
Abstract
Breast cancer poses a significant threat to women's health. Dynamic Optical Breast Imaging (DOBI) is a medical imaging method based on the theory of early neovascularization in breast tumors. This technique is fast, non-invasive, and radiation-free, with the potential for early diagnosis of breast cancer, thereby helping to enhance patients’ survival rate and treatment outcomes. However, due to limitations such as limited data volume and class imbalance, existing medical image classification methods often suffer from low classification accuracy, poor generalization ability, and low sensitivity to malignant samples when applied to DOBI. To address these issues, this paper proposes the Bayesian Dynamic Ensemble Selection (BDES) method. In the BDES method, the K-Nearest Neighbor Dynamic Classifier Selection (KNND-CS) method is designed to construct specific classifiers pool based on all available base classifiers for each test sample. Subsequently, the simulated annealing algorithm is utilized to dynamically select classifiers from this pool for inclusion in the ensemble. Finally, the selected classifiers are ensembled by Bayesian probability fusion function to generate the final diagnosis result of benign or malignant breast tumors. The BDES method dynamically selects and integrates appropriate classifiers for each sample, enhancing DOBI's accuracy in diagnosing benign and malignant breast tumors while ensuring robustness and generalization. To validate the effectiveness of BDES, extensive experiments were conducted. Cross-validation experiment proved the generalization and robustness of the DBES method. And the comparation experiment in breast cancer diagnosing for the DOBI dataset shows that the accuracy and sensitivity of the BDES method are 83% and 78% respectively, which is significantly better than many comparative methods, proving the effectiveness of the new method in early diagnosis of breast cancer.
Introduction
Breast cancer remains the leading cause of cancer-related mortality among women worldwide. Studies underscore the significant impact of early detection and appropriate treatment in reducing mortality rates of breast cancer (Chen et al., 2017; Chhikara & Parang, 2023). These findings emphasize the critical importance of accurately differentiating between benign and malignant neoplasms during the early stages. Breast imaging plays a pivotal role in facilitating the early diagnosis of breast cancer. At present, breast imaging mainly including mammography, breast ultrasound (BUS), magnetic resonance imaging (MRI), computed tomography (CT), positron emission tomography (PET), and elastography ultrasound (EUS). Mammography uses X-ray technology to analyze density differences between tumors and normal tissue, offering high resolution and repeatability (Michell et al., 2012), though its sensitivity is limited in dense breast tissue. BUS, a non-invasive, cost-effective modality, may yield false-positive results due to similar acoustic impedance between early tumors and normal tissue (Guo et al., 2018). MRI provides high-resolution 3D breast images to assess tumor characteristics, though its high cost and long examination time limit its routine use (Terreno et al., 2010). CT generates 3D images to evaluate breast structure but involves significant radiation exposure. PET detects 18F-fluoro-deoxyglucose uptake in cancer cells for metabolic insights (Vaquero & Kinahan, 2015), though it lacks sensitivity for early-stage diagnosis. EUS evaluates tissue elasticity non-invasively but has limited resolution for small or deep lesions (Sigrist et al., 2017). While these techniques provide valuable diagnostic and prognostic capabilities, significantly contributing to the management and treatment of breast cancer, certain persistent limitations remain, such as high costs and radiation-related risks
Dynamic Optical Breast Imaging (DOBI) is a technique based on the theory of tumor neovascularization, utilizing the scattering and absorption properties of near-infrared light by blood components within tumor to differentiate between benign and malignant breast tissue (Fournier et al., 2008). Malignant tumors release angiogenic factors in their early stages, promoting endothelial cell proliferation and the development of new, highly permeable vasculature. During DOBI examination, externally applied compression temporarily increases blood retention in tumor vessels, thereby enhancing the concentration of deoxyhemoglobin. This increase amplifies the absorption of near-infrared light by deoxyhemoglobin, facilitating the detection of metabolic irregularities in malignant tissue. With its non-ionizing nature, non-invasiveness, cost-effectiveness, and ease of operation, DOBI has great potential in the early diagnosis of breast cancer.
To enhance the diagnostic capabilities of breast imaging, traditional machine learning (ML) and deep learning (DL) techniques have been increasingly applied in breast image processing. Among traditional ML methods, support vector machine (SVM), naive Bayes, k-nearest neighbors (KNN), and their improved methods are particularly commonly used. Jasti et al. (2022) used AlexNet and the Relief algorithm for feature extraction, followed by Least Squares Support Vector Machine (LS-SVM), KNN, Random Forest (RF), and Naive Bayes classifiers to classify MIAS mammographic images, with LS-SVM achieving the highest accuracy. Allugunti (2022) employed SVM and RF for classifying breast thermography images, achieving high accuracy and low error rates. Mojrian et al. (2020) proposed the Fuzzy Extreme Learning Machine - Radial Basis Function (Fuzzy ELM-RBF) model, which effectively handles complex features in digitized mammographic images by leveraging the fast learning capability of ELM and the nonlinear mapping ability of the RBF kernel. While these traditional ML techniques can effectively classify tumors based on extracted image features, they heavily rely on manual feature extraction and selection.
Deep Learning, with its powerful ability to automatically extract hierarchical features from raw data, has demonstrated remarkable achievements in breast image classification. Rathinam et al. (2024) proposed the AFCM-DCNN method, combining Adaptive Fuzzy C-Means with Deep Convolutional Neural Networks (DCNN) for early breast cancer detection, outperforming other DCNN models in efficiency and performance. Liu et al. (2022) proposed an improved ResNet-101 convolutional neural network to enhance lesion classification specificity in breast MRI images without the need for pixel-level annotations. Baccouche et al. (2022) used a stacked residual neural network with ResNetV2 models for breast tumor classification, achieving high accuracy on the CBIS-DDSM dataset, though with long training times. However, DL methods typically require large quantities of high-quality labeled data to achieve optimal performance, and their generalization capabilities are often limited when annotated datasets are insufficient.
To further improve classification accuracy and generalization, Ensemble Learning (EL), which integrates the strengths of multiple classifiers, has garnered significant attention. Zheng et al. (2023) applied a weighted voting mechanism to the outputs of pre-trained deep learning models, while Bashir et al. (2015) used a weighted approach to combine five heterogeneous classifiers, achieving an average improvement of approximately 8% in accuracy and 5% in recall across four breast cancer datasets compared to individual models. Moreover, Wang et al. (2018) proposed a Weighted Area Under the Curve Ensemble (WAUCE) method, which significantly improved classification accuracy on mammographic images by leveraging the AUC of multiple SVM models. EL generally achieves higher accuracy than single-model approaches by balancing their respective strengths and weaknesses. However, some EL methods may introduce high complexity and carry a risk of overfitting, particularly when dealing with imbalanced datasets.
In this paper, we proposed a new ensemble learning method, Bayesian Dynamic Ensemble Selection (BDES) to improve the diagnosis of benign and malignant breast tumors. The specific challenges of the DOBI dataset, include limited sample size and class imbalance, necessitate the need for methods that can mitigate issues like low sensitivity to malignant samples and poor generalization. To achieve this, BDES employs several component methods, each chosen to overcome specific issues. Firstly, KNND-CS is employed to dynamically select the most relevant base classifiers for each test sample. By doing so, it allows the framework to dynamically adjust the classification strategy based on the sample's characteristics, improving accuracy. Additionally, it helps to eliminate the interference of irrelevant or redundant classifiers, which reduces computational complexity. Then, simulated annealing is used for choosing the most appropriate classifiers for the ensemble within the specialized classifier pool. A key feature of this process is the incorporation of expected misclassification loss, which applies greater penalties for misclassifying minority class samples. This is particularly important for addressing the class imbalance issue in the DOBI dataset and improving the sensitivity to malignant samples. Finally, Bayesian formula is used to combine prior probability and the output of the selected classifiers in a probabilistic manner, which ensures that the ensemble decision process accounts for the uncertainty and variability of each classifier, thereby enhancing the generalization. Main contributions of this work are as follows: A Bayesian Dynamic Ensemble Selection (BDES) method is proposed. BDES selects the most appropriate base classifier combination for each test sample through two selection steps, and integrates them through Bayesian probability function to improve the breast cancer diagnosis ability. K-Nearest Neighbor Dynamic Classifier Selection (KNND-CS) method is established to construct a specific classifiers pool based on all available base classifiers. This step effectively reduces search scope for further selection and integration of multiple base classifiers. The simulated annealing algorithm and Bayesian probability function are combined to select and ensemble the optimal base classifiers stably, which can effectively enhance breast cancer diagnosis accuracy and generalization.
The rest part of this paper is organized as follows: Section 2 details compute of the BDES method. Section 3 outlines the experimental design and comparative methods. Section 4 presents experimental results and discusses the effectiveness of the proposed method. Section 5 discusses the performance, limitations, and future directions of the BDES approach. Section 6 concludes this paper and provides outlook on future research directions.
Method
To improve the classification accuracy on the data-limited DOBI dataset, Bayesian Dynamic Ensemble Selection (BDES) method is proposed, the architecture of BDES is shown in Figure 1. The BDES method is implemented based on predictions of multiple trained base classifiers.
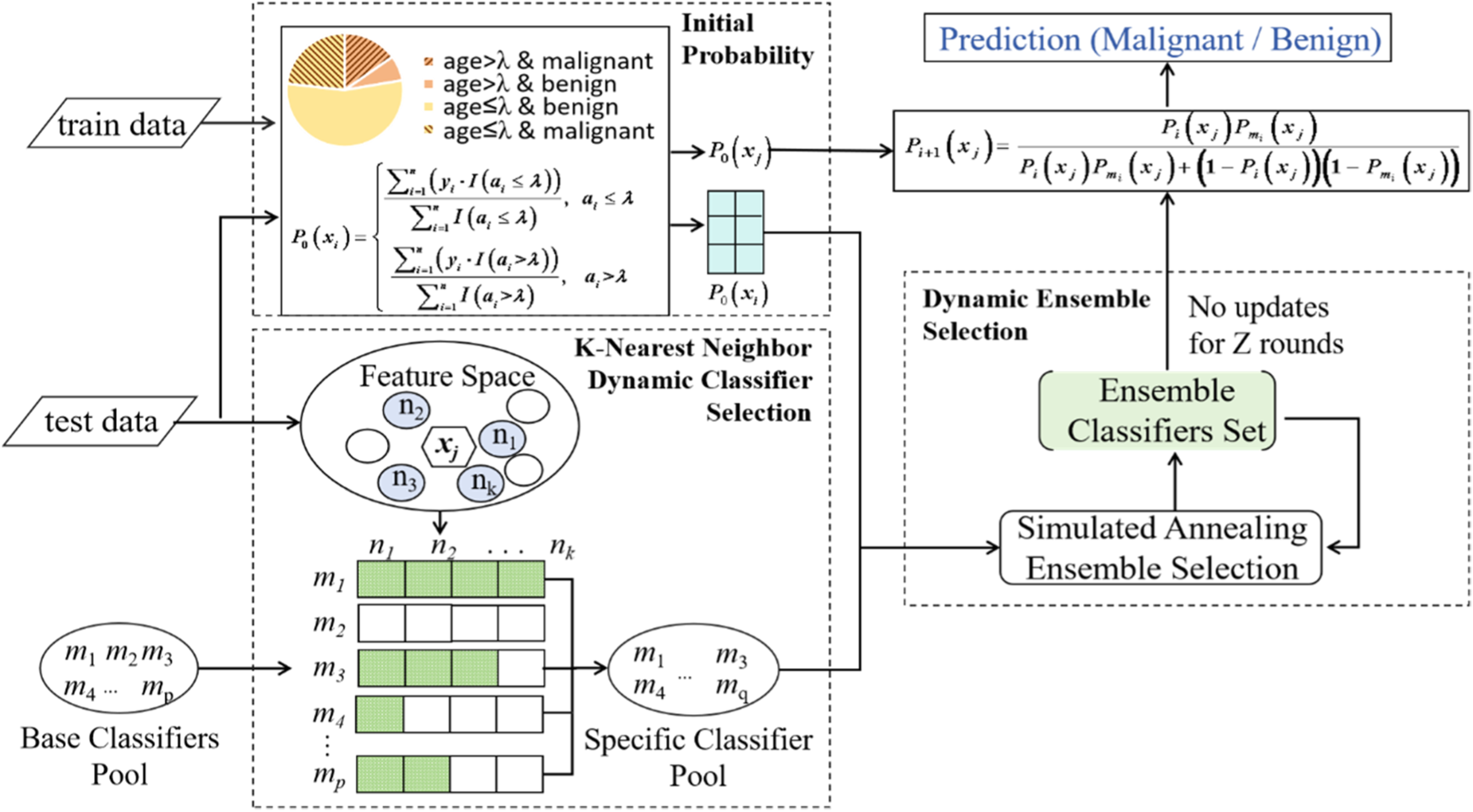
Bayesian Dynamic Ensemble Selection Architecture Diagram. The BDES Uses Training Data to Calculate Prior Probabilities and Construct a Classifier Pool Tailored to Each Test Sample Based on KNND-CS. It Then Applies Simulated Annealing and a Bayesian Function to Select Classifiers and Generate Final Predictions.
In the BDES method, as illustrated in Figure 1, the training data is used to determine the prior probability based on the distribution of benign and malignant samples of different ages. The feature space is composed of features extracted by the pyradiomics method. And then KNND-CS selects n training samples that are closest to the test sample in the feature space. The base classifiers that correctly classify these n training samples are dynamically selected to form a specific classifier pool for each test sample. On this basis, simulated annealing and the Bayesian function are employed to select the classifiers for integration and to generate the final prediction results. The following sections will provide a detailed description of the different steps of the BDES method.
The survey reveals the risk of breast cancer varies with age, with an estimated 1 in 53 for women under 50 years of age, 1 in 43 for those aged 50 to 59, and increases to 1 in 23 for women over 60 (Giaquinto et al., 2024; Kim et al., 2025; McGuire et al., 2015). These findings underscore the correlation between age and the malignancy probability of breast tumor. Thus, we initially establish the prior probability of malignant breast tumors based on age. To calculate these age-dependent priors, the training samples are grouped with a 50-year threshold. The proportion of malignant cases among samples <=50 years determines the malignancy prior for individuals under 50. Similarly, the proportion of malignant cases among samples >50 years sets the prior for those over 50 years old. This process is as shown in Equations (2)-(3).


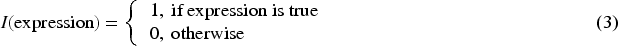
Thus, the initial malignant prior probability of sample can be expressed as follow.

In this part, we propose K-Nearest Neighbor Dynamic Classifier Selection (KNND-CS) method to construct a specific classifiers pool for each test sample. During the ensemble process, classifiers are dynamically selected from this pool.
In the calculation of KNND-CS, we employ the Mutual Information (MI) method for feature selection. MI (Vergara and Estévez, 2014) provides a robust measure of the dependence between each feature and the target variable, enabling us to select representative features. This selection process minimizes the impact of irrelevant features and reduces the computational cost of model training, facilitating the search for neighbors in a low-dimensional, highly correlated feature space. So, following the extraction of radiomics features from each image sample by the pyradiomics method, we calculate the MI-score for each feature within the training set. And then we select the top v features with highest MI-scores, as detailed in Equation (5).
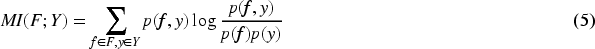
Based on the v features selected by MI, we calculate the Euclidean distance between the test sample and all training samples, and then select the k training samples with the closest distance as the nearest neighbors. The Euclidean distance is shown in Equation (6).

The specific classifiers pool for each test sample can be constructed by selecting the classifiers that predicts correctly at least one nearest neighbor sample from the base classifiers, as shown in Equation (7).
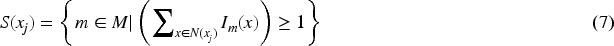
In the KNND-CS method, two parameters are involved: number of Neighbors (k) and number of Features (v). The number of neighbors, k, is selected based on the size of the training data. Specifically, when the training data size is less than 500, we set k = 5 to avoid overly complex calculations and reduce variance in classifier selection. When the training data size exceeds 500, k is set to 10% of the total number of samples. This choice ensures that enough neighbors are considered to improve classifier selection while maintaining computational feasibility as the dataset grows larger. For the v (number of features) in KNND-CS, we did not set an explicit value, as the method is designed to work flexibly with a wide range of feature sets. Instead, we ensure that the features selected are relevant and non-redundant.
In summary, KNND-CS method filters out the classifiers that are more helpful for the ensemble, which can help to enhance the robustness and pertinency of the model.
After constructing the specific classifiers pool, we implement a Simulated Annealing method to globally search for the optimal ensemble of classifier and use the Bayesian probability function to fusion these selected classifiers.
The procedure of Simulated Annealing Ensemble Selection is illustrated in Figure 2. We initialize the parameters firstly, including an initial temperature T of 1.0, termination temperature

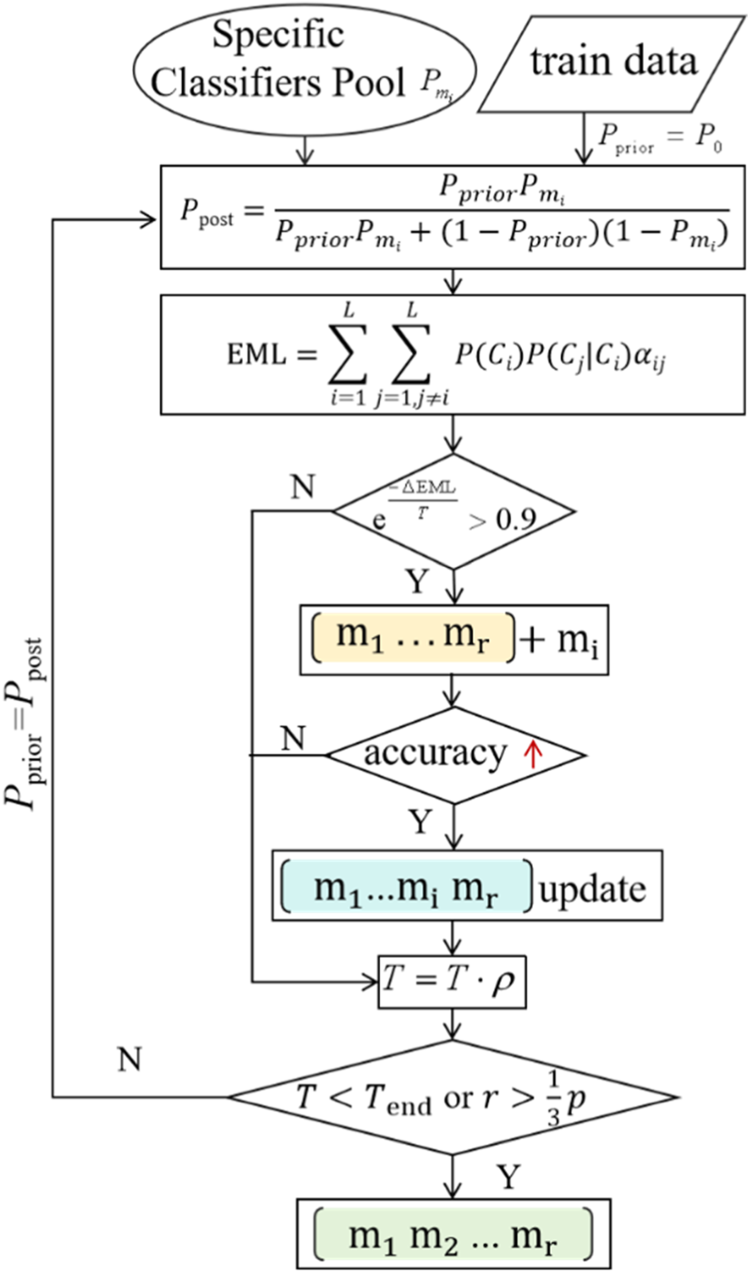
Dynamic Ensemble Selection. This Process Employs Simulated Annealing to Dynamically Select Suitable Base Learners from the Test Sample’s Specific Classifier Pool. The Predictions of these Learners are then Combined using Bayes’ Theorem and Prior Probabilities to Produce the Final Result.
Bayesian theory provides a robust framework for reasoning with empirical data by integrating prior knowledge with observed information to compute the posterior probability of an event (Balasubramanian et al., 2020; Xiong et al., 2021). In dynamic ensemble selection, as shown in Figure 2, Bayesian probability fusion function and simulated annealing are combined to dynamically select the suitable classifiers. As shown in equation (9), the principle of Bayesian probability fusion function is to constantly adjust our estimate of the probability of an event based on new evidence. Classifier
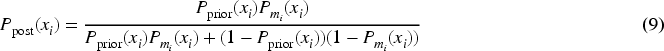
At each iteration in Figure 2, the posterior probability obtained from the previous fusion step is used as the new prior. A new base classifier from the selected pool then provides updated likelihoods (i.e., predicted class probabilities), which are treated as new evidence to update the posterior. By continuously updating classification beliefs using all available evidence, the Bayesian probability fusion function can reduce the impact of any single classifier error, thereby improving the accuracy and stability of the final prediction, which is particularly valuable in uncertain or imbalanced datasets such as DOBI.
Upon obtaining the malignant posterior probability, we calculate the new EML and accuracy, then substitute the changes in EML and the current temperature into the acceptance condition formula. If the acceptance condition is met, the classifier


After selecting the ensemble classifiers for each test sample, the prediction of the test sample can be obtained based on the initial malignant prior probabilities and formula (10).
It should be noted the performance of the simulated annealing (SA) algorithm is indeed affected by parameters such as initial temperature, cooling rate, termination temperature and acceptance threshold. The setting of these parameters has the following considerations.
Initial Temperature: We set the initial temperature to 1.0 to cover a reasonable range of potential misclassification errors, which helps the algorithm escape local minima during the early iterations.
Cooling Rate: We chose a cooling rate of 0.95, which provides a moderate decrease in temperature, ensuring a balance between exploration and exploitation during the optimization process.
Termination Temperature: The termination temperature was set to 0.1, which is the threshold for stopping the algorithm. Given the initial temperature of 1.0, the temperature decreases to 0.1 after approximately 45 iterations, providing a suitable stopping condition that ensures the algorithm has enough time to converge to a solution.
Acceptance Threshold: We use an acceptance probability threshold of 0.9. This high acceptance threshold ensures that the algorithm remains stable and is less likely to prematurely reject potentially beneficial solutions during the search process.
In summary, within the specific classifiers pool constructed by KNND-CS, BDES dynamically selects the optimal classifiers using the simulated annealing ensemble selection and computes the ensemble result through Bayesian probability fusion function.
Datasets
The datasets used in experiments include mini-DDSM and DOBI datasets. The mini-DDSM (Lekamlage et al., 2020) dataset is a condensed version of Digital Database for Screening Mammography (DDSM) offering breast mammography dataset for academic research. mini-DDSM dataset has 5388 samples, including 2682 benign samples and 2706 malignant samples. DOBI dataset consists of 2927 samples, including 1825 benign samples and 1102 malignant samples, which shows data imbalance.
The data divisions of the mini-DDSM dataset and the DOBI dataset are shown in Tables 1 and 2, respectively. For the base classifier, the mini-DDSM dataset has 3769 samples in the training set and 1619 samples in the testing set. The DOBI dataset has 2261 samples in the training set and 666 samples in the testing set. For the ensemble model, the mini-DDSM dataset has 1079 samples in the training set and 540 samples in the test set. The DOBI dataset has 533 samples in the training set and 133 samples in the test set.
Data Splitting of mini-DDSM and DOBI Datasets for Base Classifiers.

Data Splitting of mini-DDSM and DOBI Datasets for Base Classifiers.
Data Splitting of mini-DDSM and DOBI Datasets for Ensemble Learning.

In this paper, the performance of model is evaluated by metrics of accuracy, sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV) and F1 score. These metrics are calculated based on confusion matrix in Table 3, as shown in Equations (12)-(17).






Confusion Matrix for Binary Classification.

where, TP is the number of samples correctly predicted as malignant (true positive), FP is the number of samples incorrectly predicted as malignant (false positive), TN is the number of samples correctly predicted as benign (true negative), and FN is the number of samples incorrectly predicted as benign (false negative).
It should be noted that sensitivity and specificity are the core metrics to measure the performance of cancer diagnosis models. It is difficult to balance sensitivity and specificity. When setting high specificity, it usually leads to a decrease in sensitivity. Therefore, the performance can’t be judged only by these two metrics. PPV represents the proportion of patients predicted to be positive (cancer) who actually have cancer, and is a measure of the model's ability to avoid “miscalculation”. NPV represents the proportion of patients predicted to be negative (benign), and is a measure of the model's ability to avoid “missed judgments”. The F1-score is a harmonic average of accuracy and recall used to comprehensively evaluate the performance of the model.
Before applying ensemble learning methods, we constructed 10 classifiers using both traditional machine learning and deep learning models on the mini-DDSM dataset. Table 4 shows the methods of base classifiers and their performance on the mini-DDSM test set. Among these basic classifiers, the EfficientNet model had the best comprehensive performance, with accuracy, sensitivity and specificity of 72%, 79% and 65%, respectively. The VGG16 model performs best in sensitivity, reaching 80%. The RF_WT model performs the best on specificity with 76%.
Base Classifiers and Their Performance on the mini-DDSM Test Dataset.
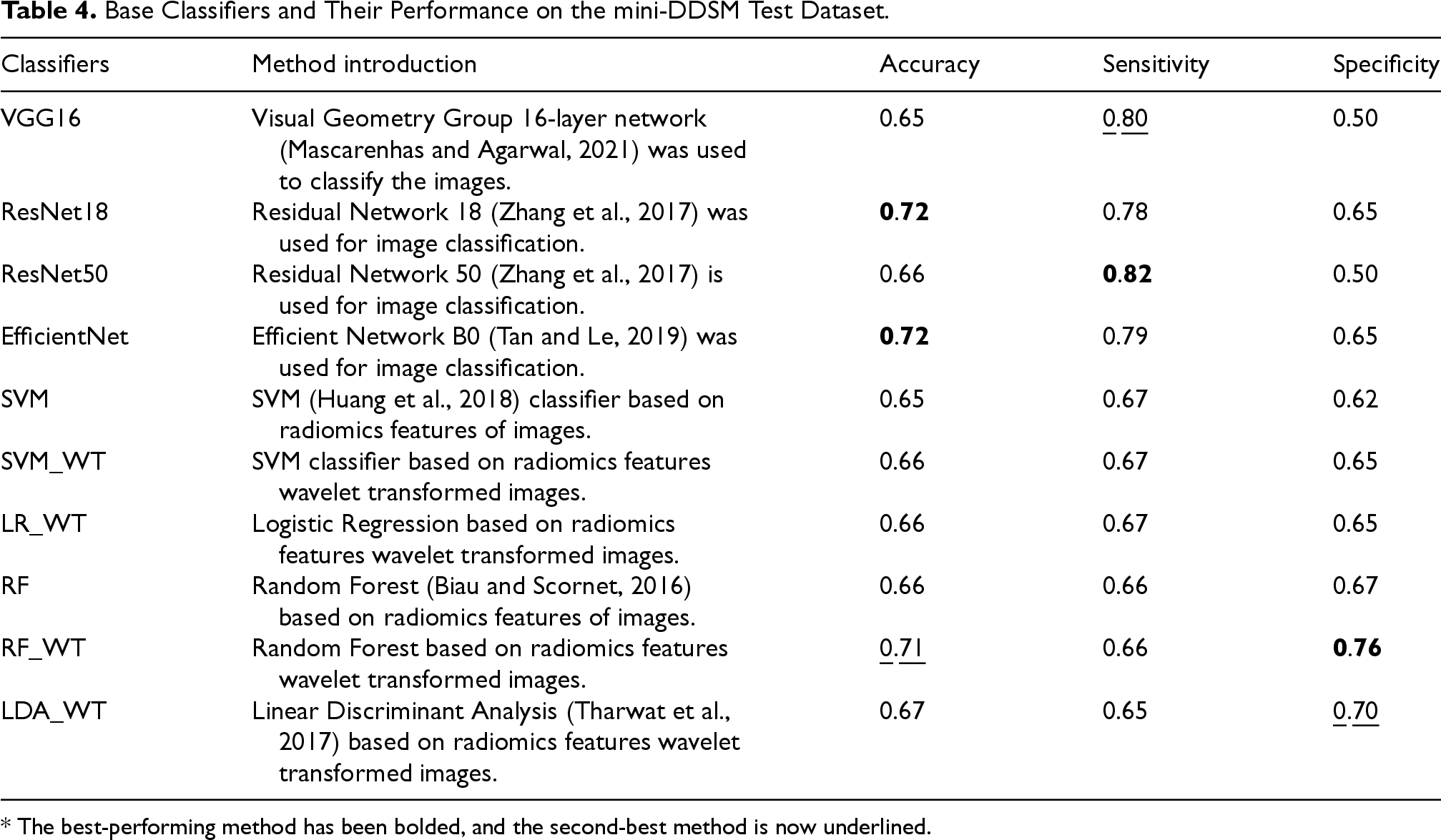
Base Classifiers and Their Performance on the mini-DDSM Test Dataset.
* The best-performing method has been bolded, and the second-best method is now underlined.
For the DOBI dataset we designed 10 base classifiers. Table 5 shows the base classifiers and their performance on the DOBI test set. As shown in Table 5, the NIRCL model has the best performance, with accuracy, sensitivity and specificity of 72%, 74% and 71%, respectively. ResLRA model has the best sensitivity, reaching 74%. The VQRes18 model performs the best specificity with 78%.
Base Classifiers and Their Performance on DOBI Test Dataset.
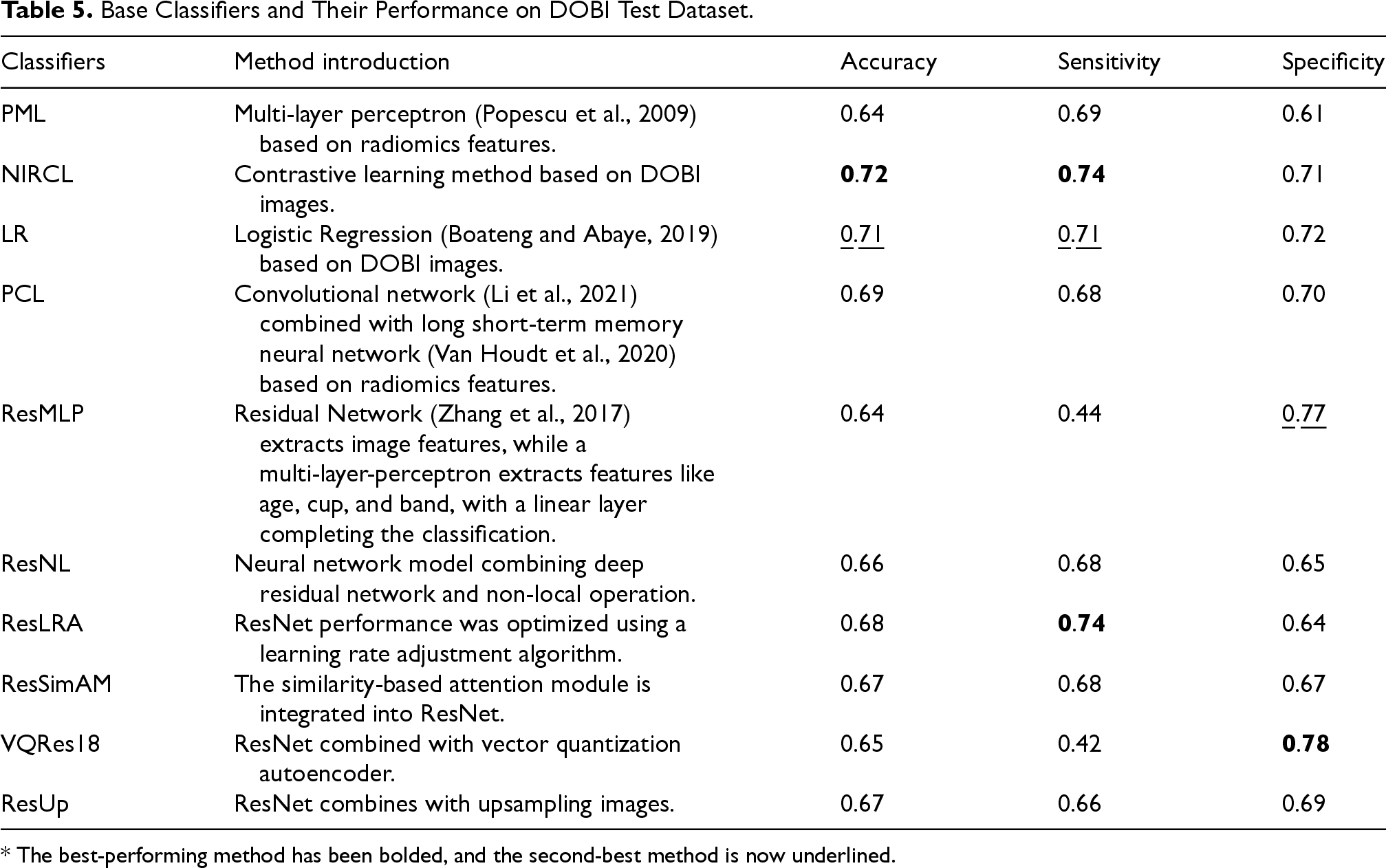
* The best-performing method has been bolded, and the second-best method is now underlined.
We compare the BDES with several advanced ensemble methods to evaluate its effectiveness in classifying benign and malignant of breast tumors.
Results
To evaluate the effectiveness of the BDES method, we conducted comprehensive experiments by integrating the base classifiers of mini-DDSM dataset listed in Table 4. The performance of BDES method is compared with advanced ensemble methods in section 4.4. Moreover, the robustness of our approach is analyzed through five-fold cross-validation experiments. To further validate its generalization potential under data-scarce conditions, BDES is applied to the Dynamic Optical Breast Imaging (DOBI) dataset. Additionally, ablation experiments were conducted to evaluate the contributions of each BDES component, ensuring a comprehensive understanding of its effectiveness.
Comparison Experiment on mini-DDSM Dataset
In this section, we employ the proposed BDES method to integrate the base classifiers of Mini-DDSM in Section 4.3. A comparative analysis conducted against other advanced ensemble methods introduced in Section 4.4. The experimental results with highlighted comparative performance metrics are shown in Figure 3.
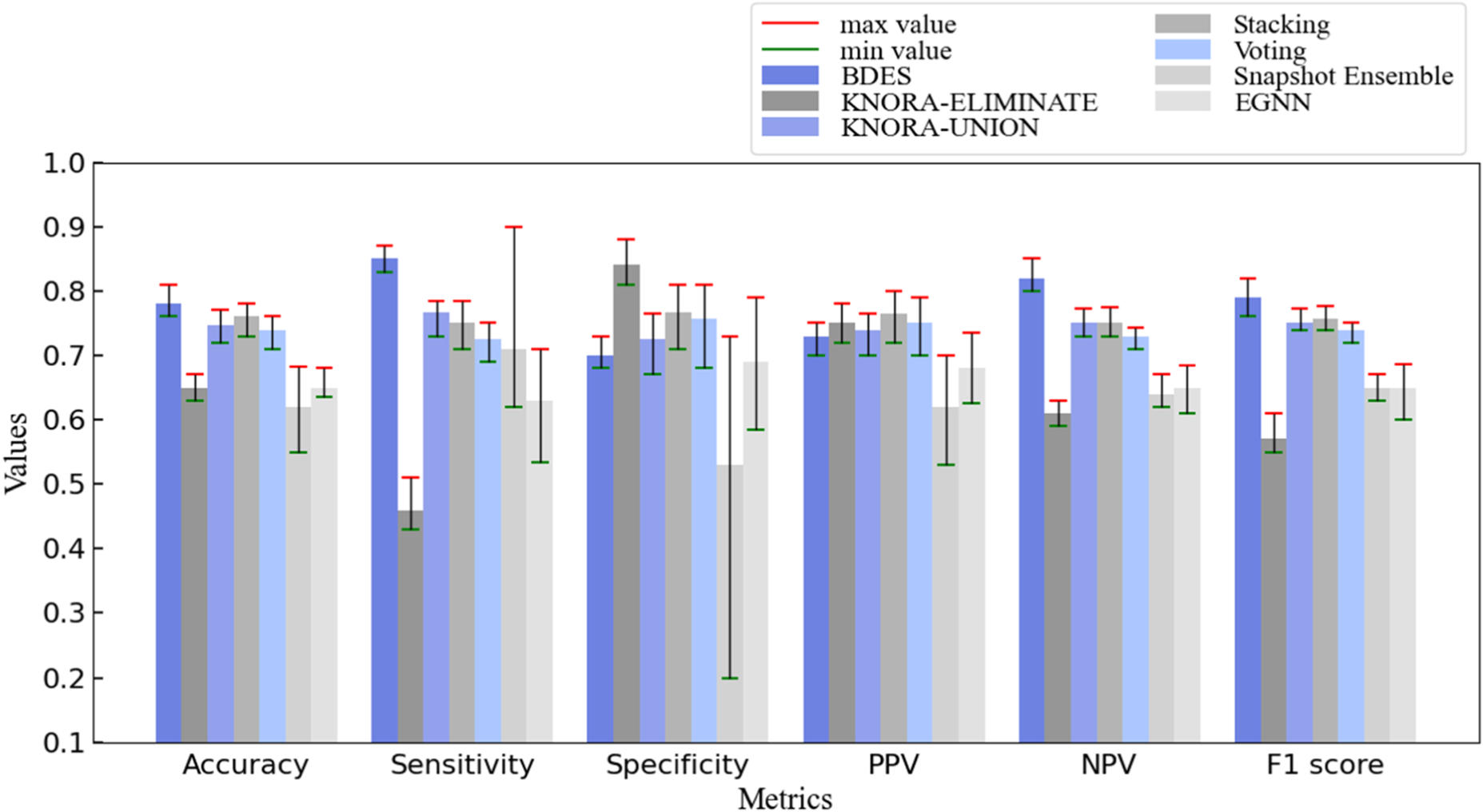
Results of Cross-Validation and Comparative Experiments for mini-DDSM Dataset. the BDES Method Predicts Results with Higher Performance in Multiple Indicators and has Less Fluctuation During the Cross-Validation Process.
The experimental results presented in Figure 3 demonstrate that the BDES model achieved the highest performance across metrics, including accuracy, sensitivity, NPV and F1 score. While the KNORA-ELIMINATE method exhibits the highest specificity (0.84), its sensitivity is relatively low at 0.46. In the diagnosis of breast tumors, sensitivity is of critical importance due to the potentially severe consequences of misdiagnosing malignant tumors as benign. The BDES model addresses this challenge by incorporating a modified EML function that imposes a higher penalty for misclassifying malignant cases as benign. This process enhances the model's ability to accurately identify the malignant tumors, thereby improving sensitivity and ensuring more reliable detection of potential malignant cases. In addition, as for the generalization ability of the model, we can see from the fluctuation range of the five-fold cross validation that although the performance indicators of most of the comparison methods fluctuate within a small range, the sensitivity and specificity of some comparison methods fluctuate greatly. The BDES method shows a small fluctuation in all performance indicators, which proves that the BDES method has good generalization ability.
In order to verify the effectiveness and robustness of the DBES method on the DOBI dataset, this section designed a five-fold cross-validation experiment based on the DOBI dataset and compared it with multiple ensemble learning methods. In the experiment, each fold contains 533 training samples and 133 test samples.
Figure 4 illustrates the performance comparison of six models on different metrics. Each bar is the average value of a specific metric for the corresponding model in five-fold cross-validation, with higher height indicating better results. The error bar represents the fluctuation range, where the red upper edge is the max value and the green lower edge is the min value. A shorter length of the error bar indicates a more stable result. According to the results of BDES shown in Figure 3, the BDES model outperformed the best-performing base classifier NIRCL in Table 5, by 11%, 4%, and 15% in accuracy, sensitivity, and specificity, respectively. These results means that BDES method can provide more accurate classification decisions, which proves that the BDES method can select and ensemble excellent base classifiers by simulated annealing ensemble selection and Bayesian probability fusion function.
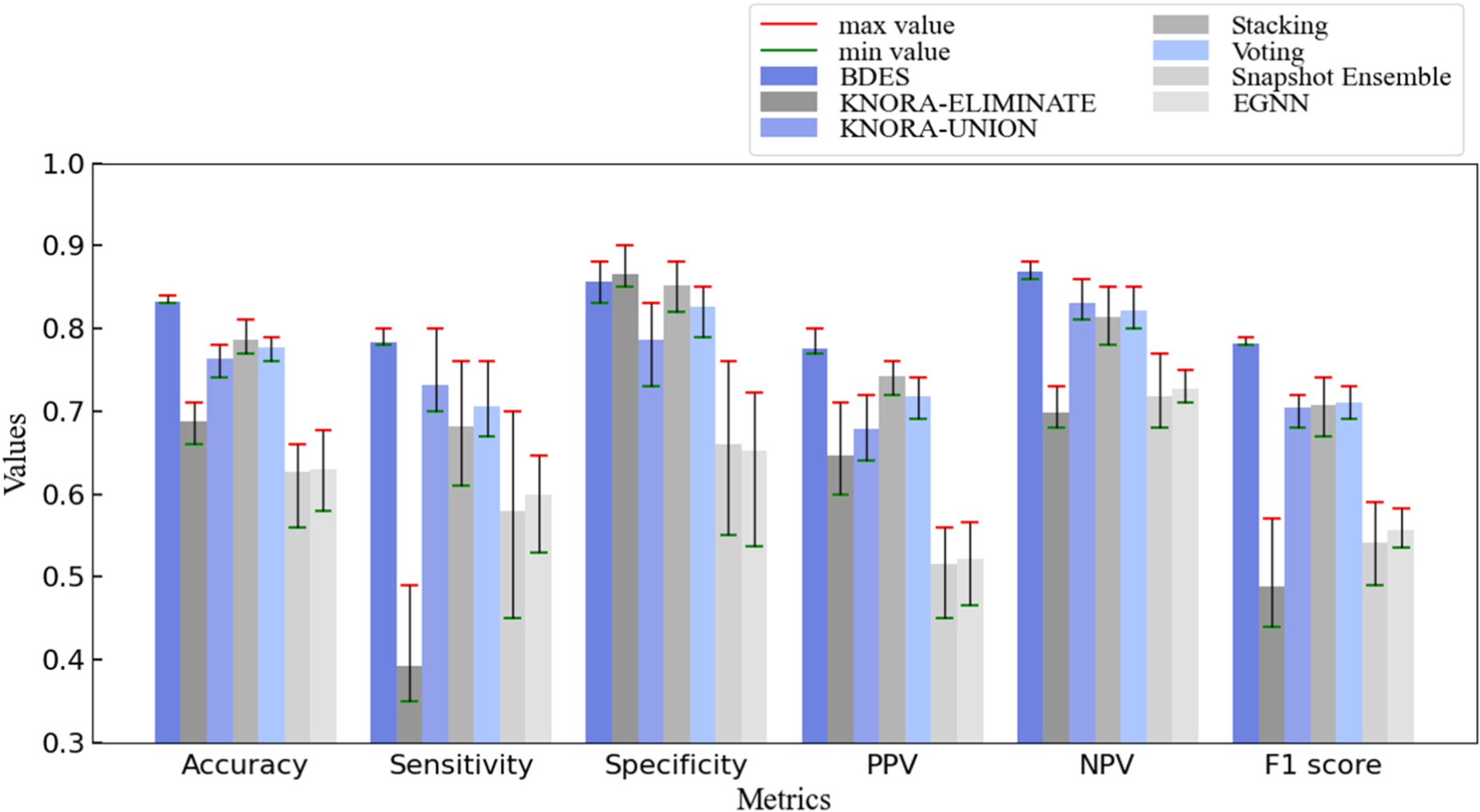
Results of Cross-Validation and Comparative Experiments for DOBI Dataset. The BDES Method Predicts Results with Higher Performance in Multiple Indicators and has less Fluctuation During the Cross-Validation Process.
In comparison with other methods, BDES achieves a higher average accuracy (0.83), which represents a 4% and 5% improvement over Stacking (0.79) and Voting (0.78), respectively. Compared with the medical image integration school method EGNN, the performance of the BDES method is also significantly better than EGNN. Moreover, BDES exhibits smaller differences between the maximum and minimum values across all metrics, indicating greater model stability. This can be attributed to the well-designed initialization of prior probability, which provides more accurate priors for Bayesian probability fusion. In addition, the simulated annealing ensemble selection performs global optimization during classifier selection, ensuring the stability of the ensemble results. Therefore, the BDES model can get better stability and generalization ability in the DOBI dataset with small amount of data.
In this study, the BDES method incorporates KNN-CS and simulated annealing, which increases computational complexity. To evaluate the real-time performance of the proposed approach, this section compares the training time, the total inference time on 133 test samples, and the average inference time per sample of the BDES method and various ensemble learning methods presented in Section 3.4. The results are summarized in Table 6.
Comparison of Computational Time of Different Ensemble Learning Methods (s).
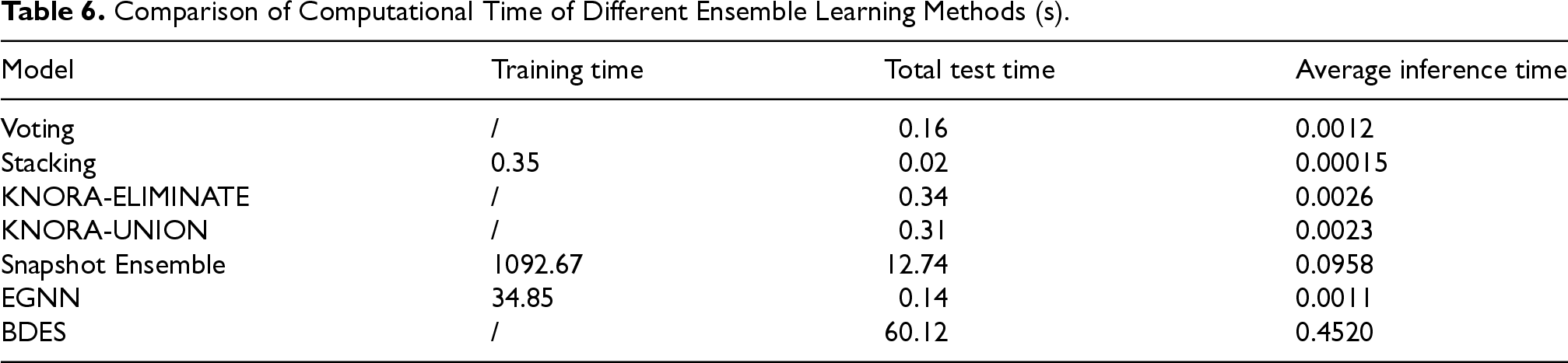
Comparison of Computational Time of Different Ensemble Learning Methods (s).
As shown in Table 6, the inference time per sample for the BDES method is 0.4520 s, which is significantly higher than that of the compared methods. This indicates that the increased computational complexity of BDES indeed leads to longer inference times. However, considering the application scenario of this study—benign and malignant breast tumor diagnosis—the inference time remains well below 1 s, which is acceptable for clinical diagnosis.
It is also important to note that when the BDES method is extended to higher-dimensional feature spaces or incorporates a larger number of base classifiers, the computational time will inevitably increase further. In such cases, it is recommended to perform dimensionality reduction and base classifier selection in advance, in order to avoid unnecessary computational overhead caused by redundant features and classifiers.
The main part of BDES method include the dynamic ensemble selection, simulated annealing algorithms and Bayesian probability fusion function. In order to validate the contributions of these three parts, we conducted ablation experiments on the DOBI dataset and the mini-DDSM dataset.
Here, BDES-noDynamic refers to the model using a fixed set of classifiers for all test samples, without constructing a specific classifiers pool and ensemble for each individual sample. BDES-noSA indicates that the model does not employ the simulated annealing algorithm, but selects the classifier with the smallest EML at each layer. If this classifier improves accuracy, it is added to the ensemble classifiers set, otherwise the process halts. BDES-noBayesian refers to the approach where the Bayesian probability fusion function is omitted, and the average predictions from each classifier are used instead. Random Priors experiment does not use the prior probability based on the age distribution, but uses a random probability value as the prior. In order to avoid contingency, each cross-validation experiment is repeated 10 times, and the mean of the repeated experimental results is taken as the final result.
As shown in Table 7, compared with the ablation methods, the BDES method has the best performance on both the DOBI dataset and the mini-DDSM. The performance of the BDES-noDynamic model on both datasets declined, especially on the DOBI dataset. This result proves that the dynamic selection of classifiers provides a stable classifier foundation for the subsequent integration process and effectively alleviates the model instability caused by severe data imbalance. The accuracy of BDES-noSA is 1% lower than that of BDES, with decreases also observed in sensitivity and F1 score. This indicates that the simulated annealing algorithm can effectively explore the global search space to find near-optimal classifiers combinations, thereby enhancing the overall performance of the model. Additionally, BDES-noBayesian shows a 2% drop in accuracy and a 3% decrease in F1 score, which demonstrates that the Bayesian probability fusion function effectively combines prior information with the outputs of base classifiers to make the final decision, thereby improving the model's accuracy. Finally, the performance of the random prior experiment is lower than that of the BDES method on both DOBI and mini-DDSM dataset, which proves the effectiveness of the prior probability based on age distribution.
Results of Ablation Experiments.
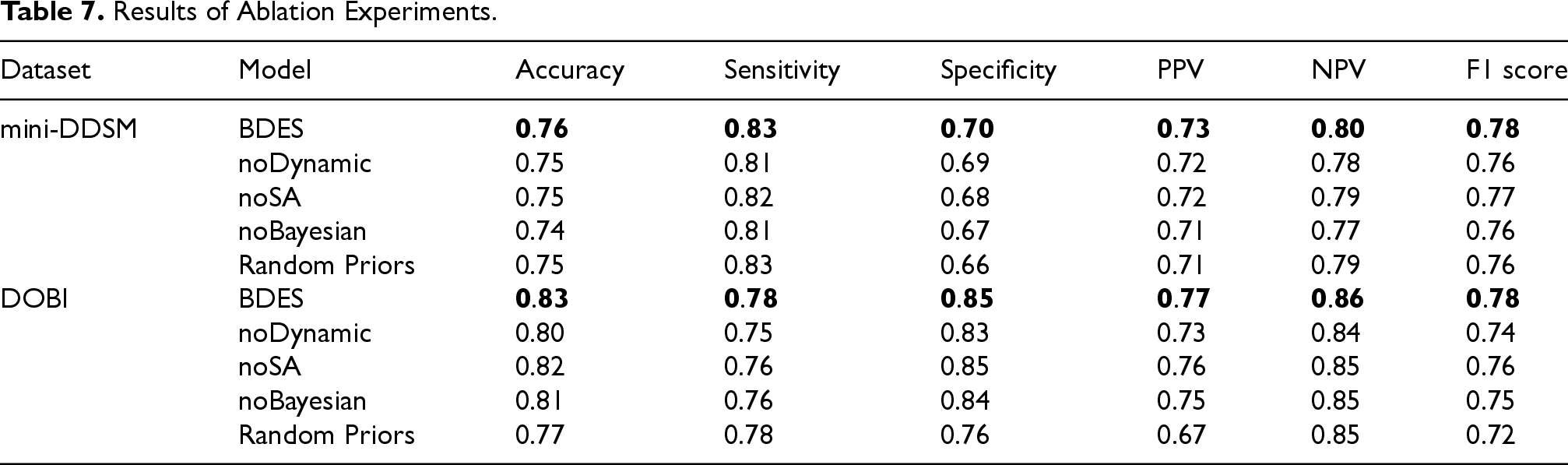
Results of Ablation Experiments.
Furthermore, we further analyze the cross-validation of ablation experiments. As shown in Figure 5, BDES achieves an accuracy variance of only 0.42 × 10−4, significantly lower than that of other models, indicating the most stable classification performance across different folds. The simulated annealing algorithm and Bayesian probability fusion contribute to the optimization and adjustment of base classifier ensembles, thereby enhancing classification stability.
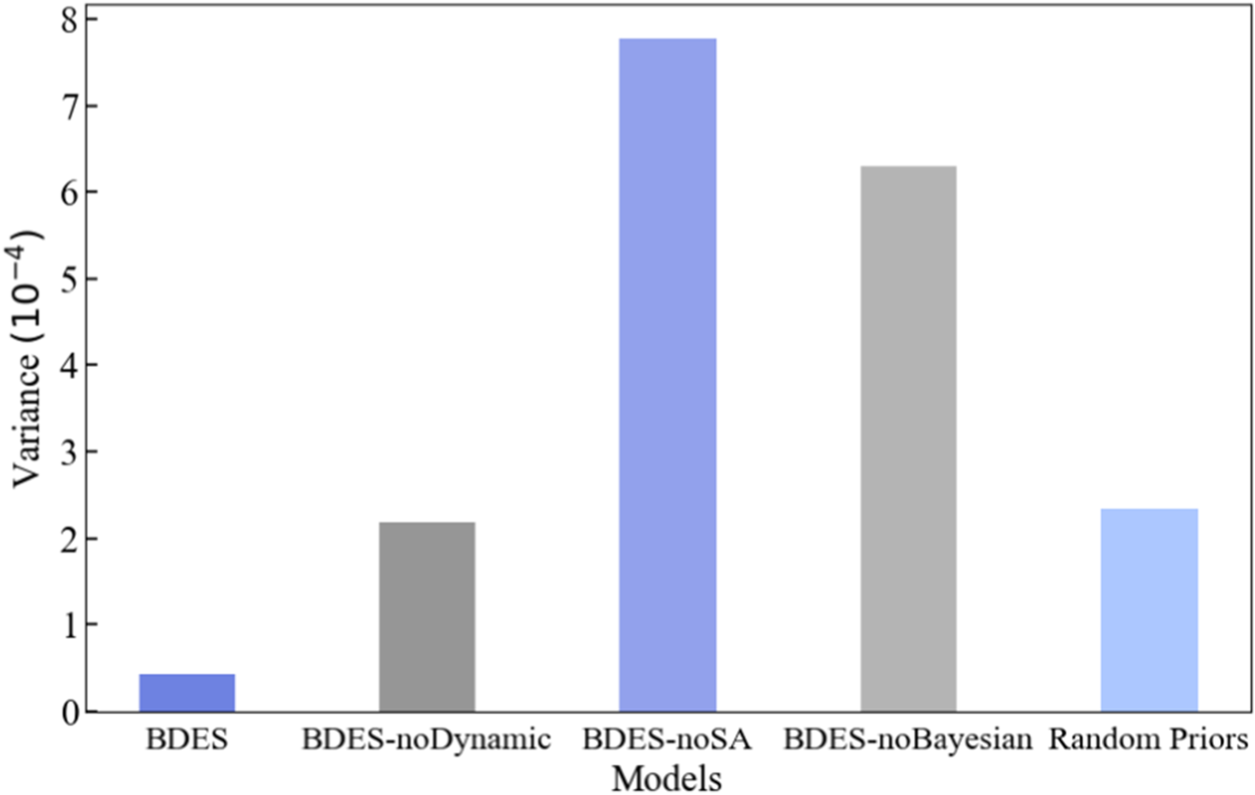
Variance of the Cross-Validation Accuracy on the DOBI Dataset. the Variance of BDES Without Ablation is Significantly Smaller Than That of Other Methods with Ablated Models.
The accurate diagnosis of breast tumor benignancy and malignancy is critical for early detection and timely treatment. In this study, we aimed to address the challenges posed by limited and imbalanced data in dynamic optical breast imaging (DOBI) datasets, which hinder the development of robust diagnostic models. By designing an ensemble learning method, Bayesian Dynamic Ensemble Selection (BDES), we achieved significant improvements in classification accuracy, robustness, and generalization for early-stage breast tumor diagnosis.
Discussion of BDES Performance
The BDES framework demonstrated excellent accuracy and sensitivity across both the mini-DDSM and DOBI datasets, highlighting its effectiveness in medical image classification. Additionally, the use of five-fold cross-validation further corroborated the robustness of the model. However, it is important to note that the specificity of BDES was suboptimal on both datasets. This can be attributed to the inherent trade-off between sensitivity and specificity. During the design of the BDES method, a greater penalty was assigned to the misclassification of malignant samples, reflecting the clinical prioritization of minimizing false negatives. The Expected Misclassification Loss (EML) function embedded in BDES enforces this bias by imposing a higher penalty on the misclassification of malignant samples, thereby prioritizing sensitivity over specificity. As a result, while sensitivity is maximized, specificity for benign samples is slightly compromised, which is consistent with our clinical focus on reducing false negatives.
Moreover, the performance of BDES, like most ensemble learning methods, is contingent on the quality of the base classifiers. The primary objective of BDES is to harness the complementary strengths of multiple base classifiers to enhance overall classification performance, with the aim of exceeding the performance of the best individual base learner. This strategy, grounded in the principles of ensemble learning, underscores the importance of diversity and accuracy among base classifiers. However, it is important to acknowledge that if the base classifiers are weak or inadequately trained, the ensemble's performance may be suboptimal, as the model would lack sufficient useful information to exploit. This limitation is a general characteristic of ensemble-based approaches and is not unique to BDES. In this study, we assume that the base classifiers are reasonably well-trained and exhibit a degree of diversity, which is a standard assumption in ensemble learning research.
Discussion on Prior Information
In the BDES, we used patient age to initialize the prior probability of malignancy, which is because multiple studies indicating differences in breast cancer between younger (< 50 years) and older (≥ 50 years) populations (McGuire et al., 2015; Giaquinto et al., 2024; Kim et al., 2025). In the current study, the prior probability is estimated from the distribution of the training dataset. Although this assumption may not be entirely accurate, it holds statistical significance and thus provides a reasonable basis for supporting benign and malignant classification of breast tumors. The effectiveness of this approach has also been validated through ablation experiments conducted in this study.
However, this prior probability may not generalize well to populations with different age distributions. Therefore, when applying the BDES method to other domains or datasets, it is necessary to recalculate the prior probability based on the corresponding training data. In future work, we plan to incorporate additional demographic and clinical variables to further enhance the model's performance and adaptability.
Discussion on Computational Complexity
Firstly, while KNND-CS is effective in capturing local patterns within the data, its computational complexity increases with both the size of the dataset and the dimensionality of the feature space. Specifically, the time complexity of the k-NN algorithm is O(n⋅d), where n is the number of samples and d is the number of features. Although the number of features and neighbors we currently use is small and will not bring too much computational burden, when the feature dimension of the data increases, it may still lead to major computational challenges in high-dimensional space. To mitigate this, we plan to incorporate dimensionality reduction techniques for the case with higher dimensional features, which can reduce the feature space while retaining key information, thereby improving the efficiency of k-NN without substantial loss of performance.
Secondly, to reduce the computational burden of the simulated annealing process, we implement early stopping rules, where the algorithm terminates once the number of optimal ensemble classifiers exceeds one-third of the base classifier pool. This helps minimize unnecessary iterations, especially when convergence is achieved quickly, thus enhancing computational efficiency while preserving the integrity of model selection. At the same time, in order to further improve the limitations of the simulated annealing method in the BDES method, in future research, we will consider distributed computing and adaptive optimization algorithms.
In addition, the BDES method involves hyperparameters, which we currently set empirically based on the characteristics of the data, which does have certain complexity. In future work, we plan to explore automated hyperparameter tuning techniques to simplify the process and determine optimal parameter values more efficiently.
Discussion on Transparency of Decision-Making Process
The key motivation of BDES is to improve diagnostic performance while addressing challenges such as limited data and class imbalance. While ensemble methods like BDES inherently involve multiple models, we have taken specific steps to enhance interpretability and transparency:
Interpretability of Component Methods: Although BDES utilizes several algorithms, each component method—such as KNND-CS, simulated annealing, and Bayesian fusion—has a clear, well-defined role. We have ensured that the individual steps in the process are transparent, and the influence of each classifier selection is explainable. For example, KNND-CS dynamically selects base classifiers based on their relevance to the specific test sample, which can be traced and understood by clinicians.
Classifier Selection Process: The simulated annealing algorithm employed for classifier selection works by evaluating classifier performance in a way that can be monitored and interpreted, ensuring that the ensemble reflects a balance between accuracy and efficiency. Although the final ensemble model may appear complex, clinicians can review the chosen base classifiers and their contributions to the final decision.
It should be noted that the goal of BDES is not to replace clinical decision-making but to assist clinicians by providing them with a more accurate and data-driven diagnostic tool. Thus, the ensemble's decision process can be made more transparent by integrating clinician feedback in future iterations of the model, allowing practitioners to understand the reasoning behind each prediction.
Limitations and Future Directions
In summary, although the Bayesian dynamic ensemble selection (BDES) method performs well in the diagnosis of benign and malignant breast tumors, there are still some limitations in practical applications. First, the KNND-CS and simulated annealing algorithms in the BDES method significantly increase the computational complexity when facing high-dimensional data sets, which may lead to performance bottlenecks. Second, BDES involves the selection of multiple hyperparameters, and the current empirical settings may affect the model stability and tuning efficiency. Finally, the interpretability of the model still needs to be further improved.
Future research will focus on several key directions. First, the research will explore dimensionality reduction techniques and distributed computing to address the challenges brought by high-dimensional data and large-scale data sets. And automated hyperparameter optimization will also be the core of future research. Secondly, new optimization algorithms will be studied to alleviate the computational complexity limitations of simulated annealing. At the same time, in order to improve the interpretability and transparency of the model, explainable artificial intelligence (XAI) methods will be combined to enhance clinicians’ understanding of the model's decision-making process. In addition, the research will also focus on multimodal data integration, especially the fusion of imaging, clinical and genetic data, to enhance diagnostic support and promote the real-time deployment and application of BDES models on edge computing and mobile platforms.
Conclusion
In this study, we proposed the BDES (Bayesian Dynamic Ensemble Selection) method to address the challenges of limited and imbalanced data in the DOBI dataset, aiming to enhance breast cancer diagnosis. BDES dynamically select the optimal combination of classifiers for each test sample based on KNND-CS (K-Nearest Neighbor Dynamic Classifier Selection) and simulated annealing method, and fuse selected classifiers’ prediction based on Bayesian probability function to obtain accurate diagnosis results of breast tumors. Experiments shown that the accuracy and sensitivity of the BDES method on the mini-DDSM dataset are 76% and 83%, and on the DOBI dataset are 83% and 78%. These results are significantly better than those of many comparative methods, underscoring the high sensitivity of BDES in identifying malignant tumors. In addition, cross-validation and ablation experiments further validated the generalization and robustness of the proposed BDES method and the contributions of its various components.
This research contributes valuable insights into breast cancer diagnosis. By combining Bayesian probability fusion with an adaptive classifier dynamic selection mechanism, BDES achieved improved robustness and generalizability, and the simulated annealing in BDES ensures the model avoids local optima to improves overall performance. These advancements provide an accurate and rapid breast cancer diagnosis tool, which enhancing early breast cancer detection and improving patient outcomes.
However, the utilization of the simulated annealing method in BDES introduces computational complexity. Future research will focus on developing more efficient optimization algorithms to reduce computational overhead while maintaining or improving the model's performance.
Footnotes
Acknowledgments
This work was supported by the Joint Funds of the Zhejiang Provincial Natural Science Foundation of China under Grant No.LHZY24F05001. We thank the DOBI Medical Technology Co. for access to the data.
Authors’ Contributions
Xue Li: Conceptualization, Investigation, Formal analysis, Methodology, Validation, Writing - original draft, Writing – review and editing. Pengyue Liu: Conceptualization, Investigation, Validation, Writing- original draft. Xiguo Yuan: Data curation, Project administration, Supervision, Writing – original draft, Writing – review and editing, visualization. Ruowen Rong: Data curation, Supervision, Formal analysis, and Visualization. Yaoyao Li: Funding acquisition, Validation, visualization. Rong Luan: Data curation, Validation, Visualization.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Joint Funds of the Zhejiang Provincial Natural Science Foundation of China under Grant No. LHZY24F05001.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Statement
Data in this paper is unavailable to access or unsuitable to post, because the research data includes sensitive information.