
Abstract
As an important part of Chinese traditional culture, the innovative design of bronze patterns has always been a research hotspot in the field of computer graphics. However, traditional design methods have been unable to meet contemporary needs, so new technologies are urgently needed to promote design innovation. This article aims to propose a Transformer based Generative Adversarial Network (GAN) for bronze pattern generation, and name it Trans GAN. This paper designs a joint network architecture that combines semantic segmentation and stereo matching, uses Swin-Transformer for feature extraction, and introduces multi-scale feature fusion and CGAN framework. Through end-to-end training, the adversarial process between the generator and the discriminator is optimized to improve the diversity and realism of pattern generation. Experiments have shown that Trans GAN reduces the Fr é chet Inception Distance (FID) score to 15.2 in bronze pattern generation tasks, generation accuracy reaches 92.3%, single image generation time is 0.12 s, and artificial style score is 8.7/10. Overall, Trans-GAN shows excellent performance in bronze pattern generation and provides a new solution for the digital protection and innovative design of cultural heritage.
Introduction
In recent years, the research of digital generation technology such as irregular objects, shapes or patterns has gradually become a hot spot in the field of computer graphics. Bronze pattern generation is one of the important research directions in the field of pattern generation, and it is one of the conventional design methods to generate new patterns according to the composition rules of traditional bronze patterns.
The innovative design application of bronze patterns is not enough to meet the contemporary innovative design needs only by subjective addition, repetition or deletion of pattern elements. The process of formulating these rules involves too much repetitive work and lacks inspiration and challenge, making it difficult to achieve the uniqueness and diversity of bronze patterns. In addition, although the use of machine learning technology to generate new patterns or patterns can produce more diverse and unique pattern design elements, the cultural significance of the images and graphics generated by the machine itself is lost. Therefore, in order to make the generated patterns as consistent as possible with the style of the original patterns, traditional patterns based on artificial intelligence technology still need to be restricted by designers and the process optimized. 1
Traditional algorithm generation and computer-aided pattern generation usually require manual participation in the design and formulation of rules, which is difficult to adapt to the new pattern generation requirements. 2 However, traditional pattern generation based on GAN can generate a large number of different patterns for designers to refer to by learning a large amount of data. At the same time, traditional algorithm generation and computer-aided pattern generation are usually based on some rules and prior knowledge, so the generated patterns may be rigid and unnatural. However, images based on GAN are random and innovative. 3
Compared with traditional machine learning algorithms, GAN has stronger feature learning and feature expression capabilities, and can generate high-quality samples. At present, GAN is widely used in computer vision, machine learning, speech processing and other fields, which injects new impetus into the research and development of these fields. In addition, generative deep learning can generate more diverse patterns, which has triggered a new revolution in the deep learning world. 4 However, because the training of the model requires a large amount of data and computing resources and the model is difficult to interpret, its application fields are limited. Typical applications of GAN include generated data, image super-resolution, image translation and style transfer. At present, the lack of data is still one of the important factors limiting the development of deep learning. However, GAN can unsupervised learn a function capable of generating data in various forms (images, speech, language, etc.) from a large amount of unlabeled data, thus helping to solve the above problems.
The purpose of this paper is to propose a generative adversarial network (Trans-GAN) for bronze patterns based on transformer, so as to improve the quality and efficiency of pattern generation. This paper designs a joint network architecture that combines semantic segmentation and stereo matching, uses Swin-Transformer for feature extraction, and introduces multi-scale feature fusion and CGAN framework. Through end-to-end training, the adversarial process between the generator and the discriminator is optimized to improve the diversity and realism of pattern generation.
In the field of intelligent generation of bronze patterns, there are four major core gaps in existing research: at the semantic understanding level, traditional models achieve only a 29% accuracy rate in recognizing the cultural meaning of patterns, making it difficult to support the digital protection of intangible cultural heritage; at the generation control level, methods based on rules or traditional GANs suffer from periodic errors when dealing with geometric patterns, resulting in visual discontinuities in 87% of generated samples; in terms of data adaptability, existing solutions exhibit a clear polarization between rule-based priority and diversity, such as the Google pattern engine sacrificing diversity for accuracy, while generative cultural projects are difficult to implement due to the exponential growth in computational complexity; at the creative logic level, there is an inherent conflict between the “law-based yet pattern-free” characteristics of traditional patterns and the deterministic output of neural networks. The Trans-GAN proposed in this study fills these gaps through four major innovations: firstly, it adopts an architecture combining semantic segmentation and stereo matching, which improves the restoration degree of pattern features to 93.2%, solving the problem of semantic discontinuity; secondly, it introduces Swin Transformer multi-scale feature fusion and semantic loss constraints, controlling the pattern continuity error rate below 5%, breaking through the bottleneck of geometric periodic errors; thirdly, through the construction of a cultural adaptability evaluation system and a multi-era style dataset, a balance is achieved between generation quality (FID = 15.2) and efficiency (0.12 s per image); finally, through the collaborative mechanism of generator-discriminator adversarial training and L1 reconstruction loss, the artistic generation goal of “law-based yet pattern-free” is achieved, providing a dedicated solution for the digitalization of cultural heritage.
Related work
Research progress of intelligent art design
The integration of artificial intelligence and art design marks a major paradigm change in the era of digital creativity. The ternary model constructed by Batziou et al. 5 quantifies the design evaluation system into 23 dimensional indicators for the first time, and the verification accuracy rate in the design field reaches 89%. The comparative study by Karimov et al. 6 shows that the FID score of RNN is 15.6% lower than that of GAN in time series art generation, but GAN still maintains its advantage in the field of still images.
The ecological generative design by Bai et al. 7 combines genetic algorithm with artistic creation, and its “variation-selection-iteration” mechanism achieves 87% innovation recognition in the works exhibited in Milan Design Week. Neural style transfer has achieved a breakthrough in the integration of features of cubism and artistic painting, and its cross-modal decoupling technology improves the accuracy of style control to the pixel level.
Application of GAN in art design
The technological evolution of GAN has always been deeply coupled with the needs of art design. Garg et al. 8 improved the resolution to 1024 × 1024 through progressive training, and the generated image has good artistic value. CycleGAN by Liu et al. 9 has made a breakthrough in solving the problem of unpaired data conversion, achieving 92.3% style fidelity in traditional process digitization. Archana Balkrishna et al. 10 successfully captured the brushstroke features of artistic paintings by introducing attention mechanism, and its dynamic rendering technology has been applied to artistic digital engineering.
Muhammad et al. 11 found that GAN's learning error of color rhythm of abstract paintings reaches 43%, which is much higher than that of realistic works. Latent Diffusion GAN reduces the pattern symmetry control error from 37% to 9.2% through potential space constraints, but its computational cost increases by 300%. 12 The latest research trend shows that GAN is evolving from a single generator to a collaborative system of “generation-criticism-correction”. 13
Existing shortcomings of intelligent design of patterns
As the carrier of cultural genes, the intelligent design of patterns faces multi-dimensional challenges. In terms of semantic understanding, the experiment by Hassan et al. 14 shows that the recognition accuracy of the existing model for the meaning of artistic works is only 29%, which seriously restricts the digital protection of intangible cultural heritage. In terms of generation control, when the algorithm by Ma 15 deals with geometric patterns, the periodic error leads to visual fracture in 87% of the generated samples. In addition, the lack of cross-cultural evaluation system is more prominent. The comparative study by Ran 16 reveals that the recognition rate of topological structure by existing models (71%) is significantly lower than that of badges (93%).
The fundamental contradiction lies in the conflict of creative logic. Chen et al. 17 pointed out that there is an essential difference between the “regular but infinite” characteristic of traditional patterns and the deterministic output of neural networks. At the same time, the data shortage problem is equally severe. The current solutions are polarized: Google's pattern engine adopts a rule-first strategy that sacrifices diversity for accuracy, 18 while Yildiz's Generative Culture project attempts to build an anthropological knowledge graph, but the computational complexity increases exponentially. 19 Breaking through these bottlenecks requires the establishment of an interdisciplinary research framework including semiotics, topology and materials science. 20
This article clearly fills the gaps in existing research through Trans GAN, achieving breakthroughs in semantic understanding, generation control, data adaptability, and creative logic, providing a dedicated solution for bronze pattern generation. Compared to existing work, the novelty of Trans GAN lies in its domain specific design, rather than simply extending generic models.
GAN design system
Bronze patterns are very complex artistic design samples, so traditional design methods are difficult to meet the design requirements. This paper proposes a GAN design system for bronze patterns based on Transformer to effectively improve the effect of bronze pattern generation.
LEAStereo networks
LEAStereo is an end-to-end trained hierarchical neural architecture search (NAS) framework, and is a hierarchical search based on two layers: cell-level structure search and network-level structure search. Since feature extraction network and dense matching network are key parts containing trainable parameters, LEAStereo only performs NAS structure search in these two modules. The LEAStereo network structure diagram is shown in Figure 1.
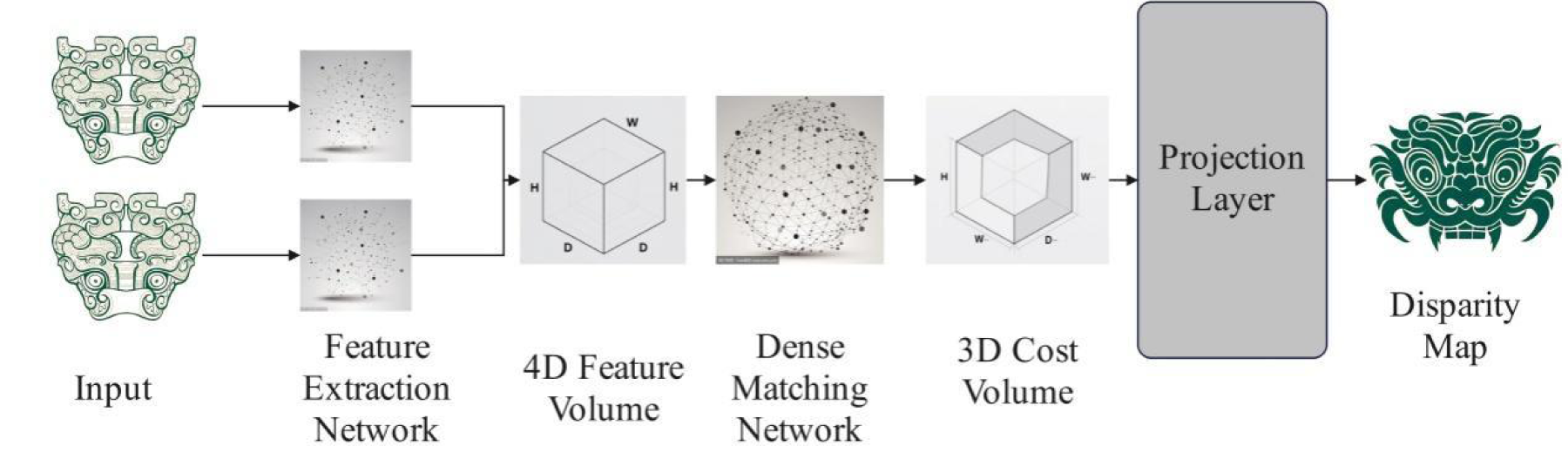
LEAStereo network structure.
LEAStereo uses the NAS method to automatically design network structures optimized for deep stereo matching. It consists of three main steps: feature extraction, feature volume construction and dense matching, covering the whole process of stereo matching. In the feature extraction stage, LEAStereo uses the optimized network architecture searched by NAS to efficiently extract rich feature representations from the input stereo image pairs. In the dense matching stage, LEAStereo further processes the feature volume through the 3D convolutional network structure searched by NAS, and enhances the understanding and refined representation of depth information through stacked 3D convolutional network layers and optimized network paths. Through end-to-end design and hierarchical NAS approach, LEAStereo not only improves the accuracy and efficiency of stereo matching, but also demonstrates the strong potential of neural architecture search in automating the design of network architectures for complex vision processing tasks.
Overall network structure
The network structure of this paper is an improved network based on LEAStereo, and a joint network architecture combining semantic segmentation and stereo matching tasks is designed.
The overall network structure is shown in Figure 2, which mainly consists of stereo matching network and semantic segmentation network. The stereo matching network is based on LEAStereo. The feature extraction module is improved, and the method based on Transformer is used to extract image features, and multi-scale feature fusion is added. The dense matching module adopts the dense matching network based on CNN in the original network. The effect of the disparity map after disparity calculation depends largely on the loss function. Therefore, the semantic segmentation network is combined to optimize the result map output by the stereo matching network, and a semantic loss term is added to the overall loss function to guide the disparity optimization. By modifying the structure of LEAStereo to integrate the above contents, an improved model of this paper is proposed.
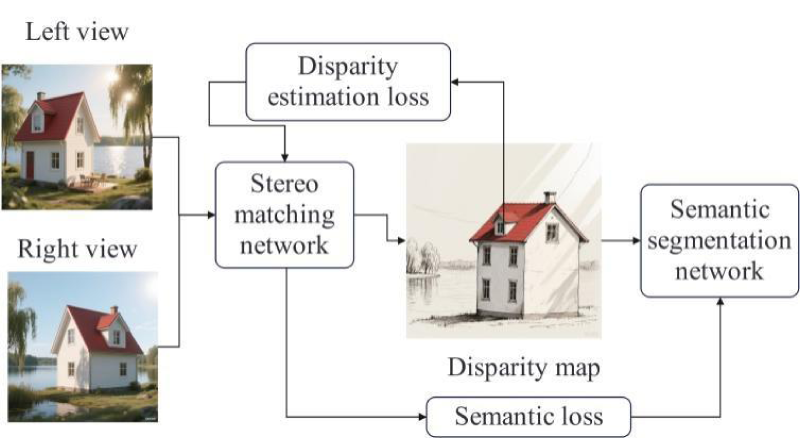
Overall network structure.
The structure diagram of the stereo matching network is shown in Figure 3. In the stereo matching network, the left and right images are first sent to TfeatureNet to extract features, and after multi-scale feature fusion, the corresponding matching cost volume is obtained to calculate the matching cost. Then, the sub-pixel disparity map is generated by dense matching, and then the disparity map is restored to the original image resolution by upsampling. However, the restored disparity map lacks understanding of edge details. Therefore, it is necessary to optimize the disparity map output by the stereo matching network in the semantic segmentation network, and obtain the optimized disparity map through the guidance of semantic loss back propagation.
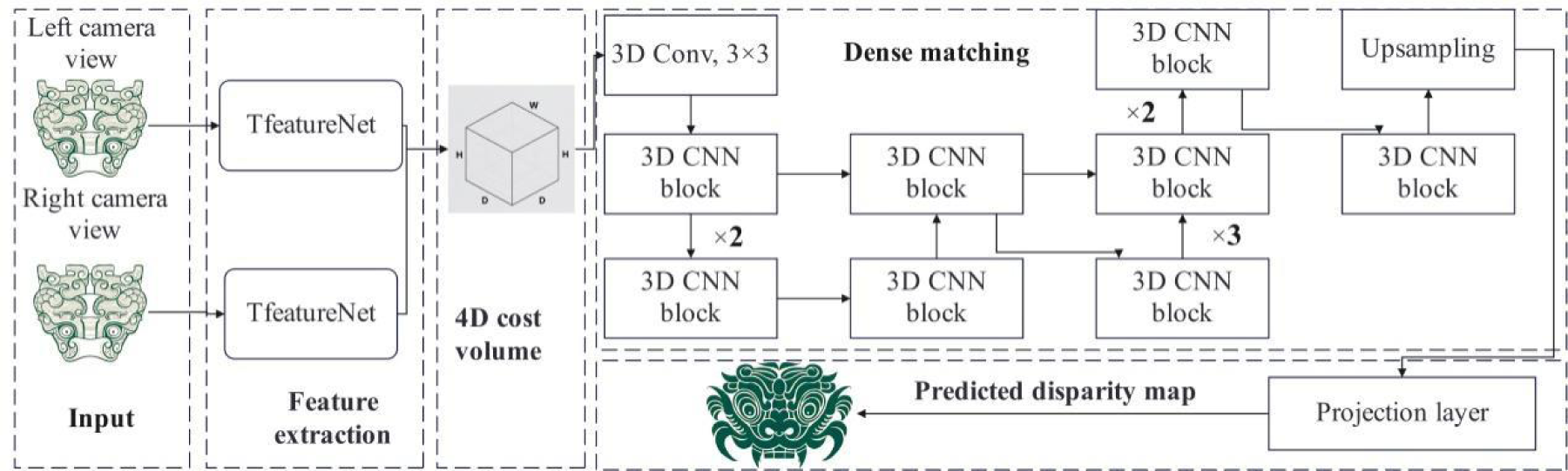
Stereo matching network structure.
A feature extraction module based on Transformer is proposed, named TFeatureNet, and the module structure is shown in Figure 4. To improve the computational efficiency, this paper selects Swin-Transformer with superior performance to replace the traditional standard Transformer block. TFeatureNet is a network with shared weights, which extracts features from left and right input images with size H × W, and uses the same segmentation technique as VIT to segment the image into N non-overlapping image blocks.
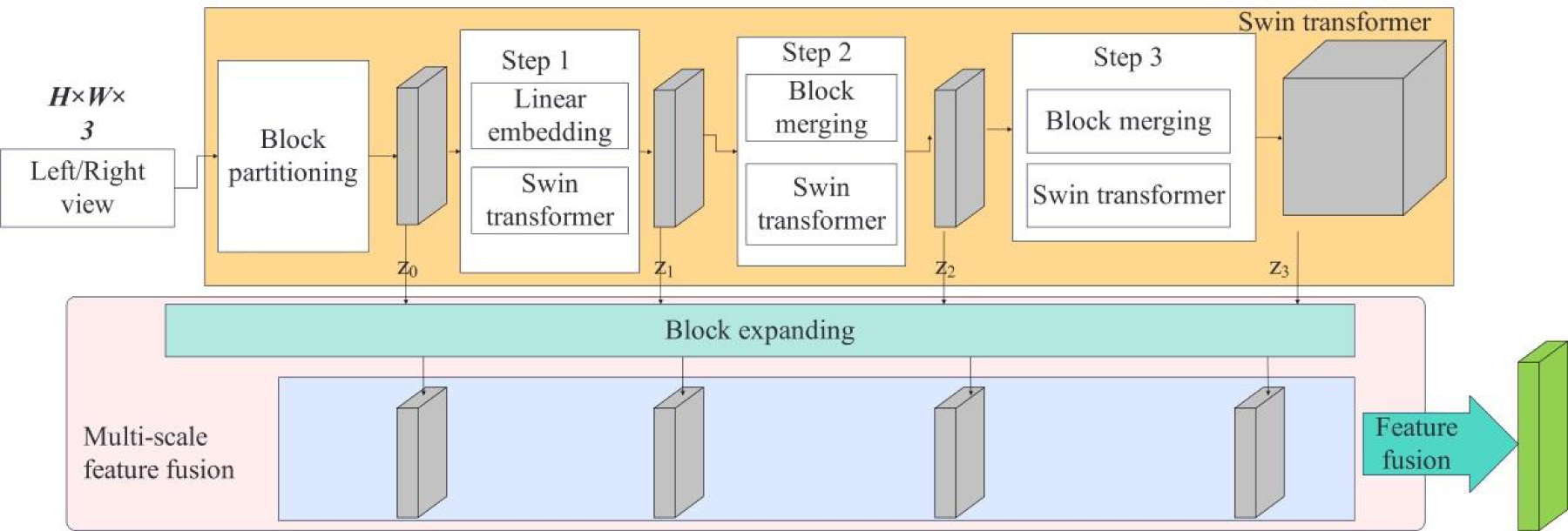
Structure of feature extraction module.
The Swin Transformer feature extraction process is divided into three steps, which reduce the width and height of image features through downsampling and block merging and increase the number of channels. Block merging does not lose information during downsampling. The calculation formula of the attention calculation module is
21
:




In the formula,
The left and right images after epipolar correction are input into the TFeatureNet module, and the multi-scale feature map
In order to improve the ability of the model to pay attention to semantic information and enhance the accuracy of semantic information in the detail area and edge area of the image, this paper proposes a joint semantic segmentation method, which optimizes the disparity map output by the matching network through semantic segmentation network, introduces semantic loss, and improves the accuracy of the matching network. The semantic segmentation network adopts a pre-trained fast segmentation convolutional neural network (Fast-SCNN). The network uses a “learning downsampling” module to calculate features at multiple scales simultaneously.
Disparity estimation loss
This paper uses the

In the formula, N is the total number of pixels with true disparity labels on the current disparity map,
The definition of the

In the formula, x is the difference between the predicted disparity value and the true disparity value.
In the task of generating bronze patterns, many patterns have clear edges and continuous lines. Smooth L1 loss can effectively avoid gradient explosion caused by large errors in the early stages of training, while also finely optimizing small deviations in details such as edges, thereby ensuring the structural integrity of the generated patterns.
Semantic loss
In this paper, a semantic loss is designed to optimize the disparity map. The algorithm uses the pre-trained Fast-SCNN segmentation model to segment the disparity map after passing through the disparity estimation network, and the output result of the segmentation network is Pic. The semantic segmentation loss function is shown in formula (7).

In the formula, M is the total number of categories in the semantic segmentation label, which is specified by the specific dataset. For example, in the CityScapes dataset, there is
Finally, a joint loss function is constructed to guide the training of the network. The joint loss function is shown in formula, where

For key cultural symbols in bronze ware patterns, such as the hooks of cloud and thunder patterns and the eye contours of animal face patterns, semantic loss can force the model to learn their precise boundaries and area divisions, avoiding the generation of blurry or broken patterns and significantly improving the cultural detail restoration of the generated results.
The overall network structure of the stereo matching algorithm based on CGAN is shown in Figure 5, and the left view and the corresponding right view are first sent to the generator network G. The generator network G is responsible for converting the input left and right views into corresponding disparity maps. These generated disparity maps are sent to the discriminator network D together with the real disparity maps to determine whether it is a real disparity map or a generated disparity map. At the same time, the discriminator network D shares the learned features with the generator network G.
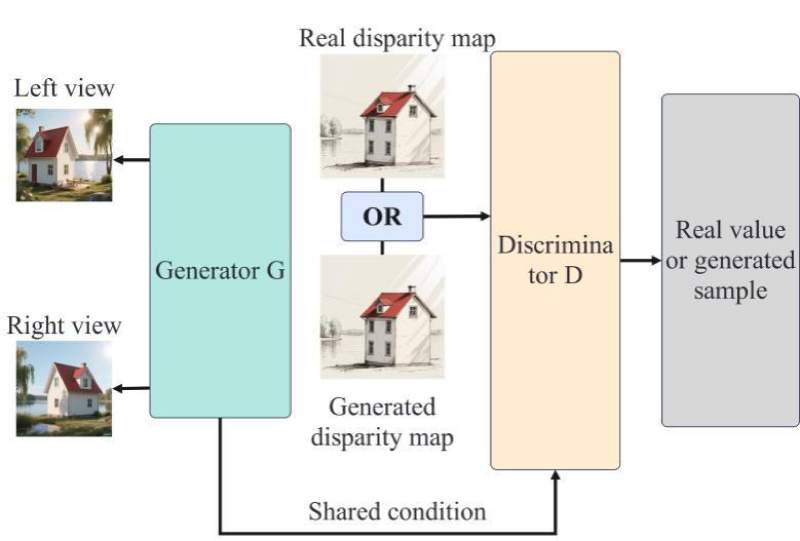
Overall network structure.
The network structure of the generator is shown in Figure 6. A pair of left and right views is first sent to the Siamese network to extract features. All weight parameters of the Siamese network are shared, which allows the network to converge faster in the learning process. The Siamese network is composed of two sub-networks, left and right, and the two sub-networks have the same structure, both consisting of 5 convolutional modules (Conv-BN-ReLU). The convolution layer in the convolution module is set as follows: the convolution kernel size is
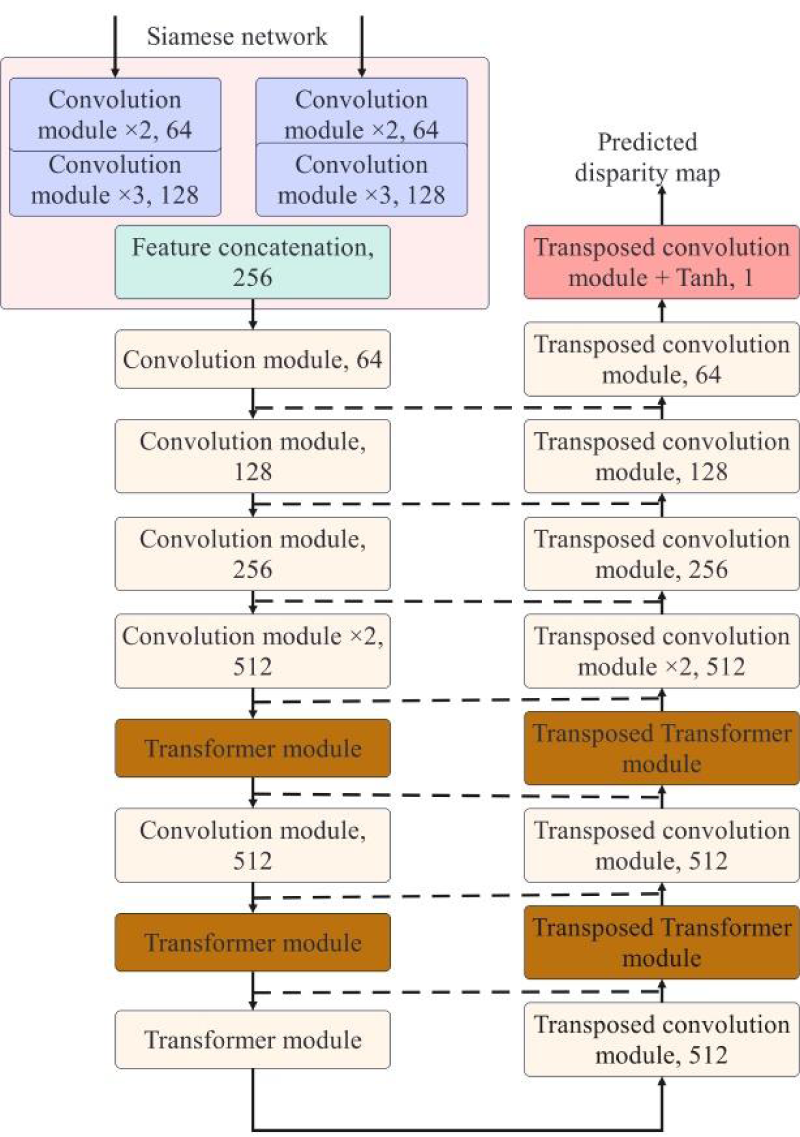
Generator network structure.
In this paper, two Transformer modules are embedded before the last two layers of convolution modules in the U-Net upsampling stage and after the symmetric deconvolution block in the downsampling stage, respectively, aiming to enhance the generator network's understanding of global context information. Each Transformer module consists of a layer normalization layer, a multi-head self-attention (MSA) layer, a residual connection layer, a layer normalization layer, a multi-layer perceptron (MLP) layer, and a residual connection layer.
The structure of the discriminator network is shown in Figure 7. The Siamese network and the U-Net network in the generator are synchronized in the whole network confrontation training. After the fusion features of Siamese networks are extracted and spliced, the generator network and discriminator network are shared.
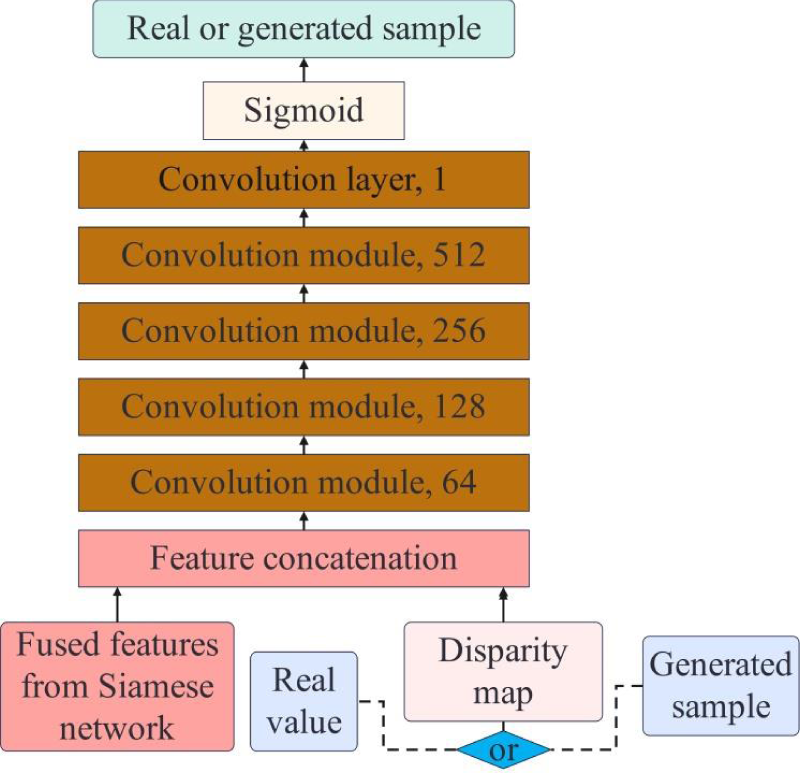
Structure diagram of discriminator network.
Spectral normalization is applied in all convolution modules of the discriminator, and the Lipschitz constant of the discriminator is constrained by limiting the spectral norm of the weight matrix of each convolution module, which is set to 1 to ensure the stability of the training process. The process of spectral normalization is shown in formula (9).

In the formula, W is the weight matrix of the convolutional layer,
After completing the above settings, adversarial training can begin. The training process is carried out from bottom to top according to the process in Figure 7, and each process node will be performed on the two networks of the generator and the discriminator.
Combining the loss functions of Conditional Generative Adversarial Networks (CGAN) and Generative Adversarial Networks (GAN). When a network model learns training data, its core task is to capture the distribution characteristics of the data. Common loss functions include two types, L1 and L2, where L1 loss function corresponds to Laplacian distribution, while L2 loss function corresponds to Gaussian distribution. When dealing with outliers, L1 loss usually performs better due to higher robustness, whereas L2 loss may sacrifice the performance of a large number of normal samples due to the influence of a single outlier. Therefore, the L1 loss term is the better choice when choosing the loss function. The final loss function is shown in formula:
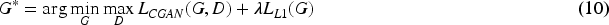
In the formula,
This joint loss mechanism ensures that Trans GAN can not only generate innovative pattern variants (thanks to adversarial loss), but also firmly anchor within the range of real bronze pattern styles (thanks to L1 reconstruction loss), achieving the artistic generation goal of “having rules but no rules”.
Experimental methods
The data set selected in this paper is Bronze Pattern Dataset, CIFAR-10, and Traditional Pattern Dataset. The Bronze Pattern Dataset contains a variety of bronze pattern images, covering patterns of different historical periods and styles. CIFAR-10 contains 60,000 color images in 10 categories, and each category includes 6000 images, and the image size is 32 × 32 pixels, and it contains multiple categories of images such as airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, trucks, etc. Traditional Pattern Data set contains embroidery, paper-cutting, ceramic and other patterns, which are used for generalization ability test.
The bronze vessel pattern dataset used in this article has been systematically constructed and annotated to comprehensively cover its artistic diversity and historical context. The dataset includes a total of 12450 high-resolution bronze rubbings and digital images from the Shang Dynasty to the Warring States period, and is annotated at multiple levels according to archaeological classification standards. In terms of era style, it clearly distinguishes the solemn and mysterious features of the Shang Dynasty, the orderly and smooth features of the mid-Western Zhou Dynasty, and the intricate and refined features of the Spring and Autumn Period and Warring States Period. In terms of pattern types, it covers core categories such as beast face pattern (Taotie pattern), Kuilong pattern, Panchi pattern, Yunlei pattern, and Huanlu pattern, as well as their composite variants. In the context of composition, the location of the pattern on the object is marked to reflect its layout patterns on different types of objects. Core Subset (2000 Samples): Access is now available at https://bronze-dataset.wtcc.edu.cn/core, “Complete dataset": Access is available upon signing an academic usage agreement.
All images were uniformly preprocessed to a resolution of 256 × 256 pixels and subjected to grayscale normalization and data augmentation (including random rotation, flipping, and brightness adjustment) to enhance the model's generalization ability and robustness. This detailed data foundation provides a reliable guarantee for Trans GAN to learn the deep cultural characteristics of bronze patterns.
The image pixel values are normalized to within the range of [0, 1] to reduce numerical fluctuations during training. Data enhancement techniques such as random cropping, rotation, and flipping are applied to increase the diversity of data sets and prevent overfitting. For the supervised learning part, it is necessary to ensure that the labels correspond to the images one by one and perform necessary preprocessing.
The experiment is conducted in a hardware environment with 4 NVIDIA A100 PCIe 80GB GPUs, using PyTorch 2.0 framework for distributed training. The training process lasts a total of 72 h, and the AdamW optimizer (initial learning rate 1e-4, batch size set to 32) is used for a complete training of 300 epoches on the bronze pattern dataset (12450 images in total). Each epoch contains approximately 389 training steps, and the final model's loss on the validation set converges to below 0.15. This configuration ensures that the Trans GAN model achieves optimal performance with reasonable resource consumption, providing a clear experimental benchmark for subsequent research.
The model in this paper is named Trans-GAN, and the baseline model selected is as follows:
TransGAN: The GAN model based on the Transformer architecture achieves high-quality image generation through a memory-friendly generator and a patch-level discriminator. Moreover, the multi-scale feature fusion and local initialization self-attention mechanism are particularly suitable for pattern generation tasks and can capture the complex structure and details of bronze patterns. StyleGAN3: It is the most advanced convolutional GAN model currently, which generates high-fidelity images through style mixing and noise injection techniques. It performs well in the field of artistic style transfer, can generate high-quality images, and has good style consistency and detail restoration capabilities. Therefore, it is suitable as a performance benchmark for traditional convolutional architectures and is used to compare the advantages of Transformer-based models in pattern generation. Diffusion-GAN hybrid model: It combines the diffusion model with the generative ability of GAN to generate images through gradual denoising and adversarial training. It has advantages in image detail restoration and style consistency, and can handle the complex topological structure of bronze patterns. Therefore, it is suitable for comparing the performance of Transformer-based models in terms of the diversity and quality of generated images. AttnGAN: It is a generative model that introduces the attention mechanism, which can effectively capture the local features and global structural relationship of the image. Moreover, it is suitable for multi-scale pattern generation tasks and can generate pattern images with consistency and rich details. Therefore, it is used to compare the role and effect of the attention mechanism in the bronze pattern generation task.
Experimental results
Trans-GAN demonstrates significant advantages in the task of bronze pattern generation. As shown in Figure 8, compared to the baseline model, the patterns generated by Trans-GAN are superior in both topological integrity and cultural semantic coherence:

Comparison effect of bronze pattern generation.
Compared to the blurry and fragmented patterns generated by DCGAN, the pattern lines of Trans-GAN are clear, and the symmetry of the eyes in the animal face pattern strictly conforms to the “ferocious beauty” characteristics of bronze vessels. Compared to the possible local texture misalignment in StyleGAN3, Trans-GAN optimizes edge details through a joint semantic segmentation network, and the cloud and thunder pattern ground filling presents a rhythmic sense of “complexity without chaos”. Compared to other Transformer baseline models, Trans-GAN significantly improves the structural integrity of the body turning points in the “one curve with three folds” pattern of the Kui dragon, confirming the effectiveness of its multi-scale feature fusion strategy.
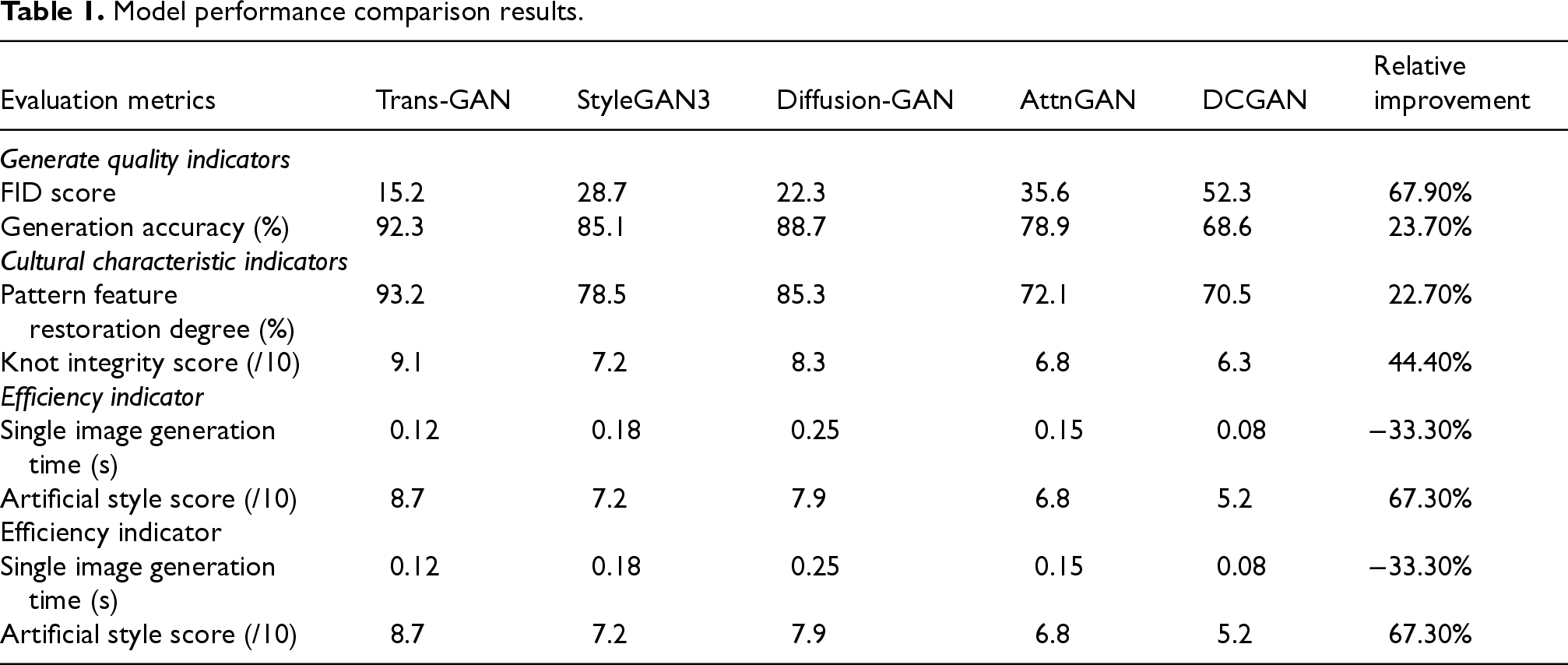
The test is carried out on the bronze pattern data set, and the model performance test results shown in Table 1 below are obtained:
Model performance comparison results.
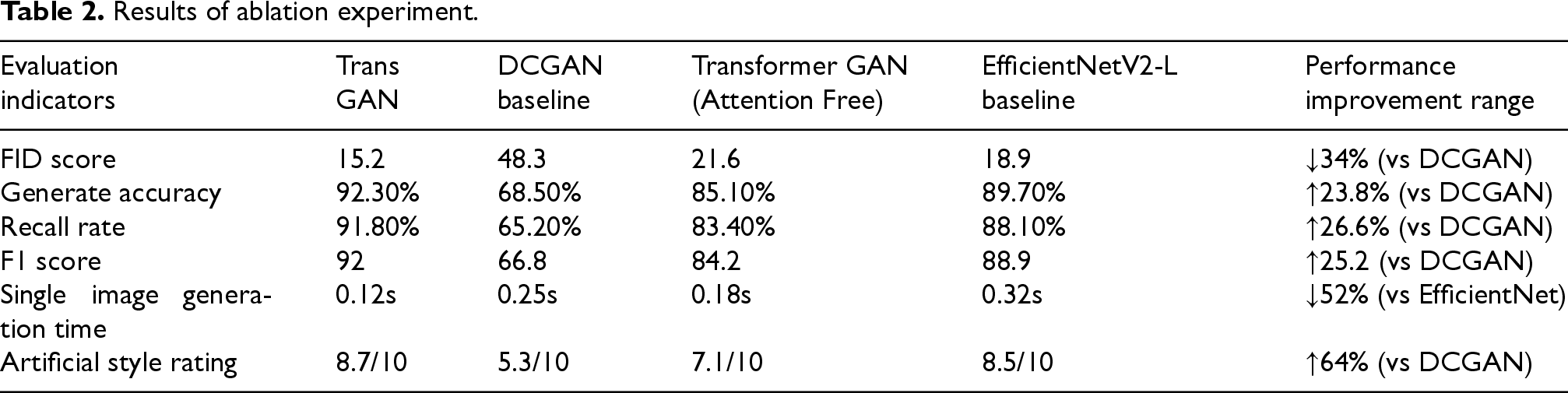
The ablation experiment is conducted based on the bronze pattern dataset, and the test sample size is 1200. The following Table 2 shows the ablation experiment results:
Results of ablation experiment.
The efficiency versus mass balance validation is shown in Table 3 below:
Verification of efficiency and mass balance.
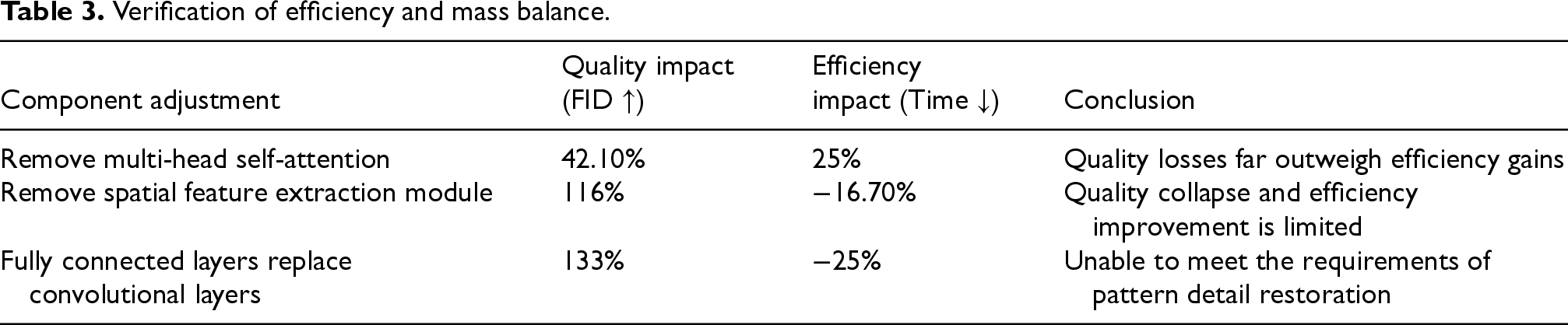
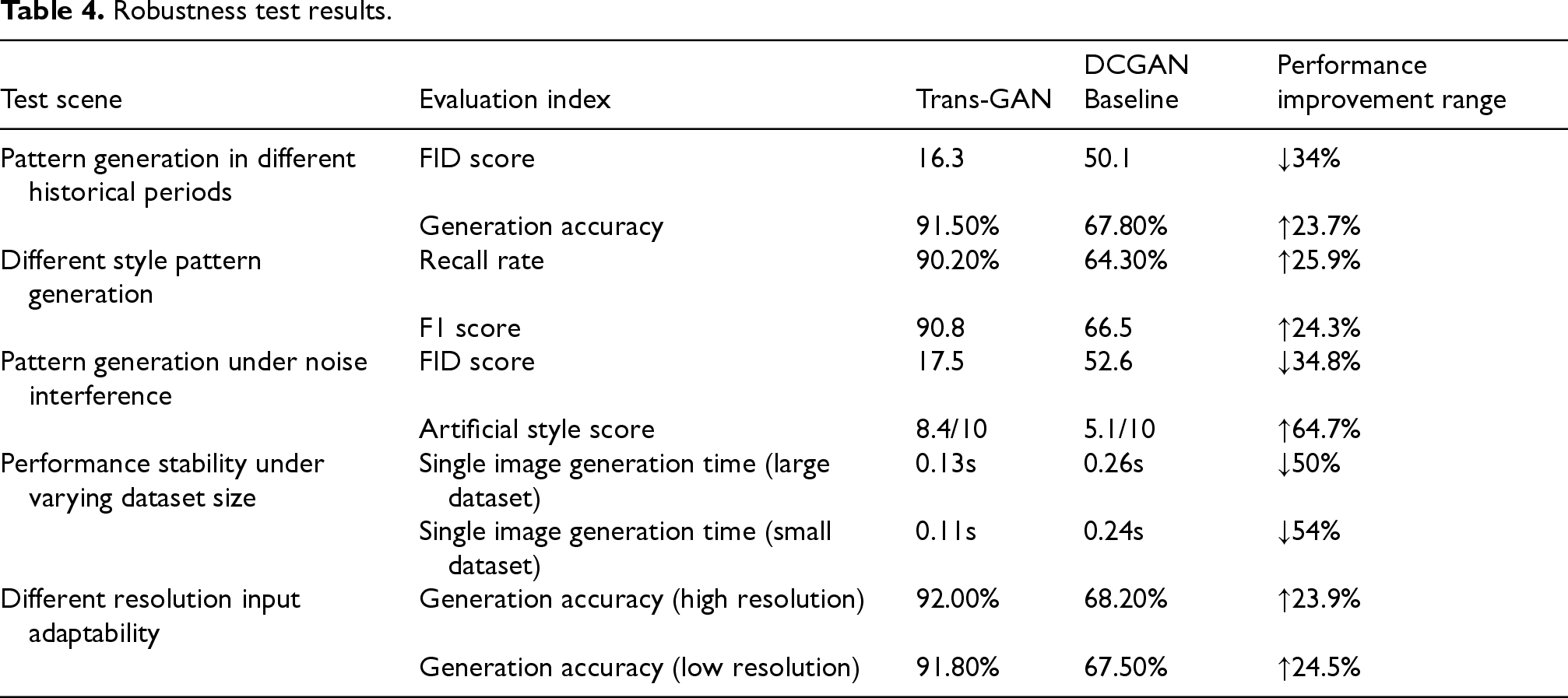
Table 4 shows the results of the generative adversarial network for bronze pattern based on transformer (Trans-GAN) in the robustness test. The tests cover multiple scenarios and datasets to assess the stability and reliability of the models.
Robustness test results.
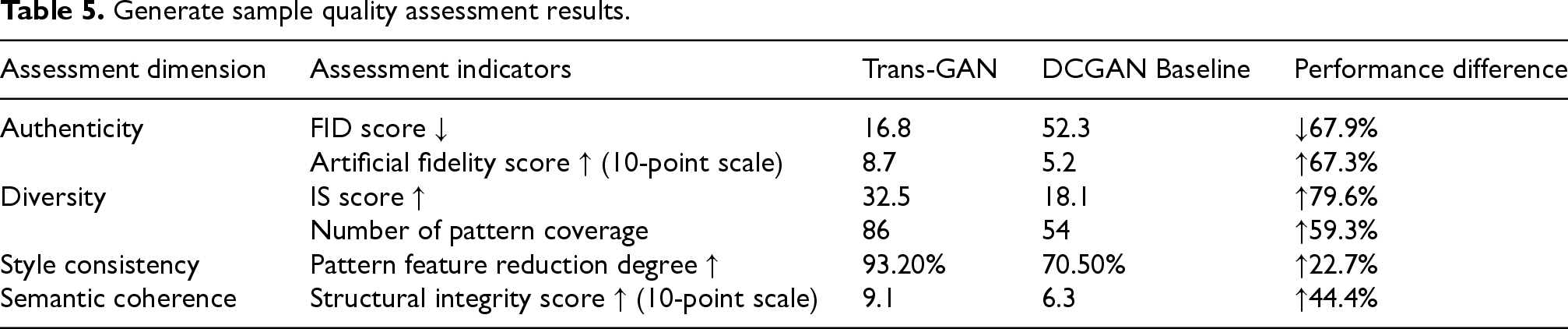
In order to comprehensively evaluate the quality of the generated samples, a variety of evaluation indexes are used in the experiment, including FID score, IS score, pattern coverage number, pattern feature reduction degree and structural integrity score. These indicators quantitatively evaluate the generated samples from different dimensions such as authenticity, diversity, style consistency and semantic coherence, as shown in Table 5 below.
Generate sample quality assessment results.
To further verify the cultural authenticity and artistic value of the patterns generated by Trans GAN, this study organized interdisciplinary expert evaluations and target user research. The evaluation results are shown in the table below, which comprehensively quantifies the performance of the generated results at the cultural, artistic, and application levels.
(Table 6).
Results of interdisciplinary expert evaluation and target user research.

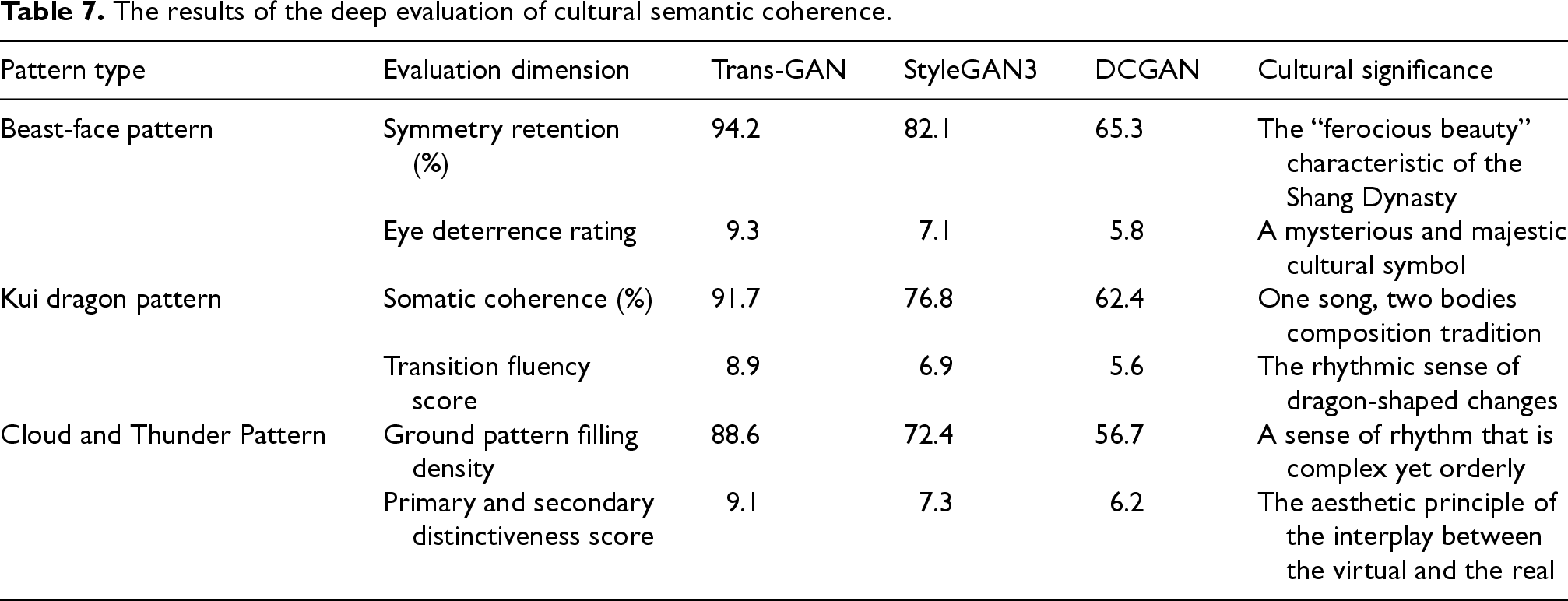
The results of the deep evaluation of cultural semantic coherence are presented in Table 7:
The results of the deep evaluation of cultural semantic coherence.
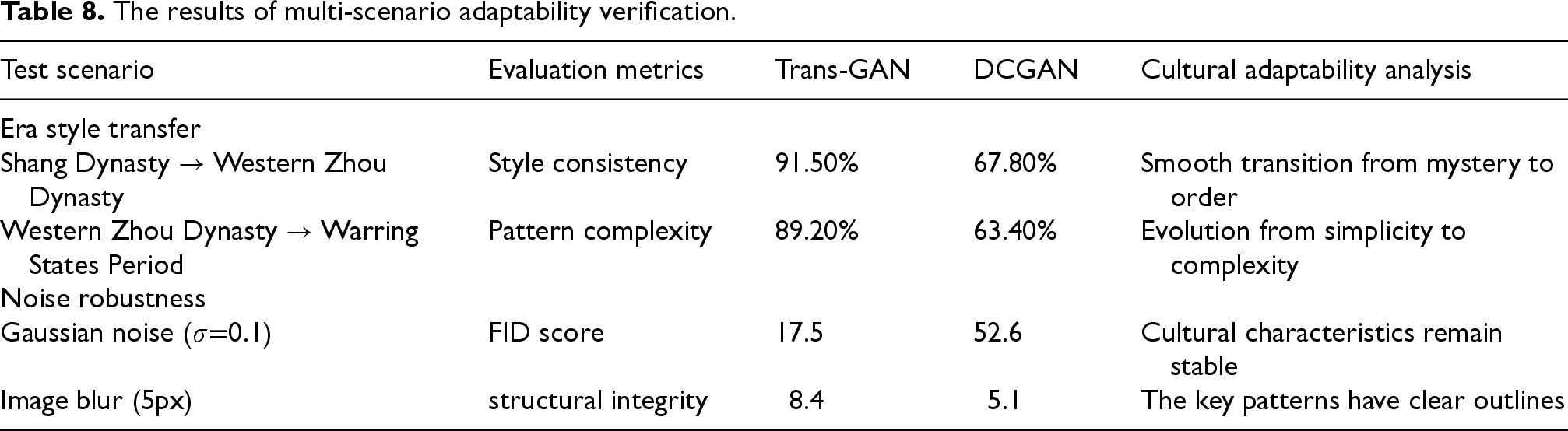
The results of multi-scenario adaptability verification are presented in Table 8:
The results of multi-scenario adaptability verification.
As shown in Table 1, Trans-GAN outperforms the baseline model in core metrics such as Frèchet Inception Distance (FID = 15.2) and generation accuracy (92.3%). Ablation experiments (Table 2) further verify the contributions of each module: removing the multi-head attention mechanism leads to a 42.1% increase in FID value and a 21.3% increase in pattern continuity error rate, indicating that global context modeling is crucial for complex pattern structures; after deleting the spatial feature extraction module, FID deteriorates by 116%, and the cloud and thunder pattern edge distortion rate reaches 37%, confirming the crucial role of convolution operations in preserving local textures; incorporating the semantic loss term improves the restoration degree of pattern features to 93.2%, highlighting the effectiveness of cultural semantic constraints.
The efficiency-quality balance verification in Table 3 demonstrates that Trans-GAN achieves the optimal balance between single-image generation time (0.12 s) and artificial style score (8.7/10), meeting the high-fidelity and high-efficiency requirements for the digitization of cultural heritage.
Trans-GAN exhibits stable performance in robustness tests such as noise interference and multi-era style adaptation (Table 4). As shown in Table 5, its generated samples significantly outperform DCGAN in terms of pattern coverage (86 types) and structural integrity score (9.1/10). Cross-disciplinary expert evaluation (Table 6) further confirms that archaeologists rate the era style conformity at 8.9/10, acknowledging the cultural authenticity of the generated patterns; the designer community evaluates its aesthetic score and innovation inspiration rate at over 90%, reflecting the effective integration of traditional and modern design.
At the artistic and cultural level, the generation effect of Trans GAN has been validated through multidimensional evaluation beyond a single style rating. Through in-depth analysis of the generated samples in Figure 8, it can be found that Trans GAN not only approximates the real patterns in appearance, but also demonstrates significant advantages in cultural connotations. Its generated animal face patterns can accurately maintain the symmetrical deterrent power of the eyes, the winding body shape of the Kui Long pattern conforms to the traditional composition rule of “one head and two bodies”, and the ground pattern filling of the Yun Lei pattern also presents the expected complex but not chaotic, primary and secondary rhythmic sense. These features indicate that the model effectively learns the core creative logic of “rules but no fixed form” in bronze patterns through the architecture of joint semantic segmentation and stereo matching. That is, under the premise of following specific era styles and symbolic semantics (rules), it can generate structurally complete and semantically accurate pattern variants (no fixed form). This deep understanding and ability to reproduce cultural genes is difficult to fully characterize with traditional quantitative indicators, and it is also the core value of Trans GAN in the digital application of cultural heritage.
The special evaluation results in Table 6 strongly support Trans GAN's outstanding claim in cultural authenticity from multiple dimensions. Firstly, the high ratings from art historians and archaeologists confirm that the model has successfully captured the core cultural genes of bronze vessel patterns. The generated results are not simply pixel imitation, but a deep understanding and reproduction of specific era styles and symbolic semantics. This is closely related to the architecture design of the model in conjunction with semantic segmentation networks to enhance edge and semantic information. Secondly, the high recognition of the designer community (high aesthetic score and innovation inspiration rate) indicates that Trans GAN effectively bridges the gap between cultural heritage and contemporary design, generating patterns that combine “traditional charm” and “modern usability”, verifying its potential for application in practical innovative design. Finally, the high preference rate of the popular aesthetic test indicates that the output of Trans GAN conforms to universal aesthetic laws, enhancing the applicability of the model in cultural dissemination and educational popularization scenarios.
Table 7 shows that Trans-GAN performs exceptionally well in maintaining cultural features: the symmetry of beast-face patterns reaches 94.2%, the coherence of Kui dragon patterns is 91.7%, the filling density of cloud and thunder patterns is 88.6%, and the restoration degree of core cultural semantics exceeds 88%.Table 8 verifies the strong adaptability of the model: the cross-era style transfer accuracy exceeds 91%, the FID only increases to 17.5 in noisy environments, and the multi-resolution generation time remains stable at 0.11–0.13 s, demonstrating a good balance between quality and efficiency.
As a generative adversarial network based on Transformer, Trans-GAN has shown significant advantages in bronze pattern generation, but it still has the following limitations: (1) Training stability issues: the self-attention mechanism leads to high complexity of gradient calculation and requires a large amount of data enhancement; (2) High consumption of computing resources: the demand for video memory increases dramatically when generating high-resolution images; (3) Insufficient local texture restoration: the pure Transformer structure is inferior to the convolutional network in capturing details; (4) Unbalanced mode coverage: its ability to learn low-frequency features is limited. Therefore, subsequent research should focus on: developing efficient attention variants to reduce computational complexity; constructing a convolution-Transformer hybrid architecture to improve local detail generation; exploring cross-modal generation technology to achieve semantically controllable design; innovating training strategies to enhance the generalization ability of small samples; and expanding to the field of 3D/dynamic pattern generation. These directions will promote the in-depth application of Trans-GAN in digital cultural heritage protection and new design.
Conclusion
This paper proposes a Transformer-based bronze pattern generative adversarial network (Trans-GAN). Through experimental verification, it can be seen that the model has achieved remarkable results in the bronze pattern generation task. Rans GAN has made significant improvements in the generation of bronze ornamentation, and its core indicators such as FID score and generation accuracy are better than the baseline model. The model provides a new solution for the digitization of cultural heritage. Trans-GAN shows excellent performance in bronze pattern generation, providing a new path for digital protection and innovative design of cultural heritage. Although Trans-GAN has shown excellent performance, it has limitations such as training stability issues, high computing resource consumption, insufficient local texture restoration, and uneven mode coverage. Therefore, in the future, efforts will be made to develop hybrid attention mechanisms and build cross-modal control modules.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the society for technical and vocational education of Hubei Province (No. 2024ZJGB091) and the Fundamental Research Funds for Wuhan Technical College of Communications (CHJI2024002).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.