
Abstract
We regularly form impressions of who a person is from their voice, such that we can readily categorise people as being female or male, child or adult, trustworthy or not, and can furthermore recognise who specifically is speaking. How we establish mental representations for such categories of person characteristics has, however, only been explored in detail for voice identity learning. In a series of experiments, we therefore set out to examine whether and how listeners can learn to recognise a novel person characteristic. We specifically asked how diagnostic acoustic properties underpinning category distinctions inform perceptual judgements. We manipulated recordings of voices to create acoustic signatures for a person’s handedness (left-handed vs. right-handed) in their voice. After training, we found that listeners were able to successfully learn to recognise handedness from voices with above-chance accuracy, although no significant differences in accuracy between the different types of manipulation emerged. Listeners were, furthermore, sensitive to the specific distributions of acoustic properties that underpinned the category distinctions. We, however, also find evidence for perceptual biases that may reflect long-term prior exposure to how voices vary in naturalistic settings. These biases shape how listeners use acoustic information in the voices when forming representations for distinguishing handedness from voices. This study is thus a first step to examine how representations for novel person characteristics are established, outside of voice identity perception. We discuss our findings in light of theoretical accounts of voice perception and speculate about potential mechanisms that may underpin our results.
Introduction
Being able to categorise other people as belonging to different social groups is usually thought to help us navigate social interactions (Fiske & Neuberg, 1990; Liberman et al., 2017). This process of social categorisation can be achieved based on any information about the person we are encountering—faces, voices, verbal descriptions of another person, and beyond. In the case of voices, we can, for example, distinguish whether a person is male or female, an adult or a child, a native speaker or someone using a second language, and additionally form more subjective impressions of a person’s trait characteristics (Belin et al., 2011; Lavan, Burton, et al., 2019; McAleer et al., 2014). Category membership in the context of person perception and beyond is often tightly linked to the acoustic properties of the perceived voices: For example, voices that have a relatively higher F0 and wider formant dispersion (associated with a shorter vocal tract) are usually perceived as being female, while lower pitch voices with narrow formant spacing are usually perceived as male (Hillenbrand & Clark, 2009; Huber et al., 1999; Titze, 1989). Similarly, male voices with lower F0 are perceived to be more dominant (McAleer et al., 2014).
But how are such acoustics-based representations of different categories of person characteristics learned or established, such that they can later support the categorisation or recognition of that characteristic? Although many studies have explored how well listeners can categorise voices into different person characteristics, the question of learning appears to not have been tackled in detail in the context of voice perception (Kreiman & Sidtis, 2011). In fact, for voices, the only context in which the question of how representations of person characteristics are established has been examined in some detail is identity perception. In voice identity learning studies, listeners are usually asked to learn to recognise a small set of previously unfamiliar voices via a training procedure. In these studies, the outcome measure of interest tends to be accuracy of recognition. Studies then find that new voice identities can be learned after relatively brief training with accuracy depending on the tasks, voices, and specific stimuli used (e.g., Aglieri et al., 2017; Fontaine et al., 2017; Lavan, Burston, et al., 2019; Papcun et al., 1989; Von Kriegstein & Giraud, 2006).
In terms of how new voice identity representations are established to support recognition, models of voice identity perception have proposed that novel identities are encoded in relation to an average or prototypical voice (Belin et al., 2011; Lavner et al., 2001; Maguinness et al., 2018, see also Lavan, Knight, & McGettigan, 2019 for individual voices). However, there is no comprehensive account of which (and how) acoustic properties are used to establish representations during voice identity learning in naturalistic settings (Kreiman & Sidtis, 2011; Maguinness et al., 2018). This is perhaps not surprising given proposals that suggest that different acoustic cues are salient for different voices (and listeners, Kreiman & Sidtis, 2011). This does in turn make it difficult to comprehensively track how new identities are learned based on naturalistic stimuli.
There is therefore overall very little work empirically testing how listeners learn to distinguish between different categories of person characteristics, with the few studies that look into representations of person characteristics appearing to exclusively examine voice identity learning. In this study, we asked how novel person characteristics are learned outside of voice identity learning. We specifically asked how acoustic information is used to learn to distinguish between categories for a person characteristic. Listeners were asked to learn to distinguish categories within an entirely novel person characteristic—handedness (left-handed vs. right-handed) from voices. Handedness has no known acoustic signature in human voices, such that we could avoid asking listeners to carve out new categories in an already existing perceptual space. That is, although it is conceptually meaningful to ask listeners to learn any number of new voice identities, it is less straightforward for listeners to, e.g., learn what a third or fourth category of gender would sound like from voices. Asking listeners to learn about a novel person characteristic thus creates more of a perceptual blank slate upon which new categories can be formed with the interference of existing categories in this process being minimal.
Although there is not much work in the voice perception literature that tackles the research question above, relevant work can be found in a different literature that is looking at abstract auditory category learning. In auditory category learning studies, listeners are trained to be able to distinguish between two or more novel auditory categories. These studies report that listeners can in principle readily learn to recognise novel auditory categories, although the overall accuracy of learning depends on the specific nature of the acoustic manipulation (e.g., Ashby et al., 1998; Gabay et al., 2015; Goudbeek et al., 2009; Holt & Lotto, 2008; Roark & Holt, 2018, 2019; Scharinger et al., 2013).
Crucially, some of these studies have also directly explored how listeners use specific acoustic cues during learning to build representations of the newly learned categories. In these studies, listeners are usually trained to recognise novel auditory categories that either differ in one acoustic property or two co-varying acoustic properties (Ashby et al., 1998; Goudbeek et al., 2009; Roark & Holt, 2019; Scharinger et al., 2013). When relating these acoustic properties to listeners’ category judgements, during and after training, these studies usually show that listeners at least partially base their category judgements on the acoustic properties that do indeed distinguish between the categories. Depending on the nature of the relevant acoustic manipulation, however, listeners have at times been observed to apply non-optimal categorisation strategies: In these cases, listeners, e.g., do not use one or more of the diagnostic acoustic properties to make category judgements or conversely base partially their judgements on acoustic properties that are in fact not diagnostic in differentiating categories (Goudbeek et al., 2009; Roark & Holt, 2019; Scharinger et al., 2013). The latter finding suggests that even in the presence of a perceptual blank slate—created by training people to recognise sound categories that have no direct real-world correspondence—perceptual preferences or biases exist. That is, listeners apply their prior experience with how sounds work in naturalistic settings to their learning of novel categories (Roark & Holt, 2019; Scharinger et al., 2013).
In this study, we therefore, for the first time, ask how acoustics-based representations of different categories of person characteristics are learned from voice stimuli. To address this question, we apply the frameworks and methods used in auditory category learning to person perception from voices to our stimuli and data to examine how listeners learn to distinguish categories within a novel person characteristic, handedness, from the voice. To this end, we systematically manipulated the acoustic properties of natural voices (F0 and/or vocal tract length [VTL]) to create acoustic signatures of the handedness of a person (left-handed vs. right-handed) in their voice. To maintain rigorous experimental control and to be able to examine how specific acoustic properties are used when learning new categories of person perception, our stimulus manipulations followed the type of manipulations used in the category learning literature (Goudbeek et al., 2009; Roark & Holt, 2019), such that handedness was distinguished via differences in one acoustic property in Experiment 1 (Experiment 1a: VTL; Experiment 1b: F0) and via differences in two, co-varying acoustic properties in Experiment 2 (Experiment 2a: F0 and VTL, positive relationship; Experiment 2b: F0 and VTL, negative relationship). Listeners first completed a short training task with feedback to learn to distinguish the handedness categories. They then completed a test phase in which they were asked to categorise a set of novel voices based on their handedness. The current studies’ novelty thus lies in the fact that category learning for person characteristics (beyond identity learning) is entirely unexplored in the voice perception literature.
As a basic prediction, we expected that participants will be able to learn these novel person characteristics with above-chance accuracy, although accuracy may differ depending on the specific acoustic manipulations. More importantly, we also predicted that listeners would be sensitive to the specific acoustic properties that underpin the category differences, such that category judgements after training would at least to some degree reflect acoustic manipulations (Goudbeek et al., 2008, 2009; Roark & Holt, 2019; Scharinger et al., 2013). Given previous findings suggesting systematic perceptual biases (Roark & Holt, 2019; Scharinger et al., 2013), we furthermore expected that listeners may not come to this task with a “perceptual blank slate” but that instead, (relevant) prior experience with the properties of how human voices vary might also shape participants’ learning.
Methods
Participants
Participants were recruited via the online platform Prolific.co. All participants were fluent in English, born in the United Kingdom, aged between 18 and 40 years of age, had no self-reported hearing difficulties, and had an approval score for previous studies completed on Prolific of over 90%. This study was approved by the local Research Ethics Committee.
We tested 161 participants in total across 4 experiments. A total of 40 participants (mean age: 29.8 years, SD = 6.1 years, 35 female) participated in Experiment 1a, 40 participants (mean age: 30.1 years, SD = 5.4 years, 25 female) participated in Experiment 1b, 41 participants (mean age: 30.3 years, SD = 6.0 years, 24 female) participated in Experiment 2a, and 40 participants (mean age: 30.2 years, SD = 5.9 years, 26 female) participated in Experiment 2b. No participants were excluded from the final sample as all participants completed the vigilance trials (see section “Procedure”) with 90+% accuracy and no significant technical difficulties were reported.
Materials
Notably, 148 male voices were selected from the Saarbrücken Voice Database (Pützer & Barry, n.d.). All speakers were aged 18–25 years and had no reported voice pathologies. Voices were thus sampled from within one broad demographic. This was done to limit existing categories of person perception interfering with the to-be-learned categories in unexpected ways. Male voices were chosen over female voices as the acoustic manipulations applied to the stimuli (F0 and formant spacing) were less likely to result in shifts in the perceived demographic category. Notably, 74 voices were assigned to form the basis of the training stimuli, and the remaining 74 voices formed the basis of the test stimuli. Each speaker was represented by the sustained vowel /a/. To create voices that belong to purportedly left- and right-handed people, respectively, we then applied systematic acoustic manipulations to all the voices in the training and test stimulus sets: In Experiments 1a and 1b, we created voices of purportedly left- and right-handed people by manipulating one acoustic property, either F0 or VTL. In Experiments 2a and 2b, we created voices of purportedly left- and right-handed people by manipulating two acoustic properties, F0 and VTL. Thus, the same voices were used across all experiments, with only the type of acoustic manipulation changing. The acoustic manipulations were applied to the original stimuli using STRAIGHT (see Figure 1; Kawahara & Morise, 2011). Through this procedure, we thus created 74 stimuli representing left-handed and another 74 stimuli representing right-handed people for the training and another independent set of 74 stimuli representing left-handed and another 74 stimuli representing right-handed people for the test task. As a result of this manipulation strategy, voices of purportedly left- vs. right-handed people were identical to one another in training and test sets respective in all but the manipulated acoustic properties (see Goudbeek et al., 2008; Scharinger et al., 2013).
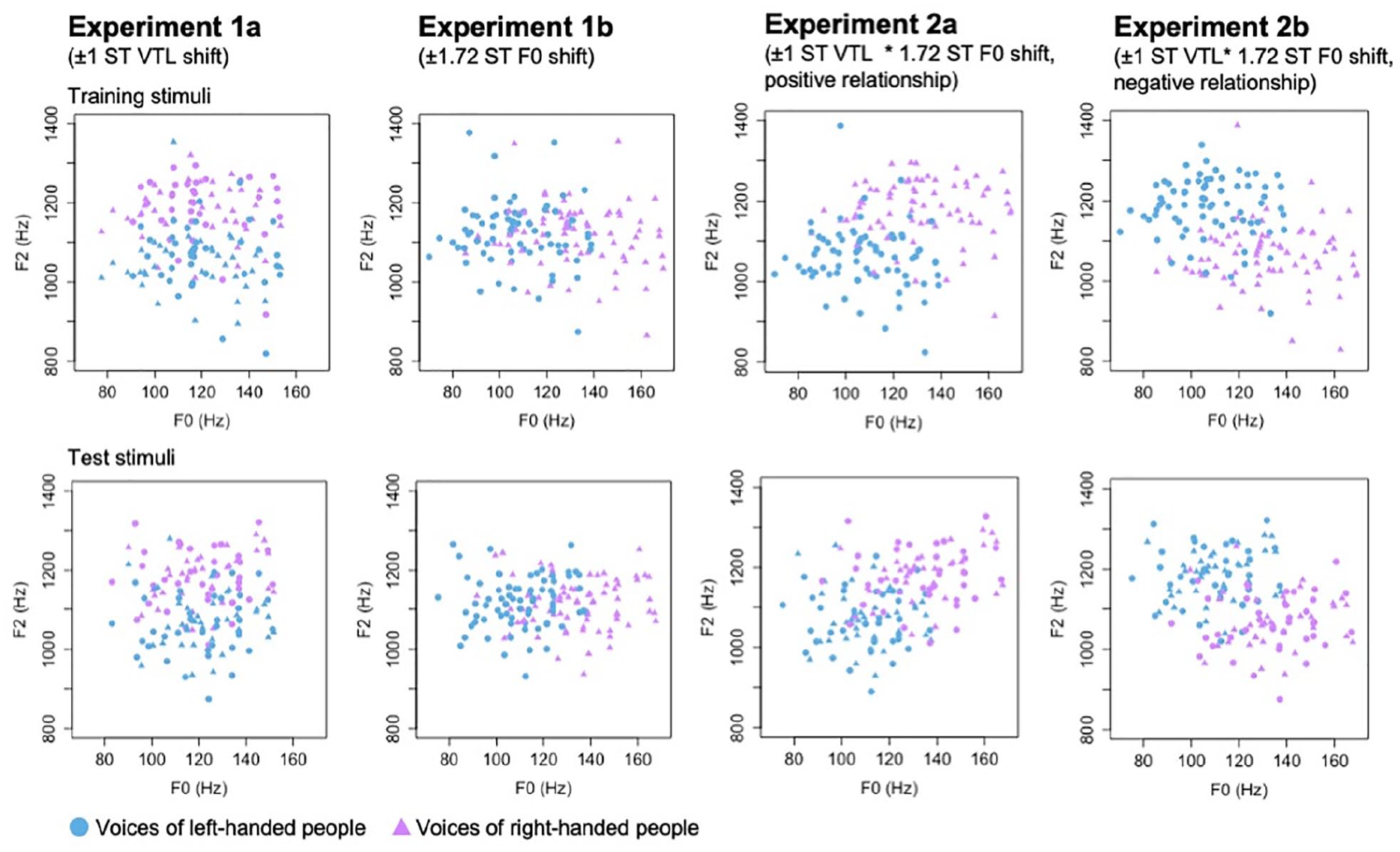
Scatterplots showing the distributions of voices manipulated to signal left-handedness (blue circles) and right-handedness (purple triangles) across the four experiments.
Throughout this article, we use the second formant (F2) to describe and assess the acoustic manipulation of the VTL applied to the voice recordings using STRAIGHT. This is because the formant tracks for the voice recordings in PRAAT (version 6.11.26, Boersma & Weenink, 2020) were overall substantially noisier for F3-F5 compared with F1 and F2. Summary measures taking all formants into account, such as the apparent VTL (aVTL) (e.g., Reby & McComb, 2003) were thus likely to be affected by this noise, rendering them less reliable and informative. When we furthermore compared how accurately F1 and F2 reflect acoustic manipulations applied to each set of stimuli across the four experiments, we observed that F2 could provide a more accurate index of the acoustic manipulation. We note that all of the reported findings of quantitative analysis in the article replicate when using F1 instead of F2 as a measure. This suggests that using a single formant is a valid way of assessing the formant shifts in the context of our experiments.
Below additional details about the acoustic manipulations of the voice recordings are provided: In Experiment 1a, F2 was shifted downwards by 1 semitone (ST) for left-handed people’s voices, while F2 was shifted upwards for right-handed people’s voices. In Experiment 1b, the voices differed in F0, where left-handed people’s voices were shifted down by 1.72 STs from the original F0, while right-handed people’s voices were shifted up by the same amount; 1.72 STs was used based on Gaudrain et al. (2009) who show that for every semitone change in VTL, a change in F0 of 1.72 STs is necessary to result in a comparable change in perception of voice identity—another person characteristic. After the acoustic manipulations, an informal check confirmed that all voices still sounded like adult male voices, such that the basic demographic properties of the original speakers were retained. Crucially, however, the manipulations of the respective acoustic properties introduced differences of 3.44 STs in F0 and 2 STs in VTL in the left-handed vs. right-handed versions of the original stimuli. These differences will have resulted in the left- and right-handed versions of the same original stimuli being perceived as separate voice identities if directly compared (see Gaudrain et al., 2009). Due to this and the fact that listeners only heard each voice once, it is therefore unlikely that listeners will have been aware that voices from left- and right-handed samples were identical aside from the acoustic manipulation.
In Experiment 2a, F0 and F2 were both shifted, such that higher F2 was associated with higher F0. This positive relationship created through the acoustic manipulation reflects how F0 and F2 tend to be related in voices across the population (higher-pitched voices are associated with a shorter vocal tract, indexed here through a higher F2). In Experiment 2b, the voices were shifted such that a higher F0 was associated with a lower F2. This negative relationship is therefore the opposite of the manipulation in Experiment 1a and is also not a relationship of F0 and F2 that is usually observed in voices across the population. For both Experiments 1a and 1b, we maintained the ratio of 1:1.72 ST shifts for F2 and F0.
We further validated our acoustic manipulations showing that across all four types of manipulations, left- and right-handed stimuli indeed differed on the manipulated acoustic property in both mean and distribution: Two-sample t-tests showed that the left- and right-handed stimuli were significantly different from one another terms of the manipulated acoustic properties (all ps < .001). Two-sample Kolmogorov–Smirnov tests furthermore confirmed that left- and right-handed stimuli were indeed sampled from two distinct distributions when looking at the manipulated acoustic properties (all ps < .001).
To confirm that the properties of the training and test stimuli were similar for left- and right-handed stimuli, respectively, we also ran two-sample t-tests and Kolmogorov–Smirnov tests by handedness category and acoustic feature. All t-tests showed that training and test samples for left- and right-handed stimuli, respectively, were similar in means for F0 (all ps > .486) as well as F2 measures (all ps > .375). All Kolmogorov–Smirnov tests showed that training and test samples for left- and right-handed stimuli, respectively, were taken from the same distribution for F0 (all ps > .485) as well as F2 measures (all ps > .511).
Procedure
The experiment was hosted on Gorilla (Anwyl-Irvine et al., 2020). After reading an information sheet and providing informed consent, participants completed a sound check to ensure the audio playback was working as expected. Following this, participants started the main experiment, where they completed two brief training tasks to learn to recognise handedness from voices, followed by a test phase.
For the first training phase, participants were informed that they are going to learn to recognise from someone’s voice whether this person is left-handed or right-handed. First, participants passively listened to a block of 13 examples of the voices of right-handed people and another block of 13 examples of the voices of left-handed people. For each block, the text “This person is right-handed/left-handed” was shown on the screen. The order in which the blocks were presented, as well as the order of stimuli within each block were randomised across participants. Following this passive exposure, the second part of the training started: Participants were presented with 148 recordings (half of which were left-handed, and half were right-handed people), one after the other, and were asked to indicate whether they thought the person was left-handed or right-handed. Participants received audio-visual feedback for each trial on whether they were correct or incorrect and were then shown the correct answer in writing on the screen. The order of stimuli in this part of the training was again randomised across participants.
After the training phase, participants entered the test phase to assess how and how well they had learned to distinguish the two groups of people. The test phase was identical to the second part of the training, aside from participants being presented with 148 new recordings (half labelled as left-handed and half labelled as right-handed, depending on the acoustic manipulations applied to them) that had not been part of either training task. Participants were once again asked to indicate whether the person was left-handed or right-handed. In contrast to the training, no feedback was provided at any point during the test phase. In addition to the 148 experimental trials, there were 8 further vigilance trials during which participants were presented with a recording of a voice instructing them to give a specific response for this trial (either “left-handed” or “right-handed”). The order of stimuli was randomised across participants (see exclusions). After the test phase, participants finally provided information on whether they had significant technical issues while completing the task (none reported). All data and stimuli are available from the author upon reasonable request.
Results and discussion
Recognition accuracy at test is above chance
The mean accuracy was 58.8% for Experiment 1a (±1 ST formant shift), 59.4% for Experiment 1b (±1.72 ST F0 shift), 63.6% for Experiment 2a (±1 ST formant * ±1.72 ST F0 shift, positive relationship), and 61.4% for Experiment 2b (±1 ST formant * ±1.72 ST F0 shift negative relationship).
We first analysed whether learning was significantly above chance (>50% correct) in each of the experiments. To do this, we ran a generalised linear mixed model (GLMM) predicting raw accuracy with experiment as a fixed effect with no intercept and participant, handedness, and stimulus as random effects with intercepts but no slopes using the lme4 package in R (Bates et al., 2007). Due to singular fits, we dropped the random effect of handedness from the final model:

From the final model, we then simulated confidence intervals (CIs) around the cell means for the fixed effects using the arm package (Gelman et al., 2015) in R. If these CIs did not include 0.5 (i.e., chance performance), accuracy in the respective condition was interpreted as being different from chance.
These models confirmed that accuracy for all four experiments was different from chance (all CIs [>0.55, >0.64]). This analysis therefore shows that listeners were indeed able to learn to recognise handedness from voices with some success. However, the analyses of overall accuracy presented here should be interpreted with some caution: Acoustic distributions for the voices of purportedly left- vs. right-handed speakers were overlapping (see Figure 1). As such, our assignment of handedness is at times at odds with the actual acoustic cues to handedness (e.g., if left-handedness was indicated by a downwards shift in F0, a purportedly left-handed person with naturally high F0 will be labelled as “left-handed” in the experimental design, even though its acoustic properties are objectively more representative of the acoustic signature of right-handedness). Future experiments may thus create more distinct stimulus categories to remove some of the constraints on the interpretability of the overall accuracy in these kinds of experiments.
Recognition accuracy at test is similar across all experiments
Overall accuracy may only be interpretable in the context of whether it is above chance (or not) in the current experiment. However, it is nonetheless meaningful to examine whether accuracy differs across the four acoustic manipulations. For this purpose, we re-ran the GLMM described above, now including an intercept for the fixed effect of the experiment. As for the model described above, we included handedness (left- vs. right-handed) in the random effects structure. This again led to a singular fit, leading us to drop this random effect from the final model:
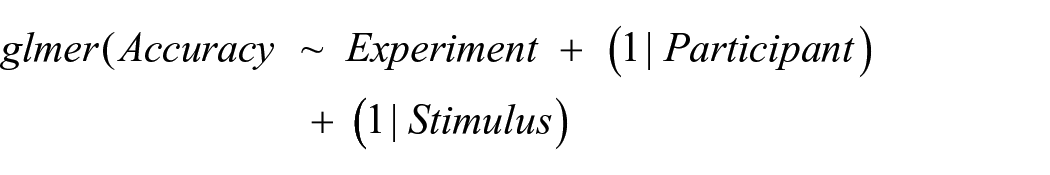
To assess the significance of the effect of the experiment, we used log-likelihood tests to compare this model to a reduced model, where the fixed effect of the experiment had been removed.
The inclusion of the experiment as a fixed factor did not significantly improve the model fit (χ2[3] = 4.32, p = .229, see Figure 2). Pairwise comparisons being computed via emmeans (Lenth, 2016) also suggested that there were no significant differences in accuracy between any of the experiments (zs < 1.90, ps > .057; alpha = .008 corrected for 6 comparisons). Thus, in contrast to previous research (e.g., Goudbeek et al., 2009; Roark & Holt, 2019; Scharinger et al., 2013) that has reported that category learning success depends on the type of acoustic manipulation applied to the stimuli, there was no statistically significant difference in how well listeners were able to learn to recognise handedness from voices for any of the four acoustic manipulations.
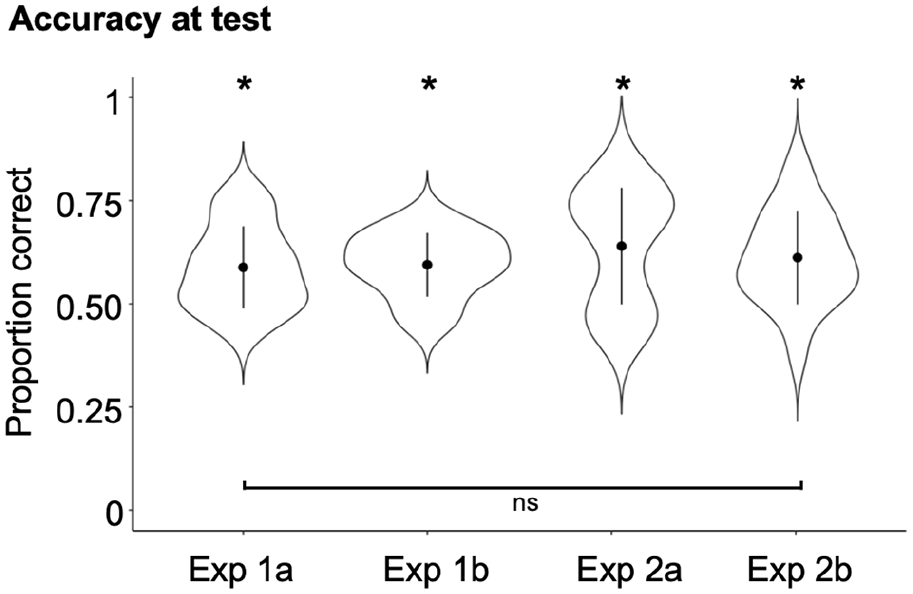
Violin plots of the mean accuracy by the participant for each experiment. Black circles show the means per experiment, and lines show the standard deviation.
Both diagnostic and non-diagnostic acoustic cues inform handedness responses at the group level
Listeners were trained to recognise handedness from voices using different configurations of acoustic cues. Consequently, listeners should have used acoustic properties differentially to inform their handedness responses across the different experiments (see Goudbeek et al., 2009; Roark & Holt, 2019; Scharinger et al., 2013). We therefore sought to formally establish if and how listeners used the acoustic properties of the voices after training to inform their judgements of handedness. To do this, we ran a series of four GLMMs to predict raw responses (1 = Left-handed, 0 = Right-handed) based on the voices’ acoustic properties, with one model being run for each type of acoustic manipulation. Specifically, in the models, we included z-scored F0 and z-scored F2 as fixed effects to predict raw responses. No interactions were modelled. We included participant and stimulus as random effects with intercepts but no slopes. The significance of effects was established via z-tests from within the GLMMs:
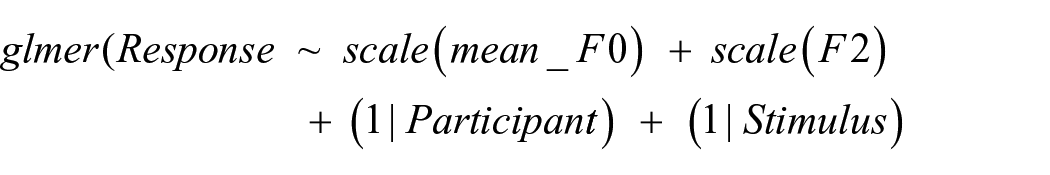
If listeners used the manipulated acoustic properties to inform their handedness judgements, we would expect to see that the effect of those manipulated acoustic properties is significant, with responses tracking the direction of the specific acoustic manipulation(s) applied to the stimuli in each experiment. For example, in Experiment 1a, left-handedness was indicated by F2 being 1 ST lower in relation to the original stimuli, while right-handedness was indicated by F2 being 1 ST higher relative to the original stimuli. We would therefore expect a significant negative effect of F2 for Experiment 1a in our GLMMs, with listeners providing more “left-handed” responses (coded as 1) for voices with lower F2, while higher F2 should lead to more “right-handed” responses (coded as 0; see Figure 3 top row). We would furthermore expect no effect of F0 on handedness judgements as F0 was not an informative cue to handedness in Experiment 1a. In our models, we now also included handedness as a fixed effect to reflect the experimental design. Significant effects of handedness would indicate response biases where participants were overall more likely to use one handedness category over the other. Listeners’ responses in the context of the acoustic properties of stimuli are illustrated in Figure 4. Model outputs are shown in Table 1. Directions of effects can be seen in the odds ratios (ORs), where an OR under 1 shows a negative relationship and an OR over 1 shows a positive relationship.
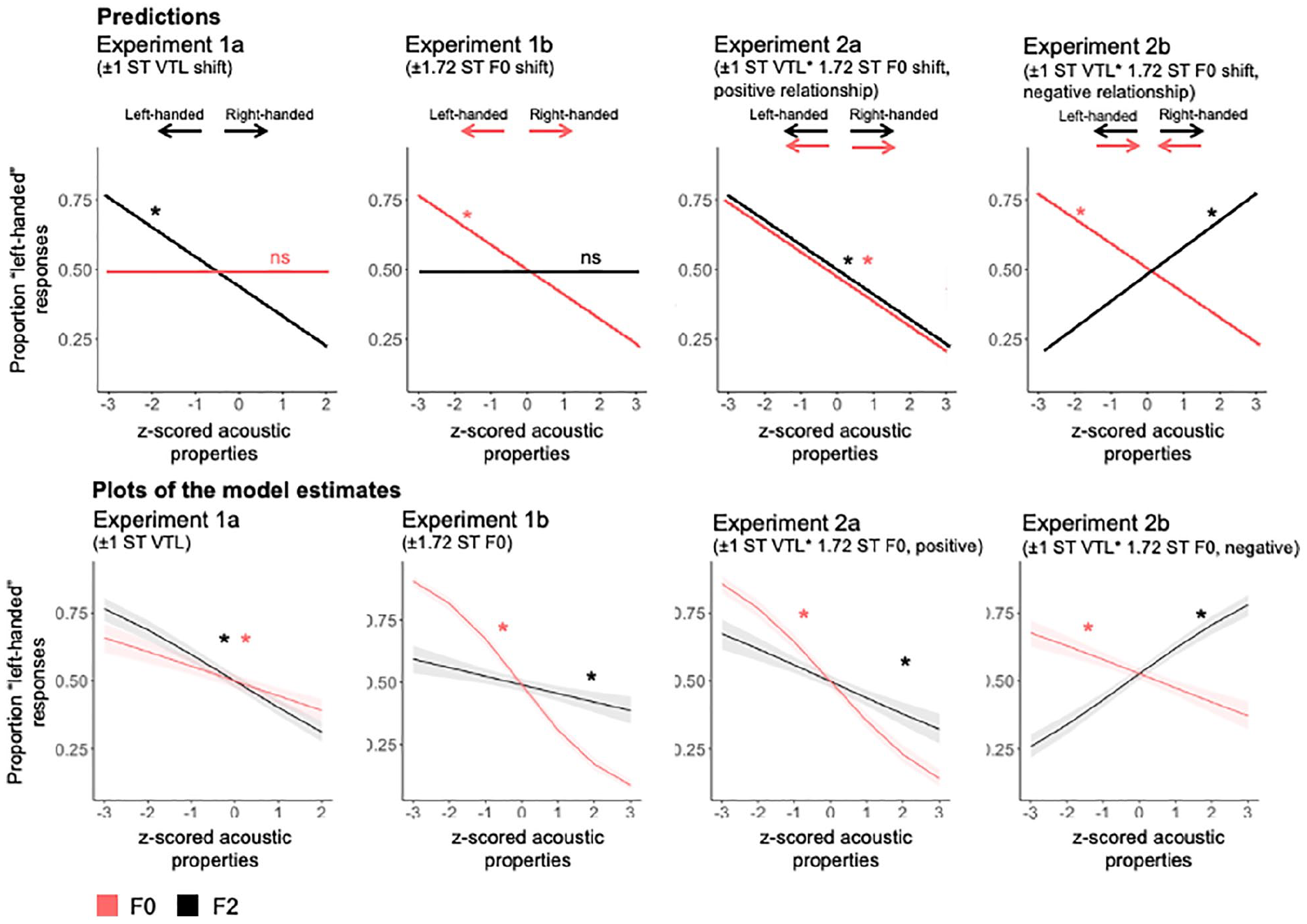
Top row: Illustrations of effects of acoustic measures on handedness judgements as predicted based on the acoustic manipulations across experiments. Bottom row: Model plots of the observed effects in the data. * indicates significant predicted and observed effects. Arrows indicate the direction of the acoustic manipulation for F0 (pink) and F2 (black).
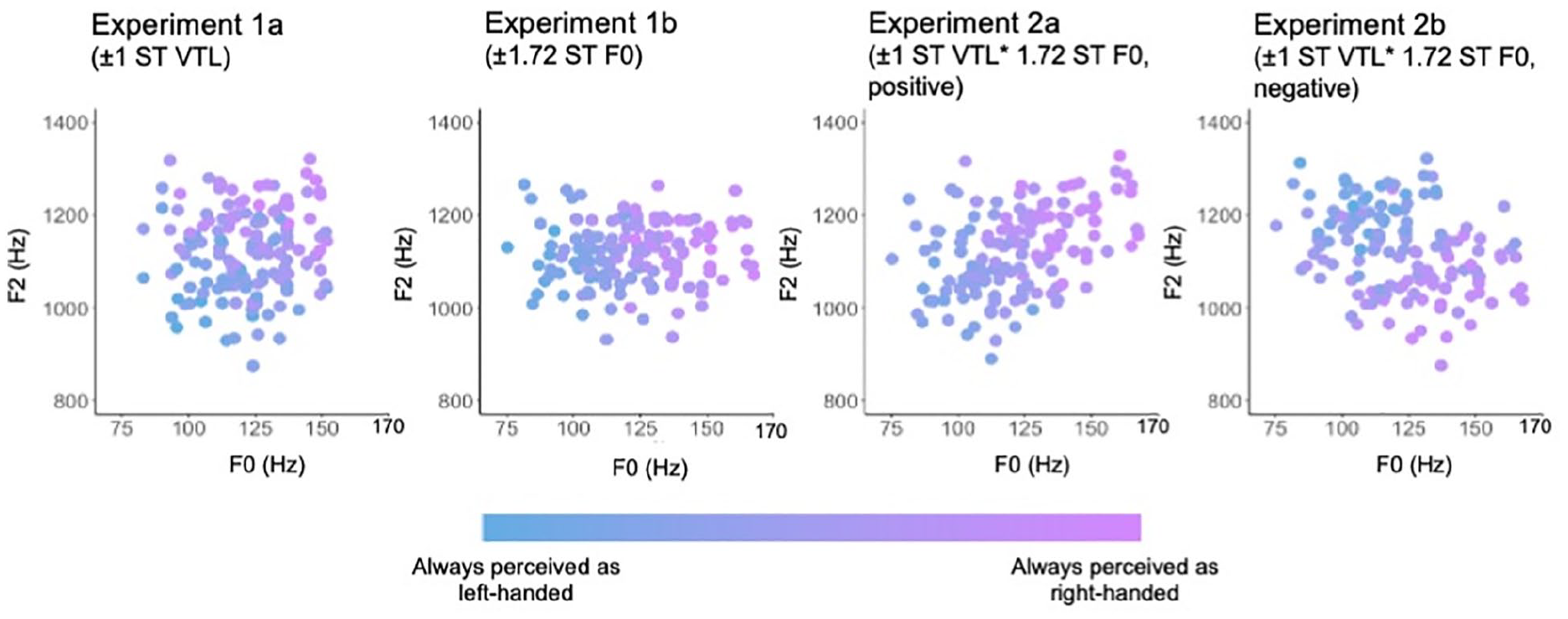
Scatterplot of F0 and F2 values for all training stimuli. Stimuli with increasingly blue shading were on average more often perceived as being left-handed, while increasingly purple shading indicates being on average more often perceived as right-handed.
Model outputs for GLMMs predicting handedness responses from acoustic properties.
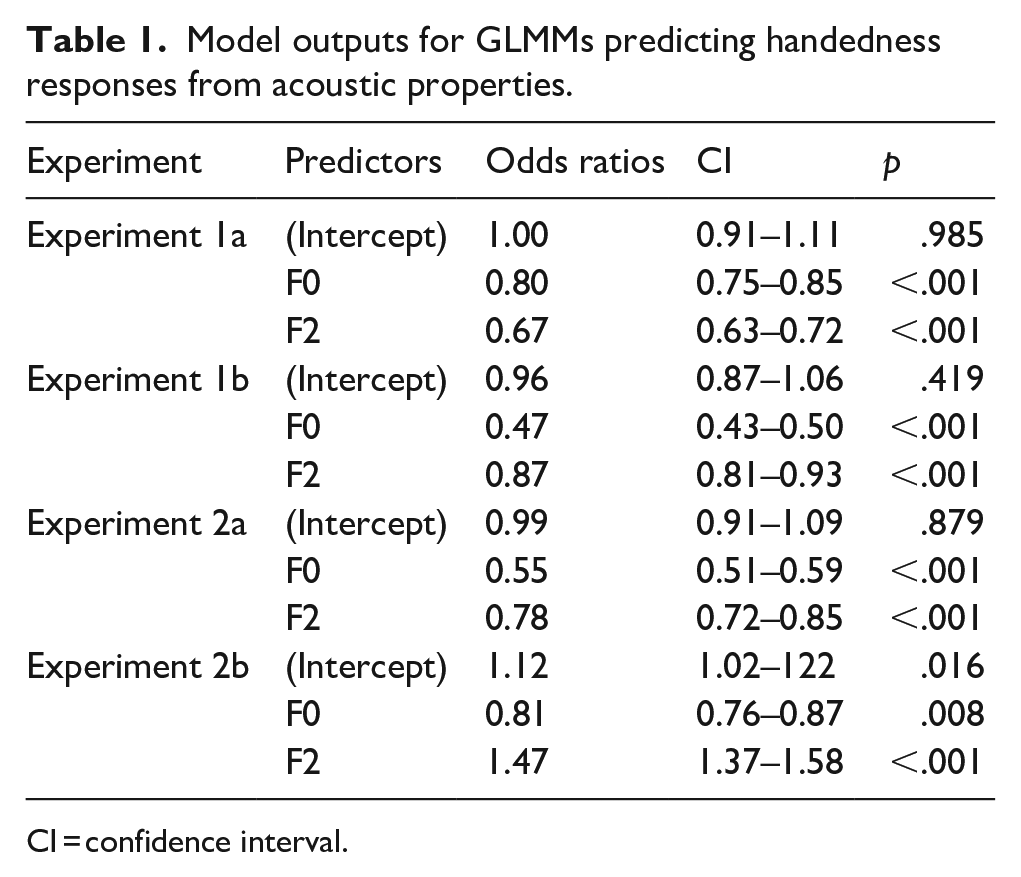
CI = confidence interval.
For Experiment 1a, we found, as expected, an effect of F2 that reflects the acoustic manipulations applied to the voices to indicate left- and right-handedness (OR = 0.67, CI[0.63–0.72]; p < .001): Listeners thus indeed perceived left-handedness in the context of the lower the F2 of the stimuli, while right-handedness judgements were made in the presence of higher F2 (see Figure 3). Unexpectedly, however, we also observed a significant effect of F0 (OR = 0.80, CI[0.75–0.85]; p < .001), showing that participants’ handedness judgements were also influenced by F0, despite F0 being uninformative in this experiment (see Figure 3).
For Experiment 1b, we found a significant effect of F0 reflecting the acoustic manipulations applied to the voices to signal left- and right-handedness (OR = 0.47, CI[0.43–0.50]; p < .001): The lower the F0, the more frequently listeners judged voices as being left-handed, while voices with higher F0 led to more “right-handed” judgements (Figure 3). As in Experiment 1a, we again unexpectedly observed a significant effect of F2 (OR = 0.87, CI[0.81–0.93]; p < .001), in the same direction of effects as the effect of F0 (Figure 3).
In the analysis of the data for Experiments 1a and 1b, we sought to establish how listeners use acoustic cues to inform their handedness judgements after training. In each of these two experiments, only one acoustic property, respectively, was manipulated to signal left- vs. right-handedness via the voice. We confirm that listeners identified the diagnostic acoustic properties that distinguish left- from right-handed individuals in training and used these acoustic properties to make handedness judgements. Listeners, however, also use the other, non-diagnostic acoustic property to inform their judgements in these experiments. Listeners have thus generalised this learning to another acoustic measure—even though the acoustic property is not informative for category distinctions. To establish that the observed effect is specific to these two related acoustic properties (F0 and F2), we re-ran the above models with another acoustic measure (harmonics-to-noise ratio [HNR]) included. HNR was not systematically manipulated in this study nor is there a (perceptually salient) existing relationship between HNR and F0 or F2. As a result, we should observe no effect of HNR on handedness responses if the effects observed are specific to F0 and F2. These models show that for both Experiments 1a and 1b, there is no effect of HNR on handedness responses, while the effects of F0 and F2 remain significant (see the online Supplementary Material). This analysis further confirms the relative specificity of the perceptual bias that links F0 and F2.
Our findings are therefore reminiscent of the findings of Roark and Holt (2019) and Scharinger et al. (2013) where listeners also showed a bias to use the two acoustic properties in their auditory category learning study, even when only one of these acoustic properties was informative or diagnostic. The authors argue that these perceptual biases are the result of long-term prior exposure to natural sounds that then consequently shape the category learning. This explanation of the results could also hold for our study, where effects for F0 and F2 go in the same direction in both Experiments 1a and 1b. It could therefore be argued that our findings reflect the positive relationship between F0 and F2, where higher F0 is associated with a shorter vocal tract (indexed by a higher F2), which is usually present in human voices and beyond (e.g., Assmann & Nearey, 2007).
For Experiments 2a and 2b, the F0 and F2 were manipulated at the same time to create either positive or negative relationships between the two acoustic properties. Given the use of both F0 and F2 for handedness judgements in Experiments 1a and 1b, Experiments 2a and 2b can be considered as a test of how expected (positive) vs. unexpected (negative) relationships between F0 and F2 affect how these acoustic properties are used to make handedness judgements.
Specifically, for Experiment 2a there was a positive relationship between F0 and F2 that aligns with listeners’ perceptual biases as observed in Experiments 1a and 1b. In Experiment 2a, we see the same pattern of results as for Experiments 1a and 1b, such that both F0 and F2 can significantly predict handedness responses (F0: OR = 0.55, CI[0.51–0.59], p < .001; F2: OR = 0.78, CI[0.72–0.85], p < .001; Figure 3). Although this is perhaps unsurprising, it is worth pointing out that the observed effects for the first time reflect the objective acoustic manipulations that were applied to the stimuli.
For Experiment 2b, where F0 and F2 were manipulated to create a negative relationship, we also found significant effects of F2 (OR = 1.47, CI[1.37–1.58], p < .001) and F0 (OR = 0.81, CI[0.76–0.87], p = .008). However, although the effects of acoustic properties have consistently been in the same direction for F0 and F2 for the previous experiments, there is now a positive relationship with handedness responses for F2, while a negative relationship is apparent for F0 for Experiment 2b. As in Experiment 2a, these effects thus also reflect the stimulus manipulations and show that listeners are capable of learning unexpected relationships between acoustic properties—despite their expectations about how these two acoustic properties usually co-vary in natural sounds. To again test the specificity of the relationships of F0 and F2 to handedness judgements, we re-ran the analyses above while adding HNR as an additional acoustic predictor. As in Experiments 1a and 1b, HNR was not a significant predictor of handedness responses, while F0 and F2 were once again significant predictors in Experiments 2a and 2b, confirming the relative specificity of the reported effects (see the online Supplementary Material).
The analyses above thus show that listeners can learn to make category judgements based on diagnostic acoustic cues that distinguish between categories, even in the presence of cues that include unexpected acoustic relationships. There is, however, evidence that the different types of relationships can modulate the degree to which the manipulated acoustic properties are used when making handedness judgements. A GLMM across all four experiments, modelling F0, F2 and Experiment, alongside all possible interactions as fixed effects and participant and stimulus as random effects, shows that the slopes for F0 are steep when the relationship between F0 and F2 aligns with listeners’ expectations (Experiment 2a, beta = –.60, 95% CIs = [–0.69, –0.52]; see Figure 3) and when F0 was manipulated on its own (Experiment 1b, beta = –.77, 95% CIs = [–0.84, –0.69]). In contrast, slopes for F0 effects are shallower for Experiments 1a (beta = –.21, 95% CIs = [–0.28, –0.14]) and 2b (beta = –.22, 95% CIs = [–0.29, –0.15]), where F0 was either not manipulated at all or where perceptual expectations for how F0 and F2 usually relate to one another were not met. CIs for the slopes for Experiments 1a and 2b overlap or touch, indicating that slopes can be considered similar (Cumming, 2009). The same is true for CIs for the slopes for Experiments 1b and 2a. Conversely, CIs for all other pairwise comparisons do not overlap, such that these slopes can indeed be considered different from one another.
Although the slope for the effect of F0 differs markedly across experiments, this pattern of results is much less pronounced for F2: Independently of the direction of the observed effect, the steepness of slopes is relatively similar across all experiments: CIs around the slopes for F2 effects overlap or touch for Experiment 1a (beta = –.39, 95% CIs = [–0.46, –0.33]), Experiment 2a (beta = –.25, 95% CIs = [–0.32, –0.17]), and Experiment 2b (beta = .39, 95% CIs = [0.33, 0.46) when considering absolute numbers, i.e., inverting the values for Experiment 2b. The slope for the F2 effect for Experiment 1b is somewhat shallower (beta = –.14, 95% CIs = [–0.21, –0.06]), such that CIs overlap with those from Experiment 2a but not for the other experiments. Overall, however, these findings nonetheless confirm that slopes are more much uniform for the effects of F2, while they vary substantially systematically for F0.
Although individual differences exist, group-level findings are also reflected for individual listeners
To provide a further visualisation of how the group-level effects reported above relate to individual listeners’ strategies, we ran a logistic regression on each participant’s data. In these logistic regressions, we predicted a participant’s binary handedness responses from the F0 and F2 of the relevant stimuli. We then extracted the β-weights for the F0 and F2 predictors for each participant (see Scharinger et al. [2013] for a similar analysis). For Experiments 1a, 1b, and 2a, most β-weights fall into the lower, left-hand quadrant of the graph (see Figure 5). This means that across these experiments, most listeners judged voices as left-handed in the context of both lower F0 and lower F2. For Experiment 2b, the pattern is somewhat less clear: There are β-weights across all quadrants, potentially suggesting overall more variability in listeners’ perceptual strategies in making handedness judgements when F0 and F2 are negatively correlated to signal handedness. Numerically, most listeners fall onto the upper right-hand quadrant (17 out of 37), which would indicate that voices with higher F0 and higher F2 were associated with left-handedness. β-weights in this quadrant for F0 are, however, small (<1) in the context of this experiment, suggesting no substantial reliance on F0. A substantial number of listeners (13 out of 37) also fall onto the upper left-hand quadrant: Listeners falling into this quadrant perceived voices with lower F0 and higher F2 as left-handed, which reflects the stimulus manipulations in Experiment 2b. When comparing, absolute β-weights for F0 appear to be larger, while β-weights for F2 appear to be of similar size to what is observed in the upper right-hand quadrant—thus driving the observed effects at the group level. This increased heterogeneity in how individual listeners used F0 to inform their handedness judgements can thus explain why we see a relatively shallow slope for the effect of F0 at the group level.
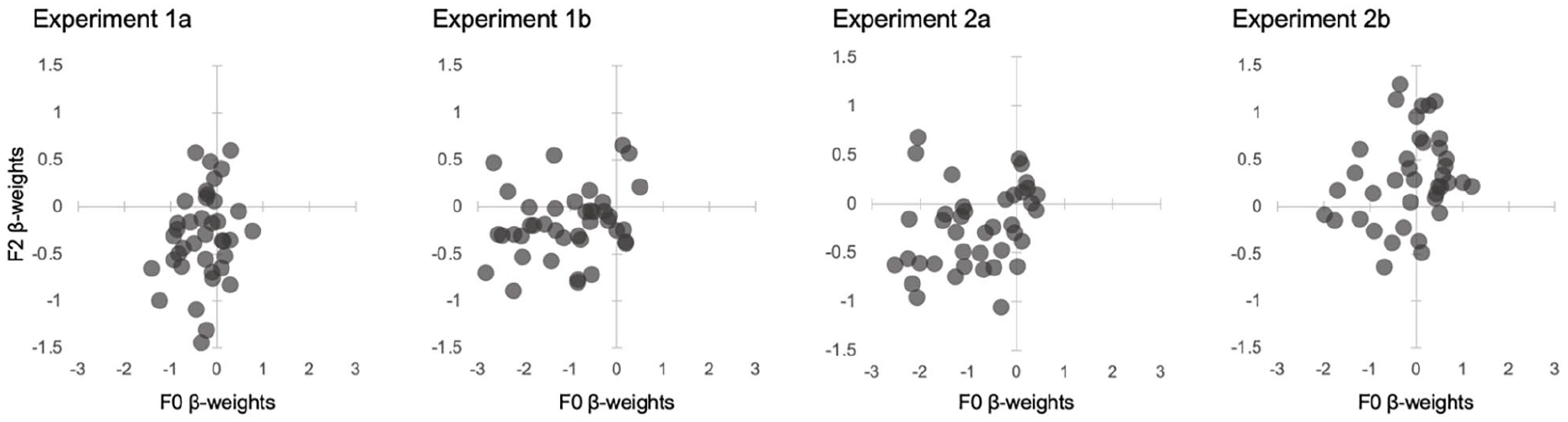
Scatterplots of listener-specific β-weights for F2 and F0 as predictors of handedness. The higher the β-weights for an acoustic parameter, the more a listener has used this acoustic parameter to inform their handedness judgements.
Crucially, across all experiments, most β-weights are at least numerically different from 0, thus showing that most listeners have used both F0 and F2 to some degree to inform their handedness decisions. This again ties in with our group-level observations being broadly reflected in individual listeners’ handedness responses. In addition to these broad trends, individual differences are also apparent in these scatterplots, as indicated by the spread of the individual data points in Figure 5. What drives these potential individual differences in listening strategies cannot be determined from our data. We can, however, speculate that the individual differences could simply reflect ad hoc differences in learning strategies that are specific to the task and stimuli used here. Alternatively, these differences could potentially reflect individual differences in prior experience with human voices—or at least in how the prior experience was evaluated by the listeners—such that the perceptual biases that lead to listeners assuming a negative relationship between F0 and F2 may be more or less salient for some listeners.
General discussion
Listeners can indeed learn novel person characteristics—in this case handedness—from the voice with above-chance accuracy. Although this kind of auditory category learning is informed by diagnostic acoustic cues, we observed additional perceptual biases that shape learning and consequent perceptual judgements and argued briefly that these biases may reflect listeners’ long-term exposure to natural sounds and/or, more precisely, human voices. Our study is thus to our knowledge the first to systematically explore whether novel categories of person characteristics can be learned and how this is achieved, outside of the context of voice identity perception.
Specifically, we observed that listeners can learn novel categories with above-chance accuracy and use diagnostic acoustic information to make handedness judgements from voices after training. That is, if F0 was manipulated during training to distinguish between left-handed and right-handed individuals based on their voice, listeners did in fact use F0 to categorise voices according to their handedness after training. Handedness distinctions in relation to acoustic properties were made in an apparently continuous manner, where, e.g., left-handedness was associated with relatively lower F0, while right-handedness was associated with relatively higher F0 (see Experiment 1b). Voices with the most extreme values for the diagnostic acoustic properties were perceived as most clearly being left or right-handed, with less extreme values being generally perceived as more ambiguous in terms of handedness (see Figure 4).
This apparently continuous use of acoustic features for handedness judgements could potentially also shed light on how mental representations of handedness were formed. As voices with the most extreme values for diagnostic acoustic properties are best recognised as being left- vs. right-handed, there is then limited scope for what would be understood as average-based coding for within-category representations: For example, for average-based coding, voices close to the within-category average should be best recognised as belonging to that category (see Lavan, Knight, & McGettigan, 2019). Thus, although the encoding of categories in a continuous manner certainly aligns with findings from the auditory category learning literature, our results do not fully align with the predictions of models of voice perception that often stress the role of averages when, e.g., learning to recognise new voice identities (e.g., Maguinness et al., 2018; Fontaine et al., 2017; Lavan, Knight, & McGettigan, 2019). Why average-based coding does not seem to be apparent here is not clear: Perhaps the short training was not sufficient to establish average-based representations or that the specific training and test tasks did not encourage average-based coding (e.g., Fontaine et al., 2017; but see Lavan, Knight & McGettigan, 2019). Similarly, we can speculate that our findings could be due to there only being two categories of handedness instead of the many categories present for voice identity perception. In the context of only two categories, the coding of categories as two ends of a continuum of an acoustic cue based on a simple rule may be more efficient than average-based coding (see also, e.g., continuous shifts in the perception of gender from voices, Mullennix et al., 1995). However, although ours as well as other findings (e.g., Goudbeek et al., 2009; Roark & Holt, 2019; Scharinger et al., 2013) suggest that there are potentially multiple ways in which acoustic information is encoded in representations of person characteristics, more work is needed to explore when and how these potentially different coding strategies are used.
In our study, we furthermore observed that the use of acoustic properties to inform handedness judgements did not always reflect how left- and right-handed voices were objectively distinguishable. Specifically, we found evidence for perceptual biases where listeners systematically used non-diagnostic acoustic properties in addition to the diagnostic cues in handedness judgements (i.e., integrating F0 and F2, see Experiments 1a and 1b). That is, if F0 was manipulated during training but F2 was not, listeners nonetheless based their judgements of handedness on both F0 and F2. These findings are broadly in line with what Scharinger et al. (2013) and Roark and Holt (2019, see also Roark et al., 2022) report: How categories differ physically or acoustically does not always align how these differences are or can be perceived and thus learned and later on used to information category judgements—even when listeners learn entirely novel categories on what should therefore be a perceptual blank slate.
We note, however, that, at the same time, our results differ in some respects from previous studies: For example, Roark and Holt (2019) report that perceptual biases do not only shape how acoustic cues are used to make category judgements but also affect the accuracy of these judgements. Scharinger et al. (2013) report similar differences in accuracy depending on the specific acoustic manipulation applied to distinguish category membership, where acoustic manipulations that fall in line with how acoustic properties align naturally, led to higher accuracy. In our study, accuracy is, however, not affected but the different acoustic manipulations. Furthermore, the perceptual biases observed in this study appear to be somewhat weaker than the ones reported in Roark and Holt (2019): In Roark and Holt (2019), most participants persist in using a single perceptual strategy, even when that strategy is not optimal. We observe that even for Experiment 2b, where acoustic manipulations went in the opposite direction to the relationship listeners appear to be biased to use, most participants’ strategies differed from the strategy that would align with the perceptual bias. Not finding differences in accuracy, alongside more malleable perceptual biases when processing voices. We might speculate that this might be a reflection of how variable voices as a category are within and between individuals (Lavan, Knight et al., 2019). If voices are a highly variable category per se and voice use (i.e., adapting how our voice sounds depending on the speaking situation) introduces further variability, having strong perceptual biases around what voices “should” sound like might be detrimental to voice learning and voice perception. More generally, however, it should be noted that the above studies as well as ours all use different types of acoustic manipulations, such that discrepancies in the specific patterns of results across these studies are perhaps not surprising. Instead, the discrepancies further illustrate how prevalent perceptual biases are across a range of acoustic properties and how these biases can shape listener’s experience and decisions when perceiving voices or sounds more broadly.
In terms of perceptual mechanisms underpinning our findings and the perceptual biases more broadly, two largely independent explanations could be relevant to explain our findings. First, it is well-established that sets of acoustic properties are, often not readily perceived in isolation but are integral during perception (e.g., Garner, 2014; Roark & Holt, 2019). Indeed, the acoustic properties manipulated in our study, F0 and F2, are thought to often be perceived in an integral manner (Goudbeek et al., 2009; Scharinger et al., 2013). This integral nature of the perception of manipulated acoustic properties could then explain patterns of results in our study. In the context of our study, we have furthermore already briefly speculated that the propensity for integrating F0 and F2 following a positive relationship reflects how F0 and F2 usually (co-)occur for human voices in the population. For example, female voices usually have a higher F0 than male voices and are associated with a shorter vocal tract, which is associated with higher F2 (e.g., Hillenbrand & Clark, 2009; Huber et al., 1999; Titze, 1989), while children also have a higher F0 and F2 than adults (Assmann & Katz, 2000). This prior experience could similarly explain the observed results. More broadly, we may also speculate that the integral perception of specific acoustic properties may in itself be the result of long-term exposure to the statistical regularities of these acoustic properties in natural sounds (e.g., Roark et al., 2022; Roark & Holt, 2019). As such, instead of putting integral perception and prior experience against each other, both could be interlinking factors that may contribute to perceptual biases observed in our study. Notably, these kinds of explanations rest on fairly low-level perceptual mechanisms, which are appropriate for auditory category learning for categories are abstract and have no clear relationship with the sounds we may perceive and categorise in everyday life. In the context of person perception from voices, where the auditory categories are arguably more meaningful, there is, however, scope to speculate about other, higher-level processes that may alternatively, or additionally, explain our findings.
When considering such higher-level processes, the perceptual biases observed may be a reflection of existing representations of voice or person characteristics being used to support learning. For example, listeners could have perceived left- and right-handedness to not only be signalled via systematic differences in low-level acoustic properties but may have also perceived differences in higher-level social attributes. For example, changes in either F0 or formants (or both) as they were implemented in this study, have previously been shown to affect the perception of voice identity (Baumann & Belin, 2010; Gaudrain et al., 2009), gender (Bachorowski & Owren, 1999; Hillenbrand & Clark, 2009) and social traits (Belin et al., 2017; McAleer et al., 2014; Tsantani et al., 2016) among many other person characteristics. If the acoustic manipulations that distinguished handedness from voices happened to align with shifts in, e.g., the perceived social traits of the voices of purportedly left- vs. right-handed people, listeners may have used these higher-order characteristics as a scaffold when learning to distinguish handedness.
Which types of representations (low- vs. higher-level) were used during our task cannot be determined from the current data. However, we could speculate that if different listeners use different types of strategies and representations, this could in principle give rise to individual differences as we have observed in our data. There is some anecdotal evidence for such heterogeneity of listening strategies across participants from the debrief questionnaire: Here, participants were asked to provide brief free text responses describing how they thought left- and right-handed voices differed from one another. In these responses, some participants appear to describe listening out for low-level acoustic properties, be they diagnostic or not, such as F0, duration, periodicity, and basic intonation patterns. Other participants described clearly higher-level properties, such as perceived emotional content, social traits, and perceived age. In light of this, it could be predicted that listeners who used higher-order representations may have used additional non-diagnostic acoustic properties during handedness judgements, as higher-order representations are likely more complex and a less accurate match to the specific acoustic manipulations applied to our voices. Conversely, listeners, who were able to focus on the lower-level acoustic differences between handedness may have been more likely to objectively analyse any perceived acoustic differences. As a result, they may have thus been able to derive rules that guided their handedness judgements that are more reflective of the low-level acoustic manipulations we applied to the voices to signal handedness. This interpretation of the individual differences observed is, however, highly speculative, such that more careful research is needed to further explore how potential differences in listening strategies across individuals arise and how they affect auditory perception.
Overall, our study thus raises some intriguing questions about how representations of auditory categories of person characteristics are formed and how acoustic information is consequently used to make judgements about these person characteristics. From a methodological point of view, this study also opens up new, fruitful avenues for future work in voice perception research by applying methods from the (auditory) category learning literature to questions around person perception from voices. Through training listeners to learn novel person-related categories via acoustically manipulated voice recordings, this study demonstrates how we can study how novel categories of person perception (and beyond) are formed, outside of the context of voice identity perception. Using this approach, basic research questions can be asked about how such perceptual categories are established on what can be considered a perceptual blank slate and how they may interact and change according to the listeners’ experience. Future work could then, for example, replicate some well-established findings from voice identity learning in the context of another person-related characteristic, such as distinctiveness effects of voice identity perception (Stevenage et al., 2018), perceptual aftereffects (Bestelmeyer & Mühl, 2021; Latinus & Belin, 2011, 2012), and potential high-variability benefits of category learning (Lavan, Knight, et al., 2019). Such studies could help establish the generalisability of these findings from voice identity perception, potentially highlighting perceptual effects and mechanisms that are present in many aspects of voice perception and face perception (and beyond), while also pinpointing which findings are specific to voice identity perception.
Similarly, we stress that this study is only an initial step to examine category learning in the context of person perception from voices, where we opted to distinguish between categories in highly artificial ways. For example, we used the same sets of voices for left-handed and right-handed individuals, marking category differences via systematic changes in one to two acoustic cues. This type of manipulation was chosen deliberately to ensure experimental control over the stimuli. However, this type of manipulation also limits the ecological validity of the categories to be learned: Naturally occurring voice-based categories will differ from the categories used in our experiments in terms of category separability, variation in non-diagnostic features, their multi-dimensionality, and complex co-dependencies among these multiple dimensions. Further research is therefore needed that builds on this study and adapts the methods from the category learning literature to create more naturalistic and ecologically valid voice-based categories. Such work could then evaluate if and how the current findings generalise to more ecologically valid contexts and might eventually be able to address the question of whether and how the learning of socially relevant auditory categories may differ from non-social categories.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218241228849 – Supplemental material for Left-handed voices? Examining the perceptual learning of novel person characteristics from the voice
Supplemental material, sj-docx-1-qjp-10.1177_17470218241228849 for Left-handed voices? Examining the perceptual learning of novel person characteristics from the voice by Nadine Lavan in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: N.L. was supported by a Sir Henry Wellcome Fellowship (220448/Z/20/Z).
Supplementary material
The supplementary material is available at qjep.sagepub.com.
Data availability
All data and stimuli are available upon reasonable request from the author.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.