
Abstract
This study aims to develop a new ANFIS-based ensemble modeling approach that provides high prediction accuracy and generalization capability on large datasets. The proposed approach utilizes the parallel processing capacity of the MapReduce algorithm to divide large datasets into smaller chunks and create and train independent ANFIS models for each chunk. While the input and output membership functions obtained from the trained structures are directly transferred to the new architecture, the rule bases are integrated using the rule adjustment function. The number of rules has been significantly reduced compared to the classical ANFIS structure. In this way, both the computational cost has been reduced and the model complexity has been effectively managed. In traditional ensemble approaches found in the literature, the output values of the models are generally combined, whereas in this study, the proposed approach combines the ANFIS structures obtained from each subset of the data to create a single ANFIS-based ensemble model. The obtained results demonstrate that a single ensemble system architecture, encompassing the entire large dataset and possessing high generalization capability, has been successfully created.
Plain Language Summary
This study presents a new intelligent prediction model developed to analyze large data sets more effectively. Today, the rapid growth of data volume causes traditional methods to experience difficulties in processing this data. An artificial intelligence model called ANFIS was used to solve this problem. ANFIS creates logical rules using data and makes predictions using these rules. However, working capacity and time interval restrictions occur with large data sets.
In this study, separate models were created for each piece by dividing large data sets into smaller pieces and then these models were combined into a single model. With this method, data processing time is reduced and prediction accuracy is increased. Additionally, a special editing function is designed that reduces the number of unnecessary rules in the model. In this way, the model made predictions both faster and more accurately.
In the study, the performance of the proposed model has been compared with other widespread and it has been proven that superior results are obtained. As a result, it has been proven that this new model can make more accurate and reliable predictions in large data sets.
Introduction
ANFIS is an effective approach used to create a set of fuzzy “if-then” rules with appropriate membership functions based on the information obtained from datasets consisting of input and output features. ANFIS, this approach that combines the strengths of fuzzy logic and artificial neural networks, stands out with features such as strong learning capacity, parallel processing capability, adaptation, error tolerance, and distributed information representation. On the other hand, it excels in managing complex reasoning processes using fuzzy logic techniques (Wan et al., 2012). This combination makes ANFIS an effective tool for dealing with uncertainty and optimizing learning processes. Due to its flexibility and resilience against errors in the data collection process, this approach is frequently preferred, especially in time series forecasting and regression problems, where it has found a significant place in the literature due to the high accuracy it provides (Jang & Tung, 2019).
ANFIS requires a significant amount of computational power for both the creation of fuzzy rules and the training of neural networks, and when working with large datasets, these requirements become even more pronounced, leading to various scalability issues. Thoughts and approaches related to big data still require long-term innovation and effort (Wang & Zhang, 2017). Researchers have proposed hybrid methods such as Ensemble ANFIS to solve the scalability problem and process big data more effectively. These hybrid methods combine multiple models to analyze different subsets of the dataset in parallel, thereby reducing the computational load and enhancing overall performance.
Akan and Demir (2019) emphasized that the ANFIS architecture yields higher performance results with large datasets. Their research shows that increasing the size of the dataset significantly improves prediction accuracy. In this context, the MapReduce algorithm, which significantly contributes to big data analysis and processing, can be combined with Ensemble ANFIS models to create structures that operate in parallel on different parts of the dataset (Vatsal & Patel, 2015).
The aim of this study is to obtain a more comprehensive and robust model by combining the ANFIS models created for each subset of data after partitioning large datasets into subsets through parallel processing into a single architecture. The input and output membership functions of the models created separately for each data section are added to the newly created ANFIS-based ensemble model, and the rules of the models created separately for each data section are restructured with the developed rule adjustment function and integrated into the model. As a result, a single ANFIS-based ensemble model that models the entire dataset is obtained.
The performance of the obtained model has been compared with popular ensemble methodologies frequently used in the literature, such as Particle Swarm Optimization (PSO), Genetic Algorithms (GA), and Scott-Knott techniques. These comparisons were conducted to evaluate the accuracy and generalization ability of the developed model according to different ensemble strategies and to more clearly highlight the advantages of the proposed structure.
The remainder of the paper is structured as follows. The subsequent section comprises a literature review of the ANFIS model. The third section discusses ANFIS and Ensemble ANFIS structures, while the fourth section addresses the methodology of the MapReduce-based Ensemble ANFIS (MR-Ensemble ANFIS) model suggested in the study, including implementations on various datasets. The fifth section pertains to the debate and conclusions.
Literature Review
In recent years, many studies have been conducted on big data modeling using ensemble ANFIS approaches. Suhartono et al. (2012) proposed a community ANFIS method based on ANFIS and Autoregressive Integrated Moving Average (ARIMA) models to predict monthly rainfall data in a specific region. Ali et al. (2018a) proposed an ensemble learning technique aimed at improving prediction performance by combining multiple ANFIS models. Seng et al. (2012) proposed the ensemble-ANFIS (EN-ANFIS) method to predict the air pollution index in the Macau region.
Chen and Zhang (2005) examined the integration of ensemble learning and ANFIS techniques for time series forecasting. In their study, they applied the En-ANFIS algorithm, which was developed by combining ensemble learning techniques with ANFIS, to time series prediction. Melin et al. (2012) proposed a novel approach for time series forecasting using the structure of Ensemble-ANFIS models. Gürkan and Demir (2017) applied Ensemble ANFIS methods to sub-datasets obtained by using dimensionality reduction methodologies such as Auto-Encoders and Principal Component Analysis (PCA) on high-dimensional datasets. Benbriqa et al. (2023) employed the Scott-Knott test to statistically compare the performance of different neuro-fuzzy classifiers.
Ali et al. (2018b) combined the obtained ANFIS models using the Firefly Algorithm (FA), Particle Swarm Optimization (PSO), and Imperialist Competitive Algorithm (ICA). Ouifak et al. (2024) performed hyperparameter optimization of four neuro-fuzzy systems—ANFIS, DENFIS, HyFIS, and NEFCLASS—on four different medical datasets. Zanganeh and Chaji (2024) developed a model by proposing a novel approach to the application of the Approximate Entropy (ApEn) method, in which multiple adaptive ANFIS models were integrated using Particle Swarm Optimization (PSO) to forecast the Caspian Sea levels.
In the literature, in commonly used methods, the outputs of multiple ANFIS models are combined through weighted averaging, max-min selection or other information fusion techniques. However, in this study, it differentiates in terms of creating a new model by integrating the membership functions and rule bases obtained from the ANFIS models trained on each subset into a single ANFIS model.
ANFIS and Ensembling Model Structure
In this section, the fundamental principles of ANFIS are explained to ensure a better understanding of the algorithm's operation. Subsequently, the ensemble approach is addressed to support the proposed method, and the role of this concept in practical applications is detailed.
ANFIS
ANFIS is proposed in 1993 and represents a powerful hybrid approach that combines the learning capabilities of artificial neural networks with the ability to handle uncertainty of fuzzy systems for input–output modeling and predictive analysis (Yadegaridehkordi et al., 2018). This feature provides an effective and useful solution in engineering applications with non-linear or highly complex structures where traditional methods are inadequate (Vakhshouri & Nejadi, 2018). ANFIS has the Takagi-Sugeno and Mamdani-type fuzzy inference systems (FIS). Figure 1 represents a simple Takagi-Sugeno FIS with two inputs and a single output.
Tagaki-Sugeno FIS uses the rules to model the relationship between inputs and outputs. However, the most notable difference of the Takagi-Sugeno system is that the output is a linear function or a constant value (Melin et al., 2012). The general structure of a rule in the Takagi-Sugeno FIS is as follows:
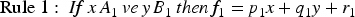
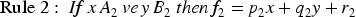
The goal of the Takagi-Sugeno type ANFIS is to establish a model that accurately relates input values to output values (Akan & Demir, 2019). Figure 2 represents the ANFIS architecture of a simple Takagi-Sugeno type model.
Takagi-Sugeno Type FIS (MathWorks).
The ANFIS architecture represented in Figure 2 consists of five basic layers. Each layer supports the system's learning and inference processes by performing a specific function.
In this layer, the system's input variables are fuzzified. Each of the input variables (x and y) is generally represented by multiple membership functions (A1, A2, B1, B2) of Gaussian, triangular, bell, or sigmoid types. These functions calculate the membership degree of each input variable:

Here, µ expresses the degree to which an input is compatible with a specific fuzzy set.
In this layer, the firing strength (or weight) of each rule is calculated. Rule weights are calculated by taking the product or minimum of the membership degrees of the input variables coming from the first layer. In Takagi-Sugeno ANFIS, the product method is generally preferred:

Each
This layer normalizes the weight of each rule. The weight of each rule coming from the second layer, denoted as

This process ensures that the sum of the weights equals 1 and reveals the relative importance of each rule.
In this layer, the output function of each rule is calculated. In the Takagi-Sugeno type, the output of each rule is defined as a linear function:

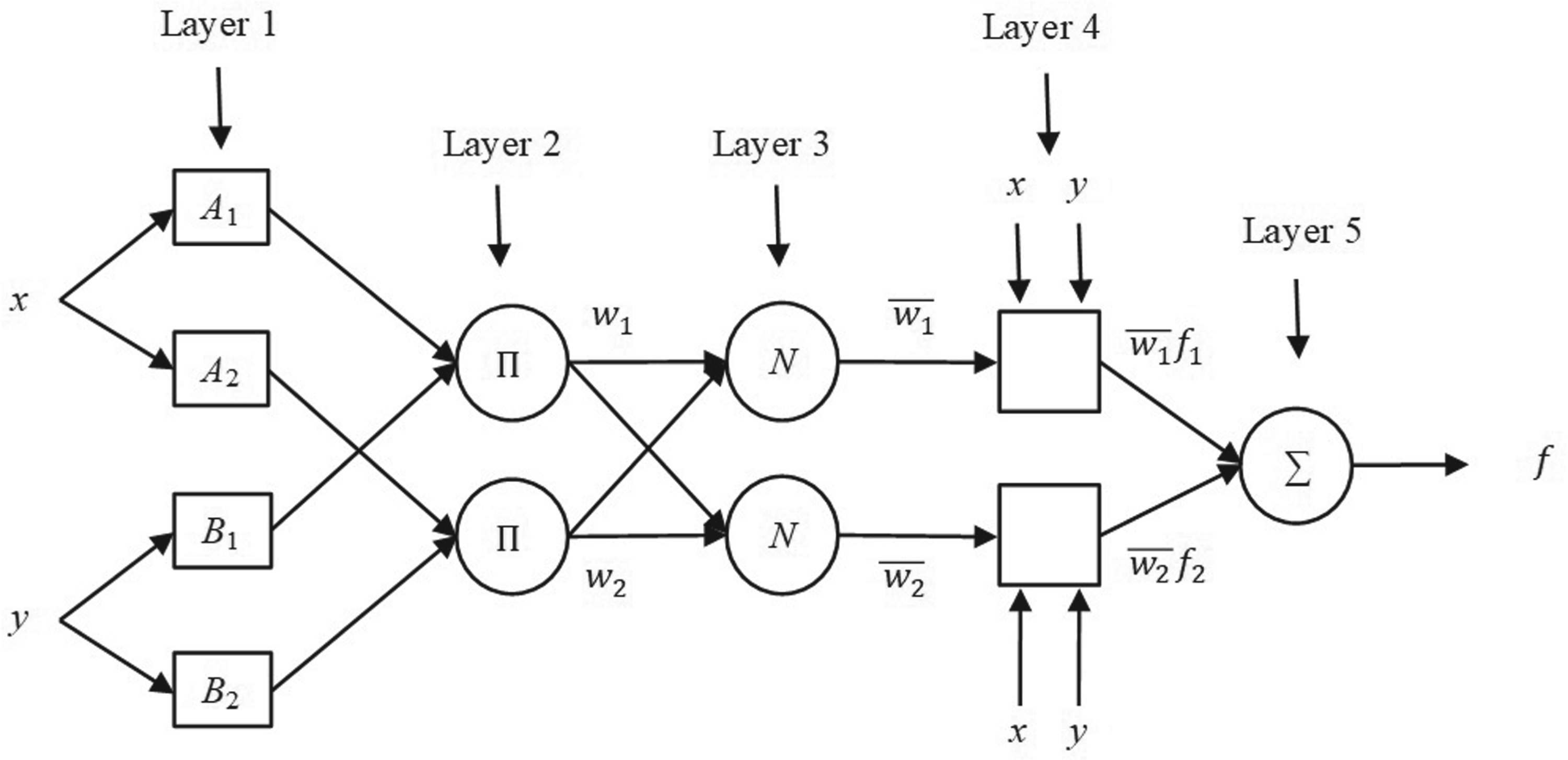
ANFIS Architecture for a Takagi-Sugeno Type Model.
Here, the rule parameters

This layer sums the weighted contributions of each rule from the fourth layer and calculates the final output of the system:

This process combines the contributions of all the rules and produces the system's output. The result is a value that represents the nonlinear input-output relationships.
Ensemble modeling is an approach aimed at obtaining stronger and more generalized predictions by combining multiple models. Ensemble ANFIS modeling aims to achieve better performance by focusing on methods for combining the outputs of different ANFIS models (Polikar, 2006). Among the commonly used Ensemble ANFIS modeling methods and optimization algorithms in the literature, Particle Swarm Optimization (PSO), Genetic Algorithm (GA), and the Scott-Knott Ensemble method stand out.
Particle Swarm Optimization-Optimized ANFIS Model (PSO-ANFIS)
It is an optimization algorithm developed by drawing inspiration from the movements of organisms in nature that travel in groups. The main purpose of this algorithm is to continuously update the movement and positions of particles in the solution space to find the best solution. In the initial stage, a starting population is created by assigning random positions and velocities to the particles in the solution space, forming an initial group (Nou et al., 2021). PSO aims to reach the optimal ANFIS model output by considering the best position of the particles and the swarm in each iteration.
In the Ensemble PSO-ANFIS approach, each ANFIS model is trained with different subsets of data, and the outputs of each model are combined to form the solution space (Kaloop et al., 2020). Each particle's initial personal best (pBest) value is assigned as the starting position of that particle, while the global best (gBest) value is determined as the position of the particle with the best pBest value among all particles. Then, in each iteration, the velocities and positions of the particles are updated.
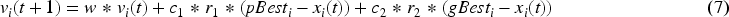
Equation 7, the velocity update formula, takes into account the particle's current velocity

In this process, particles continuously move in the solution space and progress towards the global optimum. Especially, the combination of multiple ANFIS model outputs enhances the model's generalization capability and enables achieving lower error rates.
It is a search and optimization method aimed at finding optimal solutions by mimicking evolutionary processes. GA-ANFIS aims to determine the best combination of multiple ANFIS models’ prediction results using Genetic Algorithm and optimizes the prediction results with the lowest error rate (Ahmed, 2020). The basic steps of the GA_ANFIS model consist of fitness calculation, selection, crossover, mutation, and new population update stages, as represented in Figure 3.
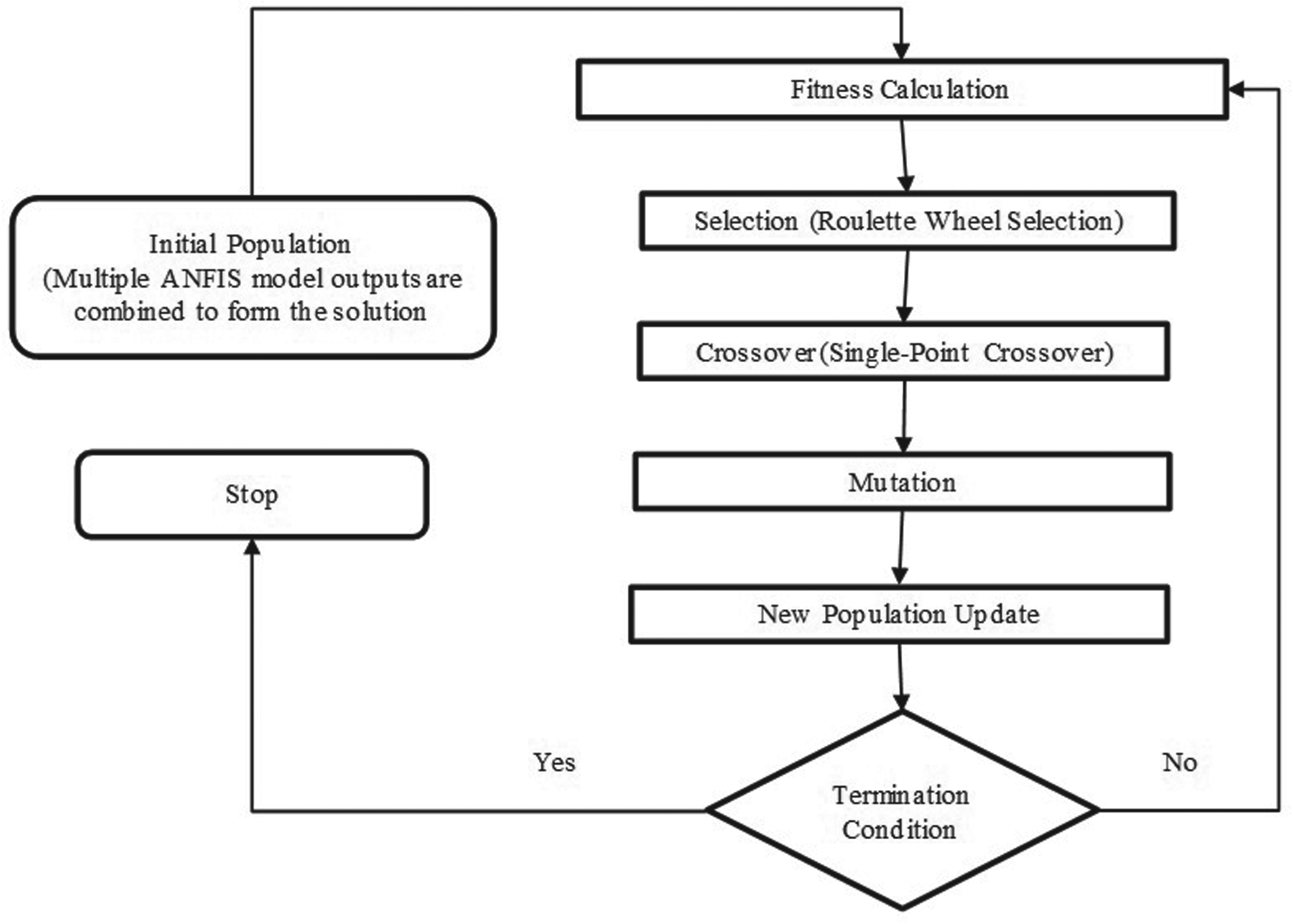
Fundamental Steps of the GA-ANFIS Model.




Here, L is the chromosome length.
Parents:

Offspring:

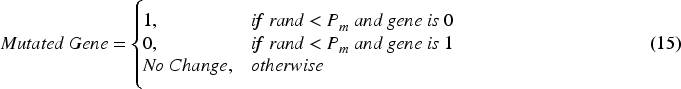


The Scott-Knott method is a hierarchical clustering approach aimed at selecting the most suitable model combinations by identifying significant differences between groupings. SK-ANFIS determines the optimal merging strategy by analyzing the variances between the outputs of different models (García et al., 2008). This method is used, especially in big data and machine learning applications, to compare model performances and identify the best sub-models.
In the SK-ANFIS algorithm, the first step is to combine the outputs of multiple ANFIS models

In Equation 18,
The final step is to select the best models determined by the Scott-Knott method. The predicted values of the selected models are combined using a weighted average to obtain the final prediction:

In Equation 19,
Big data analytics plays an important role in effectively processing the rapidly increasing amount of data today and transforming it into meaningful information. One of the strategies for dealing with big data, parallel processing allows large data sets to be divided into smaller chunks and processed across numerous nodes. To enable ANFIS models to work effectively with large datasets, advanced techniques such as parallel computing and distributed systems are used. These techniques enhance the performance of ANFIS models by distributing the computational load and reducing processing times (Zhang et al., 2024). This way, ANFIS models can operate more quickly and efficiently with large datasets. However, modeling large datasets with ANFIS is significantly challenging in terms of both computational resources and model complexity. Large datasets prolong the training process of ANFIS models and require more memory and processing power.
In the existing ensemble ANFIS approaches in the literature, each sub-model is generally trained independently, and the results are combined using statistical techniques. In these methods, the entire system is not represented by a single structure, and the final decision is made based on the outputs of numerous models. This situation both limits the model's applicability and can cause delays in real-time prediction tasks. Additionally, as the number of membership functions defined in each sub-model increases, the number of output membership functions and the rule base grow exponentially, significantly increasing computational complexity and processing time.
The proposed MR-Ensemble ANFIS approach aims to overcome such limitations. Thanks to the proposed method in the study, the input and output membership functions of the ANFIS models trained on each subset of the data are directly transferred to the model, while the rules are restructured to create a simplified and optimized rule base. Thus, the system was modeled with a single ANFIS structure representing the entire dataset, while the number of rules was significantly reduced compared to traditional methods in the literature.
Considering an ANFIS model with two features, each having two membership functions, there are 22 = 4 output membership functions and the same number of rules. If 12 separate ANFIS models with the same structure are combined, the number of membership functions for the input variables increases to 24, and in the case of direct combination, the number of output membership functions becomes 48. However, in a 2-feature ANFIS structure where 24 membership functions are defined for each feature, there should theoretically be 242 = 576 output membership functions. Considering this situation, the MR-Ensemble ANFIS model offers an efficient structure with lower computational cost and less complexity. Thus, the combined ANFIS model both maintains generalization performance and offers a more efficient solution by optimizing the computational load.
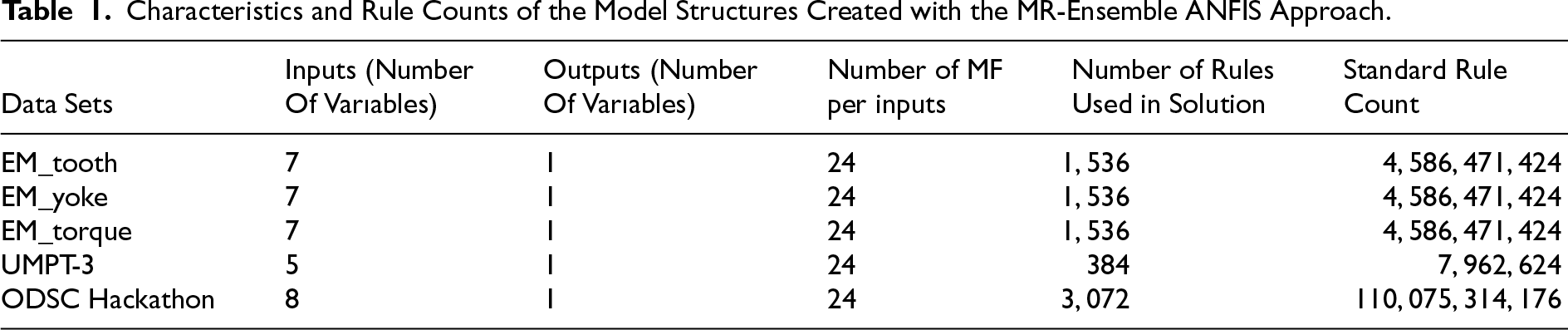
As presented in Table 1, instead of the approximately 4.5 billion rules that would need to be created with 24 membership functions in traditional ANFIS models, a similar accuracy was achieved using only 1536 rules with the proposed MR-Ensemble ANFIS structure. This feature both reduces the computational cost and ensures that the model operates more quickly and effectively. Especially in applications that require high processing power, such as big data analyses, the proposed method's single model structure and low number of rules stand out in contrast to ensemble ANFIS models. The MR-Ensemble ANFIS model structure is as shown in Figure 4.
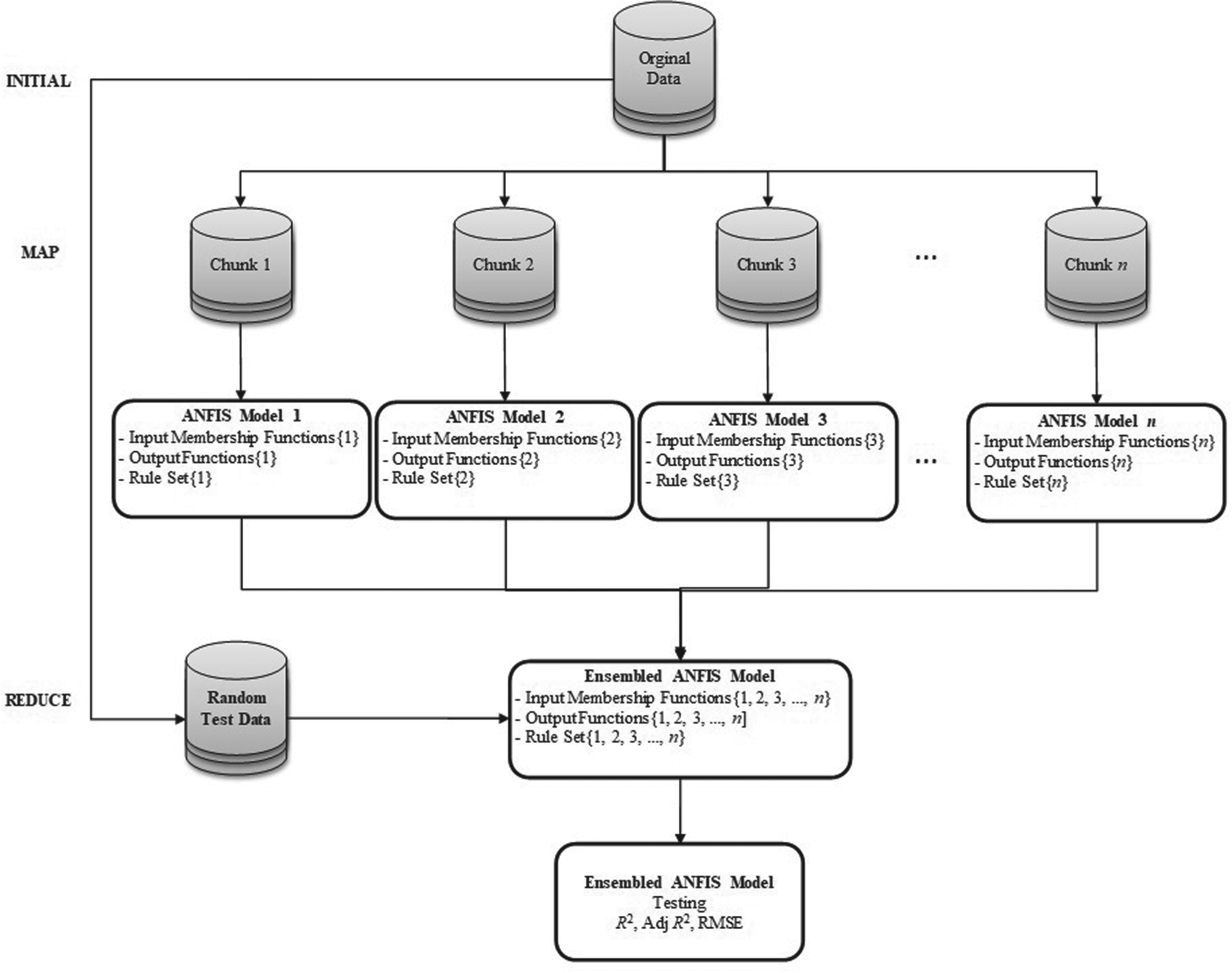
MR-Ensemble ANFIS Modeling Architecture.
Characteristics and Rule Counts of the Model Structures Created with the MR-Ensemble ANFIS Approach.
The pseudocode structure containing the basic steps of the map phase of the MR-Ensemble ANFIS model proposed in Algorithm 1, which is based on parallel processing, is presented.

In Algorithm 1, after the normalization process is applied to the large dataset, the dataset is divided into two subsets: 70% for the training dataset and 30% for the test dataset. The training dataset is evenly divided and assigned to 12 nodes, where the ANFIS model is trained at each node and model performance values are calculated based on the specified performance metrics (Root Mean Square Error (RMSE), Adjusted R-squared (Adj. R2), and R-squared (R2)).
In Algorithm 2, the operations performed during the reduce phase of the MapReduce-based MR-Ensemble ANFIS model are presented in pseudocode form. In the Map phase, the input and output membership functions of the ANFIS models created independently are integrated into the newly created ANFIS model in this phase. Thus, a single integrated ANFIS model containing the information from all sub-models is created.

Finally, in Algorithm 3, the basic steps of the function used to create the rule base of the integrated ANFIS model formed in Algorithm 2 are presented in pseudocode. This function reconstructs the rules using the input and output membership functions combined during the reduce phase.

Within the scope of the study, the datasets Electric Motor Temperature (EM) (Kirgsn), UCI MetroPT-3 (UMPT-3) (pattinson9999), and ODSC Hackathon (ODSCH) (Shetty), which are accessible at https://www.kaggle.com/datasets, have been used.
The “stator_tooth,” “stator_yoke,” and “torque” variables found in the Electric Motor Temperature dataset are critically important for the thermal management and performance analyses of the motor. Stator tooth temperature (stator_tooth) is the internal temperature value of the motor. This temperature value is an important indicator of the cooling system efficiency and the motor load condition. Stator yoke temperature is an important metric for understanding the motor's temperature and cooling efficiency, and accurately predicting the temperature will prevent the motor from overheating, ensuring long-lasting and efficient operation. Motor torque is a critical variable for evaluating the performance and load-carrying capacity of electric motors. In particular, real-time torque estimation minimizes power losses, allowing the motor to operate more efficiently. Figure 5 represent the correlation matrix between the features of the Electric Motor Temperature dataset.
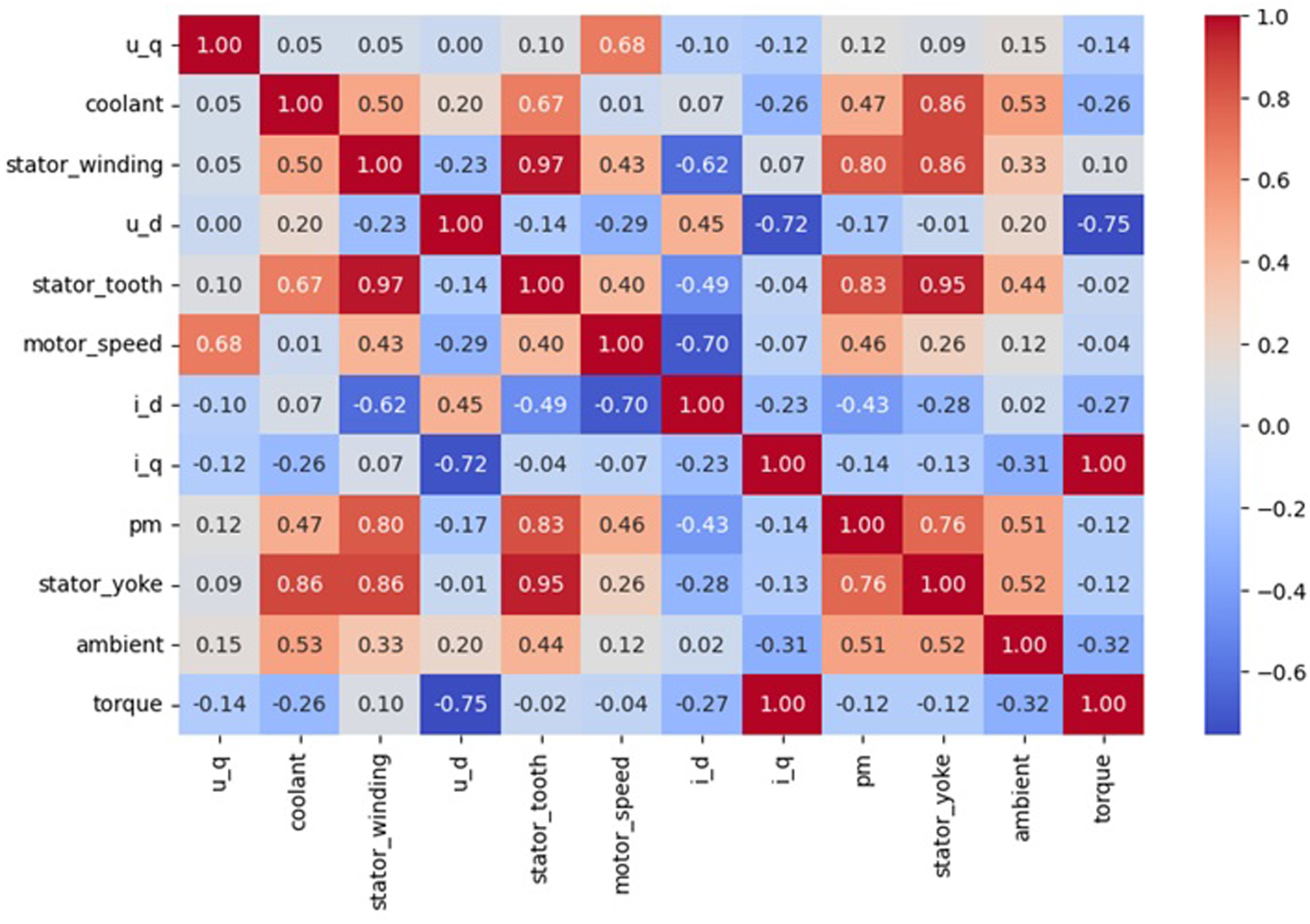
Correlation Matrix of Features in the Electric Motor Temperature Dataset.
The UCI MetroPT-3 dataset contains sensor measurements and electrical signals related to the compressor system of a metro train. When performing ANFIS modeling, the aim of the model is to detect anomalies in order to identify potential faults in the compressor system in advance. Figure 6 represent the correlation matrix among the features of the UMPT-3 dataset.
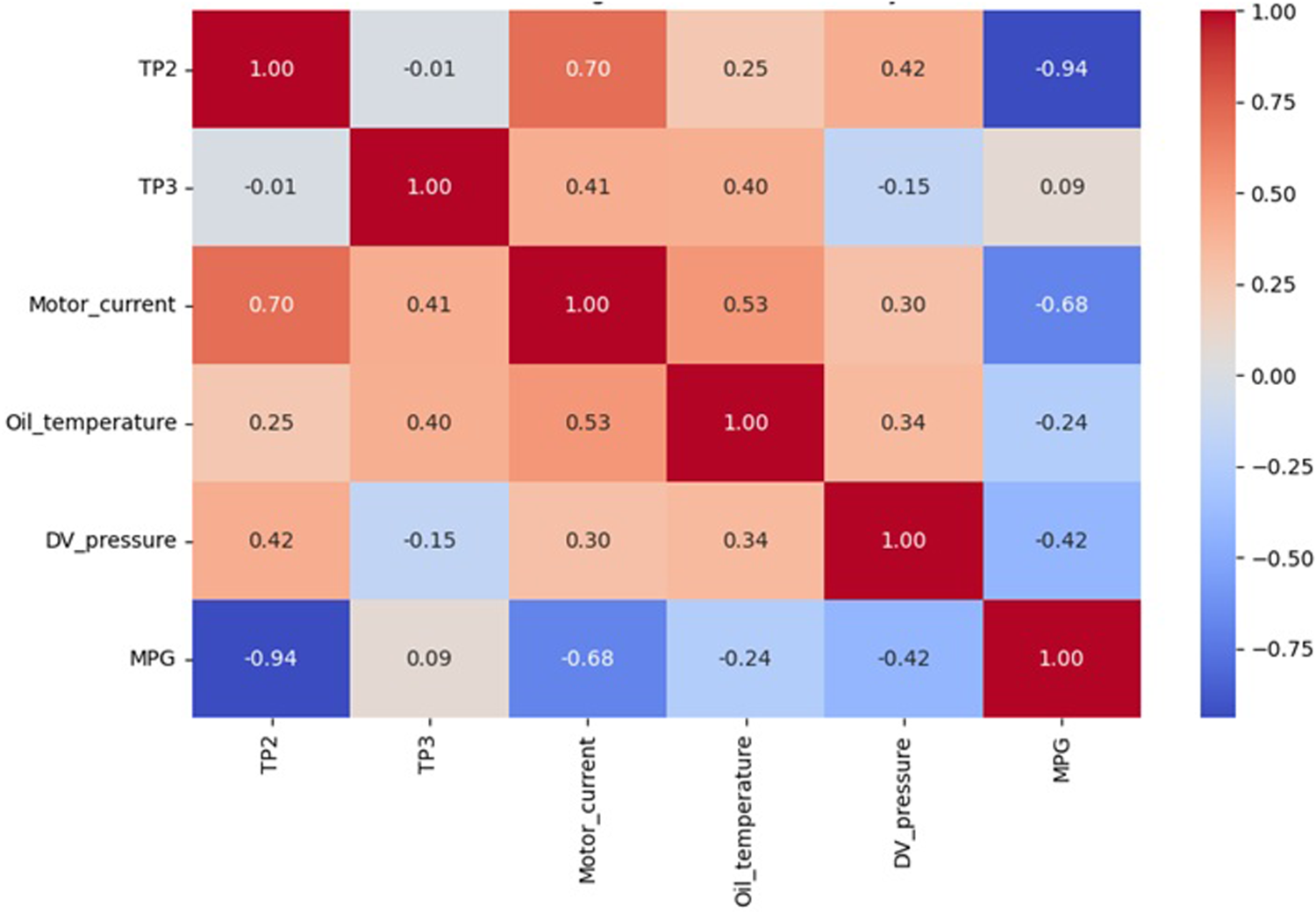
Correlation Matrix of Features in the UMPT-3 Dataset.
The ODSC Hackathon dataset contains sensor data used to improve the efficiency and production process of electric vehicles. The purpose of the established ANFIS model is to optimize the temperature of the coolant in electric vehicle engines. Engine temperatures are an important factor in preventing the engine from overheating and increasing the efficiency of the cooling system. Figure 7 represent the correlation matrix between the features of the ODSCH dataset.
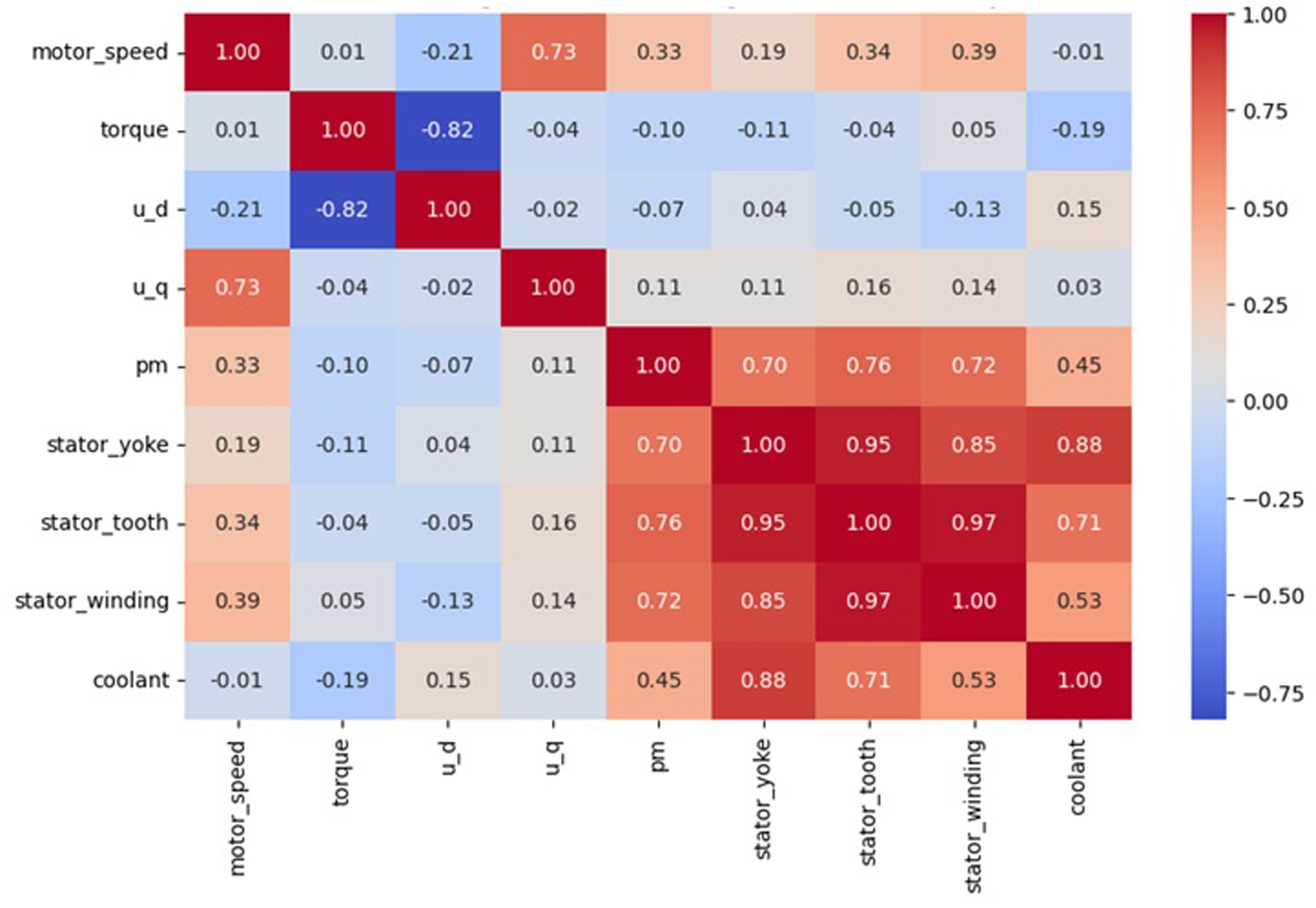
Correlation Matrix of Features in the ODSCH Dataset.
Characteristics of the Datasets Used in the Experiment.

In Table 2, the number of observations, the number of variables, and the number of observations divided into training and test subsets for each dataset used in the experiments are represented.
These datasets have been selected to analyze the generalization capability of the proposed MR-Ensemble ANFIS model on large-scale data of different sizes and characteristics. The EM dataset includes variables such as voltage, current, and temperature, which are used to analyze the electrical and thermal dynamics of the engine. The UMPT-3 dataset includes parameters such as motor current, oil temperature, and differential pressure and is aimed at evaluating the mechanical and hydraulic performance of the motor. The ODSCH dataset, on the other hand, includes variables such as motor voltage components, torque, and permanent magnet parameters, and is used to analyze the overall operating conditions of the motor.
The installation of the Adaptive Clustering Method (ARF) was carried out at the MODSİMMER Data Center, and MATLAB-based solutions were implemented on the TRUBA infrastructure. For five different datasets (EM_tooth, EM_yoke, EM_torque, UMPT-3, and ODSC Hackathon), an ANFIS model was developed using the genfis1 function to provide a data-driven initial FIS on 12 nodes. The structure of the model includes two fuzzy sets for each input variable, and these sets are defined by Gaussian-type membership functions (gaussmf). Output variables have constant output functions expressed as constant values for nonlinear system modeling.
The performance criterion values of the ANFIS models implemented on 12 nodes based on MATLAB are presented in Table 3.
Performance Criteria of Twelve ANFIS Models for Five Different Datasets.
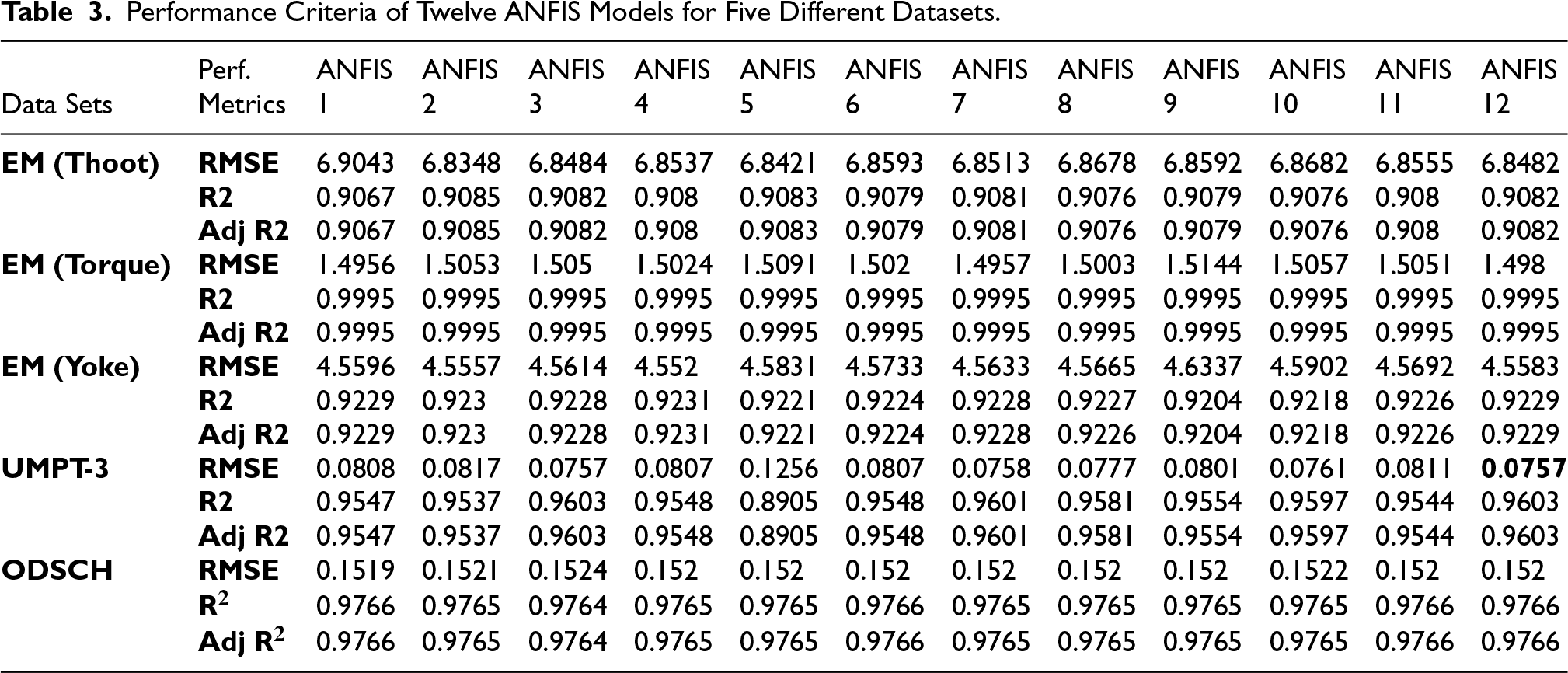
Performance Criteria of Twelve ANFIS Models for Five Different Datasets.
For each big data set, when algorithm 1, algorithm 2 and algorithm 3 are executed, the number of input and output variables of the ANFIS models obtained with the MR-Ensemble ANFIS approach, the number of membership functions (MF) created for each input, and the number of rules are provided in Table 1.
In Table 1, for the EM_tooth dataset, the number of input variables is 7, and the number of MFs defined for each variable is 24. In classical Sugeno-type ANFIS models, the theoretical number of rules that will be generated as a result of the MF defined for each variable increases exponentially, as represented in the Standard Rule Count column, resulting in 247 = 4,586,471,42424.
In classical Sugeno-type ANFIS models, the high number of theoretical rules formed as a result of membership functions (MFs) defined for each variable makes the applicability of the classical approach difficult in terms of computational complexity and training time. With the MR-Ensemble ANFIS approach, to reduce this complexity, when 2 membership functions per variable in 12 ANFIS sub-models for the EM_tooth dataset are brought together, 24 membership functions and 1536 rules are generated.
In the construction of the MR-Ensemble ANFIS structure, these rule structures were not directly combined but rather reorganized to represent each input MF. For instance, in the MR-Ensemble ANFIS model, the first 128 rules were structured to represent the 2 MFs of the first sub-model, and the subsequent 128 rules represented the MFs of the second sub-model. Through this approach, a total of 12 × 2 = 24 MF definitions for each input variable were preserved, resulting in a systematically distributed rule structure.
Thanks to the MR-Ensemble ANFIS approach: A high number of MFs per input has been achieved. And instead of billions of rules formed by all possible combinations, a highly representative and optimized model has been obtained with only 1536 rules.
It has provided a meaningful simplification with 1536 rules for the EM_tooth, EM_yoke, and EM_torque datasets and with 384 and 3072 rules for the UMPT-3 and ODSC Hackathon datasets, respectively.
Table 4 presents the statistical performance criteria, such as RMSE, R2, and Adj R2 obtained for each dataset using four different ANFIS-based methods: GA-ANFIS, PSO-ANFIS, SK-ANFIS, and MR-Ensemble ANFIS.
Performance Values Table of MR-Ensemble ANFIS Modeling.
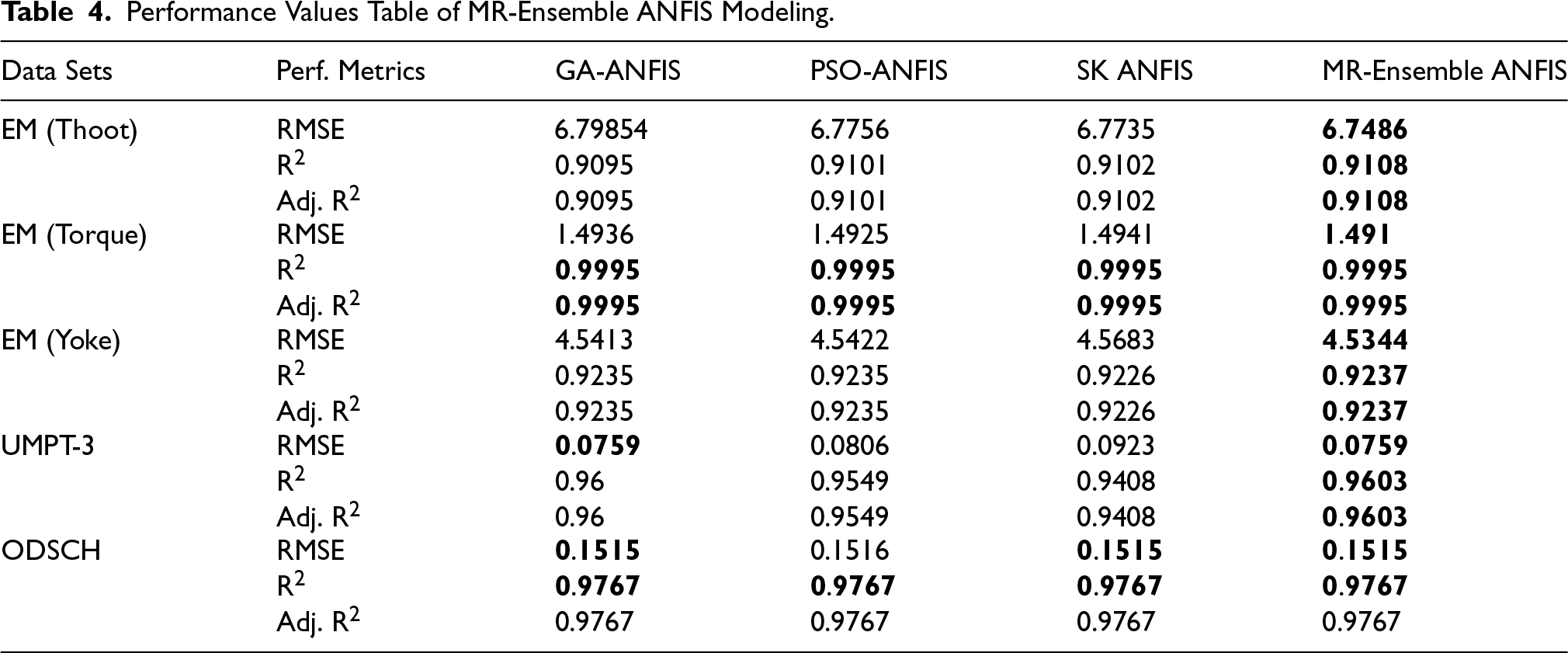
In Figure 8, the performance of the proposed MR-Ensemble ANFIS algorithm for the EM (Thoot) dataset is evaluated using RMSE, R2, and Adj. R2 metrics, comparing it with Ensemble ANFIS models (GA-ANFIS, PSO-ANFIS, and SK-ANFIS) integrated with commonly used optimization techniques. According to the RMSE criterion, the GA-ANFIS algorithm produced the highest prediction error, while the lowest error rate and thus the highest model accuracy were achieved with the MR-Ensemble ANFIS approach. When evaluated according to the R2 metric, similar results were observed: while the coefficient of determination for the GA-ANFIS model was 0.9095, the MR-Ensemble ANFIS model reached a value of 0.9108, indicating a better fit to the data and a stronger explanatory power. The same trend continues in terms of the Adj. R2 metric. In conclusion, in terms of both RMSE and R2 and Adj. R2 metrics, the MR-Ensemble ANFIS approach has provided higher prediction accuracy and stronger model fit compared to existing methods.

Comparison of RMSE, R2, and Adj R2 Values Across EM (Thoot) Data Set for GA-ANFIS, PSO-ANFIS, SK ANFIS, and MR-Ensemble ANFIS Models.
When the results are compared, it is revealed that the MR-Ensemble ANFIS model demonstrates good performance by achieving generally the lowest error rates and the highest coefficient of determination values. The findings support the potential applicability of the proposed method in large-scale applications. The prediction and actual value graphs created using the first 200 data points from the EM (Thoot) Test dataset are presented in Figure 9.
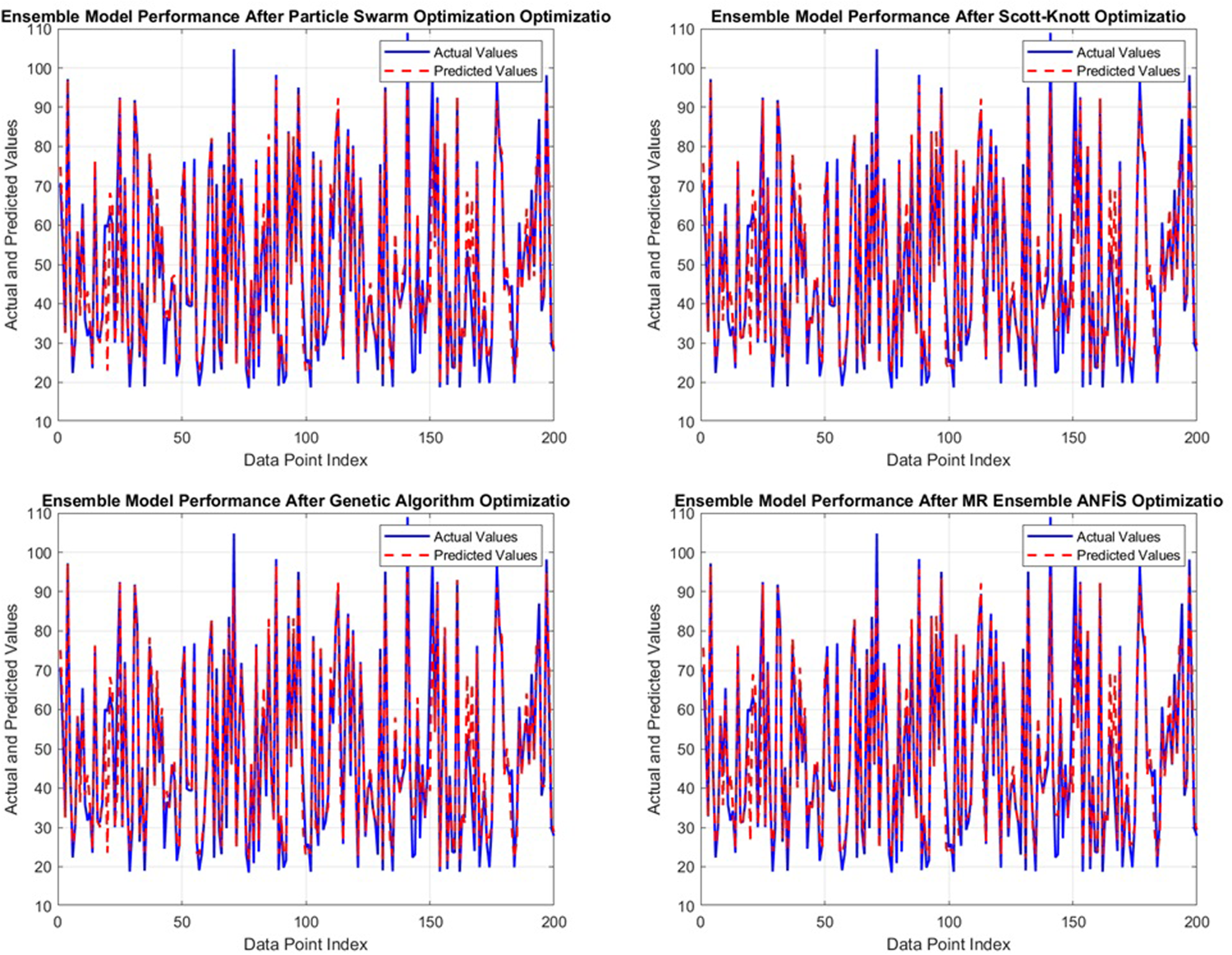
Graphs of Actual and Predicted Values for the EM (Thoot) Dataset Using four Different Ensemble ANFIS Models.
In the study, the membership functions and rule bases of ANFIS models, which were independently trained on different sub-datasets by utilizing the parallel processing power of the MapReduce algorithm, were optimized and combined into a single model.
Comparative analyses conducted on different datasets have revealed that the MR-Ensemble ANFIS model has lower error rates and higher determination coefficients compared to alternative methods frequently used in the literature, such as GA-ANFIS, PSO-ANFIS, and SK-ANFIS. The proposed approach reduces computational costs while maintaining the model's generalization performance, especially in large-scale datasets.
Additionally, thanks to the rule adjustment function, the MR-Ensemble ANFIS architecture has kept computational complexity under control and significantly reduced the number of rules that theoretically need to be generated. This situation increases the computational efficiency of the model and demonstrates its more effective usability in practical applications.
The obtained results indicate that the MR-Ensemble ANFIS model offers a strong alternative in big data analysis and forecasting processes and can be used with high accuracy in extensive applications. Although the MR-Ensemble ANFIS model has achieved successful results in big data analysis, factors such as the diversity of data structures and the limitation of processing resources may affect the generalizability of the method. Additionally, the model's performance may degrade in datasets with a very high level of noise or imbalanced data distributions. In this case, special filtering or synthesis techniques may be needed in the data preprocessing steps. Future studies may aim to further improve the model with different optimization techniques and enhance its applicability across various disciplines. In this regard, it seems possible to diversify the potential application areas of the proposed approach.
Footnotes
Acknowledgements
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors. During the preparation of this work, the first author utilized Qwen by OpenAI to assist with the translation and rephrasing of certain sentences in the manuscript. Both authors thoroughly reviewed and revised the content, taking full responsibility for the final version of the publication.
Ethical Considerations
This study does not involve human participants, human data, or human tissues. Therefore, ethical approval was not required.
Informed Consent
This study does not include research involving human participants. Therefore, obtaining informed consent was not necessary.
Consent for Publication
This article does not contain any individual person's data (including images, videos, or personal details). Therefore, obtaining informed consent for publication was not required.
Author Contributions
The contributions of each author are as follows:
Ahmet Artut : Research design, model development, data analysis, writing, and editing.
Adem Göleç : Validation of analyses and evaluation of results.
Both authors actively participated in all stages of the study and approved the final version.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was not supported by any funding provider. The design of the study, data collection and analysis, decision to publish, and preparation of the manuscript were entirely funded by the authors.
Conflicts of Interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
The datasets used in the analysis of this study are available in accordance with applicable ethical and legal regulations. The datasets can be accessed through the relevant storage platform. Requests for access to the data can be made by contacting the authors.