
Abstract
Text summarization condenses a text into its essential points for a quick grasp of the main ideas. Multi-document summarization integrates information from several sources to provide a comprehensive overview. Techniques include extractive methods, which select key sentences, and abstractive methods, which generate new sentences. Hybrid methods combine these approaches to improve summary quality. Limitations include challenges in maintaining coherence, context, and nuance. Further improvements are needed to enhance coherence, accuracy, and comprehensiveness in summaries. To address these issues, this research proposes the Improved Bidirectional Gated Recurrent Unit (IBi-GRU) model for Multi-document Text Summarization through COOT optimization updated Coati Optimization Algorithm (CuCOA). The process involves preprocessing, feature extraction, and summarization. Initially, tokenization is performed during the preprocessing. Pertinent features are then extracted from the preprocessed text in the phase of feature extraction, followed by summarization using the IBi-GRU model with its weight parameters optimally tuned by the CuCOA approach. Comprehensive simulations and experimental assessments in terms of accuracy, Mathews Correlation Coefficient (MCC), False Negative Rate (FNR), etc., validate the IBi-GRU model. This demonstrates its robustness and potential for various text summarization applications in comparison with conventional approaches. The CuCOA + IBi-GRU scheme achieved the highest scores, with a Rouge of 0.866, Precision of 0.887, Recall of 0.853, and F-Measure of 0.913.
Keywords
Introduction
The rapid growth of social media has led to an overwhelming amount of information being generated. Processing this vast influx of data manually is impractical. A major challenge with text data is the large volume from diverse sources like social media, documents, blogs, and forums, often in unstructured formats. 1 Text, being a primary medium on social media, efficiently conveys real-time news and opinions. 2 Text summarization,3,4 a technique for condensing lengthy texts into shorter summaries while retaining key details and meaning, is crucial for obtaining summary results from a document.2,5 This technique is especially valuable for handling large volumes of text data by grouping information dynamically and minimizing the dimensionality of corpora.
Text summarization simplifies this task by distilling the essential information from a document, 6 making it quicker and easier to read, a valuable trait in today's fast-paced world. 2 This process extracts the most important features from individual documents. 3 Reducing the volume of text with information can be beneficial for various Natural Language Processing (NLP) 7 tasks. A condensed version of the textual information is produced in summarization, which captures the essential details of the original document. 8 Text summarization processes depend on machine learning (ML) based text classification for text mining. During text extraction, the sentences identified as key sentences are crucial to this process. 9
Automated text summarization (ATS)10–17 methods have been developed to automatically generate concise versions of documents, allowing users to grasp the essential content more efficiently. ATS12–15 aims to identify and synthesize the main topics and concepts of a document, enhancing data processing and retrieval. 18 There are two main types of summarization: abstractive and extractive.2,8,11,18,19 Abstractive summarization6,20,21 is an NLP task 5 which generates a summary that may include new phrases or sentences not found in the original text, while extractive summarization 6 identifies and extracts the key details to create a condensed version of the original content.
Abstractive methods
22
involve rewriting the document using internal semantic representations and NLP techniques.23,24 Various methods, including genetic algorithms, NLP, Long Short-Term Memory (LSTM), and Sequence-to-Sequence (Seq2Seq) structures, are employed for summarization.19,25 Multi-document
25
summarization presents more challenges compared to single-document summarization.
10
With the rise of deep learning, abstractive text summarization now relies on large datasets rather than complex models,
12
improving NLP
7
in areas like machine translation, speech recognition, and sequence generation. Despite the range of available methods, some face limitations that affect their effectiveness. Considering these aspects, the aim is to develop an Improved Bi-GRU for Multi-document Text Summarization via the CuCOA approach. This suggested approach has three main contributions, which are explained below.
Implementing an Improved Aspect Term Extraction in the feature extraction phase, utilizing T-score and improved cosine similarity to improve this feature. This advancement allows for more precise identification of relevant aspects within the text, thereby improving information retrieval effectiveness. Presenting the COOT updated COA optimization algorithm to better tune the weight parameters of the Improved Bi-GRU model for text summarization. This optimization upgrade accelerates convergence and quickly identifies the optimal solution by updating COOT within the COA framework. Developing an Improved Bi-GRU classifier in the process of summarizing the Multi-Document Text. This model is enhanced with additional max pooling and convolution layers. These developments reduce sequence length by summarizing local features more effectively.
The structure of this research work includes five main sections, each dedicated to a particular aspect. The relevant existing approaches are reviewed in Section 2. The structure of the IBi-GRU model for summarization is described in Section 3. The IBi-GRU model's experimental analyses are shown in Section 4. The conclusion is in Section 5.
Literature review
A thorough overview of text summarization approaches, derived from the analysis of eight pivotal research papers, is provided in this section.
In 2023, Junqing Fan et al., 2 has introduced the MFMMR-BertSum model for extractive summarization, applying the pre-trained BERT model for the task. The model used an integrated MMR to cut down on redundancy and improve the quality of the summary, and a classification layer to aid with extractive summarization. Its superior efficiency was demonstrated by the fact that it outperformed earlier extractive summarization algorithms on the CNN/DailyMail dataset.
In 2023, Gianluca Moro and Luca Ragazzi et al., 5 has tackled two critical research issues in summarizing lengthy documents, namely long-input processing and document representation, with a single coherent model designed for LRS. The creative model with an emphasis on maximizing the alignment of chunk-target pairs generated from text segmentation, ATHENA was created to train both a segmenter and a summarizer.
In 2022, Minakshi Tomer and Manoj Kumar et al., 10 has developed a firefly algorithm, based on nature-inspired swarm intelligence, for multi-document text summarization. It used an innovative fitness function that included three key features: cohesion factor, topic relation factor, and readability factor. Results were assessed via ROUGE scores and compared with other nature-inspired algorithms, including PSO and GA.
In 2023, Aniqa Dilawari et al., 8 has presented a feature-rich automatic text summarization model aimed at minimizing manual effort and providing rapid summaries through a combination of extractive and abstractive methods. The feature-rich retriever highlighted key sentences, with linguistic features used to improve results. The summarized text was subsequently input into an abstracter that leveraged features such as named part of speech tags, entity tags, and term weights. To tackle inconsistencies between word-level and sentence-level attentions, a loss function was introduced.
In 2020, Jingwei Cheng et al., 11 has employed an ATS model that enhanced the traditional Seq2Seq neural summarization model by incorporating a syntax-augmented encoder and a headline-aware decoder. A dual-memory-cell LSTM network and a headline attention mechanism were added to the decoders, which increased the quality of the summary. Qualitative analysis suggested that the generated summaries were more readable and less redundant, consistent with our hypotheses.
In 2021, Jiawen Jiang et al., 12 has implemented four novel ATS models based on a Seq2Seq architecture through attention-based Bi-LSTM. These models included improvements to enhance the correlation between summaries and source texts, reduce word repetition, manage OOV words, and minimize cumulative errors in created summaries.
In 2023, Ángel Hernández-Castañeda et al., 20 has suggested that a GP could automatically generate heuristic functions for use in the ATS task. This approach then offered an automatically generated objective function made for cluster-based unsupervised methods. The approach outcomes were using two standard collections, and verified that the generated orientation function produced abstracts of good quality.
In 2022, P. Mahalakshmi and N. Sabiyath Fatima 13 has designed a new DL-based information retrieval and text summarization model. First, the Bi-LSTM model was applied to extract textual data by processing the respective word in a sentence, information retrieval, and embedding it into a semantic vector. Then, the DL model was used to create templates. The DBN model was then utilized for summarizing the textual content. Furthermore, descriptions were produced for visualized entities in the images.
In 2023, Yaser M. Wazery et al., 26 has introduced a novel extractive text summarization method that leveraged word embeddings and statistical features from a single document. The respective sentence was encoded via a CNN and an FFNN based on these embeddings and characteristics. The outcomes of the CNN and FFNN were concatenated and then used to classify the sentences with an MLP. The Newsroom dataset was used to evaluate the model, and the outcomes showed how well it captured both statistical and semantic information from documents.
In 2024, Bhukya, V. K., 27 has suggested that the abstractive text summarization has successfully transitioned from linear models to sparse models of nonlinear neural networks. This achievement stems from the use of deep learning models for NLP tasks, which allow these models to model related patterns in data without the need for manually created features. The text summarizing problem was examined using the Text to Text Transfer Transformer (T5) technique, and the findings demonstrated that the Transfer Learning-based model outperformed the Sequence-to-Sequence Recurrent Model in abstractive text summarization.
In 2024, Ülker, M., & Özer 28 has developed the BART-based model was offered as a solution to this issue. It selects key terms from the input document's text to produce a scientific summary. Terms and keywords from the source material are included in the input text. The suggested model is predicated on how graph-based approaches operate. As a result, the suggested model can condense the original document into the fewest possible words that still convey the essential ideas. Table 1 further reviews the studies mentioned, providing a thorough examination of their features and limitations.
Examination of models for text summarization in the existing literature with their features and limitations.
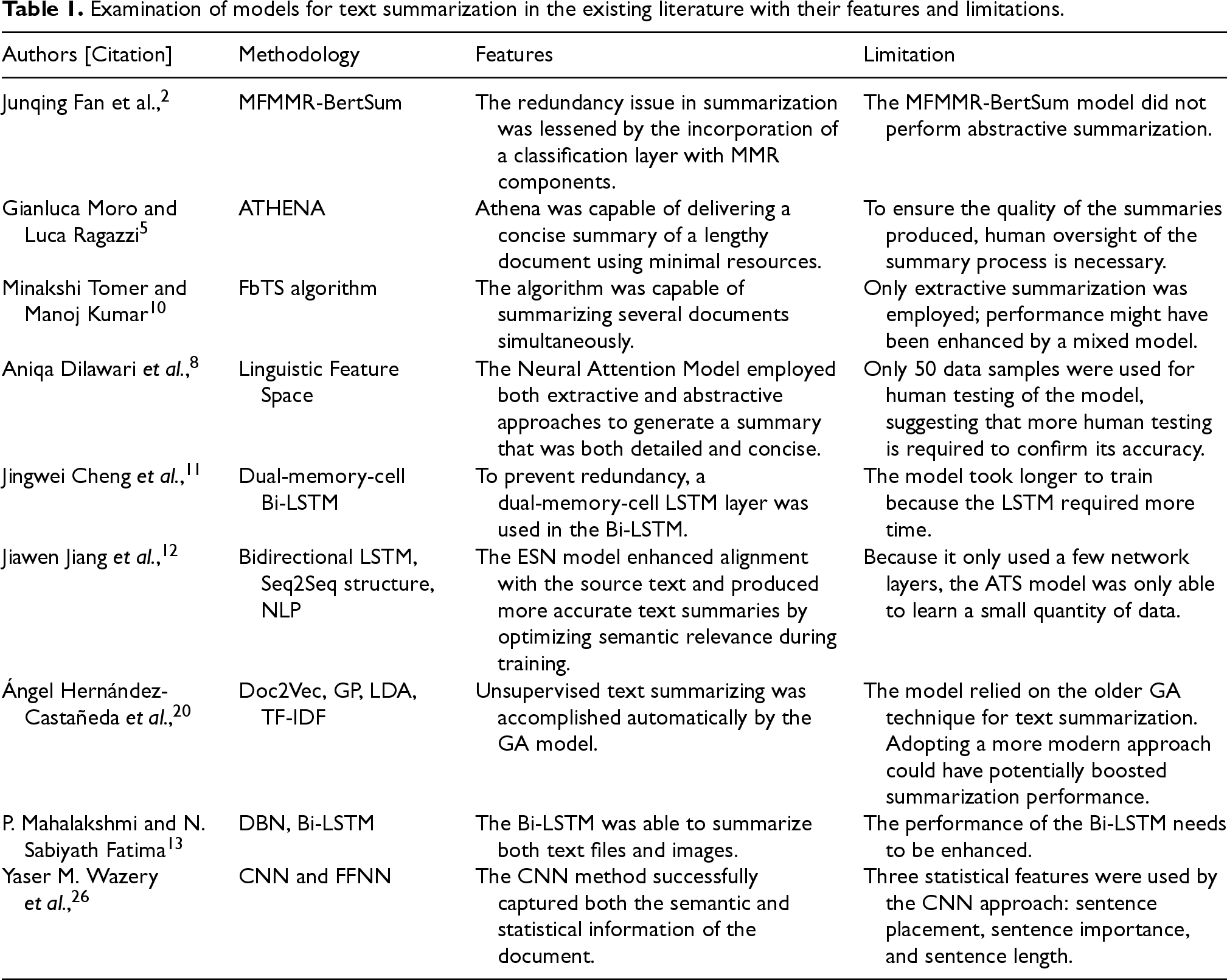
Examination of models for text summarization in the existing literature with their features and limitations.
Despite advancements in text summarization, existing approaches still face challenges in terms of accuracy, efficiency, and robustness. In existing approaches, feature extraction is often carried out using techniques such as TF-IDF 10 and Bi-LSTM. 13 However, these methods can struggle with ambiguity and multiple meanings, impacting their ability to accurately extract features. Notably, ATE-based features have not been fully explored in conventional research. Existing summarization models include MFMMR-BertSum, 2 GRU, 8 and DBN. 13 Although GRU is used in some studies, 8 it is computationally intensive and requires substantial memory, particularly for long sequences. Furthermore, there has been no research on optimization algorithms for tuning the weight parameters of the Bi-GRU model, leading to slow convergence in high-dimensional spaces. To address these limitations, this research introduces a novel DL model for summarizing the multi-document text via the IBi-GRU model.
Proposed IBi-GRU model for multi-document text summarization via CuCOA approach
It involves generating a coherent and concise summary from multiple documents that cover similar topics, aiming to capture the most pertinent information from each source while maintaining the context and ensuring that the summary is not overly repetitive. Traditional methods for text summarization, such as extractive and abstractive techniques, often struggle with issues like redundancy, lack of coherence, and inability to handle diverse document structures effectively. These limitations highlight the need for advanced deep learning (DL) and machine learning (ML) approaches, which employ sophisticated models and algorithms to better understand context, reduce redundancy, and generate more cohesive summaries.
This research presents an IBi-GRU model for summarizing the Multi-Document Text, which performs via three distinct levels: preprocessing, feature extraction, and summarization.
Each of these phases is elaborated upon in the subsequent sections, and a visual diagram of the entire process is shown in Figure 1.
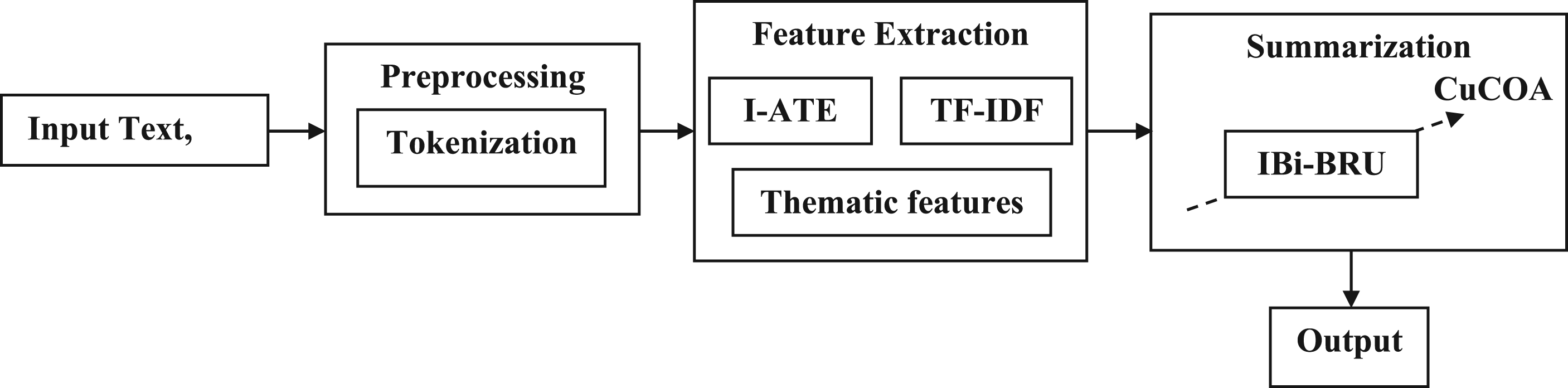
Architecture of the IBi-GRU model for summarizing the multi-document text.
Tokenization
29
is a critical preprocessing phase for text summarization, as it determines the input units that will be fed into the summarization model. Tokenization is the process of dividing the combined text from several documents into smaller units, like words or subwords, for the purpose of multi-document summary. This step is particularly important in languages with rich morphology, where a single word can have many forms due to numerous affixes. For this phase, the input text
Breaking respective sentences into a continuous sequence of tokens denoted as
Feature extraction
Feature extraction in summarization involves identifying and selecting key attributes or elements from the input tokenized text
Improved aspect term extraction
Aspect Term Extraction (ATE) is a method in NLP and text analysis which involves recognizing and retrieving precise terms or phrases that represent particular topics of interest within a collection of documents. These aspects are usually entities, features, or attributes related to the subject matter being summarized. The aspect term extractor begins by classifying each token at the token level.
30
For instance, if 
According to Eq. (1), there are N token categories, and
Conventional ATE can sometimes fail to correctly identify aspect terms due to their multiple meanings. To address this issue, the ATE process has been enhanced using improved similarity techniques to more accurately extract and identify aspect terms.
The procedure steps under the Improved Aspect Term Extraction (I-ATE) for identifying the aspect term are explained below. Eq. (2) expresses the I-ATE equation for aspect term identification.
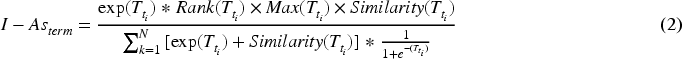
For Eq. (2), the aspect term identification process for the example sentence, “The Lord is my strength and my song; he has become my salvation; glad songs of salvation are in the tents of rejoicing,” is performed by the following four steps:
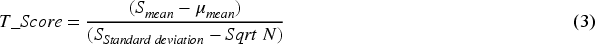
In Eq. (3),
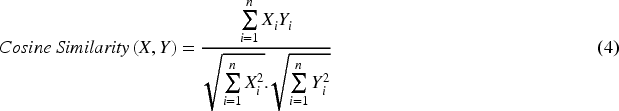
In Eq. (4), the 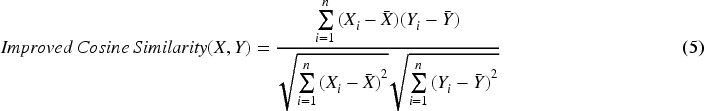
Here, the mean term frequencies of the vectors X and Y are represented by 

Eq. (8) and Eq. (9) estimate the center of the vector by subtracting the mean from each term frequency


Therefore, the final expression for the improved cosine similarity is given in Eq. (10).
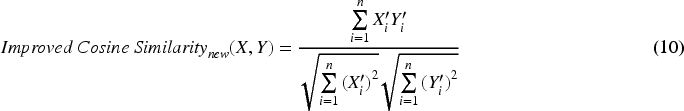
In multi-document text summarization, thematic features are extracted from the tokenized text
TF-IDF-based feature
Term Frequency-Inverse Document Frequency (TF-IDF) is applied to assess the relevance of words across multiple documents. TF-IDF
31
evaluates word importance based on two factors via input tokenized text
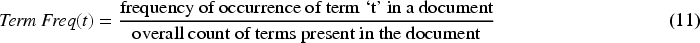
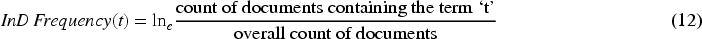
Consequently, the TF-IDF is determined by combining both TF and IDF as signified in Eq. (13).
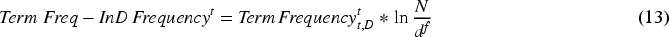
From Eq. (13), the frequency of the term t is indicated as
Multi-document summarization consolidates information from several documents into a unified summary by processing extracted features
Weight optimization in the IBi-GRU model via CuCOA
Weight optimization in the IBi-GRU model is performed by CuCOA optimization. This optimization fine-tunes the IBi-GRU model's weights for better performance. Specifically, the CuCOA combines COA 32 and COOT optimization techniques, with COOT being incorporated into COA. This hybrid approach enhances the accuracy and efficiency of weight adjustments, leading to more effective model training. Our work uses early stopping as a regularization technique to prevent overfitting during model training. The training process is stopped once the validation performance stops improving, avoiding unnecessary computations. This approach helps reduce training time while maintaining model generalization.
CuCOA algorithm

In Eq. (14), the 

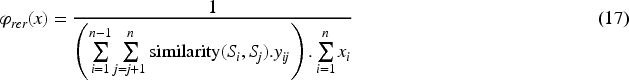
In Eq. (17), the redundancy reduction criterion is signifies as

From Eq. (18), the content coverage criterion is defined by
The population of the CuCOA algorithm is made up of coatis, making it a population-based metaheuristic algorithm. The relative coati's location in the search space, which shows potential values for the decision variables, is a prospective solution. At the start, the coati's locations are randomly initialized in the search space according to Eq. (19).
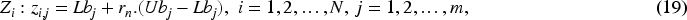
From Eq. (19), 
Evaluating the objective function values of candidate solutions is possible through their placement within decision variables as given in Eq. (14). In CuCOA, candidate solutions are assessed by their objective function values, with the highest value indicating the best solution. As the algorithm iterates and refines the candidate solutions, the member of the population with the highest objective function value is continuously updated to reflect the best solution.
In the CuCOA, the coati's location update (candidate solutions) is guided by modeling the coati's two natural behaviors: (i) their approach to attacking iguanas and (ii) their escape approach from predators. Consequently, the population of the CuCOA undergoes updates in two distinct phases based on these behaviors.
In this phase, when updating the population of the coati, the model imitates their hunting behavior. Coatis simulate climbing trees to scare iguanas, while others stay on the ground to capture the iguana as it descends. This behavior results in Coatis exploring different areas of the search space, showcasing CuCOA's ability to perform extensive global exploration in problem-solving.
In CuCOA, the location of the optimal population member is treated as the iguana's location. As a result, Eq. (21) mathematically represents the locations of the coatis climbing the tree.
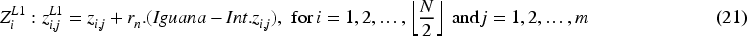
The iguana is dropped at random into the search area if it hits the ground. Coatis on the ground then move according to this random location, with their movement simulated by Equations (22) and (23).
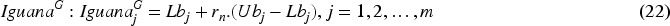
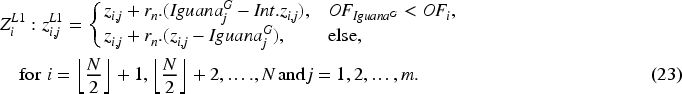
Each coati's new location is accepted and updated if it improves the objective function value; if not, the coati remains in its previous position. The condition for updating 
This phase, updating coati's locations in the search space, is inspired by their behavior when evading predators. When threatened, a coati quickly moves to a safer nearby location, reflecting the CuCOA's strength in refining solutions through local search. This behavior is simulated by generating a random location near each coati's present location, as described by Eq. (25) and (26).
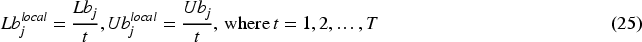
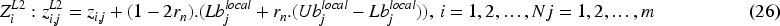
However, the exploitation phase in the COA (Eq. (26)) often struggles with slow convergence, especially in complex or high-dimensional problem spaces. To overcome these issues, CuCOA utilizes the COOT algorithm exploration capabilities. By incorporating diverse optimization approaches from COOT, CuCOA enhances the exploration phase to quickly locate promising areas and improves the refinement process for faster identification of optimal solutions. Consequently, Eq. (27) is derived from the chain movement strategy used in the COOT algorithm.
33
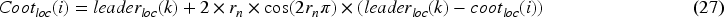
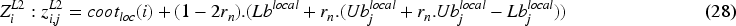
Thus, Eq. (26) is replaced by Eq. (28) in the CuCOA. The random value is computed via the tent map as expressed in Eq. (29). A new location is considered acceptable if it enhances the objective function value, with this condition being estimated via Eq. (30).


After tuning the weights of the IBi-GRU model using the CuCOA approach, the model performs the summarization process by using the features extracted
The improved Bidirectional Gated Recurrent Unit (IBi-GRU) 34 model is a sophisticated architecture designed to improve text summarization by processing input sequences in both forward and backwards directions. This model is better able to collect dependencies from both sides and effectively simulate complicated temporal dynamics by taking into account both past and future contexts at the same time. The input layer, convolution layer, max pooling layer, forward layer, backwards layer, and output layer make up the IBi-GRU structure seen in Figure 2.
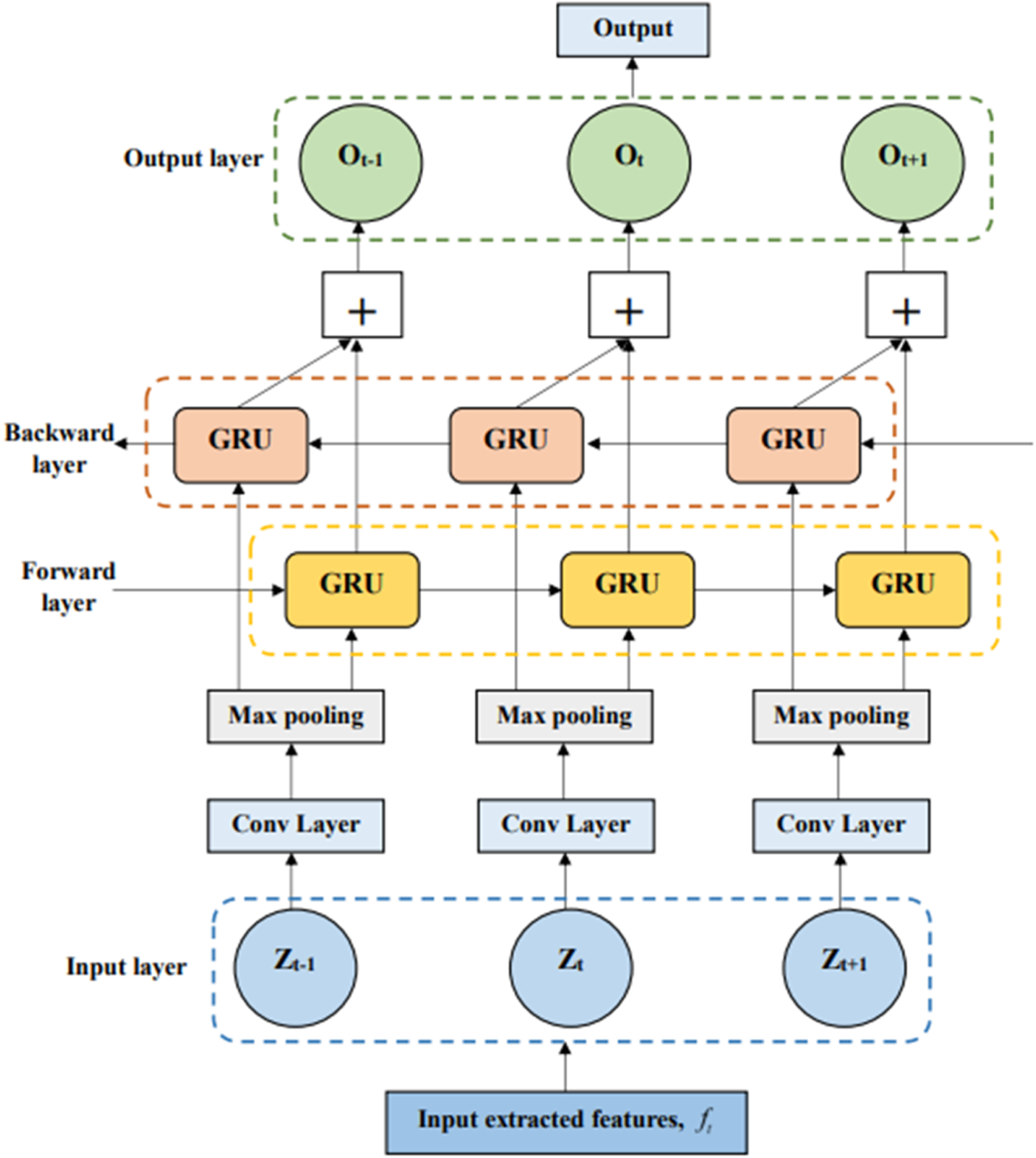
Architecture of the IBi-GRU model.
At each time step t, the forward hidden state, denoted as 
For each time step, the final representation 
Here, the IBi-GRU model is applied to perform nonlinear transformations on the input forward

As a result, the IBi-GRU model summarizes the input text based on the extracted features, with its output represented as
Simulation procedure
Python 3.7 was used to implement the suggested multi-document text summarizing. The simulation was conducted on a machine with an “11th Gen Intel® Core™ i3-1115G4 processor running at 3.00 GHz and 8.00 GB of installed RAM.” Additionally, the multi-document text summarization was evaluated using the DUC 2004 dataset. 35
Dataset description
This repository includes a dataset organized in the Summarization Document Folder, with separate tasks for each data segment. The Reference Folder contains the target summaries for these documents. The dataset used in our analysis comprised 106 data points, classified under the “Headline” category. We used different percentages of training data for the analysis: 60%, 70%, 80%, and 90%. This resulted in 52 testing samples and 64 training samples for a 60% training data split. There were 32 testing samples and 74 training samples, with 70% of the data going toward training. We had 21 testing samples and 85 training samples, where 80% of the data was used for training. There were 95 training samples and 11 testing samples with a 90% training data split.
Example of text summarization
Original text
KUALA LUMPUR Malaysia AP _ US Treasury Secretary Robert Rubin arrived in Malaysia Sunday for a two-day visit to discuss the regional economic situation the US Embassy said Rubin on a tour of Asias economic trouble spots arrived from Beijing where he had accompanied US President Bill Clinton on a visit Rubin was scheduled to meet and have dinner with Finance Minister Anwar Ibrahim on Sunday On Monday Rubin will meet privately with Prime Minister Mahathir Mohamad and separately with senior Malaysian and American business leaders the embassy said in a statement Rubin will leave Monday for Thailand and South Korea.
Bi-GRU
KUALA LUMPUR Malaysia AP _ Treasury Secretary Robert Rubin arrived in Malaysia Sunday for a two-day visit to discuss the power of a civilian government and are said Rubin on a tour of Asian economic trouble spots arrived from Beijing where he had accompanied US President Bill Clinton on a visit Rubin was scheduled to reforming and have dinner with denying him bail as his government for obstructing international cooperation On Monday Rubin will meet privately with Prime Minister Mahathir Mohamad and separately with senior Malaysian and message to the jury has seemed Jimmy Carter in a statement Rubin will leave Monday for land and South Korea
LSTM
KUALA LUMPUR Malaysia AP _ US Treasury Secretary Robert Rubin arrived in Malaysia Sunday for a two-day visit to discuss the regional economic situation the US Embassy said Rubin on a tour of Asias economic trouble spots arrived from Beijing where he had accompanied US President Bill Clinton on a visit Rubin was scheduled to meet and have dinner with Finance Minister Anwar Ibrahim on Sunday On Monday Rubin will meet not worried that the world’ Mahathir Mohamad and separately with senior Malaysian and American business leaders the embassy possible contender for Rubin will leave Monday for Thailand and Sorth.
RNN
KUOLA LUMPUR Malaysia AP _ US Treasury Secretary Robert Rubin arrived in Malaysia Sunday for a two-day visit to discuss the situation of the regional record the US Embassy said Rubin on a tour of ias economic trouble obtaed arrived from companies US President Bill Clinton on a visit Rubin was scheduled to meet and have dinner with Finance Minister Anes tigati onhim on Sunday On Monday Rubin will meet privately with Prime nformation Mahathir Momad and separately with senior Malaysian and American business leaders the embassy said in a statement Rubin will leave Monday for Thfland and South Korea.
GRU
KUALA LUMPUR Malaysia PN _ US Secretary Robert Rubin arrived in predictive Sunday for a two-day visit to discuss the regional economic situation the US Embassy said information on a tour of As economic trouble spots arrived from Beijing where he had accompanied US President Bill reflect on a visit Rubin was playing to meet and have dinner with Finance Minister context Ibrahim on Sunday On Monday Rubin will meet privately with Prime minister Mahathir Mohamad and separately with senior Malaysian and American business leaders the embassy said in a participants Rubin will leave Monday for Thai and Korea.
DBN
KUALA LUMPUR Malaysia AP _ US Treasury Secretary Robert quality arrived in Malaysia Sunday for a two-day visit to discuss the regional directly crucial the US Embassy said Rubin on a prioritize of As economic trouble spots organizing from Beijing where he meaningful accompanied US President Bill Clinton on a visit Rubin was scheduled to meet and accurate dinner management Finance Minister Anwar Ibrahim on Sun day On day Rubin meet privately with Prime Minister Mahathir Mohamad and separately with senior Malaysian and American business consuming the embassy said in a statement Rubin will leave for essential and South Korea.
CNN + FFNN
KUALA LUMPUR Malaysia APP _ US Treasury Secretary Robert Ru bin arrived in Malaysia Sunday for a two-day visit to discuss regional economic practices the US Embassy said that Rubin on a tour of Asias economic trouble spots comprehensive from Beijing informed he had accompanied US President Bill matter on a visit Rubin was scheduled to meet and have dinner with Finance Minister Anwar Ibrahim on Sunday On Monday Rubin will serves privately already Prime Minir separately with senior Malaysian and American business leaders the embassy said in a statement Rubin will leave Monday for Thailand and South Korea.
IBi-GRU
KUALA LUMPUR Malaysia AP _ US Treasury Secretary Ro bert Rubin arrived in Malaysia Sun for a two-day visit to discuss the regional economic situation the US Embassy said Rubin on a tour of Asias economic trouble spots arrived from Beijing where he had US President Bill Clinton on a visit Rubin was scheduled to meet have dinner with Finance Minister Anwar Ibrahim on Sunday On Monday Rubin will meet privately with Prime Minister Mahathir Mohamad and separately senior Malaysian and American business leaders that embassy said in the statement Rubin will be leave Monday for Thailand and South Korea.
Performance analysis
To thoroughly assess the CuCOA + IBi-GRU method, an in-depth evaluation was conducted comparing it with traditional strategies for multi-document text summarization. The evaluation made use of a wide range of metrics, such as F-measure, Precision, Rouge, and Recall. Statistical comparisons, convergence analysis, and ablation experiments were also included in the analysis. In comparison to AOA, BMO, BOA, COA, and COOT, the CuCOA approach was assessed. Additionally, the performance of the IBi-GRU scheme was compared with state-of-the-art methods such as DBN 13 and CNN + FFNN, 26 alongside traditional classifiers like Bi-GRU, LSTM, RNN, and GRU. The DUC 2004 dataset was used to gauge the performance of both the CuCOA + IBi-GRU method and traditional methodologies in multi-document text summarization.
Comparative analysis on f-measure and precision
To evaluate the effectiveness of CuCOA strategy for multi-document text summarization, of existing models like AOA, BMO, BOA, COA, and COOT. This comparison is illustrated in Figures 3(a) and 3(b), which display the F-measure and Precision metrics for each method. The CuCOA strategy regularly outperforms alternative methods on a variety of training data when assessed by the F-measure, which strikes a compromise between precision and recall. For example, the CuCOA achieves an F-measure of 0.745 with 60% training data, outperforming the AOA (0.685), BMO (0.695), BOA (0.518), COA (0.534), and COOT (0.575). The CuCOA approach continues to perform exceptionally well with increasing training data, achieving a remarkable F-measure of 0.915 at 90%, whereas COOT achieves 0.825, and other methods fall short.
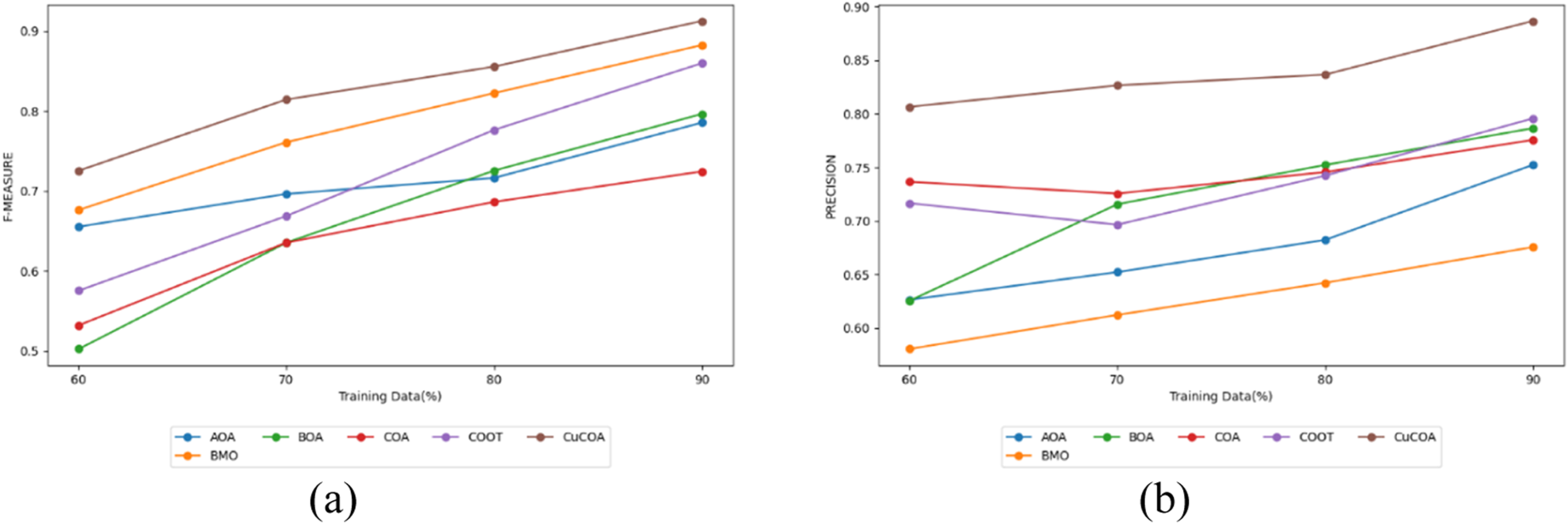
Evaluation on CuCOA and traditional approaches a) F-measure and b) Precision.
The CuCOA achieves the highest Precision score of 0.896 of the analyzed techniques at 90% of the training data. This score significantly surpasses that of COOT (0.776), BOA (0.763), COA (0.751), BMO (0.652), and AOA (0.736). The elevated Precision indicates that the CuCOA approach is particularly effective at generating highly accurate and relevant summaries, demonstrating a superior ability to focus on the most pertinent information in the text. Hence, the CuCOA model significantly outperforms conventional methods in both F-measure and Precision. These improvements are ascribed to the integration of I-ATE, IBi-GRU, and the hybrid optimization algorithm, which collectively augment the model's performance by effectively capturing relevant content and optimizing summarization quality.
Figures 4(a) and 4(b) present a detailed comparison of the CuCOA model with established models like AOA, BMO, BOA, COA, and COOT, focusing on Recall and ROUGE metrics. Maximizing Recall and ROUGE scores is crucial for effective summarization, as these metrics assess the model's ability to retrieve relevant information and produce comprehensive summaries. This outperforms AOA with a Recall of 0.663, BMO at 0.685, BOA at 0.658, COA at 0.776, and COOT at 0.725. The advantage of the CuCOA model becomes even more pronounced with 90% of the training data. Here, it achieves a Recall score of 0.859, compared to AOA's 0.671, BMO's 0.689, BOA's 0.738, COA's 0.794, and COOT's 0.764. This consistent superior performance underscores the CuCOA model's effectiveness in capturing and retaining relevant information across varying data sizes, thus providing more comprehensive summaries.
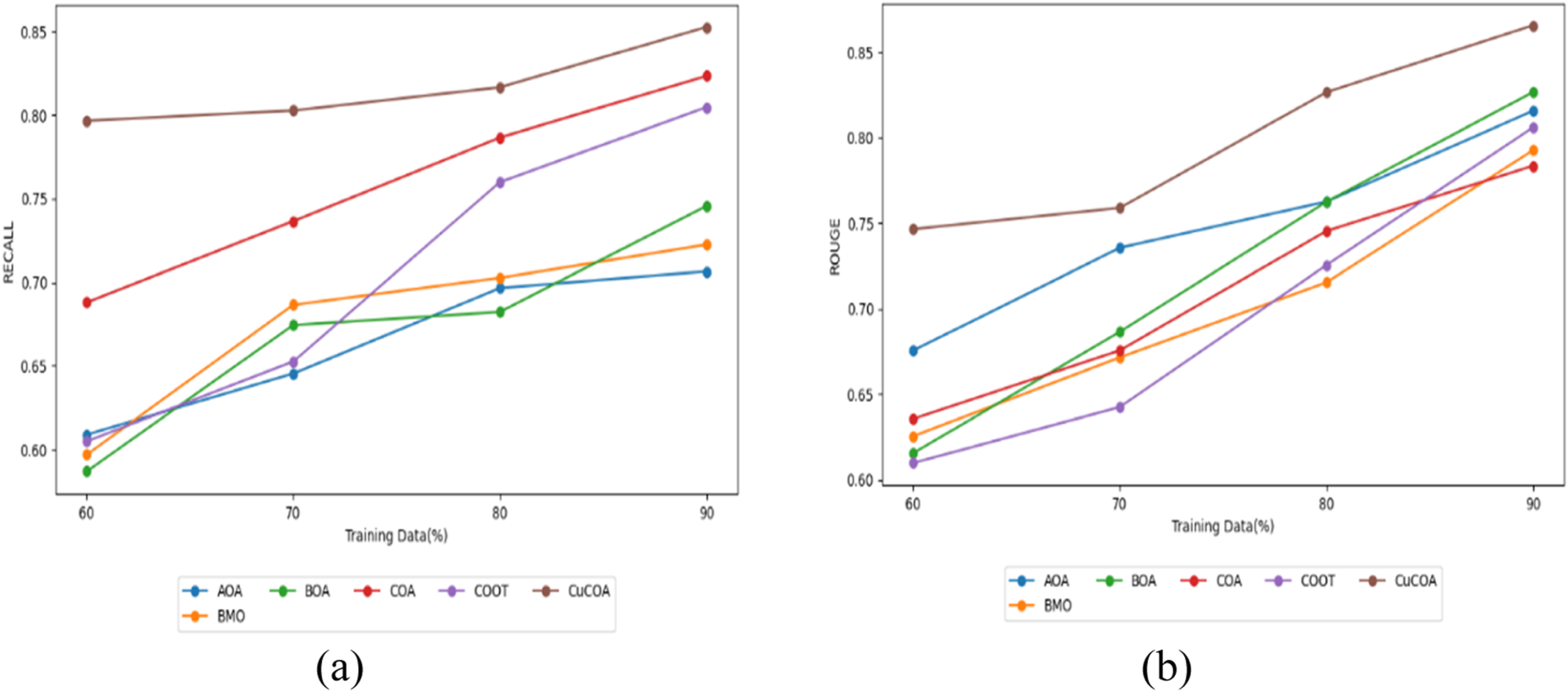
Evaluation on CuCOA and traditional approaches a) Recall and b) Rouge.
The CuCOA model outperforms AOA (0.674), BMO (0.634), BOA (0.627), COA (0.647), and COOT (0.615) with a ROUGE score of 0.748 with 60% training data. This advantage continues with increasing training data: at 70%, the CuCOA method's ROUGE score is 0.751, and at 80%, it reaches 0.836. By 90% of the training data, the CuCOA model attains a ROUGE score of 0.865, surpassing COOT (0.768) and other methods. This consistently high ROUGE score underscores the CuCOA model's effectiveness in producing more accurate and comprehensive summaries. Thus, the CuCOA model achieves superior Recall and ROUGE scores compared to traditional strategies. The key reason for this improvement is the combination of I-ATE, IBi-GRU, and a hybrid optimization method, which together improve the model's capacity to extract and include pertinent data and generate summaries that closely resemble the reference summaries. These advanced techniques contribute to the CuCOA model's effectiveness in delivering comprehensive and relevant multi-document text summarizations.
Figure 5 compares the CuCOA model with conventional multi-document summarization methods, contrasting its performance with AOA, BMO, BOA, COA, and COOT. Achieving effective multi-document text summarization requires the model to minimize cost ratings and converge more rapidly. At the beginning, both CuCOA and conventional methods have elevated cost ratings, but as iterations proceed, a general decline in cost values is noted for all models. Significantly, the CuCOA approach delivers lower cost ratings than conventional methods, underscoring its enhanced efficiency in attaining optimal performance. At the 25th iteration, the CuCOA achieves the least cost value of 1.0204, indicating its superior performance in comparison to other methods. Specifically, AOA records a cost value of 1.0207, BMO reaches 1.0214, BOA obtains 1.0208, COA has a higher cost of 1.206, and COOT achieves a cost value of 1.0209. These results highlight the CuCOA model's ability to converge more effectively to a minimized cost, outperforming the conventional methods in terms of optimization efficiency.
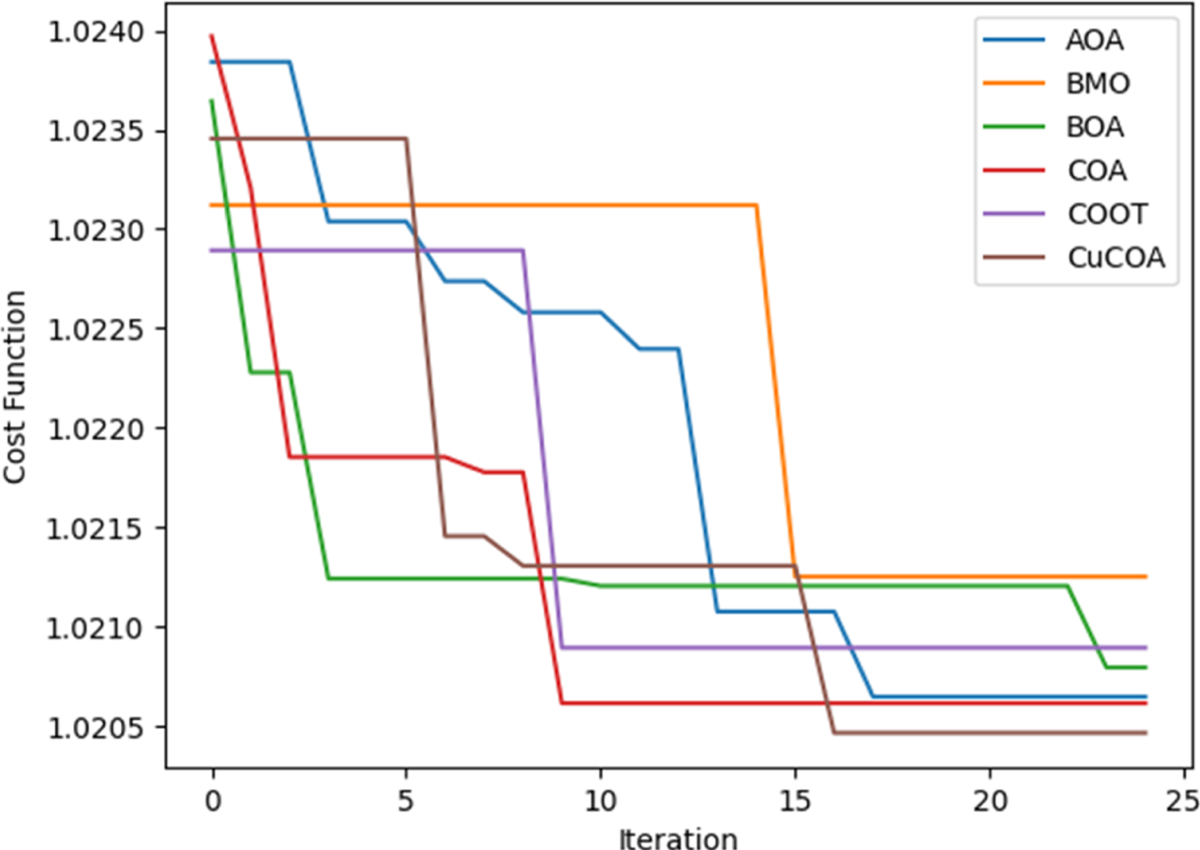
Convergence analysis on CuCOA and conventional methods.
Table 2 provides a detailed statistical evaluation of the CuCOA strategy in comparison to established methods: AOA, BMO, BOA, COA, and COOT, for Multi-Document Text Summarization. For the CuCOA model, the lowest fitness is 1.0205, which is the lowest among all compared methods. This means that the CuCOA strategy consistently achieves the smallest fitness value, outperforming AOA (1.0206), BMO (1.0213), BOA (1.0208), COA (1.0206), and COOT (1.0209). In the median statistic metric, the CuCOA model has a fitness value of 1.0213. This is slightly better than AOA, which has a fitness rate of 1.0224, and BMO at 1.0231. It is also comparable to BOA (1.0212) and close to COA (1.0206) and COOT (1.0209).
Statistical evaluation on fitness.

Statistical evaluation on fitness.
Table 3 illustrates a comparative analysis of the IBi-GRU scheme against conventional classifiers, including Bi-GRU, LSTM, RNN, GRU, DBN, 13 BART, T5 and CNN + FFNN, 26 for Multi-Document Text Summarization. The F-measure for the IBi-GRU model is notably high at 0.913, outperforming all conventional classifiers. TIn comparison, Bi-GRU, LSTM, RNN, GRU, DBN, 13 BART, 28 T5 27 and CNN + FFNN 26 have lower F-measure scores of 0.886, 0.880, 0.876, 0.857, 0.826, 0.866, 0.892 and 0.862, respectively. The Precision metric for the IBi-GRU model is 0.887, the highest among the evaluated classifiers. This indicates that the IBi-GRU model excels in delivering summaries with a high proportion of relevant and accurate content. In comparison, Bi-GRU has a Precision of 0.800, LSTM scores 0.776, RNN also records 0.776, and GRU achieves 0.756, while DBN 13 and CNN + FFNN 26 have Precision values of 0.829 and 0.859, respectively.
Comparative study on IBi-GRU and conventional classifiers.
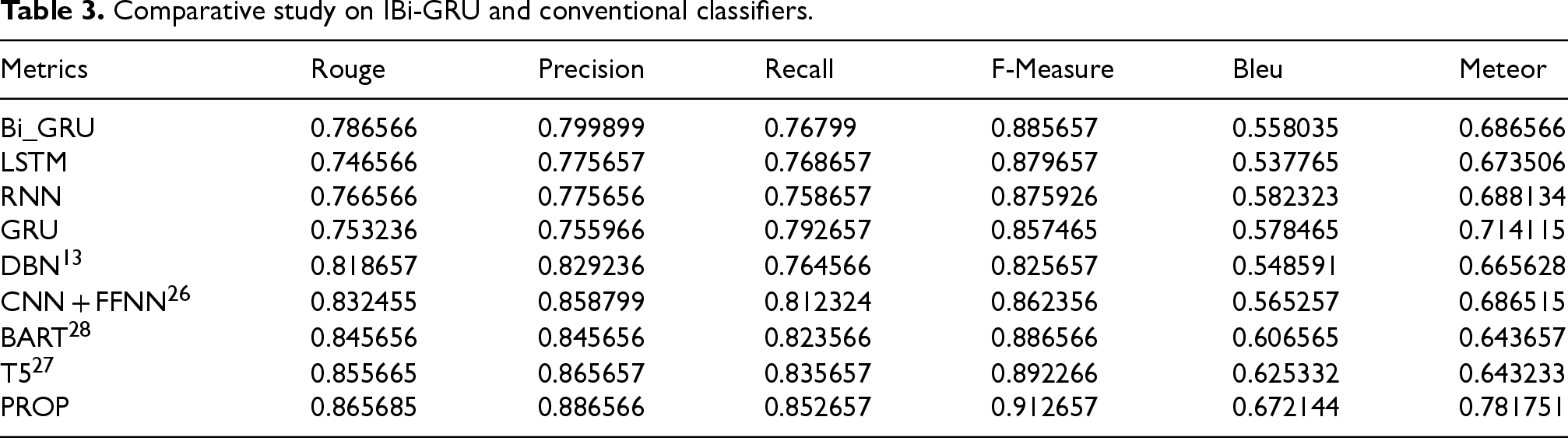
Comparative study on IBi-GRU and conventional classifiers.
Table 4 presents the results of an ablation study for multi-document text summarization, comparing the CuCOA + IBi-GRU model with three variations: a model without features, a model incorporating conventional aspects, and a model lacking optimization. In Table 4, the CuCOA + IBi-GRU model realizes the maximum Recall score of 0.853. This specifies that it is the most effective at retrieving all relevant information compared to the other models. The Model without Features scores lower at 0.754, the Model with Conventional Aspect has a Recall of 0.764, and the Model without Optimization attains 0.826. The ROUGE metric for the CuCOA + IBi-GRU model is 0.866, the highest among the evaluated configurations. In contrast, the model without features scores 0.818, the model with conventional aspects scores 0.834, and the model without optimization reaches 0.836.
Ablation evaluation on CuCOA + IBi-GRU strategy.

Ablation evaluation on CuCOA + IBi-GRU strategy.
Scalability refers to the ability of the proposed Improved Bi-GRU (IBi-GRU) model and its associated optimization methods (such as CuCOA) to maintain or improve its performance as the size of the dataset increases. Table 5 presents a comparison of different models like Bi-GRU, LSTM, RNN, GRU, DBN, CNN + FFNN, BART, 28 T5 27 and IBi-GRU across various evaluation metrics (Rouge, Precision, Recall, F-Measure, Bleu, and Meteor) for data sizes of 500, 1000, and 1500. As the data size increases, IBi-GRU shows stable performance, maintaining superior results even with larger datasets, though the performance slightly decreases with larger data sizes, which is observed across all models. For instance, while IBi-GRU achieves a Rouge score of 0.855685 for a dataset of 500, it drops to 0.801259 for 1500, indicating some decrease in performance as data size increases. Although IBi-GRU still performs better than other models, indicating its robustness, the table offers no information on how well this method scales for bigger datasets or real-time summarizing tasks.
Scalability analysis on variation of data.
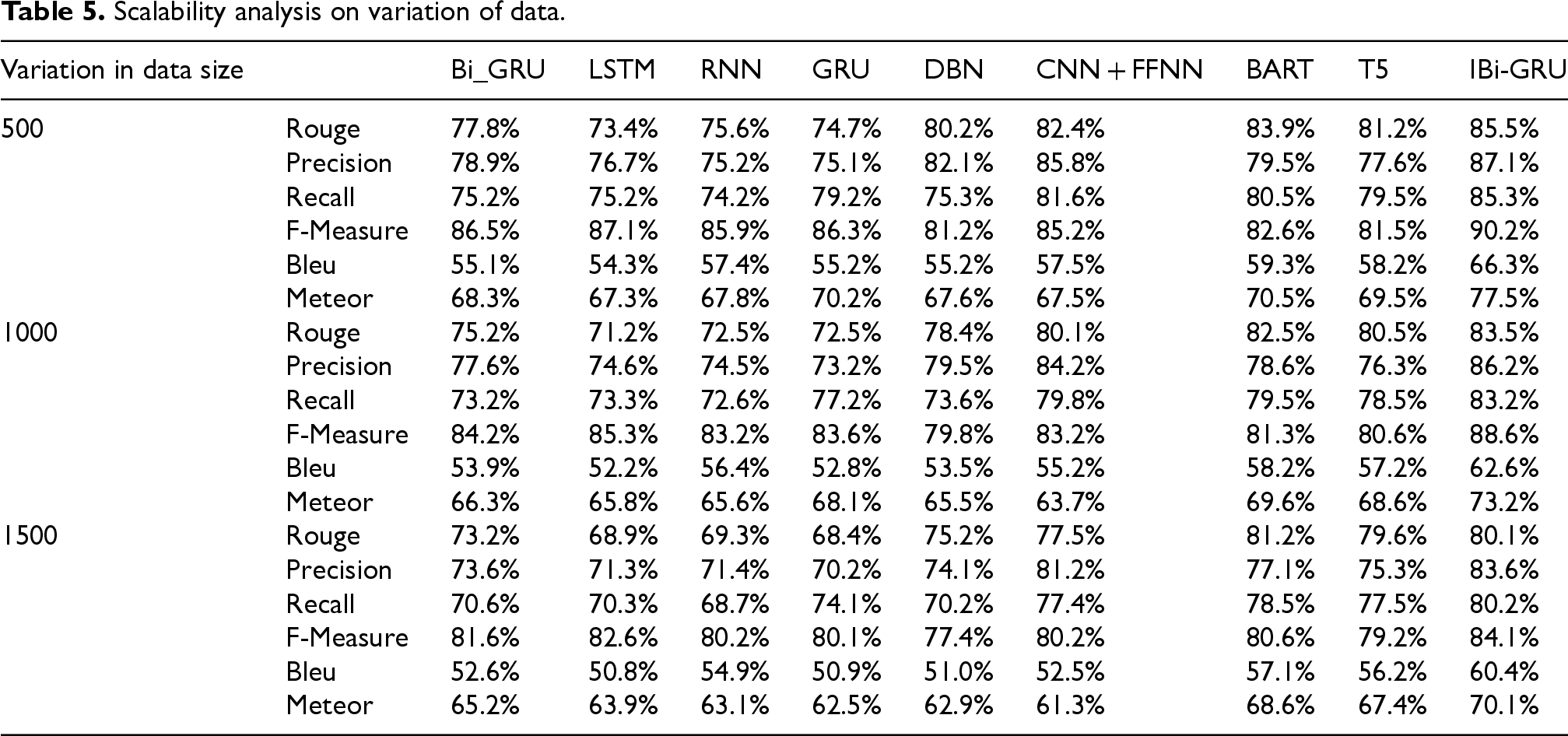
Scalability analysis on variation of data.
In text summarization or document comparison, cosine similarity is often used to measure how close a generated summary is to a reference or human-generated summary. Table 6 presents the cosine similarity scores of various models of the proposed method. The IBi-GRU model stands out with the greatest cosine similarity score of 0.954665, indicating that it provides the most accurate and relevant summaries compared to other models. Additionally, the LSTM model, while performing well with a score of 0.922999, is slightly less effective than the IBi-GRU. Other models such as GRU (0.893454), RNN (0.878385), BART (0.916566), T5 (0.935656) and CNN + FFNN (0.893086) also perform reasonably well, but still fall behind the IBi-GRU. The DBN model scores the lowest at 0.854669, suggesting that it is less effective at capturing the relevant aspects of the input documents for summarization. Overall, the IBi-GRU model outperforms all other approaches, demonstrating its superior ability in generating coherent and relevant summaries based on cosine similarity.
Cosine similarity analysis.

Cosine similarity analysis.
Table 7 illustrates the comparative analysis of the computational efficiency of the IBi-GRU model when paired with different optimization algorithms. Among the various combinations, the CuCOA + IBi-GRU method demonstrates the fastest execution time at 48.656 s, outperforming all other optimization methods. The next fastest are BOA + IBi-GRU at 51.565 s and AOA + IBi-GRU at 52.355 s, indicating that these methods are relatively close in performance. On the other hand, the BMO + IBi-GRU and COA + IBi-GRU combinations take 55.565 s and 56.656 s, respectively, showing slightly longer processing times. At 58.566 s, the COOT + IBi-GRU technique takes the longest, indicating that although COOT enhances optimization, it does so at the expense of longer computation times. Overall, the CuCOA optimization is the most computationally efficient, providing faster processing times for the IBi-GRU model.
Computational time analysis of IBi-GRU model with CuCOA optimization.

Computational time analysis of IBi-GRU model with CuCOA optimization.
Evaluating summary quality from a human perspective is essential to reflect the readability, clarity, or informativeness of the generated summaries. 36 To provide a more comprehensive assessment, four key dimensions are considered: coherence, which measures the logical flow and structure of information; consistency, which evaluates whether the summary remains faithful to the source content without contradictions; fluency, which reflects grammatical correctness and natural language usage; and relevance, which assesses how well the summary captures the most important and meaningful content from the original documents.
The proposed IBi-GRU model optimized with CuCOA is evaluated from a human-centric perspective focusing on coherence, consistency, fluency, and relevance as described in Table 8. The proposed text summarization model achieved high scores across these dimensions, demonstrating its ability to generate summaries that are not only accurate but also readable and logically structured. For coherence, the model attained a F-Measure of 0.865 and a Rouge score of 0.836, indicating strong logical flow within the summaries. In terms of consistency, the F-Measure reached 0.851, with Rouge and Precision both at 0.828, reflecting the model's effectiveness in maintaining a stable narrative. Fluency results were also promising, with a high F-Measure of 0.886 and a Meteor score of 0.747, showing that the summaries are grammatically sound and natural to read. For relevance, the model achieved a F-Measure of 0.876 and a Meteor score of 0.753, though the slightly lower Recall of 0.797 suggests a potential area for improvement in fully capturing all key content. Therefore, these results confirm that the proposed approach performs well from a human evaluation standpoint, ensuring that the generated summaries are coherent, consistent, fluent, and relevant.
Summary quality analysis for proposed IBi-GRU with CuCOA based text summarization model from human perspective.
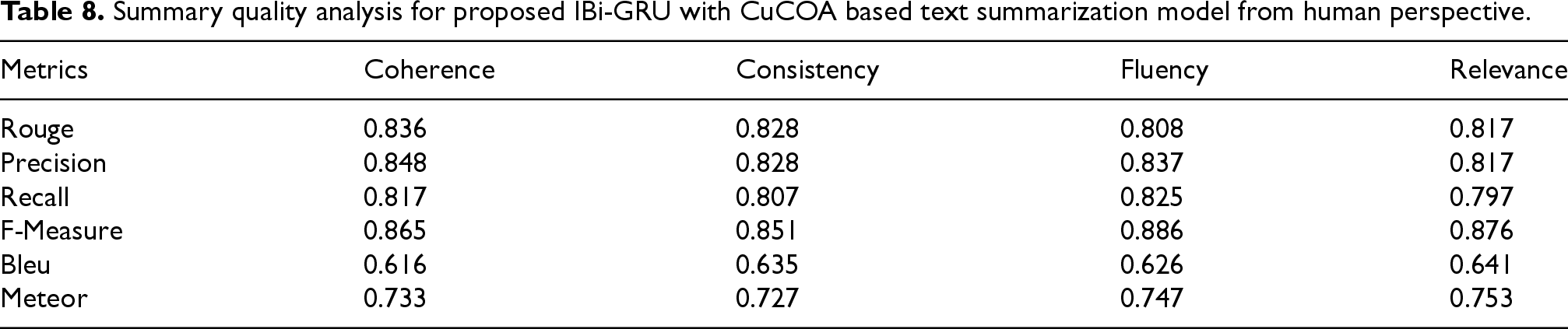
Summary quality analysis for proposed IBi-GRU with CuCOA based text summarization model from human perspective.
The proposed IBi-GRU model optimized with CuCOA offers significant potential in various real-world applications requiring accurate and efficient text summarization. In live news environments, the model can rapidly generate concise summaries from multiple articles or real-time feeds, allowing users to stay informed without reading full reports. In social media monitoring, it can help organizations track and summarize large volumes of user-generated content to identify trends, sentiments, or emerging issues quickly. For legal and academic fields, the model can assist in condensing lengthy documents, case files, or research papers into digestible summaries. In customer support, it can enhance chatbot responses by summarizing previous interactions or relevant documentation. Additionally, the method can be integrated into content recommendation systems to provide preview snippets. Thus, the proposed model relatively has fast processing time makes it suitable for real-time applications.
Conclusion
This research presented an IBi-GRU model for summarizing the multi-document text through the CuCOA approach. The research followed an efficient process that included data preprocessing, feature extraction, and summarization. The input text performed tokenization during the preprocessing stage. I-ATE, thematic, and TF-IDF features were among the pertinent features that were recovered from the preprocessed text during the feature extraction step. The IBi-GRU model was then used to summarize the multi-document text using these properties. The weight parameters of the IBi-GRU model were optimally tuned using the CuCOA approach. The proposed IBi-GRU model was validated through an in-depth analysis involving both simulation and experimental evaluations. At 60% training data, the CuCOA obtained a ROUGE score of 0.748, outpacing AOA (0.674), BMO (0.634), BOA (0.627), COA (0.647), and COOT (0.615). In real-time applications, such as news article summarization, real-time social media monitoring, or real-time customer support, speed is of paramount importance. In these scenarios, summaries need to be generated quickly to ensure timely information delivery. The CuCOA optimization process, while effective in improving the quality of summaries, could face challenges due to its computational intensity, potentially delaying the output and reducing the timeliness of the information provided. Therefore, for these time-sensitive applications, optimization techniques that balance speed and accuracy are essential to meet real-time demands. Future work includes exploring optimization techniques such as model pruning and knowledge distillation to reduce inference time. Incorporating approximate optimization methods can enhance efficiency in real-time applications. Adaptive summarization strategies may also improve scalability across diverse document sets.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.