
Abstract
Effective building energy management (BEM) relies on extracting actionable intelligence from vast volumes of operational data. Association Rule Mining (ARM) is a cornerstone of knowledge discovery; however, traditional techniques face a dual challenge: either they generate a prohibitive volume of redundant patterns that obscure decision-making, or they employ aggressive pruning that compromises interpretability. In addition, existing approaches often treat energy awareness as a disjointed post-processing step rather than an intrinsic systemic constraint. To address these issues, this paper proposes Minimal Non-Redundant FP-Growth (MNR-FP-Growth), an intelligent algorithm that integrates energy-semantic redundancy pruning directly into the frequent pattern mining process. The core innovation lies in a multi-criteria pruning mechanism: a pattern is eliminated only when it is found to be both statistically redundant and operationally inefficient–defined as having equivalent support to a subset but an equal or higher energy penalty. This approach ensures the retention of a compact, non-redundant set of patterns with high operational utility. Through rigorous evaluation using a year of real-world building operational data, MNR-FP-Growth achieves an 11.2% reduction in pattern redundancy compared to standard FP-Growth. Moreover, the algorithm operates 61% faster than the state-of-the-art FP-Close while maintaining high structural integrity (Jaccard similarity
Keywords
Introduction
Operational efficiency in buildings is a crucial factor for global energy sustainability, as it accounts for a substantial share of worldwide electricity consumption and carbon emissions (Pérez-Lombard et al., 2008). Despite advancements in sensing and data acquisition that have offered unprecedented insights into building operations, a significant challenge persists: converting extensive multivariate time-series data into actionable insights for energy savings, all while maintaining occupant comfort (Amasyali & El-Gohary, 2018).
Association Rule Mining (ARM) (Agrawal et al., 1993) has emerged as a powerful technique for extracting actionable insights from extensive datasets pertaining to building operations. It is particularly effective in identifying significant co-occurrence relationships among operational states, such as occupancy, equipment settings, and environmental conditions (Fan et al., 2015). Nevertheless, the practical implementation of ARM often generates an excessive number of rules, which can obscure genuinely actionable insights, increase computational demands, and complicate decision-making for facility managers. This phenomenon, known as pattern explosion, has led to the development of condensed representations, although these provide only partial mitigation and entail certain trade-offs. For example, FP-Close reduces the output size by retaining only closed itemsets—those with no proper superset sharing identical support—but often retains longer, less interpretable patterns (Pasquier et al., 1999). FP-Max achieves extreme compression by retaining only maximal itemsets—those with no frequent superset—but at the expense of discarding valuable intermediate patterns crucial for comprehending operational sequences (Grahne & Zhu, 2003). Conversely, setting a high minimum support threshold to avoid pattern explosion introduces the complementary pattern missing problem, where rare but potentially valuable patterns are discarded (Kiran & Reddy, 2009). Additionally, while weighted ARM methods incorporate domain-specific importance, they generally apply it as a computationally inefficient post-processing step (Ahmed et al., 2008), thereby failing to address the fundamental issue of redundancy during the mining process itself.
In contrast, the proposed MNR-FP-Growth (Minimal Non-Redundant FP-Growth) introduces a fundamentally different pruning logic. Rather than examining all proper supersets (as in FP-Close) or all frequent supersets (as in FP-Max), it operates at the granularity of immediate subsets. A pattern is retained only when it adds new frequency information or provides energy benefits over its immediate subsets. This approach yields the minimal representative per support class—the smallest itemset capturing the frequency information—unless a larger pattern provides superior energy efficiency. By integrating energy-aware pruning directly into the mining recursion, MNR-FP-Growth eliminates statistically redundant and energetically inefficient patterns at the point of discovery rather than through disjoint post-filtering. This during-mining approach avoids the computational overhead of generating exhaustive pattern sets only to later prune them, while ensuring that energy semantics actively guide exploration of the search space. A conceptual overview comparing MNR-FP-Growth against standard and condensed methods is presented in Figure 1.
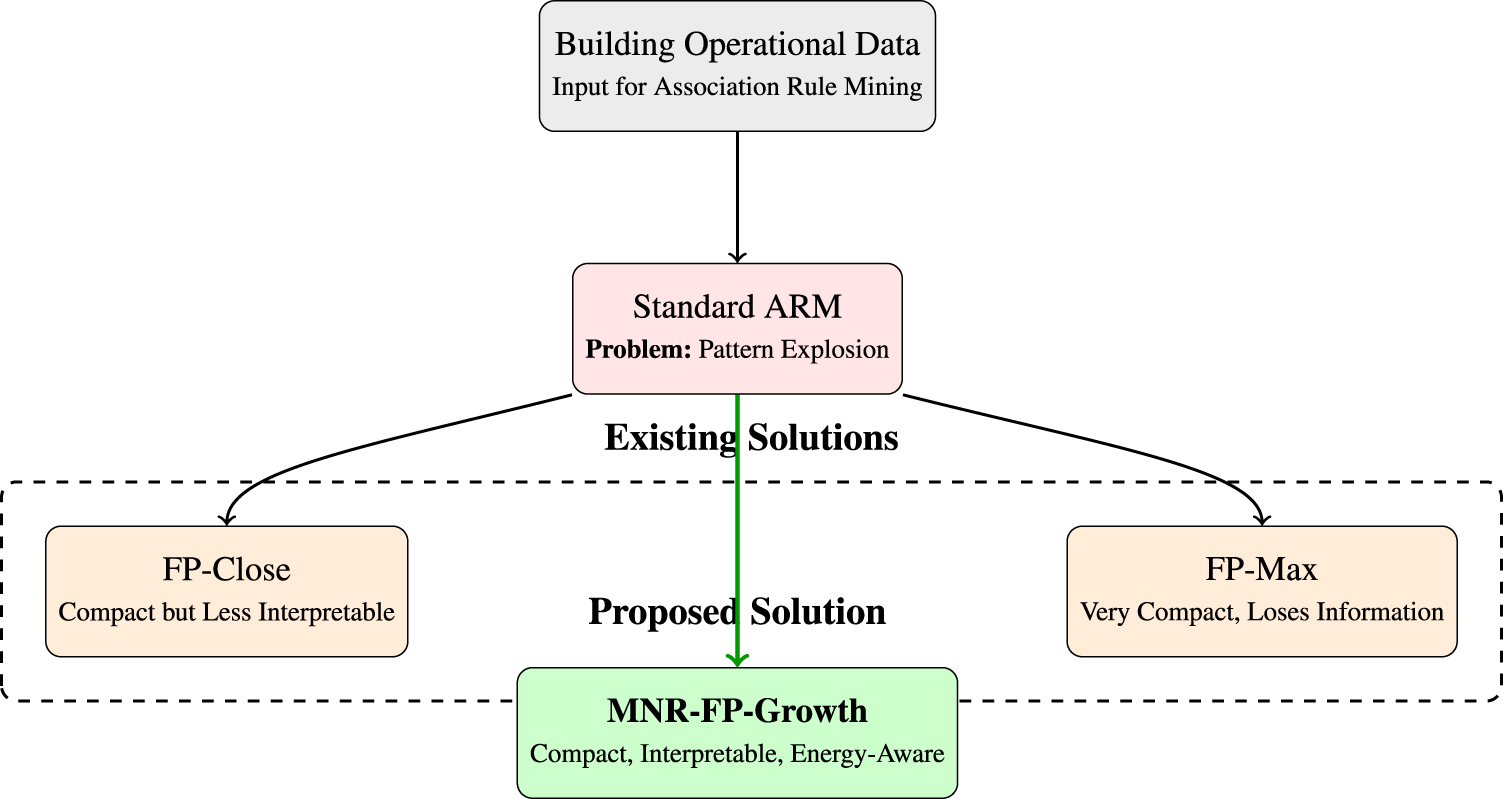
Comparison of pattern mining approaches, positioning MNR-FP-Growth against standard and condensed methods.
The primary contributions of this work are as follows:
A novel pruning criterion applied during mining that simultaneously ensures pattern minimality while considering energy cost. The first application of weight-aware pruning to the building energy management domain, where patterns carry operational semantics beyond statistical frequency. Demonstration of practical impact: 61% speedup over FP-Close and 34% zero-cost energy-saving rules, translating algorithmic efficiency into actionable energy conservation.
The remainder of this paper is structured as follows: Section 2 2 reviews related work in building data mining and condensed representations. Section 33 details the methodology and the MNR-FP-Growth algorithm. Section 44 presents the experimental results and analysis. Section 55 discusses limitations. Finally, Section 66 offers concluding remarks.
Contemporary architectural structures generate substantial amounts of diverse data from sensors, automation systems, and the Internet of Things (IoT) platforms, thereby presenting opportunities to transition from conventional rule-based control to more adaptive, data-driven strategies. In this context, frequent pattern mining has emerged as a potent tool for extracting operational insights. However, its direct application in energy domains encounters several challenges, including rule redundancy, interpretability, and the limited integration of domain semantics. The subsequent subsections examine the foundations and limitations of existing approaches, underscoring the motivations for the proposed MNR-FP-Growth algorithm.
Data-Driven Building Operations
The transition from static, schedule-based control to dynamic, data-driven management is a cornerstone of modern building energy efficiency. The availability of high-resolution data from building automation systems and IoT sensors has enabled a shift towards diagnostic and prognostic analytics (Drgoňa et al., 2020). Within this paradigm, unsupervised learning techniques such as clustering and pattern mining are particularly valuable for uncovering hidden structures without requiring pre-labeled data, which is often scarce in building applications (Miller et al., 2018). These methods provide interpretable insights that can directly inform operational strategies.
Pattern Mining for Energy Analytics
Association Rule Mining (ARM) (Agrawal et al., 1993) offers a framework for quantifying and extracting if-then relationships within operational data. While its applications originated in traditional market basket analysis, ARM now extends to complex systems like buildings, where it has been used to identify key drivers of energy demand (Wang et al., 2018), diagnose faulty operational sequences (Zhang et al., 2019), and analyze system-level loads (Fan et al., 2015). Additionally, the efficiency of algorithms such as Frequent Pattern Growth (FP-Growth) (Han et al., 2004) has made data-driven methods practical for large-scale building datasets, supporting applications including occupancy detection from smart meters (Kleiminger et al., 2013). More recently, in response to the challenge of overwhelming rule sets, post-mining approaches have been explored to filter or aggregate rules, aiming to distill actionable knowledge (Zhang et al., 2020).
The key features relevant to energy-aware pattern mining in building management — including temporal (hour, day, season), environmental (temperature, humidity, solar radiation), occupancy, HVAC operational states, end-use loads, and thermal comfort — are detailed in Section 3.1 and summarized in Table 1. These features collectively enable the discovery of actionable patterns for energy optimization.
Discretization Scheme with Normalized Illustrative Weights.
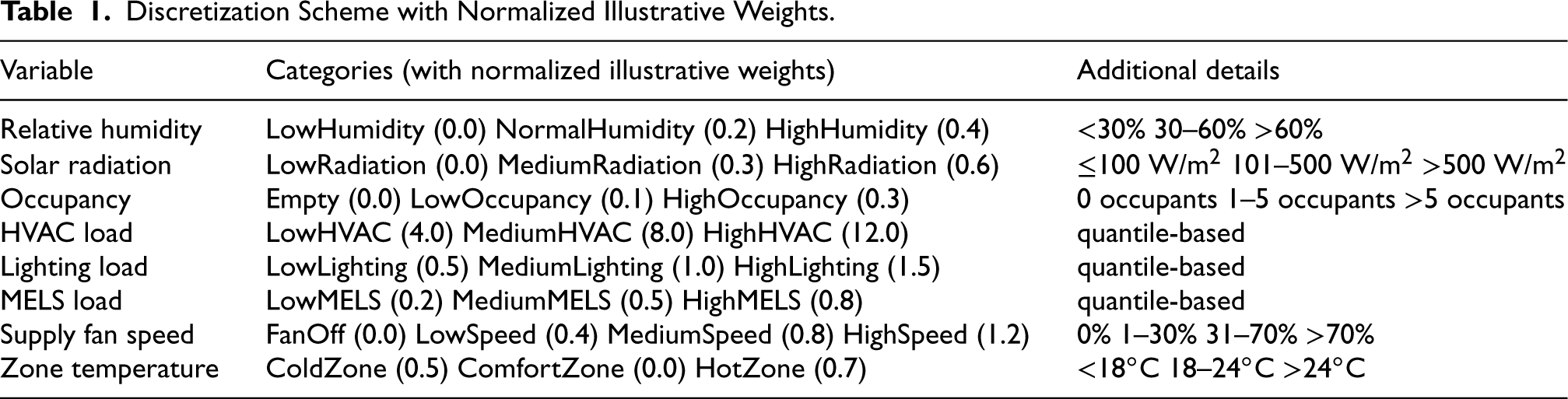
Discretization Scheme with Normalized Illustrative Weights.
Recent advances have extended pattern mining to dynamic and weighted scenarios. Nguyen et al. (2023) introduced frequent weighted utility pattern mining with dynamic item weights, demonstrating the growing interest in weighted pattern mining. However, this approach does not integrate energy-aware pruning during FP-Growth recursion as proposed in this work.
A well-known limitation of ARM is the exponential growth of its output. The vast number of generated rules creates interpretability and computational challenges for downstream applications (Zhang et al., 2020). To address this, compact representations using closed and maximal itemsets have been developed. Closed itemset mining (Pasquier et al., 1999) identifies the longest patterns for each unique support value, while maximal itemset mining (Grahne & Zhu, 2003) finds the broadest patterns without any frequent supersets. Each method offers a distinct balance between conciseness and completeness, but neither fully eliminates redundancy in energy analytics.
Recent studies on closed pattern mining have addressed the problem of pattern explosion in weighted and utility-based contexts. Le et al. (2026) proposed an efficient algorithm for mining frequent weighted utility closed patterns, demonstrating that closed representations can significantly reduce pattern counts while preserving information. However, these methods do not incorporate energy semantics or immediate-subset pruning during mining.
Incorporating Semantic Weights
An important evolution in pattern mining has been the shift from purely frequency-based discovery to approaches that incorporate domain semantics through weighted measures (Tseng et al., 2015). This perspective enables the mining process to prioritize patterns involving items of greater significance, such as high-impact energy states. Nevertheless, a common limitation of existing approaches is that item weights are often assumed to be fixed or are only introduced as a post-processing filter (Ahmed et al., 2008). Such decoupling reduces computational efficiency, since the mining procedure itself remains unaware of semantic importance during pattern construction.
The literature reports efforts to incorporate semantic or automated weights in pattern mining. Datta et al. (2021) proposed an automated weighting scheme for unweighted transactional databases based on inter-item links, while Wan et al. (2017) introduced semantic intensity for trajectory pattern mining, and Palmes et al. (2010) used tf-idf weighting for activity recognition. Despite demonstrating the value of automated weighting across various domains, none integrate automated weighting with immediate-subset pruning during FP-Growth recursion or address building energy management. This gap underscores the need for algorithms that deliver semantically meaningful, efficient, and interpretable patterns, specifically for building energy management.
Methodology
This section outlines the framework for discovering interpretable, energy-aware patterns from building operational data. The process begins with a description of the datasets and preprocessing steps to ensure high-quality inputs. Building on this foundation, the MNR-FP-Growth algorithm is then introduced, which extracts frequent patterns while pruning redundant itemsets. Once these patterns are identified, the methodology moves to the energy-aware association rule generation process, which extends mined patterns with operational weights to highlight low-cost energy-saving rules. By integrating these steps sequentially, this methodology combines statistical reliability with operational relevance, providing facility managers with actionable insights for energy-efficient control.
Data Collection and Preprocessing
The datasets used in this study comprised multi-source operational data from a commercial building in Berkeley, California, USA, spanning the full year of 2019 (Hong et al., 2021). The data included weather measurements (solar radiation, relative humidity), occupancy sensors, electricity end-uses (heating, ventilation, and air conditioning (HVAC), lighting, and miscellaneous electrical loads (MELS), HVAC control signals (supply fan speed), and indoor zone temperatures. These heterogeneous streams exhibited temporal misalignment, differing resolutions, and missing values due to sensor malfunctions and communication errors.
To ensure analytical consistency, a structured preprocessing pipeline consisting of temporal alignment, missing data imputation, and discretization was implemented. All datasets were unified into an hourly resolution framework comprising 8,760 timestamps (365 days
Missing values were addressed using a tiered imputation strategy inspired by Cho et al. (Cho et al., 2020), with methods selected according to the size of the missing gap:
This strategy reduced the overall missing-data rate from 28.6% to 0.0%, while preserving both temporal patterns and inter-variable dependencies.
Since ARM requires categorical inputs, continuous features were discretized into semantically meaningful states derived from domain knowledge and building management practices. This transformation preserved interpretability for facility managers while enabling efficient symbolic pattern discovery.
The numerical weights in Table 1 do not represent exact physical consumption values. Instead, they are normalized illustrative values that reflect relative operational intensities (e.g., HighHVAC > MediumHVAC > LowHVAC; HighLighting > LowLighting). For the proposed MNR pruning mechanism, only ordinal relationships are critical; precise magnitudes are not. In practical deployments, these weights can be replaced with measured energy consumption values from building meters or simulation tools.
The normalized weights in Table 1 are constructed as
Specifically:
For HVAC load, weights 4.0, 8.0, 12.0 reflect that HighHVAC consumes more than MediumHVAC, which consumes more than LowHVAC. For humidity, weights 0.0, 0.2, 0.4 preserve the same ordinal property but on a different numerical scale. The absolute difference between 12.0 (HighHVAC) and 1.5 (HighLighting) does not imply that HVAC consumes exactly 8
When items from different variables are combined into an itemset, the total weight Ordinal relationships within each variable are preserved, Summation preserves the relative ranking of itemsets as long as the ordinal structure is consistent, The criterion uses comparison (
In practical deployments, these illustrative weights would be replaced with empirically measured energy values (e.g., kWh) from building meters, at which point cross-variable comparability is naturally established. The current weighting scheme is sufficient to demonstrate the algorithm’s functionality and is consistent with standard practice in weighted ARM literature (Ahmed et al., 2008).
Thus, the weights serve as a proxy for real consumption values. As shown later in Section 4, even with normalized weights, the algorithm effectively identifies redundant patterns and highlights energy-saving rules. The normalized illustrative weights are adopted solely to demonstrate the algorithm’s functionality while preserving consistent ordinal relationships across all variables, a common practice in weighted ARM literature (Ahmed et al., 2008).
The final preprocessed dataset contained 8,760 hourly instances, each represented by nine categorical attributes capturing environmental conditions, occupancy states, energy system loads, and thermal comfort levels. This symbolic representation provided a compact yet interpretable basis for subsequent knowledge discovery.
Table 2 presents a sample of the preprocessed dataset, illustrating the categorical representation used for pattern mining.
Sample of the Preprocessed Dataset (Representative Rows).

Sample of the Preprocessed Dataset (Representative Rows).
Frequent pattern mining in building energy datasets often yields numerous redundant itemsets. Specifically, larger itemsets may share the same support as their immediate subsets, offering no new frequency information while increasing both output size and downstream processing cost. Several condensed representations have been proposed: FP-Close (Pasquier et al., 1999) favors longer supersets when supports match, reducing redundancy but compromising both compactness and interpretability, whereas FP-Max (Grahne & Zhu, 2003) prunes all subsets, risking the discarding of informative intermediate patterns.
Building on these methods, this work formally defines pattern compactness as the total number of frequent itemsets generated by an algorithm for a given minimum support threshold. Greater compactness corresponds to a lower pattern count, as more information is condensed into fewer itemsets. The proposed evaluation compares compactness and information fidelity across baseline methods–FP-Growth, FP-Close, and FP-Max—using Jaccard similarity with FP-Close.
To address the identified limitations, MNR-FP-Growth is proposed. This variant integrates redundancy pruning directly into the mining process, retaining only the shortest non-redundant itemsets, thereby preserving interpretability while reducing runtime and output size.
Each categorical state (e.g., HighHVAC, LowLighting) is associated with a normalized illustrative weight reflecting its relative operational intensity (see Table 1). For an itemset
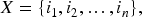

A pattern 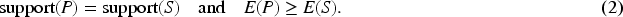
Intuitively, if adding an item to
It is important to note that the pruning criterion uses only ordinal relationships between weights, not their absolute magnitudes. The condition
MNR-FP-Growth performs this redundancy check during mining while merging conditional subtree patterns. The recursive procedure is summarized in Algorithm 1.

Formally, the set of mined patterns is:
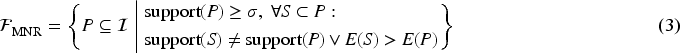
Example
Using the weights in Table 1, consider:
If both 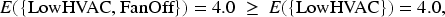
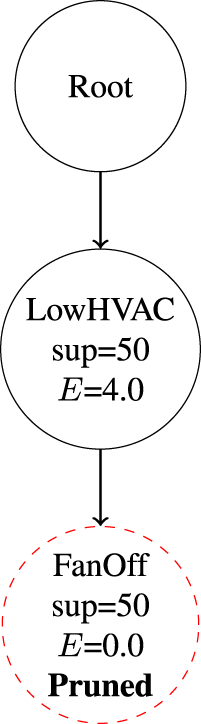
Illustration of FP-tree branch pruning under the MNR criterion.
Illustrative Weights for the Example Pattern.

Implementation
MNR-FP-Growth was implemented by adapting the
Key modifications include:
Use of normalized illustrative weights for all discrete states. Itemset weight computation to enable redundancy checks. A pruning counter to track how many patterns are removed on-the-fly. A toggle to switch between baseline FP-Growth (no pruning) and MNR-enabled mode.
By pruning redundant, higher-weight supersets during mining, MNR-FP-Growth produces a more compact, frequency-relevant pattern set without requiring a separate post-processing step.
Once frequent patterns are extracted using the proposed MNR-FP-Growth algorithm, the framework derives interpretable knowledge in the form of association rules. While classical ARM (Agrawal et al., 1993) evaluates rules based on support and confidence, the presented framework extends this process by incorporating an explicit energy-awareness component. This addition is crucial, as patterns alone do not indicate whether the discovered relations preserve operational efficiency or introduce additional operational intensity.
Formally, let 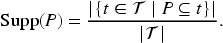
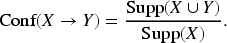
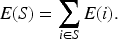
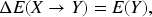
This formulation allows rules to be evaluated using two complementary perspectives: (i)
The energy-aware rule generation procedure is summarized in Algorithm 2. For each frequent pattern

Complexity Analysis
Algorithm 2 iterates over each frequent pattern
Building on this efficiency, the resulting rules provide dual insight: (i) statistical reliability through support and confidence, and (ii) operational relevance through the weight-based energy proxy. These rules can be ranked jointly by
To ensure comprehensive evaluation, while minsup is varied to assess scalability,
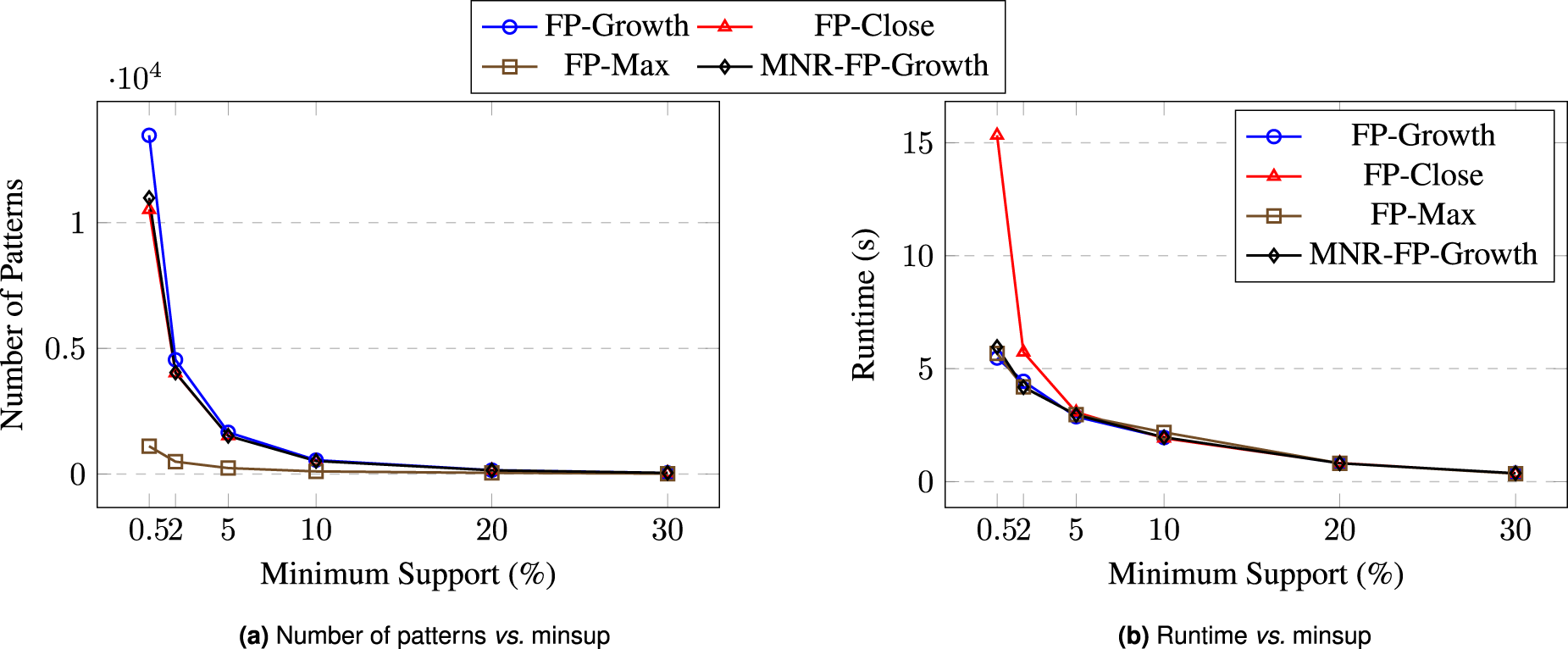
Scalability comparison of redundancy-aware baselines across minsup thresholds. (a) Number of patterns vs. minsup and (b) Runtime vs. minsup
Comparison with Redundancy-Aware Baselines
The effectiveness of MNR-FP-Growth was evaluated against established redundancy-handling baselines—FP-Growth, FP-Close, and FP-Max—across minimum support thresholds from 0.5% to 30%.
The results, summarized in Table 4, reveal several key trends. As expected, higher minsup values yield fewer patterns and faster runtimes for all methods. Crucially, MNR-FP-Growth achieves high compactness, producing 10,985 patterns at 0.5% minsup compared to 13,476 for FP-Growth – an 18.5% reduction. This pattern count is nearly identical to FP-Close (10,524), confirming that MNR-FP-Growth preserves the informational content of closed itemsets while achieving comparable compactness. Unlike FP-Max, which achieves extreme compactness (1,108 patterns) by discarding intermediate patterns, MNR-FP-Growth retains fine-grained operational information essential for energy analysis.
Pattern Counts and Runtime Performance Across Different Minimum Support Thresholds.
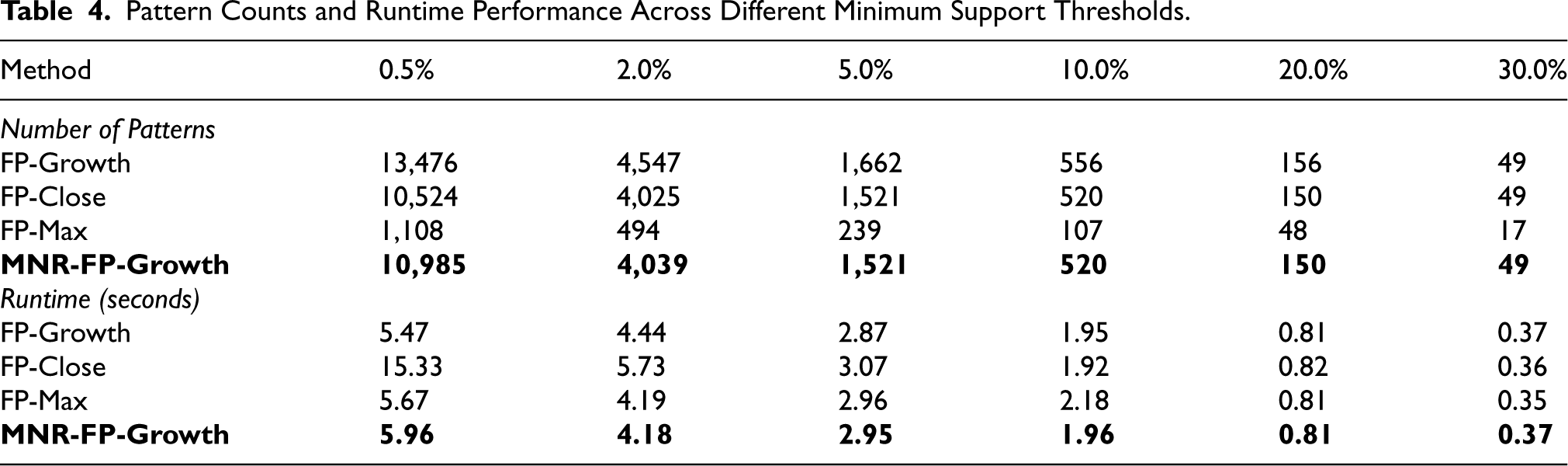
Pattern Counts and Runtime Performance Across Different Minimum Support Thresholds.
The Jaccard similarity (Jaccard, 1901) between the sets mined by MNR-FP-Growth and FP-Close was consistently
Runtime comparisons highlight the efficiency advantage of MNR-FP-Growth. While FP-Growth is fastest, it retains all redundancies. FP-Close incurs significantly higher computational cost due to closure-based checks that compare each candidate against conditional subtree supersets. At 0.5% minsup, FP-Close required 15.33 seconds versus 5.96 seconds for MNR-FP-Growth, a 61.1% improvement. FP-Max achieves compactness but discards fine-grained intermediate patterns. By contrast, MNR-FP-Growth delivers the interpretability and coverage of FP-Close while maintaining runtimes competitive with FP-Growth and FP-Max.
Collectively, these results indicate that MNR-FP-Growth achieves an effective balance among pattern quality, interpretability, and computational efficiency. In contrast to FP-Max, it retains fine-grained patterns, while, unlike FP-Close, it removes redundancy in a single efficient step. These characteristics establish MNR-FP-Growth as a scalable, practical approach for extracting interpretable, non-redundant knowledge from large building datasets, thereby directly facilitating energy-optimization tasks.
In addition to its condensed representations, MNR-FP-Growth fundamentally differs from weighted association rule mining (WARM) approaches. Datta et al. (2021) introduced an automated weighting scheme for unweighted transactional databases using inter-item links; however, their method operates within an Apriori-like framework and applies weights as a post-processing filter. Feng and Li (2017) used WARM to identify coordinated equipment control in building energy systems, demonstrating domain relevance but lacking pruning during mining. Zhang et al. (2020) developed a post-mining method for building operation data, emphasizing filtering after rule generation rather than integration during the mining phase.
In contrast, MNR-FP-Growth uniquely integrates three characteristics not present in previous WARM approaches: (i) energy-aware weighting during FP-Growth recursion, (ii) pruning based on immediate subsets using a dual-condition criterion of statistical redundancy and energetic non-improvement, and (iii) retention of the minimal representative for each support class. This combination results in improved computational efficiency, achieving a 61% speed increase over FP-Close, as well as enhanced interpretability of the resulting patterns.
Energy-Aware Rule Analysis
To assess the practical impact, patterns mined at 2% minsup were extended into energy-aware association rules. From 4,039 frequent patterns, a total of 12,679 rules were generated, of which 4,316 (34.0%) were classified as energy-saving (i.e., rules with zero additional energy cost,
As shown in Figure 4, approximately one-third of all discovered rules are energy-saving, demonstrating the prevalence of efficient patterns in building operation data. This distribution highlights the potential for significant energy conservation through data-driven operational adjustments.
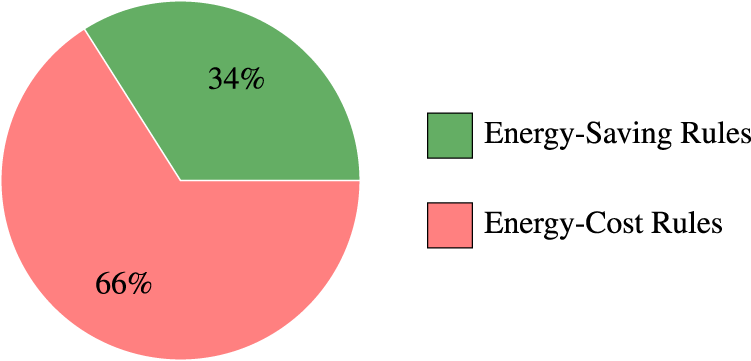
Distribution of energy-saving vs. energy-cost rules among all generated association rules (minsup = 2%).
Figure 5 illustrates the relationship between confidence and additional energy cost for the top 2000 rules. The concentration of points in the high-confidence, low-cost region highlights the abundance of reliable and efficient patterns.
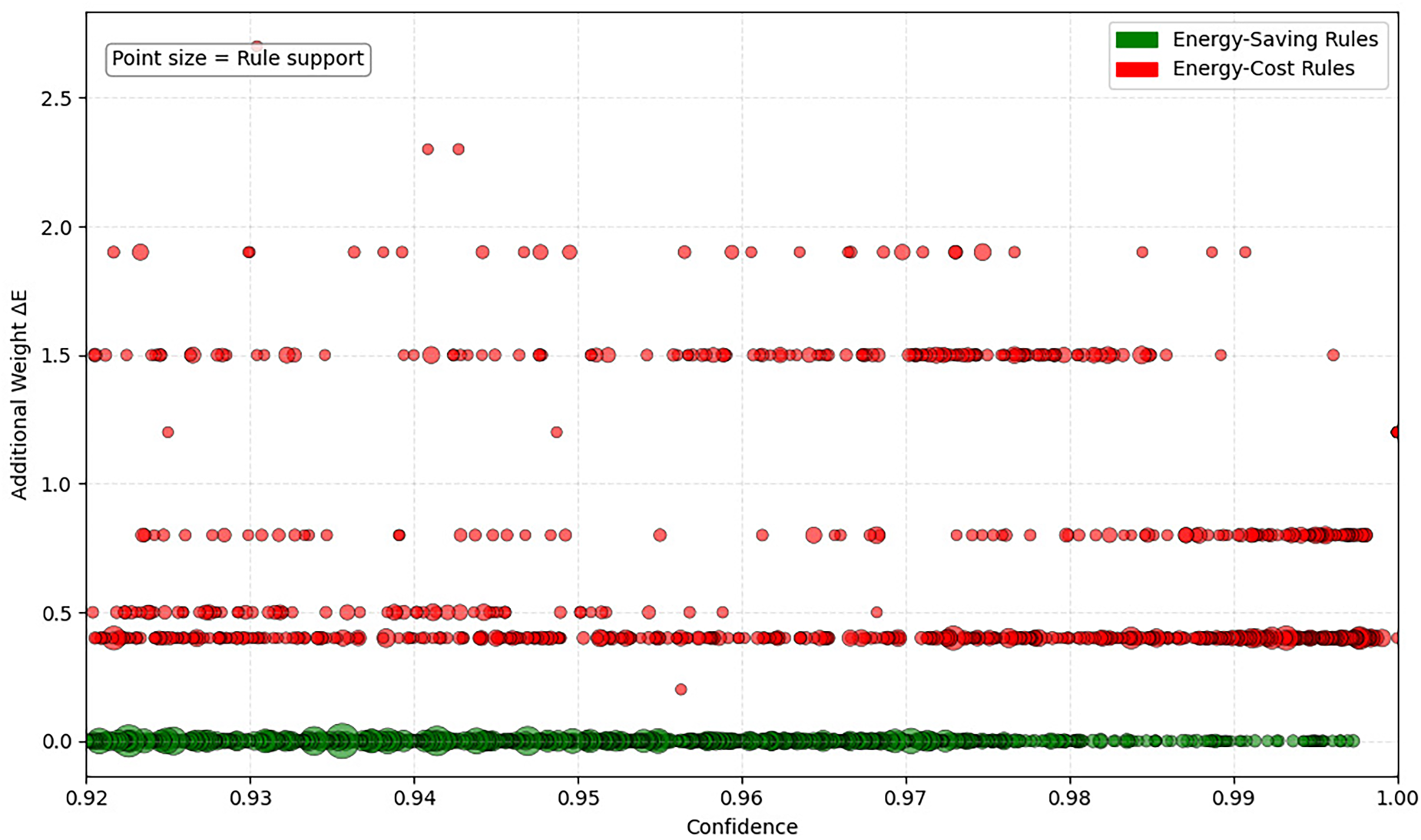
Confidence vs. additional energy cost (
These rules provide interpretable insights that can directly inform building control strategies, such as prioritizing fan-off during low occupancy or maintaining comfort-zone temperatures without additional energy consumption Table 5.
Representative Energy-aware Association Rules (minsup
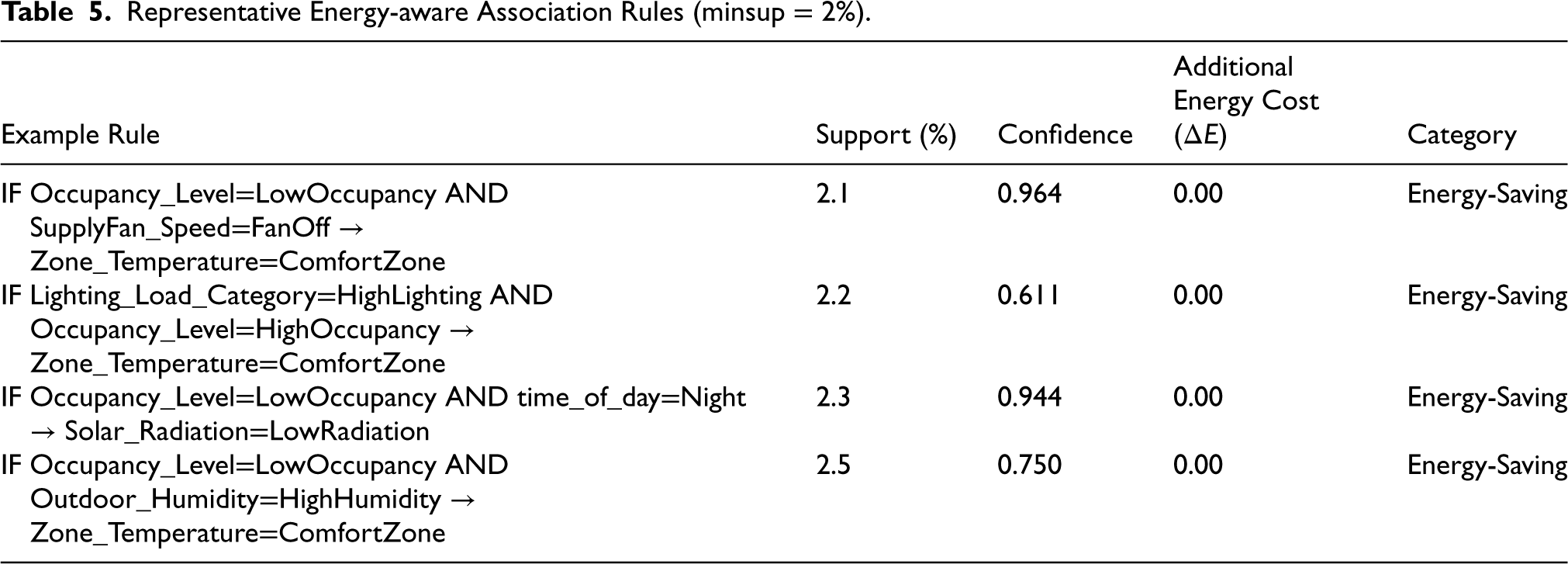
Conversely, rules with positive
Although MNR-FP-Growth achieves effective redundancy reduction and energy-aware rule generation, several limitations warrant discussion. First, the normalized illustrative weights, while adequate for methodological validation, simplify the complexities of real building energy dynamics. In practice, these should be replaced with empirically measured consumption data from building meters or high-fidelity simulations should be used to provide a more accurate assessment of operational impacts. Second, while during-mining pruning enhances computational efficiency, scalability issues may occur when the method is applied to extensive building portfolios or high-frequency IoT data streams. Third, the current framework assesses rules primarily from an energy perspective, without incorporating considerations such as thermal comfort, equipment lifespan, or occupant satisfaction.
Conclusion
In this work, MNR-FP-Growth was introduced, a variant of FP-Growth that integrates minimal non-redundancy pruning and energy-aware weighting directly into the frequent pattern mining process. Unlike FP-Close, which examines all proper supersets, or FP-Max, which considers all frequent supersets, MNR-FP-Growth operates at the level of immediate subsets. It retains a pattern only when it introduces new frequency information or provides energy benefits relative to its immediate subsets. This method produces the minimal representative for each support class, defined as the smallest itemset that captures the frequency information, unless a larger pattern demonstrates superior energy efficiency. By embedding energy-aware pruning within the mining recursion, the algorithm removes statistically redundant and energy-inefficient patterns at the point of discovery. This represents the first application of weight-aware pruning in the building energy management domain, where patterns possess operational semantics in addition to statistical frequency.
Experimental results demonstrated that MNR-FP-Growth reduces redundant patterns by over 11% while achieving runtime performance competitive with FP-Growth and up to 61% faster than FP-Close at low support thresholds. Unlike FP-Max, which sacrifices interpretability, or FP-Close, which incurs substantial computational overhead, the proposed method preserves fine-grained yet non-redundant patterns with significantly improved efficiency. When extended into energy-aware association rules, 34% (
The practical implications are clear: by transforming raw building data into interpretable and energy-conscious rules, MNR-FP-Growth provides facility managers with a scalable tool for identifying efficiency opportunities and supporting data-driven decision-making. Its efficiency also makes it suitable for periodic re-analysis as building conditions evolve, ensuring continued adaptability.
Future research should address the limitations noted in Section 5 by incorporating empirical energy measurements, extending to multi-objective optimization, and validating across diverse building types. Integration with predictive control frameworks would further broaden applicability.
In summary, MNR-FP-Growth demonstrates that integrating redundancy reduction and semantic weighting within a unified mining process can yield interpretable, efficient, and operationally significant patterns. This establishes a robust foundation for advancing sustainable, data-driven optimization in the built environment and beyond.
Footnotes
Acknowledgements
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions on the earlier versions of this paper.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.