
Abstract
This paper presents a novel prediction model for Regional Economic Development (RED) levels using the Self-Organizing Map (SOM) algorithm. It posits that the SOM algorithm can effectively forecast RED levels by processing multidimensional datasets that include economic, social, and environmental indicators. The approach involves constructing an Evaluation Index System (EIS) comprising 14 indicators across three domains: financial performance, social conditions, and ecological sustainability. The performance of the SOM model is compared to the traditional Support Vector Regression (SVR) model. The analytical tools utilized in this study include the SOM neural network and the SVR model, both applied to predict the Gross Domestic Product (GDP) and the Consumer Price Index (CPI) in Region C. The SOM model achieves a relative error of 0.01% in predicting GDP and 0.12% in predicting CPI, outperforming the SVR model. Additionally, the model is applied to forecast the economic development levels of two Chinese provinces from 2026 to 2035, revealing significant regional disparities. The findings suggest that the SOM algorithm is a promising tool for predicting RED, providing valuable insights for policy-making processes.
Keywords
Introduction
As China's socialist market economic reform continues to deepen, China has gradually established a market-based economic model with macro-guidance by the central government. Such a model has effectively generated much economic growth, with increasing emphasis being placed on RED. Regional economic systems themselves are multi-dimensional systems determined by economic, political, resource, technical, and educational forces. Interactions among such forces lead to highly nonlinear data whose forecasting is especially problematic.1–3 In China, data available about economic operations being limited complicates these even more, with additional issues being placed on using conventional forecasting as well as analytical methodology. 4 Additionally, the planned economy legacy has made some local governments depend on policymakers’ subjective decisions instead of macroeconomic planning, resulting frequently in coarse and inaccurate management decisions with limited rigorous quantitative analysis.5–8 These management practices depend heavily on local decision-makers’ expertise, thus compromising their robustness and accuracy to a considerable extent. 9 It is critical to transition from management-based decision-making to more scientific data-driven decision-making. 10
To address these challenges, the integration of digital technologies in regional economic management is critical. Digital infrastructures equipped with sensors provide real-time data across industries, enabling the collection of vast amounts of economic information, including production details and market consumption trends. 11 By leveraging advanced algorithms, these data can be analyzed to reveal industrial trends and forecast market demands more accurately.12,13 In this context, predicting RED has become an essential tool for advancing the quality of economic governance and enhancing management practices.14,15 Evaluating and forecasting the size of local Economic Development (ED) is central to regional economics and economic geography. It helps policymakers to make regional economic policy decisions, to allocate resources efficiently, and to enhance balanced development among regions. 16 As China's problem of regional economic disequilibrium has been rising, economically accurate evaluation and scientific forecasting have never been more imperative to support efficient decision-making. Conventional forecasting tools, such as regression analysis as well as time series models, have limited capacities to process multidimensional, nonlinear economic data, whose complication is not suitable for RED. 17 Latest developments in artificial intelligence, especially Machine Learning (ML), open new possibilities to overcome such limitations.18,19 One such auspicious example is the SOM neural network. Due to its excellent capability to map high-dimensional data into lower-dimensional spaces with topology preservation, SOM has been highly utilized in image processing and speech recognition applications. However, applying it to regional economic forecasting is still a less tapped area. 20 There is a unique strength for SOM to overcome conventional methodologies, such as SVR, especially with complex, nonlinear data to be handled with high flexibility and robustness, qualifying it as a good candidate to enhance RED forecasting accuracy. 21 The construction of a scientific assessment index system for RED is vital to forecasting correctly. RED is not merely economic growth but also social development and environmental sustainability. Therefore, an assessment system should combine economic, social, and ecological parts to comprehensively represent a region's development level. 22 Based on the above analysis, this study firstly elaborates the basic principle and learning process of SOM neural network in detail, focusing on the method of determining the winner based on neuron activation and distance, as well as the influence of the choice of domain geometry on the learning effect of SOM; secondly, it constructs the EIS of the RED level that includes three dimensions of economy, society and environment; and then, taking Region C as an example, it combines the SOM prediction model proposed in this paper with the SVV model. Then, take region C as an example, the SOM prediction model proposed in this paper is compared and analyzed with the SVR prediction model to verify the accuracy and effectiveness of the SOM prediction model; finally, the SOM prediction model is applied to predict the RED level of province A in the north and province B in the south of China, and to analyze the future ED trend and differences between the two provinces.
Literature review
The prediction of RED has garnered significant attention in economics because it is a crucial element for effectively designing regional policies and distributing funds successfully. Traditional methods, such as time series forecasting and regression analysis, have been used with great success for economic prediction. These models do not capture the economic data's nonlinearity and comprehensiveness appropriately. In order for such limitations and complexities not to manifest themselves, there is a need to use superior computational approaches, and this is primarily in reference to ML tactics.
Self-Organizing Map (SOM), developed by Kohonen in 1981, is one such ML algorithm that has been highly effective across a variety of applications, including economic forecasting. An unsupervised neural network called SOM is highly efficient in data clustering and pattern identification by projecting high-dimensional input data into a lower-dimensional space where the topological properties of the data are maintained. Applications of successful usage of SOM include image processing, speech processing, and, more recently, ED forecasting. 23
Ostrovskii (2024) and Wei et al. (2022) have investigated links between regional economic growth and variables including economic complexity, technological innovation, and urbanization to recognize the necessity for higher-order models to capture the rising economic systems’ complexity.24,25 Additionally, Zhang and Cao (2021) have illustrated the usage of hybrid models applying a combination of SOM with additional methods to enhance the predictive accuracy of ED. 26 Some research has also categorized the benefits of applying SOM compared to conventional forecasting models. Yang et al. (2020) compared SVR with SOM to predict regional GDP and concluded that SOM performed better than SVR with respect to accuracy as well as flexibility to capture nonlinear economic data. 27 Likewise, Dong and Zhang (2024) highlighted SOM's ability to handle regional economic data with intrinsic nonlinearities effectively, once again proving its suitability for regional economic forecasting. 28 Despite its empirical success, models trained with SOM often cannot avoid hardship in finding appropriate development evaluation indicators for ED. 29 When presenting their arguments, Kutasi et al. (2020) and Wang et al. (2021) subscribe to the opinion that a comprehensive development framework with a reflection of ED, social welfare, and environmental effects is needed to predict as well as assess RED levels efficiently. Processing multi-dimensional data also requires accurate data preprocessing as well as feature selection to enable the model to be reliable as well as relevant.30,31 The SOM approach, as discussed in this paper, demonstrates the potential of machine learning to handle multi-dimensional data for regional economic forecasting. This aligns with recent findings in the literature, such as those presented by Chahal et al., (2024), in Systematic analysis based on Conflux of machine learning and internet of things using bibliometric analysis, which explore how the combination of ML and IoT can overcome data processing constraints. 32 The ability to integrate multiple indicators from diverse sectors, as demonstrated by the SOM model, makes it a robust tool for addressing the complexities inherent in regional economic development analysis.
In brief, although conventional forecasting models cannot appropriately cover the entire complexity of regional economic systems, adopting SOM-based models is a breakthrough innovation. In the latest investigation, a comprehensive index system evaluation is added to this growing literature, along with an illustration of the stronger forecasting ability of SOM for regional economic growth.
Novelty and contribution
This paper introduces a novel method for forecasting levels of RED by leveraging the highly effective SOM neural network, which is adept at handling nonlinear multidimensional economic data. A significant contribution of this work is the development of a comprehensive EIS encompassing economic, social, and environmental indicators, enabling a holistic analysis of RED. Unlike conventional methods, the SOM framework can capture complex interactions within economic data, leading to enhanced predictive capabilities, as demonstrated by its ability to predict both GDP and the CPI. Another key contribution is the application of this framework to forecast the economic trajectories of two distinct provinces in China, highlighting inter-provincial development disparities. By advancing the understanding of SOM's applicability in practical economic forecasting, this paper offers a robust alternative to traditional models such as SVR. As a methodology, SOM provides valuable insights for policymakers in formulating region-specific economic strategies.
The remainder of this paper is structured as follows: Section 2 reviews the literature on regional economic development prediction models and highlights the strengths of SOM neural networks. Section 3 outlines the methodology, including the SOM model, the construction of the Evaluation Index System, and the learning process. Section 4 presents the predictive results for Region C and the two provinces, along with a comparative analysis against the SVR model. Finally, Section 5 concludes the paper, offering policy implications and suggestions for future research.
Forecasting the level of regional economic development based on the SOM algorithm
Self-organizing feature mapping neural network model (SOM)
The SOM is based on ideas derived from how bodies and the brain function. It combines the different ways that neural networks respond to outside input patterns. Its goal is to find the best responses to different signals, creating a meaningful graph that shows order.
23
The design of the network is meant for unsupervised competitive learning, making a model that acts like the human brain. The SOM network uses a two-dimensional array model. In this model, the input layer has n nodes, and the output layer is set up as an
To obtain a better input and output mapping relationship, the SOM neural network needs to be trained to continuously adjust the connection weights of the input and output nodes to each other and achieve a steady state. For the input vector Initialize the connection weight matrix: randomly select a specific value in the interval [0, 1], and assign a specific connection weight Select the input sample data set: in accordance with the n -dimensional vector pattern, select specific samples in the sample set to form the sample vector X, as the input sample data set of the network. Calculate the Euclidean distance between input vectors and output nodes: Equation (1) is used to calculate the distance between input vectors and all output nodes: where t represents a particular moment in time, The output node that is closest in Euclidean distance between the output node and the input vector is selected to be the winning node and is designated as Adjust and update the output node connection weights using the Gaussian domain function as shown in equation (2):
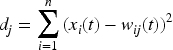
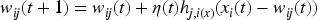
Where
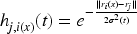
Where the position of the output node Steps (3) and (4) are repeated until the learning of all samples is completed, at which time the SOM neural network has reached a steady state relative to the sample space, and the training process is completed in stages. Through training, the set of weights of the output nodes
Determining winners based on neuronal activation
The competitive mechanism of neurons of SOM networks is realized by competitive activation of weight vectors. Any neuron has its weight vector, and when it is fed by the vector of inputs to the network, it activates the nearest neuron to it, called the winning neuron or simply the winner for short.
SOM belongs to unsupervised learning, which provides inputs to the network during the learning process to find winners based on the activation of neurons. The input sample data x is provided to the network, and the weighted input sum is calculated for each neuron. Therefore:
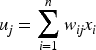
Where
Once the output neurons have completed their activation calculations, the competitive phase begins. During this phase, each neuron sends inhibitory signals to the others, effectively overriding the signals from competing neurons. If a neuron receives an inhibitory signal, it adjusts its net activation by incorporating the incoming inhibitory input. If the resulting activation level falls below a predefined threshold or is reduced to zero, the neuron is excluded from further competition. This inhibition phase continues until only one neuron remains active, possessing the highest activation value. The neuron with the highest activation, which best represents the input vector, is referred to as the winner. This competitive process is fundamental to the operation of self-organizing maps, as the winner identifies the most salient features of the input data.
Competition in Self-Organizing Maps (SOM) is typically resolved by measuring the distance of the weight vectors to the input data. For standardization of the comparison, the input and the weight vectors are normalized such that their relative sizes, denoted by x and w, become 1. Normalizing the sizes ensures that the closeness of vectors is analyzed at the same scale. Thus, the weight vector nearest to the input vector will exhibit the most significant activation level through the receptive field, showing that it is the “winning” neuron. The Euclidean distance is the most commonly utilized distance metric for measuring the proximity of the weight vectors from the input data. The Euclidean distance is mathematically defined as:
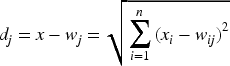
Where
Distance measures play a crucial role in various machine learning algorithms, including SOM. While Euclidean distance is the most commonly used due to its simplicity and effectiveness in quantifying the proximity between two vectors, several other distance metrics can be employed, each offering distinct advantages depending on the data structure and application requirements. For example, correlation measures the similarity between two vectors by calculating a weighted sum of the input and weight vectors. A higher weighted sum indicates greater similarity, suggesting a stronger relationship between the vectors. The directional cosine, another distance measure, evaluates the angle between two vectors, where a smaller angle results in a higher cosine value, which signifies greater similarity. Lang's distance, on the other hand, transforms the data into rank-based format and calculates the difference between ranks, making it particularly suitable for ordinal data. Manhattan distance calculates the total absolute difference between corresponding components of two vectors, reflecting their linear dissimilarity. Additionally, the Minkowski distance generalizes the previous two metrics by incorporating a parameter that allows for flexibility in distance calculation, with different values enabling the use of various distance measures. In the present study, Euclidean distance, Lang's distance, Manhattan distance, and Minkowski distance are applied to train the SOM model, identify winning neurons, and generate the corresponding weight matrices. The results are then visualized through a heatmap function, which enhances the interpretability of the SOM output.
During the learning of a Self-Organizing Map (SOM), not only do the winning neurons change their weights, but neighboring neurons also change. To what degree neighbor neurons change their weights depends on how far neighbor neurons are from the winning neuron, and it is the neighborhood property that keeps the relationships of the input data. Those neurons that are closest to the winning neuron tend to change their weights rather than those that are farthest. Therefore, neighborhood size is vital during learning and needs to be clearly defined. Some common neighborhood shapes are linear, square, and hexagonal structures. In the linear structure, radius 1 has one neighbor to its right and left of the winning neuron, and radius 2 has two extra neighbor neurons to either side, four neighbor neurons in total. In the square structure, radius 1 has all of the neighbor neurons at one step, while in the case of the hexagonal structure, radius 1 has six neighbor neurons, and radius 2 adds another step of neighbor neurons. The neighboring neurons’ weight vectors move toward the input vectors during learning in the SOM, but the winning neuron's updating is the largest. The farther from the winning neuron, the smaller the weight changes of neighbor neurons become. It is controlled by the Neighborhood Size (NS) function that considers how the weight changes become less by the distance from the winning neuron. The SOM supplies the NS function in many forms, such as linear, Gaussian, and exponential decay functions. A linear decay function implies continuously decreasing neighborhood strength with higher distances from the winning neuron. The Gaussian equivalent permits a smoother and more gradual descent of the weight changes based upon the distance from the winning neuron. Both the neighborhood structure and the function of the NS are essential for the network to preserve its self-organizing property, yet be capable of transforming higher-dimensional sets of inputs into lower-dimensional output sets. The quality of the SOM model and its effectiveness in representing complex data sets rest entirely upon the choice of neighborhood shape and decay function:
33
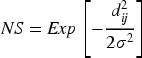
Where
The exponential decay NS function is:
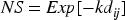
Where k is a constant.
As the size of the map increases, it is essential to adopt a method for quantifying the distance between the winning neuron and its neighboring neurons to assess the neighborhood's strength. Geometric configurations, such as the linear, rectangular, and hexagonal neighborhoods, are usually employed to define these distances. For instance, the direct neighbor is assigned a distance of 1. In contrast, the next immediate neighbors increase their distance by increments of 1 (e.g., the next immediate neighbors are assigned a distance of 2). It is employed to quantify these distances for use in defining the distance matrix (NM) that defines the structure and size of the winning neuron's neighborhood and thus facilitates easy computation of distances between the neighboring neurons and the winning neuron. It enables an organized and efficient mapping of the space of inputs, and it maintains the topographic relationships between the output space and the space of inputs for large networks. 34
When the neighbor matrix can be defined as:
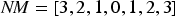
The value of the distance to the centroid of the winning neuron in the collar matrix is 0.
Selection of indicators
The 14 indicators for the Evaluation Index System (EIS) were selected as an overall measure of regional economic development (RED) with the supplement of economic, social, and environmental elements. The economic indicators, such as GDP per capita and openness of trade, reflect economic efficiency and openness. Social indicators such as per capita disposable income and urbanization rate reflect social well-being and the development of technology. Environmental indicators such as the comprehensive utilization rate of industrial solid waste and discharge of wastewater represent sustainability. These indicators were selected due to the fact that they represent well the different dimensions of the development of regions and enable the model to forecast accurately economic developments with additional consideration of social and environmental dimensions. This overall approach increases the reliability and precision of the predictive model.
To assess the level of RED, it is indisputably required to devise a scientifically credible EIS, as indicated by previous research. 35 ED is typically measured using economic aggregates and growth rates, but to assess it holistically, it is also imperative to consider social and environmental parameters to reflect the region's development comprehensively. The following, therefore, considers indicators at three levels: economic, social, and environmental.
At the economic level, analysis starts with economic efficiency, structural composition, and external openness, and five essential indicators are chosen: GDP per capita, per capita financial income, and energy output rate, all of which indicate economic efficiency; the value-added proportion of the tertiary sector, which shows economic structure; and the trade openness degree, which reveals external economic integration. The social dimension emphasizes indicators that show how RED contributes to social well-being. These indicators encompass disposable income per capita, consumption level, urban-rural income difference, urbanization rate, research and development (R&D) investment, and the population aged 15 and older's literacy rates, all reflecting living conditions, educational progress, and technology development. The environmental dimension considers indicators showing economic sustainability, including the comprehensive utilization rate of industrial solid waste, per-unit GDP wastewater emissions, and SO2 per-unit Industrial added value emissions, showing the region's environmental influence and sustainability.
The derived EIS, as shown in Table 1, consists of 14 indicators that cover all three analysis levels: economic, social, and environmental. The indicators are relative, and the required data can be acquired from official sources like statistical yearbooks. The index system proposed here aligns with the principles of systematic sorting and provides a scientifically reliable framework for RED evaluation.
EIS of EDL in China.
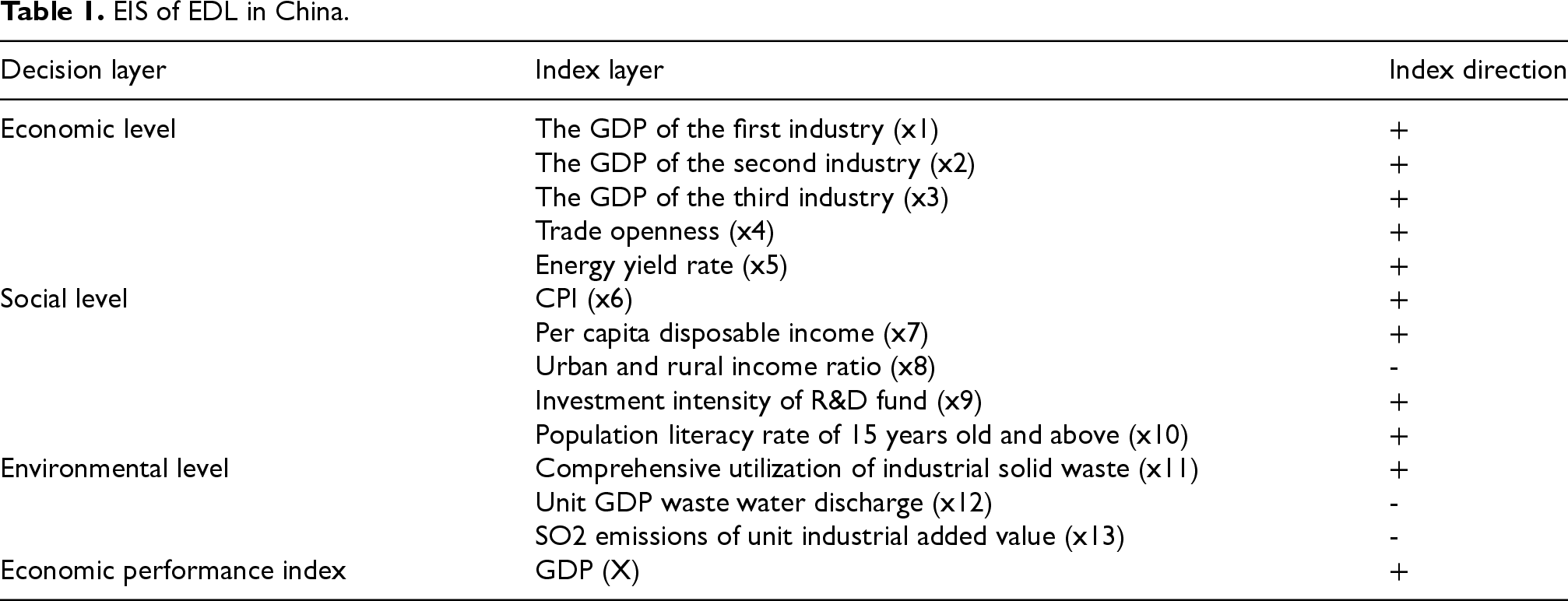
EIS of EDL in China.
The data for most indicators in the evaluation system can be retrieved from the China National Data Website, except for the following: trade openness (x4), energy output rate (x5), R&D investment intensity (x9), and comprehensive utilization rate of industrial solid waste (x11). The values for GDP in the Primary Industry (x1), Secondary Industry (x2), and Tertiary Industry (x3), as well as energy output ratio (x5), the (CPI, x6), per capita disposable income (x7), and wastewater emissions per unit of GDP (x12), are derived from the actual values from the fixed base period (2014). For indicators such as trade openness (x4), urban-rural income ratio (x8), R&D investment intensity (x9), and SO2 emissions per unit of industrial added value (x13), nominal values are used due to the unavailability of comparable price calculation data or because the numerator and denominator units are identical. The ratio of total exports and imports to GDP usually calculates the trade openness ratio (x4). Because U.S. dollars measure the data on export and import, they can be converted to Renminbi (RMB) at the average exchange rate of USD to RMB per year, which can be obtained from the People's Bank of China. Energy output rate (x5) is calculated by dividing regional GDP by total energy consumption. Regional total energy consumption is acquired from the China Energy Statistics Yearbook. R&D investment intensity (x9) is derived by dividing R&D expenditure by GDP. R&D expenditure is acquired from the China Science and Technology Statistical Yearbook and the National Statistical Bulletin of Scientific and Technological Investment. The comprehensive utilization rate of industrial solid waste (x11) was acquired from the China Science and Technology Statistical Yearbook. The years 2014 to 2024 are utilized for this study to ensure it is complete and current. Similar data sources and calculations are of primary importance to construct a plausible and coherent EIS for RED, as indicated by Table 1 of the paper. In addition, the results of those calculations, as indicated by Figure 1, represent the effects of those elements upon the regional economic performance.
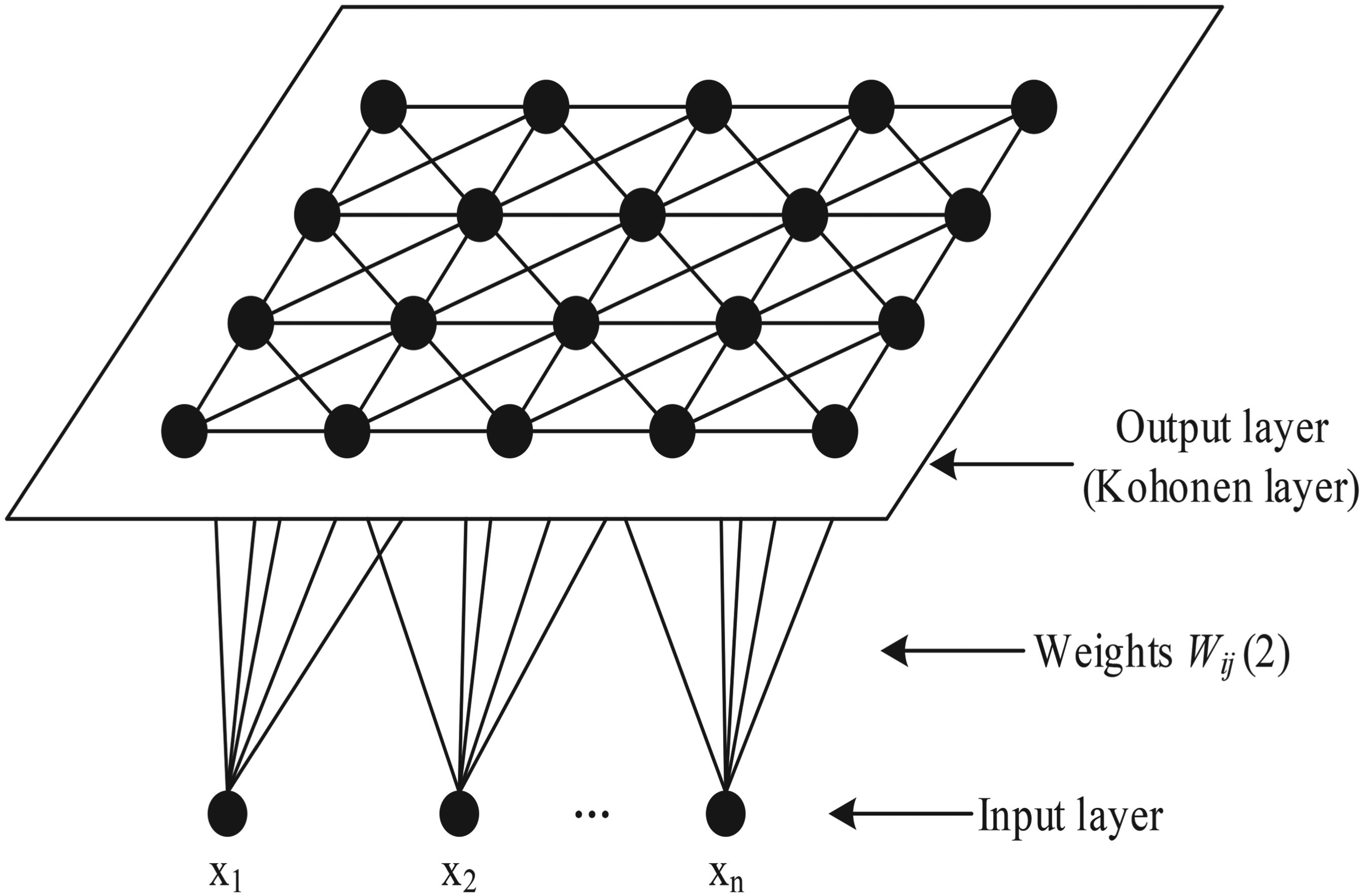
Two-dimensional array SOM network model.
Forecast accuracy
Region C is the research object of this work and is used to predict the GDP and the CPI from March 2020 to February 2022 through the Self-Organizing Map (SOM) model. The correctness of the SOM predicting model is compared with the traditional SVR model to test the validity of RED forecasting. GDP, as an essential index for measuring a region's economic strength and development level, is of much concern for this work, as it has an immense influence over national and regional economic policies.
Table 2 demonstrates the comparison of actual GDP values, SVR predictions, and SOM predictions for Region C. From the table, it can be seen that the average relative errors for the SVR model and the SOM-based RED level prediction model of GDP predictions during the period from March 2020 to February 2022 are 0.07% and 0.01%, respectively. Both models made exact predictions, and the relative errors of the two models were less than 0.1%. It is remarkable that the SOM-based model significantly outperformed the SVR model, indicating much higher precision for the former model in predicting the region's GDP. These findings, from Table 2, highlight the higher capability of the SOM model for predicting regional GDP and its promise for more accurate economic prediction.
Comparison of GDP real value, SVR predict value, and SOM predict value.
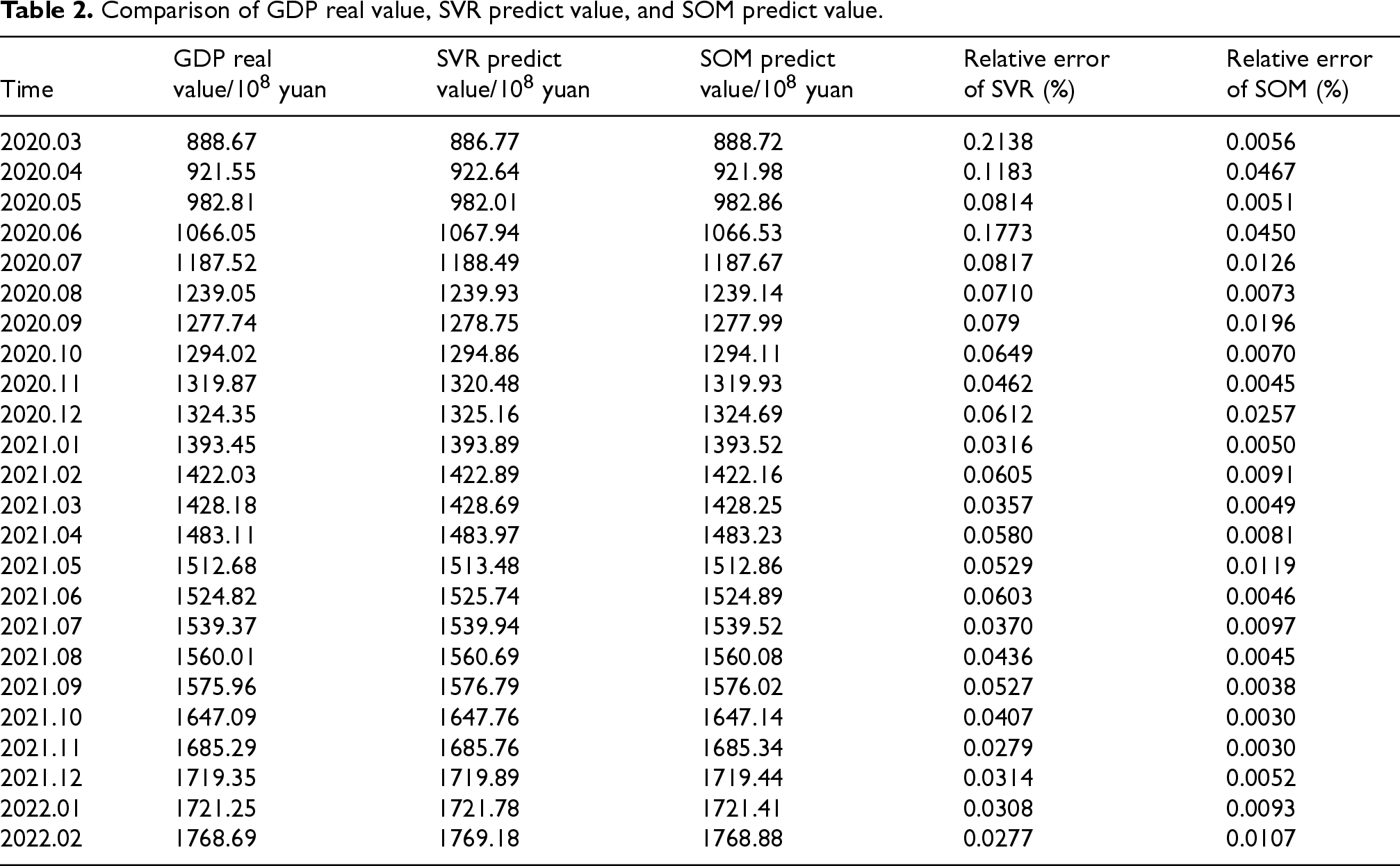
Comparison of GDP real value, SVR predict value, and SOM predict value.
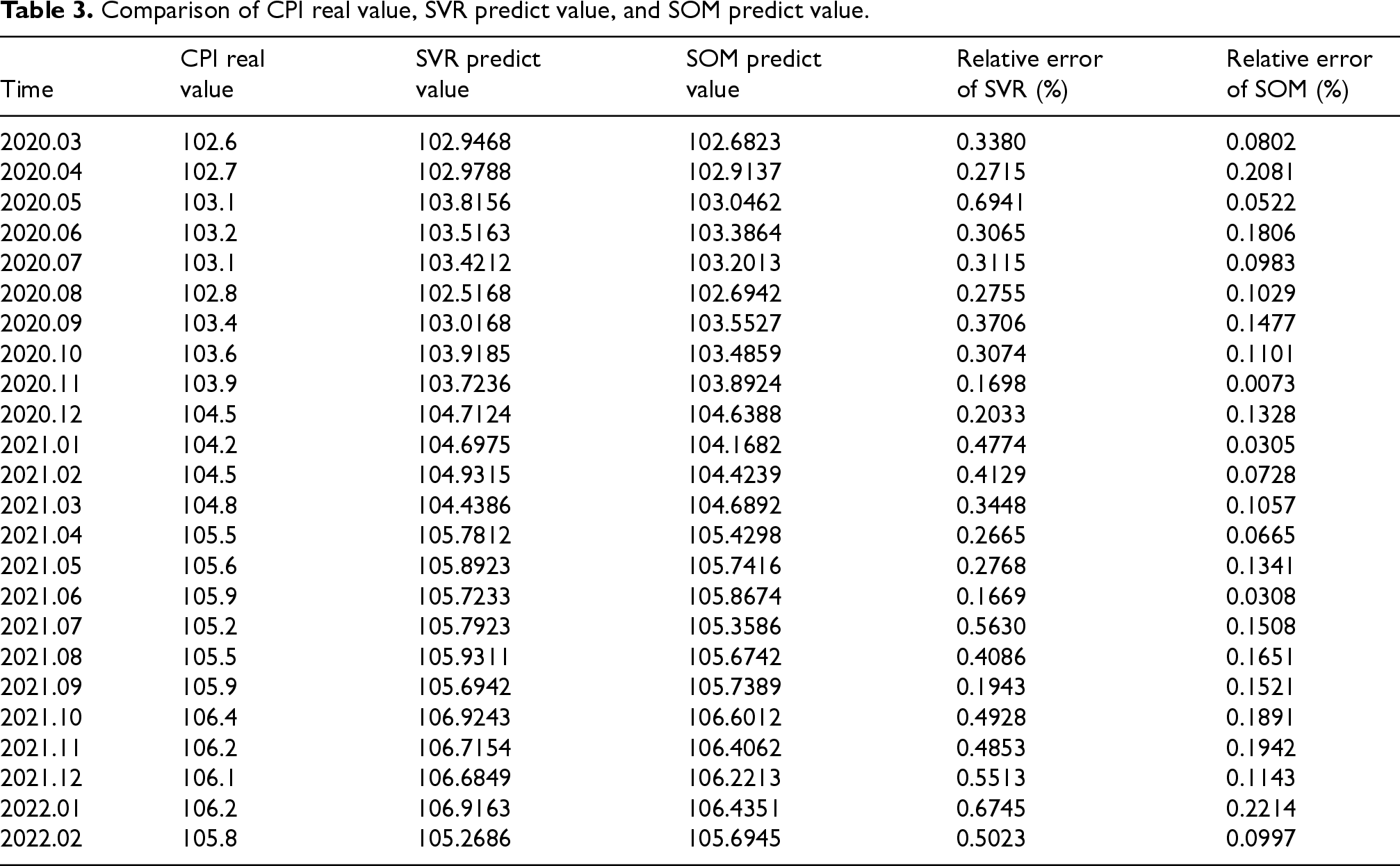
CPI is a significant economic variable utilized to indicate changes in the price level of consumer goods and services. It measures the variation in the cost of living, for it has mattered to government policies relating to finance, currency, consumption, wages, and social security. CPI is widely utilized for macroeconomic analysis and regulation and contains precious information concerning the social stability and the standard of living. CPI prediction is therefore of immense practical significance, particularly concerning economic planning and policy making. The comparison of the actual CPI, the SVR forecast, and the SOM forecast results is presented in Table 3. As indicated in Table 3, the SOM-based prediction model significantly outperforms the traditional SVR model regarding prediction accuracy. Specifically, between March 2020 and February 2022, the average relative error for the CPI prediction using the SVR model was 0.38%. In contrast, the SOM model yielded a much lower average relative error of 0.12%. These results highlight the improved accuracy of the SOM model in forecasting CPI, which demonstrates its advantage over conventional methods in predicting economic indicators with greater precision.
Comparison of CPI real value, SVR predict value, and SOM predict value.
After verifying the SOM model's prediction precision, the model was employed to predict the RED of two typical Chinese provinces: north province A and south province B. Historical economic data from the last 15 years for the two provinces were used as inputs to the SOM prediction model to predict their ED from 2026 to 2035. Section 2.3's RED test index system was referenced to inform the economic data input. The RED prediction results for the two provinces from 2026 to 2035 can be seen in Tables 4 and 5.
A province 2026–2035 RED prediction results (units: dimensionless index, unbounded).
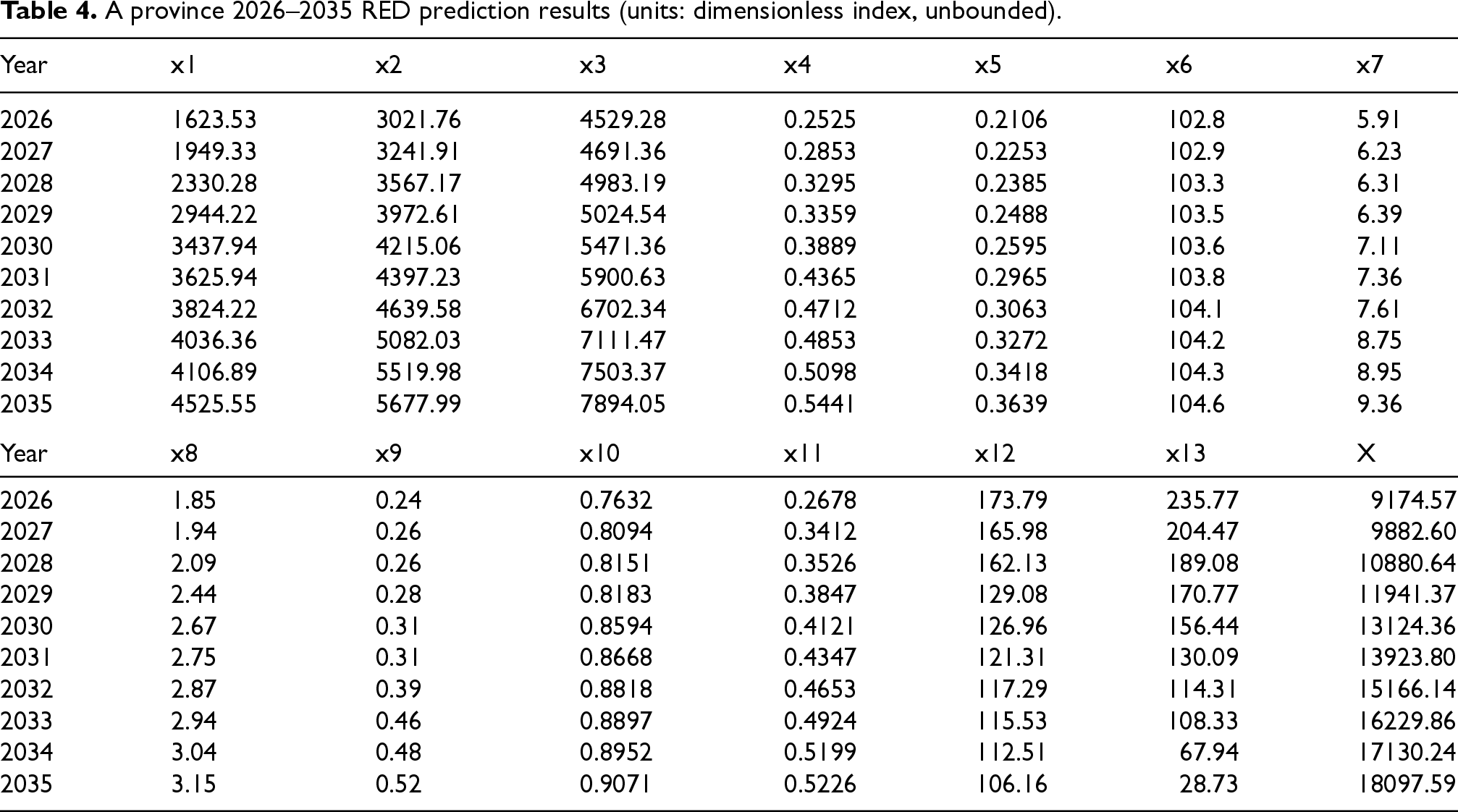
A province 2026–2035 RED prediction results (units: dimensionless index, unbounded).
B province 2026–2035 RED prediction results (units: dimensionless index, unbounded).
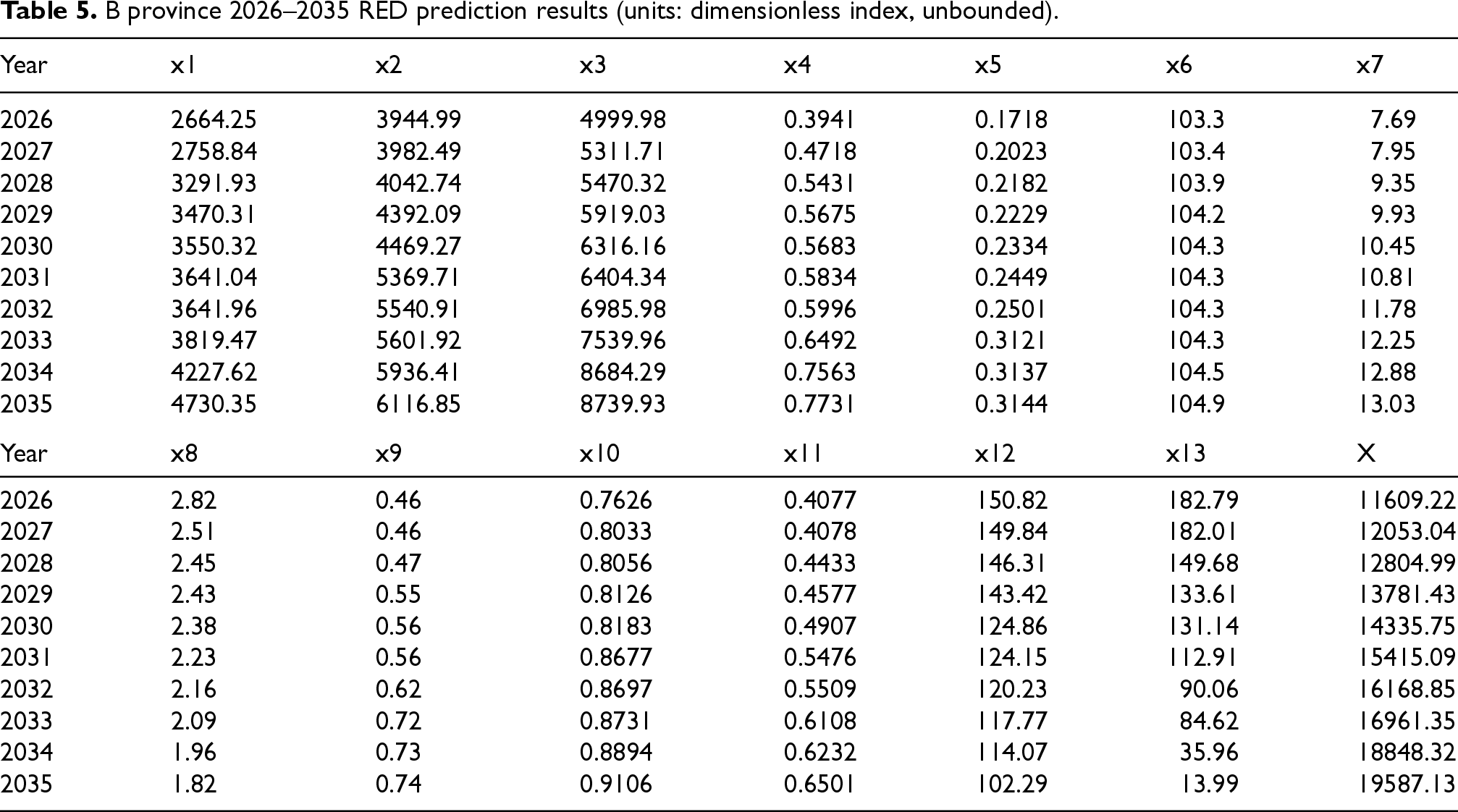
The Economic Performance Index (EPI), shown as X in Tables 4 and 5, provides a comprehensive measure of regional economic development. Since X is a dimensionless index, it allows for a flexible representation of economic growth without being constrained by units. The increasing values of ‘ across the forecast period for both A Province and B Province suggest strong, sustained economic development. However, it is important to note that the absence of units for X may limit direct comparability with other individual indicators, which is why this dimensionless measure is contextualized within the overall composite framework. As shown in Tables 4 and 5, both provinces demonstrate steady economic growth, with development levels increasing consistently over the forecast period. However, notable differences in development between the two provinces emerge from the evaluation indicators. Province A, located in northern China, is less developed in secondary and tertiary industries than Province B in the south. For instance, trade openness (x4) in Province B is considerably higher than in Province A, reflecting the south's more globalized economy. Additionally, due to the differences in mineral resource distribution, Province A has a higher energy output rate than Province B. In contrast, Province B outperforms Province A regarding the consumer value index (x6) and per capita disposable income (x7). Overall, the EDL of Province B is expected to remain higher than Province A's over the next decade, which aligns with the regional disparities in China's ED. They point out the geographical differences in China's economic growth and emphasize regional elements that should be considered for correct economic forecasting.
One limitation of the SOM approach is its implicit handling of the relationships between indicators. The model captures correlations between variables but does not explicitly account for causal dynamics. This inherent limitation restricts the model's interpretability, particularly in the context of policy implications, where understanding causal relationships is crucial. Future research could integrate causal inference methods, such as Granger causality or structural equation modeling, to better understand the underlying mechanisms driving regional economic development and improve the model's applicability for policy decision-making. Also, while the SOM model demonstrates improved performance compared to the SVR model, the comparison is based on average relative error. Future research will incorporate statistical tests
This paper develops a prediction model based on the Self-Organizing Map approach to estimate regional economic development levels, showing improved performance compared to conventional Support Vector Regression models, with significantly lower prediction errors for both GDP and the Consumer Price Index. The SOM model excels in handling complex, nonlinear economic data and is applied to estimate the development levels of two Chinese provinces, revealing disparities in financial performance that highlight the need for region-specific development strategies. By utilizing a comprehensive evaluation index system incorporating economic, social, and environmental indicators, the model provides valuable insights for policymakers. However, the model's performance may be compromised during crises or abrupt policy changes, as it relies on past data trends that may not hold in chaotic economic conditions. To enhance the robustness of the model, future research could explore integrating multi-modal data, such as real-time digital infrastructure data, which would better capture dynamic economic changes. Incorporating additional variables, such as global market trends, geopolitical shifts, or climate change impacts, would further increase the model's flexibility and resilience in rapidly changing environments. The integration of real-time data would also enable the development of more responsive forecasting models, particularly for high-tempo socio-economic changes. A promising future application of this model is its potential for real-time policy-making support, which could generate significant interest in future research. This could involve the creation of a policy simulation framework within the model, allowing policymakers to simulate and optimize various intervention strategies based on real-time economic data. Such a framework would enable the simulation of the effects of different economic policies on regional development, which provide actionable insights for decision-making.
Footnotes
Nomenclature
Ethical approval
Every author has been deeply involved in the work that led to this paper and is fully committed to its content.
Authorship contribution statement
Wang Bo: Supervision, Conceptualization, Writing-Original draft preparation, Project administration.
Funding
Not applicable.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Available upon request.
Competing interests
No competing interests are disclosed by the authors.
Declarations
Not applicable.
Author statement
Every author has reviewed and approved the manuscript, confirming it meets the authorship criteria stated earlier. Each author also confirms that the manuscript represents original research and effort.