
Abstract
Professional magicians regularly use pantomimed grasps (i.e., movements towards imagined objects) to deceive audiences. To do so, they learn to shape their hands similarly for real and pantomimed grasps. Here we tested whether this form of motor expertise provides them a significant benefit when processing pantomimed grasps. To this aim, in a one-interval discrimination design, we asked 17 professional magicians and 17 naïve controls to watch video clips of reach-to-grasp movements recorded from naïve participants and judge whether the observed movement was real or pantomimed. All video clips were edited to spatially occlude the grasped object (either present or imagined). Data were analysed within a drift diffusion model approach. Fitting different models showed that, whereas magicians and naïve performed similarly when observing real grasps, magicians had a specific advantage compared with naïve at discriminating pantomimed grasps. These findings suggest that motor expertise may be crucial for detecting relevant cues from hand movement during the discrimination of pantomimed grasps. Results are discussed in terms of motor recalibration.
Keywords
Introduction
Most of us are poor at faking actions, including everyday actions. When pantomiming to pick up an object, for example, an imaginary glass on the table, we move and shape our hands differently than when we grasp a real glass (Goodale et al., 1994). For actual grasping, the hand opens wider than the diameter of the to-be-grasped object during the reach and closes again when approaching the object (Goodale et al., 1994; Laimgruber et al., 2005; Rinsma et al., 2017). When performing pantomimed grasps, in contrast, naïve participants move slower, take more time to initiate the movement, and, despite an overall narrower grip aperture, express exaggerated differences in object size in their hand aperture (Fukui & Inui, 2013; Whitwell et al., 2015).
Professional magicians regularly using pantomimed grasps to deceive their audience do not make these mistakes. Their pantomimed grasps resemble real grasps to the point that they can almost convince us they picked up an object that is not really there (Cavina-Pratesi et al., 2011). When performing a classic sleight known as French Drop Sleight, for example, the deception is achieved by pretending to drop an object from the thumb and forefinger of one hand into the palm of the other hand while the opposite hand approaches and connects, appearing as if the object is being grasped, while actually maintaining the coin in the original hand (Phillips et al., 2015). It has been proposed that this remarkable skill does not simply result from an increased awareness of the kinematics involved in the action being simulated (i.e., attention to the kinematics of the real grasp), but rather reflects an action recalibration mechanism (Cavina-Pratesi et al., 2011). Grasping real objects engages automatic visuomotor transformations within the cortical grasping network. These transformations are normally not available when the object is taken away or displaced (Króliczak et al., 2007; Lewis, 2006). With prolonged practice, however, professional magicians learn to recalibrate control of their reaching movements applying the information from the real objects at a spatially separate location (Cavina-Pratesi et al., 2011; but see Rinsma et al., 2017). This recalibration of reaching actions attained by practicing pantomime grasps has been suggested to improve hand mental representation. For instance, magicians using sleight of hand hold a more accurate internal metric hand representation than controls (Cocchini et al., 2018). The question addressed in the current study is whether the set of visuomotor skills acquired by magicians also influences action observation.
An influential hypothesis in psychology and neuroscience is that an observer’s understanding of another’s actions results from mapping the observed action onto sensorimotor representations of that same action in the observer’s brain (Flanagan et al., 2006). This hypothesis predicts that the more experienced an observer is in producing an action, the more accurate will be the perception of the same action performed by another person (Schütz-Bosbach & Prinz, 2007). Based on this, we expect that professional magicians, who routinely perform pantomimed grasps, will be better able to detect observed pantomimed grasps compared with naïve participants. This advantage is not expected for real grasps, for which magicians and non-magicians have equal motor familiarity. We call this the specific advantage hypothesis. Alternatively, one might hypothesise that by studying closely how real grasps are performed, magicians are generally more aware of movement kinematics. Based on this, they will be better at detecting both real and pantomimed grasps. We call this the general advantage hypothesis.
In this study, we formalised and tested these hypotheses using a drift diffusion model (DDM) approach. The DDM is a sequential sampling model that regards a decision process as the accumulation of sensory information over time until a decision boundary threshold for choice is reached (Bogacz, 2007; Gold & Shadlen, 2007; Ratcliff et al., 2016; Ratcliff & McKoon, 2008; Wagenmakers, 2009). In the experiment reported here, magicians and naïve participants were asked to judge whether reach-to-grasp movements towards an occluded object were “real” or “pantomimed”. Fitting alternative versions of the DDM to represent our research hypotheses revealed a specific advantage for magicians in the processing of pantomimed but not real grasps.
Materials and methods
Participants
Seventeen professional magicians (all males, mean ± SD age = 44.12 ± 8.27 years; age range: 30–60 years) and 17 age-matched naïve participants, all males (mean ± SD age = 46.35 ± 9.91 years; age range: 31–65 years), t(32) = –0.71, p = .48, took part in the experiment. All participants were right-handed, with normal or corrected-to-normal vision, and with no history of either psychiatric or neurological disorders. Professional magicians were screened to ensure that they had practised magic tricks, and, specifically, sleight of hand tricks based on pantomimed grasps, for at least 10 years preceding the day of the experiment (mean experience = 23.41 years, range = 10–42 years). Data from one participant in the magician group were discarded due to problems with data recording. After data examination, participants with accuracies and reaction time (RT) values exceeding ±2.5 SD from their respective group mean were considered as outliers and excluded from subsequent analysis; as a result, analyses included 15 participants in the magician group (mean ± SD age = 44.47 ± 7.62 years) and 16 participants in the naïve group (mean ± SD age = 46.31 ± 10.23 years), t(29) = –0.57, p = .14. All research methods were approved by the local ethics committee (Azienda Sanitaria Locale 3 Genovese; approval number—P.R.192REG2015) and carried out in accordance with the principles of the revised Helsinki Declaration (World Medical Association General Assembly, 2008). Written informed consent was obtained from all participants.
Stimuli
Motion capture and video recording
For the stimuli used in the current experiment, we employed video clips of actions recorded in a previous study. Details of the apparatus and procedure used are provided in Ansuini et al. (2016). Briefly, we filmed 15 naïve agents (nine females, mean age = 26.8 years, age range = 24–32 years) performing either real or pantomimed grasping movements. The to-be-grasped object was a glass filled with iron screws (weight = 838 g). For real grasps, the glass was placed at a distance of 48 cm from the participant’s body. For pantomimed grasps, the glass was displaced 12 cm further away, for a total distance of 60 cm from the participant’s body. Participants were asked to imagine that an identical glass was positioned at the target position, signalled by a mark on the table, and to pretend to reach towards and grasp the imagined glass.
Both real and pantomimed movements were filmed from a lateral viewpoint using a digital video camera (Sony Handycam 3D, 25 frames/s; Sony Corporation, Tokyo, Japan). Simultaneously, hand movement kinematics were recorded using a near-infrared camera motion capture system (frame rate: 100 Hz; Vicon Motion Systems Ltd, Oxford, UK). Each participant was outfitted with 13 light-weight retro-reflective hemispheric markers (4 mm in diameter) to create a hand model for kinematics analysis. Markers were placed on the dorsal aspect of the hand and the radial and the ulnar aspect of the wrist. Additional markers were placed at the tip, the meta-carpo-phalangeal joint, the phalangeal–phalangeal joint of thumb, the index finger and the little finger, and on the trapezium bone of the thumb. To characterise real and pantomimed grasps over time, a set of kinematic parameters was calculated using a custom MATLAB (MathWorks, Natick, MA, USA) script (see Table 1 for a detailed description of kinematic parameters used). All parameters were computed during the reach-to-grasp phase of the movement, from “reach onset,” defined as the first time point at which the velocity of the marker on the radial aspect of the wrist crossed a 20 mm/s threshold and remained above it for longer than 100 ms, to “reach offset,” defined as the time at which the velocity of the marker on the radial aspect of the wrist dropped below a 20 mm/s threshold. For movements for which the wrist velocity did not drop below the 20 mm/s threshold, a dynamic threshold based on the acceleration profile of the wrist marker was applied. Specifically, we determined the reach offset as the last frame before the start of the acceleration phase associated with the lifting. All parameters were computed at intervals of 10% of the normalised movement time. Thus, for each kinematic parameter, we computed 10 values, one for each time interval. Please refer to Ansuini et al. (2016) for further details on data processing and normalisation.
Description of kinematic parameters computed throughout the reach-to-grasp phase of the movements.

Stimuli selection
Data from one participant were discarded due to technical problems with video recording. For stimuli selection, we modelled the computed kinematic parameters of real and pantomimed grasps using a linear discriminant analysis (LDA) to find the linear combinations of features that separated between real and pantomimed grasps.
The resulting discriminant function accounted for 100% of the total variance (eigenvalue = 2.583; canonical R2 = .84) and significantly distinguished between real and pantomimed grasps, λ value = .27, χ2(43) = 793.1, p < .001. Classification analysis using a leave-one-trial-out cross-validation (Efron, 1982) revealed an above chance level classification (93.3% of accuracy with an a priori probability of 50%).
We next identified a set of 100 representative movements by selecting, for each grasp type (real, pantomimed), the 50 movements that minimised the within-weight distance, that is, the distance from the mean variate score of each grasp type. To quantify the kinematic information in the selected subset of stimuli, we re-ran an LDA on these 100 movements. Classification analysis using a leave-one-trial-out cross-validation revealed a classification accuracy of 95%.
Video editing
The 100 unique video clips corresponding to the selected movements were edited using Adobe Premiere Pro CS6 (avi format, disabled audio, 25 frames/s; Adobe Systems Software Ltd, Dublin, Ireland). To occlude the object from observers’ view, a grey rectangular mask (height = 1,080, width = 744 pixels) was superimposed over the target object location. The size and the position of this mask were kept constant across trials and participants. Each video was edited to begin at reach onset and to end immediately after reach offset (see sample Supplementary Video 1 and Supplementary Video 2; for more details, please refer to the “Supplementary Materials” section). Videos were individually checked to exclude the inclusion of post-grasp events.
Procedure
The experiment took place in a dimly lit room. Participants sat in front of a 17-inch computer screen (1,280 × 800 pixels; refresh rate = 75 Hz) at a viewing distance of 50 cm and performed the experiment individually. They were presented with video clips of the reach-to-grasp phase of the selected movements. A one-interval discrimination design was employed (see Figure 1). Participants were asked to observe the video clip and judge as accurately and as quickly as possible whether the observed movement was real or pantomimed, and indicate their response by pressing with their right index or middle finger, one of two buttons on a keyboard. Participants were instructed to respond either during the video, or within a maximum of 3,000 ms after the video ended. After each response, participants were also requested to rate the confidence of their decision on a four-level scale by pressing a key (from 1 = least confident, to 4 = most confident). To prevent anticipation and to ensure that participants could temporally attend to movement sequences, a random number of static frames (range: 14–23 frames) were added to the beginning of all video clips presented to participants. To equalise stimulus duration within each movement condition (real vs. pantomimed observed movement), static frames were also added at the end of video clips (range: 1–18 frames) so that each video clip lasted 2,000 ms.
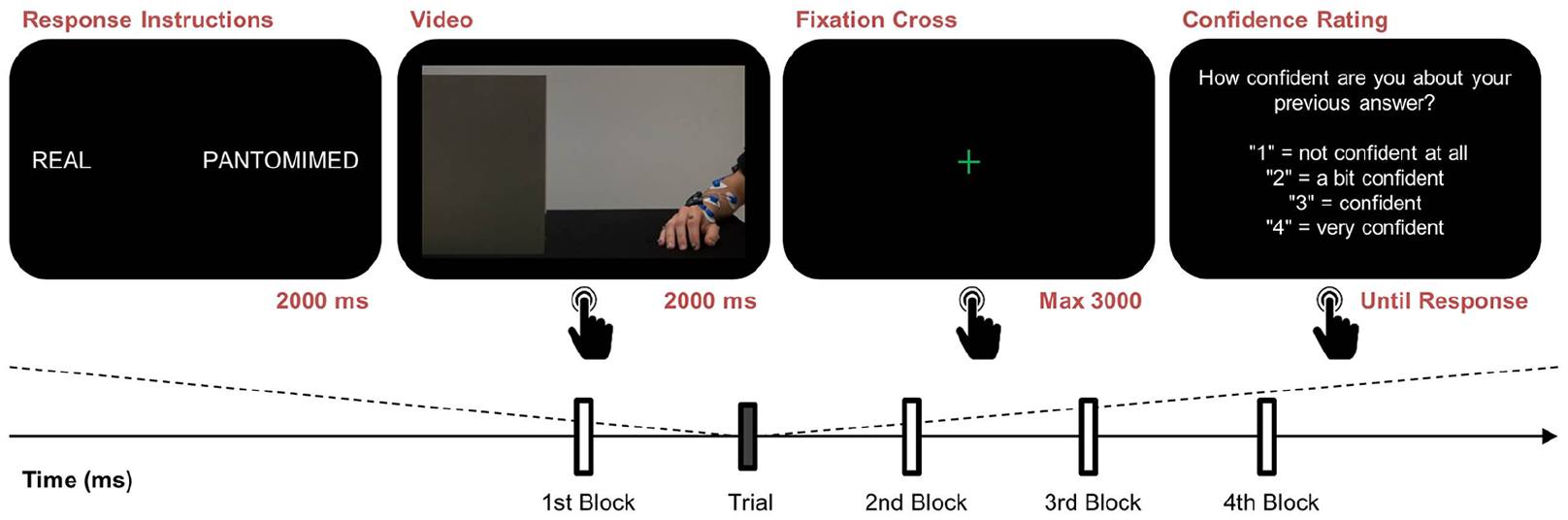
Experimental design. In each trial, participants first observed an instruction slide indicating the buttons to press for the movement type (“real” or “pantomimed”), followed by a video clip showing the reach-to-grasp phase of the movement. Participants could respond either during the presentation of the video or up to 3,000 ms after the end of the video. After providing a response, participants were then asked to rate the confidence of their decision on a 4-point scale (from 1 = least confident, to 4 = most confident).
Participants completed four blocks of 100 trials (50% real grasp trials). There was a 5 min break between each block. Video clips were pseudo-randomised over the blocks so that within each block, any movement occurred only once. At the beginning of an experimental session, participants were presented with eight movement samples (i.e., two for each movement type repeated twice) without spatial occlusion, so that they could see the phase during which the agent grasped (or pantomimed to grasp) the glass, and lift it. Participants also completed a practice session of 10 trials (50% real) to familiarise themselves with the task. Stimuli presentation, timing, and randomisation procedures were controlled using E-prime version 2.0.10.242 (Psychology Software Tools, Inc., Sharpsburg, PA, USA). Each experimental session lasted about 90 min.
Data analyses
RTs were normalised by expressing each RT as a fraction of duration of the grasp, from reach onset to reach offset, displayed in the video. The proportion of correct responses and correct RTs for magicians and naïve participants are shown in Figure 2.
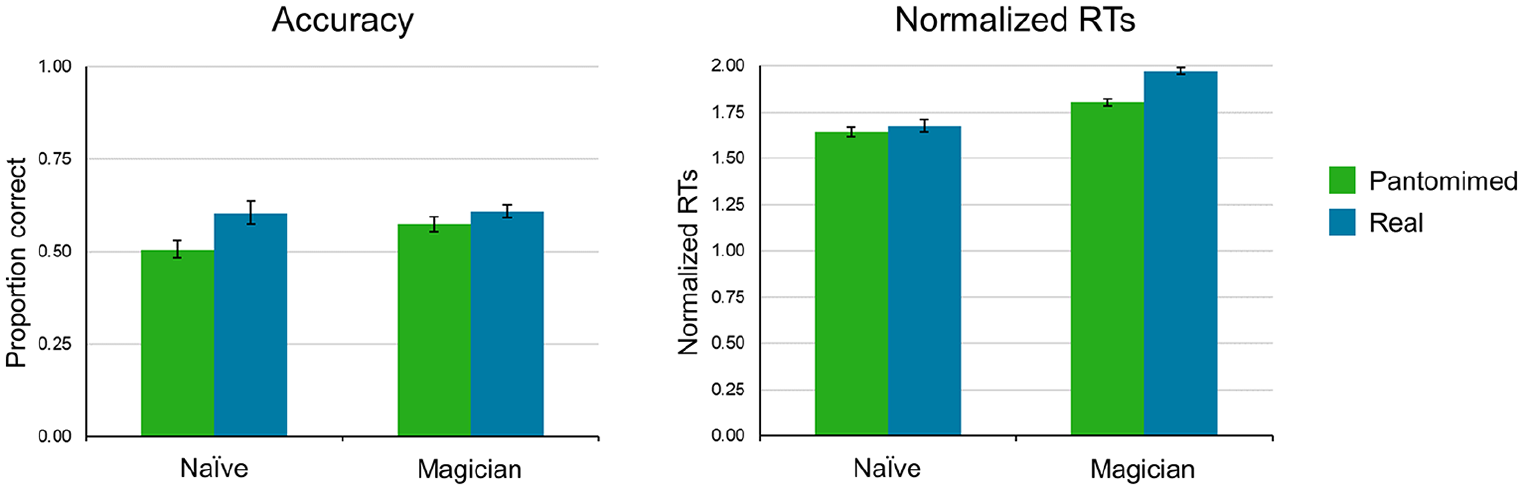
Behavioural results. Accuracies and correct RTs for magician and naïve participants in discriminating real and pantomimed grasps.
Participant performance was assessed by fitting alternative DDMs to accuracies and the overall distribution of RTs obtained in the discrimination task. In DDMs, evidence is stochastically accumulated in a single decision variable (DV) from a predetermined starting point z, located at some point between two decision boundaries, separated by a distance a. As evidence is sampled, the DV drifts towards the boundary supported by the signal at an average rate of v, called the drift rate. Evidence accumulation is terminated once the DV reaches one of the two criterion boundaries, initiating the corresponding choice and marking the response time (Ratcliff, 2002; Ratcliff & McKoon, 2008) (see Figure 3 for representation of a hypothetical DDM).
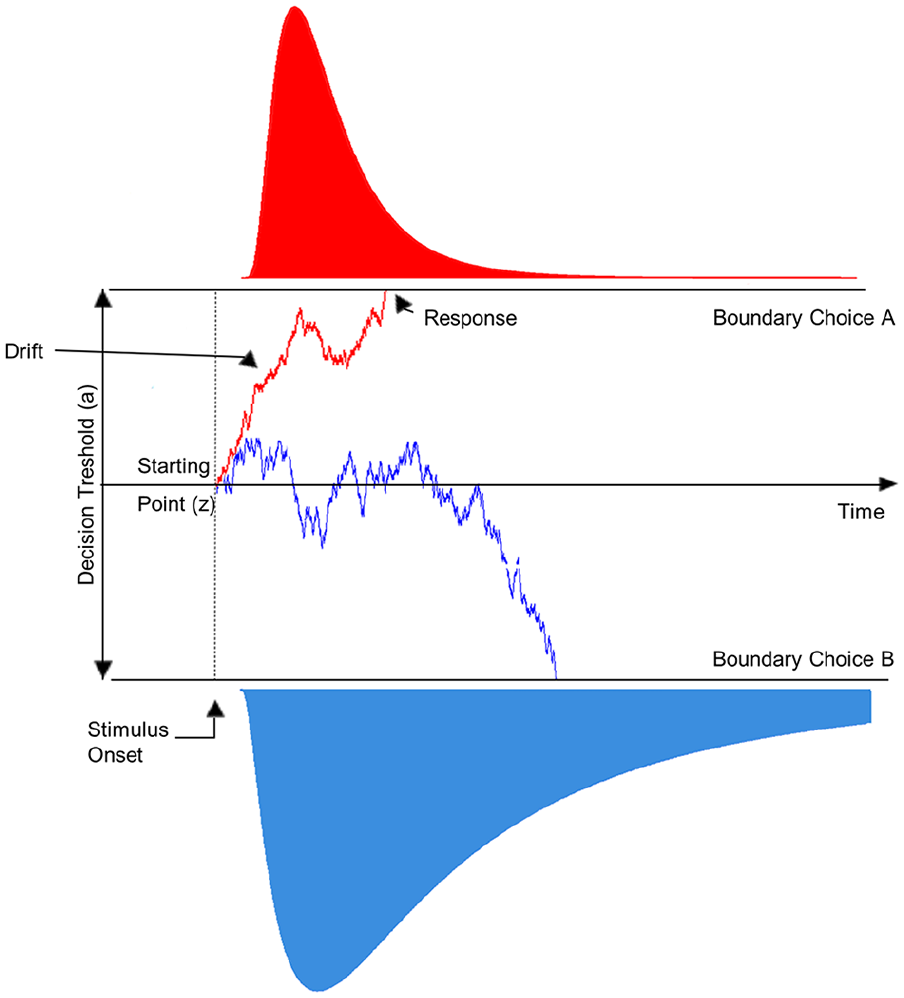
Representation of a drift diffusion model (DDM). The DDM models decision process as an accumulation of evidence over time from an initial starting point (“z”) towards one of two criterion boundaries separated by a distance “a.” The average rate of accumulation of evidence is denoted as drift rate (“v”) and provides a measure of perceptual sensitivity for the stimulus. As an example, two hypothetical drift diffusion processes resulting in two different choices are represented.
One main advantage of DDMs compared with standard analysis of accuracy and RT relates to the high degree of information utilised. In contrast to the standard data analysis, diffusion models incorporate both RTs for correct responses and errors, as well as the ratio of correct and erroneous responses. As shown by Wagenmakers et al. (2007), the standard analysis method is based on accuracy (computed as % correct responses) and correct RTs and cannot inform us as to how much better or worse one participant performs than another, as this requires response speed and response accuracy to be combined in some unspecified manner. The DDMs represent different components of the decision process (rate of information uptake, bias, etc.) by different parameters of the model. In this way, theoretically distinct aspects of the decision process can be separated statistically (Voss et al., 2004). DDMs have thus been proposed to provide deeper insights into the observed behaviour compared with merely using accuracies or RTs (Forstmann & Wagenmakers, 2015; Wagenmakers, 2009).
Estimation of the DDM parameters was performed using the python-based hierarchical DDM (HDDM) toolbox (Wiecki et al., 2013). This toolbox estimates the parameter estimates in a Bayesian framework and additionally allows for quantification of estimation uncertainty in the form of the posterior distribution. We built two hypothetical diffusion models to represent our specific hypotheses (Burnham & Anderson, 2002). The two hypothetical diffusion models differed in the drift rate parameter, specifically:
General advantage model, in which drift rate was allowed to vary as a function of group (magicians vs. naïve), but was fixed between grasp types (real vs. pantomimed). This model represents the hypothesis that magicians are better at detecting both real and pantomimed grasps compared with naïve participants;
Specific advantage model, in which drift rate was allowed to vary both between groups and grasp types. This model represents the hypothesis that, compared with naïve participants, magicians are better at detecting pantomimed grasps but not real grasps.
For completeness, we additionally tested two models in which drift rate was fixed between groups, specifically:
Null model, in which drift rate was constrained to be of equal magnitude for magicians and naïve participants for both grasp types. This model represents the hypothesis that magicians are no better than naïve participants at detecting both real or pantomimed grasps;
Grasp type model, in which drift rate was allowed to vary as a function of grasp type, but was fixed between groups. This model represents the hypothesis that real grasps are easier to detect compared with pantomimed irrespective of the group.
To evaluate HDDM model performance, we used the Posterior Predictive Checks (PPC). PPC evaluates model performance by estimating how closely a fitted model is able to reproduce key patterns in the dataset. Specifically, PPC simulates new data from the posterior of the fitted model. A model that adequately describes the data would generate predictions that closely approximate the observed data (Matzke et al., 2013). To obtain the model fits, we performed a total of 500 simulations and computed the median of the 500 mean squared errors (MSEs) resulting from the comparison between the observed accuracy and the simulated accuracy. The model that produced the lowest median MSE was interpreted as the best-fit model. This method was preferred over the Deviance Information Criterion (DIC) because it protects against the bias towards selecting the model with greater complexity (Gelman & Hill, 2007; Spiegelhalter et al., 2002, 2014).
For the best-fit model, follow-up contrasts were performed to test whether drift rate reliably changed across conditions. As the HDDM toolbox utilises a Bayesian framework, significance testing can be performed directly on the posterior distributions and results can be interpreted in terms of probabilities. We thus calculated the proportion of the posteriors in which the drift rate for each condition was higher than the other. A difference of less than 5% in the posterior distribution overlap (Pp|D) was considered significant (suggesting a higher probability of difference between the conditions). To further examine the robustness of our results, we performed non-parametric permutation analyses on all comparisons. Permutation tests examine whether an observed effect could reasonably occur “just by chance” (Hesterberg et al., 2003) and have been proposed to be robust and superior to the generally utilised t and F tests (Ludbrook & Dudley, 1998).
We also evaluated whether the drift rates were significantly greater than zero to ascertain the likelihood of drifting towards the correct alternative. A drift rate close to 0 corresponds to a process which is equally likely to move towards either of the choices, indicating a slow rate of evidence accumulation. On the contrary, a higher positive drift rate indicates faster evidence accumulation towards the correct alternative. As the hierarchical estimation procedure violates the independence assumption, we did not analyse subject parameter estimates in frequentist tests.
Results
Table 2 shows the median MSE for the four models. Based on the MSE values, the specific advantage model produced the least error between the simulated and observed accuracy and, thus best fit the data. The specific advantage model predicts that the behavioural performance varies both as a function of group and grasp type. To investigate this hypothesis more precisely, we next tested the significance of the estimated parameter for the four conditions resulting from the factorial combination of group (magician vs. naïve) and grasp type (real vs. pantomimed): “magician real,” “magician pantomimed,” “naïve real,” and “naïve pantomimed.”
Median MSEs of the models.

MSE: mean squared error.
As predicted by the specific advantage model, drift rates for pantomimed grasps were significantly faster in the magician group compared with the naïve group (Pp|D [“magician pantomimed” > “naïve pantomimed”] = 0.038, permutation p value < .05), whereas no such between-group difference was observed for real grasps (Pp|D [“magician real” > “naïve real”] = 0.33; permutation p value = .22) (see Figure 4). This points out an advantage for magicians in the processing of pantomimed grasps.
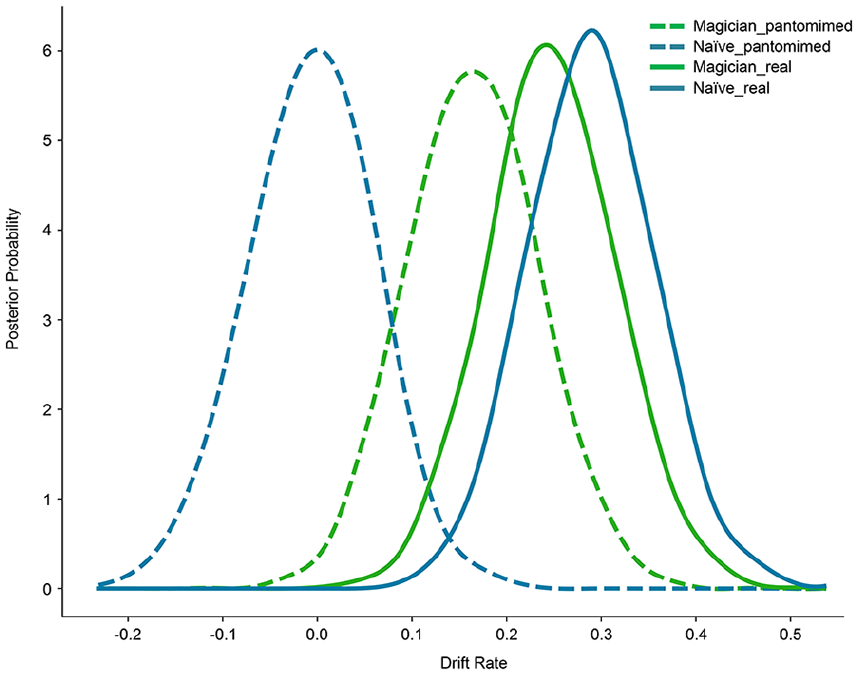
Posterior distribution densities of drift rates for magicians and naïve while processing real and pantomimed grasps. Posterior distribution densities for “magician pantomimed” (dashed green), “naïve pantomimed” (dashed blue), “magician real” (continuous green), and “naïve real” (continuous blue) drift rates. Significantly greater drift rates were obtained for pantomimed grasps for magicians compared with naïve while no difference was observed between the groups for real grasps. Differences were considered significant when the overlap between distributions was less than 5%.
Interestingly, comparison of drift rates between grasp types indicated that drift rates for real grasps were significantly higher than drift rates for pantomimed grasps in the naïve group (Pp|D [“naïve real” > “naïve pantomimed”] < 0.001; permutation p value < .001), but not in the magician group (Pp|D [“magician real” > “magician pantomimed”] = 0.80; permutation p value > .05), suggesting that experienced magicians processed the observed pantomimed grasps as effectively as the observed real grasps. Reinforcing this interpretation, drift rates were significantly higher than 0 for all conditions (Pp|D [“magician real” < 0] < 0.001; Pp|D [“magician pantomimed” < 0] < 0.01; Pp|D [“naïve real” < 0] < 0.001), except for the processing of pantomimed grasps by naïve (Pp|D [“naïve pantomimed” < 0] = 0.48). These results suggest that although both magicians and naïve participants were able to discriminate real grasps, only magicians performed above chance level in discriminating pantomimed grasps.
Discussion
In contrast to the unrealistic efforts of most people, professional magicians can produce very convincing movements with imaginary objects. The present study is the first to show that magicians are also better than naïve at detecting pantomimed grasps, but not real grasps. These results argue against a general advantage in processing grasping movements as would be expected if magicians were generally more aware of movement kinematics. Rather, they suggest that prolonged practice confers magicians a specific advantage in the processing of pantomimed movements.
Evidence that action perception and anticipation is precisely tuned to an individual’s acquired motor repertoire comes from sports psychology. Expert performers are better than naïve at predicting the outcome of highly learned and practised actions, such as predicting the landing position of a volleyball or tennis serve (e.g., Abernethy, 1989; Abernethy & Zawi, 2007; for a review, see Jackson et al., 2006; Müller et al., 2006). Most relevant to the present research, expert performers are also better at detecting deceptive movements. For example, Sebanz and Shiffrar (2009) reported that expert basketball players were better than naïve at judging whether a perceived action would lead to a basketball pass or a fake. This suggests a link between motor expertise and the superior detection of nonverbal deception from bodily movement. Our findings suggest a similar link between magicians’ experience and the enhanced ability to detect pantomimed grasps. Professional magicians who regularly use pantomimed actions are better than naïve at detecting pantomimed grasps from bodily movement.
In expert–naïve research studies, the influence of motor expertise on action perception is typically investigated by comparing the observation of movement patterns previously learned (and therefore within the observer’s acquired motor repertoire) and unfamiliar patterns. An interesting aspect of the present study relates to the possibility of comparing patterns within the observer’s acquired motor repertoire (pantomimed grasps) with fundamental patterns already present at birth (real grasps). This comparison revealed a significant expert–naïve difference. While for naïve, drift rates for pantomimed grasps were close to zero and significantly slower than drift rates for real grasps, for magicians, drift rates showed a substantial overlap between movement types, suggesting that processing of pantomimed grasps was as good as processing of real grasps. One might ask whether magicians were more accurate than naïve controls in correctly rejecting the appearance of real grasps rather than correctly identifying the appearance of pantomimed grasps. If this were the case, however, we would predict a similar pattern of results for real and pantomimed grasps in the two groups. That drift rates were faster in the magician group compared with the naïve group for pantomimed grasps, but not for real grasps suggests that the advantage shown by magicians was genuinely pantomime-related.
These findings might be interpreted as indicating that action recalibration mechanisms transfer to action observation. However, we urge caution with this interpretation. For one thing, the nature of action recalibration mechanisms in magicians is unclear. Action recalibration has been associated with the finding that pantomimed and real grasps strongly resemble each other in magicians (Cavina-Pratesi et al., 2011). However, not all studies report such a strong resemblance. For example, Rinsma et al. (2017) found that both experienced magicians and inexperienced participants showed kinematically distinct movement patterns when performing pantomimed and real grasps. Moreover, experience did not reduce the effect of illusory biases on hand aperture during pantomimed grasps, suggesting that pantomimed grasps were based on allocentric information in inexperienced participants as well as in experienced magicians (Rinsma et al., 2017). In the current study, we did not record the kinematics of magicians. This limits inferences regarding the potential contribution of action recalibration (if any) to magicians’ readout of pantomimed kinematics.
For another thing, enhanced motor expertise associated with action recalibration may be intrinsically linked to enhanced perceptual expertise. Magicians’ specific advantage in processing pantomimed grasp may relate to action recalibration. Alternatively, however, it may also depend on magicians’ enhanced visual familiarity with pantomimed grasps (for a related discussion in the sport psychology domain, see Brenton & Müller, 2018). Our results do not allow us to disambiguate between these (not mutually exclusive) alternatives. Future studies employing alternative experimental manipulations (e.g., viewing perspective; Cañal-Bruland et al., 2010) will be important to clarify the respective contributions of motor and perceptual experience.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work received funding from the European Research Council under the European Union’s Seventh Framework Programme (FP7/2007-2013)/ERC grant agreement n. 312919.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.