
Abstract
In this study, two event-related potential experiments were conducted to investigate whether readers adapt their expectations to morphosyntactically (Experiment 1) or semantically (Experiment 2) anomalous sentences when they are repeatedly exposed to them. To address this issue, we experimentally manipulated the probability of occurrence of grammatical sentences and syntactically and semantically anomalous sentences through experiments. For the low probability block, anomalous sentences were presented less frequently than grammatical sentences (with a ratio of 1 to 4), while they were presented as frequently as grammatical sentences in the equal probability block. Experiment 1 revealed a smaller P600 effect for morphosyntactic violations in the equal probability block than in the low probability block. Linear mixed-effects models were used to examine how the size of the P600 effect changed as the experiment went along. The results showed that the smaller P600 effect of the equal probability block resulted from an amplitude’s decline in morphosyntactically violated sentences over the course of the experiment, suggesting an adaptation to morphosyntactic violations. In Experiment 2, semantically anomalous sentences elicited a larger N400 effect than their semantically natural counterparts regardless of probability manipulation. Little evidence was found in favour of adaptation to semantic violations in that the processing cost associated with the N400 did not decrease over the course of the experiment. Therefore, a dynamic aspect of language-processing system was demonstrated in this study. We will discuss why the language-processing system shows a selective adaptation to morphosyntactic violations.
Keywords
Introduction
Adaptation in response to physical properties of an environmental stimulus has been found in various mechanisms, such as in perception. For example, it has been known in psychophysiology that an event-related potential (ERP) called N1 attenuates in amplitude with repetitive exposure to the same auditory stimulus and increases in response to a novel (“deviant”) auditory stimulus (i.e., mismatch negativity [MMN]; Fishman, 2014; May & Tiitinen, 2010; Näätänen et al., 2005). There has been a great debate as to whether such an ERP effect can be accounted for by the adaptation hypothesis, according to which people become tuned to represent a frequent stimulus at relatively little neural cost and the input of an infrequent stimulus recruits more neuronal populations, inducing greater neural cost (May & Tiitinen, 2010; May et al., 1999), or by the predictive coding hypothesis, according to which people expect a probable stimulus and the input of an improbable stimulus violates such an expectation and increases the neural cost (Friston, 2005; Garrido et al., 2009; Winkler, 2007). Although the debate continues, it is generally assumed that people detect physical changes in the environment and adapt to them immediately.
Adaptive mechanisms in response to physical features of stimuli have also been found in human language processing, namely, in categorical perception (Kleinschmidt & Florian Jaeger, 2015, 2016). However, when it comes to human language processing, it is possible that adaptation is pervasive beyond just physical features. In daily language use, people process sentences effortlessly in spite of the prevalence of variable factors, such as a speaker’s syntactic preference, as well as lexical choice. That is, some speakers prefer to use a certain construction where other speakers would use another construction to express the same proposition, and thus, the distribution of syntactic constructions necessarily varies among speakers. In this example, what people should adapt to is a generative rule that a speaker uses to produce a sentence, rather than the physical properties of a sentence, such as sound pitch and intensity. This poses an important question for cognitive science of language: Do people adapt to such sentence-level variations in comprehension, and if so, how do they adapt?
Such a flexible aspect of sentence processing has not attracted attention until very recently. Traditionally, studies of human sentence processing have focused on fixed aspects of processing mechanisms, with an (implicit) assumption that the processing is invariant. For example, a number of previous studies have examined how people routinely resolve structural ambiguities, such as attachment ambiguity, assuming that they should be consistent in responding to such ambiguities (e.g., Frazier, 1979; Frazier & Rayner, 1982; Tanenhaus et al., 1995).
According to recent behavioural studies, however, people change their behaviour according to probabilistic occurrences of syntactic structures during an experiment (Farmer et al., 2014; Fine & Jaeger, 2013, 2016; Kaan & Chun, 2018; Kamide, 2012; Wells et al., 2009). For instance, while traditional studies showed that people experience difficulty in the processing of garden-path sentences that require a revision of syntactic structures (e.g., The experienced soldiers warned about the danger conducted the midnight raid), Fine et al. (2013) found that the difficulty of processing garden-path sentences lessened as their participants were repeatedly presented with garden-path sentences during an experiment (see Harrington-Stack et al., 2018, for the failure to replicate Fine et al.’s experiment). Previous accounts that explain this result and other similar results of temporal ambiguity resolution can be categorised into two different positions. The expectation updating account proposes that when encountering a less frequent structure (i.e., reduced relative clauses) many times, the language-processing system updates its expectation about the probability of the structure occurrence and resolves a structural ambiguity to the less frequent structure (Fine & Jaeger, 2013; Fine et al., 2013). The alternative interpretation, in contrast, assumes that syntactic frames are stored in declarative memory. According to this interpretation, when a less frequent syntactic frame (i.e., relative clause) is repeatedly used, its base-level activation increases and therefore its activation requires a less cost subsequently. Therefore, the processing of sentences associated with such infrequent syntactic frames is facilitated. We refer to this account as the representation-based account (cf. Reitter et al., 2011). As previous behavioural studies of adaptation have mainly focused on the processing of structural ambiguity resolution, it is difficult to tease these two accounts apart.
This study disentangles these two accounts by examining whether people are able to adapt to ungrammatical sentences (cf. Kaan & Chun, 2018). If people adapt to ungrammatical sentences, it supports the expectation updating account, but not the representation-based account. The expectation updating account predicts that native speakers can adapt to ungrammatical sentences if the distribution of ungrammatical sentences enables people to expect them. In contrast, the representation-based account predicts that people do not adapt to them because, by definition, native speakers have no licit representation of ungrammatical sentences, and therefore, the activation level of its syntactic representation cannot increase. Note that the absence of such adaptation provides support for neither the expectation updating account nor representation-based account. To date, it remains controversial as to whether ungrammatical sentences trigger adaptation.
Yoshida and Miyamoto (2017) show that native speakers of Japanese do not adapt to ungrammatical sentences. In their self-paced reading experiment, Japanese speakers were presented with grammatical and ungrammatical verbal nouns. 1 The results showed a longer reading time for the ungrammatical sentences but the difference between the grammatical and ungrammatical sentences did not decrease over the course of their experiment. The authors propose that the repeated exposure to ungrammatical sequences does not facilitate the processing of them, and therefore, the adaption is limited to grammatically licit constructions. According to the representation-based account, assuming that the structure of the ungrammatical sentences used in their study does not have a licit syntactic representation, the absence of adaptation is attributable to the possibility that the repeated exposure to ungrammatical sentences has not induced an activation that could facilitate subsequent processing. However, the absence of adaptation is also compatible with the expectation-based account, as mentioned above.
Several ERP studies reported results consistent with the view that the behaviour of the language-processing system is affected by repeated exposure to ungrammatical sentences (Coulson et al., 1998; Gunter & Friederici, 1999; Hahne & Friederici, 1999; but see also Osterhout et al., 1996). For example, Gunter et al. (1997) manipulated the probability of grammatical and ungrammatical sentence occurrence (verb inflection violations) in Dutch (High: grammatical: 25% vs ungrammatical: 75%, Low: grammatical: 75% vs ungrammatical: 25%). They found a robust P600 effect for verb inflection violations (“De vuile matten werden door de hulp kloppen” The dirty doormats were
This study, therefore, addresses this issue of whether a P600 effect elicited by syntactic violations is modulated by the number of exposures to them, using mixed-effects modelling of single-trial data (i.e., trial order effect on P600). In standard ERP studies, Electroencephalograms (EEGs) are averaged across many trials to obtain ERPs and compared between conditions of interest using analysis of variance (ANOVA) (Luck, 2005). The averaging procedure assumes that the electrophysiological response to a particular stimulus is invariant throughout an experiment, but such an assumption has been rarely verified (cf. Polich, 1989). Furthermore, the averaging procedure loses important information as to a dynamic aspect of underlying cognitive processes. The use of regression analyses, such as linear mixed-effects (LME) models, does not necessitate the averaging procedure and allow for more flexible analyses. For example, regression analyses enable us to handle continuous variables, such as trial order (i.e., nth trial in an experiment), as well as lexical properties of words (e.g., frequency). Analyses of trial orders have been incorporated in recent psychological and psychophysiological studies, including the studies of face and pain perception and cognitive controls, to investigate cognitive processes underlying what has been referred to as habituation and learning (Volpert-Esmond et al., 2018; Von Gunten et al., 2018; Vossen et al., 2011). In contrast, such an investigation has not been conducted until recently in the literature of human language processing (see Delaney-Busch et al., 2019; Nieuwland et al., 2018; Smith & Kutas, 2015a, 2015b; Yano, 2018). In this study, we use mixed-effects modelling to examine how the language-processing system dynamically changes the way it processes syntactic violations and discuss an implication for the representation-based and expectation-based accounts.
This study also examines whether the adaptation that occurs depends on the type of linguistic violation, such as (morpho)syntactic violation and semantic violation. In the ERP literature of sentence processing, the sensitivity to probabilistic manipulation has been discussed with respect to the P600 (in relation to P3b), as explained above (Coulson et al., 1998; Gunter & Friederici, 1999; Hahne & Friederici, 1999; Osterhout & Hagoort, 1999; Osterhout et al., 1996). Previous studies are informative as to syntactic adaptation to different environments. However, few studies have examined whether non-syntactic processes also exhibit a sensitivity to probabilistic manipulation, which should be informative as to the flexibility/limit of adaptation in sentence processing. Specifically, this study examines whether the language-processing system adapts to semantic violations and, if so, how semantic adaptation differs from syntactic adaptation.
In sum, this study examines whether the language-processing system adapts to anomalous sentences, and if so, whether such an adaptation depends on the types of linguistic violations. By doing so, this study aims to contribute to an understanding of a dynamic aspect of the language-processing system, which has not been examined extensively. In the next section, we report the results of two experiments that examine how ERPs elicited by morphosyntactic and semantic violations change over the course of experiments.
Experiment
In this study, two ERP experiments were conducted that investigated adaptation to morphosyntactically anomalous sentences (Experiment 1) and semantically anomalous sentences (Experiment 2). Although previous studies on syntactic adaptation have used self-paced reading methods, ERPs are more suitable for the purpose of this study. It has been known that different cognitive processes are associated with different ERP components. This study focused on P600 and N400. The P600 effect has been observed for (morpho)syntactic violations (e.g., Coulson et al., 1998; Kaan & Swaab, 2003a, 2003b; Osterhout & Holcomb, 1992; Osterhout & Mobley, 1995, see also Note 2). In contrast, an N400 effect has been observed for semantical violations and semantically unpredicted words (e.g., Kutas & Federmeier, 2000, 2011; Kutas & Hillyard, 1980, 1984; Lau et al., 2013, 2016; Nieuwland et al., 2020). Although the exact functional role of the N400 in sentence processing has been a matter of debate, there is a consensus that it reflects lexico-semantic processing. Because this study aims to compare syntactic adaptation with semantic adaptation, the ERP recording provides an advantage over other experimental methods in that it enables us to selectively track how processes of interest change during the experiments.
However, the ERPs may change during experiments for several reasons other than adaptation, such as fatigue and lack of attention (Volpert-Esmond et al., 2018). This means that if an ERP effect decreases in amplitude during experiments, the difference is attributable to factors other than adaptation. To avoid such interpretations, we manipulated the probability of grammatical and ungrammatical sentences, as in Gunter et al. (1997), and assessed whether ERP differences between ungrammatical and grammatical sentences decreased only when the participants were exposed to a large proportion of ungrammatical sentences.
Materials
Fifty-two pairs of the target sentences were created for Experiments 1 and 2. In both experiments, the target sentences consisted of two phrases (NP with a case marker + verb with a period). The sentences given in (1)–(3) show a sample set of the sentences. The sentence shown in (1a) is grammatical while the sentence shown in (1b) involves a case-assignment violation, as unaccusative intransitive verb “kareta” (withered) must mark a single argument with a nominative case (“-ga”) but not with an accusative case (“-o”) regardless of thematic roles of the argument (i.e., agentivity) in Japanese (a language with the nominative-accusative case alignment system). This sentence is syntactically ungrammatical. Unaccusative verbs are, by definition, unable to assign an accusative case to its single argument in Japanese, like in many other languages. Thus, the internal argument must move to the specifier position of Tense Phrase (TP) to receive a nominative case from the head, Tense (T) (Kishimoto, 2001, 2010; Miyagawa, 1989). Given this widely held assumption, the ungrammatical sentence in (1b) is analysed such that the argument “bara-o” stays in the structurally unlicensed position within the Verb Phrase (VP) and apparently receives a structural accusative case from the verb with no ability to assign an accusative case. Note that starting a sentence with NP-ACC does not affect the grammaticality because subjects often drop in Japanese.
The sentence given in (2a) is semantically natural while the sentence given in (2b) is semantically anomalous because the intransitive verb “naita” (cried) takes an inanimate noun “shikibo” (baton) as its subject in (2b). Note that (2b) is syntactically well-formed, as the single argument is nominative case-marked.
The ratio of the morphosyntactically/semantically natural and anomalous sentences was manipulated by intermixing filler sentences exemplified in (3) to balance the number of trials of the target sentences. Twenty-six sentences included two phrases and 52 sentences included three phrases. To prevent participants from expecting (1b) to be ungrammatical when reading the accusative case-marked noun phrase, 26 grammatical sentences with an accusative-marked noun phrase were included, as exemplified in (3a). The ungrammatical fillers involve violations of some types different from the target sentences. The ungrammatical sentences in (3c) and (3d) are syntactically and semantically anomalous. In Japanese, mono-transitive verbs take an accusative or dative case for objects. As case assignment is structurally dependent, the ungrammaticality in (3c) and (3d) is caused by “shogakko-o” and “mado-ni” not occupying in the place where they should (Matsuoka, 2003). Nevertheless, unlike the nominative case in intransitive verbs, the selection of dative and accusative cases is also semantically dependent in mono-transitive verbs (Inoue, 1983). Verbs of action, such as “kick” and “punch” tend to take an accusative case while non-action verbs, such as “call” and “greet” tend to take a dative case. In other words, an accusative-marked object is interpreted as an entity that is affected by an action (e.g., patient) whereas a dative-marked object is not (e.g., goal, theme). Therefore, the anomalous sentence in (3c), for example, is interpreted such that the resulting state of elementary school is somehow affected by the event of the son going there.
(1) Experiment 1 (Morphosyntactic violation) a. Grammatical sentence: bara-ga kare-ta. rose-NOM wither(intransitive)-PAST “The rose withered.” b. Morphosyntactically anomalous sentence: *bara-o kare-ta. rose-ACC wither(intransitive)-PAST (2) Experiment 2 (Semantic violation) a. Semantically natural sentence: shinseiji-ga nai-ta. baby-NOM cry(intransitive)-PAST “The newborn baby cried.” b. Semantically anomalous sentence: *shikibo-ga nai-ta. baton-NOM cry(intransitive)-PAST “The baton cried.” (3) filler sentences: a. remon-o shibotta. lemon-ACC squeeze (transitive)-PAST “(someone) squeezed a lemon”). b. *eda-ga otta. branch-NOM break (transitive)-PAST “The branch broke something.” c. musuko-ga shogakko-{ni/*o} it-ta. son-NOM school-DAT/ACC go-PAST “The son went to the elementary school.” (“go” is a dative-taking verb) d. seisoin-ga mado-{*ni/o} fui-ta. cleaning.staff-NOM window-DAT/ACC wipe-PAST. “The cleaning staff wiped the window” (“wipe” is an accusative-taking verb)
In each experiment, 52 pairs of the target sentences, such as (1) and (2), were distributed into two lists according to the Latin square design such that each participant read 26 sentences of each condition. Seventy-eight filler sentences were added to each list such that the probability of grammatical and anomalous sentences was 50% and 50% for the equal probability block and 80% to 20% for the low probability block (i.e., 130 sentences in total). Concretely, the equal probability block included 39 grammatical and 39 ungrammatical filler sentences in addition to 26 grammatical and 26 ungrammatical target sentences (i.e., 65 grammatical and 65 ungrammatical sentences in total). The low probability block included 78 grammatical sentences in addition to 26 grammatical and 26 ungrammatical target sentences (i.e., 104 grammatical and 26 ungrammatical sentences in total). The target sentences were identical between the low probability and equal probability blocks (see the online Supplementary Material 2 for all sentences). Table 1 summarises the number of target and filler sentences in each list (i.e., for each participant).
The summary of the number of target and filler sentences in each list.
An anonymous reviewer pointed out that the ungrammatical sentences “bara-o kareta” in (1b) still have a highly frequent, thematic representation such as “withered the rose” although the position of the thematic role was violated. This is not true. We should point out that the Japanese language strictly distinguishes intransitive verbs from transitive verbs and all target verbs are intransitive. There is no intransitive-transitive alternation like “The rose withered” and “(Someone) withered the rose” in Japanese. Therefore, in ungrammatical sentences, there is no syntactic/thematic position in which a theme/patient can occupy as an object. To put it simply, the sentence in (1b) cannot be interpreted such that someone withered a/the rose.
As noted in the Introduction, previous studies (Coulson et al., 1998; Gunter et al., 1997) have compared high and low probability blocks. However, this study compared high and equal probability blocks because the equal probability is considered a deviant case to participants to some degree as grammatical sentences occur far more frequently than ungrammatical sentences in typical language use. Furthermore, these studies manipulated the probability of grammatical and ungrammatical sentences with target sentences. In contrast, to avoid the interpretation of results in terms of simple repetition priming, the manipulation of the probability was achieved by including filler sentences in this study.
An offline acceptability judgement survey was conducted to check the acceptability of target and filler sentences. Acceptability was measured from 24 native speakers of Japanese who were undergraduate students at Tohoku University (11 females and 13 males, mean age = 20.5, standard deviation of age = 1.5, age range: 18.5–23.2). They were assigned to the low or equal probability condition (i.e., between-participant factor). They were presented with each sentence in the centre of a screen and instructed to rate it from 1 (unacceptable) to 5 (acceptable) with no time restrictions. Target and filler sentences were randomised for each participant using the Ibex Farm platform (Drummond, 2007).
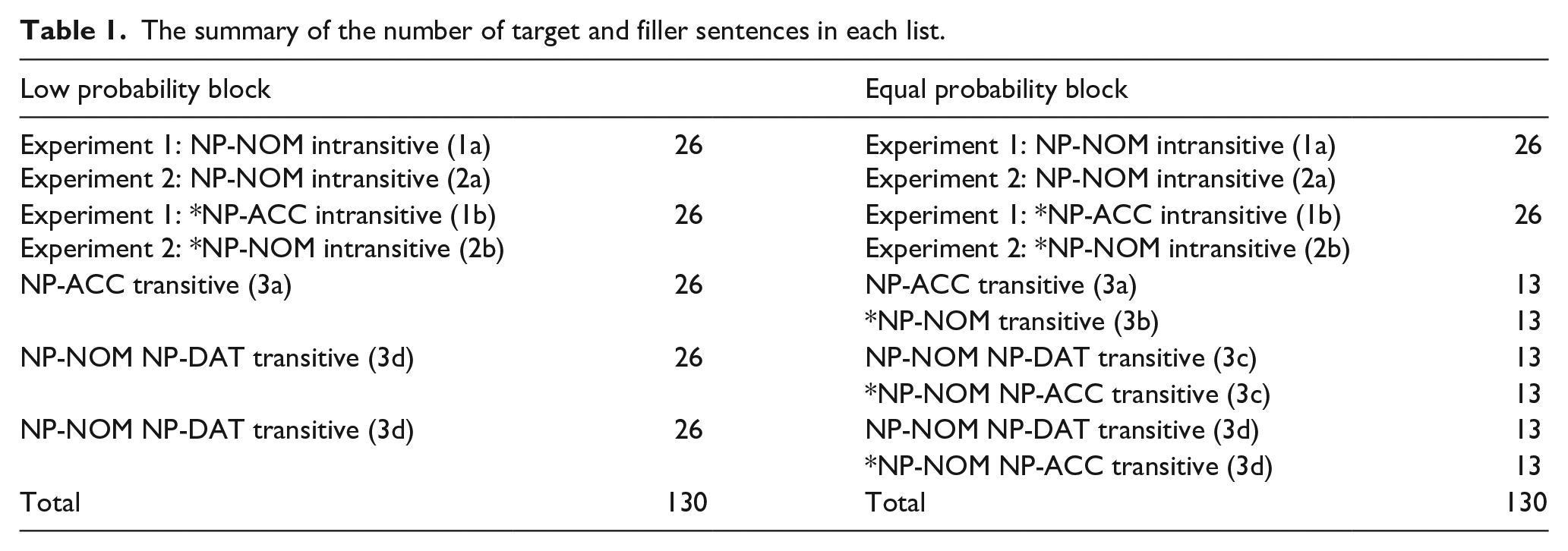
Figure 1 shows the results of the acceptability judgement survey. The morphosyntactically/semantically grammatical sentences were judged as acceptable, while the morphosyntactically/semantically anomalous sentences were judged as unacceptable. The LME model was used to examine the acceptability of the experimental sentences (fixed factors: EXPERIMENT, PROBABILITY, VIOLATION, and their interactions; random factors: participants and items; covariant: item order). The model revealed a main effect of VIOLATION (β = −3.48, t = −36.97, p < .01) and a main effect of EXPERIMENT with the sentences of Experiment 2 being more acceptable (β = 0.22, t = 2.29, p < .05). Other effects were not significant (p > .10). As the result of the offline acceptability judgement showed a robust difference between morphosyntactically/semantically grammatical and anomalous sentences, these materials were employed for subsequent ERP experiments.
Mean acceptability derived from the offline acceptability judgement survey. The y-axis indicates an acceptability of each type of sentence shown in the x-axis. Error bars indicate standard errors.
A sentence completion task was also conducted to examine cloze and transitional probabilities of the target verbs. 4 The participants were 20 native speakers of Japanese who were undergraduate or graduate students at Kyushu University (16 females and 4 males, mean age = 21.6, standard deviation of age = 2.6, age range: 18.11–24.10). The participants were presented with the first phrase of a sentence (e.g., “bara-ga,” rose-NOM) in the centre of the screen and asked to complete a sentence. The target sentences of Experiments 1 and 2 were used and distributed into two lists according to the Latin square design such that each participant saw 26 sentence fragments of each condition (i.e., 104 trials for each participant). The experimental sentences were randomised for each participant using the Ibex Farm platform (Drummond, 2007).
Table 2 shows the results of the sentence completion task. 5 The cloze probability of the target verbs of Experiment 1 was 0.14 (74/520) for the grammatical sentences (i.e., a nominative noun + target verb) and 0.00 (0/520) for morphosyntactically violated sentences (i.e., an accusative noun + target verb). The transitional probability of intransitive verbs following a nominative noun was 0.76 (395/520) while the transitional probability of the intransitive verbs following an accusative noun was 0.00 (1/520). This means that the accusative nouns trigger an expectation for transitive verbs and thus the input of an intransitive verb should violate such an expectation.
The responses in the sentence completion task.
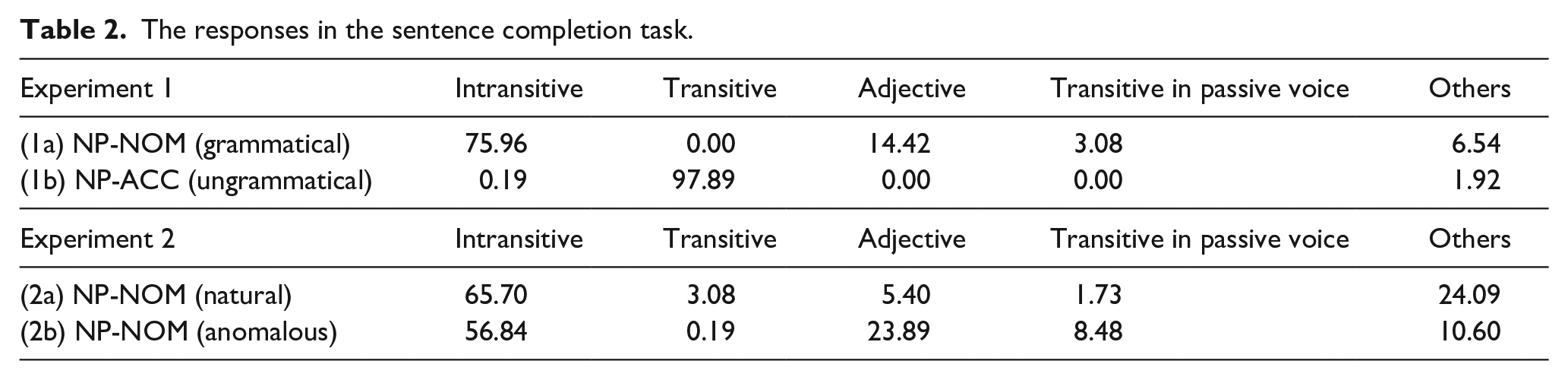
In Experiment 2, the cloze probability of the semantically natural and anomalous verbs was 0.05 (28/519) and 0.00 (0/519), respectively. This means that the semantically anomalous verbs are not predictable. The transitional probability of intransitive verbs given a nominative case was 0.65 (341/519) for semantically natural sentences and 0.56 (295/519) for semantically anomalous sentences.
Experiment 1: morphosyntactic violation
Participants
Twenty native speakers of Japanese were recruited from Tohoku University and Kyushu University (10 females and 10 males, mean age = 21.5, standard deviation of age = 1.5, age range = 19.4–23.3). The sample size of this experiment was based on our previous study that showed the sample size of 20 is sufficient to observe a reliable P600 effect (Yano et al., 2019). All participants were classified as right-handed based on the Edinburgh handedness inventory (Oldfield, 1971). Three participants had at least one left-handed family member. All participants had normal or corrected-to-normal vision and no history of reading disabilities or neurological disorders. Written informed consent was obtained from all participants prior to the experiments, and they were paid for their participation. The experiments were approved by the ethics committee of Graduate School of Arts and Letters of Tohoku University and by the ethics committee of the Department of Linguistics of Kyushu University.
Procedure
For the ERP experiment, stimuli were presented in a word-by-word manner in the centre of a monitor using Presentation (Neurobehavioral Systems). The order of stimuli was randomised for each participant. Each trial started with a fixation of 1,000 ms followed by the presentation of a blank screen for 200 ms (Figure 2). Each phrase of the sentences was presented for 800 ms with a 100 ms inter-stimulus interval. Upon being presented with a response cue (a blue diamond shape) shown 500 ms after the offset of the final phrase, participants were required to judge whether the sentence is acceptable and to press the YES (acceptable) or NO (unacceptable) button of the response pad (Cedrus, RB-740). The participants pressed the YES and NO buttons with thumbs of different hands. The response buttons (left vs right) were counterbalanced among the participants. The response cue was presented for 1,500 ms. The sentences and response cue were presented in Meiryo UI font with the size of 28.

Illustration of the sentence presentation.
The participants were presented with two lists, one in the equal probability block and the other in the low probability block. The order of the blocks was counterbalanced among the participants (i.e., 10 participants for each order). The participants took a break between these two blocks. Prior to each block, 10 practice trials were administered with the same grammatical/ungrammatical probability as for the subsequent block. The participants were informed that they completed two experiments but not of how they differed (i.e., the manipulation of probability).
Electrophysiological recording
EEGs were recorded from 19 Ag electrodes (QuickAmp, Brain Products and NE-113A, Nihon Kohden) located at Fp1/2, F3/4, C3/4, P3/4, O1/2, F7/8, T7/8, P7/8, Fz, Cz, and Pz according to the international 10–10 system (Acharya et al., 2016). Additional electrodes were placed below and to the left of the left eye to monitor horizontal and vertical eye movements. The online reference was set to the average of all electrodes and EEGs were re-referenced offline to the average value of the earlobes. The impedances of all electrodes were maintained at less than 10 kΩ throughout the experiment. The EEGs were amplified with a bandpass of DC to 200 Hz, digitised at 1,000 Hz.
Electrophysiological data analysis
EEGs were filtered offline with a 30 Hz low-pass filter and were time-locked to the onset of the second phrase of the target sentences (i.e., verbs), in which morphosyntactic violations can be detected. The time window of −100 to 900 ms relative to the onset of the second phrase was epoched. The 10 Hz low-pass filter was applied only for plotting grand average ERPs. EEGs were normalised for each trial using a 100 ms prestimulus baseline. Trials with large artefacts (exceeding ±80 µV) were automatically removed from the analysis. The number of rejected trials was not statistically significant between conditions in Experiment 1, χ2(3) = 5.10, n.s., the mean number of rejected trials was 3.43, standard deviation was 3.68, or in Experiment 2, χ2(3) = 3.97, n.s., the mean number of rejected trials was 3.83, standard deviation was 3.59.
Statistical analyses were conducted using LME models fitted with the lmer function of the lme4 package in R (Bates et al., 2015) to examine how the ERP effect changed throughout the experiment. The dependent variables included mean amplitudes calculated for each participant, trial, and electrode. 6 Although P600 effects were expected to appear in response to morphosyntactic violations in the time windows of 700–900 ms on the basis of previous studies in Japanese(Mueller et al., 2007; Nashiwa et al., 2007; Yano, 2018; Yano & Sakamoto, 2016; Yano et al., 2018), the mean amplitudes of 300–500 ms and 500–700 ms were also analysed to examine at which time windows the ERPs started to change over the course of the experiment. The division of a P600 time window into early and late time windows (i.e., early P600 time window of 500–700 ms and late P600 time window of 700–900 ms) is motivated by previous studies showing that different types of sentences show a P600 effect with different peak latencies and topographical distributions (Barber & Carreiras, 2005; Carreiras et al., 2004; Hagoort & Brown, 2000; Kaan & Swaab, 2003a, 2003b; Molinaro et al., 2011, see also Note 2).
One might wonder why the time window of P600 is late in Japanese. This issue may be related to verb-finality of Japanese because the argument-verb relation is formed at the verb position. Although it is often said that a critical word should not be placed at the sentence-final word, it cannot be avoided in Japanese, a strict verb-final language. However, Stowe et al. (2018) argue that there is little evidence to believe that sentence-final ERPs reflect sentence wrap-up. Furthermore, to preview our results, the sentence-final verb did not show any prolonged negativity trend that has been interpreted as a wrap-up effect in the literature (see, for example, Friederici & Frisch, 2000; Ueno & Kluender, 2003) because our experimental sentences were short and did not induce an excessive working memory load. The late peak latency of P600 may also be related to the task. In the present experiment, the participants were asked to not execute the button press quickly to avoid the movement-related artefact contaminating the ERPs of the second phrase. As the peak latency of P600 is response-aligned (Sassenhagen & Bornkessel-Schlesewsky, 2015; Sassenhagen et al., 2014), it is plausible to expect a late P600 effect rather than an early P600 effect. Furthermore, previous experiments using similar materials and the same instruction have observed a P600 at the late time window (Yano, 2018; Yano & Sakamoto, 2016; Yano et al., 2018, 2019).
The models included independent variables of interest, namely, PROBABILITY (low vs equal), VIOLATION (morphosyntactically grammatical vs anomalous sentences), and ITEM ORDER of each block (1–130) with their interactions as fixed factors. Note that ITEM ORDER refers to the order of sentences that the participants have read in each block, not the order of the two blocks. Because the ordering of the block did not have a significant impact on the P600 effect, the following results section reports results of the models without the ordering as a factor of interest. The morphosyntactically grammatical and anomalous sentences were coded as −0.5 and 0.5, respectively. The deviation coding of ±0.5 was used because a positive estimated coefficient indicates a P600 effect for ungrammatical sentences relative to grammatical sentences and an intercept indicate a grand mean P600 amplitude across conditions. Note that we use the term P600 to refer to a positivity observed in a single condition, while we refer to the P600 difference between two conditions as a P600 effect. The coding choice is only for the ease of interpreting results of coefficients and does not affect a significance of statistical analyses reported below. The low and equal probability blocks were assigned values of −0.5 and 0.5, respectively. The participant, item, and position of the electrode were treated as random factors (Payne et al., 2015). 7 Including random intercept and slope of participants and items for the Item Order term caused a convergence problem due to the complexity of models. Thus, the random intercept and slope of participants and items were assumed for PROBABILITY and VIOLATION, but not for ITEM ORDER. As the topographical distribution of P600 is well known, the statistical analyses used EEG data for the centro-parietal regions (Cz, Pz, C3/4, P3/4, P7/8, and O1/2). 8 The maximal model was built and then compared with more parsimonious models with simpler random effects in the backward stepwise method using the ANOVA function (cf. Matuschek et al., 2017). The final models were reported for each analysis below. p-values were calculated based on the Satterthwaite’s method by submitting the final model to the lmer function of the lmerTest package (Kuznetsova et al., 2017).
The effects of interest included the VIOLATION effect, the interaction of PROBABILITY × VIOLATION, the interaction of VIOLATION × ITEM ORDER, and the interaction of PROBABILITY × VIOLATION × ITEM ORDER. The interaction of PROBABILITY × VIOLATION was resolved by conducting separate analyses at each level of PROBABILITY. When the interaction of VIOLATION × ITEM ORDER (continuous variable) was significant, simple slopes of VIOLATION were calculated on values of +1 SD and −1 SD from the mean of ITEM ORDER, following Cohen and Cohen (1983) on the website of Preacher et al. (2006). Only for the sake of simplicity, we refer to the trials of +1 SD and −1 SD from the mean as the first and second halves of the experiments. When multiple comparisons were conducted, an α level of .05 divided by the number of comparisons is considered to be a significant level (i.e., the Bonferroni correction).
Prediction
The morphosyntactic violations were expected to elicit a P600 effect, according to similar experiments in Japanese (Yano, 2018; Yano & Sakamoto, 2016; Yano et al., 2018) and the literature of other languages. A left anterior negativity (LAN) effect has also been observed for morphosyntactic violations in Indo-European languages with verb agreement system (see Molinaro et al., 2011, for review), but less often in East Asian languages including as Japanese, except for a special case such as a verb is distant from its subject, when a reader makes a strong prediction for a verb morphology (Yano, 2018). Thus, we did not expect the LAN to be elicited in the present experiment.
The focus of this study was whether the magnitude of the P600 effect changed over the course of each block, depending on the probability of anomalous sentences. If the language-processing system does not adapt to anomalous sentences, the P600 effects were expected to appear throughout both low and equal probability blocks. Alternatively, if the language-processing system is adaptive in nature, the P600 effect should decrease in amplitude during the equal probability block, in which the participants were exposed to a large number of anomalous sentences. Statistically speaking, this should expect the interaction of VIOLATION × ITEM ORDER to be significant in the equal probability block, due to the attenuation of the P600 effect. In the low probability block, the interaction of VIOLATION × ITEM ORDER reflecting the attenuation of the P600 effect is not expected even if the language processing system is adaptive because the number of anomalous sentences is small in this block. Accordingly, the interaction of PROBABILITY PROBABILITY × VIOLATION × ITEM ORDER VIOLATION × ITEM ORDER should be expected if the language-processing system adapts to anomalous sentences.
Results
Behavioural data
The result of the acceptability judgement task was analysed with a LME model that included PROBABILITY, VIOLATION, and ITEM ORDER as fixed effects and participants and items as random factors. The main effect of VIOLATION was significant, showing that the acceptability of morphosyntactically grammatical sentences was higher than anomalous sentences (β = −7.95, t = −20.63, p < .01) (Table 3). The interaction of PROBABILITY × VIOLATION × ITEM ORDER was also found to be significant (β = 1.80, t = 2.67, p < .01). To examine which condition ITEM ORDER affected, post hoc analyses were conducted. The result showed a significant ITEM ORDER effect for the morphosyntactically violated sentences for the equal probability block (β = 1.04, t = 2.58, p < .01), showing that the participants were more likely to accept them with increasing exposure. The ITEM ORDER effect was found to be significant for morphosyntactically grammatical sentences of the low probability block, showing an increase in their acceptability (β = 0.57, t = 2.01, p < .05).
Mean and SD (in parentheses) of acceptability of reaction times (RT) in Experiment 1.

The response times were analysed in the same manner. The ITEM ORDER effect was significant, showing that faster response times were achieved over the course of the experiment (β = −9.58, t = −2.82, p < .01). A marginally significant interaction of PROBABILITY × VIOLATION × ITEM ORDER was also observed (β = 25.65, t = 1.88, p = .05). Post hoc analyses showed a marginally significant interaction of VIOLATION × ITEM ORDER was found for the low probability block but not for the equal probability block (Low: β = −16.84, t = −1.79, p = .07; Equal: β = 8.23, t = 0.83, p > .10). The interaction of VIOLATION × ITEM ORDER means that the tendency for the slower response times at the grammatical sentences relative to the morphosyntactic violation increased during the low probability block.
Electrophysiological data
Figure 3 shows grand average ERPs of the second phrases (i.e., verbs) in Experiment 1. A visual inspection suggests that morphosyntactically ill-formed sentences elicited a larger P600 than grammatical counterparts in Experiment 1. Furthermore, the P600 effects were greater for the low probability block than for the equal probability block.
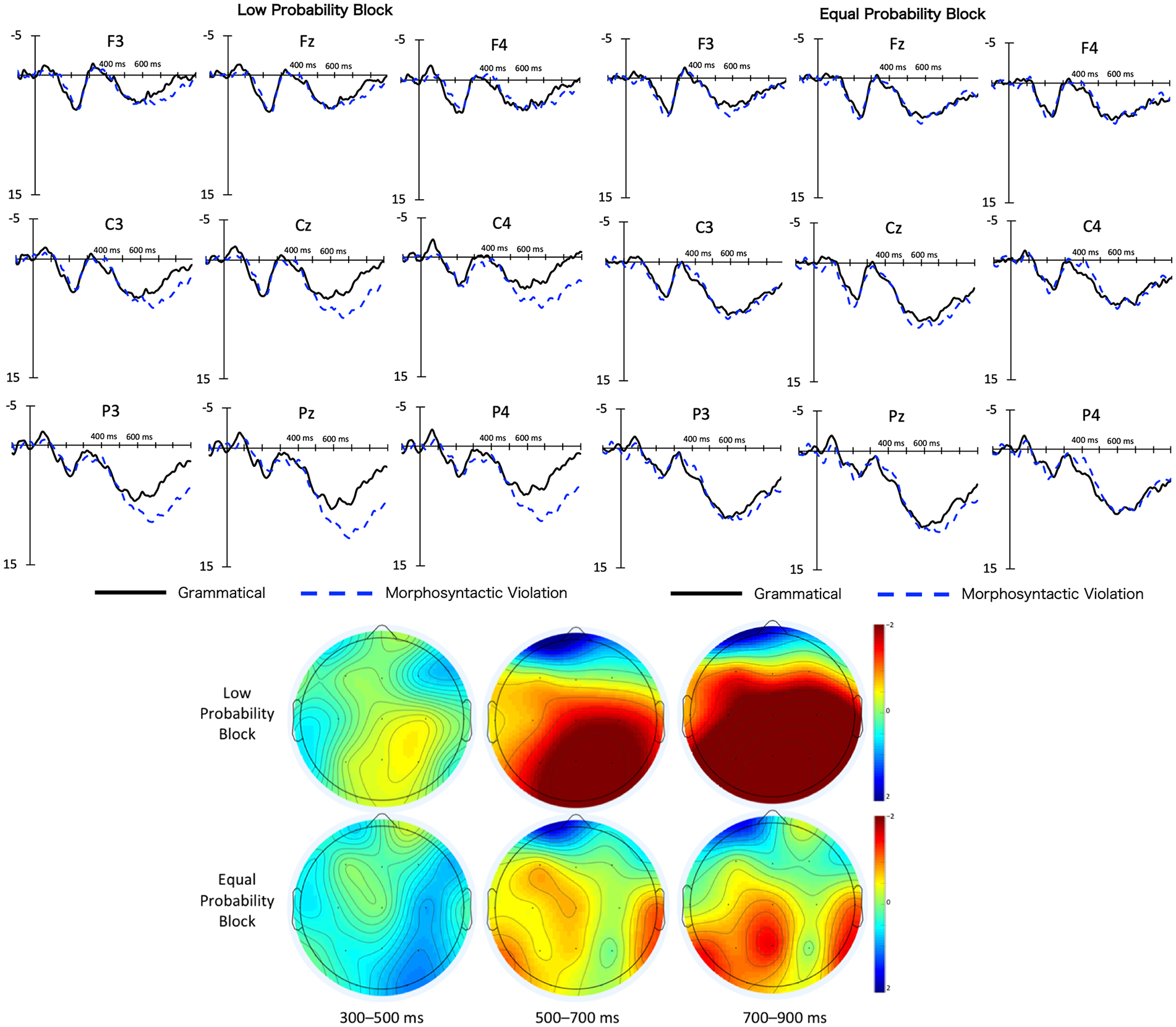
Grand average ERPs of the second phrase in Experiment 1.
At the 300–500 ms time window, a significant interaction of VIOLATION × ITEM ORDER and PROBABILITY × VIOLATION × ITEM ORDER was observed (Table 4). Planned comparisons made at each level of PROBABILITY revealed a significant interaction of VIOLATION × ITEM ORDER only for the equal probability block (β = −0.91, t = −4.21, p < .01), showing that ungrammatical sentences elicited a small negativity compared to grammatical sentences for the second half of the experiment but not the first half of the experiment (β = 0.45, t = 0.60, p > .10; β = −1.34, t = −1.78, p = .08). 9
The linear mixed-effects model for the 300–500 ms time window for Experiment 1.
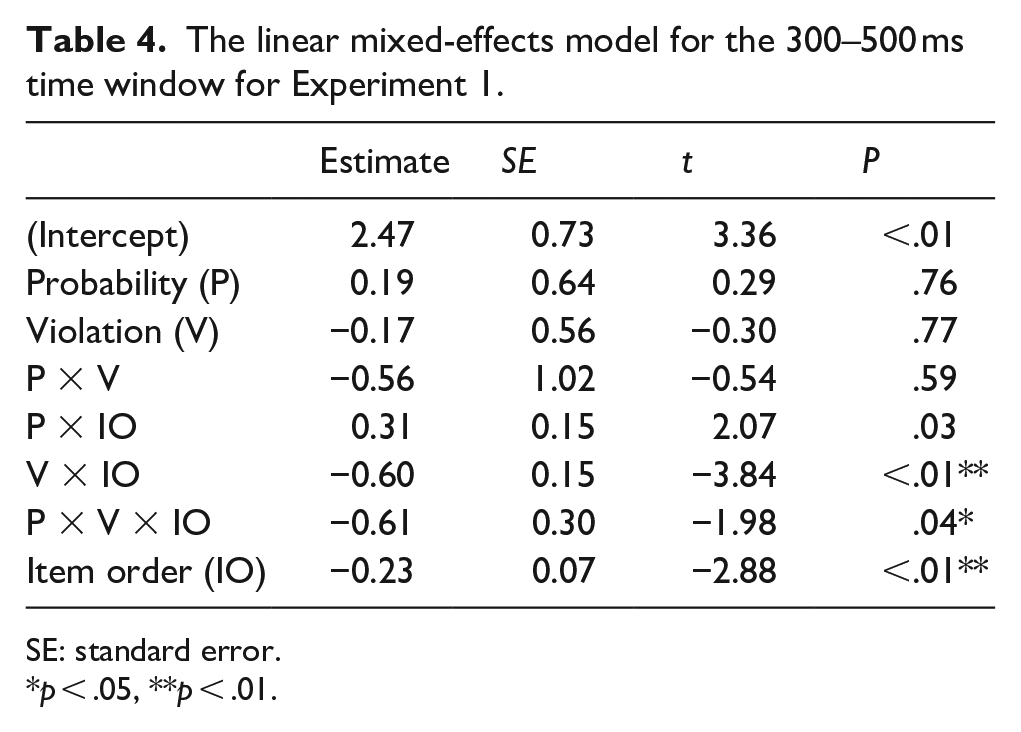
SE: standard error.
*p < .05, **p < .01.
For 500–700 ms the main effect of VIOLATION was found to be marginally significant, showing a greater positivity found for the ungrammatical sentences (Table 5). Furthermore, interactions of VIOLATION × ITEM ORDER and of PROBABILITY × VIOLATION × ITEM ORDER were significant. The planned comparison showed a marginally significant effect of VIOLATION for the low probability block but no significant effect for the equal probability block (β = 1.80, t = 1.65, p = .10; β = 0.60, t = 0.71, p > .10).
The linear mixed-effects model for the 500–700 ms time window for Experiment 1.
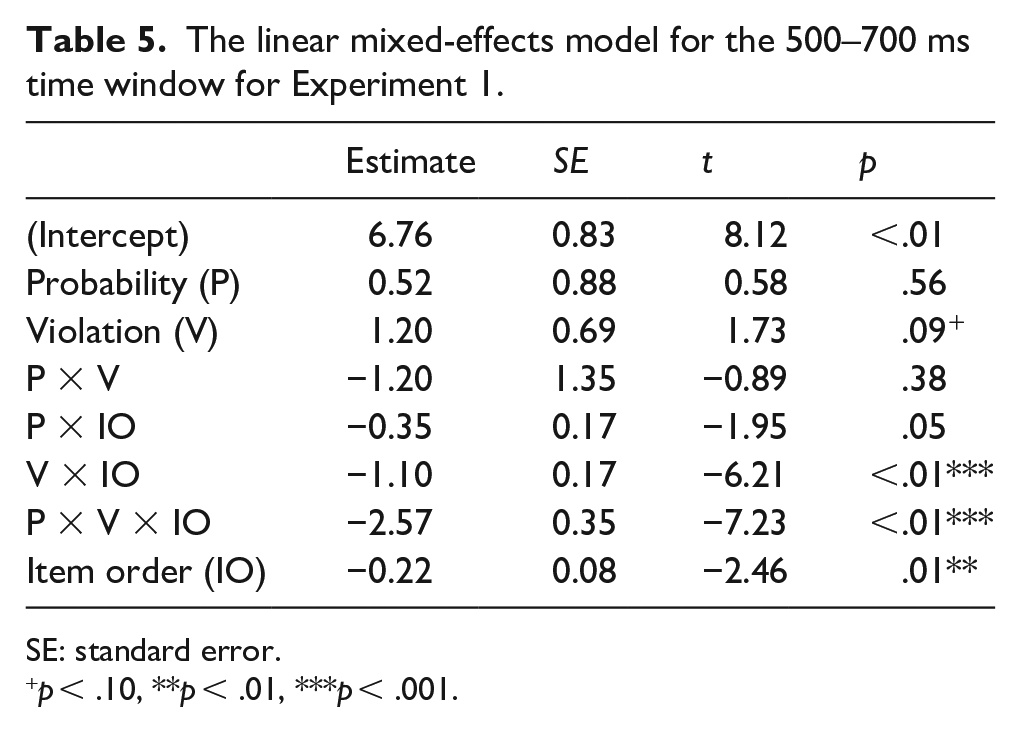
SE: standard error.+p < .10, **p < .01, ***p < .001.
From 700 to 900 ms, the VIOLATION effect and the interaction of PROBABILITY × VIOLATION × ITEM ORDER reached a significant level (Table 6). The VIOLATION effect was found to be significant for the low probability block but not for the equal probability block (β = 3.85, t = 3.08, p < .01; β = 0.88, t = 0.77, p > .10). The interaction of VIOLATION × ITEM ORDER was significant in both low and equal probability blocks (β = 1.27, t = 4.56, p < .01; β = −1.57, t = −5.72, p < .01). As indicated by their coefficients in the opposing direction, ITEM ORDER had a different effect on the P600 effect for the low and equal probability blocks. For the low probability blocks, ungrammatical sentences exhibited an increasing P600 effect over the course of the experiment consistent with the marginally significant effect of VIOLATION observed for the first half and with a significant effect observed for the second half of the experiment (β = 2.58, t = 2.01, p = .05; β = 5.13, t = 4.00, p < .01). For the equal probability block, however, the P600 effect was observed for the first half and it then declined throughout the experiment (β = 2.45, t = 2.07, p < .05; β = −0.68, t = −0.57, p > .10).
The linear mixed-effects model for the 700–900 ms time window for Experiment 1.

SE: standard error.+p < .10, **p < .01, ***p < .001
To examine which condition contributed to P600 changes during the experiment, additional LME analyses were conducted for each condition, that is, EEG ~ IO + (1|Participant) + (1|Set) + (1|ch). The model included ITEM ORDER as a sole independent factor and a mean amplitude of 700–900 ms as a dependent variable. The results showed a significant effect of ITEM ORDER for all four conditions (Low/Grammatical: β = −0.68, t = −3.46, p < .01; Low/Ungrammatical: β = 0.58, t = 2.95, p < .01; Equal/Grammatical: β = 0.54, t = 2.78, p < .01; Equal/Ungrammatical: β = −1.03, t = −5.27, p < .01; positive coefficients denote an increase in the P600’s amplitude). 10 As is shown by the positive/negative coefficients of ITEM ORDER, the P600 decreased in amplitude under the grammatical condition while it increased under the ungrammatical condition for the low probability block (Figure 4, left). However, the P600 increased under the grammatical condition and decreased under the ungrammatical condition in the equal probability block (Figure 4, right).
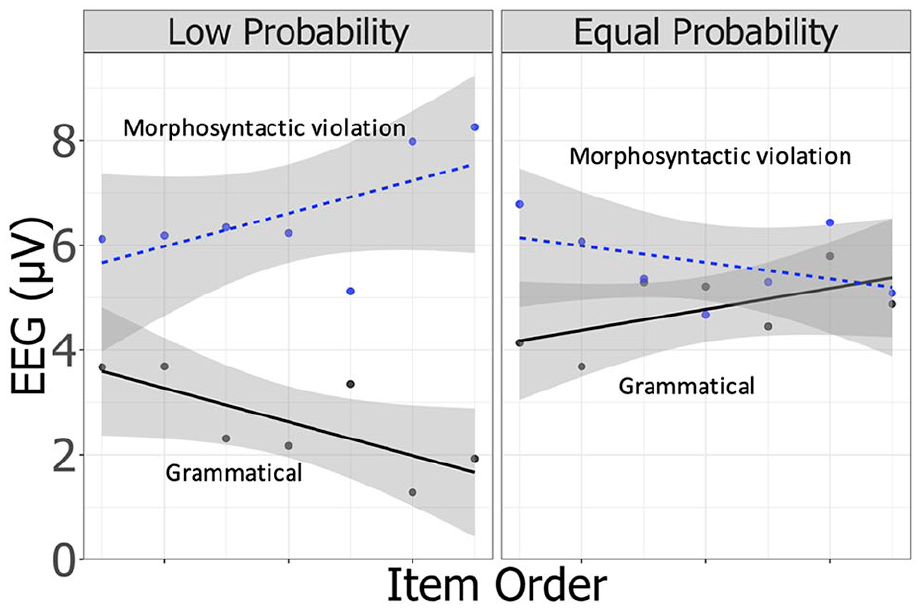
The P600 change in the low (left) and equal (right) probability blocks of Experiment 1.
We also examined the effect of ITEM ORDER on the P600’s peak latency for the grammatical and ungrammatical sentences. 11 The results showed a significant interaction of VIOLATION × ITEM ORDER reflecting the increasing peak latency of the P600 throughout the experiment (β = 10.16, t = 5.70, p < .01). The three-way interaction of PROBABILITY × VIOLATION × ITEM ORDER was significant (β = 8.68, t = 2.43, p < .01), as the peak latency of the ungrammatical sentences slowed relative to that of the grammatical sentences as the participants were repeatedly exposed to them during both low and equal probability blocks (Low: β = 5.84, t = 2.29, p < .05; Equal: β = 14.59, t = 5.84, p < .01).
Discussion
To summarise the result of Experiment 1, a P600 effect for the morphosyntactically anomalous sentences decreased when the probability of ungrammatical sentences was the same as that of grammatical sentences while it increased when their probability was low relative to that of grammatical sentences.
The equal probability block
In the equal probability block, the P600 effect was smaller because of a decline in the P600’s amplitude under the ungrammatical condition and an increase under the grammatical condition. If the P600 reflects a syntactic repair (Kaan & Swaab, 2003), the attenuation of the P600 suggests that the participants experienced less syntactic processing difficulty when encountering a mismatch between the accusative-marked noun and the intransitive verb as they increased their expectation for them. Alternatively, the result can be interpreted in terms of other functional interpretations of P600. For example, there have been a number of reports that semantic violations, such as “The hearty meal was devouring … ,” elicit a P600 effect, suggesting that the P600 indexes more general integration difficulty when the syntactic information conflicts semantic information (Bornkessel-Schlesewsky & Schlesewsky, 2008; Brouwer et al., 2012; Chow & Phillips, 2013; Kim & Osterhout, 2005; Kolk et al., 2003; Kuperberg et al., 2003, 2006, 2007; Oishi et al., 2011; Van Herten et al., 2005). In the case of our sentences (i.e., *bara-o kareta, “rose-ACC withered”), the morphosyntactic information signals an argument as a patient of the event whereas the semantic information indicates it is a theme. If the P600 effect reflects a resolution of such conflict, the decline of the P600 effect suggests that the language processing system became familiarised with the conflict resolution during the experiment. More recently, Fitz and Chang (2019) propose that a P600 reflects a cost of a learning process to develop an accurate probabilistic model. According to their computational model, when the language processing system faces a processing error, it propagates the error back to the lower-level units to enable learning probable syntactic representations. If their interpretation of the P600 is correct, the P600 change reflects a successful learning process that attempt to minimalise the prediction error.
Although the exact functional contribution of P600 to language comprehension is still debated, the result of the equal probability block suggests that the language-processing system can adapt to morphosyntactically violated sentences and supports the expectation-based account. This finding might lead one to expect that the language-processing system is generally adaptive and attempts to minimise a prediction error. We will return to this issue in General discussion in relation to the result of Experiment 2.
In contrast, the present result is not compatible with the hypothesis that accounts for syntactic adaptation in terms of (cumulative) syntactic priming, which is assumed to involve more passive processing (cf. Reitter et al., 2011; Traxler & Tooley, 2008). According to this interpretation, increased base-level activation (or residual activation) of syntactic frames facilitates the processing of subsequent sentences with the same syntactic frames. We, however, consider this interpretation unlikely in the present case. As noted in Introduction, ungrammatical sentences, such as case-assignment violations, do not have a licit syntactic representation that Japanese speakers can have. Thus, it is impossible to increase an activation level of such syntactic representation. Furthermore, the number of ungrammatical target sentences was kept constant between the low and equal probability blocks. Therefore, the repeated presentation of case-assignment violations in target sentences should prime their processing to the same degree for the low and equal probability blocks if this interpretation is correct. P600 attenuation was observed for the ungrammatical sentences only for the equal probability block, which is at odds with the representation-based account.
Another possible interpretation of the result is that, as the participants read ungrammatical sentences many times, they were reluctant to repair anomalous input to avoid wasting cognitive resources, resulting in a decrease in the P600 amplitude. If the interpretation is correct, we would expect the acceptability of ungrammatical sentences to not change and for the response times of the acceptability judgement and the peak latency of the P600 to shorten during the experiment because the participants should respond “NO” without repairing a morphosyntactic violation after detecting it. However, neither of these outcomes resulted. The acceptability of the ungrammatical sentence improved during the equal probability block. Furthermore, response times for ungrammatical sentences did not shorten relative to those of the grammatical sentences although a general pattern of acceleration was observed as often reported from behavioural experiments. The peak latency of the P600 in response to ungrammatical sentences slowed throughout the experiment.
Therefore, we interpreted the decline in the P600 observed for ungrammatical sentences of the equal probability block as evidence for adaptation to morphosyntactic violations. One might wonder whether the participants were aware of the probability manipulation and took some strategies to process the ungrammatical sentences. After the experiment, the participants were asked if they noticed any difference between the first and second experiments (i.e., a difference between the low and equal probability blocks). Those who noticed our probability manipulation were not representative (i.e., only three of 20). Thus, the adaptation to morphosyntactic violation seems unconscious rather than conscious and strategic.
The grammatical sentences, however, exhibited an increase in P600 for the equal block. This may be related to the cue validity of case markers in predictive processing. As the half of the sentences were ungrammatical in the equal block, the participants recognised that the pre-verbal phrases were not informative as to syntactic structure of a sentence as the experiment continued and thus did not incorporate a potentially expected verb into the syntactic representation prior to its appearance. Consequently, the processing cost of a verb increased throughout the processing of grammatical sentences. This type of increased processing load is reminiscent of those described in Fine et al. (2013), who reported a trade-off of processing costs between a priori frequent and infrequent structures. According to their self-paced reading experiment, adjusting expectations to infrequent structures increased the processing costs of frequent structures. However, adaptive behaviour was limited in that the processing of a less frequent structure did not become easier than that of a more frequent structure. This holds true for the present case, as the P600 effect was not reversed for the equal probability block of Experiment 1 (i.e., P600 effect for grammatical sentences). Other studies also show no differences in P600 between grammatical and ungrammatical sentences for the high probability block (Hahne & Friederici, 1999). This implies that morphosyntactic rules (e.g., case assignment and verb inflection) are robust to the extent to which they cannot be replaced by a priori ungrammatical morphosyntactic rules, like an intransitive verb marks an argument with an accusative case.
The low probability block
The observation that the opposite pattern was found for the low probability block supports our interpretation of the results of the equal probability block. For the low probability block, the P600 amplitude decreased for the grammatical sentences and increased for the ungrammatical sentences. As the pre-verbal phrase provided useful information on the syntactic structure of a sentence in this block, the participants incorporated this information into their predictive computations. Consequently, processing was facilitated at the verb, attenuating the P600 amplitude of grammatical sentences. However, such an expectation should lead to a severe processing cost at the verb of the ungrammatical sentences. 12 Thus, the participants needed to repair the syntactic structure of the sentence upon encountering the verb. The increase in the P600 amplitude observed for the ungrammatical sentences can be considered a consequence of such processing errors, as the participants expected a grammatical sentence more over the course of the experiment.
An anonymous reviewer pointed out that the nominative-initial sentences are always grammatical and the accusative-initial sentences are either grammatical or ungrammatical in the low probability block. In contrast, a great deal of the nominative-initial fillers is ungrammatical as well in the equal probability block, so the response mapping is not as straightforward as in the low probability block. Thus, adaptation patterns found may be reflecting adaptation of response strategies rather than adaptation to the anomalies. However, this possibility seems less likely. If the participants strategically judged the acceptability of a sentence based on the first phrase, we should expect the P600 effect to decrease over the course of the low probability block, in which the participants were more certain about the acceptability of a sentence upon reading the first phrase. In a similar vein, if the participants strategically judged the acceptability of a sentence in the equal probability block as well, they were more uncertain about an acceptability at the timing of the first phrase. Accordingly, they should have needed to perform more effortful processes in the second phrase and thus the ungrammatical sentences should elicit a robust P600 effect. These predictions were not borne out by the present results because the P600 effect increased in the low probability block and it decreased in the equal probability block.
Experiment 2: semantic violation
Experiment 1 showed evidence for syntactic adaptation to ungrammatical sentences. In Experiment 2, we aim to extend an understanding of the nature of linguistic adaptation by examining whether adaptive behaviour depends on the type of linguistic violations, using semantic violations.
Some previous studies examined the probability effect on semantic processing associated with an N400, although there are few studies that directly examined adaptation to semantic violations. Zhang et al. (2019) examined the effect of the ratio of predictable and unpredictable words in sentences on the N400 effect. The result showed an N400 effect for unpredictable words regardless of the ratio, suggesting that the probability manipulation does not affect the way the language-processing system processes semantic information. However, another study reported a different pattern. Lau et al. (2013) manipulated the probability of semantically related and unrelated word pairs (Related: shove–push vs Unrelated: blaze–push). In their priming experiment, a robust N400 effect (i.e., the difference between the semantically primed and unprimed word) was observed in the high relatedness block (50% of primes are related to targets), unlike in the low relatedness block (10% of primes are related). 13 Nevertheless, it is difficult from the observation of these studies to discern the limit of adaptive behaviour.
Experiment 2 focuses on adaptation to semantic violations to clarify this issue. Given the result of Experiment 1, the language-processing system seems to track the probability distribution of anomalous sentences and adapt to it by updating its expectation. However, it is conceivable that the language-processing system does not always adapt to anomalous input considering that there should be a trade-off between flexible and fixed behaviour. A flexible processing system can reduce expectation error, allowing for more efficient processing in a given situation. However, it consumes the cost of keep estimating the probability distribution of the input. In contrast, a more fixed processing system is more likely to experience expectation error, but does not need to change the way it processing the input constantly. Thus, it is hypothesised that there is a mediating factor, such as typicality of error, which encourages or discourages the language-processing system to adapt to unexpected input. Given that semantic anomaly is more atypical than (morpho)syntactic error (e.g., non-native utterances, agreement illusion, syntactic blends, cf. Frazier, 2014), it may not be optimal for the language-processing system to adapt to semantic errors. This issue will be investigated in Experiment 2.
Participants
Twenty undergraduate and graduate students were recruited from Kyushu University (15 females and 5 males, mean age = 20.6, standard deviation of age = 1.6, age range = 19.4–23.11). None of them took part in Experiment 1. Four participants had at least one left-handed family member. All participants had normal or corrected-to-normal vision and no history of reading disabilities or neurological disorders. Written informed consent was obtained from all participants prior to the experiments, and they were paid for their participation. The experiments were approved by the ethics committee of the Department of Linguistics of Kyushu University.
Because Experiments 1 and 2 were conducted for different participants, their individual cognitive traits were obtained to assess the extent to which the participants were different between experiments, using Paced Auditory Serial Addition Test (PASAT) (Gronwall, 1977), Symbol Digit Modalities Test (SDMT) (Smith, 1968, 1973), autistic-spectrum quotient (AQ) (Wakabayashi et al., 2006), and P3b. 14 Two sample t-tests were conducted for each score. The results showed no significant difference in any of these measures, suggesting that the participants of Experiments 1 and 2 were not different in terms of cognitive abilities (Table 7).
Mean and SD of individual cognitive traits in Experiments 1 and 2.
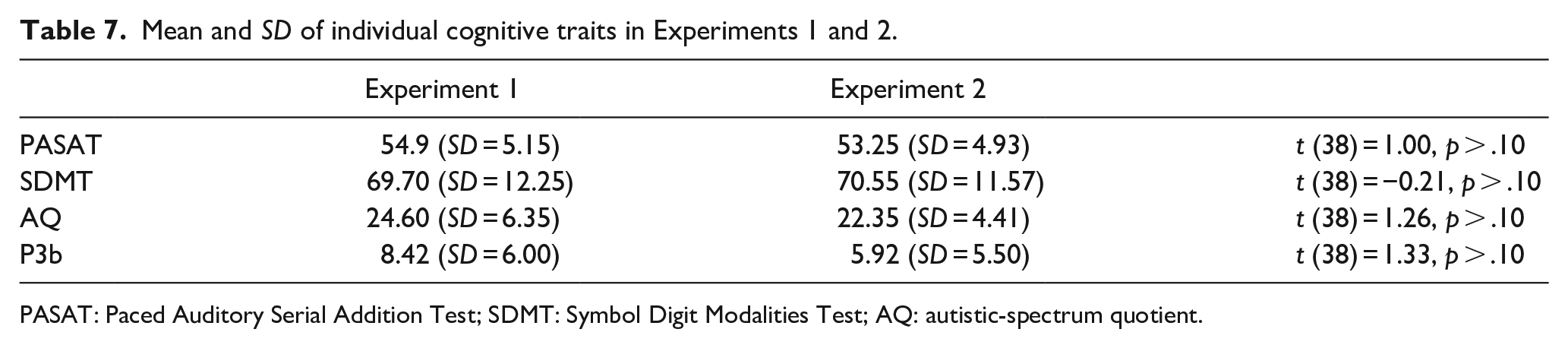
PASAT: Paced Auditory Serial Addition Test; SDMT: Symbol Digit Modalities Test; AQ: autistic-spectrum quotient.
Materials
The target sentence of Experiment 2 is reproduced in (4). The sentence in (4a) is semantically natural, whereas (4b) is semantically anomalous due to animacy violation.
(4) Experiment 2 (Semantic Violation) a. Grammatical sentence: shinseiji-ga nai-ta. baby-NOM cry-PAST “The newborn baby cried.” b. Semantically anomalous sentence: *shikibo-ga nai-ta. baton-NOM cry-PAST “The baton cried.”
Fifty-two pairs of the target sentences were distributed into two lists according to the Latin square design such that each participant read 26 sentences of each condition. The filler sentences used in Experiment 1 were added to create the equal and low probability blocks (i.e., 130 sentences in total). The participants saw two lists, one in the equal probability block and the other in the low probability block. The order of the blocks was counterbalanced among the participants. EEG recordings and analyses were conducted in the same way as those used in Experiment 1 (see section “Procedure”).
Electrophysiological recording and data analysis
The recording and data analyses were conducted in the same way as in Experiment 1. As in Experiment 1, the models included independent variables of interest, namely, PROBABILITY (low vs equal), VIOLATION (semantically natural vs anomalous sentences), and ITEM ORDER (1–130) with their interactions as fixed factors. As it has been well known that an N400 effect appears over the centro-parietal regions at the time window of 300–500 ms post-stimulus onset (Kutas & Federmeier, 2000, 2011), the statistical analyses used EEG data of this time window at the centro-parietal regions (Cz, Pz, C3/4, P3/4, P7/8, and O1/2) as dependent variables. The semantically natural and anomalous sentences were coded as −0.5 and 0.5, respectively, such that a negative estimated coefficient of Violation indicates an N400 effect for anomalous sentences relative to natural sentences.
Prediction
Semantic violation was expected to elicit N400 effects according to previous literature (e.g., Kutas & Hillyard, 1980). The focus of Experiment 2 was whether the magnitude of the N400 effects changed over the course of experiments. If language processing is susceptible to semantically anomalous sentences, the N400 effect should decrease in amplitude during experiments. However, it is also conceivable that the type of linguistic violations affects such an adaptation. This hypothesis predicts that the N400 effect should appear throughout the experiments.
Results
Behavioural data
For acceptabilities of the sentences, the result showed a significant VIOLATION effect, indicating that the semantically anomalous sentences were judged less acceptable than the semantically natural sentences (β = −9.34, t = −15.91, p < .01) (Table 8). The other effects were not significant.
Mean and SD (in parentheses) of acceptability of reaction times (RT) in Experiment 2.

As for response times, only the effect of ITEM ORDER was significant because the participants responded faster over the course of the experiment (β = −15.40, t = −4.28, p < .01).
Electrophysiological data
Figure 5 shows grand average ERPs of the second phrases in Experiment 2. Unlike what was observed for Experiment 1, semantically anomalous sentences exhibited a negativity irrespective of probability manipulation. A small P600 effect appeared in response to semantically anomalous sentences only for the low probability block.
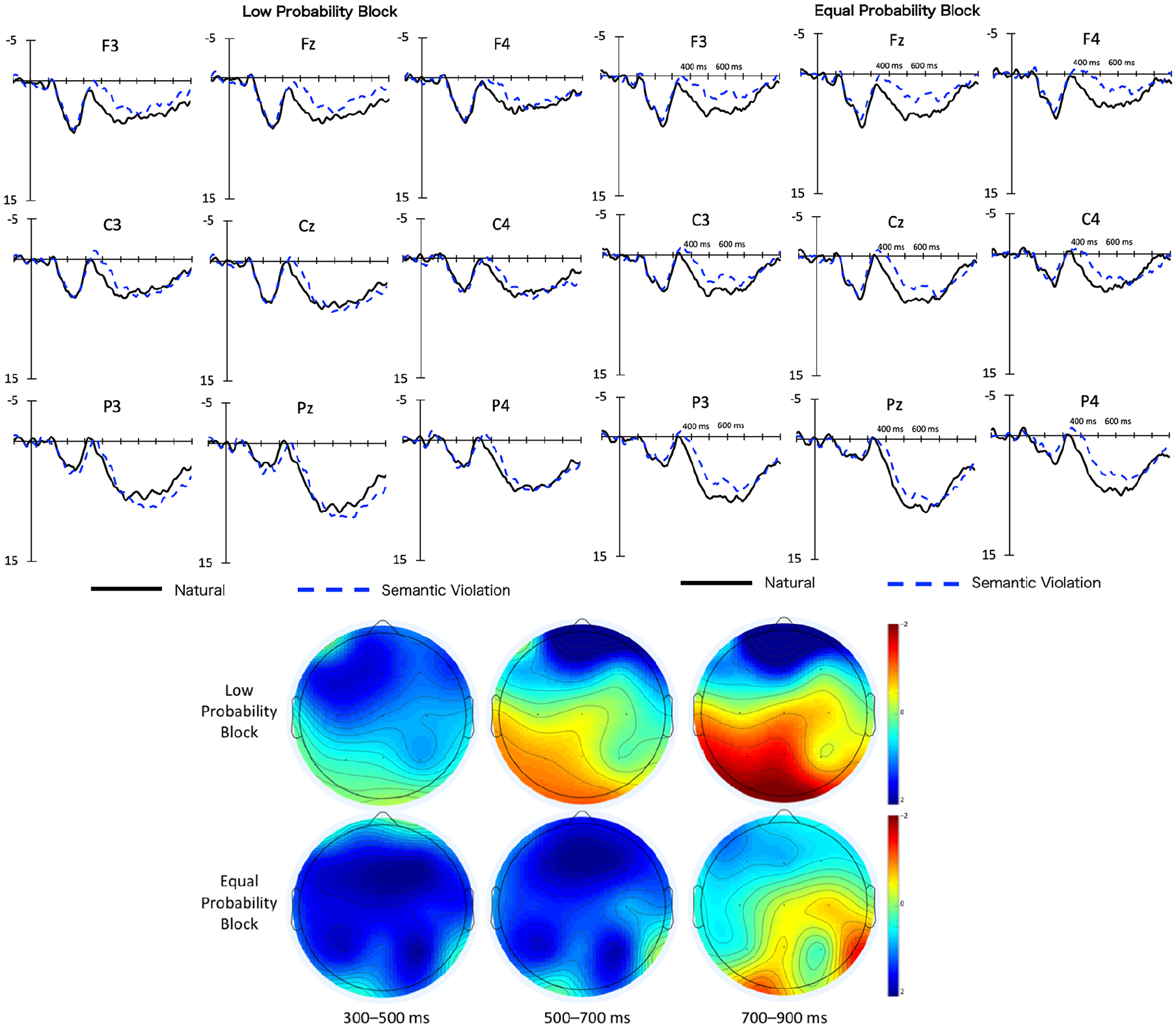
Grand average ERPs of the second phrase in Experiment 2.
In the 300–500 ms time window, the main effect of Violation was marginally significant (p = .053), showing that the semantically anomalous sentences elicited an N400 effect compared with the semantically natural sentences (Table 9). Although Figure 6 suggests that the N400 effect increased over the course of the experiment, the interaction of Violation and Item Order was not significant. Importantly, the three-way interaction of Probability, Violation, and Item Order was not significant, indicating that there is no evidence that the N400 effect decreases during the experiment as the participants read more anomalous sentences.
The linear mixed-effects model for the 300–500 ms time window for Experiment 2..
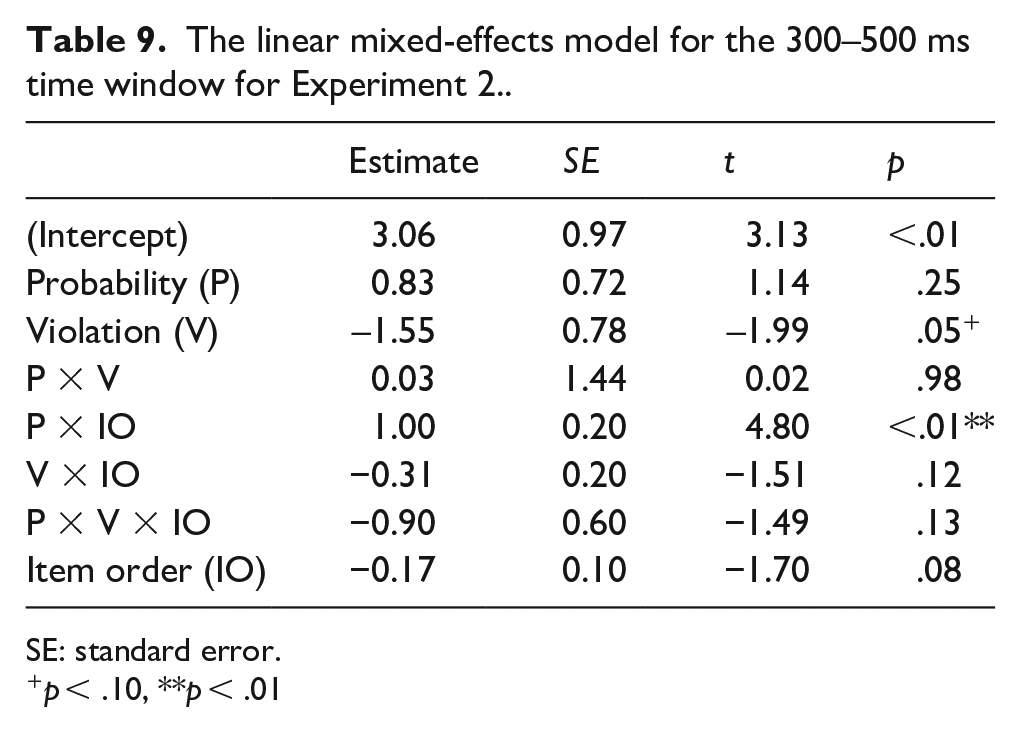
SE: standard error.+p < .10, **p < .01
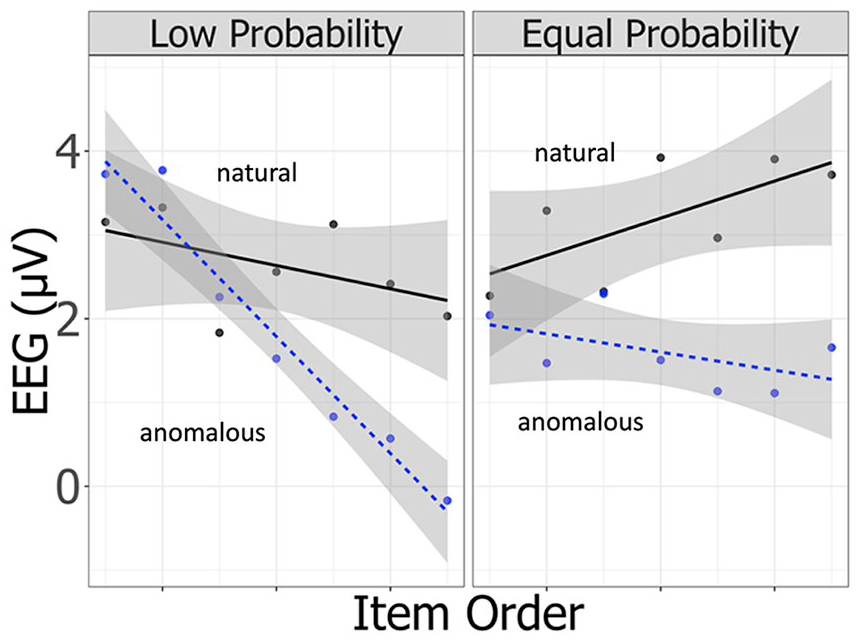
The N400 change in the low (left) and equal (right) probability blocks of Experiment 2.
For 500–700 ms, the interaction of VIOLATION × ITEM ORDER was significant (Table 10). However, post hoc analyses revealed no significant effect of Violation for the first or second half of the experiment. For 700–900 ms, interactions of VIOLATION × ITEM ORDER and of PROBABILITY × VIOLATION × ITEM ORDER were significant (Table 11). A planned comparison conducted at each level of PROBABILITY revealed a significant interaction of VIOLATION × ITEM ORDER for the low probability block (β = −1.13, t = −4.14, p < .01), showing the greater positivity for the semantically anomalous sentences for the first half of the experiment but not for the second half of the experiment (β = 2.39, t = 1.75, p = .09; β = 0.14, t = 0.10, p > .10). We again examined the effect of ITEM ORDER for each condition. The results showed that the P600 increased in natural sentences and decreased in semantically anomalous sentences of the low probability block, suggesting that P600 amplitude changes observed in both semantically natural and anomalous sentences contributed to a reduced P600 effect during the experiment (β = 0.59, t = 3.10, p < .01; β = −0.53, t = −2.72, p < .01). The equal probability block did not have an ITEM ORDER effect on the semantically natural or anomalous sentences.
The linear mixed-effects model for the 500–700 ms time window for Experiment 2..
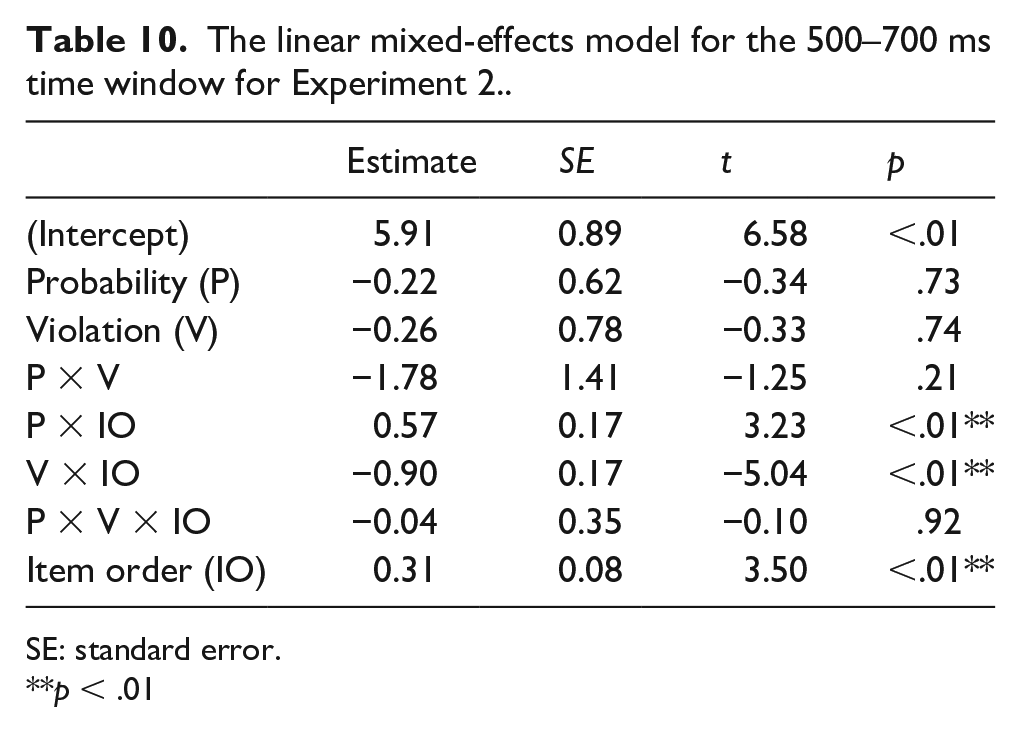
SE: standard error.**p < .01
The linear mixed-effects model for the 700–900 ms time window for Experiment 2.
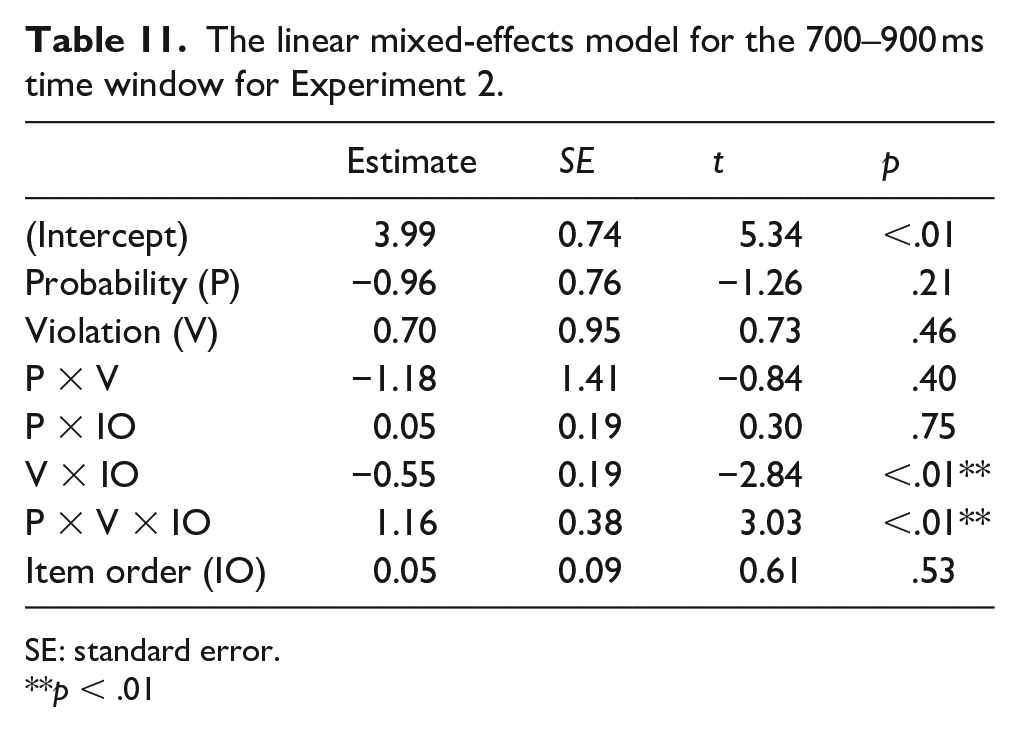
SE: standard error.**p < .01
We directly compared the N400 effect elicited by semantic violations with the P600 effect elicited by morphosyntactic violations to check whether they were differently affected by ITEM ORDER and PROBABILITY. If the decrease of the ERP effect due to the repeated exposure to violations is specific to the P600 effect in the equal probability block of Experiment 1, the interaction of EXPERIMENT × PROBABILITY × VIOLATION × ITEM ORDER should be significant. To this end, we created a larger dataset by merging P600 data (700–900 ms) of Experiment 1 and N400 data (300–500 ms) of Experiment 2. The result of the LME analysis showed a significant four-way interaction, supporting the results reported above (β = 2.47, t = 5.03, p < .01) (Figure 7).

The grand average of the P600 effect in Experiment 1 (left) and the N400 effect in Experiment 2 (right).
We also compared the P600 effects in Experiments 1 and 2 to examine whether the reduction in the P600 to grammatical violations unfolded differently in Experiments 1 and 2. We created a larger dataset by merging P600 data (700–900 ms) of both experiments. Again, the results showed a significant interaction of EXPERIMENT × PROBABILITY × VIOLATION × ITEM ORDER, suggesting that the P600 effect decreased drastically in the equal probability block of Experiment 1, unlike in the other blocks of Experiments 1 and 2 (β = 3.68, t = 6.79, p < .01).
To summarise, the semantically anomalous sentences elicited a negativity in the N400 time window, regardless of the manipulation of probabilities. There was no evidence that the N400 effect changed over the course of the experiment.
Discussion
In Experiment 2, semantically anomalous sentences elicited a P600 effect in the first half of the low probability block, but this effect diminished as the experiment proceeded. In the 300–500 ms time window, they elicited a greater N400 effect.
In the low probability block, a P600 was observed for semantically anomalous sentences. A strong semantic anomaly, such as animacy violation, has been known to elicit a P600 effect, often referred to as semantic P600 (Bornkessel-Schlesewsky & Schlesewsky, 2008; Brouwer et al., 2012; DeLong et al., 2014; Kuperberg, 2007). The P600 effect observed in this study could reflect similar underlying processes as the semantic P600, such as repairing processes of semantic anomalies. The reduction of the P600 effect can be attributed to a reduced effort for repairing processes or to adaptation to anomalies. Nevertheless, the latter interpretation is less plausible in the case of Experiment 2, as the participants did not accept semantically anomalous sentences consistently. Furthermore, the P600 attenuation was not observed for the equal probability block, for which the participants were more heavily encouraged to adapt their expectations to anomalous input. Therefore, the reduction of the P600 suggests that the participants became more likely to be reluctant to engage in severe semantic anomalies.
The N400 result suggests that the processing difficulty of semantic violations did not decrease during the experiment. In the 300–500 ms time window, the three-way interaction of Probability, Violation, and Item Order was not significant. Although the interaction of Violation and Item Order was not significant, the negative coefficient of the interaction suggests that there was a trend for the increased N400 effect during the experiment. Therefore, the effect was opposite if people were expected to adapt to semantic violations. The reason that the N400 effect is small is probably because the semantic anomaly is less robust for eliciting an N400 effect compared to other factors such as cloze probabilities (Lau et al., 2016).
The finding is consistent with the result of a recent ERP study in Chinese (Zhang et al., 2019). They found that an N400 effect for unpredictable words was not modulated by the ratio of predictable and unpredictable sentences in the experiment. However, there is another study by Lau et al. (2013) that showed that the experimental setting modulated the magnitude of the N400 effect. In their priming experiment, a robust N400 effect (i.e., the difference between the semantically primed and unprimed word) was observed in the high relatedness block (50% of primes are related to targets), unlike in the low relatedness block (10% of primes are related). The priming experiment differs from the experiments by Zhang et al. (2019) and ours because people are supposed to routinely generate a semantic prediction for subsequent input during sentence comprehension (e.g., Altmann & Kamide, 1999), but probably not during the processing of word pairs. In Lau et al.’s (2013) experiment, the highly probable occurrence of semantically related words likely encouraged participants to process a target word predictively. This interpretation is supported by the finding of Delaney-Busch et al. (2019) that reanalyzed Lau et al.’s (2013) data to examine the effect of item order on the N400 magnitude. According to their analysis, the semantically primed and unprimed target words showed a similar N400 amplitude at the beginning of the experiment, which diverged as their participants read more semantically related pairs (see also Nieuwland, n.d., for a counterargument against semantic adaption in Lau et al.’s (2013) experiment). 15
The same anonymous reviewer who raised a concern over the response strategy in Experiment 1 noted that an inanimate nominative is always unacceptable and served as a cue that the sentence is unacceptable. Thus, the results of Experiment 2 may reflect a response strategy. Again, this possibility seems incompatible with our results. If the participants have noticed an inanimate nominative-marked phrase is a useful cue for the NO response as they saw more sentences, as the reviewer suggested, they would take a strategy to simply ignore the second phrase (i.e., verb) while performing the task correctly. Accordingly, an N400 effect should be expected to decrease as the experiment went along. This prediction is not consistent with the results of Experiment 2.
General discussion
This study explored the adaptive nature of the language-processing system by examining how ERPs change over the course of experiments. Experiment 1 tested two hypotheses about linguistic adaptation, namely, the expectation updating account and the representation-based account. According to the expectation updating account, people have a probabilistic belief about the occurrence of syntactic structures and adapt to a new linguistic environment by updating it. In contrast, the representation-based account explains a linguistic adaptation in terms of increased base-level activations. When a sentence associated with a less frequent syntactic frame is repeatedly encountered, the base-level activation of the syntactic frame increases and therefore its subsequent activation requires a less cost. The former account expects people to be able to adapt to ungrammatical sentences if they can update its probabilistic belief, whereas the latter account does not expect people to be able to adapt to ungrammatical sentences because the ungrammatical sentences do not have a licit representation. The results of Experiment 1 showed that the P600 amplitude decreased when the participants were repeatedly exposed to morphosyntactic violations, suggesting that the participants adapted to morphosyntactic violations. Therefore, the results provided support for the expectation updating account and against the representation-based account.
The finding of Experiment 1 raised a question of whether the language-processing system is generally adaptive such that it attempts to minimise any types of errors. Thus, we further explored whether Japanese speakers can also adapt to semantic violations in Experiment 2 because the limit of linguistic adaptation is yet unknown. The results of Experiment 2 showed no interaction of Violation and Item Order, showing that the N400 effects did not change over the course of the experiment. Therefore, we found little evidence that Japanese speakers adapt to semantic violations to alleviate a difficulty in the processing of semantic violations as long as the result of the N400 is concerned. The plausible interpretation of the P600 effect in Experiment 2 requires further experiments to be conducted.
Selective adaptation
Overall, Experiments 1 and 2 present ERP evidence for a rapid adaptation to morphosyntactic violations but do not show solid evidence for adaptation to semantic violations. This suggests that people take into consideration not only the probability of violations but also types of violations in determining whether to adapt to deviant linguistic input. This brings us a new question of why it is the case that people adapt to morphosyntactic violations, but not to semantic violations.
This selective adaptation might involve a frequency/typicality of morphosyntactic and semantic violations. In spontaneous speech, native Japanese speakers as well as Japanese-speaking children and non-native speakers sometimes produce morphosyntactic errors. In contrast, semantic errors are infrequent. Therefore, the difference in adaptive behaviour suggests that the language-processing system is easily familiarised with morphosyntactic violations whereas semantic knowledge is so fixed that that the language-processing system is immune to the repeated exposure to semantic anomalies.
Consistent with this possibility, recent studies have found that the error typicality affects ERPs, although they focused on the processing of non-native utterances. Hanulíková et al. (2012) observed that native speakers of Dutch exhibited a P600 effect for gender disagreement between a determiner and a noun when a sentence was produced by a native speaker but did not show any effect when a sentence was produced by a non-native speaker (whose native language is Turkish). In contrast, semantic violations elicited an N400 effect irrespective of the speaker’s manipulation (see also Grey & Van Hell, 2017; Romero-Rivas et al., 2015, 2016). Similarly, Caffarra and Martin (2019) showed that native Spanish speakers exhibited a P600 effect for subject-verb gender errors (frequent errors) but not for subject-verb number errors (infrequent errors) in English accented speech. However, there are some differences between their studies and ours. Hanulíková et al. (2012) interpreted the absence of the P600 effect as a result of participants’ prior experiences with error likelihood in accented speech and not of a gradual adaptation during the experiment because the P600 did not appear in accented speech even in the first half of the experiment. This difference between Hanulíková et al.’s study (2012) and the present study in the time course of the P600 decline may be related to the difference in the way that participants adapted to deviant linguistic input. According to Qian et al. (2012), adaptation can be executed in several different ways, namely, resetting parameters of an existing model and switching models learned in the past (see also Kuperberg & Jaeger, 2016). As Hanulíková et al. (2012) reported that their participants were familiar with Turkish accented speech, the participants knew how likely Turkish speakers produce morphosyntactic errors, and therefore, they switched their model that best represent their probability distribution. However, the present result is more likely to be attributable to the update of an existing model about how likely morphosyntactic violations occur.
From a broader perspective, the present findings suggest the importance of examining how physiological responses change according to a preceding trial. In traditional studies, EEGs are averaged across many trials to obtain ERPs. However, the assumption that physiological response to a stimulus is invariant throughout an experiment has been rarely verified. Using single-trial analyses, such as LME models, offers a new insight into the dynamic aspect of cognitive processes, which remains unexplored especially in the domain of language processing.
Remaining issues
Finally, we mention four remaining issues. The first issue pertains to the involvement of domain-general ability to the linguistic adaptation. The present finding revealed an adaptive nature of the language-processing system. Although the linguistic adaptation must employ language-specific mechanisms to some extent because the linguistic knowledge of case makers, verb subcategorisation (intransitive/transitive), and lexical information (e.g., animacy) plays an integral part of how the processing system changes the way it processes linguistic information, it is unknown whether the linguistic adaptation involves some domain-general mechanisms. Although we conducted an exploratory analysis for individual cognitive traits (i.e., PASAT, SDMT, AQ, and P3b), no correlation was found between individual cognitive traits and the change of the N400/P600 amplitudes. Obviously, it does not preclude the possibility that other cognitive traits involve linguistic adaptation. It is premature to draw a conclusion about how the language-processing system adapts to linguistic violations in relation to non-language-specific mechanisms.
The second issue involves the effect of a secondary task. Previous studies have shown that the acceptability judgement task affected the way the participants processed linguistic violations, reflected by P600 effects (Gunter & Friederici, 1999; Kolk et al., 2003; Münte et al., 1997, see Kuperberg, 2007, for review). This issue is applied to this study, although it cannot explain the difference between the low and equal probability blocks or the difference between Experiment 1 and 2 because the participants performed the task after every trial.
The third issue is the effect of the type of filler sentences on adaptation. The participants could have perceived the filler sentences as syntactically anomalous but not semantically anomalous. If so, the non-adaptive behaviour in Experiment 2 may be attributable to the possibility that the amount of semantic violations is not enough to trigger an adaptation to semantic violations in the equal probability block. Future study needs to examine semantic adaption using unambiguously semantically violated sentences.
The fourth issue is the difference of the probability of ungrammatical sentences between the present study and previous studies (Coulson et al., 1998; Gunter et al., 1997). As noted in section “Materials,” this study employed the equal probability block in contrast to the previous studies that used the high probability block (grammatical: 25% vs ungrammatical: 75%) because the equal probability is considered a deviant case to participants to some degree as grammatical sentences occur far more frequently than ungrammatical sentences in typical language use. As the result showed adaptation to syntactic violations, the one-to-one ratio of grammatical and ungrammatical sentences is sufficient to trigger it.
An anonymous reviewer pointed out that the two-word sentences used in this study are almost flat with little hierarchical syntactic structure and questioned whether the present results can generalise to longer sentences. We do not believe the two-word sentences used in this study are hierarchically flat given that a VP-internal subject moves to the specifier of TP and forms a structural case-assignment relation with T and that a verb moves to T to be conjugated with it. Furthermore, the two-word paradigm is useful to avoid possible confounding factors (Lau et al., 2013, 2016; Pylkkänen, 2019, 2020 and therein). They can avoid the effect of a wrap-up process that elicits a robust negativity at the sentence-final position (Friederici & Frisch, 2000; Yano & Koizumi, 2018). This concern is important given that Japanese is strictly verb-final and thus the region of interest is often at the sentence-final position. The research question of this study is whether the language-processing system is capable of adapting to (morpho)syntactic/semantic violations. Because the issue of whether people routinely adapt to such anomalies in longer sentences is another issue, which we could not cover, further investigation is necessary to answer the question of the generalisability.
Conclusion
This study investigated the dynamic nature of the language-processing system using mixed-effects model of single-trial EEG data. Our results suggest that native speakers of Japanese adapt their expectations to morphosyntactically ill-formed sentences, as evidenced by a P600 attenuation pattern observed from our experiments. However, we found no evidence of adaptation to semantic anomalies. We argue that differential adaptive behaviour results when participants consider how likely certain types of errors are to occur.
Supplemental Material
sj-docx-1-qjp-10.1177_1747021820984623 – Supplemental material for Selective adaptation in sentence comprehension: Evidence from event-related brain potentials
Supplemental material, sj-docx-1-qjp-10.1177_1747021820984623 for Selective adaptation in sentence comprehension: Evidence from event-related brain potentials by Masataka Yano, Shugo Suwazono, Hiroshi Arao, Daichi Yasunaga and Hiroaki Oishi in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by JSPS KAKENHI (JP17K02755, PI: Hiroaki Oishi, JP19K13182, PI: Masataka Yano).
Compliance with ethical standards
The experiments were approved by the ethics committee of the Department of Linguistics of Kyushu University and Graduate School of Arts and Letters of Tohoku University.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.