
Abstract
Respondent-driven sampling (RDS) is a widely used methodology for estimating characteristics of hard-to-reach populations, such as homeless individuals, undocumented immigrants, and indigenous communities. Despite its effectiveness in obtaining representative samples, RDS lacks a robust estimation framework for total population figures. This limitation hinders its application in disaggregating Sustainable Development Goal (SDG) indicators, which are crucial for monitoring marginalized groups under the “leaving no one behind” principle of the 2030 Agenda. Building on previous research, we propose an improved estimator for total population counts based on the Generalized Weight Share Method (GWSM). Our approach employs a multi-phase sampling technique and ensures unbiased estimates when post-seed selections are random. Additionally, we introduce an approximation method for cases where some network information is unknown. We compare our method to traditional RDS estimators, highlighting its advantages and limitations. The paper is structured as follows: we first analyze RDS as an indirect sampling method, then extend our model to scenarios with partial link observations. We also address potential biases and present empirical analyses that validate our approach. Our findings contribute to refining RDS estimation techniques, enhancing its reliability for policy-relevant data collection.
Keywords
Introduction
This paper focuses on respondent-driven sampling (RDS), an effective survey methodology for estimating characteristics of hidden populations, such as homeless individuals and undocumented immigrants, as well as hard-to-measure groups, like minorities and indigenous peoples.
The 2030 Agenda emphasizes the principle of “leaving no one behind.” However, many Sustainable Development Goal (SDG) indicators need to be more broadly accessible to the most marginalized and vulnerable populations. Currently, most SDG indicators lack the necessary level of disaggregation to effectively monitor the socioeconomic conditions of these groups. As a result, it is challenging to gather reliable structural data or to keep up with emerging phenomena that necessitate targeted, evidence-based policy actions.
RDS gathers information on these populations by leveraging relationships between their members. Its effectiveness increases when used alongside other information sources, such as administrative or geographical data. RDS is a network-based sampling technique1,2 first developed by Heckathorn (1997,. 3 ) Due to its viable sampling technique and reasonable inferential approaches, RDS has become the preferred method for sampling hard-to-reach populations. Since its inception, RDS has been used in numerous investigations worldwide. 4
The research process begins with a small group of participants who are already known to the researchers. Each participant is given a few unique coupons to distribute, using a random method, to individuals in the larger population, inviting them to participate in the study. This process continues until the desired number of respondents is reached, which helps to expand and diversify the sample. While the selection of the initial participants is non-random, subsequent contacts are chosen at random. The process concludes when only previously identified individuals are encountered, or after reaching a predetermined data collection point, such as the fifth step.
Heckathorn (1997 3 ) employed a Markov model to analyse the peer recruitment process, demonstrating that bias inherent in the initial convenience sample gradually diminished as the sample size increased over successive waves. He found that, irrespective of the initial sample or the chosen seeds, the process ultimately reached an equilibrium as it expanded. The conclusion drawn was that this sampling technique could yield reliable results, provided enough waves were conducted, indicating that any selection of seeds could ultimately lead to the same equilibrium sample composition. However, the paper did not clarify how to derive an unbiased estimate of totals.
The RDS method lacks a robust estimation methodology that can adapt to various conditions. While it is useful for estimating mean and proportion values, the accuracy of total estimates relies on unknown information regarding the total number of links. Additionally, it is affected by several factors, including the characteristics of the network that connects individuals within the population. 5
In our paper, we build upon the findings of Falorsi et al. (2023 6 ). We propose a straightforward estimator of totals based on the Generalized Weight Share Method (GWSM) developed by Lavallé in 2007. 7 This estimator employs a multi-phase sampling approach. If the selection of sampling units after the initial seeds is done randomly, our proposed estimator will be unbiased. Most of the quantities needed for the estimation can be known by the researcher responsible for calculating the survey estimates, as long as they effectively organize the data collection process. Additionally, we discuss how to compute an approximate version of the estimator if some of these quantities are unknown. The RDS method is well established in the literature, with a comprehensive summary of significant works available in. 6 In this paper, we introduce a slightly different approach from those previously developed. To maintain conciseness, we will reference only the most essential works that are crucial for understanding the fundamental aspects of our proposal.
The article is organized as follows: Section 2 explains the RDS search process when all unit links are observed and discusses how this can be interpreted as indirect sampling. Section 3 extends this discussion to scenarios where only a few links are randomly observed at each step. Section 4 addresses potential issues that could undermine the proposed approach. Section 5 presents a discussion of the empirical analyses, providing a solid basis for our conclusions. Finally, Section 6 offers the conclusions.
The RDS research path
We denote by U a target population where each element is related to some of the others by some kind of relationship. Our aim is to estimate the sum of a variable
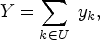
Let's use a specific example to illustrate how hand-induced notation can be applied to explore the RDS research method. To simplify the discussion, in the example, we assume that the value of each variable
The accompanying Figure 1 displays a population of fourteen elements, labeled with the letters A through P from the Italian alphabet. These elements form a graph with bidirectional relationships, meaning that if Unit A knows Unit B, then Unit B also knows Unit A. The bidirectional relationships are represented by grey arrows in figure below pointing in both directions. The bidirectionality of the relationship implies that a unit cannot indicate as a link a unit with which the mutual relationship is weak, and that would not indicate the unit itself. Moreover, this property would limit the sizes and complexity of the networks.
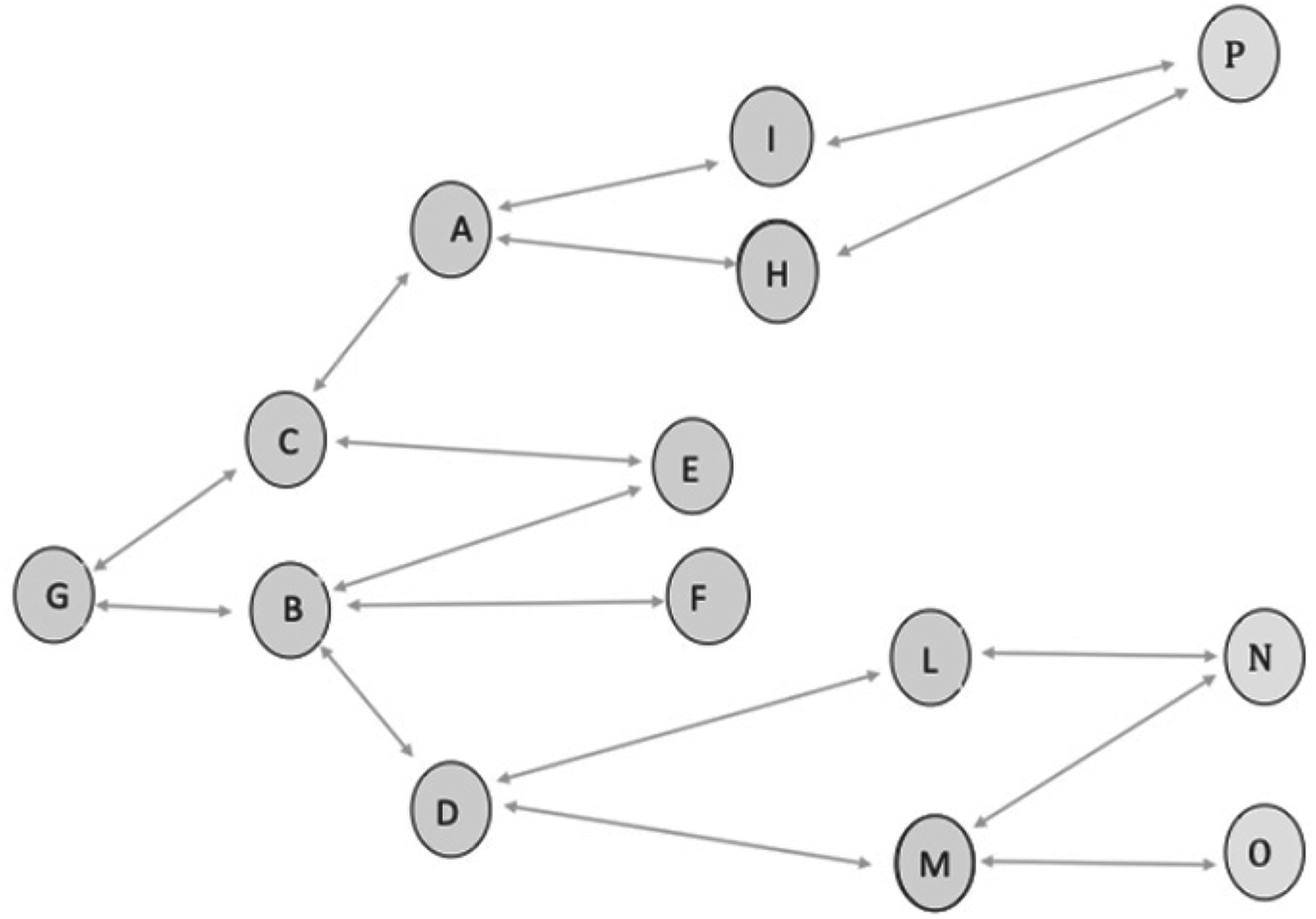
Population of the example.
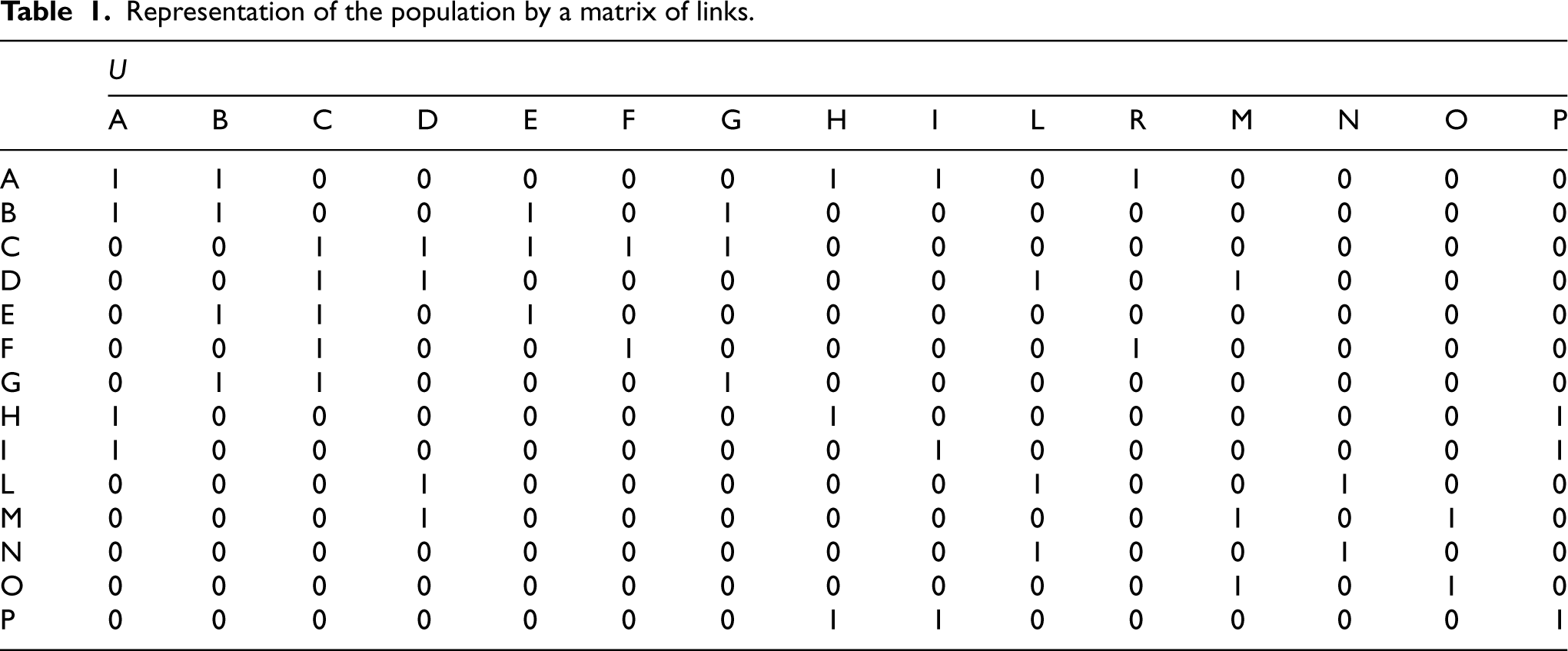
The latter population can be represented by a symmetric matrix of 0 s and 1 s, where 1 indicates a link between the units (see Table 1).
Representation of the population by a matrix of links.
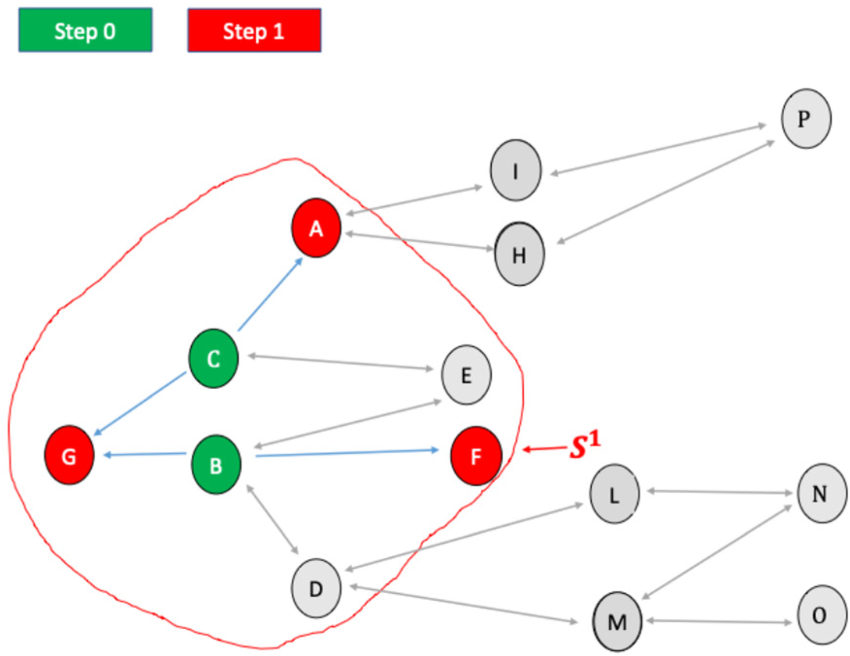
RDS is developed through a series of successive search steps. In each step, after the initial one (referred to as step 0), links to the units listed in the previous step are chosen. Each search path ends when a unit that has already been selected is encountered. Once all search paths have come to an end, the RDS process is completed. Below, we will illustrate the RDS process step by step, assuming we observe all the units connected to those involved in the previous step.
Step 0 involves selecting an initial sample (
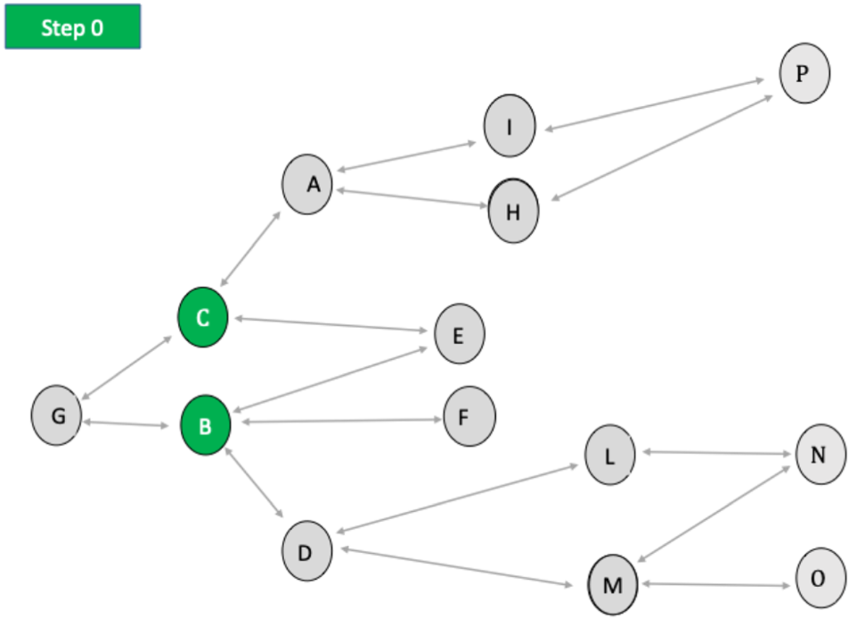
Step 0 of the RDS process.
The total of the 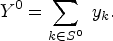
In the example, we have
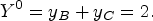
In Step 1, as shown in Figure 3, we observe
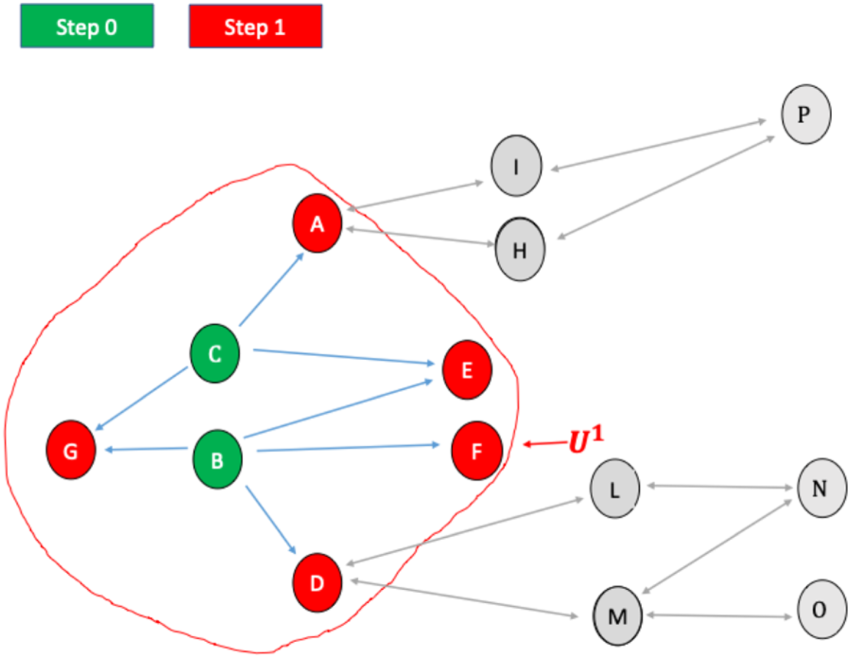
Step 1 of the RDS process.
In the example, the units in
Let 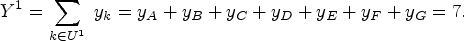
We can represent this situation as a specific case of 


Here,
It is useful define 


The indirect sampling formulation for writing the total may seem unnecessarily complex at first. However, it is essential because, it helps us address the issue of multiplicity, which arises when the same unit is detected through the connections of different units as seen below. To better understand the structure of the estimation method, it is helpful to introduce Table 2 that illustrates the relationships between the units selected in step 0 and those identified in step 1.
Example of the calculus of
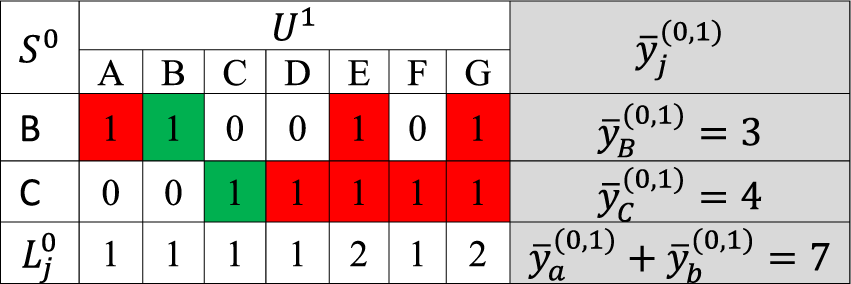
Using a standard result from indirect sampling, with 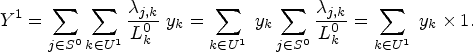
Proof of Formulae 2.4, 2.5 and 2.6.
Let 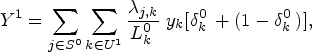
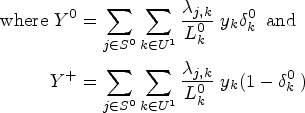
Let's continue the explanation from step 1 by noting that in the notation we've introduced and will continue to use for all subsequent steps, the units involved up to the second-to-last step (in our case, step 0) will always be identified by subscript j, while the units identified in the last step (in our case, step 1) will be denoted by subscript k.
Step 2
We observe
In our example, the units involved in
We compute 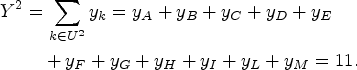
In this case,
Example of the calculus of
via the indirect approach.
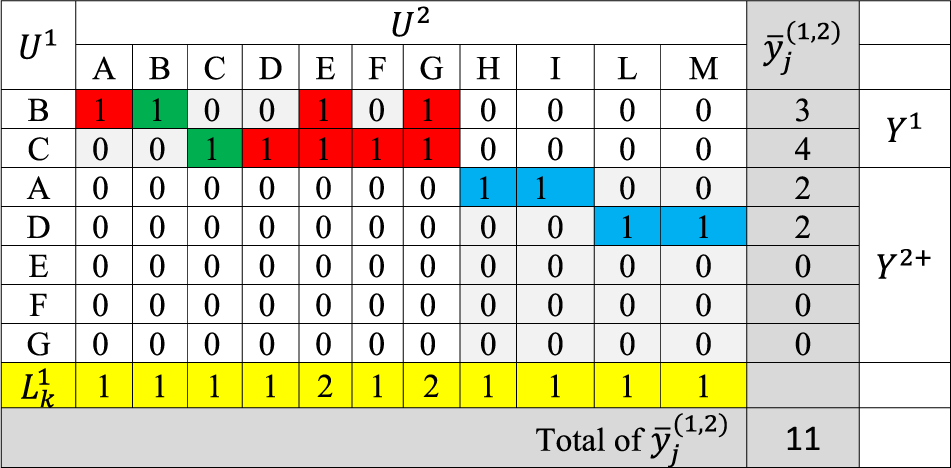
Example of the calculus of
On the basis of such a matrix, we have
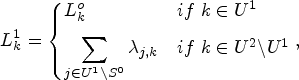
When computing the total 

Adopting the incremental approach, we have

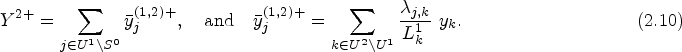
We observe 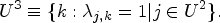
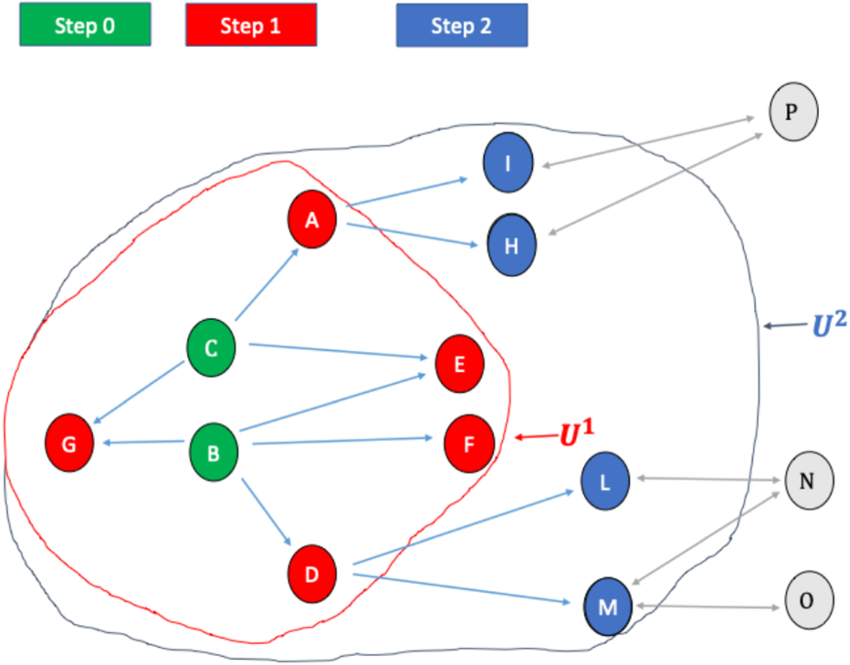
Step 2 of the RDS process.
In this case, 
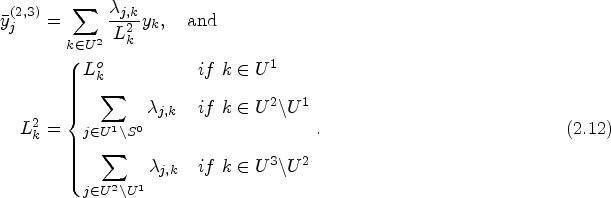
Below is Table 4 for calculating
Example of the calculus of
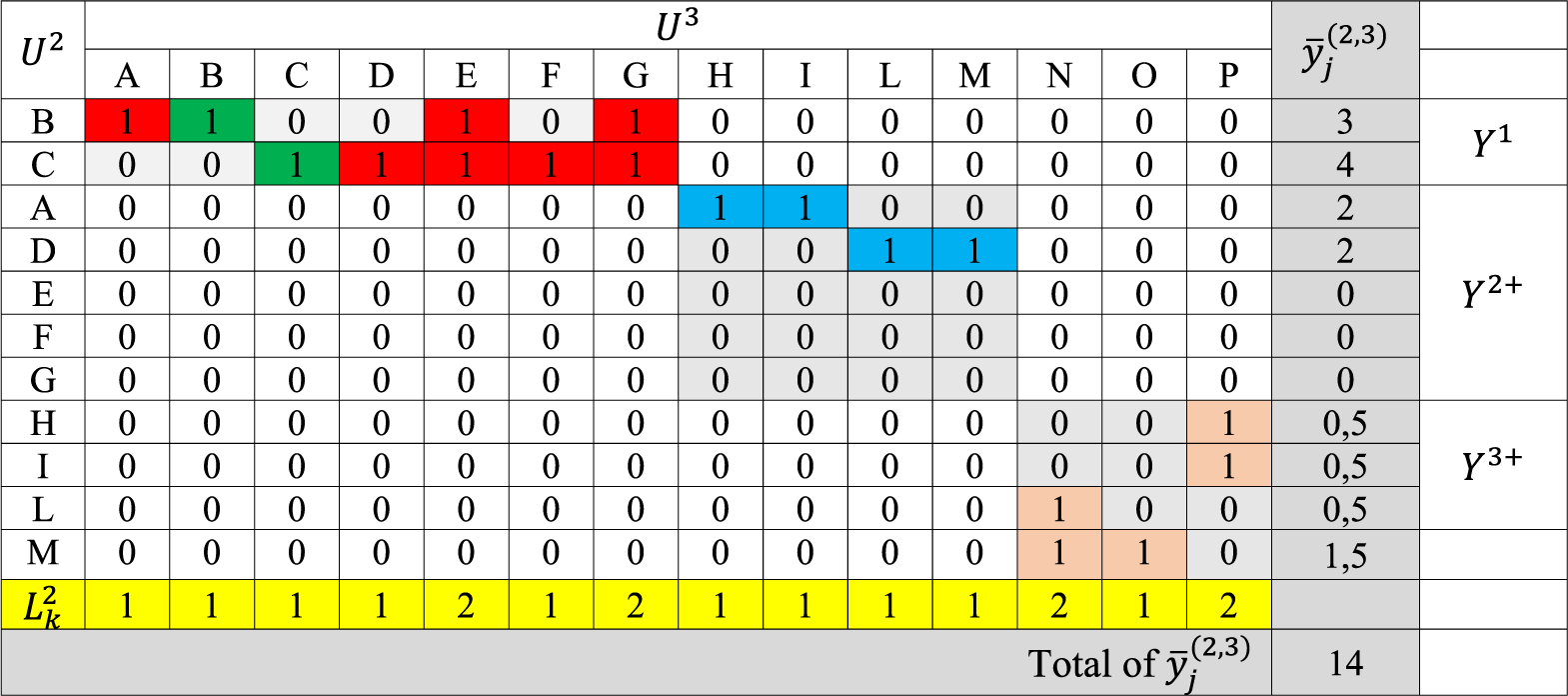
Adopting the incremental approach, we have

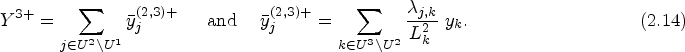
When restarting the RDS process, one notices that all the links of the N, O, and P Units have already been listed in previous steps. Hence, the RDS process closes, and the total of the cluster coincides with
Caveat
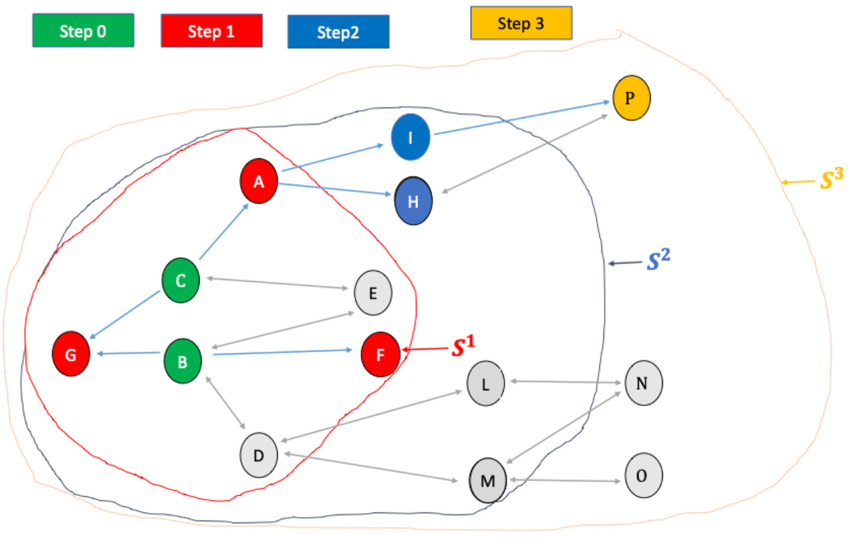
Before concluding this section, it is important to emphasize the relationship between the total network defined at the end of the RDS process and the actual total of the variable of interest. Consider the example illustrated in Figure 6, where the population is divided into three clusters: α, β, and γ. The total variable of
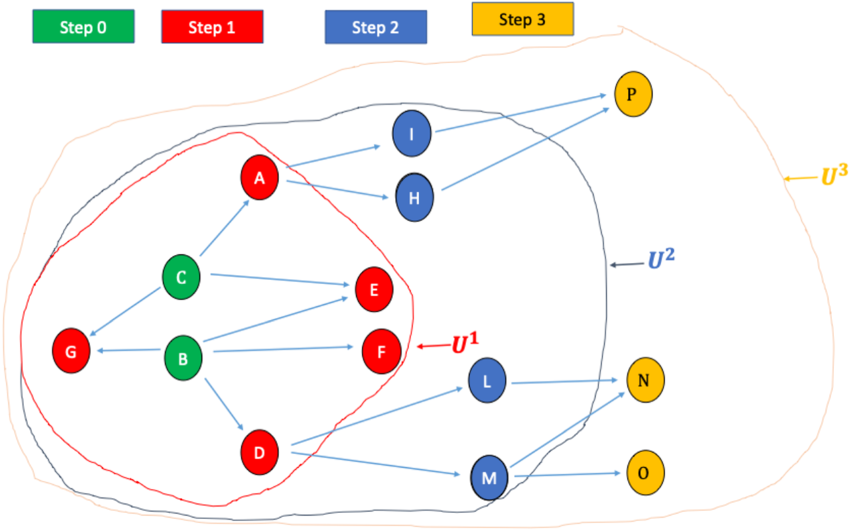
Step 3 of the RDS process.
In this section, we will discuss situations where not all links are observed, and enumerators randomly select only some of them.
Sampling process
We will use r to represent the RDS step and
The sampling selection is carried out independently for all the
To describe this process, consider a new unit j belonging to List of Units Connected. During the initial selection process, the interviewer compiles a list of all units connected to Unit j. This collection is defined as the set Determination of Selectable Units. The set Let Simple Random Sampling Without Replacement. From the
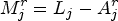
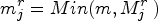
The estimation 


We note that inserting Expression (3.3) in (3.2), we have
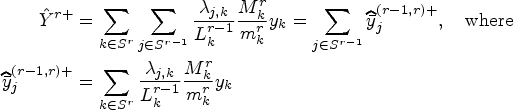
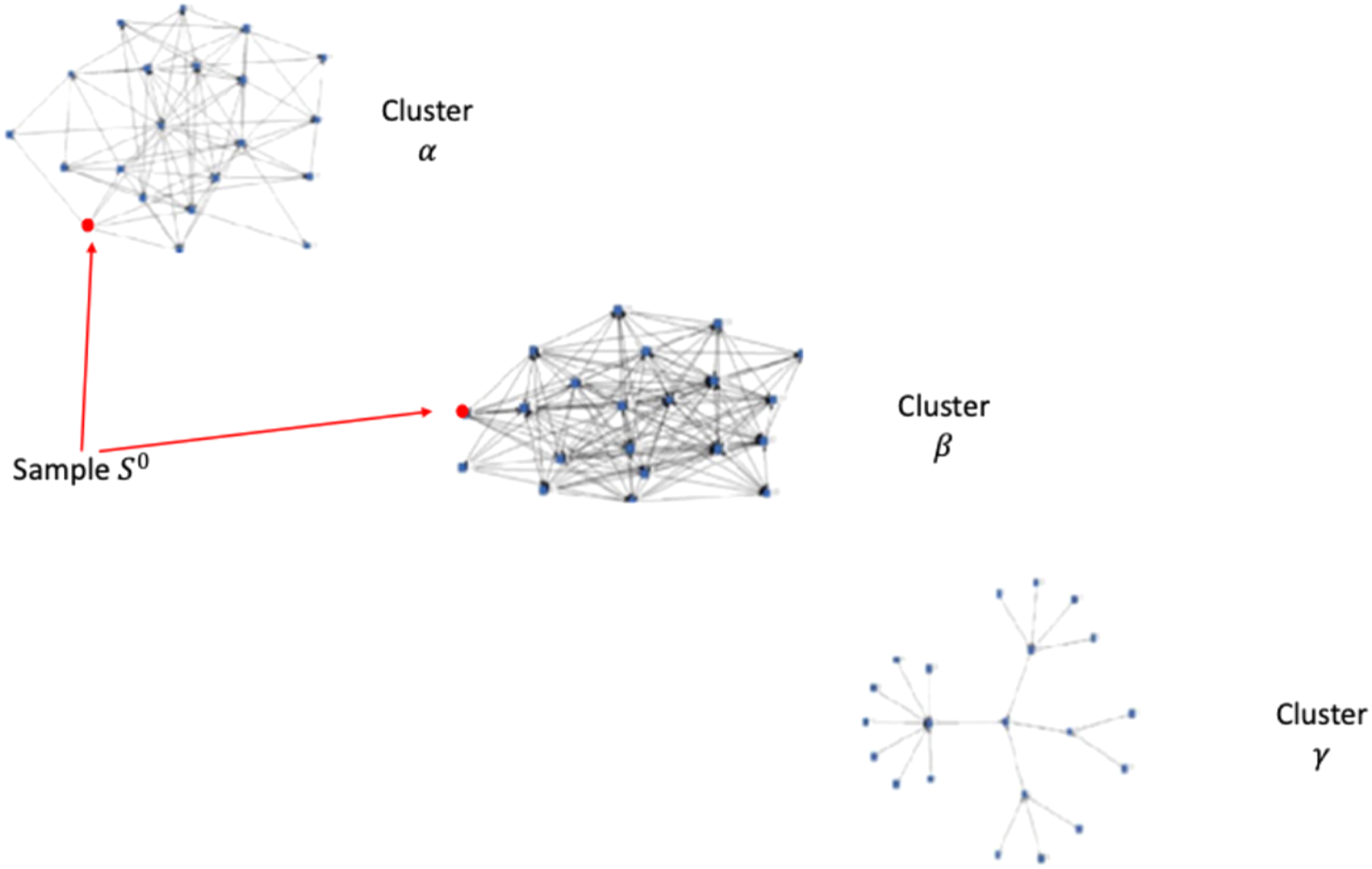
To help clarify the methodological developments and the notation used, we will discuss the population depicted in Figure 2, where units B and C are selected in sample
Step 1
Let us consider the case illustrated in Figure 7, where
Relationship of the true total in the population and that defined at the end of the RDS process.
Let's first consider unit B of
Let us now consider Unit C of
Please note that Unit G has been selected twice in the sample, highlighting the issue of multiplicity that can occur with this type of sampling.
At the end of the process, sample
The calculus of the estimate 
Table 5 illustrates the elements for the calculus of the estimate
Example of the calculus of

We randomly select a sample of additional units from
All links of units G and F are already included in sample
Step 1 of the sample in the RDS process.
The calculus of the estimate 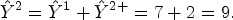
Both Unit I and Unit H have a single unexplored link pointing to Unit P. As a result, both Unit I and Unit H select Unit P with certainty. Figure 9 and Table 7 illustrate this case.
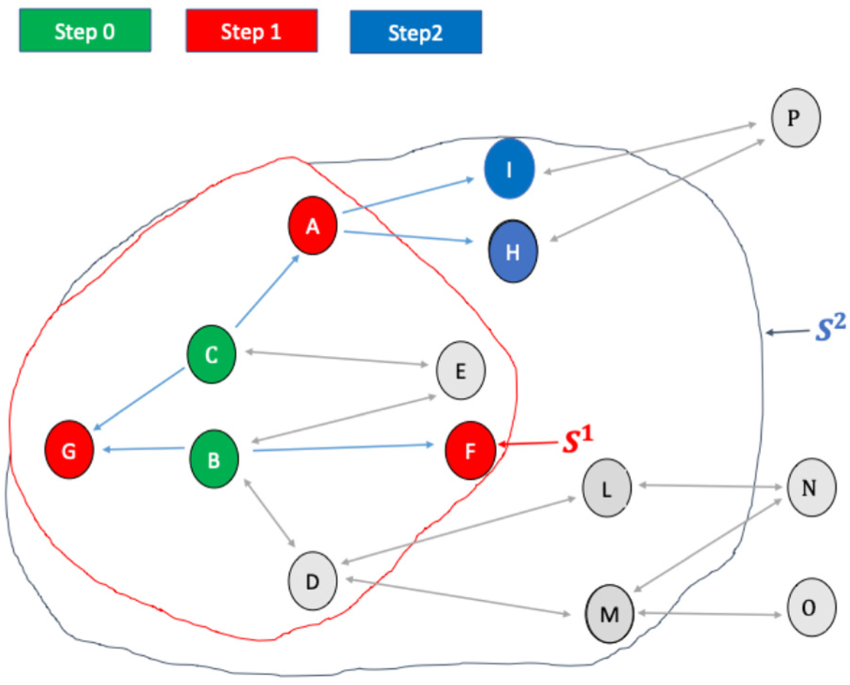
Step 2 of the sample in the RDS process.
The calculus of the estimate 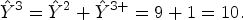
When restarting the RDS process, one notices that all the links of Unit P have already been explored. Hence, the RDS process ends, and we set
Feasibility and outlook
This section addresses various issues that could threaten the proposed strategy. We will briefly suggest approaches to mitigate some of the problems arising from these issues. However, each topic discussed here deserves its own paper, complete with empirical and theoretical research.
Example of the calculus of
via the indirect approach.

Example of the calculus of
Estimators 3.2 (with weights given by Expression 3.3) may face computability issues because some values
In contrast,
A reasonable approximation of 
We can determine the maximum and minimum values that the estimate 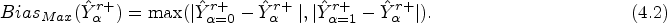
Setting
The sampling strategy we proposed is valid only when the RDS search is exhausted. This means it is applicable only when the stopping rule is that no new units are found to include in the sample. This characteristic may make the strategy less appealing to those managing the survey, as it poses a risk of an uncontrolled increase in sampling costs.
There are some alternatives to overcome this issue. The first is to model the trend of the
Another possible approach is to restrict the geographic size of the graph. The search for new units would stop if they fall outside the predefined geographical boundary of the network. In other words, a network spanning two distinct geographic locations can be analyzed as two separate networks. To implement this approach, the sampling design can be structured as a two-stage (or two-phase) process. In the first stage, a sample of geographic locations is selected. In the second stage, the RDS search is conducted within these selected locations, ensuring that contacts living outside the geographical boundaries are not explored. However, this method necessitates identifying seeds for each first-stage sample unit. To reduce economic and operational costs, first-stage units can be selected with a probability proportional to the concentration of the target population in each area, provided this quantity is known. Alternatively, if these concentrations are unknown or only approximately known, they can be classified using an ordinal scale, assigning higher selection probabilities to PSUs associated with higher values on the scale.
Example of the calculus of
via the indirect approach.
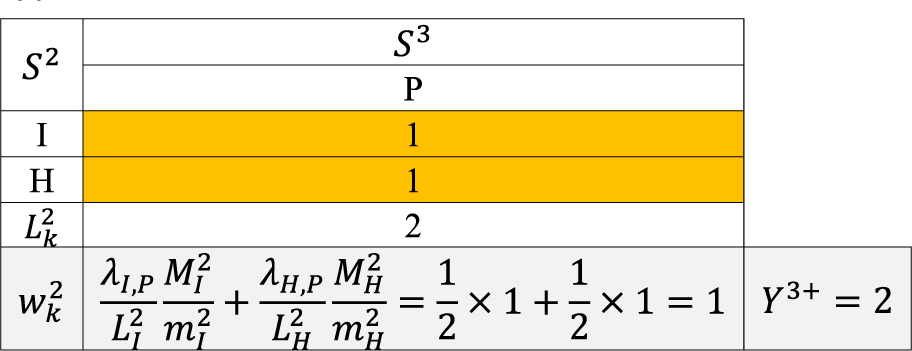
Example of the calculus of
One of the main challenges is obtaining the data necessary for both sample selection and estimate construction. In the described procedure, the surveyor must identify selectable units from the list of units associated with a given sample unit. This step can be performed in real time during the interaction with the respondent, but only if the interview is conducted using computer-assisted methods. Furthermore, the interview application must store historical data to differentiate between individuals listed by the current sample unit and those recorded in previous RDS steps.
Alternatively, after collecting the respondents’ contact information, the researcher can forward this data to the survey's central processing unit. The central unit would then carry out linkage operations to identify units previously mentioned by other respondents and generate a random list of new units for the researcher to contact.
A key challenge related to the previously mentioned topic is the need to divide the survey into distinct steps. This subdivision can be particularly difficult if enumerators in the field are expected to carry it out independently. From an operational perspective, these steps can be organized in a chronological sequence—for instance, initiating a new step every two days. After completing each step, enumerators must download the data on the contacts and respondents collected during the interviews. This information must then be properly processed, including performing record linkage operations, to ensure that enumerators can clearly define the list of selectable units for the next step.
Empirical analysis
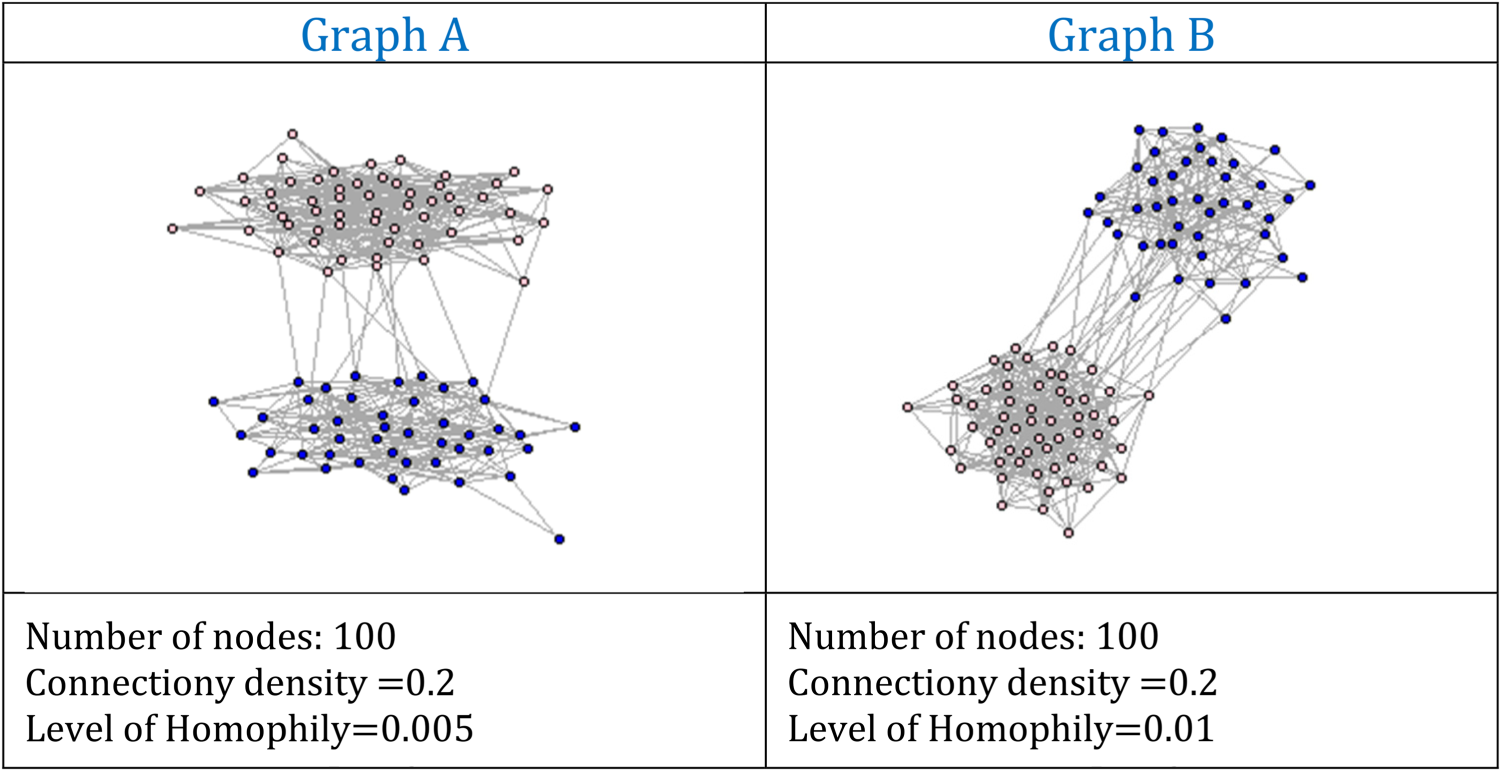
A simulation study was conducted using the R statistical software to evaluate the properties of the sampling method presented in the paper. The simulation aims to validate the proposed estimation strategy by examining two types of graphs, referred to as Graph A and Graph B, each featuring varying degrees of homophily and a moderate level of complexity. The number of units in each graph was set to 100.
Each graph is divided into two distinct groups, each with a connection density—defined as the probability of connection between two units within the same group—of 0.2. Graph A has a level of homophily, or the probability of connection between the two groups, set at 0.005. In contrast, Graph B has a level of homophily of 0.01.
Figure 10 below represents the two graphs, summarizing their characteristics.
Step 3 of the sample in the RDS process.
On each of these two graphs, we applied two RDS processes. In the first process, we selected a single initial seed, while in the second process, we selected two initial seeds. For each subsequent RDS steps, the number of units selected (
By analyzing the characteristics of the graphs and the RDS process, we have considered four distinct scenarios in total, as shown in Table 8 below.
Characteristics of scenarios.

We simulated four scenarios, conducting 1000 RDS (Respondent-Driven Sampling) search processes (iterations) as detailed in Section 3. The initial number of seeds was consistent for scenarios 1 and 3, as well as for scenarios 2 and 4. At the end of each iteration, we calculated the GWSE (Generalized Weighted Sampling Estimates) for the total population, which is set at 100. A summary of the results can be found in Table 9, while Figures 11 to 14 illustrate the box plots of the sampling estimates for each scenario.
Representation of the 2 population schemes considered.
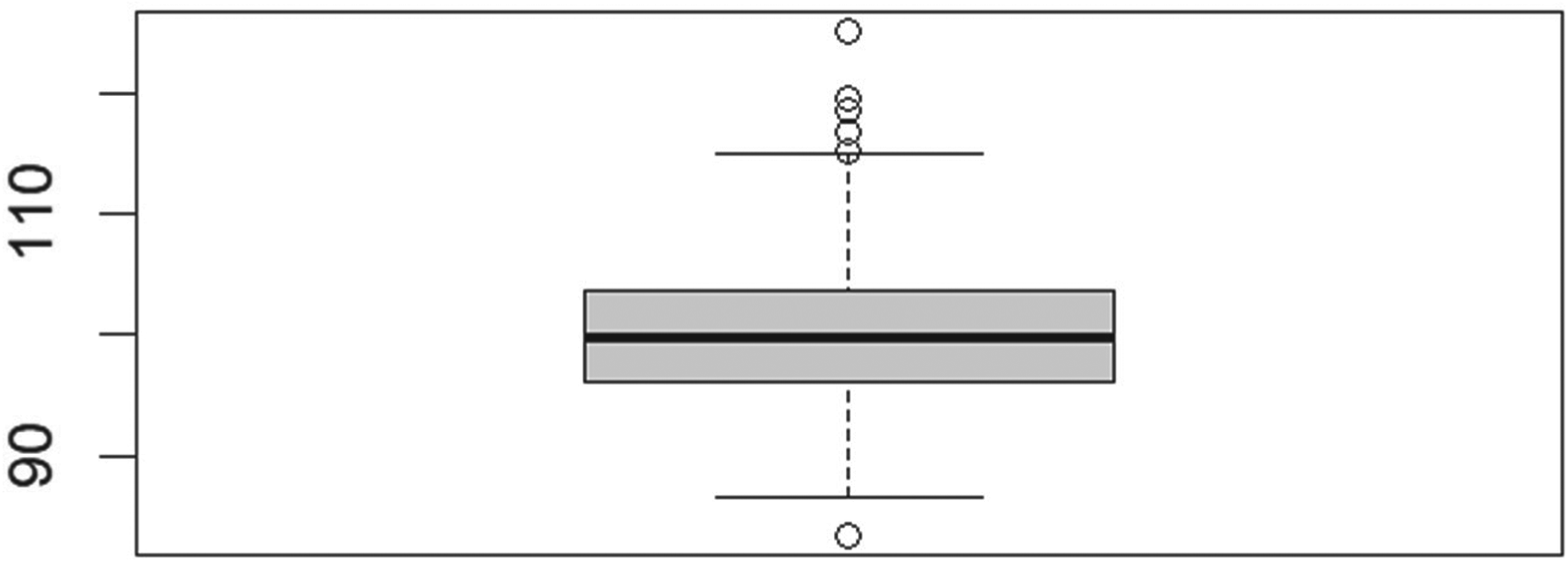
Boxplot of Scenario 1 showing the total population estimates. Homophily = 0.005, #Seeds = 1.
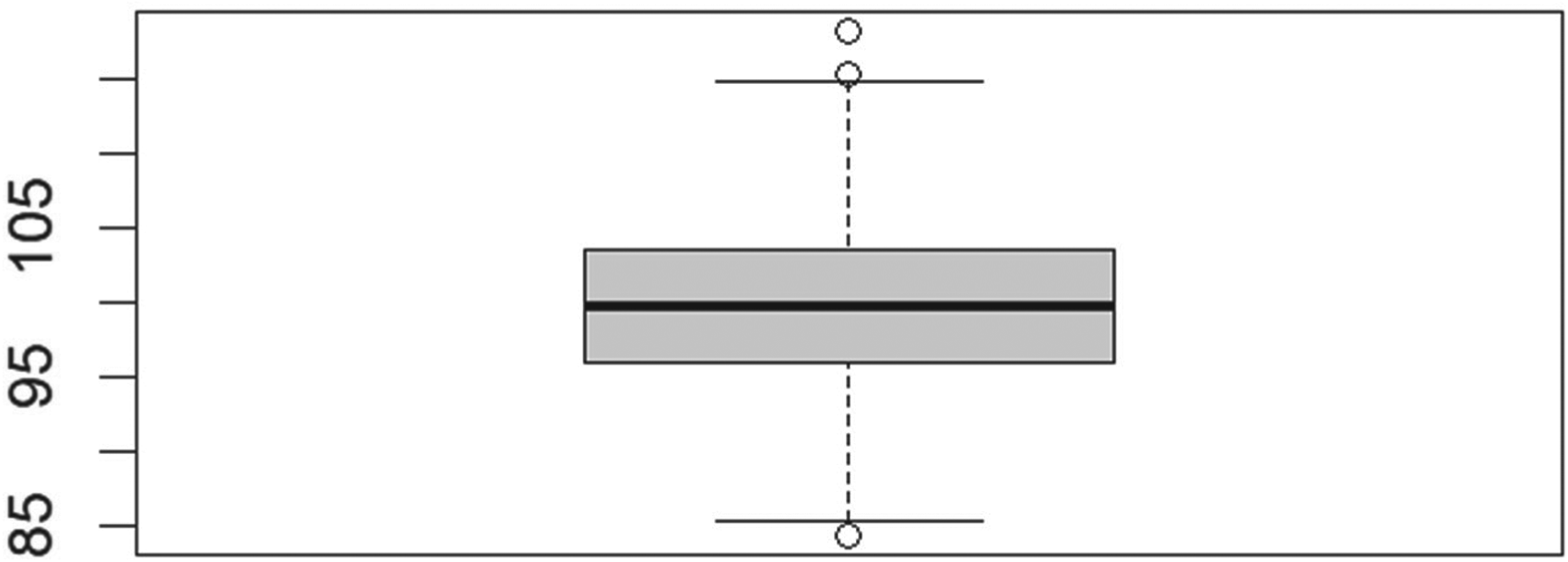
Boxplot of Scenario 2 showing the total population estimates. Homophily = 0.005, #Seeds = 2.
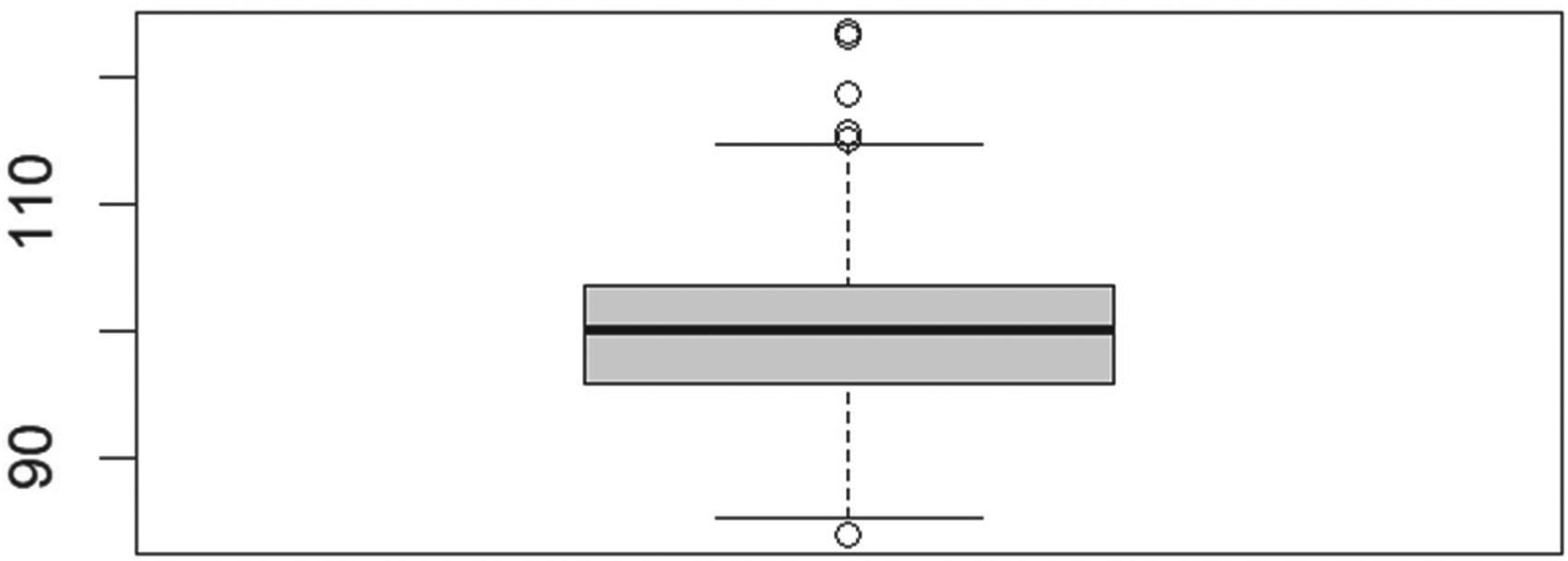
Boxplot of Scenario 3 showing the total population estimates. Homophily = 0.01, #Seeds = 1.
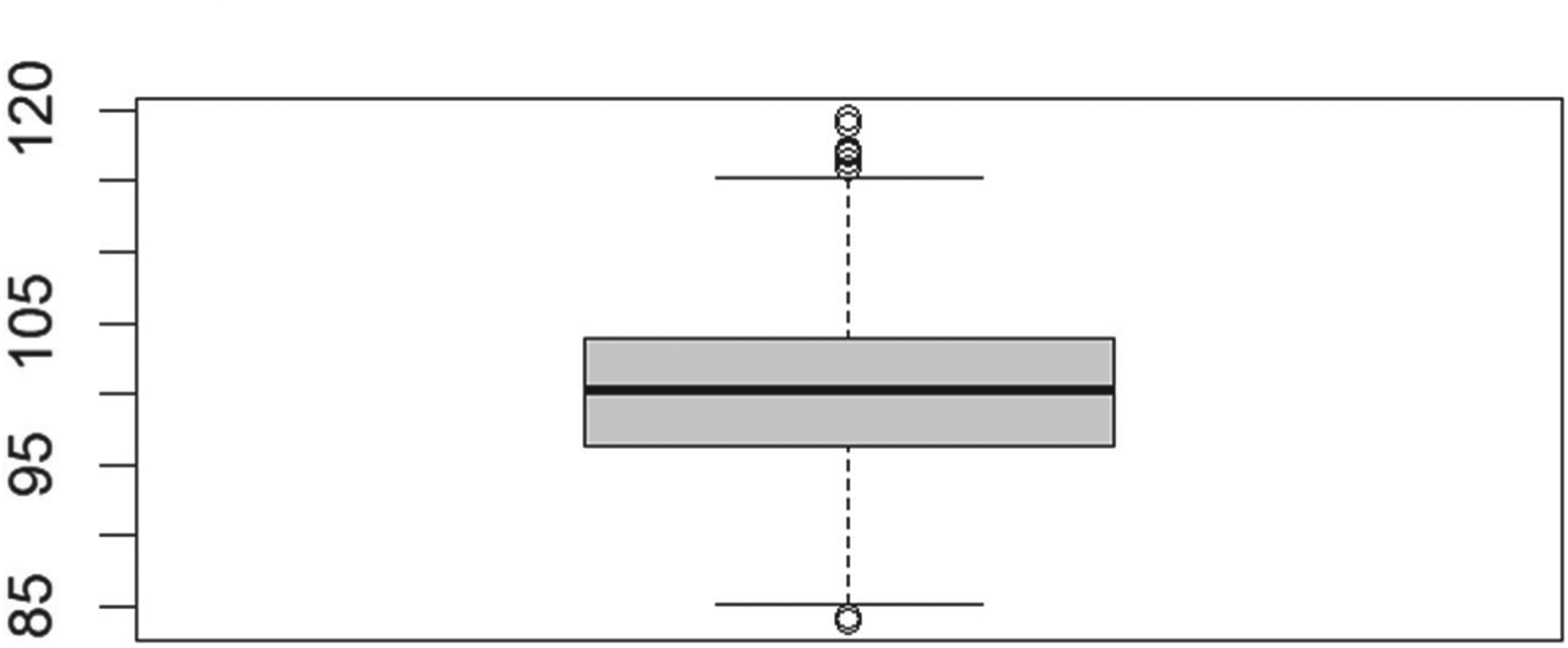
Boxplot of Scenario 4 showing the total population estimates. Homophily = 0.01, #Seeds = 2.
Summary of results by scenario.

The results we obtained are very encouraging. We have successfully demonstrated the fundamental outcome we aimed to achieve: our proposed method generates unbiased estimates of the total population across each of the four scenarios.
The coefficients of variation (CVs) of the estimates remain consistent, although selecting only two initial seeds helps limit extreme outlier values. Furthermore, in all four scenarios, the variability of the estimates between the first and third quartiles is minimal.
These initial findings are indeed promising. To enhance the robustness of our methodological proposal, we will need to conduct further experiments based on the guidance provided in Section 4 of this work.
Disaggregating data for SDG indicators on hard-to-reach populations presents several critical challenges that are difficult to overcome within the current framework of official statistics in many countries. In this context, estimating the characteristics of such populations using traditional modeling approaches is not feasible.
Therefore, it is crucial to define and implement a sampling strategy that can effectively address this issue. Priority should be given to sampling designs that maximize the number of observed individuals within the target population.
Respondent-driven sampling (RDS), which leverages existing social connections within the target population, proves to be a valuable tool for surveying these groups and providing approximate estimates of their actual size.
The article discusses the challenges involved in estimating totals within RDS and proposes a new methodological framework to address these issues. After outlining the limitations of traditional techniques, the authors introduce an innovative approach that utilizes indirect sampling methods. They clarify the practical requirements for implementing this new method, which includes collecting contact information and performing linkage operations to identify previously sampled units.
The methodology was validated through simulations and empirical applications, demonstrating its effectiveness and reliability. This approach offers a robust and practical solution to overcome the shortcomings of traditional RDS estimates, ensuring greater accuracy and applicability in complex network settings.
The findings we obtained are preliminary but show significant promise. To enhance the reliability of our proposed methodology, additional experiments should be conducted following the recommendations outlined in Section 4 of this study.
The research team is currently conducting additional experiments using simulated data, and the findings will be presented in a new paper.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.