful than those from perception, suggesting that as memory further decays, the utility of the verbal descriptions may decline further as well. Experiment 3 tests these competing predictions by inserting a 24-hr delay between encoding and the verbal description phase.
Method
Participants
Forty-five participants, 33 females and 12 males, completed the study. Their mean age was 19 years.
Design and procedure
Experiment 3 was identical to Experiment 2, except that a delay of 24 hr was inserted between Phases 1 and 2. Participants encoded 150 photographs on Day 1. They returned 24 hr later and completed a verbal description of 50 objects in a similar manner as in Experiment 2. Immediately after the verbal description, participants completed the identification task using either the 4AFC (N = 23) or the 2AFC task (N = 22).
Coding of the verbal descriptions
Three research assistants served as judges in the coding phase. The procedure was the same as in Experiments 1 and 2.
Results
Judges’ coding accuracy
Judges performed poorly based on participants’ verbal descriptions of the objects (Figure 2). The mean accuracy was as follows: Judge 1 51.3% (SE = 0.97%), Judge 2 51.5% (SE = 1.0%), and Judge 3 52.7% (SE = 1.2%). As in the first two experiments, the judges produced highly similar levels of accuracy, with a mean of 51.8% and an SE of 0.8%. The judges’ data were therefore averaged to produce an index of the utility of the participants’ verbal descriptions.
Judges’ accuracy—51.8%—was very low. It was statistically above chance, t(44) = 2.25, p = .03, but significantly lower than that observed in Experiment 2, t(91) = 4.46, p < .001, or Experiment 1, t(55) = 14.10, p < .001. Thus, following a 24-hr delay, the verbal descriptions were of little value to third parties.
Difference between judges’ accuracy and participants’ own identification
As in Experiment 2, the judges’ accuracy was lower than participants’ own identification accuracy. In Phase 3, for the 50 objects they described, participants tested in the 4AFC task rarely chose the wrong category (correct category was chosen 87.2% of the time, SE = 1.7%). Among trials in which the correct object category was chosen, participants chose the target object (as opposed to the within-category foil) 63.4% of the time (SE = 1.4%). This was significantly higher than the judges’ accuracy (M = 52.3%, SE = 1.4%), t(22) = 8.86, p < .001. Participants tested in the 2AFC task chose the target object 63% of the time (SE = 1.6%), again significantly higher than the judges’ accuracy (M = 51.3%, SE = 0.87%), t(21) = 7.58, p < .001. Clearly, participants had access to information that was not part of their verbal descriptions.
Correspondence between judges’ accuracy and participants’ own identification
Even though the judges’ overall accuracy was close to chance, they did not perform randomly. Instead, their performance corresponded strongly with the participants’ performance. First, when participants were given the 4AFC task in Phase 3, judges were significantly above chance (M = 60%, SE = 2.2%) for images that participants themselves successfully identified later, t(22) = 4.57, p < .001. Judges’ accuracy declined to a level not different from chance (M = 47%, SE = 4.2%) when participants later chose a between-category foil, t(21) = 0.66, p = .52. 4 Judges were significantly below chance (M = 41%. SE = 2.1%) when participants later chose the within-category foil instead of the target, t(22) = 4.18, p < .001. Similar results were found in participants who completed the 2AFC recognition task. For images that participants later accurately identified, the judges also performed above chance based on the participants’ descriptions (M = 59%, SE = 1.6%), t(21) = 5.83, p < .001. For images that participants later incorrectly identified, judges were also more likely to choose the within-category foil—the judges’ accuracy was 36% (SE = 2.0%), a level significantly below chance, t(21) = 6.78, p < .001. These data confirm once again that participants’ verbal descriptions contained both accurate and misleading information and that this information was the common source of errors for both the participants themselves and for the judges.
As in Experiment 2, we examined the relationship between the diagnosticity of the verbal descriptions and the participants’ recognition performance. Objects receiving a diagnostic description (i.e., when judges were correct) were associated with higher recognition accuracy than objects receiving a non-diagnostic description. This was found in the 4AFC recognition test (M = 63.2%, SE = 2.3% for diagnostic, M = 46.5%, SE = 2.5% for non-diagnostic), t(22) = 5.75, p < .001, as well as the 2AFC task (M = 71.7%, SE = 2.6% for diagnostic, M = 52.2%, SE = 1.8% for non-diagnostic), t(21) = 6.03, p < .001.
Good vs. bad descriptors, good vs. bad identifiers
As in Experiment 2, for each participant, we computed their average identification accuracy and the judges’ accuracy based on their descriptions (Figure 5). The results suggest that good descriptors also tended to be good identifiers. For participants who completed the 4AFC task (Figure 5, left), Pearson’s correlation between the participants’ and the judges’ accuracy was .48, p = .02. The correlation failed to reach significance in participants who completed the 2AFC task (Figure 5, middle), Pearson’s r = .37, p = .09. When all participants were combined (Figure 5, right), the correlation was r = .43, p = .004. These correlations were lower than in Experiment 2, possibly due to near-floor performance of the judges, restricting the range of data and lowering the correlations.
Scatterplots on the relationship between the judges’ accuracy and the participants’ own identification accuracy in Experiment 3. Each data point corresponds to a single participant.
Discussion
With a 24-hr delay before verbal recall, the utility of verbal reports decreases to a level near chance. This finding suggests that time delay causes memory for the visual stimuli to decay such that people are less able to provide useful verbal descriptions for third parties. Even though people are suggested to have excellent memories for the visual details of common objects (Brady et al., 2008), this memory does not necessarily translate to useful descriptions for third parties’ use, as compared with when the objects are described from perception.
Despite very low utility for third parties, Experiment 3 again confirmed strong correspondence between participants’ identification based on their visual memory, and the diagnosticity of their prior verbal descriptions (i.e., judges’ choices based on participants’ verbal descriptions). When participants were correct in identification, their earlier verbal descriptions were more diagnostic, containing sufficiently accurate information for the judges to perform above chance. When participants were incorrect in identification, their earlier reports were not diagnostic, containing inaccurate information that misled the judges towards choosing the wrong object. As in Experiment 2, this finding suggests that participants may rely on content in their own verbal descriptions during recognition tasks later on. Thus, verbal recall and visual identification appear to share common memory sources (Haist et al., 1992; Meissner et al., 2008).
General discussion
In this study, we examined how useful verbal reports of objects are for third parties. We found that when verbal descriptions are constructed from perception, people are able to provide useful descriptions. However, when verbal descriptions are provided from memory, utility of the descriptions drops drastically. Minutes after the initial memory encoding, the verbal descriptions enable judges to choose the target object with just 57% accuracy, where chance is 50%. Twenty-four hours later, the utility declines to 51.8%, a level just barely above chance. The participants’ ability to produce a significantly more useful verbal report of the objects from perception compared with memory suggests that the low verbal report utility is largely due to memory limitations, rather than poor verbal descriptive ability overall.
The contrast between perception and memory sheds light on the debate between two camps of thought on visual memory. One camp states that people have highly impressive visual long-term memory. For example, Standing et al. (1970) showed that people can recognise more than 90% of photographs presented a day earlier, even though they initially saw each of several thousand photographs for just 10 s. Brady et al. (2008) found that people have accurate memory about the state and exemplar of several thousand visual objects they viewed for just 3 s each. They estimate that visual long-term memory can hold 217.8 bits of unique information. In contrast, others propose that instead of representing visual details in memory, people rely on the external world as their “memory” (O’Regan & Noë, 2001), and visual details are lost as soon as they are no longer in view (Simons & Levin, 1997). In a virtual reality block-construction task, Ballard et al. (1995) found that people tend to code just one piece of information (e.g., the colour of a block) at a time and frequently make repeated fixations on the same object to extract additional information (e.g., the shape of a block). So, does visual memory have high capacity or is it sparse? There is no doubt these contrasting views can both be correct under different circumstances. The question is, which view more accurately captures performance in specific situations? Our study shows that when it comes to the transmission of visual information from one person to another, verbal descriptions from visual memory may have limited utility for others. When allowed to look at the visual stimulus itself (Experiment 1), people do notice details and are able to describe them to produce a useful report for third parties.
Several reasons may explain the low utility of verbal descriptions for these seemingly verbalisable stimuli. First, participants had imprecise memory for the objects. This could be due to the large number of objects they had to encode and the brief encoding duration of each object. In fact, misinformation included in the participants’ verbal descriptions was a source of the judges’ inaccurate choices.
A second reason for the low utility of verbal descriptions was the loss of information when people translate visual codes to verbal codes. In Experiment 1 when participants described objects from perception, judges were able to identify the target object at 87%, a level significantly below perfect. In Experiments 2 and 3 when participants described objects from memory, the judges’ accuracy was significantly below the participants’ own identification accuracy. This loss of information may be due to a variety of reasons. Part of the information loss may stem from a mismatch between the non-linguistic processing that the recognition task involves and the linguistic verbal processing that the recall task involves (Pozzulo et al., 2006). In addition, with perception-based descriptions, participants could rely on the picture to cue them to features that could be included in their descriptions. With memory-based descriptions, however, a less precise representation of the object, which fades with time, may make the translation more difficult. Finally, because participants had no prior knowledge of the nature of the foils, they could not tune their encoding and descriptions to the diagnostic aspects of the objects. This means that even if they had access to diagnostic features, they may not have included that information in the verbal descriptions. For these reasons, people are likely to have difficulty representing the full extent of their visual memory in verbal reports, despite the stimuli being verbalisable.
Even when the judges’ overall accuracy was near chance, we found strong correspondence between the participants’ identification and the judges’ choices. In both Experiments 2 and 3, there was a systematic pattern in the judges’ performance which aligned with how participants themselves performed in the final memory test. Judges performed better (i.e., participants’ verbal descriptions were more useful) when participants themselves recognised those objects later on. Conversely, when participants later chose the within-category foil, the verbal descriptions they provided for those objects also misled judges to choose the within-category foil more often than the target. These findings suggest that recognition and recall, when requiring the retrieval of similar information, rely on shared common sources. This finding is consistent with a previous meta-analysis on eyewitness testimony (Meissner et al., 2008) as well as in some studies using word list as stimuli (Haist et al., 1992). It differed from other studies which used line drawings of objects or faces (Pozzulo et al., 2006; Tversky, 1974). A possible reason for the discrepancy is that in Tversky (1974) and Holdstock et al. (2002), participants were retrieving different information in the recall and recognition task—they recalled the names of the objects, but distinguished the target from a within-category foil in the recognition test. In contrast, similar information was retrieved in the initial recall and subsequent recognition task in our study.
The correlation observed in our study appears to be stronger than what was found in the past. This may be due to the use of objects rather than faces in the present study, and the similarity between the judges’ task and the participants’. Instead of asking the judges to rate the participants’ verbal descriptions as accurate or inaccurate, our study design involved the same identification task for the judges and the participants, changing only the basis of the identification (i.e., someone else’s verbal description vs. one’s own experience).
Intuitively, both the reduction in information from perception to memory and the loss of information from visual to verbal codes are expected. Nevertheless, it is surprising that these factors together nearly abolish the utility of one’s verbal descriptions to others. Even for a type of stimuli that is somewhat verbalisable and associated with high memory capacity, the judges’ identification accuracy was close to chance after just minutes (or 24 hr) of delay. This finding presents strong constraints to the utility of one’s visual memory. As we gain ready access to other people’s knowledge, via text messaging or other social media, there is no guarantee that the expansion of cognition from one’s own brain to the external world would bring the type of gains we would like to have. The unreliability of information transmission from one person to another suggests, instead, that such transmission can be a major source of errors, a hotbed for “fake news.” The situation presented here—brief exposure to multiple objects and immediate or delayed recall—thus presents conditions that are not ideal for useful visual information transfer from person to person.
This is not to say that useful information cannot be transmitted. Though visual memory for exemplars within a category may not be accurately transmitted, visual memory for categorical information may be better preserved. In addition, conditions that improve the initial memory, such as increased encoding duration, repetition, and a reduction in the number of objects encoded, may be beneficial. Other situations in which verbal report utility may be higher than what was found in this study are when more familiar third parties and situations are involved. In our study, participants were presented with individual, generic, objects and were told to describe them for someone else. They were not aware of who the third party was. Judges, likewise, had no prior interactions with the participants. Therefore, they had to base their decisions entirely on the participants’ verbal descriptions. In the real world, however, there are many cases when the person we are speaking to and providing the description for are familiar to us. The context in which an object is seen may also be familiar (e.g., a grocery store that one’s family frequents). In these cases, we are likely able to tap into shared knowledge between ourselves and that family member, highlighting what we know to be diagnostic features of the object we are describing. This prediction is supported by past work on the phenomenon of common ground, which shows that the more shared knowledge people have, the fewer words they need to communicate with each other and direct the other person to a specific picture they are referring to in a matching task (Clark & Wilkes-Gibbs, 1986). Hence, in these cases, it is likely that the utility of verbal descriptions, even those from memory, is much higher than is reported in this study. Future studies would benefit from examining the utility of verbal descriptions across different situations to determine which factors increase or decrease the usefulness of verbal descriptions produced for third parties. In addition, to eliminate any possible practice effects, this study should also be repeated with different judges coding different images.
Overall, our findings suggest that in real-world situations that resemble the current study, where there is brief exposure to multiple objects and descriptions are provided to unfamiliar persons, it would be more beneficial to depend on surveillance images or video records rather than witnesses’ verbal descriptions when trying to decipher the visual details of what was seen previously. The low level of accuracy observed in this study is dangerous in higher stakes situations, such as during the identification of a critical object used in a crime. Our study only presented two choices, while in reality, an infinite number of possibilities for an object often exist, likely lowering “judges’” accuracy further. The strong correspondence between the judges’ choice and the participants’ own identification, even in cases when both were wrong, suggests that internal consistency is no proof for accuracy. Unless corroborated by additional sources, such internal consistency may further misguide investigations, allowing inaccurate information to perpetuate through multiple channels. In cases where surveillance records are unavailable, a more non-linguistic task, such as pointing out and describing similarities and differences (Brown & Lloyd-Jones, 2005) between the person’s memory and another exemplar presented visually, rather than a pure verbal report task, should be used to uncover people’s visual memories. Relying solely on verbal reports likely prevents significant portions of a person’s visual memory from being transmitted to third parties, as observed from the discrepancy between the judges’ accuracy and the participants’ own identification accuracy.
The advancement of technologies, including search engines and social media, has significantly changed the way people access information. Because the external world often functions as an extension of one’s own cognition (O’Regan & Noë, 2001), as our access to the external world changes, it also profoundly affects how we function. Instead of remembering essential information, for instance, people now tend to remember where to find it (Sparrow et al., 2011). As people gain instant access to others’ knowledge through social media and other apps, we become increasingly reliant on others to guide our actions, plans, and understanding. In this study, we show that there are constraints on the reliability and utility of others’ knowledge to us. Other people’s visual memories, in particular, may be useless or even misleading after just a day of delay. This limitation underscores the importance of more reliable sources of information and may help us understand the perpetuation of misinformation in the modern world.
Footnotes
Acknowledgements
This study was part of the thesis that Deborah Tan submitted to the University of Minnesota in partial fulfilment of the requirements for the PhD. We thank Taylor Mikkalson, Allan Ojambo, Anthony South, Brittany Nelson, Yuyan Wang, Catherine Ogilvy, Erin Motley, Abigale Schmidt, and Claudia Hebert for assisting this research. Thanks also to Wilma Koutstaal, Sashank Varma, and Jonathan Gewirtz for helpful suggestions. Correspondence should be directed to Deborah Tan (
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.