
Abstract
The EuroGroups Register (EGR) is the European statistical business register on multinational enterprise (MNE) groups developed by the European Statistical System and managed by Eurostat. Primarily sourced by the National Statistical Institutes (NSIs) of the European Union (EU) and European Free Trade Association (EFTA) countries, alongside a commercial data provider, the EGR is the authoritative source for producing consistent globalisation statistics in the EU-EFTA. Since demand for EGR data is rising, there is a need to address data gaps, specifically in economic variables. Improving the EGR’s accuracy and completeness will boost its utility as the authoritative source for MNE group statistics. At the Conference on New Techniques and Technologies for Statistics 2023, Eurostat presented a feasibility study which responded positively to the question of whether there is value in using public sources as a potential source to enrich the EGR’s data. This paper outlines the systematic process of choosing, evaluating and using public data sources before integrating them into the EGR, their application in producing EGR data, and the resulting improvement in the EGR’s data quality.
Introduction
The EuroGroups Register (EGR) is the European statistical business register on multinational enterprise (MNE) groups created by the European Statistical System and managed by Eurostat. It is governed by the European Business Statistics Regulation 2019/2152. 1 It contains information about the control structures of MNE groups, their constituent legal units and corresponding enterprises, where at least one legal unit is located in an EU Member State or EFTA country. The main suppliers of data for the EGR are the National Statistical Institutes (NSIs) of the EU and EFTA countries, together with a commercial data provider that is used mainly to provide data for non-EU and non-EFTA legal units.
The EGR frames are produced at different stages of the production cycle. The first frame is produced at T + 4 months and is the starting point of the production cycle. It includes a copy of the previous cycle plus some additional information which the NSIs can provide in advance. During the cycle, two more intermediate frames are produced: the initial frame at T + 11 months, and the preliminary frame at T + 13 months. Finally, at T + 15 months, the final frame is released, and the production cycle concludes.
The most recent (final) frame is the EGR reference year 2023. This includes a total of 151 004 MNE groups employing 49.0 million people, and their perimeter in terms of legal units (about 1.5 million) and enterprises (530 400 enterprises inside EU and EFTA countries and 511 900 enterprises outside the EU and EFTA). Updated yearly, a Eurostat publication 2 provides information about the EGR and is available to the general public.
The EGR’s data quality is good and sufficiently stable to allow the EGR to fulfil its role as the authoritative source for producing consistent globalisation statistics. 1 Increasing numbers of statistical domains are interested in using the EGR as their main source of data to analyse MNE groups, and policy domains are requesting new experimental statistics to meet their needs. Some gaps still need to be filled to be able to respond quickly to these needs, particularly regarding incomplete economic variables (e.g. turnover or total assets) at group level, and to improve the non-EU and non-EFTA part of MNE groups data. The EGR will consolidate its role by further improving its accuracy and completeness, allowing it to become the trusted infrastructure for producing new statistics on MNE groups.
To further improve the accuracy and completeness of EGR data, different activities are ongoing which will help to supply missing values and improve the delineation of the groups’ structure, while helping to monitor events and changes that may occur in these MNE groups. The legal landscape set out by the amended Regulation (EU) 223/2009 3 and the Directives on open data and high value datasets 4 are now in place, creating opportunities to take advantage of open data sources and privately held data.
Eurostat presented a feasibility study at the Conference on New Techniques and Technologies for Statistics 2023, which led to a publication 5 concluding that the EGR can use public sources to support users and improve data quality. In this paper, we present the process used to assess the public data sources before they are selected for the EGR, how they are used in the EGR’s production process, and the results obtained in terms of increased data quality and coverage.
The paper is structured as follows: first, we present the methodology to evaluate and integrate new data sources into the EGR’s regular production cycle; second, we present the results of the evaluation and the different data sources which have either been integrated or are in the process of being integrated; next, improvements in terms of user interface for both producers and users of EGR data are presented; following on from that, some considerations about the production process are described and the main findings presented; and finally, our conclusions.
Methodology
The process of assessing the use of new public data sources in the EGR requires specific steps to determine their pertinence. Each step of the process requires specific actions to ultimately decide whether investment in the new data source is worth the effort and whether it can complement and improve the EGR’s quality (each data source is evaluated individually; data sources are analysed and integrated one by one when the conditions are met):
The first step is to identify potential data sources by assessing the relevance of their available information and identifying any technical limitations imposed by the source on retrieving the content of interest (e.g. resources required to collect and process the data). At this stage, a data source is selected. When a potential data source is identified, quality checks on the data source are carried out to determine whether it is reliable. The next step is to identify whether the source will improve the quality, accuracy and completeness of the EGR. Finally, if all conditions are met, the EGR team will invest in integrating the source into the EGR, if the data are for non-EU, non-EFTA legal entities. Alternatively, for EU-EFTA data, the EGR team will propose the data to the responsible NSIs for them to consider using in the MNE groups.
Thus, the process can be illustrated in four main steps as shown in Figure 1.
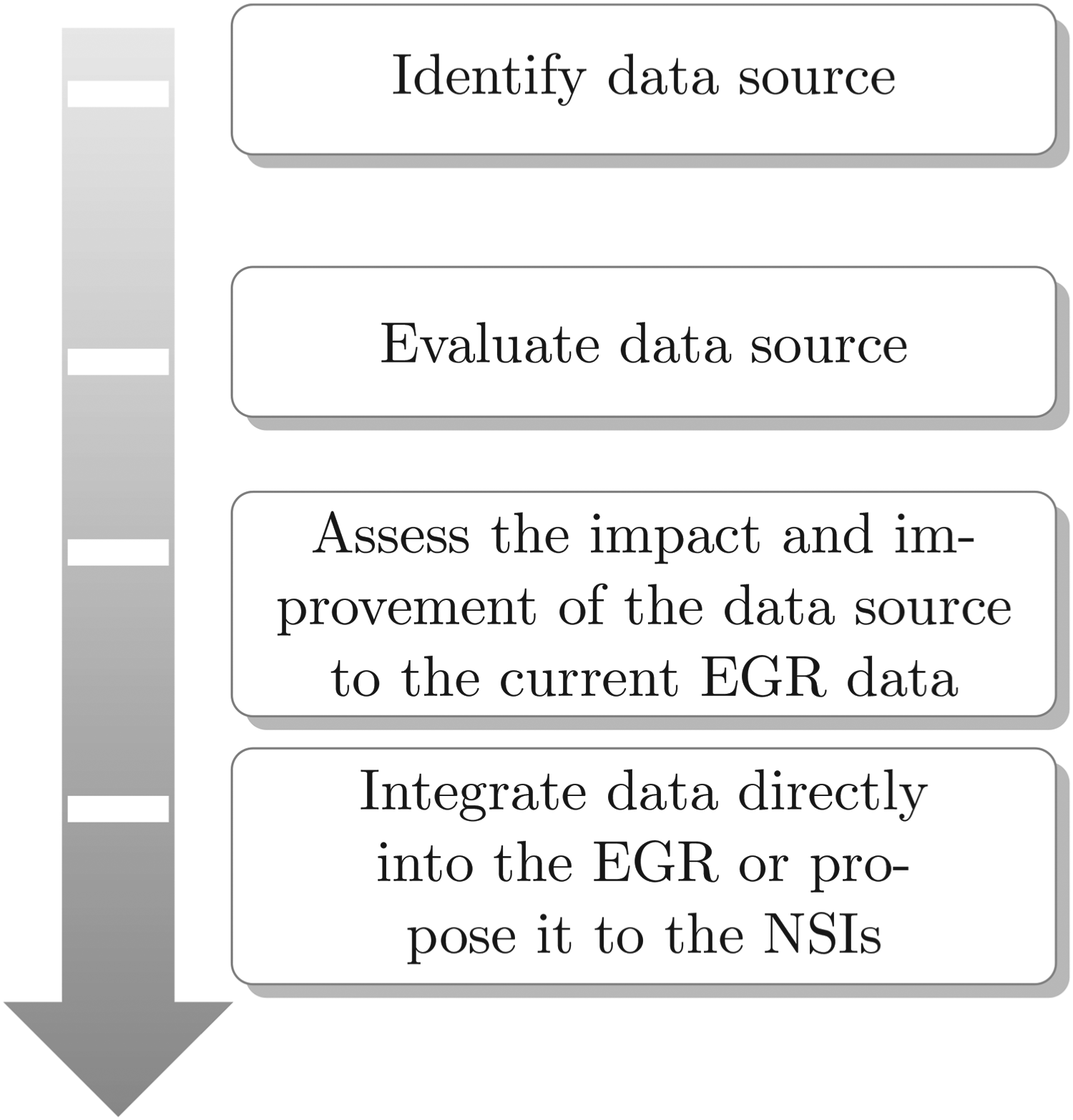
Main steps in the evaluation of a new data source.
The different data sources are evaluated according to a list of criteria. The new data source must satisfy (most of) them to be considered for integration into the EGR (see Table 1).
List of evaluation criteria for a new data source.

Qualified data for non-EU, non-EFTA legal entities and/or MNE groups can be integrated directly into the EGR. Alternatively, for EU-EFTA data, the collected information is proposed to the responsible NSIs. At present, communication and data exchanges with NSIs take the form of reports and/or datasets using the secure Electronic Data files Administration and Management Information System (EDAMIS) channel. This channel is the system Eurostat uses to exchange data.
A new data visualisation and comparison module for EGR producers and users, the value of which has been demonstrated by a proof of concept, is currently being developed, which will allow the NSIs to compare the data from external data sources to decide whether or not to use it. It is expected that, in time, trusted data sources will become more and more accepted by NSIs, and data from them will be regularly and automatically integrated directly into the EGR.
Following the process to integrate the new data sources, five data sources were selected and prioritised for evaluation: (i) Companies House from the British government 6 ; (ii) EDGAR from the Securities and Exchange Commission in the US 7 ; (iii) web-scraped data from Wikipedia 8 ; (iv) GLEIF from the Global Legal Entity Identifier Foundation 9 ; and (v) the Multinational Enterprise Information Platform (previously known as ADIMA) from the OECD-UNSD. 10
These open data sources fulfil all or most of the criteria and provide several benefits to the EGR by:
completing the missing variables at MNE group level (e.g. consolidated turnover, total assets and global employment); improving the delineation of the MNE groups (e.g. additional control relationships between legal units); helping to monitor changes or modifications in the MNE groups (mergers and acquisitions, etc.);
Once the matching of the public data source data with the EGR data is completed, each Member State receives the information for the groups under their responsibility, and the corresponding comparison with the EGR data for their assessment.
Companies House
The first public data source which has already been integrated into the EGR is Companies House, 6 which is the executive agency of the UK’s Department for Business and Trade, which maintains the administrative business register of companies. Since the reference year 2022, Eurostat has used three main products from Companies House in the EGR:
Company data product: a register of live legal units with around 5 million entities. These data are used to update the set of British legal units valid for the EGR (incorporated legal units). Accounts data product: daily/monthly updated data on electronically filed company accounts (instance documents). These files are used to retrieve economic variables such as employment, turnover and activity status, for around 3 million records. Data product identifying people and/or legal units with significant control: around 13 million upward relationships. An ’upward relationship’ refers to the person and/or legal unit controlling (more than 50% of the voting rights of) another legal unit.
Integrating this data source allowed the EGR to partially replace the work done by the British NSI after Brexit. For the EGR cycles between 2019 and 2021, the EGR relied on commercial data for the units located in the United Kingdom; by using Companies House, Eurostat has managed to rely less on commercially acquired data. This new source enlarges coverage of legal units and provides relevant information about the residence country of the ultimate owner, which is a key element for some statistical domains such as foreign affiliates statistics (FATS).
EDGAR
The data collection in EDGAR, available from the Securities and Exchange Commission in the US, 7 can be used to complement EGR data. The main benefit of this dataset is that it provides the data available in the quarterly and annual accounts of MNE groups in a machine-readable structured format.
To use this data, a matching task between the EGR and EDGAR is necessary as a first step. This has been done using string-distance algorithms with an additional manual check of the potential matches. In total, around 1 000 MNE groups are matched.
EDGAR contains information on many variables. For instance, there are approximately 200 000 different information fields in the dataset. However, for the purpose of the EGR, we only extract the data on employment, turnover and total assets.
The EDGAR data collection provides coverage in the EGR mainly for the MNE groups which are located outside the EU-EFTA territory with at least one legal unit in an EU or EFTA Member State.
The values for employment can be used to update the EGR figures, as this is a variable mostly available in EGR. On the other hand, turnover and total assets are largely missing, and EDGAR can be used to fill in the missing data.
If we look at the values for employment (see Figure 2), we observe how most values are for MNE groups with their decision centre Other, which means outside the EU-EFTA territory. The values present certain dispersion, with a clear case of underestimation from the EGR.
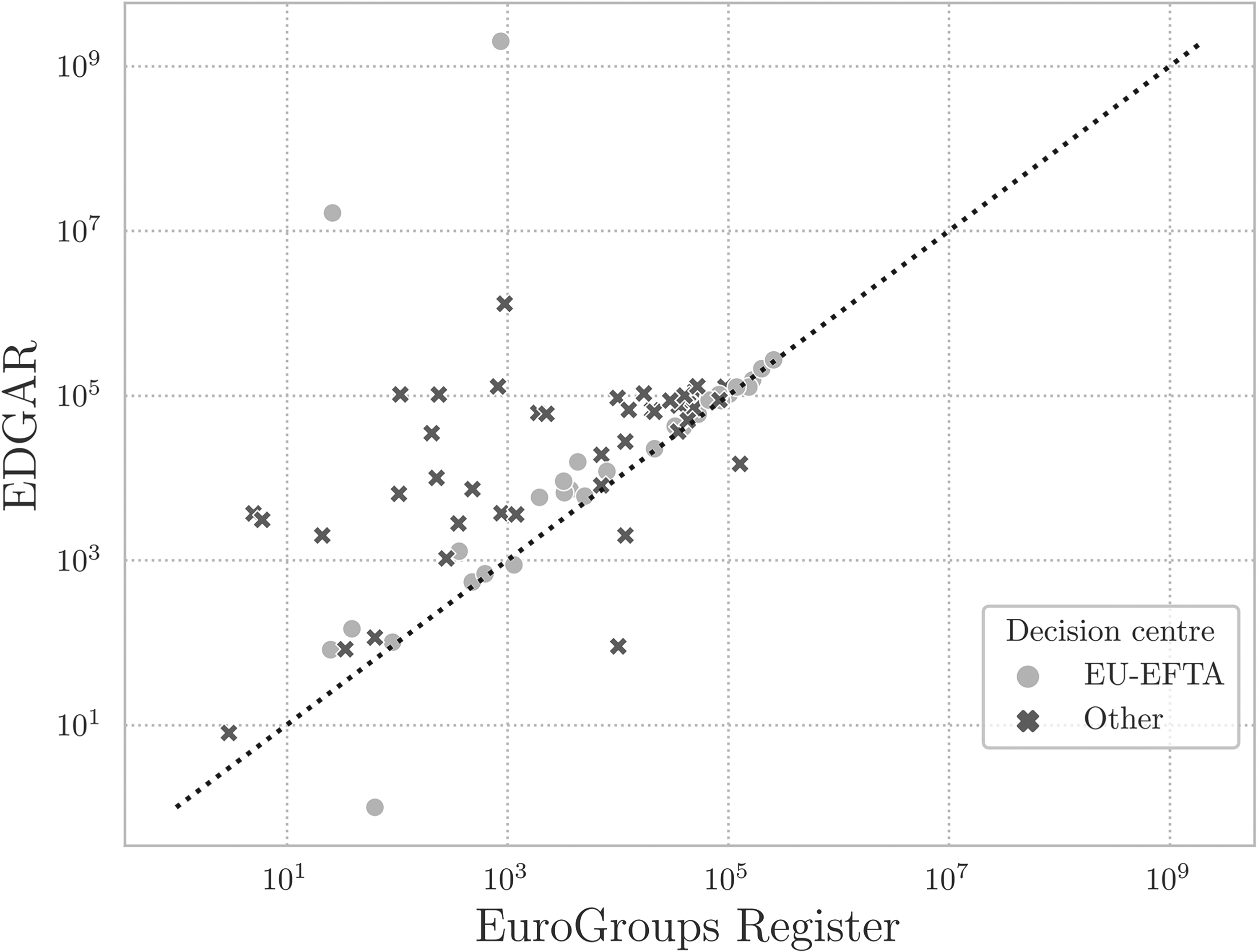
EDGAR data compared to the EGR. Total number of persons employed (including self-employed) at the end of the year, 2023.
The underestimation can be explained by examining how the EGR initially fills in missing employment values with information available in EDGAR. When employment data is not provided, the EGR calculates the consolidated employment of the MNE group by aggregating the employment figures of each individual enterprise. Due to poorer coverage for groups outside the EU-EFTA (as data is not received from official government bodies), individual enterprises are more likely to have missing values. This increases the likelihood of underestimating the consolidated MNE group employment compared to an official source like EDGAR. Therefore, EDGAR data can be used to enhance the accuracy of the data.
On the other hand, MNE groups with their decision centres within the EU-EFTA territory tend to be mostly active within the EU-EFTA. This means that most of the data is collected directly from the NSIs, resulting in less missing data (Figure 2).
Eurostat computes every year the complexity and statistical impact (CSI) index. The impact of MNE groups on the economy is measured by the CSI index considering the number of jobs, the number of countries in which they operate, the number of ownership layers, and the number of different economic activities. The index captures a total of around 2 000 MNE groups.
To measure the improvement to the EGR by using EDGAR, we calculate the number of missing values for the CSI index MNE groups that are filled by this data source. The results show that 7.53% of the groups improved their coverage by using data from EDGAR.
The data collection from Wikipedia 8 is targeted to the most relevant MNE groups for the EU-EFTA economy using the CSI index.
In a previous publication, 5 the authors demonstrated how Wikipedia is a valuable data source for the EGR and that investing in collecting and integrating its information is worthwhile. However, data collection currently faces two main limitations:
Currently, only articles in English are parsed, which limits the number of articles extracted to around 1 050. The reference year of the values extracted from Wikipedia is a key element to match them with the corresponding EGR data frame. This creates some limitations when the reference year is missing or in the past.
As mentioned before, EGR data are mostly complete for the values of employment. However, the values for turnover and total assets are mostly missing. The extracted data can therefore be used to either update or to fill in the missing data.
If we look at the values for employment (see Figure 3), we can observe how the Wikipedia data can improve the accuracy of the EGR values. Moreover, we can also observe, in line with expectations, that the values for groups with a decision centre within the EU-EFTA territory tend to be more in line with the values available in Wikipedia. On the other hand, the values for employment for other groups, for which the EGR relies mostly on commercial data, seem to be systematically underestimated.
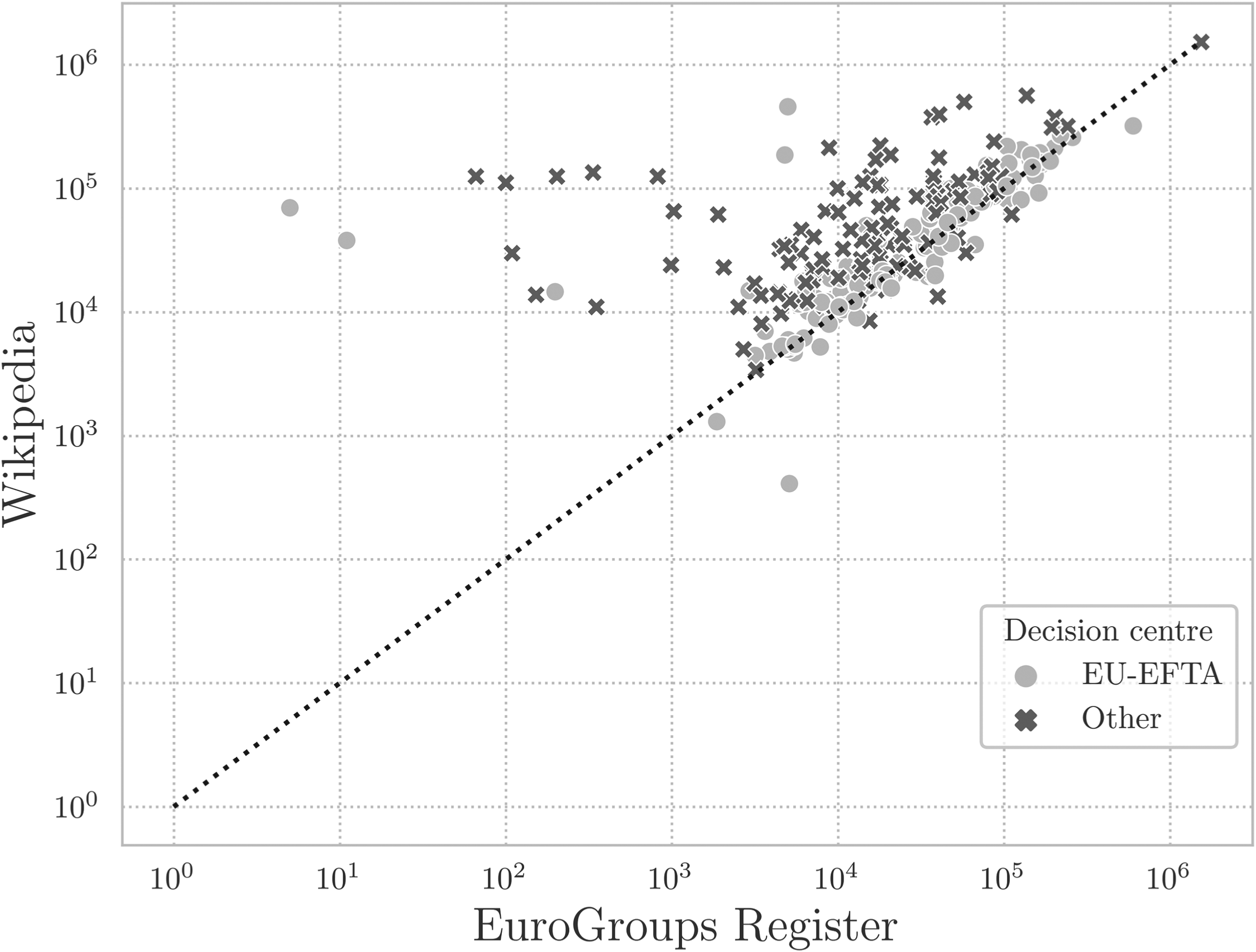
Wikipedia data compared to the EGR. Total number of persons employed (including self-employed) at the end of the year, 2023.
Similar to what is done for EDGAR, we measure the improvement to the EGR by using Wikipedia by computing the number of missing values of the CSI index MNE groups filled by Wikipedia data. The results show that 1.62% of the groups improved its coverage by using data from EDGAR.
The Global Legal Entity Identifier Foundation (GLEIF) 9 is a non-profit organisation established in 2014 by the Financial Stability Board, under the mandate of the G20.
GLEIF oversees the global implementation of the Legal Entity Identifier (LEI), which provides unique and standardised identification for legal entities involved in financial transactions.
These entities can also register their relationships with other units identified by GLEIF. In this way, GLEIF provides, free of charge, a set of legal units with multiple identifiers worldwide (Level 1) and, at the same time, their relationships with other entities (Level 2). The datasets contain around 3 million entities (58% located in the EU or EFTA) and half a million relationships.
After matching the Level 1 dataset with the legal units that already exist in our database, the LEI identifier can be included in our database to help the NSIs to identify foreign legal units involved in their relationships. Based on the second dataset (Level 2) concerning relationships, we have compared the group structures and plan to inform the EGR producers (NSIs) of the most significant differences for the largest MNE groups, which they can analyse further.
This approach will improve coverage outside the EU-EFTA territory. However, some limitations need to be addressed - the matching process, lapsed data in GLEIF and the probable under-coverage of subsidiaries.
Multinational Enterprise Information Platform
The Multinational Enterprise Information Platform (MEIP), 10 an OECD-UNSD database, contains the largest 500 MNE groups in the world. These groups account for around 125 000 legal units, 29 000 of them within the EU-EFTA territory.
After matching the MEIP with EGR data, we find 66% of the units in the EU-EFTA, and 43% for the whole world. In total it is possible to compare 87% of the MNE groups available.
Following a similar approach to that described for the GLEIF source, the main idea here is also to challenge the EGR data by identifying the main differences.
The added value of MEIP is that it leverages a broader range of sources, although only for a very small portion of the MNE groups in the EGR (the largest ones). The main constraint is the limited number of groups. This source will be the first one disseminated to the NSIs during the production cycle for them to assess.
Data visualization
The EGR’s new data visualisation module will soon make data from these public data sources available in dashboards, which will allow the NSIs to see the differences or gaps between EGR data and the public data sources, evaluate the quality and decide whether to use them in the EGR final frame. Proof of concept dashboards have already been developed using the Power BI data visualisation platform.
The next step is to allow EGR producers to simply select the data they deem of good quality which complement their data from the user interface and consolidate them in the EGR. We can split the visualisation dashboards for new data sources into two main categories: (i) data to complete group level information (e.g. global employment) and (ii) data to complement the perimeter of an MNE group (i.e. subsidiaries and their country).
Group level information
An example of the visualisation for group level variables is shown in Figure 4.
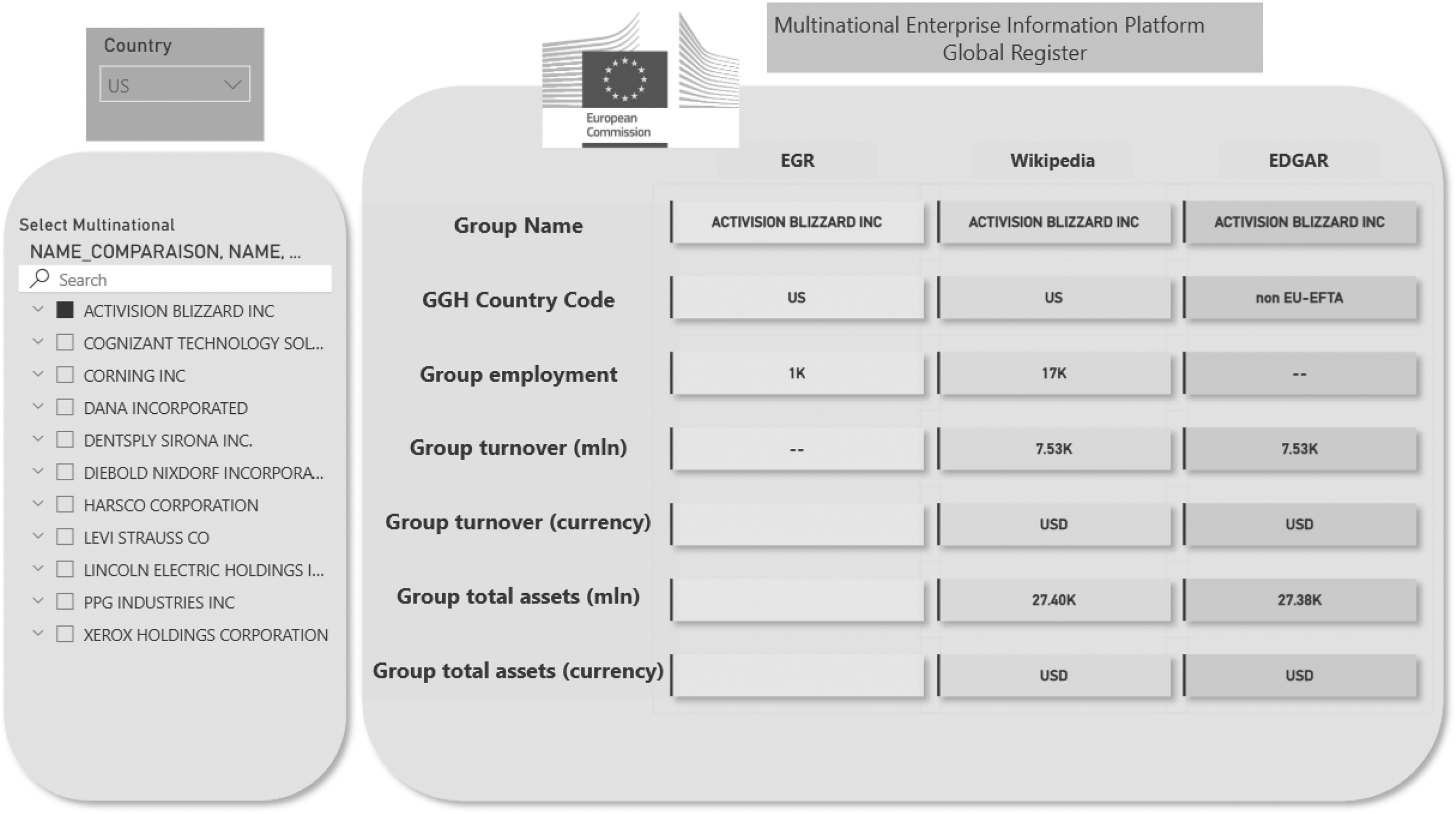
Visualization tool to compare several data sources, 2022.
Figure 4 not only allows users to compare the values between the EGR data and the collected data sources, but also provides a comprehensive picture of the information between different data sources.
In the example, one can see how the values for turnover are consistent between the two data sources collected (Wikipedia and EDGAR), while for the value of total assets, Wikipedia could be rounding the values.
Moreover, comparing the employment values, even though they are only available from Wikipedia, one can already see the underestimation of EGR values.
The other possibility is to compare the content of an MNE group (i.e. the delineation). An example of this can be seen in Figure 5.

Visualization tool to compare subsidiaries, 2022.
Figure 5 provides a clear insight into the potentially missing subsidiaries of a specific group. In this particular example, a comparison is made with the Multinational Enterprise Information Platform collected and disseminated by the OECD-UNSD. 10
In this case, one can observe how the subsidiaries that could be missing from this specific MNE group are all located outside the EU-EFTA territory. This is in line with expectations from the EGR, as the data from outside the EU-EFTA territory comes mainly from a commercial provider, rather than the responsible NSI.
Another important aspect when integrating data from different data sources is to consider any potential conflicting data between the different sources.
The EGR system to consolidate data already takes this situation into account. The EGR has been working with different data sources providing the same information for a long time, and a set of priority rules has been defined and refined over the years. For instance, data from the European profiling teams (specialised teams working manually and at the level of detail of the most relevant MNE groups for the European economy; see European Commission - Eurostat 11 for more insights into profiling exercises) usually conflict with the data provided by the Business Registers of the Member States.
The profiling methodology is based on manual work aimed at providing a detailed description of a group, its activities, and its delineation. This work relies on the expertise of national specialists who use published accounting documents and, where applicable, direct interactions with the group itself. Such information is of high quality and is preferred over administrative data received at the level of legal units. The concepts of ‘enterprise’ and ‘group’ usually do not exist in administrative data, and very often such data cannot be exploited automatically due to the lack of harmonisation in the available documents.
In these cases, profiled data are given priority over register data.
A priority order is also defined for those integrated data sources. For example, official data, like Companies House data, 6 will have priority over commercial data, while Wikipedia data 8 will have the lowest priority due to its nature.
Conclusions and way forward
The accuracy and completeness of the EGR have already significantly improved thanks to the process outlined above to evaluate and integrate new data sources into the EGR. For instance, the use of Companies House data improved the EGR’s coverage by around 5 million legal units for the UK and reduced the cost of data acquisition from commercial providers by 25% in 2023.
Thanks to the exchange of matched data between public data sources and EGR data, the NSIs will be able to use data which they are missing or consider of better quality.
The new EGR data visualization and comparison module will make the EGR production process more efficient by reducing costs and the burden on the NSIs and Eurostat.
This solution opens up the possibility of integrating any additional new and open data source (e.g. Base Erosion and Profit Shift 12 Country by Country Reports; Corporate Sustainability Reporting Directive 13 ; OpenCorporates 14 ; etc.) into the EGR core infrastructure in a flexible and cost-effective way, progressively expanding the variables available in the EGR beyond what NSIs can provide from their national data sources.
Moreover, the availability of open data sources could help the EGR to generate an additional frame earlier, thereby improving the timeliness of the EGR, which is highly relevant for some users. In many cases, open data also provides more economic information than that strictly covered by the EGR, potentially allowing Eurostat to add more economic variables to the EGR. This expansion will consolidate the EGR’s role as the authoritative source for globalisation statistics and satisfy more requests from policy Directorates-General for data that currently lack the requested economic variables.
In conclusion, the legal landscape set out by the amended Regulation (EU) 223/2009 3 and the Directives on open data and high value datasets 4 are now in place, creating opportunities to take advantage of open data sources and privately held data. Eurostat is moving in the direction of starting to use data from open data sources, applying a systematic approach to evaluate these data sources and to decide whether to invest in them.
It is clear that using these data sources can improve the accuracy and completeness of the EGR. Eurostat will continue to add new data sources while following the established systematic process, investing in additional data sources and using the early availability of data from these open sources to generate an additional frame even sooner, enhancing the timeliness of the EGR further.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.