
Abstract
Topic modelling is an important technique for extracting meaningful insights from large volumes of unstructured text data. The paper presents a federated technique for topic modelling that is based on a novel approach of the Latent Dirichlet Allocation (LDA) method for topic model generation. The proposed approach enables a topic model to be developed in a distributed environment using data continually generated from multiple sources without the need for sharing actual data. The first iteration of the topic modelling uses unsupervised LDA at each device generating the data. The results of each device are aggregated at a central server to generate a set of seed words that are used for guided LDA by the subsequent iterations of topic modelling. The proposed work, Federated LDA (F-LDA) has been evaluated using two datasets: a text dataset of dialogues between patients and doctors based on factual conversations and another comprising tweets related to depression. Comparing the performance of F-LDA with that of a centralized LDA, it was observed that F-LDA results in improved coherence score as well as diversity score in comparison to centralized LDA. This indicates that F-LDA achieves better interpretable topics covering a wide range of themes without redundancy.
Introduction
Generation of data by applications and devices has increased exponentially in recent years. The value of this data is enhanced if meaningful patterns and valuable insights can be obtained from this data from large and complex datasets. Handling, storing and analysing this Big Data is challenging. 1 The challenges are further compounded if the data is unlabelled. Topic analysis models have been found useful in extracting meaningful insights from large volumes of unstructured text data. Apart from discovery of trends and patterns over time, identification of latent topics within documents improves information retrieval, facilitates content recommendation, aids in document clustering and summarization. 2 Topic modelling helps organizing and structuring information and enables effective analysis and utilization of datasets across various applications.
Latent Dirichlet Allocation (LDA) is a popular generative probabilistic topic-modelling approach that can be easily applied to discover topics. It is an unsupervised method that does not require predefined keywords. 3 Although other algorithms, such as Probabilistic Latent Semantic Analysis (PLSA), Correlated Topic Models (CTM), Latent Semantic Analysis (LSA) and Neural-ProdLDA (Neural LDA) etc. exist for finding topics, they are either not efficient or are not as robust or are more computationally intensive. 4 Latent Dirichlet Allocation (LDA) is often preferred for topic modelling due to its flexibility in handling diverse document collections and assumption of topic mixtures in documents. However, generating LDA models requires large volumes of text data. Further, if this data is personal or sensitive, there are chances of data leakage in the training process; thereby causing significant privacy issues. These concerns are elevated in a distributed environment where multiple data sources exist.
Considering the benefits as well as challenges of LDA, this paper proposes a federated approach of topic modelling based on LDA. In a federated learning-based approach, model training is performed with multiple distributed servers or devices which hold local datasets, and the model is updated collaboratively on a global server without exchanging local, private data. A federated approach of model training is particularly applicable in scenarios where privacy concerns or data security limits the sharing of raw data. The paper employs federated learning in the context of topic modelling to implement a model on distributed datasets without data centralization. Each device or server generates a subset of the documents and a global topic model is trained collaboratively by utilizing the topics generated by each device. The aggregated model reflects the topic model from data of all participating devices without actual sharing of the data.
A novel framework named Federated LDA (F-LDA) has been developed in which multiple devices train a high-quality topic model collaboratively without data centralization. Data is assumed to be generated continually at each device, referred to as local servers. Each local server employs Latent Dirichlet allocation (LDA) algorithm on its local data to generate a set of local topics. These local topics are shared with a global server that aggregates these local topics. Cosine similarity is used to detect similarity among local topics received from multiple devices and avoid redundancy in the global topics list. Final optimal topics formed using the global topics as well as local topics and shared with local servers for being used as seed words for Guided LDA in the next round on the new data. The global model is evaluated based on its coherence score and diversity score, the rounds continue till the coherence score keeps improving. Implementation of the proposed approach provides high coherence score as well as diversity score. These are comparable to a centralized approach without the need of sharing data.
The main contributions of the proposed work, F-LDA are as follows:
Allows training models on local data without the requirement for raw data sharing. The topic model is generated in multiple rounds and thus, handles streaming data as well as new, emerging topics. Sharing only the topics or seed keywords reduces communication overhead, making it suitable for distributed scenarios with limited bandwidth. Handles non-IID (non-identically distributed) data across devices and ensures convergence of the global model.
The paper is organized as follows: Section 2 presents a few important preliminaries and a brief survey of work done by researchers in these fields. Section 3 describes the proposed method and algorithm supported with a running example. Sections 4 puts forth the experimental results. Finally, we conclude the article and present directions for future work.
Background and related work
The proposed work is motivated by a large range of past studies. Below we describe the fundamentals and prominent research work related to topic modelling, federated learning.
Topic modelling
Topic modelling is a valuable tool for dealing with large volumes of text data, as it can help to uncover hidden patterns and insights that might otherwise go unnoticed. Topic modelling finds a number of applications such as for information retrieval, i.e., obtaining relevant information from a large corpus of documents; understanding trends and patterns over time such as market trends, consumer preferences etc.; for efficient data analysis; summarization of large amounts of data and many more.
There are several methods of topic modelling such as Latent Dirichlet Allocation (LDA), Probabilistic Latent Semantic Analysis (PLSA), Correlated Topic Models (CTM), and Non-Negative Matrix Factorization (NMF) etc. 5 Each method has its own strengths and weaknesses and may be better suited to different types of data. This work employs LDA for topic modelling since it is particularly well-suited for situations where there is a large corpus of text data with a relatively small number of underlying topics. One major advantage of LDA is that it can automatically identify the latent topics present in the data without prior knowledge of the topics or any pre-labelled data. 6 LDA is a versatile and powerful tool for analysing and understanding large volumes of text data and has been applied successfully in many different domains, including social sciences, healthcare, finance, and more. 7
LDA is a generative probabilistic model that assumes that there is a mixture of a small number of topics present in each document in a corpus and that each word in the document is generated by one of these topics. 8 The LDA model is defined by specifying the number of topics K and the hyperparameters alpha and beta. LDA uses the Dirichlet distribution as a prior distribution for the topic proportions in each document and the word proportions in each topic. The Dirichlet distribution allows for sparsity or concentration depending on the value of the hyperparameters α and β. Alpha is the Dirichlet prior on the per-document topic distributions, while beta is the Dirichlet prior on the per-topic word distributions.
The algorithm randomly assigns each word in each document to one of the K topics. Then it iterates over each word in each document and reassigns the word to a new topic with a probability proportional to the topic's prevalence in the document and the word's probability of belonging to that topic. After all the words in all the documents have been assigned to topics, the model is updated by recalculating the topic distributions for each document and the word distributions for each topic. The algorithm continues iterating until the model converges to a stable solution, meaning that the topic assignments for each word are consistent across iterations. Once the model has converged, the topic distributions for each document and the word distributions for each topic can be inferred from the model parameters.
Since Regular LDA is unsupervised, it may result in unsatisfactory topics or may not be able to identify topics that have low representation in documents, although they may be important. A variation that overcomes the limitations of Regular LDA is of Guided-LDA. This is a supervised technique that provides initial seed words to the LDA model. The proposed work performs topic modelling using both Regular-LDA and Guided-LDA. A comparison of both is given in Table 1:
Regular LDA vs Guided LDA.

Regular LDA vs Guided LDA.
Research has presented numerous applications of LDA. In study, 9 authors have classified user reactions on Covid-19 news, especially related to death news due to Covid-19. Dataset was collected from Twitter from January 2020 to April 2021. Because it was complex and time consuming to analyse this data-set, LDA was used for the topic modelling purpose. The authors implemented a topic coverage approach for the evaluation of topics discovered by the algorithm by matching with the given reference topics for the matching. Reference topics hold the expected topics of the implemented topic-model method. In another study, 10 depression detection has been performed with real life unlabelled Twitter data by using LDA A new implementation called as supervised and unsupervised measure of coverage have been proposed in. 11 With the rising demand for automatic analysis of large data-sets, several machine-learning methods have also been developed. According to the authors, 12 the objective and subjective meaning of given documents can be easily understood by different words depending on topics that can be defined by topic modelling. The assumption was that the objective and subjective meaning of different words varies with their impute topics. To improve the performance of topic modelling, a new model known as identified objective–subjective latent Dirichlet allocation (LDA) (iosLDA) was proposed and its prediction power was improved by replacing the traditional SPU (simple POlya urn) model with BoDW (Bag-of-Discriminative-Words).
The authors of, 13 state that there may be sensitive data leakage issues in the model training process for LDA. Therefore, in this work, the authors presented a brief study related to the privacy protection of the LDA training algorithm based on Collapsed Gibbs Sampling (CGS) and developed a differential privacy-based LDA algorithm called ‘locally private LDA training algorithm’ (LP-LDA). Four real-world publicly available datasets have been used for analysing the proposed models’ performance by using the parameter of ‘perplexity’. It is concluded that the proposed models achieved high model efficiency under differential privacy.
It is observed that research has not been directed adequately towards the concerns of data privacy in topic modelling. LDA model training process typically requires large text data aggregation and there are chances to leak private information in the training process, thereby incurring significant privacy concerns. Hence, there is a need to perform model training in a local data site without data centralization to reduce the data leakage. The proposed work takes inspiration from the technique of federated learning to develop a federated topic modelling method.
Federated learning is a machine learning approach in which multiple devices or clients collaborate to train a machine learning model without the need for centralized data storage. In this approach, the data stays on the clients’ devices, and only the updates to the model are sent to a central server, which aggregates them to improve the model. The idea behind federated learning is to leverage the data available on a large number of distributed edge devices, such as user systems, mobile phones, to train a high-performance machine learning model. By training the model locally on each device, the user's data remains private and secure, as it is never sent to a central server. Therefore, federated learning has huge potential in scenarios where large amounts of sensitive data are involved, such as healthcare or finance. 14
Federated learning has emerged as a feasible technique for facilitating AI applications while maintaining privacy according to the study. 15 However, maintaining FL efficiency is challenging when it is integrated with mobile edge computing (MEC) architecture. For addressing this problem, the authors have developed a hybrid multilayer architecture called HybridFL, which enhances the FL training process in terms of lowering the federated round length, speeding up the global model's convergence and reduces end device energy usage. The authors implemented a Dynamic-Fusion-Based Federated Learning model in 16 for the detection of covid by using the CT scan/X-ray image dataset. As a large dataset is needed for training to obtain a better model, the existing traditional method collect data from all sources at a centralized location but this method holds a high risk in terms of data privacy and is also expensive in terms of data handling. In order to overcome these issues, here the authors in, 17 implemented a federated learning-based model for covid detection which does not need data centralization. For improvement in communication in the FL process, a dynamic fusion method has been proposed. According to, 18 the demand for Industrial Internet of Things (IIOT) is increasing day by day. For improving the performance of the IIoT networks, several deep learning algorithms have been used. The authors have proposed an efficient and scalable strategy for MEC-aided IIoT networks based on a federated learning method along with the deep reinforcement learning (DRL)to preserve data privacy and reduce communication costs for system improvement. In the end, the proposed method's evaluation has been performed.
With automation in the medical field, 19 large health-related data is generated daily. This data can utilize for advancement in health sectors by using machine learning (ML) but privacy concerns exist while using such sensitive data for training ML models. Federated learning (FL) is an approach that can perform model training in a distributed manner without sharing the data with another. In this work, the authors have given a brief description of existing FL solutions, the general approaches followed, system challenges and privacy issues. Data privacy is a significant concern while working with medical datasets in. 20 Authors of 21 point out that the central analyser involved in federated learning may not be trustworthy. Therefore, they have proposed a random hybridization method for training the model without direct integration of model parameters called federated machine learning with anonymous random hybridization (FeARH). Before sharing the parameters to the central analyser, the connections between datasets and models’ parameters are degenerated by randomization with the help of hybrid algorithms. The data-sets generated by different distributed may also face some data leakage attacks such as membership inference. Hence, for the reduction in these types of attacks, the authors of 22 have presented a distributed perturbation algorithm for privacy preservation of horizontally partitioned data, named as DISTPAB. Performance evaluation showed that DISTPAB has a good efficiency in terms of model convergence time and reduced the data leakage problem also. Medical named entity recognition (NER) is used to identify medical entities which is helpful in many intelligent healthcare tasks such as pharmacovigilance and health monitoring in. 23 In the health sector finding enough labelled data on a particular site or hospital is difficult and NER requires a large amount of data for model training purposes. Authors of 23 implemented a federated-learning-based NER model, called FedNER. The model training is performed locally so as not to require data sharing and three medical NER data-sets were used for model training and testing purpose.
Federated learning is an important tool towards privacy preservation. Further, the decentralization of training makes it apt for a distributed environment, such as an edge, fog and cloud system. Therefore, this work endeavours to apply LDA in a federated setting to overcome the challenges of handling distributed data and privacy concerns.
Proposed federated LDA-based approach
The proposed work, Federated LDA (F-LDA) is a federated approach for topic modelling that integrates Regular LDA and Guided LDA with a two-fold objective for a distributed environment. The first objective is to effectively handle large streams of data being continually generated by the data sources. Continual streaming data leads to evolution of topics over time, which is also effectively captured by the proposed work. The second aim of F-LDA is to maintain privacy of user data by utilizing it locally and not sharing the data to a central server. Additionally, the federated topic modelling approach also handles the volume of data by eliminating the need for centralized, computationally expensive operations on the complete data set.
The F-LDA method is discussed in the context of edge-fog-cloud based environment but is flexible enough to be implemented in any similar distributed setting.
System model
The method is based on a 3-tier system, as shown in Figure 1. The lowest layer denotes the devices that generate or collect data to be used for topic modelling. The next layer comprises of the client or local servers connected to the data sources. One local server may be responsible for data from d (d >= 1) devices. In a distributed environment, these servers may be placed at any location proximate to the data source. For example, if the data is being generated by an IoT or edge device, then the local server may be a fog device in the same local area network. Each local server performs topic modelling using LDA on the received data, as described in section, and shares the generated topics with a master or global server. The actual data remains at the local server close to the data source and is not shared with the global server. The master or global server aggregates the topics received from all the local servers, as described in section 3.2. The aggregated list of topics is then transferred to each local server. This completes one round of federated topic modelling. In the next round, each local server uses the received topics to apply guided LDA on the data received after the previous round.
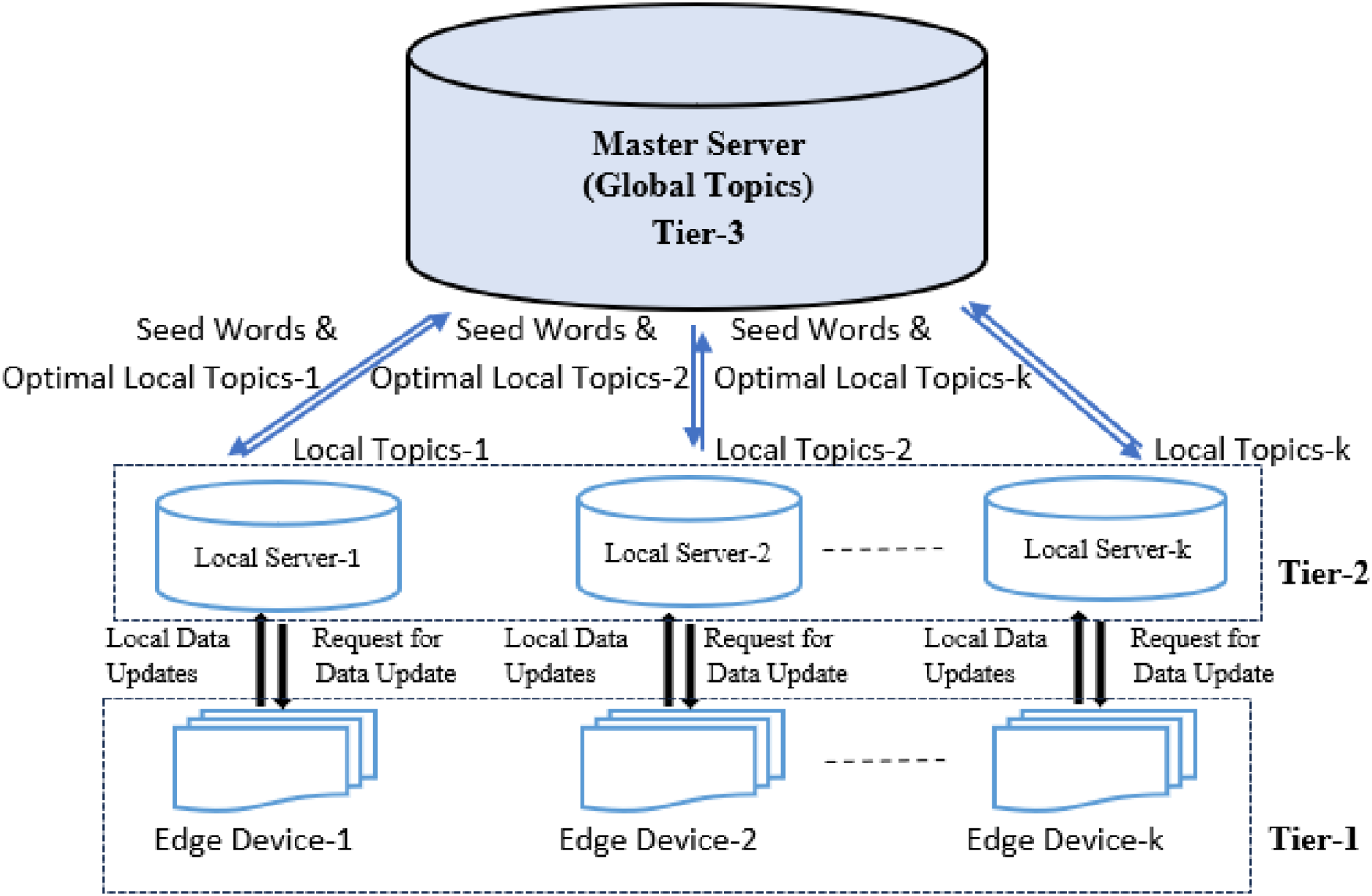
Federated LDA (F-LDA) framework.
The approach of local topics aggregation is discussed in section 3.2.1 of the methodology. Section 3.2.2 describes optimal local topic and seed word composition.
The proposed federated topic modelling methodology is based on the use of unsupervised, regular LDA at the local servers in the first round and guided LDA in subsequent rounds till the model converges. At the end of each round, the global server aggregates the topics received from the local servers. This involves a weighted averaging of the topic probabilities and removal of redundancy. These steps are described next.
Unsupervised LDA at local servers
The first round of federated topic modelling is different from the subsequent rounds. This is because the first round uses unsupervised LDA due to the lack of any labelled data initially. Subsequently, the topics of previous rounds act as seed words and hence, improve the quality of the developed topic model. In each round, topic modelling is executed at the local servers so that actual data corpus does not need to be shared or sent to the global server.
The working of LDA is based on the representation of each document D, contained in a corpus, as a distribution over topics. It is assumed that there are K topics in the entire document collection, where K is a user-defined parameter and every word is associated with a latent or hidden topic (Z). Each document D is associated with a topic distribution 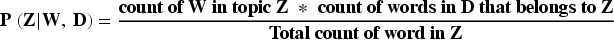
Text data, such as from human conversations, is typically non-IID (not independent and identically distributed) due to the dependencies between words, variability in language use, and the influence of context and social factors. Analyzing such data requires models and techniques that can account for these complexities. This work handles challenges of non-IID data while performing aggregation of topics generated by local clients.
The topics derived from the clients’ data, henceforth referred to as local topics, are transferred to a global server where they are aggregated to yield a set of global topics. This aggregation is not straightforward merging of these due to the non-IID nature of data. When the local topics are collected at the global server, there may be redundancy in the topics. Hence, it is required to identify similar topics during topic aggregation. Further, the topics from one client may be completely different from those of other clients. Therefore, the infrequent or low presence topics also need to be considered. Each client should receive relevant seed words for subsequent rounds.
For similarity analysis, a number of methods available such as cosine similarity, Jaccard similarity etc. are available. This work has utilized cosine similarity method as it is reliable and flexible with different inputs. 24 An optimum threshold value is firstly determined for topic similarity detection. 25 If the cosine similarity score between two topics is greater-than or equal to the threshold value, they are considered as similar topics and hence they are merged or combined. Combining of similar topics is performed by calculating the mean value of each keyword in the topic distribution. Formally, those values are the likelihood that a given word will be used in conjunction with a given topic.
Equation (2), shows the similar topic aggregation via cosine similarity method. Firstly, a dataset Lm is created to hold all possible combinations of raw topics, as received from different clients where m is the total number of topic combinations. Ti is a local-topics set achieved from a client Ci. Subsequently, 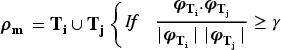
Topic model aggregation process defined in Algorithm 1. Here, M is the global topics set.
For topics aggregation process, it is required to identify the similar topics across clients. For similarity analysis, a number of methods available such as cosine similarity, jaccard similarity, etc. are available. This work has utilized cosine similarity method as it is reliable and flexible with different inputs.
25
However, we need to determine a threshold (
Firstly, cosine similarity of each topic is calculated with every other topic. Since it was not possible to manually check similarities of every topic combination, a sample of topics was randomly selected from T. After selection, the authors manually assigned binary values (0 for not similar or 1 for similar) to each topic pair, without considering their cosine similarity score. Based on the human decision-based values for the sample topics, logistic regression method 26 was utilized to generate similarities for the remainder topics’ pairs. Next, cosine similarity scores were sorted in descending order as per probabilities generated by regression. Threshold was chosen as the Cosine similarity value corresponding to the human decision-based value from where a decline was observed.
ALGORITHM 1:
M = ϕ, int i = 1, int j = 1
calculate
M = M ∪
Optimal local topic and seed word composition
Due to the extensive size of the global topic model (M), it is possible that certain topics within M may lack relevance for specific clients. Consequently, distributing the entire set of topics to each client may not be feasible. To enhance the efficiency of this approach in terms of communication cost, we generate a new and optimized local topic set for each client, denoted as M*. We conduct a comparison between each topic set (Ti) of every client (Ci) and the global model (M), identifying the most relevant topics (Tm) from M. Subsequently, we substitute Ti with Tm, creating a new optimal local topic model represented by M*. These optimal local topics, M*, are then dispatched to each client for further processing. Algorithm 2, outlines the comprehensive procedure for M*, with the cosine similarity score denoted as CSS.
ALGORITHM 2:
flag = 0
for each
if CSS (Tm, ti)
M*=replace ti with Tm
flag = 1
if flag==0 then
remove ti from M*
As we already have optimal local topics, these topic keywords are used as seed words in subsequent rounds. These seed words play a crucial role in enhancing the model's quality, serving as guiding inputs to achieve optimal results in terms of accuracy. In the subsequent iterations, we conduct topic modelling using Guided-LDA instead of Regular LDA. Guided LDA is a supervised form of LDA where the use of seed words enhances the performance of LDA by enabling convergence around seed words.
F-LDA work flow
Complete workflow of F-LDA defined in Algorithm 3. In every iteration of the algorithm, firstly each local server or client performs topic modelling on its own dataset, as described in Section 3.1 and sends these local topics to the global server for further processing. On the global server, local topics aggregation is performed according to Algorithm 2. As a result, global topics (M) are obtained which reflect information from all clients. As a last step, a set of optimal local topics (M*) is determined for each client based on the data received from the client. Once the local servers receive these topics, they update their topic model with these global topics. Now, since seed words are available, Guided LDA is performed instead of Regular LDA from the next iteration and continued till new data is generated.
ALGORITHM 3:
//Local topics (Ti) training
perform Regular LDA
perform Guided LDA
send local topics (Ti) to the master server
extract global topics (M) using Algorithm 1
find the optimal local topics (M*) using Algorithm 2
extract seed words (K) and send M* & K to c
Experiments
The performance of F-LDA has been evaluated experimentally to compare it with various baselines. The implementation has been done via pretrained inbuilt libraries such as Gensim, MALLET LDA, 27 LDA and Guided LDA. 28 For implementation, Google Colab environment has been used.
Dataset
Since a text dataset was required for generation of topic model, two real-world datasets have been used in this study. such as medical dataset and twitter depression related dataset.29,30 Experiments have been performed on Diagnose me dataset which is an LFQA (Long Form Question Answering) dataset of real-life conversation between doctors and patient related to their health issues. 29 To validate the results, experiments were repeated using a dataset of tweets related to depression from Twitter. 30 Figure 2, shows a snapshot of the datasets after preprocessing. We refer to the 2 datasets as Medical dataset and Twitter dataset in the subsequent sections.
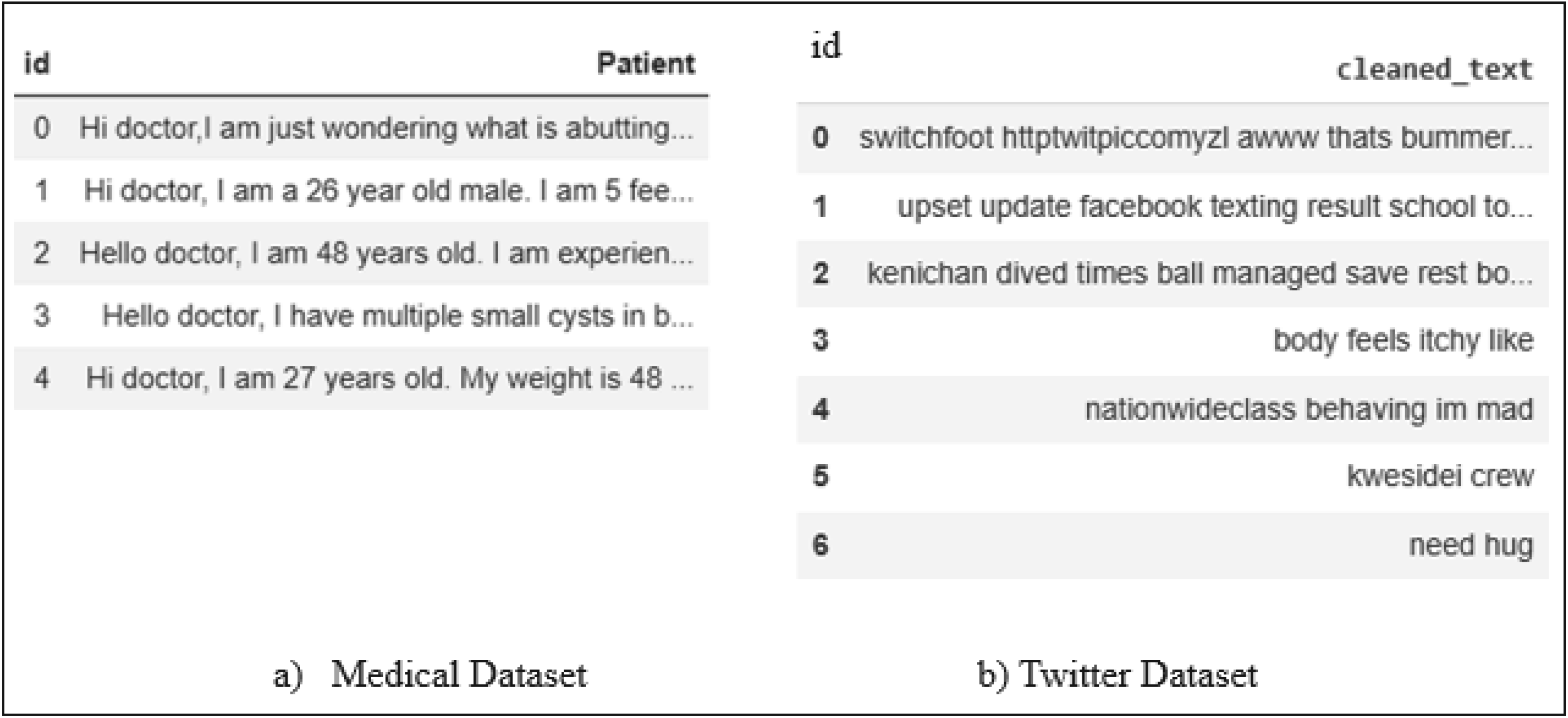
Snapshots of datasets.
where id column shows the sample number, Patient column and cleaned_text column holds the patient related conversation text data and depression related tweet data respectively.
Since Guided LDA requires some seed words, the first iteration used regular LDA. Three clients (C1, C2 and C3) were assumed for model performance evaluation and 1000 records from the dataset were assigned to every client without overlapping for the first iteration.
We firstly illustrate the steps of processing F-LDA for the considered datasets. Subsequently, we evaluate the model's performance in terms of predefined metrics.
Illustration of F-LDA
Firstly, each client uses regular LDA to generate topics from their local data. Figures 3 and 4 demonstrate the topics generated locally by each client in first round for the two datasets respectively. It can be observed that these topics hold similar keywords, although with different weights.

Local topics at clients with medical dataset.

Local topics at clients with twitter dataset.
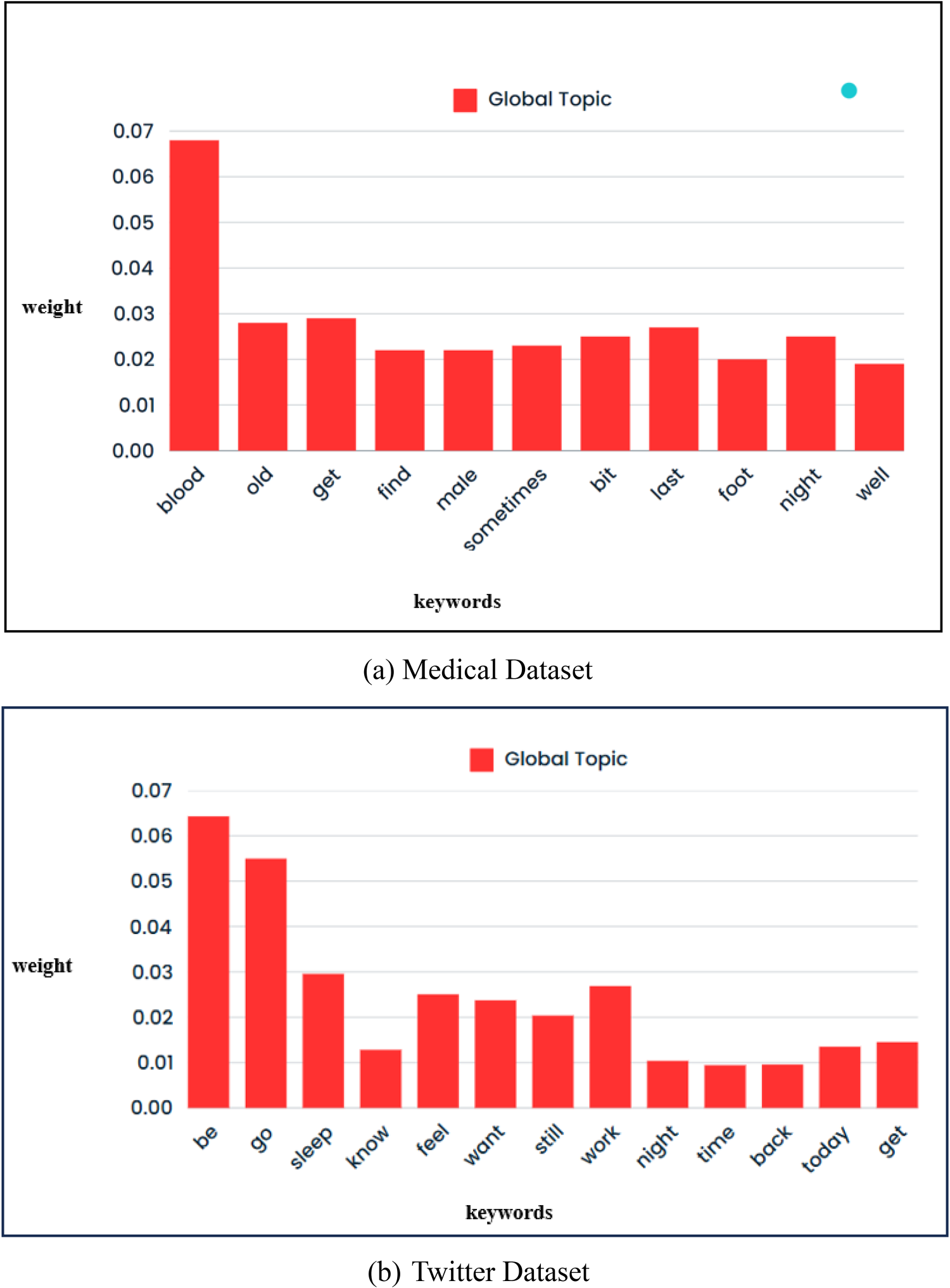
To demonstrate the overlap, the weights of common keywords of client-1 and client-3 topics of Medical dataset are plotted in Figure 5(a). For instance, the keywords, (blood, old, get, find, male, sometimes, last, foot and night) appear with different weights in local topics of clients 1 and 3. Client-1 and client-3 both hold the same keyword ‘blood’ with weights 0.085 and 0.051 respectively. Similar observations can be made for Twitter dataset from Figure 5(b), which shows the weights of common keywords in topics generated by client-1 and client-2 Here, the keywords, (be, go, sleep, feel, want, still and work) hold different weights in local topics of client-1 and 2. A keyword, sleep has been assigned two weights, 0.031 and 0.028 in local topics of client-1 and client-2 respectively. When these local topics from clients are collected at the global server, redundancy will exist in the topics of global model. Hence, it is required to identify the similar topics during topic aggregation at the global server.
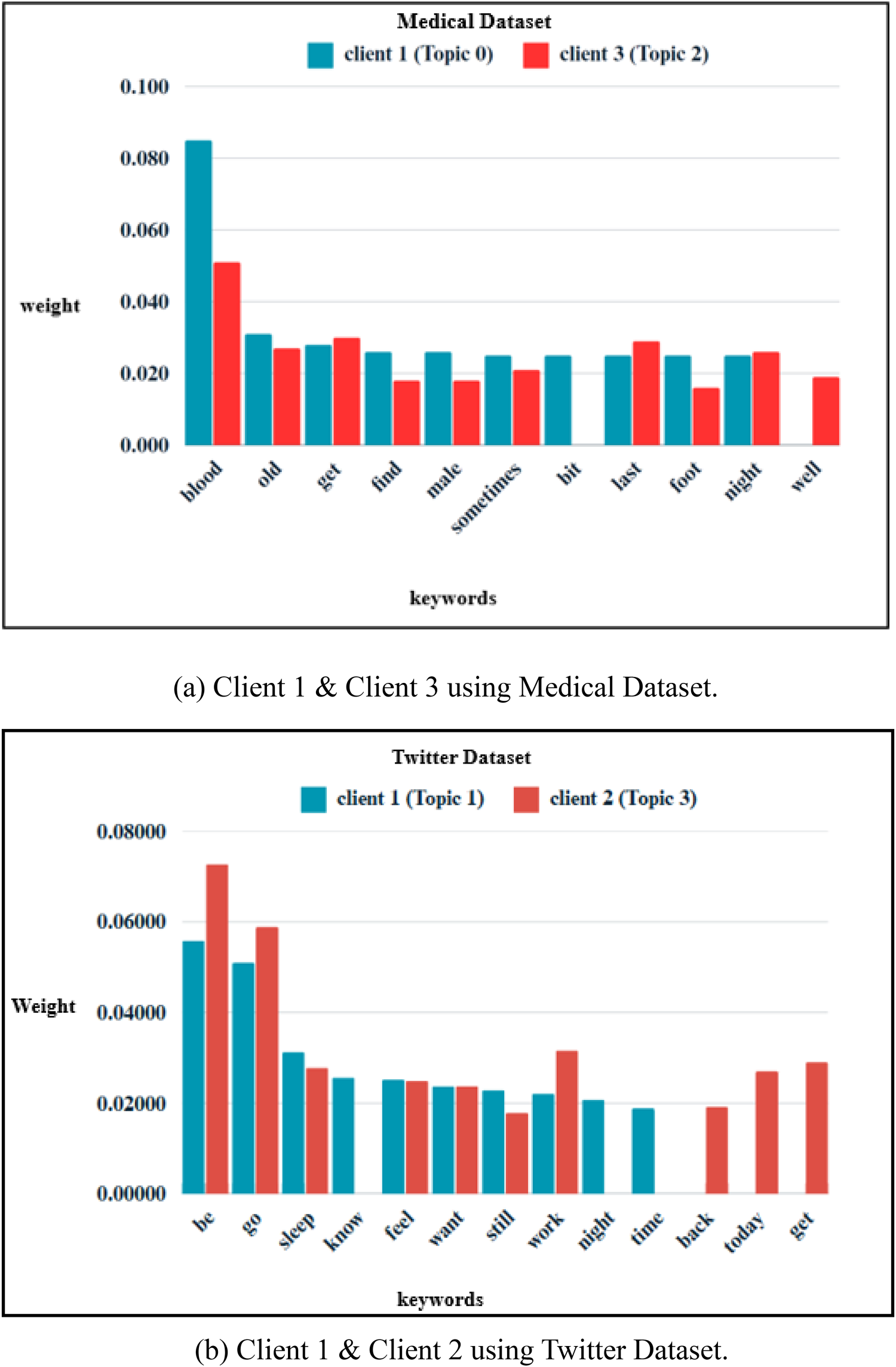
Similar local topics.
For topic similarity detection, an optimum threshold value is firstly determined using the method described earlier. The similarity threshold, γ was determined as 0.45 and 0.20 for the Medical and Twitter datasets respectively, as can be observed from Figure 6.
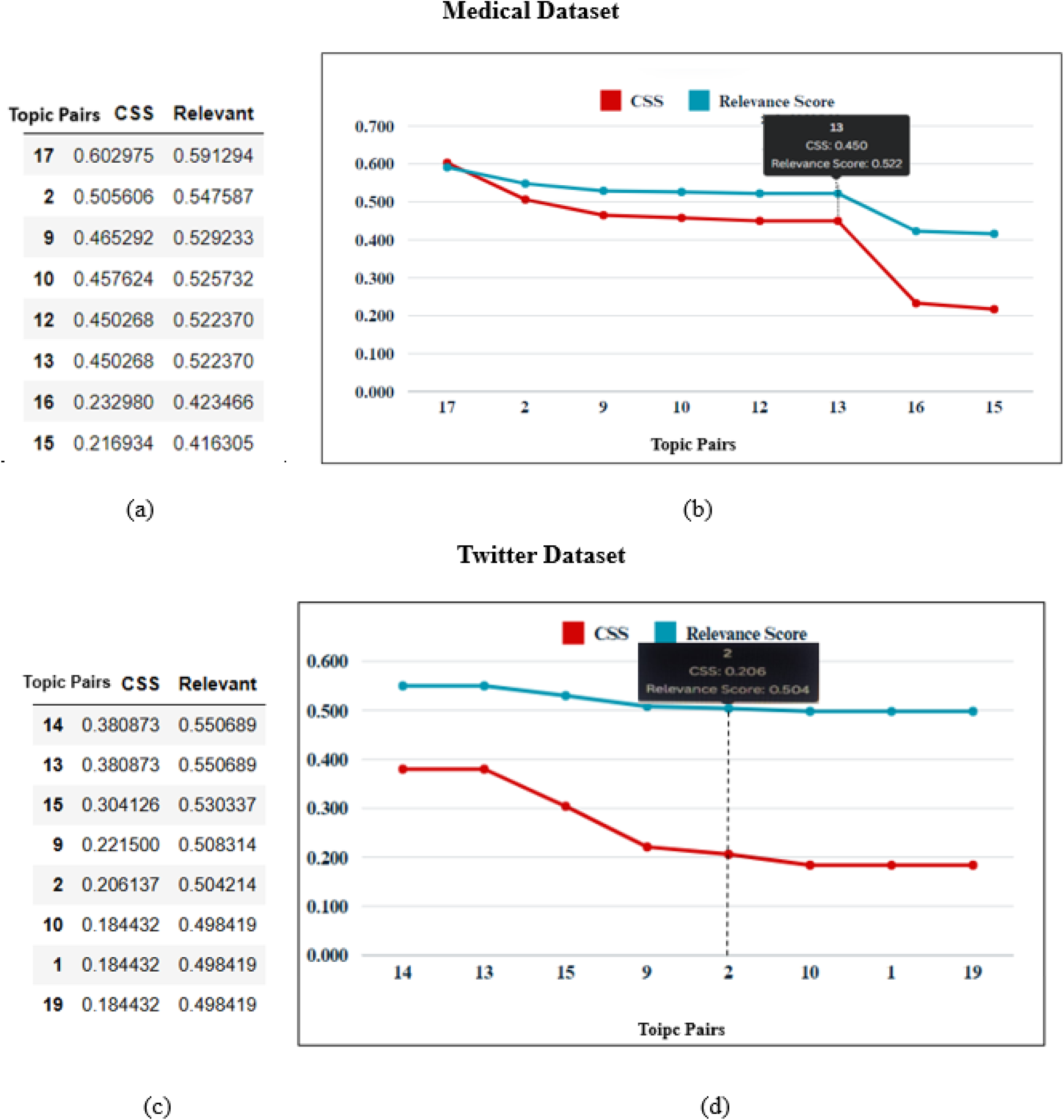
Cosine similarity score and probability of relevance score.
Number of topics depend on k-value of LDA and Guided LDA. Only top 10 keywords were extracted of every topic.
For topic aggregation, all the possible combinations of topics of client1, client 2 and client 3 were created in pairs and stored as keywords_1 and keywords_2. If the cosine similarity score between two topics is equal or greater than the threshold value (γ), they are considered as similar topics and labelled as ‘1’, otherwise as ‘0’. A snapshot is illustrated in Figure 7.
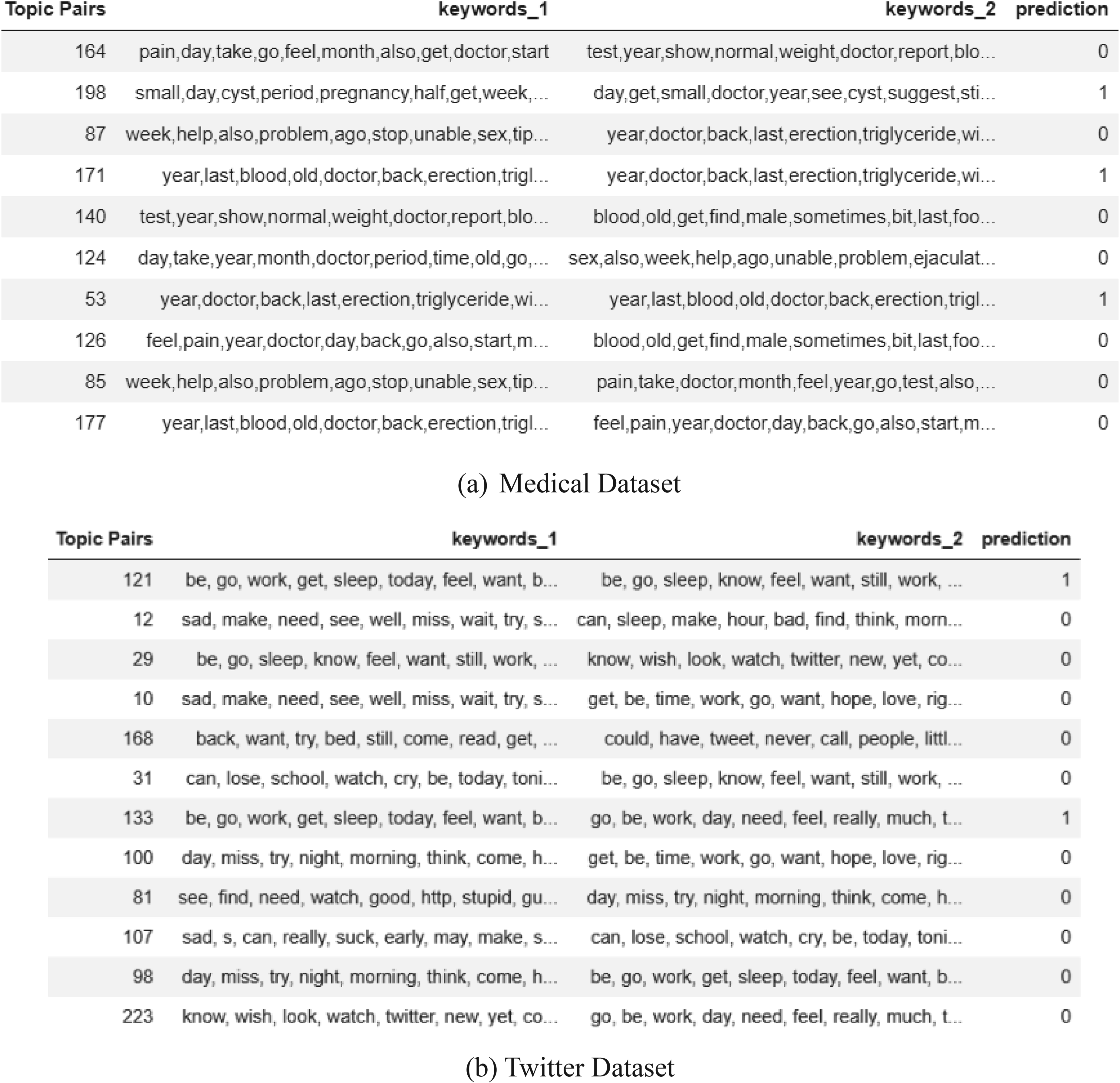
Local topics similarity prediction on global server.
Similar topics are combined by calculating the mean value of each keyword in the topic distribution. Formally, those values are the likelihood that a given word will be used in conjunction with a given topic. A straightforward aggregation of local topics can be seen in Figure 8(a, b), while Figure 9(a, b) demonstrates the merging of topics after similarity detection. From the Figure 8(a, b), it can be observed that aggregate topics hold some repeated keywords with different weights. For instance, ‘old’ keyword is repeated two times with weights ‘0.031’ and ‘0.027’ in Figure 8(a). Similarly, ‘sleep’ keyword in Figure 8(b) repeated two times with weights 0.031 and 0.028. However, once these are aggregated, redundancy has been removed as defined in algorithm 1. Final global topic can be observed in Figure 9(a, b), where keywords ‘old’ and sleep are now present with a single weight value of ‘0.029’ and 0.030 without any redundancy or loss of information.
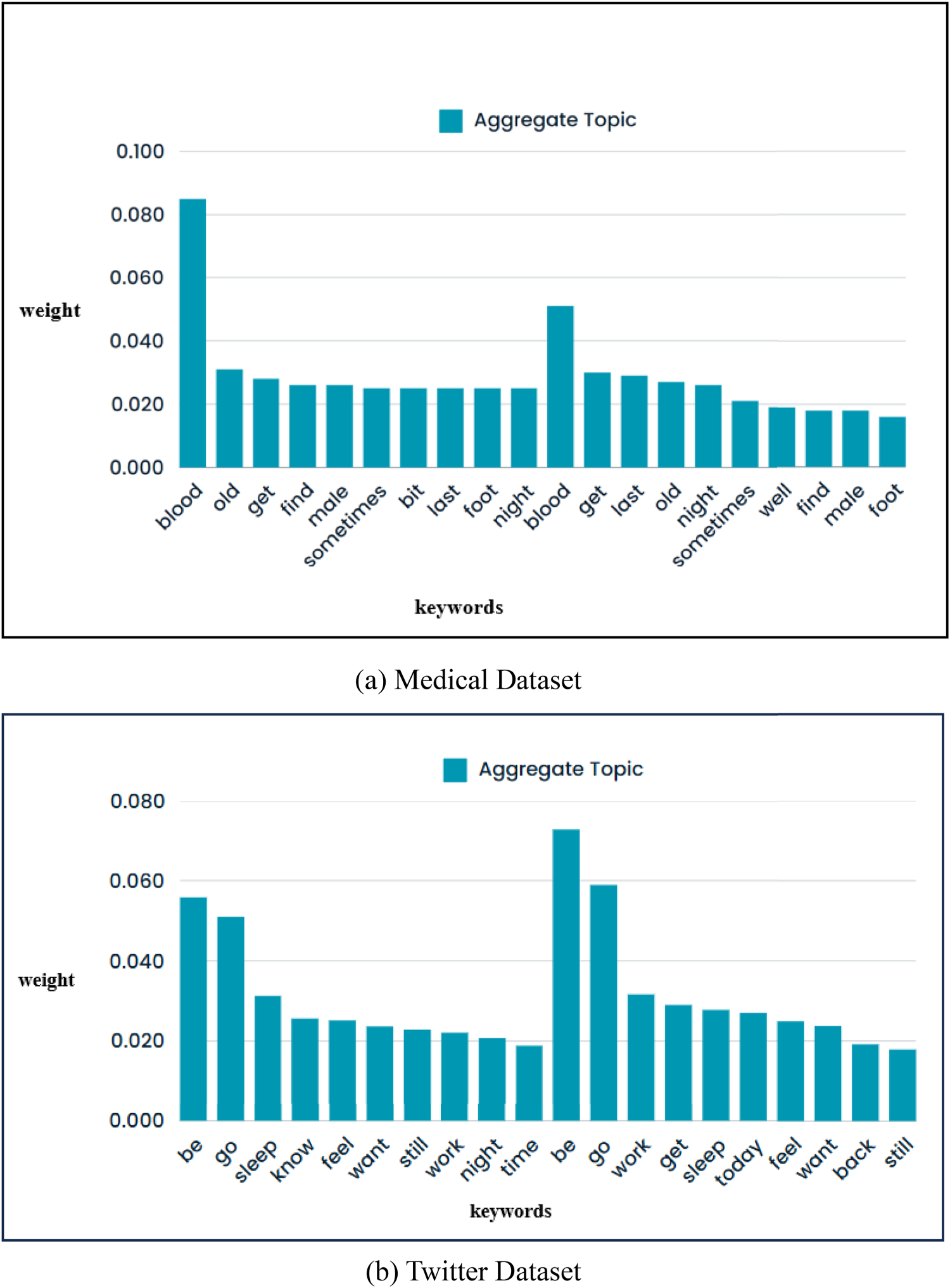
Aggregation of topics with redundant keywords.
Global topic without redundant keywords.
The experiments were carried out in different data setups for model performance evaluation, as defined in below sections. The performance was evaluated in terms of coherence score and diversity score. Here, coherence score has been used for the model performance measurement as this is the best quantitative metric for LDA evaluation.
31
Coherence score works on semantic context it is provides the probability of topic interpretation via humans. For this work, we have utilized the cv coherence metric, where each topic word is compared with the set of all topics.
32
A boolean sliding window is employed to determine if two words co-occur. The confirmation measure includes both direct and indirect confirmations. For the top N most likely words in each topic, a “word vector” of size N is constructed, where each element represents the Normalized Pointwise Mutual Information (NPMI) between a given word and another word |K| is the total number of topics. Coherence(t) is the coherence score for topic t, which is computed based on the pairwise NPMI scores of the top words in the topic.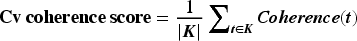
The diversity score calculation is based on the measure proposed in
33
where the Jaccard distance between topical term lists is calculated. A larger distance between topics shows higher topical diversity. We have calculated diversity score of the topic model based on the Cosine Dissimilarity between topics returned by the model. Higher the dissimilarity, greater is the topic diversity. It is calculated as follows:
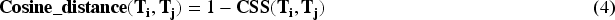
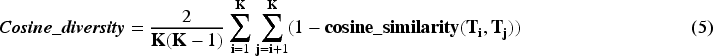
The first experiment applied both methods to a centralized dataset. 3000 samples of patients’ conversation text dataset and Twitter dataset have been used for centralized data setup. From the results in Figure 10, it can be observed that Guided LDA works better than LDA in terms of the coherence metric as well as Diversity Score. These results establish that it is preferable to use Guided LDA if seed words are available. Further, these results will be used as baseline for comparison with the proposed approach since these methods utilize the entire data together. However, a centralized dataset implies that data from all sources is collected at one place leading to high chances of data leakage or data privacy concerns.
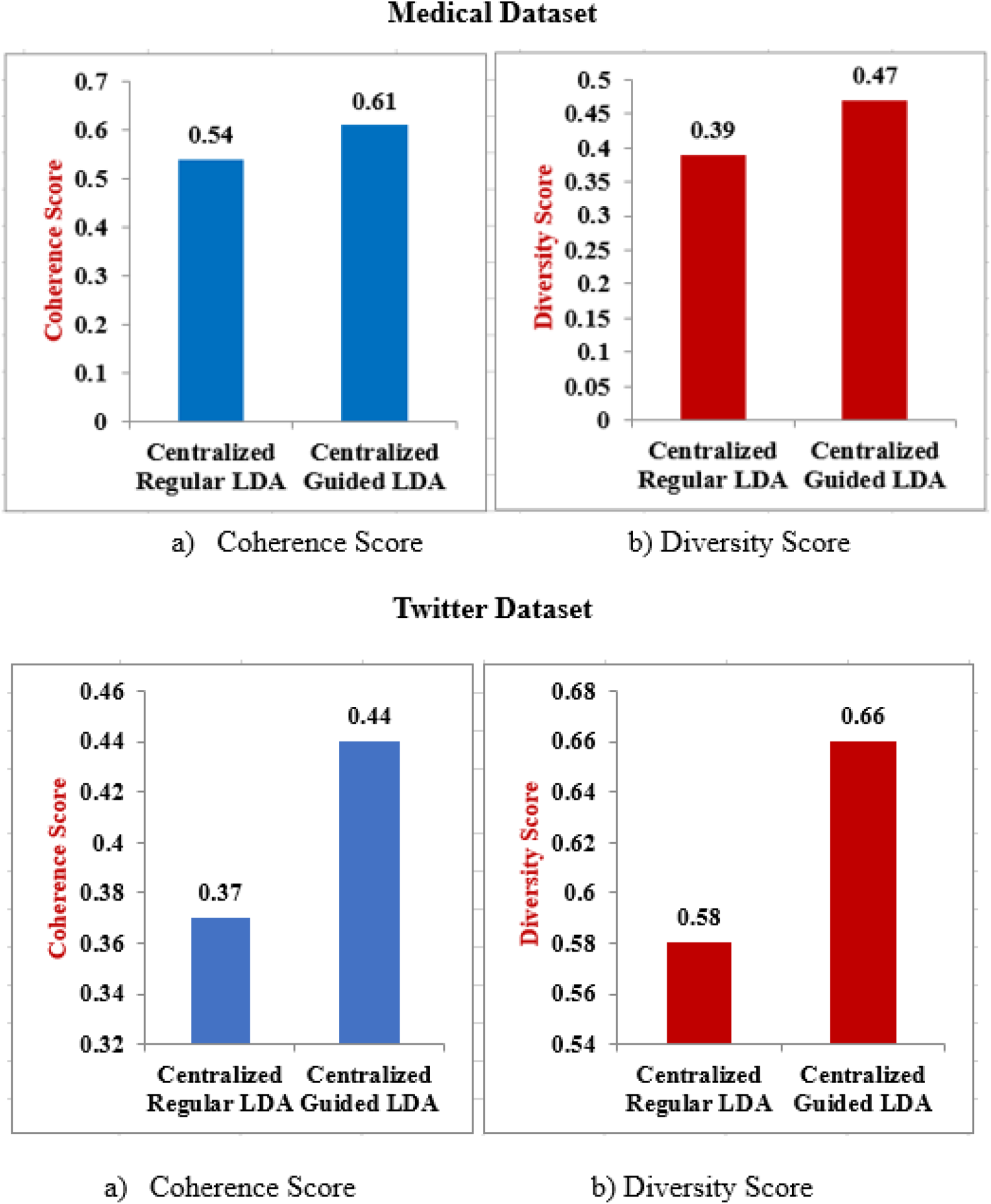
Regular LDA vs Guided LDA with data centralization.
Here, regular LDA and Guided LDA have been applied on every client's dataset individually without data centralization. Since model training is performed with individual datasets, it resolves any privacy concerns. From the Figure 11, it can be observed that Guided LDA again gives better coherence score as well as diversity score than regular LDA. Further, it can be seen that regular LDA's coherence score is lower than that of a centralized LDA of previous experiment. This can be attributed to the comparatively lower sized data at each client. However, guided LDA benefits from the presence of seed keywords and its performance improves. However, both regular and Guided LDA achieve slightly lower diversity score in non-centralize data setting due to the smaller size of data available at each client. Thus, a large dataset is required for better performance but data aggregation affects the data privacy. Hence, next we apply LDA in a federated setting.
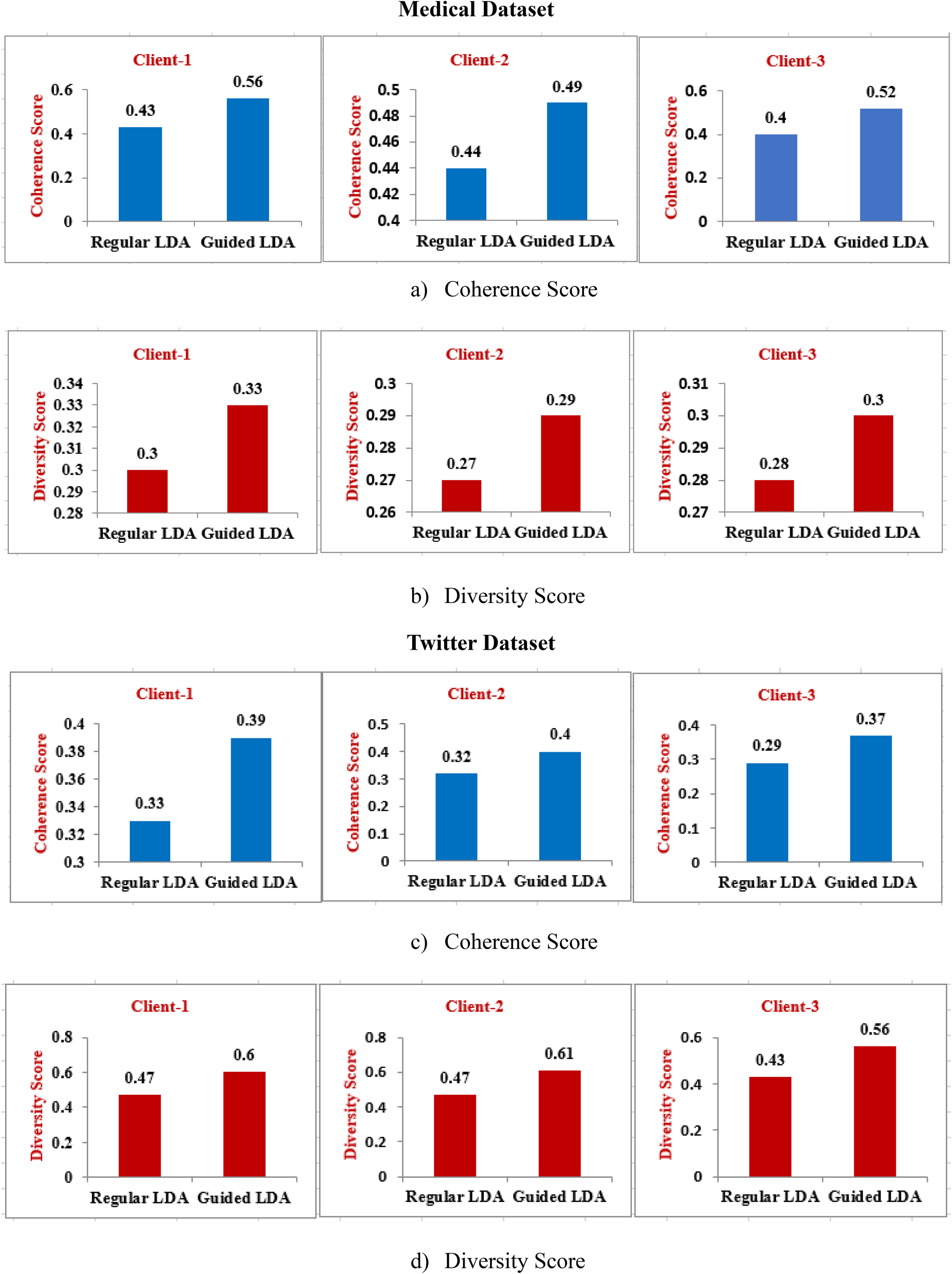
Regular LDA vs Guided LDA without data centralization.
In this experiment, regular LDA has been implemented with federated data and its performance compared with F-LDA. In both, topic aggregation is performed instead of data centralization but they differ in that F-LDA uses guided LDA in second iteration. From Figure 12, it is corroborated that F-LDA provides better coherence, diversity as well as data privacy. The increase in coherence and diversity scores indicates that a better model is generated when seed words are utilized.
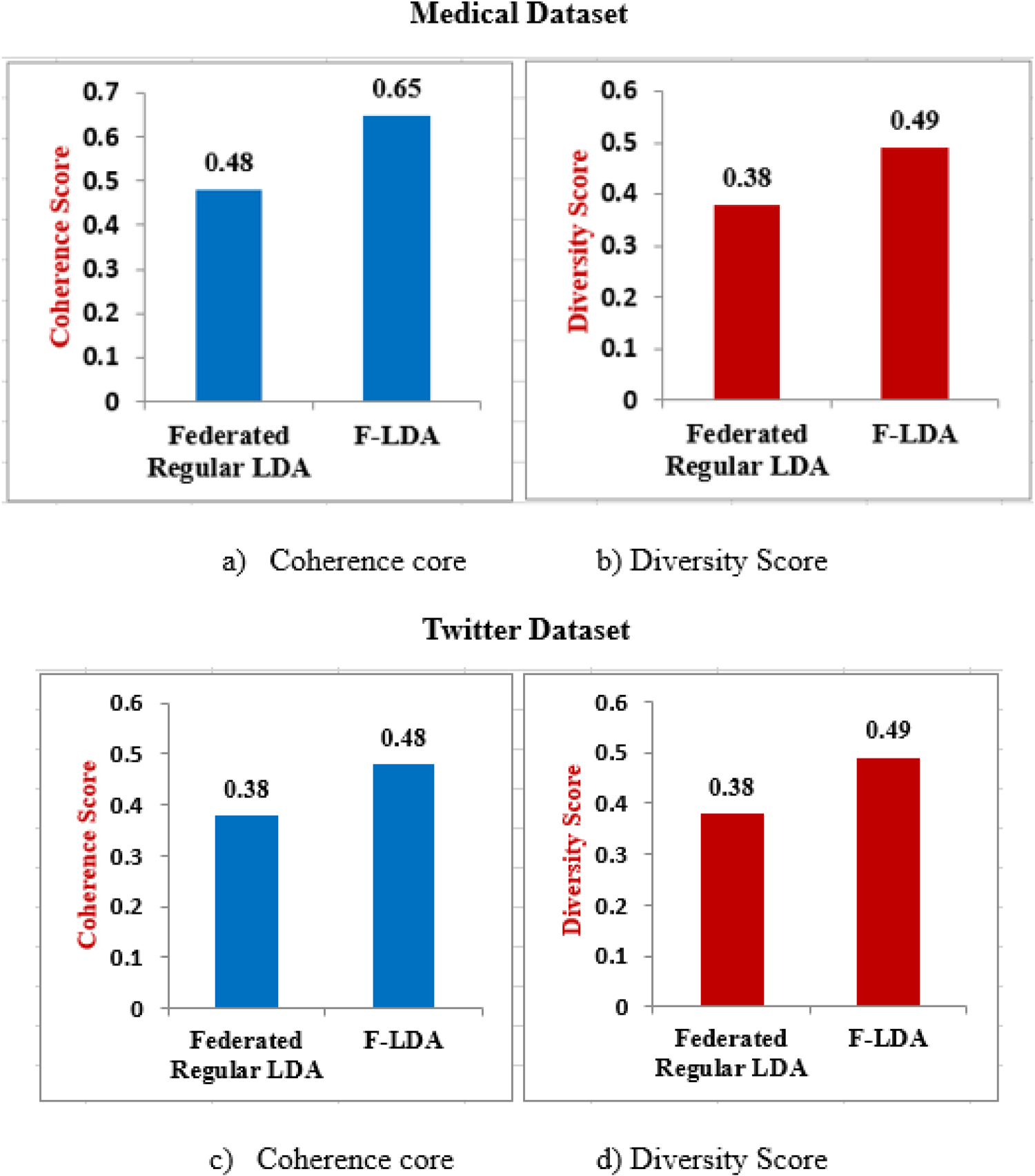
Federated regular LDA vs F-LDA.
The proposed approach of F-LDA was further tested for multiple rounds beyond the initial iteration. In each round, 1000 samples of data were assigned to each client.
It was observed that as new data is input, the coherence score shows a decrease or increase, in range of approximately 10% (Figure 13(a, c)), but remains higher than regular LDA in all cases (Figure 11). The variation in scores is the result of new data being input to the model in each round. The performance of the model is dependent on the type of data that is being used for training it in each round. A similar pattern is also observed for diversity scores although the variation is low since data remains related in its theme over rounds. Thus, F-LDA solves the problem of sensitive data sharing in real life with improved performance. In fact, the values of coherence and diversity score after third round are slightly better than the baseline values achieved with centralized settings.
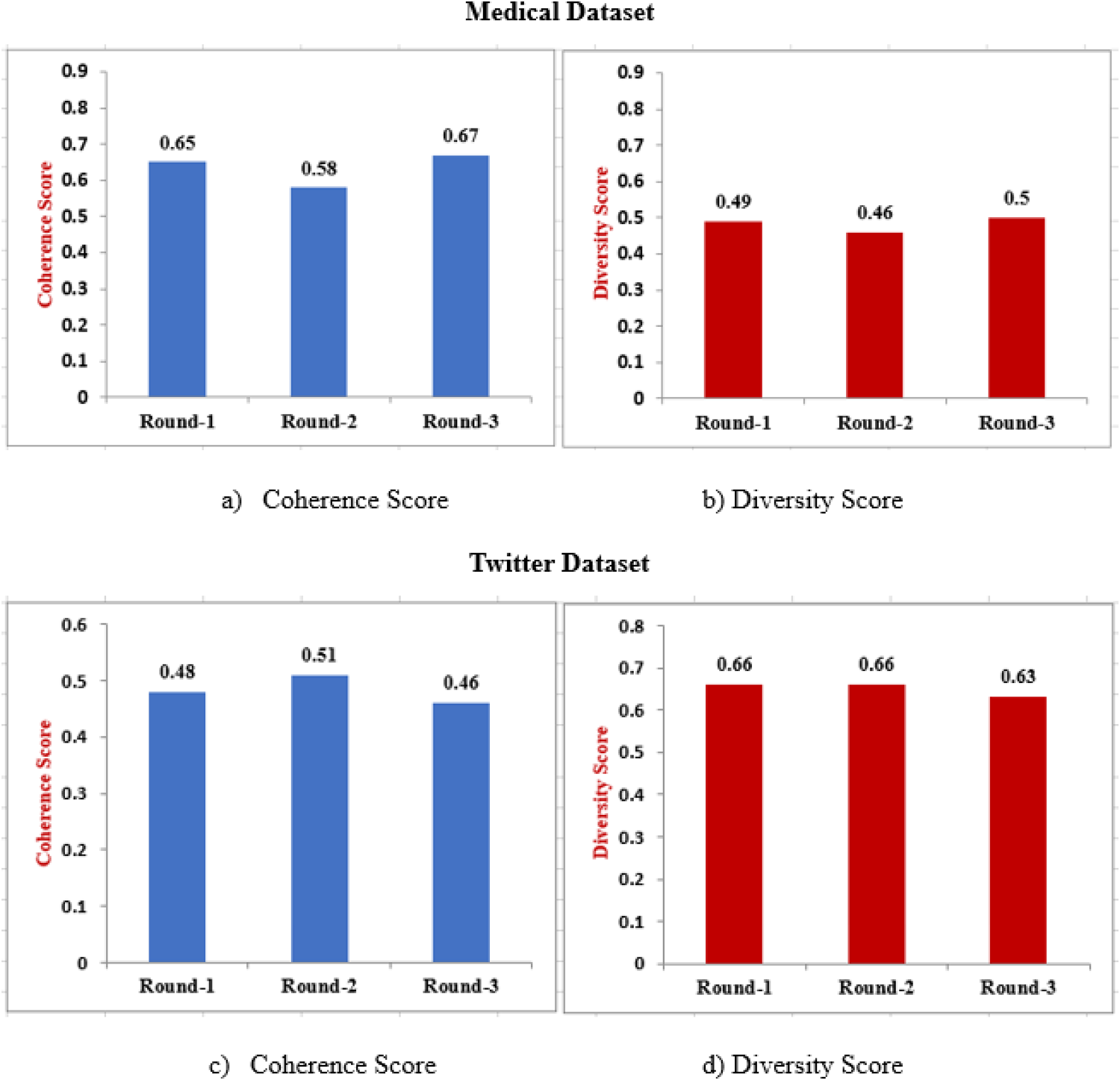
Three rounds of F-LDA.
Once topics are generated by F-LDA, the recipient of topics can utilize the same for decision making. For the current work, topics derived from conversation data between patients and doctors can yield valuable insights and improve healthcare services. For instance, these may be used by hospitals to identify frequently discussed health issues, seasonal illnesses or mental health concerns. These topics can improve patient education materials or health practitioners’ training. Similarly, these may be used to detect new or unusual patterns in patient complaints, such as symptoms of emerging diseases or side effects from new medications.
However, the interpretation of topics present in the global model is challenging, especially without knowledge of the actual dataset task. Qualitative evaluation is frequently employed in real-world applications. This involves reviewing the top five or ten keywords for each topic and assessing the interpretability of the topics based on human expert judgment. However, this relies heavily on expert domain knowledge and a deep understanding of the documents being analyzed. F-LDA does not share the documents and hence, can instead be used in conjunction with automatic topic labelling methods for topic interpretation. 34 A few solutions for topic interpretation based on automatic generation of labels for topics generated by LDA exist in literature. For instance, the method of. 35 introduces an algorithm for automatically labelling topics based on a hierarchical structure. The core components of the algorithm include a set of similarity measures and topic labelling rules. These rules are designed to identify the labels that best align with both the given topic and the hierarchy. The hierarchy is derived from the Google Directory service using a custom-developed software procedure and further enriched with the OpenOffice English Thesaurus. Similarly, the approach in 36 constructs a candidate set of labels from the top-ranking terms of each topic, the titles of Wikipedia articles containing these terms, and sub-phrases derived from the Wikipedia article titles. The label candidates are then ranked using a combination of association metrics and lexical features, which can optionally be refined using a supervised ranking model. These labels are then assigned to the topics for easy interpretation. Methods for topic interpretation with conceptual frameworks also exist in literature. Such methods map the generated topics to existing conceptual frameworks or ontologies; for example, health-related topics could be mapped to predefined categories like ICD-10. 37
Conclusion and future work
The work has developed a novel approach, F-LDA for text dataset analysis. The use of a federated approach solves the problem of data privacy while giving the benefits of LDA. A 3-tier system model with edge devices, local servers and a global server is proposed for working of F-LDA. To evaluate the performance of proposed approach, multiple experiments have been performed using two real-world datasets, a medical Diagnose-me dataset and a Twitter depression dataset in centralized and federated data-setups. From the experiments, it was confirmed that that the proposed Federated LDA (F-LDA) enhances model coherence and diversity as compared to centralized LDA. Moreover, it ensures data privacy and handles streaming data by iterative training of the model. Future work can focus on federated semantic topic models for more efficient performance. Further, generative Artificial Intelligence can be explored for automatic labelling of topics generated by F-LDA.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The datasets analyzed during the current study are available at https://www.kaggle.com/datasets/dsxavier/diagnoise-me, Access on 25 July 2022 and ![]() , Access on 01 January 2025.
, Access on 01 January 2025.