
Abstract
The Australian Bureau of Statistics (ABS) is committed to improving microdata access while maintaining privacy and confidentiality through its virtual DataLab, which enables researchers to conduct complex analyses. Currently, DataLab research outputs must comply with strict disclosure rules before clearance, but the manual vetting process is cost-inefficient and error-prone. As output volumes grow across diverse projects, so too does the risk of differencing — even when individual outputs meet disclosure requirements. To address this, the ABS has been developing streamlined output protection by equipping safe users with protection tools and implementing automated vetting systems. These tools use an enhanced cellkey methodology, assigning unique random keys to each contributing record and applying protection based on aggregated keys within each table cell. This ensures consistent protection across projects sharing the same contributors. The ``same contributors, same noise'' feature mitigates differencing risks and reduces protection costs when applied universally, while vetting systems verify that outputs are generated using approved tools before dissemination. Our first contribution is a prototype ``Fortified, Assured, Streamlined, Trusted (FAST)'' output protection toolkit built in R and R Shiny to streamline DataLab vetting processes. We also developed a sequential descent optimisation algorithm supporting both asymmetric and symmetric perturbation distributions. Our method integrates $(\epsilon, \delta)$ differential privacy parameters directly into the noise distribution design used in the ABS perturbation methodology.
Introduction
National statistics offices (NSOs) offer research data centre services to address the challenge of balancing better data access and confidentiality protection. For example, the United Kingdom’s Office for National Statistics offers the Secure Research Service, Statistics Canada offers Research Data Centres, in the US, there are Federal Statistical Research Data Centres, and Statistics Netherlands offers the Data & Development Lab. In Australia, the ABS DataLab provides a safe environment for researchers to access a variety of individual, household and business microdata in response to the need to balance better access to data and address confidentiality risks. The ABS DataLab is a data analysis solution for high-end data users who want to extract full value from ABS microdata.
1
The DataLab supports researchers to undertake complex research. DataLab sessions have grown significantly since 2020, rising from
There are various approaches and methodologies for developing effective confidentiality tools to ensure safe outputs. This work builds on the ABS perturbation methodology, which comprises two components: the cellkey methodology, ensuring consistency in output protection, and the entropy maximisation methodology, which maximises uncertainty—making it more difficult for an attacker to “invert” the noise-while maintaining the utility of the statistical outputs.3–5 We use the improved ABS perturbation methodology to develop these tools because it is widely accepted in Australia, and other national statistical offices also apply this approach to safeguard outputs (see Dove et al. 6 for the United Kingdom and de Vries et al. 7 for Portugal and Germany).
Our first contribution is the development of a prototype suite of output protection tools, termed “Fortified, Assured, Streamlined, Trusted (FAST)”, implemented in R. These tools build on prior research on output protection methods,4,8–14 and are developed within an R Shiny framework. R Shiny was selected as the implementation platform due to the increasing adoption of R by NSOs for statistical production. As an open-source programming language, R facilitates transparency, collaboration, and the industrialisation of official statistics.15,16
The
To further support NSOs in managing disclosure control workflows, the
Our final contribution is the development of a
The paper is organised as follows: Section 2.1 provides a summary of the prototype tools, Section 2.2 describes the prototype output vetting tools , Section 3.1 describes our proposed improvements to the ABS perturbation methodology and Section 4 provides a conclusion and proposes future research directions.
FAST
Figure 1 provides an overview of the workflow and relationships between the different
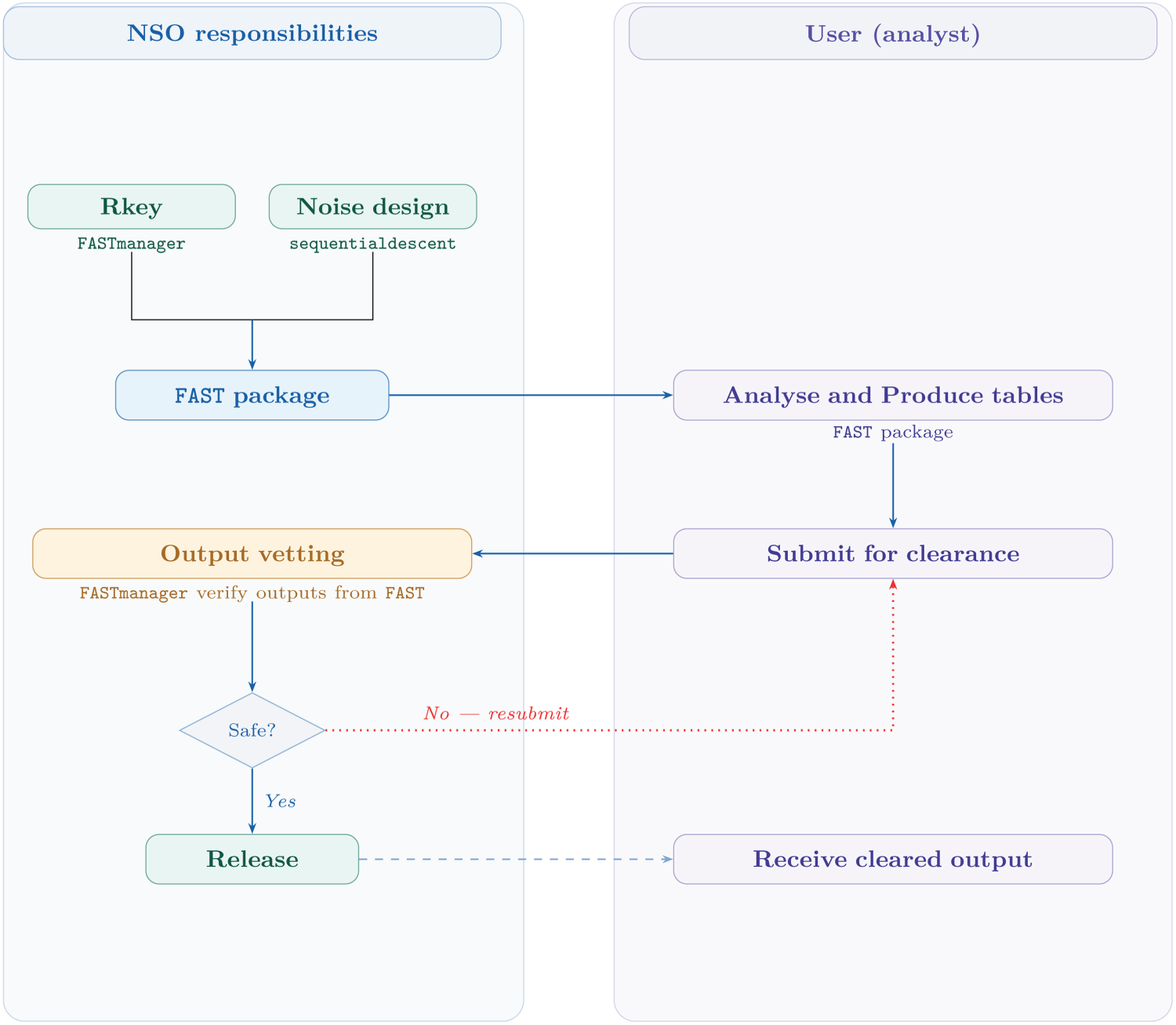
Proposed workflow.
NSO staff use the
The sequential descent mechanism for designing the noise distribution, discussed further in 3.1, represents a general methodological contribution and could be adopted by other NSOs as a principled approach to noise generation under constrained output domains. However, key parameters within the FAST framework — such as noise distributions and protection thresholds — are inherently context-dependent. These should be calibrated by individual NSOs in accordance with their legislative requirements, confidentiality policies, and risk tolerances, reflecting differing trade-offs between data utility and disclosure risk across jurisdictions.
The method uses four pseudo-random record keys
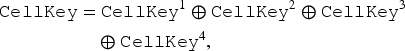

These tools intend to cater for researchers with different preferences - i.e., researchers who prefer to interact with the tools using programming or user interfaces. One important consideration is that not all NSOs have strong capabilities in developing user interfaces. There is a good argument to explore collaborative opportunities between NSOs, open source or commercial communities to continue enhancing the prototype capabilities and on-going development support. Currently,
It is important to note that
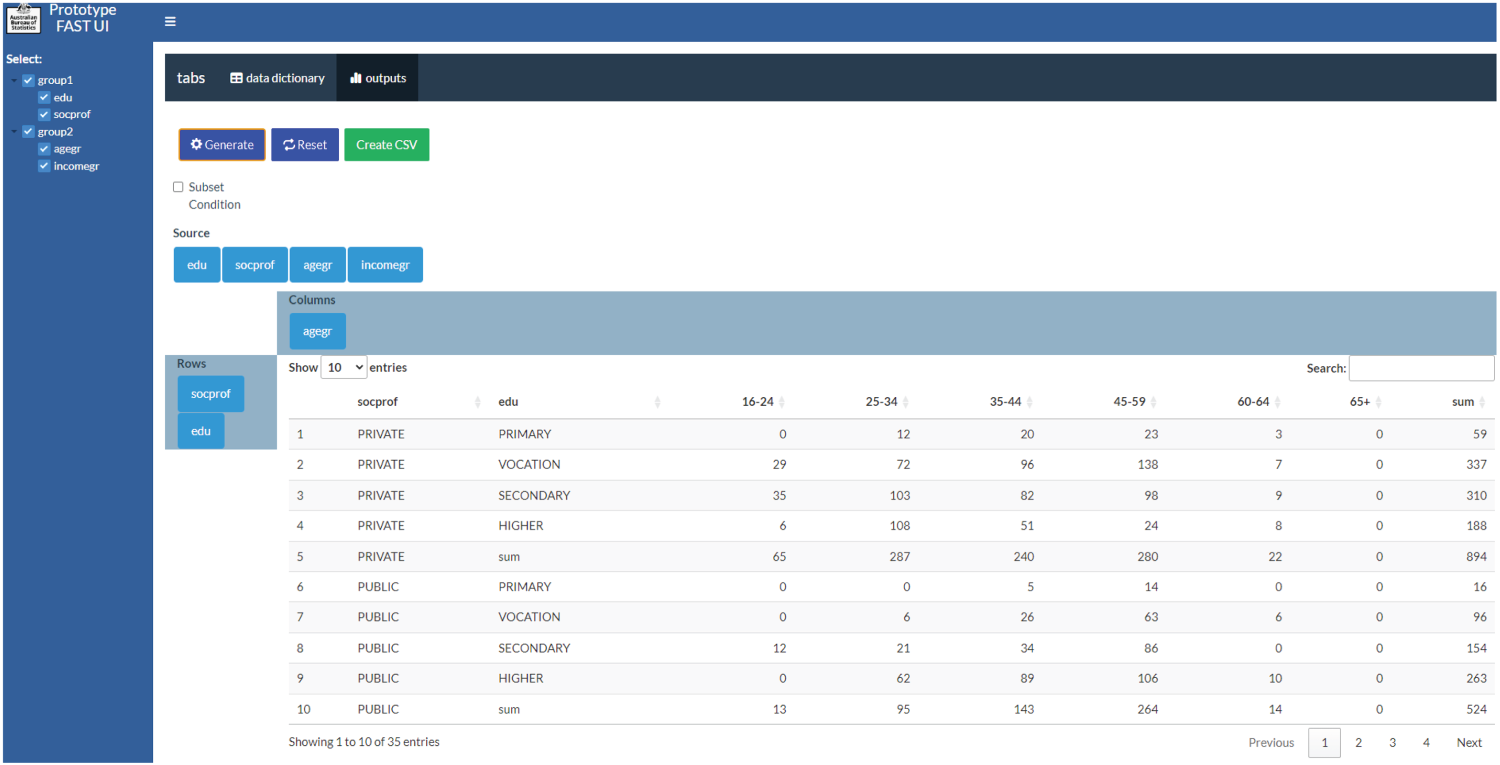
Figure 2 shows the user interface for
In addition, R Shiny also supports the development of a metadata tab to allow users explore the data assets, see Figure 3.
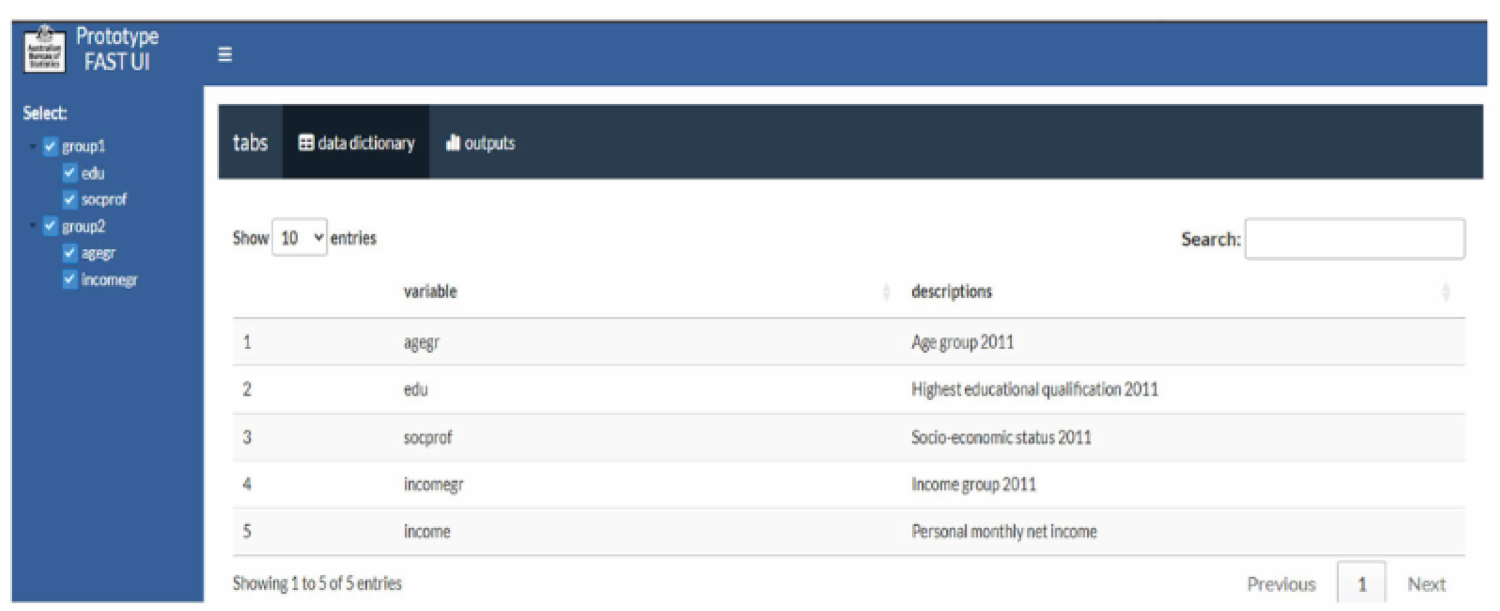
FAST user-interface meta data tab.
Figure 4 shows how researchers can use an R program to confidentialise outputs.
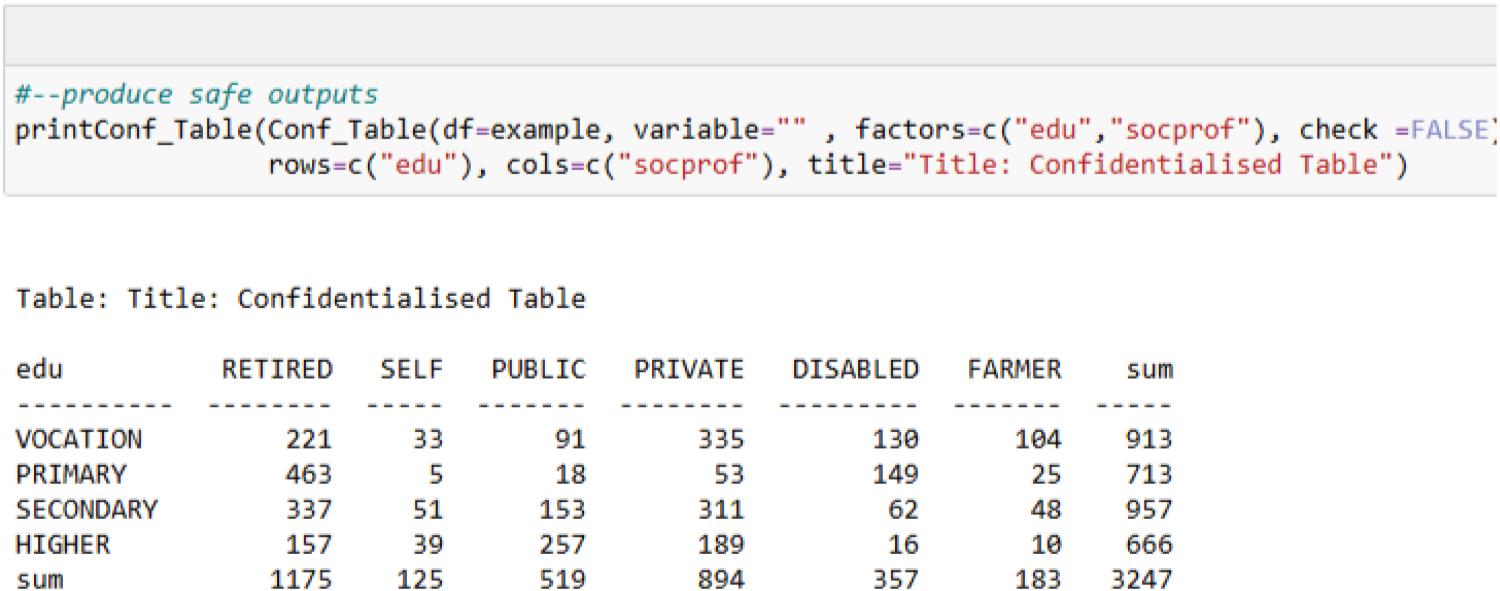
Figure 5, adapted from Dove et al.,
6
illustrates the current single-key perturbation methodology. Panel (a) shows that four contributors fall into the
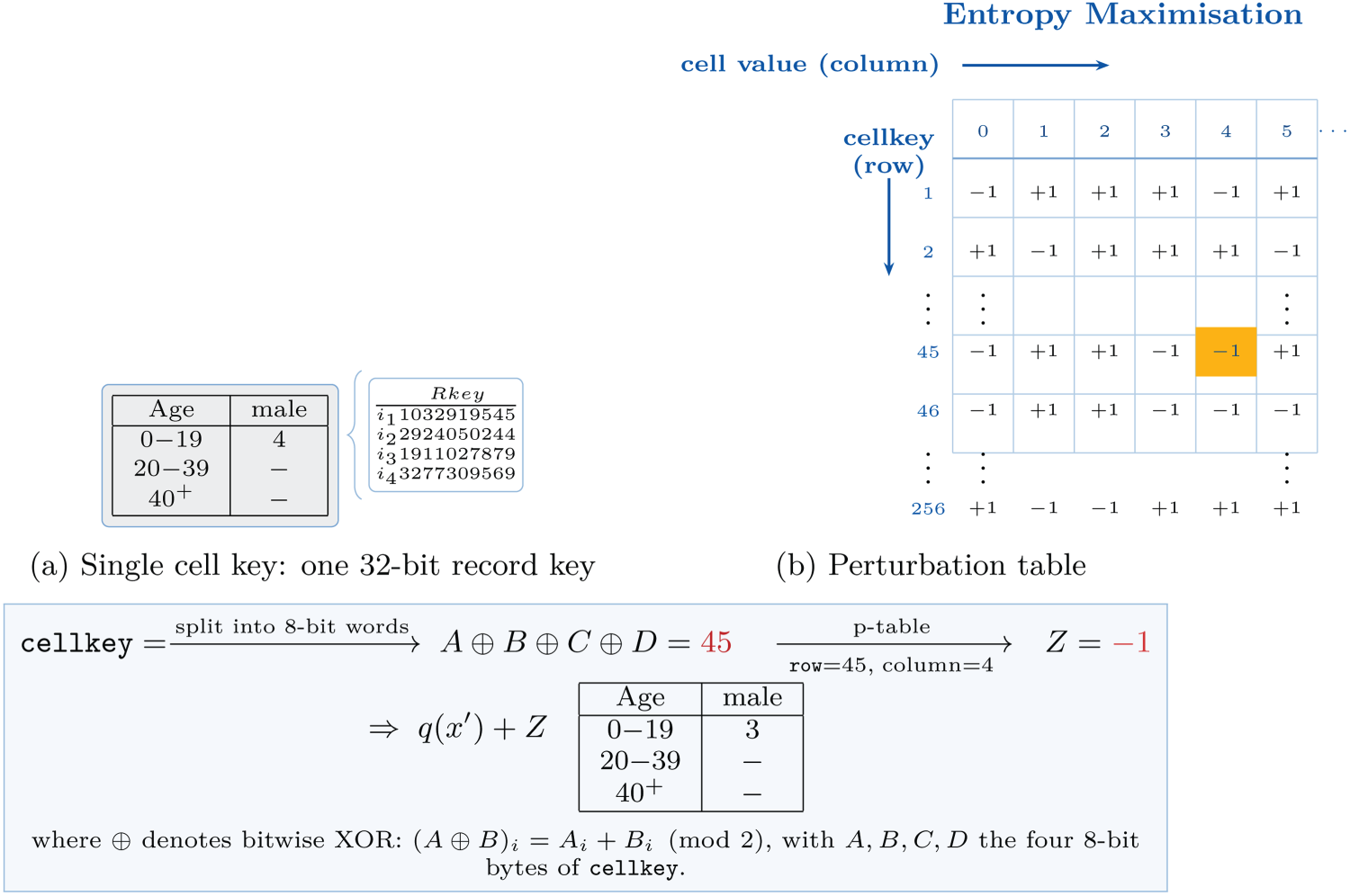
ABS perturbation method.
Figure 6 presents the FAST perturbation methodology using the same example and demonstrates how these methods achieve consistent results in this example. In general, we are not expecting these two methods to return exactly the same results. Panel (a) shows how four record keys

FAST perturbation method.
To support the management of disclosure control workflows, we develop a complementary prototype system,
While the output protection tools are deployed within a trusted user paradigm, the ABS retains responsibility for minimising processing errors and ensuring procedural compliance. For example, the ABS must verify that statistical outputs have been generated using the
Figure 7 illustrates how the SHA
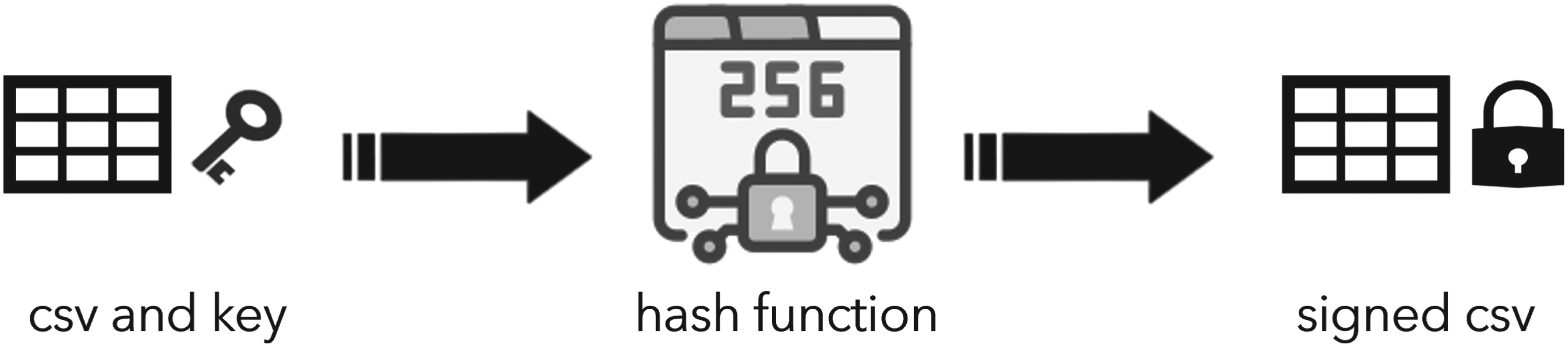
A signature approach.
Consistency in generating record keys is required to uphold the “same contributors, same noise” principle.
The risk of such collisions is well illustrated by the classical birthday paradox from probability theory. 19 The birthday paradox demonstrates that even when millions of distinct key values are available, random assignment can lead to duplicated values after only a few thousand draws. This highlights why naive random key generation may result in collisions in large administrative datasets, and why collision-resistant, deterministic hashing methods are required to ensure consistent and reproducible record keys. The proposed approach mitigates birthday-problem collisions in large administrative datasets (see Menezes et al. 20 and further details in Section Appendix E).
Perturbation with asymmetric supports under
-DP
The previous sections describe the prototype
Adding consistent statistical noise to published outputs provides mathematically rigorous protection against re-identification in today’s data-saturated environment. Ideally, the noise distribution will be unbiased and produce non-negative perturbed counts to maximise the analytical utility of the perturbed outputs, and to meet the expectations of users. The ABS employs a perturbation technique that randomly adjusts all cell values by small amounts, introducing negligible bias while preserving the analytical utility of tables and safeguarding individual confidentiality in aggregate statistics. 21 In recent years, the U.S. Census Bureau adopted differential privacy after internal research revealed that earlier disclosure avoidance methods were susceptible to database reconstruction attacks, enabling adversaries to link approximately half of the 2010 Census population to commercial datasets using publicly available information. 22 The ABS’s interest in exploring differential privacy is to improve how we can better balance the trade off between risk and utility in a more objective manner while making information more accessible.
Incorporating differential privacy into the entropy maximisation framework provides a rigorous analytical method to quantify and compare privacy-utility trade-offs through the (
In the context of designing a noise distribution, a symmetric support would be one where the possible noise values are all integers bounded between
Our notation and exposition resembles.
14
We use the natural logarithm throughout the paper. We consider a single counting query function

The ABS entropy maximisation method applies Jaynes’s
3
principle by maximising uncertainty about individual values while preserving statistical integrity through an unbiased noise distribution, thereby minimising exploitable information while maintaining aggregate accuracy for valid inference. Marley and Leaver
9
describe the entropy maximisation constraints proposed by Fraser and Wooton
8
as:
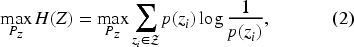

Sadeghi and Chien
14
make the following assumptions to analytically characterise and optimise the differential privacy performance of the entropy maximisation including: (1) focusing on the special symmetric case where
Sadeghi and Chien
14
specify the entropy maximisation optimisation problem in (2) as
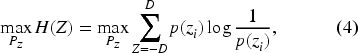
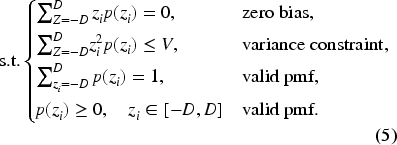
The entropy maximisation methodology with symmetric supports is
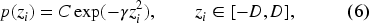
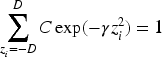
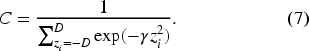
Under the formulation in Equation (6), the noise design has no bias, i.e.
Under the more general formulation in Equation (2), with an asymmetric support
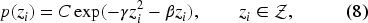
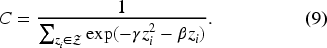
Equation (8) now has two parameters:
The
The

To justify using the bisection method to find a value of
In our framework, achieving a desired (
If the support
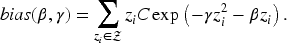
The proof of this statement can be found in Appendix B.
Second, the algorithm uses a line search to find a value of
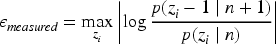
This only guarantees the
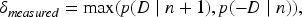
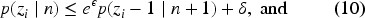
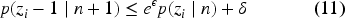
In practice, we don’t set a target
The step down process in the sequential descent algorithm is described below:

We would like to note that under the constraints of the noise being unbiased and the perturbed counts non-negative, a true count of
We also implement an alternative version of the algorithm using parallel computation to speed up the search for
Research data centre services, such as the ABS DataLab, provide secure environments that enable trusted researchers to extract value from rich microdata while maintaining confidentiality. This research contributes to strengthening NSOs capabilities by supporting more timely, consistent, and cost-effective output clearance processes. In particular, the extended use of the cellkey method promotes consistent protection across outputs and reduces differencing risks arising from similar queries across projects using the same underlying data.
This paper makes two key contributions to disclosure control for official statistics. First, we develop a practical framework for output protection, including the
Second, we propose a sequential descent algorithm for constructing symmetric and asymmetric noise distributions that satisfy
Taken together, these contributions demonstrate how modern confidentiality protection methods can be operationalised within existing NSO infrastructures. They provide a pathway towards more scalable, transparent, and efficient output release processes, while maintaining the trust and confidentiality guarantees that underpin official statistics.
Several promising directions for future research include: Extending the protection to different statistical outputs beyond counts, such as magnitude or regression outputs. Exploring alternative assumptions in the sequential descent algorithm for noise generation. For example, relaxing the zero bias constraint in 4 may facilitate achieving target Investigating high-performance database management systems such as DuckDB
23
to accelerate processing of large-scale data in Extending beyond the trusted user paradigm by developing web-based service implementations that restrict access to underlying microdata and protection parameters. Integrating knowledge graphs, large language models, and on-the-fly confidentiality mechanisms to create novel capabilities for data access and protection.
Footnotes
Acknowledgements
We gratefully acknowledge our colleagues at the Australian Bureau of Statistics, including Anders Holmberg, Andrew McMahon, Kristen Stone, Kelly Chiu, Helen Teasdale, Humaira Khan, Wolfgang Hertel, Isaac Norden, Sam Lu, Marcus Robertson-Wall, Cedric Wong, Vi Vu, and Chris Mann, as well as colleagues from the Data Access and Confidentiality Methodology Unit, for their valuable comments and their support of the FAST project. We also thank the anonymous reviewers for their constructive feedback, which has contributed to improving the manuscript.
Ethical Approval and Informed Consent
Ethical approval and informed consent were not required for this research.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Data is not used for this research.
Authorship statement
All persons who meet authorship criteria are listed as authors, and all authors certify that they have participated sufficiently in the work to take public responsibility for the content.
Additional information for editorial office
This title page contains identifying institutional and funding information for administrative purposes. A fully anonymised version has been prepared for peer review if required.
Notes
5.
We use the following example to illustrate a worst-case (maximum perturbation) attack from known support bounds to provide context on why it is important to choose a low
We consider a simple counting query with additive noise bounded within a known support. Let the perturbation mechanism add an integer-valued noise variable
Appendix B. Proof of Proposition 1
A similar argument shows that there exists a
Appendix C. Proof that variances are equivalent between sequential descent and entropy maximisation
We need the expected value
Appendix D. Sequential descent algorithm in parallel computation
Appendix E. Record key generation based on unique identifiers