
Abstract
Person re-identification (Re-ID) is vital for intelligent surveillance. Although many existing methods incorporate multi-scale modules to enhance feature discriminability, they often overlook inter-group feature consistency under cross-camera scale and view variations, which can lead to embedding drift and unstable retrieval. To address this issue, we propose a dual-branch Re-ID framework based on feature consistency. First, we introduce a vertical feature-map segmentation strategy that decouples high-level global features into complementary upper- and lower-region representations in a single forward pass. These regional features are then processed by independent bottlenecks and classifiers, improving local semantic discriminability while maintaining global contextual cues. Second, we propose a Geometric-Distribution Alignment Loss (GDALoss) to explicitly enhance robustness to scale and horizontal-flip variations by minimizing the geometric and distributional discrepancies between differently transformed samples of the same identity in the embedding space. Extensive experiments on three benchmarks demonstrate consistent improvements over the baseline. On Market-1501, our method increases mAP by 1.4% and Rank-1 by 1.5%. On DukeMTMC-ReID, it improves mAP by 1.1% and Rank-1 by 2.9%. On MSMT17, it raises mAP by 3.1% and Rank-1 by 5.3%, validating the effectiveness and robustness of the proposed approach.
Introduction
Person re-identification (Re-ID) aims to match pedestrian images across non-overlapping camera views. Given a query image, the system is required to retrieve all images of the same individual from a gallery collected by different cameras (Geng et al., 2025; Li et al., 2024a; Wang et al., 2024). Re-ID plays an important role in security surveillance, video tracking, and criminal investigation. In practical deployments, however, relying on facial attributes or motion trajectories is often costly or unreliable; therefore, most Re-ID systems primarily depend on visual appearance features. Despite significant progress, resolution and scale discrepancies (Zhang et al., 2024), viewpoint variations (Wu et al., 2024), and background clutter (Gu et al., 2022) remain fundamental challenges. Moreover, imperfect pedestrian detection (e.g., misaligned bounding boxes and partial occlusions) further amplifies feature inconsistency across cameras. Under such complex and variable conditions, learning robust and stable representations is crucial for reliable cross-camera retrieval.
Before deep learning, Re-ID mainly relied on hand-crafted features and metric learning (Khan et al., 2024). Deep networks have since enabled more discriminative representations, yet early CNN-based methods largely emphasized global features and often overlooked fine-grained cues. To compensate for this limitation, recent studies (Liu et al., 2023; Wang et al., 2022; Yu et al., 2025) exploit local representations by partitioning the human body, frequently with pose estimation or parsing guidance. While effective, these approaches typically introduce additional estimators or auxiliary branches, increasing model complexity and reducing deployment efficiency.
In parallel, loss function design for Re-ID has evolved from ID and verification objectives (Ye et al., 2021) to metric learning losses such as triplet loss (Schroff et al., 2015) and center loss (Wen et al., 2016), which encourage intra-class compactness and inter-class separation. However, an important research problem remains insufficiently addressed: how to explicitly enforce feature consistency for semantically corresponding samples under scale and view transformations and cross-camera variations. Existing metric losses exhibit notable limitations in this regard. Triplet loss depends on hard-sample mining and mainly enforces relative ordering, without providing an explicit constraint that stabilizes paired representations across views and scales. Center loss encourages samples to cluster around a class center but does not model cross-view geometric relations. Consequently, maintaining consistent feature geometry and distribution under scale and view changes remains difficult, which can degrade the overall ranking quality in challenging multi-camera settings.
Based on the above observations, we identify the following gaps in current Re-ID literature: (G1) Many part and pose guided methods rely on extra estimators or auxiliary branches, which increases computational cost and complicates deployment. (G2) Mainstream metric objectives focus on separation in the embedding space but do not explicitly enforce cross-source (cross-view and scale) feature consistency for corresponding samples. (G3) Although multi-scale augmentation is widely used, most methods lack a unified constraint that aligns both the geometric structure and the distribution of features under scale and flip transformations, leaving scale view-induced distribution shift under-constrained.
To bridge these gaps, we propose a dual-branch Re-ID framework based on feature consistency. We adopt a shared backbone to extract high-level feature maps and perform a lightweight feature-map-level vertical decoupling to obtain spatially complementary upper and lower sub-region features, without requiring pose and parsing annotations (addressing G1). Each branch produces discriminative representations with GAP and BN, and is supervised by dual classifiers. Furthermore, we design a Geometric-Distribution Alignment Loss (GDALoss) to explicitly reduce scale and view-induced distribution shift by jointly constraining geometric distances and distribution differences between multi-scale transformed samples (e.g., resizing and horizontal flipping), thereby enforcing cross-source consistency (addressing G2–G3).
In summary, our main contributions are threefold: We propose a lightweight dual-branch architecture that decouples upper and lower region features at the feature-map level to enrich local details without auxiliary estimators. We propose GDALoss, which enforces geometric and distribution consistency across multi-scale transformations to improve robustness to scale and view variations. Extensive experiments on Market-1501, DukeMTMC-ReID, and MSMT17 validate the effectiveness of the proposed method.
The remainder of this paper is organized as follows. Section 2 reviews related work. Section 3 describes the proposed method in detail. Section 4 presents experimental settings and results, followed by conclusions in Section 5.
Brief Overview of Person Re-Identification
In recent years, part-local-feature learning has become a mainstream direction for improving person re-identification (ReID), especially under occlusion, pose changes, and imperfect detections. A representative line of work introduces auxiliary cues such as pose estimation or human parsing to localize visible body regions and learn part-aware representations. For example, PPBI (Cui et al., 2025) leverages pose-guided partial attention together with batch-level information to enhance occlusion-robust matching, while DROP (Dou et al., 2024) decouples ReID and human parsing into task-specific features to reduce mutual interference and strengthen part-level modeling. Transformer-based designs have also been explored: the Part-Aware Transformer (Ni et al., 2023) injects part awareness into token-based representations to improve robustness and generalization, and PAFormer (Jung et al., 2024) further models body-part correlations to enhance part-to-part matching. Moreover, MPCC-Net (Zhou et al., 2025) enforces perception-consistency constraints across multi-state inputs to improve feature stability.
These approaches demonstrate that introducing part-level cues and consistency regularization can effectively improve recognition in challenging conditions. However, many of them still depend on additional estimators or complex attention branches, which increases computational overhead and may propagate localization errors. More importantly, existing part-based pipelines often focus on improving local discriminability, but they seldom provide a lightweight mechanism that simultaneously preserves global context and explicitly enforces stable correspondence between complementary regions under scale and viewpoint variations. This gap motivates our Dual-Branch Feature Separation (DBFS), which performs feature-map-level uniform decoupling without extra pose or parsing networks and further couples local discrimination with cross-source consistency constraints.
Multi-Scale Feature Extraction Methods
Scale and viewpoint variations are another major factor that causes feature drift and degrades ReID generalization. To mitigate these effects, a number of studies exploit multi-scale representations or scale-aware alignment. Lai et al. (Lai, 2025) explore multi-scale feature attention and strategy balancing in cross-modal ReID. For unsupervised ReID, TCMM (Zhu et al., 2025) introduces token constraints to suppress patch noise in ViT features and adopts a multi-scale memory bank for contrastive learning to improve feature consistency. In the visible-infrared setting, CM-DASN (Li et al., 2025) uses dynamic attention selection to learn more effective cross-modality representations. Other works also incorporate multi-scale cues via depth features (Zhou et al., 2024) or multi-scale and multi-granularity representation learning for person search (Han & Ma, 2024).
Although these methods improve robustness by fusing or selecting information across scales, they mainly enhance discriminability and do not explicitly require that same-identity embeddings under deterministic transformations (e.g., resizing and horizontal flipping) preserve a stable geometric structure and consistent neighborhood distribution in the embedding space. As a result, the model may still suffer from distribution shift when scale changes are large or when the training data is limited. To fill this gap, our Geometric–Distribution Alignment Loss (GDALoss) directly aligns cross-scale and cross-view features by jointly enforcing geometry-aware distance regularization and distribution-consistency constraints with minimal overhead.
Methodology
In person Re-ID, cross-camera matching is the most common and challenging setting in real deployments. Due to differences in camera hardware, installation geometry, and illumination conditions, the same identity is often observed at noticeably different apparent scales across non-overlapping cameras. Such cross-camera scale inconsistency can induce embedding drift, where semantically identical samples are mapped to inconsistent locations in the feature space, thereby weakening feature stability and degrading retrieval performance. While conventional objectives mainly emphasize intra-inter-class separation, they do not explicitly enforce consistency across deterministic scale and view transformations, which makes it difficult to learn discriminative yet scale-robust representations. To tackle this issue, we propose a dual-branch person re-identification network based on feature consistency, termed Feature Consistency Network (FCNet). The overall architecture is shown in Figure 1.
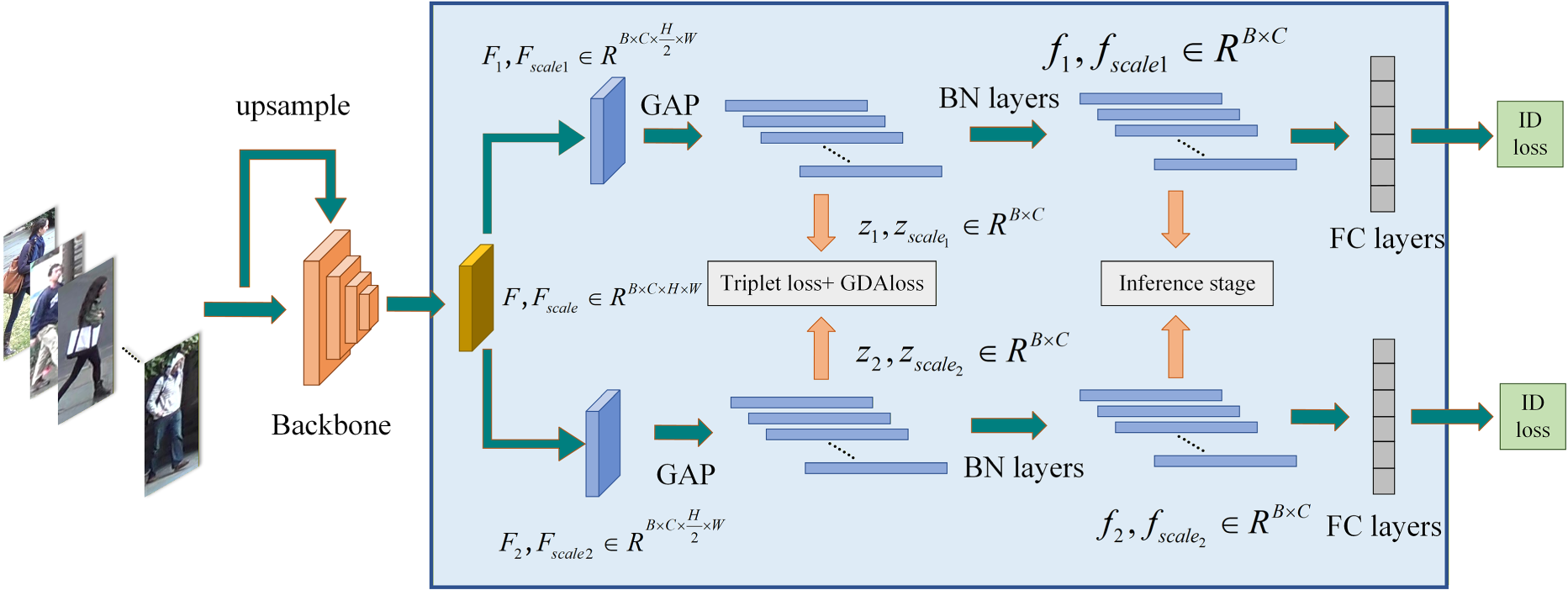
Network architecture diagram.
As shown in Figure 1, we designed a dual-branch feature decoupling structure, which uniformly segments the pedestrian feature map into upper and lower local region branches along the height direction. While preserving the global receptive field of deep features from the backbone network, this structure extracts discriminative features of the upper body and lower body respectively—thus ensuring no loss of overall spatial correlation while significantly enhancing local feature learning capability. Secondly, to improve the model's robustness to scale and pose variations, we construct multi-scale and multi-view contrastive samples by performing down sampling and horizontal flipping on the original samples


We present the detailed workflow of FCNet, as shown in Algorithm 1:

Existing person re-identification methods typically represent the target using global features. However, global aggregation often weakens fine-grained local cues such as clothing textures, backpack boundaries, and shoe shapes. In contrast, features based on local receptive fields can emphasize local details, but they are susceptible to bounding-box misalignment, pose variations, and occlusions, which leads to unstable spatial alignment of local regions across different samples and thus limits the reliability of cross-camera matching. To enhance local discriminability and improve regional alignment stability without introducing additional pose estimation or semantic segmentation networks, we uniformly split high-level feature maps along the height dimension during the feature decoupling stage, thereby obtaining structurally stable and semantically complementary local representations.
Specifically, given input images 

In this way,
Subsequently, the two local regions are processed by independent global average pooling (GAP), batch normalization (BN), and classifiers, yielding the GAP features
Finally, we concatenate the four groups of decoupled local features along the batch dimension to form the fused local features
Global features are used to represent a pedestrian's appearance holistically, whereas local features focus more on fine-grained cues from different body regions. However, under an independent training scheme, both types of features have limitations: global representations tend to over-rely on a few salient regions and fail to preserve details from other parts; local representations are constrained by limited receptive fields and may still lack sufficient contextual information even after multiple convolutional layers, thereby weakening regional discriminability. To address these issues, we propose a multi-source cross-fusion mechanism built upon the dual-branch feature decoupling architecture. As illustrated in Figure 2, it jointly leverages local supervision and cross-source consistency constraints to enhance the stability and robustness of feature representations under cross-scale and cross-view conditions.
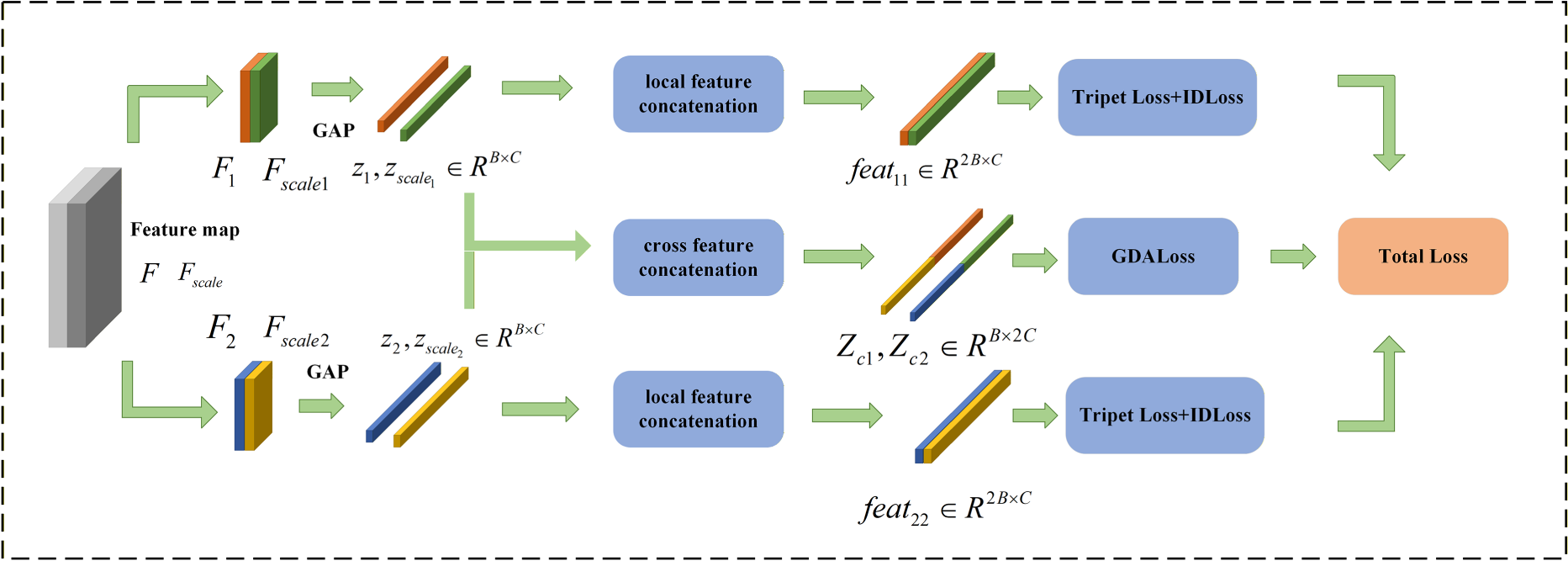
Fusion of local features.
Local feature extraction and representation. Given the high-level feature map
Local feature concatenation for identity-discriminative learning. To ensure stable identity discrimination across different scale sources, we concatenate the two-source local vectors of the same branch along the batch dimension to form the local features used for supervised learning:
Cross-fusion features for cross-source consistency constraints. Relying solely on local discriminative supervision may be insufficient to ensure that cross-scale consistency is always correct. Therefore, we further construct cross-source cross-fusion features by concatenating the two-source local vectors of the same branch along the channel dimension, yielding:
As shown in Figure 2,
Compared with attention-based fusion, we choose channel-wise concatenation mainly for two reasons. First, concatenation is lightweight and introduces almost no additional parameters or hyperparameters, resulting in negligible computational overhead, which aligns with our design goal of controlling model complexity. Second, GDALoss relies on stable geometric relationships in the feature space, whereas attention-based fusion typically produces sample-dependent dynamic reweighting that may distort feature geometry and increase the difficulty of enforcing consistency constraints. In contrast, channel-wise concatenation deterministically preserves complementary cues from the two sources, providing a more stable and effective input for subsequent geometric–distribution alignment. Moreover, cross-source concatenation makes inconsistencies between the two sources more explicitly exposed, which helps improve the model's robustness.
Pedestrian images exhibit significant appearance variations across different scales and viewpoints, which can induce distribution shifts in the feature representations of the same identity and ultimately manifest as cross-scale and cross-view feature inconsistency. To alleviate this issue, we propose the Geometric–Distribution Alignment Loss (GDALoss). By jointly enforcing geometric-structure consistency and distribution consistency, GDALoss explicitly reduces the feature discrepancies of the same identity under different scales and viewpoints, thereby encouraging the model to learn identity representations that are more robust and invariant to scale and viewpoint changes.
Input and projection normalization: GDALoss takes the cross-fusion features obtained in Section 3.2 as inputs. For the fused features of the original samples and their multi-scale and multi-view augmented counterparts, we employ a shared-weight linear projection layer
Geometric Alignment Loss (GALoss): To maintain a stable geometric structure for the same identity under different scales and viewpoints, we first compute the Euclidean distance between the two feature groups in the projection space. Its calculation is given by Equation (5).

Subsequently, GALoss is constructed by minimizing the mean squared error (MSE) between the distance of each feature-group pair and the target distance 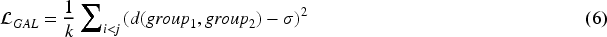
Distribution Alignment Loss (DALoss): Constraining distances alone may be insufficient to ensure consistent local neighborhood structures. Therefore, we further minimize the Kullback–Leibler (KL) divergence between the distributions of the two feature groups, encouraging them to become consistent in a probabilistic sense. We first compute the similarity matrix between the two feature groups, Its calculation is given by Equation (7).

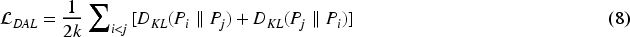

Finally, the calculation of the GDALoss is shown in Equation (10)

Here,
In the training phase, the loss consists of three components: Triplet Loss, Cross-Entropy Loss, and Geometry-Distribution Alignment Loss (GDALoss). Among them, the Triplet Loss and Cross-Entropy Loss are computed based on the score vectors of local features—where the local features are derived by concatenating the original image and multi-scale samples along the batch dimension to form the final features. Their calculations are shown in Equations (11) and (12).
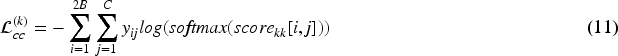

Subsequently, we introduce the proposed GDALoss to minimize the distribution difference between parallel samples, thereby obtaining the final total loss, and its calculation formula is shown in Equation (13).

Datasets and Evaluation Metrics
We evaluate the proposed method on three widely adopted person Re-ID benchmarks: Market-1501, DukeMTMC-ReID, and MSMT17, whose statistics are summarized in Table 1.
Statistics of Used Datasets.

Statistics of Used Datasets.
Evaluation Metrics: To evaluate the performance of our FCNet and compare with other ReID methods, we report two common evaluation metrics: the cumulative matching characteristics (CMC) (Bai et al., 2017) at Rank-1 and mean average precision (mAP) (Gray et al., 2007) on the above three benchmarks following the common settings.
In our experiments, we implement the proposed model using the PyTorch framework. All experiments are conducted on a workstation equipped with an NVIDIA GeForce RTX 4060 Ti GPU and a 12th Gen Intel(R) Core(TM) i5-12600KF CPU. We initialize ResNet-50 with ImageNet-pretrained weights. During training, each input image is resized to
Comparison with State-of-the-Art Methods
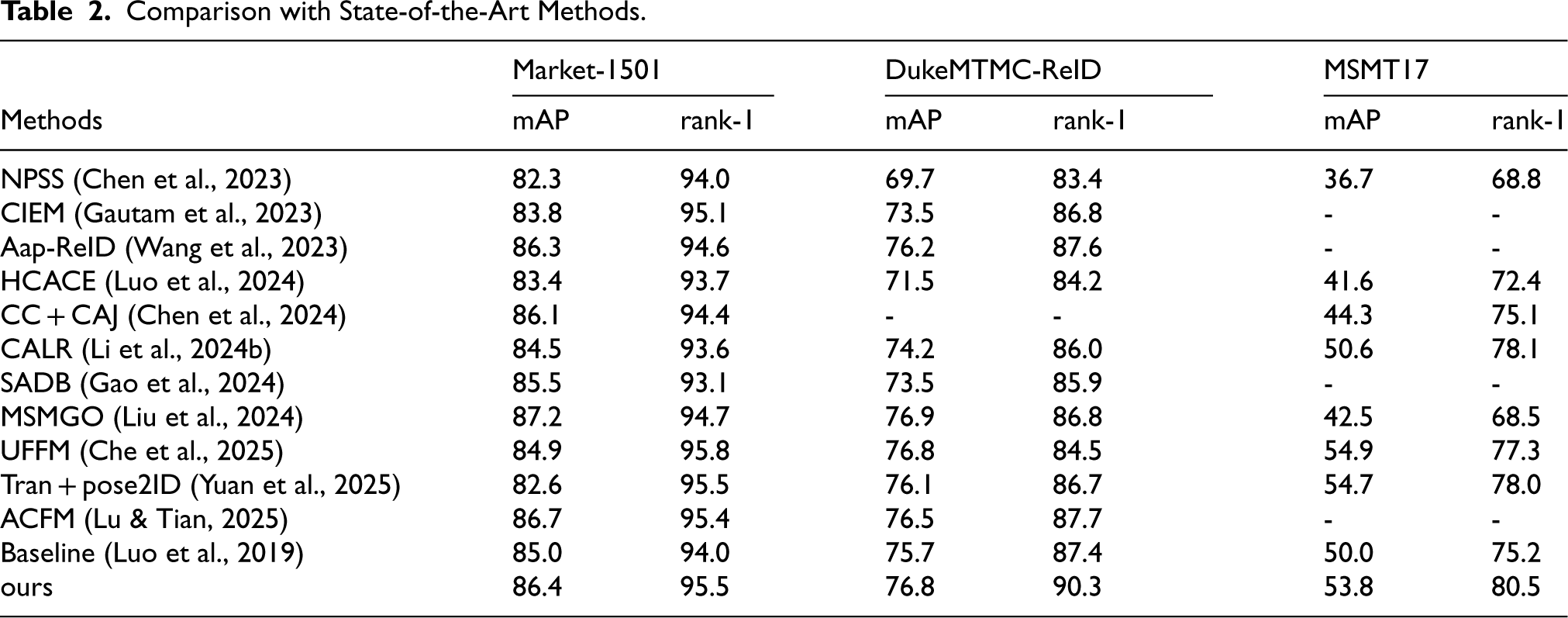
To verify the effectiveness of our method, we compare it with representative state-of-the-art approaches on three benchmark datasets: Market-1501, DukeMTMC-ReID, and MSMT17. As shown in Table 2, our method achieves competitive performance across all three datasets and consistently improves over the baseline. Specifically, on Market-1501, our method improves mAP and Rank-1 by 1.4% and 1.5%, respectively. On DukeMTMC-ReID, it surpasses the baseline by 1.1% in mAP and 2.9% in Rank-1. On MSMT17, which is considerably more challenging due to large-scale variations and cluttered backgrounds, our method obtains larger gains of 3.1% in mAP and 5.3% in Rank-1, indicating improved robustness under complex real-world conditions.
Comparison with State-of-the-Art Methods.
Comparison with State-of-the-Art Methods.
Although some recent methods achieve stronger results on certain metrics, they often target different problem settings or introduce additional components that increase training and inference complexity. For example, Liu et al. (Liu et al., 2024) propose MSAMGO for unsupervised ReID by aggregating multi-view similarity and optimizing multi-level gaps to improve pseudo-label quality, where performance gains largely depend on clustering reliability and the handling of noisy pseudo labels. In contrast, our work focuses on supervised training and explicitly addresses scale and view-induced distribution shift via multi-scale contrastive sample construction and consistency regularization. Che et al. (2025) improve ReID through Uncertainty Feature Fusion (UFFM) and Auto-weighted Measure Combination (AMC), emphasizing robust similarity computation by fusing multi-view cues and combining multiple similarity measures; such designs can be effective but may require additional fusion measure-combination steps (and are often used together with more elaborate similarity pipelines). Yuan et al. (2025) (Pose2ID) propose a training-free feature centralization framework, which leverages mechanisms such as identity-guided generation and neighborhood-based centralization to stabilize identity representations without conventional ReID training, introducing extra procedures beyond a standard supervised pipeline. Lu and Tian, 2025 introduce ACFM, which adaptively matches and aligns channel feature maps according to image content to mitigate misalignment, but this typically adds module-level complexity compared with simple deterministic fusion.
Different from these designs, our method aims to improve cross-scale and cross-view consistency mainly through training-time regularization: we build cross-source fused features and apply GDALoss to jointly enforce geometric-structure and distribution consistency, while keeping the inference pipeline lightweight (i.e., without pose estimation, generation, or complex fusion and matching at test time). As a result, even when the absolute improvements over some SOTA methods are not always the largest, our approach provides a favorable trade-off between accuracy, robustness, and deployability in practical surveillance scenarios.
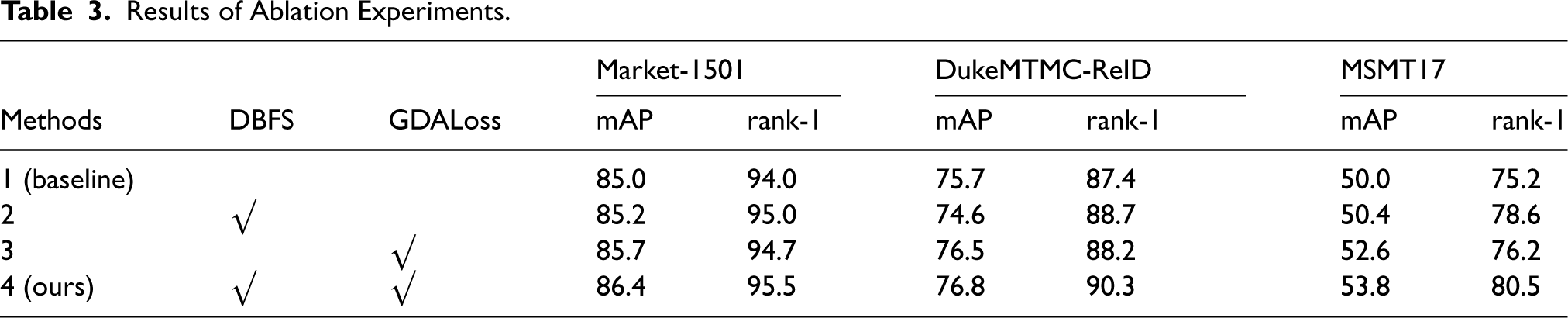
To validate the effectiveness of the proposed method, we conducted extensive experiments on three benchmark datasets: Market-1501, DukeMTMC-ReID, and MSMT17. Among the methods listed in the table, Method 1 serves as the baseline model, where other modules (including DBFS and GDALoss) are disabled. Method 2 builds on the baseline by integrating the proposed DBFS strategy, which splits the image into upper and lower regions for separate processing and converts the global features in the baseline into multiple local features. Method 3 introduces multi-scale contrastive sample input to the baseline and employs the proposed Geometric-Distribution Alignment Loss (GDALoss) for constraint. Method 4 represents the complete framework that applies both DBFS and GDALoss simultaneously. The results are presented in Table 3. Compared with the baseline, both GDALoss and DBFS demonstrate considerable improvements on most datasets.
Results of Ablation Experiments.
Results of Ablation Experiments.
As shown in Table 3, introducing DBFS leads to clear gains on Market-1501 and MSMT17, with mAP improving by 0.2% and 0.4%, and Rank-1 increasing by 1.0% and 3.4%, respectively. On DukeMTMC-ReID, DBFS yields a Rank-1 improvement of 1.3% but causes an mAP decrease of 1.1%. This phenomenon suggests that DBFS strengthens part-level discriminability and improves the top-1 match for many queries, yet it may disturb the overall ranking quality across the full gallery, which is more sensitively reflected by mAP. In DukeMTMC-ReID, larger viewpoint changes, detection-box variations, and occlusions make a fixed upper and lower partition more prone to semantic misalignment; consequently, the split features can become less consistent across cameras, leading to less stable similarity ordering beyond the top few retrieved samples. Therefore, the mAP drop on Duke can be regarded as a side effect of fixed local partitioning under severe misalignment, while GDALoss can effectively compensate for this issue.
When multi-scale contrastive inputs and GDALoss are applied (Method 3), the model consistently improves on all datasets (mAP +0.7%, +0.8%, +2.6% and Rank-1 + 0.7%, +0.8%, +1.0% on Market-1501, DukeMTMC-ReID and MSMT17). More importantly, combining DBFS with GDALoss (Method 4) mitigates the partition-induced fragmentation by explicitly enforcing cross-scale and cross-view geometric and distribution consistency on cross-source features, thereby stabilizing the similarity structure and improving both Rank-1 and mAP. Overall, DBFS primarily enhances local alignment and discriminability, while GDALoss alleviates scale and view induced distribution shift; their combination addresses both challenges simultaneously and yields the best overall performance.
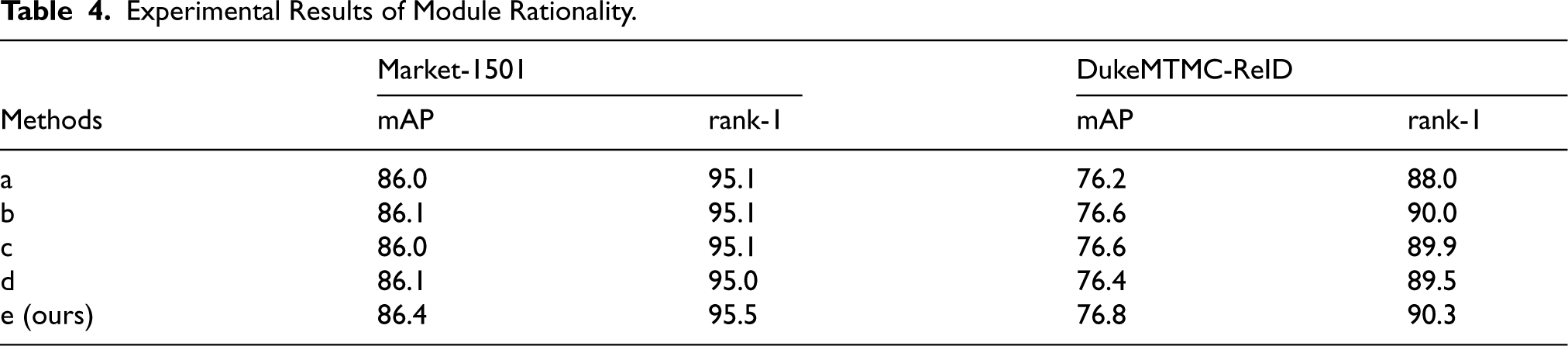
To verify the effectiveness of the cross-fusion strategy proposed in this paper and the rationality of the FCLoss design, we designed multiple groups of comparative experiments on the Market-1501 and DukeMTMC-ReID datasets. The specific settings are as follows: (a) Baseline method: The cross-fusion strategy is not adopted; instead, the original image features and multi-scale sample features are directly input into GDALoss for feature alignment; (b) Using only Euclidean distance constraint: The target distance is set to 0 to force the alignment of multi-scale sample features in the geometric space;(c) Target distance set to 1: Consistent with GDALoss; (d) Using only KL divergence constraint: To ensure the consistency of the feature distribution of multi-scale samples; (e) The method proposed in this paper: Adopting the cross-fusion strategy and the dual constraint mechanism. Experimental results are shown in Table 4.
Experimental Results of Module Rationality.
Experimental Results of Module Rationality.
As shown in Table 4, compared with Method a, the proposed method achieves an mAP improvement of 0.4% and 0.6%, and a Rank-1 improvement of 0.4% and 0.3% on the Market-1501 and DukeMTMC-ReID datasets respectively. This effectively verifies that the cross-fusion strategy can enhance the model's ability to learn discriminative features and facilitate the alignment of multi-scale local features with global features. Furthermore, compared with Methods b, c, and d that only adopt a single constraint mechanism, the proposed method achieves the optimal performance in all key metrics, fully demonstrating the effectiveness and necessity of the geometric-distribution dual constraint mechanism in multi-scale sample alignment.
To investigate the impact of the KL divergence term, the geometric–distribution alignment loss (GDALoss), and the target distance
Comparison of Hyperparameter Experimental Results.
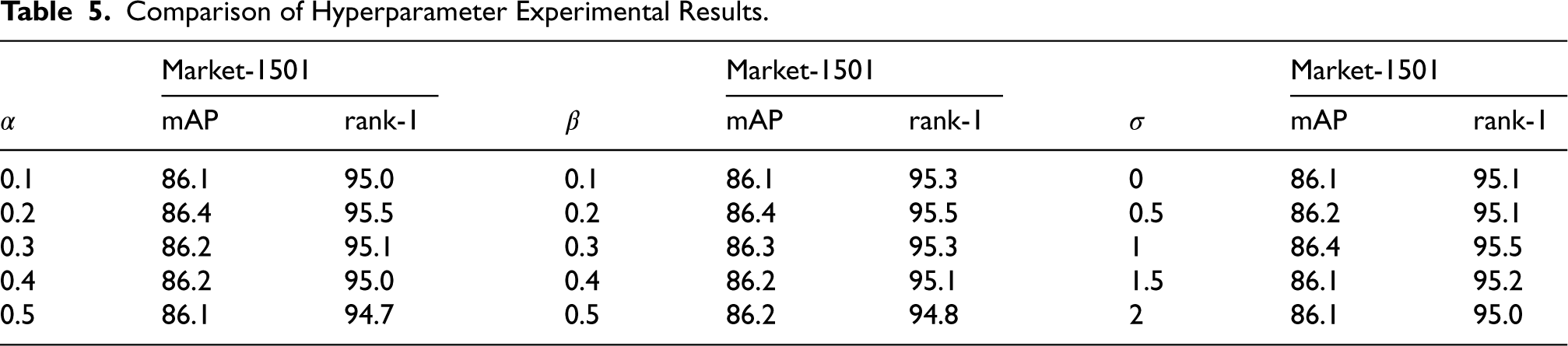
Comparison of Hyperparameter Experimental Results.
As shown in Table 5, the weight
These observations also support the rationality of our hyperparameter initialization strategy. The initial
Regarding the target distance
The Impact of Different Partition Ratios on FCNet
In this section, we report the retrieval performance of FCNet on Market-1501 under different stripe partition strategies in terms of mAP and Rank-1. The experimental results are summarized in Table 6.
Different Partition Ratios Analysis.

As shown in Table 6, under Uniform Partition, the 1Part (baseline) setting relies only on global features and achieves 85.0 mAP and 94.0 Rank-1. After introducing moderate local modeling, the performance improves noticeably: 2 Parts achieves the best results in the table with 86.4 mAP and 95.5 Rank-1, indicating that a coarse division of the human body into upper and lower regions can effectively capture complementary discriminative cues, such as clothing patterns in the upper body and shape information in the lower body, thereby improving matching robustness. When the stripes are further subdivided, the gain does not continue. 4 Parts shows a slight drop to 86.1 mAP and 94.9 Rank-1, while 8 Parts suffers a clear degradation to 84.9 mAP and 93.5 Rank-1. This suggests that overly fine partitioning reduces the amount of meaningful person information in each local region and makes the representation more sensitive to pose variation, bounding-box misalignment, occlusion or truncation, and background clutter, which weakens the stability of local features and increases false matches.
In addition, Non-uniform Division further supports the observation that the distribution of informative cues is not uniform across the body. With ratios of 4:6 and 6:4, the performance reaches 86.0 mAP and 95.3 Rank-1, and 86.0 mAP and 94.6 Rank-1, respectively, which are slightly below the 2-part setting. Overall, the results demonstrate that a two-part coarse partition provides the best balance between accuracy and robustness, while non-uniform division offers a stable and practical alternative, whereas excessive subdivision tends to cause performance deterioration.
To systematically evaluate how different downsampling strategies affect recognition performance, we conduct two groups of comparative experiments on the Market-1501 dataset: proportional scaling and non-proportional scaling. Proportional scaling preserves the original aspect ratio and is used to isolate the effect of scaling magnitude, whereas non-proportional scaling deliberately breaks the aspect ratio to introduce geometric distortion, enabling us to analyze the impact of ratio distortion on feature learning and spatial alignment.
For proportional scaling, we select two representative resolutions, 192 × 64 and 336 × 112, The former represents a more aggressive downsampling that can discard fine-grained textures and local structural cues, while the latter maintains the standard
As shown in Table 7 proportional scaling achieves the best performance at 336 × 112, and the performance degrades as the downsampling becomes more aggressive (e.g.,192 × 64), indicating that excessive resolution reduction weakens the representation of fine-grained details. The two non-proportional settings yield comparable results and are slightly inferior to the best proportional-scaling configuration, suggesting that aspect-ratio distortion introduces misalignment and structural inconsistency that can hinder discriminative feature learning. Overall, 336 × 112 provides a better trade-off between preserving fine-grained information and introducing a realistic scale perturbation, leading to the most favorable performance.
Comparison of Different Scaling Ratios on Market-1501.

Comparison of Different Scaling Ratios on Market-1501.
All efficiency evaluations were conducted on a machine equipped with a 12th Gen Intel(R) Core(TM) i5-12600KF CPU and an NVIDIA GeForce RTX 4060 Ti GPU (16 GB VRAM). Experiments were implemented under the PyTorch 1.10.0/CUDA 11.3 framework, with the input image resolution set to 384 × 128 pixels. We used the Market-1501 dataset for this evaluation, and the detailed results are reported in Table 8.
Complexity Analysis.

Complexity Analysis.
As shown in Table 8, OSNet demonstrates strong deployment friendliness with the smallest parameter size (1.28 M) and the fastest inference speed (1.84 ms/img). However, its retrieval accuracy (mAP = 84.9) still lags behind stronger architectures. In comparison, PCB achieves competitive performance but at a clearly higher computational cost (FLOPs = 6.13G, Params = 25.99 M). Transformer + Pose2ID further expands both FLOPs and parameter scale (28.83G/105.15 M), resulting in much higher inference latency (7.09 ms/img) and lower throughput (140.92 img/s), indicating a substantially heavier efficiency burden.
Notably, FCNet maintains a computational complexity on the same order as PCB (6.13G) and a similar peak memory footprint (0.43 GB), while introducing only a slight increase in inference time (2.21 ms/img, compared with 2.12 ms/img for PCB). Despite this minimal overhead, FCNet delivers the best retrieval performance in the table (mAP = 86.4, Rank-K = 95.5). These results indicate that FCNet's performance gains are not achieved by significantly increasing model size or computation, but rather by improving feature representation and matching quality with very limited additional cost, leading to a more favorable accuracy–efficiency trade-off.

Visualization results diagram.
To intuitively evaluate the robustness of the proposed method, we visualize the retrieval results in Figure 3 on three datasets (Market-1501, DukeMTMC-ReID, and MSMT17). For each dataset, we present representative query images and compare the Top- K retrieved gallery samples produced by the baseline and our FCNet, covering both successful cases and failure cases. In the figure, green bounding boxes indicate correct matches (same identity) while red boxes denote incorrect matches. As shown, FCNet consistently returns more correct matches at higher ranks than the baseline across datasets, demonstrating a clear performance gap and verifying the effectiveness and robustness of FCNet.
Although FCNet can significantly improve retrieval quality for most queries, several typical failure modes can still be observed in the Failed Cases of Figure 3. These errors mainly stem from two scenarios: identity confusion caused by highly similar appearances and missing local cues due to severe occlusion or truncation. In the former case, the model may mistakenly treat clothing color, backpack shape, and other “similar appearance” cues as decisive evidence of the same identity; in the latter case, when informative human cues are insufficient, the model is forced to rely more on weak signals such as background regions or coarse color patches, which leads to mismatches. Meanwhile, these failure examples also highlight challenging situations that remain difficult for the current method, providing useful guidance for future improvements in fine-grained discriminative cue modeling and occlusion robustness.
Conclusion
This paper proposes a dual-branch person re-identification (Re-ID) framework based on feature consistency to mitigate the adverse impact of scale variations. Specifically, we introduce a lightweight feature-map decoupling strategy that splits high-level representations into two complementary regions (upper and lower parts). Each region is optimized with an independent global average pooling (GAP) head and classifier, which strengthens fine-grained representation learning and improves the stability of local feature alignment. In addition, we propose the Geometric–Distribution Alignment Loss (GDALoss) to explicitly regularize cross-scale representations by jointly constraining feature distances and distribution discrepancies between the original images and their deterministically transformed counterparts. Extensive experiments on three public benchmarks demonstrate that the proposed method consistently improves both accuracy and robustness. Owing to its lightweight design without relying on pose estimation or human parsing, the proposed framework is well suited for practical cross-camera Re-ID systems in real-world surveillance and retrieval applications, where heterogeneous cameras and scale variations are common.
Limitations and Future Work
Although the proposed vertical decoupling is lightweight and effective, it may be less optimal under extremely severe occlusion, large pose changes, or inaccurate detections, where the upper–lower partition may not perfectly correspond to semantic body parts. In future work, we will explore adaptive or content-aware partitioning, incorporate stronger augmentation and domain generalization strategies, and extend the framework to video-based Re-ID and multi-camera tracking settings to further improve robustness in real-world deployments.
Footnotes
Acknowledgements
This work is funded by the National Natural Science Foundation of China (Grant No. 62066036) and supported by the Basic scientific research business fee project for directly affiliated universities in Inner Mongolia Autonomous Region (Grant No. 2023XKJX020), and the Scientific Research Special Project for First-Class Disciplines in Inner Mongolia Autonomous Region (Grant No. YLXKZX-NKD-001).
Ethical Approval
This study did not involve human or animal subjects, and thus, no ethical approval was required.
Author's Contribution
Implemented the entire experimental framework, including code writing (based on PyTorch), model training (ResNet50 backbone optimization), and result validation on three benchmark datasets (Market-1501, DukeMTMC-ReID, MSMT17).
Drafted the initial version of the manuscript, including the abstract, introduction, methodology, and experimental evaluation sections.
Processed experimental data, including dataset preprocessing (image resizing, data augmentation such as horizontal flipping and downsampling) and statistical analysis of experimental results (calculation of mAP and Rank-1 metrics).
Designed and drew key figures and tables in the manuscript, such as the network architecture diagram (Figure 1), feature fusion diagram (![]() ), and experimental result tables 1–8.
), and experimental result tables 1–8.
Completed the hyperparameter analysis (Section 4.6) for GDALoss (hyperparameters α and β) and the downsampling ratio experiment (Section 4.7), optimizing the model's hyperparameter configuration.
Assisted in code optimization, including improving the efficiency of multi-scale sample generation and optimizing the training process to reduce overfitting.
Conducted the visualization analysis of retrieval results (Section 4.8), including selecting representative query images from datasets and comparing retrieval performance between the proposed FCNet and the baseline model.
Assisted in revising the manuscript, including refining the logic of the “Methodology” section and supplementing discussions on experimental results.
Provided financial support (via National Natural Science Foundation of China and Inner Mongolia autonomous region research grants) and academic guidance, including optimizing the design of GDALoss and solving key technical problems in model training.
Reviewed and revised the manuscript critically, ensuring the accuracy of technical content and compliance with academic norms; finalized the manuscript and handled correspondence with journals.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the the Basic scientific research business fee project for directly affiliated univer-sities in Inner Mongolia Autonomous Region, the Scientific Research Special Project for First-Class Disciplines in Inner Mongolia Autonomous Region, the National Natural Science Foundation of China, (grant number 2023XKJX020, YLXKZX-NKD-001, 62066036).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Code Availability
The code generated and used during the current study is part of a future patent application. To protect intellectual property, it is not publicly available at this time. After the patent application has been submitted, the code can be requested from the corresponding author. (xidianjj@163.com)
Data Availability
We used freely available datasets: Market-1501, DukeMTMC-ReID, and MSMT17. The datasets can be accessed from their official or commonly used sources: Market-1501 from https://paperswithcode.com/dataset/market-1501, DukeMTMC-ReID from https://paperswithcode.com/dataset/dukemtmc-reid, and MSMT17 from its official project page at ![]() . Alternatively, the data can be obtained from the respective authors upon reasonable request.
. Alternatively, the data can be obtained from the respective authors upon reasonable request.