
Abstract
Recognising individuals through their voice requires listeners to form an invariant representation of the speaker’s identity, immune to episodic changes that may occur between encounters. We conducted two experiments to investigate to what extent within-speaker stimulus variability influences different behavioural indices of implicit and explicit identity recognition memory, using short sentences with semantically neutral content. In Experiment 1, we assessed how speaker recognition was affected by changes in prosody (fearful to neutral, and vice versa in a between-group design) and speech content. Results revealed that, regardless of encoding prosody, changes in prosody, independent of content, or changes in content, when prosody was kept unchanged, led to a reduced accuracy in explicit voice recognition. In contrast, both groups exhibited the same pattern of response times (RTs) for correctly recognised speakers: faster responses to fearful than neutral stimuli, and a facilitating effect for same-content stimuli only for neutral sentences. In Experiment 2, we investigated whether an invariant representation of a speaker’s identity benefitted from exposure to different exemplars varying in emotional prosody (fearful and happy) and content (Multi condition), compared to repeated presentations of a single sentence (Uni condition). We found a significant repetition priming effect (i.e., reduced RTs over repetitions of the same voice identity) only for speakers in the Uni condition during encoding, but faster RTs when correctly recognising old speakers from the Multi, compared to the Uni, condition. Overall, our findings confirm that changes in emotional prosody and/or speech content can affect listeners’ implicit and explicit recognition of newly familiarised speakers.
As is the case with faces (e.g., Bruce & Young, 1986), voices convey an array of important information about an individual (e.g., Schweinberger et al., 2014; Young et al., 2020). Whereas some of these cues depend on the speaker’s current emotional state and intention (e.g., prosody and speech content), others are more stable and help us recognise people we encountered in the past. This task requires the ability to extract, store, and match invariant characteristics of individuals’ voices and disregard features that can vary upon different encounters. While this may appear effortless in the case of familiar individuals, it becomes more difficult for unfamiliar individuals whom we encountered only a handful of times (e.g., see Burton & Jenkins, 2011, for faces; Lavan, Burton, Ladwa, et al., 2019; Stevenage & Neil, 2014, for voices). While there are many factors that can influence our ability to correctly distinguish previously encountered individuals from those whom we met for the first time, existing memory literature—using mainly faces and, to a lesser extent, voice—highlights the importance of emotional expression, number and variety of exposures and, in the case of speech, content.
Emotion, as a natural feature of social stimuli, is known to facilitate long-lasting same-stimulus recognition accuracy and confidence (e.g., Kensinger, 2004; Kensinger & Schacter, 2005; LaBar & Cabeza, 2006; Righi et al., 2012). However, as a majority of studies of face (e.g., LaBar & Cabeza, 2006; Sergerie et al., 2005) and voice (e.g., Armony et al., 2007; Aubé et al., 2013; Pichora-Fuller, Dupuis, & Smith, 2016) memory primarily examined item memory for the exact same stimuli, it is difficult to disentangle the possible effects of emotion on item-specific memory from those on stimulus-independent identity memory. A recent behavioural study (Liu et al., 2014) directly examined this issue by comparing the effect of six basic emotional expressions (i.e., happiness, sadness, fear, surprise, anger, and disgust) on long-term facial identity memory. Participants were shown faces of only one of the six expressions multiple times at training and completed a standard old/new identity-recognition test afterwards on faces either with the same emotion (i.e., same stimulus) or with a neutral expression. Fear-, happy-, and sad-trained identities were worse recognised when the test expression was neutral compared to when it was the same expression as during encoding, with no differences in the extent of the recognition impairment among these three types of training. Moreover, Redfern and Benton (2017a) found that participants tended to make more mistakes when discriminating pictures from two individuals when they were emotionally expressive than when they depicted a neutral expression.
Saslove and Yarmey (1980) provided initial evidence that the change of emotional prosody from anger to neutral between training and test in a voice line-up task impaired subsequent recognition. However, another voice line-up experiment showed no emotion-change effect on listeners’ voice memory, even with different testing delays (L. Öhman et al., 2013). The effect of prosody change was also examined in a same/different voice matching paradigm, in which participants were asked to make decisions on whether pairs of phrases presented in angry, happy, and neutral tones were produced by the same speaker or not (Stevenage & Neil, 2014). Results revealed a decline in performance when the emotional tone changed between two phrases. Thus, there is some evidence to suggest that changes in emotional prosody negatively influence working and/or episodic memory performance, although results are inconsistent.
Stimulus repetition is another factor that has been shown to influence identity memory. Although pure repetition may not be sufficient to form stable face representations that are stimulus-invariant (e.g., Bruce et al., 2001), several studies using faces show that subsequent recognition performance can be improved by learning from face images with a longer exposure duration (Memon et al., 2003), and repetitions of the same face images (Roark et al., 2006) or of non-identical face images in neutral expression (Kaufmann et al., 2009). In addition to explicit recognition, stimulus repetition has been shown to enhance implicit memory, a phenomenon known as repetition priming (RP) and typically reflected in faster response times (RTs) when responding about a given feature of a previously presented stimulus as a function of the number of repetitions of said item. RP effects for faces are observed for both familiar and, albeit to a lesser extent, for unfamiliar identities (Goshen-Gottstein & Ganel, 2000). In the case of unfamiliar faces, RP effects can be highly view-dependent (Martin et al., 2010), although some studies also found view-invariant RP effects with increased number of exposures (Clutterbuck & Johnston, 2005; Martin & Greer, 2011).
Although less studied, there is some evidence to suggest that memory for voice identity also benefits from multiple stimulus repetitions. For example, Neil and colleagues (see Stevenage & Neil, 2014) conducted a sequential same/different match task by increasing repetition times of the stimuli. Between each matching pair of voices, interference was introduced by adding 0 or 4 distractors. As expected, interference decreased matching performance, but repeatedly pre-exposed voices showed a resistance of the interference effect when compared to singly pre-exposed voices. Similarly, Zäske et al. (2014) showed that stimulus repetition strengthened subsequent voice identity recognition.
A related question is whether subsequent identity memory is better when the same stimulus is repeatedly encoded, compared to encoding different exemplars of the same individual. Two main representation models, largely based on faces, both predict an exemplar variation advantage. The pictorial coding model proposes that identity recognition is completed through comparisons with previously stored exemplars of the individual (e.g., Longmore et al., 2008); thus, the more variant exemplars encountered, the higher the chance of a successful match. The averaging model proposes that exemplar variation helps to construct a robust representation of encountered facial identities (e.g., Benson & Perrett, 1993; Jenkins & Burton, 2011) and that the representation becomes more stable when derived from more instances. Consistent with this hypothesis, Murphy et al. (2015) revealed a better identity recognition with novel face exemplars when face learning was enriched with multiple variant exemplars. Similar advantages were reported in name- and face-matching tasks after face learning with high within-identity variability, over low variability (Ritchie & Burton, 2017). Interestingly, Liu et al. (2015) found no difference in face identity recognition when comparing exposure to three different emotional expressions with that of only one expression during learning, but a better performance when contrasting the three emotional expression conditions to one in which only neutral faces were presented. In contrast to the face literature, the possibility of a multiple exemplar advantage for voice identity memory has been little explored, with the few studies conducted providing only limited support for such an effect (Lavan, Knight, et al., 2019).
Finally, a few studies investigated memory for voice identity when the speech content was changed between encoding and recognition. As expected, better memory performance was observed when the content was kept the same (i.e., same stimulus), but there was nonetheless an above chance identity recognition for different-content stimuli (Zäske et al., 2014, 2017). Furthermore, identity recognition has been shown to be preserved even after manipulations that altered vocal quality or temporal-based phonetic information (Sheffert et al., 2002). Interestingly, better changed-content memory performance was reported for emotional compared to neutral voices (Kim et al., 2019), suggesting that an interaction between emotion and content may exist.
Here, we report results from two studies designed to address some of the gaps and inconsistencies, as well as to extend findings, in the literature described above. Experiment 1 consisted of a between-group factorial design investigating how changes in emotional prosody (see L. Öhman et al., 2013; Saslove & Yarmey, 1980; Stevenage & Neil, 2014), content (see Kim et al., 2019; Zäske et al., 2014, 2017), and their interaction (see Kim et al., 2019) affect memory for voice identity. In Experiment 2, we applied a within-subject design in which the number of emotional speech exemplars was varied, to assess whether findings obtained in the implicit (RP) and explicit (recognition) memory literature on faces (Martin & Greer, 2011; Murphy et al., 2015; Redfern & Benton, 2017b) also apply to voices. Furthermore, a comparison between Experiment 1 and Experiment 2 allowed us to test whether increasing the number of repetitions of a stimulus improves memory performance (e.g., Memon et al., 2003; Roark et al., 2006).
Experiment 1
We employed a classic incidental old/new recognition task to investigate the effects of changed emotional prosody and content on subsequent voice identity recognition. We focused on fear, as previous studies from our group (Armony et al., 2007; Aubé et al., 2013; Sergerie et al., 2005) and others (e.g., LaBar & Cabeza, 2006; Pichora-Fuller, Dupuis, & Smith, 2016) have consistently shown enhanced memory accuracy for same-item fearful expressions, which has been ascribed to an amygdala-mediated preferential process of such stimuli that signal the potential presence of danger in the environment (Armony, 2013; Sangha et al., 2020). Thus, according to this view, fearful prosody should serve as an emotionally arousing factor that facilitates processing and storing the voice identity; however, it also introduces acoustic variability to the same identity, which would interfere with the memory encoding or retrieving process. Two groups of subjects participated in this experiment: one was exposed to fearful-prosody neutral-content sentences of various speakers at encoding and tested for identity memory using sentences from these speakers in both fearful and neutral prosodies (and with the same or different content). A second group underwent a similar paradigm but was exposed to neutral prosody sentences during encoding. Within- and between-subject analyses were conducted to assess the effects of changing prosody and content on voice identity memory and whether encoding voices with fearful or neutral prosody led to changes in memory performance.
Methods
Participants
Sixty volunteers (34 female, aged 18–43 years) were recruited from the Greater Montreal Area and participated in the experiment at the International Laboratory for Brain, Music, and Sound Research (BRAMS), Centre for Research on Brain, Language, and Music (CRBLM), or Douglas Mental Health University Institute at McGill University. A power analysis on our pilot data using G*Power 3.1 (Faul et al., 2009) indicated that 58 participants (N = 29 per group) would be sufficient to detect an expected effect of .48 with a power of .95 and an alpha level at .05. All of the participants were fluent in English, right-handed, had normal hearing and (corrected-to-) normal vision, and reported no previous diagnosis or treatment of psychiatric or neurological disorders. They provided written informed consent prior to participation and received monetary compensation after the experiment. The study was approved by the Faculty of Medicine Research Ethics Office at McGill University.
Stimuli
Auditory stimuli were selected from the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) (Livingstone & Russo, 2018). They were audio-only recordings of 24 speakers (12 female) uttering two sample sentences of semantically neutral contents (“Kids are talking by the door” and “Dogs are sitting by the door,” hereafter referred as “kids” and “dogs” sentences, respectively), in neutral and strongly fearful prosodies, resulting in 48 speech stimuli in total (12 speakers × 2 prosodies × 2 contents). The two sentence samples share the same syntactic structure and same number of syllables and were rated similarly in terms of emotional intensity (see Table S1 of Livingstone & Russo, 2018). Speakers from the RAVDESS were native English speakers, with a neutral North American accent, to minimise the possible use of accent variability as a strategy to identify speakers (Gluszek & Dovidio, 2010). Only half of the stimuli were used in Experiment 1 (selection procedure described below), as a pilot memory test using the full set of 24 speakers resulted in a chance-level memory performance. Loudness of all the speech stimuli was normalised with the Loudness Toolbox (Genesis S.A.) in MATLAB 2017b.
Speaker selection
We employed a speaker matching task to select a subset of the 12 most identifiable speakers when the speech prosody switched between fear and neutral, to reduce task difficulty and improve memory performance (Legge et al., 1984). A separate group of 18 participants (11 female; aged 18–32 years) participated in this experiment. Each participant completed the matching task sitting in front of a computer while listening to audio stimuli via Beyerdynamic DT 770/990 headphones. In each trial, a sentence in fearful prosody was presented, followed by another one with neutral prosody, with either the same or different speech content, from the same or a different (but same-sex) speaker, with a 200 ms inter-stimulus interval. Participants were asked to decide whether the two sentences were spoken by the same person or not by pressing the corresponding button on a keyboard. All possible same-sex speaker pairs of fearful and neutral sentences were divided in six runs. Each run consisted of 24 speakers (uttering a fearful sentence) paired with 3 individuals (speaking a neutral sentence): one being him-/her-self, the other two being pseudo-randomly assigned different same-sex speakers, ensuring content was counterbalanced. Each participant completed two out of the six runs, which were assigned pseudo-randomly so that in the end, each possible speaker pair was compared by six participants.
Average accuracy of matching performance was calculated for each of the 24 speakers across participants. Speakers were ranked by the matching accuracy in each sex separately (range: 0.48–0.79). The six male and six female speakers with the highest matching accuracy were selected for Experiment 1. No significant difference in accuracy was observed between the selected male (M = 0.66, SD = 0.07) and female (M = 0.71, SD = 0.04) speakers, t(10) = 1.54, p = .15, Hedges’ gs = 0.81. A post hoc t-test confirmed that the selected 12 speakers were matched significantly more accurately than the unselected ones, t(22) = 6.73, p < .001, Hedges’ gs = 2.65.
Acoustic features analysis
To examine the acoustic (dis)similarity of the speech clips, we compared the acoustic differences between stimuli as a function of their prosody and content. Seventeen physical acoustic parameters were included in the tests, which were extracted from each stimulus using Praat v6.1.04 (Boersma & Weenink, 2019); these included stimulus duration and descriptive statistics (i.e., means and standard deviations) of the fundamental frequency F0, formant frequencies (F1–F4), and amplitude, as well as min, max, and range of F0. While there is no consensus on which, and how many, parameters best represent vocal stimuli, those chosen here were selected from previous studies using shorter stimuli (e.g., Baumann & Belin, 2010; Fecteau et al., 2007; Latinus et al., 2013) and also included measures of within-stimulus variability (i.e., range and standard deviation) to account for the longer duration of the stimuli we used. These parameters have been previously shown to capture relevant aspects of speaker’s identity and emotional expression. For instance, F0 and lower formant frequencies are important for voice identification (Matsumoto et al., 1973; M. Xu et al., 2013). Specifically, average fundamental frequency is an important source for listeners to distinguish or recognise speakers (Baumann & Belin, 2010; Chhabra et al., 2012) and their emotional state (Pichora-Fuller, Dupuis, & van Lieshout, 2016). Higher formant frequencies, especially F3 and F4, which relate to the size of a speaker’s vocal tract, are thought to carry information about voice identity (e.g., Ghazanfar & Rendall, 2008; Remez et al., 1997) and remain invariant when uttering different vowels or tones (e.g., Kitamura et al., 2006; Takemoto et al., 2006).
A prosody-by-content repeated-measures analysis of variance (ANOVA) on the 12 speakers (for full results, see Supplementary Table 1) revealed significant main effects (p < .05, false discovery rate (FDR) corrected with the Benjamini–Hochberg approach; Benjamini & Hochberg, 1995) of prosody for min and max F0 and for mean F0, F1, and F2. In addition, there was a main effect of content for mean F3 and for standard deviation of F3, F4, and amplitude. No content-by-prosody interactions reached statistical significance.
In addition, to relate the acoustic features with subjects’ memory performance, we took these parameters as a feature array representing each stimulus in the multidimensional acoustic feature space (Armony et al., 2007; Baumann & Belin, 2010; Latinus et al., 2013). An average within-prosody distance for each stimulus was computed by averaging the Euclidean distances between the specific stimulus and the others from its prosody group. These mean Euclidean distances between two prosodies were compared in a Mann–Whitney U test, to avoid the violation of variance homogeneity assumption. Fearful stimuli (mean rank [MR] = 33.29) were more distant among each other than neutral ones (MR = 15.71) in the multidimensional acoustic feature space (U = 77.00, Z = 4.35, p < .001, η2 = .39). A similar analysis as a function of content revealed no significant differences in within-content distance between the “kids” (MR = 21.25) and “dogs” (MR = 27.75) sentences (U = 210.00, Z = 1.61, p = .11, η2 = .05).
Finally, a complementary analysis on the speech similarity within each prosody was further conducted with a machine learning approach using the caret library (Kuhn, 2020) in R (version 4.0.0; R Core Team, 2020). Specifically, we trained a classifier to categorise speech prosody on the acoustic parameters extracted from different (not used in the experiment) exemplars of the 48 stimuli (12 speakers, 2 contents, and 2 prosodies), taken from RAVDESS, using support vector machine (SVM) with a linear kernel and a 10-fold cross-validation procedure repeated 1,000 times. The model was then used to identify the prosody of the stimuli we used in the study. All of the acoustic parameters were beforehand normalised due to the large discrepancies between their ranges. The trained model yielded an overall classification accuracy of 89.58%, significantly above chance level (p < 10−8), with a kappa of 0.79. The prediction error was 20.83% among fearful clips, yet 0% in neutral clips. That is, results from the classifier were consistent with those from dissimilarity score comparisons and together suggest that fearful speech clips were less similar to each other than neutral ones.
Procedure
Seated in front of a monitor, participants wore DT 770/990 headphones and used a keyboard to complete the task in a quiet room. They were instructed to press one of two keys (left/right) on the keyboard to answer the questions. Key assignment was counterbalanced across participants. Participants were asked to respond as quickly and accurately as possible. The experiment was self-paced; that is, once a response was made, it moved on to the next trial automatically, without an inter-trial interval (Steinborn et al., 2010). No break was taken throughout the experiment.
The experiment consisted of a short encoding session and a recognition test. During the encoding session, participants were asked to identify the sex of the speaker. Six speech clips, each produced by a different speaker (half male), were presented twice. Half of the participants were assigned to the Fear group, where all sentences presented were in a fearful prosody; the other half (Neutral group) listened to sentences with a neutral prosody instead (content counterbalanced in both groups). The speaker recognition test took place immediately after encoding. Subjects were presented with 4 speech clips (2 prosodies × 2 contents) produced by each of the 6 speakers from the encoding session (i.e., old speakers) and 6 novel speakers, in a pseudo-randomised order. Each speech clip was followed by an old/new judgement question on voice identity. Participants were explicitly instructed to ignore any potential changes in the stimuli and only focus on speakers’ identities. Response choice and time were recorded for each trial and submitted to analyses as described below.
Data analysis
Encoding
Encoding RTs were examined for potential priming effects due to repetitions of the same voice identity, by implementing a regression coefficient analysis (RCA, Lorch & Myers, 1990) via linear mixed models (LMMs). As we assumed a linear decrease trend in RTs as a function of repeated presentation (C. Xu, 2017), the slopes of RT change were estimated via linear regression. Based on the principle of RCA, we estimated the regression slopes at individual- and speaker-specific levels. These subject- and speaker-specific slopes were then analysed in an LMM using the lme4 library (Bates et al., 2015) implemented in R, with group (Fear/Neutral) as the fixed between-subjects factor, and subject and speaker as random effects. Including speaker in the random effect structure can account for potential confounding speaker-specific effects and remove these from the fixed effects of interest (e.g., Baayen et al., 2008).
Recognition
Accuracy: Subjects’ responses to each trial of previously presented speakers, coded as a binary variable (0 = new, 1 = old), were fitted with a generalised linear mixed-effects model (GLMM) with a logit link function, with prosody (same/different, compared to encoding) and content (same/different) as the fixed within-subjects factors, and group as a between-subjects factor. For the specification of random effects, we used a maximal structure including both by-subject and by-speaker random intercepts and slopes of within-subjects fixed factors, to maximise the modelling generalisability (Barr et al., 2013). When significant interaction effects were found, we conducted post hoc t-tests (Bonferroni-corrected) to interpret the interactions using the emmeans R library (Lenth, 2020).
In addition, to investigate whether effects of prosody on memory performance could be accounted for by acoustic (dis)similarity within and between prosody categories, a stimulus-based analysis of covariance (ANCOVA) on the subject-averaged recognition accuracy was carried out, with emotional prosody (fearful/neutral) as a between factor and mean within-prosody distance as a covariate. A similar ANCOVA was conducted with within-content distance as a covariate.
Response bias: To determine whether any differences obtained in the previous analysis could be accounted for, at least in part, to a different response strategy or bias as a function of the experimental manipulation, we computed the response bias (Br) for each subject and prosody, based on the 2-high threshold model (Snodgrass & Corwin, 1988):
RTs: We first applied a conventional RT cleaning procedure to exclude those shorter than 100 ms or longer than 3 SDs above the average per participant (e.g., Steinborn et al., 2010). We then applied a log transformation to remaining RTs to reduce the skewness of the distribution. Only correct trials of old speakers were included in the analysis. RTs were fitted with a linear mixed-effects model (LMM) with the same model structure as for response accuracy. Specifically, prosody (same/different) and content (same/different) served as fixed within-subjects factors, in addition to the between-subjects factor group. Random effects included intercepts and slopes for subject and speaker factors. Post hoc tests with Bonferroni correction (emmeans R library) were conducted when necessary.
Results
Encoding
The LMM for the RT slopes (see Methods) revealed a significant effect for the intercept, (b = −0.16, SE = 0.04, t(358) = 4.40, p < .001), representing an overall decrease in RTs for the second presentation of a stimulus, compared to the first one, without a significant difference between groups, b = 0.05, SE = 0.04, t(358) = 1.43, p = .15.
Recognition
Response accuracies for all conditions in each group are summarised in Table 1. Overall accuracy across all conditions in both groups was significantly above chance level, Fear group: M = 0.60, SD = 0.07, t(29) = 8.28, p < .001, Hedges’ gs = 2.11; Neutral group: M = 0.61, SD = 0.09, t(29) = 6.96, p < .001, Hedges’ gs = 1.77, with no significant difference between groups, t(58) = 0.34, p = .74, Hedges’ gs = 0.09.
Descriptive statistics of recognition accuracy and response bias in Experiment 1.

Values are reported in format: Mean (Standard Deviation).
Trial-by-trial response accuracy for old speakers was fitted with a GLMM with prosody (same/different), content (same/different), and group (Fear/Neutral) as fixed effects, as well as random intercepts and slopes for subject and speaker effects. Table 2 lists the estimated coefficient (b), standard error (SE), z score, and p value for all of tested effects. Results showed a significant effect of prosody change (p < .001), reflecting a better recognition of old speakers when speech prosody remained the same between encoding and recognition. There was also an interaction between prosody and content (p < .001). Post hoc tests revealed that recognition in same-prosody trials was better when the content remained the same (SP/SC) than when it changed (SP/DC) (b = −1.41, SE = 0.24, z = 5.97, p < .001), but did not differ significantly as a function of content in different-prosody trials (DP/SC vs DP/DC: b = −0.11, SE = 0.18, z = 0.62, p = .54) (illustrated in Figure 1a). Finally, there was an interaction between prosody and group (p = .037), due to a larger prosody effect in the Fear group (Fear: b = −2.32, SE = 0.33, z = 7.01, p < .001; Neutral: b = −1.49, SE = 0.32, z = 4.62, p < .001).
Fixed effects from (G)LMM estimations on recognition response, bias, and log-RTs in Experiment 1.
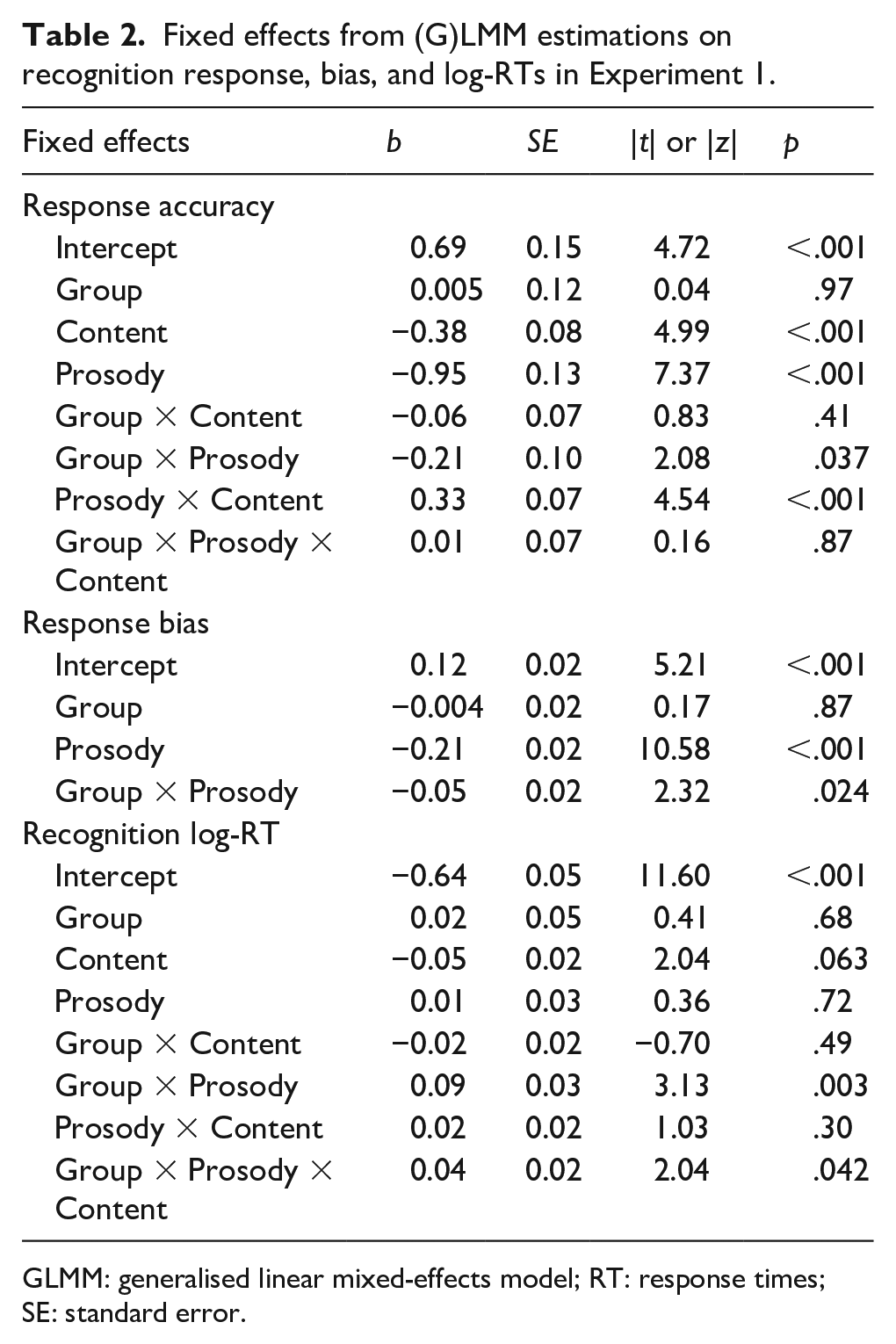
GLMM: generalised linear mixed-effects model; RT: response times; SE: standard error.
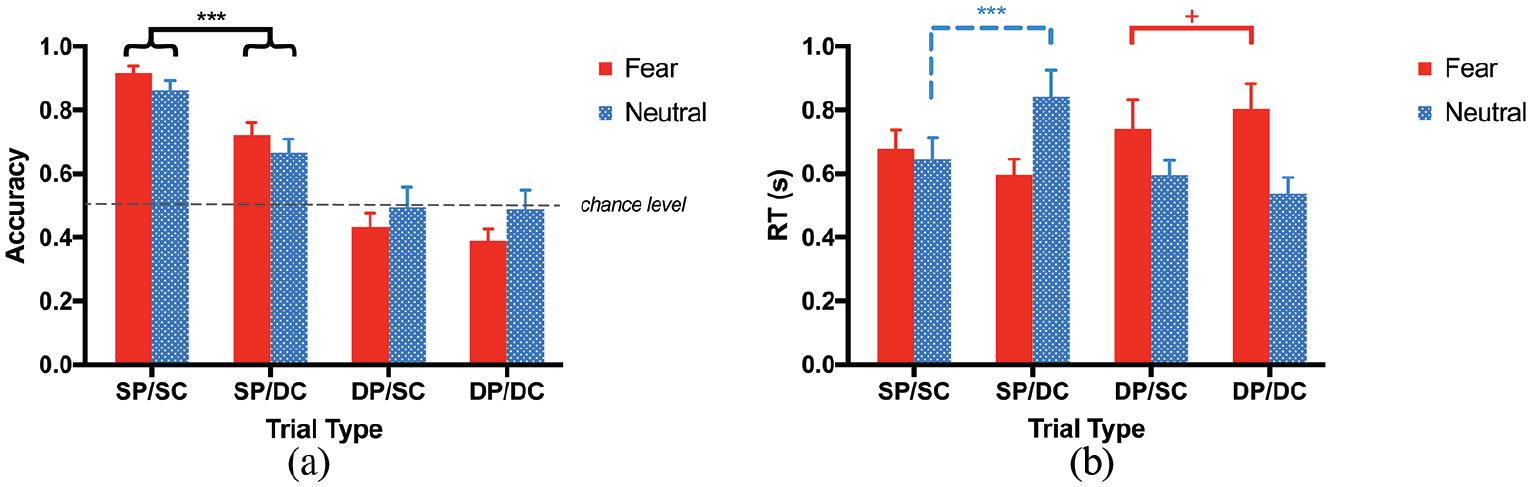
(a) Recognition accuracy and (b) response times in Experiment 1. Average (a) accuracy and (b) RTs for each trial type in each participant group. Horizontal lines show the significant differences between conditions in post hoc tests. Horizontal dashed lines in (a) represents chance-level accuracy. Solid and dashed lines in (b) correspond to significant differences in the Fear and Neutral groups, respectively.
LMM estimation of response bias yielded a significant main effect of prosody (p < .001) and a prosody-by-group interaction (p = .024), as shown in Table 2. Post hoc tests showed that these effects were due to the fact that, whereas both groups showed a significant positive bias (tendency to respond “old”) for same-prosody trials, (Fear: b = 0.38, SE = 0.03, t(57.3) = 11.04, p < .001; Neutral: b = 0.29, SE = 0.05, t(57.2) = 5.73, p < .001), only the Fear group showed a significant negative bias (tendency to respond “new”) for different-prosody trials, (Fear: b = −0.15, SE = 0.03, t(57.3) = 4.31, p < .001; Neutral: b = −0.05, SE = 0.05, t(29) = 0.89, p = .75).
Log-RTs of correct trials for old speakers in the recognition session were analysed with an LMM with the same structure as the GLMM on response (see Table 2). We observed a trend for the main effect of content (p = .063) and a group-by-prosody interaction (p = .003). Post hoc tests showed that Fear group participants responded faster to same-prosody stimuli, b = 0.19, SE = 0.08, t(34.7) = 2.41, p = .021, with a trend for the opposite effect in the Neutral group, b = −0.15, SE = 0.08, t(33.8) = 1.89, p = .071. In addition, there was a triple interaction among group, prosody, and content (p = .042). Post hoc tests were conducted to disentangle the triple interaction: in the Fear group, participants’ RTs showed no significant differences as a function of content when the recognition prosody was the same as in encoding, SP/SC vs SP/DC: b = −0.06, SE = 0.09, t(48.10) = 0.82, p = .41, but when it was different, participants’ response tended to be slower when speech content was also different, DP/SC vs DP/DC: b = 0.20, SE = 0.11, t(141.40) = 1.89, p = .061. The Neutral group, however, displayed an opposite RT pattern: no significant difference from the content change was observed when the recognition prosody changed, DP/SC vs DP/DC: b = 0.09, SE = 0.10, t(107.50) = 0.87, p = .38, but participants responded faster to same-content stimuli when the recognition prosody remained the same, SP/SC vs SP/DC: b = 0.17, SE = 0.08, t(51.80) = 2.23, p = .030. A graphical summary of these effects is shown in Figure 1b.
To assess whether differences in the acoustic parameters of the speech stimuli in the experiment were related to the behavioural effects described above, we examined the relation between the dissimilarity of each speech clip within its own emotional prosody and its overall recognition accuracy via an ANCOVA with emotional prosody as a between factor and average within-prosody Euclidean distance as a covariate. This analysis revealed a significant effect of distance, F(1, 45) = 8.64, p = .005,
Discussion
Results from Experiment 1 indicate that a change in emotional prosody between encoding and recognition had a detrimental impact on voice identity memory accuracy. This observed decline is consistent with prior findings using angry and neutral vocal phrases (Read & Craik, 1995; Saslove & Yarmey, 1980; Stevenage & Neil, 2014). Interestingly, and in agreement with Stevenage and Neil (2014), this recognition impairment was observed regardless of the encoding prosody, although there was a trend for a larger effect when the encoding prosody was fear. In addition, reduced recognition in same-prosody stimuli was observed when the content changed across both groups, which replicated the results of impairment of voice recognition from previous studies where speech content was the only experimental manipulation (Zäske et al., 2014, 2017). These results are also in line with previous studies reporting worse performance in speaker identification following changes in various voice properties, such as uttered languages (Wester, 2012; Winters et al., 2008), speech type (i.e., spontaneous or read) (Smith et al., 2018), background noise (Smith et al., 2018), vocalisation type (Lavan et al., 2016), and vocalisation approach (i.e., sung or spoken words, Peynircioğlu et al., 2017). The worse performance for identity memory when prosody or content changed was likely due, at least in part, to the within-speaker differences in key acoustic parameters as a function of changes in prosody and content (see Supplementary Table 1). Indeed, we observed a significant positive correlation between a subject-averaged stimulus-based memory accuracy and its mean distance to the other stimuli in the acoustic parameter multidimensional space, confirming that the more dissimilar a stimulus was to the others in its prosody or content group, the better it could be correctly identified as new or old. This finding is consistent with the significant correlation between perceived speaker distinctiveness and distance-to-mean in the acoustic space reported by Latinus et al. (2013).
The response strategy indicated that both groups of participants shared, as could be expected, a common positive familiarity bias for same-prosody trials (i.e., participants tended to respond “old” to stimuli presented in the same prosody as those in the encoding session), while only subjects from the Fear group showed the opposite novelty bias for different-prosody trials (i.e., tendency to categorise neutral stimuli as “new”). The significant familiarity and novelty biases in the Fear group presented with fearful and neutral prosody, respectively, suggest that participants based their decisions of whether they had previously heard a speaker mainly on their emotional tone, even though they had been explicitly instructed to ignore this feature as irrelevant for the task.
Another measure of memory performance that was less discussed in previous studies is RTs. RTs are often considered a proxy of response confidence in a memory test, as they have been shown to correlate strongly with subjective confidence ratings (Robinson et al., 1997). Although they can also reflect or be influenced by task difficulty, effort, or strategy (e.g., Jaeggi et al., 2010; Pesonen et al., 2007), there have been suggestions that in a memory recognition test, much of the information from explicit confidence ratings could be obtained from RTs (Weidemann & Kahana, 2016). Intriguingly, groups showed opposite RT patterns with regard to same/different prosody between encoding and recognition. From another viewpoint, however, these findings show that both groups displayed a consistent RT pattern with respect to the actual prosody of recognition stimuli (i.e., fearful vs neutral), regardless of the prosody presented during encoding: participants were faster in responses to fearful than neutral stimuli, and keeping the same content consistency had a significant facilitating effect only in the case of neutral voices.
Several (non-mutually exclusive) possible explanations can help account for this pattern of RTs shared by both groups. First, the facilitated response towards fearfully expressed stimuli may be a result of preferential processing of fearful voices due to their high salience. Emotional faces have been shown to either help (e.g., Chadwick et al., 2019; Phelps et al., 2006) or impede (e.g., Eastwood et al., 2003; Hartikainen et al., 2000) performance in various perception tasks, the former being more likely in difficult tasks (for a discussion, see Chadwick et al., 2019). In our case, voice recognition was a rather difficult task, as evidenced by subjects’ accuracy; thus, fearful prosody may have enhanced subjects’ attention and/or arousal (e.g., Lin et al., 2020; Sutherland & Mather, 2012), leading to a faster processing of those stimuli. Indeed, visual and auditory emotional, particularly fearful, expressions capture attention in an automatic fashion (Armony et al., 2001; Sanders et al., 2005) and thus may lead to a more rapid detection and processing than neutral ones (A. Öhman & Mineka, 2001). In this context, more attentional resources would have been allocated towards the emotional prosody of the stimuli and less was left for other characteristics, such as content. In contrast, content information was processed in neutral stimuli without competition from emotional expressions; hence, it contributed to subjects’ recognition of previously heard speakers. This interpretation is also in line with the previously reported enhanced memory for the “gist” of emotional events, with no improvement for, or even at the expense of, their details (Bookbinder & Brainerd, 2017; Christianson & Loftus, 1991). Finally, differences in acoustic features between prosodies could have contributed to the observed RT pattern. As the acoustic analysis showed that fearful stimuli were acoustically more distant to each other than neutral ones, it is possible that these larger dissimilarities of fearful stimuli made it implicitly easier for listeners to distinguish speakers. Moreover, given the larger acoustic similarity within neutral prosody samples, any additional information, such as content, would have facilitated recognition of previously encountered speakers, thus resulting in a faster identification of same- than different-content neutral stimuli.
In summary, results from this experiment indicate that changes in speech prosody and content can have a deleterious effect on identity recognition accuracy, as well as an influence on how participants decided which speakers they had not heard before (response bias). Moreover, response speed on correctly recognised speakers seemed to be dependent on the actual prosody of stimuli and, for neutral stimuli, on content change, in both groups of participants.
Experiment 2
Accuracy results from Experiment 1 suggest that the presentation of a single exemplar twice is not sufficient to form a robust representation of an individual’s voice that is immune to changes in identity-irrelevant features. In this experiment, we assessed whether increasing the number of exposures to each individual and, critically, the number of exemplars could help improve voice identity memory performance. Specifically, we employed a within-subjects design in which participants were exposed to four presentations of each unfamiliar speaker. For half of the speakers, the same sentence expressed in fearful prosody (i.e., same stimulus) was always presented, whereas for the other half the samples were all different in terms of prosody (happy or fearful) and/or content (“kids” or “dogs”). In the recognition test, all speakers were presented in a neutral prosody. As mentioned above, we expected participants to exhibit a better voice identity recognition performance when they learned their identity through exposure to different exemplars of the same individual than when they only learned one example, especially when encountering them in a novel prosody (see Lavan, Knight, et al., 2019). Moreover, we hypothesised that memory performance for the four-repetition single-exemplar speakers in this experiment would be better than that observed in the Fear group of Experiment 1, where each stimulus was presented twice.
Methods
Participants
A different cohort of 28 participants (18 female; aged 19–37 years) took part in this experiment at the same sites. Recruitment criteria were identical to those in Experiment 1.
Stimuli
All 24 speakers from the RAVDESS dataset (Livingstone & Russo, 2018) were used in this experiment. Each speaker uttered two different neutral-content sentences in three prosodies (neutral, strong fear, and strong happiness). The loudness normalisation procedure was applied in the same manner as in Experiment 1.
Procedure
The testing setup was the same as in Experiment 1, that is, it consisted of an incidental encoding session followed by a surprise speaker recognition test. During encoding, participants were asked to judge the age range (younger/older than 30 years) of presented voices (based on pilot data, this task, more effortful than the sex discrimination one used in Experiment 1, improved memory accuracy). For each participant, six speakers (half female) were pseudo-randomly assigned to the Multi condition, where four distinct exemplars (2 contents × 2 prosodies: fear and happiness) of each speaker were presented once each. The other six speakers were assigned to the Uni condition, in which only one fearful exemplar per speaker was presented four times. Speech contents were counterbalanced within each condition, and the sequence was pseudorandomised so that the number of intervening trials between presentations of the same speaker were not differently distributed between the Multi and Uni conditions. As in Experiment 1, the recognition test took place immediately after encoding. Two neutral speech exemplars (2 contents) from each old speaker in both the Uni and Multi encoding conditions, together with 12 new speakers (2 contents in neutral prosody), were presented. Each exemplar was followed by an old/new judgement question. Response choice and time were recorded for each trial and submitted to subsequent analyses.
Data analysis
We applied the same analysis approaches as used in Experiment 1. For encoding RTs, subject- and speaker-specific regression slopes were analysed in an LMM, with condition (Uni/Multi) as the within-subjects fixed factor and a maximal random effect structure (intercept and slope) of subject and speaker.
Binary recognition responses were fitted in a GLMM with the fixed within-subjects factor of condition (Uni/Multi) and by-subject and by-speaker random intercepts and slopes. A single response bias (Br) per subject was calculated to identify an overall response strategy, as there was no sub-condition for new stimuli (i.e., neither Multi nor Uni condition had corresponding conditions among new-speaker trials). Recognition RTs were cleaned, and log transformed, following the same procedure as in Experiment 1. Log-RTs of correct trials for old speakers were fitted in an LMM with the within-subjects fixed factor condition (Uni/Multi).
To test the hypothesis of better memory accuracy when increasing encoding presentation numbers, we conducted a supplementary analysis comparing performance for different-prosody old-speaker trials from the Fear group in Experiment 1 (2 presentations of each stimulus) and Uni condition trials in Experiment 2 (4 presentations). These response data were fit in a GLMM, with experiment as the between-subjects fixed factor and random effects of subject and speaker.
Results
Encoding
Changes in encoding RTs across the four presentations of speakers are illustrated in Figure 2. Results from the LMM on RT slopes revealed a significant effect of condition, b = −0.15, SE = 0.07, t(46.12) = 2.31, p = .025, due to smaller slopes for the Uni compared to the Multi speakers. Post hoc analyses for each condition separately revealed that the intercept was significantly negative for the Uni condition, b = −0.19, SE = 0.06, t(27.00) = −3.21, p = .003, but not the Multi condition, b = −0.04, SE = 0.04, t(15.93) = −0.90, p = .38, (regression lines illustrated in Figure 2). That is, only the Uni trials showed a significant decrease in RTs over repetitions of the same voice identity, which, in this case, consisted of the same stimulus.
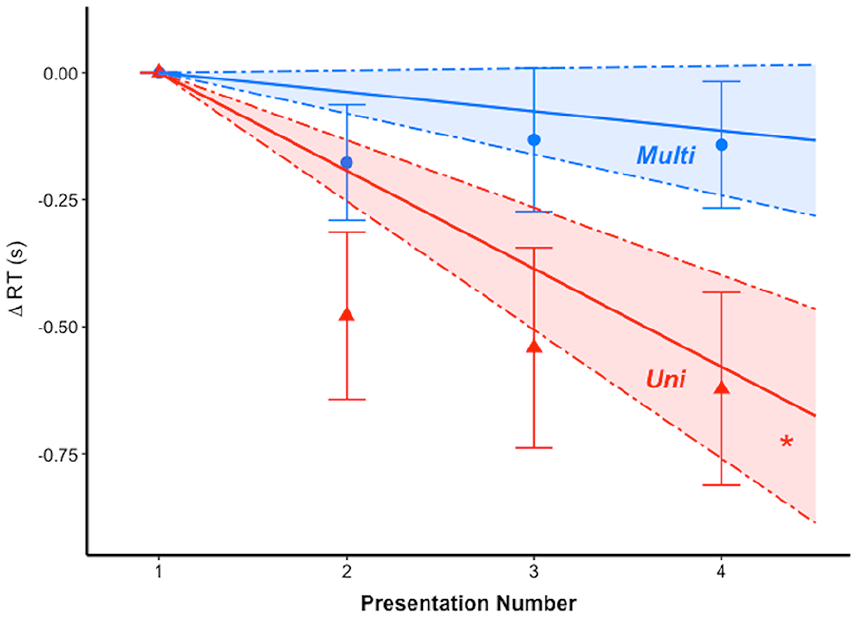
Changes in response times (RTs) during encoding in Experiment 2 for the Uni (red triangles) and Multi (blue circles) conditions (relative to the first presentation). The solid lines represent the subject- and speaker-averaged slopes obtained in the LMMs (see Methods for details). Dashed lines represent ±1 SE of the mean slope.
Recognition
Response accuracy for each condition (overall, Multi and Uni) is shown in Table 3. The overall accuracy was significantly above chance level, overall: t(27) = 4.21, p < .001, Hedges’ gs = 0.77, as well as both of old-speaker conditions, Uni: t(27) = 2.70, p = .009, Hedges’ gs = 0.49; Multi: t(27) = 4.42, p < .001, Hedges’ gs = 0.81. The GLMM on trial-by-trial responses for old speakers yielded no significant effect of condition (b = −0.04, SE = 0.22, z = 0.18, p = .86), suggesting that recognition accuracy of old speakers from the Uni and Multi conditions did not differ.
Descriptive statistics of recognition accuracy and response times (RTs) in Experiment 2.
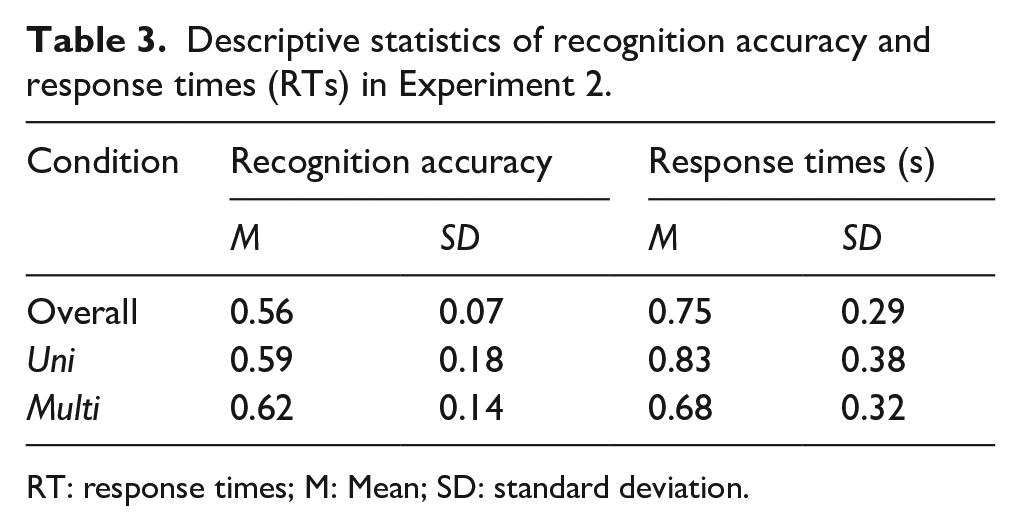
RT: response times; M: Mean; SD: standard deviation.
The comparison between the Fear group in Experiment 1 and Uni condition trials in Experiment 2 yielded a main effect of experiment (b = 1.00, SE = 0.25, z = 4.05, p < .001), due to a better recognition of speakers with changed prosody when they were presented 4 rather than 2 times during encoding. Moreover, unlike the case of the negative bias in different-prosody trials in Experiment 1, here we did not observe a significant response bias, Br = 0.06, t(27) = 0.38, p = .71, Hedges’ gs = 0.10.
Recognition RTs with correct responses, shown in Table 3, were log-transformed and estimated in an LMM with condition (Uni/Multi) as the within-subjects fixed factor. This model revealed a significant effect of condition, b = 0.20, SE = 0.08, t(664.07) = 2.43, p = .015, which indicated that RTs for correctly recognised speakers previously encoded in the Uni condition (i.e., same fearful exemplar presented 4 times) were longer than those from the Multi condition (i.e., four different exemplars varying in prosody and content).
Discussion
During the encoding session, repetition of the same stimulus resulted, as expected, in a linear reduction of RTs, as typically shown in most RP experiments (e.g., Bertelson, 1961; Pashler & Baylis, 1991). Interestingly, such a reduction was predominantly present in the Uni condition, with a substantially weaker (non-significant) effect for the repeated presentations in the Multi condition. Similar effects were found in previous studies: for instance, Manelis et al. (2013) compared the encoding RTs for object pictures in two repetition types (i.e., same-exemplar, resembling the Uni condition here; different-exemplar, where two presentation images were not identical but shared the same object gist, resembling the Multi condition). Although they observed a main effect of repetition on correctly recollected objects across both same- and different-exemplar conditions, post hoc tests indicated the effect was driven by same-exemplar trials, with no significant priming for different-exemplar trials. Furthermore, similar attenuations in neural response were also reported in neuroimaging studies. Griffin et al. (2013) reported a neural activity decrease during the second presentation of images, but to a smaller extent in different-exemplar than same-exemplar repetition. This stimulus-specific, rather than individual-specific, priming effect could be interpreted as subjects treating new exemplars of a repeated individual as new speakers. However, this seems unlikely, given the results for subsequent recognition RTs (discussed below).
Contrary to our hypothesis, increasing the variability of encoding exemplars did not improve recognition accuracy. Nonetheless, this finding is consistent with some previous studies. For instance, Liu and colleagues (2015) reported a similar lack of significant advantage in face identity recognition when presenting three different expressions over a single one during encoding. Similarly, Lavan, Knight, et al. (2019) also failed to find a clear benefit of high variability training in voice identity learning. One possible explanation, also put forward by Liu et al. (2015), is that four presentations of each voice, and without explicit feedback in terms of voice identity during encoding, were still insufficient to form a stable, prosody-invariant identity representation. Interestingly, Liu et al. (2015) did observe a benefit of multiple-expression exposure but only when comparing it to a baseline condition containing neutral faces, and this effect was only apparent when the faces at recognition were of a different expression from those presented at encoding. Thus, the lack of differences between our Uni and Multi conditions in our study could be due to the fact that in both cases the stimuli presented during encoding had an emotional prosody which, as mentioned in the Discussion of Experiment 1, could have overshadowed any potential small benefit on explicit recognition of multiple-prosody-encoding over single-prosody-encoding.
Despite the lack of a significant difference on identity recognition accuracy between Multi and Uni conditions, our findings suggest that presenting more than one exemplar of an individual’s voice facilitates subsequent speaker’s identity recognition, as reflected by the shorter RTs of correctly recognised old speakers from the Multi condition. Such reductions in RTs could reflect enhanced confidence (Weidemann & Kahana, 2016) and/or reduced difficulty (Jaeggi et al., 2010) when correctly identifying previously heard individuals who produced sentences in different emotional expressions and contents. This finding can, in turn, help address the stimulus-specific versus individual-specific priming question raised above in the discussion on encoding RTs. That is, during encoding, presentation of new exemplars of a previously presented speaker may have required participants to find the corresponding matching individual among those already heard, resulting in longer RTs, and thus a smaller priming effect (for a similar argument, see Liu et al., 2015). Although we cannot directly determine which process actually took place, participants having shorter RTs when recognising Multi-condition speakers than Uni-condition speakers provides evidence for an implicit advantage of multiple exemplar exposure on speaker memory and therefore supports the latter proposed process. In summary, the RT results are consistent with the hypothesis, mainly established from studies using faces (e.g., Murphy et al., 2015), that exemplar variation may contribute to learning and subsequent recognition of newly familiarised speakers.
Performance in the Uni condition in Experiment 2 (4 presentations of each stimulus) was significantly better than that of the Fear group in Experiment 1 (2 presentations of each stimulus). This suggests that, as previously shown in both face (e.g., Murphy et al., 2015; Roark et al., 2006) and voice learning (Zäske et al., 2014), increasing the number of presentations of a stimulus improves its recognition. Interestingly, this enhanced memory was observed even if the number of individuals in Experiment 2 was twice that of Experiment 1, which has also been shown to affect memory performance (see Metzger, 2002, for faces). One caveat is that the encoding tasks in the two experiments were different, and therefore, it is possible that the more difficult task of Experiment 2 (age judgement) resulted in a deeper stimulus encoding than the easier task in Experiment 1 (sex judgement), and thus in a better memory performance, independently (for faces, see Bower & Karlin, 1974; Grady et al., 2002; Gur et al., 2002), or in addition to, the larger number of exemplar repetitions.
Taken together, findings from Experiment 2 indicate that speaker recognition across prosody can be improved by simply increasing repetition numbers, and exemplar variance could facilitate subsequent speaker recognition, though not necessarily in terms of explicit recognition accuracy, at least under the experimental setting used here.
General discussion
This study investigated the influence of changes in emotional expression (i.e., prosody), content, and exemplar variance on subsequent identity recognition of newly familiarised speakers. We examined these factors starting with the simplest scenario where individuals’ speech prosody switched between neutral and fear and, orthogonally, content changed or remained the same (Experiment 1). We then extended the focus towards the number and variance of repeated encoding voices (Experiment 2). Whereas research on face memory extensively investigated the influence of within-person variability, from view point and facial expression, to unsystematic variability, using “ambient images”—a wide range of face photos taken in different real-life occasions (e.g., Redfern & Benton, 2017a, 2017b, 2019; Ritchie & Burton, 2017), the majority of literature on voice identity recognition explicitly controlled and minimised most aspects of within-person variability, for example, by using highly unified vocal content and tone (reviewed by Lavan, Burton, Scott, & McGettigan, 2019). Here, we took an approach similar to that previously used in studies of face identity recognition (Liu et al., 2014); namely, we varied specific features of the voice stimuli within speakers (prosody and content), while minimising other potential confounding factors that could influence memory, by using a well-controlled and validated laboratory-recorded audio-stimulus set.
Results from the two experiments revealed changes in explicit recognition performance (i.e., accuracy) between experimental conditions. Specifically, explicit recognition was impaired under certain experimental manipulations: when exposed to a novel prosody or a novel content at test (Experiment 1), or when the encoding exposure was rather limited and/or the encoding processing depth was shallow (comparison between the two experiments; see discussion in Experiment 2). Particularly, impaired recognition of previously encountered speakers in Experiment 1 was observed in both Fear and Neutral groups, reflecting a difficulty in “telling people together” (Lavan, Burton, Ladwa, et al., 2019; see Burton, 2013, for faces), when speech exemplars were in a different, rather than same prosody from the one initially encoded. Change in content also interfered with successful recognition of individuals, but only when prosody remained constant. These findings are in line with prior studies using voice line-up (e.g., Saslove & Yarmey, 1980), speaker matching (e.g., Stevenage & Neil, 2014), and the recently developed identity sorting tasks (Lavan, Burton, Ladwa, et al., 2019).
However, we did not observe any difference on accuracy (Experiment 1) as a function of the prosody presented during encoding (i.e., group effect), which is consistent with the first two experiments described in Stevenage and Neil’s (2014) review paper. This was largely due to a common response bias, as participants tended to base their responses on the prosody of the speaker, particularly in the Fear group; that is, to categorise fearful voices as previously encountered and those presented with a neutral tone as never heard before. Meanwhile, contrary to our hypothesis, we failed to detect an advantage in memory accuracy, in Experiment 2, for voices that were encoded in two different prosodies (fearful and happy), compared to those encoded in only one (fearful). Speaker familiarity could play a potential role in the absence of such differences. For instance, subjects “told together” familiar speakers better than unfamiliar speakers (Lavan, Burton, Ladwa, et al., 2019), with similar findings observed for face identity (Burton et al., 2016). As participants were only given the same limited amount of exposures to each speaker, a stable representation for each speaker might have been difficult to form and easily influenced by expression variance. On the contrary, this paradigm helps rule out potential impact on subsequent recognition from another confounding factor, namely the amount of stimulus exposure. As already shown in face studies (e.g., Memon et al., 2003), and old-speaker recognition performance between Experiment 1 and 2, more or longer exposures of an individual would lead to a better subsequent recognition. The voice sorting paradigm used by Lavan and colleagues did not allow to control the amount of time participants spent on each stimulus, which could have influenced their performance, especially for newly learned speakers.
Although accuracy did not show statistical differences between conditions, other measures of recognition performance, namely response bias (in Experiment 1) and RTs (in both experiments), did display differences between groups (Experiment 1) and presentation conditions (Experiment 2). In Experiment 1, RTs were influenced by stimuli’s actual emotional prosody in the two groups, in addition to a content change effect only observed in responses to neutral prosody stimuli. As hypothesised in the discussion of Experiment 1, this RT pattern shared by both groups could be a result of how emotional stimuli are processed. Results from Experiment 2 demonstrated a facilitated response when training with both fearful and happy speech exemplars, rather than only fearful ones, which fits the prediction from exemplar variance advantage (Murphy et al., 2015). Lavan, Knight, et al. (2019) tested listeners’ recognition performance on manipulating variability of voice stimuli (in a broader sense, not expressiveness variability in particular) and found no clear advantage for vocal identity training with high variability. They proposed that high variability advantage may be seen in situations when listeners are required to generalise to different unheard stimuli. Our results support to some extent their proposal: although no advantage of recognition towards new unheard stimuli (in a different prosody) was detected, RTs did reflect a facilitation effect for multiple exemplar training. Nonetheless, it is worth pointing out the difference in the nature of the stimulus variability between studies when comparing the results. Whereas the manipulation in Lavan, Knight, et al. (2019) was in terms of recording sessions and speaker’s speaking styles, ours was focused on prosody and content difference, with other audio settings being consistent (i.e., same recording facilities and spontaneous speaking). Whether such a distinction could account for the fact that we observed significant effects on RTs but not accuracy remains to be determined. Taken together, our findings of differences in RTs and response biases provide complementary insights and extend knowledge towards recognition of newly familiarised speakers in addition to conventional identity recognition measures such as accuracy. More importantly, it highlights the relevance of these behavioural measures that were less studied in prior experiments, as they may reflect subtle influences of experimental manipulations that target implicit memory, without necessarily influencing explicit recognition accuracy.
In addition, our findings in voice are consistent with the updated facial processing model involving identity and expression processing and integration. There is a long history of research on the topics and in what manner the two processes take place, from the seminal Bruce and Young (1986) model that emphasised a functionally sequential processing manner, where expression analysis takes place in a dedicated route which is ahead of identity processing via facial recognition unit, to the model proposed by Haxby et al. (2001), which divides facial perception into invariant features like identity, via a ventral temporal route involving the lateral fusiform gyrus and inferior occipital gyrus, and variable properties, including facial expressions, via another anatomical route involving superior temporal sulcus. The recent late bifurcation models (Calder, 2011) were based on these two models to explain integrated facial processing procedures that both variant and invariant facial features are coded in a shared pathway before visual routes split for further finer processing. As our findings strongly indicated that speech prosody contributes to speaker recognition, they fit with the notion of an interactive mechanism for vocal identity and vocal expression processing, in line with what the late bifurcation models propose for facial identification.
Finally, our results showing prominent differences in response speed, which has been reported to exhibit a consistent relation to response confidence, may be relevant to the issue of reliability of earwitness in crime and court testimony. Empirical cases have shown that voice identifications in court can be accurate, but also highly unreliable (Sherrin, 2016). Laboratory studies also show that unfamiliar voice identification tasks are difficult and error-prone, and suffer from low accuracy rates (e.g., Stevenage et al., 2011; Yarmey, 2007). As Sherrin pointed out, it is common for speakers to employ expressive tones of voice during the commission of a crime. Our results of recognition decline due to the changes in emotional prosody provide support for his suggestion that earwitnesses could be more reliable when they are exposed to the same tone of voice during the crime scene and the identification process.
Limitations
Here, we mostly focused on fear when exploring the influence of speech prosody change on identity recognition. This choice was based on previous work by us and others consistently showing an enhanced memory accuracy for emotional facial, vocal, and musical expressions (for the same-item effect). While our results suggested an impairment in voice recognition when the speech prosody changed between fear and neutral, similar to previous voice studies mostly on anger, parallel face studies have suggested a happy-face advantage (see Liu et al., 2014). Whether this advantage is emotion- (or valence-) specific, and modality-specific, requires further investigation. Likewise, more studies that include a wider variety of sentence contents are needed to fully characterise the influence of this factor on speaker identity recognition memory.
Although we interpreted the effects of our experimental manipulations on response speed as reflecting differences in response confidence, in line with an extensive existing literature (e.g., Robinson et al., 1997; Weidemann & Kahana, 2016), we cannot rule out other possibilities, such as task difficulty or cognitive demands. Future studies including explicit measures of these variables should shed light on this issue.
As discussed in Experiment 2, an additional neutral Uni condition should help further test and characterise the observed exemplar variance advantage involving emotional expressions. However, increasing the number of conditions (and therefore stimuli) would likely further reduce the already weak memory performance. Future experiments including both within- and between-subject factors could overcome this challenge.
Conclusion
In summary, our studies offered a novel insight on understanding voice perception and recognition at the early stage of familiarisation. Past research has focused largely on explicit recognition of voices and how changes in voices such as emotional prosody, speech content, and exposure amount influence identity perception. Here, we integrated these changes orthogonally in the experiments and extended the behavioural repertoire measured to include response bias and RTs. Our results indicated that the influence of these explicit and implicit recognition indices could be different, thus highlighting the usefulness of including behavioural measures other than response accuracy in future voice, and possibly face, identity memory or perception studies.
Supplemental Material
sj-docx-1-qjp-10.1177_1747021821998557 – Supplemental material for Influence of emotional prosody, content, and repetition on memory recognition of speaker identity
Supplemental material, sj-docx-1-qjp-10.1177_1747021821998557 for Influence of emotional prosody, content, and repetition on memory recognition of speaker identity by Hanjian Xu and Jorge L Armony in Quarterly Journal of Experimental Psychology
Footnotes
Acknowledgements
We are thankful to Dr Signy Sheldon for insightful comments and suggestions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by grants from the Natural Sciences and Engineering Research Council of Canada (NSERC, 2017-05832) and the Canadian Institutes of Health Research (CIHR, MOP-130516), to J.L.A. H.X. received a CRBLM Graduate Student Stipend.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.