
Abstract
This work proposes a leader–follower formation framework comprising three differential-drive mobile robots that are equipped with geometry-aware kinematics coupled with adaptive dynamics. The leader robot is directed by a nonlinear body frame tracking controller that is enhanced with an online radial basis function neural network. This network compensates for residual error in velocity-domain effects from the current position error, which enhances feedforward compensation without affecting stability. The dynamics of each robot are driven by an interval type-2 adaptive fuzzy-PID controller that adapts membership-function centers and footprint of uncertainty bounds in real time to deal with model mismatch and disturbances. As a result, the controller yields low chatter and ensures smooth control actions. The followers preserve formation using a geometric partial feedback linearization (PFL) design that integrates effectively with the adaptive layers. Controller gains for the leader and PFL formation kinematic controllers are tuned using the Secretary Bird Optimization Algorithm. A Lyapunov analysis for all the proposed controllers guarantees convergence and boundedness under nonholonomic constraints. Overall, the framework exhibits reliable path tracking and formation preservation, enhanced design for disturbance rejection, and smooth-behaved control effort through diverse operating conditions, such as robot dynamic model parameter uncertainties and control signals disturbances. Results show that all controllers ensured system stability and achieved low root mean square error values. Compared with existing works, the path accuracy for the leader was enhanced by 57%, while followers 1 and 2 achieved accuracy gains of 42.25% and 37.33%, respectively.
Introduction
Leader–follower formation control is widely used in multirobot navigation for tasks such as oil exploration and search-and-rescue (Shukla & Karki, 2016). It reduces the time, energy, and computational effort required compared with controlling each robot individually. The five main paradigms are described as follows: leader–follower, in which leaders define the path and followers keep set positions but risk failure if the leader is lost (Hirata-Acosta et al., 2021); leader-obstacle, which regards obstacles as temporary leaders to guide safe detours (Parvareh et al., 2023); virtual structure, which maintains precise geometric shapes through global coordination (Wang et al., 2024); behavior-based, which is inspired by swarms using simple local rules for flexible but less precise movement (Aldana-López et al., 2022); and consensus-based, which employs multiple leaders as shared references for improved accuracy and robustness (Xu et al., 2024).
Formation approaches manage multirobot tracking by designating one or more leaders, with followers maintaining specified distances and orientations. Since 2020, studies have explored robust, adaptive, observer-based, sliding-mode, neural-dynamics, fuzzy/adaptive, and deep-learning approaches. In observer-based control, Hassan and Hammuda (2020) proposed a least-squares smoothed regularized observer for real-time follower state prediction without predefined paths, which enables adaptive path changes (Hassan & Hammuda, 2020). Proportional–integral observers with active disturbance rejection control have also been applied to omnidirectional robots, which achieve robust distance-bearing regulation under disturbances (Nasser et al., 2021; Ramírez-Neria et al., 2023). A robust adaptive controller developed in 2023 enabled virtual leader switching for obstacle avoidance while estimating uncertainty bounds using model-free adaptation (Parvareh et al., 2023).
The hybrid sliding-mode and neural-dynamics designs by Wang et al. (2024) include combined sliding-mode control with attractive–repulsive forces for collision avoidance and dynamic gain scheduling to maintain formation (Wang et al., 2024). Xu et al. (2024) proposed a bio-inspired neural-dynamics strategy with backstepping–sliding-mode integration and an adaptive sliding filter, ensuring distributed normalized inputs, chattering suppression, and noise-robust state estimation (Xu et al., 2024). Other notable methods include bearing-based control, such as that of Trinh and Ahn (2022), who achieved finite-time convergence for acyclic formations via state-dependent gains (Trinh & Ahn, 2022), and fuzzy-adaptive control, as demonstrated by Nourizadeh et al. (2022), who developed a type-1 fuzzy-adaptive backstepping controller to manage large initial spikes and ensure global stability through Lyapunov analysis (Al Mhdawi et al., 2023; Nourizadeh et al., 2022). Lastly, Zhang et al. (2020) combined a disturbance observer with super-twisting second-order sliding-mode control to reject disturbances, eliminate chattering, and enhance leader–follower guidance under uncertainties (Zhang et al., 2020).
Notable controllers in this field include that of Ali et al. (2021), who developed an adaptive fuzzy-PID hybrid scheme for leader–follower formations under communication delays. A classical PID core was augmented with a fuzzy layer for real-time gain tuning, using trajectory error feedback to improve responsiveness and disturbance rejection while maintaining tight position–velocity coordination despite delays (Ali et al., 2021). Bui and Phung (2024) proposed a radial basis function neural network (RBFNN)-enhanced sliding-mode backstepping controller for UAV formations driven by a virtual leader. The RBFNN estimates external disturbances and unmodeled dynamics, while the nominal backstepping–sliding structure provides robust tracking with PID-like adaptive gain tuning (Bui & Phung, 2024).
Aryankia and Selmic (2021) applied neuro-adaptive backstepping with RBFNN for nonlinear multiagent swarms under delays; this method uses RBF approximation to handle unknown nonlinearities and disturbances with online weight adaptation (Aryankia & Selmic, 2021). Goto et al. (2024) employed an adaptive immune–fuzzy quasi-sliding mode controller that combines a PD core with a fuzzy–immune modulation layer to adaptively adjust control effort and suppress chattering (Goto et al., 2024). Recent studies have further explored advanced adaptive and learning-based schemes. A neural adaptive prescribed-performance controller presented in (Xie et al., 2024) integrates graph-based guidance via RBFNN approximation and backstepping, improving tracking accuracy but exhibiting structural complexity and some chattering. An adaptive distributed controller based on a recurrent soft actor–critic algorithm was proposed in (Li et al., 2024), which enables formation coordination with only position of fast adaptation in simulation. However, it lacks real-world validation and faces challenges related to data interpretability.
Despite notable progress in leader–follower formation control, ensuring accurate trajectory tracking and stable formation maintenance under nonlinear dynamics, modeling uncertainties, and unpredictable external disturbances remains a major challenge. Existing techniques often confine adaptation to the kinematic level while neglecting the intricate coupling with system dynamics. Meanwhile, dynamic-level controllers are frequently implemented without adequate mechanisms to mitigate residual tracking errors or counteract time-varying disturbances. Moreover, controller gains are commonly determined through heuristic tuning, which can result in performance degradation when operating conditions deviate from nominal scenarios. These limitations highlight the need for a unified, adaptive, and disturbance-resilient control framework that combines kinematic and dynamic considerations, ensuring robustness and high-precision formation performance across diverse and uncertain environments.
The proposed intelligence framework integrates three layers. First, an online RBFNN augments the leader's kinematic law by compensating residual errors in the velocity control signal. Second, an interval type-2 adaptive fuzzy-PID (IT2AFPID) dynamic controller adapts its membership-function centers and footprint of uncertainty (FoU) in real time. Third, gains in the nominal leader controller and the followers’ partial feedback linearization (PFL) law are refined via the Secretary Bird Optimization Algorithm (SBOA) using a root mean square error (RMSE)-based objective. Overall, these elements yield a cohesive, learning-enabled control architecture. The contributions are in three parts: Leader kinematic tracking controller - A nonlinear tracking law is augmented with an online RBFNN to compensate for residual errors in leader controller's velocities. The RBFNN modifies the nominal velocity commands in real time using online stochastic gradient descent learning laws, ensuring stability while eradicating the need for integral action. SBOA-based optimized gains are applied to the nominal nonlinear tracking law. A filtered orientation error formulation is used to achieve fast convergence without overshoot. Dynamic-level controller for leader and followers - A feedback linearization scheme is integrated with an IT2AFPID controller in the feedback loop as an inner velocity loop. The IT2AFPID adaptively tunes the centers and spreads of Gaussian membership functions (MFs, the adaptive FoU) to maintain robustness under varying dynamics, while nonlinear gain computation allows precise tracking despite time-varying uncertainties. Follower formation controller - A partial geometric nonlinear formation law with PFL, whose gains are optimized using the SBOA. The optimization minimizes formation errors, ensuring smooth orientation and distance regulation between robots.
The paper is organized as follows. Section 2 presents the mathematical kinematic and dynamic models. Section 3 illustrates the design of the proposed controllers. Section 4 introduces the Lyapunov stability analysis for the proposed controller by lemmas and their proofs. Section 5 presents the SBOA. Subsequently, Section 6 presents an analysis of the simulation results of the proposed controllers and compares them with other formation algorithms for leader–follower tracking. Lastly, Section 7 provides conclusions and opportunities for future research.
Methodology
This section presents the mobile robot kinematic and dynamic models.
Differential-Drive Mobile Robot Kinematics
The schematic of the nonholonomic differential-drive mobile robot is displayed in Figure 1, where the two axle wheels control rotational motion and the passive wheel at the head provides directional motion. Here,
Equation (1) presents the matrix form of the system constraint (Wang et al., 2023):


Let

Then,

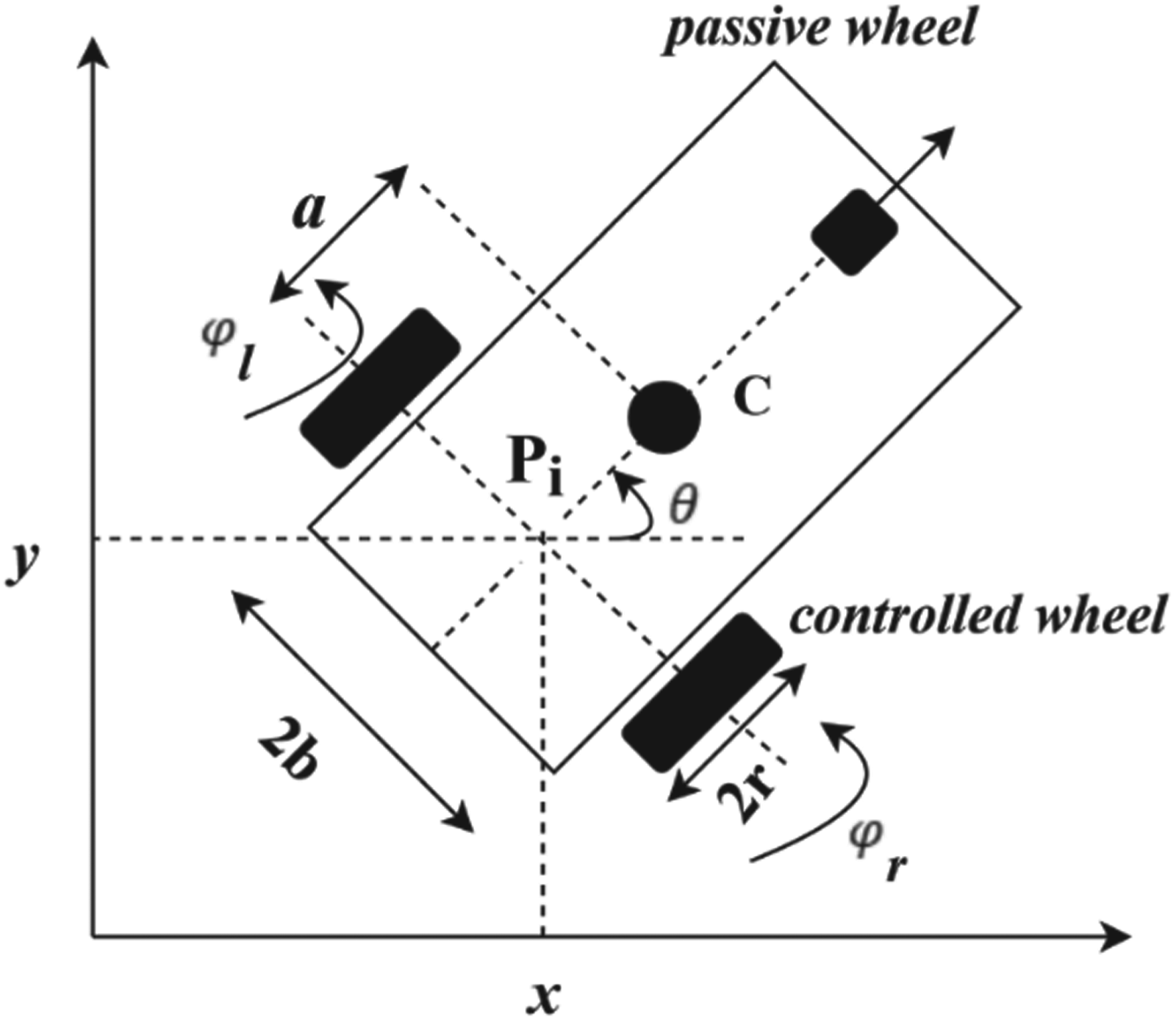
Differential drive mobile robot platform.
The kinematic model is represented as (Wang et al., 2023):

The Lagrange method used to format the dynamical equation is as follows (Fierro & Lewis, 1998):
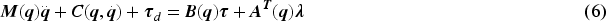
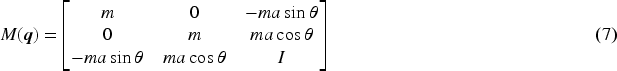


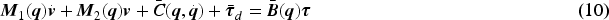
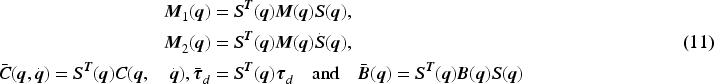
By multiplying Equation (11) by

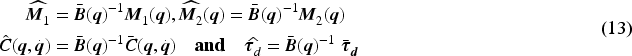
This section presents the leader's kinematic controller, the IT2AFPID dynamic controller for each robot, and the followers’ PFL-based formation law.
Leader Kinematic Controller (Path Tracking)
The tracking of the specific path problem involves guiding the robot to follow a specific path in Cartesian space under defined circumstances. The objective is to design a control signal that guides the tracking error toward zero. The goal is to follow a reference trajectory defined by a point

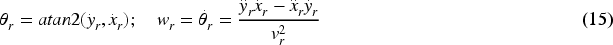

The robot frame tracking error after multiplication by the transformation matrix T is:

It is simplified to:
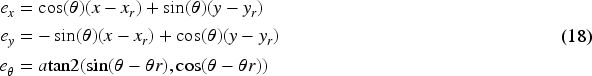

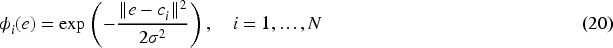




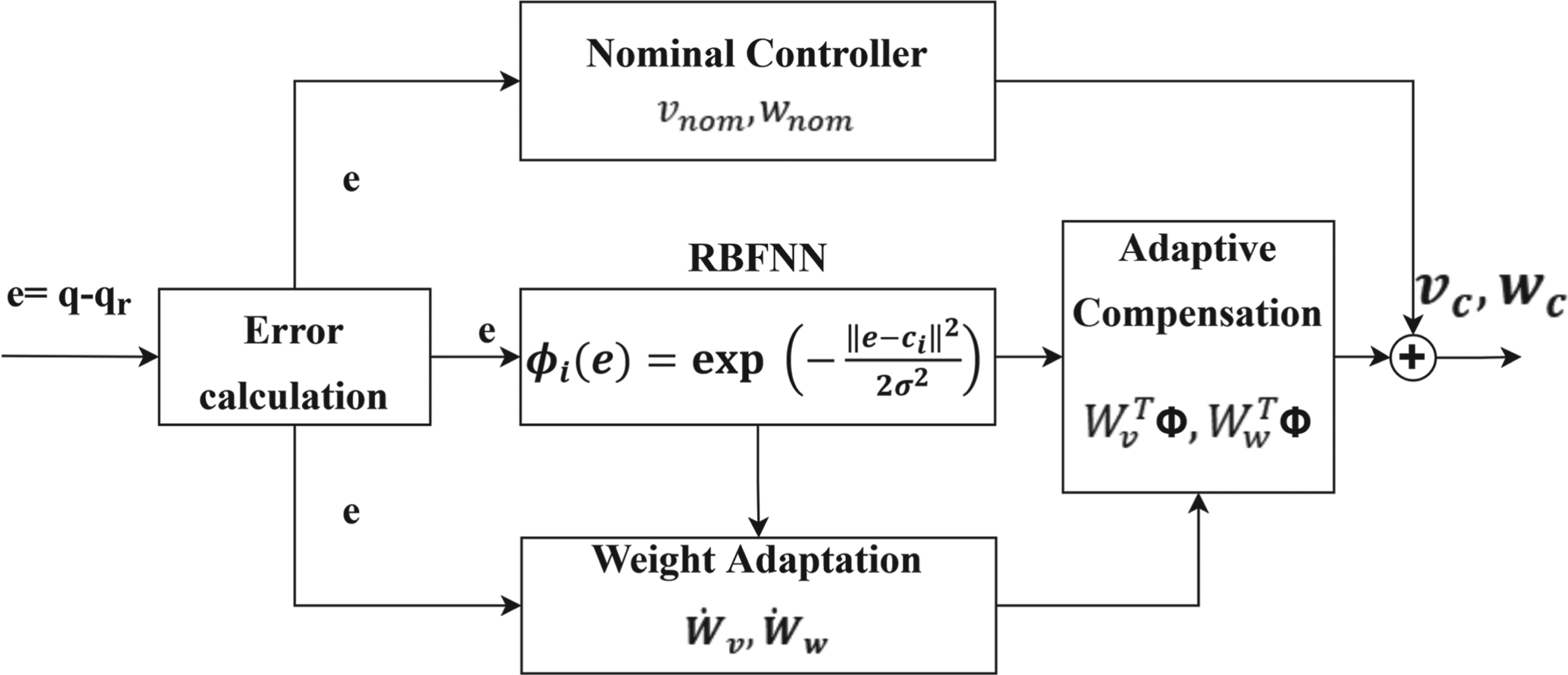
RBFNN proposed to compensate for the global leader kinematic control signal.
Parameters of RBF and the Kinematic Controller.
The dynamic controller design is based on feedback linearization of the robot dynamics, which is equipped with an IT2AFPID controller (Karam et al., 2019) and (Hassan et al., 2020). This integration aims to design a robust controller. The rules of the IT2AFPID controller are suited for nonlinear systems, where it has an FoU in its MF (Ghintab & Hassan, 2025) and (Boulkroune et al., 2025). This feature enables the controller to effectively handle uncertain systems, time-varying systems, and missing dynamics (Sabeeh et al., 2022) and (Rigatos et al., 2020).
The dynamic controller's objective is to track the desired velocity, 
Then, the control rule is
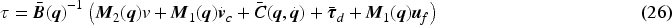

This approach ensures adaptive compensation (Merazka et al., 2017) and bounded behavior near the origin. Based on the inverse of the system dynamics, the actual velocity is given by:
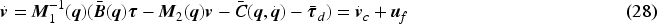

The proposed IT2AFPID adapts the Gaussian MFs and integral-enhanced output gain tuning (Challoob et al., 2024), providing improved convergence and robustness in error tracking. The following novel elements distinguish our IT2AFPID controller: Adaptive interval type-2 fuzzy inference, where each MF learns independent upper sigma Aggressive gain modulation via adaptive defuzzification gain ( Integral action with a dead-zone reset to suppress chattering and mitigate windup. Real-time adaptation of MF centers based on online error signals.
The controller receives an input vector of dimension 18, representing 6 channels of error signals for each robot, as shown in Equation (30). This vector contains the proportional error 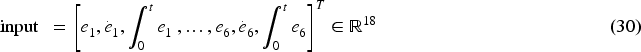
Pseudo IT2AFPID Controller Design Algorithm.

where
The block diagram shown in Figure 3 illustrates the proposed leader–follower formation strategies with controllers for one leader and two followers (Do et al., 2022). Each follower maintains a specified distance and orientation from the leader robot, as shown in Figure 4. The measurement of position for each follower with respect to the leader, along with the horizontal angle of the midline connection, is necessary for optimal coordination. In the mathematical formulation, the robot's center of gravity serves as the reference point for control. Based on Figure 4, the ith follower with position 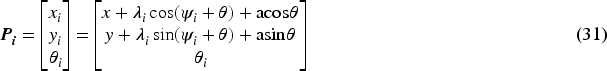
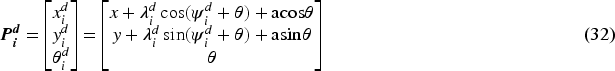

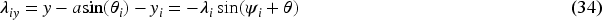
Leader-follower proposed formation control of ith- follower block diagram.
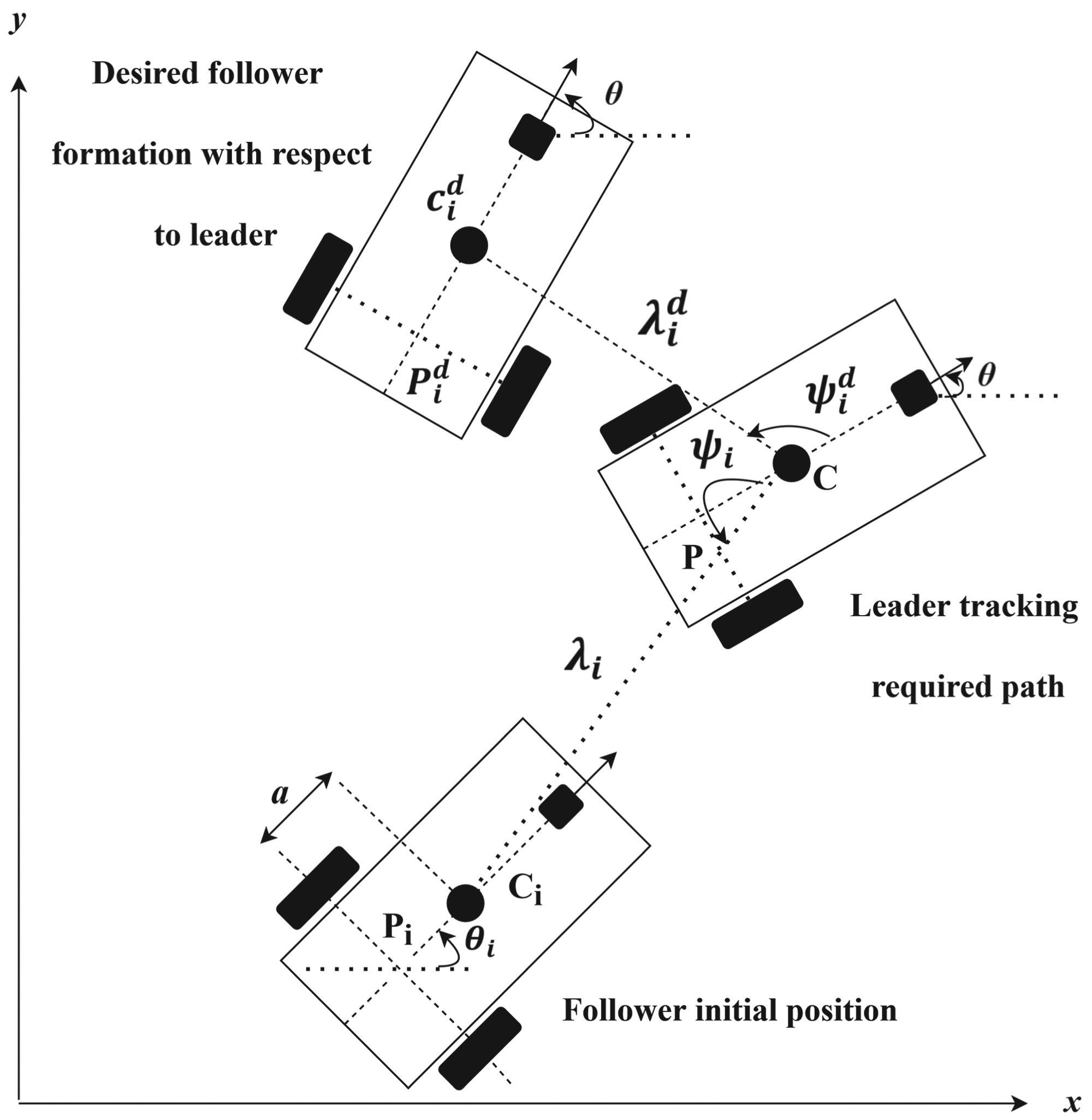
Leader-follower mobile robot formation.
The separation angle 
The system formation dynamics can be calculated and simplified with derivatives of 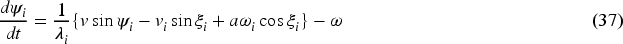

Using Equation (33), the formation control error is rewritten as:
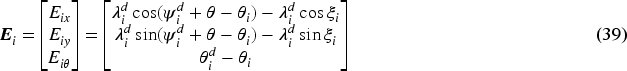
Then, the obtained error dynamics is expressed as:

The simplified form is
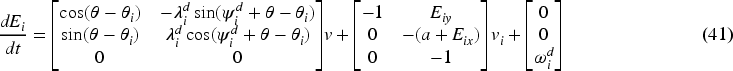
The formation controller inputs at the kinematic level 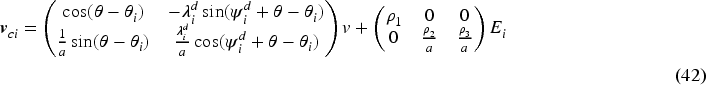
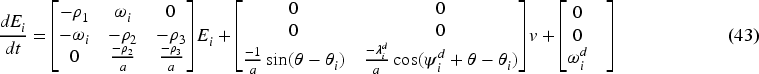
Owing to nonholonomic constraints, the angle of each follower cannot remain identical during the robot maneuvers. Thus, the desired orientation cannot be assigned as 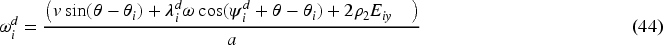
Applying it to the dynamics yields:

Lyapunov stability analysis will be presented for the kinematic controller of the leader, the dynamic controllers of all robots, and the formation-level kinematic controller. The analysis will be structured in lemmas and their proofs.
Stability Analysis of the Leader Kinematic Controller
To ensure the robustness of the proposed leader kinematic controller, it should be subjected to a candidate Lyapunov function. It should provide asymptotic stability with this controller. The proposed Lyapunov function is:

Let
Under the proposed control law, the tracking errors
Taking the derivative of 
The adaptation law cancels the approximation residuals under ideal online learning; the derivative is negative semi-definite:

Thus,
The following lemma summarizes the stability condition and its proof.
Global asymptotic stability by an IT2AFPID controller-based velocity tracking controller can be guaranteed. Based on the dynamics of Equation (28), 
Based velocity error of Equation (25), and substituting Equation (26) into Equation (28) results in:
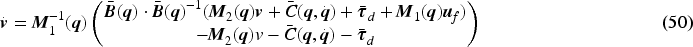
Then
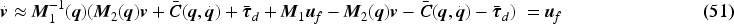
Therefore, the derivation of velocity error dynamics:

However, for stability analysis and the assumption of the desired velocity 
Now, the candidate Lyapunov function is:

Since, 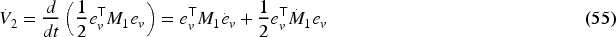
Substitute 
By using norm inequalities, the result is:
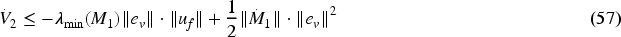
Under the assumption of 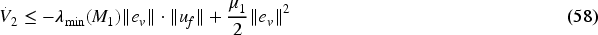
Then, for ensuring 
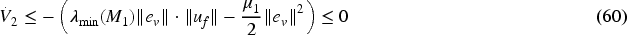
Then,
Lemma 3 provides asymptotic stability of the formation tracking error system.
Consider the error dynamics of Equation (45) with
The proposed positive definite Lyapunov function is:


Taking the time derivative as:

And substituting Equation (44), then:
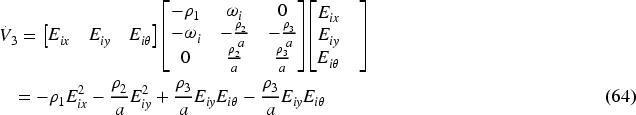

This derivative is negative semi-definite since 
Substituting equation (65) into the error dynamics, then:

Since 
By LaSalle's Invariance Principle, the origin
The SBOA is a nature-inspired schema that involves the hunting mechanism of secretary birds, designed by Fu et al. (2024). SBOA iteratively improves optimal solutions by alternating between exploration (jumping attacks) and exploitation (walking and stalking). The following are the details of the algorithm's working. (Fu et al., 2024)



Exploration scenario (Jumping Attack): This mechanism is used to explore the search space with large jumps to avoid falls in local minima:
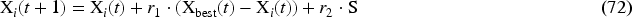
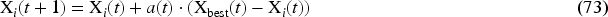

It is used to control the step size, minimizing linearly from 2 to 0 for balancing in the exploration and exploitation, and
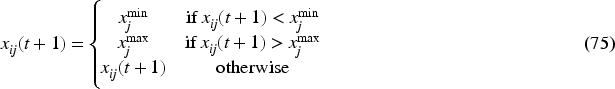

The SBOA, which outperforms in the minimization objective function over 30 optimization algorithms using various penalty functions, is used to tune the leader's kinematic controller gains based on the designed objective function
Let 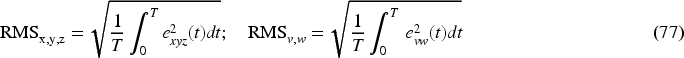

According to the kinematic-level formation controller, the objective function is based on the ith follower by finding the optimal gains. 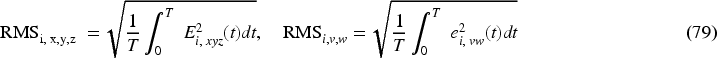
Two trajectory scenarios—star-shaped path and sinusoidal path—are used to evaluate the controllers under sharp-turn conditions that test controller performance. The controllers must optimally adjust each robot's linear and angular velocities to minimize path tracking errors, dynamic deviations, and formation discrepancies. The star-shaped path is mathematically defined as follows:
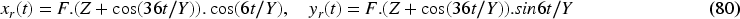

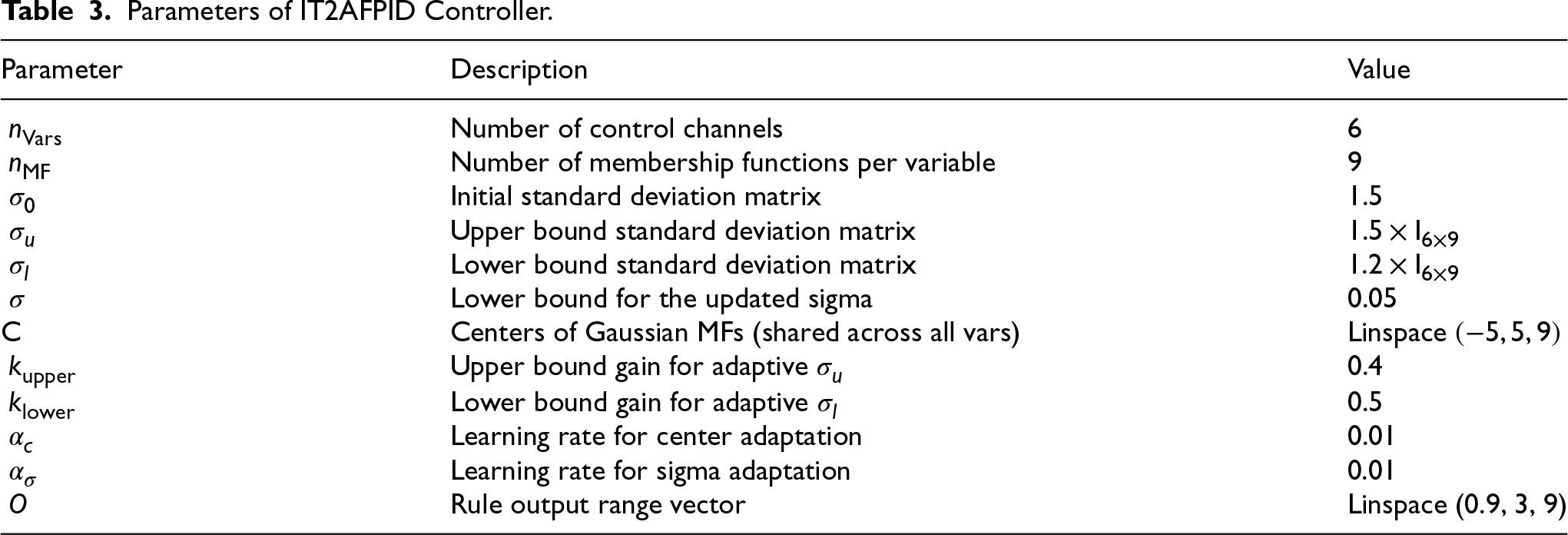
Parameters of IT2AFPID Controller.
The parameters of SBOA are as follows: population size (30–50), number of iterations (10–50), flight scaling factor (0.1–0.5), and Levy exponent of 1.5. Based on these settings, the optimal control gains based on SBOA for star and sinusoidal trajectories are: (
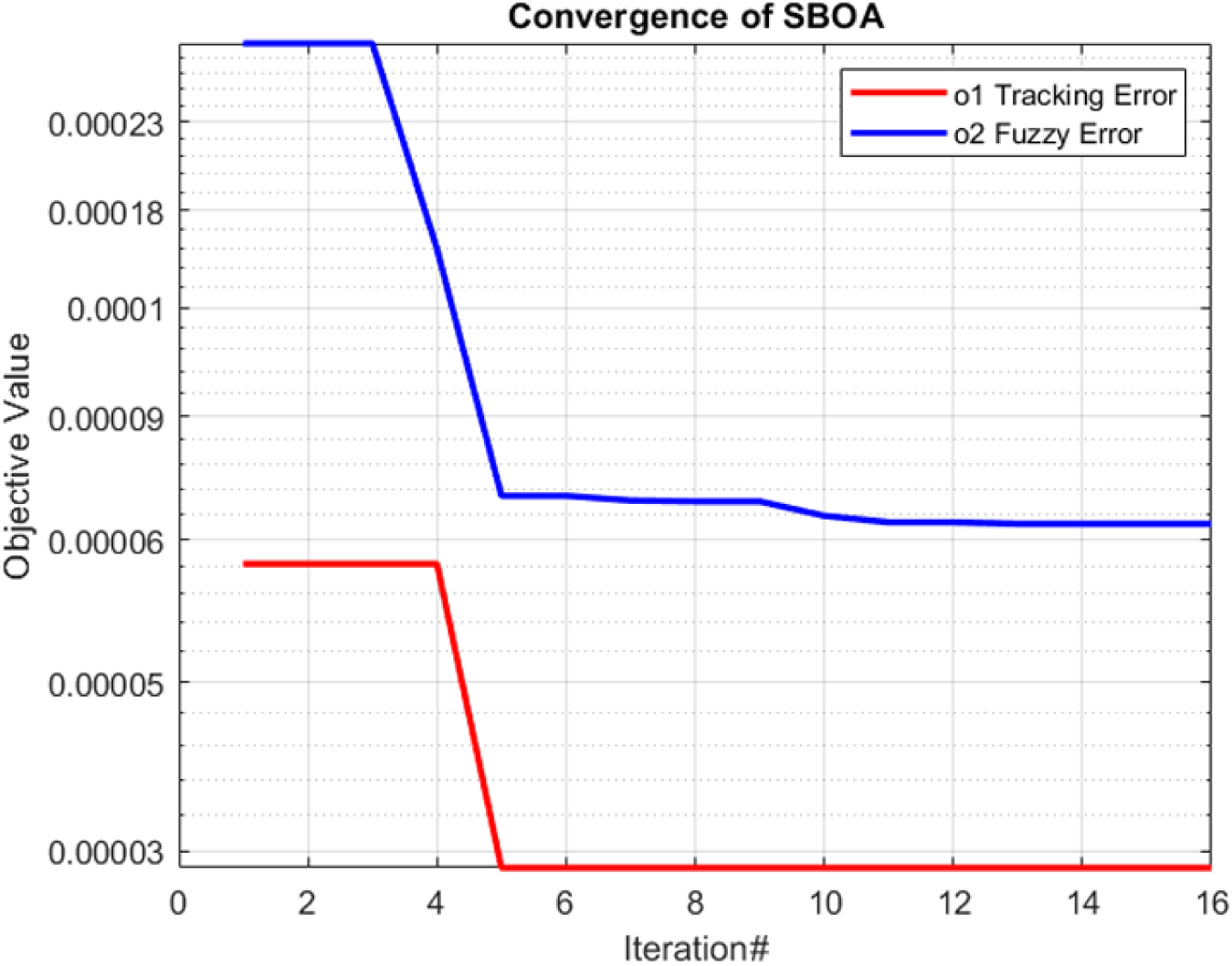
Objective functions minimization by SOBA.
The desired formation is defined by a bearing angle
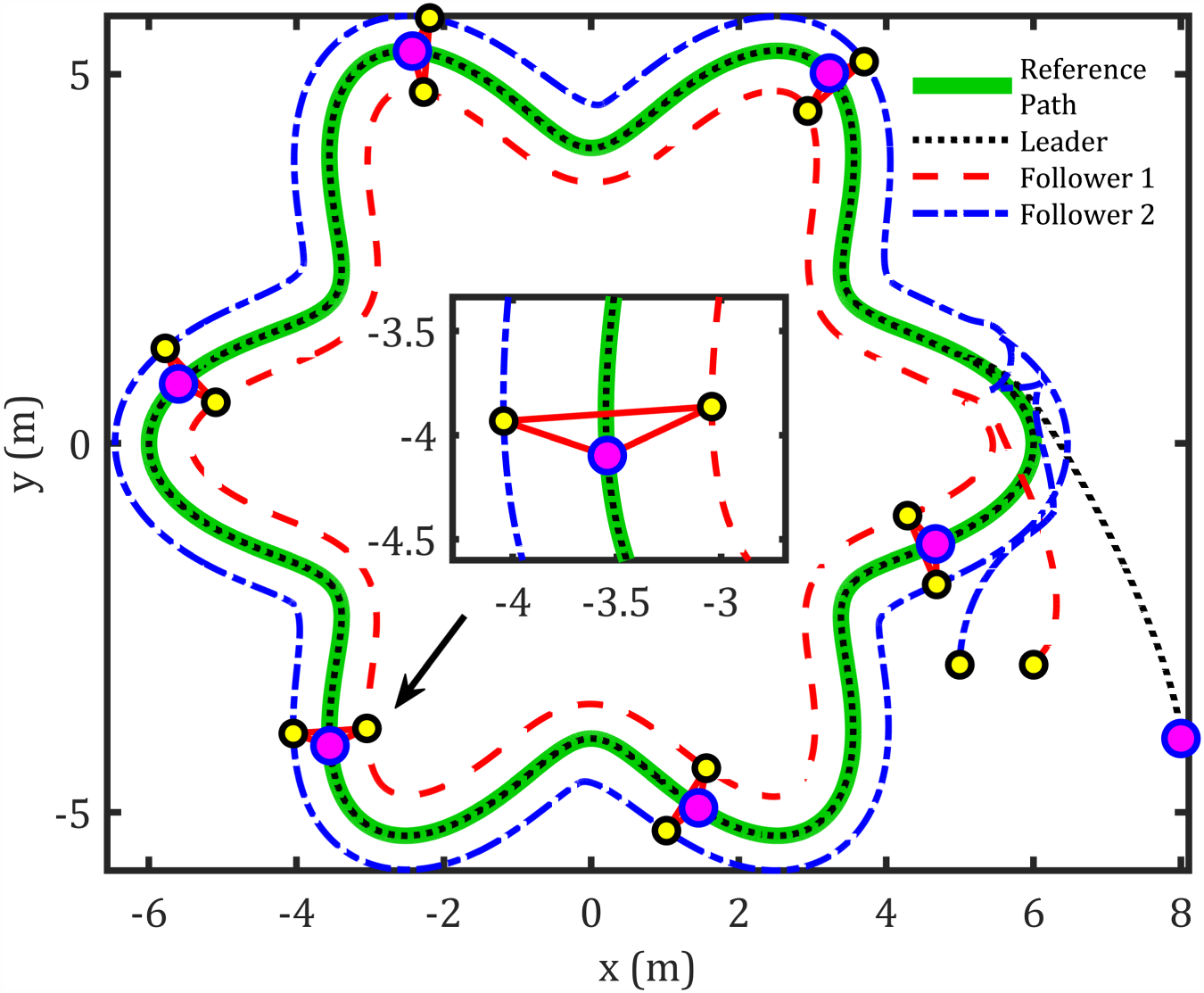
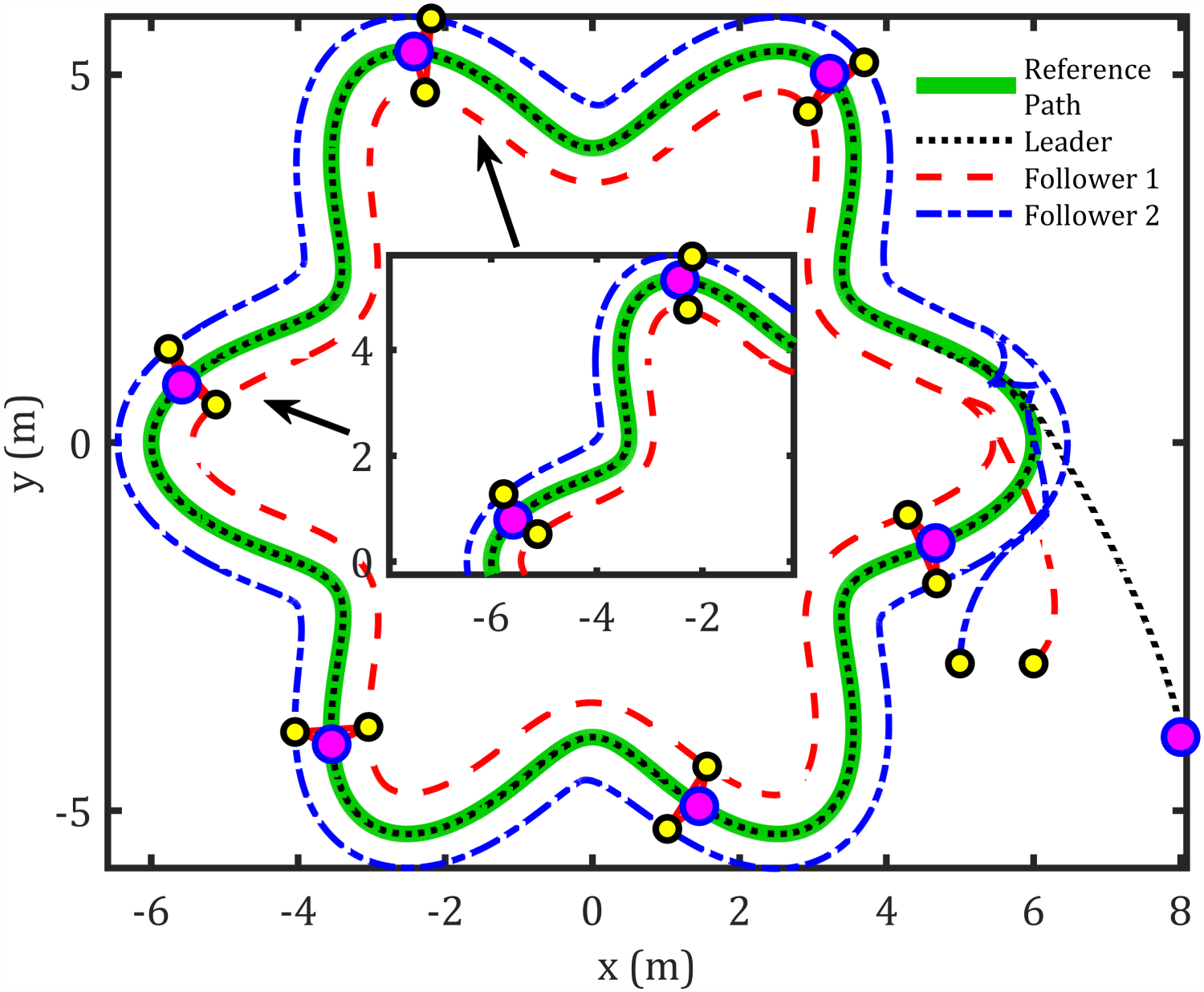
Star path formation control.
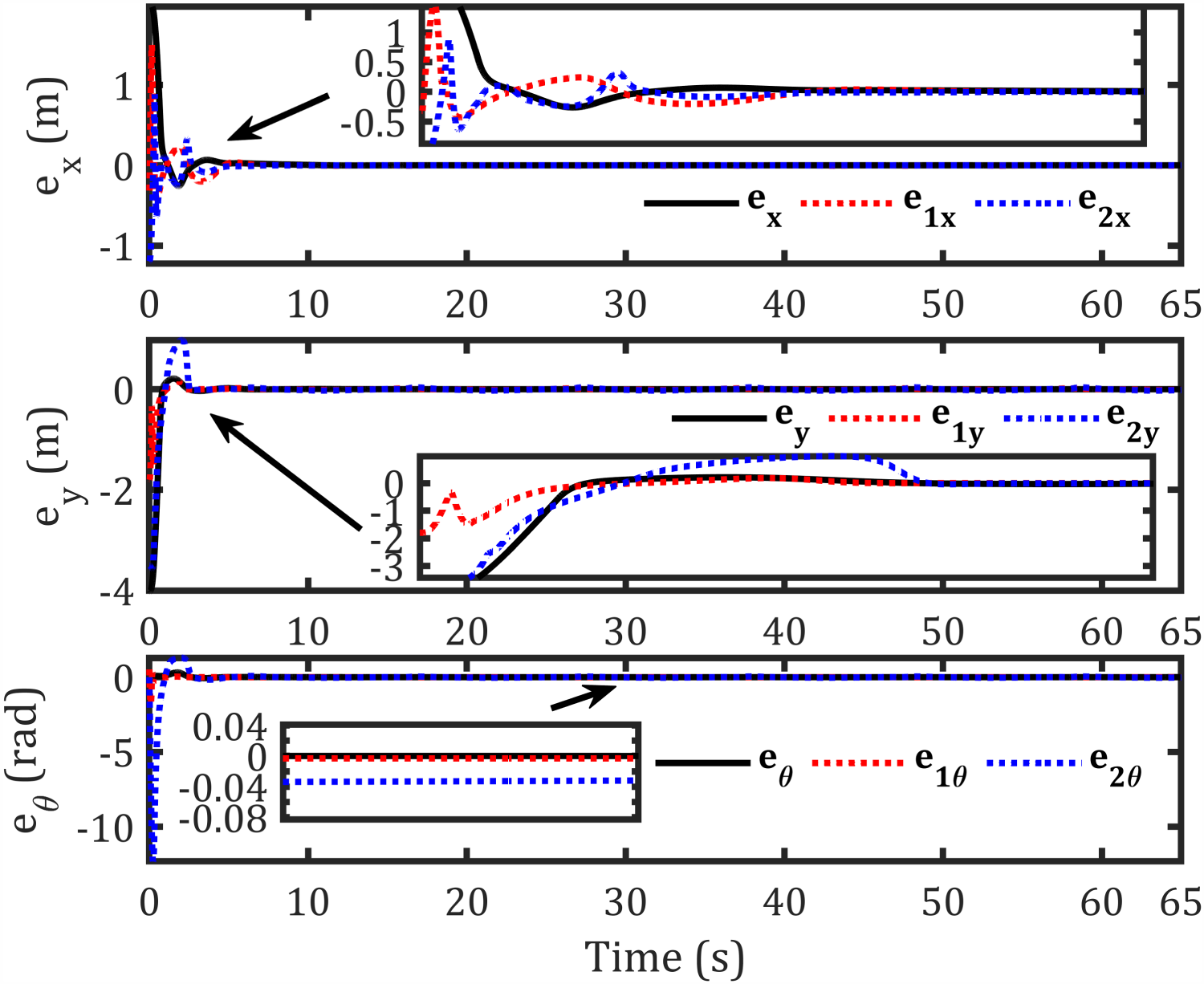
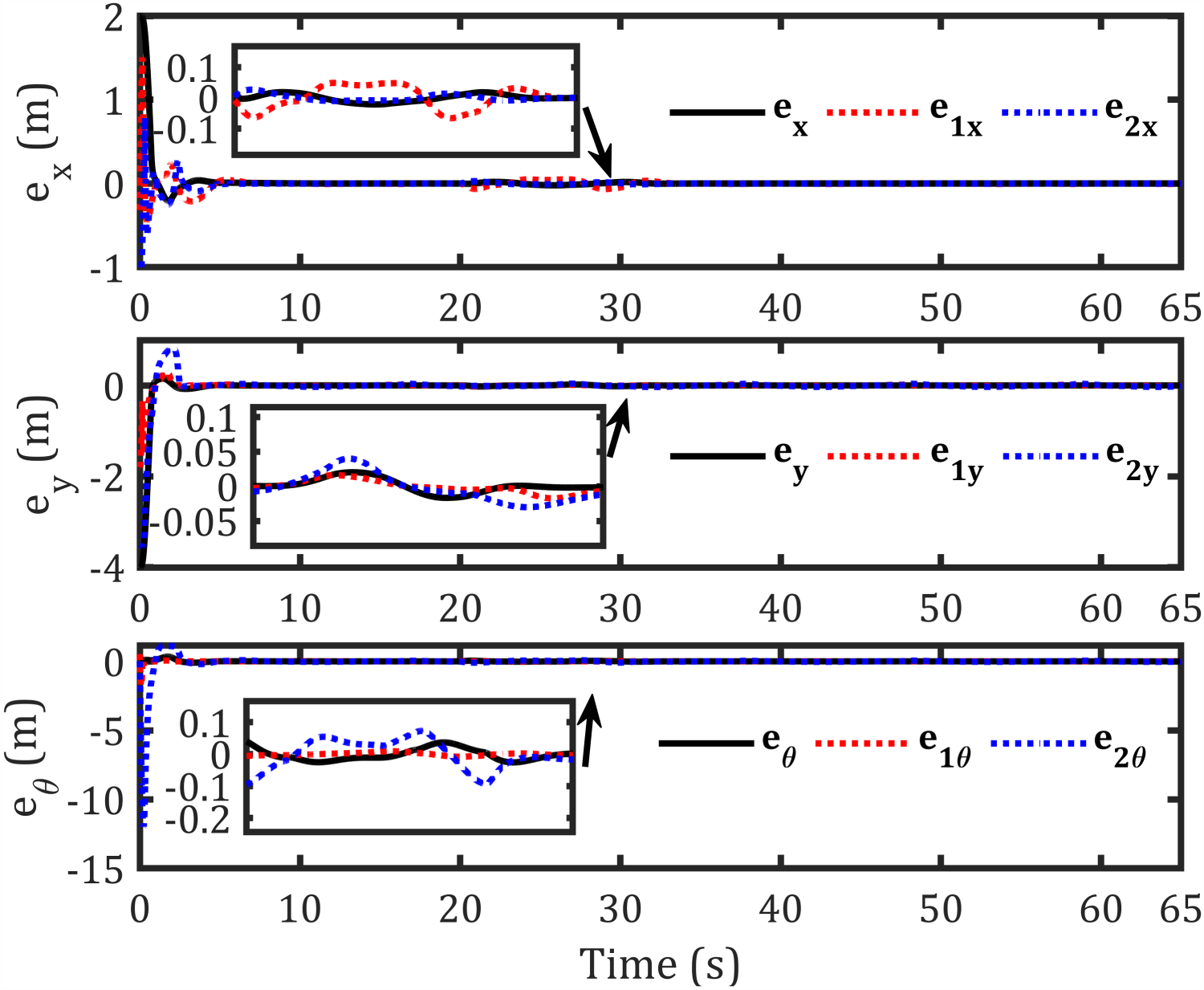
Error in axes for each robot-based formation.
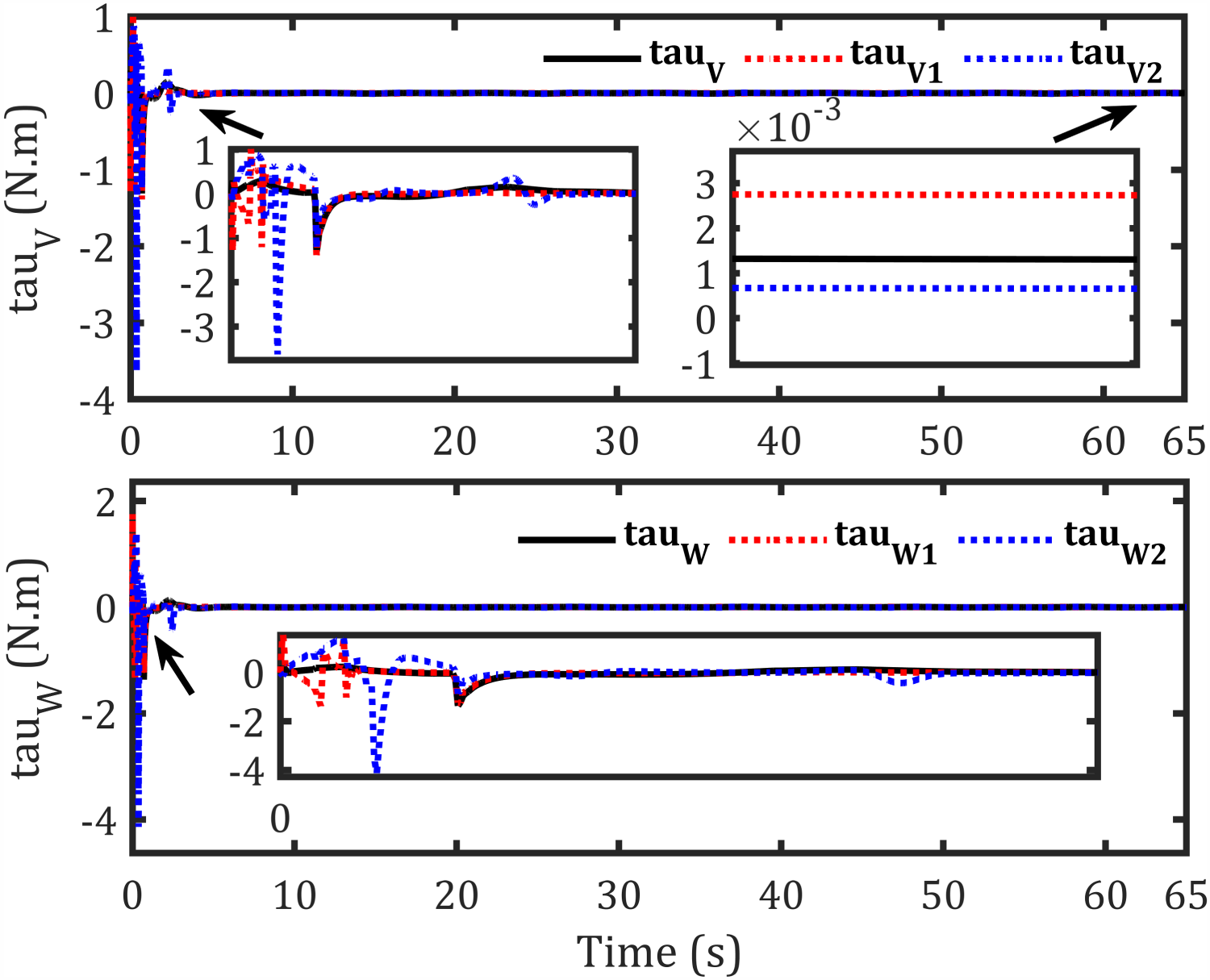
Controlling torque signals for each robot-based formation.
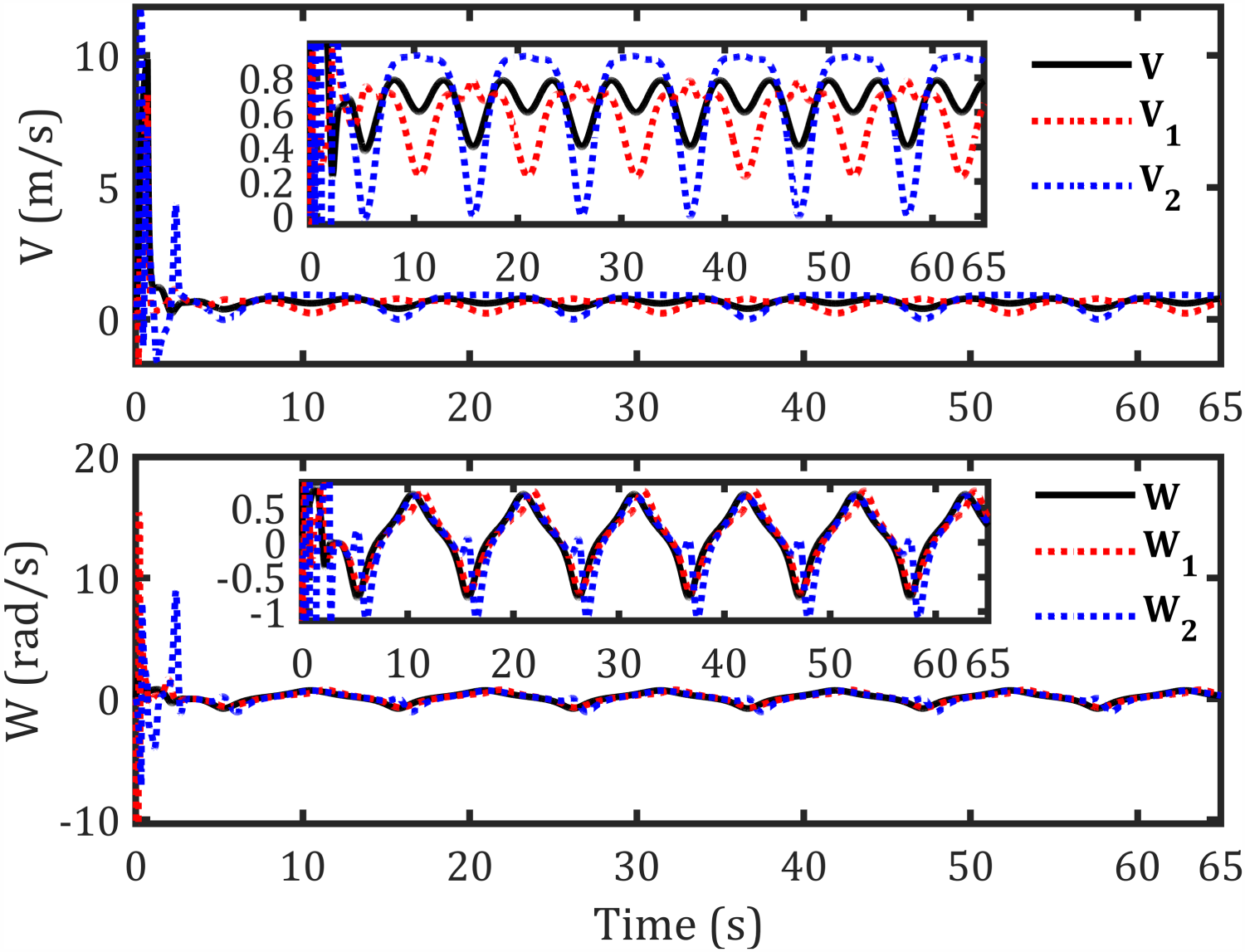
Velocities for each robot-based formation.
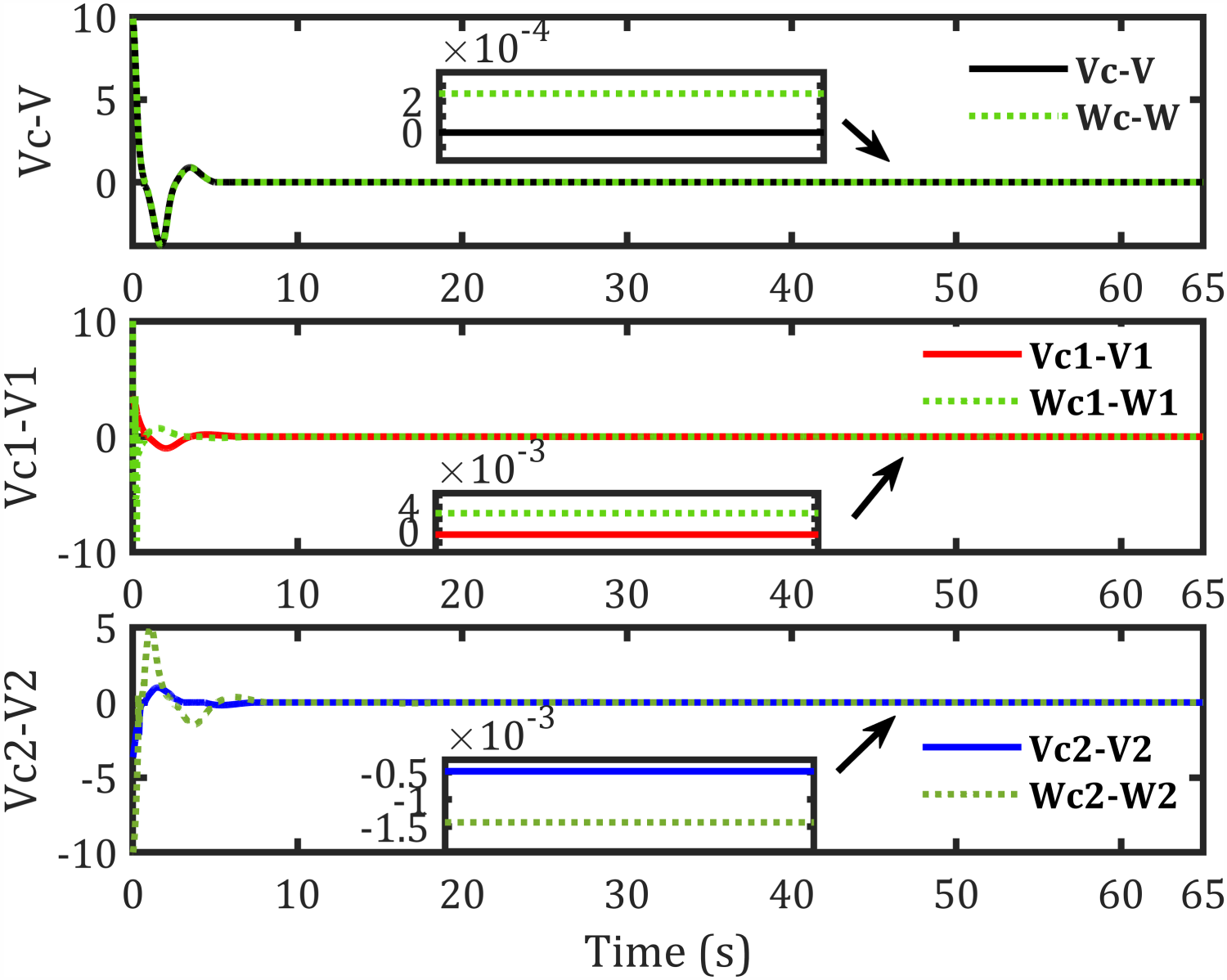
Velocities error
The tracking results for the second sinusoidal path, errors along each axis, control torques, and corresponding velocities are shown in Figures 11–14, respectively, while Figure 15 illustrates the convergence of
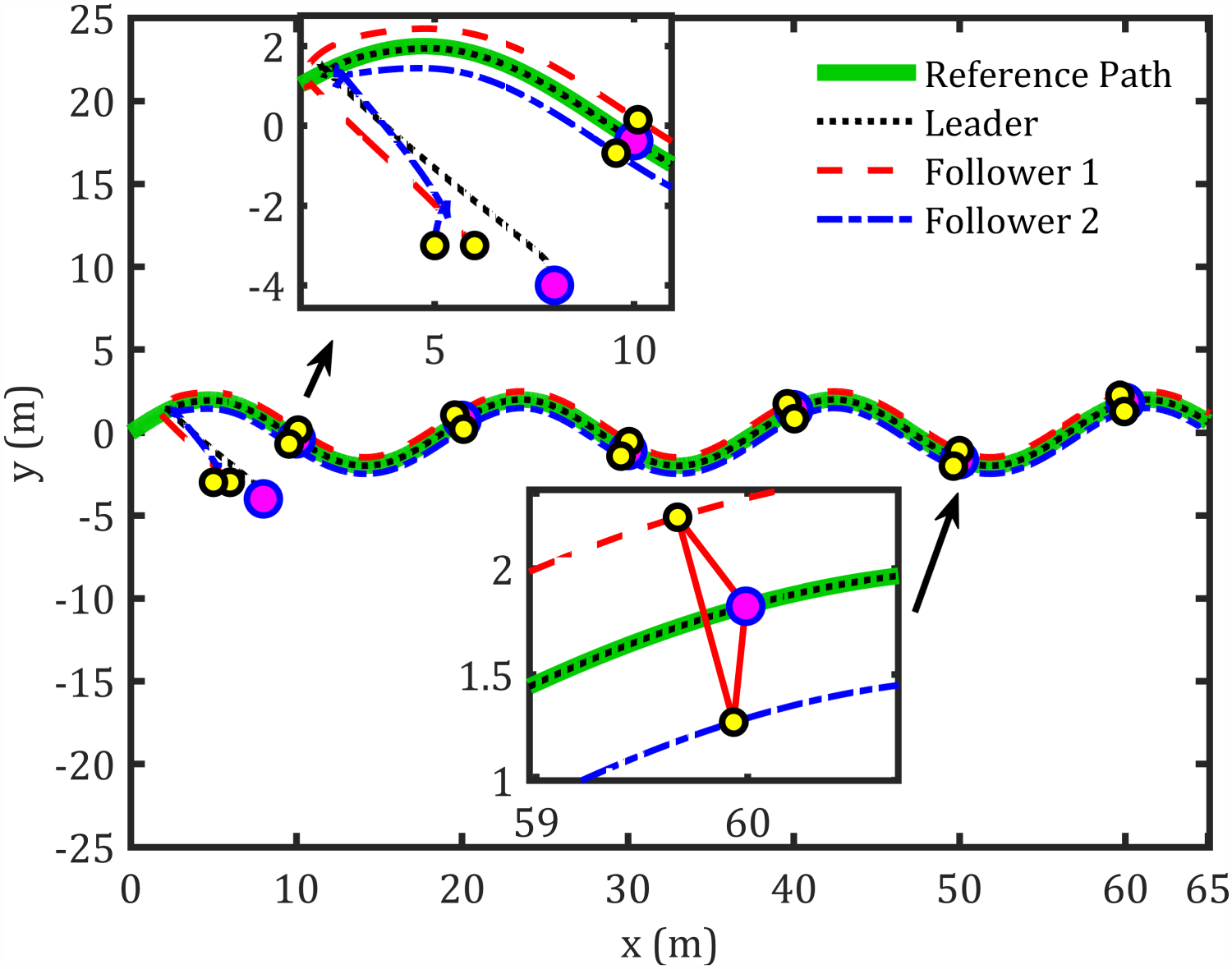
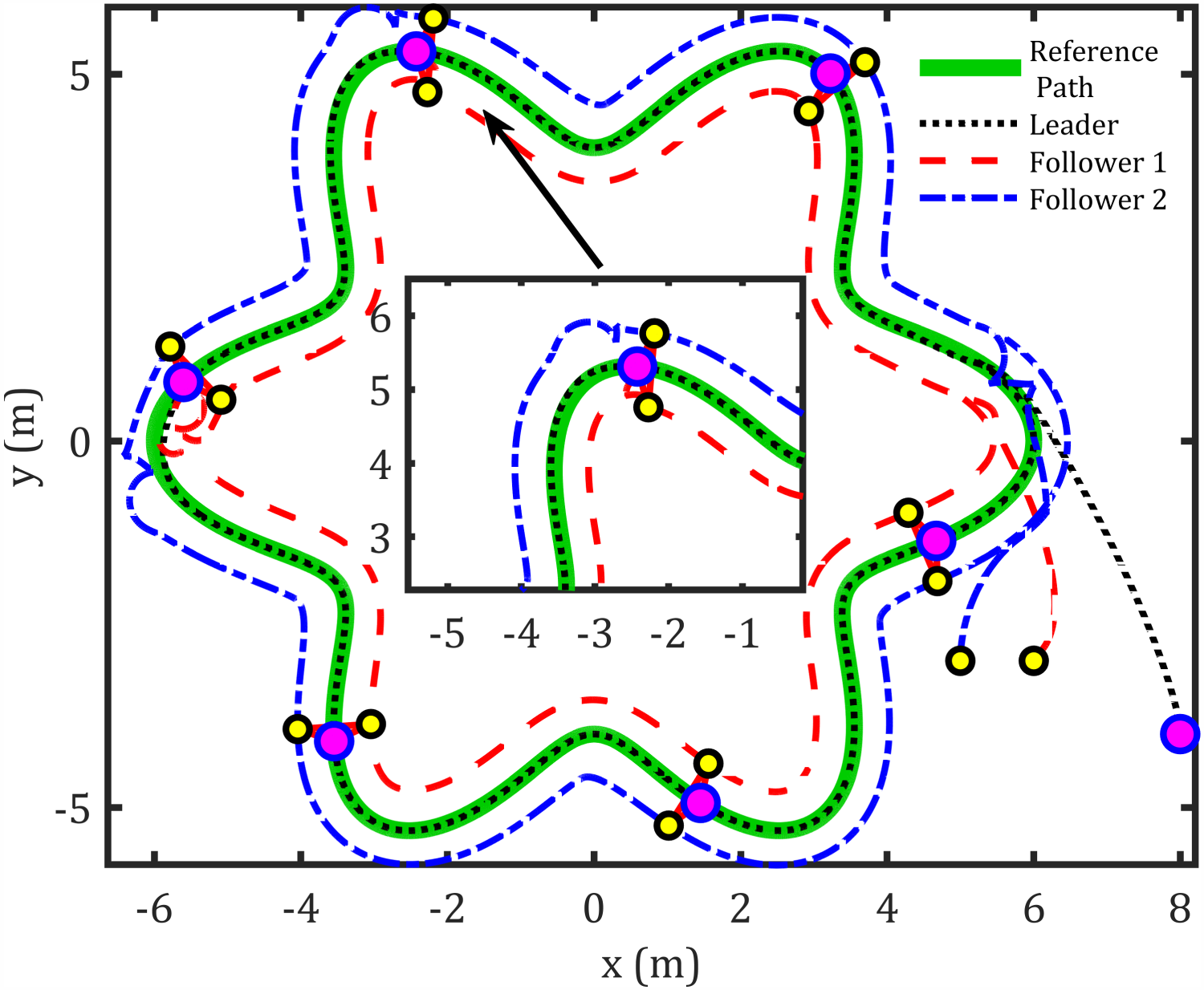
Sinusoidal path formation control.
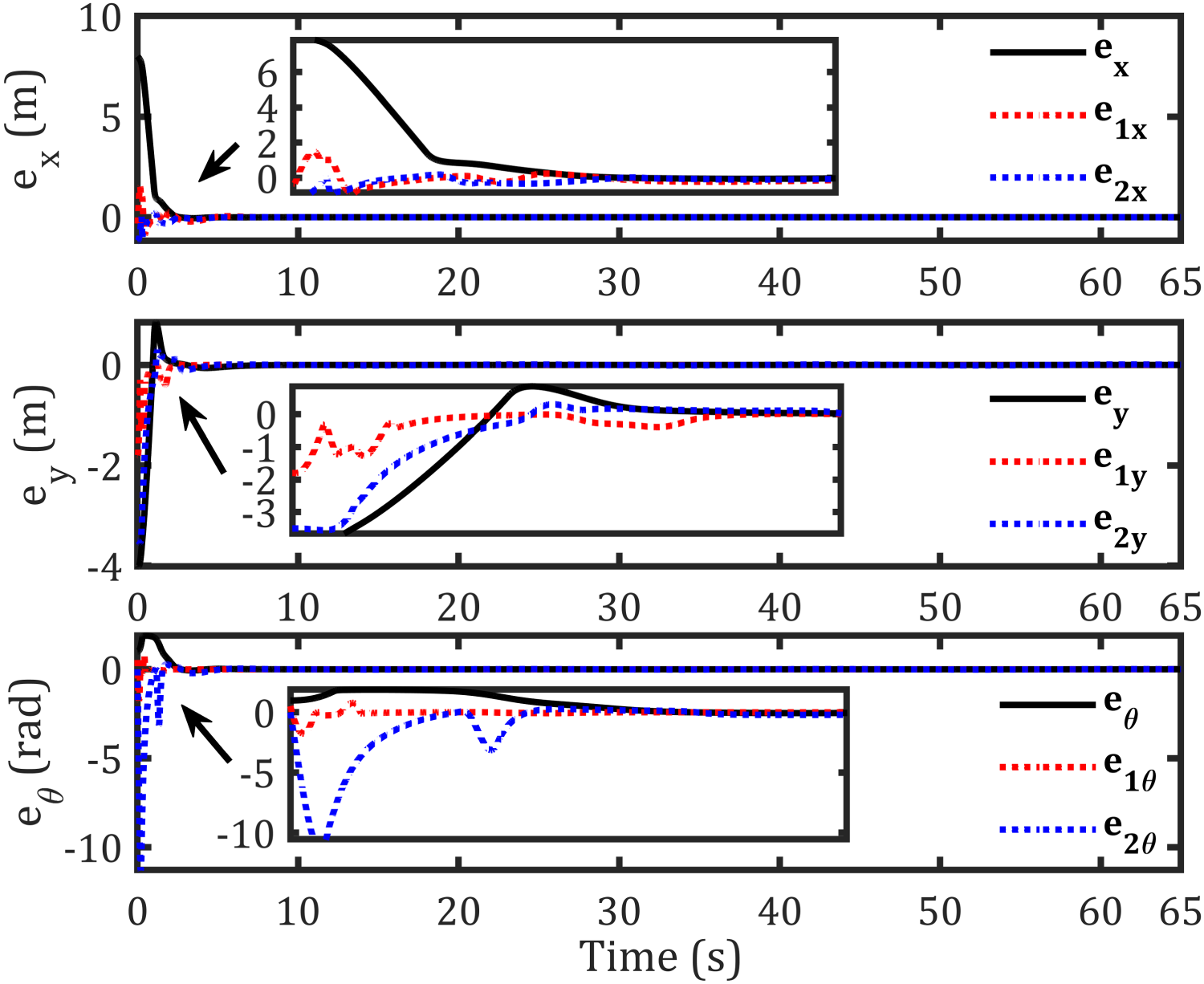
Error in axes for each robot- sinusoidal path.
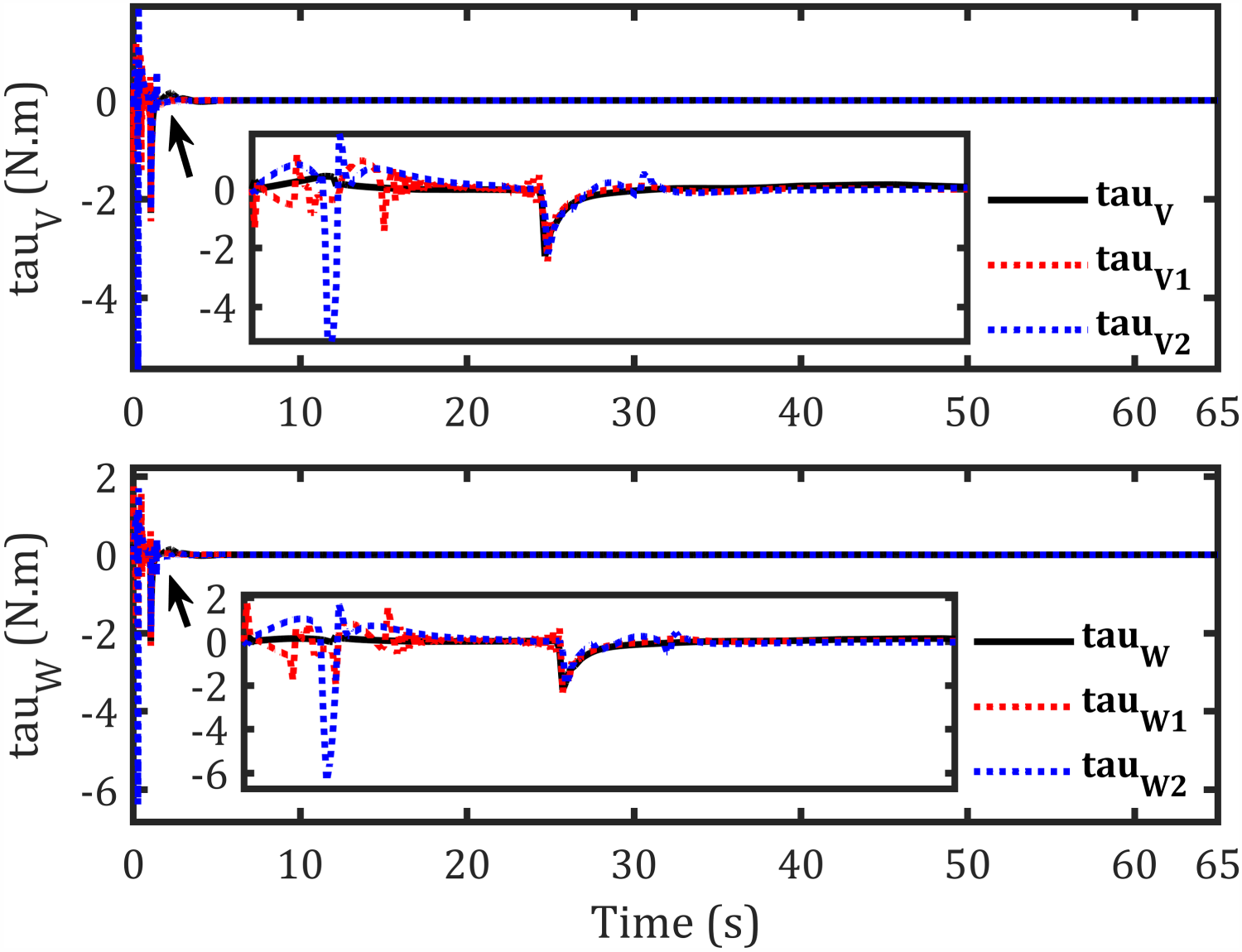
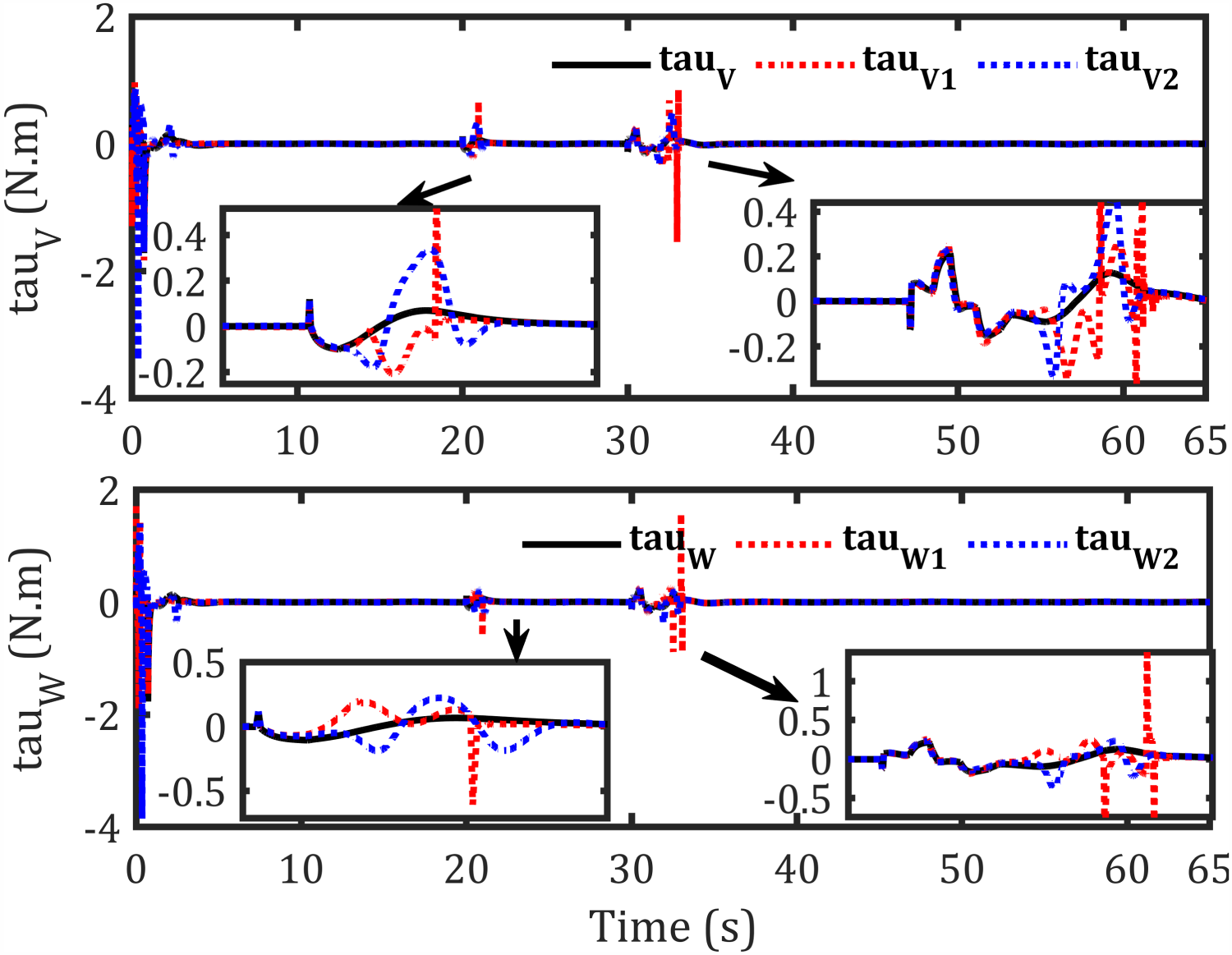
Controlling torque signals for each robot- sinusoidal path.
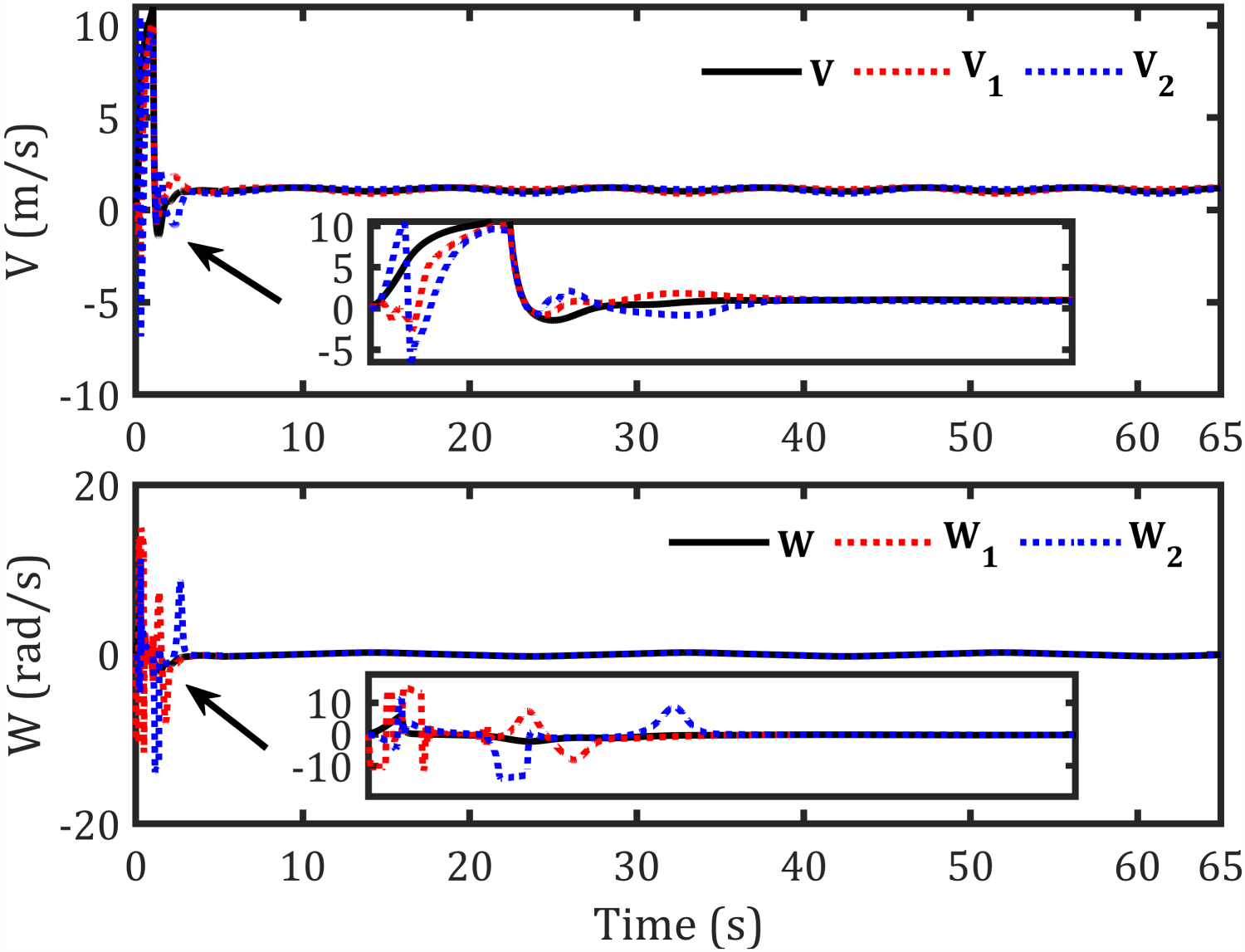
Velocities for each robot- sinusoidal path.
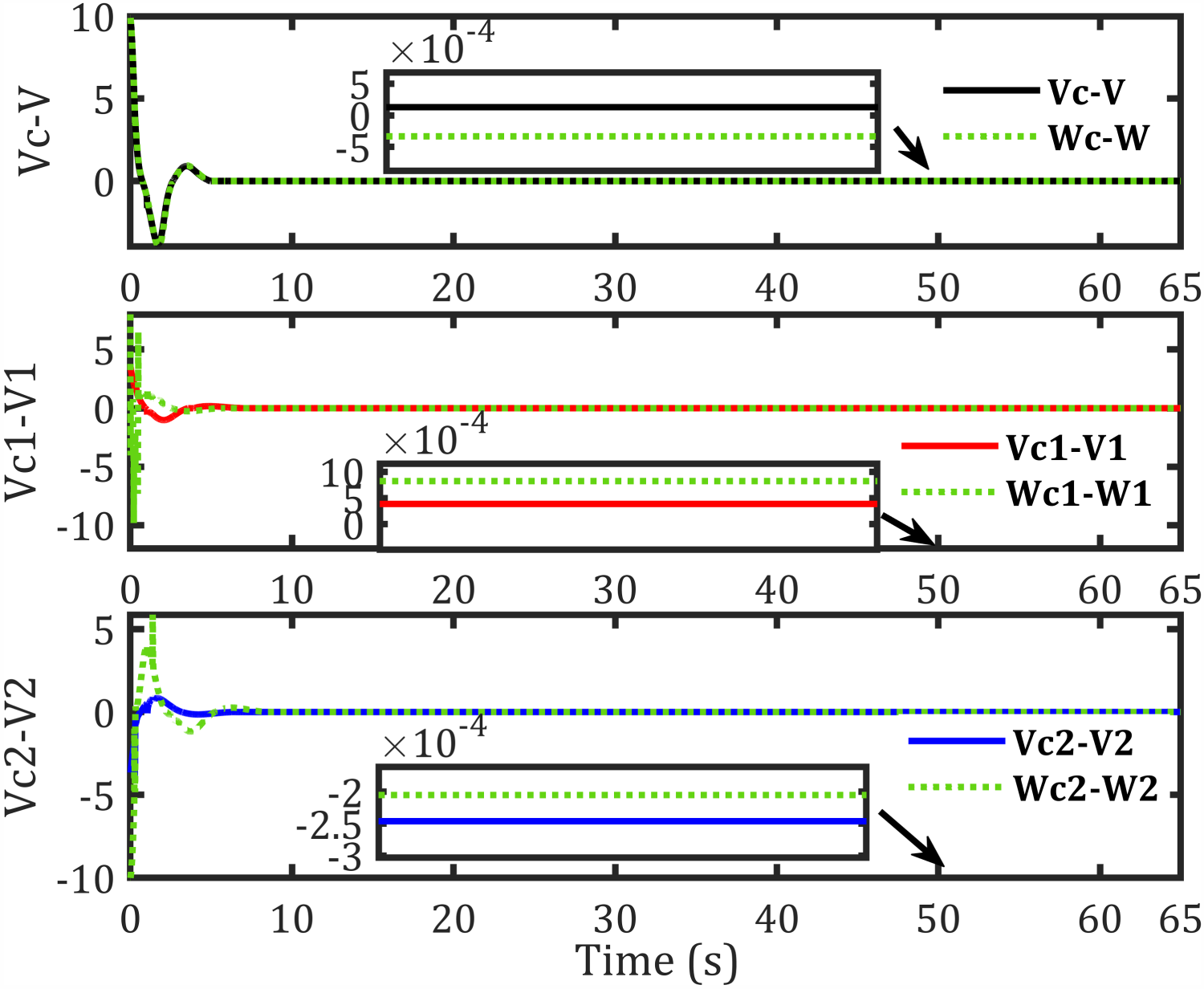
Velocities error
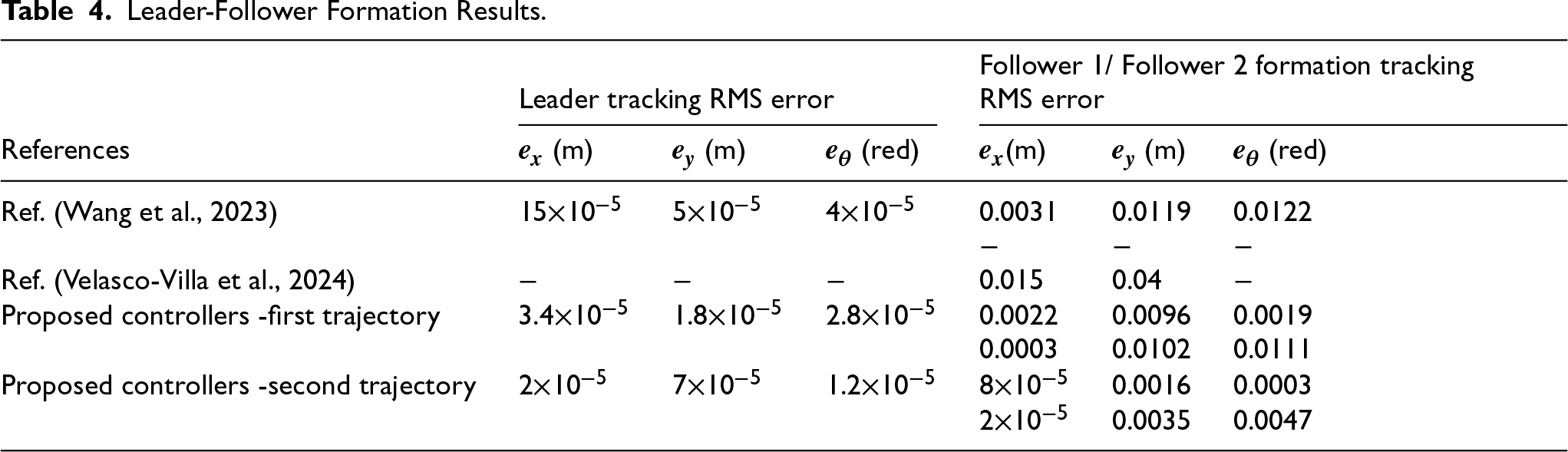
The abovementioned figures demonstrate that the tracking error for the leader relative to the reference path, as well as the formation-tracking error for the followers relative to the leader, converges to zero. Table 4 presents the RMS achieved by the proposed controllers compared to previous works using the same dynamic model for formation control-based leader–follower robots.
Leader-Follower Formation Results.
First path tracking under robot mass uncertainty of 65%.
Axes error under robot mass uncertainty.
First path tracking under robot torque disturbance by 42.222%.
Torque control signal response under disturbance by 36.222%.
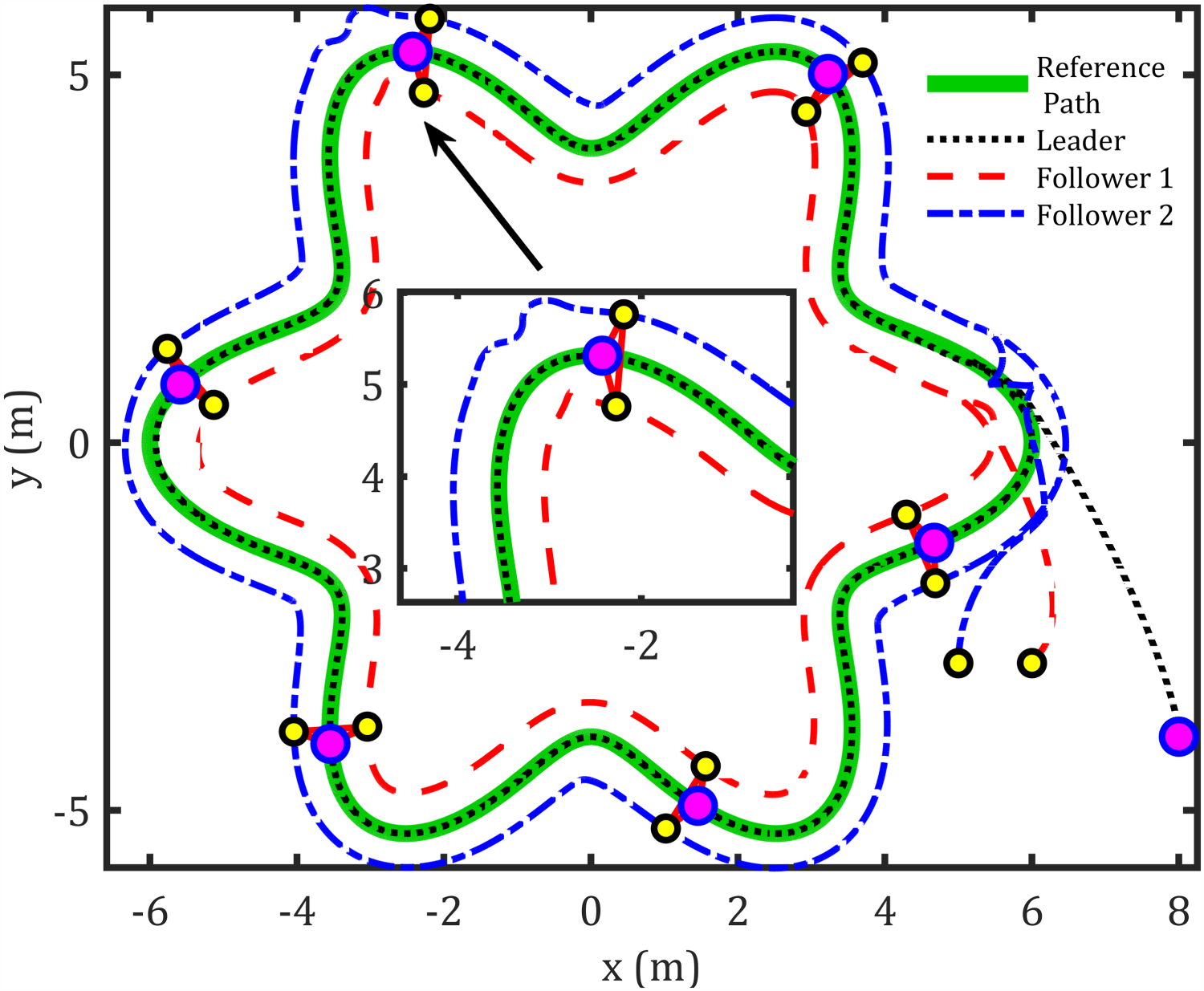
Tracking under both uncertainty and disturbance.
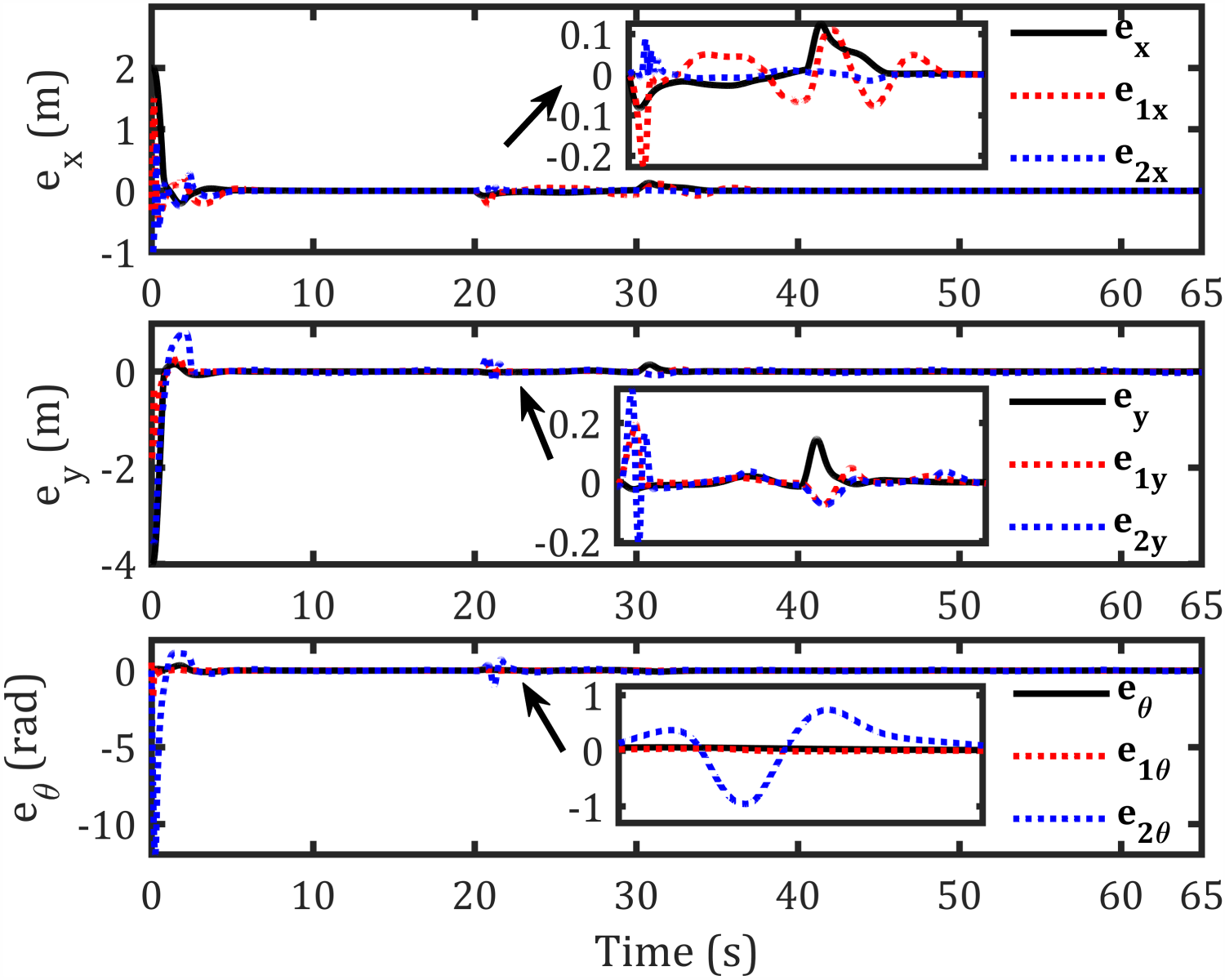
Axes error under both uncertainty and disturbance.
The work cited in reference 19 adopts feedback linearization controllers, which results in a linearized model and light linear control. A second study, which also used the same robot parameters, controlled the formation using real-time distance measurements. By contrast, our framework employs a geometric nonlinear controller for the followers and enhances the leader's kinematic controller with an online RBFNN for residual compensation of velocity errors. At the dynamic level, each robot utilizes an IT2AFPID in feedback to address model nonlinearities, parametric uncertainty, and disturbances in torque control signals. Using identical robot parameters, initial conditions, and desired formation, our intelligent, adaptive design achieves superior tracking performance and smoother control effort, as summarized in Table 4.
The proposed control framework exhibits significant improvements in path tracking accuracy, with leader position errors reduced by 77.33%, 64%, and 30% along the x, y, and θ axes, respectively. Followers also show notable enhancements, with follower 1 achieving up to 84.42% improvement in orientation tracking and follower 2 showing a 90.03% reduction in x-axis error. Compared with prior approaches, these results highlight smoother torque inputs and well-profiled velocity generation without overshoot or oscillations, confirming the effectiveness of the IT2AFPID controller in minimizing dynamic velocity errors.
Robustness tests involving mass uncertainties and control signal disturbances applied during 20 s to 30 s of a 65 s trial were conducted to further validate the resilience of the controller. Specifically, a 65% mass uncertainty coupled with a 42.67% torque disturbance and combined disturbances (55% mass uncertainty, 36.22% torque disturbance) were introduced. Despite these perturbations, the tracking performance and axis errors remained within acceptable bounds, as illustrated in Figures 16 and 17. These findings confirm the controller's ability to sustain formation accuracy under high uncertainties and abundant external perturbations.
Figure 18 depicts the tracking performance under torque signal disturbance, while Figure 19 displays the control torque signal response.
The case involving both effects simultaneously is displayed in Figure 20, while the axis-wise errors is are depicted in Figure 21.
Table 5 summarizes the RMSEs along the axes for the leader and followers based on the aforementioned three cases.
Leader-Follower Formation Results Under Uncertainty and Disturbances.
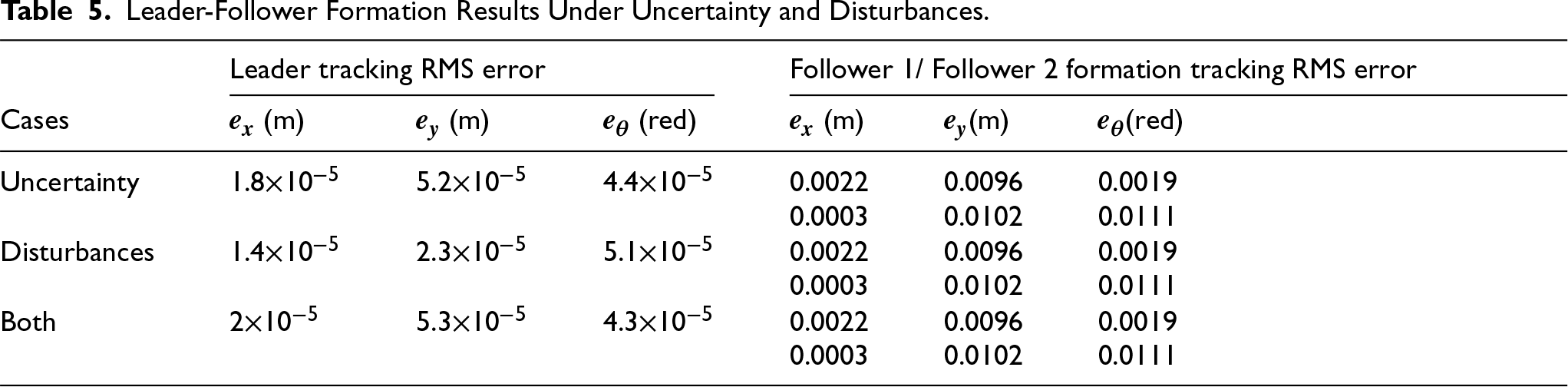
Under the uncertainty and disturbance cases, the leader's RMS tracking error remained essentially zero, while the axis-wise RMSEs of the followers in formation tracking show only minor variation. When compared with the references listed in Table 4, the proposed controllers exhibited strong robustness. Specifically, the RMSEs remained nearly invariant despite the introduction of a 55% mass uncertainty and a 36.22% torque disturbance. This resilience is attributed to the leader's robust tracking law, which incorporates online velocity-error compensation by RBFNN, and the real-time nonlinear IT2AFPID dynamic controller, which adapts effectively to model uncertainty and external disturbances.
This study developed a comprehensive leader–follower formation control framework featuring a kinematic-level RBFNN-enhanced tracking controller for the leader and a novel IT2AFPID dynamic controller for all robots. The IT2AFPID leverages adaptive Gaussian MFs and refined uncertainty handling, operating in parallel across the three robots through a vectorized structure. Formation control for the followers utilizes PFL, with gains tuned via the SBOA. When tested on star-shaped and sinusoidal trajectories involving sharp maneuvers, the controllers achieved substantial improvements over prior works. Specifically, the leader's RMSE decreased by 77.33%, 64%, and 30% along the x, y, and θ axes, respectively. Moreover, follower 1 exhibited enhancements of 29.03%, 19.32%, and 84.42%, while follower 2 showed enhancements of 90.03%, 14.28%, and 9.01% along the same axes. Collectively, these improvements translate to an average tracking-accuracy gain of over 57% for the leader robot, and formation-tracking enhancements of 44.25% and 37.77% for followers 1 and 2, respectively. The framework also demonstrated robustness under significant uncertainties, tolerating up to 65% mass variation and 42.67% torque disturbance individually and maintaining formation performance under combined uncertainties of 55% mass and 36.22% torque disturbance.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.