
Abstract
Traditional high-performance language parallel database processing learning has limitations in optimization algorithms, which is prone to falling into local optimal problems and has slow convergence. The pheromone update mechanism of the ant colony optimization algorithm lacks flexibility and is difficult to adapt to dynamic environments. This article improves the processing efficiency of high-performance language parallel database based on the improved ant colony optimization algorithm. The pheromone evaporation and reinforcement mechanism is applied in the algorithm, simulating the decay of pheromones in the natural environment and dynamically adjusting the pheromone concentration according to the path quality to guide ants to choose a better path. To cope with high-concurrency queries, a scheduling optimization strategy based on task priority is implemented, in which a weighted round-robin strategy is applied to dynamically allocate task resources to ensure that high-priority tasks can be processed in a timely manner. In addition, hash-based and range-based data partitioning methods are used to optimize data storage distribution. Through the application in high-performance language parallel database, the improved algorithm is compared and analyzed with the traditional algorithm. Under high concurrency pressure and large-data amount query load, the average query response time of the algorithm in this article is about 465.32 ms; the throughput is about 315.67 times per second; the CPU and memory resource utilization rates are 64.83% and 72.24%. The comparison results of t-test are p < 0.05, which shows that there are significant differences in the performance of the algorithm in this article compared to Dijkstra algorithm and genetic algorithm in various performance indicators. The research results indicate that the improved ant colony optimization algorithm has good application potential and can effectively improve the processing performance of parallel databases.
Keywords
Introduction
With the rapid development of information technology, the rapid growth of data scale, and the increasing demand for complex queries, traditional database processing technology faces huge challenges. In this context, seeking efficient optimization algorithms becomes the key to improving database performance. The theory of swarm intelligence is widely used in various tasks because of its ability to effectively solve complex problems. Among them, the ant colony optimization (ACO) algorithm has demonstrated powerful capabilities in various fields by simulating the foraging behavior of ants in nature.1,2
The core of the ACO algorithm is the pheromone update mechanism.3,4 Ants release pheromones along the path, and the concentration of pheromones guides the choices of other ants. This adaptive path selection mechanism enables ACO to perform well in static environments. However, in dynamically changing environments, traditional ACO algorithms often find it difficult to adapt quickly, causing the algorithm to easily fall into local optimal and converge slowly.5,6 Therefore, improving the adaptability and optimization performance of the ACO algorithm has become the focus of research.
This article designs a pheromone update mechanism to improve the ACO algorithm. This mechanism simulates the pheromone decay in the natural environment through pheromone evaporation7,8 and pheromone reinforcement mechanisms,9,10 and dynamically adjusts the pheromone concentration according to the path quality. The pheromone evaporation mechanism ensures the gradual reduction of old pheromones, while pheromone reinforcement mechanism adds pheromones to the preferred path according to the quality of the path, guiding subsequent ants to choose a better path. In the improved model, the dynamic adjustment mechanism of pheromones ensures that the algorithm can respond to changes in the database environment.
To solve the resource competition problem under high-concurrency queries, this article also implements a scheduling optimization strategy based on task priority.11,12 By analyzing the complexity, resource requirements and historical execution time of tasks, a task priority scoring formula is defined, and a weighted round-robin strategy is used to allocate task resources.13,14
In terms of data storage, this article adopts hash-based and range-based partitioning strategies to optimize data storage distribution and reduce query latency. Hash partitioning ensures that data is evenly distributed by selecting key fields and using simple hash functions, avoiding hot spot problems. 15 Range partitioning divides data according to its value ranges 16 and is suitable for query requirements with sequential characteristics.
The main contribution of this article is to improve the ACO algorithm and enhance its application effect in high-performance language parallel database processing. By designing flexible pheromone update mechanisms, optimizing task scheduling strategies, and proposing effective data partitioning methods, query response time, system throughput, and resource utilization are significantly improved, effectively solving the limitations of traditional optimization algorithms in parallel database environments.
Related work
With the popularity of data-intensive applications, traditional database optimization algorithms are unable to meet the needs of large-scale parallel queries. ACO has become an important tool for database optimization due to its flexibility and global optimization capabilities.17,18
The ACO algorithm imitates the foraging behavior of ants and forms a global optimal solution through local individual behavior.19,20 It is widely used in path selection, query plan generation and resource scheduling in database query optimization.21,22 However, traditional algorithms lack adaptability in parallel database environments, and they are prone to falling into local optimal, with slow convergence speeds.23,24 To solve these problems, in recent years, attention has been paid to the improvement of ACO algorithm, and research has been carried out on adaptive adjustment of pheromone concentration, application of heuristic information, design of parallel algorithm, etc. Kumar D et al. 25 proposed a parallel query optimization algorithm based on ACO to reduce query time. Although this method achieved certain results in improving query efficiency, it still has limited processing capabilities in large-scale distributed environments and is difficult to cope with complex multi-dimensional data query requirements.
In the ACO algorithm, the pheromone update mechanism is one of the core factors affecting the algorithm performance. The classic ACO algorithm gradually guides ants to find the optimal path through the accumulation and evaporation of pheromones.26,27 However, in large-scale parallel databases, traditional pheromone update mechanisms often face efficiency bottlenecks, and especially when data query patterns change frequently, they cannot adapt to new environments quickly. To solve this problem, many studies in recent years have proposed improved pheromone update strategies. Ning J et al. 28 proposed a negative pheromone ACO algorithm based on multi-objective decomposition to prevent pheromones from being overly concentrated on certain paths and avoid premature convergence of the algorithm. In addition, Shan D et al. 29 studied the combination of pheromone evaporation and local reinforcement, which determined the pheromone increment by path quality. These methods have improved the adaptability of the ACO algorithm to a certain extent, but further optimization is still needed when dealing with high-concurrency and dynamic data environments.
In parallel database processing, reasonable task scheduling faces the challenge of dynamically allocating resources to prioritize high-priority tasks. Although the traditional shortest task first and round-robin strategies are easy to implement, they are difficult to adapt to changes in resource requirements in complex environments. In recent years, priority-based task scheduling algorithms have gradually become a research hot spot. Dai Z et al. 30 proposed a weighted scheduling strategy based on the historical execution time of tasks and resource requirements. By dynamically allocating resources through weighted round-robin, high-priority tasks could be responded to quickly. Iqbal N et al. 31 proposed an adaptive scheduling algorithm that could dynamically adjust the scheduling strategy according to the system resource utilization and task complexity, reducing resource waste and task starvation. However, these methods still have room for improvement in terms of task scheduling flexibility and dynamic resource allocation. Especially in the face of sudden large-scale query requests, the system's response speed and stability still need to be improved.
Data partitioning technology improves query efficiency by dividing and distributing data for storage, and common methods include hash partitioning and range partitioning.32,33 With the increase of data scale and the diversification of query requirements, research on data partitioning has paid more and more attention to dynamic partitioning and adaptive partitioning strategies in recent years. Lu S X et al. 34 proposed a data partitioning strategy based on query frequency, which optimized the access speed of common queries by dynamically adjusting partition boundaries. Do T et al. 35 combined hash and range partitioning and proposed a hybrid partitioning strategy that could adaptively adjust the partition structure when the query pattern changed, thereby improving the system's response speed. However, existing strategies still have certain limitations when facing frequent data updates and complex multi-dimensional queries. Improving the flexibility of partitioning while ensuring query efficiency remains an important research direction.
The innovation of this article lies in the use of an improved ACO algorithm, which effectively solves the limitations of the traditional ACO algorithm in a parallel database environment by designing a flexible pheromone update mechanism and optimizing task scheduling strategies. In addition, this article also studies an effective data partitioning method to improve the processing efficiency of high-performance language parallel databases.
Improved ant colony optimization algorithm
Construction of swarm intelligence model
When constructing a swarm intelligence model based on ant foraging behavior, it is necessary to clarify the basic framework and key parameters of the model. The main goal of the model is to find the optimal path and solve the database query optimization problem by simulating the behavior of ants in the graph.
Definition of search space
This article defines the search space as a directed graph
The weight


To reflect the access efficiency of data at different locations, efficiency function

The initial positions of the ants in the model are allocated according to the data blocks to be queried, to ensure that when each query request arrives, the algorithm can start from a variety of starting points, effectively explore the search space and avoid falling into the local optimal solution.
Whenever the system receives a new query request, it analyzes the request and extracts the key query conditions and the data blocks to be queried. Assuming that the query request consists of a set


During the search process, when the ant moves in the graph, it needs to choose the next node to move to based on the total weight of the path. Assuming the current node is





Through the above method, the constructed swarm intelligence model can be adjusted according to the real-time changes of the database. When the amount of data changes or the query pattern changes, the model can quickly adapt to the new environment by adjusting the pheromone concentration and the weight of heuristic information.
In the improved ant colony optimization algorithm, the pheromone update mechanism is the key to improving the algorithm's adaptability and optimizing performance.36,37 By dynamically adjusting the concentration of pheromones, the algorithm can respond to environmental changes in real time, and its effectiveness in parallel database processing can be improved.
In the initialization phase of the ant colony optimization algorithm, the same initial pheromone concentration value is assigned to each edge in the directed graph, with an initial size of 1, to ensure that each edge has the same attraction at the beginning of the algorithm, allowing the algorithm to explore from multiple possible solution paths. The pheromone update mechanism consists of two parts: pheromone evaporation and pheromone reinforcement, as shown in Figure 1.
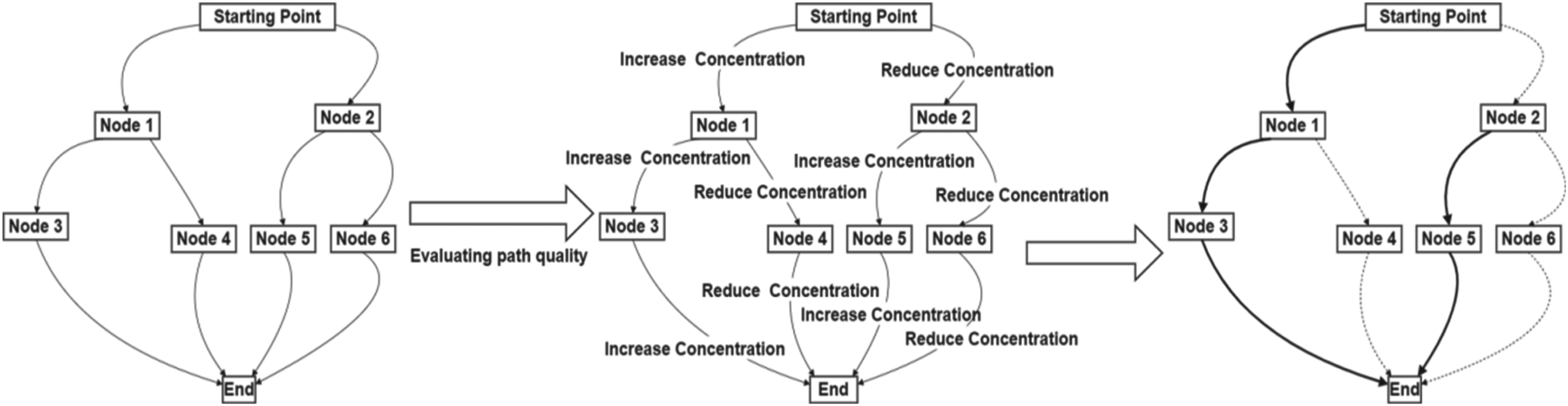
Pheromone update mechanism.
Figure 1 shows the principle of the pheromone update mechanism. After the path is selected, the pheromone concentration is increased according to the path quality to guide subsequent ants to choose a better path. The pheromone evaporation mechanism is used to simulate the decay of pheromones in the natural environment to ensure that the pheromone concentration of old paths is not accumulate indefinitely. A evaporation factor

After the ants complete the path selection, the pheromone concentration is updated according to the path quality. The quality of the path is evaluated by the path length


To further improve the adaptability of the model to dynamic environments, an adaptive pheromone update mechanism is designed, which dynamically adjusts the pheromone increment according to the query frequency and query complexity.
By counting the access frequency f of the data blocks, the system can dynamically increase the pheromone concentration of the relevant paths according to the frequent queries of certain data blocks. The specific adjustment formula is shown in Formula (14).



To improve the flexibility and accuracy of the algorithm, the pheromone update mechanism can be combined with multi-path selection. When the pheromone concentrations of multiple paths are similar, the system randomly selects a path to query. A threshold is set for each path selection, and its pheromone is updated only when the path selection probability exceeds the threshold. In addition to real-time monitoring and feedback mechanisms, experience feedback and learning mechanisms are also used. By accumulating historical data, the long-term performance of each path is analyzed, and the initial configuration of pheromones is optimized.
Task scheduling optimization requires defining task priorities based on factors such as task complexity, resource requirements, and historical execution time. The task complexity is evaluated through query types such as join queries and aggregation queries and the required computing resources. A priority scoring formula is defined:

A weighted round-robin strategy is used to dynamically allocate tasks, and each task category is assigned different weights according to its priority.38–40 The scheduler classifies all pending tasks by priority and stores them in the task queue. In each round of scheduling, processing resources are first allocated to high-priority tasks according to their weights. When resources are insufficient, medium-priority and low-priority tasks obtain corresponding scheduling opportunities based on their weights.
The resource requirements of each task are further analyzed to optimize task scheduling. By monitoring the current resource utilization status of database, the scheduling system can evaluate the available resources in real time and dynamically adjust the scheduling strategy according to the requirements of the task.
The scheduling system uses monitoring tools to collect real-time information about the system's CPU utilization, memory utilization, and I/O performance. When the system resource utilization reaches a preset threshold, the scheduler prioritizes tasks with lower resource requirements. If the CPU utilization exceeds 80%, the scheduling of low-priority and high-resource-demand tasks is suspended.
To improve the processing efficiency of high-performance language parallel database, data partitioning strategies based on hash and range are proposed. These two partitioning methods can reduce query latency and improve data access speed by optimizing data storage distribution.
In hash partitioning, one or more key fields are selected as the basis for partitioning. The selection of fields needs to take into account the query frequency and data distribution characteristics. Then the hash function is designed, which usually uses a simple modulo operation. Given a record, its hash value is calculated, and the storage node is determined, to ensure that data is evenly distributed and hot spots can be avoided. The data is then distributed to the corresponding storage nodes according to the calculated node index, effectively reducing the load on specific nodes and balancing system resource utilization. When querying, the storage node is directly located according to the hash value, which reduces unnecessary full table scans and reduces query latency.
Range partitioning divides data into different partitions based on the value range of the data. This method is suitable for data with sequential nature such as timestamps and prices. Reasonable interval boundaries are set for each range partition, and even data distribution is ensured by analyzing historical data and query patterns. When allocating data, data is allocated to corresponding range partitions according to the data value, and records whose data values fall within a certain interval are stored in the corresponding nodes. When querying, the target partition can be quickly located through range conditions, reducing the amount of data to be scanned and improving query speed.
To further optimize the data partitioning strategies, the query pattern is analyzed. The types and frequency of user queries are monitored and recorded. The most frequently accessed fields and patterns are identified, and partitioning strategies are dynamically adjusted based on changes in query patterns. In addition, partitions must be maintained and updated regularly to ensure the rationality of data distribution and avoid performance degradation due to data growth.
Application of improved ant colony optimization algorithm in high-performance language parallel database
The application of the improved ant colony optimization algorithm in a high-performance language parallel database is simulated and compared with the Dijkstra algorithm and genetic algorithm. The hardware configuration includes two servers equipped with Intel Xeon Gold 6140 processors (36 cores in total), 256GB of memory, 1TB NVMe SSD and 4TB SATA HDD storage space, and dual 10 Gigabit Ethernet ports. The software environment consists of Linux Ubuntu 20.04 LTS operating system and MySQL 8.0.23 database management system. Apache JMeter 5.2.1 is used as the performance testing tool.
In this experiment, a 10GB TPC-H data set is selected for testing. The 10GB data set is selected for testing in order to fully demonstrate the performance advantages of the improved ant colony optimization algorithm in a medium-sized database environment while ensuring the accuracy and practicality of the test results. At this scale, system resources can be effectively utilized, and the potential of the algorithm in actual application scenarios can be demonstrated, while ensuring the repeatability and manageability of the test, providing a reasonable starting point for further research and application of the algorithm. The data is inserted into the MySQL database in bulk, and all non-essential indexes are disabled during the import process to speed up data loading. After the data is imported, the indexes are rebuilt to optimize query performance and ensure that the data is evenly distributed in the database.
Various test scripts are configured using Apache JMeter to simulate query requests of different complexity. These scripts include simple queries, combined queries, complex queries, and queries for large amounts of data. In the concurrency test, the concurrency levels are divided into three levels: low, medium, and high, corresponding to different numbers of concurrent users and request frequencies.
The query response time, system throughput, and resource utilization of each algorithm are recorded during the experiment. After data collection is completed, the performance data of the three algorithms is compared using t-test, and the mean and standard deviation are calculated to evaluate the significance of the performance difference.
The data of the three concurrency levels under complex query load are displayed in Figure 2, Figure 3 and Table 1 respectively.
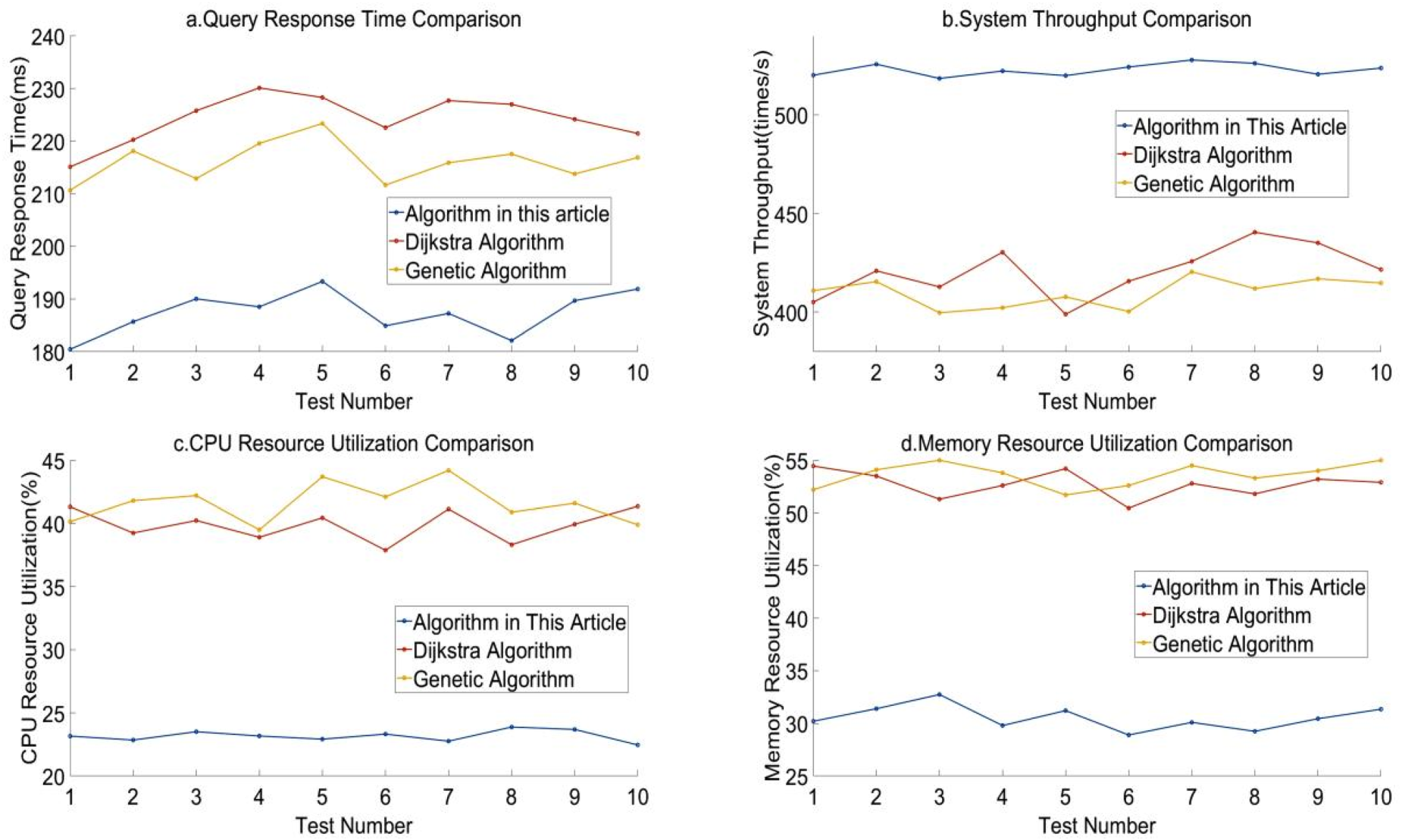
Performance of three algorithms under complex query load and low concurrency pressure.
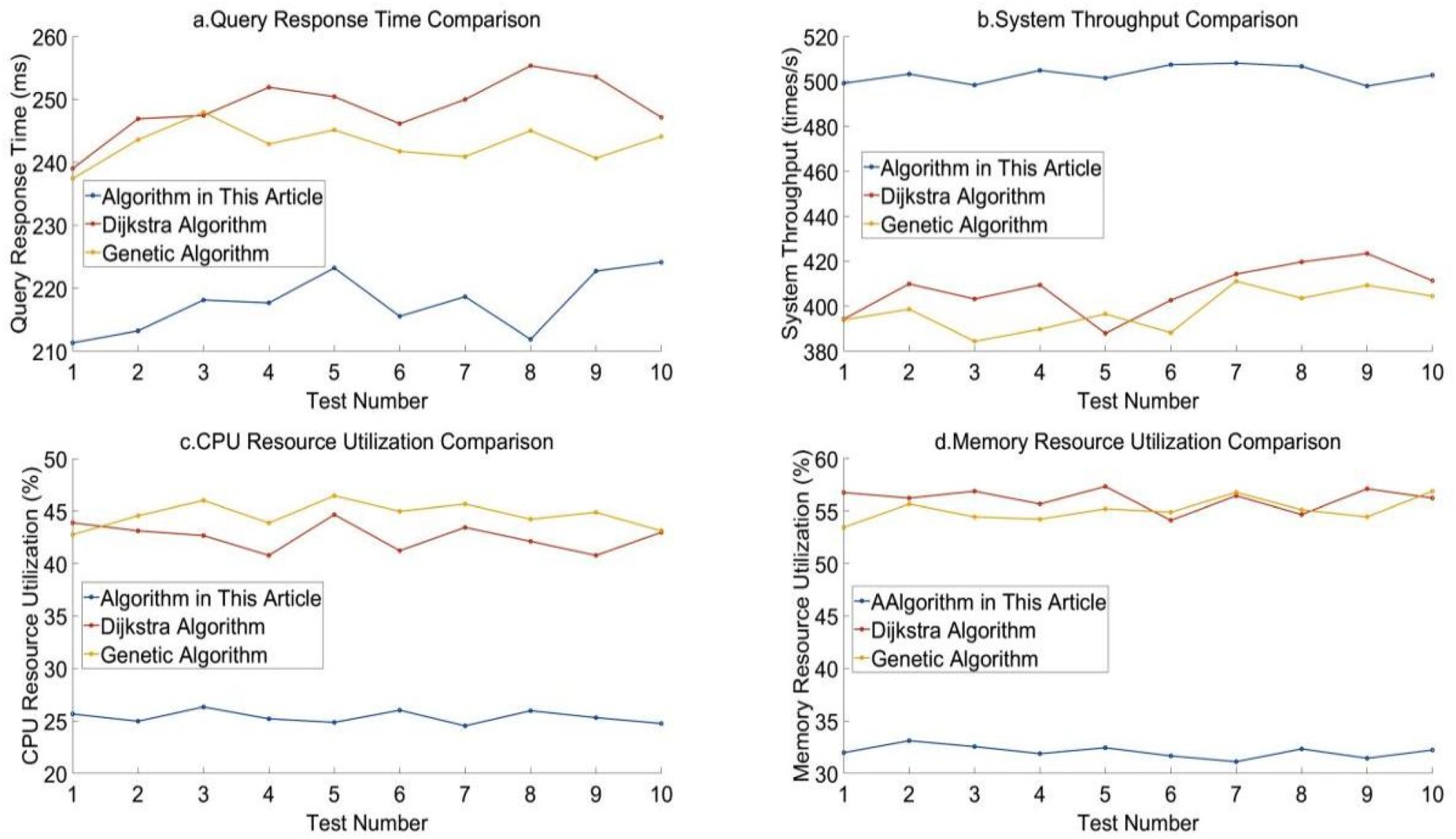
Performance of three algorithms under complex query load and medium concurrency pressure.
Statistical results of three algorithms under complex query load and high concurrency pressure.
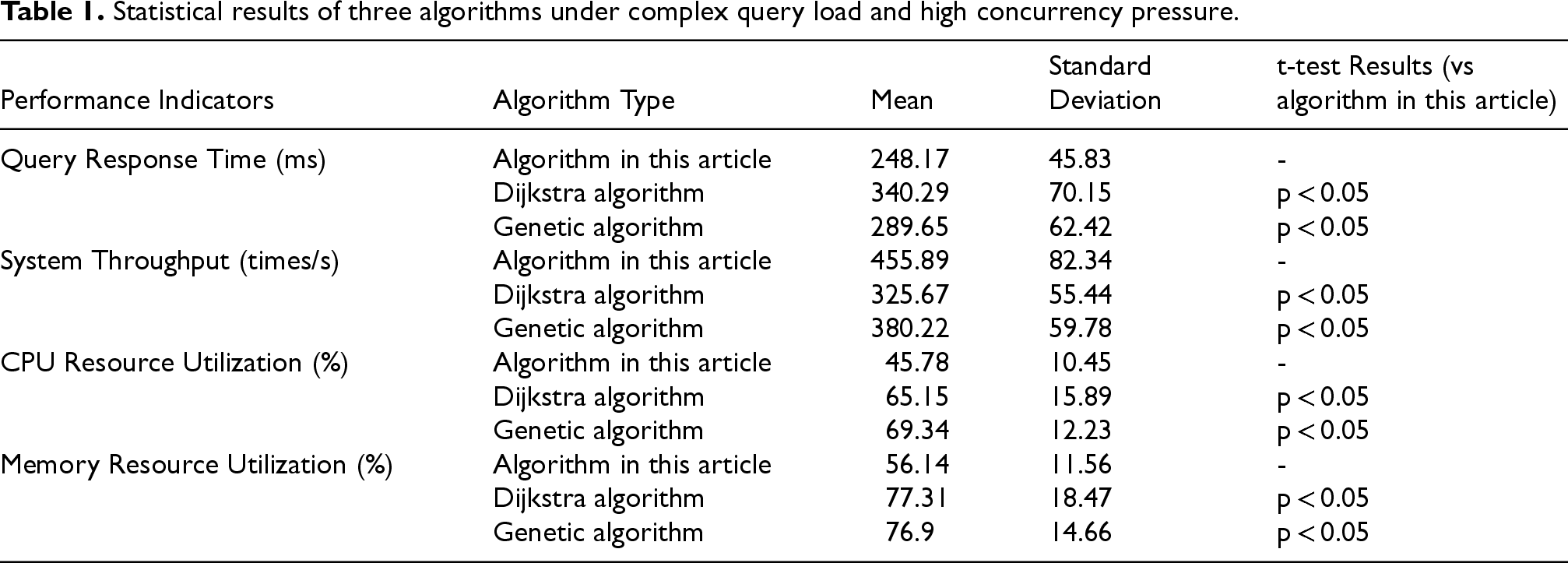
Figure 2 shows the performance of the three algorithms under complex query load and low concurrency pressure. The algorithm in this article performs better than the other two algorithms. The results show that in the 10 tests, the minimum response time of the algorithm in this article is about 180.45 ms, and the throughput per second is greater than 518 times. At the same time, the CPU resource utilization and memory resource utilization of the algorithm in this article are both low, with the lowest CPU utilization being 22.46% and the lowest memory utilization being 28.9%.
The data in Figure 3 show that the performance of the algorithm in this article under complex query load and medium concurrency pressure is lower than that under low concurrency pressure, but its performance is still better than that of traditional algorithms. Its query response time is generally lower than that of the other two algorithms, with the lowest being 211.35 ms. Its system throughput is up to about 508 times per second, and CPU utilization and memory utilization are also relatively low.
Table 1 shows the statistical results of the three algorithms under complex query load and high concurrency pressure, which reflects the superiority of the algorithm in this article. In terms of query response time, the average value of the algorithm in this article is 248.17 milliseconds, which is significantly better than that of the Dijkstra algorithm and genetic algorithm, and the t-test results are all p < 0.05. In terms of system throughput, the result of the algorithm in this article is about 455.89 times per second. The CPU resource utilization rate of the algorithm in this article is about 45.78%, and the memory resource utilization rate is about 56.14%, both of which are lower than the results of the other two algorithms. These data show that the algorithm in this article excels in both performance and resource efficiency.
Under high concurrency pressure, the data of simple query load, combined query load, and large-data amount query load are displayed in Figure 4, Figure 5, and Table 2, respectively.
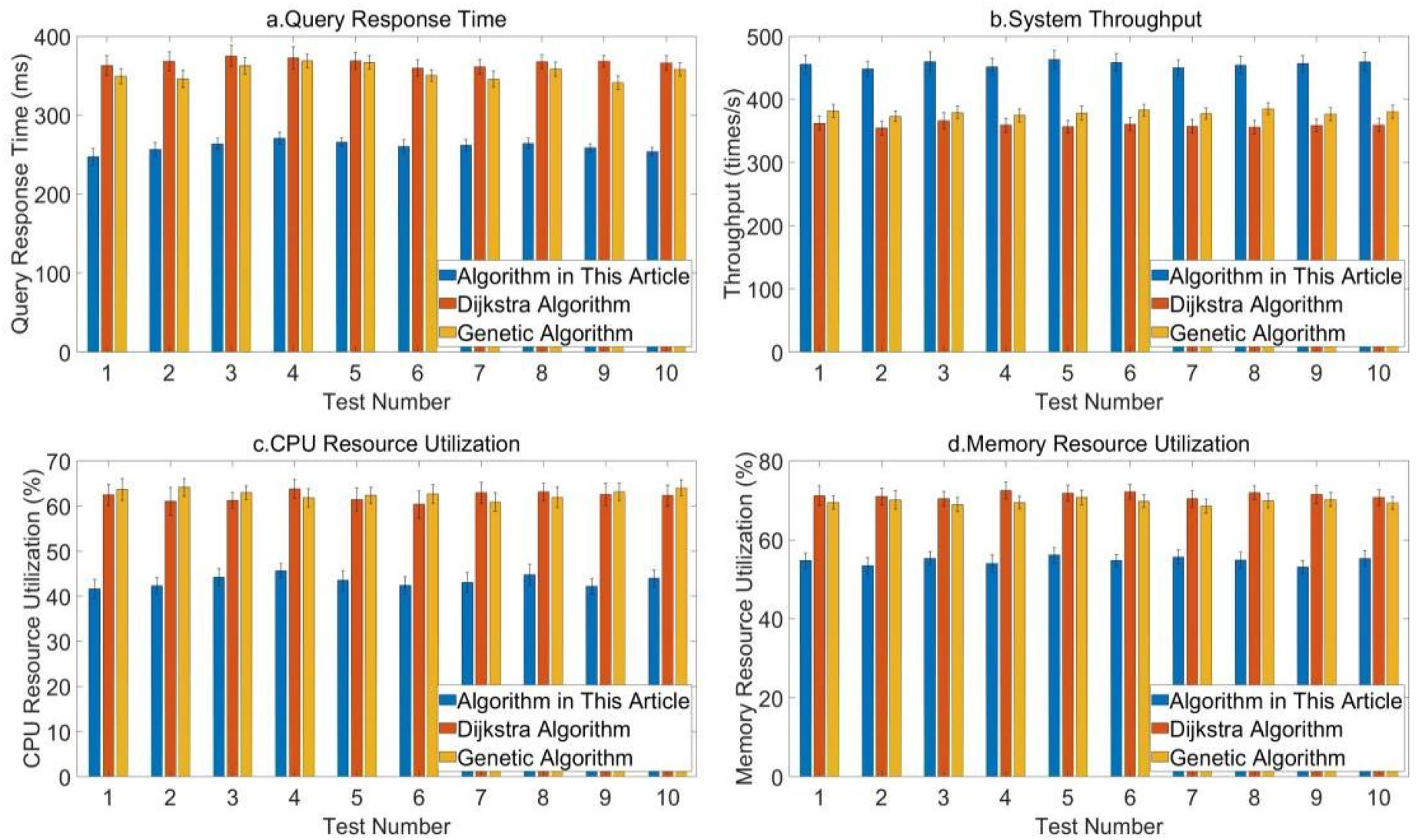
Performance of three algorithms under high concurrency pressure and simple query load.
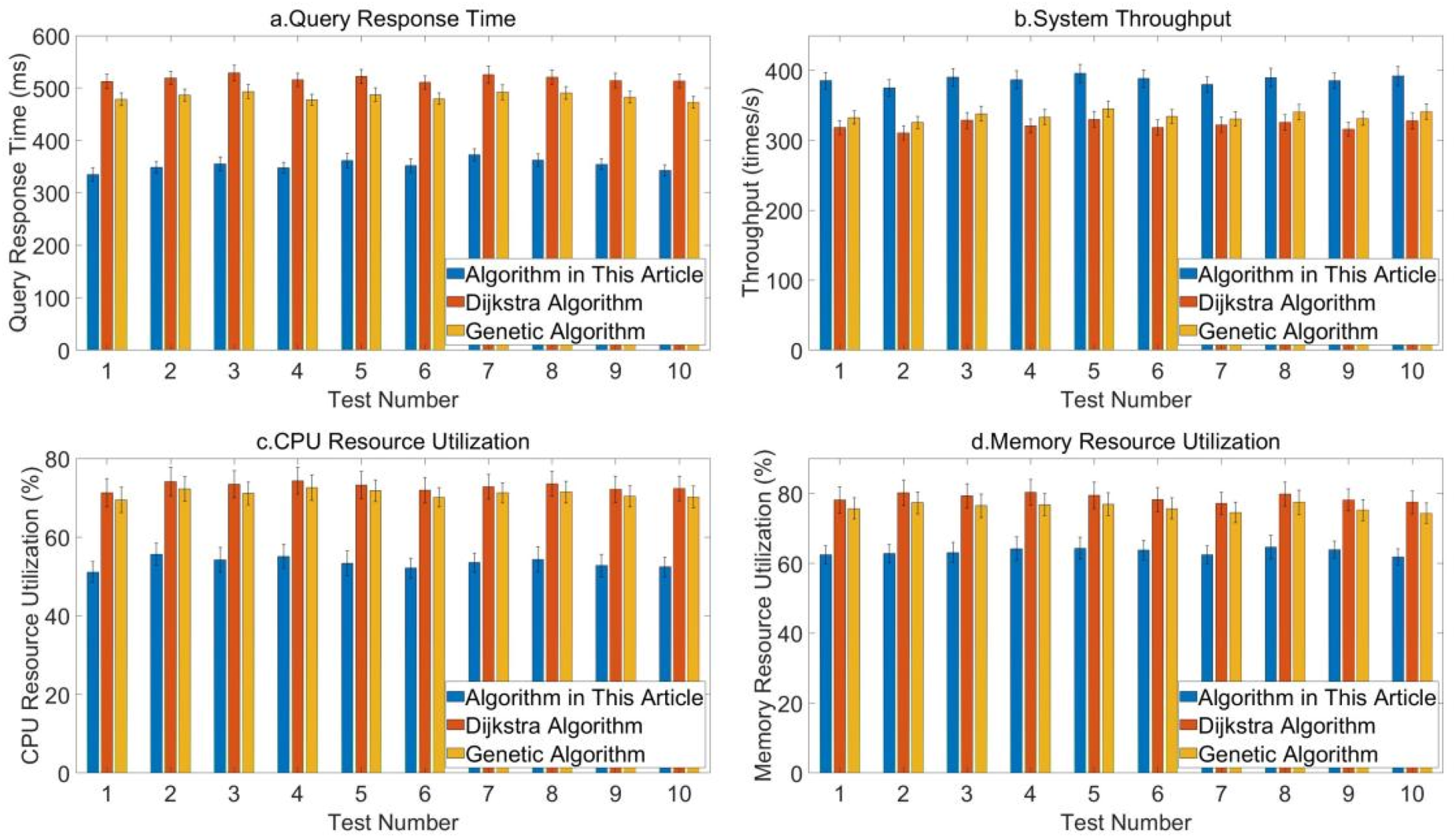
Performance of three algorithms under high concurrency pressure and combined query load.
Statistical results of three algorithms under high concurrency pressure and large-data amount query load.
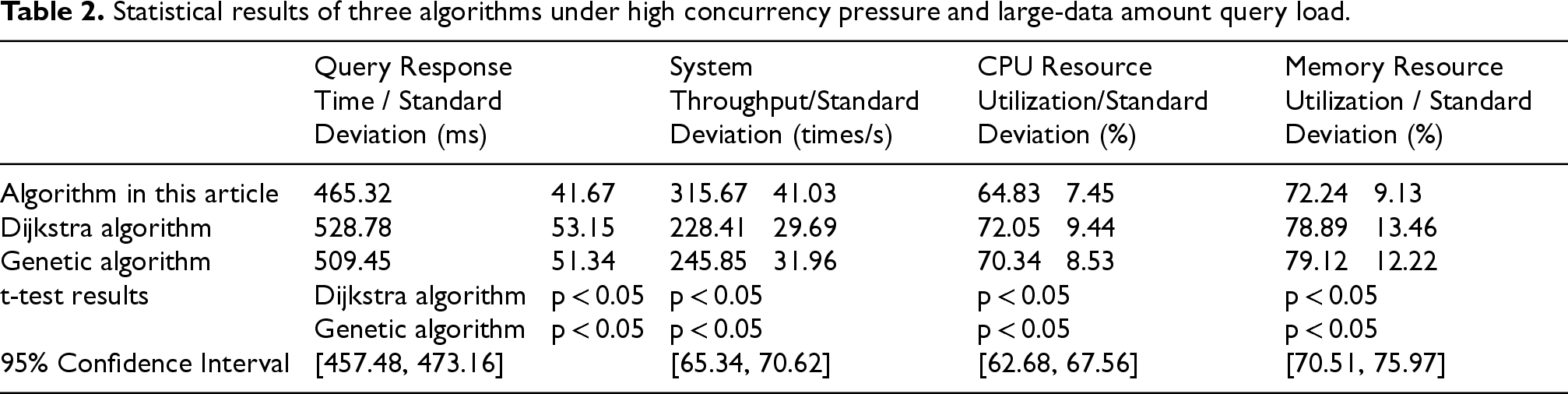
Figure 4 shows the comparison data of query response time, system throughput, CPU resource utilization, and memory resource utilization of the three algorithms under high concurrency and simple query load conditions. According to the data, the query response time of the algorithm in this article performs relatively well in the test, with an average of about 260.18 milliseconds and a maximum error of about 10.23 milliseconds. The minimum response time of Dijkstra algorithm is about 359.54 milliseconds, and the minimum response time of genetic algorithm is about 341.12 milliseconds. In terms of system throughput, the maximum throughput of the algorithm in this article is about 462.78 times per second, which is much higher than that of Dijkstra algorithm and genetic algorithm, reflecting its excellent processing ability under high concurrency. In terms of CPU resource utilization and memory resource utilization, the algorithm in this article has maximum utilization rates of approximately 45.67% and 56.12%, which are significantly lower than those of the other two, indicating its high efficiency.
Figure 5 shows the comparison data of query response time, system throughput, CPU resource utilization, and memory resource utilization of the three algorithms under high concurrency and combined query load. In the 10 tests, the average query response time of the algorithm in this article is about 353.33 milliseconds, and the minimum error is about 10.45 milliseconds, which are lower than the results of Dijkstra algorithm and genetic algorithm, showing the efficiency advantage of the algorithm in this article in processing combined queries. In terms of system throughput, the maximum throughput of the algorithm in this article is about 395.67 times per second, which is significantly higher than that of the Dijkstra algorithm and the genetic algorithm, indicating its processing capability in a high-concurrency environment. In terms of CPU resource utilization, the algorithm in this article has a minimum utilization rate of about 51.12%, which is significantly lower than the 71.23% of the Dijkstra algorithm and the 69.45% of the genetic algorithm. In addition, the algorithm in this article also has a lower memory resource utilization rate than the Dijkstra algorithm and the genetic algorithm.
Table 2 shows the statistical results of the three algorithms and the 95% confidence interval of the algorithm in this article under high concurrency pressure and large-data amount query load. The average query response time of the algorithm in this article is about 465.32 ms, while that of the Dijkstra algorithm is about 528.78 ms and that of the genetic algorithm is about 509.45 ms. These data show that the algorithm in this article is superior to the other two algorithms in terms of response time. In terms of throughput, the average value of the algorithm in this article is about 315.67 times per second, which is higher than the results of the other two algorithms, and its performance in CPU and memory resource utilization is also better than the other two.
In different test scenarios, the proposed algorithm shows significant potential for database query optimization, maintaining low response time and high throughput for both simple and complex combined queries. Compared with Dijkstra's algorithm and genetic algorithm, the proposed algorithm more effectively balances exploration and utilization in a dynamic environment through pheromone volatilization and enhancement mechanisms, showing advantages in query response time and system throughput.
Optimization of pheromone update mechanism
In order to further improve the adaptability of the model to dynamic environments, this paper uses an adaptive pheromone update mechanism to dynamically adjust the increment of pheromone. By calculating the access frequency of data blocks, the system can dynamically increase the pheromone concentration of relevant paths according to the frequent queries of certain data blocks. For complex queries, a higher pheromone increment is set to quickly guide subsequent ants to select the optimal path. The query complexity can be evaluated by calculating the resources and time consumption required for the query. When the query complexity is high, the pheromone increment is adjusted by a specific formula.
Optimization of task scheduling strategy and data partitioning strategy
This paper implements task scheduling optimization. It sets task priorities by comprehensively considering task complexity, resource requirements, and historical execution time, and divides tasks into three levels: high, medium, and low. A weighted round-robin strategy is used to dynamically allocate processing resources according to task priorities, ensuring that high-priority tasks can be processed in a timely manner, and that medium and low-priority tasks are reasonably scheduled when resources permit.
In addition, in order to improve the processing efficiency of high-performance language parallel databases, this paper uses data partitioning strategies based on hashing and ranges. The hash partitioning strategy selects key fields and uses hash functions to ensure that data is evenly distributed. The range partitioning strategy divides data according to the range of data values, which is suitable for processing data with sequential characteristics.
Parameter sensitivity analysis
Meanwhile, in the improved ant colony optimization algorithm, the weight coefficient of node storage location overhead (α), the weight coefficient of node access frequency (β), and the weight coefficient of query cost (γ) are analyzed. These parameters jointly determine the behavior patterns of ants during the search process and affect the efficiency and effectiveness of the entire algorithm.By adjusting these parameters, the algorithm can be optimized according to specific application scenarios and performance requirements to achieve the best query performance and resource utilization.
The value of α is increased from 1 to 5, and its impact on query response time and system throughput is observed. At a lower value of α, the algorithm is less inclined to consider the cost of storage locations, resulting in more reliance on access frequency and query cost when selecting a path, which ignores potential optimization paths that have lower storage costs but longer paths. As the value of α increases, the algorithm begins to prefer paths with low storage location overhead, which reduces the speed of queries. When the value of α exceeds 3, the throughput of the system begins to decline. This is because ants tend to choose nodes that have low storage costs but long paths, increasing the overall query latency.
The parameter β controls the sensitivity of the algorithm to the frequency of data block access. When the value of β is low, ants are more inclined to explore data blocks that are not frequently accessed, which helps the algorithm escape from the local optimal solution but reduces the convergence speed of the algorithm. As the value of β increases, the algorithm increasingly prefers those frequently accessed data blocks, which speeds up the convergence of the algorithm but also increases the risk of the algorithm falling into a local optimal solution consisting of high-frequency access paths. Experimental data show that when the value of β exceeds 4, the performance of the algorithm begins to decline significantly. This is because ants are overly concentrated on a few paths and ignore other possible optimization paths.
The query cost includes response time and resource consumption, and its weight coefficient γ has a direct impact on the resource utilization efficiency of the algorithm. At a lower value of γ, the algorithm takes less account of the cost of the query, which may result in the selection of paths with higher resource consumption. As the value of γ increases, the algorithm begins to prefer paths with low resource consumption, improving the system throughput and resource utilization. However, when the value of γ is too high, the algorithm over-optimizes the query cost and ignores the path length and access frequency, resulting in the selection of an overly long path and increased query latency.
Through analysis, it is found that each parameter needs to be carefully adjusted according to the specific application scenario and performance requirements. In a resource-constrained environment, the values of α and γ need to be increased to optimize storage cost and query cost. In query scenarios that require fast response, the values of these parameters need to be appropriately reduced to maintain a high system throughput. The value of β needs to be adjusted according to the characteristics of the data access pattern to balance the convergence speed and search breadth of the algorithm.
Algorithm analysis
In terms of parallel implementation, the algorithm in this article divides the search space into multiple subspaces, each of which is processed by a group of independent processors. The parallel implementation of the algorithm relies on the parallel processing framework of the database management system, which can allocate and synchronize multiple parallel tasks. Each processor is responsible for query optimization of a part of the data block. The localization of the pheromone update mechanism ensures that the update of pheromones will not conflict between processors. In addition, the algorithm adopts a master-slave architecture. The master processor is responsible for coordinating the execution and result aggregation of each subtask, while the slave processor focuses on the optimization of the data block assigned to it.
In order to improve the adaptability of the algorithm, this paper monitors the query response time, system throughput and resource utilization in real time, and dynamically adjusts the pheromone concentration and the weight of heuristic information according to the monitoring data. In addition, the experience feedback and learning mechanism is introduced. By accumulating historical data to analyze the long-term performance of each path, the initial configuration of pheromones is optimized, and the algorithm's ability to respond to dynamic environmental changes is improved.
This paper improves the utilization efficiency of CPU and memory resources through the pheromone update mechanism, optimizing the task scheduling strategy and proposing an effective data partitioning method. For example, task resources are dynamically allocated through a weighted polling strategy to ensure that high-priority tasks can be processed in a timely manner, while reducing resource waste and task starvation.
The algorithm in this article has the ability to handle growing data scale and query load. Through the dynamic adjustment of pheromones and the adaptive task scheduling strategy, the algorithm can maintain a low query response time and high system throughput when the amount of data increases, showing good scalability.
Error handling problems may be encountered during database queries, and the algorithm in this article has a certain fault tolerance. The algorithm reduces the reliance on a single path through multi-path selection and the volatilization mechanism of pheromones, so that it can quickly reroute when an error occurs. In addition, the algorithm monitors key performance indicators during execution, and once an anomaly is found, it will trigger a retry mechanism or fall back to the previously valid query path.
This study simulates data environments of different scales and analyzes the number of iterations and computing time required by the algorithm before reaching a stable solution. The results show that as the data scale increases, the convergence speed of the algorithm decreases slightly, but the overall performance remains within a reasonable range. In addition, this paper also finds that after introducing additional security mechanisms, the performance of the algorithm decreases slightly, but by optimizing the pheromone update frequency and adjusting the task scheduling strategy, it can effectively balance security and efficiency. Finally, in response to the fairness and resource allocation issues in a multi-user concurrent environment, this paper constructs a resource allocation model based on user priority to optimize the resource utilization of the overall system. By comparing the performance with structured data queries, this paper finds that the algorithm can still maintain low query latency and high throughput in an unstructured data environment, although the performance decreases slightly in some complex query modes. This result proves that the ant colony optimization algorithm has certain applicability and flexibility in processing diverse data types.
Conclusion
This study successfully improved the ant colony optimization algorithm by introducing pheromone volatilization and enhancement mechanisms, and applied it to high-performance parallel database processing. Experiments show that the algorithm has achieved remarkable results in pheromone update, task scheduling optimization, and data partitioning strategy, effectively improving query response time and system throughput, while optimizing the utilization of CPU and memory resources. Compared with the Dijkstra algorithm and genetic algorithm, the algorithm proposed in this paper shows superior performance under high concurrency and large data query loads. These results verify the potential of the improved ant colony algorithm in solving the limitations of traditional database optimization algorithms and provide a new optimization path for parallel database processing.
Although this study has achieved certain results, the stability and adaptability under extremely high concurrency conditions need to be further verified, and the algorithm's responsiveness to real-time dynamic data changes has not been fully evaluated. In the future, the performance of the algorithm in extremely high concurrency environments and its adaptability to real-time dynamic data changes will be further explored. In addition, the research will be expanded to combine machine learning technology to enhance the algorithm's responsiveness to changes in data features and optimize the intelligence level of database processing. Expected goals include achieving adaptive adjustment of the algorithm, improving the accuracy of query optimization, and enhancing the scalability of the system to meet the growing amount of data and query complexity.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by High-level Talents Project of Hainan Provincial Natural Science Foundation: Practical Research on Building College English Intelligent Class with Artificial Intelligence, Project number: 522RC617.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Data sharing is not applicable to this article as no new data were created or analyzed in this study.