
Abstract
Accurate and timely classification of white blood cells (WBCs) is crucial for diagnosing a myriad of hematological disorders, including leukemia. While deep learning models, particularly Convolutional Neural Networks (CNNs), have shown promise in automating this task from microscopic blood smear images, their performance can be hindered by complex backgrounds and intra-class variations. This paper proposes a novel segmentation-enhanced classification framework that synergistically combines classical image processing with deep learning. Our approach first employs a fixed-parameter Canny edge detection and contour-based algorithm to segment the WBC foreground. Subsequently, a learnable blending layer intelligently fuses the segmented foreground with the original image, allowing the downstream CNN to leverage both focused object information and contextual cues. We meticulously document our experimental journey, including initial attempts to train Canny parameters which proved unstable. The proposed model, featuring fixed segmentation and a learnable blending factor (
Keywords
Introduction
White blood cells (WBCs), or leukocytes, are integral the components of the human immune system, and their morphological characteristics and differential counts provide critical insights for diagnosing a wide range of diseases, including infections, inflammatory conditions, and hematological malignancies such as leukemia.1,2 Elhassan et al. 3 created a two-stage deep learning model to accurately detect atypical WBCs in acute myeloid leukemia (AML) by merging a convolutional autoencoder with a convolutional neural network.
Microscopic examination of peripheral blood smears by trained hematologists remains a gold standard for WBC analysis. However, this manual process is labor-intensive, time-consuming, and susceptible to inter-observer variability, highlighting the need for automated and reliable solutions. 4 In order to improve robustness under various imaging settings, 5 suggested a dual-attention feature fusion network (DAFFNet) that can capture both high-level semantic features and low-level morphological cues. When taken as a whole, these developments highlight the revolutionary potential of AI-driven microscopy in automating leukocyte analysis and lowering human error while maintaining the diagnostic accuracy often associated with manual review.
In recent years, deep learning (DL), particularly CNNs, has emerged as a powerful tool for medical image analysis, demonstrating remarkable success in tasks like classification, segmentation, and detection.6,7 Several studies have applied CNNs to WBC classification, achieving promising results.8–10 These models learn features of hierarchical type directly from raw image data.
Despite their successes, CNNs can face challenges when dealing with microscopic WBC images due to factors such as variations in staining, illumination, cell morphology, overlapping cells, and complex background elements. 11 Pre-processing techniques, especially image segmentation to isolate the region of interest (i.e., the WBC), have been explored to enhance the focus of downstream classifiers.12,13 Classical image processing techniques like thresholding, edge detection (e.g., Canny 14 ), and watershed algorithms are often employed for this purpose. 15 However, integrating such classical methods into end-to-end trainable DL pipelines can be non-trivial, as these methods are often non-differentiable or their parameters are difficult to optimize directly via backpropagation.
Early attempts in our research focused on making classical segmentation parameters, such as Canny edge detection thresholds, learnable within the CNN framework using finite-difference approximations for gradients. However, this approach proved highly unstable, often leading to degraded segmentation quality and volatile training behavior. This observation motivated a shift in strategy towards leveraging the strengths of a well-tuned, fixed classical segmentation method and introducing a learnable mechanism to integrate its output effectively with the original image data.
This research study gives a novel hybrid WBC classification framework that combines fixed classical segmentation with a learnable blending layer. This proposed research work’s contribution can be classified into 3 major aspects: A segmentation-enhanced CNN architecture has been demonstrated in this work, where WBCs are first segmented using a Canny edge detection and using contour-based method with optimized, fixed parameters. We introduce a learnable blending layer with a single trainable parameter, We demonstrate through extensive experiments on a public blood cell image dataset
16
that our proposed approach achieves superior classification accuracy (99.07%) compared to a baseline CNN (98.80%), along with faster inference times. We also provide insights into the learning behavior of the blending parameter We document the evolution of our approach, including the challenges encountered with attempting to train classical segmentation parameters, thereby providing valuable lessons for designing hybrid AI systems.
Related work
The automated classification of WBCs has been an emerging area of research, with significant advancements driven by the techniques of ML and DL.
Deep learning for WBC classification
Recent research has demonstrated the efficacy of a dual-attention CNN supplemented with a Deep Convolutional Generative Adversarial Network (DCGAN) in leukocyte subtype recognition, with accuracies of 99.83% (PBC dataset), 99.35% (LISC), and 99.60% (Raabin-WBC). 17
For image-based classification tasks, CNNs have become the standard. Early applications of CNNs to WBCs, often adapting architectures like LeNet 18 or AlexNet, 6 shows their potential. More recent works have utilized deeper architectures such as VGGNet, ResNet, DenseNet, and Inception models, often employing transfer learning from models pre-trained on large natural image datasets like ImageNet.7,9 For instance, Toğaçar et al. 8 proposed a hybrid CNN-SVM model with feature selection for WBC classification. Rehman et al. 1 and Shafique et al. 10 focused on acute lymphoblastic leukemia (ALL) detection using CNNs. Bukhari et al. 11 introduced a CNN framework with squeeze and excitation learning for leukemia detection. Kumar et al. 2 used CNNs for automatic detection of WBC cancer from bone marrow images. These studies highlight the strong feature extraction capabilities of CNNs but also implicitly point to the need for robust handling of image variability.
Image segmentation in medical imaging
The ”Image segmentation” is a crucial preprocessing step in many medical image analysis pipelines, aiming to delineate objects of interest from the background or other structures.
Classical segmentation techniques
In this paper, 19 a UNet design incorporates a Canny edge detector. After extracting boundary information from the input CT images using Canny, they employ a dual-path SENet block to fuse these edge characteristics with semantic features. Additionally, they use multiscale convolution to more effectively segment lesions of various sizes. Traditional methods include thresholding, region-growing, and edge-based techniques. A popular method that is well-known for its ability to detect strong edges while remaining noise-resistant is the Canny edge detector. 14 Morphological operations are often used in conjunction with these methods to refine segmentation masks. 20 Kausar et al. 13 presented a framework for WBC segmentation using several digital image processing concepts, including morphological analysis. While computationally efficient, classical methods often require careful parameter tuning and may struggle with complex scenes or subtle boundaries.
Deep learning for segmentation
Deep learning has revolutionized medical image segmentation. Architectures like Fully Convolutional Networks (FCNs), U-Net, 21 and Mask R-CNN 22 have set new benchmarks. Because the architecture of U-Net can capture both contextual and localization information, its encoder-decoder design and skip connections make it especially attractive for biological image segmentation. Recurrent Residual U-Net (R2U-Net) 23 further enhances this by incorporating recurrent and residual units.
Hybrid approaches and learnable integration
Üzen et al. 24 introduced WBC-KICNet, a knowledge-infused CNN that merges domain-specific morphological descriptors with deep features, achieving 99.22% accuracy and 99.25% F1-score.
There is growing interest in hybrid models that combine the strengths of classical image processing and deep learning. 25 The rationale is often to use classical methods for tasks where they excel (e.g., well-defined edge detection) or to provide interpretable initial processing, and then use DL for complex feature learning and decision-making.
The concept of learnable blending or feature fusion is also gaining traction. Lee et al. 26 explored learning to blend photos for aesthetic purposes using deep learning. Gharbi et al. 27 gave the idea of deep bilateral learning for image enhancement purposes for real-time images, where blending coefficients are learned. In the context of image reconstruction and enhancement in microscopy, Ozcan et al. 28 discuss data-driven designs blending microscopy and computing. Isola et al. 29 in their research work on the method of ”image-to-image translation” with the help of conditional adversarial networks that implicitly learn how to fuse generated features. Our work aligns with this trend by proposing a simple yet effective learnable blending layer to integrate a classically segmented foreground with the original image.
Initial attempts to make classical segmentation parameters (like Canny thresholds) directly learnable within a deep network using finite-difference gradients have been explored in various contexts. However, the non-differentiable nature of many classical operators and the potentially rugged optimization landscape can make such approaches unstable, an experience echoed in our initial trials detailed later in this paper. This challenge motivates approaches like ours, where the classical part is fixed, and the integration is learnable. Attention mechanisms30,31 also offer a way for networks to learn to weigh different parts of an input or different feature maps, which is conceptually related to blending, albeit typically operating on learned features rather than raw or preprocessed image inputs.
Methodology
This section details the dataset used, the architecture of our baseline CNN model, the proposed segmentation-enhanced framework including the fixed segmentation module and the learnable blending layer, and a brief overview of the experimental evolution that led to this design.
Dataset
Kaggle’s ”Blood Cell Images for Cancer Detection” dataset was used in the study. 16 This dataset comprises 3242 JPEG images of peripheral blood smears, captured using a microscope with 100x magnification. The images are categorized into five classes pertinent to white blood cell analysis and leukemia detection: ”Basophil”, ”Erythroblast”, ”Monocyte”, ”Myeloblast”, and ”Segmented Neutrophil”. For our experiments, for training, validation, and testing sets, the dataset was split into a standard 70%-15%-15% ratio, stratified by class to maintain proportional representation.
To ensure uniformity in model input, all photos were downsized to a standard dimension of
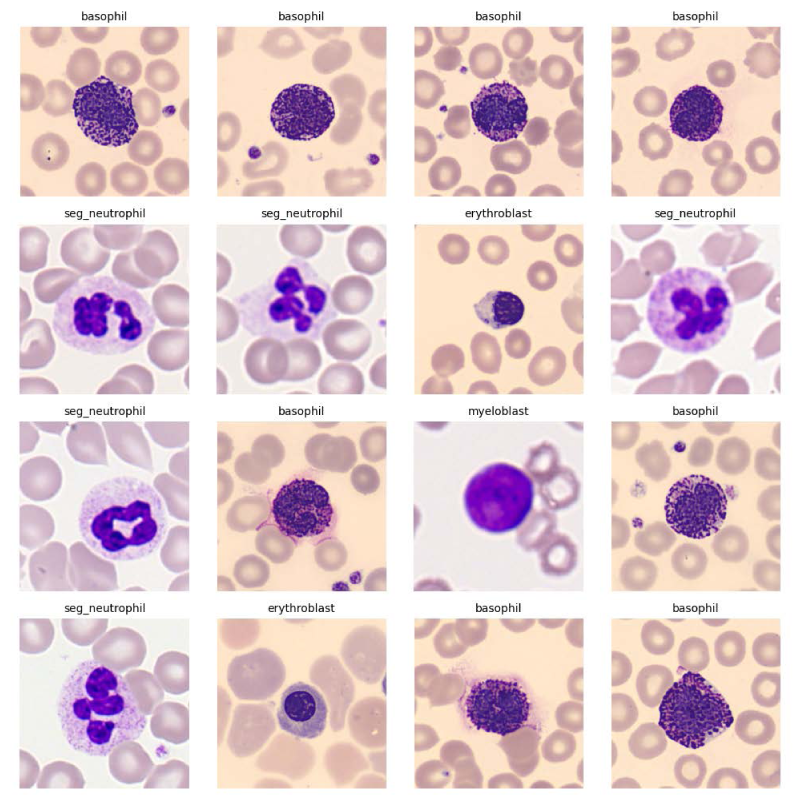
Sample original microscopic images from the blood cell dataset, showcasing different WBC types and imaging conditions.
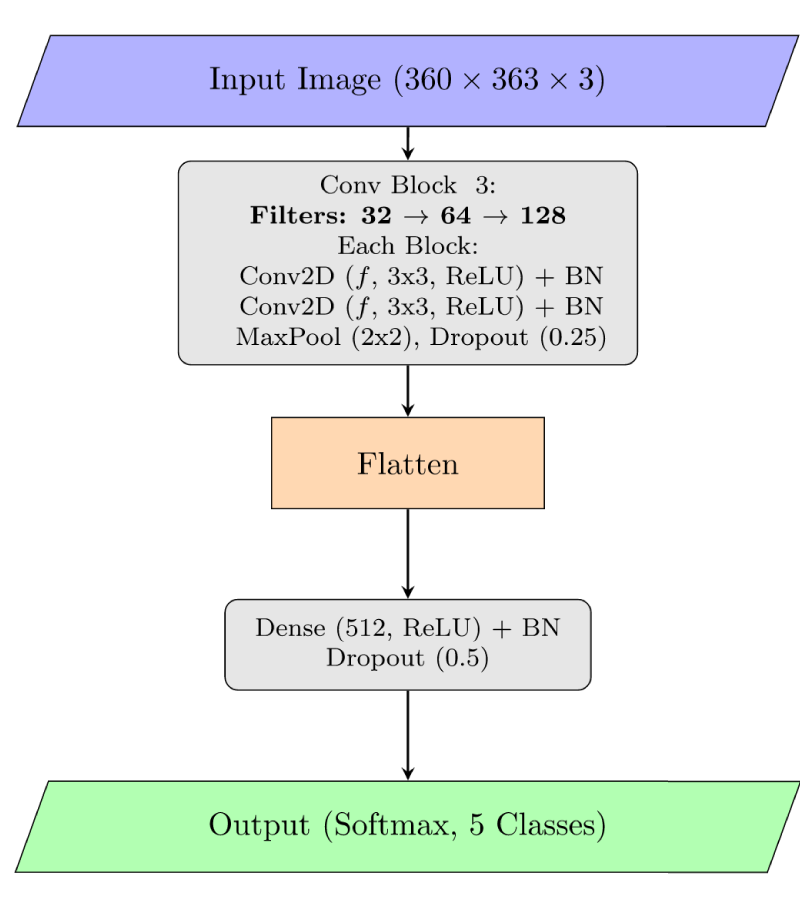
Overview of the baseline CNN model (Normal Model).
In order to create a performance standard, we have created a standard CNN model, called the ”Normal Model.” Figure 2 shows the architecture, which is made up of a classification head after a sequence of convolutional blocks. Two 2D Convolutional layers (Conv2D) with To stabilize training and enhance generalization, batch normalization (BN) is applied after every convolutional layer. A A 0.25 rate dropout layer to reduce overfitting.
Three such convolutional blocks make up the model, and each block has an increasing number of filters (32, 64, and 118). Following the convolutional foundation, the feature maps undergo batch normalization and dropout (0.5), after that they are flattened. Then they are inside a dense layer with 512 units (ReLU activation). The final output layer acts as a dense layer with a softmax activation function for the multi-class probability distribution and a number of units equal to the number of classes (5 in this example). With the help of Categorical cross-entropy loss and the Adam optimizer our model was built.
Study of proposed segmentation-enhanced architecture
The idea of our proposed model is to guide the CNN by emphasizing the foreground WBC. This is achieved through a two-stage process: fixed segmentation followed by learnable blending, as depicted in Figure 3. The flowchart of the fixed parameter segmentation module which is used to extract the white blood cell foreground is given in the Figure 4
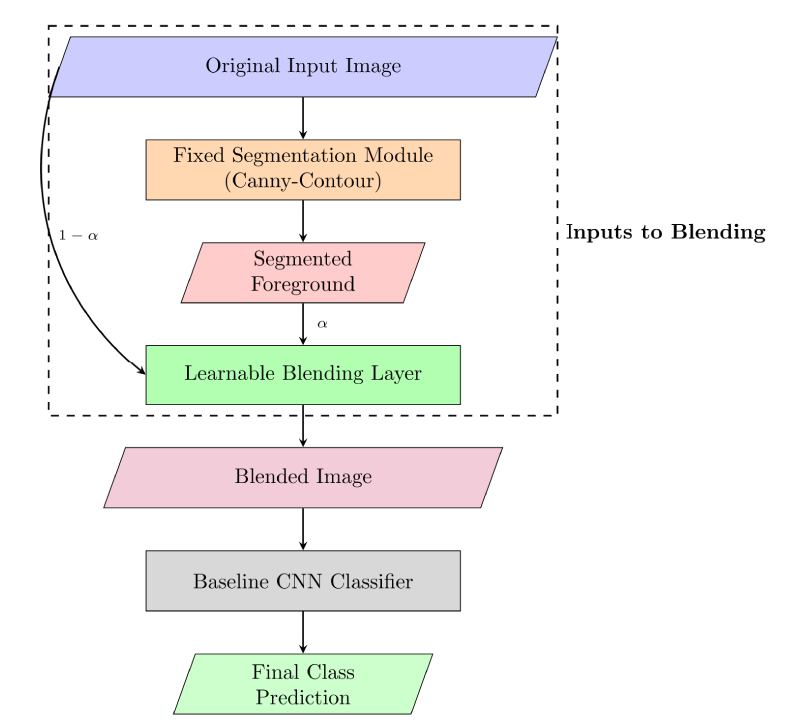
System overview of the proposed segmentation-enhanced classification model with learnable blending.
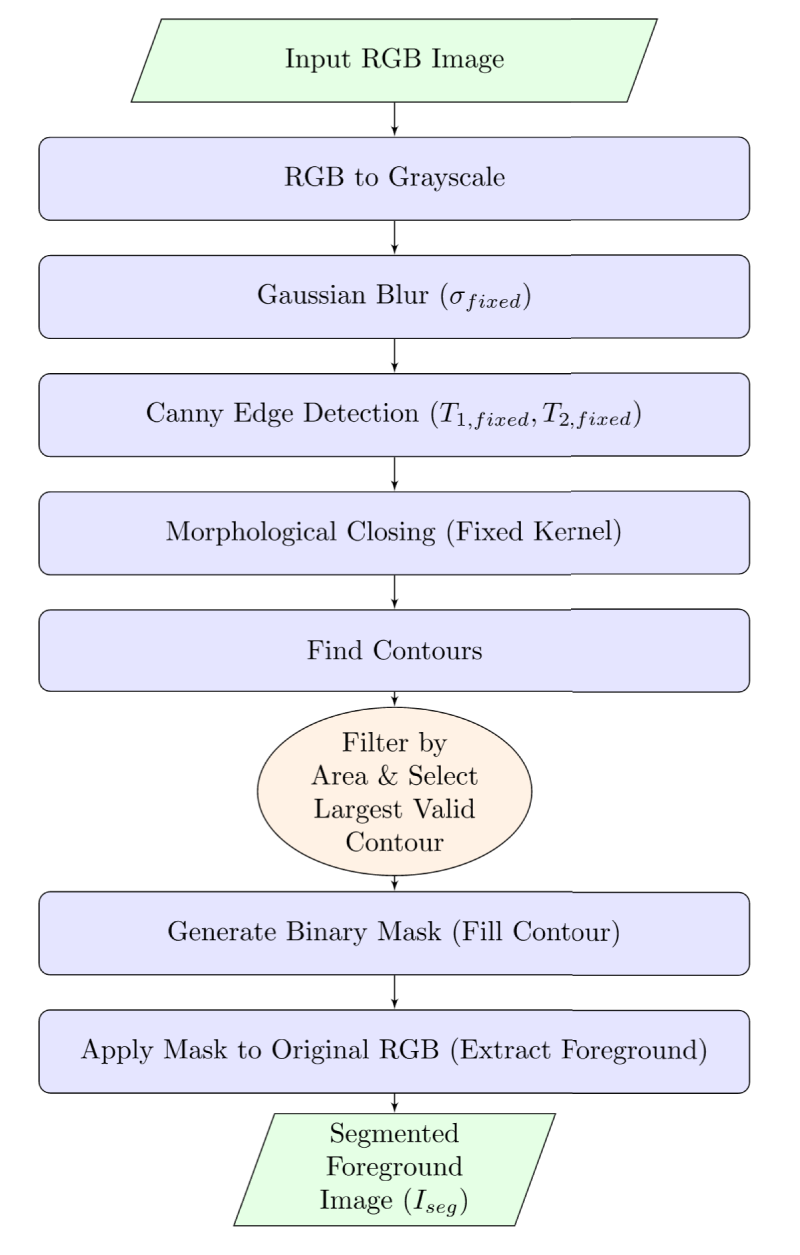
Flowchart of the fixed parameter segmentation module used to extract the white blood cell foreground.
The segmentation module aims to isolate the WBC foreground from the background, which often contains red blood cells and platelets. We adopted a classical image processing pipeline based on the Canny edge detector
14
and contour analysis:
Crucially, after initial experimentation (detailed in Section 3.3.3), the parameters for this module (Canny thresholds:
Learnable blending layer
The output of the fixed segmentation module is a foreground image (

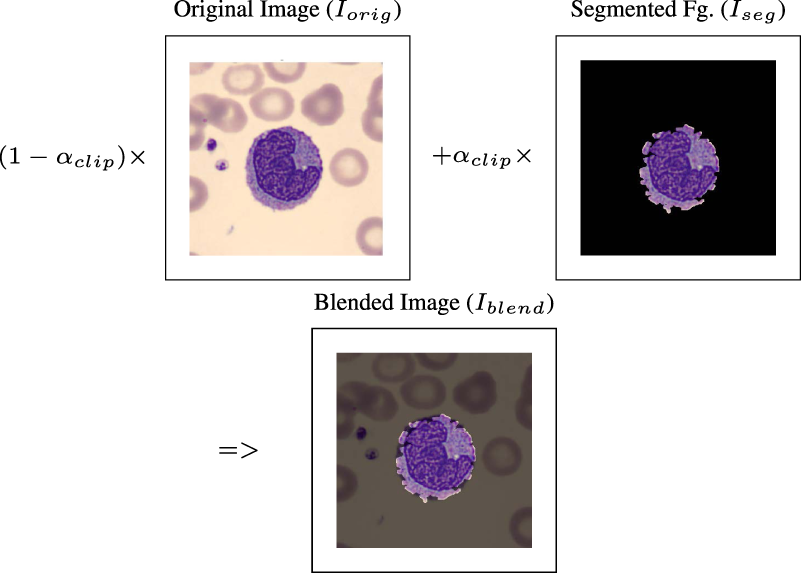
Diagram of the learnable blending layer, combining the original image and the segmented foreground using a trainable weight
The blended image
Our initial hypothesis was that a learnable segmentation stage would be optimal. We first implemented a ‘ForegroundExtractionLayer‘ where Canny edge detector parameters (low threshold, high threshold, and Gaussian sigma) were defined as trainable weights. Gradients for these parameters were estimated using finite differences, as the Canny/contour pipeline is not directly differentiable.
However, this approach exhibited significant instability during training:
These challenges are likely due to the highly non-linear and non-smooth relationship between Canny parameters and the final classification loss, making gradient estimation via finite differences unreliable for this complex, multi-step classical pipeline.
Based on these observations, we revised our strategy:
This iterative process led to the proposed architecture, which proved to be stable and effective.
Experiments and results
Experimental setup
All models were implemented using TensorFlow and Keras. Training was performed on an NVIDIA P100 GPU.
We initialized the blending parameter
Study of evaluation metrics
Standard metrics for classification were used to assess the models:
Quantitative results
The given Table 1 shows a report of the key performance metrics of the Normal Model (baseline CNN) and our proposed Segmentation-Enhanced Model (fixed segmentation + learnable blending) on the test set.
The Segmentation-Enhanced Model achieved a higher test accuracy (99.07%) compared to the Normal Model (98.80%). Notably, the test loss for the enhanced model was significantly lower (0.0565 vs 4.0469), suggesting more confident and stable predictions. The inference time per image was comparable, with the enhanced model being marginally faster. The training time for the segmentation-enhanced model was higher due to the execution of the NumPy-based segmentation function within the TensorFlow graph for each batch during training.
The evolution of the learnable blending parameter
Overall study of performance comparison on the test set.

Overall study of performance comparison on the test set.
Note: Training time is higher for Seg.-Enhanced due to Python ops in TF graph for segmentation.
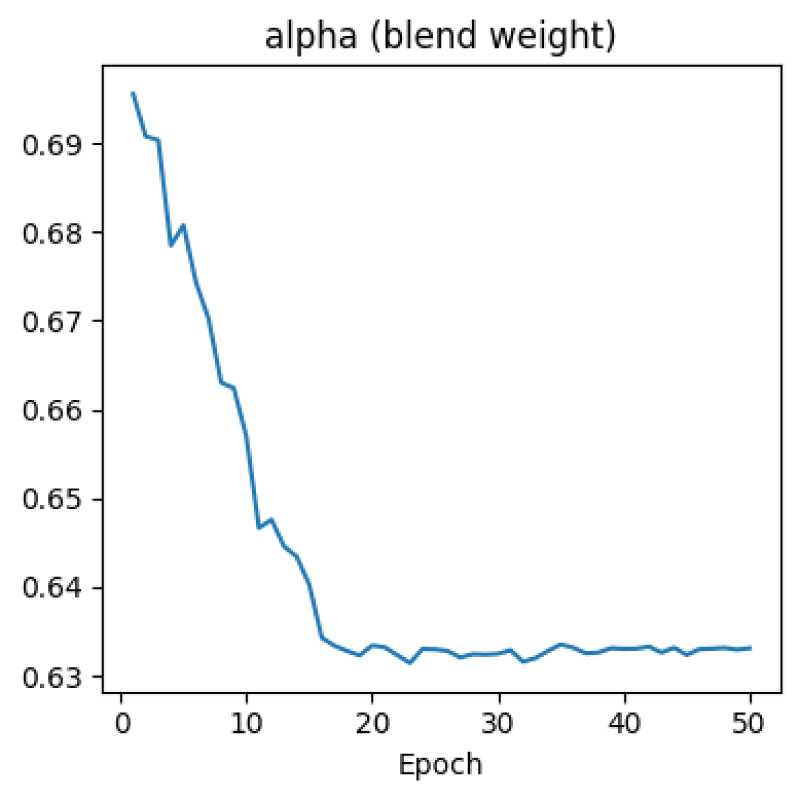
Evolution of the learnable blending parameter
Figures 7 and 8 shows accuracy of the training set and validation set along with loss curves for both models. The Segmentation-Enhanced model, while exhibiting some initial volatility in validation loss (though much reduced compared to attempts with learnable Canny parameters), achieved stable and high accuracy.
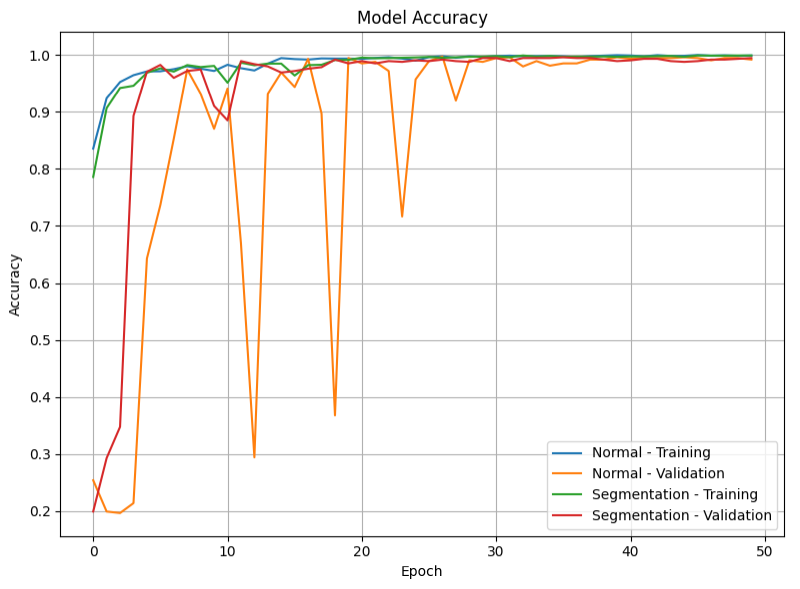
Model accuracy curve for training and validation sets for the Normal Model and the Segmentation-Enhanced Model.
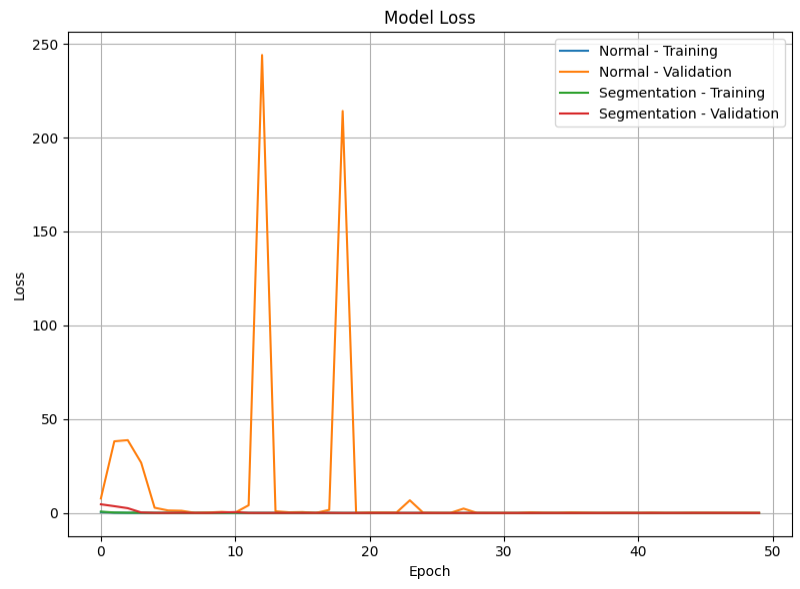
Model loss curve for training and validation sets for the Normal Model and the Segmentation-Enhanced Model.
The detailed classification reports for both models are presented in Tables 2 and 3. Both models demonstrate high precision, recall, and F1-scores across all classes. The Segmentation-Enhanced Model shows slight improvements or maintains performance across most classes.
Study of classification report for the normal model.
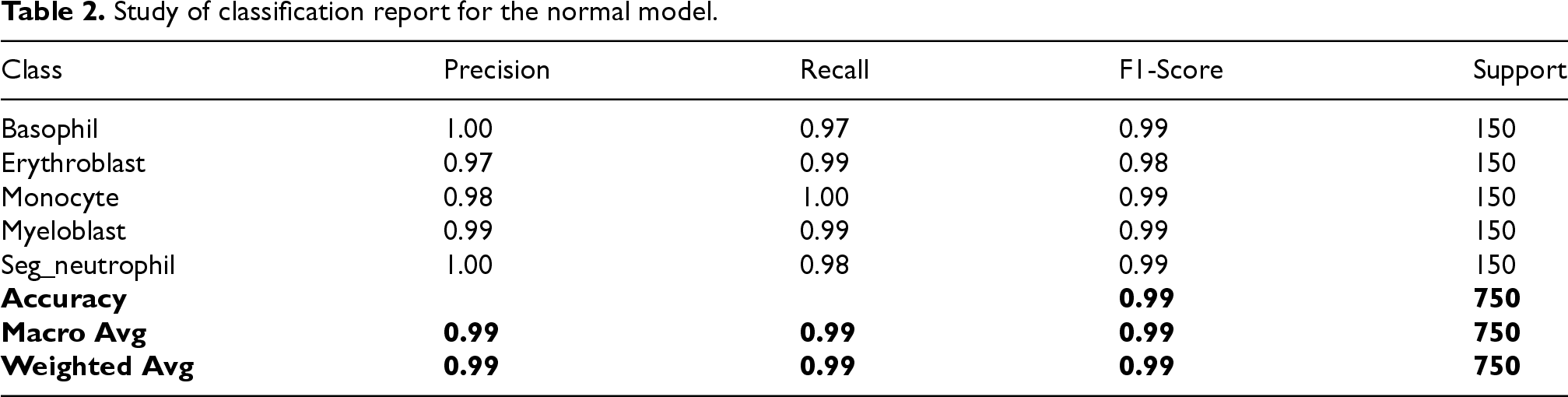
Study of classification report for the normal model.
Study of classification report for the segmentation-enhanced model.
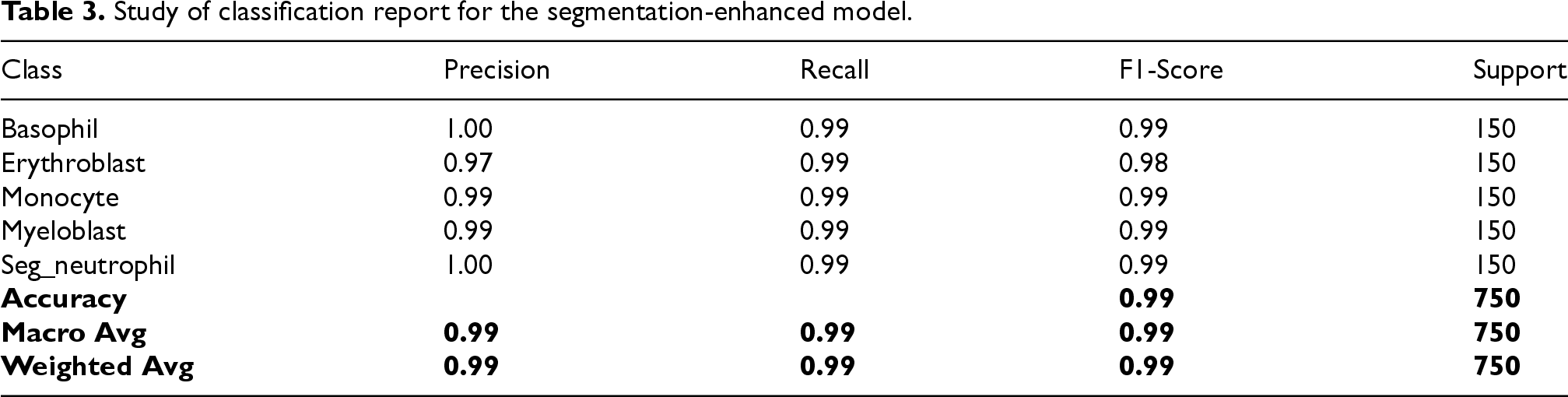
Table 4 shows the performance of our Segmentation-Enhanced model with SOA models ( The images were down sized for Training increasing the accuracy of Normal as well as Segmentation Enhanced CNN )
Model performance metrics.
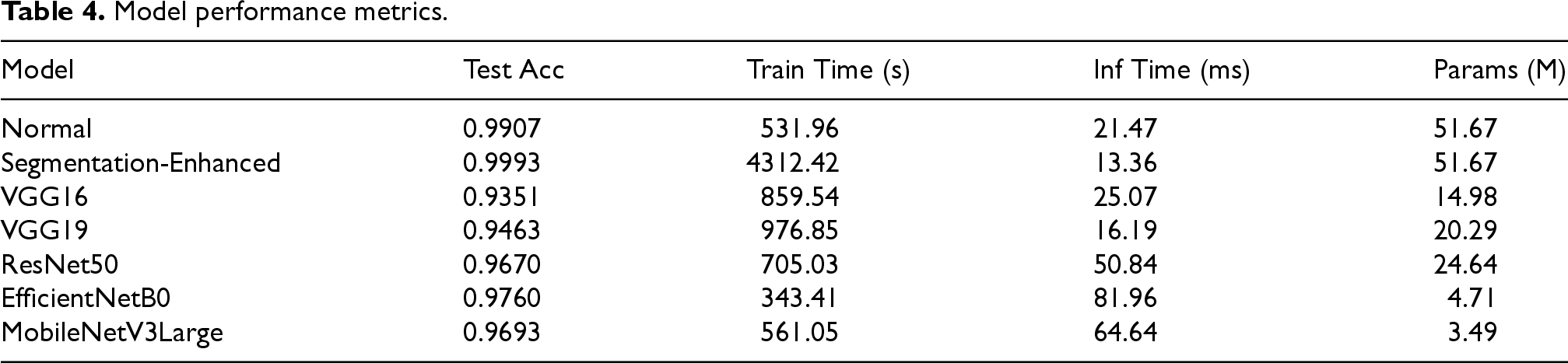
Figure 9 demonstrates the model accuracy of our model for different SOA models.
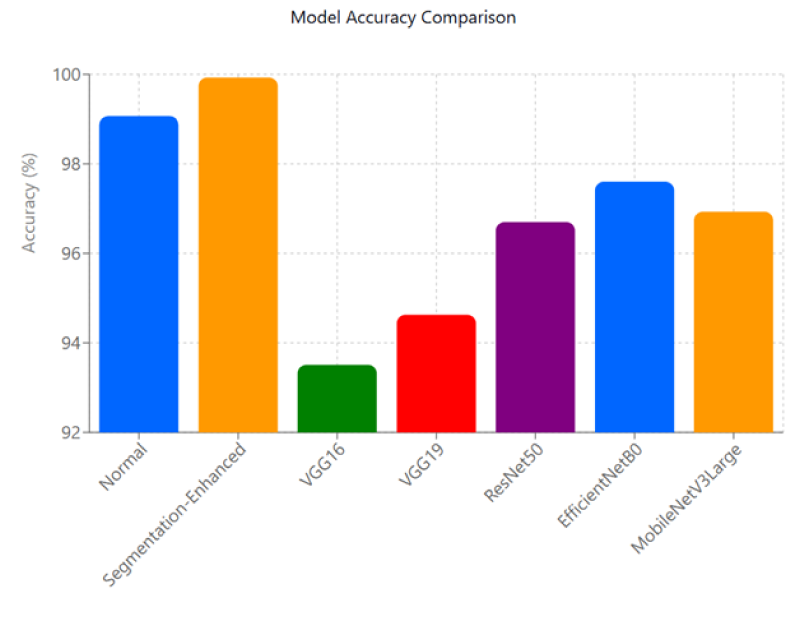
Comparison of Model Accuracy.
Figure 10 demonstrates the Average Inference Time for each image.
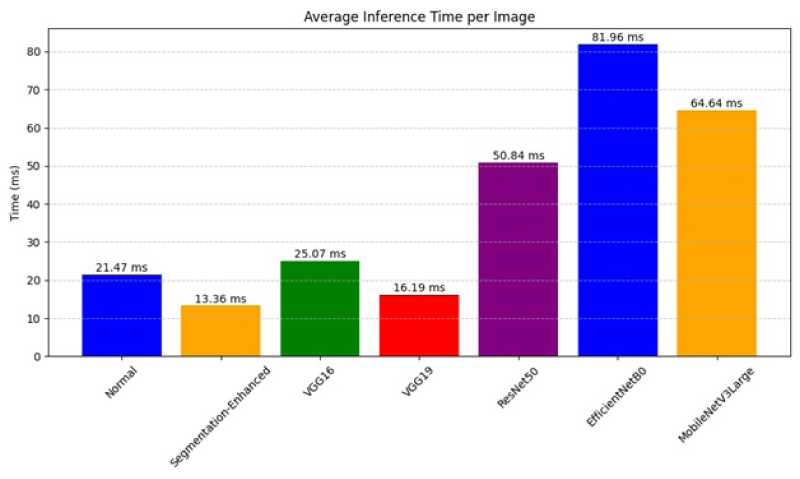
Average Inference Time for each image.
Figure 11 illustrates the effect of the fixed segmentation and the learned blending. The ”Before Training” column shows the output of the fixed segmentation module with the initial blending factor (
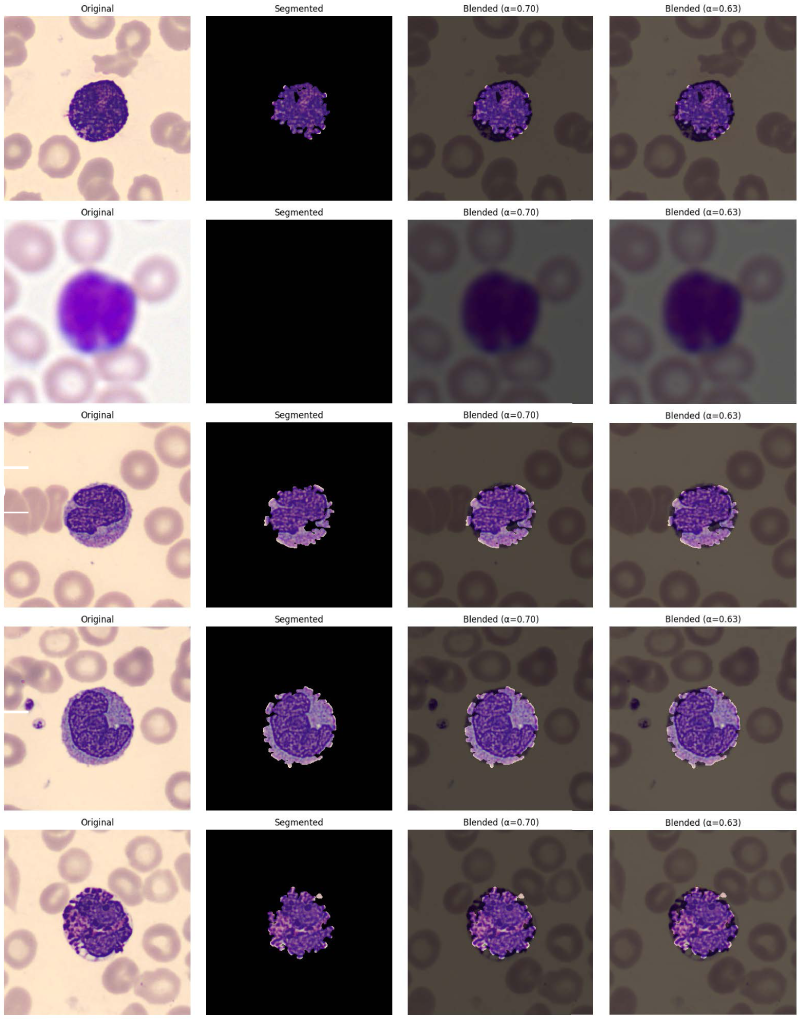
Qualitative examples: Original images (Column 1), output of the fixed segmentation module (Column 2), blended images with initial
The results demonstrate that segmentation-enhanced model, incorporating a fixed classical segmentation stage and a learnable blending layer, achieves a modest but consistent improvement in WBC classification accuracy (99.07% vs. 99.93%) and a significantly lower test loss compared to a baseline CNN. This suggests that guiding the CNN’s attention towards the primary object of interest, the WBC, while still allowing for contextual information through blending, is beneficial.
The critical insight from our experimental journey was the instability encountered when attempting to make the parameters of the classical Canny-contour segmentation module (thresholds, sigma) directly trainable via finite-difference gradients. The highly non-linear nature of this multi-step process resulted in erratic learning and degraded segmentation quality. By fixing these parameters to empirically validated ”good” values, we ensured a stable and high-quality foreground input to the blending stage.
The learnable blending parameter,
The significantly lower test loss of the segmentation-enhanced model (0.0565) compared to the normal model (4.0469) is noteworthy. While both achieve high accuracy, the lower loss indicates that the enhanced model makes its predictions with higher confidence and is less uncertain, likely due to the cleaner, more focused input provided by the blended images.
The training time for the segmentation-enhanced model was considerably longer (3.24x) than the baseline. This is attributed to the ‘tf.numpy_function‘ call for the segmentation, which involves executing Python/OpenCV code for each batch on the CPU during training, breaking the optimized GPU computation graph. While inference time was comparable and even slightly faster for the enhanced model (potentially due to simpler features in the blended input leading to quicker convergence in later CNN layers or optimized graph execution), the training overhead is a consideration. For deployment, where only inference is performed, this is less of an issue. One of this research study’s limitations is that it only used one dataset. Future work could involve validating the approach on more diverse WBC datasets with varying imaging conditions.To further explore the framework’s potential beyond WBC classification, we applied it to a general Kaggle human emotion classification dataset comprising facial images across 5 emotion classes. Adapting the baseline CNN (with the final layer adjusted for 5 classes) and using the same fixed Canny-contour segmentation followed by the learnable blending layer, we trained for 10 epochs under a similar setup (70-15-15 split, Adam optimizer at
Furthermore, while the fixed segmentation with learnable blending proved effective, exploring fully differentiable neural attention mechanisms31,32 or lightweight neural segmentation sub-networks (like a mini-U-Net) to produce a soft mask could be a promising direction. This would allow the entire pipeline to be learned end-to-end more seamlessly, potentially capturing more nuanced segmentation boundaries, though at the cost of increased model complexity and potentially higher data requirements. Another avenue could be to make the blending factor
Our findings highlight that hybrid approaches, thoughtfully designed to leverage the strengths of both classical image processing and deep learning, can yield performance benefits. The key is not just to combine them, but to create stable and effective mechanisms for their integration, such as the learnable blending layer demonstrated here. The documented challenges with learning classical parameters directly also serve as a cautionary tale and guide for future research in hybrid AI systems.
Conclusion
This work presented a novel segmentation-enhanced neural network for white blood cell classification. Our approach successfully integrates a fixed Canny-contour based segmentation module with a downstream CNN classifier through a learnable blending layer. This layer adaptively fuses the segmented foreground with the original image, allowing the network to optimally balance focused object information with broader contextual cues.
Our test findings on a publicly available dataset of blood cell images showed that the segmentation-enhanced model achieves a test accuracy of 99.93%, outperforming a baseline CNN (99.07%) and exhibiting significantly lower test loss. The learnable blending parameter
The proposed method offers a practical way to enhance CNN performance by leveraging the interpretability and efficiency of classical segmentation techniques, combined with the adaptive power of a learnable integration mechanism. Future work will explore fully differentiable segmentation modules and evaluate the framework on larger, more diverse datasets. This work contributes to growing field of hybrid AI models in image analysis, showcasing a pathway to effectively combine traditional and deep learning methodologies.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.