
Abstract
We present experimental evidence showing that different wh-filler-gap dependencies are processed differently, depending on their syntactic licensors. Our studies compared the active storage profiles for why, how, and who (serving as subject or object of the verb). The results of offline and online experiments revealed that these wh-fillers are stored in memory for different durations, and predictably so based on the hypothesised structural distance between each wh-filler and the licensor which determines its grammatical and interpretive functions. Furthermore, the results showed that once the wh-filler is licenced, it is integrated to the current structure, and no longer engenders additional memory costs. Based on these findings, we argue that the mechanism of online sentence processing may employ both storage and integration components in memory.
Keywords
Introduction
A prominent feature of human language is its display of dependencies that span across unbounded distances (Chomsky, 1977). Sentence (1) is an example of such a dependency.
(1) What did Jason eat yesterday?
Specifically, a Wh-Filler-Gap Dependency (WhFGD) involves two elements: a wh-filler like what in (1) and its grammatical licensor. In (1), the wh-filler is licenced by the verb, eat. The grammatical properties of the wh-filler (e.g., whether it relates to subject or object position, whether it bears nominative or accusative case) and its interpretation (e.g., whether it questions the agent or patient roles of the event described by the clause) are controlled by its grammatical licensor (See Huddleston & Pullum, 2005, p. 1079, for the description of this type of dependency relation). In (1), the wh-filler is licenced by the verb eat: what functions grammatically as the direct object of that verb, and is interpreted as ranging over the patient of the event described by the verb (i.e., the thing eaten). Evidence of the close-knit relationship between what and the verb in (1) can be found by filling the surface object position with some other distinct expression, and observing that this uniformly leads to judgements of unacceptability (e.g., *What did the student in the playground eat sushi?; Chomsky, 1981). The wh-filler is thus occasionally referred to as the “dependent element” and its licensor as the “controller.” 1
The possible distance between the wh-filler and its licensor has no necessary limit, and so constructions like (1) are often described as instantiating “unbounded dependencies” (McElree et al., 2003; Ross, 1984). The existing literature provides a useful framework within which to talk about how WhFGDs are processed. Wagers and Phillips (2014) identified three processes involved. First, upon encountering a wh-filler, the comprehender’s syntactic parser recognises the presence of a WhFGD. This wh-element—the wh-filler—is then stored in memory until its licensor is encountered and the filler can be integrated into the existing structural representation (Wagers & Phillips call this a “retrieval event”). 2 Gibson (1998) and Gibson and Warren (2004) furthermore identified two sources of processing complexity induced by WhFGDs: (a) Storage cost: holding an open dependency is difficult, and therefore processing of material within an open dependency is more costly than processing the same material when it is not within an open dependency; (b) Integration cost: the longer the filler is stored in memory, the harder it is to integrate into the structure.
The processing of WhFGDs involves these component processes due to their grammatical properties. A wh-filler cannot be interpreted unless it has a licensor; and, often, a wh-filler and its licensor are not adjacent to one another. Therefore, a wh-filler needs to be stored until the parser encounters the appropriate licensor. Given that the wh-filler does not dictate the structural location of its licensor, and given that the distance between the two is potentially unbounded, the filler must be stored over a potentially long period regardless of any concomitant cost to memory resources. The WhFGD will no longer impact memory resources once it is integrated into the current parse and interpreted (Gibson, 1998, 2000; Wagers & Phillips, 2014; Wanner & Maratsos, 1978). The intrinsic cost of storing a wh-filler, then, could serve as a strong motivation for a comprehender to complete the dependency as soon as possible, which has been observed in a number of studies related to active gap filling (Chacón et al., 2016; Crain & Fodor, 1985; Frazier, 1987; Gibson, 1998; Gibson & Warren, 2004; Stepanov & Stateva, 2015; Stowe, 1986; Wagers et al., 2015; Wagers & Phillips, 2014; Wanner & Maratsos, 1978).
These properties of WhFGD processing raise the interesting question of how different kinds of WhFGDs are processed (de Vincenzi, 1991; Frazier, 1987; Gibson, 1998, 2000; Stepanov & Stateva, 2015; Wagers & Phillips, 2014; Wanner & Maratsos, 1978). Grammatically, different WhFGD constructions have different dependency lengths, which is to say that they reliably resolve at different structural distances from their licensors. This study investigates how wh-fillers such as who (serving as subject or object of the verb), how, and why are processed online, paying special attention to the storage and integration components of the mechanism of online dependency formation. If both storage and integration costs are at play in the mechanism of sentence processing, we expect that the processing should incur costs between a filler and its licensor because the filler has to be maintained in memory (i.e., storage costs; Chen et al., 2005) and there is an associated difficulty with completing the dependency (i.e., integration costs; de Vincenzi, 1991; Grodner & Gibson, 2005; Warren & Gibson, 2002). Our results provide supporting evidence for storage and integration components in the mechanism of online sentence processing (Gibson, 1998; Gibson & Warren, 2004; Kim et al., 2020; Ness & Meltzer-Asscher, 2017, 2019; Wagers & Phillips, 2014; Wanner & Maratsos, 1978).
The processing of wh-filler-gap dependencies
Grammatical properties of wh-fillers
Different wh-fillers enter dependency relations with different licensors (Chapman & Kučerová, 2016; Chomsky, 1986; Huang, 1982; Lasnik & Saito, 1994; Stepanov & Tsai, 2008). What is constant between these wh-fillers, we observe, is that their surface sentence-initial position marks their presence at the syntactic level CP. 3 The difference between them is not where they start out but where they are licenced. Differences in dependency length for a WhFGD are thereby captured in the syntactic theory in terms of the distance between the CP and position of the licensor. Thus, we begin with the structural positions of different wh-phrases, briefly reviewing the uncontroversial cases of who and how, and spending a little more time on the relatively more abstract case of why.
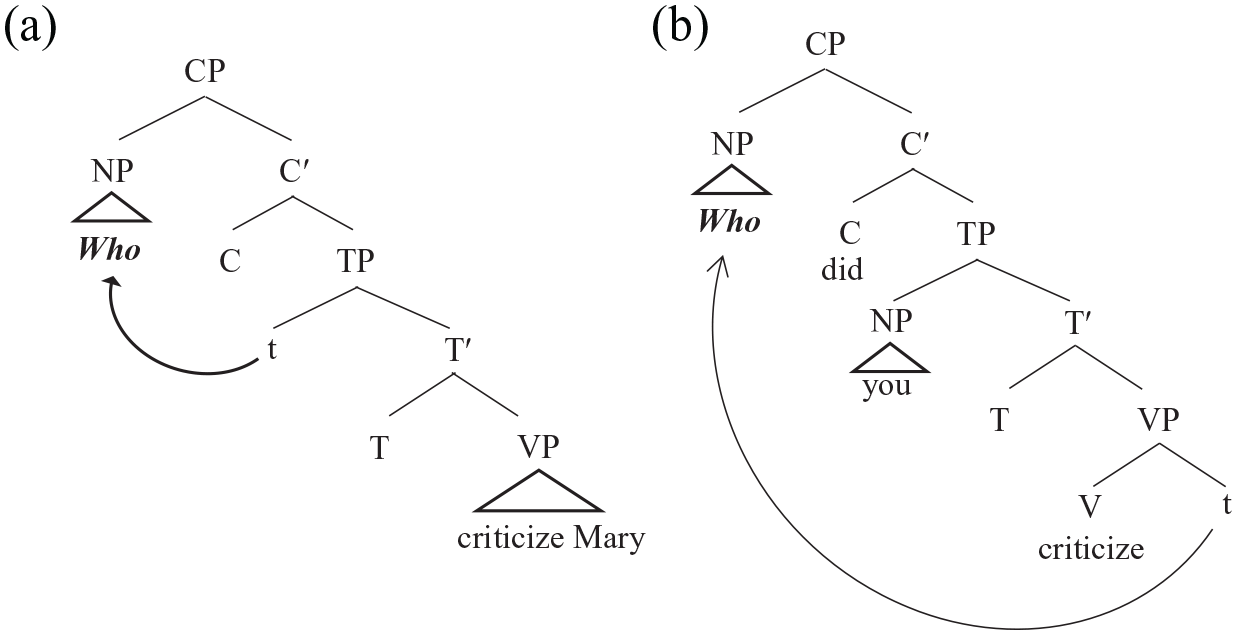
First, the wh-filler who can function as a subject or object, and it is interpreted roughly as ranging over the agent or patient roles, respectively, of the event described by the verb. These distributional and interpretive facts are captured as follows: when who functions as the subject (whosubj), a grammatical dependency is established between its initial position in the TP and its surface position in the CP, as shown in (2a) (in this article, we refer to the lower position of the dependency as “the gap”). When who functions as the object (whoobj), a dependency is formed between CP and its initial position as sister to V, as shown in (2b).
(2)
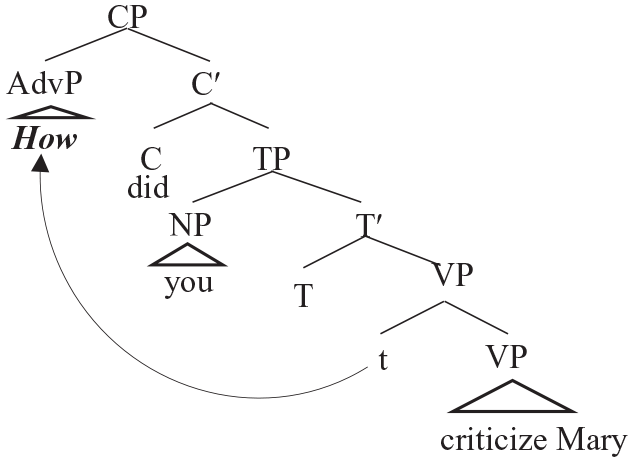
The wh-filler how, interpreted as ranging over manners in which the agent carries out the described event, functions as an adjunct of VP (Ernst, 2001, 2007; Jackendoff, 1972). Dependency formation with how, in this case, links VP with CP, as shown in (3); it has been shown that manner adverbs appear at the VP-edge position as illustrated in the sentences with a manner adverb (e.g., You have harshly/mildly criticised Mary; Ernst, 2001; Jackendoff, 1972).
(3)
The case of why is more subtle. Sentences involving why are known to give rise to distinct “reason” and “purpose” interpretations, typically captured in terms of structural ambiguity (Bale, 2007; Bromberger, 1992; Chapman & Kučerová, 2016; Kawamura, 2007; Ko, 2005; Stepanov & Tsai, 2008; Tsai, 2008; Yoshida et al., 2015). In general, the two different readings of why can be distinguished by the form of their answers (Chapman & Kučerová, 2016; Li & Kim, 2022), as shown in (4). A response such as that in (4a) indicates that the why-question is interpreted as a request to know the reason the agent performed the described action. By contrast, a response such as that in (4b) indicates that the why-question is interpreted as a request to know the purpose for which the agent performed the described action: (4) Why did you criticize Mary? a. Because she deserved it. (reason why) b. In order to demonstrate my critical-thinking skills. (purpose why)
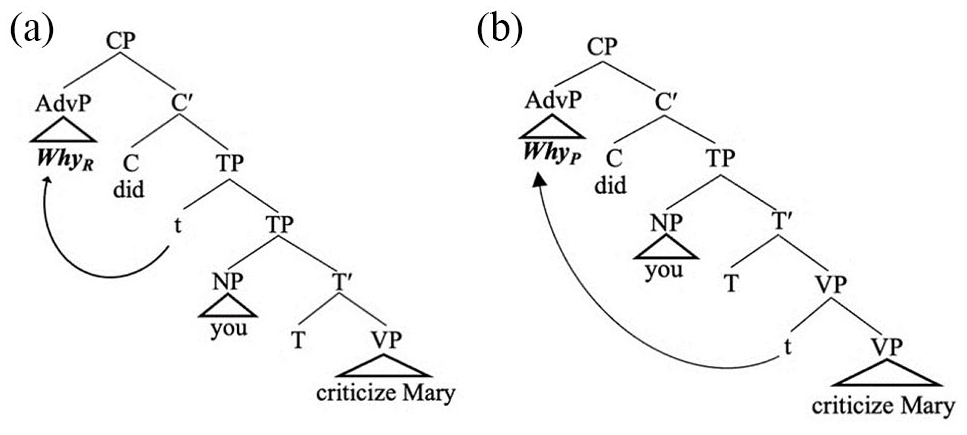
In structural terms, reason why (whyR) forms a dependency with TP, (5a), while purpose why (whyP) forms a dependency with VP, (5b) (Chapman & Kučerová, 2016; Ko, 2005; Stepanov & Tsai, 2008; Tsai, 2008; Yoshida et al., 2015). Semantically, this analysis dovetails nicely with the idea that purpose adverbs relate to events (association with VP; Kawamura, 2007), whereas reason adverbs relate to propositions (association with TP; see Bale, 2007; Bromberger, 1992; Chapman & Kučerová, 2016; Kawamura, 2007; Ko, 2005; Stepanov & Tsai, 2008; Tsai, 2008; Yoshida et al., 2015). The intended interpretation for why may not be evident in an out-of-the-blue context. However, fixing one of the two interpretations involves representing different dependency lengths, with one being shorter than the other:
(5)
Importantly for our purposes, this syntactic analysis in combination with general expectations about how dependency lengths relate to online processing effects makes clear predictions. Specifically, we expect to observe differential preferences between the two interpretations of why in out-of-the-blue contexts or in the context of questions such as (4) that leave both answering options available. Specifically, given that the dependency length for whyR is shorter than that for whyP, readers may be more inclined to interpret why as whyR in such cases.
However, some syntactic contexts can differentiate between the two senses of why (in Section “Experiments 1b and 1c,” we report the results of a rating experiment supporting this claim). For example, why-questions have been suggested to interact differently with sentential negation, depending on how they are interpreted. In general, the acceptability of an adjunct WhFGD is degraded when it spans sentential negation (i.e., so-called “negative islands”; see also Abrusán, 2011; Cinque, 1990; Rizzi, 1990; Ross, 1984; Rullmann, 1995). As we have seen, whyP, comparable to how, involves dependency-formation between the VP and CP. Since VP is structurally lower than sentential negation, we should therefore expect degraded acceptability for both how and whyP with sentential negation, but we would not expect this for whyR, because it involves dependency-formation between phrases that are structurally higher than negation (CP and TP; Chapman & Kučerová, 2016; Yoshida et al., 2015). Now consider (6): it appears that sentential negation is unacceptable with embedded how, (6a); with embedded why, the only available interpretation concerns reasons, (6b) (Chapman & Kučerová, 2016; Stepanov & Tsai, 2008; Yoshida et al., 2015). The structures underlying (6a) and (6b) are shown in (6c) and (6d), respectively: (6) (a) Q: I know how you did not eat pizza. A: *Quickly. (b) Q: I know why you did not eat pizza. A: Because I was too full. A’: *In order to not get ill.
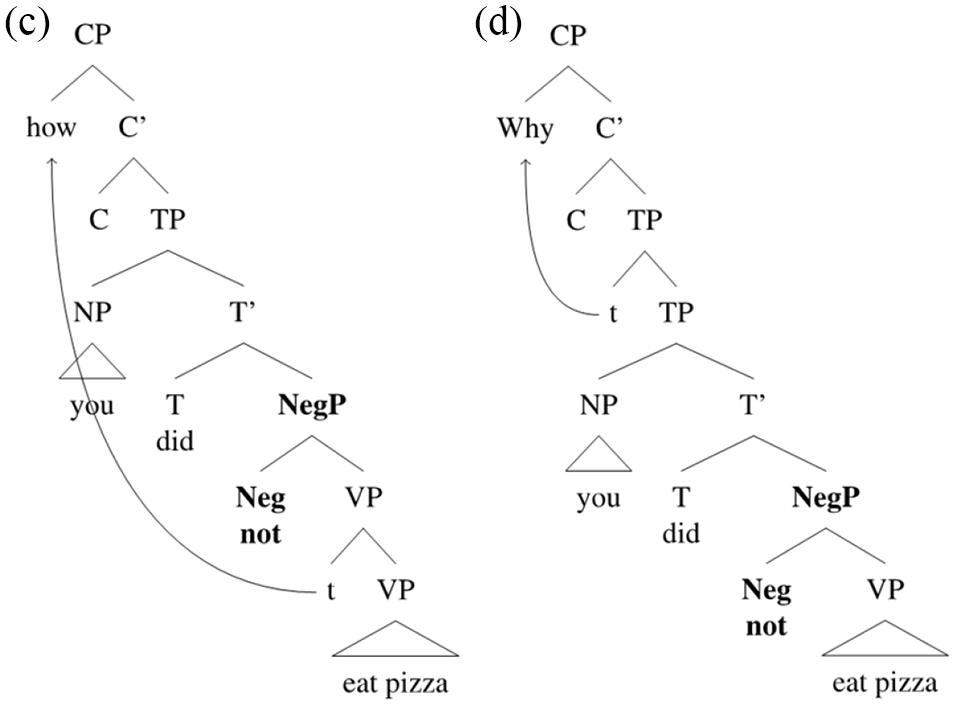
Thus, the different dependency lengths of whyR and whyP appear well-supported by their difference in sensitivity to negative islands (Bale, 2007; Bromberger, 1992; Chapman & Kučerová, 2016; Kawamura, 2007; Ko, 2005; Stepanov & Tsai, 2008; Tsai, 2008; Yoshida et al., 2015): whyR dependencies relate TP to CP (see Miyagawa, 2004), and do not span across sentential negation; whyP dependencies, in contrast, relate VP to CP and span across sentential negation.
Taken together, the data sketched in this section support a representational theory in which different wh-fillers are linked at different syntactic lengths depending on the location of their licensor. The question we are interested in is whether these differences are predictive with respect to the time-course and cost of processing WhFGDs.
Processing of wh-fillers
How are the wh-fillers with different licensors processed? Different WhFGDs have different dependency lengths. If wh-fillers need to be stored in memory until their licensors are recognised, different wh-fillers may incur differing processing costs as they are held in memory for different durations.
Adopting models of sentence processing in which storage and integration are involved in the processing of dependencies (Gibson, 1998; Gibson & Warren, 2004), we expect dependency length to predict both storage and integration costs. If the dependency is longer, we expect that the reader needs to hold the wh-phrase for a longer duration, and we expect concomitant integration costs; the reverse is true for shorter dependency. This could be due to the introduction of new discourse referents throughout the dependency (Gibson, 1998) or due to decay (Lewis & Vasishth, 2005). Furthermore, if the relevant dependency is constructed, we do not expect to see the storage or integration cost associated with the dependency in question after the point where the dependency is constructed.
Models of sentence processing that incorporate storage and integration allow us to empirically investigate the processing cost that may arise between the wh-filler and the licensor, and the cost that arises at the point where the wh-filler is integrated into the existing structure (Chen et al., 2005; Gibson, 1998; Gibson & Warren, 2004; Grodner & Gibson, 2005; Stepanov & Stateva, 2015). Thus, such theories could potentially help us to investigate the time-course of filler-gap dependency formation in detail.
One way to calculate storage costs is to count the number of open dependencies (Gibson, 1991; Gibson, 1998). By counting “open dependencies,” we mean counting the first member of any dependency that is held awaiting its licensor, an idea formulated most clearly in Gibson and Warren (2004, p. 63). Among the ways of calculating complexity effects (e.g., Lewis & Vasishth, 2005; see also Hale, 2016 for a recent survey), Gibson’s (1998, 2000) proposal is the most useful for our purposes. 4 We provide arguments for this view below.
As Gibson and Warren (2004) suggested, if the time-course of online sentence processing is influenced by storage, we could expect reading time slowdowns associated with the storage cost in regions lying in the middle of a WhFGD. Comparing a sentence that involves a WhFGD with one that does not involve such a dependency, Gibson and Warren (2004) observed that regions lying between the wh-filler and the gap were read slower than the corresponding regions in sentences that did not involve WhFGD.
In a previous study, Stepanov and Stateva (2015) adopted a similar approach and examined storage cost effects for VP-level wh-filler modifiers such as how quickly and why in English. Filler-gap dependencies with wh-adjuncts are processed similarly to wh-arguments, despite the lack of thematic or subcategorisation information associated with the verb. The results of their study revealed that not all adjuncts induce similar storage and integration costs because their dependencies are resolved at different positions. Specifically, how quickly needs to be stored in memory until the integration point located in the VP domain is encountered, whereas why, assuming it is whyR, does not need to be stored in memory because its integration site overlaps with the point at which why is encountered, in line with what we have explained above with regards to the different resolution sites. Based on these findings, they argued that the storage costs were linked to the number of incomplete syntactic heads (or incomplete phrase structure rules), and could be traced to the syntactic position of the licensors of different wh-fillers (Gibson, 1998, 2000). Our study further investigates whether different dependency lengths create different storage costs in the middle of the dependency, at the most deeply embedded noun.
Processing material which is within an open dependency, between the filler and its licensor, is expected to be harder than processing the same material when it is not within an open dependency, but should be reduced once the WhFGD formation is completed and integrated into the current structure (Gibson, 1998; Gibson & Warren, 2004). Following this logic, it is possible to observe differences in processing complexity with respect to the length of the dependency. With an aim to examine the effects of storage costs, we investigate a site between the filler and its licensor. In principle, any site between the filler and the licensor should show the storage costs. However, to increase the chances of finding any effects of storage, we use a complex structure that will put a strain on participants’ memory resources.
The key to testing such effects for our purposes is to include a complex domain such as a centre-embedded relative clause that increases the structural distance within WhFGDs. Example (7) is an object-gapped relative clause modifying a subject NP, a type of centre-embedded relative clause configuration known to independently induce a processing cost (Abney & Johnson, 1991; Chomsky, 1964; Chomsky & Miller, 1963; Gibson, 1991; Gibson, 1998, 2000; Gibson & Thomas, 1999): (7) [TP [NP The babysitter [CP that the
Considering (7), there are at least three open dependencies at the most deeply embedded noun children: the dependency between [NP the babysitter] and the third verb, handed, between [NP the children] and the embedded verb, loved, plus the prediction of a gap in the object position within the RC. In theories of processing complexity wherein open dependencies are associated with storage costs, and with the number of open dependencies as a predictor (Chen et al., 2005; Gibson, 1998, 2000; Grodner & Gibson, 2005; Kaan & Stowe, 2002; Kluender & Kutas, 1993; Stepanov & Stateva, 2015), the processing complexity for centre-embedded clauses is expected to be highest at the most deeply embedded position, at the word children in the present example.
Let us consider what is expected if a centre-embedded relative clause such as that in (7) is added in the context of different WhFGD constructions. When a wh-filler is encountered during online processing, it signals the presence of a dependency that remains open until it is linked to an appropriate licensor. Encountering a relative clause, as in (7), before the dependency is completed should incur an additional processing cost. Given that different wh-fillers have different licensors, with concomitant differences in dependency length, different WhFGDs should thereby incur different costs along with the centre-embedded relative clause. These are detectable at the most deeply embedded noun position (children) in the relative clause, because the highest processing cost is predicted there. Storage costs are expected throughout the embedded subject (the babysitter that the children loved), and the choice of measuring them on the most embedded noun (children) supports increased chances to observe measurable costs.
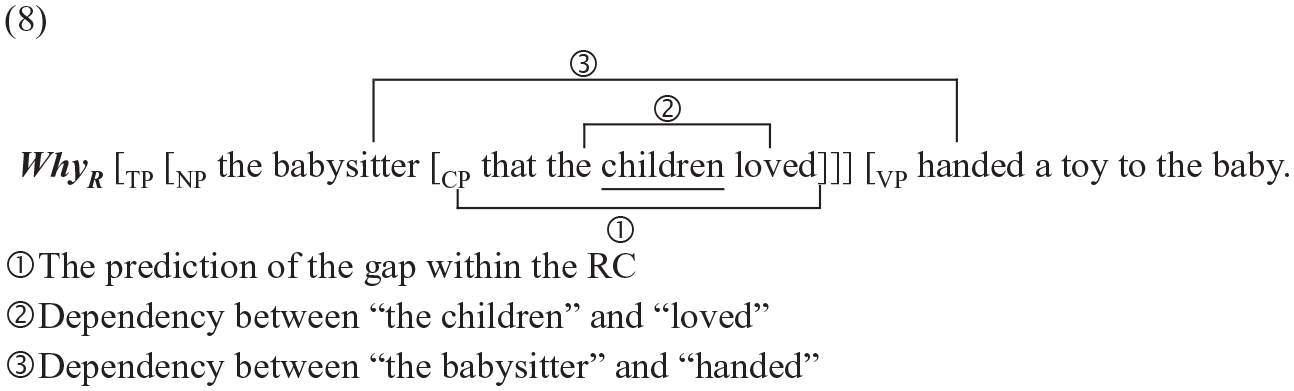
To observe our predictions more exactly, let us walk through the hypothesised representation of each WhFGD construction, now including the complex-embedded NP. First, in (8), whyR forms a dependency with TP, 5 and results in three open dependencies at the point of the most deeply embedded noun children. This is because the dependency between whyR and TP is completed even before the complex domain is encountered, leaving only the dependencies between [NP the babysitter] and the third verb, that between [NP the children] and the embedded verb loved, plus the prediction of a gap in the object position within the relative clause:
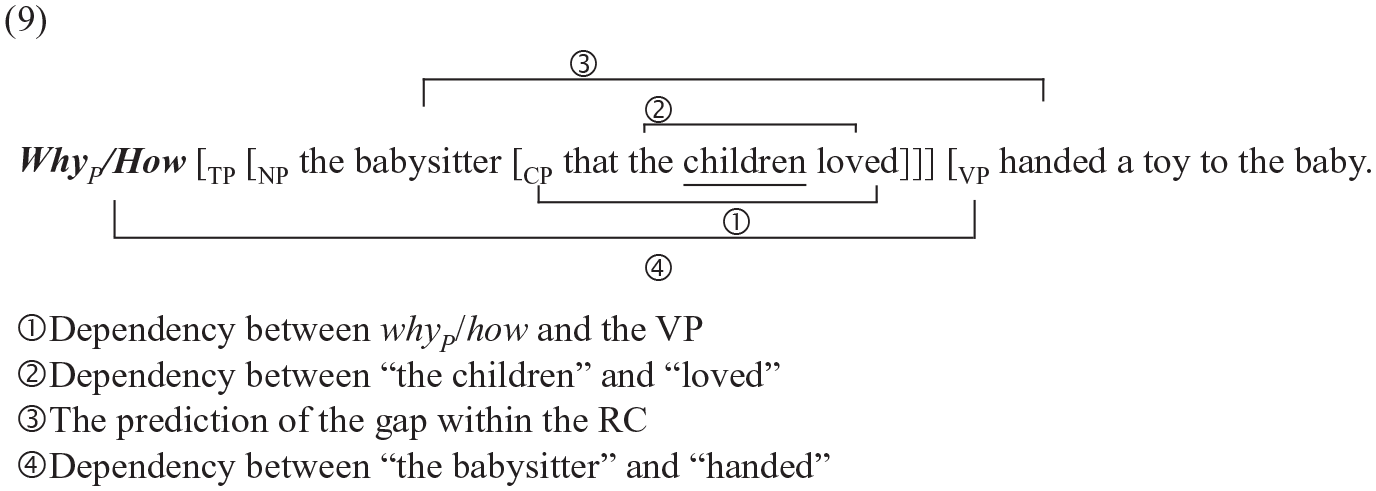
Second, whyP and how are both licensed by the VP, and there are four open dependencies at the point of children, as shown in (9):
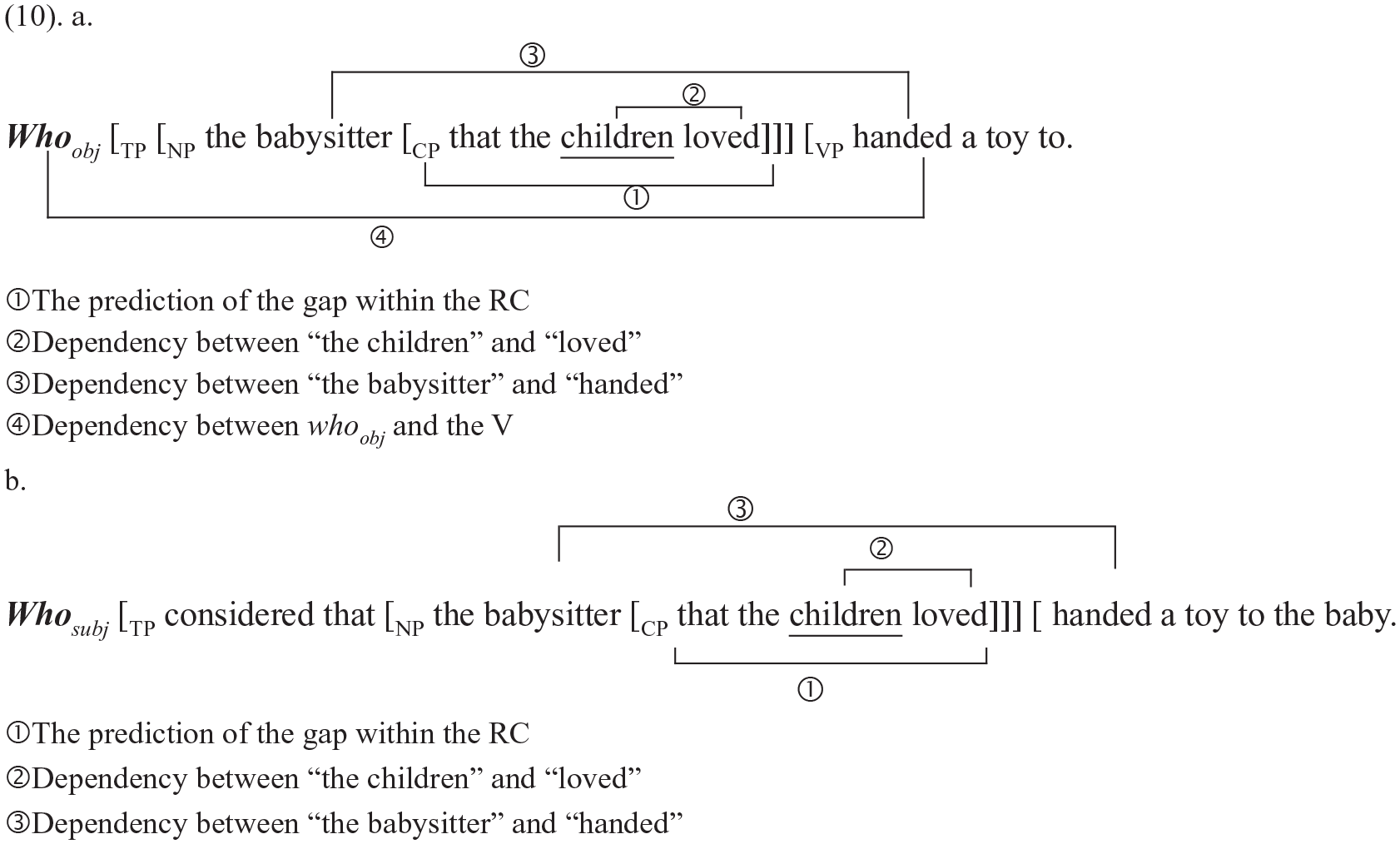
In the construction involving whoobj, which is linked to the verb as in (10a), there are also four open dependencies at the point of children. By contrast, the construction involving whosubj involves three open dependencies at the point of children (Browning, 1987; Contreras, 1993; Stowell, 1985):
Thus, if the number of open dependencies predicts processing complexity, we expect that complexity associated with the processing at the point of children will be higher in whyP, how, and whoobj constructions relative to whyR and whosubj constructions. 6 Given that the processing complexity is associated with a reading time slowdown in real-time sentence processing (Gibson, 1998; Gibson & Warren, 2004), we expect that the most deeply embedded noun children in the whyP, how, and whoobj constructions will be processed significantly slower than in the whyR and whosubj constructions. Furthermore, we expect integration costs when attempting to complete the dependency (de Vincenzi, 1991; Grodner & Gibson, 2005; Warren & Gibson, 2002); integration costs will be higher for whoobj and whyP compared with how, whyR, and whosubj constructions at the third verb (handed) position.
Given that whyR and whyP constructions are string ambiguous in English (i.e., the parser cannot hear the difference between reason and purpose why in this language; thus, it is typically an inferential matter), we face challenges in teasing apart any processing differences between them. To recap the expectations, whyR is linked with TP whereas whyP is linked with VP; therefore, whyP should lead to higher cost at the most deeply embedded noun. One challenge is that people may have parsing preferences for resolving this string-ambiguous element; assuming that the parser generally prefers to minimise dependency lengths to conserve memory resources (Gibson, 1998, 2000; Kazanina et al., 2007; Phillips, 2006; Pickering & Barry, 1991; Stowe, 1986), whyR, with its shorter dependency length, might be preferred. We keep this in mind in our studies, as any test of the whyR versus whyP processing distinctions needs to consider whether constructions intended with a whyP analysis are parsed as involving whyR, obscuring any differences that we otherwise expect to see.
Offline Experiments: 1a, 1b, and 1c
The purpose of Experiment 1a was to show that whyR had a shorter dependency length than other wh-fillers (how and whyP) by examining their sensitivity to negative islands. If whyP moves from VP to CP, the whyP–VP dependency spans sentential negation, and we can expect a negative island effect. If whyR moves from TP to CP, then the whyR–TP dependency does not span sentential negation and a negative island effect cannot be expected. In light of this, Experiment 1a shows the distinct structural positions of whyR and whyP where the different ratings reflect the acceptability of distinct structures due to the negative island. The longer dependency formed by whyP spans across negation, while the shorter dependency formed by whyR does not. If there are two potential dependencies formed by why, and if only whyP is sensitive to negative islands, then we should observe ratings for whyP to be lower than those for whyR.
The second acceptability rating Experiments 1b and 1c (Experiments 2a and 2b are the online counterparts of 1b and 1c) were conducted wherein Experiment 1b tested sentences with whoobj, how, and why and Experiment 1c tested sentences with whoobj, whosubj, and why. Our goal in the offline experiments was to check whether processing complexity (storage or integration costs) is manifested in offline experiments, if we assumed that greater complexity corresponds to lower ratings. If so, we might argue that this would constitute another tool to test for storage effects.
Given that different wh-fillers have different licensors depending on their grammatical functions, with concomitant differences in dependency lengths, we expected measures of processing cost to track those differences. As a control, we included sentences with that instead of a WhFGD, as these constructions do not involve movement (Ross, 1984). In Experiment 1b, at the most deeply embedded N of an intervening centre-embedded RC (at the word children in Table 3), the complexity costs would be the highest for whoobj and how compared with that (control) and why. These differences in costs could potentially be reflected in the offline acceptability ratings. Experiment 1c tested for storage effects with whosubj, whoobj, and why. At the most deeply embedded N of an RC (at the word children in Table 4), the complexity would be the highest for whoobj, with no differences between whosubj, why, and that.
Experiment 1a
Previous studies have shown that there are two different whys (Stepanov & Tsai, 2008), one licenced by the TP and the other by the VP. Experiment 1a investigated whether the distinction between reason why and purpose why in relation to their distinct licensors in TP and VP could be observed directly (Stepanov & Tsai, 2008).
We tested the acceptability ratings of Question–Answer pairs (Q/A) pairs for different wh-fillers in a negative island context.
7
The answers for why were divided between those with because-clauses (indicating whyR) and those with in order to-clauses (indicating whyP). Owing to their different licensors, we expected that whyP should be sensitive to negative islands and whyR should be insensitive to negative islands. This is because the former moves from a VP-adjoined position to the CP, spanning negation, whereas the latter moves from the TP which does not involve spanning negation. Given the relationship between the types of answers and types of why dependency, we expected that Q/A pairs with because-clause answers would elicit higher acceptability ratings than those with in order to-clause answers in negative islands. Examples of such questions embedding negative islands are illustrated in (11a) for whyR and (11b) for whyP: (11) (a) A: Why didn’t Mary criticize John? B: Because his answer was correct. (b) A: Why didn’t Mary criticize John? B: In order to look nice.
The finding that acceptability differences are modulated by answer type 8 would provide evidence for a representational theory in which why-questions in English can have distinct structural analyses. Meanwhile, in the absence of such a representational distinction, acceptability differences between examples such as (11a) and (11b) are not straightforwardly predicted, although there may be pragmatic sources contributing to a preference for whyR relative to whyP.
Participants, materials, and design
For this experiment, 43 native English speakers from Northwestern University participated and gave informed consent. They were granted one credit for introductory linguistic classes taught at Northwestern University.
The critical items consisted of 32 sentence sets in the form of a 1 × 4 within-subjects design, in which four different conditions were generated: how, whyR, whyP, and that (control). In addition to the current experimental items, we included 32 filler sentences that involved orthogonal manipulations of the current ones. A sample set of stimuli is shown in Table 1.
Sample stimuli for Experiment 1a.

Procedure
Stimuli were presented on a desktop PC using the Linger software (Rohde, 2003). For each stimulus, participants read the sentence on a desktop screen, and were directed to rate the sentences from 1 to 7 on the basis of their acceptability (1: totally unacceptable; 7: totally acceptable). To familiarise the participants with the rating process, five practice items were presented prior to presenting the actual experimental items.
Analysis
Data were analysed using cumulative logit models performed with the ordinal package (Christensen, 2019) in R version 3.2.3 (Baayen, 2008; Baayen et al., 2008; Bates et al., 2014).
Results and discussion
The mean acceptability scores are shown in Figure 1, and the ordinal mixed-effect model outputs (Estimate, SE, z-value, and p-value from drop1 function) are listed in Table 2. Overall, the results revealed significant differences between how, whyR, and whyP versus that. They also revealed a significant difference between how versus whyR and whyP. We also found a significant difference between whyR and whyP, which provided evidence that whyR did not involve a negation-spanning dependency (i.e., it shows no sensitivity to negative islands) whereas whyP does, supporting the representational theory (Li & Kim, 2022).
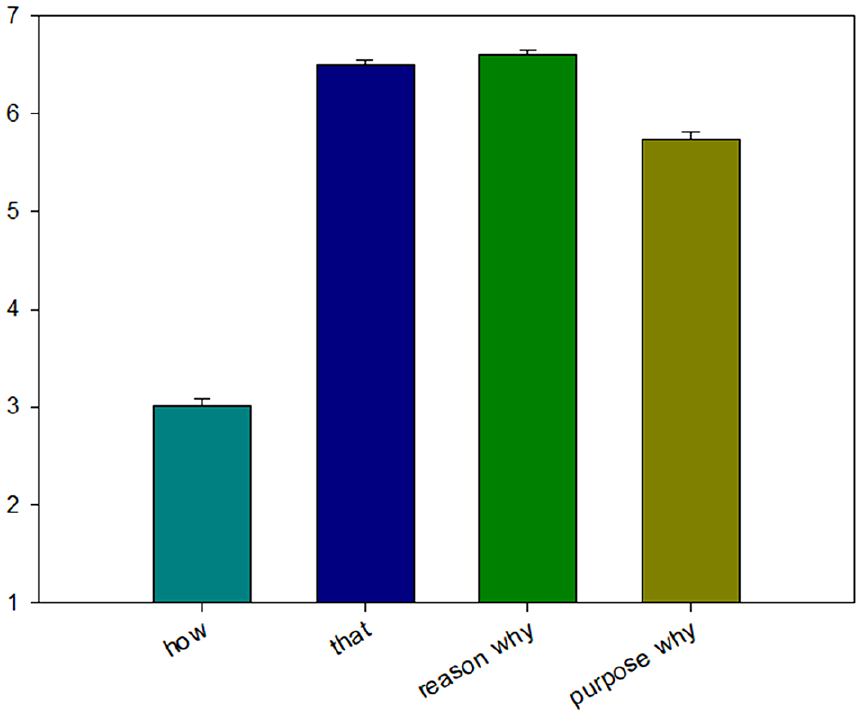
Mean acceptability ratings from Experiment 1a.
Summary of ordinal mixed-effect model outputs in Experiment 1a.
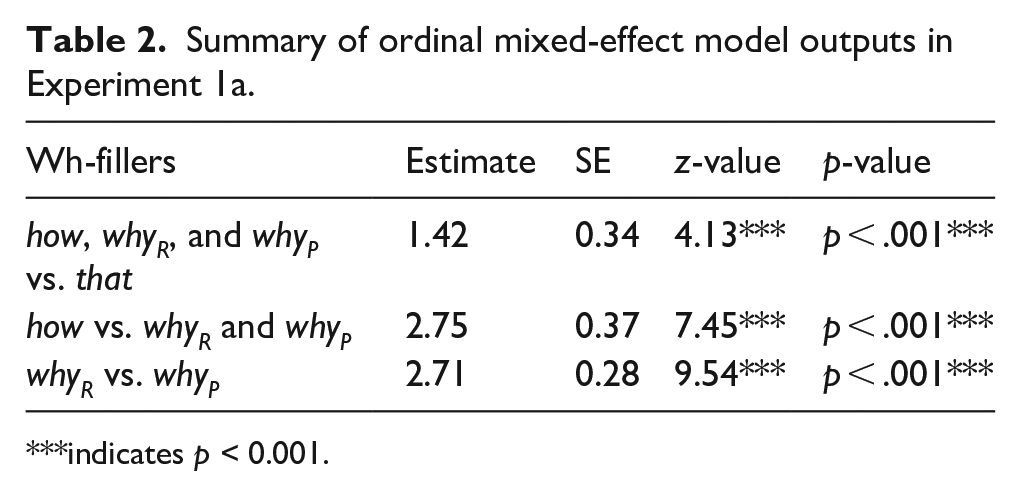
indicates p < 0.001.
Experiments 1b and 1c
Experiments 1b and 1c examined the storage effects of different kinds of wh-fillers by embedding WhFGDs with centre-embedded RCs. As reviewed above, until a wh-filler is licenced, it participates in an open dependency. Interpolating a centre-embedded NP within the WhFGD introduces additional cost. Based on the representational differences of WhFGDs, we expect any measurable differences in cost to be predicted by the dependency lengths associated with each specific wh-filler and licensor.
Participants, materials, and design
For Experiments 1b and 1c, 45 native English speakers (Experiment 1b) and 24 speakers (Experiment 1c) from Northwestern University participated and provided their informed consent. They were granted one credit for introductory linguistic classes or were paid US$8/hr.
Critical items consisted of 24 sentence sets in a 1 × 4 design, in which four different conditions with whoobj, how, that, why (Experiment 1b) and whoobj, whosubj, that, and why (Experiment 1c) were generated. For Experiment 1c, we included whosubj in addition to whoobj, why and that and whosubj question sentences were about an altogether different verb (considered rather than loved in Table 4), that is, the dependency is resolved in a completely different clause. A sample set of stimuli is presented in Tables 3 and 4, respectively.
Sample stimuli for Experiment 1b.

Sample stimuli for Experiment 1c.

To avoid participants encountering the same types of target items consecutively, we presented the items in a pseudo-randomised manner in a Latin-square design. In addition to the current experimental items, we included 32 filler sentences 9 that involved orthogonal manipulations to the current ones.
Procedure
The same procedure as 1a was employed.
Analysis
Data were analysed using cumulative logit models performed with the ordinal package (Christensen, 2019) in R version 3.2.3 (Baayen, 2008; Baayen et al., 2008; Bates et al., 2014). Each model included Helmert coding: for Experiment 1b, we compared (a) whoobj, how, and why with that as a baseline; (b) whoobj and how with why; and (c) whoobj and how. For Experiment 1c, we compared (a) whoobj, whosubj and why with that as a baseline; (b) whosubj and why with whoobj; and (c) whosubj and why. 10 All models contained the maximal random effects structure (Barr et al., 2013), which involved random intercepts for participants and items as well as random slopes for fixed effects, given that the model successfully converged. In cases where the model failed to converge, the random effects with the smallest variance were taken out stepwise.
Results and discussion
The mean acceptability scores for Experiment 1b and 1c are shown in Figures 2 and 3, and the ordinal mixed-effect model outputs are shown in Tables 5 and 6. The results of Experiment 1b revealed no differences between whoobj, how, and why versus that. Furthermore, no differences between whoobj and how versus why were observed. But the results revealed a significant difference between whoobj and how. The relatively low acceptability of whoobj may reflect complexity effects: whoobj sentences reflect both the greatest number of open dependencies (four) and the longest duration to complete the last of those dependencies (at matrix V, later than matrix VP for how and whyP, or for whyR). Following an anonymous reviewer’s suggestions, we also directly compared that with the wh-phrases by employing t-tests. In Experiment 1b, we found significant differences between whoobj and that (β = −.44, SE = 0.11, t = −3.98) but no differences between why and that (β = .07, SE = 0.11, t = .62), which are consistent with our predictions. But we also found significant differences between how and that (β = .24, SE = 0.11, t = 2.15), where how was rated higher than that. 11
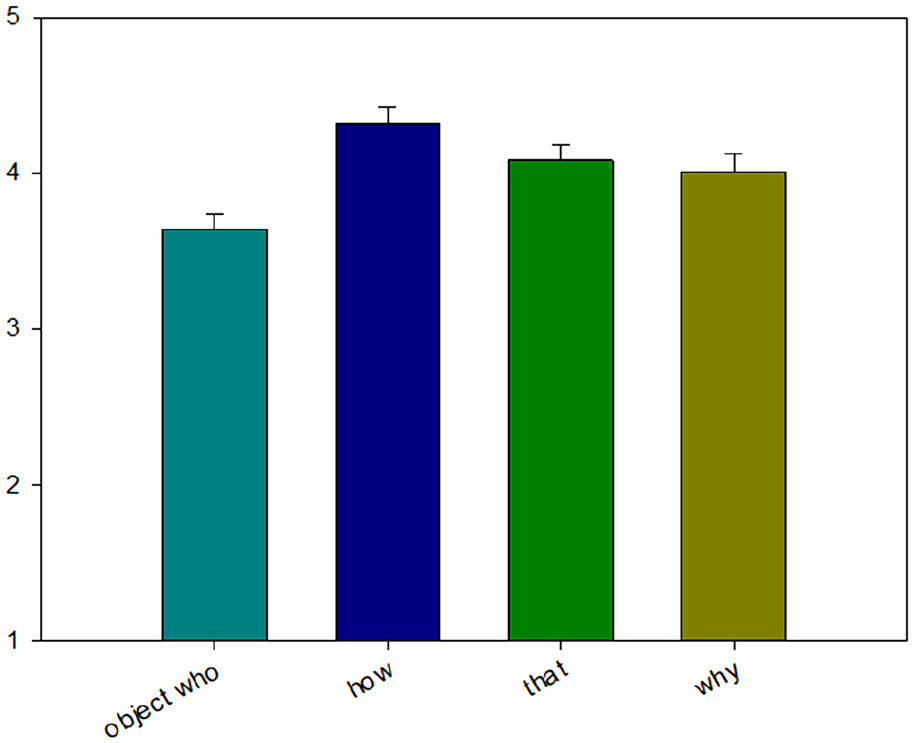
Mean acceptability ratings from Experiment 1b.
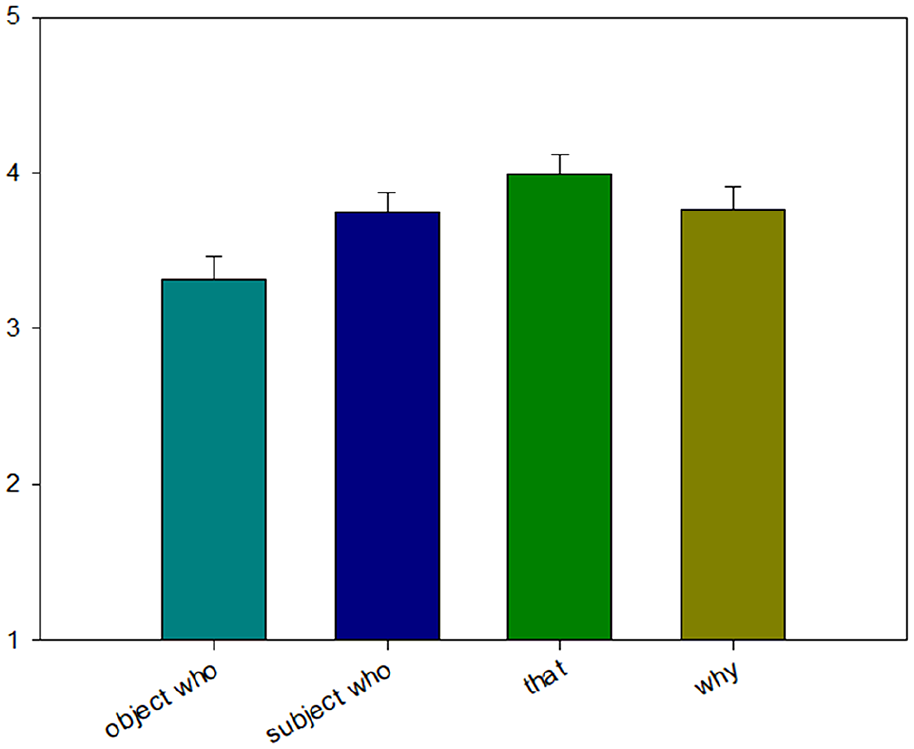
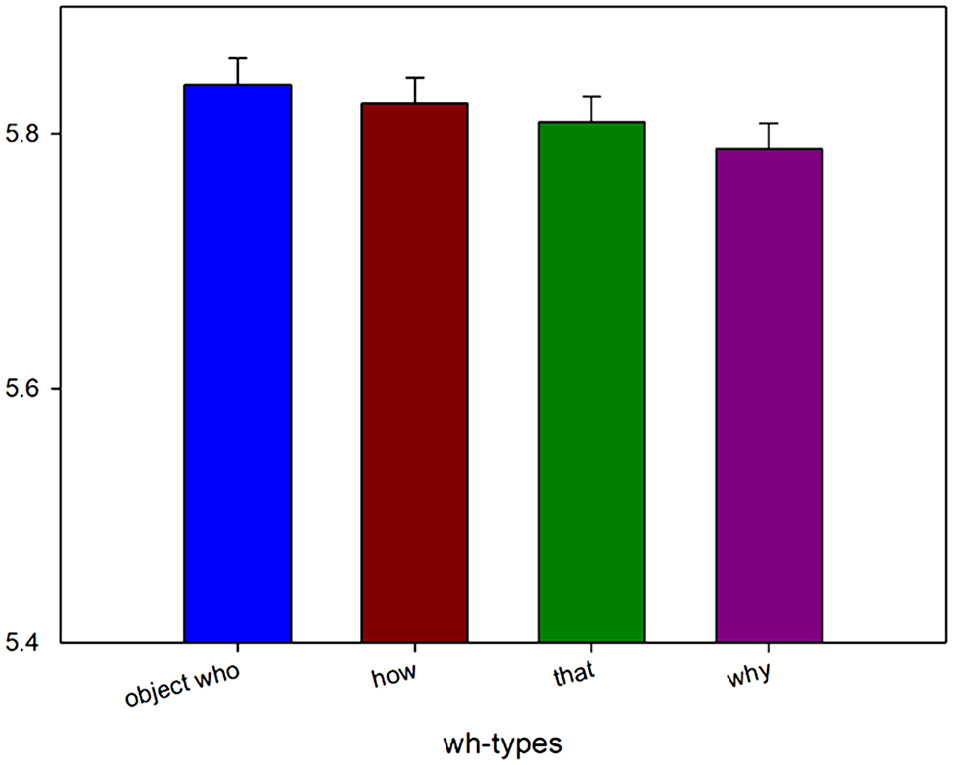
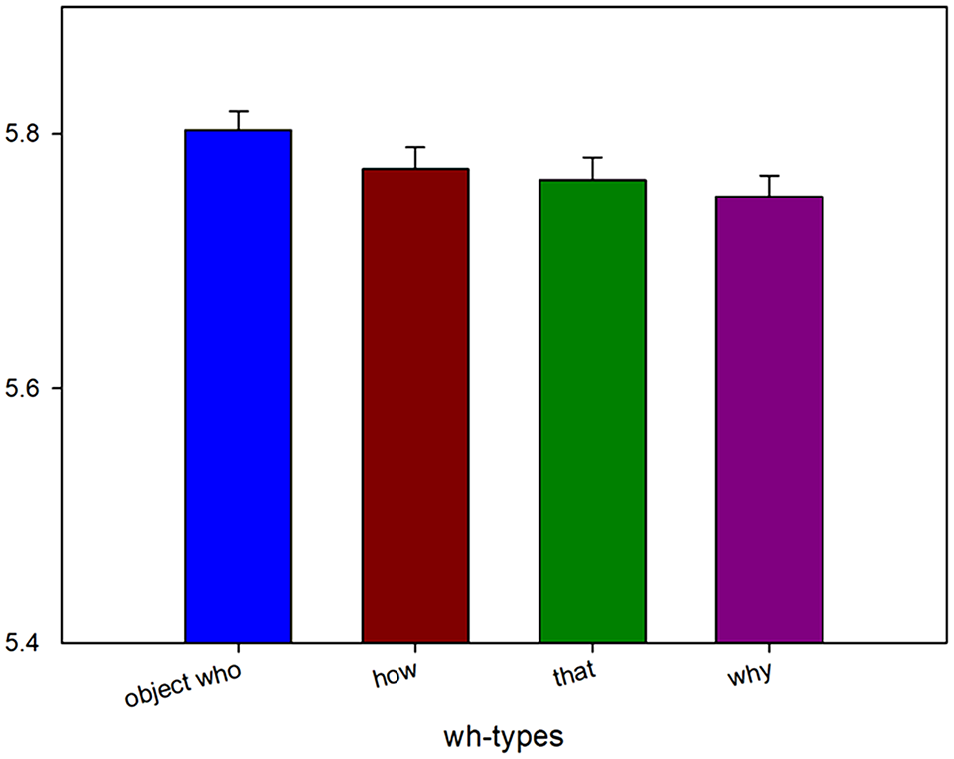
Mean acceptability ratings from Experiment 1c.
Summary of ordinal mixed-effect model outputs in Experiment 1b.
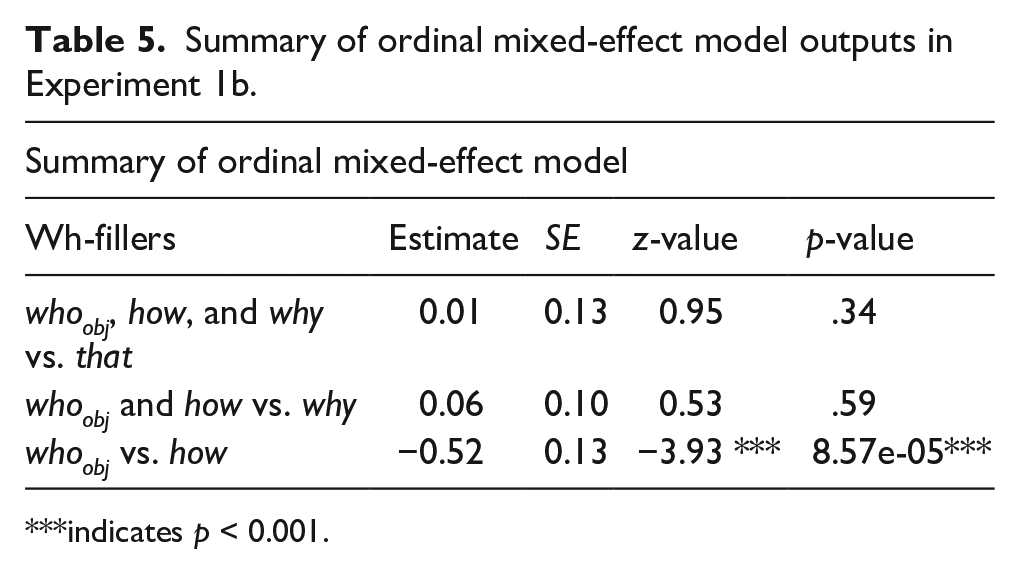
indicates p < 0.001.
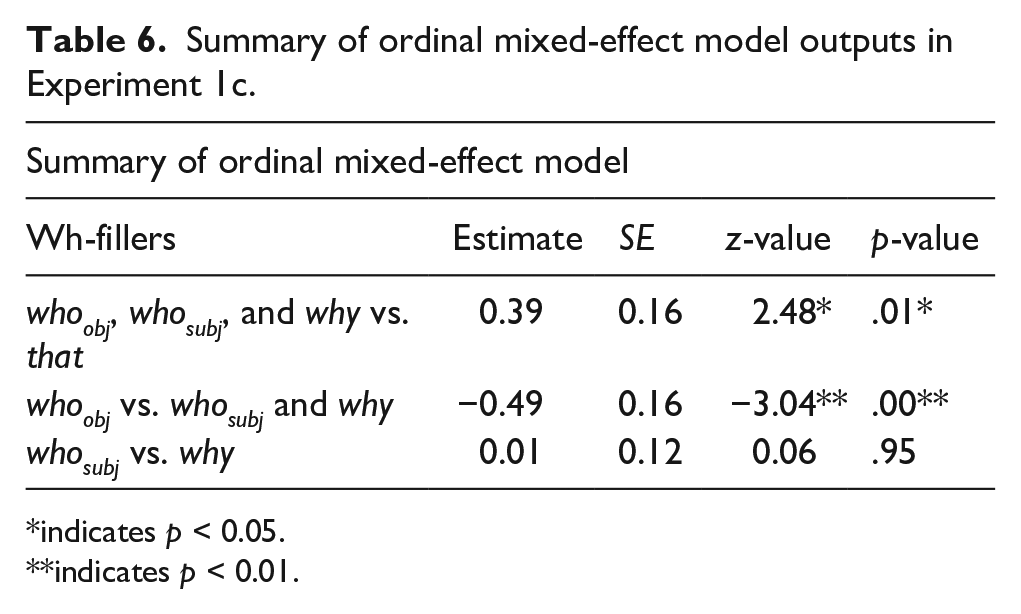
Summary of ordinal mixed-effect model outputs in Experiment 1c.
indicates p < 0.05.
indicates p < 0.01.
In Experiment 1c, we found a significant effect between whoobj, whosubj, and why versus that. Further, we also observed significant differences between whoobj versus whosubj and why. But we found no differences between whosubj and why. Following an anonymous reviewer’s suggestions, we also directly compared that with the wh-phrases by employing t-tests in Experiment 1c. We found marginal significant differences between whoobj and that (β = −.24, SE = 0.14, t = −1.70) but no differences between whosubj and that (β = −.20, SE = 0.11, t = −1.40) nor between why and that (β = .21, SE = 0.14, t = 1.46), consistent with our predictions.
Overall, the results of Experiment 1c revealed some differences in processing complexity with respect to the different hypothesised dependency lengths; whoobj was rated significantly lower than other wh-phrases (whosubj and why), which could be predicted from the greatest number of open dependencies until the licensor was encountered.
Summary of Experiments 1a–1c
Experiment 1a, involving Q/A pairs, tested whether different wh-fillers were sensitive to negative islands, a different source of evidence for their specific structural complexity. The results revealed that whyR was insensitive to negative islands in contrast to how and whyP, as expected, and that whyR and whyP, as suggested by different answer types, were differentially sensitive to negative islands. A dependency formed by an adjunct wh-filler that spans sentential negation is judged worse than that formed by an argument wh-filler or a wh-adjunct filler that does not (Li & Kim, 2022; Ross, 1984). If whyP moves from VP to CP, then the whyP–VP dependency spans sentential negation, and a negative island effect may be expected. If whyR moves from TP to CP, then the whyR–TP dependency does not span sentential negation, and we expect no negative island effect (Li & Kim, 2022). WhyR was rated higher than whyP and how. This result supports the claim that the whyR–dependency differs from the whyP–and how–dependencies.
The primary goal of Experiments 1b and 1c was to examine whether integration and storage costs arising from wh-phrases could be revealed in offline experiments. Experiment 1b revealed significant differences between whoobj and how such that whoobj was rated lower than how. Experiment 1c revealed a difference between whoobj versus whosubj and why where whoobj was rated lower than whosubj and why, but no differences between whosubj and why. These results align with our general expectation that whosubj and why (with a general preference for interpretation as high whyR) are grammatically similar.
Note that in Experiment 1b, whoobj was rated lower than how, which was not compatible with our claim that storage/integration costs are dependent on dependency length. Although the reasons for this are unclear, studies on RCs show that subject RCs are easier to process than object RCs because of the shorter linear/structural dependency length (e.g., Gibson, 1998; Hawkins, 1994; Keenan & Comrie, 1977; King & Just, 1991). In the case of the processing of who, who can be discharged in the subject or object position. Thus, readers can initially assume that who is the subject. However, when the parser encounters the subject NP, the parser needs to discard the whosubj analysis. Then the parser needs to stretch the wh-dependency towards the object position, which is a longer dependency. Meanwhile, how cannot serve as the subject; thus, there is no ambiguity and no need for a reanalysis. Thus, the processing of how is potentially easier, leading to higher acceptability ratings than whoobj. In Experiment 1c, whoobj is rated lower compared with other wh-phrases and this could also be understood in the context of a reanalysis process.
Online Experiments 2a–2c
In Experiments 2a and 2b, we examined the storage and integration costs for different wh-fillers and asked whether these differences were predicted by their hypothesised dependency lengths. Specifically, we asked whether the conditions under which the wh-fillers (whosubj, whyR) were interpreted before the centre-embedded RC was processed could be easier than the conditions where the wh-filler had to be interpreted at or inside the VP, which requires the wh-filler to be maintained throughout the subject and centre-embedded RC (whoobj, how, whyP).
Our assumptions are as follows: storing the wh-filler in memory gives rise to processing complexity in such a way that (a) the processing should be harder in cases where the intervening material is within the dependency (between the wh-filler and its respective licensor) (storage cost); and (b) the longer the wh-filler is stored in memory, the more difficult it is to integrate the filler into the structure (integration cost) (Chen et al., 2005; Gibson, 1998, 2000; Gibson & Warren, 2004; Grodner & Gibson, 2005). If storage and integration are crucial in the mechanism of real-time sentence processing, we predict that the distance between the wh-filler and licensor should correlate with processing complexity associated with the materials intervening between the wh-filler and licensor. By including a complex domain between different wh-fillers and their clause’s verb, we expected reading times to differ in accordance with the dependency lengths of different kinds of wh-fillers at the most deeply embedded N position of that complex domain. Furthermore, we predict processing complexity at the licensor position where the dependency is completed and the wh-filler is integrated into the structure.
In anticipating the critical regions in our online studies to include the most embedded N (children) and third verb (handed), we tested sentences featuring several adjectives before the most deeply embedded noun and adverbs occurring before the third verb (see Table 8). This was expected to ensure a sufficient distance between the point at which dependency was initiated and the storage costs were measured. Specifically, we reasoned that introducing a wh-filler could introduce a new discourse referent (Gibson, 1998; Warren & Gibson, 2002), inducing an initial, independent, and non-structure-dependent processing cost. Any slowdown associated with this process at the point of the wh-filler could spill over to subsequent regions and can be misclassified as costs associated with open dependencies. The adjectives included prior to the most embedded N provide a region where such a slowdown can be accommodated.
Meanwhile, similar independent costs associated with integrating the wh-filler at the end of a dependency could contribute to processing complexity (i.e., integration costs; Gibson & Warren, 2004). By including adverbs prior to the third verb region (handed), we provide the best conditions for observing any clear differences in reading time for whoobj versus how and why at the third verb. If how associates with VP, while whoobj associates with V, then the integration costs associated with the former would arise earlier than those for the latter: for the former they would arise at the adverb, whereas only on the verb itself for the latter.
Experiment 2a
In Experiment 2a, we investigate the storage and integration costs for whoobj, how, why, and that. We predicted that reading times at the most deeply embedded N position would be longest for whoobj and how; why could be interpreted before the centre-embedded RC is processed, and hence easier to process relative to whoobj and how, which need to be interpreted at or inside the VP, requiring these wh-fillers to be maintained throughout the RC. At this point, increased processing costs for why should not be observed, given our expectation that the parser prefers a whyR parse. Specifically, if a wh-filler is integrated into the current structure only once its licencing element is encountered, we predict no differences in reading times for how and whoobj (licenced at/in VP) at the preverbal, most deeply embedded N position, but whyR must have a shorter reading time (licenced at TP). If the parser chooses whyp, the expected pattern is similar to how and whoobj.
In terms of integration costs, we expect slower reading times for sentences with how (compared with why) at the adverb because the adverb is located at the edge of VP and can signal the presence of VP and induce integration costs before the third verb is introduced. Thus, we predict that at the first adverb and spill-over regions (right before the third verb), a reading time slowdown should be observed for how compared with why. We expected storage costs for whoobj at the adverb position. For the third verb, we expected the integration costs to be the highest for whoobj compared with why and how because the dependency terminates before the third verb is encountered for why and how. The predictions of Experiment 2a are presented in Table 7.
Predictions for Experiment 2a.

Participants, materials and design
Sixty-four Northwestern University students who were native English speakers provided informed consent and participated in this experiment. They were granted one credit required for introductory linguistic classes at Northwestern University.
The critical items consisted of 24 sentence sets in the form of a 1 × 4 within-subject design, in which four different conditions were generated: whoobj, how, why, and that (control). A sample set of stimuli is illustrated in Table 8 (i.e., the same as in Table 3; Kim, 2019). The items were presented in a pseudo-randomised manner. In addition to the current experimental items, we included 74 filler sentences that involved orthogonal manipulations to the current ones.
Sample stimuli for Experiment 2a (same as 1b).

Procedure
Stimuli were presented on a desktop PC using Linger software (Rohde, 2003) employing a self-paced word-by-word moving window paradigm (Just et al., 1982). Each experimental trial was initiated with dashes that masked words in the sentence. As participants pressed a button to move forward, each subsequent word appeared. Participants were instructed to read the sentences as they would normally read and to answer a comprehension question after reading each sentence. The yes/no comprehension question asked participants to press the F (yes) or J (no) keys. An example of a comprehension question is, Was the word “toys” mentioned in the story?. After receiving feedback on their responses, participants pressed the spacebar to proceed to the next experimental item. Six practice items were presented at the beginning of the experiment to allow participants to grasp the experimental format. The experiment took each participant approximately 30–45 mins to complete.
Analysis
Data were analysed using linear mixed-effect regression models performed with the lme4 package in R version 3.2.3 (Baayen, 2008; Baayen et al., 2008; Bates et al., 2014). Each model included Helmert coding, where at the deeply embedded N, we compared (a) whoobj, how, why with that as a baseline; (b) whoobj and how with why; and (c) whoobj with how. 12 At the adverb before the third verb and the third verb region, we compared (a) whoobj, how, why with that as a baseline; (b) whoobj with how and why and (c) why with how. At this region, we compared whoobj with how and why because the adverb already signals the introduction to the VP at which how should be integrated. Thus, we expected how and why to be read similarly unlike whoobj which induces storage costs. All models contained the maximal random effects structure that fit the data (Barr et al., 2013), including random intercepts for participants and items, and random slopes for fixed effects if the model successfully converged. In cases where the model did not converge, random effects containing the smallest variance were removed in a step-wise manner. Participants with an accuracy lower than 68% were excluded (Kim et al., 2019, 2020).
The reading times were log-transformed (Box & Cox, 1964). Two regions of interest were identified in this study. The first critical region was the most deeply embedded N (embedded N critical region: children in Table 8) where the processing complexity due to storage was expected to be the highest. We were also interested in one word following the most deeply embedded N critical region (embedded N spill-over region), given that effects arising in the critical region often spill over to one region following, that is, the spill-over region (Mitchell, 1984, 2018; Vasishth, 2006). The second critical region was the adverb region before the third verb, the third verb (e.g., benevolently and handed in Table 8) and the word following it (third verb spill-over region).
As Gibson (1998) suggests, the effect of the integration of the wh-filler can be observed at the point where the dependency is completed. At these regions, whoobj should be read slower compared with how and why because the adverb already signals the introduction to the VP at which how should be integrated. We were also interested in the spill-over regions following the third verb (e.g., the).
Results and discussion
The mean accuracy for the critical trial comprehension questions was 77.0%. We speculate that this low level of accuracy reflects the level of complexity which was necessary given the hypothesised storage and integration costs. Figures 4 to 6 present the region-by-region reading times, graphs at the critical region (the most deeply embedded N), and graphs at the third verb spill-over region, respectively. The mixed-effects model outputs are listed in Table 9.
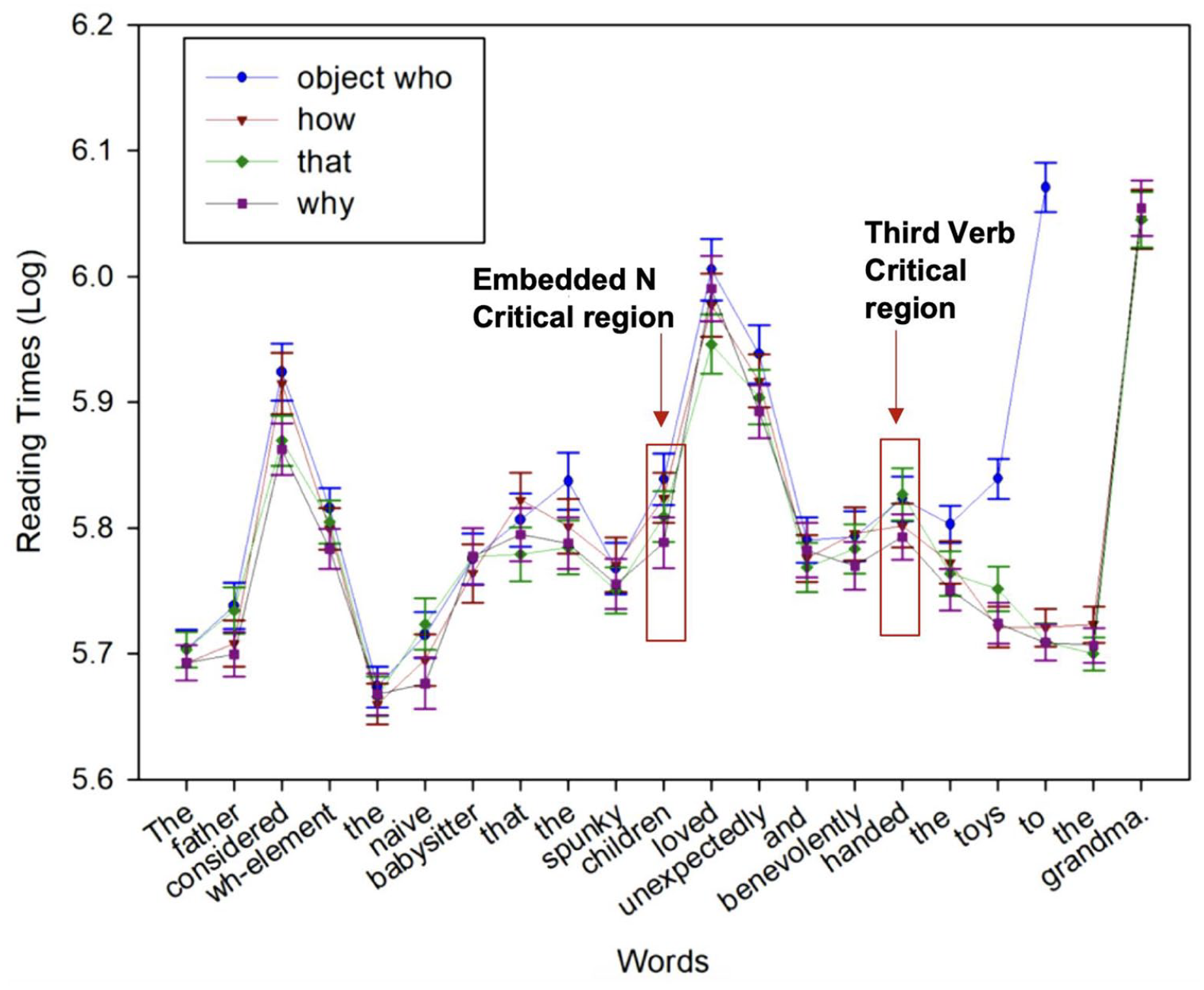
Means of region-by-region reading times from Experiment 2a.
Reading times at the most deeply embedded N region (children) in Experiment 2a.
Reading times at the third verb spill-over region (the) in Experiment 2a.
Summary of mixed-effect model outputs for Experiment 2a.

indicates p < 0.05.
indicates p < 0.01.
The results revealed that, at the most deeply embedded N (children), whoobj and how were read significantly slower than why, whereas whoobj and how showed no significant difference from one another. We found no significant differences among whoobj, how, and why versus that. The region after the embedded N revealed a marginal difference between whoobj, how, and why versus that. 13 The difference between why versus whoobj and how shows that these wh-fillers are processed differently, where whoobj and how behave similarly slowly at the most deeply embedded N compared with why. This is in the expected direction, given the grammatical differences between them. This finding adds to the evidence suggesting that a whyR parse is preferred to a whyP one.
At the second critical region, no significant effects were observed at the adverb and spill-over regions of the first adverb (benevolently). At the third verb (handed), there were no significant differences in reading times for different wh-phrases. However, at the third verb spill-over region (the), who obj was read significantly slower than why and how, and no differences were observed between how and why. We return to this issue and interpret the results in the context of storage and integration costs in the "Discussion of Experiment 2a-2c" section.
Experiment 2b
In Experiment 2b, we investigate the storage and integration costs for whoobj, whosubj, why, and that. This study, in particular, examined constructions in which who is interpreted as a matrix subject (whosubj). We expected different complexity effects between who interpreted as the subject (whosubj) and as the object (whoobj), because they form dependencies with different licensors. Specifically, at the most deeply embedded N (at the word children in Table 11), in the middle of the RC, sentences involving whoobj are predicted to be read significantly slower than those involving whosubj and why. This is because the presence of the subject NP entails the presence of TP since the subject NP must be located in Spec_TP in English (Chomsky, 1981). Therefore, as for why, upon encountering the subject NP, the parser can recognise and project the TP, to which the parser can immediately link why. As for whosubj, upon encountering whosubj, the TP is projected and whosubj can be linked to Spec_TP. At the second critical region (the adverb and the third verb), we expected whoobj to be read slower than whosubj and why due to integration costs. The predictions for Experiment 2b are presented in Table 10.
Predictions for Experiment 2b.

Participants, materials, and design
Seventy-eight Northwestern University students who were native English speakers provided informed consent and participated in this experiment. They were granted one credit necessary for introductory linguistic classes at Northwestern University or were paid US$8 for their participation.
The critical items consisted of 24 sentences in the form of a 1 × 4 within-subjects design, in which four different conditions were generated: whoobj, whosubj, why, and that (control). A sample set of stimuli is presented in Table 11 (i.e., the same as in Table 4; Kim, 2019). In addition to the current experimental items, we used 80 filler sentences that involved orthogonal manipulations to the current sentences.
Sample stimuli for Experiment 2b (same as 1c).

Procedure
The same procedure was used as in Experiment 2a.
Analysis
A similar analysis was employed as with Experiment 2a. 14 For each region, reading times slower than 2,000 ms were excluded from the analysis. Participants with an accuracy below 72% were excluded from the analysis. 15 The critical regions include the embedded N critical region (e.g., children in Table 11), and one word following it (embedded N spill-over region). The second critical region was the adverb region before the third verb, the third verb (e.g., benevolently and handed in Table 11) and the word following it (third verb spill-over region). Each model included Helmert coding, where at the deeply embedded N as well as at the adverb before the third verb/third verb, we compared (a) whoobj, how, why with that as a baseline; (b) whoobj with whosubj and why; and (c) whosubj with why.
Summary of mixed-effect model outputs for Experiment 2b.
indicates p < 0.05.
indicates p < 0.01.
indicates p < 0.001.
Results and discussion
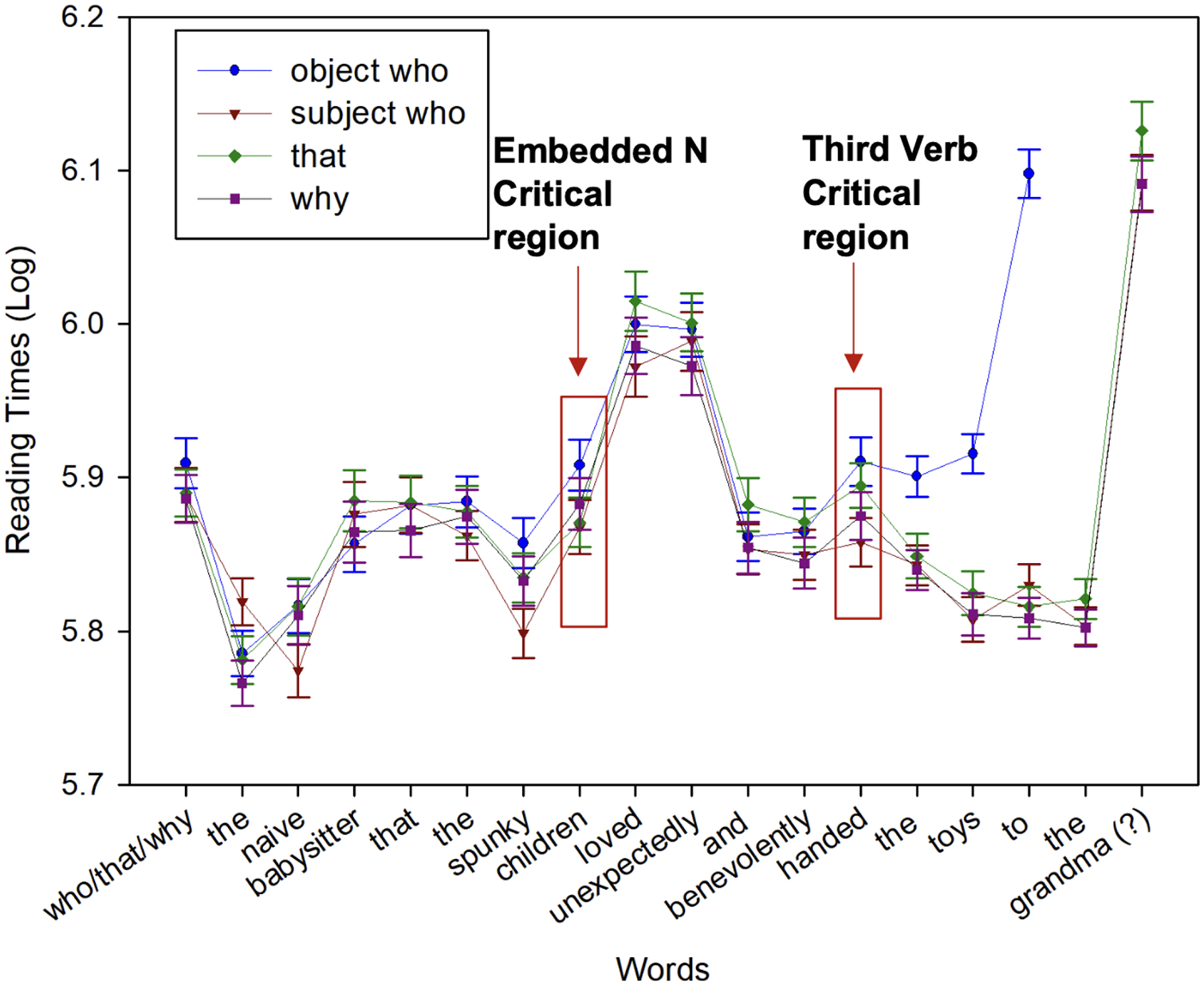
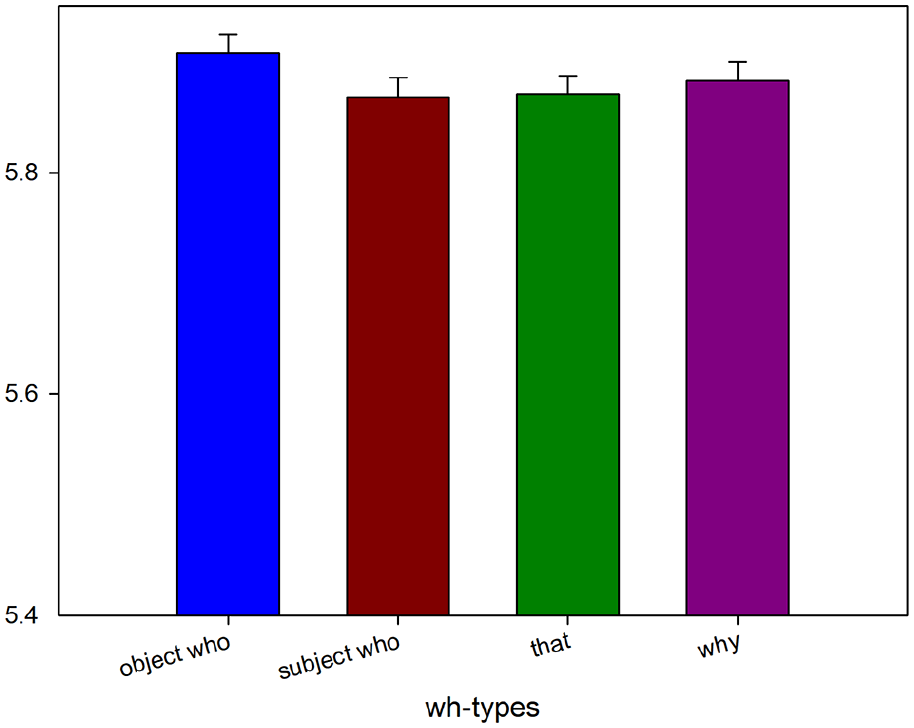
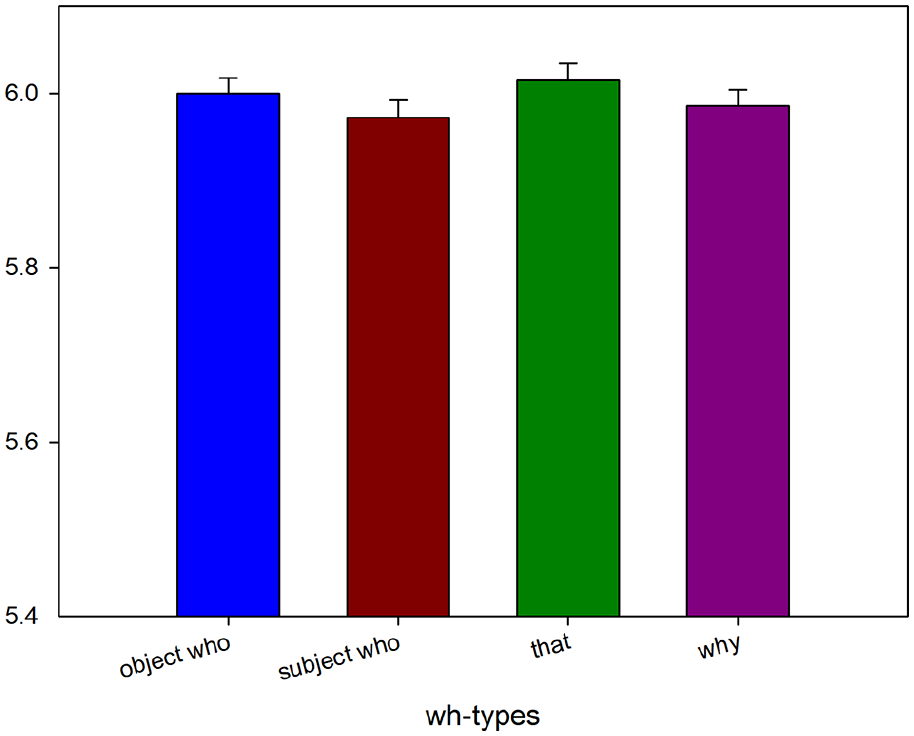
The mean accuracy for the critical trial comprehension questions was 79.0%. Region-by-region reading times are shown in Figure 7. The results for the critical region (the most deeply embedded N), embedded N spill-over region, third verb, and third verb spill-over region are shown in Figures 8 to 11. The mixed-effects model outputs are listed in Table 12.
Means of region-by-region reading times from Experiment 2b.
Reading times at the most deeply embedded N region (children) in Experiment 2b.
Reading times at the embedded N spill-over region (loved) in Experiment 2b.
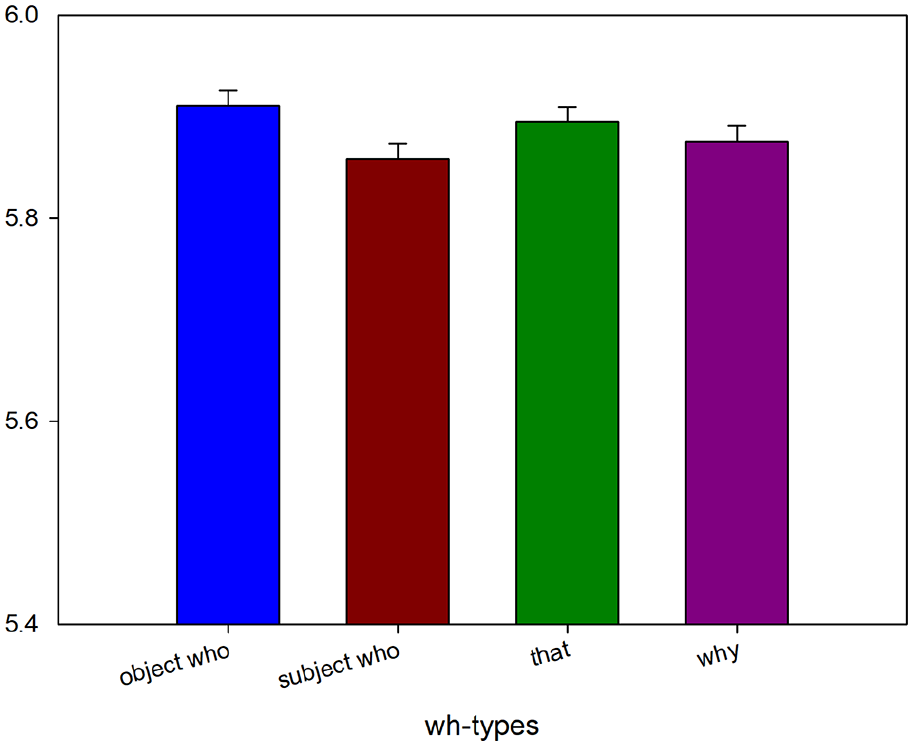
Reading times at the third verb (handed) in Experiment 2b.
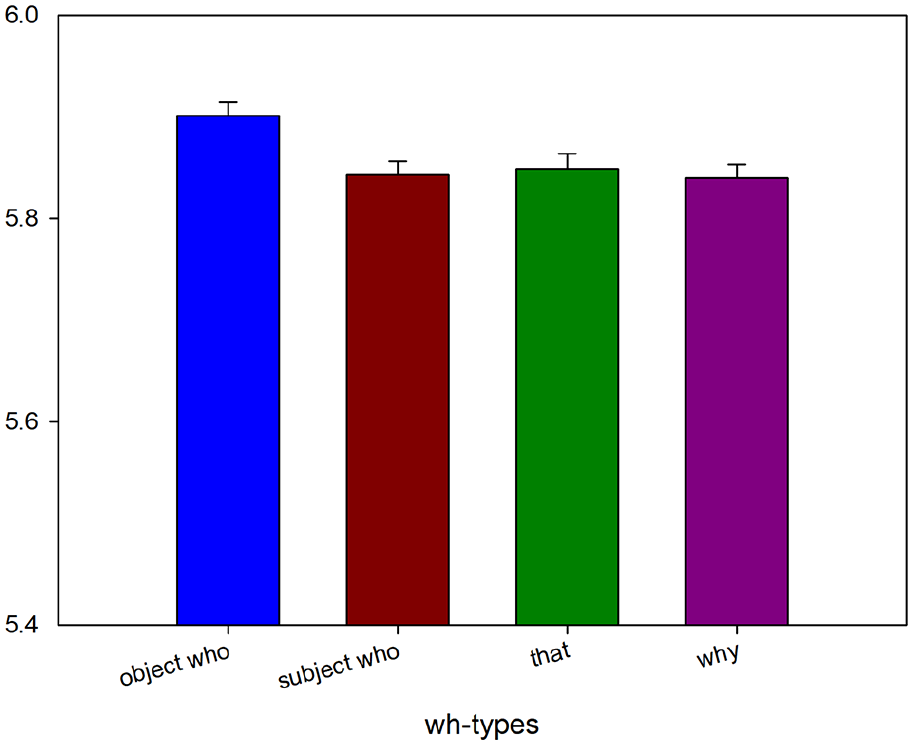
Reading times at the third verb spill-over region (the) in Experiment 2b.
The results revealed that at the most deeply embedded N, children, whoobj significantly slower than whosubj and why. In the most deeply embedded N spill-over region, loved, the difference between whoobj, whosubj, and why and that reached near significance.
We did not find any effect at the adverb regions including the spill-over regions of the first adverb (benevolently). 16 However, as predicted, whoobj was read significantly slower than why and whosubj at the third verb critical region (handed) and at the third verb spill-over region (the). This suggests that the effect at the third verb and the spill-over regions is consistent with integration costs for whoobj at that point.
Experiment 2c
In Experiments 2a and 2b, we included the that condition as a baseline because that does not trigger a relevant movement dependency (or it has one less open dependency compared with other wh-dependencies). If so, and if processing complexity is measured over the number of open dependencies, we expect the that condition to show the smallest complexity effect at the most deeply embedded N compared with other movement conditions in which wh-dependencies span across TP and VP. Thus, regarding the that condition, we did not expect any complexity effect at the most deeply embedded N position. Furthermore, we did not expect any integration costs at the later point of the sentence. Along these lines, we expected that there should be a significant difference between whoobj, how, why versus that in Experiment 2a, and whoobj, whosubj, why versus that in Experiment 2b at the most deeply embedded N position. But we found a significant difference between whoobj, how, why versus that at the embedded N spill-over region only in Experiment 2a and not in 2b. This suggests the necessity of directly comparing different wh-phrases (whoobj, whosubj, how and why) in a 2 × 2 within-subjects factorial design without the inclusion of that. In this experiment, we manipulated the Length (filler licencing condition: high/TP vs. low/VP) and Filler type (NP/entity-denoting filler vs. AdvP/non-entity denoting filler), giving four different conditions: whosubj (high-NP), whoobj (low-NP), why (high-AdvP), and how (low-AdvP).
In Experiment 1c, we further investigate storage and integration costs in the processing of different kinds of wh-phrases in filler-gap dependencies in line with our assumptions regarding the structural position in which they are licenced. We conducted an experiment that allows direct comparison by manipulating the Length (filler-licencing position: high [TP] vs. low [VP]) and the Filler type (NP/entity denoting filler vs. AdvP/non-entity denoting filler) in a 2 × 2 factorial design.
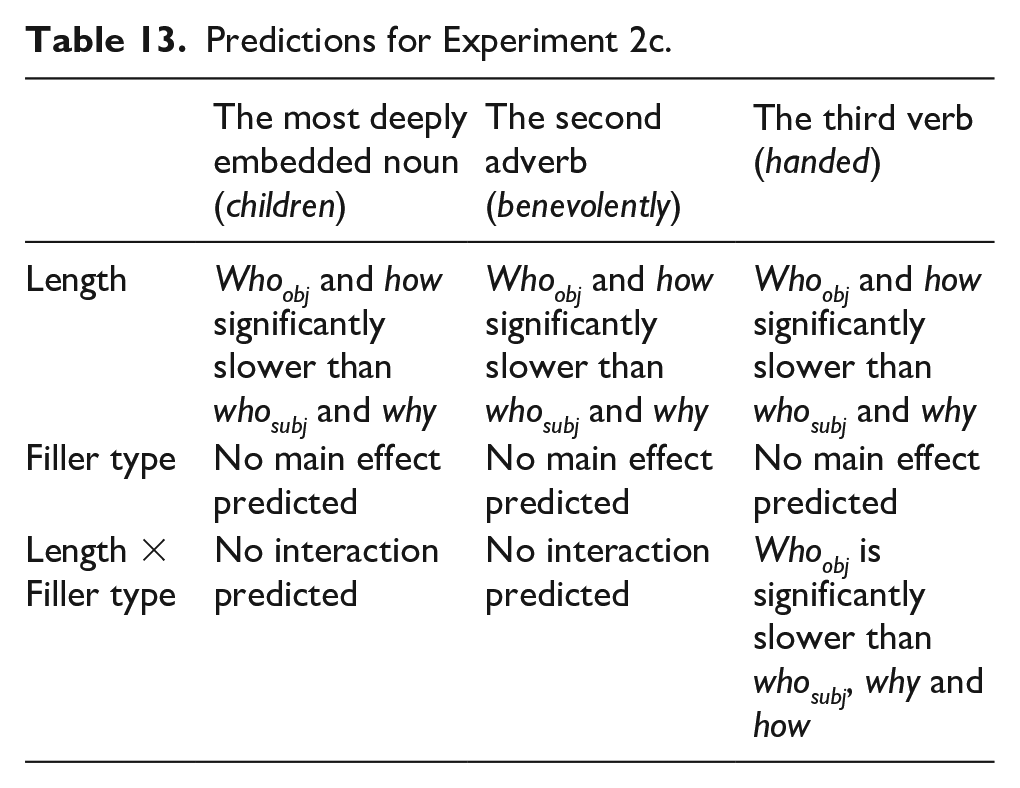
At the most deeply embedded N (at the word children), in the middle of the RC, we expect a main effect of Length where the longer dependencies spanning across VP (e.g., whoobj and how) should induce additional processing costs if processing is more difficult when the intervening material is within the dependency (between the filler and the licensor, since the filler needs to be held in memory). Thus, we expect whoobj and how to be read slower than whosubj and why. But we expect no interaction of the Length and Filler type, as well as no main effect of Filler type, at the identical region. At the adverb position prior to the third verb, we expect to observe a main effect of Length where whoobj and how should be read slower than whosubj and why due to storage costs for whoobj and integration costs for how, predictions that can be generated based on the results from Experiments 2a and 2b. At the third verb, we expect an interaction between Length and Filler type where whosubj, how and why should be read faster than whoobj. The predictions for Experiment 2c are presented in Table 13.
Predictions for Experiment 2c.
Participants, materials, and design
Eighty-seven native speakers of English from Prolific (https://www.prolific.co/) participated and provided their informed consent. They were paid US$5 for 20 mins of their time. We manipulated the Length (filler licencing condition: high/TP vs. low/VP) and Filler type (NP/entity-denoting filler vs. AdvP/non-entity denoting filler), giving four different conditions: whosubj (high-NP), whoobj (low-NP), why (high-AdvP), and how (low-AdvP).
The critical items consisted of 24 sentences in the form of a 2 × 2 within-subjects factorial design. A sample set of stimuli is presented in Table 14. In addition to the current experimental items, we used 37 filler sentences that contained orthogonal manipulations to the current sentences.
Sample stimuli for Experiment 2c.

Procedure
The same procedure was used as in Experiment 2a.
Analysis
A similar analysis was employed as in Experiment 2a. Each model included simple difference sum-coded fixed effects of Length (low filler licencing condition vs. high filler licencing condition; contrasts −0.5 and 0.5) and Filler Type (NP/entity-denoting filler vs. AdvP/non-entity denoting filler; contrasts −0.5 and 0.5) and their interactions. The critical regions include the embedded N critical region (e.g., children in Table 14), and one word following it (embedded N spill-over region). The second critical region included the adverb region before the third verb (e.g., benevolently in Table 14), the third verb (e.g., handed in Table 14), and the word following it (third verb spill-over region).
Results and discussion
Region-by-region reading times are shown in Figure 12. The results for the critical region (the most deeply embedded N), embedded N spill-over region, second adverb, third verb, and third verb spill-over region are shown in Figures 13 to 16. The mixed-effects model outputs are listed in Table 15.
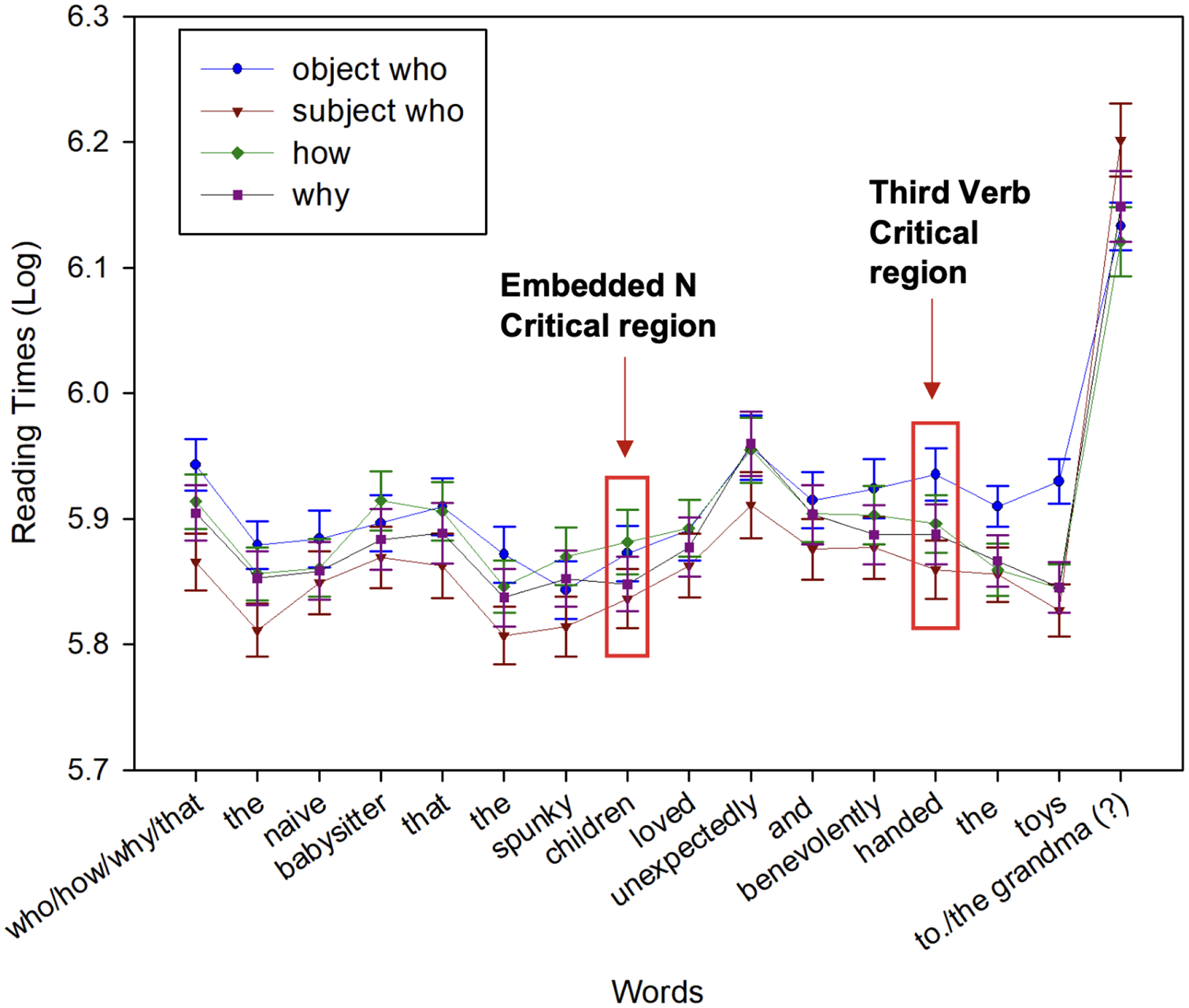
Means of region-by-region reading times from Experiment 2c.
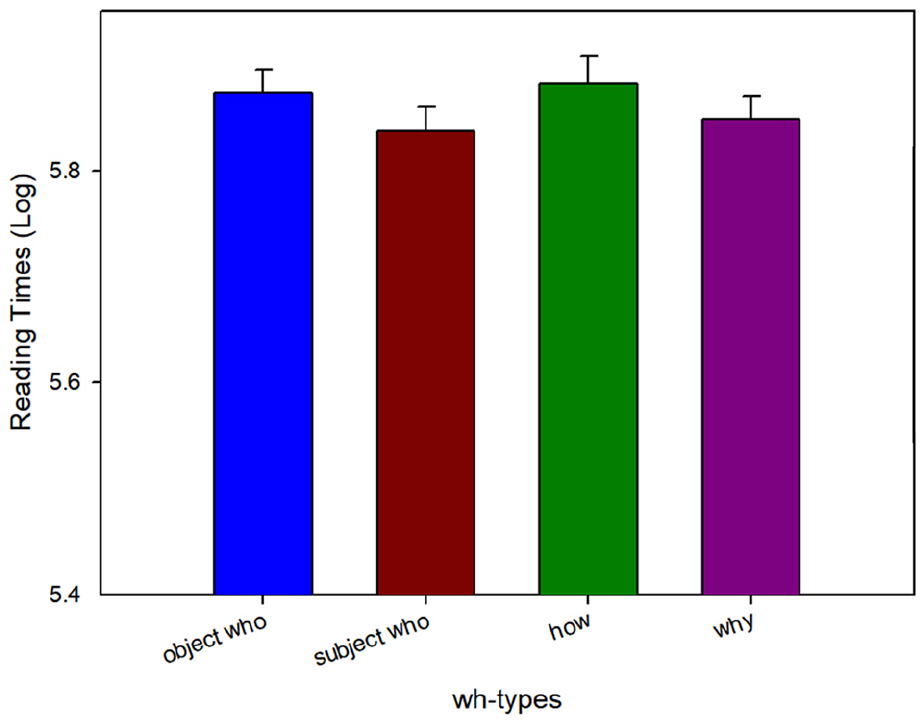
Reading times at the most deeply embedded N region (children) in Experiment 2c.
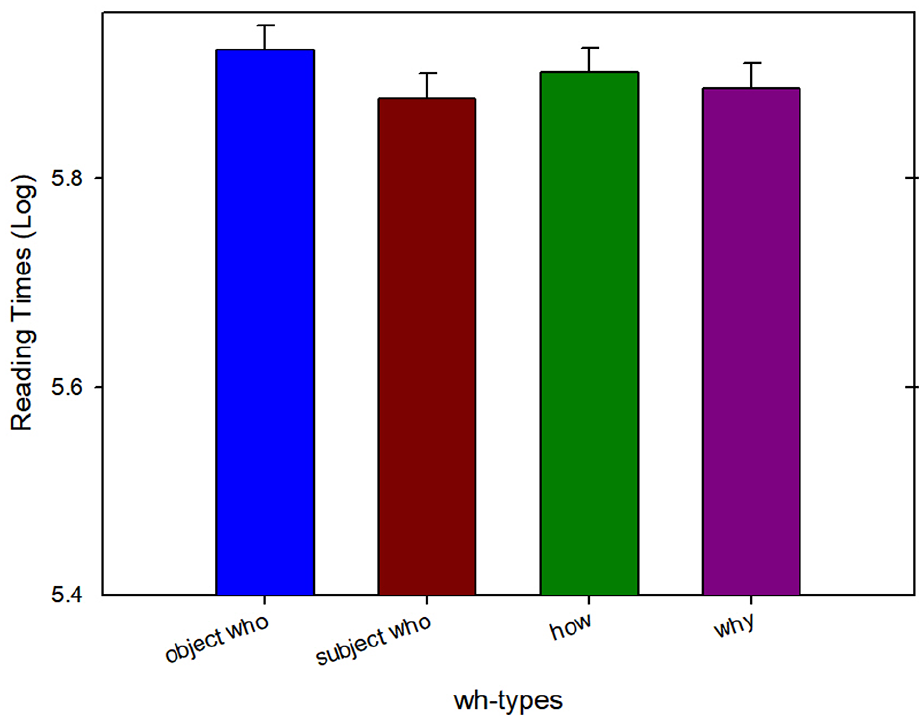
Reading times at the adverb (benevolently) in Experiment 2c.
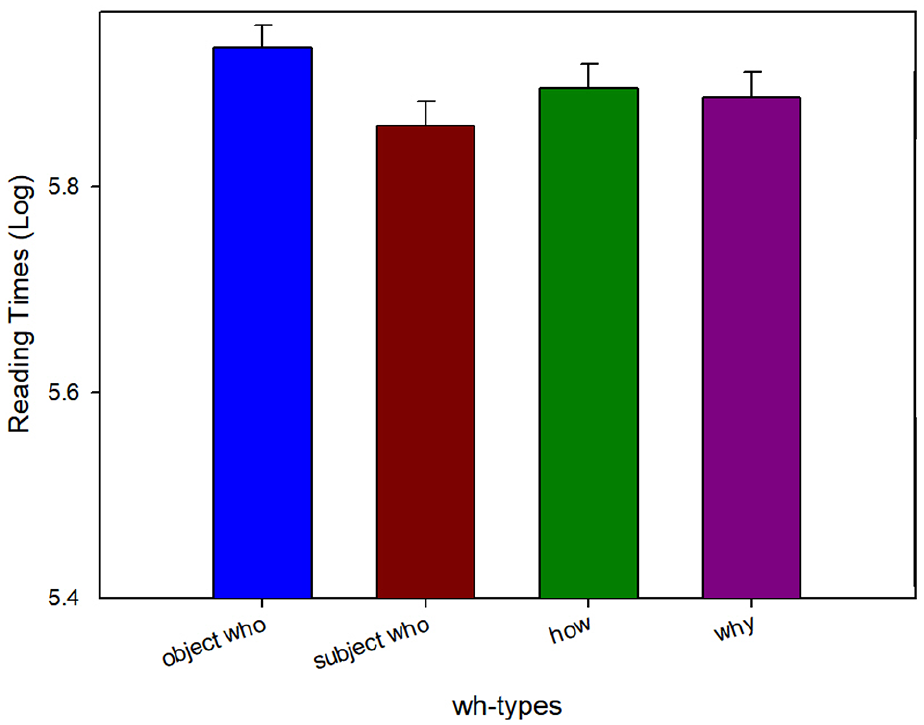
Reading times at the third verb (handed) in Experiment 2c.
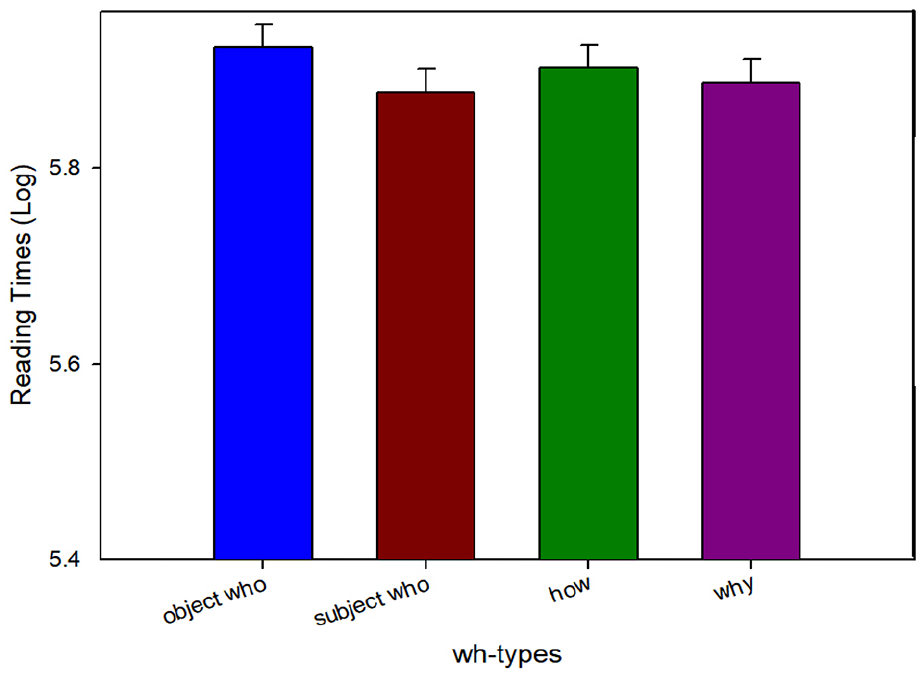
Reading times at the third verb spill-over region (the) in Experiment 2c.
Summary of mixed-effect model outputs for Experiment 2c.
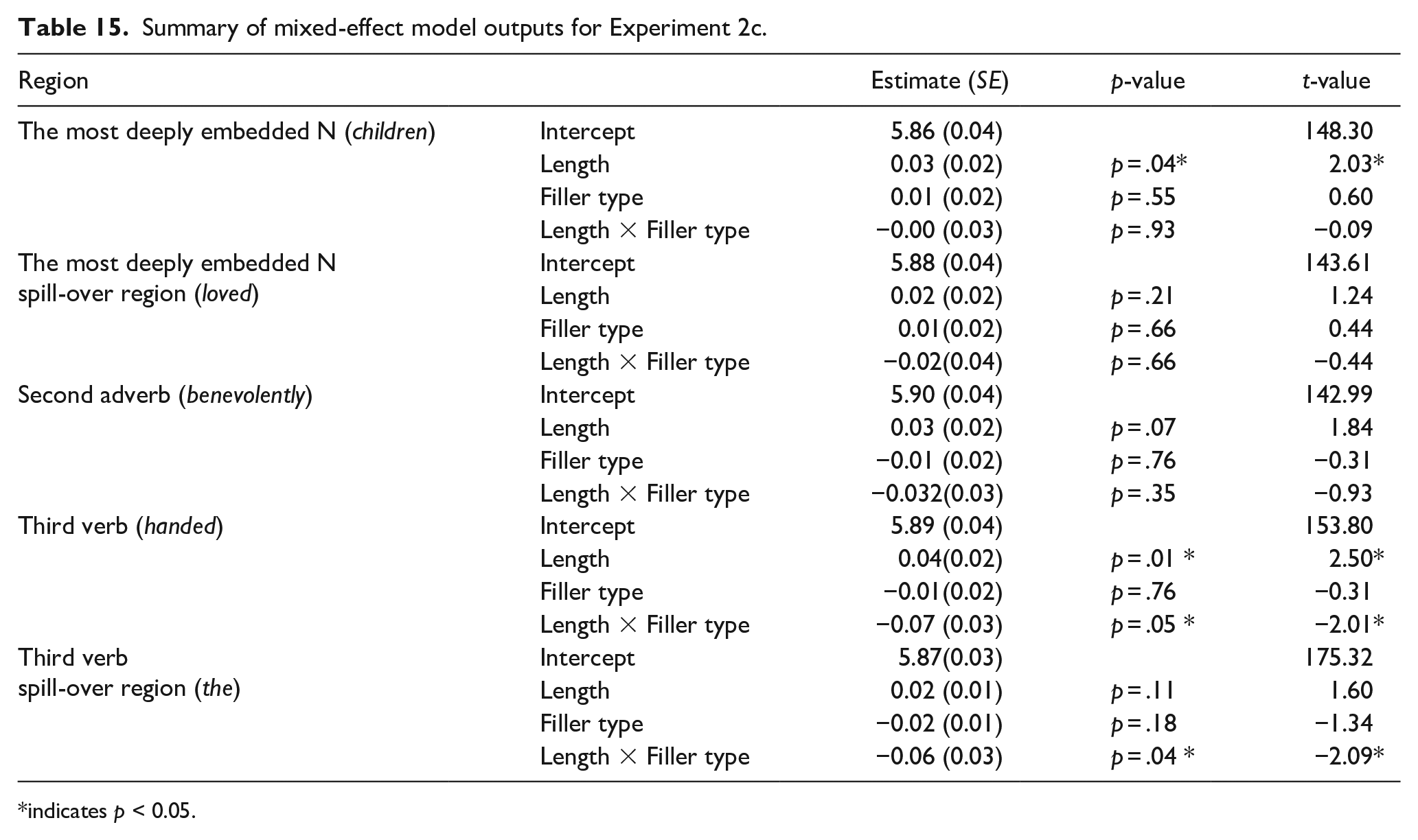
indicates p < 0.05.
At the most deeply embedded N (children), we observed a main effect of Length (β = .03, SE = 0.02, t = 2.03), such that the reading times for wh-phrases with the low filler-licencing position (whoobj and how) were read significantly slower than those for the higher filler-licencing position (whosubj and why). However, there was no main effect of Filler type (β = .01, SE = 0.02, t = 0.55) nor an interaction between Length and Filler type (β = −.00, SE = 0.03, t = −0.09).
At the second adverb position (benevolently) prior to the third verb, we observed a marginal main effect of Length (β = .03, SE = 0.02, t = 1.84) such that whoobj and how were read significantly slower than why and whosubj. This potentially suggests the integration costs for how and storage costs for whoobj lead to slower reading times even before the third verb is encountered. At the third verb region, we continued to find a main effect of Length (β = .04, SE = 0.02, t = 2.50) as well as an interaction of Filler type and Length (β = −.07, SE = 0.03, t = −2.01) where whoobj was read slower compared with the other wh-phrases (how, why, and whosubj). At the third verb spill-over region, we continued to find an interaction between Filler type and Length (β = −.06, SE = 0.03, t = −2.09) such that whoobj was read slower compared with the other wh-phrases.
Discussion of Experiment 2a–2c
We conducted three online experiments to probe whether different wh-fillers were stored in memory for different amounts of time, and whether they were integrated into the current structure once they were licenced by their licensors. Our first self-paced reading experiment revealed that whoobj and how were read significantly slower than why at the most deeply embedded N position. Thus, once why is licenced by TP (i.e., the preferred parse of reason why), it is integrated into the current structure, and no longer consumes memory. However, whoobj and how need to be kept in memory until the third verb is reached (e.g., handed), thereby leading to an additional open dependency waiting to be resolved and contributing to increased processing complexity. At the third verb spill-over region (the), we found a significant difference between whoobj versus how and why, suggesting increased integration costs for whoobj at the third verb.
The Experiment 2b revealed that whoobj processed differently from whosubj and why at the most deeply embedded N. Given that the dependency length is a predictor of the storage cost effect, we showed that whosubj and why were integrated early once the dependency was formed. As why and whosubj are integrated when TP is recognised, no corresponding increase in the complexity at the middle of the subject is found. By contrast, whoobj must be held in memory until the third verb is reached. This results in increased complexity at the center of the centre-embedded RC. At the third verb region, we observed significant differences between whoobj versus whosubj and why where whoobj was read significantly slower than whosubj and why.
In Experiment 2c, we further observed, at the most deeply embedded N, a main effect of Length in which wh-phrases with the low filler-licencing position (whoobj and how) were read significantly slower than wh-phrases with the higher filler-licencing position (whosubj and why). At the adverb region prior to the third verb, there was also a marginal main effect of Length where whoobj and how were read slower compared with why and whosubj. At the third verb, we found a main effect of Length as well as an interaction between the Length and Filler type such that whoobj was read slower compared with the other wh-phrases (how, why, and whosubj). This further provides evidence that different WhFGD constructions have different structural distances from their licensors, and that the storage and integration costs of wh-phrases can be attributed to the dependency length between the wh-filler and its respective licensor.
The differences in reading times for whoobj and how versus whosubj and why can be accounted for in terms of the grammatical differences between these wh-fillers. Different wh-fillers have different licensors; whoobj is licenced by the verb, how by the VP, and whyR and whosubj by TP. Because different wh-fillers have different licensors with which they form dependencies, the reading times at the most deeply embedded N also differ accordingly. In our examples (see Table 14), at the point of the most deeply embedded N (children), each WhFGD construction had a different number of open dependencies. If the number of open dependencies corresponds to the processing complexity, the storage costs for whoobj and how are higher at the most deeply embedded N compared with whosubj and why.
For whosubj and why, only three open dependencies must be resolved at the most deeply embedded N in a centre-embedded RC. However, whoobj and how have four open dependencies. Thus, an extra open dependency for whoobj and how (whoobj with the verb and how with VP) leads to slower reading times at the most deeply embedded N. These results are consistent with the Syntactic Prediction Locality Theory (SPLT: Gibson, 1998; Gibson & Warren, 2004), where the WhFGD formation and the object-gapped centre-embedded RC interact in such a way that the storage costs are at their highest when the highest number of dependencies are awaiting resolution.
In Experiment 2a, as we have discussed earlier, at the adverb position, we expected whoobj to be read slower compared with how and why due to storage costs, whereas how and why should be read similarly. Regarding integration costs, given that whoobj is an argument of the verb handed, and how serves as a modifier of the VP, we expected the reading time differences at the adverb because the parser integrates how upon encountering the adverb already, which marks the beginning of the matrix VP. However, we found no reading time differences between whoobj versus how and why nor between how and why at the adverb position. Why did we observe no reading time differences? This may be because at the point of an adverb marking VP, how induces an integration cost that spills over to the first and second adverbs. Thus, reading times at the adverbs prior to the third verb were still slower because of integration costs for how. Consequently, we did not observe the expected difference between how and whoobj at the first or second adverb. For whoobj, it is read similarly to how because of storage costs.
Also, we did not observe reading time differences between how and why. This is possibly because when the verb is encountered, the parser attempts to reanalyse whyR to whyP. From the retrieval point of view, the verb could deploy retrieval cues related to adverbs that reactivate why, as adverbs can form a dependency with the verb. Since why is an adverb which can be attached to VP (as in whyP), certain interference effects due to the memory retrieval could potentially cause a reading time slowdown at the adverb position for why. But if we assume that retrieval of adverbs (including why and preverbal adverbs) is only triggered at the point of the verb, as adverbs and verbs form dependencies, then an adverb should not trigger retrieval of another adverb. In this sense, the observed effect can be better explained by an encoding interference effect, that is, the encoding interference effect arises when the elements within the sentence are of similar properties, which are encoded in memory with less distinctiveness. In our experiment, why is an adverb which can be attached to VP (as in whyP) and facing another adverb prior to the third verb would lead to degraded representation in memory (Gordon et al., 2001, 2004)
But in Experiment 2c, when we compared only wh-phrases with the exclusion of that, we did observe a marginal main effect of Length at the adverb position where reading times for whoobj and how were slower than why and whosubj.
In Experiment 2a, our results showed that whoobj was read significantly slower than why and how at the spill-over region after the third verb (handed), but no differences were observed between how and why. In Experiments 2b and 2c, at the third verb (handed) as well as at that verb’s spill-over region (the), whoobj was read significantly slower compared with why and whosubj. Given that whoobj is an argument of that verb, and given that how is a modifier of its VP, the reader integrates how upon encountering the adverb before the third verb which marks the beginning of the matrix VP; hence, how does not affect reading time at the third verb.
General discussion
We examined the storage cost for different kinds of wh-fillers in a complex domain, namely when paired with a centre-embedded RC configuration. We hypothesised that if distinct wh-fillers need to be stored until their licensors are encountered, and are subsequently integrated to the current structure, then different wh-fillers should incur different processing costs according to their dependency lengths at the most deeply embedded N on the subject. Through both acceptability and online reading experiments, we presented evidence that readers store wh-fillers in memory by showing that processing costs are higher for whoobj and how, and less so for whosubj and why at the most deeply embedded noun position within the subject.
Sentences with why are structurally ambiguous (why asking for the reason, or whyR, and why asking for purpose, or whyP). As Stepanov and Tsai (2008) note, whyP specifically forms a dependency with VP (Bale, 2007; Bromberger, 1992; Chapman & Kučerová, 2016; Kawamura, 2007; Stepanov & Tsai, 2008; Tsai, 2008; Yoshida et al., 2015). The longer dependency formed by whyP spans across negation, and the shorter dependency formed by whyR does not span across negation. Our Experiment 1a confirms this claim, as whyP was rated lower in negative island contexts. Thus, this experiment confirms that there are two different dependencies formed by why with only whyP sensitive to negative islands. If the parser prefers the shorter dependency, the parser prefers the whyR dependency over the whyP dependency.
We observed why behaving differently from other wh-fillers such as whoobj and how, but similarly to whosubj in our online experiments. This pattern may be due to the principle of the parsing economy: the parser assumes the shortest dependency that is grammatically licenced (de Vincenzi, 1991; Gibson, 1998, 2000; Kazanina et al., 2007; Phillips, 2006; Pickering & Barry, 1991; Stowe, 1986). That is, why could be licenced either by TP or VP, but wh-TP dependency (reason why) is shorter than wh-VP dependency (purpose why). Thus, when encountering a why-sentence, the parser tries to find a way to licence why, and discharges the dependency as soon as it encounters the TP. If so, it naturally follows that sentences with why are read faster than other wh-fillers at the most deeply embedded N—it is preferentially read as the shorter-dependency whyR. In our online experiments, the reading times for sentences with why were shorter than those for how and whoobj and behaved similarly with whosubj at the most deeply embedded N. Given that why forms a dependency with TP, only three open dependencies need to be resolved at the most deeply embedded N.
Regarding the integration effects of how and whoobj in Experiment 2a, whoobj induces the storage cost effect in the regions before the third verb because the whoobj dependency is not yet terminated at the point of the adverb, and needs to be actively stored in memory. We further predicted that how should be read faster than whoobj and should be read similarly to why at the adverb position. But we found no reading time differences between whoobj versus how and why at the adverb position. Why did we not observe reading time differences at this region? If the adverb position before the third verb signals the upcoming VP, this could lead to integration costs for how before the third verb is encountered. Integrating newly encountered materials into the existing structure causes integration costs, which gives rise to reading time slowdown. If this is the case, the third verb region in whoobj is read slower than in the other conditions, and the adverb region in how condition is read significantly slower compared with other conditions owing to differences in integration costs. Such costs of how at the adverb could be conflated with the active maintenance cost of whoobj at the same point. Consequently, the difference between how and whoobj at the first and second adverbs was not observed. The differences between whoobj versus how and why were observed only at the third verb spill-over region in Experiment 2a, which could be due to integration with the verb and spill-over to the subsequent region. Our results showed that increased reading times at the third verb integrating whoobj with the third verb was costly at that point.
Regarding the general implications of our study, we argue that various components of memory (storage and integration) actively interact with online structure building. Specifically, both storage and integration elements play important roles over the course of online dependency formation. In our experiments, the distance between different wh-fillers (whoobj, whosubj, why, and how) and their licensors led to different storage cost effects at a most deeply embedded position, in our case the most deeply embedded N in a centre-embedded RC. The differences in the complexity effects for different wh-fillers follow naturally if we assume that different wh-fillers are stored in memory for different durations, and integrated at targeted points. According to processing complexity accounts wherein processing complexity rests on the number of open dependencies, the highest storage costs can be observed at the most deeply embedded N position.
Our account of the differences between how and whoobj at the third verb assumes that integration of whoobj occurs when the reader encounters the verb. A dependency can be established only when the licencing element (the word that deploys the retrieval cues and triggers the search, such as a verb) is introduced as lexical input, and when the reader encounters that element. It is also possible that the dependency relation may be terminated earlier in the middle of the dependency before the licencing element is encountered. Specifically, if readers can predict the relevant verb to come, they can trigger retrieval using this predictively inserted verb. One potential problem of the “predictive retrieval” frame is that it cannot explain the different complexity effects observed for different wh-fillers at the most deeply embedded N within the complex domain since this account does not assume that wh-phrases are actively maintained in memory until the dependency is resolved and makes no predictions pertaining to the storage cost effects. It remains unanswered whether the insertion of the head is predictive and stochastic, or deterministic and tightly linked to the licencing element.
If the dependency formation process involves only the integration process under the content-addressable memory store (Lewis & Vasishth, 2005) at the end of the dependency, then the storage cost effect at the middle of the sentence is not expected. In other words, the effect should be observed only at the end of the dependency or at the position where it is resolved. However, we do not expect to observe an effect at a position irrelevant to the dependency. On the contrary, if storage is at work, we can observe the effect at the middle of the sentence; thus, we can observe the effect at the position that is not relevant to the dependency itself (i.e., not the beginning or end of the dependency).
Finally, we can ask what kind of information is stored in the processing of different wh-fillers. Even if fillers such as why or whosubj form a dependency and are integrated earlier in the sentence, some information needs to be kept in memory at least for semantic purposes. Whosubj depends on VP for its thematic information, whereas why is interpreted relative to a complete proposition. Thus, while the fillers’ syntactic information is integrated at points before the verb, some aspects of their representation should still be kept in memory. The specific aspects are understood in terms of the features encoded by each wh-filler. Wh-fillers encode syntactic, semantic, and morphological features, and engage in dependency relations with licencing elements. The termination of the syntactic part of the dependency (e.g., checking formal/syntactic features) leads to the effects of processing complexity. For example, why has features like [wh], [Q(uestion)], and [T(ense)] and semantic features (Stepanov & Tsai, 2008; Tsai, 2008; Yoshida et al., 2015). When C is encountered, the [wh] and [Q] features can be eliminated; however, the semantic features are not checked or eliminated. Thus, the number of open dependencies is reduced at “integration,” but this need not entail that all relevant aspects of the why-dependency are established and terminated. Some semantic information (e.g., thematic roles) can be maintained in memory and used to achieve semantic interpretation later.
Thus, our study provides strong evidence that unintegrated wh-fillers are actively maintained in working memory, and that both active maintenance and integration components play critical roles in the mechanism of real-time sentence processing (Gibson, 1998; Gibson & Warren, 2004; Kim et al., 2020; Ness & Meltzer-Asscher, 2017, 2019; Wagers & Phillips, 2014; Wanner & Maratsos, 1978).
Conclusion
Our study showed that readers store different kinds of wh-fillers for different durations, depending on the licensors of these wh-fillers. We compared the storage profiles for the adjunct why, how, and argument who (serving as subject or object of the verb). The results of our experiments revealed that different kinds of wh-fillers are stored in memory for different amounts of time, depending on the structural distance between each wh-filler and its respective licensor, by which the grammatical function and interpretation of the wh-filler are governed. Our results also demonstrated that once the wh-filler is licenced, it is integrated into the current structure, no longer engendering additional memory costs. Based on these findings, we argued that the mechanism of online sentence processing employs both storage and integration components in the memory.
Supplemental Material
sj-pdf-1-qjp-10.1177_17470218241231872 – Supplemental material for Processing wh-filler-gap dependencies
Supplemental material, sj-pdf-1-qjp-10.1177_17470218241231872 for Processing wh-filler-gap dependencies by Nayoun Kim, Alexis Wellwood and Masaya Yoshida in Quarterly Journal of Experimental Psychology
Footnotes
Acknowledgements
The authors are extremely grateful to the anonymous reviewers for their invaluable suggestions and comments. They also thank the members of the Syntax, Semantics, and the Sentence Processing Lab at Northwestern University, audiences at Haskins Laboratories, and the audiences at the 30th and 32nd Annual CUNY Conference on Human Sentence Processing.
Authors' note
This paper is based on the second chapter of the first author's Ph.D dissertation. It is the natural extension and modification of some portions of Kim (2019)'s dissertation (Kim, 2019).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2023S1A5A8079483) as well as the National Science Foundation DDRI Grant (BCS-1749580).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.