
Abstract
To address low accuracy, difficult parameter determination, and inefficient data use in safety risk prediction, this study proposes an intelligent prediction framework. It uses rough set theory to preprocess data (eliminate incompleteness, discretize continuous data, remove redundancy) and introduces an improved particle swarm optimization (IPSO) by introducing a mutation operator to optimize key parameters of the least squares support vector machine (LSSVM), forming the IPSO-LSSVM model. Experiments on 43 risk samples (33 for training, 10 for testing) show that it outperforms the BP neural network and standard PSO-LSSVM with faster convergence. It enriches integrated intelligent algorithms in safety risk prediction and provides technical references for improving prediction accuracy.
Keywords
Introduction
The rockburst prediction technology refers to the in-depth study of the causes and mechanism of the formation process based on coal geological exploration or the occurrence of rockburst cases.1–3 According to statistics on the causes of rockbursts, studying and identifying the core triggering factors of rockbursts, conducting advance assessment of rockburst severity in coal geological formations, and clarifying its spatial distribution can provide guidance for rockburst safety management and prevention technology, and offer a reliable, targeted foundation for rockburst prevention and control.4,5
Nowadays, the traditional rockburst prediction methods can be roughly divided into the following two categories except for the analogy experience method:
(1) The first type is the local detection method based on the drilling chip method, which estimates the stress state according to the drilling chip amount and then evaluates the impact risk. The drilling cuttings method is simple, reliable, and intuitive, and widely used. Its disadvantage is that it can predict the discontinuity of rockburst in time and space, and the monitoring results are easily affected by human factors. It is only used as an auxiliary prediction method for local impact. (2) The second type is the systematic monitoring method that uses all kinds of shooting information caused by coal rockburst and strain softening, including the Geophysical Monitoring Method (geomagnetism, geotemperature, and geoelectricity). It is based on the structural stress failure process of rock mass structure and the advance appearance of a series of radiation phenomena. These radiation phenomena are considered as the precursors of stress failure. In general, continuous monitoring points are set up underground, and a continuous monitoring network is established to continuously monitor the rockburst dangerous area. The microseisms and ground sounds continuously monitored are converted into electrical pulse signals and transmitted to the surface monitoring station. The data are automatically processed and analyzed by the computer to predict the danger of the rockburst dangerous area. Although this square section can realize continuity in time and space, it is expensive, and it is difficult to manage and maintain the equipment. It is difficult to analyze the data and evaluate the stress state of coal and rock. It needs to test and further analyze and collate the accumulated large amount of empirical data to accurately evaluate the prediction results.
All kinds of methods for evaluating and predicting rockburst risk have their limitations and shortcomings. They cannot prevent and control the rockburst hazard well. The root cause is that they have not grasped the mechanism affecting the rockburst and have not taken qualitative and quantitative measures to predict and prevent the occurrence of disasters. In order to closely integrate with the actual project, research on the method of the test site must be carried out and is of great significance.6–8 However, how to use the measured information to predict the impact ground pressure is the key research direction of the field test technology. In recent years, with the rapid development and continuous updating of intelligent algorithms, most of the engineering problems have been solved.
In view of this, this paper makes an in-depth study on the dangerous dynamic disasters of rockburst in the underground driving roadway of coal mines. In view of the shortcomings of the current prediction methods in this field, it systematically and comprehensively analyzes the impact indices (such as mining depth, geological structure, etc.) closely related to the formation and development of rockburst in many coal mines where rockburst disasters have occurred, and applies the advanced intelligent algorithm theory to the prediction of rockburst.
Theoretical background
Statistical learning theory provides excellent solutions to minor sample modeling problems. Support vector machine (SVM)9–13 and support vector regression machine14–18 are essential components of statistical learning. In solving the problem of rockburst with a limited number of samples, the vector machine model can be said to have opened up a good idea in its prediction research. This method only needs to select highly representative sample data and has low requirements for mastering the internal mechanism of the rockburst. It is also unnecessary for each correlation index to model the complex nonlinear mathematical relationship between rockburst pressure. The risk minimization principle constructs a successful prediction of the down hole shock state and its changing trend, which saves much workforce and material resources and dramatically improves the prediction efficiency. In this way, it is possible to predict the rockburst level at a specific time and place in the mining area in the future. However, the typical data of rockburst is often not enough in practice, so in the case of small samples, it is necessary to consider the time-varying and nonlinear characteristics of rockburst data and make accurate and reliable data in this field. The promotion and application of prediction models have become the focus of current prediction problems.
This paper brings the data after rough structure and intensive reduction into the SVM model and constructs models for each nonlinear relationship. It makes up for the vacancy of low theoretical degree in traditional shock prediction methods, which only rely on run test results and human experience to grade rockburst risk.
Statistical learning theory
Statistical learning theory19–21 was once considered an empirical experimental science when studying the patterns of machine learning. However, after in-depth research by a large number of researchers, it has been found to have significant advantages in addressing small-sample (non-asymptotic) problems. Based on data, it seeks general patterns from limited sample data and attempts to analyze objective objects using some patterns that cannot be derived through principles, thereby accurately predicting the future or data that is not easily discoverable.
VC dimension
The VC dimension is an index of the learning performance of function sets defined in statistical learning theory to study the convergence speed and generalizability of the empirical risk optimal value converging to the expected risk optimal value when the number of indicator function sets tends to infinity. It is used to describe the capacity of a collection of functions.
The intuitive definition of the VC dimension can be expressed as follows: in the indicator function set, if there are possible 2 n forms that are separated by the functions in the function set through n data samples, it is said that n samples can break up this function set, and the maximum number of samples n refers to the VC dimension. The VC dimension is infinite if the functions in the function set can break up any number of samples.
The VC dimension further reflects the strength of the learning ability of the function set. If the VC dimension is smaller, the learning machine is more straightforward, and the capacity is correspondingly smaller. However, the current calculation of the VC dimension has certain limitations, and the VC dimension of complex function sets is difficult to determine. Usually, only the VC dimension of some particular function sets can be accurately calculated. Therefore, in the research of statistical learning theory, how to obtain the VC dimension of any function set is still the focus of research in this field.
The generalization bounds
The generalization bounds in statistical learning theory refer to the relationship between the empirical risk
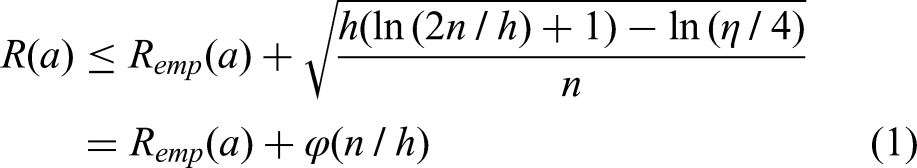
In the formula, n is the number of data samples, and h is the VC dimension.
From formula (1), the actual risk consists of the empirical risk
Structural risk minimization
From equation (1), it can be known that in order to achieve the minimum limit of actual risk, the empirical risk should be minimized, and the learning machine (function set) with the smallest VC dimension should be used, but in fact, these two types of requirements are contradictory. Therefore, in order to minimize empirical risk, a wider set of functions should be used instead of a smaller VC-dimensional set when selecting functions. It requires us to control two conflicting factors while searching for the optimal solution to minimize the actual risk. In order to solve this problem, a new inductive principle in statistical learning theory, namely the principle of structural risk minimization (SRM), is obtained.
The basic idea of SRM is: if the size of the number of training samples n is fixed, the actual risk
Decompose the function set
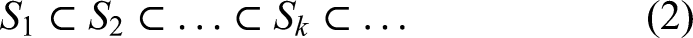
Among them,
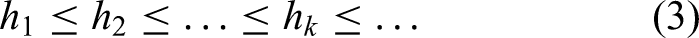
Each subset has a unified confidence range, and as the complexity of each subset increases, the empirical risk will decrease. At this time, the confidence range and empirical risk should be kept similar in the subset, so that the actual risk reaches a minimum.
SVM model
SVM proposes a novel machine learning method based on the principle of SRM.16–18 It effectively addresses problems related to limited samples, non-linearity, and high dimensionality. Essentially, SVM solves a convex quadratic optimization problem, ensuring the effectiveness of the solution while avoiding local optima, thereby guaranteeing that any extremum solution found is a global extremum.
Fundamentals of support vector machines
A SVM is a learning machine based on statistical learning theory and linear separable optimal classification surface. It minimizes the actual risk according to the empirical risk minimization criterion and takes the minimization of the confidence range as the goal.
The SVM performs a nonlinear transformation on the input sample vector. This process is completed by using an appropriate kernel function, and then the transformed input space vector is mapped to another high-dimensional feature space through the kernel function. In order to construct the optimal classification hyperplane and replace the linearly inseparable problem with the linearly separable problem, the rational selection of the kernel function effectively solves the “dimension curse” of the internal computer calculation and the feature space. The intuitive definition of the vector machine method is to construct the optimal classification hyperplane by obtaining the support vector by bisecting the closest point of the maximum separation plane.
Linearly separable optimal classification hyperplane
The SVM was initially developed for binary classification problems.22–25 A given set is assumed to be divided into positive and negative samples. The goal is to find a unique maximum hyperplane to classify positive and negative data patterns using linear classification.26,27 When solving the optimal hyperplane problem with the SVM, it is transformed into the solution of the Lagrangian function's functional convex quadratic optimization problem.
The method of constructing the optimal classification hyperplane: set a given training sample set
Defining the linear classification model
Constraints on g(x) are:

The above formula (5) can be transformed into a limiting condition, namely:

The distance from H1 and H2 to H is
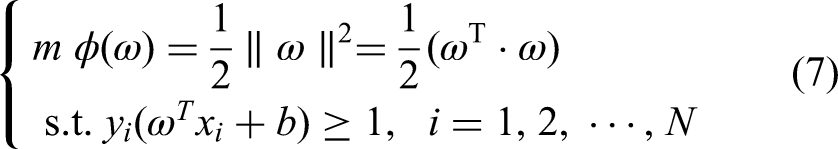
The solution for parameters
Construct the Lagrange function:

The above formula
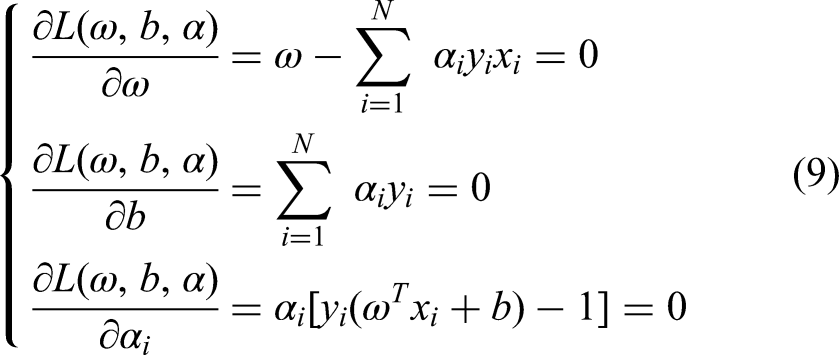
Then:
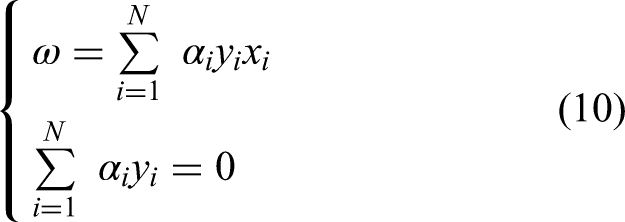
Substitute equation (10) into equation (8), and replace the original optimization problem with solving the dual problem:
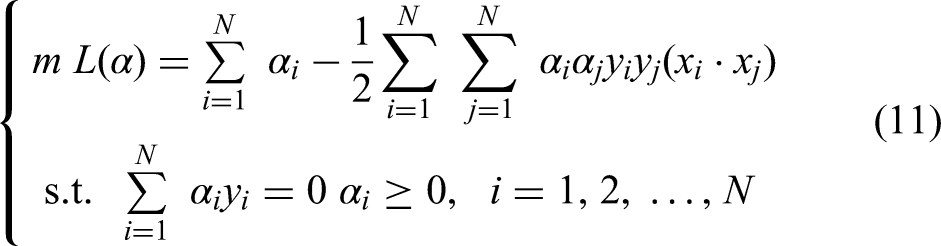
The optimal solution of equation (11) must satisfy:
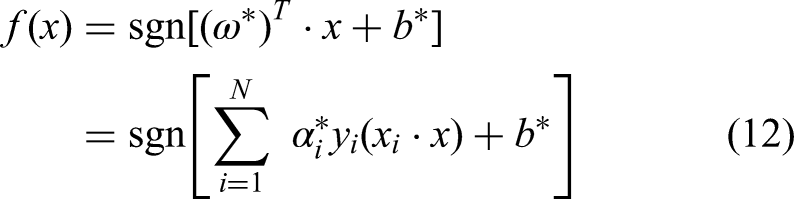
Equation (12) can be regarded as a quadratic function optimization problem, which is based on the inequality constraints and has only one solution. If the optimal solution is
The objective function of the optimal classification can be obtained as
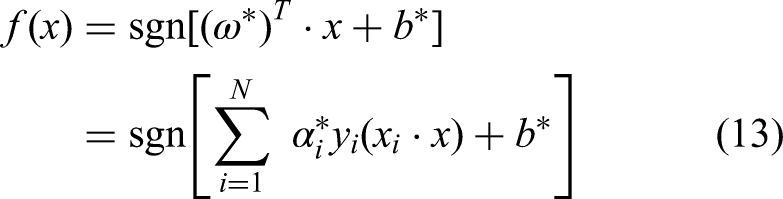
Among them, N is the number of SVMs,
In order to distinguish the category of the test sample, which category the sample finally belongs to can be obtained from the positive and negative values of
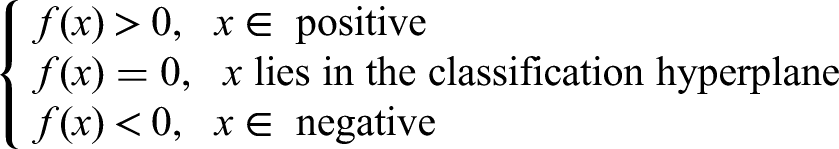
Nonlinear support vector machines
For the case of linear inseparability, a nonlinear mapping function
Although the nonlinear mapping of the low-dimensional space complex problem through the high-dimensional feature space is adopted to simplify the classification problem, with the change of the spatial dimension, the calculation of the inner product also increases, resulting in the high-dimensional feature space in the high-dimensional feature space. The optimal classification surface solution problem becomes much more complicated. The introduction of the kernel function makes the problem equivalent to computing in the original space. The solution of the inner product of the high-dimensional feature space is cleverly avoided, and the computational complexity is reduced accordingly.
Kernel function of SVM
The successful application of SVMs in the field of statistical learning benefits from the following two characteristics, one uses the principle of minimum structural risk to construct the optimally spaced classifiable hyperplane, and on the other hand uses the convolution of the inner product to ingeniously construct the kernel function without knowing the explicit expression of the nonlinear mapping. The specific nonlinear problem-solving process adopts the kernel function. The random vector x in the N-dimensional vector space is not the original characteristic to participate in the calculation, but the vector is linearly separable after mapping in the high-dimensional space. In the linearly separable problem, all coordinate components are cleverly solved by the inner product cyclotron calculation, so it is unnecessary to spend time extracting the specific form of the nonlinear transformation. As long as the validity of the kernel function satisfies Mercer's theorem, it can be applied in the inner product computed in the original input space, resulting in a suitable nonlinear algorithm.
In the SVM, the kernel function determines the structure of the high-dimensional feature space. In order to obtain a learning machine of the nonlinear decision surface, the kernel function with different inner products should be selected in the sample space. That is to say, the choice of the constructed kernel function parameters directly affects the complexity and generalization performance of the classifier. At present, the kernel inner product functions currently used mainly include the following categories:
(1) Polynomial inner product function: one is the P-order non-homogeneous polynomial kernel function
The polynomial kernel function has achieved extensive application results in the application of SVMs in many fields. But for the polynomial kernel function, when the dimension is high, the calculation amount increases sharply, which slows down the operation rate, and sometimes it is even difficult to solve at all; that is, the problem of “dimension disaster” occurs. The polynomial kernel function constructed in the SVM can only solve low-dimensional space.
(2) Radial basis function (RBF)
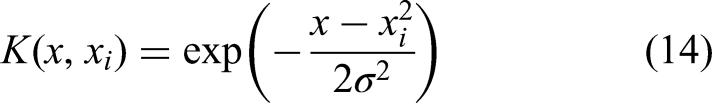
The so-called radial basis function is a symmetrical scalar function along the radial direction. In the above formula,
The RBF represents the monotonic function of the Euclidean distance from the kernel function center (3) Sigmoid kernel function:
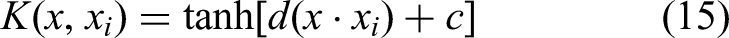
In the above formula, d and c are the kernel function coefficients, that is, the hyperbolic tangent function
The choice of kernel function and different kernel function parameters has a profound impact on the learning performance and generalization ability of the SVM model. According to the polynomial kernel function mentioned above, there are more parameters than the RBF, which will increase the difficulty of solving practical problems; and the Sigmoid kernel function has poor generalization ability in practical applications, while the RBF kernel function has a very high locality and regression performance, and more accurate prediction.
Least squares support vector machine
Although the SVM was first proposed for the classification problem, by introducing the ingenious idea of the loss function, the SVM can be extended to the function regression problem, thus providing a new idea for solving the modeling problem of some problems.28–32
The least squares support vector machine (LSSVM)33–37 transforms the inequality constraints in the classification problem into equality constraints in order to fit the accuracy, and all training samples can be fitted with a linear function under the condition of a specific accuracy, and finally directly solve the linear equation system, and it is no longer necessary to solve the quadratic programming problem to find the hyperplane for the optimal classification. The LSSVM does not need to solve the quadratic programming problem, so the complexity of the calculation is reduced, and the learning and solving speed is also improved, which is suitable for predicting the risk level of rockburst.
The solution process of the LSSVM algorithm38–42 is as follows:
Given a training sample set
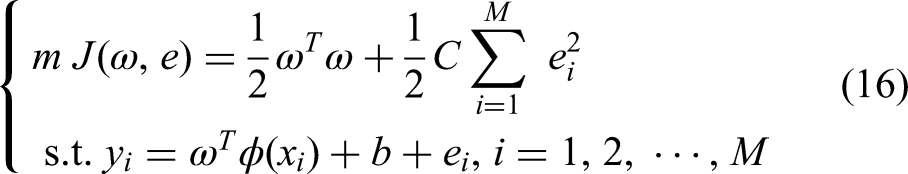
Among them,
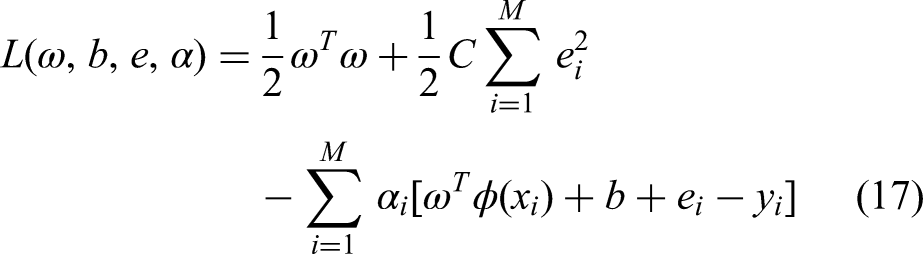
According to the optimization conditions, the partial derivatives of each variable of the Lagrange function are obtained, and the partial derivatives are set equal to zero, we get:
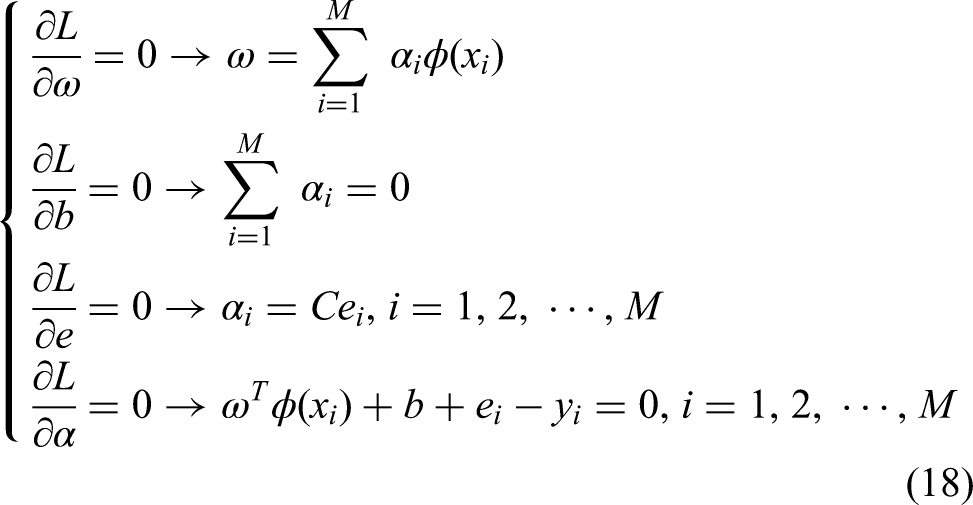
Substitute into equation (18) to eliminate
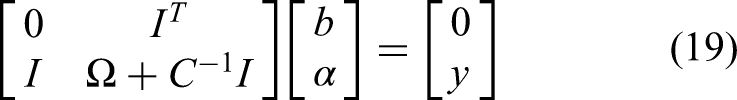
Among it,
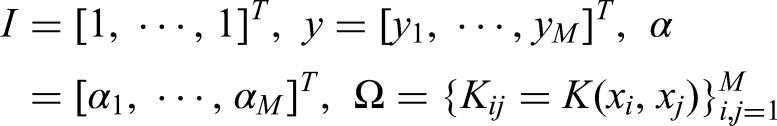
Finally, the least squares method is used to solve
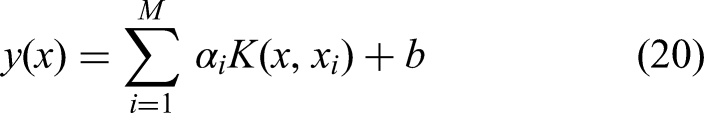
Rough set theory
Rough set theory is a mathematical tool for describing incompleteness and uncertainty.19–22 It can effectively analyze inaccurate, incomplete, inconsistent, and other uncertain information with strong randomness, and further analyze and reason about data to uncover hidden information and reveal inherent knowledge rules. By utilizing rough set theory, the various influencing factors of intermediate impact pressure are reduced to eliminate redundant information, obtaining the main factors affecting impact pressure. A precursor processor is then constructed to provide simplified sample data for the SVM prediction model.
In the extraction of data indexes for impact pressure in rough sets, discrete data is required to express the numerical values in the decision table, and continuous impact pressure index data must be discretized. Effective discretization methods can reduce the time and space overhead of algorithms, improve the clustering ability of samples, and enhance learning accuracy. The discretization of continuous attributes refers to dividing the value domain of continuous attributes into breakpoints, and then classifying the attribute values into multiple intervals according to the judgment criteria, with each code representing a different interval, thereby obtaining discrete attribute values. This paper adopts the fuzzy C-means clustering (FCM) algorithm18,29–31 for fuzzy clustering partition of the sample space, as it has strong adaptability and is easy to operate. This algorithm has been widely applied in many fields such as image segmentation and system identification.
Particle swarm optimization
In the LSSVM algorithm, the penalty factor C and the kernel function width coefficient σ need to be determined manually. Their selection has a significant impact on both the generalization prediction accuracy and computational efficiency of the algorithm. Typically, grid search combined with cross-validation is employed to obtain optimal parameters, but this method is heavily influenced by human factors and is complex and time-consuming to implement. Therefore, this paper leverages the powerful global search capability of the recently popular particle swarm optimization (PSO) algorithm37–40 to optimize these two parameters of the SVM, thereby greatly improving the performance of the SVM in predicting impact pressure.
The PSO algorithm randomly initializes a swarm of particles, and then searches for the best solution during each iteration. Each particle follows its individual best position (pbest) and the global best position (gbest), meaning that the particle updates its position and flight velocity based on its historically best solution found and the best solution found by the swarm, gradually converging towards the optimal solution.
Methods
Theoretical foundations
Based on a comprehensive analysis of historical rockburst cases and relevant literature,43–50 we selected seven geological and mining indicators closely related to the occurrence of rockburst as input features for the model, including mining depth, geological structure type, coal seam thickness, drill cuttings volume, maximum principal stress, uniaxial compressive strength, and elastic deformation energy index. The model uses rough set theory as a precursor data processor combined with LSSVM to predict the hazard level of rockburst. The fundamental reason is to provide a practical basis for strengthening rockburst risk prediction and a reliable and effective decision support method for the prediction of rockburst. PSO is employed to automatically search for and determine the optimal parameters for the LSSVM model, which is crucial for its predictive performance.
The attribute reduction (i.e. deleting redundant attributes without affecting decision-making ability) of rough set aims to remove redundant conditional attributes without changing the basic classification and decision-making ability of the data set, so as to reduce the input dimension of the subsequent LSSVM model and simplify the model complexity. The construction process of the prediction model involves the following steps: First, use the attributes of rough set theory and the idea of attribute reduction to perform redundancy processing (i.e., eliminate the redundancy of sample information, remove the duplicate or samples that do not provide new information) on each impact index, that is, use rough set as a processor, and then use least squares support vector machine as a back-end processor to perform regression fitting on the simplified sample information.
Safety prediction model
Overall process
The model of this study is mainly based on conventional indicators that are easily obtainable during geological exploration and mining processes (such as depth, geostress, etc.), and does not include electromagnetic radiation and other data from geophysical monitoring methods. This is both a simplification of this study and a direction that can be expanded in the future.
A rough set-particle swarm SVM prediction model is constituted. The learning process of rockburst hazard level and the steps of the prediction algorithm are as follows:
Step 1: Eliminate redundancy in sample information: obtain and complete specific sample information, eliminate incomplete data, ensure that the decision attributes of the remaining sample condition attribute sets are not missing, and perform normalization processing.
We removed any samples containing missing values to ensure data integrity. Here, “sample information redundancy” means that if two samples have exactly the same indicators (such as mining depth, geostress value, etc.) and risk level, then one of them can be considered redundant data and removed to avoid misleading model training.
Step 2: Discretize the continuous rockburst hazard sample information in the data by constructing the membership degree using the FCM algorithm.
For continuous indicators, we use the FCM algorithm to automatically divide them into several fuzzy sets, with each data point having a membership degree to each fuzzy set, thus achieving soft discretization of the data, which can better preserve the uncertainty information of the data than hard partitioning (such as equidistant discretization).
Step 3: Reduce the discretized decision table with the idea of rough set theory, and ensure that redundant information samples and irrelevant condition attributes are eliminated without affecting the dependency relationship between the decision attributes and condition attributes in the decision table. The final attribute decision table is obtained through the reduction of the kernel.
The reduction algorithm based on the discernibility matrix is used to reduce the attributes of the discretized decision table. By constructing the discernibility matrix, the algorithm finds out all the attribute combinations that can distinguish different decision categories, and then solves the minimum attribute reduction set, so as to eliminate those redundant condition attributes that do not affect the decision classification ability.
Step 4: Extract training and testing samples from the final training samples of the reduced kernel, select the radial basis kernel inner product function, and use the improved particle swarm optimization (IPSO) algorithm to optimize the optimal penalty factor and kernel width coefficient. The training sample trains the regression estimation function
Step 5: Finally, use the test sample to evaluate the output result of the LSSVM against the rockburst risk level model, and evaluate from the two aspects of convergence speed and prediction accuracy. If the prediction requirements are not met, repeat steps (1)–(5) until the final model is satisfactory and stop.
Among them, the prediction error is verified with the mean absolute percentage error (MAPE). Let the sample time sequence be
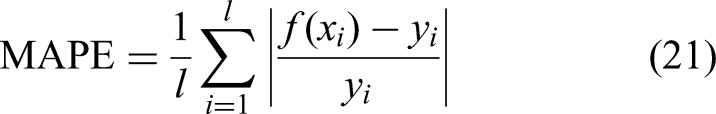
The characteristics of this model are: rough set does not require additional artificial assumptions and uses its reduction idea to dig deep into the classification rules and internal correlations of the input samples of rockburst hazard levels to extract the implicit knowledge of the samples, not only to remove the support vector, the abnormal data sensitive to the machine algorithm also ensures the elimination of large-scale high-dimensional redundant attributes and information and noise in the sample; and the introduction of the construction membership method of FCM in the discretization of rough sets enhances the individual distinction; this kind of precursor processor not only enhances the subsequent LSSVM regression accuracy but also reduces the prediction and learning burden and training time through information dimension reduction and redundancy elimination. The SVM is used as the post-information processing system, which makes up for the complexity of the samples in practical applications and the limitation of the SVM for samples with strong fault tolerance and interference; the introduction of the swarm algorithm not only improves the accuracy of the test set but also dramatically improves the efficiency.
The core of rough set theory lies in simplifying the dataset and extracting core decision rules by identifying and removing redundant attributes that do not contribute or contribute very little to decision-making, without altering the data's classification ability. This is akin to slimming down the data by removing noise and irrelevant information. Through attribute reduction in rough sets, the number of input features has been reduced. This not only reduces the input dimension and computational complexity of the LSSVM model, but more importantly, eliminates redundant and noisy information, allowing the model to focus more on core decision attributes, thereby improving prediction accuracy and generalization ability.
The specific flow is shown in Figure 1. Figure 1 shows the complete process of the proposed IPSO-LSSVM prediction model, clearly presenting the various stages and their interrelationships from data input, rough set preprocessing, IPSO parameter optimization to LSSVM model training and prediction.
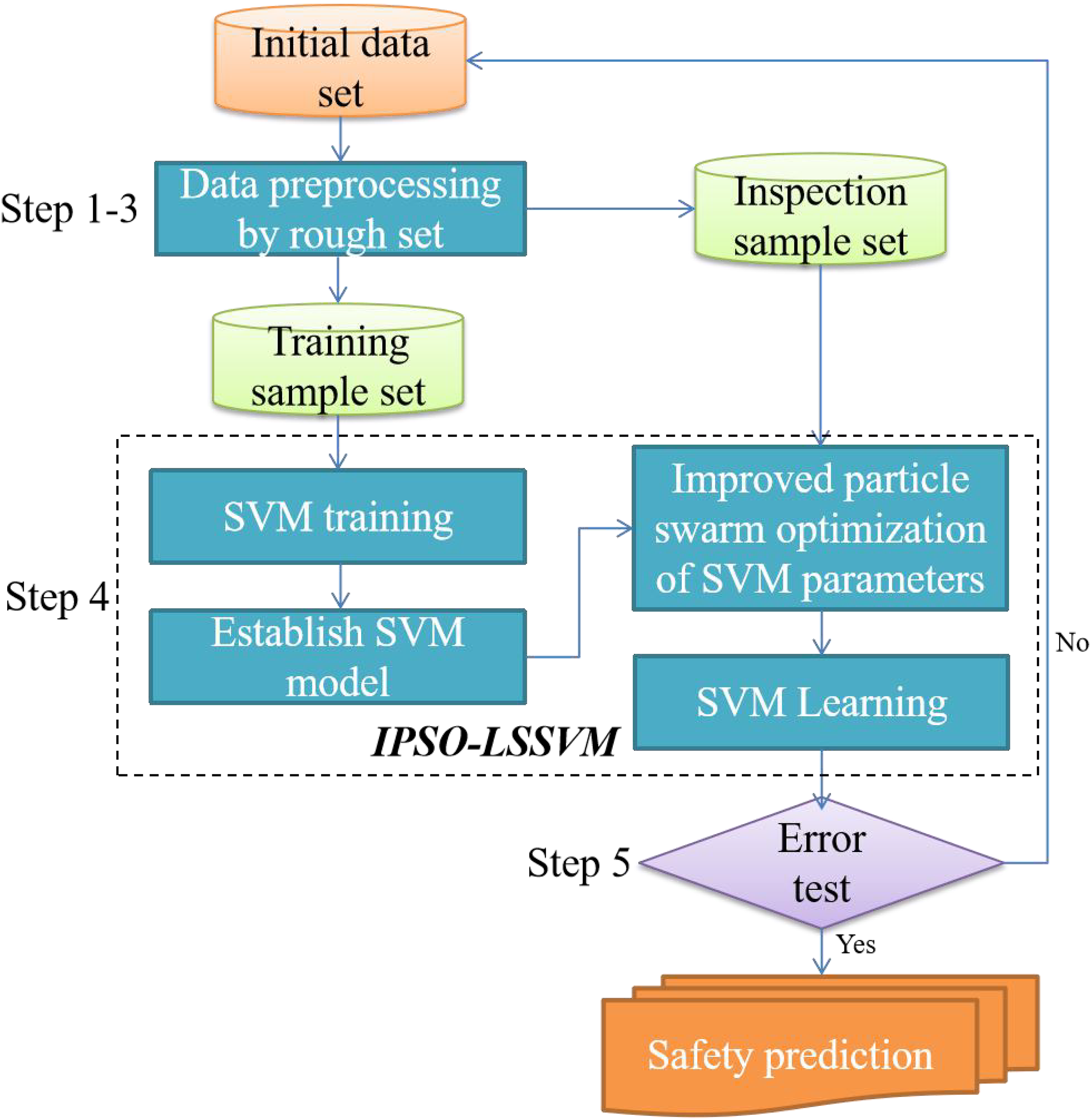
Safety prediction flow.
Optimizing LSSVM parameter by IPSO
In the later stages of iteration, the standard particle swarm algorithm tends to cluster particles near a local optimum, resulting in loss of population diversity and premature convergence. To enhance the algorithm's ability to escape from local optima, this paper introduces a mutation operator (referred to as IPSO) in the PSO framework. The specific operation is as follows: after updating the velocity and position of particles in each iteration, mutation is performed on some particles with a certain probability. The mutation method uses Gaussian perturbation to randomly shift the position of particles. This strategy can effectively increase population diversity, help particles escape local extremum points, and avoid excessive random disruption of the convergence direction through adaptive probability.
The detailed steps are as follows:
(1) Initialization. Randomly initialize the speed and position of each particle in the entire particle swarm, the current position is the historical optimal position of a single particle,
The performance of LSSVM is highly dependent on the penalty factor C (the trade-off between control model complexity and error) and the kernel function parameter σ (which affects the radial range of the RBF). In order to obtain the optimal (C, σ) combination, we use the IPSO algorithm to conduct a global search within the preset empirical range (e.g. C ∈ [0.1, 1000], σ ∈ [0.01, 100]).
Initialize the kernel parameter vector (2) Evaluate the population. The evaluation function is also the fitness function, which is mainly used to distinguish the quality of the individuals in the population. The fitness value of the particle is inversely proportional to the quality of the position. The individual extreme value pbest of each particle stores the fitness value and position of each particle, and the global extreme value gbest stores the fitness value and position of the individual with the best fitness value among all the individual extreme values. The fitness function can be defined as:
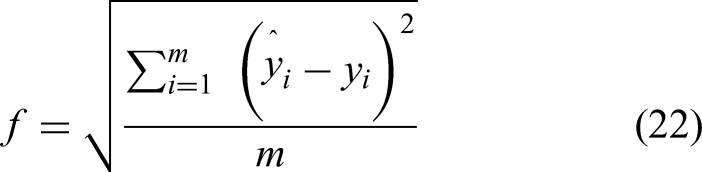
Among them, (3) Comparison of fitness values. For each particle, compare the optimal position that the particle flies through and the fitness of the particle. According to the comparison between all the current individual extreme values pbest and the global extreme value gbest, update gbest. (4) Particle state update. (5) Check whether the end conditions are met. If the maximum number of iterations is reached or the fitness value is less than the given precision, the iteration is stopped, and the optimal solution is output. Otherwise, return to step (2) to continue the iteration. The condition of iteration stop is to meet one of the following two conditions: (1) reach the preset maximum number of iterations t (set as 2000 in this paper); (2) In successive iterations (such as 50 times), the change of the global optimal fitness value is less than the preset minimum threshold (set as 1×10−6 in this paper). (6) The optimal position of the particle found, that is, the optimal parameter vector
We set the population size to 20, the acceleration factor
Experimental results and analysis
We choose the classic BP neural network as the benchmark model, because it is widely used in all kinds of prediction problems. At the same time, the standard PSO-LSSVM is selected as a comparison to verify the effectiveness of the proposed improvement strategy (IPSO). Although there are other advanced methods such as random forest and gradient lifting tree, this study focuses on performance improvement under the SVM framework, so it is mainly compared with the homologous LSSVM model.
In order to better analyze the prediction effect of the rockburst prediction model based on the IPSO-LSSVM algorithm proposed in this paper, according to the sample data, the prediction and simulation of the rockburst hazard level are carried out. The sample data is described as follows.
Data source: The data specifically comes from Meihuajing Coal Mine in Ningxia, China.
Data size: A total of 43 samples, each containing 4 features.
Feature description: The feature description is shown in Table 1.
Feature description.

Output tags: Rockburst risk level: 1-Weak risk, 2-Medium risk, 3-Strong risk.
Data partitioning: 33 training sets and 10 testing sets are randomly partitioned.
Given the small sample size, in order to more reliably evaluate model performance and prevent overfitting, five-fold cross-validation is used during the model training process. The training set is randomly divided into five parts, with four parts used for training and one part used for validation in turn. The average error of the five validations is used as the basis for selecting model parameters.
Compared with the PSO-LSSVM network learning algorithm and the BP neural network prediction model, it starts from two aspects of training efficiency and prediction accuracy. Taking 1–33 groups of data in the sample as the training object of the network model, the hazard level of rockburst is tested through 34–43 groups of sample data, and after 2000 iterations of training.
The hardware environment used in this performance comparison experiment is:
CPU: Intel Core i7-10700k (8-core 16 thread, 3.8 GHz basic frequency, 5.1 GHz maximum RF).
GPU: NVIDIA geforce RTX 3060 (12gb gddr6, CUDA acceleration supported).
Memory: 32GB DDR4 3200mhz.
Operating system: Ubuntu 22.04 LTS.
Software environment: Python 3.9 + scikit learn 1.3 + pytorch 2.1 + numpy 1.24.
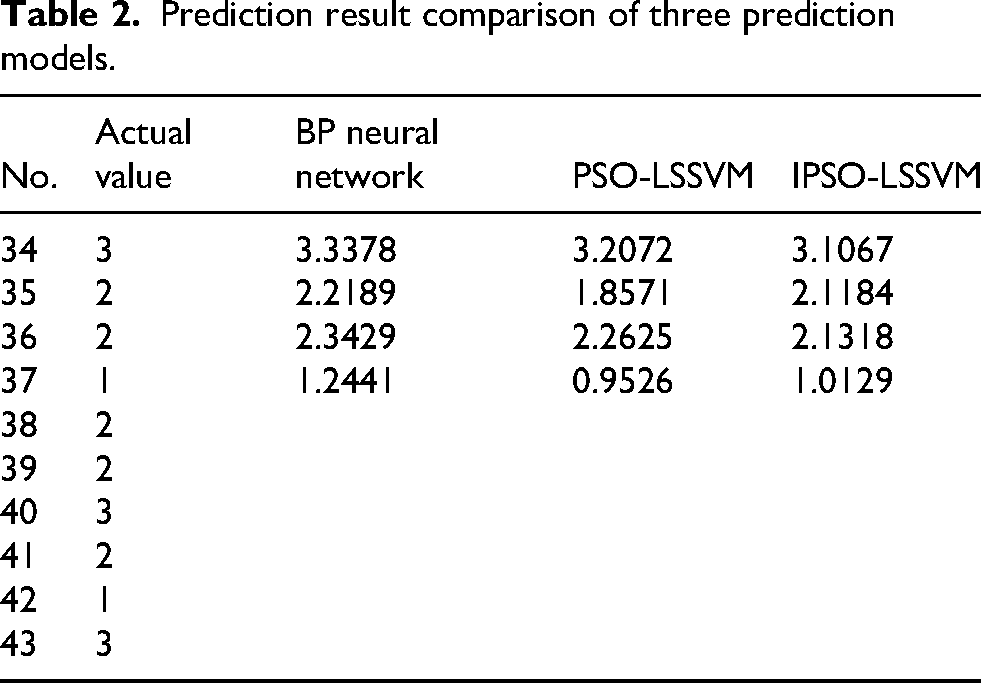
The comparison of the prediction results of IPSO-LSSVM, BP neural network, and PSO-LSSVM prediction models is shown in Table 2.
Prediction result comparison of three prediction models.
Mean absolute error (MAE), root mean square error (RMSE), and MAPE of three models are shown in Table 3.
Prediction performance comparison.

From the error results in Table 3, the three error indices of ipso-lssvm are the lowest, indicating that its prediction accuracy is the highest; PSO-LSSVM takes the second place; the error index of the BP neural network is the highest, and the prediction accuracy is relatively low.
BP neural network is trained for 3000 epochs, while PSO and IPSO-LSSVM models are optimized for parameters using the PSO algorithm, and their internal LSSVM models do not involve iterative training. Comparative analysis of training time is shown in Table 4.
Comparative analysis of training time.

BP structure is simple, but it is easy to fall into a local optimum. PSO-LSSVM uses PSO to optimize kernel parameters, avoiding manual parameter adjustment. IPSO-LSSVM introduces a mutation operator to simplify the model structure. Under the same hardware environment, BP neural network training takes about 187 s, PSO-LSSVM takes about 124 s, while IPSO-LSSVM significantly improves the convergence speed and simplifies the kernel parameter optimization process due to the introduction of mutation factor, which takes about 68 s, and the training efficiency is about 64% higher than BP neural network and 45% higher than standard PSO-LSSVM.
From Figure 2, it can be seen that the curve rapidly decreases at the beginning, indicating that IPSO can quickly find the optimal area in the early stage of the search. The mid-term decline rate slows down, and the algorithm gradually shifts from global exploration to local development. The stable curve in the later stage indicates that the algorithm has converged and there has been no significant oscillation, demonstrating good stability.
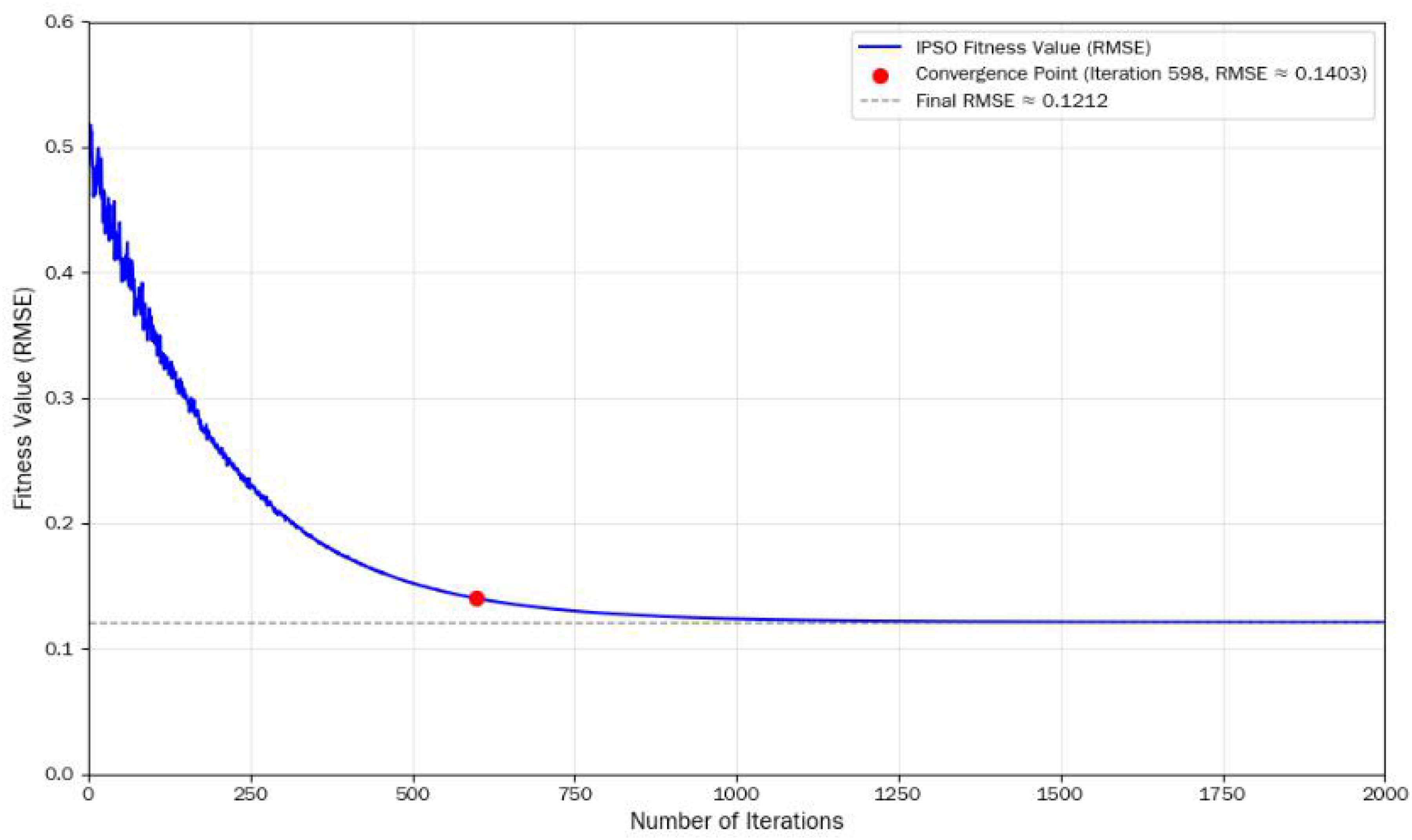
Convergence curve of fitness value (RMSE) with iteration number during IPSO optimization of LSSVM parameters.
The prediction results show that the IPSO-LSSVM prediction model has higher prediction accuracy and better generalization ability, and can accurately predict the hazard level of rockburst, achieving an ideal prediction effect. Although the model performs well on the current dataset, its generalization ability still needs further validation. There are significant differences in coal rock mechanical properties and geological structures among different mining areas, which may lead to a decrease in the predictive performance of the model. Therefore, when applying the model to a new mining area, it is necessary to fine-tune or retrain the model using historical data from that mining area.
Conclusions
This paper proposes an algorithm combining rough set theory and improved particle swarm least-squares SVM to predict the historical data. The accurate prediction of this model can provide a quantitative basis for mine safety management. For example, when the model predicts a high-risk level, managers can take preventive measures such as pressure relief blasting and optimizing mining layout in advance, effectively reducing the probability of rockburst accidents and ensuring the safety of personnel and equipment.
The main contribution of this article lies in: (1) Organically combining rough set theory, IPSO algorithm, and LSSVM, an intelligent integrated model is constructed for small sample, nonlinear rockburst risk prediction problems. (2) An improved PSO algorithm (introducing a mutation operator to prevent premature convergence) has been proposed, effectively enhancing the global search capability and convergence speed of parameter optimization. (3) Through actual data verification, it has been proven that the model significantly outperforms the BP neural network and standard PSO-LSSVM models in terms of prediction accuracy. The model proposed in this study provides theoretical support and technical reference for the real-time prediction of rockburst risk. In the future, it can be embedded in the coal mine safety monitoring system to dynamically update the prediction results by using the data collected in real time (such as microseism and ground stress), so as to provide timely early warning information for on-site engineering personnel.
The prediction of rockburst is quite complex. This paper attempts to apply an intelligent algorithm to the prediction of the risk level of rockburst. However, this study also has some limitations. First of all, due to the difficulty of obtaining data on rockburst cases, this study only used 43 sets of samples. Such a small sample size limits the training of complex models and may result in uneven distribution of samples with different risk levels in the dataset, which may lead to a decrease in the model's ability to predict risk categories with smaller sample sizes. In the future, it is necessary to collect more data from different mining areas to enhance the robustness and generalization ability of the model. The sample data is small (only 43 groups) and comes from a specific mining area. The generalization ability of the model needs to be verified under a wider range of geological conditions. Secondly, although the improved PSO algorithm performs well, its parameters (such as learning factor and population size) still need to be adjusted according to specific problems. Thirdly, it is important to check and discuss whether the sample size of different risk levels in the dataset is balanced. Due to the small sample size of this article, it is difficult to achieve data balance. In future research, Synthetic Minority Oversampling Technique (SMOTE) will be used to overcome this limitation.
Future research can be conducted from the following aspects: (1) Algorithm optimization: We will explore combining other heuristic algorithms such as simulated annealing and genetic algorithms with LSSVM, or developing hybrid optimization strategies to further improve model performance. (2) Data fusion and model generalization: We will combine multi-source heterogeneous data such as microseismic monitoring and electromagnetic radiation, and verify them in more mining areas with different geological conditions to improve the robustness and generalization ability of the model. The intelligent prediction framework adopted in this research, with its core idea of data preprocessing + parameter optimization + prediction model, is not only applicable to rockburst prediction, but can also be transferred to other engineering and scientific fields by adjusting input features. For example, in medical science,33–39 this framework can be used for predicting drug efficacy or diagnosing diseases; in environmental science,40–42 it can be used for water resource management or air quality warning; in engineering science,43–50 it can be applied to geomechanical stability analysis or other geological hazard prediction. (3) Dynamic prediction: We will develop a dynamic prediction model capable of processing time series data to achieve real-time and online warning of rockburst risks.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the National Natural Science Foundation of China (Grant No: 52165061) and the Research Initiation Project of Wenzhou Polytechnic (Grant No: RC202307).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request. Restrictions may apply to the availability of these data, which were used under license for this study.