
Abstract
In the quest for efficiency and innovation in manufacturing, intelligent retrieval and reuse technologies have emerged as critical strategies for optimizing the manufacturing processes of electromechanical products. This study systematically reviews 140 seminal theoretical contributions from 2010 to 2024, examining the current status, key technologies, and specific implementations within the manufacturing sector. The analysis categorizes intelligent retrieval into six distinct methods and examines reuse from four key dimensions, revealing a fundamental trade-off between efficiency and flexibility. By synthesizing the key technological evolution trends and primary system bottlenecks, this research provides actionable guidance for researchers and practitioners to navigate future challenges and opportunities in the field.
Introduction
In the contemporary global economy, manufacturing's significance as a foundational industry is paramount. Empirical evidence indicates that the manufacturing sector accounts for approximately 5% of the GDP in developed nations, underscoring its integral role within the economic framework (Rao, 2011). The machining center market, in particular, is projected to surpass a value of $44 billion by 2026, with a compound annual growth rate (CAGR) exceeding 5% (Iqbal et al., 2020). Such figures underscore not only the ubiquity and significance of manufacturing processes but also highlight the imperative for innovation and process design optimization, which serves as a critical nexus between product design and production (Esmaeilian et al., 2016).
However, the manufacturing sector currently faces multiple structural challenges: First, the shift from traditional mass production toward low-volume, high-mix manufacturing demands more flexible production systems (Zhang et al., 2022). Second, continuously compressed product lifecycles intensify time-to-market pressures. Third, increasingly integrated product designs lead to exponentially rising process complexity. Fourth, accelerating attrition of experienced engineers creates critical gaps in tacit knowledge retention (Wu & Liang, 2024). These challenges urgently call for intelligent solutions and efficient knowledge reuse in manufacturing processes.
In the realm of product manufacturing, empirical data reveal that only 20% of the processes for new product development necessitate a novel design approach, whereas 40% are achieved through the direct application of existing processes, and the remaining 40% involve modifications to established processes (Boothroyd et al., 2010). This distribution underscores the substantial potential for intelligent retrieval and reuse technologies within the manufacturing domain of electromechanical products. Advanced intelligent retrieval systems can swiftly and accurately identify the most suitable product design or manufacturing solution from extensive databases of processes or products, thereby significantly reducing the product development timeline, enhancing the quality and uniformity of production, and substantially mitigating the costs associated with trial and error (Li et al., 2020).
The efficient reuse of knowledge is inherently embedded across the entire product lifecycle. From conceptual design and detailed design to process planning, manufacturing, utilization, maintenance, and final recycling, each stage generates substantial data and accumulates valuable expertise (Zhang et al., 2017b). Intelligent retrieval serves as the critical mechanism enabling knowledge flow and transformation across stages and disciplines. It facilitates the effective reuse of prior experiences and assets in subsequent phases, thereby establishing a virtuous cycle: data collection → knowledge acquisition → intelligent retrieval → reuse (knowledge/processes/designs/resources) → knowledge feedback and update.
Nevertheless, while intelligent retrieval and reuse techniques have demonstrated considerable potential, discernible distinctions exist between them. Table 1 delineates these differences, providing a comprehensive overview of the key contrasts between retrieval and reuse within manufacturing processes from multiple perspectives.
Difference Between Retrieval and Reuse in Manufacturing.

Difference Between Retrieval and Reuse in Manufacturing.
Some of their typical problems in manufacturing processes also need to be addressed. Initially, intelligent retrieval techniques often encounter challenges due to their reliance on large and intricate process databases (Vieira et al., 2023). This complexity can impede the processing efficiency and prolong response times for retrieval algorithms. Current retrieval models may struggle with the efficient handling of multi-dimensional data, thereby compromising the precision of their matches. Furthermore, the adaptability of retrieval systems is typically limited, making it challenging to accommodate diverse process requirements with agility. This is particularly evident in specific industry contexts or when dealing with unique products, where the relevance and accuracy of retrieval outcomes may be suboptimal.
On the other hand, although reuse technology promotes the reuse and optimization of processes/products, it also reveals some shortcomings in practical application. Firstly, the design of reuse mechanisms frequently overlooks the necessity for process personalization and customization, potentially diminishing the market competitiveness of products in a dynamic market setting (Ziout et al., 2013). Secondly, the standardization of manufacturing information is often inadequate, complicating the integration and reuse of process data from disparate sources. Thirdly, current reuse strategies and processes are occasionally non-specific, failing to leverage historical data and sophisticated analytical methods to inform decisions on process reuse effectively. Consequently, establishing a unified data standard and sharing platform to enhance the efficiency and quality of reuse is an urgent issue that warrants immediate attention.
This review aims to delve into the current landscape, pivotal technologies, illustrative case studies, and prospective trends of intelligent retrieval and reuse technologies within the machining processes of electromechanical products. Through a systematic review and analytical synthesis of scholarly works published in high-impact journals (both domestic and international) between 2010 and 2024, this study seeks to address three pivotal research questions: RQ1: To what extent do contemporary intelligent retrieval systems demonstrate operational efficacy across heterogeneous manufacturing contexts? RQ2: How effectively do state-of-the-art process reuse methodologies address the competing requirements for operational efficiency and adaptive flexibility in dynamic manufacturing operations? RQ3: What interdisciplinary approaches could transcend existing limitations in intelligent retrieval-reuse integration through cross-domain methodological innovation?
The subsequent sections of this paper are organized as follows: Section 2 delineates the research methodology employed in the literature review and presents the outcomes of the statistical analysis; Section 3 provides an overview of the contemporary research on intelligent retrieval within manufacturing processes; Section 4 offers a comprehensive review of the current research on process reuse in manufacturing; Section 5 discusses the existing limitations and potential future trajectories; and Section 6 summarizes the findings and concludes the study.
The purpose of a literature review is to critically examine and synthesize the existing body of knowledge within a specific domain, thereby identifying research gaps and deficiencies in current scholarly work. This process is essential for informing researchers and stakeholders of the state of knowledge and guiding future inquiry (Huang et al., 2020). Saunders et al. (2012) conducted a structured literature review by establishing appropriate search criteria, retrieving relevant documents, and engaging in a cyclical analysis of the literature. Rowley and Slack (2004) outlined a systematic approach that encompasses resource scanning, mind map creation for literature organization, research report drafting, and bibliography compilation. Fahimnia et al. (2015) delineated a systematic literature review into five stages: keyword identification, preliminary search, search refinement, initial data collection, and data analysis. Adopting a similar methodology, our study employed a four-step process for reviewing and statistically analyzing literature on intelligent retrieval and reuse in manufacturing processes. This process included defining search terms, setting criteria for article inclusion and exclusion, conducting a article search and selection, and performing a statistical analysis of the collected data.
Defining Search Terms
In the retrieval section, the keywords encompass, but are not restricted to, terms such as “retrieval,” “manufacturing,” “knowledge,” “model,” “case,” “feature,” “processing,” “assembly,” “semantic,” and other pivotal keywords. The combinations of these keywords for the search queries were as follows: (1) “manufacturing” AND “retrieval,” (2) “manufacturing” AND “knowledge” AND “retrieval,” (3) “manufacturing” AND “modeling” AND “retrieval,” (4) “manufacturing” AND “case” AND “ retrieval,” (5) “manufacturing” AND “characterization” AND “retrieval,” (6) “manufacturing” AND “semantic” AND “retrieval.”
In the reuse section, the keywords encompass, but are not confined to, “reuse,” “manufacturing,” “process,” “resource,” “design,” “assembly,” “product,” “part,” and other core terms. The combinations of these keywords for the search queries were as follows: (1) “manufacture” AND “reuse,” (2) “manufacture” AND “resource” AND “reuse,” (3) “manufacture” AND “design” AND “reuse,” (4) “manufacture” AND “assembly” AND “reuse,” (5) “manufacturing” AND “process” AND “reuse.”
Criteria for Article Inclusion and Exclusion
The objective of this phase was to establish standardized search protocols for the literature included in the study, thereby ensuring consistency and precision in the retrieval of search outcomes. The detailed criteria are as follows:
Temporal Scope
This study was conducted in January 2025, and the last 14 years of relevant literature were selected for the study, so the selected papers span from 2010 to 2024. The literature selected for this study spans publications from 2010 to 2024, a temporal scope determined by dual considerations: Firstly, this period covers the critical evolution from the official promulgation of the Industry 4.0 paradigm in 2011 to the recent emergence of the human-centric Industry 5.0 framework, which have collectively driven a structural transformation in intelligent manufacturing systems; Secondly, bibliometric analysis reveals a concentration of high-impact studies during this period that exhibit substantial disciplinary representativeness within manufacturing informatics research.
Research Quality
To ensure a comprehensive and in-depth literature review, this study employed the Web of Science (WOS) database as the principal platform for literature search, complemented by the Engineering Index (EI)-indexed papers from the China National Knowledge Infrastructure (CNKI) database. The search was conducted using the keywords specified in Section 2.1, with a preference for papers from high-impact factor journals indexed in the WOS Core Collection, reflecting the pursuit of research papers of high quality. When keyword, title, and abstract searches did not yield sufficient information, a thorough examination of the full-text articles was conducted to refine the results. Ultimately, a meticulous review of the abstracts, followed by a qualitative manual assessment, facilitated the selection of high-caliber papers closely aligned with the themes of intelligent retrieval and reuse in manufacturing processes.
Article Search and Selection
The keywords delineated in Section 2.1 were utilized to query the WOS and CNKI databases. Adhering to the inclusion and exclusion criteria outlined in Section 2.2, the search parameters were as follows: (1) keyword presence in the “subject” or “title” fields, (2) a publication timeframe spanning from 2010 to 2024, and (3) a focus on journal articles while excluding reviews, conference proceedings, books, and similar formats. The search includes high impact factor international journals included in the WOS Core Journal Collection, as well as high quality Chinese journals included in the CNKI database. This initial search yielded 692 records, which was reduced to 345 unique articles after deduplication. A subsequent review of the titles and abstracts narrowed the selection to 244 articles. A thorough examination of the full-text content was then conducted to exclude off-topic articles, resulting in a final selection of 140 papers pertinent to the study's subject matter. Figure 1 provides a detailed overview of the study's literature review process.
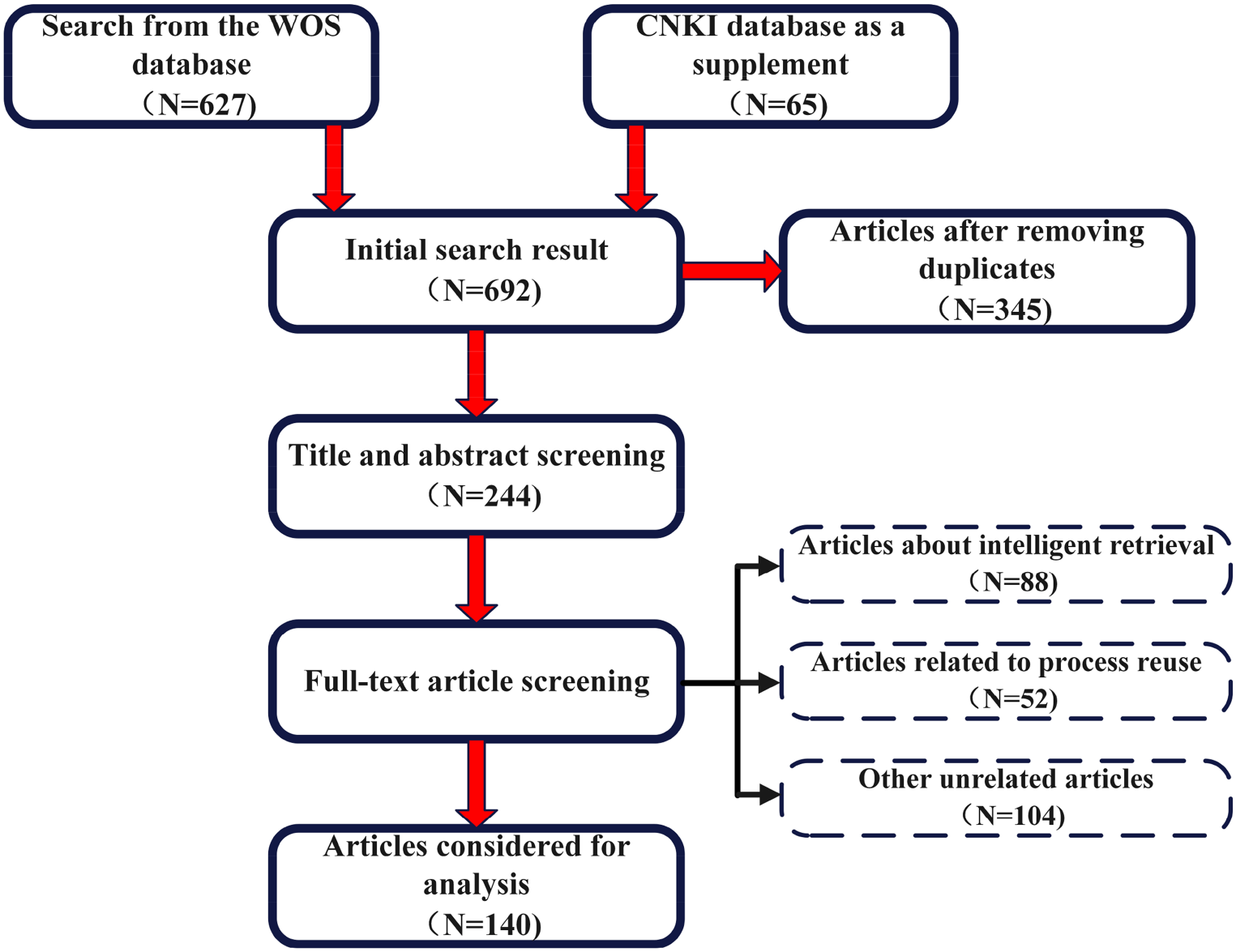
Article Selection Process.
Figure 2 presents a categorization of publications by journal, highlighting those with a count of three or more articles. Notably, The International Journal of Advanced Manufacturing Technology stands out with the highest publication count. Figure 3 depicts the distribution of these studies by year of publication, with blue representing literature on retrieval and red on reuse. This visualization indicates a sustained interest from researchers in the field over the past decade. The early period belongs to the technology-enabling phase, when the construction of a retrieval system is a necessary prerequisite for the practice of reuse, and therefore more literature is retrieved than reused. Although the annual publication count does not exhibit a pronounced upward trend, this does not diminish the significance and potential of intelligent retrieval and reuse techniques in manufacturing. The field continues to thrive in technological innovation and practical application, remaining a focal point for scholarly inquiry.
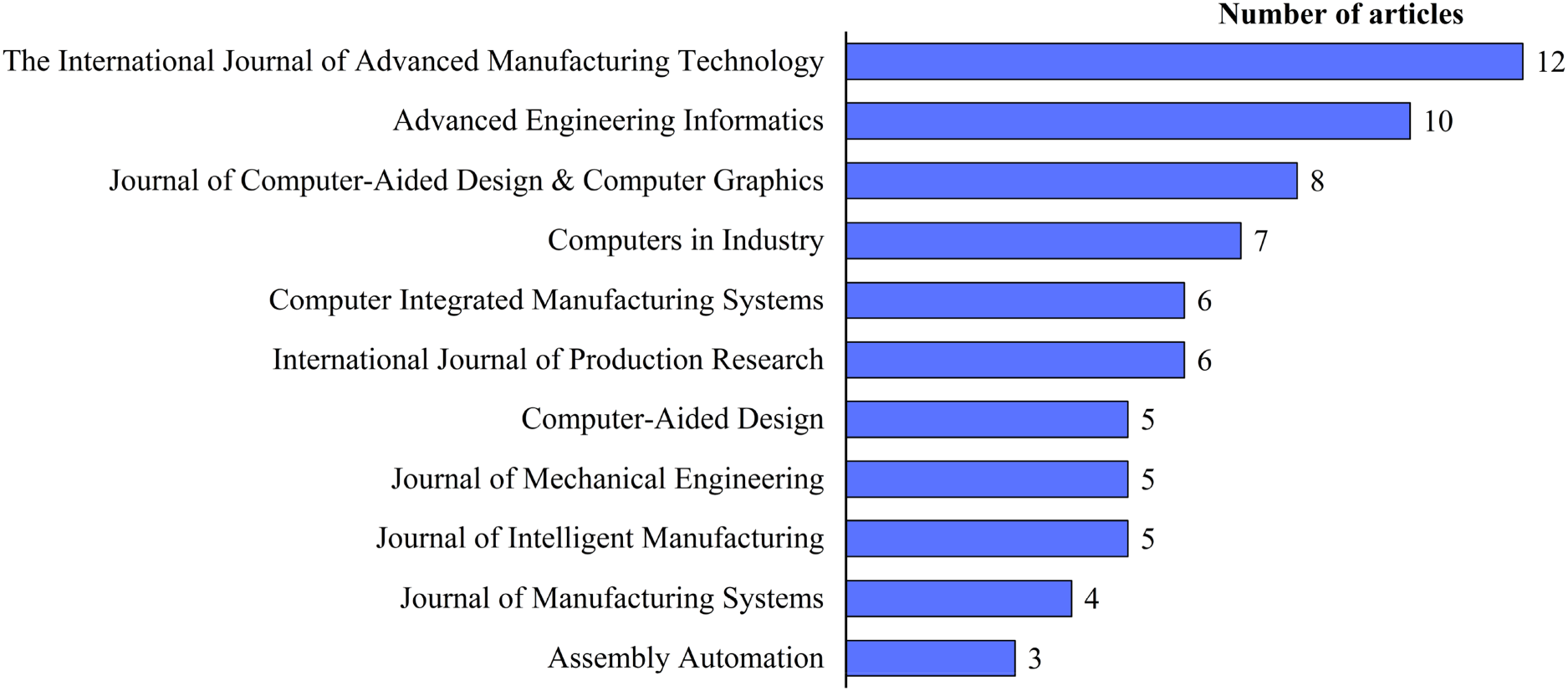
Number of Publications By Journal.
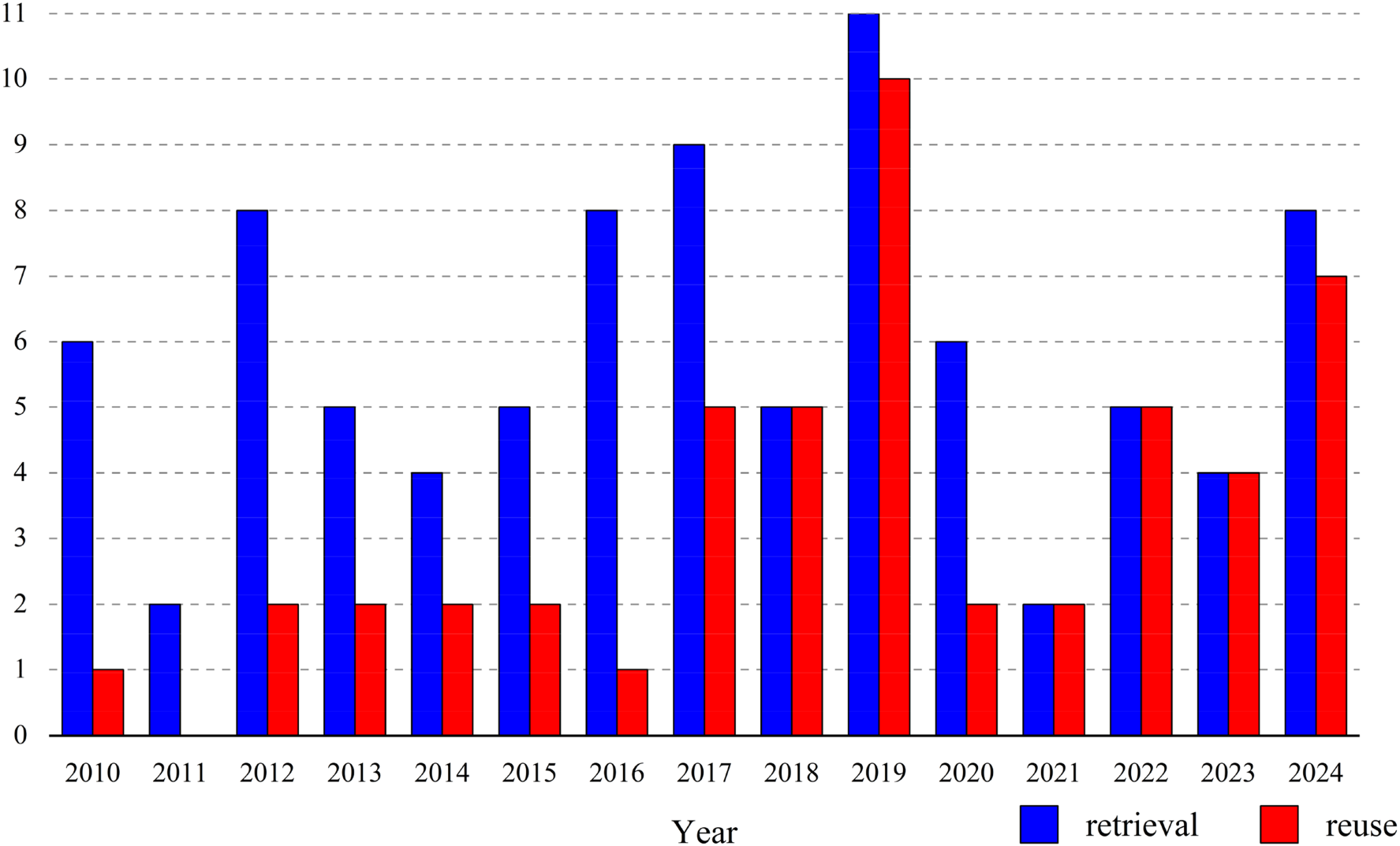
Publication and Distribution by Year.
The manufacturing process encompasses the transformation of raw materials into value-added products through a sequence of controlled processes and operational procedures. This sequence encompasses design, machining (which may include cutting, molding, welding, or casting), and further extends to sub-processes such as assembly, painting, and quality inspection. During the knowledge retrieval phase of manufacturing, it is suggested that the process be systematically categorized based on distinct retrieval methodologies. This categorization is illustrated in Figure 4.
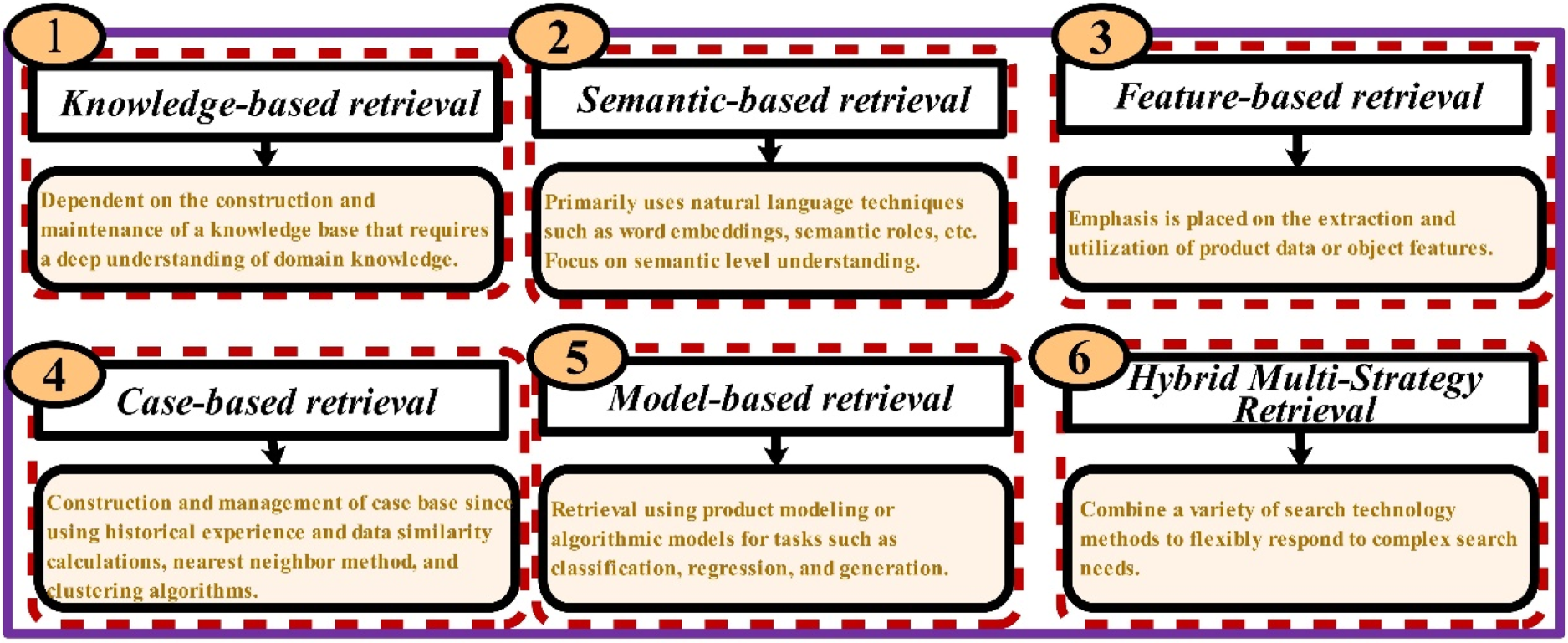
Classification of Different Retrieval Methods.
As delineated in Table 2, Knowledge-based retrieval systems enhance the efficiency of acquiring manufacturing knowledge by employing structured representations and intelligent computational methods. The methodology underpinning these systems has evolved along three primary trajectories:
Comparative Analysis of Knowledge-Based Retrieval Studies.
Comparative Analysis of Knowledge-Based Retrieval Studies.
Ontology model-OM, Semantic network-SN, Optimize retrieval-OR, Improve retrieval efficiency-IRE, Support innovative design-SID, Local-L, Global-G
Structured semantic modeling provides the technical foundation for these systems. Researchers primarily employ ontologies and semantic networks to construct domain-specific knowledge frameworks. For instance, Liu et al. (2017a; 2019c) developed an ontology (a formal model for representing knowledge as a set of concepts and their relationships) semantic extension and collaborative weighted fusion method to enhance retrieval relevance. Ma and Tian (2015) established an ontology-based knowledge base system to facilitate standardized search. Li et al. (2013, 2014) proposed a structured design rationale retrieval model to integrate multi-source design data and improve knowledge localization. Further contributions, such as Qiang et al.'s fault diagnosis ontology (2017), Guo et al.'s functional process ontology (2017), Hahm's engineering document semantic ranking mechanism (2015), and Liu's domain semantic association analysis (2020b), significantly advance knowledge organization and reasoning capabilities. Building on this foundation, Peng et al. (2019) introduced a Bayesian collaborative reasoning hypernetwork, enabling the modeling of relationships among multiple knowledge elements. Similarly, Jing et al. fused TF-IDF with word vector models to construct a design knowledge semantic network, incorporating statistical semantic mining to reveal implicit design preferences within a structured framework (Jing et al., 2023).
Dynamic learning-driven methods have emerged to surmount the limitations of traditional frameworks by leveraging machine learning techniques. For example: Huang et al. (2024) constructed a case-based reinforcement learning knowledge graph, employing similarity calculations to identify key modification points and balance case adaptation efficiency with quality. Xu et al. (2024b) developed a multimodal verification framework to assess knowledge confidence and utilized domain-specific Transformers for visual-knowledge feature alignment, significantly enhancing multimodal retrieval robustness. Wang et al. (2024) proposed a method where pre-trained models actively screen external knowledge sources to improve visual question-answering reliability. While these approaches enhance contextual awareness, they must still address challenges related to computational efficiency and domain generalization.
Neural-symbolic fusion represents a cutting-edge research frontier. This approach integrates neural networks with symbolic reasoning to advance knowledge processing. Key contributions include: Kumar and Starly (2022) employed a BiLSTM-CRF neural network to extract structured entities from manufacturing text, enabling automated knowledge base population. Siddharth and Luo (2024) pioneered a two-stage methodology: first fine-tuning language models to extract engineering facts from patents for knowledge base population, then leveraging LLMs to generate precise responses. Further developments in this paradigm—such as Yu et al.'s domain ontology natural language parsing (2011), Tu et al.'s three-level mapping model (2013), and Wen et al.'s integration of mathematical models with semantic computing (2017)—demonstrate its capacity to transcend traditional methodological boundaries. However, optimizing mechanisms for ensuring knowledge consistency remains a critical challenge.
Research in this field centers on a core challenge: constructing dynamic, evolving knowledge systems that adapt to complex manufacturing environments while optimizing the trade-off between accuracy and efficiency in multimodal retrieval. Future breakthroughs will likely hinge upon advancements in neural-symbolic fusion, particularly the innovative deployment of LLM technology for automating knowledge acquisition and enabling trustworthy reasoning.
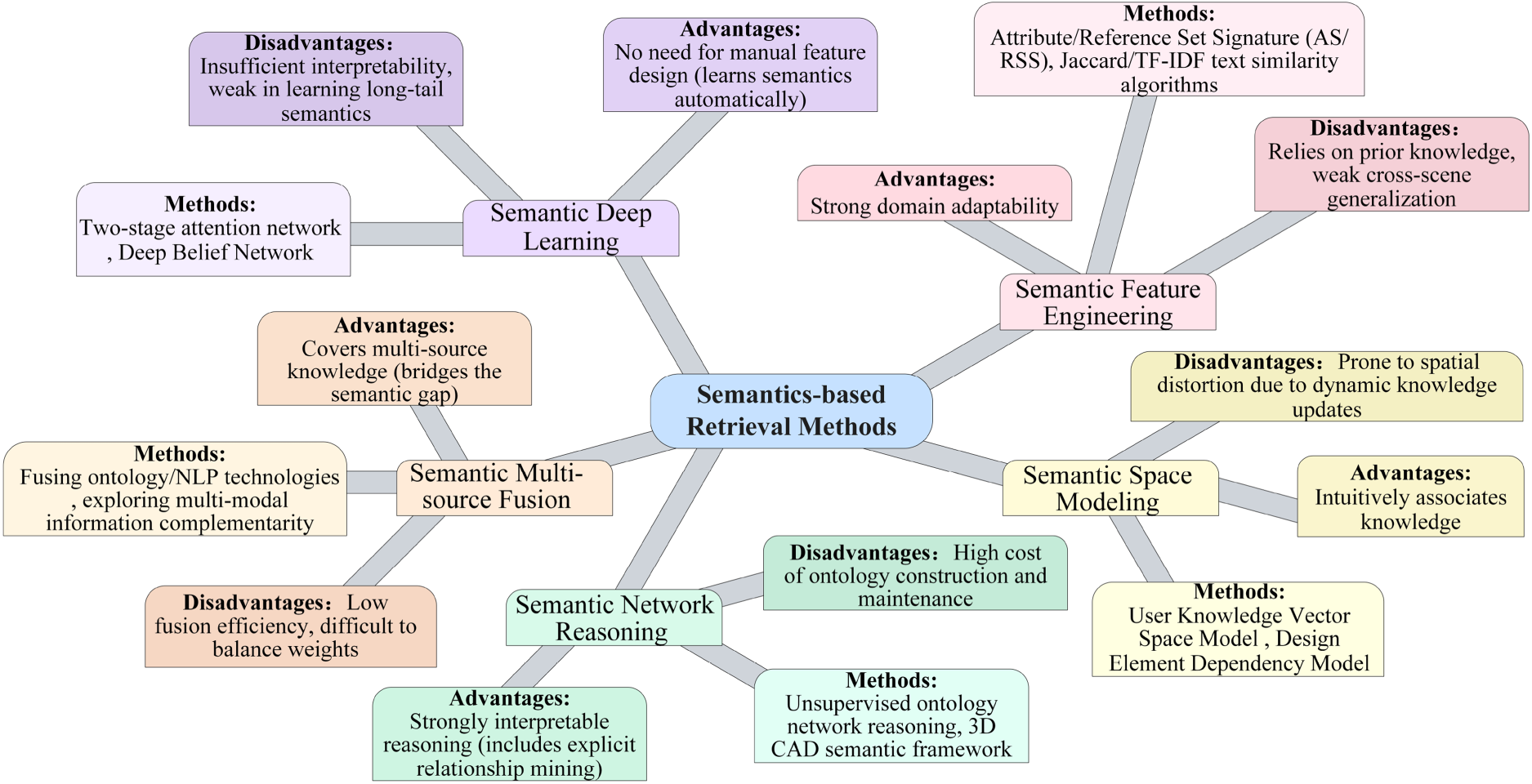
Semantic-based retrieval aims to transcend the limitations of keyword matching by leveraging the semantic associations inherent in manufacturing knowledge. The technical methodology for achieving accurate retrieval is commonly structured as a five-level framework (Figure 5):
Semantic-Based Retrieval Technology Approach.
Semantic feature engineering quantifies semantic information through contextual semantic carriers. For example, attribute/reference set signatures construct semantic identifiers for 3D objects (Gong et al., 2012), while text similarity algorithms (e.g., Jaccard and TF-IDF) retrieve assembly instructions (Renu & Mocko, 2016a). Although these methods exhibit high domain adaptability, they rely on prior knowledge and demonstrate limited cross-scenario generalizability. Semantic space modeling characterizes knowledge associations in high-dimensional spaces. Spatial distance metrics measure semantic similarity (a metric for quantifying the closeness in meaning between concepts) and intuitively link knowledge (Gao et al., 2023; Wang et al., 2012b), though such models remain susceptible to spatial distortion during dynamic knowledge updates. Semantic network reasoning utilizes ontologies and rules to infer implicit relationships. An unsupervised ontology network establishes concept relevance (Shi et al., 2017), and a layered ontology with SWRL rules enables constraint-based automatic inference for 3D CAD semantics (Qin et al., 2016). Despite strong interpretability, this approach incurs substantial ontology construction and maintenance costs. Semantic deep learning employs models to autonomously extract features. A two-stage attention network integrating enhanced weighted LDA and Word2Vec extracts fault semantics for diagnostic applications (Hu et al., 2024), and a deep belief network aligns 3D model semantics (Chen et al., 2019). These eliminate manual feature design but suffer from limited explainability and inadequate long-tail semantic recognition. Semantic multi-source fusion integrates heterogeneous information to bridge knowledge gaps. Ontology and NLP techniques connect CAD and design document semantics (Jeon et al., 2016), while multi-modal attitude metrics support heterogeneous 3D model retrieval. Despite encompassing multi-source knowledge, these approaches face challenges including low fusion efficiency and difficulties in weight balancing.
Although the field is evolving from manual feature engineering toward automated learning, from single-source data to multi-source fusion, and from static matching to dynamic inference, significant challenges impede the advancement of knowledge retrieval in intelligent manufacturing. Key among these are dynamic semantic updating, personalized adaptation, robustness, and the efficiency of multimodal data fusion.
In the domain of feature retrieval, scholars have been delving into innovative methodologies to augment the efficacy and precision of assembly model retrieval. This section provides a comprehensive review of pertinent literature, underscoring the pivotal contributions and technical frameworks established by various researchers, as summarized in Table 3. Feature-based retrieval leverages geometric, semantic, and process-related feature associations within manufacturing knowledge to achieve efficient information access. This approach can be categorized into three principal technical methodologies: Geometric Feature-Driven Retrieval
Comparative Analysis of Studies Based on Feature Retrieval.
Geometric feature-driven retrieval quantifies geometric similarity using shape and topology as primary attributes. This approach facilitates retrieval by focusing on the inherent forms and structural arrangements of objects. For instance, Wang et al. (2016) employed shape distribution and Earth Mover's Distance to streamline assembly queries. Similarly, Li et al. (2016) quantified CAD model similarity using feature dependency graphs (directed graphs that represent the relationships and constraints between design features) and shape distribution. Huang et al. (2017) utilized tensor fields and D2 descriptors for retrieving free-form surfaces, while Wang et al. (2012a) developed a sheet metal feature location model. In assembly contexts, Chen et al. (2012) implemented multi-level assembly descriptors and fast indexing to filter mismatched models, and Renu and Mocko (2016b) assessed similarity through assembly and component attribute histograms. While effective in scenarios prioritizing geometric characteristics, these methods often fall short in capturing non-geometric semantics (e.g., manufacturing processes or material properties). Furthermore, their robustness diminishes significantly when topological variations occur. Semantic-Process Integration
Semantic-process integration involves transforming functional and process constraints into structured features by combining design semantics with process knowledge. For example, Qiao et al. (2019) inferred semantic matching using assembly semantic adjacency graph conjugate subgraphs. Bai et al. (2010) utilized extended feature trees to partition design semantics and perform tree matching. Other researchers have focused on integrating manufacturing considerations: Huang et al. (2018) evaluated features from a manufacturing perspective based on central axis transformations. Huang et al. (2015) encapsulated manufacturing information through manufacturing feature coupling and developed corresponding matching algorithms. Kong et al. (2024) defined gear partitioning templates to facilitate intelligent retrieval of multi-alloy manufacturing processes. While these methods satisfy the “function-manufacturing-geometry consistency” requirement, they often depend heavily on expert knowledge, which limits their cross-scenario generalizability. Data-Driven Feature Learning
Data-driven feature learning leverages deep learning to automatically extract high-dimensional features, overcoming the limitations of manually engineered features. For instance, Song et al. (2024) employed a semantic transfer network to facilitate 2D-to-3D retrieval. Gao et al. (2020a) conducted a comparative analysis on the robustness of manually selected versus deep learning-based features in view-based representations. Additionally, Siddiqua and Fan (2019) utilized supervised autoencoders to extract 3D features from depth images. While this approach excels at efficiently processing multimodal data, it often presents challenges in model interpretability and offers limited customization capabilities for specialized feature learning in niche applications.
The evolution of feature-based retrieval technology is progressing from a reliance on geometry to the integration of semantic and process information, and more recently, to enhancement via data-driven methods. Geometric features form the foundation of this technology; their efficiency and universality are valuable in applications where shape is the primary retrieval criterion. A significant limitation, however, is that geometric similarity does not equate to functional similarity. To address this challenge, research is now focused on the deep integration of semantic and process-related features. These approaches involve constructing hierarchical feature descriptors or using graph theory methods, such as assembly adjacency graphs, to represent complex design and manufacturing relationships. The objective is to satisfy advanced retrieval needs that require consistency across function, process, and geometry. Concurrently, data-driven deep learning techniques have introduced new and powerful methods for processing multimodal data and automating feature extraction (Hussain et al., 2021).
However, significant challenges in existing research persist. Manually designed semantic features often lack generalizability across different scenarios, and achieving an optimal balance between efficiency and weighting in feature fusion remains a considerable difficulty. Furthermore, the lack of explainability in data-driven, or “black box,” methods conflicts with the manufacturing sector's stringent requirements for traceability and reliability. Future breakthroughs in feature retrieval technology will depend on bridging the gap between theoretical innovation and industrial application. One priority is to integrate explainable AI with domain-specific manufacturing knowledge. For example, deep learning features can be fused with traditional descriptors that have clear physical or geometric meaning, thereby enhancing model performance while ensuring the reliability of the results. A second priority is to strengthen the performance evaluation and optimization of algorithms in realistic industrial environments to address critical issues of deployment and usability within complex manufacturing systems.
In the domain of case-based retrieval, numerous scholars have proposed innovative methodologies that have substantially advanced the field, as detailed in Table 4. CBR operates on a cyclical process of case reuse, modification, and storage, allowing for the resolution of novel problems by drawing parallels with historical cases. Current research has expanded beyond traditional limitations, focusing on four key areas: semantic enhancement, multidimensional matching, technology coupling, and scenario customization. Semantic Enhancement
Analysis of Case-Based Retrieval Studies.
CBR-Case-based reasoning, SM-Similarity metric, OM-Ontology model, HE- High efficiency, GA- Good accuracy, DP- Design phase, PP- Processing phase, OT-Other.
Semantic enhancement leverages domain knowledge to structure case semantics, making information more organized and meaningful for retrieval. For example, Li et al. (2022) combined ontologies with a two-stage retrieval process to develop a semantic case repository for chiller unit variant design. Similarly, Chen et al. (2016) integrated ontologies with CBR to create an automated framework for disassembly decision-making. Guo et al. (2012) further demonstrated this approach by incorporating domain ontologies into injection mold design to improve semantic retrieval capabilities. While these methods effectively encapsulate knowledge and enhance the accuracy of associations through ontologies, they often depend heavily on expert experience and can struggle to keep up with dynamic scenario updates. Multi-Dimensional Matching
Multi-dimensional matching enhances similarity assessment by integrating geometric, semantic, and process attributes. This approach aims to provide a more comprehensive and accurate retrieval of cases. For example, Wu et al. (2017) quantified various design factors to achieve efficient retrieval of design service cases. Similarly, Ren et al. (2019) improved the reuse of low-carbon designs by employing multi-dimensional correlation functions and dimension reduction techniques. Further advancements in this area include Zheng et al.'s (2019) use of bilateral Data Envelopment Analysis for automatic weight assignment, replacing traditional manual weighting. Hu et al. (2015) proposed the Grey Relational Analysis-Weighted Mean adaptive method to address challenges in parametric mechanical design. Additionally, Kang et al. (2013) constructed an association knowledge system by integrating similarity knowledge with association rule mining, which demonstrated superior performance compared to conventional similarity retrieval methods. While multi-dimensional coverage enables more comprehensive retrieval, it introduces challenges related to weight balancing among different attributes and increased computational complexity. Technical Coupling
Technical coupling integrates CBR with other advanced methodologies, such as rule-based reasoning, machine learning, and intelligent optimization. This synergistic approach enhances CBR's capabilities and addresses its limitations. For instance, Huo et al. (2022) coupled CBR with machine learning to decompose complex subproblems, effectively mitigating issues related to small sample sizes and high-dimensional data. Li et al. (2023) combined CBR with process reasoning (PR) to filter process schemes based on feature weights and similarity, optimizing decision-making. Furthermore, Xu et al. (2021a) demonstrated a highly integrated approach by combining CBR, k-nearest neighbors, neural networks, and Gaussian processes with vibration particle swarm optimization to predict high-speed milling performance. While this multi-technology collaboration significantly improves adaptability to complex scenarios, the high degree of coupling can lead to reduced model interpretability and increased development costs. Scenario Customization
Scenario customization involves reconstructing case libraries and refining retrieval logic to suit specific applications. For example, Chazara et al. (2016) developed a connectionist model and a novel similarity framework tailored for waste treatment processes. You et al. (2010) employed planar bending graphs to encapsulate the structural information of automotive exterior parts, thereby accelerating process and mold design. Hashemi et al. (2014) optimized case retrieval for machining fixtures through a two-step strategy. Additionally, Xavior and Anouncia (2012) utilized CBR to predict surface roughness and tool life in hard machining operations. While these scenario-specific approaches significantly enhance efficiency within their intended domains, the need to extensively customize case libraries often leads to high costs when attempting cross-scenario transfer.
Case-based retrieval is fundamentally built around the “case reuse—modification—storage” cycle. As technologies have advanced, particularly in areas like semantic enhancement (which uses ontology-based knowledge encapsulation), multi-dimensional matching (integrating geometric and process features), technology coupling (combining CBR with machine learning and optimization algorithms), and scenario customization (reconstructing cases for specific domains), case-based retrieval has become a core methodology. It's now essential for streamlining processes and facilitating knowledge reuse in both product design and engineering.
From a technical standpoint, the use of graphical descriptors, semantic queries, and advanced feature extraction enables the precise identification of similar cases in complex scenarios. Furthermore, integrating deep learning and intelligent optimization allows CBR to overcome the challenges of “small samples and high dimensions” and efficiently process large-scale datasets. However, several developmental challenges persist. Complex algorithms often lack explainability, which makes it difficult to meet the demand for traceability in decision-making. Achieving a balance between scenario customization and cross-scenario generalization remains an ongoing hurdle. Additionally, improving the efficiency of knowledge reuse under conditions of data scarcity (e.g., cases involving niche processes) continues to be a core challenge. Looking ahead, future efforts should focus on enhancing algorithm explainability, potentially through neuro-symbolic integration. Developing multi-scenario adaptive frameworks, incorporating dynamic weights and lightweight case repositories, will also be crucial. Moreover, improving data augmentation techniques for scarce data, with continuous breakthroughs in transfer learning and generative models, is essential. The synergistic integration of cutting-edge technology and practical needs will drive CBR's evolution from “scenario customization” to “intelligent ubiquity,” ultimately unlocking the full value of knowledge reuse.
In the domain of model-based retrieval, a plethora of scholars has introduced a variety of methodologies aimed at augmenting the classification and retrieval efficacy of 3D models. As delineated in Table 5, these approaches encompass geometric and topological feature extraction (Li et al., 2015b; Mohamed & Ben Hamza, 2012; Wang et al., 2017a), the application of deep learning (Bai et al., 2019a), similarity assessment and graph structure analysis (Huang et al., 2019a; Zhang et al., 2018b), feature volume and region coding (Katayama & Hirashima, 2020; Tao et al., 2013), graph structure and subgraph mining (Ma et al., 2010; Qiao et al., 2022), semantic information and model representation (Han et al., 2018; Wu & Gao, 2014), structural topology and case retrieval (Luo et al., 2017; Wang et al., 2014), and other efficient model retrieval strategies (Hu et al., 2013; Zhao et al., 2019). The diverse models and algorithms explored within the literature underscore the significance of feature extraction and similarity assessment, while also highlighting the utility of semantic information and structured data in the complex retrieval of 3D models. Collectively, these research findings offer a solid theoretical framework and practical direction for the further refinement of 3D model retrieval techniques, signaling ongoing progress and innovation within this academic discipline.
Analysis of Model-Based Retrieval Studies.
Analysis of Model-Based Retrieval Studies.
Within the realm of model retrieval, an array of methodologies has surfaced in recent years, each distinguished by its unique attributes, indicative of an ongoing quest to enhance retrieval precision and efficiency. The literature reveals a predilection for statistically based methods, attributed to their practical applicability and minimal constraints on model types. These methodologies are typically characterized by robustness and an adeptness at managing a spectrum of model data. However, they fall short in the realm of shape description accuracy, particularly when it comes to local similarity retrieval, often failing to satisfy the requisite standards. Consequently, future research endeavors may necessitate the exploration of more nuanced shape description mechanisms, while preserving the merits of statistical methods, to broaden their applicability. In the domain of 3D model retrieval, the technique of repartitioning triangular meshes and incorporating spherical summing functions has proven to be an efficacious approach for shape-based retrieval. This methodology enhances retrieval precision by augmenting the dimensionality of the descriptors, and its straightforward structure and straightforward similarity computations have rendered it extensively utilized in practical applications. Nevertheless, the method is susceptible to the impacts of preprocessing and voxelization, which can escalate computational complexity and potentially diminish retrieval efficiency, particularly when managing large-scale datasets. Consequently, optimizing the preprocessing phase to enhance efficiency and bolster local shape retrieval capabilities presents a significant challenge within the field. Retrieval of CAD models utilizing attribute adjacency graphs offers a novel perspective, enabling a more precise representation of model topology and facilitating localized model searches. This distinct advantage significantly enhances the method's utility in engineering contexts. However, the extensive computational demands associated with graph similarity assessments remain a formidable challenge, constraining broader adoption. Consequently, future research endeavors should focus on optimizing graph similarity computation efficiency or on developing more efficient approximation algorithms. Such advancements would be instrumental in elevating the overall performance of the method without compromising search accuracy.
In conclusion, the field of model retrieval confronts numerous challenges, notably the need to balance retrieval accuracy with computational efficiency, enhance the capacity for local shape retrieval, and refine the model preprocessing procedures. As cutting-edge technologies like deep learning continue to evolve, it is anticipated that future research will achieve substantial advancements in these domains, thereby offering more robust support for the efficient retrieval of 3D models.
In product manufacturing, single retrieval methods struggle with the growing complexity and multimodal nature of engineering data, primarily due to their limited ability to integrate diverse information. To address this, hybrid multi-strategy retrieval has emerged as a solution. This approach organically combines two or more distinct retrieval mechanisms, information sources, or processing paradigms. By leveraging the advantages of each and compensating for the shortcomings of single strategies, hybrid methods significantly enhance the comprehensiveness, accuracy, and robustness of retrieval.
Current research on hybrid retrieval focuses on various fusion models designed to enhance retrieval efficiency across multiple levels. A key strategy involves deeply integrating heterogeneous information sources and features, which is essential for capturing the inherent complexity of product models. For instance, in CAD assembly model retrieval, research has moved beyond solely geometric features. Instead, it now integrates multi-source attribute information and structural relationships. This is exemplified by approaches that use attribute adjacency graphs and enhanced spectral clustering algorithms to uncover deep associations within models (Han et al., 2019). Similarly, in 3D model retrieval, hybrid strategies move beyond traditional single-feature descriptors. They achieve this by mapping 2D image features, 3D model features, and even user-drawn sketches—among other multimodal information—into a unified semantic space. Deep learning networks facilitate this by extracting and integrating multi-level, multi-scale features. Notable examples include Liu et al.'s Semantic and Context Fusion Network (2020a) and Bai et al.'s sketch retrieval based on a ternary network (2019b). These advancements significantly improve the understanding of complex semantics and enhance cross-modal retrieval capabilities. Furthermore, by extracting features from 2D images and 3D models and integrating multi-clustering information, researchers can improve the robustness of pseudo-labels and achieve better class-level semantic alignment. This, in turn, optimizes the performance of image-based 3D model retrieval (Chu et al., 2022).
Another hybrid strategy integrates diverse methodologies or reasoning paradigms to leverage complementary advantages in decision-making and evaluation. For instance, manufacturing process similarity assessments increasingly integrate subjective judgment frameworks, such as the Analytic Hierarchy Process (AHP), with objective data-driven techniques like information entropy (Wu et al., 2021). This synthesis assigns weights to multi-dimensional process characteristics, strengthening the scientific rigor and reliability of similarity analyses. Similarly, in complex fault diagnosis, singular approaches like rule-based or Case-based reasoning (CBR) can exhibit limitations. Hybrid strategies address this by integrating ontology knowledge with case-based and rule-based reasoning, thereby improving diagnostic accuracy and comprehensiveness for identifying fault causes, locations, and corrective actions (Xu et al., 2018). Furthermore, to optimize design knowledge reuse, researchers combine CBR with advanced text mining techniques (Hu et al., 2023). This integration enables the automated generation of assembly instructions, significantly increasing design efficiency and accuracy. This integrative approach further manifests in methods that automatically extract and encode geometric and structural data through attribute mapping (Lupinetti et al., 2018). Such techniques enrich assembly model information, facilitating efficient design knowledge retrieval and reuse.
In summary, hybrid multi-strategy methods offer substantial advantages. By integrating multi-dimensional features, they enhance both the comprehensiveness and discriminative power of retrieval, allowing systems to better interpret data complexity. Additionally, incorporating multiple methodologies improves the system's decision-making and reasoning capabilities, making it more robust and reliable for complex engineering challenges. Specifically, when leveraging deep learning and machine learning technologies, hybrid strategies can harness the powerful feature learning capabilities of neural networks. This enables the extraction of deeper, more complex feature representations from large datasets. Combining these with traditional features strikes a crucial balance between computational efficiency and the depth of semantic understanding, ultimately driving advancements in automated retrieval methods.
Despite its notable advantages, hybrid multi-strategy retrieval still faces several challenges. The most prominent issue lies in customizing and optimizing strategy combinations. Specifically, it's difficult to scientifically select, design, and dynamically adjust the combination of multiple strategies based on varying data types, application scenarios, and performance requirements, all while determining appropriate weights and priorities among these strategies. The current lack of universal theoretical guidance often leads to inconsistent performance. Another critical challenge is balancing computational complexity with real-time performance. Hybrid models typically involve more intricate structures and additional data processing steps. Therefore, ensuring high accuracy while simultaneously reducing computational costs and meeting real-time retrieval demands for large-scale datasets is an urgent issue. Finally, the complexity of knowledge acquisition and integration, along with the reduced interpretability of models, are areas requiring focused attention in future research. Enhancing the interpretability of results, especially in deep learning hybrid models, is crucial for practical engineering applications.
Comparison and Consistency Analysis of Different Retrieval Methods
This study organizes intelligent retrieval technologies into six primary categories: knowledge-based, semantic-based, feature-based, case-based, model-based, and hybrid strategies. Each classification represents a distinct approach to tackling the challenges of information retrieval and reuse within product manufacturing. While their specific implementations and data dependencies vary, all share the common objective of enabling more efficient and precise information acquisition and knowledge reuse in complex and dynamic design and manufacturing environments.
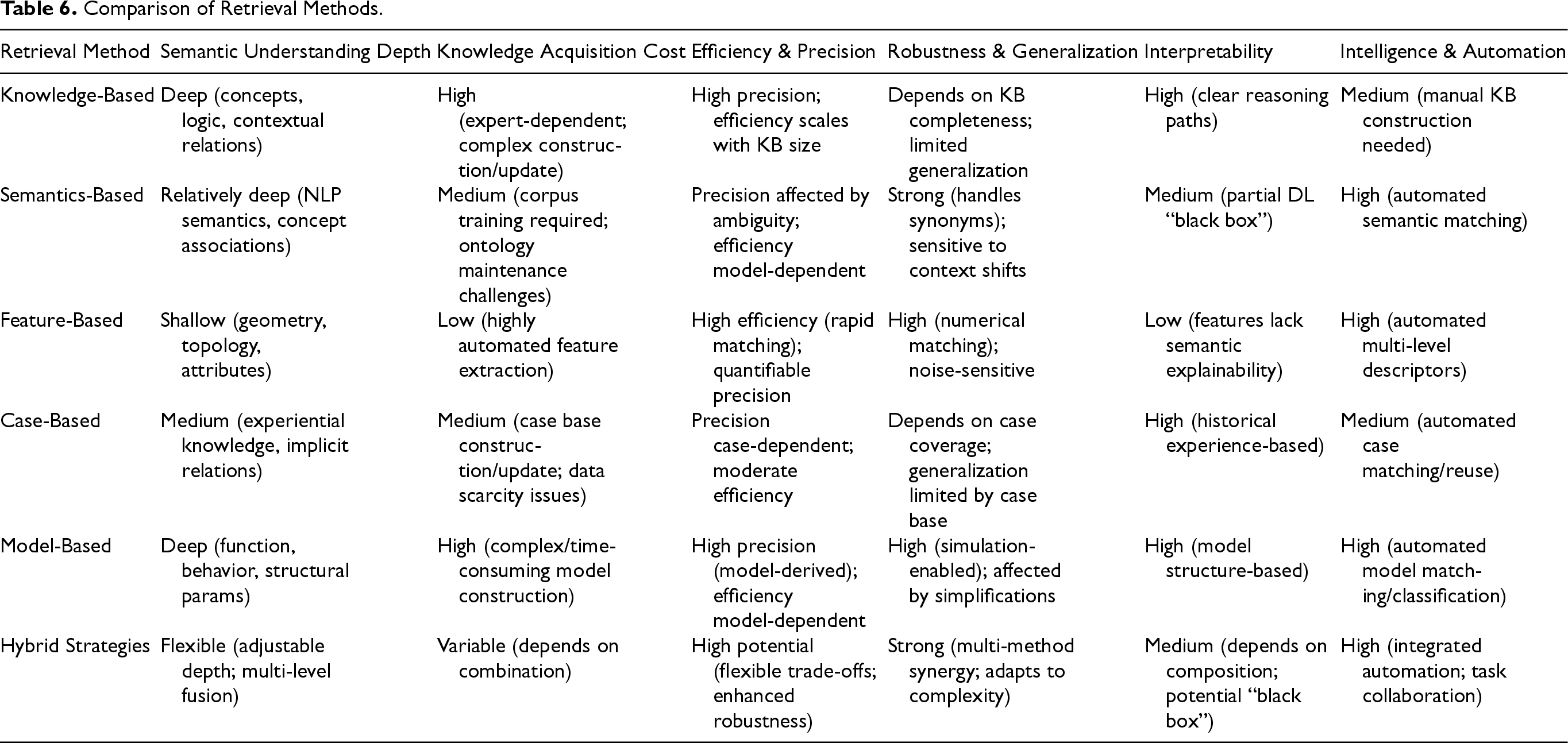
To facilitate a comprehensive understanding of the advantages, disadvantages, and interconnections among these six retrieval methods, this paper conducts a comparative analysis based on the following six core dimensions, as presented in Table 6.
Comparison of Retrieval Methods.
Comparison of Retrieval Methods.
Table 6 reveals a clear technical evolution and complementary objectives among the various retrieval methods. Together, these methods address the complex retrieval demands of product manufacturing.
The depth of semantic understanding is a core driver in the evolution of retrieval technology. While feature-based methods offer high retrieval efficiency, they often suffer from a “semantic gap.” To compensate, semantics-based methods (utilizing natural language processing, semantic signatures, and deep learning) and knowledge-based methods (employing ontologies, rules, and knowledge graphs) enhance semantic analysis capabilities for product functions, relationships, and context. Model-based retrieval encodes product information using computable models, deepening understanding in areas like simulation and performance prediction. Overall, there's a unified evolutionary trend from shallow structural feature matching to profound conceptual semantic understanding.
Regarding knowledge acquisition costs, knowledge-based methods demand significant human and expert input for constructing ontologies and rule bases. Case-based methods, while relying on historical data accumulation, face core challenges in case base indexing and dynamic updating. Feature-based methods, however, benefit from automated feature extraction, which lowers their acquisition costs. Deep learning technology further reduces the costs associated with manual feature engineering and knowledge encoding by providing semantic and hybrid methods with automatic feature learning capabilities. This advancement is moving the field toward “data-driven automated knowledge representation.”
Regarding efficiency, accuracy, robustness, and generalization, single retrieval methods inherently struggle to balance these trade-offs. For example, while knowledge-based methods offer high accuracy, they often lack generalizability. Conversely, feature-based methods are efficient but may not fully capture contextual understanding. Hybrid strategies address these limitations by integrating the strengths of various methods through multi-dimensional fusion, such as combining semantic-geometric features or case-rule reasoning. This approach meets the demands of complex, dynamic retrieval by shifting from single-path optimization to a more multi-path collaborative and complementary paradigm. The goal is to achieve a globally optimal balance of efficiency, accuracy, and robustness.
Finally, explainability and intelligence present common challenges and shared goals across these methods. While knowledge-based and case-based methods offer high explainability, their automation capabilities are often limited. Conversely, semantic and hybrid methods, particularly those driven by deep learning, are highly intelligent but face controversy due to their “black box” nature. In the future, explainable AI technology will be essential to bridge this gap, driving the evolution of retrieval technology toward the ultimate goal of being efficient, accurate, intelligent, and explainable.
Process reuse is predicated on the retrieval of established processes, thereby enabling their subsequent application. It involves the reapplication of validated processes, design elements, resources, and product components within the production cycle, with the objectives of enhancing productivity, minimizing costs, and fostering innovation. This study will delve into the theoretical underpinnings of process reuse, its practical methodologies, and its significance in the contemporary manufacturing sector. The analysis will be conducted across four key dimensions: resource reuse, process reuse, design reuse, and component reuse, as illustrated in Figure 6.

Process Reuse in Manufacturing.
Research on resource reuse encompasses a diverse array of disciplines and methodologies, exhibiting a plethora of promising applications, as delineated in Table 7. Existing research on resource reuse demonstrates significant multi-level characteristics. Its analytical scope spans various dimensions, from micro-level material technology to macro-level supply chain strategy. Collectively, this research establishes a robust theoretical and practical foundation for sustainable manufacturing.
At the fundamental material and process level, research aims to directly regenerate value from waste through technological innovation. For instance, Gebhardt et al. (2021) developed closed-loop recycling technology to transform production waste into high-value composite materials. This not only reduces reliance on virgin materials but also significantly enhances material performance. Similarly, Branca et al. (2020) systematically analyzed by-products in the steel industry, highlighting the substantial potential for traditional industries to achieve environmental sustainability through resource utilization. Additionally, Xia et al. (2025) applied heterogeneous graph neural network technology to efficiently generate reuse plans for scrap mechanical parts.
At the system and process level, researchers focus on enhancing overall resource efficiency by optimizing the architecture and operation of manufacturing systems. Arista et al. (2022) highlight that reconfigurable manufacturing systems (RMS), as a flexible production paradigm, are crucial for improving resource utilization during the design phase of complex products like aerospace components. Similarly, Gaiardelli et al. (2024) introduced the RRPDG model, an innovative approach for quantifying and optimizing resource allocation within regional manufacturing processes.
From a broader perspective, researchers are leveraging advanced information technology and management paradigms to facilitate resource reuse across the entire value chain. For example, Koppelaar et al. (2023) introduced the concept of a digital product passport, which addresses critical information barriers in circular economies by enhancing transparency throughout a product's lifecycle, from production to recycling. Similarly, Fisher et al. (2018) explored cloud manufacturing as an emerging service model, demonstrating its value in promoting cross-enterprise resource sharing and recovery. Building upon this foundation, Su et al. (2025) developed a cognitive manufacturing framework leveraging manufacturing knowledge graphs, thereby enabling advanced intelligent decision-making through dynamic knowledge reasoning and updating. These multi-level explorations ultimately contribute to higher-level strategic objectives, such as enhancing supply chain resilience and sustainability and driving design innovation and efficiency improvements through knowledge reuse (Liu et al., 2019a; Napoleone et al., 2022).
Analysis of Resource Reuse Studies.

Analysis of Resource Reuse Studies.
Given escalating resource scarcity and environmental concerns, resource reuse in manufacturing has transitioned from a peripheral issue to a central competitive advantage. This section's analysis indicates that research in this field has progressed beyond fragmented technological advancements to form a multi-level systemic framework spanning from micro to macro scales. This framework incorporates foundational material process innovations (e.g., closed-loop recycling and by-product valorization), intermediate manufacturing system and process optimization (e.g., reconfigurable manufacturing systems), and top-level cyber-physical integration and strategic management (e.g., digital product passports and supply chain resilience).
This trend clearly indicates a shift in the focus of resource reuse from isolated technical applications to comprehensive solutions spanning technical, operational, and strategic dimensions. This evolution offers practical avenues for businesses to enhance supply chain resilience and accelerate research and development innovation. It also underscores the crucial need for interdisciplinary knowledge integration. Therefore, the main challenge moving forward won't just be achieving breakthroughs in individual technologies at various levels. It will also involve enabling efficient collaboration and data integration across these levels. This will maximize the resource efficiency of the entire manufacturing system and establish a robust foundation for a truly sustainable industrial growth model.
Process reuse, recognized for its potential to enhance efficiency and minimize costs, has increasingly garnered attention from both industry and academic spheres. Scholars have introduced a plethora of innovative approaches to facilitate this efficiency. As delineated in Table 8, academic research has concentrated on addressing the challenges inherent in specific process types and the manufacturing phases under scrutiny. The analysis reveals that the discourse on process reuse encompasses several key domains: the generation and optimization of process solutions (Huang et al., 2019b, 2022; Liang et al., 2022), the identification and reuse of process features (Xu et al., 2019), the reuse and optimization of assembly processes (Li & Xie, 2015), the recycling of manufacturing information and knowledge (Li, 2022; Liu et al., 2018; Wen et al., 2023), the adoption of modularization and platform-based design strategies (Xu et al., 2012), and the integration of intelligence and automation (Duan & Duan, 2024; Li et al., 2015a, 2019; Xu et al., 2024). Collectively, these studies have offered a spectrum of strategies and technical frameworks that have propelled the manufacturing sector towards greater process intelligence and resource optimization.
Analysis of Process Reuse Studies.
Analysis of Process Reuse Studies.
Numerical control machining-NC, Assembly process-AP, Manufacturing system-MS, Other-OT.
In conclusion, the examination of process reuse within the manufacturing sector has emerged as a pivotal strategy for enhancing productivity and curtailing costs. The extant literature indicates that scholars have methodically addressed the principal challenges associated with process reuse through a spectrum of innovative methodologies, thereby propelling the industry towards a trajectory of intelligence and sustainability. Notably, the implementation of dynamic machining features has not only amplified the descriptive capacity of process data but has also substantially facilitated the recognition and reuse of analogous local structures and intersecting features. Furthermore, advancements in modular design and similarity assessment technologies have markedly enhanced both the utilization and efficiency of resources within the assembly process. Cumulatively, these investigations have furnished a theoretical underpinning and practical directives for process reuse, while simultaneously establishing a critical technical infrastructure for the intelligent evolution of forthcoming manufacturing systems. This underscores the significant potential for optimizing resource allocation within intricate manufacturing settings. Looking ahead, the integration of state-of-the-art technologies, including big data and artificial intelligence, is anticipated to augment the depth and scope of process reuse. This integration is poised to engender a more efficacious production paradigm and to bolster the competitive edge within the market.
In order to shorten the development cycle, reduce the cost and improve the product quality, design reuse has received increasing attention as an effective strategy. Researchers have proposed various methods and techniques to optimize the design reuse process.
Regarding the realms of knowledge reuse and decision-making support, Li et al. (2018) have notably decreased the iterative cycle times between design and manufacturing professionals by promoting the reuse of knowledge that is fully aligned with manufacturing constraints. This approach has streamlined the exchange between designers and manufacturing engineers, particularly in response to design modifications. Zhang et al. (2017a; 2018a) have leveraged existing knowledge to assist decision-makers in making informed judgments during the new product development phase, thereby enhancing both the pace and the caliber of innovation. Furthermore, they have introduced a graph-based knowledge reuse methodology that integrates knowledge graphs with personalized PageRank algorithms. This innovative approach offers a knowledge-driven framework for decision support in the context of new product development.
In enhancing the efficacy of design reuse knowledge representation and application, Giovannini et al. (2016) employed an anti-logicist methodology to ensure a clear and unambiguous knowledge representation. This approach facilitates swift retrieval and automated application of knowledge during the design phase of product families. Conversely, Urwin and Young (2014) introduced a methodology for rapid development and deployment, which facilitates the capture and dissemination of machining knowledge, thereby accelerating the design and manufacturing processes. Additionally, Chhim et al. (2019) constructed an ontology grounded in product design and manufacturing processes. This ontology was designed to enable the fine-grained reuse of manufacturing knowledge, and its efficacy was substantiated through a case study analysis.
Within the domain of reverse engineering and customized design, Durupt et al. (2019) have advanced a knowledge model designed to facilitate the rapid assimilation of reverse-engineered components into novel product designs. This model is instrumental in streamlining the integration process. Meanwhile, Kyriakou et al. (2017) have delineated a clear distinction between the conventional replication of knowledge and the innovative application of knowledge, advocating for a novel process of knowledge reuse tailored to customized design requirements.
In the realm of manufacturing process optimization and cost management, Huang et al. (2014) have introduced a multi-tiered structured Model-Based Definition model that leverages machining characteristics. This model is intended to enhance the manufacturing process efficiency and bolster the reuse of design elements. Letaief et al. (2020), on the other hand, have presented a methodology for the estimation of manufacturing costs. This approach involves harnessing the manufacturing expertise from previous projects to formulate a machining strategy for new model development, thereby optimizing cost control and process integration. Furthermore, Hua et al. (2024) leveraged knowledge graphs combined with deep reinforcement learning to automate the generation and reuse of manufacturing process designs.
In the domain of modular design and system integration, Ferreira et al. (2019) have developed a service-oriented framework that integrates reusability into the design of modular assembly systems. This framework is designed to optimize resource utilization and enhance the sustainability of systems. Pakkanen et al. (2019) conducted a literature review and a case study to analyze the challenges in modular system design for manufacturing. Their work underscores the pivotal role of knowledge retrieval in achieving modularity and the critical importance of design reuse. Wang et al. (2021) have established an ontology-driven framework for the reuse of information in complex product design. This framework employs multi-strategy ontology alignment techniques to enable automatic matching and reuse of design information, thereby significantly enhancing design efficiency and information interoperability. To facilitate collaborative design of complex systems, Arista et al. (2023) developed an ontology and knowledge graph-based framework to enable multi-stakeholder coordination during manufacturing systems’ conceptual design.
Within the manufacturing sector, the study of design reuse has emerged as a critical field for enhancing innovation efficiency and curtailing development expenses. The extant literature indicates that the practice of design reuse is contingent upon the efficient extraction and synthesis of pre-existing knowledge, as well as the establishment of adaptable knowledge management systems throughout the design process. Scholars have advocated for the precise representation and expedited retrieval of design knowledge, employing a variety of technological instruments. These include anti-logistic methodologies and graph-based knowledge navigation systems, which streamline the exchange of information between design and manufacturing engineers and diminish the temporal expenditure associated with design iterations. Notably, for intricate product systems, an ontology-based framework for knowledge reuse has demonstrated promising potential. This framework facilitates the automated alignment and reuse of design data, thereby bolstering information interoperability through sophisticated ontology alignment strategies. Central to this process is a comprehensive understanding of the distinctions between customized design knowledge and traditional replication and innovation knowledge, which paves the way for new insights into design reuse. Furthermore, leveraging reverse engineering techniques and modular design frameworks, researchers have expedited the integration of existing designs into new product development initiatives. This approach efficiently harnesses established knowledge to propel product innovation. In conclusion, research on design reuse not only enhances the efficiency and adaptability of manufacturing processes but also provides a robust theoretical underpinning and practical direction for the advent of smart manufacturing and digital transformation initiatives. However, given the escalating complexity of product specifications and market dynamics, future research endeavors should persist in the exploration of more sophisticated knowledge management tools. The goal is to achieve more effective design reuse, aligning with the swiftly evolving demands of the manufacturing industry.
Component Reuse
The significance of component reuse in manufacturing has escalated amidst escalating global environmental concerns and the burgeoning imperative for resource conservation and recycling. Scholars have delved into the realm of component reuse, examining its potential benefits from various angles. Lee et al. (2024) conducted a study on the independent and combined effects of technology search and product component reuse on new product innovation. Their findings indicated that the initial internal reuse of components was instrumental in driving innovation, while the repeated reuse of external components amplified the positive outcomes of cross-boundary search. In another study, Paris and Mandil (2018) introduced a direct material reuse strategy that integrates additive and subtractive manufacturing techniques. This approach aims to convert end-of-life or existing parts into new components through a systematic methodology that circumvents the material recycling phase. This strategy ensures that the newly fabricated parts meet stringent mechanical property and quality standards. Wang et al. (2017b) conducted a study to assess the influence of product diffusion dynamics on the extent of component reuse in the context of multigenerational product remanufacturing. They developed analytical models to examine the trade-offs associated with component versatility in product family design, thereby contributing theoretical underpinnings and practical insights for managerial decision-making. Furthermore, the researchers introduced a comprehensive quantitative decision-making model (Wang et al., 2019) aimed at evaluating the economic viability of component reuse within remanufacturing management. This model takes into account various cost elements and quantifies the financial impact of component versatility on overall remanufacturing cost savings. Galbreth et al. (2013) examined the influence of innovation velocity on corporate performance in the context of product reuse decisions and assessed the repercussions of various reuse strategies on environmental and economic costs. Building on this, Wang et al. (2017c) conducted a thorough economic analysis of part reuse within a remanufacturing supply chain. They utilized the Bass model to investigate the influence of product diffusion dynamics on part reuse quantities throughout the lifecycle of a single-generation product, with the goal of optimizing the remanufacturing process. In a related vein, Go et al. (2012) devised a method employing genetic algorithms to optimize disassembly sequences, thereby enhancing product reusability and reducing disassembly timeframes. Concurrently, Xu et al. (2010) introduced a classification and coding approach tailored for the reuse requirements of components in a mass customization production setting. They also developed an accompanying system designed to streamline the design reuse process and bolster the efficiency of the design workforce. Jiang et al. (2024) proposed a non-cooperative game-theoretic modular design method for electromechanical products, which balances reusability and assembly complexity to achieve dual optimization of production efficiency and manufacturing cost.
Empirical research has consistently demonstrated that the practice of component reuse is instrumental in curtailing production expenses, minimizing resource depletion, and reducing waste output, thereby fostering sustainable development. The literature reviews a spectrum of strategies, including direct material reuse, the enhancement of component adaptability, and the optimization of disassembly sequences through sophisticated algorithms, all of which underscore the efficacy of diverse methodologies in augmenting the efficiency of resource utilization. These investigations highlight the pivotal role of internal resource recycling as a stimulus for innovation and underscore the necessity for crafting agile reuse strategies within the context of an evolving market landscape. Concurrently, the integration of information technology in the realm of design reuse has been shown to bolster both design efficacy and managerial productivity. Collectively, these scholarly endeavors offer both theoretical validation and pragmatic insights, steering the manufacturing sector towards a circular economy paradigm and underscoring the extensive utility of component reuse in the pursuit of resource optimization and environmental sustainability. Subsequent inquiries should endeavor to investigate the seamless integration of these strategies within intricate manufacturing settings, aiming to surmount escalating resource and ecological challenges.
Current Shortcomings and Future Research
From “Single Data Processing” to “Comprehensive Data Fusion Processing
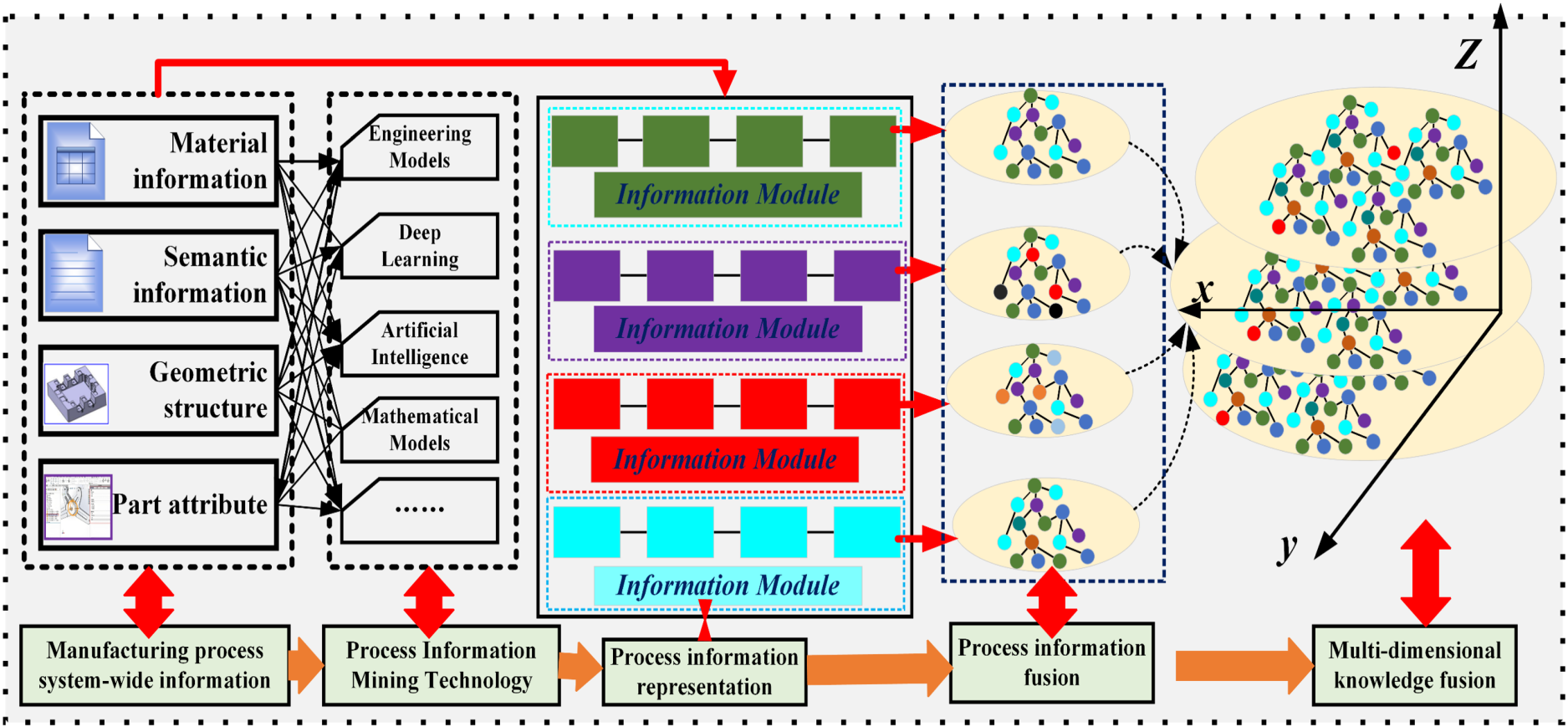
Currently, while existing Product Data Management (PDM) and Product Lifecycle Management (PLM) systems enable information retrieval and analysis via filtering tools during manufacturing, they are predominantly restricted to single modalities (e.g., text or structured data). Consequently, these systems cannot effectively integrate heterogeneous information sources—such as CAD geometric models, process videos, and sensor time-series data—resulting in cross-modal semantic gaps and imprecise retrieval capabilities.
The development of a multimodal information fusion retrieval system is therefore essential (Agrawal & Moparthi, 2023). Such a system must integrate geometric data from Computer-Aided Design (CAD) models with semantic information from PDM/PLM systems (Figure 7). To achieve this, it should employ cross-modal alignment techniques to construct a unified semantic space for joint retrieval based on semantic, geometric, and process features. As simple data concatenation fails to resolve semantic discrepancies between modalities, multimodal large models are required to facilitate deep feature interaction. Furthermore, incorporating granular manufacturing process information is critical for enhancing the system's retrieval accuracy (Lupinetti et al., 2019b). Achieving high precision and comprehensiveness in retrieval necessitates not only advanced algorithms but also continuous optimization and iteration within real-world application scenarios. Knowledge management of manufacturing process reuse “static” to “dynamic” intelligent management
Multimodal Information Fusion for Manufacturing Retrieval and Reuse.
While research has underscored the significance of instituting agile knowledge management systems throughout the manufacturing process, current systems frequently fall short in facilitating effective knowledge reuse across the various levels of complex product systems. For instance, ontology-based frameworks excel in automated information matching and reuse; however, their capacity to swiftly adapt to evolving design specifications and market demands within real-world engineering contexts presents a pressing challenge (Beaubouef & Petry, 2009). Moreover, the reuse of manufacturing processes is impeded by several obstacles, including the intricacy of process integration, the comprehensive and precise identification of manufacturing characteristics, the multidimensional articulation of process knowledge, the real-time and anticipatory application of technology, cross-domain applicability, and the timeliness of data management and utilization.
Future research on manufacturing process reuse should focus on developing advanced intelligent knowledge management systems that leverage Generative AI. As illustrated in Figure 8, such systems would extend beyond conventional data analysis and retrieval. In addition to collecting and analyzing data to dynamically update knowledge repositories, they would employ Generative AI to synthesize novel process solutions. This approach represents a paradigm shift from mining historical data for potential reuse opportunities to the on-demand generation of optimal solutions. Consequently, the adoption of this technology is poised to fundamentally enhance both decision-making efficiency and innovation capabilities. The shift from “certainty” to “uncertainty” in complex product information.
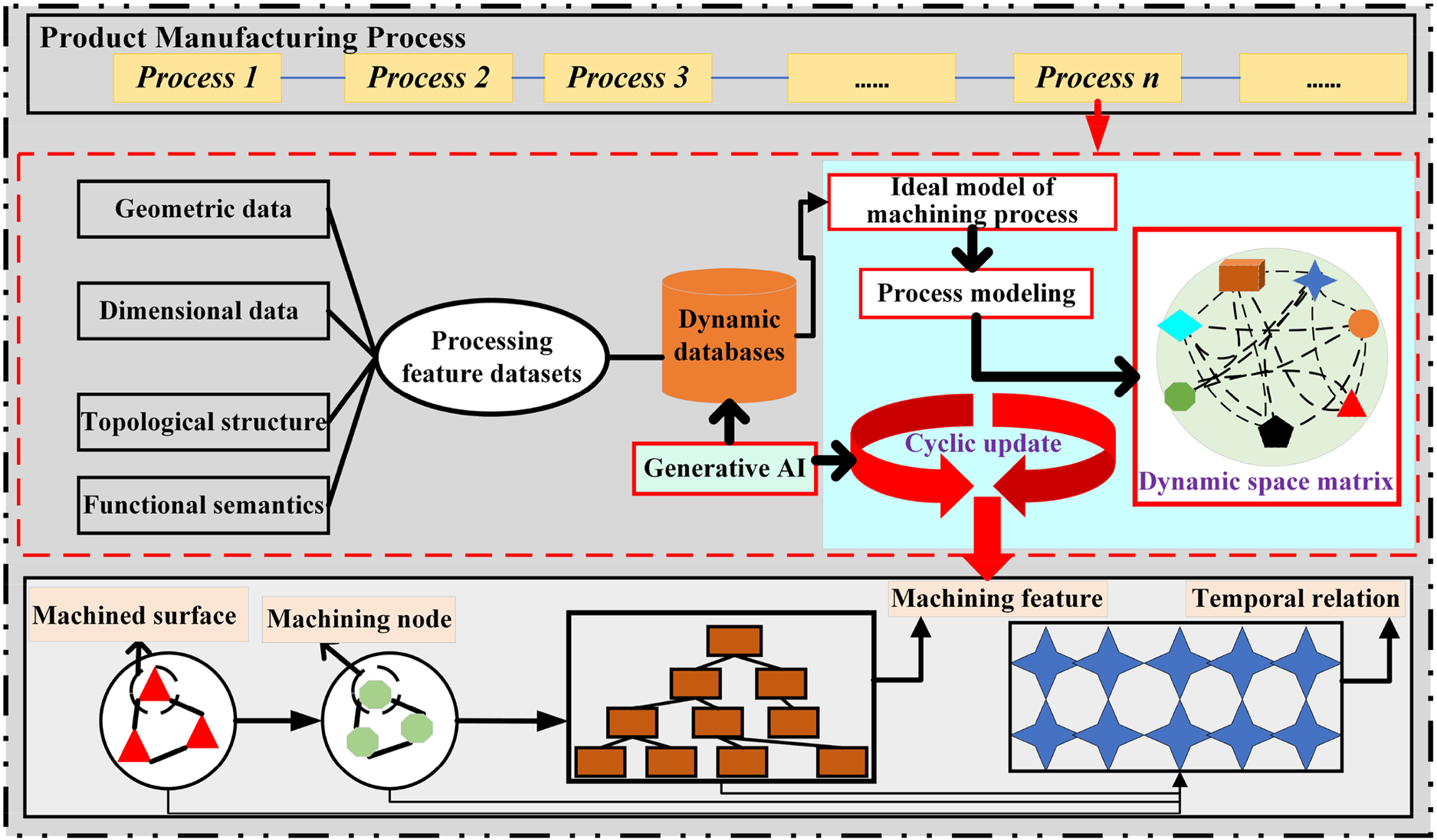
Acquisition and Understanding of Dynamic Information for Manufacturing Process Reuse.
As sustainability technologies advance and product integration improves, the informational landscape within the manufacturing process of complex products is undergoing a pivotal transition from a state of “certainty” to one of “uncertainty” (Liu et al., 2021). This evolution accentuates the ambiguity and complexity inherent in manufacturing, posing substantial challenges for information acquisition, feature recognition, and decision-making processes. Consequently, the systematic extraction and management of uncertainty-related information from manufacturing processes have emerged as a central research endeavor. Uncertainty in manufacturing can stem from various sources, such as fluctuations in production equipment performance, variations in material properties, random process parameter disturbances, and dynamic market demand shifts. These factors not only influence product quality and performance but also significantly affect information retrieval and reuse.
Therefore, establishing a comprehensive assessment framework to systematically address these uncertainties is a critical priority. The development of such an intelligent framework can be driven by large models, as illustrated in Figure 9. Within this framework, large models serve as the core analytical engine, integrating heterogeneous data sources that include quantitative sensor data, qualitative market demand text, and expert knowledge. For instance, a large language model can analyze extensive market reviews to quantify demand uncertainty and correlate it with production-line process parameters, thereby revealing latent causal relationships. This model-driven approach provides decision-makers with a deeper understanding of uncertainty across the manufacturing value chain, enabling the formulation of more robust and proactive reuse strategies to achieve concurrent improvements in economic, environmental, and social outcomes. Practical Challenges of Intelligent Reuse
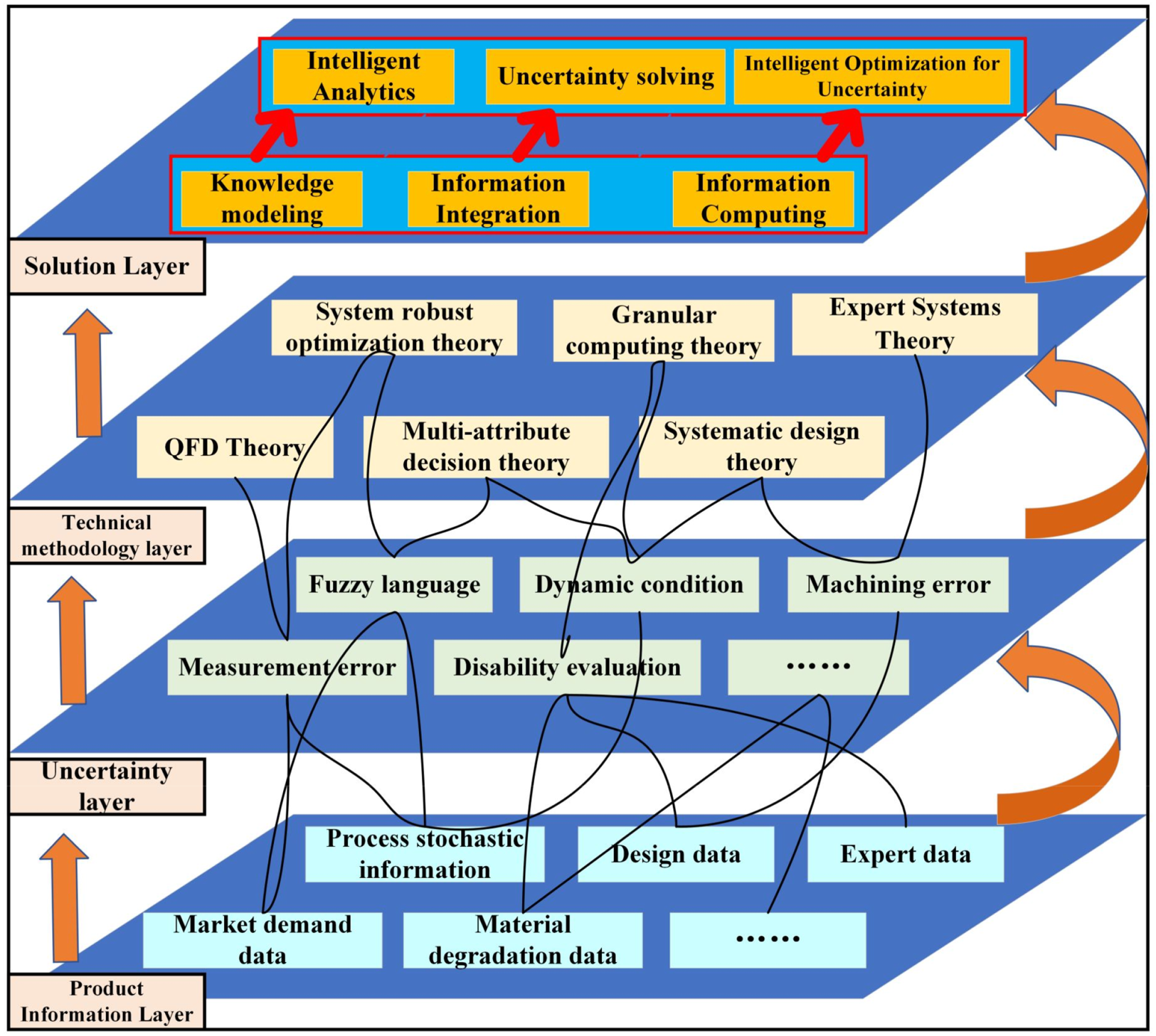
Uncertainty Handling for Manufacturing Retrieval and Reuse.
Despite the promise of advanced technologies such as multimodal, generative AI, and large-scale models, their practical implementation in industrial settings presents significant challenges. First, substantial data silos persist between enterprise systems (e.g., CAD, PLM, MES), which necessitates costly data integration and cleansing. Furthermore, widespread adoption is hindered by two additional factors: the technical complexity of embedding AI into existing workflows and user distrust of opaque “black box” models. Collectively, these obstacles can lead to prolonged product development cycles, increased costs, and the erosion of valuable tacit knowledge.
Significant unresolved challenges also persist within academic research. A primary issue is the inherent conflict between the opaque nature of end-to-end models and the high-reliability requirements of industrial decision-making. Further open research questions include adapting these models for data-scarce environments, which are typical of small and medium-sized enterprises, and establishing a uniform definition of similarity across different modalities. Addressing these issues necessitates a strategic shift in research: from using idealized datasets to handling noisy, real-world industrial data, and from developing fully automated systems to creating human-AI collaborative frameworks. This involves building trust through Explainable AI and intuitive user interfaces, as well as establishing comprehensive evaluation metrics that include cost-effectiveness and solution innovation alongside traditional accuracy. Ultimately, meaningful progress depends on deep collaboration between industry, academia, and research institutions, as the practical impact of research is maximized when problems are defined jointly and technologies are validated in real-world scenarios.
This paper systematically analyzes the application of intelligent retrieval and reuse technology in the product manufacturing process and obtains the following conclusions:
(1) Adaptability and Diversity of Intelligent Retrieval Technology
Existing intelligent retrieval techniques can be categorized into six types of methods, and their applicability varies depending on the needs of the scenario. For example, knowledge and rule-based retrieval is significantly efficient in structured parameter matching (e.g., standardized tool paths), but is difficult to adapt to non-standard process requirements. Semantic-based retrieval significantly improves the retrieval accuracy of complex scenarios by associating contextual information (e.g., troubleshooting) through knowledge graphs. Hybrid multi-strategy based retrieval synthesizes multiple feature extraction techniques, which improves retrieval accuracy and also reduces the reliance on manual feature engineering, which promotes the development of automation research.
(2) Efficiency-Flexibility Tradeoff in Process Reuse
The four reuse paradigms (resource, process, design, and component reuse) delineated in Section 4 embody distinct dimensions of knowledge reuse mechanisms: Resource reuse optimizes deployment cycles for standardized processes through shared equipment configuration templates. Process reuse enhances operational flexibility via dynamic adjustment of machining sequences, albeit introducing complexities in multi-source data integration. Design reuse reduces temporal costs in iterative design processes, contingent upon the availability of comprehensive historical databases. Component reuse prevails in SMEs due to resource constraints, yet faces compatibility challenges stemming from insufficient standardization levels.
(3) Bottlenecks and Breakthrough Directions for Intelligent Synergy Mechanisms
The main shortcomings of current technology are reflected in three major transformation challenges. From single data processing to all-round data fusion, existing retrieval methods are difficult to extract implicit knowledge from the combination of multiple data, especially fine-grained manufacturing process information, which requires in-depth analysis and intelligent processing. From “static” to “dynamic” knowledge management, adaptive reuse technology relies on real-time feedback, but the existing system lags behind in responding to uncertainty. From deterministic to uncertainty information processing, the process design of complex products needs to integrate probabilistic modeling and deep learning to cope with parameter fluctuations and fuzzy demands.
To overcome existing limitations, future research should focus on advancing intelligent integration and human-machine collaboration. A primary area of concentration must be multimodal knowledge fusion, which involves mapping heterogeneous, multi-source information—such as geometry, text, and performance data—into a unified semantic space. This is foundational for enabling a system to interpret an engineer's complex design intentions. Building on this, research should progress toward dynamic intent understanding and proactive recommendation mechanisms, which would transform the system from a passive retrieval tool into an active design partner that anticipates user needs. Furthermore, a novel paradigm for generative design should be established that prioritizes reusability, using metrics like reuse rates and manufacturing costs as core constraints. This would guide the AI to balance economic viability with engineering feasibility in structural innovation. Finally, driving the technology toward maturity requires concurrent research into explainable AI to build user trust and the development of scientific models to quantify the technology's value.
For industry practitioners, successful technology implementation hinges on a strategic balance of cost, benefits, risk, and reliability. To manage cost and risk, a phased, agile strategy is advisable, beginning with the creation of a high-value “preferred parts library.” This approach validates benefits quickly and at a low cost—for instance, by reducing new material coding and shortening procurement cycles—while mitigating the technical and adoption risks of a large-scale investment. Reliability can be enhanced by embedding these internally validated parts directly into engineers’ CAD/PLM workflows, which in turn improves the quality and stability of new products. Furthermore, companies must establish strict data privacy and security standards from the project's outset. When using third-party AI or cloud services, these standards must clearly define data ownership and usage boundaries, a measure that is fundamental to protecting core intellectual property. Ultimately, by establishing quantifiable Key Performance Indicators, such as component reuse and design cycle reduction rates, and linking them to performance incentives, organizations can ensure long-term value. The resulting benefits—including sustained innovation and lower operational costs—are expected to far exceed the initial investment and establish a significant competitive advantage.
Footnotes
Acknowledgment
This work was supported by the National Natural Science Foundation of China (Nos,72361024, 71661023); Science and Technology Research Program of Jiangxi Provincial Department of Education (GJJ2201520) and University Doctoral Research Initiation Program (2022kyqd024) and Special Funding Program for Graduate Student Innovation in Jiangxi Province(YC2024-S882).
Author Contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Science and Technology Research Program of Jiangxi Provincial Department of Education, National Natural Science Foundation of China, Special Funding Program for Graduate Student Innovation in Jiangxi Province, University Doctoral Research Initiation Program, (grant number GJJ2201520, 72361024, YC2024-S882, 2022kyqd024).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
Data will be made available on request.