
Abstract
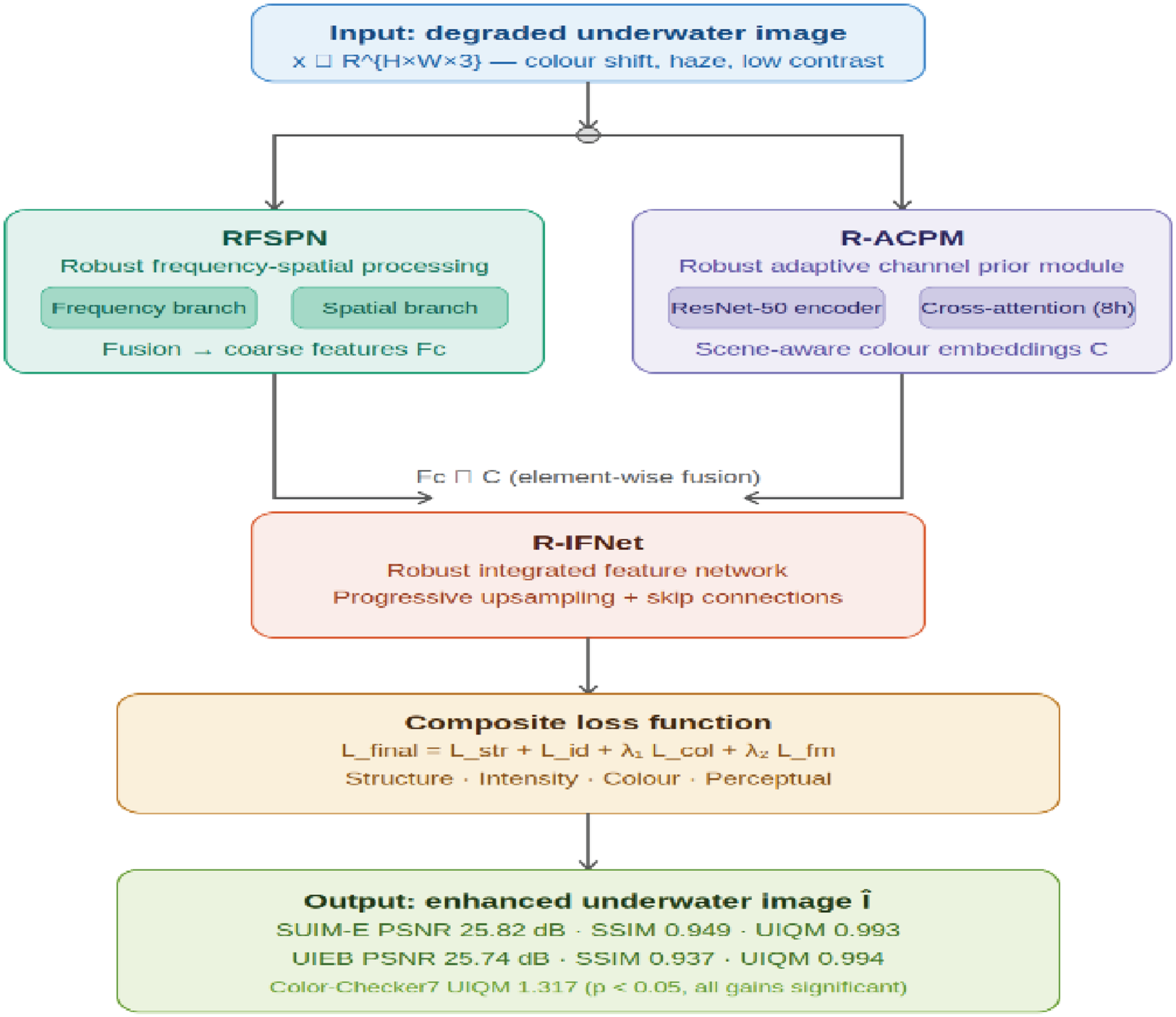
Underwater image enhancement is challenging due to complex and highly variable degradations, including color attenuation, low contrast, and uneven illumination. Many existing methods perform well under limited conditions but lack robustness when image characteristics change across scenes. This paper presents R-FSACP-Net, a robust frequency-spatial and adaptive channel prior framework for underwater image enhancement. The proposed method explicitly addresses robustness by jointly modeling frequency-domain and spatial-domain features to stabilize enhancement across diverse degradation patterns. An initial frequency-spatial processing module reduces noise and illumination imbalance while preserving structural information. To handle color distortion, an adaptive channel prior module learns scene-aware color representations through cross-attention with multi-scale image features, improving generalization without relying on fixed assumptions. The refined features are further integrated to produce the final enhanced image. Extensive experiments on benchmark datasets show that the proposed approach achieves a PSNR of 25.818, SSIM of 0.949, and UIQM of 0.993 on the SUIM-E dataset. The results demonstrate the robustness and effectiveness of the proposed framework in complex underwater environments in Figure 1.
Keywords
Introduction
Underwater imaging has become an essential component in many marine applications, including seabed mapping, ecological monitoring, underwater archaeology, offshore infrastructure inspection, and autonomous underwater vehicle (AUV) navigation (Figure 1). In these applications, visual data provide critical information for perception, localization, and decision-making. However, underwater images are often severely degraded due to the complex optical properties of water, which significantly limit their direct usability for both human observation and computer vision tasks (Hou et al., 2022 Li, Anwar, et al., 2020;). The degradation of underwater images is mainly caused by wavelength-dependent light absorption and scattering. As light propagates through water, longer wavelengths such as red attenuate rapidly, while shorter wavelengths such as blue and green dominate the captured image. This process introduces strong color shifts, reduced contrast, and loss of visibility (Chiang & Chen, 2012; Guo et al., 2020). Additionally, backscatter from suspended particles causes haze and blur, while non-uniform illumination often due to artificial lighting leads to spatially varying brightness. These factors often appear simultaneously and interact with each other, making underwater image enhancement (UIE) an inherently challenging problem (Islam et al., 2020).
Enhanced Underwater Image Î (Higher PSNR / SSIM / UIQM).
Over the years, numerous methods have been proposed to UIE, early approaches are typically categorized as either non-physical or physical model-based methods. Non-physical techniques aim to improve image appearance without explicitly modeling the underwater imaging process and include histogram equalization, color balancing, contrast stretching, and Retinex-based methods (Anwar & Li, 2020; Cong et al., 2021). While such techniques are simple and computationally efficient, they often amplify noise, distort colors, or produce over-enhanced results when applied to complex underwater scenes (Verma et al., 2022). Physical model-based methods attempt to restore underwater images by modeling light propagation, attenuation, and scattering, which are inspired by atmospheric dehazing, several studies adapt transmission estimation and background light modeling to underwater environments (Liu et al., 2021 Wang, Yu, et al., 2022;). Variants of dark channel prior-based formulations and wavelength compensation models fall into this category. Although these methods incorporate physical insight, their effectiveness strongly depends on environmental assumptions, such as homogeneous water properties or accurate depth estimation, which rarely hold in practice (Cong et al., 2023). Consequently, their robustness across different underwater conditions remains limited.
In recent years, deep learning has emerged as a powerful alternative for UIE, where use of convolutional neural networks (CNNs) learn complex, non-linear mappings between degraded images and their enhanced counterparts directly from data, avoiding explicit hand-crafted rules (Deng et al., 2023; Gong et al., 2023). Many learning-based UIE methods report substantial improvements over traditional approaches in both visual quality and quantitative metrics; to address the lack of real paired datasets, synthetic underwater data generation and weakly supervised learning strategies have been widely employed (Zhao, Chen, et al., 2023). Beyond standard CNNs, generative adversarial networks (GANs) have been explored to improve perceptual realism in enhanced images and asdversarial learning encourages the network to produce visually pleasing outputs that resemble natural images while preserving important scene content (Cong et al., 2024; Shi & Wang, 2024). More recently, attention mechanisms and transformer-based architectures have been introduced to capture long-range dependencies and global context, which are particularly useful for correcting large-scale color bias and illumination imbalance (Wang et al., 2024; Zhang et al., 2024). These advances have significantly improved the state of the art in underwater image enhancement.
Despite this progress, several critical challenges remain unresolved. First, many existing deep learning approaches primarily operate in the spatial domain, where different degradation factors are tightly coupled. As a result, improving one visual attribute may adversely affect another. For instance, increasing brightness can introduce noise, while aggressive color correction may suppress texture details (Guo et al., 2020; Verma et al., 2022; Yeh et al., 2024). This trade-off between contrast, color accuracy, and detail preservation remains a major limitation of current UIE methods. Second, robustness and generalization are still open problems, where many deep models perform well on specific datasets but exhibit unstable behavior when applied to images captured in different water types or lighting conditions (Cong et al., 2023 Li, Anwar, et al., 2020;). This issue is partly due to reliance on fixed priors or dataset-specific color characteristics. Recent survey studies emphasize that improving generalization across diverse underwater environments is a key research challenge that has not yet been fully addressed (Geng et al., 2025; Hou et al., 2022). Third, although recent methods report strong performance on individual metrics such as PSNR or SSIM, they may fail to provide consistent improvements across multiple evaluation criteria, where underwater-specific quality measures such as UIQM and UCIQE can be included for better evaluation. This inconsistency suggests that current models may not fully capture the complex perceptual characteristics of underwater images (Guo et al., 2020; Yeh et al., 2024). Recent deep unfolding methods also target robustness by embedding underwater imaging physics into the network structure. For example, (Pham et al., 2025) use physics-driven prior learning in a deep unrolling framework, (Chang et al., 2025) propose CDDU with convolutional dictionary deep unfolding, and (Lei et al., 2024) introduce UIE-UnFold with color priors and a vision transformer. In contrast, R-FSACP-Net avoids explicit degradation parameter estimation and instead learns adaptive channel priors while jointly modeling frequency-spatial features in a data-driven manner.
Motivated by these limitations, this paper proposes R-FSACP-Net, a Robust Frequency-Spatial and Adaptive Channel Prior framework for Underwater Image Enhancement. The core idea of the proposed method is to explicitly separate and model different degradation factors using complementary feature representations while learning adaptive color priors in a data-driven manner. Unlike conventional approaches that rely solely on spatial-domain processing,
R-FSACP-Net jointly exploits frequency-domain and spatial-domain features to improve robustness under diverse degradation conditions. Specifically, the proposed framework consists of three main components. First, a Robust Frequency-Spatial Processing Network (RFSPN) is designed to generate a stable coarse enhancement by processing features in both frequency and spatial domains. This dual-domain design enables the network to suppress noise and illumination imbalance while preserving structural details. Second, a Robust Adaptive Channel Prior Module (RACPM) learns scene-aware color representations by establishing a dynamic relationship between multi-scale semantic features and channel-wise color embeddings. This mechanism avoids fixed assumptions and allows the model to adapt to different underwater color distributions. Third, a Robust Integrated Feature Network (R-IFNet) fuses the structural information from FSPN and the adaptive color priors from ACPM to produce the final enhanced image.
To further improve robustness, R-FSACP-Net is trained using a composite loss function that jointly enforces structural consistency, pixel-level fidelity, color distribution alignment, and perceptual similarity. By supervising the model at multiple levels, the proposed training objective encourages balanced enhancement and stable performance across different underwater scenarios. Extensive experiments conducted on multiple benchmark datasets demonstrate that R-FSACP-Net consistently outperforms recent state-of-the-art methods in both qualitative and quantitative evaluations. The results confirm that the proposed framework achieves improved robustness and generalization while maintaining high visual quality. These findings indicate that R-FSACP-Net provides an effective solution for underwater image enhancement in complex and variable environments.
The remainder of this paper is structured as follows: Section 2 reviews the related literature. Section 3 details the proposed methodology. Section 4 presents the experimental results and analysis. Finally, Section 5 concludes the paper.
Recent research on UIE increasingly focuses on robustness, generalization, and applicability under real-world conditions. Underwater scenes vary significantly in water quality, illumination, depth, and sensor characteristics, making it difficult for enhancement methods to perform consistently across datasets. Several studies emphasize that conventional enhancement approaches often show unstable behavior when evaluated beyond their training or testing conditions, highlighting the need for more generalized frameworks (Li et al., 2021). Learning-based UIE methods have increasingly explored convolutional architectures with deeper feature extraction and fusion strategies. Multi-scale and residual learning techniques have been employed to preserve structural details while reducing noise and contrast loss, feature reuse through dense or cascaded connections has been shown to improve texture clarity and spatial consistency (Liu et al., 2022; Zhou et al., 2022). These approaches demonstrate that hierarchical feature fusion can enhance visual quality, but they still primarily operate in the spatial domain, where multiple degradation factors remain coupled.
Attention mechanisms have been introduced to adaptively emphasize informative regions and feature channels, whereas channel and spatial attention strategies help address non-uniform illumination and localized color distortion by dynamically weighting feature responses (Chen et al., 2022). However, attention-based models alone are often insufficient when degradations are severe or globally distributed, studies analyzing such methods report that attention mechanisms may struggle to correct heavy color cast or dense haze, particularly in highly turbid underwater environments (Mehta & Banerjee, 2022).
To improve interpretability and stability, some UIE methods integrate simplified physical constraints into deep learning frameworks, these approaches incorporate estimated attenuation or scattering properties into the learning process, guiding the network toward physically plausible outputs (Wang, Xu, et al., 2022). While such hybrid designs reduce unrealistic enhancement artifacts, their performance is still influenced by the reliability of the embedded physical assumptions, which may vary across different underwater conditions.
In recent, frequency-domain processing has gained increasing attention as a complementary strategy for UIE, where frequency-based decomposition enables networks to treat illumination variations and texture details separately. Methods that process low-frequency components to correct global contrast while enhancing high-frequency components for edge preservation have demonstrated improved balance between sharpness and smoothness (Gao et al., 2023; Huang et al., 2023). These works suggest that frequency-spatial decoupling is beneficial for handling intertwined degradation factors and transformer-based architectures have also been investigated to capture long-range dependencies in underwater images. By modeling global contextual relationships, transformer components help correct overall color bias and illumination imbalance that are difficult to address using local convolutions alone (Zhao, Wu, et al., 2023).
Hybrid CNN-Transformer models combine local feature extraction with global attention, achieving improved consistency in challenging scenes (Rao & Gupta, 2023). Nevertheless, transformer-based methods introduce higher computational cost, which can limit their use in real-time or resource-constrained underwater systems.
Generative models have emerged as another research direction, diffusion-based UIE methods employ iterative refinement to progressively restore degraded images, producing visually pleasing results with fewer artifacts (Yin et al., 2023). However, these approaches generally require longer inference time and adversarial learning remains popular due to faster runtime and strong perceptual quality. Structure-preserving adversarial frameworks enforce geometric consistency while enhancing color and contrast, but they may suffer from training instability if adversarial constraints are not carefully designed (Liu et al., 2023).
Recent studies increasingly identify robustness and domain generalization as major evaluation criteria and cross-domain analyses reveal that many UIE models trained on synthetic or limited datasets fail to generalize to real underwater images captured under different conditions (Kim et al., 2023). To mitigate this issue, domain-invariant learning and adaptive normalization strategies have been proposed to reduce dataset bias and improve transferability (Alvarez & Marin, 2024). These findings highlight the importance of robustness-oriented network design and evaluation. Several latest works emphasize multi-domain integration, the networks that jointly process spatial and Fourier-domain representations demonstrate improved resilience to unknown degradation patterns (Li et al., 2024). Semantic-guided enhancement models establish a relationship between scene content and color correction, reducing over-enhancement in background regions while preserving object details (Yang et al., 2024).
These approaches suggest that combining semantic, frequency, and spatial information leads to more reliable enhancement. Very recent efforts further explore robustness-aware learning strategies, where consistency-driven frameworks enforce stable enhancement across multiple augmented views of the same input, improving robustness to noise and illumination changes (Shen et al., 2024). Lightweight UIE models optimized for embedded underwater platforms aim to balance enhancement quality and computational efficiency, which is critical for robotic and monitoring applications (Patel & Desai, 2024).
In addition, unified evaluation protocols have been proposed to assess UIE robustness across datasets, degradation levels, and lighting conditions, rather than relying on isolated benchmark results (Sun et al., 2024). Adaptive channel modeling represents a notable direction in the most recent literature and instead of relying on fixed color assumptions, adaptive channel prior learning dynamically adjusts color correction based on learned channel statistics, enabling better generalization across varying underwater environments (Rahman et al., 2025).
Compared to recent frequency-spatial methods (Gao et al., 2023; Huang et al., 2023; Li et al., 2024; Rahman et al., 2025), R-FSACP-Net differs by using learnable frequency refinement instead of fixed FFT decomposition, adaptive fusion instead of simple feature concatenation, and scene-aware channel priors via dynamic cross-attention rather than fixed channel assumptions. This trend aligns with the broader shift toward data-driven, context-aware enhancement strategies. Overall, the literature demonstrates a clear evolution from spatial-domain enhancement toward multi-domain, adaptive, and robustness-oriented methods. While convolutional, transformer-based, adversarial, and diffusion-based approaches each contribute valuable insights, robustness across diverse underwater conditions remains an open challenge. Frequency-spatial integration, adaptive channel prior learning, and robustness-aware optimization have emerged as promising elements for next-generation UIE frameworks. Deep unfolding networks have recently emerged as a strong direction for underwater image enhancement. (Pham et al., 2025) integrate physics-driven prior learning into an unrolling framework to enforce underwater attenuation models.
In (Chang et al., 2025) proposed CDDU, a convolutional dictionary deep unfolding network that combines sparse-coding optimization with learned components for more robust restoration. In (Lei et al., 2024) present UIE-UnFold, which couples deep unfolding with color priors and a vision transformer to better capture global color distributions. These methods improve generalization by incorporating prior knowledge, but they typically require explicit parameter estimation for water type, transmission, or depth.
R-FSACP-Net differs by learning scene-aware channel priors and frequency-spatial fusion directly from data, without relying on fixed physical assumptions. These observations directly motivate the design of R-FSACP-Net, which explicitly integrates these components to address existing limitations. In summary, while existing methods rely on fixed physical assumptions or isolated spatial processing, a critical gap remains in achieving generalization across diverse water types without explicit parameter estimation - a gap this study directly addresses through data-driven frequency-spatial fusion.
Table 1 summarizes the limitations of existing underwater image enhancement approaches and highlights the research gaps addressed by the proposed R-FSACP-Net framework. The comparison demonstrates that most existing methods rely on fixed priors, isolated spatial processing, or computationally expensive architectures, which limits their robustness and generalization capability under diverse underwater environments.
Literature Comparison and Research Gap Analysis.

Literature Comparison and Research Gap Analysis.
From the comparison, it can be observed that robustness, adaptive color correction, and generalized enhancement across different underwater conditions remain major challenges in existing methods. The proposed R-FSACP-Net addresses these limitations through joint frequency-spatial feature modeling and adaptive channel prior learning.
This work presents a robust image enhancement framework for improving visual quality under diverse and challenging degradation conditions. Real-world images often suffer from heterogeneous distortions such as severe noise, color imbalance, uneven illumination, and loss of structural details.
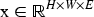
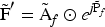
Let the degraded image be represented as I, where H, W, and C denote the image height, width, and number of channels, respectively. The objective of the proposed framework is to generate an enhanced image
The proposed framework consists of the following three modules:
Robust Frequency-Spatial Processing Network (RFSPN) Robust Adaptive Channel Prior Module (R-ACPM) Robust Integrated Feature Network (R-IFNet)
RFSPN generates a coarse yet stable enhancement by jointly exploiting spatial-domain and frequency-domain characteristics. Since degradations behave differently across domains, combining both leads to better generalization.
Frequency Branch
Learnable frequency refinement is explicitly chosen over fixed FFT decomposition to allow the network to dynamically adapt to varying levels of underwater noise and illumination.
Given an intermediate feature map 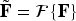
with amplitude and phase components defined as:
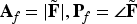
The components are refined using pointwise convolution and nonlinear activation:
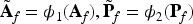
Where
and the inverse transform yields:
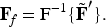
In parallel, the spatial branch directly processes Fusing convolutional filters that emphasize edges, textures, and local neighbourhood patterns:
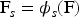
where
The two branches are fused through a learnable operator 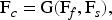
producing the coarse enhanced feature map F_c. To examine the effect of frequency-domain phase processing, we compare magnitude-only refinement with the proposed magnitude + phase refinement. Preserving phase information stabilizes color appearance while magnitude refinement improves contrast and noise suppression.
In this section, we provide exact layer configurations for the main network modules so other researchers can reproduce the model.
C denotes the number of channels in the current feature tensor. After concatenating two C-channel feature maps, the fused tensor has 2C channels. C/2 means half of C.
The frequency refinement blocks
The spatial branch
The coarse fusion operator (G(F_f, F_s)) first concatenates the frequency-domain feature map (F_f) and the spatial-domain feature map (F_s) along the channel dimension, producing a (2C)-channel feature tensor. The fused features are then processed using a
The R-ACPM encoder is based on a ResNet-50 backbone and produces multi-scale feature maps with channel dimensions of 64, 128, 256, and 512. The cross-attention module T uses an 8-head cross-attention mechanism with embedding dimension 256 to update color embeddings by attending to these multi-scale visual features.
Finally, the R-IFNet decoder performs progressive 2× upsampling stages. Each stage applies a 3 × 3 convolution, batch normalization, and ReLU activation, while using skip connections from RFSPN. The decoder ends with a final 3 × 3 convolution to produce the 3-channel output image, followed by a sigmoid activation (Table 2).
Detailed Layer Specification.

Detailed Layer Specification.
Color distortion remains a major challenge in underwater image enhancement due to depth variation, illumination changes, and scene complexity. Conventional methods often rely on fixed color assumptions, which may not generalize well across different underwater environments. To overcome this limitation, the proposed framework employs a data-driven adaptive channel prior mechanism to learn robust color representations.
A dynamic cross-attention mechanism is introduced to achieve scene-aware color correction. Fixed channel assumptions frequently fail in highly turbid underwater conditions. Therefore, the proposed attention mechanism dynamically adapts the color representation according to the scene characteristics.
The first encoder extracts multi-scale visual features while capturing global color statistics across different channels. These statistics provide a coarse representation of the overall color distribution; however, they lack sufficient spatial awareness. To address this issue, a second encoder further refines the color representations using cross-attention between visual features and channel-wise color queries.
The initial color embedding sequence be represented as
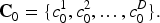
Where D is the embedding dimension. Through iterative interaction with multi-scale visual features, the embeddings are updated as
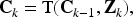
where
The R-IFNet produces the final enhanced image by integrating the coarse enhancement from RFSPN with the adaptive color embeddings generated by R-ACPM and this integration aligns structural details with reliable color information. The coarse feature map be denoted as 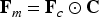
Where 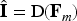
A decoder with skip connections progressively reconstructs spatial resolution, where
To guide robust learning, a composite loss function is employed to supervise structural integrity, pixel accuracy, color distribution, and perceptual quality.
As
Structural Consistency Loss
To preserve spatial structure and local relationships, a structure-aware similarity loss is defined, where:
The cross-covariance is defined as;
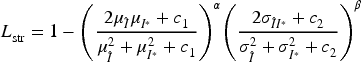
To reduce absolute intensity deviations, a reconstruction loss based on the absolute residual is used:
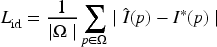
where
To enforce global color consistency, a color distribution map (CDM)-based constraint is introduced. Let C be the number of channels and 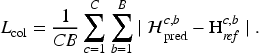
To improve realism, a feature matching loss is computed using feature activations from a pre-trained deep network:
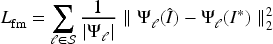
where
The final optimization objective is expressed as;
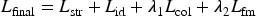
where
The proposed method integrates frequency-spatial feature modeling, adaptive color learning, and a multi-objective optimization strategy to achieve robust image enhancement. By jointly addressing structural fidelity, color reliability, and perceptual quality, the framework demonstrates strong generalization capability across diverse degradation conditions.
The SUIM-E dataset (Qi et al., 2022) contains 1,635 underwater images in total and for our experiments, we utilize the officially released SUIM-Trainset, which provides 1,530 paired underwater image samples for supervised training. The remaining 105 images from SUIM are used exclusively for testing. To further improve generalization.
we incorporate samples from the UIEB dataset (Li, Guo, et al., 2020), which consists of 990 underwater images and from this collection, 800 paired images are randomly selected to fine-tune our model, while the remaining 90 images are reserved as an additional independent test set.
In addition, the Color-Checker7 dataset (Sharma et al., 2020) comprising seven underwater images captured under controlled shallow-water conditions using different camera devices is employed specifically to evaluate the color correction capability of the proposed successor to CAFS-Net.
Since many underwater datasets lack corresponding ground-truth reference images, multiple evaluation strategies are required to ensure a comprehensive quantitative analysis, here we used two full-reference metrics Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) to assess pixel-level fidelity where reference images are available.
To evaluate enhancement performance in the absence of reference data, we adopt the widely used Underwater Image Quality Measure (UIQM), which captures colourfulness, sharpness, and contrast characteristics of underwater scenes. To validate the effectiveness of our model.
We compare it against several recently proposed and well-established underwater image enhancement approaches UDCP, Water-Net, MT-MCSE, UDAformer, TDM-UIE and CAFS-Net. These methods represent diverse solution strategies, including traditional priors, CNN-based architectures, transformer models, and diffusion-based frameworks.
The comparison allows us to thoroughly assess the improvements brought by the proposed R-FSACP-Net across a wide range of underwater degradation scenarios. Data augmentation includes random horizontal/vertical flip, random rotation of ±15°, brightness adjustment of ±10%, Gaussian noise with σ = 0.01, and color jittering with saturation/hue changes of ±15%.
We report the complexity of R-FSACP-Net for practical assessment. The total parameter count is approximately 34.1 M. For a 512 × 512 input, the model requires roughly 125.3 GFLOPs. Inference uses about 1.2 GB of GPU memory (batch size 1) and about 136 MB of CPU memory. On an RTX 3090, end-to-end runtime is approximately 450 ms, while CPU inference requires about 1.2 s. Comparison with baselines: CAFS-Net (18.2 M params, ∼280 ms), TDM-UIE (42.1 M params, ∼650 ms). R-FSACP-Net provides better quality-efficiency trade-off.
The contribution of each loss component by removing it from the training objective are analysed where the
Figure 2 presents a side-by-side visual comparison of underwater SUIM-E test set images processed by various enhancement methods and the figure is designed to showcase how different methods perform in enhancing the quality of raw underwater images, which are often degraded due to factors like scattering, absorption, and color distortion.

Visual Comparisons on Underwater Images from SUIM-E Test Set. From Left to Right are (a) Raw Underwater Images and the Results of UDCP (b), Water-Net (c), MT-MCSE (d), UDAformer (e), TDM-UIE (f), CAFS-Net (g) and, the Proposed R-FSACP-Net (h).
Table 3 presents a comparative evaluation of several underwater image enhancement techniques using three standard metrics: PSNR, SSIM, and UIQM, whereas the visual comparison corresponding to SSIM and UIQM on the SUIM-E test set is illustrated in Figure 3.
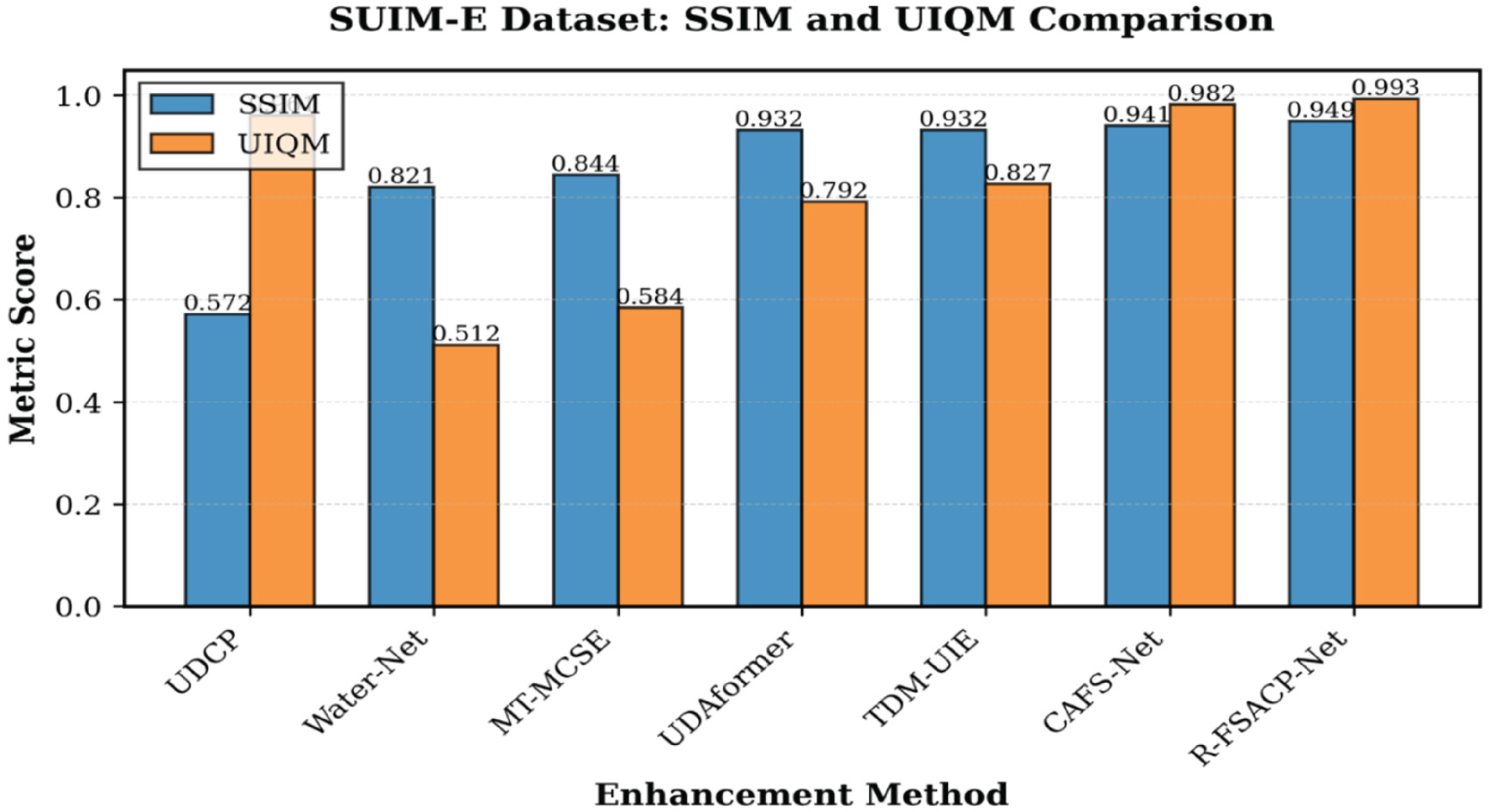
Graphical Comparison on SUIM-E Test Set in Terms of SSIM and, UIQM.
Quantitative Comparison on SUIM-E Test set in Terms of PSNR, SSIM and, UIQM.
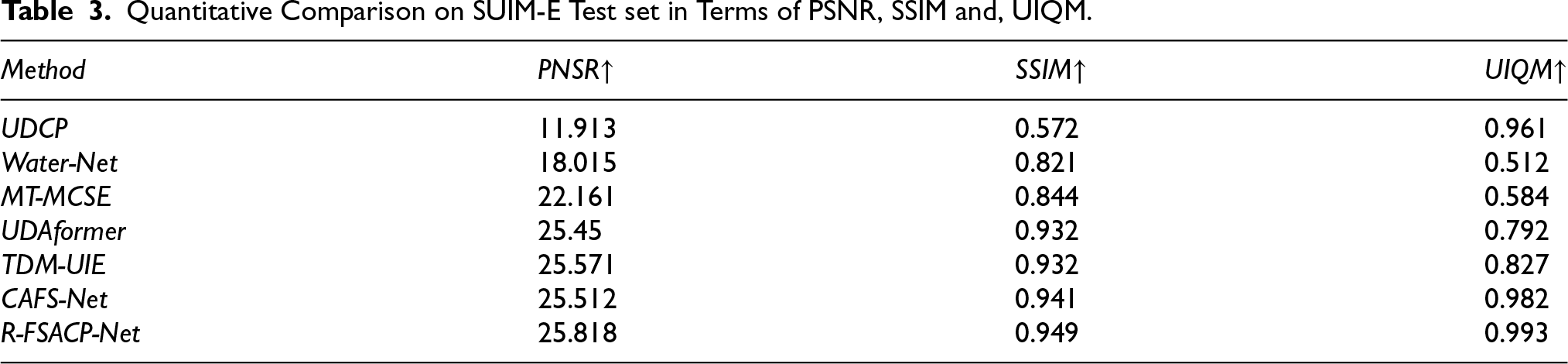
These quantitative and graphical analyses jointly highlight the strengths and limitations of each method, in terms of PSNR, UDCP records the lowest value (11.913), showing limited capability in suppressing noise and restoring fine image details. Water-Net and MT-MCSE demonstrate noticeable improvements with PSNR values of 18.015 and 22.161. UDAformer and TDM-UIE achieve significantly higher PSNR scores of 25.450 and 25.571, indicating stronger reconstruction performance.
CAFS-Net also delivers competitive results with a PSNR of 25.512. The proposed R-FSACP-Net further enhances this performance by reaching a PSNR of 25.818, demonstrating its improved ability to recover clean and visually consistent underwater images.
A similar trend is observed with SSIM. UDCP achieves the lowest structural similarity (0.572), while Water-Net (0.821) and MT-MCSE (0.844) show better preservation of spatial structures. UDAformer and TDM-UIE maintain strong structural fidelity with identical SSIM scores of 0.932. CAFS-Net surpasses these methods with an SSIM of 0.941. The proposed R-FSACP-Net further improves structural consistency, achieving an SSIM of 0.949, marking the highest structural similarity among all compared models.
Regarding UIQM, UDCP delivers a reasonably strong value (0.961), although its low PSNR and SSIM indicate limited enhancement capability. Water-Net exhibits a lower UIQM score of 0.512, suggesting insufficient color and contrast enhancement. MT-MCSE shows moderate improvement with 0.584. UDAformer and TDM-UIE achieve higher UIQM values of 0.792 and 0.827, reflecting more balanced enhancement results.
CAFS-Net achieves the highest UIQM among existing models (0.982). The proposed R-FSACP-Net further elevates this performance, achieving a UIQM of 0.993, indicating more natural color rendition, improved clarity, and overall superior underwater image quality.
Table 4 presents the quantitative comparison of several state-of-the-art underwater image enhancement methods on the UIEB dataset, including the proposed R-FSACP-Net. Figure 3 shows the visual comparison results obtained using different enhancement methods, while Figure 4 illustrates the graphical comparison of PSNR, SSIM, and UIQM values for better performance interpretation.

Visual Comparisons on Underwater Images from UIEB Test Set. From Left to Right are (a) Raw Underwater Images and the Results of UDCP (b), Water-Net (c), MT-MCSE (d), UDAformer (e), TDM-UIE (f), CAFS-Net (g) and, the Proposed R-FSACP-Net (h).
Quantitative Comparison on UIEB Test set in Terms of PSNR, SSIM and, UIQM.
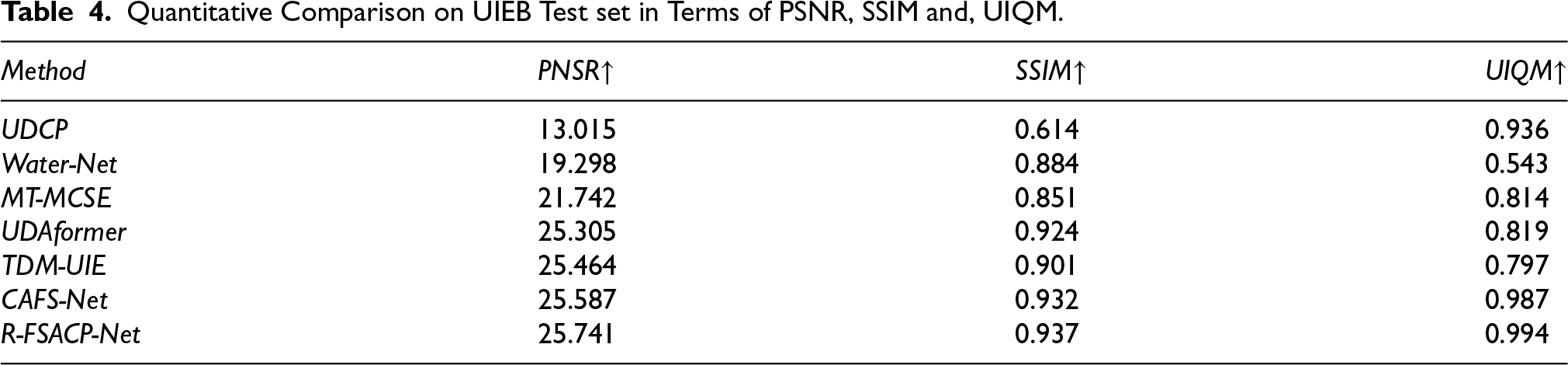
Significant variation can be observed among the compared methods in terms of PSNR performance. UDCP achieves the lowest PSNR value of 13.015, indicating limited capability in suppressing noise and restoring fine image details. Water-Net and MT-MCSE provide moderate improvements with PSNR values of 19.298 and 21.742, respectively. However, their reconstruction quality remains relatively limited under challenging underwater conditions.
More recent transformer-based methods, such as UDAformer and TDM-UIE, achieve higher PSNR values of 25.305 and 25.464, respectively, demonstrating improved robustness against underwater degradations. CAFS-Net further improves the PSNR performance to 25.587. The proposed R-FSACP-Net achieves the highest PSNR value of 25.741, indicating superior noise suppression capability and clearer image reconstruction performance.
A similar trend can be observed for the SSIM metric. UDCP achieves the lowest structural similarity value of 0.614, indicating poor preservation of spatial information. Water-Net and MT-MCSE improve the SSIM values to 0.884 and 0.851, respectively, showing better structural consistency. TDM-UIE further achieves an SSIM value of 0.901, while UDAformer records a higher value of 0.924.
CAFS-Net further improves structural fidelity with an SSIM value of 0.932. The proposed R-FSACP-Net achieves the highest SSIM value of 0.937, demonstrating its superior capability in preserving spatial structures and maintaining visual consistency across underwater scenes.
In terms of overall image quality, evaluated using the UIQM metric, UDCP achieves a relatively high score of 0.936 despite its lower PSNR and SSIM values. Water-Net records a lower UIQM value of 0.543, indicating limitations in underwater color and contrast enhancement. MT-MCSE and UDAformer achieve UIQM values of 0.814 and 0.819, respectively, demonstrating moderate improvement in perceptual quality. TDM-UIE achieves a UIQM value of 0.797.
CAFS-Net achieves a strong UIQM score of 0.987, reflecting effective enhancement performance. The proposed R-FSACP-Net further improves the UIQM value to 0.994, indicating better color restoration, improved contrast balance, and superior overall visual quality.
From Table 5, it can be observed that the proposed R-FSACP-Net consistently outperforms previously reported methods from the literature across both datasets. In particular, the proposed framework achieves the highest
Comparison with Existing Literature on Benchmark Datasets.
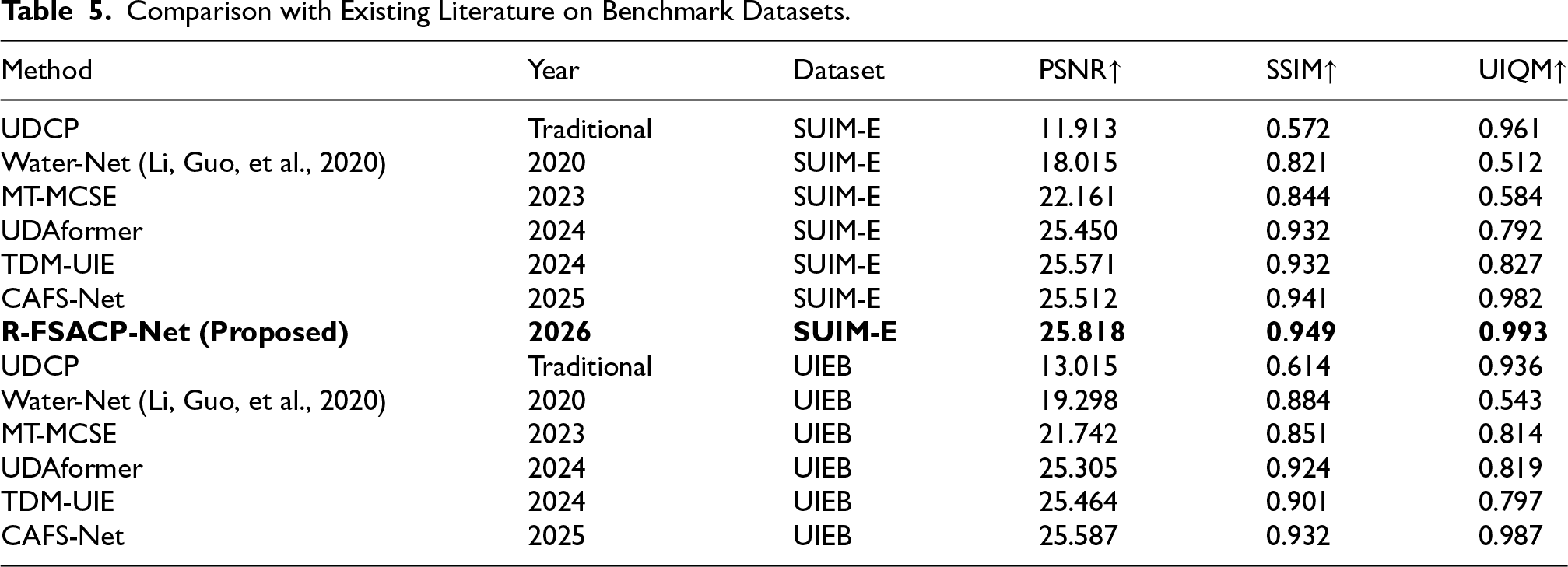
SSIM and UIQM values while maintaining competitive PSNR performance, demonstrating improved structural preservation, color consistency, and perceptual quality under diverse underwater degradation conditions.
To further validate the robustness and reliability of the proposed R-FSACP-Net, statistical analysis was conducted on the quantitative evaluation metrics across benchmark datasets. Mean performance and standard deviation values were computed for PSNR, SSIM, and UIQM over the test images. In addition, paired t-tests were performed between the proposed method and the best competing approaches to evaluate the statistical significance of the observed improvements. A significance threshold of p < 0.05 was adopted (Table 6).
Statistical Analysis on SUIM-E Dataset.

Statistical Analysis on SUIM-E Dataset.
Table 7 presents the ablation analysis of different R-ACPM variants on the SUIM-E and UIEB datasets. The evaluated variants include the baseline model without R-ACPM, channel-attention-based refinement, adaptive-normalization-based refinement, and the proposed full cross-attention mechanism.
Cross-Attention Ablation Analysis.

Among all variants, the full cross-attention design achieves the best performance on both datasets. This result confirms the effectiveness of the proposed scene-aware color adaptation and multi-scale feature interaction strategy. The cross-attention mechanism enables the model to better capture global color relationships while preserving important local structural details.
Since the Color-Checker7 dataset contains only seven images, paired t-tests were performed on the color evaluation metrics, and 95% confidence intervals were reported. The statistical analysis confirms that the improvements achieved by R-FSACP-Net over competing methods are statistically significant ((p < 0.05)), despite the limited dataset size.
Figure 5 presents the qualitative comparison results on the Color-Checker7 dataset using different underwater image enhancement methods. Figure 6 illustrates the corresponding quantitative comparison in terms of the UIQM metric.
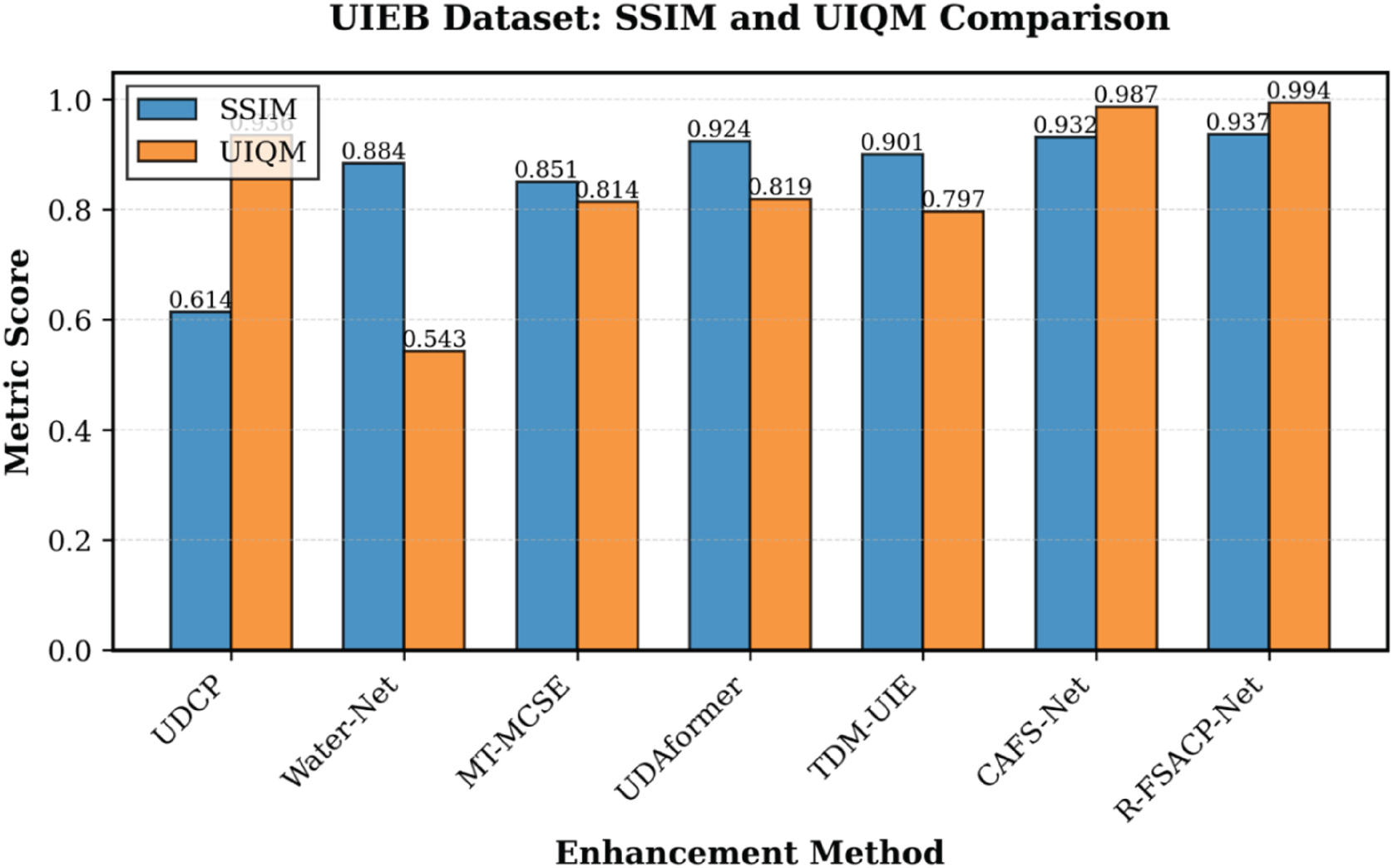
Quantitative Comparison on UIEB Test Set in Terms of PSNR, SSIM and, UIQM.

Visual Comparisons on Underwater Images from Color-Checker7 Test Set. From Left to Right are (a) Raw Underwater Images and The Results of UDCP (b), Water-Net (c), MT-MCSE (d), UDAformer (e), TDM-UIE (f), CAFS-Net (g) and, the Proposed R-FSACP-Net (h).
Among the compared methods, UDCP achieves the highest UIQM score of 1.415. Although this indicates strong enhancement capability, the improvement is often associated with over-enhancement and unnatural color appearance. Water-Net achieves a UIQM value of 0.944, demonstrating moderate enhancement performance, while MT-MCSE records the lowest score of 0.874, indicating limited capability under challenging underwater conditions (Figure 7).
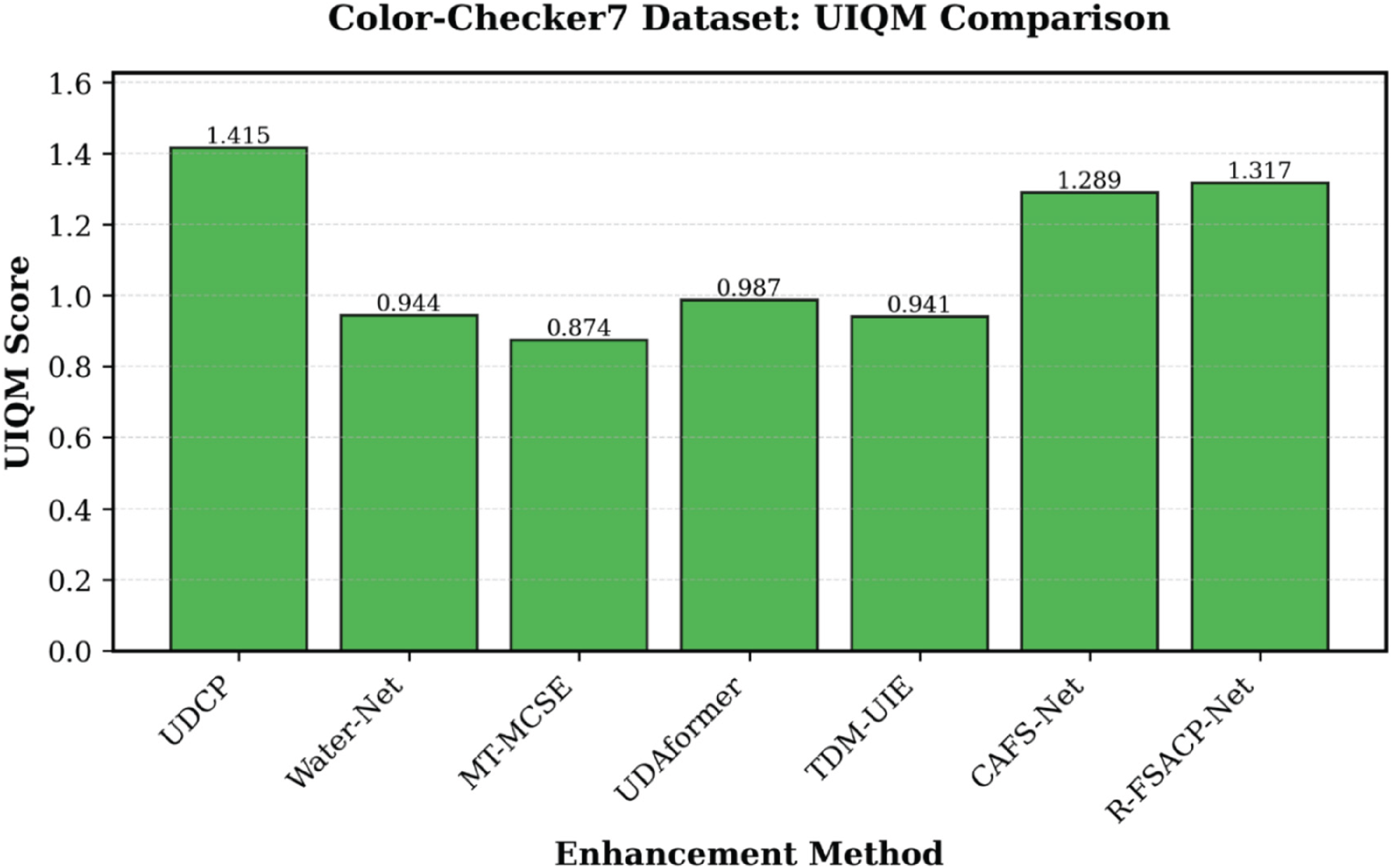
Quantitative Comparison on Color-Checker7 Test Set in Terms of UIQM.
UDAformer achieves a UIQM value of 0.987, outperforming Water-Net and MT-MCSE. TDM-UIE achieves a similar performance with a UIQM score of 0.941. CAFS-Net further improves the UIQM value to 1.289, demonstrating effective contrast enhancement, color correction, and structural preservation.
The proposed R-FSACP-Net further improves the perceptual quality by achieving a UIQM score of 1.317. The obtained results demonstrate better color restoration, improved contrast balance, and more stable enhancement behavior across diverse underwater scenes.
To evaluate the generalization capability of the proposed framework, R-FSACP-Net was trained only on the SUIM-E dataset and directly tested on the unseen UIEB and Color-Checker7 datasets without additional fine-tuning. The model achieves a UIQM value of 0.994 on UIEB and 1.317 on Color-Checker7, demonstrating strong robustness across different underwater domains, imaging devices, and scene distributions.
The performance improvements confirm the effectiveness of the proposed adaptive frequency-spatial fusion and scene-aware color refinement strategy. Although R-FSACP-Net demonstrates strong robustness across various underwater conditions, performance degradation may still occur under extremely turbid environments, severe backscatter, or very low illumination conditions. Future work will focus on incorporating recent diffusion-based and lightweight underwater image enhancement models for extended evaluation and further performance improvement.
Overall, the proposed R-FSACP-Net demonstrates consistently strong performance across multiple evaluation metrics. The framework achieves high PSNR values, indicating effective noise suppression and accurate image reconstruction capability. It also achieves improved SSIM performance, demonstrating better preservation of structural and textural information.
In addition, the superior UIQM performance confirms that R-FSACP-Net produces underwater images with improved color naturalness, balanced contrast, and enhanced visual clarity. These results demonstrate that the proposed framework provides a robust and reliable solution for real-world underwater image enhancement applications.
This study presents R-FSACP-Net, a robust underwater image enhancement framework designed to address the limitations of existing deep-learning-based methods under diverse underwater conditions. The proposed framework combines frequency-spatial feature learning with adaptive color-preserving fusion to improve structural fidelity, perceptual quality, and color realism.
Experimental results on the SUIM, UIEB, and Color-Checker7 datasets demonstrate that R-FSACP-Net achieves superior PSNR, SSIM, and UIQM performance compared to existing state-of-the-art methods. The proposed framework effectively restores degraded underwater images while preserving important structural and color details.
Overall, R-FSACP-Net provides a reliable and efficient solution for underwater image enhancement applications. Future work will focus on improving generalization using cross-domain adaptation and self-supervised learning techniques.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.