
Abstract
National statistical offices (NSOs) increasingly rely on record linkage to link census data, administrative sources, and survey responses. However, conventional string-similarity methods often struggle with free-text fields. To address these challenges, this paper systematically benchmarks modern open-source large language models (LLMs) against classic string-based comparators for record linkage. Building on these findings, this paper introduces a hybrid approach that retains well-established probabilistic frameworks yet integrates an LLM-based classifier for ambiguous record pairs. A Bayesian update is applied to combine the LLM's output with the prior probability, with the aim of reducing the burden on manual clerical review. The experiments show that selectively deploying open-source LLMs for the most uncertain pairs can significantly reduce manual effort by refining decisions through Bayesian updating. As NSOs must ensure transparency, explainability, and adherence to official statistical standards, this paper systematically addresses these concerns while evaluating the potential of LLMs for record linkage. Practical considerations including secure on-premises deployment, computational cost, human-in-the-loop review, and calibration are discussed to support responsible adoption in official statistics.
Keywords
Introduction
Record linkage (also called entity resolution) is the process of determining whether two or more records refer to the same underlying real-world entity, often in the absence of unique identifiers, by combining evidence across multiple fields. For National statistical offices (NSOs), linkage underpins the production of integrated statistics by enabling the use of administrative registers and by reducing respondent burden. NSOs routinely link census, survey, and administrative records to improve data quality and reduce respondent burden. Increasingly, NSOs use administrative registers to reduce respondent burden and lower data-collection costs, resulting in more free-text fields and datasets lacking unique identifiers. Accurate record linkage is therefore more critical than ever. The Fellegi–Sunter (FS) framework,
1
is a long-standing, trusted method in many national statistical offices. In the Fellegi–Sunter (FS) framework, comparison outcomes across fields are converted into weights using m- and u-probabilities, where m is the probability of observing a comparison outcome given a true match and u is the probability of observing that outcome given a true non-match. These weights can be combined to produce an overall match score or calibrated match probability for each record pair. Under this framework, comparators like Jaro–Winkler
2
produce a similarity score that is converted into a weight using precomputed probabilities. These weights reflect the likelihood of agreement (
Recently LLMs have demonstrated superior performance compared to the average human on several widely recognized standardized assessments. GPT-4 surpassed average human performance on Scholastic Assessment Test (SAT), Law School Admission Test (LSAT), and math competition scoring a 95% accuracy rate on SAT math exam, and 92.5% accuracy on the English test of the Chinese national college entrance exam.3,4 Despite impressive performance (and considerable hype), LLMs are resource-intensive and produce incorrect outputs. Furthermore, LLMs introduce data privacy and safety concerns especially in the context of NSOs handling sensitive data.
This paper takes a pragmatic view, treating LLMs as tools that can be valuable in certain scenarios but may be unfeasible or error-prone in others. Table 1 illustrates examples where standard string-similarity scores (fuzzy matching) can struggle, while an LLM-based classifier captures the underlying semantic match more effectively. In the LLM column, ‘1’ indicates that the model considers the two entries to be the same entity, whereas ‘0’ indicates they refer to different entities. The similarity scores in Table 1 are descriptive (not calibrated match probabilities) and are intended to build intuition rather than serve as a formal evaluation; calibrated match probabilities and threshold-based routing are introduced in Section 2.
Illustrative examples: abbreviations and free-text variants.

Illustrative examples: abbreviations and free-text variants.
Section 1.1 reviews how LLMs work and where they are most useful, followed by data privacy and safety concerns in Section 1.2. Throughout this paper modern open-source LLMs deployable in a secure NSO environment are utilized. Section 2 proposes a hybrid solution (Figure 1) which incorporates estimates from an LLM-based classifier for the most ambiguous record pairs while explicitly accounting for the probability that LLM outputs can be wrong. The first layer uses Fellegi–Sunter to compute a baseline probability of match/non-match for every record pair. For ambiguous cases an LLM-based classifier is invoked. The LLMs output are fused with the Fellegi-Sunter prior probability via Bayesian updating. By treating the LLM's classification as a new piece of (imperfect) evidence, this reduces manual clerical review while maintaining transparency and statistical rigour.
LLMs are neural networks with hundreds of millions to billions of parameters, trained to predict the next token in a sequence given the preceding context. They rely on the transformer architecture, which uses ‘self-attention’ to compute discrete probability distributions over possible tokens. During pre-training, an LLM ingests massive text corpora such as web pages, books, and news articles and learns statistical patterns of language. This process adjusts the model's internal weights to maximize the probability of correct next-token predictions. Modern LLMs often undergo supervised fine-tuning and reinforcement learning from human feedback. Due to the scale of training data (often terabytes of text) and model size, LLMs like GPT-3 (175 billion parameters) or Google's PaLM (540 billion) can capture subtle linguistic patterns and factual associations. 5 In practical terms, an LLM can take a prompt (some input text) and continue it or respond in a contextually appropriate way. Modern LLMs have proven to be versatile: the same model can answer questions, translate languages, summarize documents, or engage in dialogue, simply by being given different prompts. 6 This is a key difference from traditional statistical machine learning models which are typically trained to perform just one specialized task.
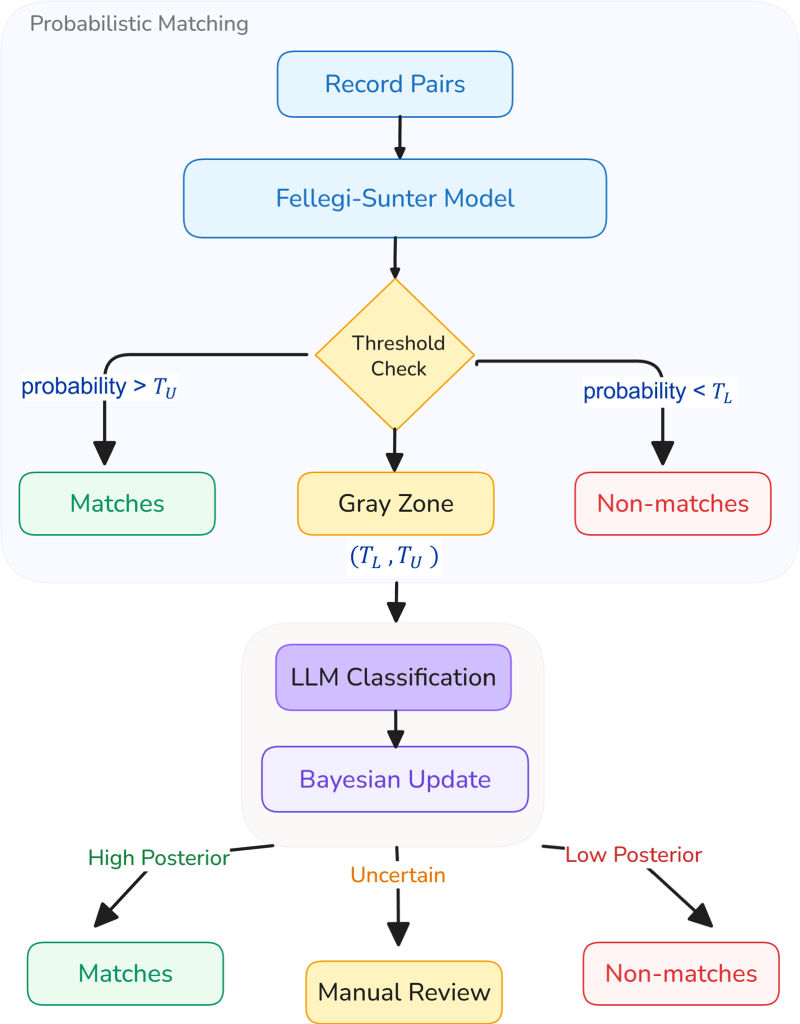
Overview of the hybrid record linkage framework integrating probabilistic matching with LLM-assisted classification for uncertain cases.
Under the hood, an LLM represents text as sequences of tokens (words or subword pieces) and produces a conditional probability distribution for the next token at each step, given the immediately preceding text. For instance, when asked, “Do these two records refer to the same entity?” an LLM assigns logits to “Yes” vs. “No”. While this ability to generate a probability distribution is powerful, it must be approached with caution and rigour. LLMs are not infallible oracles, and they can produce confident yet incorrect outcomes. Consequently, these predictions must be calibrated and verified to account for potential errors. This is especially important in the context of NSOs, where strict data governance constraints are paramount. The Bayesian framework in Section 2 addresses precisely this need.
National statistical offices operate under strict mandates of accuracy, reproducibility, and confidentiality. Although many people associate LLMs with cloud-based chatbots that could pose data-security risks, these concerns are mitigated by leveraging open-source LLMs that run entirely on-premises. Conceptually an open-source LLM is simply a large file of parameter matrices, similar to installing an open-source software library. This means all the model's matrix operations and data flows remain under the NSO's direct control and no external servers are involved. This ensures that no confidential information ever leaves the agency's secure environment. This approach not only preserves confidentiality but also enables precise audit trails by logging every classification request. All outputs are fully repeatable because the model's parameters and randomness seeds remain fixed within the agency's secure environment. (Section 3 provides the specific model variants used in the experiments.)
Methodology
This paper presents a multi-step approach that integrates traditional probabilistic framework (Fellegi–Sunter) with selective LLM usage. First, FS (or any linkage method that outputs calibrated match probabilities) produces an initial prior match probability,
Two thresholds are then specified: A lower threshold An upper threshold
Record pairs with a probability
Mathematical framework
Let
Baseline match probability
String-comparison features (e.g., Levenshtein distance
7
and Jaro–Winkler similarity) are used within the Fellegi–Sunter (FS) framework to compute an initial match probability:
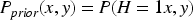
Although FS is used here, any linkage method that outputs calibrated match probabilities could be substituted. The value
Any pair whose probability
LLM output
For pairs selected for LLM processing, open-source Llama 3 models are used as the LLM classifier.
6
The model is prompted with ‘Do these two records refer to the same entity? Answer YES or NO’ and map the response to 1 or 0. Let
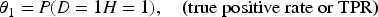
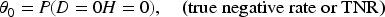
Hence, if
Bayesian probability updating
After observing the LLM's binary output Case 1:
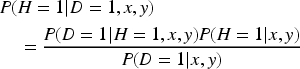
Since
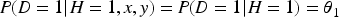
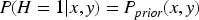
The marginal probability is:
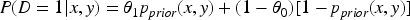
Putting these together:
Case 2: D = 0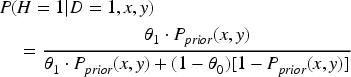
The marginal probability is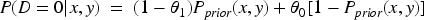
The posterior probability is:
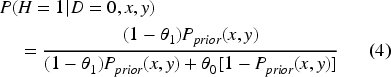
Here,
Theoretically these parameters can also be set based on prior beliefs about the model's performance. However, their values also depend on factors such as the LLM's size, the complexity of the data, the quality of prompts, and whether the model was fine-tuned.
It is therefore recommended estimating
Certain pairs will remain inherently ambiguous, particularly where minimal contextual data exist or where text entries are outright contradictory. In official statistics, human-in-the-loop (HITL) workflows provide a crucial safety net. The proposed framework does not aim to eliminate or replace human judgment; instead, it aims to reduce manual workload so that human experts can focus on the most complex edge cases. The LLM serves as an automated triage step prior to human intervention, identifying cases that can be resolved automatically and flagging residual uncertainty. The remaining hardest cases are then escalated to clerical review for final quality control. This ensures accuracy, maintains transparency, and aligns with longstanding practices within national statistical offices.
Experimental results and discussion
Dataset
In official statistics, record linkage typically involves large datasets with no definitive “ground truth,” requiring agencies to rely on threshold-based decisions and selective clerical review. However, to rigorously evaluate new linkage methods, researchers often create curated datasets with verified matches and non-matches, enabling precise measurements of precision, recall, and related metrics. Following that approach, a set of 1000 real pairs of Canadian business records was compiled —balanced to include 500 confirmed matches and 500 verified non-matches. To ensure the non-matches were challenging, for each real business, the single most similar record that was confirmed as a distinct entity were identified. Although this controlled design does not capture every operational constraint that national statistical offices face, it provides clear empirical evidence of how an LLM-based approach can enhance record linkage on messy, free-text data, and suggests a viable route for selective large-scale deployment with minimal human oversight.
The experiments in this paper use the open-weight Llama 3 family of models (1B, 3B, and 8B parameter variants) deployed on-premises within a secure environment. Inference is performed locally so that record data do not leave the NSO network, and deterministic decoding settings (e.g., temperature 0) can be used to support repeatable outputs for audit purposes. The availability of open weights enables transparency, inspection, and local adaptation (e.g., fine-tuning) within the agency's environment. These models have also undergone assessment by Statistics Canada's IT security team, supporting their suitability for this application.
Results
Having established a balanced dataset, this section evaluates how different matching techniques, ranging from simple string comparators to LLMs, perform on this set. Table 2 shows that an 8B-parameter Llama model achieves an F1-score of 0.87, higher than Jaro–Winkler and Levenshtein. However, this improvement comes at a clear computational cost: on CPU, the 8B Llama model required around 179.5 min for 1000 comparisons, compared to just seconds for basic string comparators. Using a GPU cuts LLM inference time by roughly 70%, but it remains substantial compared to classic similarity measures.
Performance and approximate runtimes for 1000 pairs.

Performance and approximate runtimes for 1000 pairs.
Performance is reported using precision, recall, true negative rate (TNR), and the F1-score. Precision and recall summarize match detection quality, TNR summarizes non-match detection quality, and the F1-score balances precision and recall in a single metric. Runtime is reported for inference on a central processing unit (CPU) and on a graphics processing unit (GPU), reflecting common infrastructure choices for NSOs. Table 2 highlights two major observations. First, LLMs demonstrate higher F1-scores than classic string metrics, underscoring their ability to recognize nuanced textual patterns (e.g., acronyms vs. full names). Second, computational costs grow notably with model size, even when using a GPU. This is an important factor for large-scale deployments in official statistics.
During prompt development, zero-shot, few-shot, and chain-of-thought prompting strategies10,11 were explored to encourage consistent entity-matching decisions. In practice, the primary objective of these experiments was to stabilize the output format (e.g., inconsistent responses) rather than to report a separate prompting ablation study. Table 2 reports results using the final prompt configuration used for evaluation.
Although LLM inference is slower than classic string comparators, the relevant comparison for operational use is often against manual clerical review rather than against GPU runtime. Clerical review requires trained staff time and consistent procedures, and it becomes costly when large fractions of pairs fall into the gray zone. By restricting LLM use to the ambiguous subset, the approach aims to trade additional compute for reduced human review effort, while still preserving auditability and reproducibility. 12
Before proceeding, Table 3 demonstrates the Bayesian updating step used in the proposed framework. Six record pairs with different prior probabilities
Example of Bayesian updating for six gray-zone pairs (
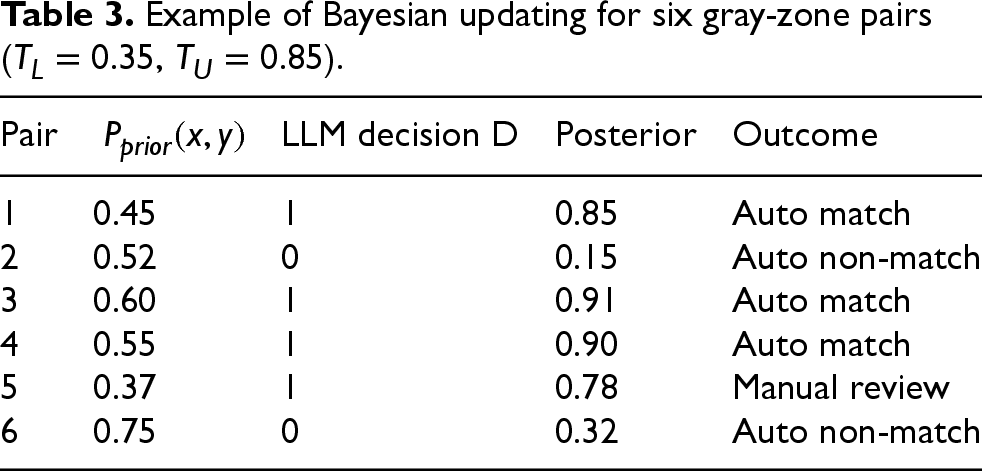
There are a few things to notice in the above table. First, in the Bayesian framework, when two probabilities are combined, the resulting posterior depends on how strongly each input leans toward or away from a match. When both probabilities fall below 0.5, they reinforce a “non-match” conclusion and drive the posterior even lower. Conversely, if both exceed 0.5, they reinforce a “match” verdict, pushing the posterior higher. In other words, whenever two independent pieces of evidence point in the same direction, whether match or non-match, Bayesian updating strengthens the conclusion by combining independent evidence, yielding higher confidence than either source alone. This principle lies at the core of the Bayesian framework. Note that not all cases are resolved. For instance, pair 5 remains uncertain because its initial probability was 0.37 yet the LLM output was 1 (match). Although the LLM decision was correct here, it might have been wrong. In that case, the updating mechanism provides a safeguard against misclassification. Next, the distribution of match probabilities is compared before and after the LLM-based Bayesian update.
Table 4 shows how Bayesian updating pushes many pairs out of the uncertain 0.35–0.85 range. Initially, 44.8% of pairs had probabilities in the gray zone. After incorporating LLM outputs, that proportion decreased to 21.5%. In practice, this means fewer borderline decisions for human adjudicators to handle, ultimately streamlining the linkage workflow. These findings show that selectively applying LLM outputs moves many borderline cases into clearer categories, reducing manual reviews.
Distribution of match probabilities before vs. after Bayesian updating.

A more granular analysis of the score distribution shift revealed a clear pattern across the gray-zone sub-bands (Table 5). Empirical observations suggest that the hardest cases, those with prior probabilities closest to 0.50, had higher error rate. This reflects that these cases are fundamentally difficult to resolve and often lack sufficient information for a definitive decision. These challenging cases were deliberately included. It is often the case in realistic modeling situations that the data fundamentally lacks predictive power (epistemic uncertainty).
In the current study, only gray-zone pairs are routed to the LLM because these are the cases where the baseline model is least certain and where LLM inference yields the highest expected value per unit of computation. By contrast, pairs near
Techniques such as quantization and batching can significantly reduce inference time and costs. Fine-tuning was considered as an extension, but this study focuses on zero-shot/few-shot prompting and Bayesian updating; fine-tuning is left to future work. Directions for work include experimenting with calibration techniques and leveraging the LLM's internal probability scores for Bayesian updating. Tools like Platt scaling or isotonic regression can potentially calibrate the LLM's probabilities. This could further improve the overall quality of LLM outputs and reduce the fraction of pairs sent to manual review.
LLM performance on sub-bands within the gray zone (
,
).
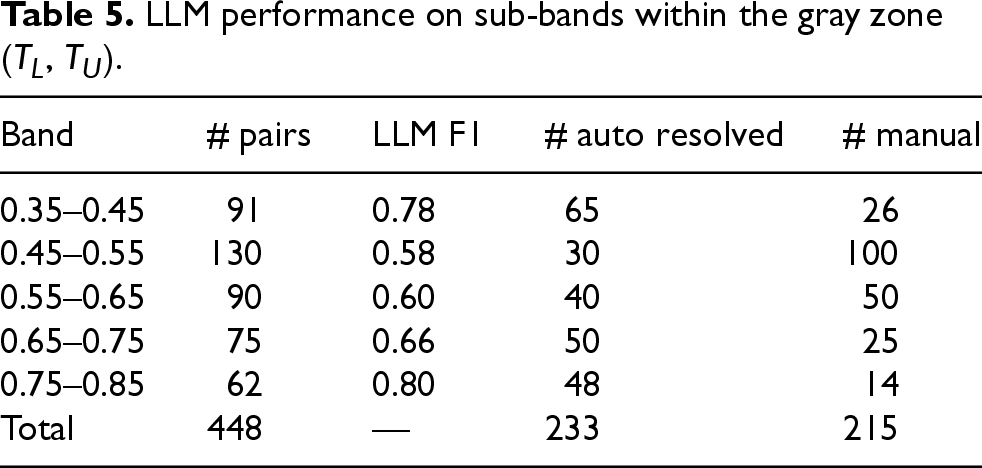
LLM performance on sub-bands within the gray zone (
However, even the best automated methods will encounter ambiguous cases. Developing enhanced tools for clerical review to highlight areas of uncertainty or conflicting evidence can potentially help experts make faster and potentially more accurate final judgments. Additionally, labeled data from human experts can be used to fine-tune the LLM, creating a reinforcing feedback loop (a “data flywheel”) that could be a valuable long-term investment for NSOs.
Next steps involve conducting larger trials and rolling out a prototype on tens of thousands, or even millions, of records to identify bottlenecks and integration issues not evident in smaller datasets. This includes securing on-premises infrastructure, ensuring data governance, and integrating the approach seamlessly into existing record linkage pipelines. By systematically exploring these paths to improvement—particularly in cost management, privacy compliance, and model calibration—statistical agencies can more confidently incorporate LLMs into their existing linkage workflows.
This paper has demonstrated how LLMs, when used selectively within a traditional probabilistic record linkage framework, can substantially reduce the clerical review burden for ambiguous record pairs and overall improve the quality of linkage if clerical review is not feasible. In these experiments, Bayesian updating that combines Fellegi–Sunter scores with LLM-based classification produced posterior match probabilities with stronger performance than string-only comparators, most notably in difficult free-text scenarios.
The aim is not to replace long-standing methodologies but to augment them with the nuanced textual understanding that modern language models offer. Through targeted prompting, selective invocation, and improved calibration, LLM-assisted record linkage can become a more efficient, accurate, and transparent approach for national statistical offices. LLMs are tools that rely on statistical patterns in training data rather than “knowing” ground truth and must be integrated with care, particularly under tight data governance constraints.
These findings suggest that the hybrid approach may improve data quality in official statistics while reducing manual burden. By continuing to refine model calibration, optimize runtime, and develop better human-in-the-loop processes, agencies can chart a realistic path forward that preserves the proven strengths of probabilistic linkage while harnessing the ever-improving capabilities of large language models.
Footnotes
Acknowledgements
The author thanks colleagues at Statistics Canada for helpful discussions on record linkage practice and for feedback on secure deployment considerations. Any errors or omissions remain the author's responsibility.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.