
Abstract
Word recognition occurs across two sensory modalities: auditory (spoken words) and visual (written words). While each faces different challenges, they are often described in similar terms as a competition process by which multiple lexical candidates are activated and compete for recognition. While there is a general consensus regarding the types of words that compete during spoken word recognition, there is less consensus for written word recognition. The present study develops a novel version of the Visual World Paradigm (VWP) to examine written word recognition and uses this to assess the nature of the competitor set during word recognition in both modalities using the same experimental design. For both spoken and written words, we found evidence for activation of onset competitors (cohorts, e.g., cat, cap) and words that contain the same phonemes or letters in reverse order (anadromes, e.g., cat, tack). We found no evidence of activation for rhymes (e.g., cat, hat). The results across modalities were quite similar, with the exception that for spoken words, cohorts were more active than anadromes, whereas for written words activation was similar. These results suggest a common characterisation of lexical similarity across spoken and written words: temporal or spatial order is coarsely coded, and onsets may receive more weight in both systems. However, for spoken words, temporary ambiguity during the moment of processing gives cohorts an additional boost during real-time recognition.
Keywords
Introduction
Word recognition is a complex process. Listeners must integrate multiple input cues, accumulate information across segments or letters, and weigh thousands of lexical candidates to transduce the sensory signal into meaning. Although word recognition can occur across a range of sensory modalities (tactile, gestural, visual, auditory), for most adults, this process occurs across two sensory inputs: auditory (spoken words) and visual (written words). While the goals are similar across modalities, each imposes differential demands. As a result, the precise cognitive mechanisms underlying spoken and written word recognition likely differ.
In spoken word recognition, the central challenge is time. Spoken words unfold over time and this creates temporary uncertainty regarding word identity (Marslen-Wilson, 1987). Moreover, spoken words are often distinguished by temporal order—when a phoneme occurs in a word changes its identity (e.g., mug vs. gum). In contrast, for short written words, all the letters can be perceived at once. This makes the process of accumulating information less important. However, in written words, order is defined spatially rather than temporally, and the same letters can indicate different words depending on position. Therefore, readers must also encode information about letter position (Rastle, 2016, for a review).
Despite the distinct challenges faced by the auditory and written word recognition systems, both are often described as deriving from a competition process. In this process, the system builds activation for multiple lexical candidates on the basis of their match (or partial match) to the input. In spoken word recognition, the temporary ambiguity creates brief periods where the bottom-up input is consistent with multiple candidates (Marslen-Wilson, 1987; McClelland & Elman, 1986; Norris & McQueen, 2008). For example, as candy unfolds, after hearing can- listeners may activate candy and candle as both are matches to the input thus far. Models of written word recognition also posit parallel activation of multiple candidates (McClelland & Rumelhart, 1981). However, here the parallel activation derives from a different source: the fact that each letter in the input is associated with multiple words. For example, when reading CANDLE, the C, A, N and D all lead to some activation for CANDY (even though CANDLE will have more). Secondarily, in both domains, partially active competitors may be suppressed in part by interlexical inhibition by which candidate words directly inhibit one another (Dahan et al., 2001; Davis & Lupker, 2006; Forster & Davis, 1991). That is, as candle starts to achieve more activation than its competitors, it can suppress candy and handle. This is posited as deriving from direct, lateral, inhibitory connections between words.
Decades of empirical research have uncovered the nature of this competition process for spoken words (e.g., Allopenna et al., 1998; Hendrickson et al., 2020; Marslen-Wilson & Zwitserlood, 1989; Toscano et al., 2013; Weber & Scharenborg, 2012). This research uses methods like cross-modal priming and eye-tracking in the Visual World Paradigm (VWP; Cooper, 1974; Tanenhaus et al., 1995) that measure which words are activated between the first moment of the stimulus up to the moments of recognition. Such paradigms allow researchers to estimate which specific words are active, when they are active, and by how much, allowing a fairly precise picture of the bottom-up parallel activation process.
Despite an equally long and successful history of work on written word recognition, research on lexical competition has largely used paradigms that emphasise the secondary inhibitory process, such as masked inhibitory priming. Such paradigms assess whether recognition of a target word is slowed by the prior presentation of a visually similar word—a key marker of these secondary inhibitory processes. These studies often treat inhibitory effects as a proxy for competition as a whole. However, in written word recognition, such inhibitory effects are not always observed (Forster et al., 1987; Forster & Veres, 1998; Grainger & Ferrand, 1994), making the case for competition more tenuous.
Yet, competition and inhibition are distinct constructs. Some models of spoken word recognition, for example, do not include lexical inhibition (Marslen-Wilson, 1987; Norris & McQueen, 208), assuming that competitors are suppressed either by decay, or by a bottom-up mismatch to the input (e.g., the -le does not match the end of candy) (Frauenfelder et al., 2001). Similarly, adolescents with developmental language disorders at least partially suppress competitors (McMurray et al., 2010), but do not show evidence for inhibition (McMurray et al., 2019). Thus, inhibition effects are secondary to bottom-up parallel activation of multiple competitors, and more work is needed in reading on this aspect of the competition process.
Almost no work in written word recognition asks the simple question of what candidates are active and when (though see Grainger et al., 2016; Scaltritti & Balota, 2013), and no studies have compared spoken and written word recognition to examine similarities and differences in how each system manages competition. Thus, the present study develops a new VWP measure of written word recognition. We then use it to examine the nature of the competitor set during word recognition in both modalities using the same experimental design.
Competition in spoken word recognition
Research on spoken word recognition is motivated by temporary ambiguity (Marslen-Wilson, 1987). Because speech unfolds over time, there are moments in which listeners only have partial information. Since many words overlap at onset, these moments create temporary ambiguity regarding the intended word. Because listeners begin lexical access immediately, this ambiguity leads them to activate multiple lexical candidates in parallel (Marslen-Wilson, 1987; McClelland & Elman, 1986; Norris & McQueen, 2008), which compete for recognition as the word unfolds (Allopenna et al., 1998; Marslen-Wilson & Zwitserlood, 1989). Eventually, lexical candidates that do not match the signal are suppressed (Dahan & Magnuson, 2006; Dahan et al., 2001; Frauenfelder et al., 2001; Luce & Pisoni, 1998; Weber & Scharenborg, 2012).
Initial demonstrations of this phenomenon used gating (Warren & Marslen-Wilson, 1987) and cross-modal priming (Marslen-Wilson & Zwitserlood, 1989). Both allow researchers to probe specific candidates that may be active. For example, in a priming paradigm, for an auditorily presented captain, one can ask whether the cohort, captive is active by visually presenting a semantically related word like PRISONER.
More recent evidence for lexical competition comes from eye-tracking in the VWP (Cooper, 1974; Tanenhaus et al., 1995). In this paradigm, listeners hear a word and click the corresponding picture from a field of four images: the target word (e.g., peach), a phonologically unrelated word (e.g., ship), and one or more phonological competitors (e.g., piece and beach). Participants make multiple fixations to plan their response, and these eye movements reflect unfolding activation among lexical competitors. In word recognition, competitor fixations can thus be taken as a relative measure of how much that word (or by inference, that class of competitors) is active.
The VWP offers clear evidence for parallel activation and competition for spoken word recognition (Allopenna et al., 1998). For example, immediately after word onset, listeners look at the target (e.g., peach) and cohort competitors that overlap at onset (e.g., piece). As the word unfolds, looks to rhymes (e.g., beach) increase. Importantly, temporary ambiguity leads competition to heavily favour initial overlap: Cohort effects are large and immediate, whereas rhyme effects tend to be small, and late, and difficult to detect (Simmons & Magnuson, 2018).
Traditional theories of spoken word recognition suggest that the degree to which competitors are considered can be described as a roughly slot-based similarity mapping. Words are represented as sequences of phonemes (or other units) and candidates are only activated that have the correct phonemes in the correct slots (Gaskell & Marslen-Wilson, 1997; Luce et al., 2000; Luce & Pisoni, 1998; Marslen-Wilson, 1987; McClelland & Elman, 1986; Norris & McQueen, 2008). More recent research has challenged a strictly slot-based account. Toscano et al. (2013) found that phonemic anadromes (words that contain the same phonemes in reverse order, e.g., mug and gum), compete for recognition above and beyond unrelated words and words with only medial vowel overlap (e.g., mud and hug). This suggests that for spoken words, phonemes in the incorrect position can drive activation. Based on these results, Toscano and colleagues suggest that more flexible and coarse encoding may drive the activation of lexical candidates (see also Dufour & Grainger, 2019 for a replication using priming). This view was partially supported by more recent findings from Gregg et al. (2019). They replicated the anadrome effect; however, there was no competition between words with transposed phonemes that did not preserve vowel overlap (e.g., flea and leaf). Thus, phonemes in the incorrect order can drive activation, though vowel overlap may be required.
Anadrome and rhyme activation do not derive from temporary ambiguity. Rather, if chunks of the input (phonemes) are directly associated with words, whenever sufficient bottom-up match to the input is achieved, these words should be active. That is, when hearing candle, the fact that -andle partially matches handle is enough to drive some bottom-up support (much like in the reading system), despite the fact that the input is not ambiguous at this point. However, these effects may also be weaker than those that are also driven by temporary ambiguity. By the time enough input accumulates to start to activate the rhyme, the target and cohort may be quite active and exert inhibitory effects on other competitors.
In sum, for spoken words, listeners consider a range of words during recognition. Competition appears to heavily favour word-initial overlap that occurs in the same order (i.e., cohorts), though this is not obligatory to achieve competition (e.g., rhyme and anadrome effects).
Competition in written word recognition
Many models of written word recognition also assume that written input activates a range of candidate words that share letters with the input. For example, reading CAKE leads to competition among CAKE, CAPE, CARE, and COKE (Coltheart et al., 2001; Davis, 1999, 2010; McClelland & Rumelhart, 1981) (much like the explanation for rhyme and anadrome activation in spoken word recognition). Some models, such as the interactive-activation model, make the more specific claim that the target word is selected via a competition process (McClelland & Rumelhart, 1981). Competition is thus a cornerstone of major models of written word recognition. As a result, research has been motivated by the question of whether this description is valid, and what word types compete.
Research on competition in written word recognition has almost entirely focused on the second-order question—whether partially active competitors inhibit the target word—with mixed results. Some studies of neighbourhood density have found evidence in line with competition: readers are slower to recognise words with larger neighbourhoods (Carreiras et al., 1997; Grainger, 1992; Grainger & Jacobs, 1996; Huntsman & Lima, 1996; Perea & Pollatsek, 1998; Segui & Grainger, 1990). However, other studies have found the opposite effect; words with larger neighbourhoods are easier to recognise (Andrews, 1992; Balota et al., 2004; Forster & Shen, 1996; Sears et al., 1995). While neighbourhood effects are based on inhibition from many competitors, inhibitory priming has been used to probe inhibition between specific pairs of words by asking how the recognition of a target word is altered by the prior presentation of a visually similar letter string. The canonical result is that similarly spelled real-word primes tend to slow recognition (e.g., Davis & Lupker, 2006; De Moor & Brysbaert, 2000; Drews & Zwitserlood, 1995; Forster & Veres, 1998; Grainger et al., 1991; Grainger & Ferrand, 1994; Segui & Grainger, 1990). However, like neighbourhood effects, this effect is not consistently observed (Evett & Humphreys, 1981; Forster et al., 1987; Forster & Veres, 1998; Grainger & Ferrand, 1994; Humphreys et al., 1987; Sereno, 1991).
The inhibitory priming paradigm has also been used to ask whether certain classes of words are stronger competitors. This work has asked whether these inhibitory effects differ for different types of similarity relations (e.g., cohorts vs. rhymes). Here, when differences are observed they are not consistent across studies (Carreiras & Perea, 2002; Grainger & Ferrand, 1996), leading many to the conclusion that most neighbours are equally good competitors. However, again we note that this is a “second order” way of addressing this question, which only asks indirectly whether a class of words is active, by asking whether they differentially inhibit the target. Thus, there is a need to address this more directly by using measures of bottom-up activation.
It is perhaps not surprising that inhibitory effects are unreliable, given the secondary nature of inhibitory processes. Inhibition cannot have observable effects if the competing words (driving the inhibition) are not sufficiently active quickly enough. Moreover, inhibition from a competing word may be small unless the competitor is more active than the target. Consequently, null inhibitory effects do not necessitate that competing words are inactive—it simply may not be active enough to drive measurable inhibition or to drive it rapidly enough. As a result, masked inhibitory priming may not be ideally suited for assessing the profile of which words are competing during word recognition. What is needed in written word recognition are methods that are analogous to those used in spoken word recognition that establish the degree to which specific competitors are active.
The issue of letter order is also important in understanding the degree to which different classes of words may compete during word reading. Similar to spoken word recognition, most traditional models of written word recognition use a slot-based coding scheme, and treat letters in the wrong position as mismatching (McClelland & Rumelhart, 1981; Rumelhart & McClelland, 1982). However, mounting empirical data suggests that letter order may be only coarsely coded (Chambers, 1979; Grainger & Whitney, 2004; Norris & Kinoshita, 2012). Indeed, readers readily recognise target words despite disruptions to the typical letter order, though letter transpositions word-initially and word-finally are more disruptive than word-medially (Rayner et al., 2006).
A form of repetition priming has been used to demonstrate that this effect is not just a tolerance for mismatch. These studies compare priming for strings with the letters in incorrect positions with strings with the wrong letters in those positions. For example, recognition for SALT is faster when preceded by the prime, SLAT, than SPIT (Grainger, 2008; Perea & Lupker, 2004). This result challenges slot-based accounts, because SLAT and SPIT have equivalent perceptual overlap with the target SALT by a slot-based similarity metric. As a result, they should speed target recognition to the same degree. Similarly, non-words with transposed letters (JUGDE) prime their real word cognates (JUDGE), whereas non-words with equivalent letter substitutions (JULPE) do not (Perea & Lupker, 2003). However, for the most part these experiments have asked whether out-of-order letters contribute to target activation (e.g., does SLAT prime SALT when the subject will later read SALT), not whether they are activated (e.g., when SLAT is read without a prime, is SALT partially activated?). Thus, again the question of what competitors are activated by a target word is left largely unaddressed.
The difficulty in identifying which types of words are partially active during competition may be, in part, due to fundamental methodological limitations to priming studies of written words. To understand why this is so, it helps to consider how priming has been used in spoken word recognition (where this is a historically important question). Priming studies of spoken words use cross-modal priming: a word form is heard in its entirety and shortly thereafter, a visual lexical decision is used to probe which competitors are active (e.g., after hearing candle was candy also active?). There are no strong reasons why interference should be observed across modalities, and semantic priming is typically facilitatory. Moreover, the initial word is heard in its complete form (unlike inhibitory paradigms in reading where the initial word may be presented for 60 ms or less). Thus, activation has time to build, and can then be probed with the visual prime. As a result, to see which words are active during spoken word recognition, one simply presents the target word, waits a short bit, and tests semantic primes of a range of phonological competitors to see which show priming.
However, in written word recognition, priming studies are typically done within a modality. This simulates a situation in which readers are reading two words (usually in rapid succession). There the demands on the system may differ as the lexical system must shut down the first word to read the next—in this way, some inhibition may be expected. Here, the prime word is presented briefly making it less likely that it will accumulate substantial activation by the time of the target. Furthermore, there has been less work on orthographic competition using semantic priming (which may be more uniformly facilitatory). Consequently, direct evidence for which words are active at any moment is lacking.
In spoken word recognition the VWP has largely supplanted priming, allowing researchers to probe the set of co-active words more directly. However, nothing like the VWP is available in written word recognition. The ability to directly gauge the magnitude of activation for different word types in reading is important for evaluating multiple aspects of theoretical models. Such evidence could contribute to ongoing debates about whether words are processed serially (letter-by-letter) or in parallel (Roberts et al., 2003): serial processing predicts greater activation for cohorts than rhymes (as in spoken word recognition). It may also help distinguish different variants of competition models. For example, SOLAR (Davis, 1999) predicts cohorts and rhymes display activation, but both should be activated more than anadromes. Yet, the majority of empirical research uses priming paradigms that focus on word-to-word inhibition, and only indirectly measures which competitors are active (via their ability to slow target recognition).
A new paradigm for written word recognition
To measure the dynamics of written word recognition, the current study developed a novel version of the VWP. Adapting the typical spoken word version of the VWP for use with written words is non-trivial because of the necessary role of eye movements in reading (but not listening). In spoken word recognition, fixations are not restricted by the auditory input. As words unfold, listeners are free to direct their gaze at the images immediately without disrupting their ability to perceive the auditory input. As a result, the eye movements largely reflect the process of matching the word to semantic features in the world and the planning of the motor response (Apfelbaum et al., 2021; Magnuson, 2019).
However, for written words, fixations are necessary to encode the word. This confounds the perceptual input with the output measure, as now the output (the fixations) may also reflect the process of gathering the input (the word). For example, while readers are still fixating the word, they may begin activating the target; however, this may not be observable in the fixation record because the reader is continuing to fixate the word (to build activation for the target). Thus, any modification of the VWP to a within-modality design needs to consider how the dynamics of fixations may be altered by the new visual demands of the task.
Moreover, the fixations may also bias the process of building activation. Consider reading the word CANDLE. As long as the word is in view, the recognition system may downplay competition because the current stimulus supports only one possibility (candle), and the unique letters in the word cannot be suppressed or ignored. This will interact with the duration of fixation. In longer fixations, the input to the system persists, potentially favouring the target. In contrast, during a briefer fixation the system will be less clamped to the bottom-up input and may drift. Thus, we needed to standardise the length of stimulus viewing.
To solve both problems we used a form of backward masking. Skilled readers recognise familiar words automatically; it takes approximately 60 ms for information about the fixated word to travel to higher cortical areas where lexical processing begins (Sereno & Rayner, 2003), though factors such as word length can lengthen fixation durations. By removing the target word from the screen after a short period, we can both control the amount of input, and release the eyes to make response-driven (not input-driven) fixations. However, visual after effects—in which the input trace is maintained—may continue to serve as input to lexical processing (and for an unknown duration). Thus, to disrupt this trace we used a visual mask (e.g., #######) immediately after word presentation.
This use of a short target word presentation along with masker was also motivated by recent empirical work. Roembke et al. (2019) tested low-to-moderate performing middle-school students in several tasks with both unmasked and masked modes of presentation. They found that accuracy in the masked tasks uniquely predicted reading fluency over and above accuracy in the unmasked tasks, whereas unmasked tasks uniquely predicted decoding skills. Given that fluency requires rapid automatic word recognition, this suggests that a briefly presented word + mask may tap the unique component of reading that derives from automatic (e.g., real-time) processing—a construct that is central to what the VWP is trying to assess.
In this way, a briefly presented word with a backward mask solves several problems. It suppresses bottom-up processes that cause fixations to dwell, and standardises the amount of input the reader sees. The fact that the eyes are then free to move early allows us to measure activation and competition immediately after the word is presented. Finally, by making the visual information fleeting, higher-level recognition processes, such as lexical access and competition, can occur without the interference of the bottom-up information (Roembke et al., 2019).
Based on these considerations and pilot testing, we thus developed a novel version of the VWP for written words. As in the spoken version, participants saw all four pictures along with a dot at screen centre. When the dot changed colour, they clicked the dot and the written word was presented for 100 ms. This presentation duration allows readers enough time to engage automatic lexical processing, while also ensuring that fixations could move quickly to the images. This was followed by a mask at which point the participant could respond.
The current study
The current study investigated the nature (timing and magnitude) of lexical activation and competition during spoken and written word recognition. We had three broad goals. First, we directly assessed competitor activation during written word recognition using our new version of the VWP. This was done for several classes of potential competitors.
Second, in both spoken and written word recognition, we examined three classes of competitors—cohort, rhyme, and anadrome competitors using items that were fairly closely matched (across competitor-type) on factors like number of overlapping letter/phonemes. While cohort and rhyme competitors have been examined previously, few studies of spoken word recognition have used closely matched items to compare them (and no study has examined this in written word recognition for lack of a measure). For this aim our goal was primarily to develop a profile of competition within each modality. A critical part of this is replicating the anadrome effects in spoken word recognition first reported by Toscano et al. (2013). Finally, by comparing these two profiles, we sought to determine how differences inherent in processing spoken and written words affect online competition. Here, a broader comparison of the structure of the competitor set (which words were active) across modalities can reveal the degree to which time (or space) affects processing.
These goals are primarily descriptive. However, as we describe in the next section the particular pattern of competition that we observe in each domain has implications for processing models of word recognition, and it is crucial to obtain this description to build models that can bridge both modalities.
Potential profiles of competition
We profile the nature of competition in each modality by the relative activation for cohorts, anadromes, and rhymes. Cohorts and rhymes preserve order word-initially or word-finally, but only a portion of the sounds/letters overlap. Anadromes, by contrast, disrupt order, but preserve sound/letter overlap with the target word. Thus, by comparing cohorts and anadromes we can tease apart the relative contribution of order and the degree of overlap to help inform theories of word recognition.
For spoken words, cohort competitors should show the most activation due to the temporary ambiguity at word onset. Moreover, as cohorts and targets are activated earlier than rhymes, they may inhibit rhymes (and potentially anadromes). Thus, cohorts should show larger effects than rhymes. This can be seen as a marker of serial processing (which is unavoidable for spoken words) coupled with inhibition. Anadromes should also compete for recognition (Dufour & Grainger, 2019; Gregg et al., 2019; Toscano et al., 2013). To the extent that these differ from what Toscano termed as overlap competitors (words that share only the vowel with a target), this suggests that out-of-position phonemes contribute to competitor activation. However, with less overlap at onset they should be reduced relative to cohorts.
For written words, the pattern is less clear. The null hypothesis that most competitors are equivalent is broadly accepted: for short words, a purely parallel processing model predicts equal activation of cohorts and rhymes provided they are matched in terms of number of letters. However, if written words are processed, in part, serially, or if word-initial overlap is more strongly weighted, this predicts greater cohort than rhyme activation. If the recognition system only coarsely codes the spatial location of letters, then anadrome activation should exceed that of overlaps. Whether or not it exceeds cohorts and rhymes may depend on how a given model weighs positional variation versus a pure mismatch in a slot. For example, in spatial coding accounts like the SOLAR model (Davis, 1999, 2010), letter identity and order are abstract. Although letter locations (initial, medial, final) are given equal weight, the recognition system is sensitive to spatial location because distal transpositions (as in anadromes where consonants move across the whole word) only display weak activation. From this account, we expect cohorts and rhymes to show comparable activation but exceeding anadromes (which are nonetheless active).
Method
Participants
Participants were 42 undergraduates recruited from the University of Iowa psychology participant pool. All participants were monolingual English speaking and had normal hearing and normal or corrected-to-normal vision. All participants underwent informed consent via an Institutional Review Board (IRB) approved process and received academic credit for participation.
This sample size was not motivated by a traditional power analysis; in part this was due to the exploratory nature of the written word recognition study, for which no estimates of effect size are available. Thus, the proposed sample size was based on previous studies of spoken word recognition (e.g., Farris-Trimble & McMurray, 2013; Hendrickson et al., 2020), in which meaningful and significant findings emerged from a similar, but smaller sample size (n = 32, 34). Given that no study has used visually presented words as targets in the visual world paradigm, we increased the sample size slightly to account for this uncertainty. With 42 participants, a minimum detectable effect size analysis suggests that a within-subject t-test should be able to detect a significant effect at β = .8 as long as its effect size is greater than d > .442 (a moderate effect).
Items and design
The same set of 64 words was used for both the spoken and written word tasks to control for item-level factors across modalities (see online Supplementary Material 1). Words were monosyllabic and consonant–vowel–consonants (CVCs), though some words began or ended with orthographic digraphs (e.g.,
In any given trial it was not possible to include the target and all three competitors. This would preclude the use of an unrelated baseline, since five objects on the screen would exceed visual working memory capacity (Luck & Vogel, 1997), which can reduce competitor effects. The use of only two competitors on the screen also creates statistical confounds as a look to the anadrome (for example) would mean that the subjects could not be looking at the cohort. Thus, on any given trial, only two pictures from a root set were included—the target and one competitor—along with two images from a different set that were phonologically and orthographically unrelated to the target word (they served as baselines). These four objects are referred to as a “trial-set” (see online Supplementary Material 1 for an example trial-set).
Across trials, the words in a root set were paired in all possible combinations to create trial-sets with six target/competitor pairs (e.g., mug–mud, mug–hug, mug–gum, mud–hug, hug–gum, mud–gum). The primary competitor-types of interest were Anadromes, Cohorts, and Rhymes. However, because all words within a set appeared as the auditory or visual stimuli as in the traditional VWP design, several competitor-types were “by-products” of this process. In the above example, mug–hug overlaps only on the vowel and mud–gum overlaps in two phonemes, one of which is out of order. In this, words with just overlap in the vowel do serve an interesting role (as a control for anadromes; Toscano et al., 2013). However, other competitor-types do not and are unavoidable by-products of this design. For example, hug and gum overlap in the vowel and share a consonant in the wrong place. We coined these “partial anadromes.” Just like vowel overlaps, these words were not truly unrelated to the targets because they shared an out-of-order consonant and the medial vowel. Thus, instead of throwing these trials out, we analysed them. This resulted in five different trial types: cohorts (mug–mud), anadromes, (mug–gum), rhymes (mug–hug), partial anadromes (hug–gum and mud–gum), and overlaps that share just the medial vowel (mud–hug).
With the target and competitor chosen, the other two objects in the trial-set would be unrelated. These two objects were a competitor pair from another root set that was unrelated to the target pair. To determine the trial sets, each root set (e.g., mug–mud–gum–hug) was paired with another root set (e.g., pan–pat–nap–van), resulting in 8 pairings. Thus, a word pair in one root set (e.g., mug–gum) served as the unrelated items for word pairs in the other root set (e.g., pan–nap). These were restricted such that pairs could not overlap semantically or phonologically. This resulted in 48 trial sets (8 root set pairs × 6 pairs per root set). Items within a trial set always appeared together.
Each word was presented as the target an equal number of times, and trial types changed depending on what word appeared as the target. For example, on trials in which the root word (mug) was the stimulus and the competitor was a cohort (mud), the trial was termed as a target–cohort–unrelated–unrelated or TCUU trial. On other trials with this trial-set, mud could also be the target (and mug was now the cohort). Critically, this meant that estimates of cohort competition (for example) are independent of the lexical properties of the target, since this was effectively counterbalanced. This further controls for any imbalance in the items in terms of lexical properties like frequency or neighbourhood density. This led to five trial types in all which are described by the array of competitors on the screen: TCUU, TAUU, TRUU, TPUU, TOUU (see Table 1).
The five trial types. The structure of the competitor set changed with what appeared as the target, resulting in five different trial types (TCUU, TAUU, TRUU, TPUU, TOUU). The letters refer to the relationship among the items on the screen depending on the auditory stimulus.
While this effectively counterbalances lexical properties within a competitor-type, we were also concerned that each class of competitors may differ in things like frequency or density (e.g., the words that were used in the cohort condition had a higher frequency than those used in the anadromes). Here, some words (particularly the target of the root set) did appear in multiple conditions, but not all. Thus, for each condition we obtained measures of word frequency (subtlex per million; Brysbaert & New, 2009), and phonological and neighbourhood density (Marian et al., 2012). A series of one-way ANOVAs by-item revealed no significant difference in word frequency, F (3, 59) = 0.94, p = .42, phonological neighbourhood density, F (3, 59) = 2.63, p = .060, and orthographic neighbourhood density, F (3, 59) = 1.23, p = .031, by condition (root, anadrome, cohort, rhyme). See Table 2 for averages and standard deviations by competitor-type.
Word frequency and neighbourhood density by competitor-type.

Trials were presented in a completely randomised order. Each trial set was repeated twice for a total of 384 trials (48 trial sets × 4 items/set × 2 reps) per task (spoken and written). This resulted in 64 trials per competitor-type (cohort, anadrome, overlap, overlap), except for partial anadromes, which appeared on 128 trials.
Procedure
The task was implemented in Experiment Builder (SR Research, Ontario, Canada). Testing was conducted in a sound-attenuated room to minimise background noise.
At the beginning of the experiment participants were seated at a computer and the eye-tracker was calibrated. Next participants were familiarised to the picture–word combinations one-at-a-time. They then received both verbal and written study instructions. Finally, two practice trials were administered to ensure participants understood the task.
On each trial, four pictures appeared on the screen (e.g., target [mug], anadrome [gum], and two unrelated items [e.g., nap and pan]). Pictures were 300 × 300 pixels and appeared 50 pixels vertically and horizontally from the edges of a 17-in. computer monitor running at 1,280 × 1,024 pixels. Picture location was counterbalanced across trials, such that all pictures and word-types (target, cohort, anadrome, rhyme, partial anadrome, overlap, and unrelated) appeared roughly equally in each location. In the middle of the screen there was a blue dot. After 500 ms the blue dot turned red at which point, participants clicked on the dot to initiate the trial. Once clicked, the red dot disappeared, and the target word was presented. Participants then clicked the corresponding picture. Participants were instructed to take their time and perform the task as naturally as possible.
For the spoken word task, the word was played over full-ear headphones at a comfortable volume. For the written word task, the orthographic form was presented in the centre of the screen for 100 ms followed by a backward mask (#######, 7 characters) for 100 ms.
Stimuli
Visual stimuli were clip art images developed using a standard lab protocol (McMurray et al., 2010). For each image, several candidates were identified from a commercial clip art library. Images were edited to remove any unnecessary features, and to use prototypical colours and orientations. Images were matched for style and visual salience, and approved by a senior member of the lab with extensive experience in the VWP. Most of the images used in this study were pulled from a database of images developed with this protocol and used across multiple studies (McMurray et al., 2010).
Spoken words were recorded by a male speaker with a standard American accent in a soundproof room using a Kay Elemetrics Computerized Speech Lab 4300B (Kay Elemetrics Corp., Lincoln Park, NJ) at a sampling rate of 44,100 Hz. Words were recorded multiple times within a sentence frame (“He said ___?”) to ensure natural intonation. Words were extracted from the sentence frame and edited to remove background noise and noise artefacts. Four exemplars of each word were selected so that subjects could not rely on idiosyncratic acoustic properties of the words (e.g., that mug had a slightly lower pitch than mud). Average word length was 422 ms (SD = 56.4 ms, range = 299–592 ms). Finally, all items were normalised to 70 dB, and 100 ms of silence was added to the beginning and end of the sound file.
Written words were presented in black Times New Roman font, size 40.
Eye-tracking recording and data processing
Eye movements were recorded with a desktop-mounted Eyelink 1000 eye-tracker in the chin rest configuration. Once the experimenter adjusted the chin rest to a comfortable position and a clear image of the pupil and corneal reflection were obtained, a 9-point calibration and validation procedure was completed. Drift correction was performed 12 times throughout the experiment (every 32 trials). No participants failed drift correction during the experiment.
For analysis, saccades and successive fixation were combined into a single unit called a “look” (McMurray et al., 2002, 2010). In identifying the object that each look was directed to, the object boundaries were extended by 100 pixels to account for noise in the eye-track. Recording began at the presentation of the pictures, and ended at the click response. It was time locked to the presentation of the target stimuli.
Results
We conducted four sets of analyses. The first examined the accuracy and reaction time (RT) of the mouse-click. Second, we analysed the overall magnitude of competitor activation using a simple area-under-the curve approach, which represents overall looking across time. Third, we examined competitor activation using a derived measure of peak fixations. Finally, we examined the time course of fixations using Bootstrapped Differences of Timeseries (BDOTS), a statistical package within R (Version 1.1.456, R Core Team, 2004; for details, see Seedorf et al., 2018). All reported ANOVAs were conducted by-subject unless otherwise specified.
During the planning of this experiment, we expected that the presentation of the written word and the masker would affect the aspects of the eye-movement record for reasons that were unrelated to lexical competition. This was unavoidable with visual stimuli, but would not affect the spoken word version of the task. 1 There was no reason to believe it would exert a differential role on different classes of competitors within a mode. However, this prevented a direct comparison between modalities. Thus, our a priori statistical plan did not call for an explicit statistical test comparing modalities, and we focus here on the profile of competition within a modality.
Reaction time and accuracy
We first examined accuracy. Overall subjects were highly accurate averaging 99.3% in the spoken word task and 98.8% in the written word task. We ran two one-way ANOVAs, one for each modality (spoken and written), to compare the effect of competitor-type (Cohort, Anadrome, Rhyme, Partial Anadrome, Overlap) on response accuracy. For spoken words, there was a significant effect of competitor-type, F(4, 164) = 13.91, p < .0001. Paired t-tests (Bonferroni corrected to α = .005) revealed that this main effect was driven by poorer performance on cohort trials compared with every other competitor-type: Anadrome, p < .0001; Rhyme, p = .00063; Partial Anadrome, p = .00016, Overlap, p = < .0001. These results provide preliminary evidence for incremental processing; competitors with word-initial overlap affect word recognition accuracy to a greater extent. For written words, there was no main effect of competitor-type, F(4, 164) = 2.12, p = .08, suggesting that the different competitor-types affected recognition accuracy to a similar degree.
Next, we analysed RT. Again, we ran two one-way ANOVAs to test the effect of competitor-type on RT. For spoken words, there was a main effect of competitor-type, F(4, 164) = 12.50, p < .0001. RTs were fastest when an Overlap competitor was present (M = 1,096.46, SD = 128.22), and slowest when a Cohort competitor was present (M = 1,148.69, SD = 136.15), with the other competitor-types displaying intermediate RTs: Rhymes (M = 1,112.89, SD = 148.68), Partial Anadromes (M = 1,115.76, SD = 147.24), and Anadromes (M = 1,118.98, SD = 148.81). For written words there was also a main effect of competitor-type, F(4, 164) = 5.68, p = .0003. Again, RTs were fastest when there was an Overlap present (M = 1,032.79, SD = 140.45), however, participants were slowest to respond on Anadrome trials (M = 1,074. 32, SD = 155.22). Rhymes (M = 1,039.677, SD = 149.60), Cohorts (M = 1,056.47, SD = 150.21), and Partial Anadromes (M = 1,068.45, SD = 173.51), displayed intermediate RTs.
Overall, however, we point out that while there were differences in both accuracy and RT these differences were quite small and subjects performed exceedingly well at both tasks.
Eye-movement data
To examine the time course of competitor fixations, we calculated the proportion of looks to competitors (Cohorts, Rhymes, Anadromes, Partial Anadromes, and Overlaps) and unrelated items every 4 ms from the onset of the stimulus. We use fixations to the unrelated items as a baseline to control for differential levels of looking across competitor-types. Only those trials in which the correct image was selected were analysed. Two participants were removed from the spoken word condition because of low proportion looking to the target (<50%) and another two were removed from the visual condition due to poor calibration and low proportion looking to the target (<50%). This left 40 subjects in each condition.
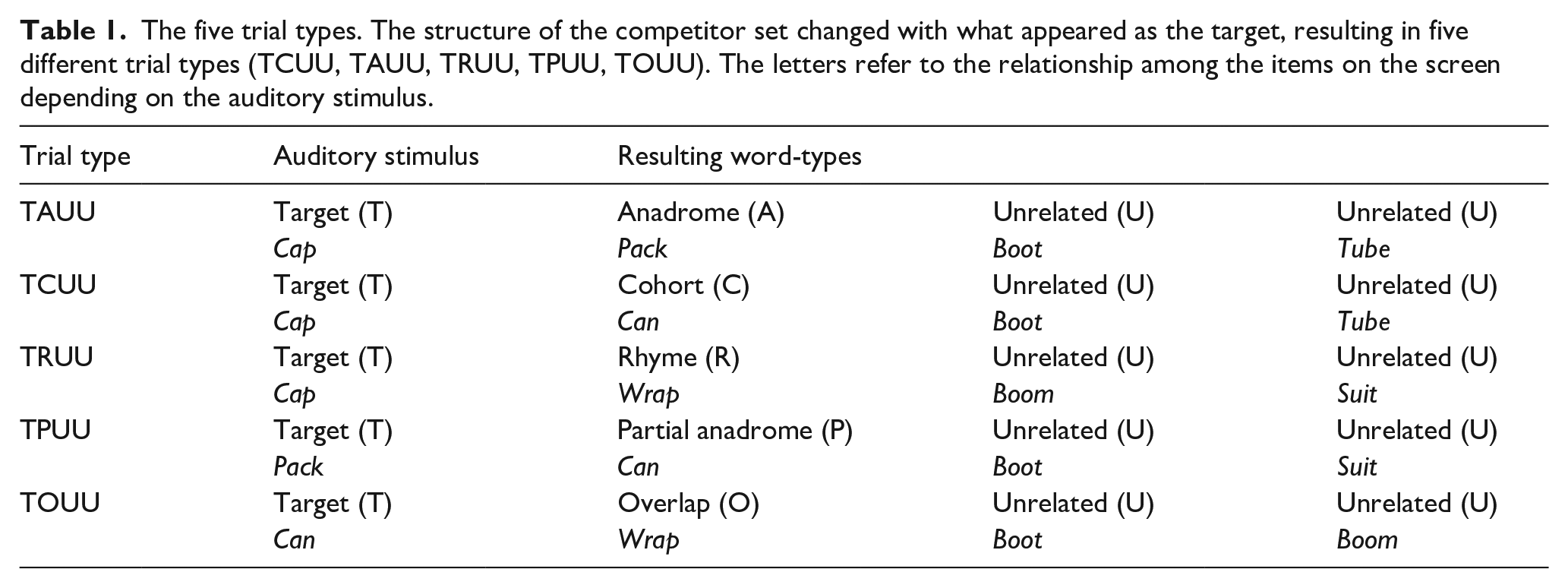
For spoken words, fixations to cohorts began to deviate from unrelated items early (~250 ms post-word onset), cohort fixations peaked at approximately 0.20, and were largely suppressed by 1,000 ms (see Figure 1). Anadromes began to deviate from unrelated items later in processing (~500 ms), and peaked lower at about 0.13. Unlike cohorts, anadromes showed more sustained consideration until the end of the recording epoch. Rhymes and partial anadromes showed slightly more fixations than the unrelated items, whereas overlaps were indistinguishable from unrelated items throughout the time course.
Spoken words. Time course of proportion fixations to competitors and unrelated items by trial-type. (a) Cohorts, (b) Anadromes, (c) Rhymes, (d) Partial Anadromes, and (e) Overlaps.
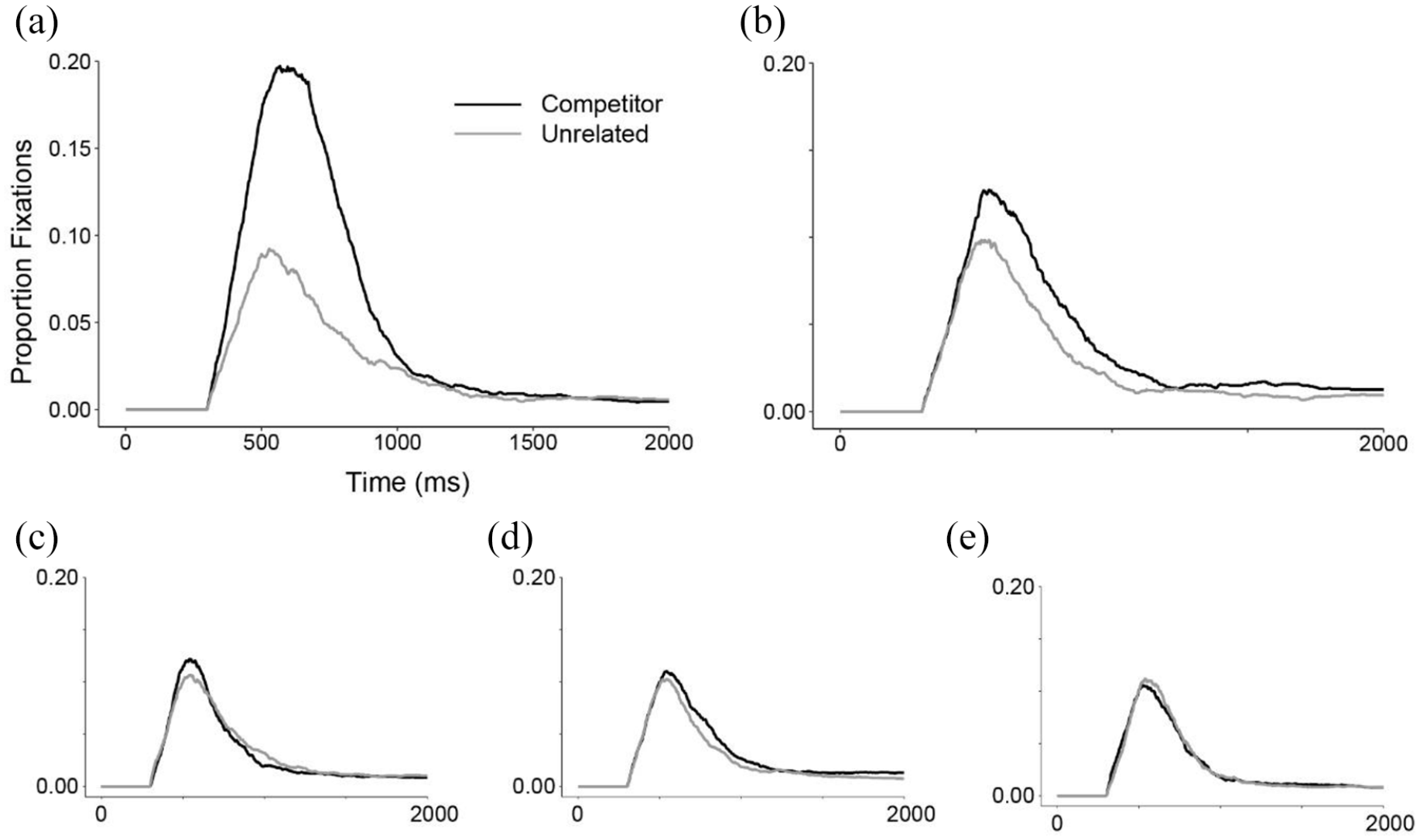
By contrast, for written words (Figure 2), the time course of fixations for cohorts and anadromes was strikingly similar to each other. Both competitor-types began to deviate from unrelated items at approximately the same time (~400 ms), reached comparable peak heights (0.12), and were suppressed at roughly 1,250 ms (see Figure 2). For the other competitor-types, the results patterned with those of spoken words with few fixations to rhyme, partial anadrome, or overlap competitors.
Written words. Time course of proportion fixations to competitors and unrelated items by trial type. (a) Cohorts, (b) Anadromes, (c) Rhymes, (d) Partial Anadromes, and (e) Overlaps.
At face value, this design would appear to call for a three-way ANOVA (Mode [spoken vs. Written] × Competitor-type [e.g., cohort, anadrome, etc.] × word-type [competitor vs. unrelated]). However, before collecting the data we had decided on using separate analyses for each mode. This was for two reasons. First, there is an inherent visual difference in the two tasks that could drive differences in eye movements that are unrelated to mode. In the visual task, there was a visual wordform on the screen and a mask; neither of these were present for the auditory version. This was expected to lead to fewer and possibly delayed looks to the objects. Second, pilot data suggested that the overall amount of competitor looking would be lower for written words. While one might expect these factors to lead to just a main effect of mode, fixation proportions are somewhat non-linear, and expected effects can scale with the overall magnitude; consequently, these factors could lead to a spurious three-way interaction. Thus, the full ANOVA was not expected to be informative. Given that these issues do not apply within a modality, our analytic plan called for separate two-way ANOVAs.
We quantified the magnitude of competitor activation in two ways. First, we examined the average proportion looking (area-under-the-curve [AUC] approach). Second, we computed the peak height of fixations. These capture subtly different properties of the time course. For example, two curves could have identical peak heights, but large differences in the duration over which the competitor is active. In this case these differences will appear in AUC, but not peak height. Conversely, two curves could have different peak heights, but the curve with the lower peak has a shallower onset and/or offset slope. In this case, AUC will likely not show an effect, whereas peak height likely will. These two magnitude measures were computed for competitors and unrelated items and compared.
Finally, to compare the timing of competitor activation, we compared fixations with competitors and unrelated items across the fixation record using a time-series approach (BDOTS, a statistical package within R, Version 1.1.456, R Core Team, 2004; for details, see Seedorf et al., 2018).
AUC
To determine whether there was an overall effect of word-type (unrelated, competitor) and competitor-type (cohort, anadrome, rhyme, partial anadrome, overlap) on the proportion of fixations, we examined the fixation data using an AUC analysis. To determine the time window of analysis, while remaining blind to condition-specific effects, we determined the time regions in which differences in word-type occurred (competitor vs., unrelated, collapsed across modality and competitor-type) based on a visual inspection of the data. Based on this, and the fact that it takes roughly 200 ms to plan a saccade (Viviani, 1990), we calculated the AUC from 250 ms to 1,400 ms post-word onset. These were empirical logit transformed prior to analysis. We analysed AUC for spoken and written words separately in two repeated measures ANOVAs. Each ANOVA included the within-subjects’ factors of word-type (competitor, unrelated) and competitor-type (Cohort, Rhyme, Anadrome, Partial Anadrome, and Overlap).
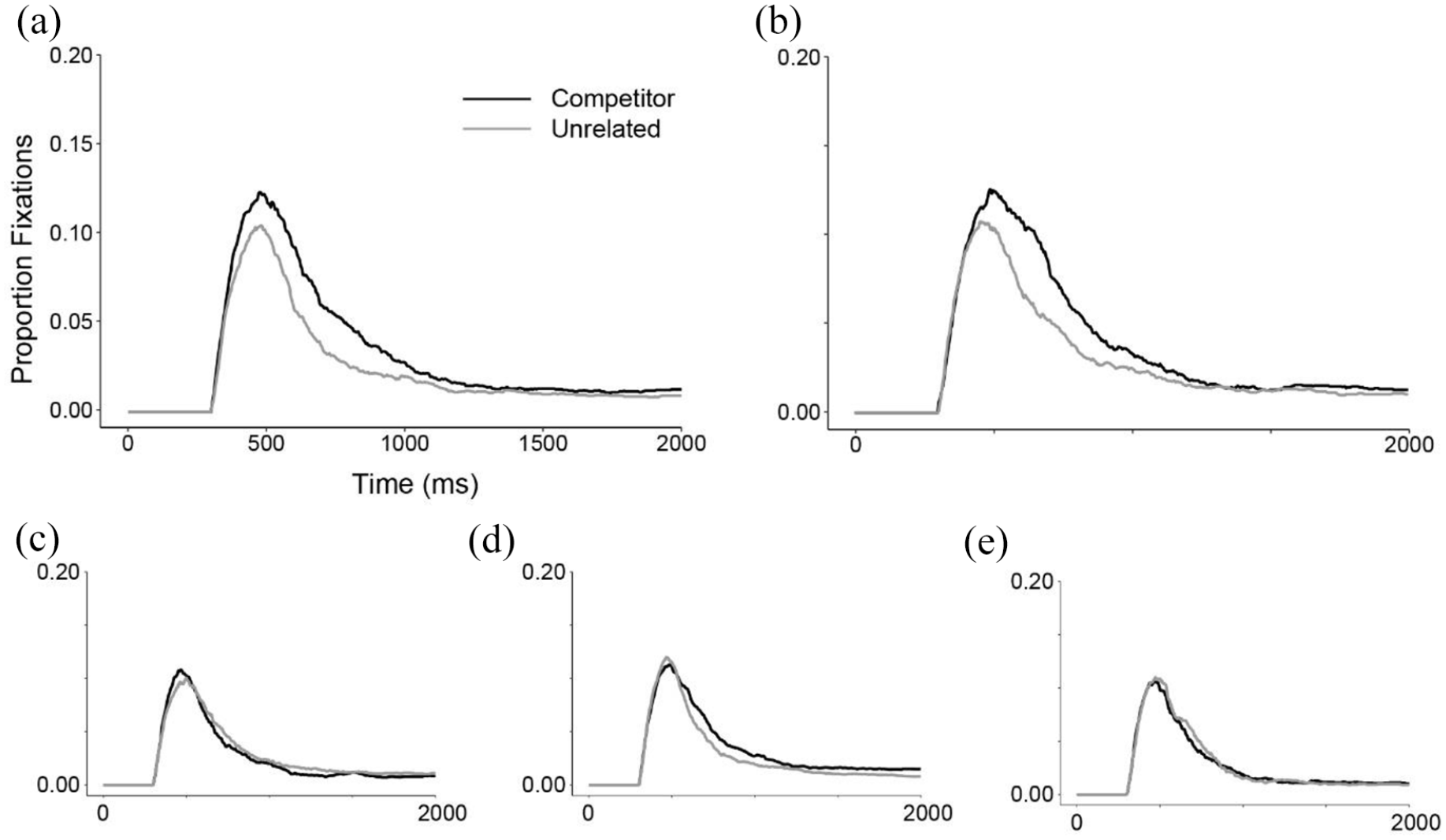
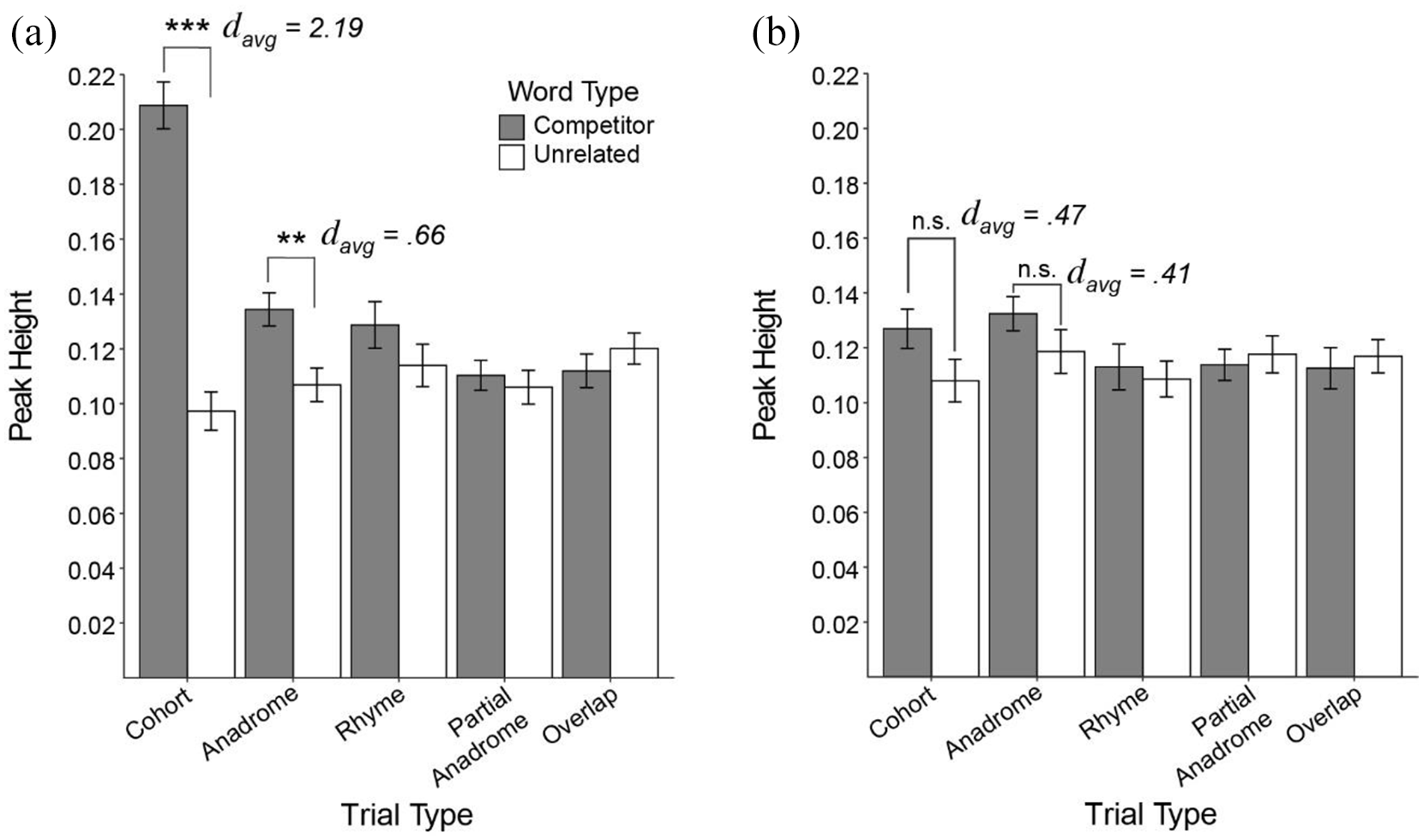
Figure 3 shows the average AUC for competitors and unrelated items for each competitor-type for both spoken words and written words. For spoken words, there was a significant main effect of word-type, F(1, 38) = 66.26, p < .0001, η ges 2 = .099, in which the AUC was greater for competitors compared with unrelated items. There was also a significant main effect competitor-type, F(4, 152) = 10.38, p < .0001, η ges 2 = .056, suggesting some differences among competitors. Finally, there was a significant word-type by competitor-type interaction, F(4, 152) = 27.47 p < .0001, η ges 2 = .15. Paired t-tests were used for the post hoc analyses of the interaction. These compared competitor to unrelated AUCs within each of the five competitor-types with a Bonferroni corrected alpha of .01. Competitors had significantly greater AUCs than unrelated items for Cohorts (p < .0001, davg = 2.43) and Anadromes (p = .0001, davg = .94). There was no significant difference between competitors and unrelated items for Rhymes (p = .9), Partial Anadromes (p = .036), and Overlaps (p = .51).
Average AUC for (a) spoken words and (b) written words by word and trial type.
For written words, there was also a main effect of word-type, F(1, 38) = 27.27, p < .0001, η ges 2 = .027, and competitor-type, F(4, 152) = 6.50, p < .0001, η ges 2 = .035, and a significant word-type by competitor-type interaction, F(4, 152) = 15.78, p < .0001, η ges 2 = .053. Paired t-test (Bonferroni corrected alpha of .01) revealed that competitors had significantly greater AUC values than unrelated items for Cohorts (p < .0001; davg = .82), Anadromes (p < .0001; davg = .81), and Partial Anadromes (p = .0002; davg = .48), and there was no significant difference between competitors and unrelated items for Overlaps (p = .29) or Rhymes (p = .05).
Thus, cohorts and anadromes were active in both modalities, while there was no statistical evidence that rhymes or overlaps were active. However, for spoken words, the size of the effect was greater for cohorts than anadromes, while for written words, cohorts and anadromes showed similar effect sizes.
To directly assess this difference in the magnitude of cohort and anadrome effects, we ran 2 × 2 ANOVAs within each modality. These examined AUC as a function of word-type (competitor vs. unrelated) and competitor-type (cohort, anadrome only). If cohorts demonstrate more activation than anadromes, we would expect a significant word-type by competitor-type interaction. For spoken words, there was a main effect of word-type, F(1, 38) = 147.04, p < .0001, η ges 2 = .38, and competitor-type, F(1, 38) = 16.00, p = .00028, η ges 2 = .072, and a significant word-type by competitor-type interaction, F(1, 38) = 27.17, p < .0001, η ges 2 = .07. For written words there were significant main effects of word-type, F(1, 38) = 71.36, p < .0001, η ges 2 = .14, and competitor-type, F(1, 38) = 6.49, p = .015, η ges 2 = .024. Crucially, however, there was no significant word-type by competitor-type interaction, F(1, 38) = .15, p = .70, η ges 2 = .00004. Thus, the enhanced cohort effect is only observed in spoken word recognition.
Peak height
To estimate the peak height, non-linear curves were fit to the raw fixation data to capture the shape of the function and to minimise any idiosyncratic patterns of significance. Competitor and unrelated fixations are best approximated by an asymmetric Gaussian function (see Figure 2) because these fixations start with a period of low looks, followed by an increase in looking culminating at the peak, and finally a low period of looks (McMurray et al., 2010). The Gaussian-like curves include six free parameters: µ = the time of the peak in ms; σ1 = onset slope (formally the standard deviation for the left side of the Gaussian); σ2 = offset slope (variance for the right-side normal distribution); Pi = peak height, B1 = baseline for the left-side normal distribution, and B2 = baseline for the right-side. However, only Pi was analysed here. Curves were fit using a constrained nonlinear gradient descent procedure implemented by McMurray (2020) (version 15). Peak height measured in this way has high test–retest reliability (r = .70; Farris-Trimble & McMurray, 2013). To evaluate goodness of fits, we measure R2 values and visually examine the observed data compared with the estimated curve for each subject.
Figure 4 shows the average peak height for competitors and unrelated items for each competitor-type for both spoken and written words and shows a similar pattern to what was observed with AUC (Figure 3). We analysed peak height for spoken and written words separately in two repeated measures ANOVAs by subject. Each ANOVA included the within-subjects’ factors of word-type (competitor, unrelated), and competitor-type (Cohort, Rhyme, Anadrome, Partial Anadrome, and Overlap).
Average peak height for (a) spoken words and (b) written words by word- and trial-type.
For spoken words, effects largely mirror the AUC analysis. There were significant main effects of word-type, F(1, 38) = 34.11, p < .0001, η ges 2 = .09, and competitor-type, F(4, 152) = 12.40, p < .0001, η ges 2 = .05, and a significant word-type × competitor-type interaction, F(4, 152) = 23.82, p < .0001, η ges 2 = .15. Paired t-tests (using a Bonferroni corrected alpha of .01) revealed that Cohorts (p < .0001, davg = 2.19) and Anadromes (p = .0009; davg = .66) had significantly higher peaks than unrelated items. There was no significant difference between competitors and unrelated items for Rhymes (p = .21), Partial Anadromes (p = .56), and Overlaps (p = .25).
For written words, there was a main effect of competitor-type, F(4, 152) = 2.47, p = .014, η ges 2 = .14, but not word-type, F(1, 38) = 2.58, p = .12. However, there was a significant word-type by competitor-type interaction, F(4, 152) = 2.74, p = .03. Paired t-tests were conducted comparing competitor and unrelated heights within each competitor-type, using a Bonferroni correction, corrected alpha of .01. Although there were differences across competitor-type, no competitor-type reached significance given the adjusted alpha level: Cohorts (p = .02, davg = .47), Anadromes (p = .03, davg = .41), Rhymes (p = .94), Partial Anadromes (p = .62), and Overlaps (p = .29).
BDOTS analyses
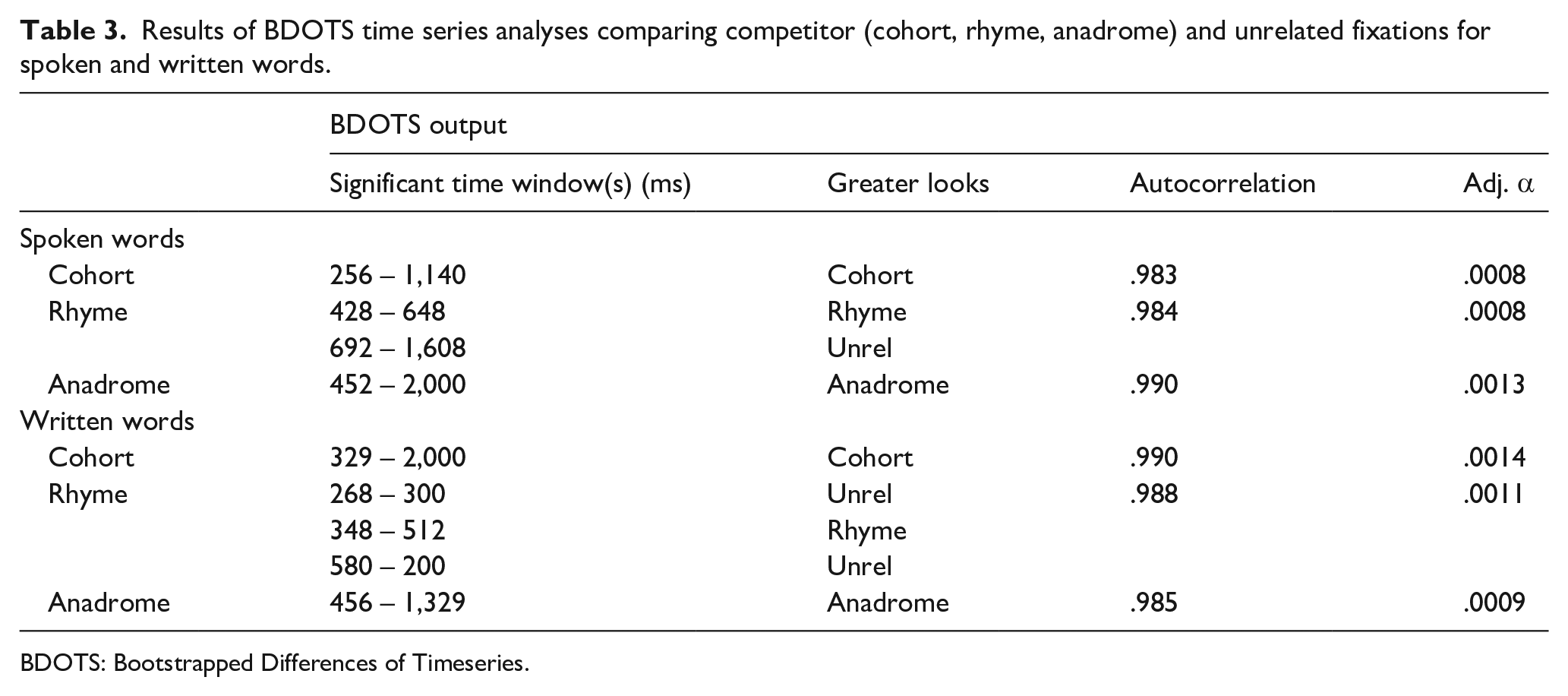
To analyse the timing of competitor looks, we used BDOTS, a statistical package within R, Version 1.1.456, R Core Team, 2004 (for details, see Seedorf et al., 2018). This analysis focused on the three word-types of interest (cohort, rhymes, and anadromes). BDOTs starts using parametric curvefits—in this case using the asymmetric Gaussian used in the peak height analysis—fit to each subject × condition. Confidence intervals around the mean fixation curves were estimated with parametric bootstrapping and used to construct t-tests between the competitor and unrelated curves at every 4 ms (see peak height analysis). Finally, to maintain the Type I error, BDOTs uses a modified Bonferroni procedure, which adjusted for the high autocorrelation between adjacent t-tests. This technique then identifies time window(s) when a significant difference between competitor and unrelated fixations occurred. Along with any time window(s) of significance, we report the autocorrelation of the test statistic (ρ.est), and the adjusted alpha value (α*). Here, we will focus on the pattern of results, but see Table 3 for full BDOTS results.
Results of BDOTS time series analyses comparing competitor (cohort, rhyme, anadrome) and unrelated fixations for spoken and written words.
BDOTS: Bootstrapped Differences of Timeseries.
The pattern of the timing of competitor activation was rather similar for spoken and written words. Cohorts were fixated more than unrelated words early for both spoken (256 ms) and written words (329 ms), though activation was suppressed earlier for spoken (1,140 ms) compared with written words (2,000 ms). Although spoken and written rhymes did not display significant differences in the magnitude of activation in the earlier analyses of AUC and peak height, rhymes were fixated more than unrelated items for both spoken and written words early, although this affect was very short-lived, lasting only about 150–200 ms. Finally, spoken and written anadromes were initially fixated more than unrelated words at approximately the same time (spoken, 452 ms; written, 456 ms), but written anadromes were suppressed earlier (1,329 ms) than spoken anadromes (2,000 ms).
The effect of presentation duration for written words
In the written word recognition task, the masking was intended to minimise participants opportunity to make multiple fixations to the target word, and to free competition from the constraints of the bottom-up input. Our initial choice of presentation interval (100 ms) was intended to be short (consistent with these goals), and based on prior work by Roembke et al. (2019). However, it was unclear whether other presentation durations could impact these results.
Critically, spoken words that unfold over time at a natural speaking rate averaged about 400 ms here. In contrast, we presented the written words at a predetermined experimentally controlled rate of 100 ms. Presentation duration could affect the proportion of fixations to images and possibly have differential effects by competitor-type. As a first step towards addressing the influence of presentation duration on fixation proportions for written words, we ran a second experiment on a separate group of 20 participants (see online Supplementary Material 2). The experiment used the same stimuli and presentation format as the written-word trials in the primary study, except that target duration was manipulated (100, 167, and 233 ms). The findings from this experiment suggest that the duration of target stimulus presentation has some effect on fixations to competitors, but this effect appears to apply evenly to both competitors and unrelated items. The main effect of duration arises as a result of greater overall looks to both competitors and unrelated items at shorter durations (see online Supplementary Material 2 for a full description of the methods, results, and discussion of this experiment).
Discussion
Our goals were threefold. First, we sought to directly assess the degree of activation for various competitors in written word recognition. To accomplish this, we developed a new variant of the VWP for reading. Second, we sought to characterise the nature of the competitor sets for spoken and written word recognition using the same words in each, and fairly closely matched sets of competitors. This was intended to provide insight to aspects of theoretical accounts of word recognition. Finally, by comparing these profiles of lexical competition across domains, we sought to characterise the degree to which the mechanisms underlying spoken and written word recognition were similar or differed.
We start by discussing our methodological goals first, and then discuss each modality separately, beginning with spoken word recognition (where the methods and expected results were more established). We then address similarities and differences between modalities, before ending with several limitations of the present study.
Methodological advance
Research on written word recognition has used inhibitory priming and neighbourhood density effects to measure lexical activation and competition. Yet, these paradigms do not directly measure which words are active and compete for recognition, but instead gauge secondary inhibitory effects. However, inhibitory effects are often not observed (Andrews, 1992; Balota et al., 2004; Evett & Humphreys, 1981; Forster et al., 1987; Forster & Shen, 1996; Forster & Veres, 1998; Grainger & Ferrand, 1994; Humphreys et al., 1987; Sears et al., 1995; Sereno, 1991). While null findings are always difficult to interpret, null findings are even more problematic when gauging secondary effects. This is because there is no straightforward relation between the presence of activation and inhibition. Indeed, a lexical item could be active but not exhibit inhibitory effects for a host of reasons (e.g., activation does not reach threshold, activation occurs late in processing, suppression occurs via decay as opposed to interlexical inhibition).
In the current study, we developed a novel variant of the typical VWP for use with written words to measure lexical activation and competition directly. We found direct evidence that multiple word-types compete for recognition during word reading. It is difficult to establish the true validity of this measure as there is an absence of alternative measures, and there are few studies in the literature that have directly assessed the profile of competitor activation in written word recognition. However, this task yielded results that look quite in line with both general competition accounts and with the results from the spoken word recognition version. Moreover, the fact that there was a differential pattern of results across competitor-types (some were active, some were not) is not consistent with some general task confound. Rather, given the strong evidence for the validity of the spoken word recognition VWP, and the coherence of these results, this measure appears to do what it set out to do.
Although the current study suggests that this novel paradigm is sensitive enough to detect written word activation and competition, a number of methodological considerations may require fine-tuning. First, the time course of competition in the written word version appears far less “peaky” and is more protracted than in spoken word recognition. This is likely why AUC measures appeared much more sensitive than peak height. It is unclear why this is so, but it is possible that the initial fixation to read the word has downstream effects on the later fixations by which we measure competition.
Second, it will be important to investigate task variables such as the form of word presentation, duration of masker, and repetition effects. Indeed, the process of exploring such design features could shed light on how competition mechanisms may change depending on the degree of bottom-up information that is available in the signal. Our supplementary experiment represents one step in this direction and suggests that the duration of the masker may not play an important role, but further work is needed.
Finally, given the importance of reading in applied contexts (e.g., work on dyslexia), it may also be important to consider measurement properties such as test–retest reliability (e.g., Farris-Trimble & McMurray, 2013, for analogous work in the spoken word VWP).
Spoken word recognition
Results replicated the commonly found and robust cohort effect. Our study, and countless other VWP studies, have shown that cohort activation far exceeds the activation of other competitor-types. Furthermore, onset neighbourhood density affects auditory lexical decision (Goh et al., 2020; Vitevitch, 2002). Together, this work demonstrates preferential weight to onset features for spoken word recognition. We also showed evidence of the anadrome effect first reported by Toscano et al. (2013) and later replicated by Gregg et al. (2019): Listeners activated anadromes above and beyond unrelated words. Furthermore, just as Toscano et al. (2013), we found that vowel overlap did not drive anadrome effects, as words with only vowel overlap (map and cat) did not demonstrate greater activation than unrelated words. A more recent model of spoken word recognition that codes temporal order via position-invariant diphones can account for the findings that position-independent phonemes play a role in spoken word recognition (TISK model; Hannagan et al., 2013). Taken together, the results of the current study are in line with the view that for spoken words, phoneme position may be only coarsely coded, though the recognition system weighs phoneme overlap at the beginning of words (Dufour & Grainger, 2019; Goh et al., 2020; Hannagan et al., 2013; Toscano et al., 2013; Vitevitch, 2002).
Our cohort results conflict with recent work by Teruya and Kapatsinski (2019), who compared cohorts that overlapped with the target by one, two, or three phonemes. They only found cohort effects for three-phoneme cohorts, unlike here where we observed robust cohort effects with only two phonemes of overlap. However, the authors conclude that their failure to find cohort effects with shorter overlap may not be because these words are inactive, but because their small amount of activation may not have been sufficient to drive an eye movement. In this way our findings do not challenge their conclusions, though they do suggest that smaller overlaps may be sufficient to drive cohort fixations in the VWP.
The current study did not find significant evidence for rhyme activation for spoken words when measuring the magnitude of activation (AUC, peak height), though we found an early, short-lived effect using our time series measure, BDOTS. This weak, or perhaps, absent effect of rhymes is not surprising in light of recent evidence. The current study used monosyllabic words because bi-syllabic anadromes are much less frequent and word length was controlled across items (see online Supplementary Material 1). Historically, rhyme effects are weaker and more difficult to detect (Allopenna et al., 1998), and this is especially true for monosyllabic words (Hendrickson et al., 2020; Simmons & Magnuson, 2018).
These null effects should be treated with caution for a number of reasons. Teruya and Kapatsinski (2019), for example, have argued that if there is a high threshold for launching a fixation, then listeners could have non-zero activation for a cohort or rhyme while failing to make eye movements. Similarly, McMurray (submitted) presents Monte Carlo simulations that suggest that the fact that fixations are sampled sequentially and must persist for several hundred milliseconds may mask small or short-lived periods of true underlying activity. Thus, it is unclear whether the lack of evidence for rhyme or overlap competitors constitutes a lack of activation.
Written word recognition
For written words, we found significant evidence of activation for cohort and anadrome words, but no evidence for rhyme and overlap competitors. Unlike spoken words, the overall magnitude (AUC) and timing of cohort and anadrome activation was very similar. Indeed, for both spoken and written words, cohorts are activated before anadromes (and at a comparable time course to a previous event-related potential (ERP) study; Massol et al., 2013), and interestingly, spoken and written anadromes become active at the same time.
The results for written words are not predicted by spatial coding accounts (e.g., SOLAR; Davis, 1999, 2010). Indeed, a spatial coding account would predict equal and robust activation for cohorts and rhymes, because the degree of letter overlap is the same and order is preserved. Indeed, cohorts showed robust evidence for activation, but rhymes did not. The difference between cohort and rhyme activation cannot be due to the proportion of letter overlap, which was equivalent between the two competitor-types (cohorts = 57%, rhymes = 60%). Indeed, accounts like SOLAR give equal weight to letter substitutions that happen word-initially and word-finally. This was clearly not supported by the data.
Instead, the current results point to a recognition system that places more importance on overlap at the beginning of words. This could be due to either (1) some degree of incremental processing (e.g., if letters are processed left to right) or (2) if all the letters of a word are processed simultaneously, but initial letters receive more weight than later letters in the word. The significant evidence of anadrome activation clarifies these contrasting explanations for why cohorts—but not rhymes—were active in written word recognition. The fact that cohorts and anadromes did not display differential activation challenges the incremental account. If readers are processing left-to-right, the first letter of the anadrome does not match the target, and should have led to lower anadrome fixations (much like in spoken word recognition). This suggests that the most plausible account is one in which letters are processed in parallel, but the initial letters play a larger role in competitor activation than later letters.
Second, spatial coding models like SOLAR also predict significant activation for anadromes but that this should be weaker than for cohorts. This is because the match to the input is coded both by the content of the “slot” and the distance of a matching letter to its correct slot—anadromes have only one phoneme in the correct slot and two that are quite far from their slots. Surprisingly, even though anadromes consist of long-distance transpositions (i.e., letter transpositions that do not occur between adjacent letters), the magnitude of activation was not different than the cohorts. These results appear more in line with a recognition system that heavily favours the amount of overlap between letters and largely, though not entirely, discounts order. That is, apparently, a mismatching letter in one slot is worth two long-distance transpositions. This finding is in line with models of written word recognition that provide a role for position-independent letters (models that are highly analogous to the TISK model of spoken word recognition and in some cases inspired it). For instance, in an extension of Grainger and Van Heuven’s (2003) model, Grainger and colleagues used an open-bigram scheme, in which bigrams are made up of adjacent and nonadjacent letters (Grainher, Mathôt, & Vitu. 2014). Thus, letters that are out-of-order can drive activation: location-specific letters activate bigrams that are order invariant, which feeds to whole-word orthographic representations.
An interesting, though somewhat unexpected finding was the significant partial anadrome effect for written words in the AUC analysis. Partial anadromes and rhymes have comparable orthographic overlap, though for rhymes the overlap is slot-based, whereas for partial anadromes order is disrupted. One explanation for these findings is that partial anadromes had more power to show effects. Due to the nature of the experimental design, all possible word pairs within a root set appeared together. Because all words appeared as the target an equal number of times, and the structure of the competitor set changed with what appeared as the target, partial anadromes appeared more frequently than did any other competitor-type. We find this interpretation unlikely given that the number of rhyme trials (64 trials) was sufficient to show effects with other competitors. However, here again, a plausible account is based on the differential weight given to the beginning versus end of the stimulus words regardless of slot-based overlap. Although the order of letters is disrupted for partial anadromes, the letters that are in common with the target appear at the beginning of the word half of the time (root word [wrap], partial anadrome [
Recent models and empirical results of multi-word reading weigh the left and right sides of words equally (Dare & Shillcock, 2013; Grainger et al., 2014). For instance, in the flanking-letters lexical decision task, words and non-words are flanked—to the left and right—by pairs of letters. Flanking letters that are represented in the target word facilitate lexical decisions to the same extent whether they are presented on the left or right of the word. This provides support for the view that perhaps readers weigh the beginnings and endings of words equally. However, these models focus on multi-word reading, and thus, rely on letters presented in the parafovea separated by a space. Other research that has examined letters within words (as opposed to across word boundaries) suggests that there is a first-letter dominance effect (e.g., Johnson & Eisler, 2012; Jordan et al., 2003; Scaltritti & Balota, 2013; Scaltritti et al., 2018).
Comparison between spoken and written word recognition
Spoken and written words differ in how order is defined (temporally vs. spatially) and the nature of the input (speech sounds that unfold over time vs. letters that are presented simultaneously). These differences are borne out in the nature of lexical competition. For spoken words, word-initial overlap is heavily favoured, though phonemes in the incorrect order are activated to a lesser extent. This emphasis on the beginnings of words during spoken word recognition is a logical solution to managing an unfolding signal. The temporary uncertainty inherent in processing spoken words easily lends itself to some mechanism of competition that changes over time as the identity of the word becomes increasingly apparent.
Such a link between temporary uncertainty and competition is less relevant for written words because orthography appears all at once. Therefore, even though written words can look visually similar (e.g., cat and can), the reader has all the information needed to identify the word at each moment in processing. Even still, the current study provides strong evidence for competition as a mechanism of lexical selection for written words as at least two classes of competitors—cohorts and anadromes—show unambiguous evidence of parallel activation during reading.
Given the vast differences in the signal across modality, it is surprising that the profile of lexical competition is quite similar. Indeed, for both spoken and written words, cohorts and anadromes are activated, and there is no evidence of activation for rhymes or overlaps. The one defining feature which differentiates lexical competition across modality, is that for spoken words, the temporary ambiguity in the signal results in a boost of activation for cohorts. Thus, the lexical system can be described as having a common core set of properties in which lexical similarity is structured fairly similarly across spoken and written words, but for spoken words temporary ambiguity during the moment of processing gives cohorts an additional boost during real-time recognition.
What is this common core? As we described in the previous section, the profile of lexical competition observed for written words is most consistent with an account in which onsets receive more weight than offsets. If we subtract off contribution of temporary ambiguity to spoken words, the result is likely to be the same. It is not clear why this need be so. The idea that onsets may be differentially weighted has not been considered in prior work on spoken word recognition—typically stronger cohort effects are thought to derive solely from the temporally unfolding inputs. However, the strong parallel with written word recognition suggests that this is worth further investigation in spoken word recognition.
Why would onsets receive more weight? One possibility is that this is a consequence of the way words are learned. Apfelbaum and McMurray (2017) present evidence that learning within the lexical system is operative throughout real-time processes. That is, the lexical system does not wait for processing to complete to begin learning. Consequently, when learning spoken words, the onsets may lay down stronger associations between segments and lexical or semantic representations, because of the temporary ambiguity that automatically leads to parallel activation. So how would this transfer to written word recognition? Early in development, word reading is thought to bootstrap off of spoken word recognition: before children are able directly recognise written words, they may decode them, mapping print to sound (and then to meaning). This is likely a partially serial (letter-by-letter) process. Over many iterations of practice, this may reinforce the strength of associations between onset letters and the lexical or semantic representation much in the same way that this could occur for spoken words.
Limitations
One limitation is the study focused on monosyllabic words. This could help explain the lack of rhyme effects for both spoken and written words in the current study. Indeed, rhyme effects are difficult to detect especially for monosyllabic words (Hendrickson et al., 2020; Simmons & Magnuson, 2018). It will be important to generalise our work on written word recognition to longer and more diverse words to flesh out this profile of competition in reading.
Another limitation is that the same set of words were used for both the spoken and written word tasks. Although this created perfect control over item effects (e.g., word frequency) across modality, it also resulted in orthographic differences between some written anadrome pairs where perfect control was not possible. Although many of the items were both phonemic and orthographic anadromes (e.g., tip and pit), some did not have complete orthographic overlap (e.g., read and deer). Thus, it is quite likely that the current results actually underestimate the degree to which written anadromes are activated during recognition. Given this property of the stimuli, it is possible that the anadrome pairs with complete letter overlap (e.g., tip and pit) were driving the effect, and phonemic anadromes without complete letter overlap (e.g., read and deer) weakened the effect. However, these incomplete anadromes could also be activated if there is automatic activation of phonology from orthography (e.g., Harm & Seidenberg, 1999). As a drastic example (which was not a stimulus in this study), consider the anadrome pair piece–seep. Although there is 100% phonemic overlap, there is only 44% letter overlap. If anadrome activation were observed, it would suggest that phonology contributes heavily to activation during single word reading. Given that only two anadrome pairs displayed a significant discordance between the amount of orthographic and phonemic overlap (choke–coach and boot–tube), it is beyond the scope of the current study to disentangle the influence of phonology versus orthography in lexical competition. Yet, such an investigation could offer interesting insights into the degree to which readers activate phonology, even for highly familiar words.
Relatedly, some pairs were not perfectly a match for the number of letters. This also might lead to an underestimation of the competitor effects. Anadromes and rhymes had roughly the same number of pairs that mismatched on the number of letters (n = 3 and 4, respectively), thus it is unlikely that the lack of rhyme effects are due to letter mismatch per se. However, cohorts had many more word pairs with letter mismatch (n = 9), and this may have lessened the overall effect of cohort activation for written words. Yet, it should be noted that in studies of spoken word recognition using the VWP, it is not uncommon to observe competition using competitor pairs that have different numbers of phonemes (e.g., beaker–speaker) (e.g., Farris-Trimble and McMurray, 2013; Hendrickson et al., 2020). A similar phenomenon has occurred in studies of written word recognition using priming. Van Assche and Grainger (2006) found evidence that 1-letter and 2-letter inserts—which create superset primes, for example, gafrdlen–garden—display as much priming as identity primes. This suggests that letter mismatch might not influence lexical competition to a significant extent.
Conclusion
This work reinforces competition as a unifying mechanism in spoken and written word recognition. By measuring the bottom-up activation of competitors directly—rather than via their indirect inhibitory effects—we observe unmistakable evidence for parallel activation. Moreover, by looking across multiple competitor-types, we see several commonalities between spoken and written word recognition: temporal or spatial order is coarsely coded, and onsets may receive more weight in both systems. While classical work has explored links between reading and speech (e.g., the degree to which phonology is accessed during reading: Harm & Seidenberg, 1999), the current work raises the need to characterise the core mechanisms of each in a common set of computational principles.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218211056842 – Supplemental material for The profile of real-time competition in spoken and written word recognition: More similar than different
Supplemental material, sj-docx-1-qjp-10.1177_17470218211056842 for The profile of real-time competition in spoken and written word recognition: More similar than different by Kristi Hendrickson, Keith Apfelbaum, Claire Goodwin, Christina Blomquist, Kelsey Klein and Bob McMurray in Quarterly Journal of Experimental Psychology
Footnotes
Acknowledgements
The authors thank Jamie Klein-Packard for assistance with participant recruitment and data collection.
Author Note
Kelsey Klein is now affiliated to Department of Audiology and Speech Pathology, University of Tennessee Health Science Center, Knoxville, TN.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by NIH R01 DC008089 (awarded to B.M.) and NIH P50 DC000242 (awarded to B.G. and B.M).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.