
Abstract
With the popularity of social media, personalized recommendation services have become increasingly important. However, traditional collaborative filtering recommendation algorithms face many challenges when dealing with social media data. To improve the accuracy and efficiency of recommendation, this paper presents a collaborative filtering recommendation service in view of social media gene map. This study creates a social media genetic map by analyzing social media data and extracting user interests and behavioral characteristics. On this basis, a collaborative filtering recommendation model is constructed that takes into account the social network, content and historical behavior of users. In the performance testing of recommendation models, the research methods were compared with collaborative filtering algorithms based on alternating least squares, collaborative filtering algorithms based on generative game neural networks, and singular value decomposition algorithms. In model training, the model constructed in this study was superior to the other three types of algorithms in convergence speed and maximum accuracy. In the recommendation testing of three resources, the constructed recommendation model showed the best performance. Through experimental verification, the method has shown excellent outcomes in terms of recommendation accuracy and timeliness, providing an effective solution for social media recommendation services.
Introduction
As the boost of the Internet, social media (SM) is essential for people's daily lives. The large amount of information generated and exchanged by users on SM provides rich data resources for personalized recommendation services.1,2 However, due to the diversity and dynamism of user interests, as well as the vast and complex nature of SM data, providing accurate and timely recommendations to users has become increasingly challenging.3, 4 Therefore, studying how to use SM data to improve the effectiveness and efficiency of recommendation services has become a hot topic in both academia and industry.5, 6 In view of this background, a personalized information recommendation system is developed. Personalized information recommendation services have been widely studied and applied in recent years due to their targeting, proactivity, and flexibility. For example, JD and Taobao e-commerce platforms, short video software such as Tiktok and Kuaishou, and music platforms such as NetEase Cloud music and Kugou Music are widely used. On the one hand, the personalized recommendation system can actively provide users with targeted information and services that can meet the needs of users, thus saving a lot of time and energy for users to search for information. Conversely, the system enhances the user-service information interaction ability with regard to the service content. This can be achieved without any waste of resources and can improve the user experience, thus enhancing user stickiness and ultimately leading to profits. However, most of the existing recommendation methods carry out information recommendation based on the similarity of users, labels or items. When the data scale is large, the accuracy of recommendation will be greatly reduced due to the single calculation method. Traditional collaborative filtering (CF) algorithms do not take into account the time factor, and often cannot timely change recommended items when user interests change, resulting in low timeliness. Therefore, this paper proposes a CF algorithm based on SM gene map (GM). This algorithm integrates project similarity, rating similarity, and semantic similarity together, and introduces weighted Slope 1 to obtain the predicted score of users for project services, thereby achieving more accurate user content comprehensive information recommendation services.
The innovations of the study and its contributions lie in two aspects. First, compared with the traditional CF, the proposed method improves the accuracy and personalization of the recommendation system by integrating richer user behavior data and social network structure. The algorithm not only analyzes the user's historical interaction data, but also considers the user's location and connection patterns in the social network, which are often ignored by traditional methods. Second, although graph neural networks have been shown to perform well in processing graph-structured data, they tend to require a lot of computational resources in practical applications and are very sensitive to the adjustment of parameters. In contrast, the algorithm proposed in this study pays more attention to the computational efficiency and stability of the algorithm while ensuring the recommendation quality, making it more suitable for use in resource-constrained environments.
This study mainly has five parts. Part 1 is an overall overview of the research. Part 2 is a summary of relevant literature at home and abroad. Part 3 is separated into two sections. The first section introduces the construction of SM GM and user recommendation services. The second section constructs a CF model in view of SM GM. Part 4 verifies the presented model. Part 5 is a summary of this study and prospects for future research. This study aims to provide a new approach and method for SM recommendation services to more effectively meet the personalized needs of users, and also provide valuable references for research in related fields. The abbreviations and their full names in this study are shown in Table 1.
A collection of abbreviations used in this study.
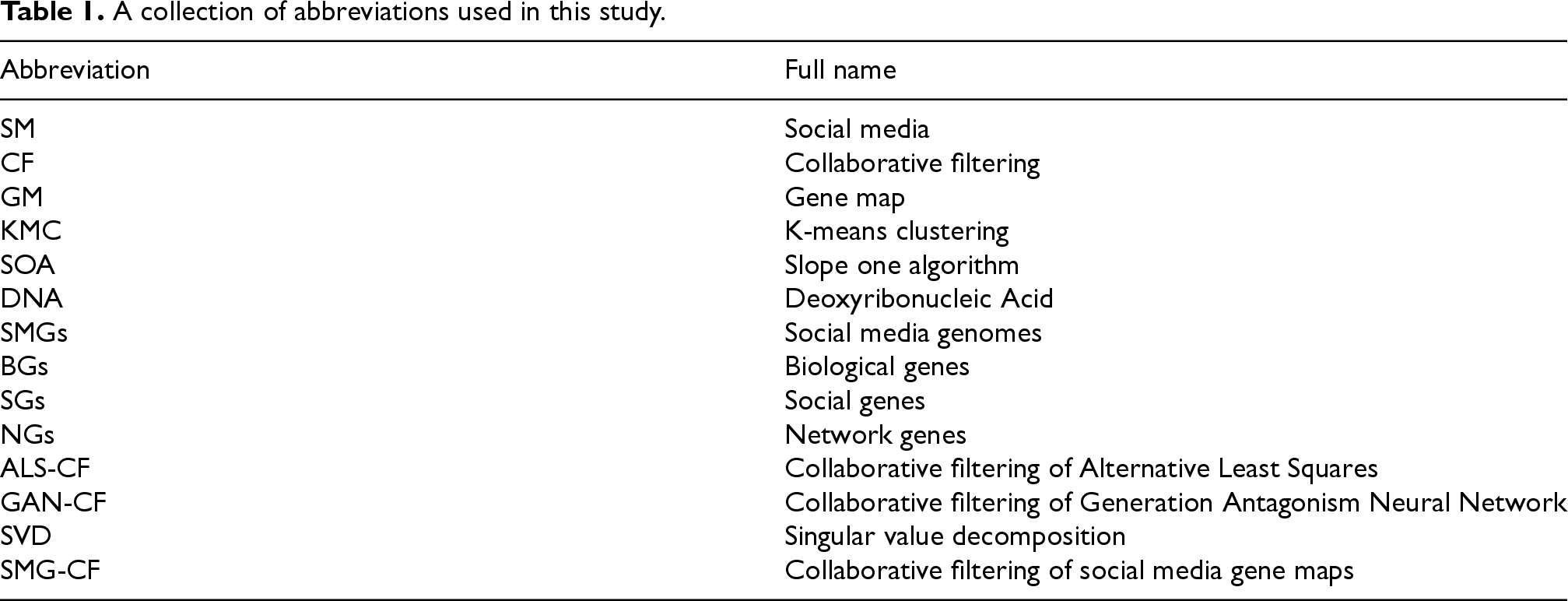
A collection of abbreviations used in this study.
As people's personalized needs increase, how to improve the recommendation effectiveness of recommendation services has become the research object of many scholars. Sun et al. found that in social networks, there are significant differences in user preference information, and various factors in each type of information also have different amounts of information about user annotation behavior. To address this issue, researchers have proposed a deep neural network for label recommendation. The effectiveness and superiority of this model have been verified through experiments. 7 Peng et al. found that existing software crowdsourcing recommendation mechanisms do not take consideration into the contextual information. Therefore, researchers have proposed a new framework for worker ability correction and short-term attention network recommendation. The experiment indicated that this framework could markedly enhance the crowdsourcing recommendations. 8 Zhang et al. found that it is hard for achieving excellent retrieval results with text labels. Therefore, researchers have proposed a new method in view of image processing for tourist attraction location recognition and personalized recommendation. The accuracy and effectiveness of the algorithm and model have been verified through experiments. 9 Lv et al. proposed an interpretable recommendation model in view of extreme gradient lifting trees. This method could provide reference reasons, ultimately achieving the goal of ensuring recommendation quality. This recommendation method could help users comprehend well the logic of system recommendations and increase their trust. 10
In the existing recommendation services, the CF algorithm can make personalized recommendations in view of user behavior and preferences, and does not rely on the content information of items. This makes it more suitable for sparse data and cold start problems, which has attracted a lot of attention from scholars. Liu et al. believed that the manufacturing service industry typically operated in the form of composite services, and existing personalized recommendation technologies based on web services were difficult to play a role. Therefore, they proposed a new hybrid algorithm, which is a CF algorithm in view of clustering to quantify customer preferences. A new hybrid algorithm was formed by combining other algorithms, and its effectiveness was verified through experiments. 11 Tripathi et al. proposed a new method and algorithm for k-means clustering (KMC) to address clustering quality issues. KMC algorithm is a commonly used partition clustering algorithm in CF recommendation system. Researchers used singular value decomposition to solve the initialization problem of k-means, and then refined it. The experiment indicated that this method helped to improve clustering quality. 12 Almu et al. believed that the CF recommendation technology currently applied to various similarity measures would take a long time to make predictions. Researchers conducted experimental evaluations on four similarity measures for the same dataset using programming languages. The final experimental results showed that the Taxicab geometry similarity measure had high efficiency in the application process. 13 Badis et al. found that as the lack of a central server with a complete network view, social network functionality was difficult to fully utilize some of its advanced features. Therefore, researchers used CF for recommending content in social networks. This method supported privacy protection and addressed relevant cold start issues, indicating that this method was effective. 14
In summary, CF recommendation services have undergone extensive research and optimization, with personalized recommendation being a key direction. 15 However, it is found that SM recommendation services do not achieve ideal results due to their complex and multidimensional data. Therefore, this paper constructs a CF recommendation model for SM GM, starting from the essential characteristics of SM, exploring more accurate and effective recommendation methods to help meet the personalized needs of SM users.
CF recommendation service in view of SM GM
In the era of big data, personalized recommendation technology is crucial for connecting users with high-quality content, so this study explores a new model of CF recommendation system, i.e., a recommendation model based on SM GM. The design of this model is mainly divided into two parts, which are “3.1 Construction of SM GM and User Recommendation” and “3.2 CF Recommendation Model in view of SM GM”. The design and implementation of the whole recommendation model can be divided into five parts: data preprocessing, user feature extraction, similarity calculation and nearest neighbor selection, recommendation list generation, and privacy protection.
In the data preprocessing stage, basic user information and social interaction data, such as liking, commenting, and retweeting behaviors, are collected through SM APIs and web crawling techniques. Then, text cleaning methods are used to remove noisy data, including removing useless characters and error messages, to ensure data quality. In the user feature extraction stage, multi-dimensional information such as biological features (gender, age), social features (friend network, participation groups) and online behavioral features (posting frequency, content preference) are first extracted based on the user's behavioral data to construct a SM GM. Secondly, the extracted features are encoded and processed for subsequent similarity calculation and recommendation algorithm application. In the similarity calculation and nearest neighbor selection stage, an improved weighted slope one algorithm (SOA) is designed, and then the similarity between items is calculated based on user ratings and SM behavior data using content analysis and CF techniques. The final designed recommendation algorithm is implemented in the recommendation list generation phase and the performance of the algorithm is tested. Finally, in terms of privacy protection measures, data security in storage and transmission is mainly protected by data anonymization process and data encrypted storage and transmission. Through the above steps, this study aims to implement a CF recommendation system that can effectively utilize SM data while taking into account the privacy and security of the users. This approach based on SMG provides a novel personalized recommendation service strategy by deeply analyzing the social networks and behavioral patterns of the users.
Construction of SM GM and user recommendation
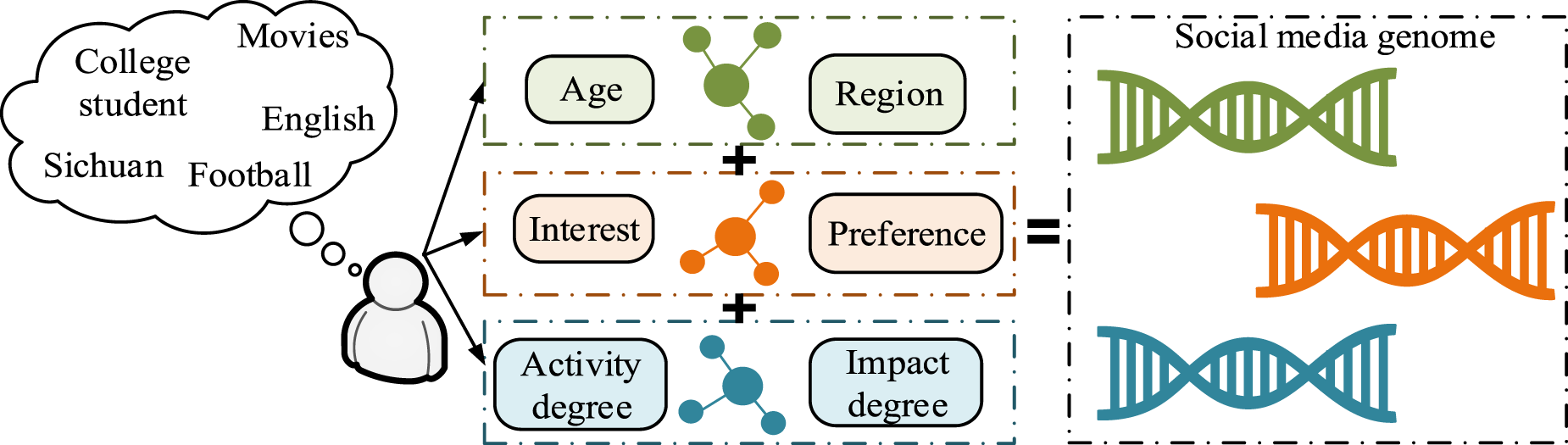
The “SM genetic map” is a novel concept that establishes a connection between human behavior on SM and their intrinsic traits, similar to the biological Deoxyribonucleic Acid (DNA) that determines their physiological characteristics. Although the concept of the “SM genetic map” originated from genetic analogies in the existing literature, this study further innovates it by applying it to recommender systems through a more detailed analysis of user behavioral data. 16 Unlike traditional recommendation systems that use simple user characteristics such as age and geographic location, this study delves deeper into user behavior patterns and social interactions on social networks, resulting in more complex and dynamic user profiles. For example, user content preferences, social circle characteristics, etc.
People's activities on SM, such as posting, music selection, and online duration, can be seen as clues to reveal their personalities and interests. These behavioral data can be collected and analyzed like studying biological DNA to identify key factors representing individual intrinsic characteristics. These factors are considered to be the “genes” of network individuals.17, 18 By collecting, processing, and analyzing data to extract user features, the decisive genes that determine these features are identified, ultimately forming a gene set as shown in equation (1).
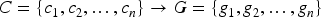
In equation (1),
Sm genome.
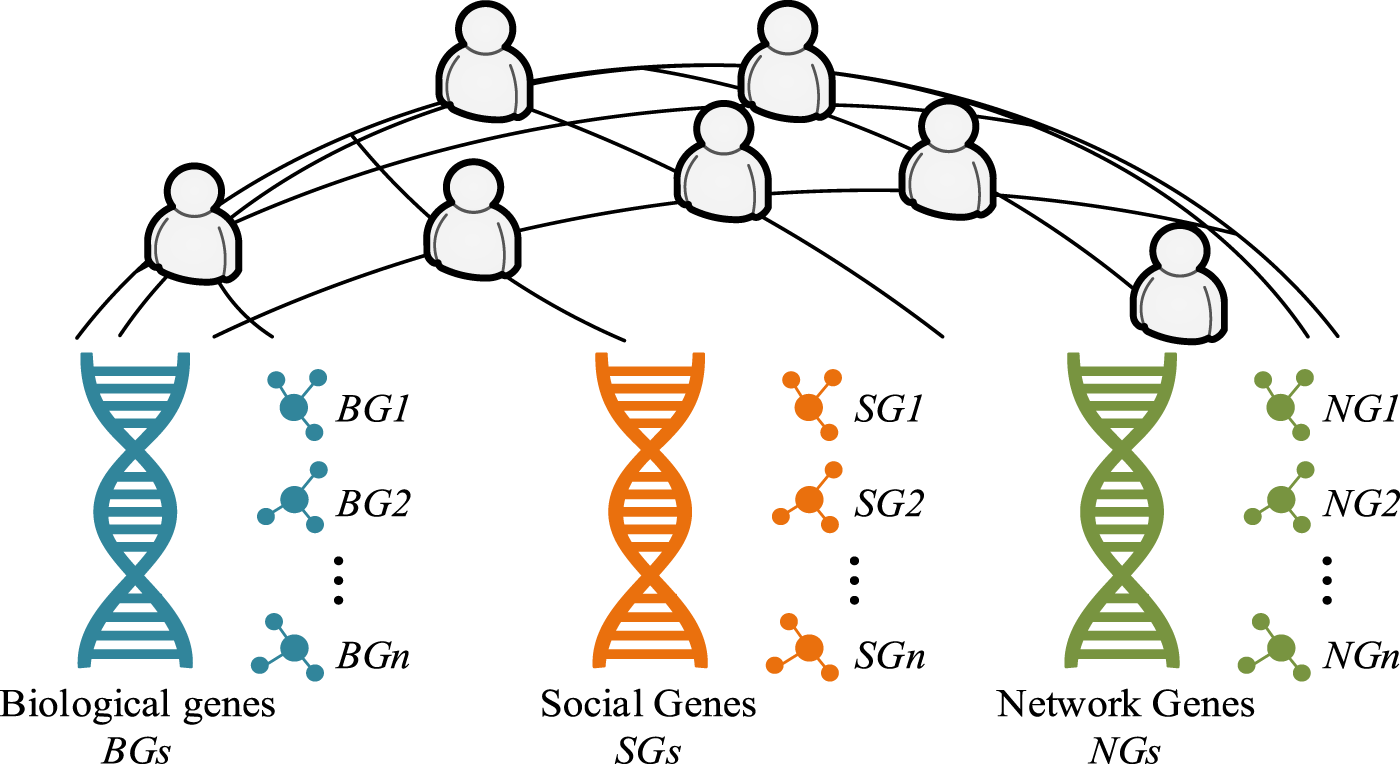
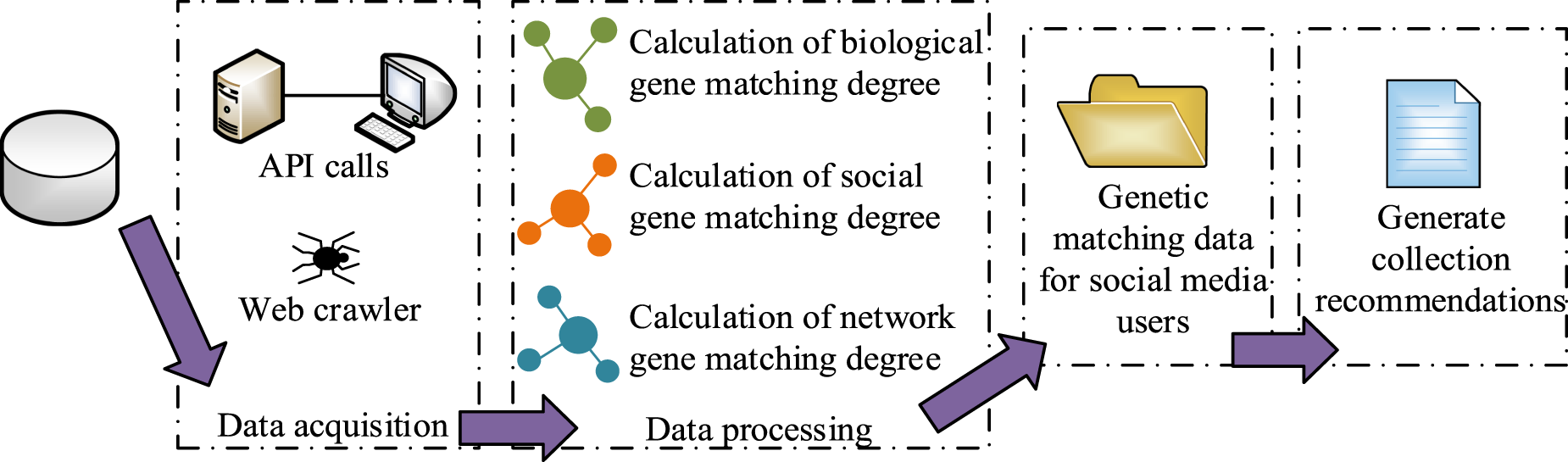
In Figure 1, in the SM GM, each gene represents a certain feature of the network entity. Gene fragments represent the characteristics of network entities in a certain aspect, and these gene fragments are unrelated to each other. By connecting these gene fragments in a specific way, a SM GM is formed. In view of the different characteristics of SM, GM can be divided into three parts, including biological gene fragments, social gene fragments, and network gene fragments. In SM, users generate a lot of behavioral data. By analyzing and mining these data to extract attributes that can stably represent the basic characteristics of users, a SM GM can be obtained. This process mainly includes two steps: first, modeling the behavioral data of SM users, and then classifying the stable attributes of users. The framework for constructing a SM GM is shown in Figure 2.
The construction framework of SM GM.
This architecture comprehensively considers multiple factors for studying the characteristics of SM users, and further separates them into three sub-categories: BGs, SGs, and NGs. The biogenetic component covers inherent characteristics of SM users such as gender, geographic location, and age. The SGs include information about the user's interests, which are collected and quantified by analyzing the user's interactions on SM, such as the frequency of liking and commenting on specific topics. For example, a user's interests can be identified by how often he or she participates in discussions and activities on a particular topic, and this data can be converted into a quantitative score. NGs, on the other hand, describe how active and influential a user is in a social network, which is quantified by analyzing the frequency of a user's posts and the average number of likes and comments on a post.
These three gene sub-classes, through interconnection and interaction, together form a SM GM, providing each user with a unique identifier. In the SM GM, the selection of gene fragments also affects the matching degree of users. The stability of SGs is relatively high, and differences are not easy to occur. If only this is used as a matching criterion, it is often recommended for people from the same region and age group. Therefore, according to the different characteristics of SM, it is necessary to select appropriate core genes and assign appropriate weights. To eliminate human bias, this study assigns gene fragments using entropy weight method.19, 20 Entropy weight method is an objective weight determination method, which is widely used in multi-attribute decision analysis. It determines the importance of each gene segment by analyzing its information entropy. Information entropy is an index to measure the degree of information disorder, reflecting the degree of data dispersion. In the study, the information entropy of each gene segment can reveal how dispersed and effective that segment is in describing user characteristics. A gene segment with high information entropy indicates that users have a large feature difference in this dimension, so this segment is less important in the analysis of user characteristics. On the contrary, gene fragments with low information entropy indicate that users have less difference in this dimension, and such fragments are more critical for the characterization of user characteristics. The weights of SM gene segments are determined as shown in Table 2.
Sm gene fragment weight confirmation system.

In the assigning values using the entropy weight method, it is first essential for standardizing the evaluation indicators, as shown in equation (2).
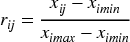
In equation (2), 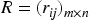
In equation (3), m serves as the quantity of gene fragments. n serves as the quantity of evaluation indicators on the gene segment.
22
The value of the entropy of the 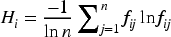
In equation (4), 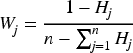
In equation (5), 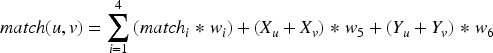
In equation (6),
A user recommendation model in view of SM gene graph.
Figure 3 shows that the user recommendation model first collects basic information and behavioral data of users through API calls and web crawler technology. Then, the initial data is organized through text preprocessing and Chinese word segmentation to extract effective information. It then calculates the matching degree of the six core genes and calculates the overall matching degree of the SM GM. Finally, it arranges the matching data in descending order and recommends the top N users to the target users.
Among the current recommendation models, CF recommendation model has unique advantages in privacy protection. CF algorithms rely primarily on user preferences or behavioral data, rather than personally identifiable information. For example, in a movie recommendation system, the algorithm focuses on a user's rating of a movie or viewing history, rather than the user's personally identifiable information such as name or address. This reliance on anonymous user preferences helps protect the privacy of users’ personal identities. CF, on the other hand, generates recommendations by aggregating data from a large number of users, rather than relying on detailed data from individual users. This clustering method means that the data of a single user is integrated into a large data set, thus reducing the risk of personal data being identified. In addition, CF is based on similarities between groups of users, rather than specific information about individual users. This means that recommendations are based on pattern recognition of user behavior, rather than in-depth analysis of individual user data. Therefore, this study improves on the SOA and obtains an improved weighted SOA. On this basis, the SM GM is introduced to obtain a CF recommendation model in view of the SM GM. This study proposes a CF recommendation model based on SM GM, which is applied to both person and item recommendations. By deeply analyzing SM data, the model not only extracts behavioral and content features that are directly related to users’ interests, but also takes into account the structure of users’ social networks. This integrated analytical approach enables the system to consider the user's social interactions when making recommendations regarding potential social connections. It also leverages the user's content preferences and historical behavioral data in item recommendations, thereby creating a unified and more efficient recommender system.
In traditional CF recommendation, user-based CF determines the set of adjacent users, and item-based CF determines the set of adjacent items.
24
This study uses SM GMs to determine the set of nearby users, and then uses an improved weighted SOA and item similarity to determine the set of nearby items. The SOA is similar to the project-based CF algorithm, and the calculation process is simple and efficient. The first step of the SOA is for calculating the average deviation, as shown in equation (7).
25
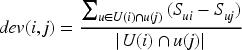
In equation (7), 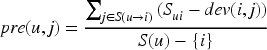
In equation (8),
Relative to other algorithms, the SOA has an intuitive and simple principle, does not require complex mathematical knowledge, and can easily process new scoring data.
26
When new scoring information appears, there is no need to recalculate the entire model, just update the relevant statistical data.
27
However, due to the relatively simple nature of the SOA, it may not be able to fully capture the complex relationships between users and projects, and it does not take into account the user audience, which greatly affects the average deviation. Therefore, this study enhances the SOA by introducing a weighted value, as illustrated in equation (9).
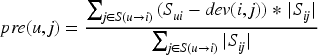
In equation (9), 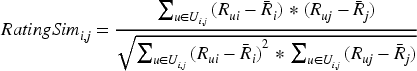
In equation (10), 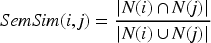
In equation (11), 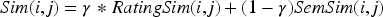
In equation (12),
In the final constructed model, semantic similarity is integrated by analyzing the text content in the product description. First, the descriptions of each project are disambiguated and vectorized using natural language processing techniques. This process involves extracting keywords and converting these keywords into vector form, which is usually done using the word embedding method Word2Vec. Next, the cosine similarity value between each pair of project descriptions and their respective vectors is calculated and used as the semantic similarity. Finally, the computed semantic similarity is linearly combined with the traditional user-rating-based similarity to form a comprehensive similarity measure. By adopting this method, the rating prediction model considers both the user's direct rating of the product and the semantic information of the product content, which can more accurately reflect the user's preferences and improve the performance of the recommendation system. Through this approach, the similarity between two projects can be more reasonably expressed, and the obtained project similarity has higher credibility. The relevant expression is shown in Figure 4.
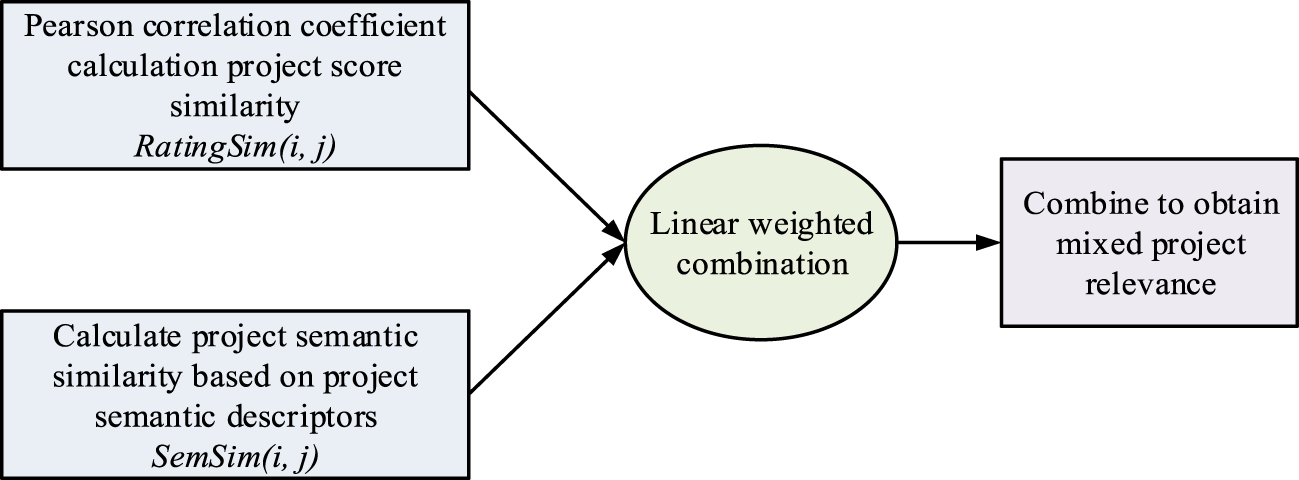
Similarity calculation process in view of project association.
This paper integrates the SM GM into the improved SOA to build a CF recommendation service model in view of the SM GM. When calculating project scoring bias, this study introduces SM user matching to calculate, as shown in equation (13).
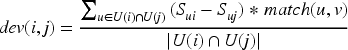
In equation (13), 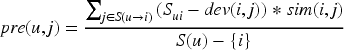
In equation (14),
This study analyzes physical behavior data in SM, generates user and project datasets, and organizes the calculation results to form user matching data. In view of the most matched N users, they provide recommendation services to the original users. 30 Next, it forms a set of close neighbors of the target user and obtains the project dataset of the users in the Top N list. It calculates the semantic and scoring similarity between these project datasets and the original project dataset, and obtains the project similarity data through weighted calculation. It predicts users’ ratings of projects through user matching data and project similarity data. Finally, it recommends the highest rated K projects to users and completes the project recommendation service. The CF recommendation service model in view of SM GM built by the research is shown in Figure 5.
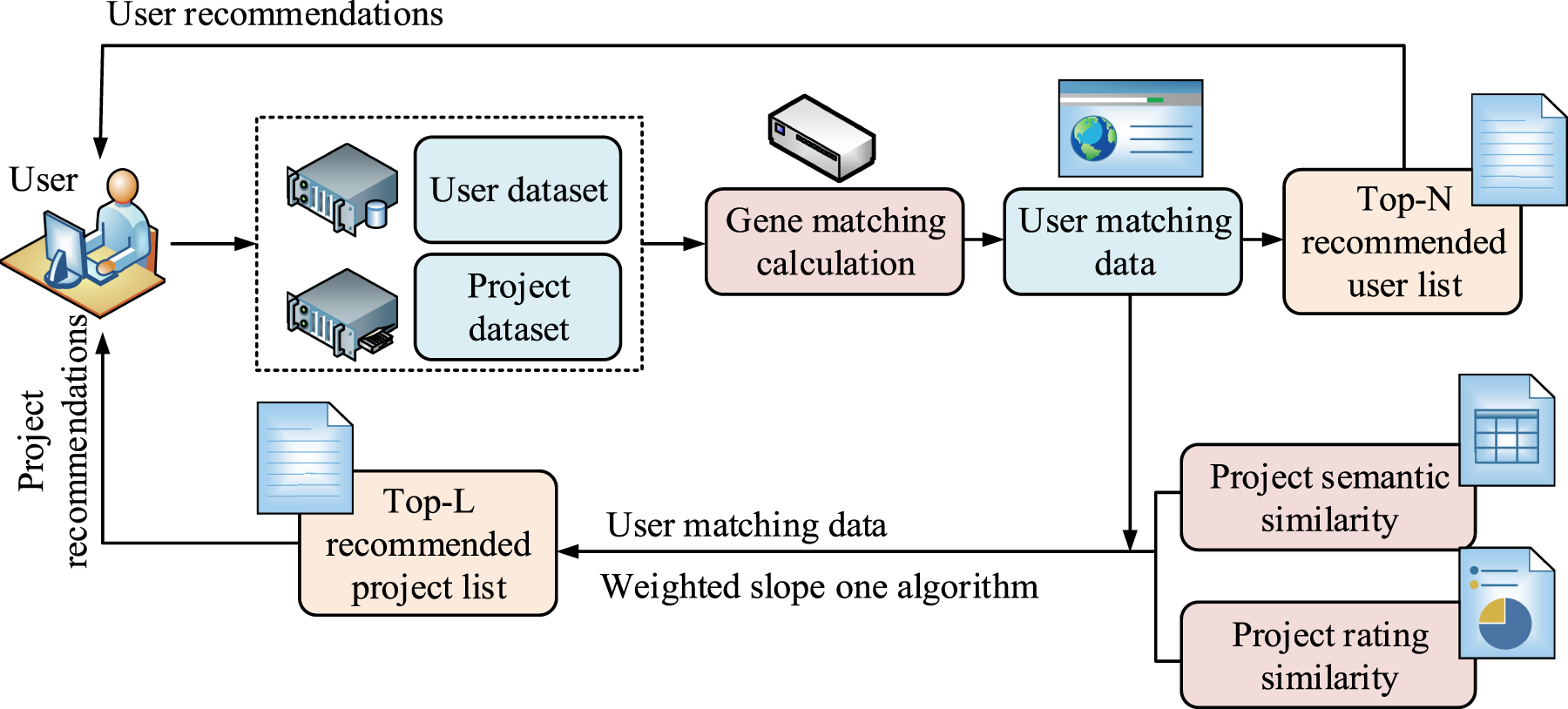
Cf recommendation service model in view of SM GM.
The data required for the experiment comes from Sina Weibo. Through API calls and web crawling technology, relevant information is collected, including personal information, follower lists, fan lists, and tweets posted or forwarded. To ensure the accuracy of the experiment, users with the number of fans and followers lower than 15 and users with no recent interaction behavior will be excluded. The final dataset consists of 4650 users, 89,214 tweets and 53,246 interactions, and is divided into a training set and a test set according to the ratio of 8:2. To objectively demonstrate the performance of recommendation systems, this study is conducted on the same device. The computer device information used is shown in Table 3.
Computer equipment information.

Computer equipment information.
Recommended algorithms for performance comparison of algorithms, including Alternative Least Squares CF (ALS-CF), Generation Antagonism Neural Network CF (GAN-CF), Singular value decomposition (SVD), and the proposed SM GM CF (SMG-CF). The accuracy of each algorithm's training iteration in the dataset is shown in Figure 6.
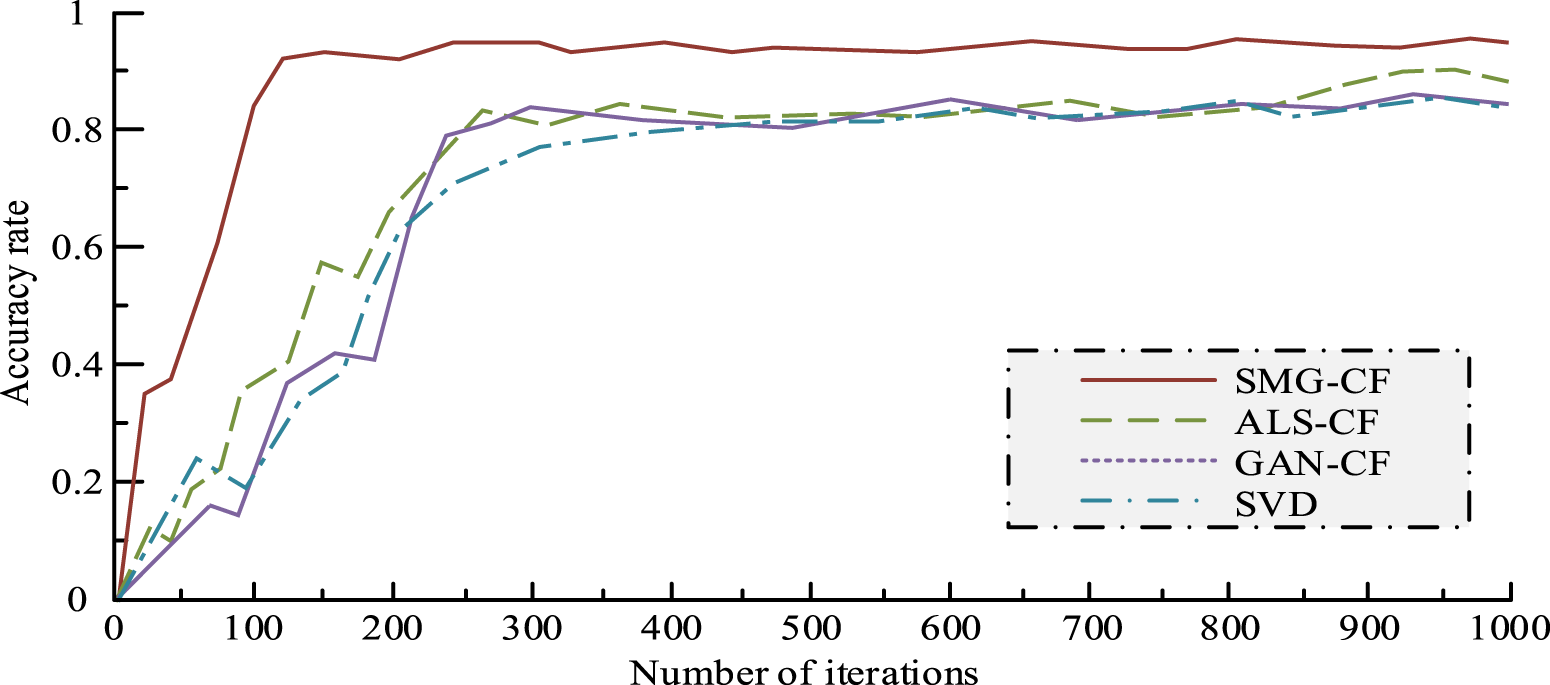
Comparison of iterative accuracy curves.
Figure 6 shows the variation curve of the training accuracy of each algorithm as the iteration's quantity grows. Figure 6 shows that as the iteration's quantity grows, the accuracy of each algorithm significantly increases. The SMG-CF algorithm is superior to others in convergence speed and maximum accuracy. Among them, the SMG-CF algorithm approaches convergence at the 130th iteration, with a convergence accuracy of 93.15%. The ALS-CF algorithm approaches convergence at the 270th iteration, with a convergence accuracy of 81.23%. The GAN-CF algorithm approaches convergence at the 290th iteration, with a convergence accuracy of 82.04%. The SVD algorithm approaches convergence at the 390th iteration, with a convergence accuracy of 80.18%. The statistical data show that there is little disparity in the convergence accuracy of the three algorithms: ALS-CF, GAN-CF and SVD, but the rate of convergence of ALS-CF and GAN-CF is better than that of SVD. Compared with the above three algorithms, the rate of convergence of the SMG-CF algorithm has grown by 51.85%, 55.17% and 66.67% respectively. The convergence accuracy of the SMG-CF algorithm has been enhanced by 14.67%, 13.54%, and 16.18%, respectively. The experiment validates the effectiveness of this study.
The collected 89214 tweets are divided into three categories: film and television resources, music resources, and entertainment news resources. After data cleaning and a series of preprocessing operations, the final amount of data related to film and television resources, music resources, and entertainment news resources is 16593, 14365, and 18215, respectively. The film and television resources dataset contains comprehensive information about movies and TV dramas, covering title, director, starring actor, year of production, movie and TV genre, duration, rating and user comments. In addition, the dataset also includes the viewing history and preferences of the audience, as well as the number of times each production has been viewed and the percentage of users who have liked it, which helps to analyze the viewing habits and preference patterns of users. The music resources dataset, on the other hand, includes various genres of music productions, with data for each song including the song title, artist, release date, music style, duration, ratings, and user comments. Similarly, the dataset records users’ listening history and ratings, making it possible to analyze which factors influence users’ music choices and preferences. The Entertainment News dataset contains a variety of types of entertainment information, such as movie release information, celebrity updates, music festival events, etc. Each news item includes news title, release time, news source, news category, content summary and full text. In addition, the dataset also collects users’ clicks, shares, and comments on the news, which helps to assess the hotness of the news and users’ attention. The three datasets are utilized to construct a recommender system. By analyzing the user's interactive behavior with the contents, the recommender system is capable of learning the user's preferences and predicting new contents that may be of interest.
In the experiments, all baseline algorithms are trained and tested on the same dataset as the proposed method to ensure fairness. Algorithms such as SVD do not directly support heterogeneous information processing. Through feature engineering, SM data is transformed into structured feature vectors, such as user activity levels and social connections, to help algorithms better understand and utilize complex information on SM. To compare the recommendation performance of different models, the study uses prediction accuracy as an evaluation metric for performance testing. The prediction accuracy is measured by calculating the difference between the user ratings predicted by the system and the actual user ratings. After several experiments, the prediction accuracies of the four models under three types of datasets of movie and television resources, music resources, and entertainment news resources are obtained as shown in Figure 7.
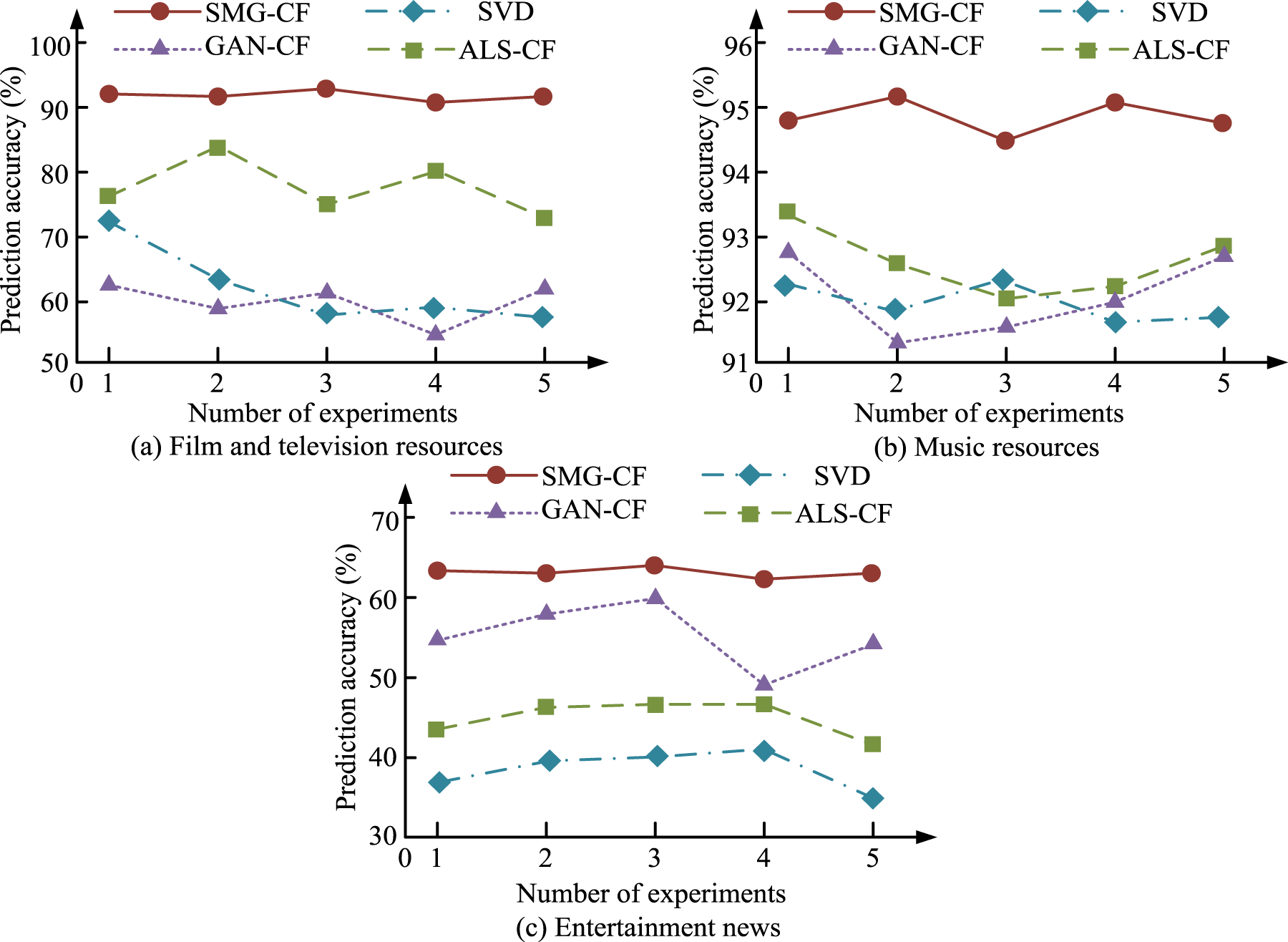
Prediction accuracy of different models.
Figure 7(a) to (c) show the prediction accuracies of the four models SMG-CF, ALS-CF, CAN-CF, and SVD for movie and TV resources, music resources, and entertainment news resources, respectively. In Figure 7(a), the prediction accuracy of the SMG-CF model is significantly higher than the other three recommendation models. The prediction accuracy of SMG-CF is 92.11%, which is 23.44%, 36.72%, and 40.89% higher compared to ASL-CF, SVD, and CAN-CF, respectively. In Figure 7(b), the prediction accuracy of SMG-CF in music resources is 94.67%, which is improved by 3.78%, 3.42% and 3.09% compared to ASL-CF, SVD and CAN-CF, respectively. In Figure 7(c), the prediction accuracy of SMG-CF in entertainment news sources is 63.12%, which is 47.32%, 17.89% and 56.81% higher compared to ASL-CF, SVD and CAN-CF, respectively. In summary, SMG-CF has the highest prediction accuracy in all three datasets, which shows that the model has the best recommendation effect.
To further validate the performance of recommendation models, this study calculates the recall rates of different recommendation models in view of the obtained accuracy, and plotted the Precision Recall (PR) curve, as shown in Figure 8.
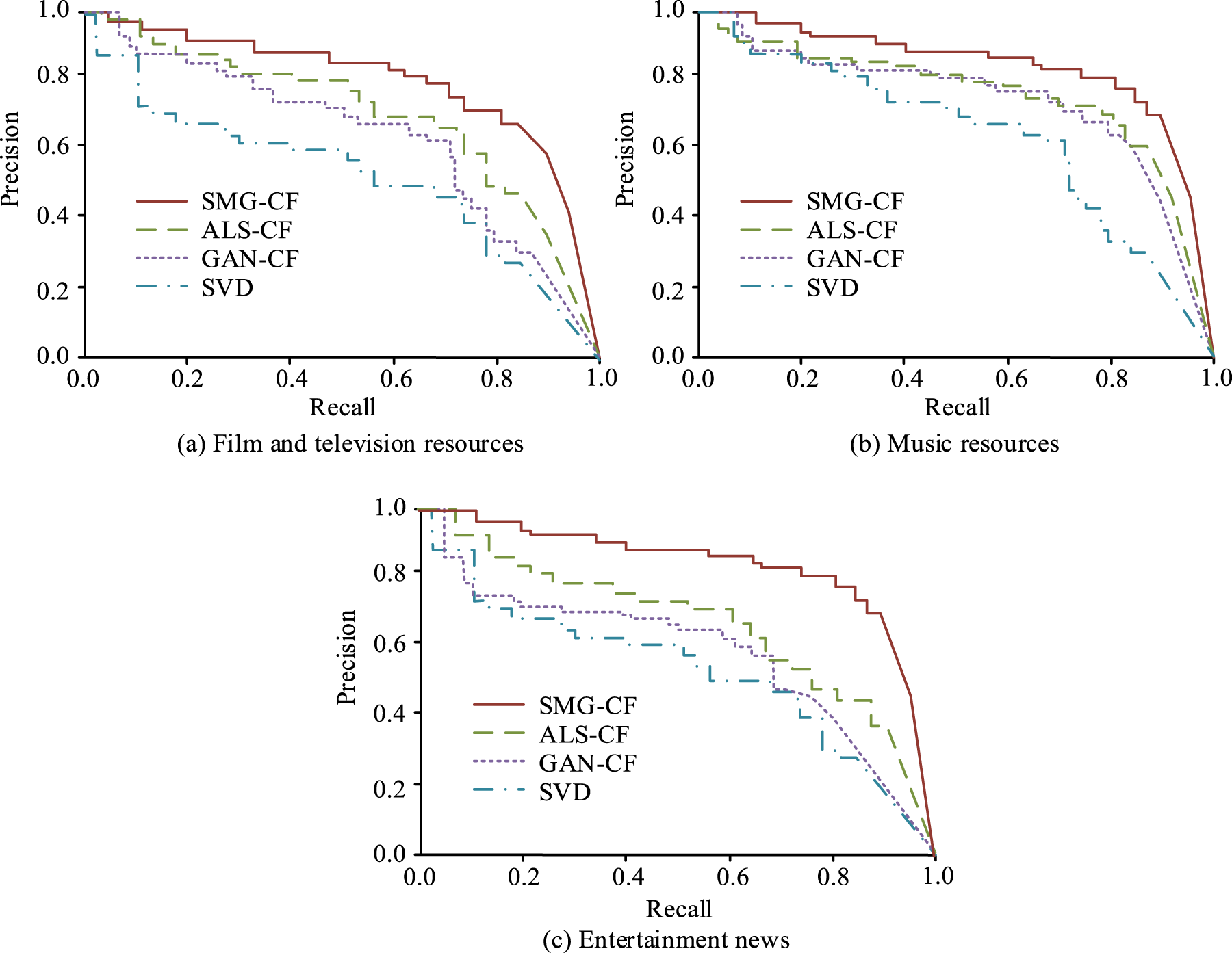
Comparison of classifiers PR curves.
The PR curve is used to validate the performance of the model. In the PR curve, the larger the area under a model curve, the better the performance of the model. Figure 8(a) shows the PR curves of various algorithms in film and television resource recommendation, with the performance of each recommendation model ranging from best to worst being SMG-CF, ALS-CF, GAN-CF, and SVD. Figure 8(b) shows the PR curves of various algorithms in music resource recommendation. The SMG-CF recommendation model has the best performance, while the ALS-CF and GAN-CF recommendation models have similar performance, and the SVD recommendation model has the relatively worst performance. Figure 8(c) shows the PR curves of various algorithms in entertainment news recommendation, with the performance of each recommendation model being SMG-CF, ALS-CF, GAN-CF, and SVD from best to worst. Overall, in the recommendation tests of the three resources, the SMG-CF recommendation model shows strong performance, followed by the ALS-CF recommendation model, the GAN-CF recommendation model, and finally the SVD recommendation model.
In this study, user satisfaction is assessed through an online questionnaire and real-time feedback mechanism. The study is conducted with 50 volunteers as experimental subjects, who are surveyed about their satisfaction with the recommendation service. The questionnaire includes several questions about the relevance of the recommended content and the user experience, and is rated on a 5-point Likert scale. Meanwhile, a real-time feedback mechanism within the system allows users to directly rate whether they liked or disliked the recommended content to collect instant satisfaction data. The satisfaction scores for different recommendation models are shown in Figure 9.
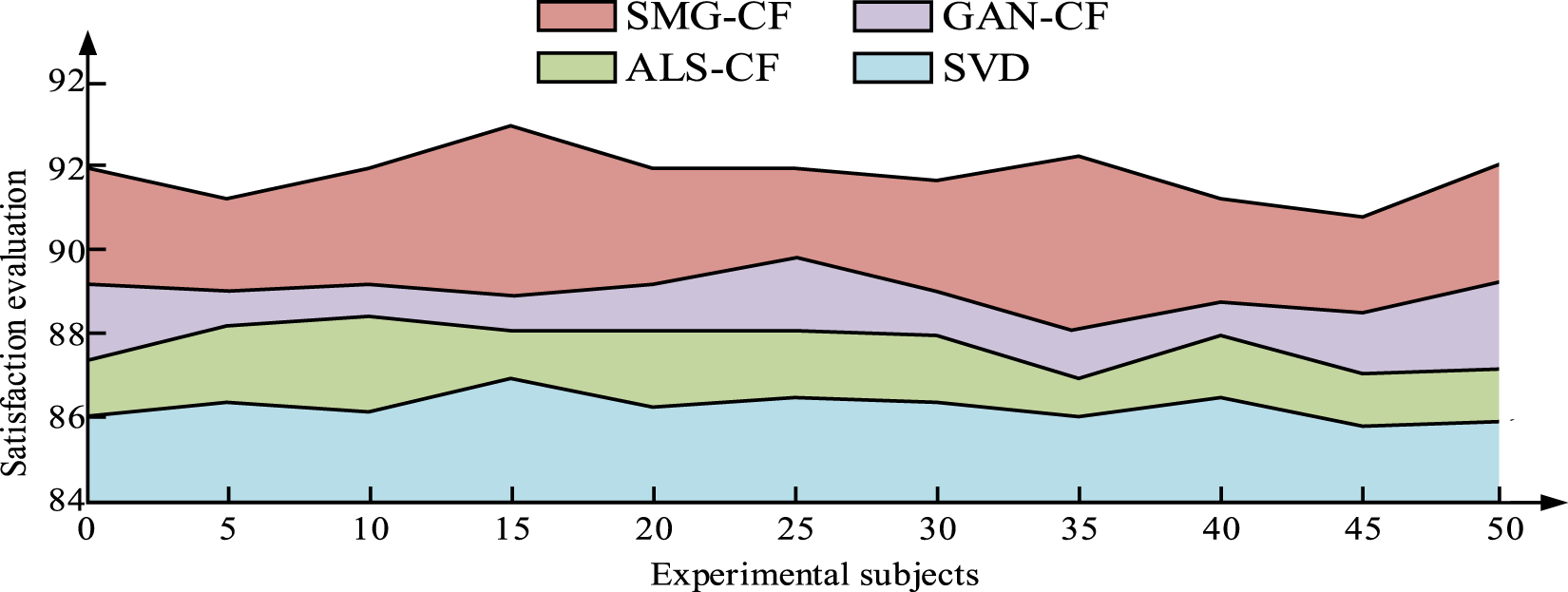
User satisfaction evaluation.
Figure 9 shows the area of the user satisfaction survey, with larger areas indicating higher user satisfaction. Figure 9 shows that the SMG-CF recommendation service receives the highest satisfaction, with an average satisfaction rate of 91.89%, followed by GAN-CF with an average of 89.02%, and ALS-CF with an average of 87.88%. SVD's recommendation service satisfaction is relatively the lowest, with an average of 86.34%. This indicates that the SMG-CF recommendation service has high recommendation accuracy and achieves high user satisfaction, verifying the effectiveness of the study.
In previous optimization of recommendation models, the integration of different algorithms resulted in an increase in CPU execution time (ET) and a decrease in efficiency. Therefore, this study also conducts CPU ET comparison experiments with different recommendation models, and the relevant outcomes are shown in Figure 10.
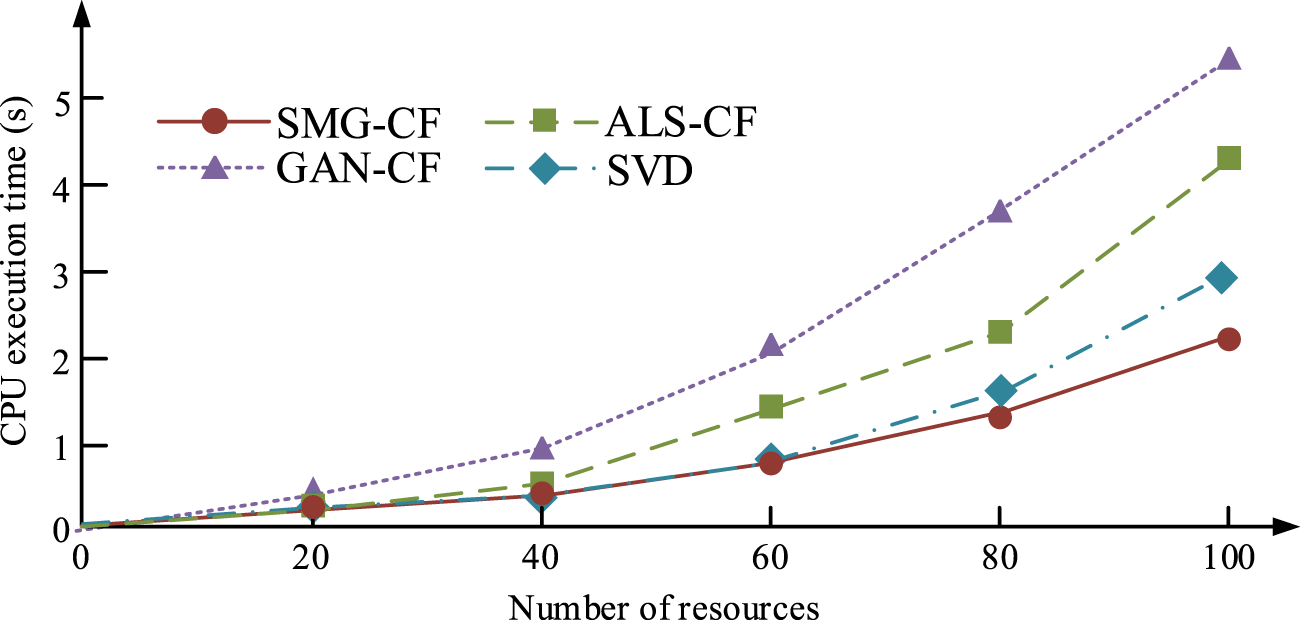
Comparison of CPU ET.
Figure 10 shows that as the resources’ quantity grows, the CPU ET of each recommendation model shows an accelerating trend. Among them, the CPU ET of the SMG-CF recommendation model is 1.88 s when the quantity of resources reaches 100. The CPU ET of the SVD recommendation model is 2.84 s when the quantity of resources reaches 100. The CPU ET of the ALS-CF recommendation model is 3.91 s when the quantity of resources reaches 100. The CPU ET of the GAN-CF recommended model is 5.81 s when the number of resources is 100. Compared to SVD, ALS-CF, and GAN-CF, the CPU ET of the SMG-CF recommendation model decreases by 33.80%, 51.92%, and 67.64%, respectively. It verifies that the SMG-CF recommendation model also performs better in CPU ET.
Figure 11 shows the accuracies of the four algorithms in the test set and the training set respectively when the number of recommenders finally presented to the user is set to 10, 20, and 30. In Figure 11(a), SMG-CF has the highest accuracy in different number of recommenders compared to other algorithms, with an average recommendation accuracy of 88%. In Figure 11(b), when the number of recommenders is 10, 20, and 30, the recommendation accuracy of SMG-CF in the test set is 81%, 88%, and 89%, respectively, which is significantly better than the other algorithms.
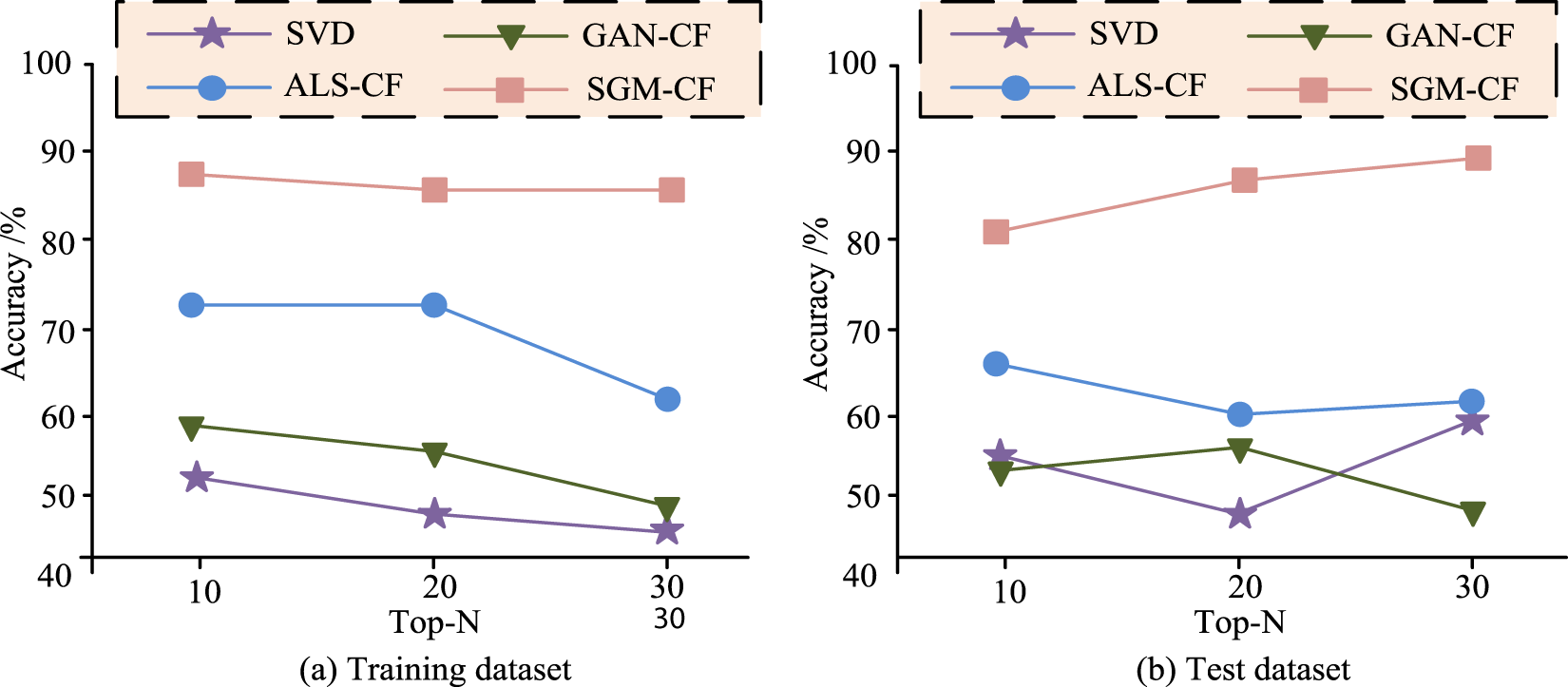
Accuracy of each model under different recommended numbers.
The performance comparison of SMG-CF with other baseline algorithms is given in Table 4. Table 4 shows that SMG-CF has the highest average recommendation accuracy and the shortest average recommendation time in completing the recommendation task, which are 98.3% and 0.6 s. Literature, 31 Literature, 32 Literature, 33 and graph neural networks also have an average recommendation accuracy of more than 90%, but these recommendation algorithms take longer, especially for graph neural networks. This is because graph neural networks tend to require a lot of computational resources in practical applications and are very sensitive to parameter tuning, so their time consumption will be far more than other baseline algorithms.
Performance comparison of other baseline algorithms with SMG-CF.

The personalized recommendation service of SM is mainly aimed at providing users with a better user experience. With the significant increase in SM resources and user numbers, the accuracy of existing recommendation methods has begun to decline. This paper aimed to solve the challenges in SM recommendation services. By constructing an SM GM and combining CF algorithm, a new recommendation service method was proposed. The results demonstrated that the SMG-CF recommendation model exhibited strong performance in recommendation tests for film and television resources, music resources, and entertainment news, followed by the recommendation model of ALS-CF, GAN-CF, and SVD. In addition, the SMG-CF recommendation service received the highest satisfaction, with an average satisfaction rate of 91.89%, followed by GAN-CF (89.02%) and ALS-CF (87.88%). SVD's recommendation service satisfaction was relatively the lowest, with an average of 86.34%. The experiment indicated that utilizing the rich information resources of SM, combined with appropriate algorithms and models, could better meet users’ personalized recommendation needs. This study provides a new perspective and method to address the issue of SM recommendation services, providing valuable references for further research and practical applications. However, while the SMG-CF model performs well in current experiments, its ability to handle large-scale data sets has not been fully validated. The massive growth of SM data can take a toll on the computational efficiency of models and the quality of recommendations. With the rapid growth of social media data, storing and efficiently retrieving all the data becomes the primary challenge for practical applications. Traditional databases are difficult to meet the real-time processing requirements of large-scale data, and the demand for large-scale data processing on computational resources such as CPU, memory and GPU will increase significantly; and the construction and updating of SMG-CF involves complex matrix operations and iterative optimisation, which will also increase dramatically with the increase of data size. Therefore, future research should focus on improving the scalability of the model and its ability to handle large datasets, and comprehensively consider optimisation algorithms to reduce computational overhead. In addition, there are still many challenges for the scalability of models in practical applications. In order to achieve large-scale dynamic data processing, the model should be able to scale linearly with the increase of data volume and improve the processing capability by adding resources on a single node. Meanwhile, in the dynamically changing social media environment, the model should be able to adaptively learn new user behaviours and preferences while maintaining the memory of old data. Therefore, future research work should consider introducing online learning or incremental learning mechanisms to update the model parameters in real time and increase the scalability of the model. On the other hand, the dynamic and complex nature of SM data is also a challenge, with users’ behaviors and preferences changing over time, and existing models may not be able to reflect these changes in a timely manner. Future research could explore real-time data processing and dynamic learning mechanisms to ensure that recommendation systems can adapt to these rapidly changing environments. In addition, despite the use of anonymization in this study, how to effectively use personal data without violating user privacy is still a question that needs further discussion. Future research should focus on how to optimize data utilization efficiency while protecting user privacy. Therefore, although this study has achieved certain results in the field of SM recommendation services, it still needs further exploration and improvement in the aspects of algorithm scalability, real-time performance and user privacy protection. Future research can further explore these areas to more fully address the challenges of SM recommendation services.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.