
Abstract
In this paper we explore the potential of large language models (LLMs) for COICOP classification in the household budget survey (HBS). The major goal is to reduce or even eliminate manual coding in the production process. We describe Norway's last survey, HBS 2022, where large savings were realized from the use of machine learning while significant manual coding remained necessary. Initial experiments with a commercial LLM were very promising, with the latest free model of ChatGPT achieving similar accuracy to a human coder. We developed a prototype classification pipeline using self-hosted LLMs. It uses retrieval augmented generation (RAG) to retrieve information about relevant codes to insert into the prompt. Performance is still limited on the smaller LLMs our computing setup at the time could handle. However, support for larger models is quickly expanding at Statistics Norway, and further development on using better quality embeddings and larger LLMs is ongoing. In addition, we describe the performance of several other methods for classification, such as a BERT-based classifier or hierarchical prompting. We also mention approaches to issues such as adapting models to a less widely-spoken language like Norwegian and extracting a measure of an LLM's confidence in individual predictions. Finally, we give some recommendations for using LLMs in conjunction with machine learning and human-in-the-loop coding.
Keywords
Introduction
Generative AI (GenAI), and especially the use of large language models (LLMs) for text generation, has revolutionized a range of routine work tasks. There is much excitement about the potential of LLMs in statistics production. The coding of survey items is a natural candidate application, being an example of a tedious, resource-intensive task that relies on interpreting short snippets of natural language. In the past few years, NSI's have reported progress towards achieving greater levels of automation with LLM-based approaches like zero-shot/few-shot learning for this type of classification task.1–3 As described below, LLMs can be used on their own or combined with supervised machine learning approaches such as.4,5 Norway is running its next household budget survey in 2026 and is exploring new LLM-based systems for the classification of purchased items to 5-digit COICOP codes (i.e. “apple juice 1L” → 01.2.1.0).
6
The COICOP 2018 classification scheme used contains roughly 300 categories at the 5-digit level. As a smaller country, we are especially interested in contributing experiences regarding:
adapting approaches to less widely spoken languages the challenges of working with receipts data (i.e. abbreviated text and OCR noise)
This is ongoing work and is partly covered by two Eurostat grants: the Innovative tools and sources for HBS 2026 (SMP-ESS-2023-HBS-IBA), and the wide ranging AIML4OS project across the ESSnet system (“one-stop-shop for AI”).
The previous household budget survey (HBS 2022)
The most recent HBS 2022 in Norway featured several major innovations: 1) a modernized data collection wherein respondents could choose to either scan receipts for processing with OCR or enter purchases, in either case in a web app (about 90% of the time they chose to scan), and 2) machine learning paired with a custom-built web application for human-in-the-loop COICOP coding.
Several algorithms were tested for coding, and random forest using 2-grams and 3-grams was found to work the best. The overall accuracy at the 5-digit level was 63%. Since that isn’t high enough to entirely automate the coding process, we used the prediction probabilities returned by the algorithm to separate items into a group that can be automatically coded vs one that needs manual coding. Prediction probabilities represent the model's estimates of the probability of each item belonging to the category it is predicted to be in, and they are calibrated during the training process. They can be used as a measure of confidence. We found a threshold value for the prediction probabilities that empirically corresponded to 90% accuracy for items above that value. We were able to automatically classify 38% of items this way.
Overall, classifying with machine learning was a success, and Statistics Norway experienced a significant savings in resources. 7 23,000 out of 60,000 unique items passing through the human-in-the-loop system could be classified automatically with quality matching human coding. Nevertheless, manual coding and editing remained a major effort. We wish to reduce or eliminate manual coding in the production process starting with the next HBS in 2026.
Data and editing
The data we used for all experiments described below is from Norway's HBS 2022. It consists of purchased items that either come from receipts that were scanned by the respondents and then OCR processed (roughly 90% of items), or that respondents entered manually in the web application (roughly 10% of items).
Various automatic checks were first done to find errors on individual receipts, such as when the sum of item prices on a receipt didn’t correspond with the total paid. Errors came from mistakes in OCR properly identifying the layout and text, mistakes in manual entry, and mistakes in handling the logic of discounts on certain items. Flagged receipts were sent to an automatic error correction step where some problems could be corrected, such as when OCR had misaligned the column of item names with the column showing prices. Receipts where errors could not be corrected automatically were manually edited. Some entries could not be associated with a single COICOP code as they refer to broader categories like “vegetables”, and we excluded these from our experiments. For all other items, a COICOP code was found in a human-in-the-loop setup, by either automatically coding with Random Forest or manual coding.
Infrastructure- Daplalab
All development work connected to AI at Statistics Norway is done in Daplalab, which is a very innovative data science platform for development and production. Daplalab is based on the Onyxia (https://datalab.sspcloud.fr/) platform developed at Insee. Statistics Norway is both an adopter and contributor to the open-source project, having developed functionality to advance data governance. Daplalab uses Google cloud computing services for computation and storage and self-hosts models for full data protection. It features a growing catalog of services such as JupyterLab. The ability for the user to choose what resources (CPU and soon GPU, RAM, disk space) they need in Daplalab while seeing cost estimates is especially useful for working with the computational demands of LLMs efficiently.
Large language models for classification
Both LLMs and BERT (a machine learning method we tested as a baseline) include an attention mechanism to dynamically encode words based on their context in very nuanced ways. One of the biggest advantages of LLMs is that they don’t require manually labelled training sets. With LLMs we implemented the prevailing retrieval augmented generation (RAG) approach, which ensures that the chatbot is pointed to updated and reliable information through inserting into the prompt the most relevant snippets of information retrieved from a trusted knowledge base. This approach can also be very advantageous in case of a transition to a new classification scheme, where the classification system can be updated seamlessly by simply replacing the classification index in the knowledge base.
Retrieval-augmented generation (RAG)
RAG 8 is a framework that allows LLMs to access additional information retrieved from a knowledge base. In this way, LLMs can access internal documents and updated knowledge. It consists of the following steps: 1) a knowledge base of documents is split into units of text, embeddings are formed from these units, and the embeddings stored in a vector store, 2) a user's prompt is embedded and sent to the vector store, 3) the k-best matches in the vector store to the user's prompt are retrieved, using a measure such as cosine similarity in the embedding space, 4) a new augmented prompt is formed, adding the text of the retrieved matches to the original prompt as context, 5) the LLM generates a response from this expanded prompt. Figure 1 shows a simple diagram.
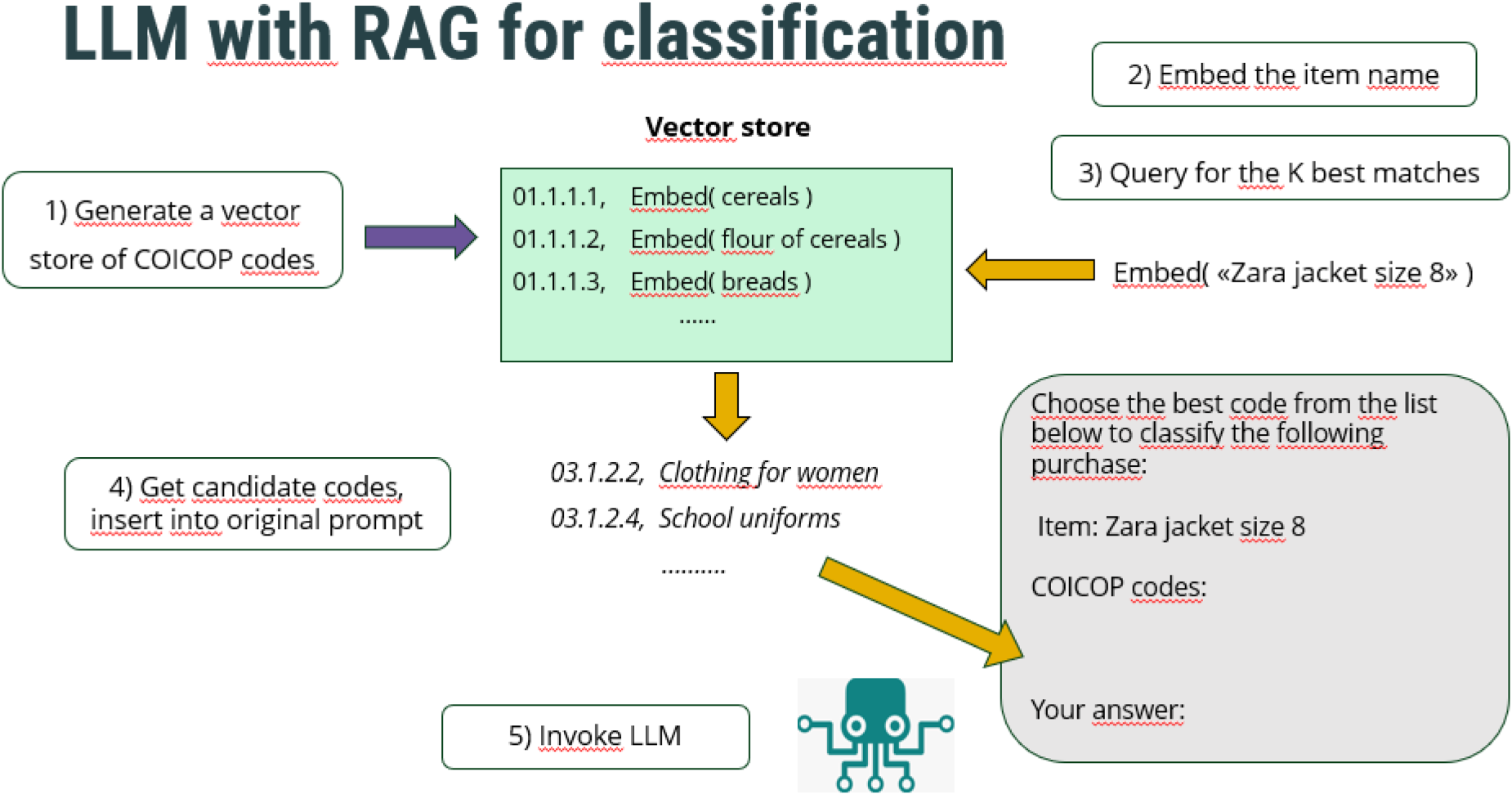
LLM with retrieval augmented generation (RAG).
For survey coding applications, this process entails that each vector in the vector store corresponds to a code in the classification scheme (i.e. COICOP, NACE), with an embedded definition or description of the code. A description of the item to be coded is embedded and used to query the vector store for the closest matching codes. The LLM is then given instructions to code the item it is shown, choosing from the retrieved list of possible codes. Section 4.1 gives many details for our implementation of RAG for COICOP coding.
We try two basic approaches to prompting: RAG as well as hierarchical prompting without RAG. In the latter approach, the chatbot is first shown all COICOP codes at a higher level, i.e. 2-digit and asked to choose. In each successive iteration, items are coded at a more refined level. Below we describe experiments where we used 3–4 hierarchical steps to classify the ∼300 COICOP classes. The main advantage of hierarchical prompting is it avoids an embedding model as a possible source of error.
COICOP classification involves a non-sensitive data source consisting of purchased items, not linked to the respondent or other variables. Nevertheless, in rare cases we have found scanned receipts to have sensitive personal information. Moreover, we have not explored the idea of getting respondents’ consent to send data out of house. Thus, standard data protection rules in place at NSI's apply which prohibit the use of external commercial LLMs like ChatGPT. We implemented LLMs with downloaded open sources models from HuggingFace run in the secured closed environment of Daplalab. This is called self-hosting of models, where data is protected and models managed fully in-house (even though our infrastructure in Daplalab is rented from an external service, namely, Google Cloud Platform). Open-source models also have a number of advantages resulting from the fully accessible model weights:
Fine-tuning of models is possible Models are fully accessible, allowing for R&D work and for EU and international collaborations There is flexibility in testing different models and building with tools from open-source libraries They are somewhat cheaper to run than closed-source (comparing similar-sized models), as measured in money or environmental footprint
LLMs to improve data quality for survey coding
LLMs can be highly useful for survey coding even when an application isn’t developed to code an entire survey. They can be used for example to:
Generate synthetic training data to help with imbalance
LLMs
2
have proved adept at generating synthetic data. At almost no cost, we can for instance ask ChatGPT for hundreds of examples corresponding to a poorly represented category, and then manually check for quality. This provides a very easy way to obtain a training set with a sufficient number of examples across all categories. Suggest edits for items flagged as needing manual editing to improve the quality of coding Help with entries spanning multiple items
In cases where the respondent has entered a description that spans multiple COICOP codes (i.e. “vegetables”), the money spent must be distributed across the codes spanned by the description. As a first step, an LLM can identify all these relevant codes. In HBS 2022, an imputation procedure was implemented to distribute the money across the codes using estimates from the rest of the data (01.1.7.1 → 50 NOK, 01.1.7.2 → 120 NOK, etc).
These examples involve a limited number of items affected, so manual prompting is sufficient and thus commercial LLMs can be used without data protection concerns.
Many leading LLMs and embedding models have been trained on overwhelmingly more data in English than in less widely spoken languages, as well as often being trained with the objective being performance on tasks in English. Thus, it cannot be taken for granted that generic models will work well for a smaller language like Norwegian. We have anecdotally heard of a major failure when one country paid for an expensive deep reasoning model whose performance for their smaller language turned out to be insufficient. In addition to language, applications often need a model to be familiar with specialized terms relating to business or cultural context. For instance names of companies or products can help with NACE or COICOP coding.
The following are ways to implement LLM applications to work with a smaller language
9
:
Use a large model with good multilingual capabilities.
Models like ChatGPT trained extensively on Internet data have outstanding ability to handle different, even blended, languages. We found outstanding support for Norwegian in ChatGPT's −4, −4o, and −4o-mini variants. Use a model trained or adapted for a particular language. For instance, for COICOP coding, we used two types of Norwegian language models that provided good support:
NorskGPT for an LLM, which is an instruction fine-tuned version of Llama3 that has been trained on pairs of instructions and desired outputs in Norwegian NorBERT and other embedding models created from large corpuses of Norwegian text Machine translation
Can be a good idea when there is a significantly higher quality model in the non-native language, and the text isn’t culturally specific. Translation can even be done at the embedding level
10
: demonstrate that it is possible to use a classifier trained for one language to classify in another language using cross-lingual embeddings.
Here are some ways an application can be domain adapted to work with terms specific to a business or cultural context
3
:
Use a RAG framework to retrieve specialized terms from a document Fine-tune an LLM (expensive and complex for larger models) Fine-tune an embedding model (much easier)
Adapting an embedding model such as BERT to the application at hand can significantly improve the performance of RAG. For example, web-scraped data from grocery chains can help an embedding model recognize brand names of products for COICOP coding.
We performed initial experiments with manually entering items to be classified into ChatGPT to test the potential of LLMs. We did this in two waves: first in September 2024, when ChatGPT-4 was the default model with free use; and next, in March 2025, when ChatGPT-4o-mini was the free, unlimited use default. Data protection concerns did not apply as we were testing on a few hundred items we inspected in each case.
Hierarchical COICOP classification
We used ChatGPT-4 in September 2024 in a hierarchical classification process. The first step was classification on the 2-digit level. In the next step, the LLM was shown items with the same 2-digit code and asked to classify at the 3-digit level. There was one final step for non-food items and two more hierarchical steps for food items. It should be noted that this basic procedure has the disadvantage that a classification error made at any level of the hierarchy will result in an incorrect final classification. A more nuanced approach would be to keep multiple options at each classification step, and then choose from the resulting options at the 5-digit level using either an extra query to the LLM, or a confidence measure such as prediction probabilities.
A Norwegian version of the prompt shown in Figure 2 was used. We validated performance using items from HBS2022 that were manually coded in our human-in-the-loop process. In the example in Figure 2, the chatbot is given a list of items with 3-digit code 01.1 and asked to classify at the 4-digit level. It is also given the definition of each possible COICOP category to choose from.

Chat-GPT prompt with hierarchical classification.
We randomly selected 200 each of scanned/OCR items and manually entered items. We found very strong performance above 90%. Next, we selected 200 items whose text had been automatically or manually edited in our processing pipeline, as described above. We ran both the pre-editing and post-editing version of the text through ChatGPT-4 to compare classification performance on items having errors vs their manually corrected versions. We found mediocre performance before editing but very strong performance of 94% post editing. These results are extremely encouraging especially in light of the fact that we used a quick-and-dirty implementation of LLMs for classification with very basic prompting. The only information about each candidate category in the prompt was the definition (i.e. “fish and seafood”). Adding example items for each category or a more extensive description, or using RAG to suggest a shorter list of candidate categories, could significantly improve these results. Further experiments are called for due to the limited number of items checked.
Below is the percent of items assigned a correct 5-digit code by ChatGPT-4 in the hierarchical procedure. 200 items were checked in each of the four cases, as described above.

By 2025, performance of ChatGPT with long input sizes had become so good that we experimented with directly entering the entire COICOP 2018 classification index into the prompt along with the item description. The classification index consisted of ∼500 lines containing all COICOP codes at the 2–5 digit levels and their definitions (translated to Norwegian). The current free unlimited use ChatGPT-4o-mini model was used as the LLM. Thus, we could forego implementing RAG to retrieve relevant sections of the classification index. Across several hundred examples, we found spectacular performance that was on par with human coding (∼90% accuracy). Moreover, ChatGPT returned helpful comments about special cases. For instance, when prompted with «coffee», it replied that «the correct category for a cafe visit is 11.1.1, but coffee purchased as a prepared product in a store would be categorized as 01.2.2.0». It detected the ambiguity between the 2 types of coffee items and explained it in its response. Moreover, it reflected that coding could only be done on the 4-digit level based on the item description when coffee is viewed as a café purchase.
Implementation on downloaded models
Statistics Norway was interested in seeing how closely we could replicate this exceptional performance using only downloaded open-source models, with the data staying in the protected Daplalab environment. We tried several LLM's of about 7B parameters and size around 15GB; larger models were prohibitive at the time as Daplalab did not yet have support for GPU's, nor for directly accessing HuggingFace or transferring large downloaded models into the platform. These models did not give any sensible output when shown more than a few dozen candidate codes, unlike today's commercial models that can handle having the entire classification index in the prompt. Therefore, we used RAG to return relevant portions, with 6–10 of the best matching COICOP codes and their corresponding text (definitions or descriptions or example items) inserted into the final prompt.
For the experiments described below, a common test set was formed by taking a random sample of 600 items that came from scanned and OCR-processed receipts in Norway's HBS 2022. The slow run time of the RAG/LLM pipeline precluded using a larger test set in this development phase. Raw accuracies (overall percent correct) are reported below. We chose this metric to reflect the potential savings in manual coding from LLMs. In contrast, using a balanced accuracy would give disproportionate weight to uncommon, hard-to-code items. Our main findings were as follows.
Vector store and retrieval
We tried the following 5 embedding models for building a vector store and performing retrieval. None of these models was trained on the task of retrieving a corresponding code from a classification index, so the choice of model was made empirically.
Norwegian BERT (NbAiLab/nb_bert_base), which is a general BERT-base model trained on a large corpus of Norwegian text by the National Library of Norway. Contextualized token-level embeddings are formed across an input sequence. These are then pooled to get a sentence-level representation by using a transformed version of the [CLS] aggregator token. Using a [CLS] token for pooling is designed to support classification tasks. An SBERT version of the Norwegian BERT model above (NbAiLab/nb_sbert_base). The nb_bert_base model is fine-tuned so that when sentence-level representations are formed from mean-pooling token embeddings, the cosine similarities of the sentence embeddings perform well on an MNLI task. Given their training, SBERT models often work well for information retrieval tasks like RAG that also use the cosine similarity in the embedding space as a measure of semantic similarity. Two non-Norwegian models known for having good multilingual support: paraphrase-multilingual-mpnet-base-v2, distiluse-base-multilingual-cased-v2
We used Chroma to build a local vector store, with each entry in the vector store corresponding to a 5-digit COICOP code, and possibly multiple entries for the same code. We use 3 documents as our knowledge base: 1) a translation into Norwegian of the official UN COICOP 2018 definitions; 2) a list of keywords corresponding to each code, and 3) some example items. While ChatGPT had excellent performance being only shown the definitions, we found that in our experiments with smaller downloaded LLMs, the correct COICOP code was found much more often during retrieval when there was a similar example item embedded in the vector store than otherwise.
Cosine similarity was used as the similarity measure for retrieval. We found that across our different embedding models, getting the embedding to capture relevance was a challenge, with the correct COICOP code only retrieved just over half of the time as one of the top candidates (57% of time in the top-10 candidates, 54% of time in top-6 in the top-performing nb_sbert_base). One reason for this challenge might have been that the text on receipts has idiosyncrasies that natural language doesn’t, such as abbreviations. Another issue is that the embedding models might have had limited training on Norwegian product and brand names.
Approaches that don’t use RAG
Upon seeing the so-far low performance of the retrieval step, we experimented with two other approaches to see if it might be possible to use LLMs without retrieval.
MNLI (multi-genre natural language inference) model:
This is a type of model that tries to infer whether statement B follows from statement A. 11 It also gives a confidence score associated with the inference. MNLI can be used for classification tasks by inputting for example the two statements:
A: « ‘Jarlsberg’ is a type of [cheese] . » B: True
The MNLI model responds “Yes” if it considers Jarlsberg to be a cheese. Then we picked all COICOP codes for which the MNLI model said “yes” and output the one with the highest score. MNLI models have both encoder and decoder architectures, and they use more logic in identifying relationships between words than an embedding-only approach like RAG. However, we found that it worked poorly when for picking the best category when there are many possibilities. We tried if perhaps a hierarchical approach could work where we first classified at the 2-digit level, then 3-digit etc. We found that at the 2-digit COICOP level, MNLI outperformed RAG, with the correct 2-digit code identified correctly 72% of the time vs only 64% with RAG. Overall performance of MNLI was not high enough to consider its use.
Prompting an LLM hierarchically without RAG:
We tried asking an LLM first for the correct 2-digit code by inserting all 2-digit codes into the prompt, then continuing to lower levels of COICOP. We found that LLMs of this size had trouble linking higher-level descriptions to items (i.e. “furnishings and household equipment” vs “curtains”) and accuracy was only 55% on 2-digit classification.
The LLM step had better performance, with 58%-71% accuracy in identifying the correct code when it appeared in a list of 6 candidates inserted into the prompt (trying two Norwegian models and Mistral_7B), as summarized here:
Bineric/NorskGPT_Llama3_8b 68% Mistralai/Mistral_7B_instruc_v0.3 58% NbAiLab/nb_gpt_j_6B_v2 71%
Improving performance of the RAG/LLM system
Upon inspection, we found two major sources of coding errors:
LLMs of this smaller size (∼7B parameters) struggled with longer templates.
The LLMs we tried could only handle a shorter prompt which described the task and showed an item and list of candidate codes. They regularly gave unreliable output when inserting examples for few-shot prompting, or giving a template for the expected output, or being asked about confidence. These are all features that large models handle routinely.
The RAG system had no knowledge of Norwegian products.
Training to recognize some of the most common items or brands could significantly help performance in both the retrieval and generation steps. The abbreviated text seen on receipts is another type of domain-specific data it could be worthwhile to tune embeddings on.
In section 4.5 we describe using BERT embeddings for classification by adding a neural network classifier head. In the procedure described, the BERT embedding gets fine-tuned on the training data (in addition to the classifier head). In further work, we will use this embedding for RAG that has been fine-tuned on the receipts data and captures Norwegian product names and the idiosyncrasies of text on receipts.
A major source for text containing many item names and descriptions is websites for online shopping, food delivery services, or other store sites. As another possibility for fine-tuning the embedding model, we will experiment with fine-tuning BERT from the webscraped text from these sites. Should the RAG step still display mediocre performance in choosing the correct candidate COICOP code, we can perform fine-tuning with sentence-level objectives to explicitly train a BERT model to give high cosine similarity between the text of items and candidate codes that are to be returned from the vector store.
As a further possibility for improvements, we found in previous work 7 that adding the store name (we used about 300 of the biggest Norwegian chain stores’ names, and an “other” category) as a feature significantly helped machine learning. Specifically, for a Random Forest classifier, we found that the overall prediction accuracy was about the same (62% vs 63%) with or without using store name as a feature. However, the percent of our test set data that could be automatically classified increased greatly when we included a feature from the store name. Items were considered to be automatically classifiable when the prediction probability was above a particular threshold that had been empirically set to correspond to 90% accuracy for items above the threshold. The percent of data that could be automatically classified increased from 15% without the store name to 37% with the store name, resulting in more than double the savings compared to manual coding. Thus, in future experiments we will add the name of the store or a description of the type of store to the prompt. It remains unclear how large an LLM trained on Internet data must be for it to have some background knowledge of the major Norwegian stores and be able to make use of the store name.
Getting a measure of prediction confidence
Until LLM coding accuracy is very high, manual coding is needed for the less reliable predictions as well as a way to identify the good vs unreliable predictions. Four common ways to get a measure of confidence for LLMs are: 1) ask the LLM for a qualitative description of its confidence (i.e. “high”, “medium”, etc), 2) ask the LLM for a quantitative description (i.e. “on a scale of 1–10, how confident are you?”), 3) use the prediction probability, 4) use the difference in prediction probabilities between the category chosen and the next best option (the one corresponding to the second highest prediction probability). We found that for the smaller LLMs we tested, prompting the LLM to give a measure of its confidence did not work well. We have begun experimenting with the use of prediction probabilities. A prediction probability gives the LLM's estimate of the likelihood that a particular token in the LLM's vocabulary comes next in the sequence of output tokens. Prediction probabilities can be accessed as the logit probabilities from the last layer of the LLM. The 5-digit codes output in COICOP classification typically correspond to multiple tokens, so one can multiple prediction probabilities over the tokens to get a measure of prediction confidence.
A machine learning approach- BERT
We also implemented a machine learning approach, a BERT-based classifier that uses Norwegian-trained BERT to embed item descriptions and a neural network classifier head. BERT is a transformer-based approach like LLMs, but it does not have generative ability and is a lightweight model in comparison.
We tried two widely-used Norwegian BERT models downloaded from HuggingFace. Nb_bert_base (NbAiLab/nb_bert_base, see https://github.com/NBAiLab/notram) is a model trained from the “Norwegian Colossal Corpus” in a major public project by the National Library, while NorBERT (ltg/norbert3_large, see https://github.com/ltgoslo/NorBERT?tab = readme-ov-file) is a larger model that originates from an academic project at the University of Oslo and features training from 2023. These models created 768 and 1024-dimensional features, respectively, from embedding the text of the item purchased.
Given our experience that adding the store name as a feature helped Random Forest predict COICOP, we passed features generated from the store name to the classifier head in addition to the BERT embedding features. These store features were generated from a neural network embedder that took as input the store name (categorical with 300 possible values) and created a 20-dimensional dense vector representation. Classification was done using the nn.linear function in PyTorch as a linear classifier head. During backpropagation training, the classifier head, BERT embedding, and store name embedder were all updated.
The training and test sets came from taking all 7780 purchased items found on scanned and OCR-processed receipts that arrived in March 2022 in Norway's HBS, and splitting randomly into 80% training, 20% testing. We chose to work with a single month's data in the first stage of testing to avoid dealing with seasonal variations in items sold. We did not do any rebalancing; however we expect reasonable balance from randomly splitting the March population. We found accuracy of 77% for the smaller model (NbAiLab/nb_bert_base) and 81% for the larger one (ltg/norbert3_large) for 5-digit classification. The F1 scores were the same as the accuracies. Thus, GenAI-based approaches need further work before they can surpass a more straightforward approach like BERT.
We plan to use the updated BERT models from this process for the RAG embedding in future experiments. Although the LLMs were extensively trained on internet data and should capture some information about the Norwegian marketplace for consumer items, we expect significantly better modelling of Norwegian brand names and products from this fine-tuning process.
Pipelines for implementing classification
Our hope is that with easier access to larger models in Daplalab from now on, the limited performance of LLMs we found in these initial experiments will improve drastically. Our standard for classification accuracy for a system is 90%, which is roughly what we found the intercoder agreement between two humans to be. Thus, if accuracy reaches 90% for an LLM, we will not need a manual coding step.
For the time being, BERT is our best-performing option. However, its performance of 80% is also not high enough to forego human coding. With the current model, we estimate about 50% of items will need to be sent to manual coding based on their prediction probabilities. If an LLM shows moderate performance and can mark its high-confidence classifications, we could use it to code those items that BERT couldn’t code well, then send all remaining items for manual coding. This 3-step approach of BERT→LLM→Manual would require significantly less manual coding than a BERT→Manual pipeline.
Summary
We have implemented experiments on using GenAI for COICOP coding in the household budget survey in Norway. We used the RAG framework to retrieve information about a subset of codes for each item that were similar in the embedding space. Below is a summary of our experiences:
ChatGPT-4o can code items at a level similar to a human coder in a zero-shot prompting fashion; however, we have not yet explored whether participants would give consent to having their purchases data sent out for external coding. Today's free ChatGPT-4o-mini could handle the entire COICOP classification index in its prompt so we can forgo the use of RAG. With the smaller LLMs (∼7B parameters) we were able to test so far, they did not yield benefits over a cheaper and simpler BERT model (a transformer without generative capabilities), which had roughly 80% accuracy. In either case, human coding is needed for a subset of items that are not predicted well by the models. Finding a good embedding for the retrieval step of RAG was a challenge, with the correct code returned just 54% of the time among the top-6 candidates. Challenges included mismatch between training examples and the COICOP classification task, idiosyncrasies of receipts data, and lack of knowledge about Norwegian products. In light of the challenges above, we tried two approaches that sidestep the need for retrieval: an MNLI model, and hierarchical COICOP coding where an LLM is used without RAG to code part of the hierarchy in each step (i.e. finding the 4th digit of COICOP in one step). Neither approach showed very promising performance. We tried two Norwegian fine-tuned LLMs with sizes of 6B-8B. Downloaded models from HuggingFace were used to protect data. These smaller LLMs showed some moderate performance at finding the correct code when it appeared in a list of 6 candidates. However, they struggled with longer prompts. This made it infeasible to enter all COICOP codes into the prompt at once; or to enter examples of the task for few-shot prompting; or to ask the LLM about its confidence in its answer. Better support for larger LLMs in our computing environment continues to evolve quickly. We expect significantly better performance in further experiments. Until LLMs show around 90% accuracy in classification (our “gold standard”, which is around the inter-coder agreement of human coders), a measure of confidence is crucial. This allows us to identify good predictions and use alternate coding methods for the rest. We are experimenting with prediction probabilities retrieved from the LLM as such a measure. We found decent support for the Norwegian language with Norwegian-trained/adapted tools such as NorskGPT and NorBERT. However, fine-tuning of models to recognize products in the Norwegian marketplace and handle irregular text on receipts could improve performance. We will explore the idea of taking non-sensitive data outside the organization for coding, while retaining privacy safeguards. With COICOP coding, it is sufficient to send for coding a collection of purchased items from many respondents having no link to any other variables or the respondents themselves. It can be worth exploring if respondents would give permission for this, and what possible risks might be.
Our first set of experiments with using LLMs for survey coding involved small models of around 7B and achieved limited performance. However, the spectacular performance of commercial models suggests that large improvements are possible as we move to much larger models, as well as implement fine-tuning.
The following are our recommendations for next steps:
Explore ways to get a measure of confidence from LLMs (i.e. prediction probabilities) that allow LLMs to be used in a pipeline, with poorly coded items being passed to manual coding. Example pipelines to use are BERT→LLM→Manual, or LLM→Manual. Test (much) larger LLMs as infrastructure and computing setups allow Use LLMs to generate synthetic training data for the many poorly represented COICOP codes Explore respondents’ openness to sending purchases data outside Statistics Norway for coding with commercial models
Our experiences on using LLMs for COICOP coding in the HBS can be transferred to prototyping systems for the numerous other coding tasks at Statistics Norway.
Footnotes
Acknowledgments
We would like to thank Susie Jentoft for helpful discussions related to this work, and Ruben Mustad for guidance in the implementation of BERT.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Eurostat, SMP-ESS-2023-HBS-IBA, AIML4OS.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.